手动制做一个Transformer
本文来自I made a transformer by hand . 一直以来,笔者对 transformer 的注意力机制、qkv的理解都浮于表面,当然也不是说我看完 I made a transformer by hand 后理解有多深入,但确实加深了我对相关概念的理解,故搬运此文章,部分表述基于笔者的理解加以修改。
手动制做一个Transformer来预测一个简单的序列,权重没有通过训练,而是手动分配。
要完成这个Transformer,基本步骤为:
1、选择一个任务
2、设计模型
3、设计位置嵌入和词嵌入矩阵
4、设计一个transformer block
5、使用之前的词嵌入矩阵,投影出下一个token的logits
一、选择任务
预测序列 "aabaabaabaab..." (也就是说 (aab)* ),这需要查询前两个 token 来知道输出应该是 a (前两个 token 是 ab 或 ba )还是 b (前两个 token 是 aa )。
设计 tokenization
由于只需要考虑两个符号,我们使用了一个非常简单的方案,其中 a 表示 0 , b 表示 1
二、设计模型
基于picoGPT/gpt2.py. 架构图为:

2.1 选择模型维度
需要选择3个模型参数:
- Context length 上下文长度
- Vocabulary size 词汇量大小
- Embedding size 嵌入维度大小
Context length是模型一次能看到的最大标记数量。理论上这个任务只需要前两个标记——但这里我们选择 5,使其稍微困难一些,因为那样我们还需要忽略无关的标记。
Vocabulary size 是模型看到的不同token的数量。在一个实际模型中,泛化能力、需要学习的不同token的数量、上下文长度使用等方面存在权衡。然而,我们的任务要简单得多,我们只需要两个标记: a (0) 和 b (1)。
Embedding size 是模型为每个token/位置学习并内部使用的向量的尺寸,这里选择了 8.
三、设计位置嵌入和词嵌入矩阵
输入列表([0,1,0,…])转换为一个 seq_len x embedding_size 矩阵,该矩阵结合了每个词的位置和类型。于是我们需要设计 wte(token embeddings权重)和 wpe(position embeddings权重),为每个使用独热编码。
使用前五个元素用于独热向量,位置 0 将表示为 [1, 0, 0, 0, 0],位置 1 表示为 [0, 1, 0, 0, 0] ,依此类推,直到位置 4 表示为 [0, 0, 0, 0, 1] 。使用接下来的两个元素表示词嵌入独热向量, token a 将表示为 [1, 0] ,而 token b 将表示为 [0, 1] 。
MODEL = {"wte": np.array(# one-hot token embeddings[[0, 0, 0, 0, 0, 1, 0, 0], # token `a` (id 0)[0, 0, 0, 0, 0, 0, 1, 0], # token `b` (id 1)]),"wpe": np.array(# one-hot position embeddings[[1, 0, 0, 0, 0, 0, 0, 0], # position 0[0, 1, 0, 0, 0, 0, 0, 0], # position 1[0, 0, 1, 0, 0, 0, 0, 0], # position 2[0, 0, 0, 1, 0, 0, 0, 0], # position 3[0, 0, 0, 0, 1, 0, 0, 0], # position 4]),...: ...,
}
如果我们使用这种方案对整个序列 "aabaa" 进行编码,我们将得到以下形状为 5 x 8 ( seq_len x embedding_size ) 的嵌入矩阵。

四、设计transformer block
我们使用一个transformer block。block由两部分组成:一个注意力头和一个线性网络.线性网络将注意力结果矩阵投影回网络处理的 seq_len x embedding_size 矩阵。
4.1 设计注意力头
def attention(q, k, v, mask):return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v
- q, or “query” q ,或“查询”
- k, or “key” k ,或“键”
- v, or “value” v ,或“值”
- mask ,这是一个非学习参数,用于在训练过程中防止模型通过查看未来的标记来作弊
注意力权重定义在 c_attn中。
Lg = 1024 # LargeMODEL = {...: ...,"blocks": [{"attn": {"c_attn": { # generates qkv matrix"b": np.zeros(N_EMBED * 3),"w": np.array(# this is where the magic happens# fmt: off[[Lg, 0., 0., 0., 0., 0., 0., 0., # q1., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[Lg, Lg, 0., 0., 0., 0., 0., 0., # q0., 1., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., Lg, Lg, 0., 0., 0., 0., 0., # q0., 0., 1., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., Lg, Lg, 0., 0., 0., 0., # q0., 0., 0., 1., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., 0., Lg, Lg, 0., 0., 0., # q0., 0., 0., 0., 1., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 1.], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., -1], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v]# fmt: on),},...: ...,}}]
}
c_attn 只是一个常规的全连接层,维度为 embed_size x (embed_size * 3) 。当我们将其与上面计算的 seq_len x embed_size 嵌入矩阵相乘时,我们得到一个大小为 seq_len x (embed_size * 3) 的矩阵——称为 qkv 矩阵。然后我们将这个 qkv 矩阵分成 3 个大小为 seq_len x embed_size 的矩阵—— q 、 k 和 v 。
def causal_self_attention(x, c_attn, c_proj):# qkv projectionsx = linear(x, **c_attn) # split into qkvq, k, v = np.split(x, 3, axis=-1) ...
将序列"aabaa"的嵌入矩阵通过 c_attn 运行一下,看看会发生什么!嵌入矩阵:

