深入掌握MyBatis:连接池、动态SQL、多表查询与缓存
文章目录
- 一、MyBatis连接池
- 1.1 连接池的作用
- 1.2 MyBatis连接池分类
- 二、动态SQL
- 2.1 if标签
- 2.2 where标签
- 2.3 foreach标签
- 2.4 SQL片段复用
- 三、多表查询
- 3.1 多对一查询(一对一)
- 3.2 一对多查询
- 四、延迟加载
- 4.1 立即加载 vs 延迟加载
- 4.2 配置延迟加载
- 五、MyBatis缓存
- 5.1 一级缓存
- 5.2 二级缓存
- 5.3 一级缓存 vs 二级缓存:核心差异
- 5.4 缓存使用陷阱与最佳实践**
- 总结
一、MyBatis连接池
1.1 连接池的作用
- 什么是连接池:存储数据库连接的容器,避免频繁创建和销毁连接。
- 解决的问题:每次执行SQL都创建连接会浪费资源,连接池复用连接提升性能。
1.2 MyBatis连接池分类
| 类型 | 描述 |
|---|---|
POOLED | 使用连接池(默认) |
UNPOOLED | 不使用连接池(适合简单场景) |
JNDI | 通过JNDI获取外部连接池 |
配置示例:
<dataSource type="POOLED"><property name="driver" value="com.mysql.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost:3306/test"/><property name="username" value="root"/>
</dataSource>
二、动态SQL
2.1 if标签
动态拼接查询条件,避免手动拼接SQL字符串。
<select id="findByWhere" resultType="User">SELECT * FROM user<where><if test="username != null">AND username LIKE #{username}</if><if test="sex != null">AND sex = #{sex}</if></where>
</select>
2.2 where标签
自动处理WHERE后的AND/OR冗余,替代WHERE 1=1。
<where><if test="username != null">username LIKE #{username}</if>
</where>
2.3 foreach标签
遍历集合生成条件,支持IN或OR拼接。
<!-- IN (1,2,3) -->
<foreach collection="ids" item="i" open="id IN (" separator="," close=")">#{i}
</foreach><!-- OR id=1 -->
<foreach collection="ids" item="i" open="id=" separator=" OR id=">#{i}
</foreach>
2.4 SQL片段复用
提取公共SQL片段,减少重复代码。
<sql id="baseSelect">SELECT * FROM user</sql>
<select id="findAll"><include refid="baseSelect"/>
</select>
三、多表查询
3.1 多对一查询(一对一)
需求:查询账户信息并关联用户信息。
JavaBean:
public class Account {private Integer id;private Double money;private User user; // 关联用户
}
XML配置:
<resultMap id="accountMap" type="Account"><id property="id" column="id"/><association property="user" javaType="User"><result property="username" column="username"/></association>
</resultMap><select id="findAll" resultMap="accountMap">SELECT a.*, u.username FROM account a JOIN user u ON a.uid = u.id
</select>
3.2 一对多查询
需求:查询用户及其所有账户。
JavaBean:
public class User {private List<Account> accounts; // 用户拥有多个账户
}
XML配置:
<resultMap id="userMap" type="User"><collection property="accounts" ofType="Account"><result property="money" column="money"/></collection>
</resultMap><select id="findOneToMany" resultMap="userMap">SELECT u.*, a.money FROM user u LEFT JOIN account a ON u.id = a.uid
</select>
四、延迟加载
延迟加载,也叫懒加载,简单来说就是在真正需要数据的时候才去加载数据,而不是在一开始就把所有关联数据都加载出来。这可以有效减少资源的浪费,尤其是在处理复杂对象关系时,避免一次性加载大量无用数据。
4.1 立即加载 vs 延迟加载
- 立即加载:查询主对象时,直接加载关联对象(默认)。
- 延迟加载:按需加载关联对象,提升性能。
4.2 配置延迟加载
开启全局延迟加载:
<settings><setting name="lazyLoadingEnabled" value="true"/><setting name="aggressiveLazyLoading" value="false"/>
</settings>
一对一延迟加载示例:
假设有 User 和 Address 两个实体,一个用户对应一个地址。在传统的查询方式中,可能会一次性将用户及其地址信息都查询出来。但在延迟加载模式下,查询用户时并不会立即查询地址信息。
然后在 User 的映射文件中配置:
<resultMap id="userMap" type="User"><id column="user_id" property="id"/><result column="username" property="username"/><association property="address" select="cn.tx.mapper.AddressMapper.findAddressByUserId" column="user_id" fetchType="lazy"/>
