排序算法之线性时间排序:计数排序,基数排序,桶排序详解
排序算法之线性时间排序:计数排序、基数排序、桶排序详解
- 前言
- 一、计数排序(Counting Sort)
- 1.1 算法原理
- 1.2 代码实现(Python)
- 1.3 性能分析
- 1.4 适用场景
- 二、基数排序(Radix Sort)
- 2.1 算法原理
- 2.2 代码实现(Java)
- 2.3 性能分析
- 2.4 适用场景
- 三、桶排序(Bucket Sort)
- 3.1 算法原理
- 3.2 代码实现(C++)
- 3.3 性能分析
- 3.4 适用场景
- 四、三种线性时间排序算法的对比与应用选择
- 总结
前言
在排序算法的大家族中,比较排序算法(如快速排序、归并排序等)的时间复杂度下限为 O ( n log n ) O(n \log n) O(nlogn)。而线性时间排序算法另辟蹊径,在特定条件下能够实现 O ( n ) O(n) O(n)的时间复杂度,大大提高了排序效率。本文我将深入介绍计数排序、基数排序和桶排序这三种典型的线性时间排序算法,从原理、实现到性能分析,结合具体代码示例,带大家全面了解它们的应用场景与优势。
一、计数排序(Counting Sort)
1.1 算法原理
计数排序是一种非比较排序算法,它适用于待排序元素的取值范围相对较小的情况。其核心思想是:统计每个元素在数组中出现的次数,然后根据统计结果将元素依次放置到正确的位置上。
具体步骤如下:
确定范围:找出待排序数组中的最大值 m a x max max和最小值 m i n min min,计算出元素的取值范围 r a n g e = m a x − m i n + 1 range = max - min + 1 range=max−min+1。
统计计数:创建一个长度为 r a n g e range range的计数数组 c o u n t count count,用于统计每个元素出现的次数。遍历待排序数组,将每个元素 n u m num num对应的 c o u n t [ n u m − m i n ] count[num - min] count[num−min]的值加 1。
累计计数:对计数数组 c o u n t count count进行累计操作,即 c o u n t [ i ] = c o u n t [ i ] + c o u n t [ i − 1 ] count[i] = count[i] + count[i - 1] count[i]=count[i]+count[i−1]( i > 0 i > 0 i>0),此时 c o u n t [ i ] count[i] count[i]表示小于等于 i + m i n i + min i+min的元素个数。
排序输出:创建一个与原数组长度相同的结果数组 o u t p u t output output,倒序遍历原数组,根据 c o u n t count count数组确定每个元素在 o u t p u t output output数组中的位置,并将元素放入,同时将 c o u n t count count数组中对应的值减 1。

1.2 代码实现(Python)
def counting_sort(arr):if not arr:return arrmax_val = max(arr)min_val = min(arr)range_val = max_val - min_val + 1count = [0] * range_valfor num in arr:count[num - min_val] += 1for i in range(1, range_val):count[i] += count[i - 1]output = [0] * len(arr)for num in reversed(arr):output[count[num - min_val] - 1] = numcount[num - min_val] -= 1return output
上述 Python 代码首先计算出元素的取值范围,创建计数数组并统计每个元素的出现次数,然后进行累计计数,最后根据计数结果将元素放入结果数组中,完成排序。
1.3 性能分析
时间复杂度:计数排序的时间复杂度为 O ( n + k ) O(n + k) O(n+k),其中 n n n是待排序数组的长度, k k k是元素的取值范围。当 k k k与 n n n同阶或 k k k相对 n n n较小时,算法的时间复杂度接近 O ( n ) O(n) O(n),表现出高效性。
空间复杂度:计数排序需要额外的计数数组和结果数组,空间复杂度为 O ( n + k ) O(n + k) O(n+k)。
稳定性:计数排序是稳定的排序算法,因为在将元素放入结果数组时,是按照原数组的顺序倒序处理的,相同元素的相对顺序不会改变。
1.4 适用场景
计数排序适用于元素取值范围有限且相对较小的场景,例如对学生成绩(分数范围通常固定)进行排序,或者对一定范围内的整数进行排序等。
二、基数排序(Radix Sort)
2.1 算法原理
基数排序也是一种非比较排序算法,它基于数字的每一位(如个位、十位、百位等)进行排序。基数排序从最低位开始,依次对每一位数字进行排序,直到最高位排序完成,最终得到有序数组。
具体步骤如下(以十进制整数为例):
确定位数:找出待排序数组中最大的数,确定其位数 d d d,例如最大数是 987 987 987,则 d = 3 d = 3 d=3。
按位排序:从个位(第 0 位)开始,依次对每一位进行排序。对于每一位,使用计数排序或其他稳定排序算法,根据该位数字的大小将元素分配到不同的桶中,然后按照桶的顺序依次取出元素,形成新的数组。重复这个过程,直到最高位排序完成。