并通过linear(x, **c_attn) 即 embedding * c_attn["w"] + c_attn["b"] 计算得到以下5 x 24 ( seq_len x (embed_size * 3) ) qkv 矩阵。(这里的粗线显示我们将在下一步将此矩阵在这些位置 split ):

从矩阵内容分析,k是从组合嵌入矩阵中分离出的1-hot position embedding, 可以将其理解为每个 token 所“提供”的内容——它的位置。
但 q 是什么?如果 k 是每个 token 所“提供”的内容,那么 q 就是每个 token 所“寻找”的内容。但这究竟意味着什么?
在注意力机制中,k 将被转置并与 q 相乘,产生一个 seq_len x seq_len 矩阵:
 当我们添加掩码并对整个结果进行 softmax 处理(
当我们添加掩码并对整个结果进行 softmax 处理( softmax(q @ k.T + mask) ),突然它就变得有意义了!

将每一行视为生成该行预测所需的信息(例如,行 0 是生成模型在看到第一个 token 后预测所需的信息),将每一列视为需要关注的 token 。此外,请记住掩码阻止模型看到未来!
这意味着第一个预测(第 0 行)无法关注任何除第一个之外的 token,因此它将 100%的注意力放在该 token 上。
但对于所有其他预测,模型至少有两个 token 可以关注,而对于 aabaabaab... 任务,它永远不会需要超过两个!因此,模型将对该 token 的注意力均匀分配给最新的两个可访问(未掩码)token。这意味着第二个 token 的预测(第 1 行)对 token 0 和 token 1 的注意力相同,第三个 token 的预测(第 2 行)对 token 1 和 token 2 的注意力相同,以此类推——所以我们看到两个非零单元格,每个单元格中都有 0.5 。
总结一下,这里的每一行代表模型在预测该位置的下一个 token时,对不同 token 位置的注意力——也就是说,预测第一个位置的下一个 token 时只能关注第一个 位置的 token ,预测第二个位置的下一个 token 时(即第三个 token )则在第一个和第二个 token 之间分配注意力,以此类推。也就是上面提到的q 是每个 token 所“寻找”的内容。
但 v 又如何呢?注意力的最后一步是将上面的矩阵与 v 相乘: softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v那么 v 是什么呢?
查看 v 部分,我们可以看到它只会有一个元素(第 7 列)被设置,当行是一个 a 时,该元素是 1 ,而当行是一个 b 时,该元素是 -1 。这意味着 v 中发生的事情就是将 one-hot 标记编码( a = [1, 0], b = [0, 1] )转换成 1 / -1 编码!
那可能听起来没什么用,但请记住我们的任务是预测 aabaab ,换句话说:
- 如果前一个词是(a,a),则预测 b
- 如果前一个词是(a,b),则预测 a
- 如果前一个词是(b,a),则预测 a
- 如果前一个词是(b,b),则错误,超出范围
既然我们可以安全地忽略(b,b)这种情况,因为它不在定义域内,这意味着我们只希望在所关注的 token 是相同的情况下预测 b !由于矩阵乘法涉及求和,这意味着我们可以利用加性抵消,换句话说: 0.5 + 0.5 = 1 ,和 0.5 + (-0.5) = 0 。
通过将 a 编码为 1 ,将 b 编码为 -1 ,这个简单的方程式正好实现了我们的目标。当 token 预测应该是 a 时,这个方程等于 0 ,当 token 预测应该是 b 时,这个方程等于 1 :
- a, b → 0.5 * 1 + 0.5 * (-1) = 0
- b, a → 0.5 * (-1) + 0.5 * 1 = 0
- a, a → 0.5 * 1 + 0.5 * 1 = 1
如果我们用之前的 softmax 结果矩阵乘以前面的分离出的 v 矩阵,并对每一行进行精确计算,我们得到输入序列 aabaa 的以下注意力结果:

第一行有一个虚假的 b 预测,因为它没有足够的数据(只有单个 a 作为依据,结果可能是 a 或 b )。但另外两个 b 预测是正确的:第二行预测下一个 token 应该是 b ,这是正确的;最后一行预测序列之后的token 也应该是 b ,这也是正确的。
所以总结来说, c_attn 权重的作用是:
- 将位置嵌入映射到
q中的“注意力窗口” - 提取
k中的位置嵌入 - 将词嵌入转换为
1/-1中的v词编码 - 当
q和k在softmax(q @ k.T / ... + mask)中结合时,我们得到一个seq_len x seq_len矩阵
在第一行中,仅关注第一个标记
在其他行结果中,平等地关注最后两个标记 - 最后,利用
softmax(...) @ v,我们通过加性抵消来获得
mask

