python创建flask项目
好的,我会为你提供一个使用 Flask、pg8000 和 Pandas 构建的后台基本框架,用于手机理财产品 App 的报表分析接口。这个框架将包含异常处理、模块化的结构以支持多人协作,以及交易分析和收益分析的示例接口。
项目结构:
financial_report_app/
├── app/
│ ├── __init__.py # 初始化 Flask 应用和蓝图
│ ├── config.py # 配置文件 (数据库连接等)
│ ├── database.py # 数据库连接和操作辅助函数
│ ├── errors.py # 统一的错误处理
│ ├── models/ # (可选) 如果使用 ORM,可以在这里定义模型
│ │ └── __init__.py
│ ├── routes/ # API 路由定义
│ │ ├── __init__.py
│ │ ├── transaction_routes.py # 交易分析相关路由
│ │ └── earning_routes.py # 收益分析相关路由
│ ├── services/ # 业务逻辑层
│ │ ├── __init__.py
│ │ ├── transaction_service.py # 交易数据分析服务
│ │ └── earning_service.py # 收益数据分析服务
│ └── utils/ # 工具函数
│ ├── __init__.py
│ └── dataframe_utils.py # Pandas DataFrame 处理工具
├── run.py # 应用启动脚本
├── requirements.txt # 项目依赖
└── README.md # 项目说明
现在,我们来逐步创建这些文件和代码。
1. requirements.txt
Flask>=2.3.0
pg8000>=1.29.0
pandas>=1.5.0
Flask-Cors>=4.0.0 # 用于处理跨域请求,方便前端调试
python-dotenv>=1.0.0 # 用于从 .env 文件加载环境变量
2. .env (在 financial_report_app 目录下创建这个文件,不要提交到版本库)
FLASK_APP=run.py
FLASK_ENV=development # 可以是 development 或 production
FLASK_DEBUG=TrueDB_USER=your_db_user
DB_PASSWORD=your_db_password
DB_HOST=localhost
DB_PORT=5432
DB_NAME=your_financial_db
请务必将 your_db_user, your_db_password, your_financial_db 替换为你实际的 PostgreSQL 数据库信息。
3. app/config.py
import os
from dotenv import load_dotenv# 加载 .env 文件中的环境变量
load_dotenv()class Config:"""基本配置类"""SECRET_KEY = os.environ.get('SECRET_KEY') or 'a_very_secret_key_that_you_should_change'DEBUG = FalseTESTING = False# 数据库配置DB_USER = os.environ.get('DB_USER')DB_PASSWORD = os.environ.get('DB_PASSWORD')DB_HOST = os.environ.get('DB_HOST')DB_PORT = int(os.environ.get('DB_PORT', 5432))DB_NAME = os.environ.get('DB_NAME')if not all([DB_USER, DB_PASSWORD, DB_HOST, DB_NAME]):raise ValueError("数据库配置不完整,请检查 .env 文件。")class DevelopmentConfig(Config):"""开发环境配置"""DEBUG = TrueFLASK_DEBUG = True # 确保 Flask 的调试模式也开启class TestingConfig(Config):"""测试环境配置"""TESTING = True# 可以为测试环境配置一个单独的数据库DB_NAME = os.environ.get('TEST_DB_NAME') or 'your_financial_test_db'class ProductionConfig(Config):"""生产环境配置"""DEBUG = FalseFLASK_DEBUG = False# 生产环境中应使用更强的 SECRET_KEY,并可能从环境变量或密钥管理服务加载# 根据 FLASK_ENV 环境变量选择配置
config_by_name = dict(development=DevelopmentConfig,testing=TestingConfig,production=ProductionConfig,default=DevelopmentConfig
)def get_config():env = os.getenv('FLASK_ENV', 'default')return config_by_name.get(env, DevelopmentConfig)current_config = get_config()
4. app/database.py
import pg8000.native
import pandas as pd
from flask import current_app, g # g 是 Flask 的应用上下文全局变量def get_db_connection():"""获取数据库连接"""if 'db_conn' not in g:try:g.db_conn = pg8000.native.Connection(user=current_app.config['DB_USER'],password=current_app.config['DB_PASSWORD'],host=current_app.config['DB_HOST'],port=current_app.config['DB_PORT'],database=current_app.config['DB_NAME'])current_app.logger.info("数据库连接成功。")except Exception as e:current_app.logger.error(f"数据库连接失败: {e}")raise # 重新抛出异常,以便上层捕获return g.db_conndef close_db_connection(e=None):"""关闭数据库连接"""db_conn = g.pop('db_conn', None)if db_conn is not None:db_conn.close()current_app.logger.info("数据库连接已关闭。")def query_db(query, args=None, fetch_one=False, commit=False):"""执行数据库查询。:param query: SQL 查询语句:param args: 查询参数 (元组):param fetch_one: 是否只获取一条记录:param commit: 是否提交事务 (用于 INSERT, UPDATE, DELETE):return: 查询结果 (列表或单个元组) 或 None"""conn = Nonecursor = Nonetry:conn = get_db_connection()cursor = conn.cursor()current_app.logger.debug(f"执行 SQL: {query} 参数: {args}")cursor.execute(query, args if args else [])if commit:conn.commit()current_app.logger.info("事务已提交。")return cursor.rowcount # 返回影响的行数if fetch_one:result = cursor.fetchone()return resultelse:results = cursor.fetchall()return resultsexcept pg8000.Error as e:current_app.logger.error(f"数据库查询错误: {e}")if conn and commit: # 如果是提交操作且出错,则回滚conn.rollback()current_app.logger.info("事务已回滚。")raise # 重新抛出,由全局错误处理器处理except Exception as e:current_app.logger.error(f"执行数据库操作时发生未知错误: {e}")raisefinally:if cursor:cursor.close()# 注意:连接的关闭由 app_context_teardown 统一处理def query_db_to_dataframe(query, args=None, columns=None):"""执行数据库查询并将结果转换为 Pandas DataFrame。:param query: SQL 查询语句:param args: 查询参数 (元组):param columns: (可选) DataFrame 的列名列表。如果为 None,则使用 cursor.description。:return: Pandas DataFrame 或 空 DataFrame"""conn = Nonecursor = Nonetry:conn = get_db_connection()cursor = conn.cursor()current_app.logger.debug(f"执行 SQL (to DataFrame): {query} 参数: {args}")cursor.execute(query, args if args else [])results = cursor.fetchall()if not results:return pd.DataFrame()if columns is None:columns = [desc[0] for desc in cursor.description]return pd.DataFrame(results, columns=columns)except pg8000.Error as e:current_app.logger.error(f"数据库查询到 DataFrame 错误: {e}")raiseexcept Exception as e:current_app.logger.error(f"转换为 DataFrame 时发生未知错误: {e}")raisefinally:if cursor:cursor.close()def init_app(app):"""注册数据库关闭函数到应用"""app.teardown_appcontext(close_db_connection)# 可以在这里添加一个 ping 数据库的命令,用于 CLI# app.cli.add_command(init_db_command)
5. app/errors.py
from flask import jsonify, current_app
import pg8000class AppError(Exception):"""自定义应用基础错误类"""status_code = 500message = "服务器内部错误"def __init__(self, message=None, status_code=None, payload=None):super().__init__()if message is not None:self.message = messageif status_code is not None:self.status_code = status_codeself.payload = payloaddef to_dict(self):rv = dict(self.payload or ())rv['error'] = self.messagerv['status_code'] = self.status_codereturn rvclass BadRequestError(AppError):"""请求参数错误"""status_code = 400message = "请求无效或参数错误"class NotFoundError(AppError):"""资源未找到错误"""status_code = 404message = "请求的资源未找到"class DatabaseError(AppError):"""数据库操作错误"""status_code = 500message = "数据库操作失败"def register_error_handlers(app):"""注册全局错误处理器"""@app.errorhandler(AppError)def handle_app_error(error):response = jsonify(error.to_dict())response.status_code = error.status_codecurrent_app.logger.error(f"AppError: {error.message}, Status: {error.status_code}, Payload: {error.payload}")return response@app.errorhandler(pg8000.Error)def handle_database_error(error):# 对 pg8000 的具体错误可以进行更细致的处理和记录current_app.logger.error(f"pg8000 Database Error: {error}")# 可以根据 error 类型返回更具体的错误信息,但对客户端通常隐藏细节app_err = DatabaseError(message="数据库服务暂时不可用或查询出错。")