2.2 代码实现(Java)
import java.util.ArrayList;
import java.util.List;public class RadixSort {public static int[] radixSort(int[] arr) {if (arr == null || arr.length == 0) {return arr;}int max = getMax(arr);for (int exp = 1; max / exp > 0; exp *= 10) {countingSort(arr, exp);}return arr;}private static int getMax(int[] arr) {int max = arr[0];for (int num : arr) {if (num > max) {max = num;}}return max;}private static void countingSort(int[] arr, int exp) {int[] output = new int[arr.length];int[] count = new int[10];for (int num : arr) {count[(num / exp) % 10]++;}for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}for (int i = arr.length - 1; i >= 0; i--) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10]--;}System.arraycopy(output, 0, arr, 0, arr.length);}public static void main(String[] args) {int[] arr = {170, 45, 75, 90, 802, 24, 2, 66};int[] sortedArr = radixSort(arr);for (int num : sortedArr) {System.out.print(num + " ");}}
}
在上述 Java 代码中,radixSort方法首先找到数组中的最大值,确定排序的位数。然后通过循环,从个位开始,每次调用countingSort方法对当前位进行排序,最终完成整个数组的排序。
2.3 性能分析
时间复杂度:假设待排序数组的长度为 n n n,元素的最大位数为 d d d,每一位上元素的取值范围为 k k k(如十进制中 k = 10 k = 10 k=10)。基数排序需要对每一位进行排序,每次排序的时间复杂度为 O ( n + k ) O(n + k) O(n+k),总共进行 d d d次,所以时间复杂度为 O ( d ( n + k ) ) O(d(n + k)) O(d(n+k))。当 d d d和 k k k相对固定时,时间复杂度接近 O ( n ) O(n) O(n)。
空间复杂度:基数排序在每一位排序时需要额外的计数数组和临时数组,空间复杂度为 O ( n + k ) O(n + k) O(n+k)。
稳定性:由于在每一位排序时使用的是稳定排序算法(如计数排序),所以基数排序是稳定的排序算法。
2.4 适用场景
基数排序适用于对整数进行排序,特别是当整数的位数相对固定且取值范围不是特别大时,效果较好。例如对身份证号码、银行卡号等固定长度的数字序列进行排序。
三、桶排序(Bucket Sort)
3.1 算法原理
桶排序的基本思想是将待排序数组分到有限数量的桶子里,每个桶子再分别进行排序(可以使用其他排序算法,如插入排序),最后将各个桶中的元素依次取出,得到有序数组。
具体步骤如下:
确定桶的数量和范围:根据待排序数组的特点,确定桶的数量 m m m。同时,找出数组中的最大值 m a x max max和最小值 m i n min min,计算每个桶的范围 r a n g e = ( m a x − m i n + 1 ) / m range = (max - min + 1) / m range=(max−min+1)/m。
分配元素到桶中:遍历待排序数组,根据元素的值将其分配到对应的桶中。通常可以通过公式 i n d e x = ( n u m − m i n ) / r a n g e index = (num - min) / range index=(num−min)/range计算元素应该放入的桶的索引。
对每个桶进行排序:使用合适的排序算法(如插入排序)对每个桶中的元素进行排序。
合并桶中元素:按照桶的顺序,依次将每个桶中的元素取出,放入结果数组中,得到最终的有序数组。