这只是防止模型在常规梯度下降训练过程中“作弊”——如果没有这个掩码,模型会根据第二个词的值来生成第一个词的预测!通过添加负无穷大,我们强制将这些位置向下,使得从 softmax 输出的矩阵在所有掩码(即未来)的词位置上为 0。这迫使模型实际上学习如何预测这些位置,而不是通过提前查看来作弊。在我们的案例中,掩码没有起到作用,因为这个小制作的 Transformer 被设计成不会作弊,但保留掩码可以使事情更接近真实的 GPT-2 架构。
五、投影回嵌入空间
为了完成 transformer block,我们需要将注意力结果投影回一个常规的embedding。我们的注意力头将其预测放在 embedding[row, 7] ( 1 用于 b , 0 用于 a )
Lg = 1024 # LargeMODEL = {"wte": ...,"wpe": ...,"blocks": [{"attn": {"c_attn": ...,"c_proj": { # weights to project attn result back to embedding space"b": [0, 0, 0, 0, 0, Lg, 0, 0],"w": np.array([[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, -Lg, Lg, 0],]),},},},],
}
之前的结果通过 c_proj 运行注意力后,我们得到了这个矩阵:

原始嵌入加上上面 c_proj 的结果:

原始嵌入被添加是因为残差连接:在 transformer_block 中,我们执行 x = x + causal_self_attention(x, ...) (注意 x + ),而不是简单地执行 x = causal_self_attention(x, ...) 。
残差连接可以帮助深度网络通过多层保持信息流,但在我们的情况下它只会造成干扰。这就是为什么 c_proj 的输出被 1024 缩放:为了压制不需要的残差信号。
下一步是将上述矩阵乘以我们开头定义的转置的 token 嵌入权重( wte ),以得到最终的 logits:

softmax 后的最终预测:

换句话说,当给定上下文序列 aabaa 时,模型预测:
a之后的词是b(可接受,可能是)aa之后的词是b(正确!)aab后面的标记是a(正确!)aaba后面的标记是a(正确!)aabaa后面的标记是b(正确!)
当然,对于推理来说,我们关心的只是最终的预测行: b 跟随 aabaa 。其他的预测结果仅用于训练模型。
六、完整的代码
import numpy as npdef softmax(x):exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))return exp_x / np.sum(exp_x, axis=-1, keepdims=True)# [m, in], [in, out], [out] -> [m, out]
def linear(x, w, b):return x @ w + b# [n_q, d_k], [n_k, d_k], [n_k, d_v], [n_q, n_k] -> [n_q, d_v]
def attention(q, k, v, mask):return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v# [n_seq, n_embd] -> [n_seq, n_embd]
def causal_self_attention(x, c_attn, c_proj):# qkv projectionsx = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]# split into qkvq, k, v = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]# causal mask to hide future inputs from being attended tocausal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10 # [n_seq, n_seq]# perform causal self attentionx = attention(q, k, v, causal_mask) # [n_seq, n_embd] -> [n_seq, n_embd]# out projectionx = linear(x, **c_proj) # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]return x# [n_seq, n_embd] -> [n_seq, n_embd]
def transformer_block(x, attn):x = x + causal_self_attention(x, **attn)# NOTE: removed ffnreturn x# [n_seq] -> [n_seq, n_vocab]
def gpt(inputs, wte, wpe, blocks):# token + positional embeddingsx = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]# forward pass through n_layer transformer blocksfor block in blocks:x = transformer_block(x, **block) # [n_seq, n_embd] -> [n_seq, n_embd]# projection to vocabreturn x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]N_CTX = 5
N_VOCAB = 2