response = jsonify(app_err.to_dict())response.status_code = app_err.status_codereturn response@app.errorhandler(400)def handle_bad_request(error):# Flask 自带的 400 错误app_err = BadRequestError(message=error.description or "错误的请求。")response = jsonify(app_err.to_dict())response.status_code = app_err.status_codecurrent_app.logger.warning(f"BadRequest (400): {app_err.message}")return response@app.errorhandler(404)def handle_not_found(error):# Flask 自带的 404 错误app_err = NotFoundError(message=error.description or "您请求的页面或资源不存在。")response = jsonify(app_err.to_dict())response.status_code = app_err.status_codecurrent_app.logger.warning(f"NotFound (404): {app_err.message}")return response@app.errorhandler(Exception)def handle_generic_exception(error):# 捕获所有未被特定处理器捕获的异常current_app.logger.error(f"Unhandled Exception: {error}", exc_info=True)# 对于生产环境,避免泄露过多内部错误细节给客户端if current_app.config['DEBUG']:message = str(error)else:message = "服务器发生了一个未预料到的错误,请稍后再试。"app_err = AppError(message=message, status_code=500)response = jsonify(app_err.to_dict())response.status_code = app_err.status_codereturn response
6. app/utils/__init__.py (可以为空)
7. app/utils/dataframe_utils.py
import pandas as pd
from app.errors import BadRequestErrordef validate_request_dates(start_date_str, end_date_str):"""验证并转换日期字符串"""try:start_date = pd.to_datetime(start_date_str)end_date = pd.to_datetime(end_date_str)except ValueError:raise BadRequestError("日期格式无效,请使用 YYYY-MM-DD 格式。")if start_date > end_date:raise BadRequestError("开始日期不能晚于结束日期。")return start_date, end_datedef format_chart_data(df, index_col, value_cols, chart_type="timeseries"):"""将 DataFrame 格式化为图表库(如 ECharts, Chart.js)常用的格式。这是一个通用示例,具体格式可能需要根据前端图表库调整。:param df: Pandas DataFrame:param index_col: 作为X轴(通常是日期或类别)的列名:param value_cols: 作为Y轴值的列名列表:param chart_type: 图表类型,可用于未来扩展:return: 字典格式的图表数据"""if df.empty:return {"categories": [],"series": [{"name": col, "data": []} for col in value_cols]}# 确保索引列是 datetime 类型,并格式化为字符串(如果需要)if pd.api.types.is_datetime64_any_dtype(df[index_col]):categories = df[index_col].dt.strftime('%Y-%m-%d').tolist()else:categories = df[index_col].astype(str).tolist()series_data = []for col in value_cols:if col in df.columns:series_data.append({"name": col,"data": df[col].tolist() # 确保数据是 JSON 可序列化的 (例如,不要有 NaN)})else:series_data.append({"name": col,"data": []})return {"categories": categories, # X 轴数据"series": series_data # Y 轴数据系列}# 更多 Pandas 相关的工具函数可以放在这里
# 例如:数据清洗、聚合、计算增长率等def calculate_daily_summary(df, date_col, value_col, agg_func='sum'):"""按天汇总数据。:param df: DataFrame:param date_col: 日期列名:param value_col: 需要聚合的值列名:param agg_func: 聚合函数 ('sum', 'mean', 'count', etc.):return: 汇总后的 DataFrame,索引为日期"""if df.empty or date_col not in df.columns or value_col not in df.columns:return pd.DataFrame(columns=[date_col, value_col]).set_index(date_col)df_copy = df.copy()df_copy[date_col] = pd.to_datetime(df_copy[date_col])summary = df_copy.groupby(pd.Grouper(key=date_col, freq='D'))[value_col].agg(agg_func).reset_index()summary = summary.rename(columns={value_col: f'daily_{value_col}_{agg_func}'})return summary.set_index(date_col)def resample_timeseries_data(df, resample_freq='D', agg_dict=None):"""对时间序列 DataFrame 进行重采样和聚合。DataFrame 的索引必须是 DateTimeIndex。:param df: 输入的 DataFrame (DateTimeIndex):param resample_freq: 重采样频率 ('D', 'W', 'M', 'Q', 'Y'):param agg_dict: 字典,键为列名,值为聚合函数或函数列表例如: {'amount': 'sum', 'price': 'mean'}:return: 重采样和聚合后的 DataFrame"""if not isinstance(df.index, pd.DatetimeIndex):raise ValueError("DataFrame的索引必须是DatetimeIndex才能进行重采样。")if df.empty:return pd.DataFrame()if agg_dict is None:# 默认对所有数值列求和numeric_cols = df.select_dtypes(include=pd.np.number).columnsagg_dict = {col: 'sum' for col in numeric_cols}resampled_df = df.resample(resample_freq).agg(agg_dict)return resampled_df
8. app/services/__init__.py (可以为空)
9. app/services/transaction_service.py
import pandas as pd
from app.database import query_db_to_dataframe
from app.utils.dataframe_utils import validate_request_dates, format_chart_data, resample_timeseries_data
from app.errors import NotFoundError, AppError
from flask import current_app# 假设的数据库表名
TRANSACTIONS_TABLE = "transactions" # 示例表名,请替换为你的实际表名
PRODUCTS_TABLE = "products" # 示例表名class TransactionService:def get_transaction_analysis(self, user_id: int, start_date_str: str, end_date_str: str,transaction_type: str = None, product_id: int = None,group_by: str = 'day'):"""获取交易分析数据。:param user_id: 用户 ID:param start_date_str: 开始日期字符串 (YYYY-MM-DD):param end_date_str: 结束日期字符串 (YYYY-MM-DD):param transaction_type: (可选) 交易类型 (e.g., 'buy', 'sell'):param product_id: (可选) 产品 ID:param group_by: (可选) 分组依据 ('day', 'month', 'product', 'type'):return: 格式化后的图表数据"""start_date, end_date = validate_request_dates(start_date_str, end_date_str)# 构建基础 SQL 查询# ****** 注意:这里的 SQL 查询是示例,你需要根据你的数据库表结构进行修改 ******# 常见的交易表字段可能包括:id, user_id, product_id, transaction_date,# transaction_type ('buy', 'sell', 'dividend', 'fee'), amount, quantity, price, currencysql_query = f"""SELECTt.transaction_date,t.transaction_type,t.amount,t.currency,p.product_name,p.product_categoryFROM {TRANSACTIONS_TABLE} tLEFT JOIN {PRODUCTS_TABLE} p ON t.product_id = p.product_idWHERE t.user_id = %sAND t.transaction_date >= %sAND t.transaction_date <= %s"""params = [user_id, start_date, end_date]if transaction_type:sql_query += " AND t.transaction_type = %s"params.append(transaction_type)if product_id:sql_query += " AND t.product_id = %s"params.append(product_id)current_app.logger.info(f"查询交易数据: user_id={user_id}, start={start_date}, end={end_date}")try:df = query_db_to_dataframe(sql_query, tuple(params))except Exception as e:current_app.logger.error(f"获取交易数据时出错: {e}")raise AppError("获取交易数据失败")if df.empty:current_app.logger.info("未找到符合条件的交易数据。")