</resultMap>
这样,当查询用户时,只有在访问 user.getAddress() 时才会去查询地址信息。
多对一延迟加载示例:
比如多个订单对应一个用户,在查询订单时,用户信息可以延迟加载。在 Order 的映射文件中配置:
<resultMap id="orderMap" type="Order"><id column="order_id" property="id"/><result column="order_no" property="orderNo"/><association property="user" select="cn.tx.mapper.UserMapper.findUserByOrderId" column="user_id" fetchType="lazy"/>
</resultMap>
当访问 order.getUser() 时才会加载用户信息。
一对多延迟加载示例:
在 User 的映射文件中配置如下:
<resultMap id="userMap" type="User"><id column="user_id" property="id"/><result column="username" property="username"/><collection property="orders" select="cn.tx.mapper.OrderMapper.findOrdersByUserId" column="user_id" fetchType="lazy"/>
</resultMap>
只有在调用 user.getOrders() 时,才会执行查询订单的SQL语句。
多对多延迟加载示例:
假设 User 和 Role 是多对多关系,需要通过中间表 user_role 来关联。
首先在 User 的映射文件中配置:
<resultMap id="userMap" type="User"><id column="user_id" property="id"/><result column="username" property="username"/><collection property="roles" select="cn.tx.mapper.RoleMapper.findRolesByUserId" column="user_id" fetchType="lazy"/>
</resultMap>
在 Role 的映射文件中也做类似配置:
<resultMap id="roleMap" type="Role"><id column="role_id" property="id"/><result column="role_name" property="roleName"/><collection property="users" select="cn.tx.mapper.UserMapper.findUsersByRoleId" column="role_id" fetchType="lazy"/>
</resultMap>
这样在查询用户或角色时,相关联的多对多关系数据只有在实际访问时才会加载。
五、MyBatis缓存
5.1 一级缓存
1. 定义与特性
- 作用范围:
SqlSession级别,默认开启。 - 生命周期:与
SqlSession绑定,Session 关闭或执行commit()/rollback()时清空。 - 工作机制:同一个 Session 内多次执行 相同查询,优先从缓存读取。
SqlSession session = sqlSessionFactory.openSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user1 = mapper.findById(1); // 第一次查询,从数据库获取数据并放入一级缓存
User user2 = mapper.findById(1); // 第二次查询,从一级缓存中获取数据
2. 缓存命中与失效
- 命中条件:相同的
SQL+ 相同的参数 + 相同的环境。 - 失效场景:
- 执行
INSERT/UPDATE/DELETE操作。 - 手动调用
sqlSession.clearCache()。 - 跨
SqlSession的查询不会共享缓存。
- 执行
3. 实战注意点
- 坑点:跨方法调用时,若使用不同
SqlSession,一级缓存不共享。 - 适用场景:短生命周期操作(如单次请求内的重复查询)。
5.2 二级缓存
1. 定义与特性
- 作用范围:
Mapper级别(跨SqlSession),需手动开启。 - 生命周期:与应用进程绑定,重启或调用
clear()时清空。 - 存储结构:序列化后的数据(需实体类实现
Serializable)。
2. 缓存策略与配置
- 开启步骤:
<!-- MyBatis 全局配置 --> <settings><setting name="cacheEnabled" value="true"/> </settings><!-- Mapper XML 中声明 --> <mapper namespace="..."><cache eviction="LRU" flushInterval="60000" size="512"/> </mapper> - 淘汰策略(
eviction):LRU:最近最少使用(默认)。FIFO:先进先出。SOFT:软引用,基于垃圾回收器状态回收。
3. 工作流程
- 查询顺序:二级缓存 → 一级缓存 → 数据库。
- 数据提交:
SqlSession关闭时,一级缓存数据同步到二级缓存。
5.3 一级缓存 vs 二级缓存:核心差异
| 维度 | 一级缓存 | 二级缓存 |
|---|---|---|
| 作用范围 | SqlSession 内 | 跨 SqlSession(同一 Mapper) |
| 默认状态 | 开启 | 需手动配置 |
| 存储位置 | 内存(JVM 堆) | 可配置为磁盘或第三方缓存(如 Redis) |
| 数据共享 | 不共享 | 多个 Session 共享 |
| 生命周期 | 随 Session 销毁 | 长期存在,需主动管理 |
5.4 缓存使用陷阱与最佳实践**
1. 常见问题
- 脏读风险:跨服务节点时,二级缓存可能导致数据不一致。
- 序列化开销:二级缓存序列化影响性能,需权衡缓存粒度。
- 缓存穿透:频繁查询不存在的数据,需设置空值缓存。
2. 优化建议
- 合理配置:根据数据更新频率选择缓存策略(如
flushInterval)。 - 第三方缓存:集成 Redis 或 Ehcache 实现分布式缓存。
- 注解控制:使用
@CacheNamespace和@CacheNamespaceRef精细化管理。
总结
掌握这些核心技能,可以高效利用MyBatis构建健壮的数据库应用。实际开发中,需根据业务场景选择合适策略,平衡性能与功能需求。
相关文章:

深入掌握MyBatis:连接池、动态SQL、多表查询与缓存
文章目录 一、MyBatis连接池1.1 连接池的作用1.2 MyBatis连接池分类 二、动态SQL2.1 if标签2.2 where标签2.3 foreach标签2.4 SQL片段复用 三、多表查询3.1 多对一查询(一对一)3.2 一对多查询 四、延迟加载4.1 立即加载 vs 延迟加载4.2 配置延迟加载 五、…...

Bootstrap 5 容器与网格系统详解
一、容器 - Bootstrap的基础构建块 Bootstrap需要容器元素来包裹网站内容,提供两种主要选择: .container - 固定宽度并支持响应式布局.container-fluid - 100%宽度,占据全部视口 1. 固定宽度容器 .container创建固定宽度的响应式页面&…...

Java反射机制详解:原理、应用与实战
一、反射机制概述 Java反射(Reflection)是Java语言的一个强大特性,它允许程序在运行时(Runtime)获取类的信息并操作类或对象的属性、方法等。反射机制打破了Java的封装性,但也提供了极大的灵活性。 反射的核心思想:在运行时而非编译时动态获…...
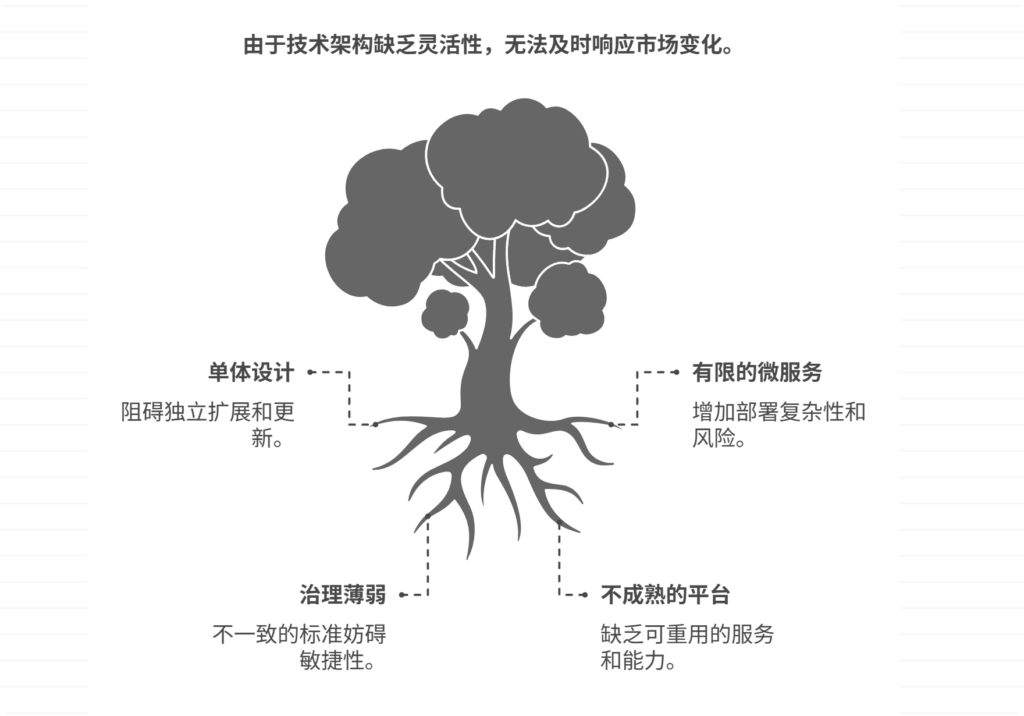
技术架构缺乏灵活性,如何应对变化需求?
技术架构缺乏灵活性会导致企业在面临市场变化、用户需求演化或新技术出现时难以及时响应,直接影响产品更新速度与竞争力。要有效应对变化需求,需要从引入模块化架构设计、推动微服务拆分、加强架构治理与决策机制、构建中台与平台化能力等方面系统推进。…...
【AI时代】Java程序员大模型应用开发详细教程(上)
目录 一、大模型介绍 1. 大模型介绍 1.1 什么是大模型 1.2 技术储备 1.3 大模型的分类 2. 入门案例 3.Token的介绍 二、提示词工程 1. 好玩的提示词案例 1.1 翻译软件 1.2 让Deepseek绘画 1.3 生成数据 1.4 代码生成 2. 提示词介绍 3. Prompt Engineering最佳实…...
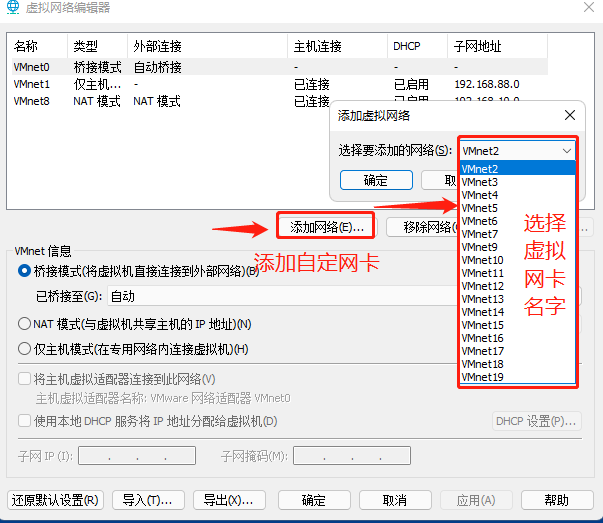
虚拟网络编辑器
vmnet1 仅主机模式 hostonly 功能:虚拟机只能和宿主机通过vmnet1通信,不可连接其他网络(包括互联网) vmnet8 地址转换模式 NAT 功能:虚拟机可以和宿主通过vmnet8通信,并且可以连接其他网络,但是…...

