26、DAPO论文笔记(解耦剪辑与动态采样策略优化,GRPO的改进)
DAPO论文笔记
- 1、项目背景与目标
- 2、DAPO算法与关键技术
- 3、过长响应奖励塑形(Overlong Reward Shaping)
- **一、问题背景:截断惩罚的缺陷**
- **二、解决方案:分层惩罚与软截断策略**
- 1. **过长过滤:屏蔽无效惩罚**
- 2. **软过长惩罚:梯度化长度约束**
- **三、实验验证:惩罚策略的有效性**
- **四、总结:平衡长度与质量的核心逻辑**
- 示例
- **一、任务背景:数学题推理(AIME风格)**
- **二、示例1:安全区内的正确响应(无惩罚)**
- **输入Prompt**:
- **模型输出(10000 tokens)**:
- **奖励计算**:
- **模型反馈**:
- **三、示例2:缓冲区内的过长响应(线性惩罚)**
- **输入Prompt**:
- **模型输出(14336 tokens)**:
- **奖励计算**:
- **模型反馈**:
- **四、示例3:超限时的过长响应(严厉惩罚)**
- **输入Prompt**:
- **模型输出(18000 tokens)**:
- **奖励计算**:
- **模型反馈**:
- **五、对比:默认惩罚 vs. 软惩罚的输出差异**
- **关键区别**:
- **六、总结:奖励塑形对Prompt响应的影响**
- 4、预备知识
- 2.1 近端策略优化(PPO)
- 2.2 组相对策略优化(GRPO)
- 2.3 移除KL散度惩罚
- 2.4 基于规则的奖励建模
- 基于规则的奖励建模
- 一、奖励博弈问题(Reward Hacking)的本质
- 二、基于规则的奖励建模:直接以正确性为导向
- 三、规则奖励的有效性:跨领域验证
- 四、规则奖励 vs. 学习型奖励模型:对比分析
- 5、汇总
- 一、项目背景与目标
- 二、DAPO算法与关键技术
- 三、开源内容与技术栈
- 四、实验结果与性能对比
- 五、数据集处理与训练细节
- 关键问题
- 1. **DAPO算法的核心创新点是什么?**
- 2. **DAPO开源了哪些内容?对领域研究有何影响?**
- 3. **DAPO在AIME 2024中的性能表现如何?相比之前的模型有何优势?**
- 参考:
论文题目:DAPO: An Open-Source LLM Reinforcement Learning System at Scale
论文链接:https://arxiv.org/abs/2503.14476
官方解释:https://air.tsinghua.edu.cn/info/1007/2401.htm
Date: March 17, 2025
Correspondence: Qiying Yu at yuqy22@mails.tsinghua.edu.cn
Project Page: https://dapo-sia.github.io/
详细原理(先看):知乎 DAPO:GRPO的改进 备份:链接
下面是对其补充
1、项目背景与目标
-
领域挑战:
- 现有LLM推理模型(如OpenAI o1、DeepSeek R1)依赖大规模强化学习(RL)实现复杂推理,但核心训练细节闭源,社区难以复现结果。
- 基线算法(如GRPO)
在长链式思维(CoT)场景中存在**熵崩塌、奖励噪声、训练不稳定**等问题,导致性能低下(如GRPO在AIME仅30分)。
-
核心目标:
- 开源可复现的大规模LLM RL系统,提供工业级训练方案。
- 提出DAPO算法,解决长CoT场景下的RL优化难题。
2、DAPO算法与关键技术
| 技术名称 | 核心作用 | 实现细节 | 效果 |
|---|---|---|---|
| Clip-Higher | 解耦高低剪辑范围,促进低概率token探索 | - 分离剪辑参数为 ε l o w \varepsilon_{low} εlow(0.2)和 ε h i g h \varepsilon_{high} εhigh(0.28) - 允许低概率token概率提升空间更大 | - 策略熵提升,生成多样性增加 - AIME准确率从基线30%提升至40%+ |
| Dynamic Sampling | 过滤无效梯度样本,稳定训练效率 | - 丢弃准确率为0或1的样本,保留有效梯度 - 动态采样直至批次填满 | - 收敛速度提升,相同性能所需步骤减少 - 训练时间未显著增加,但效率更高 |
| Token-Level Policy Gradient Loss | 按token加权损失,优化长序列训练 | - 按token数量加权损失,而非按样本平均 - 惩罚长序列中的低质量模式(如重复、乱码) | - 响应长度增长更健康 - 训练稳定性提升 |
| Overlong Reward Shaping | 软惩罚过长响应,减少奖励噪声 | - 对超过最大长度的响应分阶段惩罚 - L m a x = 20480 L_{max}=20480 Lmax=20480 tokens,缓冲区间 L c a c h e = 4096 L_{cache}=4096 Lcache=4096 | - 训练稳定性显著提升 - AIME准确率波动减小 |