N_EMBED = 8Lg = 1024 # LargeMODEL = {# EMBEDDING USAGE# P = Position embeddings (one-hot)# T = Token embeddings (one-hot, first is `a`, second is `b`)# V = Prediction scratch space## [P, P, P, P, P, T, T, V]"wte": np.array(# one-hot token embeddings[[0, 0, 0, 0, 0, 1, 0, 0], # token `a` (id 0)[0, 0, 0, 0, 0, 0, 1, 0], # token `b` (id 1)]),"wpe": np.array(# one-hot position embeddings[[1, 0, 0, 0, 0, 0, 0, 0], # position 0[0, 1, 0, 0, 0, 0, 0, 0], # position 1[0, 0, 1, 0, 0, 0, 0, 0], # position 2[0, 0, 0, 1, 0, 0, 0, 0], # position 3[0, 0, 0, 0, 1, 0, 0, 0], # position 4]),"blocks": [{"attn": {"c_attn": { # generates qkv matrix"b": np.zeros(N_EMBED * 3),"w": np.array(# this is where the magic happens# fmt: off[[Lg, 0., 0., 0., 0., 0., 0., 0., # q1., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[Lg, Lg, 0., 0., 0., 0., 0., 0., # q0., 1., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., Lg, Lg, 0., 0., 0., 0., 0., # q0., 0., 1., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., Lg, Lg, 0., 0., 0., 0., # q0., 0., 0., 1., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., 0., Lg, Lg, 0., 0., 0., # q0., 0., 0., 0., 1., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 1.], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., -1], # v[0., 0., 0., 0., 0., 0., 0., 0., # q0., 0., 0., 0., 0., 0., 0., 0., # k0., 0., 0., 0., 0., 0., 0., 0.], # v]# fmt: on),},"c_proj": { # weights to project attn result back to embedding space"b": [0, 0, 0, 0, 0, Lg, 0, 0],"w": np.array([[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, -Lg, Lg, 0],]),},},}],
}CHARS = ["a", "b"]
def tokenize(s): return [CHARS.index(c) for c in s]
def untok(tok): return CHARS[tok]def predict(s):tokens = tokenize(s)[-5:]logits = gpt(np.array(tokens), **MODEL)probs = softmax(logits)for i, tok in enumerate(tokens):pred = np.argmax(probs[i])print(f"{untok(tok)} ({tok}): next={untok(pred)} ({pred}) probs={probs[i]} logits={logits[i]}")return np.argmax(probs[-1])def complete(s, max_new_tokens=10):tokens = tokenize(s)while len(tokens) < len(s) + max_new_tokens:logits = gpt(np.array(tokens[-5:]), **MODEL)probs = softmax(logits)pred = np.argmax(probs[-1])tokens.append(pred)return s + " :: " + "".join(untok(t) for t in tokens[len(s):])test = "aab" * 10
total, correct = 0, 0
for i in range(2, len(test) - 1):ctx = test[:i]expected = test[i]total += 1if untok(predict(ctx)) == expected:correct += 1
print(f"ACCURACY: {correct / total * 100}% ({correct} / {total})")
相关文章:
手动制做一个Transformer
本文来自I made a transformer by hand . 一直以来,笔者对 transformer 的注意力机制、qkv的理解都浮于表面,当然也不是说我看完 I made a transformer by hand 后理解有多深入,但确实加深了我对相关概念的理解,故搬运此文章&…...