102. 二叉树的层序遍历递归法:深度优先搜索的巧妙应用
二叉树的层序遍历是一种经典的遍历方式,它要求按层级逐层访问二叉树的节点。通常我们会使用队列来实现层序遍历,但递归法也是一种可行且有趣的思路。本文将深入探讨递归法解决二叉树层序遍历的核心难点,并结合代码和模拟过程进行详细讲解。 …...

Github 2025-05-16 Java开源项目日报 Top9
根据Github Trendings的统计,今日(2025-05-16统计)共有9个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Java项目9Netty:异步事件驱动的网络应用程序框架 创建周期:5043 天开发语言:Java协议类型:Apache License 2.0Star数量:33219 个Fork数量:…...
)
MinerU安装(pdf转markdown、json)
在Windows上安装MinerU,参考以下几个文章,可以成功安装,并使用GPU解析。 整体安装教程: MinerU本地化部署教程——一款AI知识库建站的必备工具 MinerU本地化部署可视化界面-CSDN博客 其中安装conda的教程: 一步步教…...

Java卡与SSE技术融合实现企业级安全实时通讯
简介 在数字化转型浪潮中,安全与实时数据传输已成为金融、物联网等高安全性领域的核心需求。本文将深入剖析东信和平的Java卡权限分级控制技术与浪潮云基于SSE的大模型数据推送技术,探索如何将这两项创新技术进行融合,构建企业级安全实时通讯系统。通过从零到一的开发步骤,…...
第31讲 循环缓冲区与命令解析
串口在持续接收数据时容易发生数据黏包(先接收的数据尚未被处理,后面的数据已经将内存覆盖)的情况,循环缓冲区的本质就是将串口接受到的数据马上拷贝到另外一块内存之中。为了避免新来的数据覆盖掉尚未处理的数据,一方…...

mapbox-gl强制请求需要accessToken的问题
vue引入"mapbox-gl": "^2.15.0", 1.13以后得版本,都强制需要验证这个mapboxgl.accessToken。 解决办法:实例化地图的代码中,加入这个: const originalFetch window.fetch; window.fetch function ({ url…...