# 返回空的图表结构return format_chart_data(pd.DataFrame(), 'date', ['value'])# -------- Pandas 数据分析示例 --------# 确保 'transaction_date' 是 datetime 类型df['transaction_date'] = pd.to_datetime(df['transaction_date'])df = df.sort_values(by='transaction_date')# 根据 group_by 参数进行不同的聚合分析chart_data = {}if group_by == 'day':# 按天汇总交易总额daily_summary = df.set_index('transaction_date').resample('D')['amount'].sum().reset_index()daily_summary = daily_summary.rename(columns={'transaction_date': 'date', 'amount': 'total_amount'})chart_data = format_chart_data(daily_summary, index_col='date', value_cols=['total_amount'])chart_data['title'] = "每日交易总额"elif group_by == 'month':# 按月汇总交易总额monthly_summary = df.set_index('transaction_date').resample('M')['amount'].sum().reset_index()monthly_summary['transaction_date'] = monthly_summary['transaction_date'].dt.to_period('M').astype(str) # X轴标签monthly_summary = monthly_summary.rename(columns={'transaction_date': 'month', 'amount': 'total_amount'})chart_data = format_chart_data(monthly_summary, index_col='month', value_cols=['total_amount'])chart_data['title'] = "每月交易总额"elif group_by == 'product_category':# 按产品类别汇总交易额category_summary = df.groupby('product_category')['amount'].sum().reset_index()category_summary = category_summary.sort_values(by='amount', ascending=False)# 这种通常是饼图或柱状图chart_data = {"title": "各产品类别交易额占比","type": "pie", # 或 "bar""labels": category_summary['product_category'].tolist(),"data": category_summary['amount'].tolist()}# 或者使用 format_chart_data 转换成通用的系列格式# chart_data = format_chart_data(category_summary, index_col='product_category', value_cols=['amount'])# chart_data['title'] = "各产品类别交易额"elif group_by == 'transaction_type':# 按交易类型汇总type_summary = df.groupby('transaction_type')['amount'].sum().reset_index()# 这种通常是饼图或柱状图chart_data = {"title": "各交易类型金额占比","type": "pie","labels": type_summary['transaction_type'].tolist(),"data": type_summary['amount'].tolist()}else:# 默认按天汇总daily_summary = df.set_index('transaction_date').resample('D')['amount'].sum().reset_index()daily_summary = daily_summary.rename(columns={'transaction_date': 'date', 'amount': 'total_amount'})chart_data = format_chart_data(daily_summary, index_col='date', value_cols=['total_amount'])chart_data['title'] = "每日交易总额 (默认)"current_app.logger.info(f"交易分析完成: group_by={group_by}")return chart_data
重要提示关于 transaction_service.py 中的 SQL:
- 表名和列名:
TRANSACTIONS_TABLE,PRODUCTS_TABLE,t.transaction_date,t.amount,p.product_name,p.product_category等都是示例。你需要将它们替换为你数据库中实际的表名和列名。 - 数据类型: 确保
transaction_date在数据库中是DATE或TIMESTAMP类型,amount是数值类型 (如DECIMAL或NUMERIC)。 - JOINs: 如果产品信息在不同的表中,你需要使用
JOIN。
10. app/services/earning_service.py
import pandas as pd
from app.database import query_db_to_dataframe
from app.utils.dataframe_utils import validate_request_dates, format_chart_data
from app.errors import NotFoundError, AppError
from flask import current_app# 假设的数据库表名
EARNINGS_TABLE = "earnings" # 示例表名,请替换为你的实际表名
PRODUCTS_TABLE = "products" # 示例表名class EarningService:def get_earning_analysis(self, user_id: int, start_date_str: str, end_date_str: str,product_id: int = None, earning_type: str = None,group_by: str = 'day'):"""获取收益分析数据。:param user_id: 用户 ID:param start_date_str: 开始日期字符串 (YYYY-MM-DD):param end_date_str: 结束日期字符串 (YYYY-MM-DD):param product_id: (可选) 产品 ID:param earning_type: (可选) 收益类型 (e.g., 'interest', 'dividend', 'capital_gain'):param group_by: (可选) 分组依据 ('day', 'month', 'product', 'type'):return: 格式化后的图表数据"""start_date, end_date = validate_request_dates(start_date_str, end_date_str)# ****** 注意:这里的 SQL 查询是示例,你需要根据你的数据库表结构进行修改 ******# 常见的收益表字段可能包括:id, user_id, product_id, earning_date,# earning_type ('interest', 'dividend', 'realized_gain', 'unrealized_gain'), amount, currencysql_query = f"""SELECTe.earning_date,e.earning_type,e.amount,e.currency,p.product_name,p.product_categoryFROM {EARNINGS_TABLE} eLEFT JOIN {PRODUCTS_TABLE} p ON e.product_id = p.product_idWHERE e.user_id = %sAND e.earning_date >= %sAND e.earning_date <= %s"""params = [user_id, start_date, end_date]if product_id:sql_query += " AND e.product_id = %s"params.append(product_id)if earning_type:sql_query += " AND e.earning_type = %s"params.append(earning_type)current_app.logger.info(f"查询收益数据: user_id={user_id}, start={start_date}, end={end_date}")try:df = query_db_to_dataframe(sql_query, tuple(params))except Exception as e:current_app.logger.error(f"获取收益数据时出错: {e}")raise AppError("获取收益数据失败")if df.empty:current_app.logger.info("未找到符合条件的收益数据。")return format_chart_data(pd.DataFrame(), 'date', ['value'])df['earning_date'] = pd.to_datetime(df['earning_date'])df = df.sort_values(by='earning_date')chart_data = {}if group_by == 'day':# 按天汇总收益daily_summary = df.set_index('earning_date').resample('D')['amount'].sum().reset_index()daily_summary = daily_summary.rename(columns={'earning_date': 'date', 'amount': 'total_earnings'})chart_data = format_chart_data(daily_summary, index_col='date', value_cols=['total_earnings'])chart_data['title'] = "每日总收益"elif group_by == 'month':# 按月汇总收益monthly_summary = df.set_index('earning_date').resample('M')['amount'].sum().reset_index()monthly_summary['earning_date'] = monthly_summary['earning_date'].dt.to_period('M').astype(str)monthly_summary = monthly_summary.rename(columns={'earning_date': 'month', 'amount': 'total_earnings'})chart_data = format_chart_data(monthly_summary, index_col='month', value_cols=['total_earnings'])chart_data['title'] = "每月总收益"elif group_by == 'product':# 按产品汇总收益product_summary = df.groupby('product_name')['amount'].sum().reset_index()product_summary = product_summary.sort_values(by='amount', ascending=False)chart_data = {"title": "各产品收益贡献","type": "bar", # or pie"labels": product_summary['product_name'].tolist(),"data": product_summary['amount'].tolist()}elif group_by == 'earning_type':# 按收益类型汇总type_summary = df.groupby('earning_type')['amount'].sum().reset_index()chart_data = {"title": "各收益类型占比","type": "pie","labels": type_summary['earning_type'].tolist(),"data": type_summary['amount'].tolist()}else:daily_summary = df.set_index('earning_date').resample('D')['amount'].sum().reset_index()daily_summary = daily_summary.rename(columns={'earning_date': 'date', 'amount': 'total_earnings'})chart_data = format_chart_data(daily_summary, index_col='date', value_cols=['total_earnings'])chart_data['title'] = "每日总收益 (默认)"current_app.logger.info(f"收益分析完成: group_by={group_by}")return chart_data
重要提示关于 earning_service.py 中的 SQL:
- 表名和列名:
EARNINGS_TABLE,e.earning_date,e.amount,e.earning_type等都是示例。请替换为你的实际表名和列名。 - 收益类型:
earning_type的值(如 'interest', 'dividend')也需要与你数据库中的定义一致。
11. app/routes/__init__.py
from flask import Blueprint# 创建 API 蓝图
# url_prefix 会给这个蓝图下的所有路由加上 /api 前缀
api_bp = Blueprint('api', __name__, url_prefix='/api')# 导入各个模块的路由,这样在 __init__.py 中创建 app 时可以注册它们
# 放在这里导入是为了避免循环依赖
from . import transaction_routes
from . import earning_routes# 健康检查路由,方便确认服务是否运行