已解决——如何让网站实现HTTPS访问?
一、申请SSL证书 SSL证书是HTTPS实现的关键,它由受信任的证书颁发机构(CA)签发,用于验证网站的身份并加密数据传输。以下是申请SSL证书的常见步骤: 选择证书类型 根据网站的需求和预算,选择合适的SSL证书…...

WebRTC技术EasyRTC嵌入式音视频通信SDK助力智能电视搭建沉浸式实时音视频交互
一、方案概述 EasyRTC是一款基于WebRTC技术的开源实时音视频通信解决方案,具备低延迟、高画质、跨平台等优势。将EasyRTC功能应用于智能电视,能够为用户带来全新的交互体验,满足智能电视在家庭娱乐、远程教育、远程办公、远程医疗等多种场…...

Unreal Engine: Windows 下打包 AirSim项目 为 Linux 平台项目
环境: Windows: win10, UE4.27, Visual Studio 2022 Community.Linux: 22.04 windows环境安装教程: 链接遇到的问题(问题:解决方案) 点击Linux打包按钮,跳转至网页而不是执行打包流程:用VS打开项…...

Spring MVC HttpMessageConverter 的作用是什么?
HttpMessageConverter (HTTP 消息转换器) 是 Spring MVC 框架中一个非常核心的组件,它的主要作用是在 HTTP 请求、响应体与 Java 对象之间进行双向转换。 核心作用: 读取请求体 (Request Body) 到 Java 对象: 当 Controller 方法的参数使用 …...
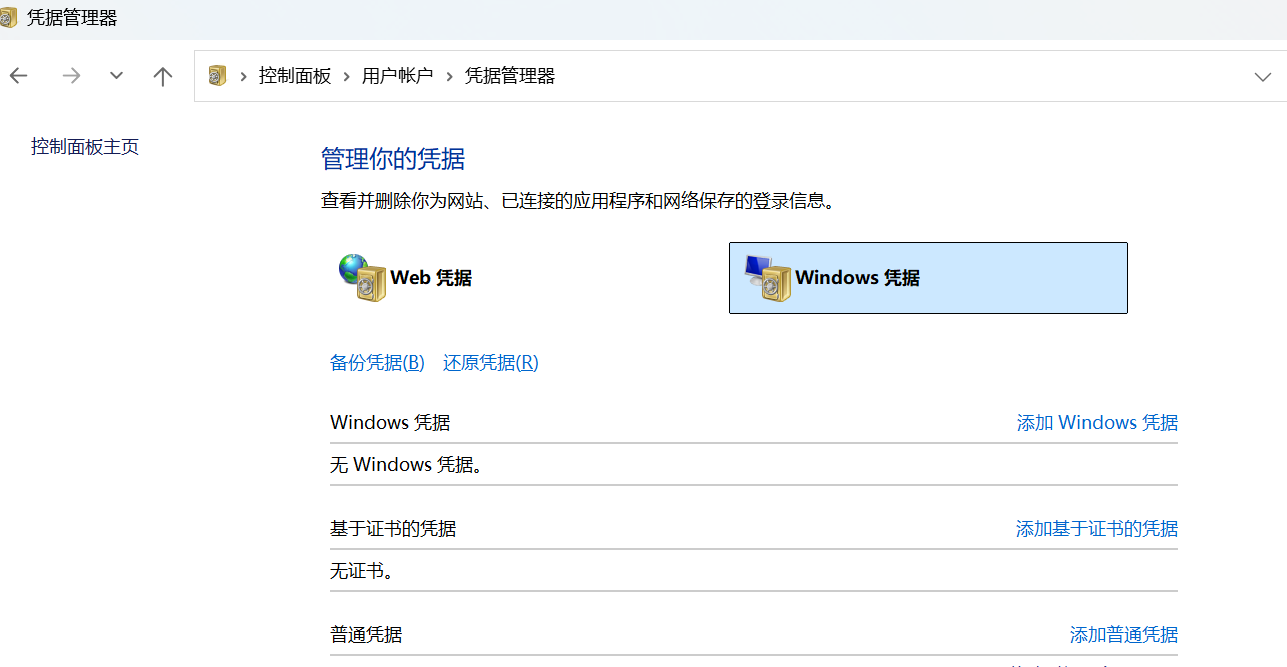
小乌龟git中的推送账户、作者账户信息修改
文章目录 修改git文档作者信息修改git推送用户信息参考文献 修改git文档作者信息 小乌龟中的用户信息为:作者信息,并非推送用户。 上边用户信息,修改的是文件的作者信息。如果想要修改git服务中记录的推送用户信息需要修改推送用户信息。 …...
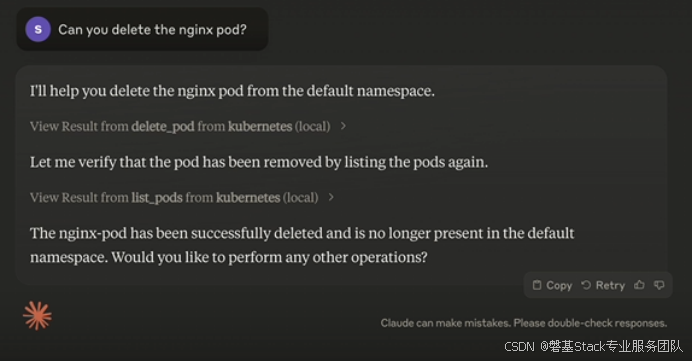
Kubernetes MCP服务器(K8s MCP):如何使用?
#作者:曹付江 文章目录 1、什么是 Kubernetes MCP 服务器?1.1、K8s MCP 服务器 2、开始前的准备工作2.1. Kubernetes集群2.2. 安装并运行 kubectl2.3. Node.js 和 Bun2.4. (可选)Helm v3 3、如何设置 K8s MCP 服务器3.1. 克隆存储…...

Node.js聊天室开发:从零到上线的完整指南
为让你全面了解Node.js聊天室开发,我会先介绍开发背景与技术栈,再按搭建项目、实现核心功能、部署上线的流程展开,还会分享优化思路。 Node.js聊天室开发实战:从入门到上线 在即时通讯日益普及的今天,基于Node.js搭建…...
R²AIN SUITE 亮相第九届智能工厂高峰论坛
2025年5月16日,在圆满落幕的第九届智能工厂高峰论坛上,上海比孚信息科技有限公司携自主研发的 RAIN SUITE 企业AI应用中台解决方案亮相展会。本次论坛以"从互联工厂到智慧工厂"为主题,吸引了400余位行业专家、制造企业代表及产业链…...

