【神经网络与深度学习】GAN 生成对抗训练模型在实际训练中很容易判别器收敛,生成器发散
引言部分
在深度学习领域,生成对抗网络(GAN)是一种强大的数据生成方法,它通过生成器(G)和判别器(D)之间的博弈来不断优化模型。然而,在实际训练过程中,GAN 往往会遇到 判别器收敛,而生成器发散 的问题,导致模型训练难以稳定进行。
这种现象的根本原因在于 GAN 的目标函数设计、训练过程中动态平衡的破坏、梯度消失与爆炸问题,以及数据分布的复杂性。判别器往往容易快速学会识别真假数据,而生成器在学习逼真数据分布时需要不断调整,容易陷入梯度问题或模式坍塌。
本文将深入分析 GAN 在训练过程中判别器收敛、生成器发散的原理,并探讨可能的解决方案,以帮助优化 GAN 的稳定性和生成质量。
1. GAN的基本原理
GAN(生成对抗网络)由两部分组成:生成器(G) 和 判别器(D)。它们就像两个对手在玩游戏:
- 生成器(G):它的任务是制造假数据,比如生成看起来像真实照片的图片。
- 判别器(D):它的任务是判断输入的数据是真实的还是假的,就像一个警察检查身份证是否是真的。
训练过程中,生成器和判别器互相竞争: - 生成器努力生成越来越逼真的假数据,试图骗过判别器。
- 判别器努力提高自己的判断能力,不被生成器骗到。
2. 为什么判别器容易收敛
判别器的任务相对简单,它只需要判断输入的数据是真实的还是假的。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来,比如生成器生成的图片可能只是一堆乱码,判别器很容易判断这是假的。
随着训练的进行,判别器不断学习,它的能力会越来越强,很快就能够很准确地判断出哪些是真实的,哪些是假的。这就像是一个警察,只要看到身份证上的照片和本人明显不符,就能轻易判断是假的。因此,判别器很容易就“收敛”了,也就是它的性能稳定下来,能够很好地完成任务。
3. 为什么生成器容易发散
生成器的任务要难得多,它需要从随机噪声中生成逼真的数据。在训练初期,生成器生成的假数据质量很差,判别器很容易就能识别出来。生成器会根据判别器的反馈进行调整,但它很难一下子找到生成逼真数据的方法。
随着训练的进行,如果判别器变得太强,生成器可能就会“绝望”了。比如,判别器已经能轻易判断出生成器生成的所有数据都是假的,生成器就会收到很强的负面反馈,它可能会朝着错误的方向调整,导致生成的数据越来越差,甚至完全失去方向。这就像是一个造假者,无论怎么努力,都造不出像样的假货,最后可能越造越离谱。
4. 为什么会发散
当判别器收敛后,生成器会收到很强的负面反馈,因为它生成的假数据总是被识破。这种情况下,生成器可能会朝着错误的方向调整,导致生成的数据质量越来越差,甚至完全失去方向。这就像是一个造假者,无论怎么努力,都造不出像样的假货,最后可能越造越离谱。
如何解决?
为了解决这个问题,研究人员想了很多办法:
- 调整训练节奏:让判别器和生成器交替训练,不要让判别器变得太强。
- 调整损失函数:让生成器的损失函数更加平滑,避免它朝着错误的方向调整。
- 增加正则化:限制生成器和判别器的复杂度,避免它们过于“聪明”,导致训练不稳定。
总之,GAN的训练就像一场复杂的博弈,需要精心设计和调整,才能让生成器和判别器都能稳定地进步。
请从原理上解释一下,为什么 GAN 生成对抗训练模型在实际训练中很容易判别器收敛,生成器发散。
好的!从原理上来说,GAN(生成对抗网络)在训练过程中容易出现判别器(D)收敛、生成器(G)发散的情况,主要是由于以下几个原因:
1. 目标函数的非对称性
GAN的训练目标是通过最小化生成器和判别器之间的博弈损失来实现的。具体来说:
- 判别器的目标:最大化对真实数据和假数据的区分能力,即最大化
E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
这个公式是生成对抗网络(GAN)的损失函数,由两部分组成:
- 判别器对真实数据的期望对数似然
- 判别器对生成数据的期望对数似然
- 生成器的目标:
min D E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] 或 max D E z ∼ p z ( z ) [ log D ( G ( z ) ) ] \min_D \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))] \quad \text{或} \quad \max_D \mathbb{E}_{z \sim p_z(z)}[\log D(G(z))] DminEz∼pz(z)[log(1−D(G(z)))]或DmaxEz∼pz(z)[logD(G(z))]