3.2 代码实现(C++)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;void bucketSort(vector<double>& arr) {int n = arr.size();if (n == 0) return;vector<vector<double>> buckets(10);double max_val = *max_element(arr.begin(), arr.end());double min_val = *min_element(arr.begin(), arr.end());double range = (max_val - min_val + 1) / 10;for (double num : arr) {int index = (num - min_val) / range;buckets[index].push_back(num);}for (auto& bucket : buckets) {sort(bucket.begin(), bucket.end());}arr.clear();for (const auto& bucket : buckets) {for (double num : bucket) {arr.push_back(num);}}
}
上述 C++ 代码中,首先确定桶的数量为 10,计算每个桶的范围,然后将元素分配到对应的桶中。接着使用std::sort函数对每个桶中的元素进行排序,最后将各个桶中的元素合并到原数组中,完成排序。
3.3 性能分析
时间复杂度:桶排序的时间复杂度与桶的数量、每个桶中元素的数量以及桶内使用的排序算法有关。如果桶的数量合理,且每个桶中的元素数量较少,桶内排序时间复杂度较低,整体时间复杂度可以接近 O ( n ) O(n) O(n)。但在最坏情况下,所有元素都分配到同一个桶中,此时时间复杂度退化为桶内排序算法的最坏时间复杂度(如使用插入排序时为 O ( n 2 ) O(n^2) O(n2))。
空间复杂度:桶排序需要额外的空间存储桶和桶内的元素,空间复杂度为 O ( n + m ) O(n + m) O(n+m),其中 m m m是桶的数量。
稳定性:如果桶内使用的是稳定排序算法,那么桶排序是稳定的排序算法。
3.4 适用场景
桶排序适用于数据分布较为均匀的情况,例如对大量的浮点数进行排序,或者对一定范围内的整数,且数据分布比较分散时,桶排序能够发挥较好的性能。
四、三种线性时间排序算法的对比与应用选择
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|
| 计数排序 | O ( n + k ) O(n + k) O(n+k) | O ( n + k ) O(n + k) O(n+k) | 稳定 | 元素取值范围有限且较小 |
| 基数排序 | O ( d ( n + k ) ) O(d(n + k)) O(d(n+k)) | O ( n + k ) O(n + k) O(n+k) | 稳定 | 对整数排序,位数固定且取值范围不大 |
| 桶排序 | 理想 O ( n ) O(n) O(n),最坏 O ( n 2 ) O(n^2) O(n2) | O ( n + m ) O(n + m) O(n+m) | 取决于桶内算法 | 数据分布均匀的场景 |
在实际应用中,应根据数据的特点(如数据类型、取值范围、分布情况等)来选择合适的线性时间排序算法。如果数据满足相应算法的适用条件,线性时间排序算法能够带来比比较排序算法更高的效率,在处理大规模数据时具有显著优势。
总结
计数排序、基数排序和桶排序作为线性时间排序算法的代表,通过独特的设计思路突破了比较排序的时间限制,在特定场景下展现出高效性。它们的原理、实现方式和适用场景各有不同,理解并掌握这些算法,能够帮助我们在面对不同的排序需求时,选择最合适的解决方案。随着数据规模的不断增大,线性时间排序算法的应用价值也将愈发凸显,值得我们深入学习和研究。
That’s all, thanks for reading!
创作不易,点赞鼓励;
知识无价,收藏备用;
持续精彩,关注不错过!
相关文章:
排序算法之线性时间排序:计数排序,基数排序,桶排序详解
排序算法之线性时间排序:计数排序、基数排序、桶排序详解 前言一、计数排序(Counting Sort)1.1 算法原理1.2 代码实现(Python)1.3 性能分析1.4 适用场景 二、基数排序(Radix Sort)2.1 算法原理2…...
Linux | mdadm 创建软 RAID
注:本文为 “Linux mdadm RAID” 相关文章合辑。 略作重排,未整理去重。 如有内容异常,请看原文。 Linux 下用 mdadm 创建软 RAID 以及避坑 喵ฅ・ﻌ・ฅ Oct 31, 2023 前言 linux 下组软 raid 用 mdadm 命令,multi…...