数据结构(十)——排序
一、选择排序 1.简单选择排序 基本思想:假设排序表为[1,…,n],第i趟排序即从[i,…,n]中选择关键字最小的元素与L[i]交换 eg:给定关键字序列{87,45,78,32,17,65,53&…...
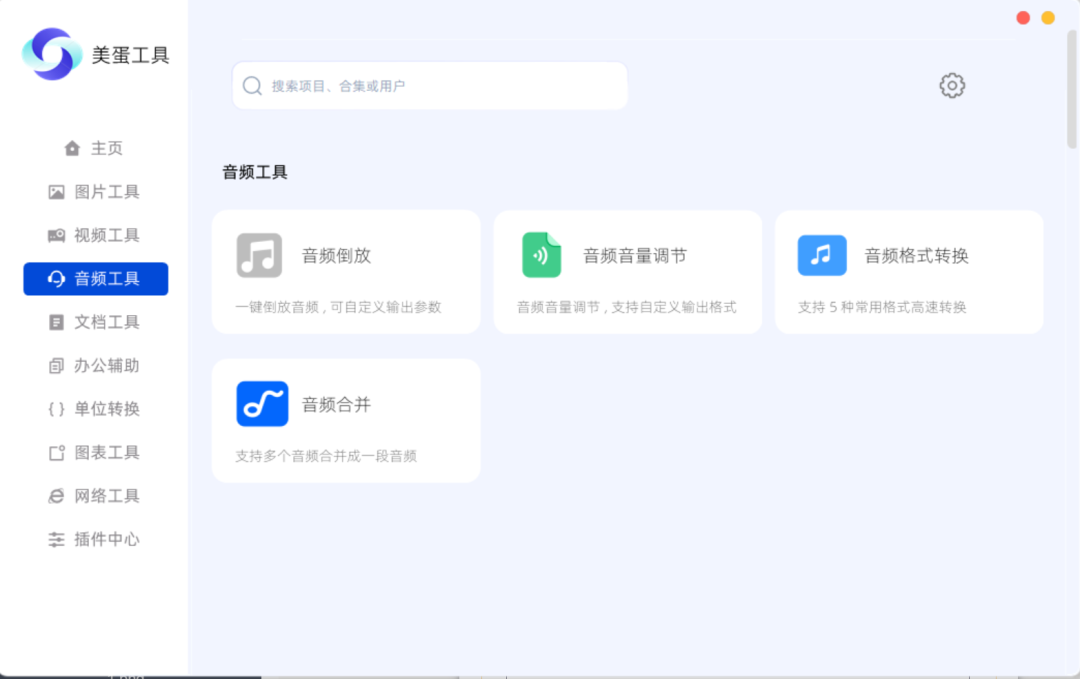
美蛋工具箱:一站式解决图片、视频、音频和文档处理需求的聚合神器
先放下载链接:夸克网盘下载 宝子们,今天不啰嗦,直接给大家安利一款超好用的聚合工具,有需要的小伙伴赶紧码住! 今天要介绍的这款工具叫美蛋工具箱,它是一款聚合类工具。这个软件是绿色版的,聚合了图片工具…...

fastadmin 数据导出,设置excel行高和限制图片大小
fastadmin默认导出图片全部都再一块,而且不在单元格里 话不多说,上代码 修改文件的路径: /public/assets/js/require-table.js exportOptions: {fileName: export_ Moment().format("YYYY-MM-DD"),preventInjection: false,mso…...