这两个公式描述了生成对抗网络(GAN)训练过程中判别器的优化目标:
- 最小化对生成样本的判别概率的对数似然
- 最大化对生成样本的判别概率的对数似然
两者在数学上是等价的,但后者在训练初期具有更好的梯度性质。
这种目标函数的设计导致了两者的优化过程是非对称的:
- 判别器的优化目标:判别器的优化目标是清晰的,它只需要尽可能区分真实数据和生成数据。只要判别器能够准确地判断输入数据的真假,它的目标就达到了。
- 生成器的优化目标:生成器的目标相对复杂,它需要生成的数据不仅要在判别器看来是真实的,还要在分布上接近真实数据的分布。生成器需要不断调整自身参数,以生成越来越逼真的数据,但这个过程很容易出现偏差。
2. 训练过程中的动态平衡问题
GAN的训练过程是一个动态的博弈过程,生成器和判别器需要相互配合、相互制约。然而,这种动态平衡很容易被打破:
- 判别器过强:如果判别器的训练速度过快,或者其模型容量过大,它可能会变得过于强大,能够轻易地识别出生成器生成的所有假数据。此时,生成器会收到强烈的负面反馈,导致其梯度消失或梯度爆炸,从而无法有效更新参数,最终导致发散。
- 生成器滞后:如果生成器的训练速度跟不上判别器,生成器生成的数据质量始终无法达到判别器的要求,判别器会一直处于优势地位,进一步加剧生成器的优化困难。
3. 损失函数的性质
GAN的损失函数本质上是一个非凸优化问题,并且生成器和判别器的优化是交替进行的。这种交替优化方式导致了以下几个问题:
- 梯度消失:当判别器过于强大时,生成器生成的数据被判别器轻易识别为假数据,此时生成器的损失函数梯度可能变得非常小,导致生成器的参数更新缓慢甚至停滞。
- 梯度爆炸:在某些情况下,生成器的损失函数梯度可能变得非常大,导致生成器的参数更新幅度过大,从而破坏了生成器的稳定性和生成质量。
4. 模型容量和复杂度的不匹配
在实际训练中,生成器和判别器的模型容量(如层数、神经元数量等)往往不匹配:
- 判别器容量过大:如果判别器的模型容量远大于生成器,判别器会更容易学习到复杂的特征,从而更轻易地识别出生成器的假数据。这会导致生成器的优化更加困难。
- 生成器容量不足:如果生成器的模型容量不足,它可能无法生成足够复杂和逼真的数据,从而无法有效欺骗判别器。
5. 数据分布的复杂性
GAN的目标是让生成器生成的数据分布尽可能接近真实数据分布。然而,真实数据分布往往是复杂且难以建模的。生成器在训练过程中需要不断调整自身参数,以生成越来越接近真实分布的数据,但这个过程很容易出现偏差:
- 模式坍塌(Mode Collapse):生成器可能只学习到真实数据分布中的某些模式,而忽略了其他模式。例如,生成器可能只生成某几种类型的图像,而无法生成真实数据分布中的所有类型。这会导致生成器生成的数据多样性不足。
- 分布不匹配:即使生成器生成的数据在判别器看来是真实的,但其分布可能仍然与真实数据分布存在较大差异。这种分布不匹配会导致生成器的优化方向偏离目标。
解决方法
为了解决判别器收敛、生成器发散的问题,研究人员提出了许多改进方法:
- 调整训练策略:
- 交替训练:合理控制生成器和判别器的训练步数,避免判别器过于强大。
- 平滑目标:在训练判别器时,使用平滑的目标值(如将真实数据的目标值设为0.9,假数据的目标值设为0.1),避免判别器过于自信。
- 改进损失函数:
- Wasserstein GAN(WGAN):使用Wasserstein距离代替传统的JS散度,使损失函数更加平滑,减少梯度消失和梯度爆炸的问题。
- 最小二乘GAN(LSGAN):使用最小二乘损失函数,使生成器的优化过程更加稳定。
- 正则化技术:
- 梯度惩罚:对判别器的梯度进行惩罚,限制其梯度的大小,避免判别器过于强大。
- 谱归一化:对判别器的权重进行归一化,限制其谱范数,提高训练的稳定性。
- 模型架构设计:
- 合理设计生成器和判别器的模型容量:确保生成器和判别器的模型容量相匹配,避免一方过于强大。
- 引入残差连接:在生成器和判别器中引入残差连接,增强模型的训练稳定性。
总结
GAN在训练过程中容易出现判别器收敛、生成器发散的问题,主要是由于目标函数的非对称性、训练过程中的动态平衡问题、损失函数的性质、模型容量和复杂度的不匹配以及数据分布的复杂性等因素共同导致的。通过调整训练策略、改进损失函数、应用正则化技术以及合理设计模型架构,可以在一定程度上缓解这些问题,提高GAN的训练稳定性和生成质量。
相关文章:

【神经网络与深度学习】GAN 生成对抗训练模型在实际训练中很容易判别器收敛,生成器发散
引言部分 在深度学习领域,生成对抗网络(GAN)是一种强大的数据生成方法,它通过生成器(G)和判别器(D)之间的博弈来不断优化模型。然而,在实际训练过程中,GAN 往…...
基于SpringBoot的家政预约系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

[服务器备份教程] Rclone实战:自动备份数据到阿里云OSS/腾讯云COS等对象存储
更多服务器知识,尽在hostol.com 各位服务器的守护者们,咱们都知道,数据是数字时代的“黄金”,而服务器上的数据更是我们业务的命脉。可天有不测风云,硬盘可能会突然“寿终正寝”,手滑执行了“毁灭性”命令…...

使用 Whisper 生成视频字幕:从提取音频到批量处理
生成视频字幕是许多视频处理任务的核心需求。本文将指导你使用 OpenAI 的 Whisper 模型为视频文件(如电视剧《Normal People》或电影《花样年华》)生成字幕(SRT 格式)。我们将从提取音频开始,逐步实现字幕生成…...
Axure难点解决分享:垂直菜单展开与收回(4大核心问题与专家级解决方案)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:垂直菜单展开与收回 主要内容:超长菜单实现、展开与收回bug解释、Axure9版本限制等问题解…...
Linux:网络层的重要协议或技术
一、DNS DNS(Domain Name System)是一整套从域名映射到IP的系统 1.1 DNS的背景 TCP/IP中使用IP地址和端口号来确定网络上的一台主机的一个程序. 但是IP地址不方便记忆. 于是人们发明了一种叫主机名的东西, 是一个字符串, 并且使用hosts文件来描述主机名和IP地址的关系. 最初,…...

【Hadoop 实战】Yarn 模式上传 HDFS 卡顿时 “No Route to Host“ 错误深度解析与解决方案
🌟 飞哥带你攻克 Hadoop 网络通信难题 大家好,我是小飞!最近在大数据集群运维中遇到一个典型问题:使用 Yarn 模式向 HDFS 上传大文件时进度条卡住不动,查看日志发现关键报错: No Route to Host from BigDat…...

JAVA请求vllm的api服务报错Unsupported upgrade request、 Invalid HTTP request received.
环境: vllm 0.8.5 java 17 Qwen3-32B-FP8 问题描述: JAVA请求vllm的api服务报错Unsupported upgrade request、 Invalid HTTP request received. WARNING: Unsupported upgrade request. INFO: - "POST /v1/chat/completions HTTP/1.1&…...
基于 CSS Grid 的网页,拆解页面整体布局结构
通过以下示例拆解网页整体布局结构: 一、基础结构(HTML骨架) <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"…...
的概念梳理)
华为云Astro轻应用创建业务对象(BO)的概念梳理
目录 一、业务对象(BO)是什么?——【详细概念解释】 二、形象理解业务对象(BO) 🍱 类比方式: 📦 举个具体例子:以做一个“智能烟雾报警系统”应用 三、为什么使用BO很重要? 四、小结: 一、业务对象(BO)是什么?——【详细概念解释】 在华为云Astro轻应用…...