在长链式思维(CoT)场景中存在熵崩塌、奖励噪声、训练不稳定等问题,导致性能低下:
- 解决熵问题(熵崩塌):Clip-Higher
- 解决输出样本问题(训练不稳定):Dynamic Sampling 和Token-Level Policy Gradient Loss
- 解决输出长度问题(奖励噪声):Overlong Reward Shaping
具体细节:
1. **Clip-Higher**:增强系统多样性,避免熵崩塌;
2. **Dynamic Sampling**:提高训练效率和稳定性;
3. **Token-Level Policy Gradient Loss**:在长CoT RL场景中至关重要;
4. **Overlong Reward Shaping**:减少奖励噪声,稳定训练过程。
提出 Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO),包含四大关键技术:
-
Clip-Higher
• 问题:传统PPO/GRPO的上下剪裁对称限制(如ε=0.2)导致低概率token难以提升,引发熵崩溃(生成样本同质化)。
• 方案:解耦上下剪裁范围(如ε_low=0.2,ε_high=0.28),允许低概率token有更大提升空间,提升多样性(图2b熵增加,图3a概率分布更均衡)。 -
Dynamic Sampling
• 问题:当某组样本全对/全错时,优势函数为零,梯度消失,训练效率下降。
• 方案:动态过滤掉全对/全错的提示,仅保留部分正确样本,确保批次内有效梯度信号(图3b减少无效样本,图6加速收敛)。 -
Token-Level Policy Gradient Loss
• 问题:GRPO的样本级损失平均导致长序列token贡献被稀释,难以学习有效推理模式。
• 方案:改为Token级损失计算,按总token数平均,平衡长短序列影响,提升稳定性(图4a/b长度增长更健康)。 -
Overlong Reward Shaping
• 问题:过长响应的截断惩罚(如直接-1)引入噪声,干扰有效推理步骤的奖励。
• 方案:采用软惩罚(公式13),根据超长程度逐步增加惩罚,并过滤截断样本的损失(图5训练更稳定)。·
3、过长响应奖励塑形(Overlong Reward Shaping)
在强化学习(RL)训练中,生成序列的长度控制是关键挑战之一。模型可能因过度探索生成冗长无效的响应,或因截断机制导致合理推理被误罚。本节介绍过长响应奖励塑形技术,通过精细设计惩罚策略平衡响应长度与推理质量。
生成内容长度控制,及其超出阈值截断:
- 传统做法:对截断样本直接施加惩罚性奖励(如 R = − 1 R=-1 R=−1)。
- 平滑引导:缓冲期的线性惩罚避免了截断点附近的奖励突变,引导模型逐步缩短响应长度,而非突然终止有效推理。 (平缓过度)
一、问题背景:截断惩罚的缺陷
-
截断机制的必要性
- 在长链式思维(CoT)任务中(如数学推理、代码生成),模型需生成较长的中间步骤,但无限制生成会导致计算成本激增。因此,通常设定最大生成长度 L max L_{\text{max}} Lmax,超过该长度的样本会被截断。
-
默认惩罚的弊端
- 传统做法:对截断样本直接施加惩罚性奖励(如 R = − 1 R=-1 R=−1)。
- 核心问题:
- 奖励噪声:合理但未完成的推理可能因长度超限被误罚。例如,数学题中一个复杂证明需20000 tokens,但因 L max = 16384 L_{\text{max}}=16384 Lmax=16384 被截断,模型会错误地将“长度”与“错误”关联,而非优化推理逻辑。
- 训练不稳定:频繁的误罚可能导致模型收敛困难,甚至退化为生成短但无意义的响应。
二、解决方案:分层惩罚与软截断策略
为解决默认惩罚的缺陷,本文提出双重策略:过长过滤(Overlong Filtering)和软过长惩罚(Soft Overlong Punishment)。
1. 过长过滤:屏蔽无效惩罚
- 核心思想:对于长度超过 L max L_{\text{max}} Lmax 的样本,忽略其损失计算,避免误罚干扰训练。
- 实现方式:在计算奖励时,若样本被截断,则不将其纳入梯度更新。
- 效果:
- 如图5(a)所示,启用过滤后,AIME准确率波动显著减小,训练稳定性提升。
- 模型不再因“长度”错误地抑制合理推理,专注于优化内容质量。
2. 软过长惩罚:梯度化长度约束
-
核心思想:引入缓冲区间 L cache L_{\text{cache}} Lcache,对接近但未超过 L max L_{\text{max}} Lmax 的响应实施梯度化惩罚,而非一刀切式的严厉处罚。
-
数学定义:
R length ( y ) = { 0 , ∣ y ∣ ≤ L max − L cache (安全区:无惩罚) ( L max − L cache ) − ∣ y ∣ L cache , L max − L cache < ∣ y ∣ ≤ L max (缓冲期:线性惩罚) − 1 , ∣ y ∣ > L max (超限区:严厉惩罚) R_{\text{length}}(y) = \begin{cases} 0, & |y| \leq L_{\text{max}} - L_{\text{cache}} \quad \text{(安全区:无惩罚)} \\ \frac{(L_{\text{max}} - L_{\text{cache}}) - |y|}{L_{\text{cache}}}, & L_{\text{max}} - L_{\text{cache}} < |y| \leq L_{\text{max}} \quad \text{(缓冲期:线性惩罚)} \\ -1, & |y| > L_{\text{max}} \quad \text{(超限区:严厉惩罚)} \end{cases} Rlength(y)=⎩ ⎨ ⎧0,Lcache(Lmax−Lcache)−∣y∣,−1,∣y∣≤Lmax−Lcache(安全区:无惩罚)Lmax−Lcache<∣y∣≤Lmax(缓冲期:线性惩罚)∣y∣>Lmax(超限区:严厉惩罚) -
安全区:长度在 L max − L cache L_{\text{max}} - L_{\text{cache}} Lmax−Lcache 以内,视为有效响应,奖励为0。
- 缓冲期:长度超出安全区但未达 L max L_{\text{max}} Lmax,惩罚随长度线性增加(例如, L cache = 4096 L_{\text{cache}}=4096 Lcache=4096 时,每超出1 token惩罚减少 1 / 4096 1/4096 1/4096)。
- 超限区:长度超过 L max L_{\text{max}} Lmax,惩罚为-1,强制抑制过长生成。
-
直观示例:
- 假设 L max = 16384 L_{\text{max}}=16384 Lmax=16384, L cache = 4096 L_{\text{cache}}=4096 Lcache=4096,则安全区为 0 ∼ 12288 0 \sim 12288 0∼12288 tokens,缓冲期为 12289 ∼ 16384 12289 \sim 16384 12289∼16384 tokens。
- 若生成14336 tokens的响应(缓冲期中间点),惩罚值为 12288 − 14336 4096 = − 0.5 \frac{12288 - 14336}{4096} = -0.5 409612288−14336=−0.5,即奖励为原规则奖励(±1)基础上叠加-0.5。
- 若生成17000 tokens(超限区),奖励直接为-1,无论内容是否正确。
-
设计优势:
- 平滑引导:缓冲期的线性惩罚避免了截断点附近的奖励突变,引导模型逐步缩短响应长度,而非突然终止有效推理。
- 区分惩罚:将“合理但稍长的响应”与“无意义的超长响应”区分对待,前者仅受轻微惩罚,后者被严厉抑制。
三、实验验证:惩罚策略的有效性
-
关键指标对比
策略 训练稳定性(AIME准确率波动) 平均响应长度 熵值(探索能力) 无惩罚 高(因超长样本干扰) 极高(冗余) 高(含无效探索) 默认惩罚(-1) 中(误罚导致震荡) 低(可能过短) 低(抑制探索) 软过长惩罚 低(稳定收敛) 中等(合理) 中等(平衡探索) -
图5实验结果解析
- 图5(a):启用软惩罚后,AIME准确率从基线的波动上升变为稳定增长,验证了奖励噪声的减少。
- 图5(b):模型生成熵值(多样性)维持在合理区间,表明软惩罚未过度抑制探索,仅淘汰无意义的超长响应。
四、总结:平衡长度与质量的核心逻辑
过长响应奖励塑形的本质是在约束中保留灵活性:
- 过滤策略解决“合理推理被误罚”的问题,确保模型专注于内容正确性;
- 软惩罚机制通过梯度化约束,引导模型自动优化响应长度,避免因生硬截断导致的训练偏差。
该技术在DAPO系统中的应用,使得模型在AIME竞赛中以20480 tokens的长上下文实现50分准确率,证明了长度控制与推理能力的协同优化可行性。
示例
以下是结合具体输入输出Prompt说明 Overlong Reward Shaping(过长响应奖励塑形) 的完整示例,包含任务背景、模型输入输出、奖励计算过程及优化反馈:
一、任务背景:数学题推理(AIME风格)
题目:
已知等边三角形ABC为四面体S-ABC的底面,点A在面SBC上的投影H是△SBC的垂心,二面角H-AB-C为30°,SA=2,求四面体体积。答案需以整数k+m形式给出,其中体积为k/m。
设定参数:
- 最大生成长度 L max = 16384 L_{\text{max}} = 16384 Lmax=16384 tokens
- 缓冲区间 L cache = 4096 L_{\text{cache}} = 4096 Lcache=4096 tokens
- 安全区长度阈值: L max − L cache = 12288 L_{\text{max}} - L_{\text{cache}} = 12288 Lmax−Lcache=12288 tokens
二、示例1:安全区内的正确响应(无惩罚)
输入Prompt:
问题:已知等边三角形ABC为四面体S-ABC的底面...(完整题目)