物联网工程毕业设计课题实践指南
1. 智能家居控制系统 1.1 基于ZigBee的智能家居控制 实践过程 硬件选型主控:CC2530/CC2531传感器:温湿度、光照、人体红外执行器:继电器、电机、LED灯系统架构 A[传感器层] --> B[ZigBee网络] B --> C[网关] C --> D[云平台] D --> E[手机APP] 开…...

CodeEdit:macOS上一款可以让Xcode退休的IDE
CodeEdit 是一款轻量级、原生构建的代码编辑器,完全免费且开源。它使用纯 swift 实现,而且专为 macOS 设计,旨在为开发者提供更高效、更可靠的编程环境,同时释放 Mac 的全部潜力。 Stars 数21,719Forks 数1,081 主要特点 macOS 原…...
LLaMA-Factory 微调 Qwen2-7B-Instruct
一、系统环境 使用的 autoDL 算力平台 1、下载基座模型 pip install -U huggingface_hub export HF_ENDPOINThttps://hf-mirror.com # (可选)配置 hf 国内镜像站huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat -…...

mac本地docker镜像上传指定虚拟机
在Mac本地将Docker镜像上传至指定虚拟机的完整步骤 1. 在Mac本地保存Docker镜像为文件 通过docker save命令将镜像打包为.tar文件,便于传输至虚拟机。 # 示例:保存名为"my_image"的镜像到当前目录 docker save -o my_image.tar my_image:ta…...
从代码学习深度学习 - 风格迁移 PyTorch版
文章目录 前言方法 (Methodology)阅读内容和风格图像预处理和后处理抽取图像特征定义损失函数内容损失 (Content Loss)风格损失 (Style Loss)全变分损失 (Total Variation Loss)总损失函数初始化合成图像训练模型总结前言 大家好!欢迎来到我们的深度学习代码学习系列。今天,…...

软件设计师考试《综合知识》设计模式之——工厂模式与抽象工厂模式考点分析
软件设计师考试《综合知识》工厂模式与抽象工厂模式考点分析 1. 分值占比与考察趋势(75分制) 年份题量分值占总分比例核心考点2023111.33%抽象工厂模式适用场景2022222.67%工厂方法 vs 抽象工厂区别2021111.33%工厂方法模式结构2020111.33%简单工厂模式…...

轻量级离线版二维码工具的技术分析与开发指南
摘要 本文介绍一款基于本地化运行的轻量级二维码处理工具。该工具采用标准QR Code规范实现,具备完整的生成与识别功能。通过实测验证其核心功能表现及适用场景。 主要功能模块分析 编码生成模块:支持文本/URL等多种数据类型转换;提供尺寸调…...

中级网络工程师知识点4
1.Portal认证:可以以网页的形式为用户提供身份认证和个性化信息服务。如台式电脑,笔记本,手机等智能终端 2.MAC认证:无法安装和使用802.1X客户端软件的终端,如打印机,门禁等非智能终端 3.CAPWAP隧道&…...
机器学习--特征工程具体案例
一、数据集介绍 sklearn库中的玩具数据集,葡萄酒数据集。在前两次发布的内容《机器学习基础中》有介绍。 1.1葡萄酒列标签名: wine.feature_names 结果: [alcohol, malic_acid, ash, alcalinity_of_ash, magnesium, total_phenols, flavanoi…...