深入理解仿函数(Functors):从概念到实践
文章目录 1. 什么是仿函数?2. 仿函数与普通函数的区别3. 标准库中的仿函数4. 仿函数的优势4.1 状态保持4.2 可定制性4.3 性能优势 5. 现代C中的仿函数5.1 Lambda表达式5.2 通用仿函数 6. 仿函数的高级应用(使用C2020标准库及以上版本)6.1 函数…...
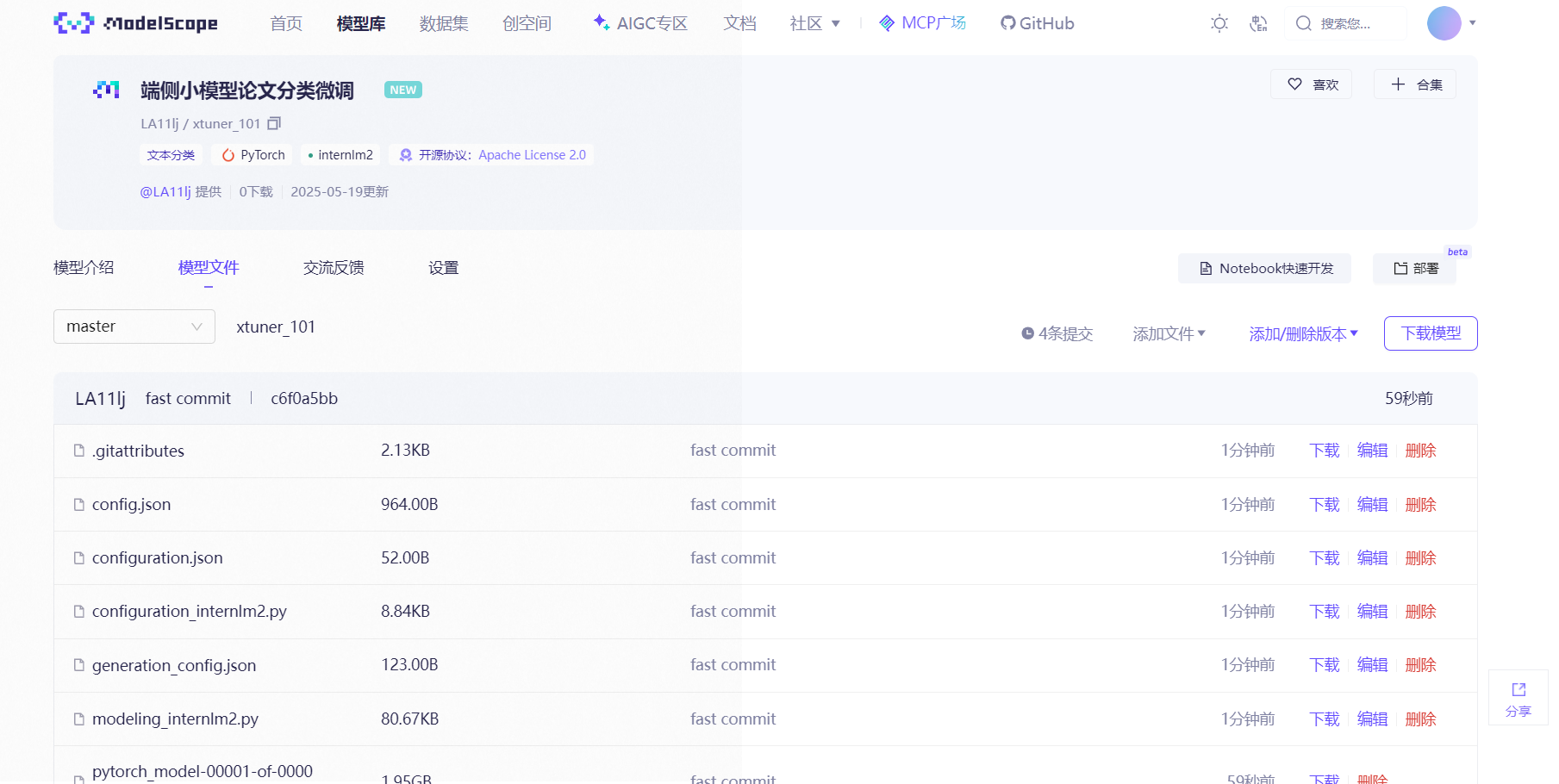
InternLM 论文分类微调实践(XTuner 版)
1.环境安装 我创建开发机选择镜像为Cuda12.2-conda,选择GPU为100%A100的资源配置 Conda 管理环境 conda create -n xtuner_101 python3.10 -y conda activate xtuner_101 pip install torch2.4.0cu121 torchvision torchaudio --extra-index-url https://downloa…...

《Python星球日记》 第88天:ChatGPT 与 LangChain
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、ChatGPT 简介1. 如何与ChatGPT交互?2. Prompt Engineering 的技巧二、LangChain框架1. 什么是LangChain?2. LangChain的核心组件3. 如何使…...
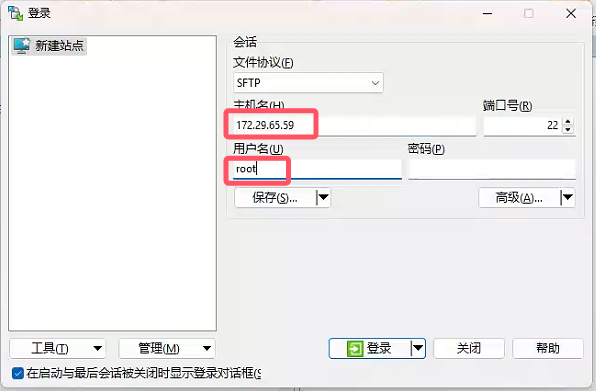
PC:使用WinSCP密钥文件连接sftp服务器
1. 打开winscp工具,点击“标签页”->“新标签页” 2. 点击“高级"->“高级” 3. 点击"验证"->“选择密钥文件” 选择ppk文件,如果没有ppk文件选择pem文件,会自动生成ppk文件 点击确定 4. 输入要连接到的sftp服务器的…...

1688正式出海,1688跨境寻源通接口接入,守卫的是国内工厂资源
在1688平台的跨境招商直播中,许多想要进入跨境市场的初学者商家纷纷提问:货通全球的入口在哪里?小白商家应该如何操作?商品为何上传失败? 从表面上看,这似乎是1688平台在拓展海外市场的一次积极“进攻”。…...

力扣303 区域和检索 - 数组不可变
文章目录 题目介绍题解 题目介绍 题解 不用管第一个null,从第二个开始看就可以 法一:暴力解法 class NumArray {private int[] nums;public NumArray(int[] nums) {this.nums nums;}public int sumRange(int left, int right) {int res 0;for (int i…...