利用systemd启动部署在服务器上的web应用
0.背景 系统环境: Ubuntu 22.04 web应用情况: 前后端分类,前端采用react,后端采用fastapi 1.具体配置 1.1 前端配置 开发态运行(启动命令是npm run dev),创建systemd服务文件 sudo nano /etc/systemd/…...

ArkUI Tab组件开发深度解析与应用指南
ArkUI Tab组件开发深度解析与应用指南 一、组件架构与核心能力 ArkUI的Tabs组件采用分层设计结构,由TabBar(导航栏)和TabContent(内容区)构成,支持底部、顶部、侧边三种导航布局模式。组件具备以下核心特…...
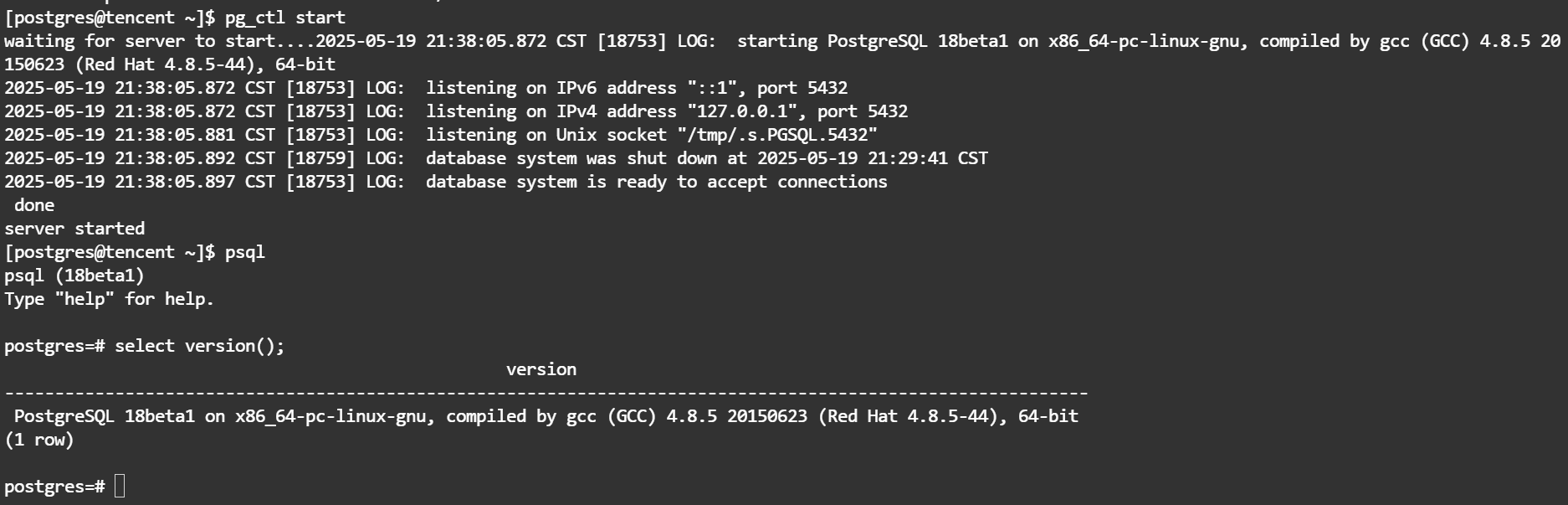
psotgresql18 源码编译安装
环境: 系统:centos7.9 数据库:postgresql18beta1 #PostgreSQL 18 已转向 DocBook XML 构建体系(SGML 未来将被弃用)。需要安装 XML 工具链,如下: yum install -y docbook5-style-xsl libxsl…...

虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系
虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系 code review! 文章目录 虚幻引擎5-Unreal Engine笔记之Pawn与胶囊体的关系1. 什么是Pawn?2. 什么是胶囊体(Capsule Component)?3. Pawn与胶囊体的具体关系(1&#x…...

python创建flask项目
好的,我会为你提供一个使用 Flask、pg8000 和 Pandas 构建的后台基本框架,用于手机理财产品 App 的报表分析接口。这个框架将包含异常处理、模块化的结构以支持多人协作,以及交易分析和收益分析的示例接口。 项目结构: financial_report_ap…...