LeetCode 每日一题 2025/5/12-2025/5/18
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 5/12 2094. 找出 3 位偶数5/13 3335. 字符串转换后的长度 I5/14 3337. 字符串转换后的长度 II5/15 2900. 最长相邻不相等子序列 I5/16 2901. 最长相邻不相等子序列 II5/17 …...

Unreal 从入门到精通之SceneCaptureComponent2D实现UI层3D物体360°预览
文章目录 前言SceneCaptureComponent2D实现步骤新建渲染目标新建材质UI控件激活3DPreview鼠标拖动旋转模型最后前言 我们在(电商展示/角色预览/装备查看)等应用场景中,经常会看到这种3D展示的页面。 即使用相机捕获一个3D的模型的视图,然后把这个视图显示在一个UI画布上,…...
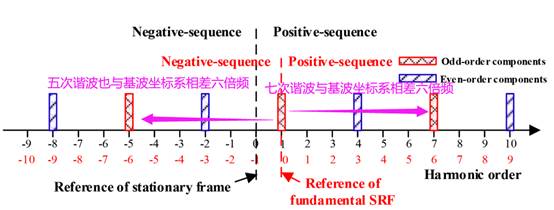
电机控制杂谈(25)——为什么对于一般PMSM系统而言相电流五、七次谐波电流会比较大?
1. 背景 最近都在写论文回复信。有个审稿人问了一个问题——为什么对于一般PMSM系统而言相电流五、七次谐波电流会比较大?同时,为什么相电流五、七次谐波电流会在dq基波旋转坐标系构成六次谐波电流? 回答这个问题挺简单的,但在网…...

多模态大语言模型arxiv论文略读(七十八)
AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction ➡️ 论文标题:AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction ➡️ 论文作者:Zhen Xing, Qi Dai, Zejia Weng, Zuxuan W…...

项目中把webpack 打包改为vite 打包
项目痛点: 老vu e-cli1创建的项目,项目是ERP系统集成了很多很多管理,本地运行调试的时候,每次修改代码都需要等待3分钟左右的编译时间,严重影响开发效率. 解决方案: 采用vite构建项目工程 方案执行 第一步 使用vite脚手架构件一个项目,然后把build文件自定义的编译逻辑般到…...

【C语言】易错题 经典题型
出错原因:之前运行起来的可执行程序没有关闭 关闭即可 平均数(average) 输入3个整数,输出它们的平均值,保留3位小数。 #include <stdio.h> int main() {int a, b, c;scanf("%d %d %d", &a, &…...

哈夫曼编码:数据压缩的优雅艺术
哈夫曼编码:数据压缩的优雅艺术 在数字信息时代,数据压缩技术扮演着至关重要的角色。其中,哈夫曼编码(Huffman Coding)作为一种经典的无损压缩算法,以其简洁优雅的设计和卓越的压缩效率而闻名。本文将通过…...
说一说Node.js高性能开发中的I/O操作
众所周知,在软件开发的领域中,输入输出(I/O)操作是程序与外部世界交互的重要环节,比如从文件读取数据、向网络发送请求等。这段时间,也指导项目中一些项目的开发工作,发现在Node.js运用中&#…...

扫描网络内所有设备的IP地址
arp 命令本身不能直接列出网络中所有 IP 地址,它只能显示本机 ARP 缓存中已知的 IP-MAC 映射,即:本机通信过的设备。 如果你想查询局域网中所有在线的 IP 地址,需要配合 ping 扫描或使用更强大的工具。以下是几种常见的方法&…...

web3 前端常见错误类型以及错误捕获处理
在Web3前端开发中,常见的错误类型包括用户拒绝交易、RPC节点超时、网络连接问题、智能合约调用错误等。正确捕获这些错误并提供友好的用户提示是提升用户体验的关键。以下是一些常见的Web3前端错误类型及其处理方法: 1. 用户拒绝交易 根据错误码 4001 …...