@api_bp.route('/health', methods=['GET'])
def health_check():return {"status": "healthy", "message": "API is running."}, 200
12. app/routes/transaction_routes.py
from flask import request, jsonify, current_app
from . import api_bp # 从同级 __init__.py 导入蓝图
from app.services.transaction_service import TransactionService
from app.errors import BadRequestError
# from app.auth import token_required # 如果需要认证,取消注释@api_bp.route('/transactions/analysis', methods=['POST'])
# @token_required # 如果需要认证,取消注释并确保 auth.py 已实现
def transaction_analysis_report():"""交易分析图表接口请求体 (JSON):{"user_id": 123,"start_date": "2024-01-01","end_date": "2024-12-31","transaction_type": "buy", // 可选"product_id": 1, // 可选"group_by": "month" // 可选: 'day', 'month', 'product_category', 'transaction_type'}"""data = request.get_json()if not data:raise BadRequestError("请求体不能为空且必须是 JSON 格式。")user_id = data.get('user_id')start_date = data.get('start_date')end_date = data.get('end_date')if not all([user_id, start_date, end_date]):raise BadRequestError("缺少必要的参数: user_id, start_date, end_date。")try:user_id = int(user_id)except ValueError:raise BadRequestError("user_id 必须是整数。")transaction_type = data.get('transaction_type')product_id_str = data.get('product_id')product_id = Noneif product_id_str:try:product_id = int(product_id_str)except ValueError:raise BadRequestError("product_id (如果提供) 必须是整数。")group_by = data.get('group_by', 'day') # 默认为 'day'service = TransactionService()try:current_app.logger.info(f"请求交易分析: user_id={user_id}, start={start_date}, end={end_date}, group_by={group_by}")chart_data = service.get_transaction_analysis(user_id=user_id,start_date_str=start_date,end_date_str=end_date,transaction_type=transaction_type,product_id=product_id,group_by=group_by)return jsonify({"status": "success", "data": chart_data}), 200except BadRequestError as e:raise e # 直接抛出,由全局处理器处理except Exception as e:current_app.logger.error(f"处理交易分析请求时发生错误: {e}", exc_info=True)# 对于未预料的错误,返回一个通用的 AppErrorfrom app.errors import AppErrorraise AppError("生成交易分析报告时发生内部错误。")13. app/routes/earning_routes.py
from flask import request, jsonify, current_app
from . import api_bp
from app.services.earning_service import EarningService
from app.errors import BadRequestError
# from app.auth import token_required@api_bp.route('/earnings/analysis', methods=['POST'])
# @token_required
def earning_analysis_report():"""收益分析图表接口请求体 (JSON):{"user_id": 123,"start_date": "2024-01-01","end_date": "2024-12-31","product_id": 1, // 可选"earning_type": "dividend", // 可选"group_by": "month" // 可选: 'day', 'month', 'product', 'earning_type'}"""data = request.get_json()if not data:raise BadRequestError("请求体不能为空且必须是 JSON 格式。")user_id = data.get('user_id')start_date = data.get('start_date')end_date = data.get('end_date')if not all([user_id, start_date, end_date]):raise BadRequestError("缺少必要的参数: user_id, start_date, end_date。")try:user_id = int(user_id)except ValueError:raise BadRequestError("user_id 必须是整数。")product_id_str = data.get('product_id')product_id = Noneif product_id_str:try:product_id = int(product_id_str)except ValueError:raise BadRequestError("product_id (如果提供) 必须是整数。")earning_type = data.get('earning_type')group_by = data.get('group_by', 'day')service = EarningService()try:current_app.logger.info(f"请求收益分析: user_id={user_id}, start={start_date}, end={end_date}, group_by={group_by}")chart_data = service.get_earning_analysis(user_id=user_id,start_date_str=start_date,end_date_str=end_date,product_id=product_id,earning_type=earning_type,group_by=group_by)return jsonify({"status": "success", "data": chart_data}), 200except BadRequestError as e:raise eexcept Exception as e:current_app.logger.error(f"处理收益分析请求时发生错误: {e}", exc_info=True)from app.errors import AppErrorraise AppError("生成收益分析报告时发生内部错误。")14. app/__init__.py
import logging
from flask import Flask
from flask_cors import CORSfrom app.config import current_config, get_config
from app.routes import api_bp # 从 app.routes 包导入蓝图
from app.errors import register_error_handlers
from app.database import init_app as init_db_appdef create_app(config_name=None):"""应用工厂函数"""app = Flask(__name__)# 1. 加载配置if config_name:app_config = get_config(config_name)else:app_config = current_config # 使用 .env 中 FLASK_ENV 决定的配置app.config.from_object(app_config)# 2. 配置日志# 如果不是调试模式,可以配置更详细的日志记录到文件if not app.debug and not app.testing:# 可以配置 logging.FileHandler() 等passelse: # 开发和测试时,使用 Flask 的默认 logger,输出到控制台app.logger.setLevel(logging.DEBUG) # 确保 DEBUG 级别的日志能被看到app.logger.info(f"应用以 '{app.config.get('ENV', 'unknown environment')}'模式启动。")app.logger.info(f"调试模式: {'开启' if app.debug else '关闭'}")# 3. 初始化扩展CORS(app, resources={r"/api/*": {"origins": "*"}}) # 允许所有来源访问 /api/* 路径,生产环境应配置具体来源init_db_app(app) # 初始化数据库相关,主要是注册 teardown context# 4. 注册蓝图app.register_blueprint(api_bp) # api_bp 已经自带了 /api 前缀# 5. 注册错误处理器register_error_handlers(app)# 6. (可选) 添加 CLI 命令# from .commands import create_tables_command# app.cli.add_command(create_tables_command)app.logger.info("Flask 应用创建完成。")return app
15. run.py (在 financial_report_app 目录下)
import os
from app import create_app# 从环境变量获取配置名称,默认为 'development'
# FLASK_ENV 环境变量通常由 .flaskenv 或 .env 文件设置,或者在启动时直接指定
config_name = os.getenv('FLASK_ENV') or 'development'
app = create_app(config_name)if __name__ == '__main__':# host='0.0.0.0' 使其可以从外部访问 (如果防火墙允许)# debug=True 会启用 Flask 的调试器和重载器,通常由 FLASK_DEBUG 环境变量控制# port 可以自定义app.run(host='0.0.0.0', port=5000)
16. README.md (在 financial_report_app 目录下)
Markdown
# 手机理财产品 App 后台 - 报表分析接口本项目是一个基于 Flask、pg8000 和 Pandas 的 Python 后台服务,为手机理财 App 提供报表分析接口。## 项目结构financial_report_app/ ├── app/ │ ├── init.py │ ├── config.py │ ├── database.py │ ├── errors.py │ ├── models/ │ ├── routes/ │ │ ├── init.py │ │ ├── transaction_routes.py │ │ └── earning_routes.py │ ├── services/ │ │ ├── init.py │ │ ├── transaction_service.py │ │ └── earning_service.py │ └── utils/ │ ├── init.py │ └── dataframe_utils.py ├── .env.example # 环境变量示例文件 ├── .flaskenv # (可选) Flask CLI 环境变量 ├── run.py ├── requirements.txt └── README.md
## 环境搭建与运行### 1. 先决条件
- Python 3.8+
- PostgreSQL 数据库### 2. 克隆项目
```bash
git clone <your-repository-url>
cd financial_report_app
3. 创建并激活虚拟环境
Bash
python -m venv venv
# Windows
venv\Scripts\activate
# macOS/Linux
source venv/bin/activate
4. 安装依赖
pip install -r requirements.txt