python打卡day16
NumPy 数组基础 因为前天说了shap,这里涉及到数据形状尺寸问题,所以需要在这一节说清楚,后续的神经网络我们将要和他天天打交道。 知识点: numpy数组的创建:简单创建、随机创建、遍历、运算numpy数组的索引:…...
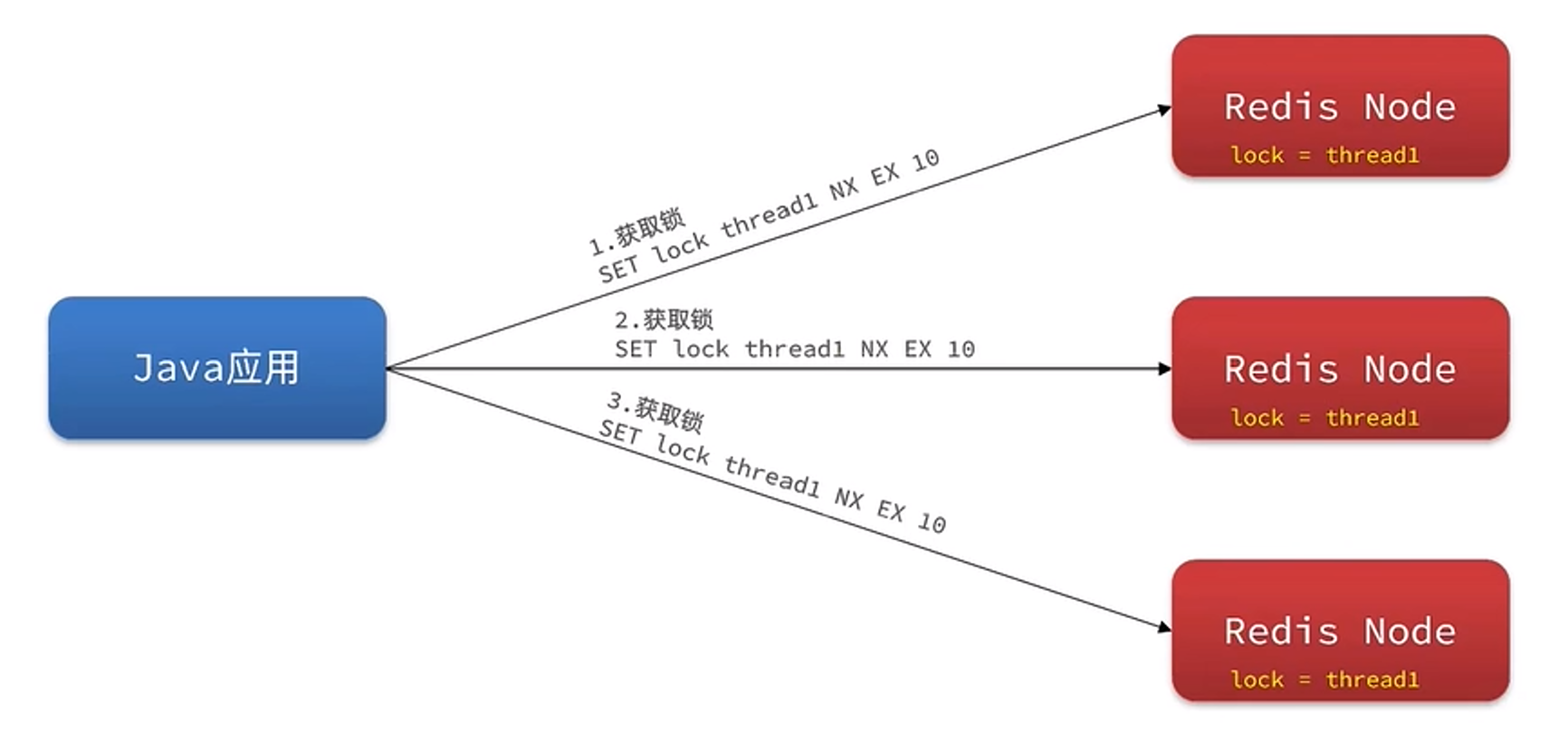
Redis 学习笔记 5:分布式锁
Redis 学习笔记 5:分布式锁 在前文中学习了如何基于 Redis 创建一个简单的分布式锁。虽然在大多数情况下这个锁已经可以满足需要,但其依然存在以下缺陷: 事实上一般而言,我们可以直接使用 Redisson 提供的分布式锁而非自己创建。…...

游戏开发实战(一):Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】
文章目录 奇美拉项目游戏规则奇美拉(Chimeras)档案领队成员 结果展示: 奇美拉项目 由于项目工程较大,并且我打算把我的思考过程和实现过程中踩过的坑都分享一下,因此会分3-4篇博文详细讲解本项目。本文首先介绍下游戏规则并给出奇美拉档案。…...

VS2017编译librdkafka 2.1.0
VS2017编译librdkafka 2.1.0 本篇是 Windows系统编译Qt使用的kafka(librdkafka)系列中的其中一篇,编译librdkafka整体步骤大家可以参考: Windows系统编译Qt使用的kafka(librdkafka) 由于项目需要,使用kafka,故自己编译了一次,编译的过程,踩了太多的坑了,特写了本篇…...

02- 浏览器运行原理
文章目录 1. 网页的解析过程浏览器内核 2. 浏览器渲染流程2.1 解析html2.2 生成css规则2.3 构建render tree2.4 布局(Layout)2.5 绘制(Paint) 3. 回流和重绘3.1 回流reflow(1)理解:(2)出现情况 3.2 重绘repaint&#x…...

Reactor模型详解与C++实现
Reactor模型详解与C实现 一、Reactor模型核心思想 Reactor模式是一种事件驱动的并发处理模型,核心通过同步I/O多路复用实现对多个I/O源的监听,当有事件触发时,派发给对应处理器进行非阻塞处理。 关键特征: 非阻塞I/Oÿ…...