应用层协议简介:以 HTTP 和 MQTT 为例
文章目录 应用层协议简介:什么是应用层协议?为什么需要应用层协议?什么是应用层协议?为什么需要应用层协议? HTTP 协议详解HTTP 协议特点HTTP 工作的基本原理HTTP 请求与响应示例为什么 Web 应用基于 HTTP 请求&#x…...
LeetCode 39. 组合总和 LeetCode 40.组合总和II LeetCode 131.分割回文串
LeetCode 39. 组合总和 需要注意的是题目已经明确了数组内的元素不重复(重复的话需要执行去重操作),且元素都为正整数(如果存在0,则会出现死循环)。 思路1:暴力解法 对最后结果进行去重 每一…...
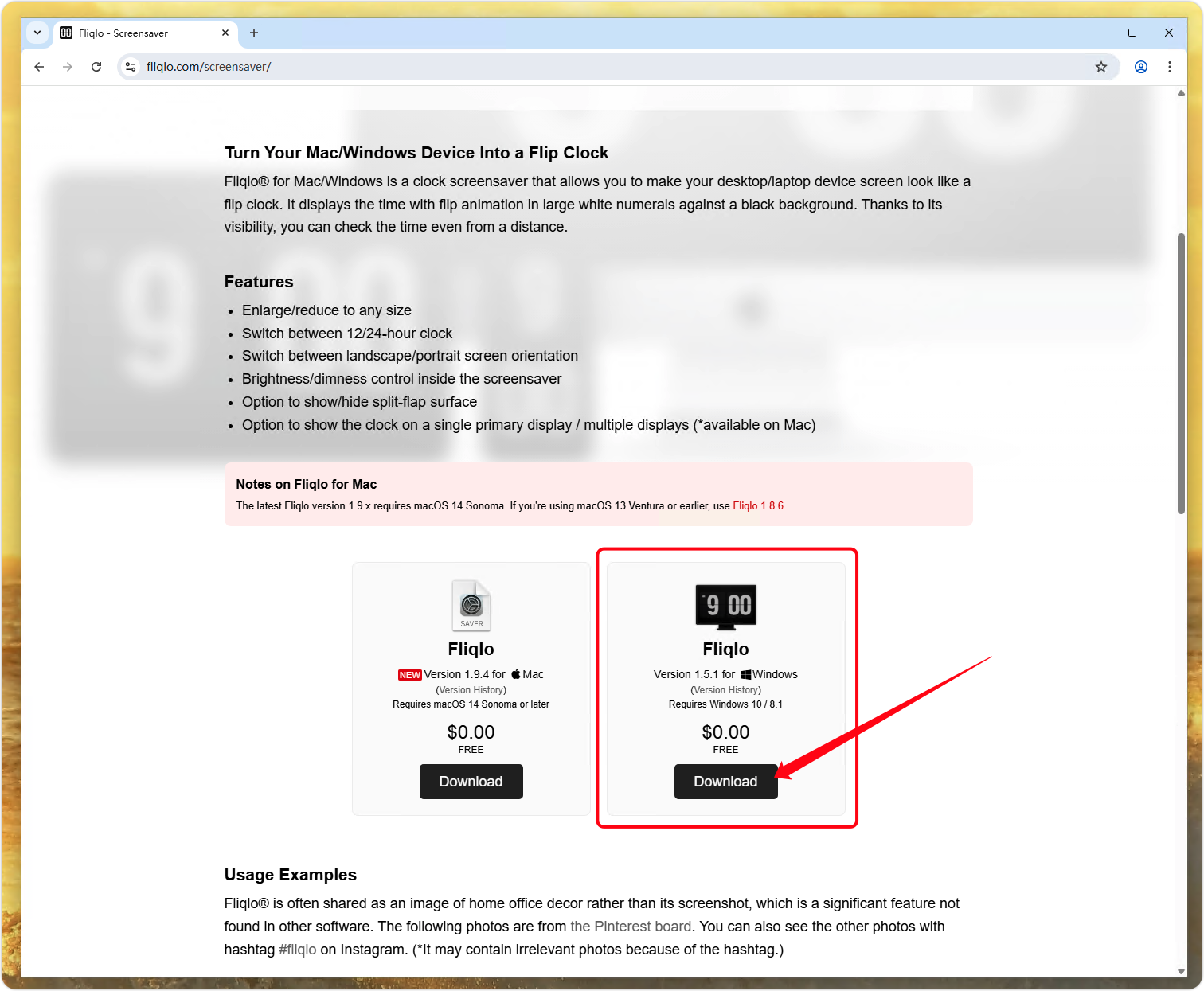
如何在 Windows 11 或 10 上安装 Fliqlo 时钟屏保
了解如何在 Windows 11 或 10 上安装 Fliqlo,为您的 PC 或笔记本电脑屏幕添加一个翻转时钟屏保以显示时间。 Fliqlo 是一款适用于 Windows 和 macOS 平台的免费时钟屏保。它也适用于移动设备,但仅限于 iPhone 和 iPad。Fliqlo 的主要功能是在用户不活动时在 PC 或笔记本电脑…...
)
Linux云计算训练营笔记day08(MySQL数据库)
Linux云计算训练营笔记day08(MySQL数据库) 目录 Linux云计算训练营笔记day08(MySQL数据库)数据准备修改更新update删除delete数据类型1.整数类型2.浮点数类型(小数)3.字符类型4.日期5.枚举: 表头的值必须在列举的值里选择拷贝表复…...
)
计算机视觉与深度学习 | matlab实现EMD-CNN-LSTM时间序列预测(完整源码、数据、公式)
EMD-CNN-LSTM 一、完整代码实现二、核心公式说明1. **经验模态分解(EMD)**2. **1D卷积运算**3. **LSTM门控机制**4. **损失函数**三、代码结构解析四、关键参数说明五、性能优化建议六、典型输出示例以下是用MATLAB实现EMD-CNN-LSTM时间序列预测的完整方案,包含数据生成、经…...