Vue环境下数据导出PDF的全面指南
文章目录 1. 前言2. 原生浏览器打印方案2.1 使用window.print()实现2.2 使用CSS Paged Media模块 3. 常用第三方库方案3.1 使用jsPDF3.2 使用html2canvas jsPDF3.3 使用pdfmake3.4 使用vue-pdf 4. 服务器端导出方案4.1 前端请求服务器生成PDF4.2 使用无头浏览器生成PDF 5. 方法…...
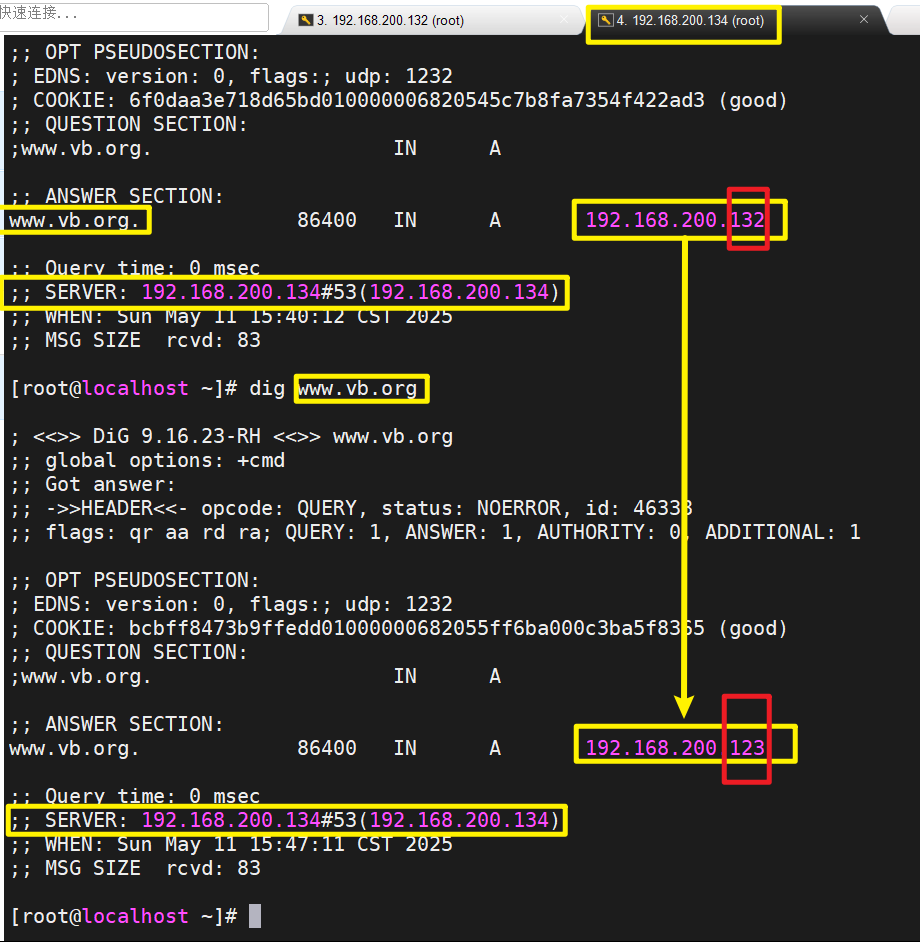
Linux中的DNS的安装与配置
DNS简介 DNS(DomainNameSystem)是互联网上的一项服务,它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。 DNS使用的是53端口 通常DNS是以UDP这个较快速的数据传输协议来查询的,但是没有查…...

linux服务器与时间服务器同步时间
内网部署服务器,需要同步时间 使用系统内置的systemctl-timesyncd进行时间同步 1.编辑配置文件 sudo nano /etc/systemd/timesyncd.conf修改添加内容入下 [Time] NTP10.100.13.198 FallbackNTP#说明 #NTP10.100.13.198:你的主 NTP 时间服务器 IP #Fall…...
【数据结构篇】排序1(插入排序与选择排序)
注:本文以排升序为例 常见的排序算法: 目录: 一 直接插入排序: 1.1 基本思想: 1.2 代码: 1.3 复杂度: 二 希尔排序(直接插入排序的优化): 2.1 基本思想…...
《Linux服务与安全管理》| DNS服务器安装和配置
《Linux服务与安全管理》| DNS服务器安装和配置 目录 《Linux服务与安全管理》| DNS服务器安装和配置 第一步:使用dnf命令安装BIND服务 第二步:查看服务器server01的网络配置 第三步:配置全局配置文件 第四步:修改bind的区域…...