Spring的后置处理器是干什么用的?扩展点又是什么?
Spring 的后置处理器和扩展点是其框架设计的核心机制,它们为开发者提供了灵活的扩展能力,允许在 Bean 的生命周期和容器初始化过程中注入自定义逻辑。 1. 后置处理器(Post Processors) 后置处理器是 Spring 中用于干预 Bean 生命…...
[ linux-系统 ] 进程地址空间
验证地址空间 父子进程的变量值不同但是地址相同,说明该地址绝对不是物理地址 我们叫这种地址为虚拟地址/线性地址 分析与结论 上述实验表明,父子进程的变量地址相同但内容不同,说明地址为虚拟地址,且父子进程有各自独立的物理…...
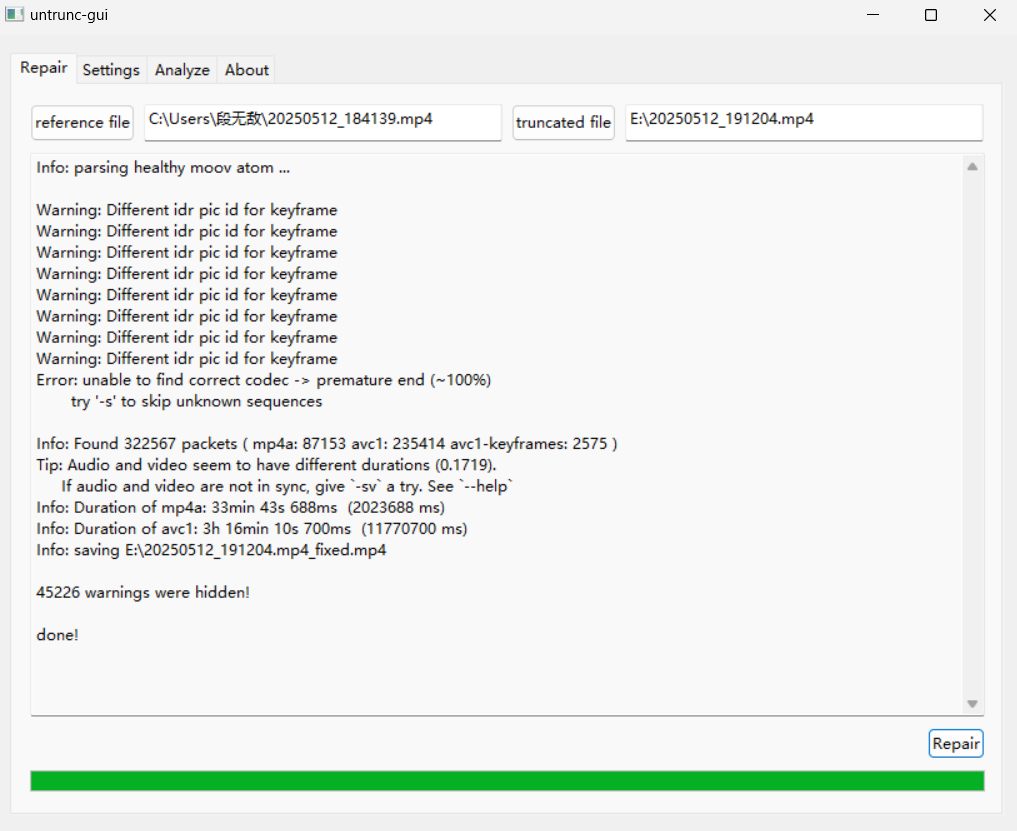
文件名是 E:\20250512_191204.mp4, EV软件录屏,未保存直接关机损坏, 如何修复?
去github上下载untrunc 工具就能修复 https://github.com/anthwlock/untrunc/releases 如果访问不了 本机的 hosts文件设置 140.82.112.3 github.com 199.232.69.194 github.global.ssl.fastly.net 就能访问了 实在不行,从这里下载,传上去了 https://do…...

Java常见API文档(下)
格式化的时间形式的常用模式对应关系如下: 空参构造创造simdateformate对象,默认格式 练习.按照指定格式展示 package kl002;import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date;public class Date3 {publi…...