【vue】【环境配置】项目无法npm run serve,显示node版本过低
解决方案:安装高版本node,并且启用高版本node 步骤: 1、查看当前版本 node -v2、配置nvm下载镜像源 1)查看配置文件位置 npm root2)找到settings.txt文件 修改镜像源为: node_mirror: https://npmmirro…...
国芯思辰| 轮速传感器AH741对标TLE7471应用于汽车车轮速度感应
在汽车应用中,轮速传感器可用于车轮速度感应,为 ABS、ESC 等安全系统提供精确的轮速信息,帮助这些系统更好地发挥作用,在紧急制动或车辆出现不稳定状态时,及时调整车轮的制动力或动力分配。 国芯思辰两线制差分式轮速…...

鸿蒙PC操作系统:从Linux到自研微内核的蜕变
鸿蒙PC操作系统是否基于Linux内核,需要结合其技术架构、发展阶段和官方声明综合分析。以下从多个角度展开论述: 一、鸿蒙操作系统的多内核架构设计 多内核混合架构 根据资料,鸿蒙操作系统(HarmonyOS)采用分层多内核架构,内核层包含Linux内核、LiteOS-m内核、LiteOS-a内核…...
小程序弹出层/抽屉封装 (抖音小程序)
最近忙于开发抖音小程序,最想吐槽的就是,既没有适配的UI框架,百度上还找不到关于抖音小程序的案列,我真的很裂开啊,于是我通过大模型封装了一套代码 效果如下 介绍 可以看到 这个弹出层是支持关闭和标题显示的…...