【NLP】34. 数据专题:如何打造高质量训练数据集
构建大语言模型的秘密武器:如何打造高质量训练数据集? 在大语言模型(LLM)如 GPT、BERT、T5 爆发式发展的背后,我们常常关注模型架构的演化,却忽视了一个更基础也更关键的问题:训练数据从哪里来…...
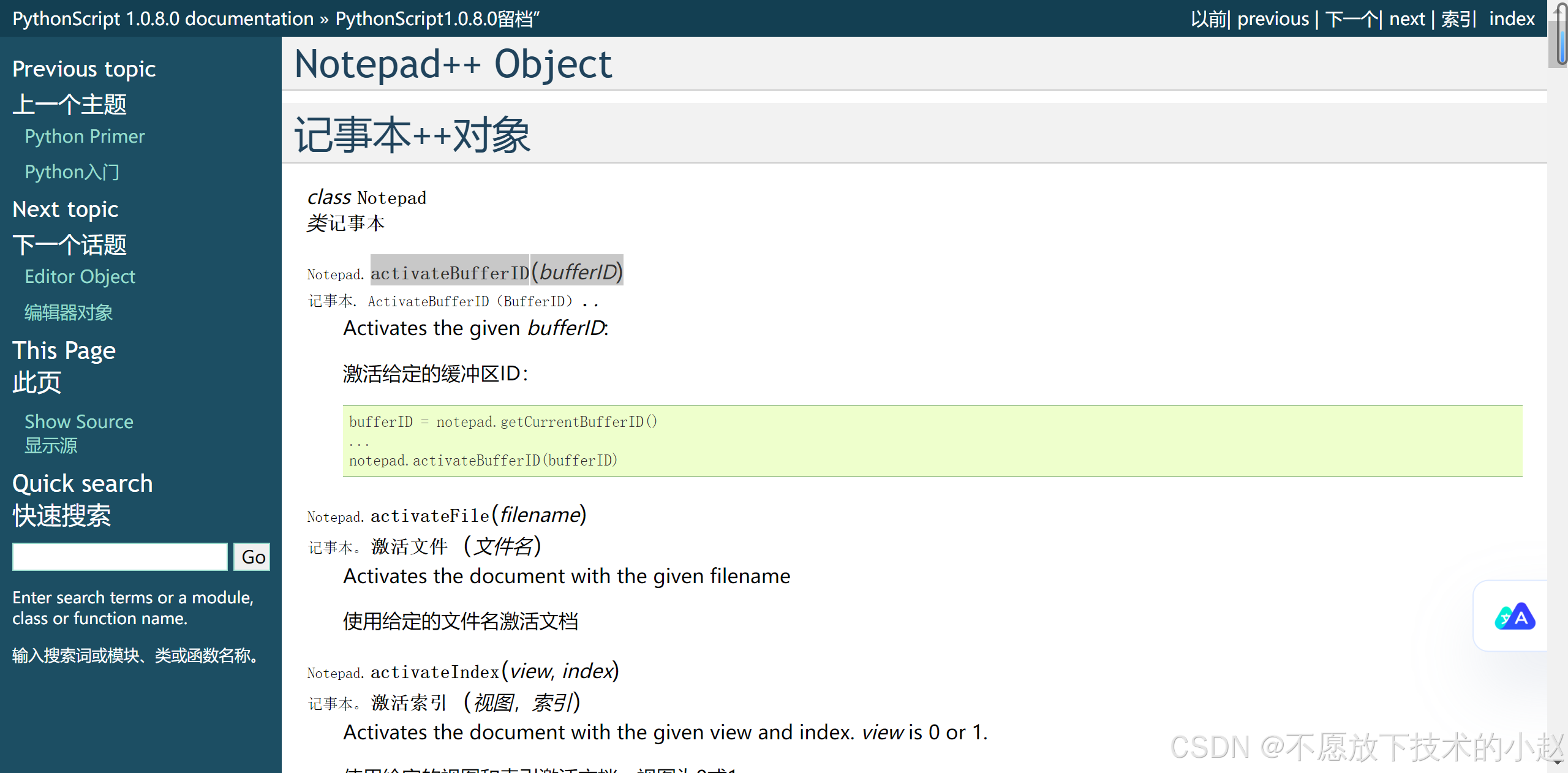
Notepad++ 学习(三)使用python插件编写脚本:实现跳转指定标签页(自主研发)
目录 一、先看成果二、安装Python Script插件三、配置Python脚本四、使用脚本跳转标签页方法一:通过菜单运行方法二:设置快捷键(推荐) 五、注意事项六、进阶使用 官网地址: https://notepad-plus-plus.org/Python Scri…...