人工智能重塑医疗健康:从辅助诊断到个性化治疗的全方位变革
人工智能正在以前所未有的速度改变着医疗健康领域,从影像诊断到药物研发,从医院管理到远程医疗,AI 技术已渗透到医疗服务的各个环节。本文将深入探讨人工智能如何赋能医疗健康产业,分析其在医学影像、临床决策、药物研发、个性化医…...
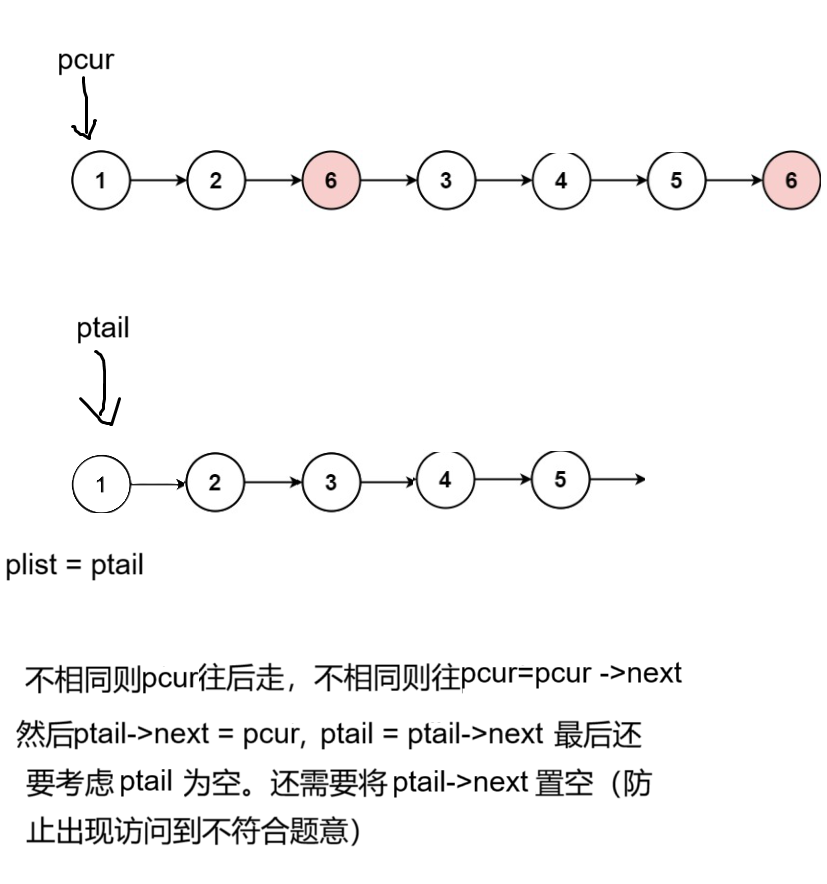
移除链表元素数据结构oj题(力扣题206)
目录 题目描述: 题目解读(分析) 解决代码 题目描述: 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点,并返回 新的头节点 。 题目解读(分析&#…...