5. 配置环境变量
复制 .env.example (如果提供了) 或手动创建一个 .env 文件,并填入以下内容:
代码段
FLASK_APP=run.py
FLASK_ENV=development # 'development' 或 'production'
FLASK_DEBUG=True # 'True' 或 'False'DB_USER=your_postgres_user
DB_PASSWORD=your_postgres_password
DB_HOST=localhost
DB_PORT=5432
DB_NAME=your_financial_database_name
SECRET_KEY=your_very_secret_and_unique_key # 请务必修改此项
重要:
- 将
your_postgres_user,your_postgres_password,your_financial_database_name替换为你实际的 PostgreSQL 数据库凭证和数据库名。 - 确保
SECRET_KEY是一个复杂且唯一的字符串。
6. 数据库准备
- 确保你的 PostgreSQL 服务正在运行。
- 手动连接到你的 PostgreSQL 数据库,并创建必要的表。 本项目中的示例 SQL 查询假设存在以下表(你需要根据实际情况调整):
transactions(交易记录表)user_id(INT)product_id(INT)transaction_date(TIMESTAMP or DATE)transaction_type(VARCHAR, e.g., 'buy', 'sell')amount(DECIMAL or NUMERIC)currency(VARCHAR)- ... (其他相关字段)
earnings(收益记录表)user_id(INT)product_id(INT)earning_date(TIMESTAMP or DATE)earning_type(VARCHAR, e.g., 'dividend', 'interest')amount(DECIMAL or NUMERIC)currency(VARCHAR)- ... (其他相关字段)
products(产品信息表)product_id(INT, PRIMARY KEY)product_name(VARCHAR)product_category(VARCHAR)- ... (其他相关字段)
你需要根据 app/services/transaction_service.py 和 app/services/earning_service.py 中的 SQL 查询来创建或调整你的表结构。
7. 运行应用
flask run
# 或者直接运行 run.py (如果 .env 中配置了 FLASK_APP=run.py)
# python run.py
应用默认会在 http://127.0.0.1:5000/ (或 http://0.0.0.0:5000/) 启动。
API 接口
所有 API 接口都以 /api 为前缀。
健康检查
- URL:
/api/health - Method:
GET - Success Response: JSON
{"status": "healthy","message": "API is running." }
交易分析接口
- URL:
/api/transactions/analysis - Method:
POST - Request Body (JSON): JSON
{"user_id": 123,"start_date": "2024-01-01", // YYYY-MM-DD"end_date": "2024-12-31", // YYYY-MM-DD"transaction_type": "buy", // 可选"product_id": 1, // 可选"group_by": "month" // 可选, e.g., "day", "month", "product_category", "transaction_type" } - Success Response (Example for
group_by: 'day'): JSON
注意:{"status": "success","data": {"title": "每日交易总额","categories": ["2024-01-01", "2024-01-02", "..."], // X轴"series": [ // Y轴系列{"name": "total_amount","data": [1500.50, 230.00, "..."]}]} }data结构会根据group_by参数和实际分析结果变化。
收益分析接口
- URL:
/api/earnings/analysis - Method:
POST - Request Body (JSON): JSON
{"user_id": 123,"start_date": "2024-01-01","end_date": "2024-12-31","product_id": 1, // 可选"earning_type": "dividend", // 可选"group_by": "month" // 可选, e.g., "day", "month", "product", "earning_type" } - Success Response (Example for
group_by: 'month'): JSON{"status": "success","data": {"title": "每月总收益","categories": ["2024-01", "2024-02", "..."],"series": [{"name": "total_earnings","data": [50.20, 75.10, "..."]}]} }
错误处理
API 会返回标准的 HTTP 状态码和 JSON 格式的错误信息:
JSON
{"error": "错误描述信息","status_code": 400 // 或其他 HTTP 状态码
}
多人协作
- 模块化设计: 项目按功能(配置、路由、服务、工具)划分模块,方便分工。
- Service 层: 业务逻辑集中在
app/services,与路由处理分离。 - 数据库抽象:
app/database.py提供统一的数据库访问方法。 - 统一错误处理:
app/errors.py定义和处理应用级错误。 - 环境变量: 使用
.env管理敏感配置,不提交到版本库。 - 代码风格: 建议使用
flake8或black等工具统一代码风格。 - 版本控制: 使用 Git 进行版本控制,遵循合适的分支策略(如 Gitflow)。
待办/未来改进
- [ ] 添加用户认证和授权 (e.g., JWT)
- [ ] 更完善的输入验证 (e.g., using Marshmallow or Pydantic)
- [ ] 数据库迁移管理 (e.g., Alembic)
- [ ] 单元测试和集成测试
- [ ] 更详细的日志配置和监控
- [ ] 异步任务处理 (e.g., Celery)
- [ ] ORM 集成 (e.g., SQLAlchemy),如果业务逻辑更复杂
- [ ] API 文档生成 (e.g., Swagger/OpenAPI with Flask-RESTx or Flasgger)
<!-- end list -->
---**如何运行:**1. **创建项目文件夹**: `mkdir financial_report_app && cd financial_report_app`
2. **创建子目录**: 按照上面的项目结构创建 `app`, `app/routes`, `app/services`, `app/utils`, `app/models` (如果需要) 目录。
3. **保存文件**: 将上面提供的每个代码块保存到对应的文件中。
4. **创建 `.env` 文件**: 在 `financial_report_app` 目录下创建 `.env` 文件,并填入你的数据库配置。
5. **安装依赖**:```bashpython -m venv venvsource venv/bin/activate # Linux/macOS# venv\Scripts\activate # Windowspip install -r requirements.txt```
6. **准备数据库**:* 确保你的 PostgreSQL 服务器正在运行。* 创建一个数据库 (例如,你在 `.env` 中配置的 `your_financial_db`)。* **重要**: 在该数据库中创建 `transactions`, `earnings`, 和 `products` 表。这些表的结构需要与 `transaction_service.py` 和 `earning_service.py` 中的 SQL 查询所期望的列名和数据类型相匹配。你需要手动编写 `CREATE TABLE` 语句。**示例 `CREATE TABLE` 语句 (你需要根据你的需求调整):**```sql-- 产品表CREATE TABLE products (product_id SERIAL PRIMARY KEY,product_name VARCHAR(255) NOT NULL,product_category VARCHAR(100));-- 交易表CREATE TABLE transactions (transaction_id SERIAL PRIMARY KEY,user_id INTEGER NOT NULL,product_id INTEGER REFERENCES products(product_id),transaction_date TIMESTAMP WITHOUT TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP,transaction_type VARCHAR(50) NOT NULL, -- 'buy', 'sell', 'dividend_in', 'interest_in', 'fee_out'amount DECIMAL(18, 4) NOT NULL, -- 交易金额quantity DECIMAL(18, 8), -- 交易数量 (可选, 如股票份额)price_per_unit DECIMAL(18, 4), -- 单价 (可选)currency VARCHAR(10) NOT NULL DEFAULT 'CNY',description TEXT);CREATE INDEX idx_transactions_user_date ON transactions (user_id, transaction_date);CREATE INDEX idx_transactions_type ON transactions (transaction_type);-- 收益表 (可以是交易表的一部分,也可以是独立的表)-- 如果收益直接记录在交易表中 (例如 transaction_type = 'dividend_in'), 则可能不需要此表-- 如果有复杂的已实现/未实现收益计算,则可能需要此表或更复杂的逻辑CREATE TABLE earnings (earning_id SERIAL PRIMARY KEY,user_id INTEGER NOT NULL,product_id INTEGER REFERENCES products(product_id),earning_date DATE NOT NULL,earning_type VARCHAR(50) NOT NULL, -- 'realized_gain', 'unrealized_gain', 'dividend', 'interest'amount DECIMAL(18, 4) NOT NULL,currency VARCHAR(10) NOT NULL DEFAULT 'CNY',related_transaction_id INTEGER REFERENCES transactions(transaction_id) -- (可选)关联的交易);CREATE INDEX idx_earnings_user_date ON earnings (user_id, earning_date);CREATE INDEX idx_earnings_type ON earnings (earning_type);-- 插入一些示例产品数据 (可选,用于测试)INSERT INTO products (product_name, product_category) VALUES('稳健增长基金A', '基金'),('高科技股票ETF', 'ETF'),('定期存款产品X', '固收');```7. **运行应用**:```bashflask run```或者,如果 `flask run` 不工作 (可能因为 `FLASK_APP` 未被正确识别),尝试:```bashpython run.py```应用应该会在 `http://localhost:5000` (或 `http://0.0.0.0:5000`) 启动。**测试接口 (使用 `curl` 或 Postman):****交易分析接口:**
```bash
curl -X POST -H "Content-Type: application/json" -d '{"user_id": 1,"start_date": "2023-01-01","end_date": "2025-12-31","group_by": "month"
}' http://localhost:5000/api/transactions/analysis
收益分析接口:
Bash
curl -X POST -H "Content-Type: application/json" -d '{"user_id": 1,"start_date": "2023-01-01","end_date": "2025-12-31","group_by": "product"
}' http://localhost:5000/api/earnings/analysis
请务必根据你的实际数据库表结构和数据来调整 services 层的 SQL 查询和 Pandas 分析逻辑。 这个框架提供了一个起点,你可以根据具体需求进行扩展和修改。
相关文章:

python创建flask项目
好的,我会为你提供一个使用 Flask、pg8000 和 Pandas 构建的后台基本框架,用于手机理财产品 App 的报表分析接口。这个框架将包含异常处理、模块化的结构以支持多人协作,以及交易分析和收益分析的示例接口。 项目结构: financial_report_ap…...

Vue环境下数据导出PDF的全面指南
文章目录 1. 前言2. 原生浏览器打印方案2.1 使用window.print()实现2.2 使用CSS Paged Media模块 3. 常用第三方库方案3.1 使用jsPDF3.2 使用html2canvas jsPDF3.3 使用pdfmake3.4 使用vue-pdf 4. 服务器端导出方案4.1 前端请求服务器生成PDF4.2 使用无头浏览器生成PDF 5. 方法…...
Linux中的DNS的安装与配置
DNS简介 DNS(DomainNameSystem)是互联网上的一项服务,它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。 DNS使用的是53端口 通常DNS是以UDP这个较快速的数据传输协议来查询的,但是没有查…...

linux服务器与时间服务器同步时间
内网部署服务器,需要同步时间 使用系统内置的systemctl-timesyncd进行时间同步 1.编辑配置文件 sudo nano /etc/systemd/timesyncd.conf修改添加内容入下 [Time] NTP10.100.13.198 FallbackNTP#说明 #NTP10.100.13.198:你的主 NTP 时间服务器 IP #Fall…...
【数据结构篇】排序1(插入排序与选择排序)
注:本文以排升序为例 常见的排序算法: 目录: 一 直接插入排序: 1.1 基本思想: 1.2 代码: 1.3 复杂度: 二 希尔排序(直接插入排序的优化): 2.1 基本思想…...
《Linux服务与安全管理》| DNS服务器安装和配置
《Linux服务与安全管理》| DNS服务器安装和配置 目录 《Linux服务与安全管理》| DNS服务器安装和配置 第一步:使用dnf命令安装BIND服务 第二步:查看服务器server01的网络配置 第三步:配置全局配置文件 第四步:修改bind的区域…...