Stable Diffusion 学习笔记02
模型下载网站: 1,LiblibAI-哩布哩布AI - 中国领先的AI创作平台 2,Civitai: The Home of Open-Source Generative AI 模型的安装: 将下载的sd模型放置在sd1.5的文件内即可,重启客户端可用。 外挂VAE模型:…...

python:pymysql概念、基本操作和注入问题讲解
python:pymysql分享目录 一、概念二、数据准备三、安装pymysql四、pymysql使用(一)使用步骤(二)查询操作(三)增(四)改(五)删 五、关于pymysql注入…...

Scala语言基础与函数式编程详解
Scala语言基础与函数式编程详解 本文系统梳理Scala语言基础、函数式编程核心、集合与迭代器、模式匹配、隐式机制、泛型与Spark实战,并对每个重要专业术语进行简明解释,配合实用记忆口诀与典型代码片段,助你高效学习和应用Scala。 目录 Scal…...

类的加载过程详解
类的加载过程详解 Java类的加载过程分为加载(Loading)、链接(Linking) 和 初始化(Initialization) 三个阶段。其中链接又分为验证(Verification)、准备(Preparation&…...
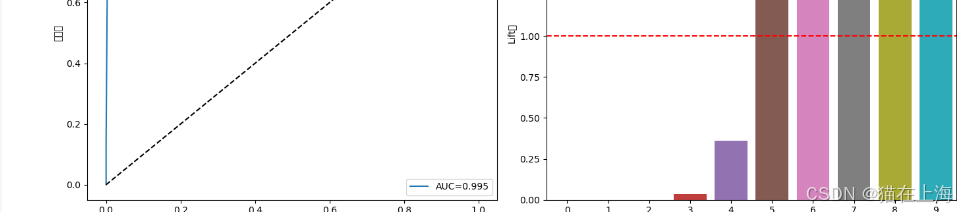
机器学习-人与机器生数据的区分模型测试 - 模型融合与检验
模型融合 # 先用普通Pipeline训练 from sklearn.pipeline import Pipeline#from sklearn2pmml.pipeline import PMMLPipeline train_pipe Pipeline([(scaler, StandardScaler()),(ensemble, VotingClassifier(estimators[(rf, RandomForestClassifier(n_estimators200, max_de…...
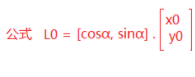
机器学习 day03
文章目录 前言一、特征降维1.特征选择2.主成分分析(PCA) 二、KNN算法三、模型的保存与加载 前言 通过今天的学习,我掌握了机器学习中的特征降维的概念以及用法,KNN算法的基本原理及用法,模型的保存和加载 一、特征降维…...

《社交应用动态表情:RN与Flutter实战解码》
React Native依托于JavaScript和React,为动态表情的实现开辟了一条独特的道路。其核心优势在于对原生模块的便捷调用,这为动态表情的展示和交互提供了强大支持。在社交应用中,当用户点击发送动态表情时,React Native能够迅速调用相…...
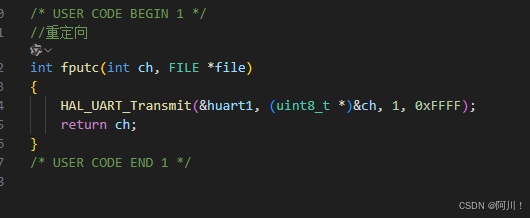
嵌入式软件--stm32 DAY 6 USART串口通讯(下)
1.寄存器轮询_收发字符串 通过寄存器轮询方式实现了收发单个字节之后,我们趁热打铁,争上游,进阶到字符串。字符串就是多个字符。很明显可以循环收发单个字节实现。 然后就是接收字符串。如果接受单个字符的函数放在while里,它也可…...