学习记录:DAY29
项目开发日志:技术实践与成长之路 前言 回顾这几天的状态,热情总是比我想象中更快被消耗完。比起茫然徘徊的小丑,我更希望自己是对着风车冲锋的疯子。 今天继续深入项目的实际业务。 状态好点的时候,再看自己EMO时写的东西&…...
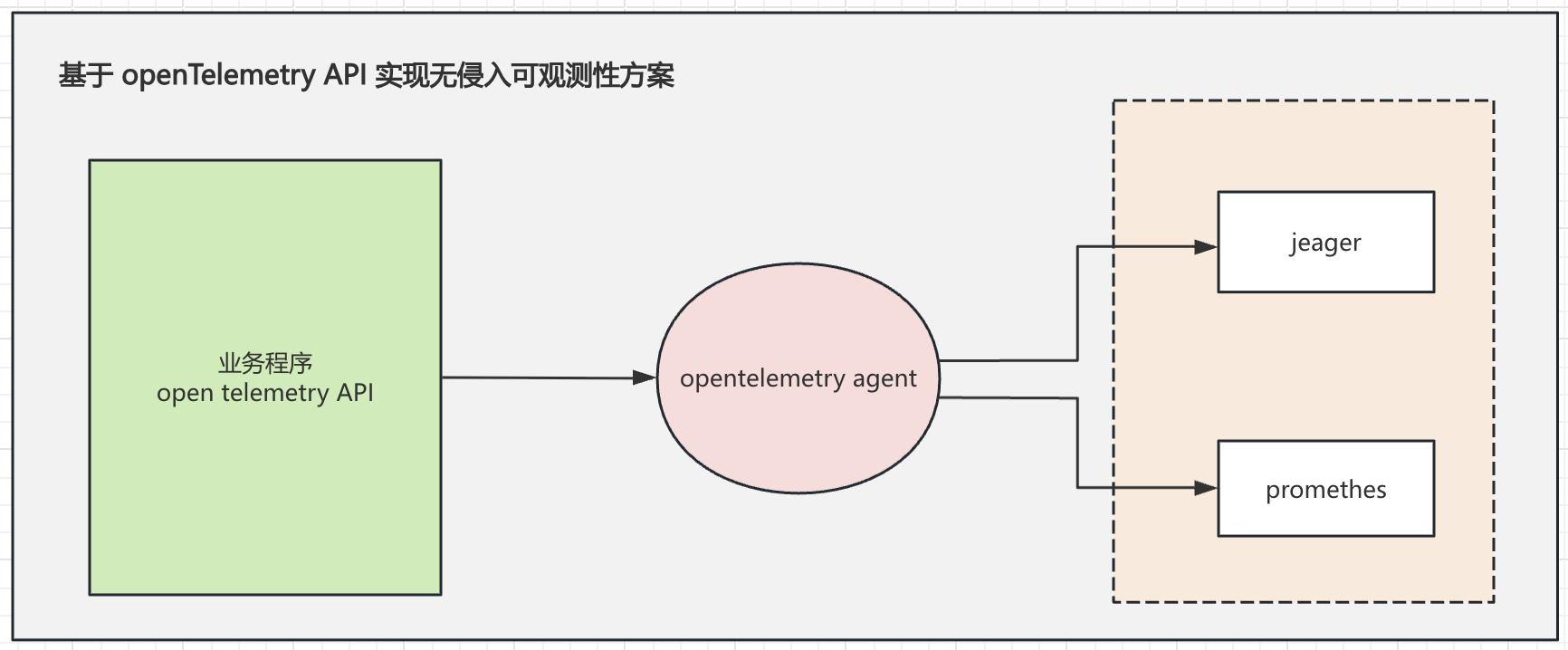
OpenTelemetry 从入门到精通
快速入门 OpenTelemetry 是一个可观测性框架和工具包, 旨在创建和管理遥测数据,如链路、 指标和日志。 重要的是,OpenTelemetry 是供应商和工具无关的,这意味着它可以与各种可观测性后端一起使用, 包括 Jaeger 和 Pro…...

数学复习笔记 17
前言 复盘泰勒公式,极限四则运算,洛必达,拉格朗日。 1.27 因为是复习泰勒公式,所以就算有别的方法,我也硬是要用泰勒公式。就是为了记一下泰勒公式。泰勒公式确实是能做,但是做的我非常非常难受。公式确…...

C语言:在操作系统中,链表有什么应用?
在操作系统中,链表是一种重要的数据结构,凭借其灵活的内存管理和高效的插入/删除特性,被广泛应用于多个核心模块。以下是其主要应用场景及详细说明: 1. 内存管理:空闲内存块管理 应用场景:操作系统需要管…...

解锁MySQL性能调优:高级SQL技巧实战指南
高级SQL技巧:解锁MySQL性能调优的终极指南 开篇 当前,随着业务系统的复杂化和数据量的爆炸式增长,数据库性能调优成为了技术人员面临的核心挑战之一。尤其是在高并发、大数据量的场景下,SQL 查询的性能直接影响到整个系统的响应…...

裸金属服务器和云服务器之间的差别
裸金属服务器能够直接在硬件上运行,不需要额外的虚化层,让每个应用程序或者是服务都能够在实际的硬件上运行,不需要和其他虚拟服务器来共享资源;而云服务器作为一种虚拟服务器,是通过虚拟化技术为企业提供一个独立的计…...

WebSocket实时双向通信:从基础到实战
一、WebSocket 基础概念 1. 什么是 WebSocket? 双向通信协议:与 HTTP 的单向请求不同,WebSocket 支持服务端和客户端实时双向通信。 低延迟:适用于聊天室、实时数据推送、在线游戏等场景。 协议标识:ws://ÿ…...