【NLP】34. 数据专题:如何打造高质量训练数据集
构建大语言模型的秘密武器:如何打造高质量训练数据集? 在大语言模型(LLM)如 GPT、BERT、T5 爆发式发展的背后,我们常常关注模型架构的演化,却忽视了一个更基础也更关键的问题:训练数据从哪里来…...
Notepad++ 学习(三)使用python插件编写脚本:实现跳转指定标签页(自主研发)
目录 一、先看成果二、安装Python Script插件三、配置Python脚本四、使用脚本跳转标签页方法一:通过菜单运行方法二:设置快捷键(推荐) 五、注意事项六、进阶使用 官网地址: https://notepad-plus-plus.org/Python Scri…...

Stable Diffusion 学习笔记02
模型下载网站: 1,LiblibAI-哩布哩布AI - 中国领先的AI创作平台 2,Civitai: The Home of Open-Source Generative AI 模型的安装: 将下载的sd模型放置在sd1.5的文件内即可,重启客户端可用。 外挂VAE模型:…...

python:pymysql概念、基本操作和注入问题讲解
python:pymysql分享目录 一、概念二、数据准备三、安装pymysql四、pymysql使用(一)使用步骤(二)查询操作(三)增(四)改(五)删 五、关于pymysql注入…...

Scala语言基础与函数式编程详解
Scala语言基础与函数式编程详解 本文系统梳理Scala语言基础、函数式编程核心、集合与迭代器、模式匹配、隐式机制、泛型与Spark实战,并对每个重要专业术语进行简明解释,配合实用记忆口诀与典型代码片段,助你高效学习和应用Scala。 目录 Scal…...

类的加载过程详解
类的加载过程详解 Java类的加载过程分为加载(Loading)、链接(Linking) 和 初始化(Initialization) 三个阶段。其中链接又分为验证(Verification)、准备(Preparation&…...
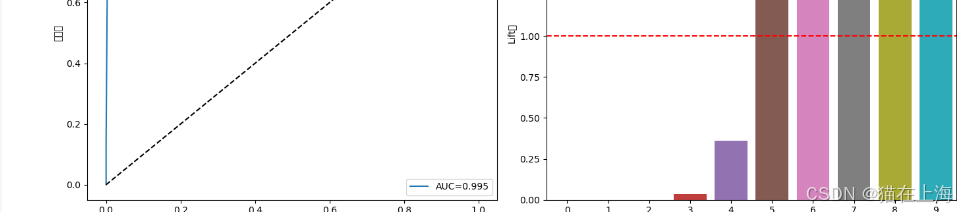
机器学习-人与机器生数据的区分模型测试 - 模型融合与检验
模型融合 # 先用普通Pipeline训练 from sklearn.pipeline import Pipeline#from sklearn2pmml.pipeline import PMMLPipeline train_pipe Pipeline([(scaler, StandardScaler()),(ensemble, VotingClassifier(estimators[(rf, RandomForestClassifier(n_estimators200, max_de…...
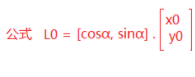
机器学习 day03
文章目录 前言一、特征降维1.特征选择2.主成分分析(PCA) 二、KNN算法三、模型的保存与加载 前言 通过今天的学习,我掌握了机器学习中的特征降维的概念以及用法,KNN算法的基本原理及用法,模型的保存和加载 一、特征降维…...

《社交应用动态表情:RN与Flutter实战解码》
React Native依托于JavaScript和React,为动态表情的实现开辟了一条独特的道路。其核心优势在于对原生模块的便捷调用,这为动态表情的展示和交互提供了强大支持。在社交应用中,当用户点击发送动态表情时,React Native能够迅速调用相…...
嵌入式软件--stm32 DAY 6 USART串口通讯(下)
1.寄存器轮询_收发字符串 通过寄存器轮询方式实现了收发单个字节之后,我们趁热打铁,争上游,进阶到字符串。字符串就是多个字符。很明显可以循环收发单个字节实现。 然后就是接收字符串。如果接受单个字符的函数放在while里,它也可…...

问题处理——在ROS2(humble)+Gazebo+rqt下,无法显示仿真无人机的相机图像
文章目录 前言一、问题展示二、解决方法:1.下载对应版本的PX42.下载对应版本的Gazebo3.启动 总结 前言 在ROS2的环境下,进行无人机仿真的过程中,有时需要调取无人机的相机图像信息,但是使用rqt,却发现相机图像无法显示…...
容器化与云原生)
69、微服务保姆教程(十二)容器化与云原生
容器化与云原生 在微服务架构中,容器化和云原生技术是将应用程序部署到生产环境的核心技术。通过容器化技术,可以将应用程序及其依赖项打包成一个容器镜像,确保在任何环境中都能一致运行。而云原生技术则通过自动化的容器编排系统(如 Kubernetes),实现应用的动态扩展、自…...
朱老师,3518e系列,第六季
第一节:概述。 首先是 将 他写好的 rtsp 源码上传,用于分析。 已经拷贝完。 第二节: h264 编码概念。 编解码 可以用cpu, 也可以用 bsp cpu 编解码的效果不好。做控制比较好。 h264 由 VCL, NAL 组成。 NAL 关心的是 压缩…...
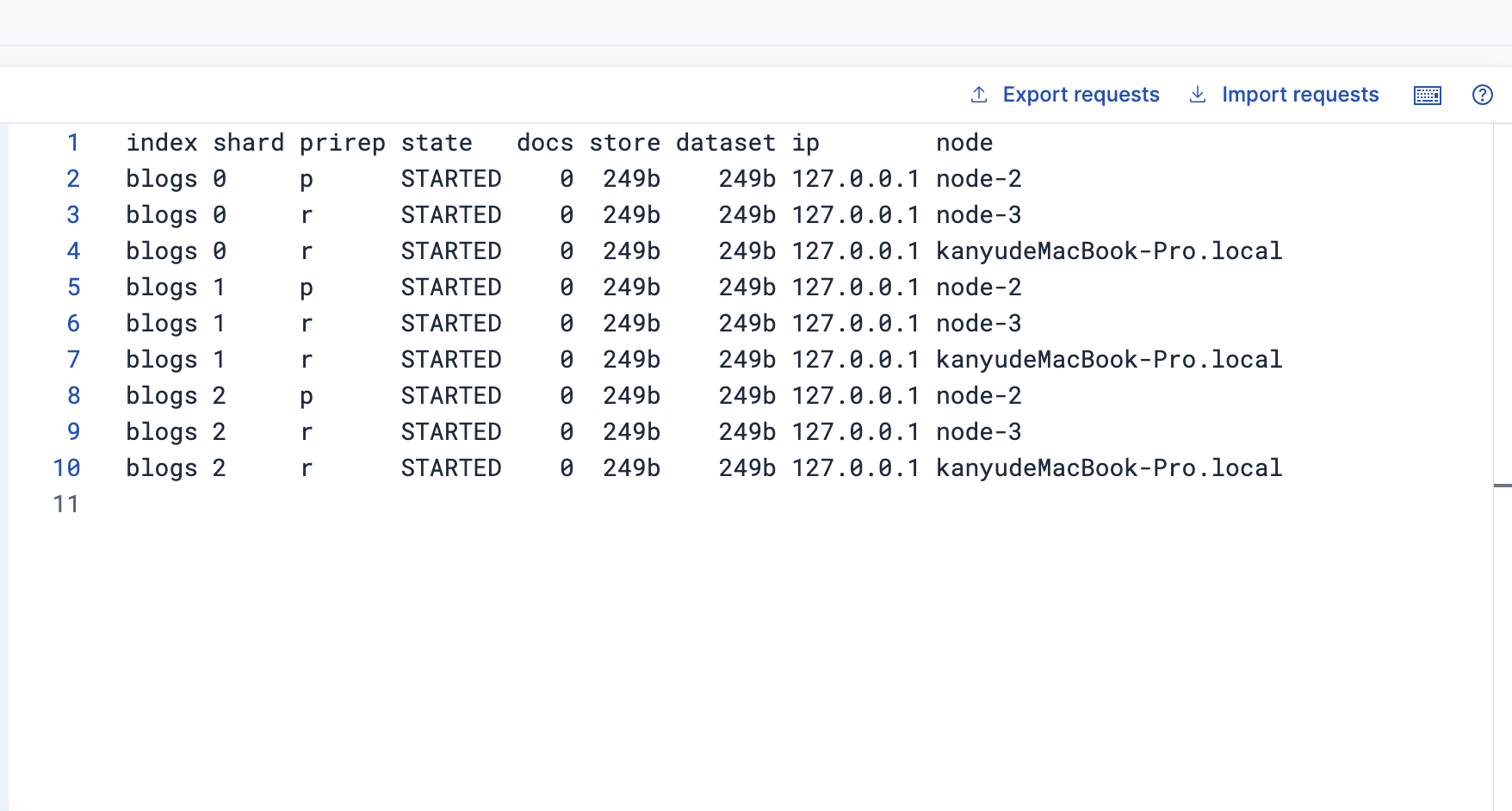
ElasticSearch-集群
本篇文章依据ElasticSearch权威指南进行实操和记录 1,空集群 即不包含任何节点的集群 集群大多数分为两类,主节点和数据节点 主节点 职责:主节点负责管理集群的状态,例如分配分片、添加和删除节点、监控节点故障等。它们不直接…...
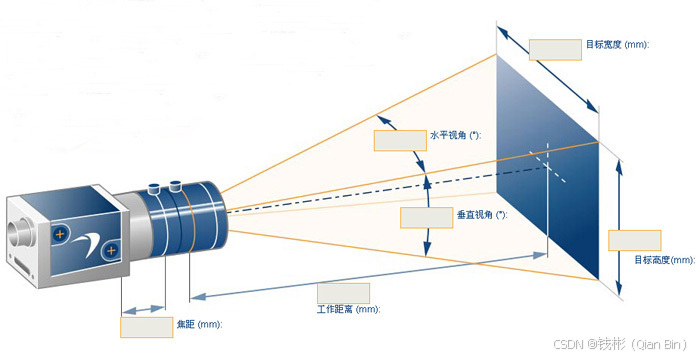
一文掌握工业相机选型计算
目录 一、基本概念 1.1 物方和像方 1.2 工作距离和视场 1.3 放大倍率 1.4 相机芯片尺寸 二、公式计算 三、实例应用 一、基本概念 1.1 物方和像方 在光学领域,物方(Object Space)是与像方(Image Space)相对的…...