DRIVEGPT4: 通过大语言模型实现可解释的端到端自动驾驶
《DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model》 2024年10月发表,来自香港大学、浙江大学、华为和悉尼大学。 多模态大型语言模型(MLLM)已成为研究界关注的一个突出领域,因为它们擅长处理…...
与大语言模型(LLM))
知识图谱(KG)与大语言模型(LLM)
知识图谱(KG)以其结构化的知识表示和推理能力,为大语言模型(LLM)的“幻觉”、知识更新滞后和可解释性不足等问题提供了有力的解决方案。反过来,LLM的强大文本理解和生成能力也为KG的构建、补全、查询和应用…...
构建共有语料库 - Wiki 语料库
中文Wiki语料库主要指的是从中文Wikipedia(中文维基百科)提取的文本数据。维基百科是一个自由的、开放编辑的百科全书项目,覆盖了从科技、历史到文化、艺术等广泛的主题。 对于基于RAG的应用来说,把Wiki语料作为一个公有的语料库…...
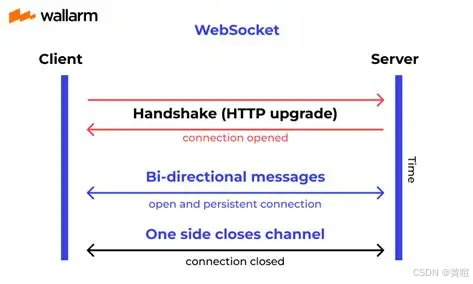
苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能
🚀 苍穹外卖项目中的 WebSocket 实战:实现来单与催单提醒功能 在现代 Web 应用中,实时通信成为提升用户体验的关键技术之一。WebSocket 作为一种在单个 TCP 连接上进行全双工通信的协议,被广泛应用于需要实时数据交换的场景&#…...
:移情阶段的深度博弈——如何避开客户访谈的认知陷阱)
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱
精益数据分析(59/126):移情阶段的深度博弈——如何避开客户访谈的认知陷阱 在创业的移情阶段,客户访谈是挖掘真实需求的核心手段,但人类认知偏差往往导致数据失真。今天,我们结合《精益数据分析》的方法论…...
Win10 安装单机版ES(elasticsearch),整合IK分词器和安装Kibana
一. 先查看本机windows是否安装了ES(elasticsearch),检查方法如下: 检查进程 按 Ctrl Shift Esc 组合键打开 “任务管理器”。在 “进程” 选项卡中,查看是否有 elasticsearch 相关进程。如果有,说明系统安装了 ES。 检查端口…...

Ansible模块——主机名设置和用户/用户组管理
设置主机名 ansible.builtin.hostname: name:要设置的主机名 use:更新主机名的方式(默认会自动选择,不指定的话,物理机一般不会有问题,容器可能会有问题,一般是让它默认选择) syst…...

【Redis】List 列表
文章目录 初识列表常用命令lpushlpushxlrangerpushrpushxlpop & rpoplindexlinsertllen阻塞操作 —— blpop & brpop 内部编码应用场景 初识列表 列表类型,用于存储多个字符串。在操作和实现上,类似 C 的双端队列,支持随机访问(O(N)…...
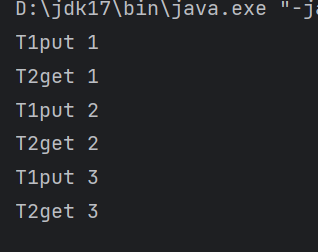
JUC入门(四)
ReadWriteLock 代码示例: package com.yw.rw;import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.ReentrantReadWriteLock;public class ReadWriteDemo {public static void main(String[] args) {MyCache myCache new MyCache…...
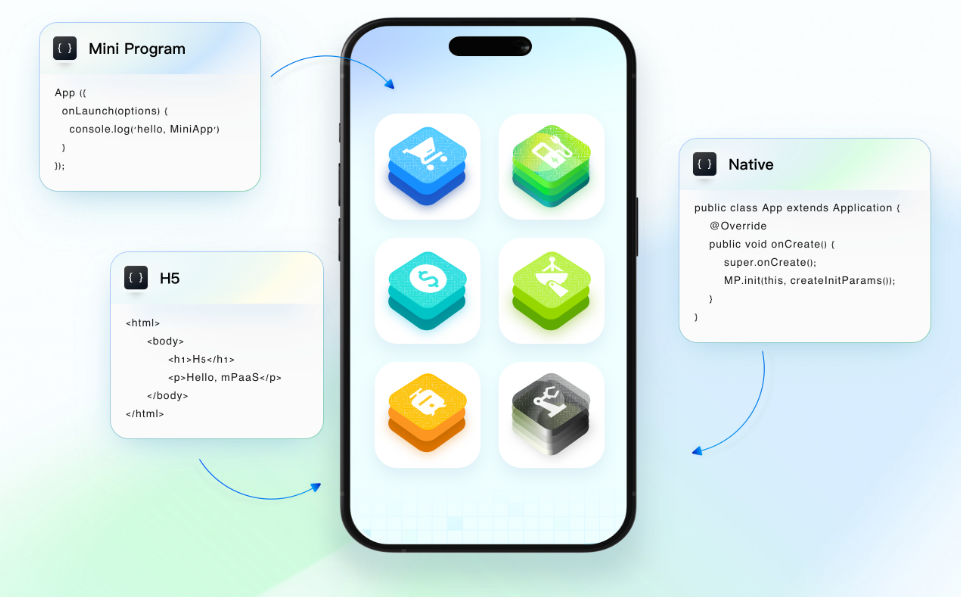
【HarmonyOS 5】鸿蒙mPaaS详解
【HarmonyOS 5】鸿蒙mPaaS详解 一、mPaaS是什么? mPaaS 是 Mobile Platform as a Service 的缩写,即移动开发平台。 蚂蚁移动开发平台mPaaS ,融合了支付宝科技能力,可以为移动应用开发、测试、运营及运维提供云到端的一站式解决…...

多线BGP服务器优化实践与自动化运维方案
背景:企业级网络架构中的线路选择难题 在分布式业务部署场景下,如何通过三网融合BGP服务器实现低延迟、高可用访问?本文以某电商平台流量调度优化为案例,解析动态BGP服务器的实战价值。 技术方案设计 核心架构:采用…...