记录心态和工作变化
忙中带闲的工作 其实工作挺忙的, 总是在赶各种功能点. 好巧的是iOS那边因为上架的问题耽搁了一些时间, 从而让Android的进度有了很大的调整空间. 更巧的是后端那边因为对客户端的需求不是很熟悉, 加上Android海外这块的业务他也是第一次接触. 所以需要给他留一些时间把各个环节…...

深入理解 TypeScript 中的 unknown 类型:安全处理未知数据的最佳实践
在 TypeScript 的类型体系中,unknown 是一个极具特色的类型。它与 any 看似相似,却在安全性上有着本质差异。本文将从设计理念、核心特性、使用场景及最佳实践等方面深入剖析 unknown,帮助开发者在处理动态数据时既能保持灵活性,又…...
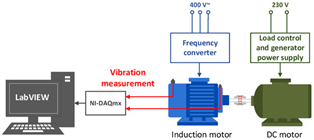
LabVIEW机械振动信号分析与故障诊断
利用 LabVIEW 开发机械振动信号分析与故障诊断系统,融合小波变换、时频分布、高阶统计量(双谱)等先进信号处理技术,实现对齿轮、发动机等机械部件的非平稳非高斯振动信号的特征提取与故障诊断。系统通过虚拟仪器技术将理论算法转化…...
)
Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)
文章目录 Helm配置之为特定Deployment配置特定Docker仓库(覆盖全局配置)需求方法1:使用Helm覆盖值方法2: 在Lens中临时修改Deployment配置步骤 1: 创建 Docker Registry Secret步骤 2: 在 Deployment 中引用 Secret参考资料Helm配置之为特定Deployment配置特定Docker仓库(覆…...
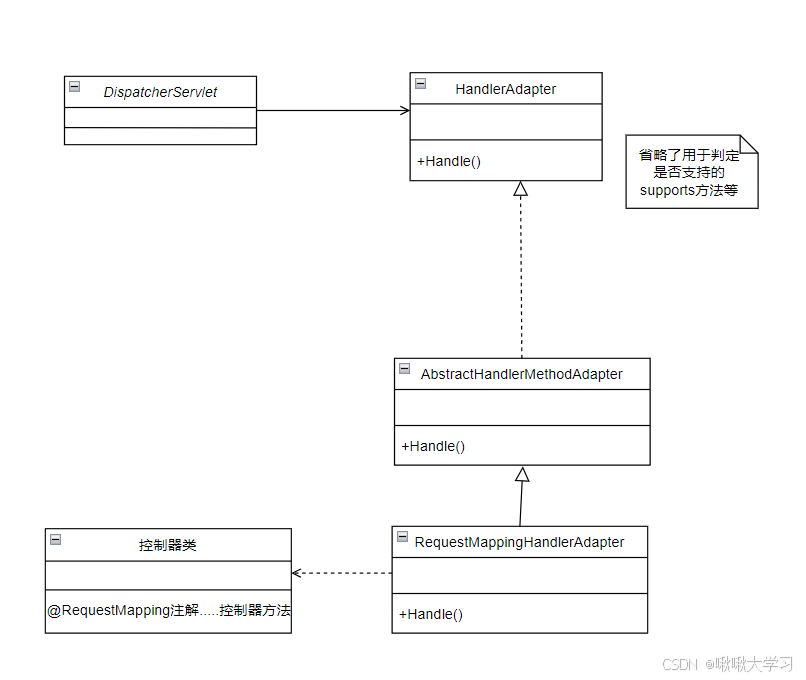
【Spring】Spring中的适配器模式
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 适配器模式Spring MVC的适配器模式 适配器模式 适配器模式(Adapter Pattern&a…...

GO学习指南
GO学习指南 主题一 go语言基础知识讲解 go语言面向对象编程 go语言接口详解 go语言协程 主题二 web基础知识 后续内容请大家持续关注,每月一主题,让各位读者能零基础、零成本学习go语言...

2、ubuntu系统配置OpenSSH | 使用vscode或pycharm远程连接
1、OpenSSH介绍 OpenSSH(Open Secure Shell)是一套基于SSH协议的开源工具,用于在计算机网络中提供安全的加密通信。它被广泛用于远程系统管理、文件传输和网络服务的安全隧道搭建,是保护网络通信免受窃听和攻击的重要工具。 1.1…...

MySQL面试知识点详解
一、MySQL基础架构 1. MySQL逻辑架构 MySQL采用分层架构设计,主要分为: 连接层:处理客户端连接、授权认证等 服务层:包含查询解析、分析、优化、缓存等 引擎层:负责数据存储和提取(InnoDB、MyISAM等&am…...

小白入门:GitHub 远程仓库使用全攻略
一、Git 核心概念 1. 三个工作区域 工作区(Working Directory):实际编辑文件的地方。 暂存区(Staging Area):准备提交的文件集合(使用git add操作)。 本地仓库(Local…...