请逐步推导四面体体积,要求逻辑清晰,每步标注关键定理。
模型输出(10000 tokens):
- 建立坐标系,设ABC在xy平面,A(0,0,0),B(a,0,0),C(a/2, (√3/2)a, 0)。
- 推导面SBC的方程,利用H为垂心的条件,得出S的坐标约束。
- 通过二面角定义计算平面HAB与平面ABC的法向量夹角,结合SA=2求解参数a。
- 最终体积公式推导: V = 1 3 × 底面积 × 高 = 3 12 V = \frac{1}{3} \times \text{底面积} \times \text{高} = \frac{\sqrt{3}}{12} V=31×底面积×高=123,故k=√3, m=12(假设转换后答案为整数和,需进一步处理)。
奖励计算:
- 长度判断:10000 tokens ≤ 12288 tokens → 安全区。
- 规则奖励:答案正确(假设最终转换后k+m=3+12=15)→ R correct = 1 R_{\text{correct}} = 1 Rcorrect=1。
- 长度奖励: R length = 0 R_{\text{length}} = 0 Rlength=0。
- 总奖励: 1 + 0 = 1 1 + 0 = 1 1+0=1。
模型反馈:
奖励为正,鼓励保持当前推理长度和质量。
三、示例2:缓冲区内的过长响应(线性惩罚)
输入Prompt:
同上(要求逐步推导,但未限制长度)。
模型输出(14336 tokens):
- 包含示例1的正确推理,但额外添加:
- 详细图解说明(文字描述投影关系,增加2000 tokens)。
- 重复验证垂心性质的不同等价条件(增加1000 tokens)。
- 关键问题:内容正确但冗余,长度超出安全区。
奖励计算:
- 长度计算:
∣ y ∣ = 14336 , L max − L cache = 12288 , L cache = 4096 |y| = 14336, \quad L_{\text{max}} - L_{\text{cache}} = 12288, \quad L_{\text{cache}} = 4096 ∣y∣=14336,Lmax−Lcache=12288,Lcache=4096
R length = 12288 − 14336 4096 = − 2048 4096 = − 0.5 R_{\text{length}} = \frac{12288 - 14336}{4096} = \frac{-2048}{4096} = -0.5 Rlength=409612288−14336=4096−2048=−0.5
2. 规则奖励:答案正确 → R correct = 1 R_{\text{correct}} = 1 Rcorrect=1。
3. 总奖励: 1 + ( − 0.5 ) = 0.5 1 + (-0.5) = 0.5 1+(−0.5)=0.5。
模型反馈:
奖励低于示例1,提示模型减少冗余内容。下一次训练中,模型可能精简图解描述,保留核心推导,长度缩短至13000 tokens,奖励提升至:
R length = 12288 − 13000 4096 ≈ − 0.174 , 总奖励 ≈ 0.826 R_{\text{length}} = \frac{12288 - 13000}{4096} \approx -0.174, \quad \text{总奖励} \approx 0.826 Rlength=409612288−13000≈−0.174,总奖励≈0.826
四、示例3:超限时的过长响应(严厉惩罚)
输入Prompt:
同上,但模型尝试生成更详细的三维几何模拟过程。
模型输出(18000 tokens):
- 包含正确推理,但未完成最终体积计算(因16384 tokens处截断)。
- 截断位置:即将代入SA=2求解参数a时被截断,答案缺失。
奖励计算:
- 长度判断:18000 tokens > 16384 tokens → 超限区。
- 规则奖励:因答案缺失,判断为错误 → R correct = − 1 R_{\text{correct}} = -1 Rcorrect=−1。
- 长度奖励: R length = − 1 R_{\text{length}} = -1 Rlength=−1。
- 总奖励: − 1 + ( − 1 ) = − 2 -1 + (-1) = -2 −1+(−1)=−2。
模型反馈:
严厉惩罚促使模型调整生成策略,例如:
- 优先生成关键步骤(如参数求解、体积公式),延后或省略次要细节(如图解)。
- 下一次尝试将核心推导压缩至16384 tokens内,确保答案完整。
五、对比:默认惩罚 vs. 软惩罚的输出差异
| 场景 | 默认惩罚(直接-1) | 软惩罚(公式13) |
|---|---|---|
| 示例2输出(14336 tokens) | 总奖励=0(假设直接惩罚长度,忽略内容正确性) | 总奖励=0.5(保留部分奖励,引导优化) |
| 模型后续行为 | 可能过度缩短至8000 tokens(牺牲推理步骤) | 逐步优化至12000-13000 tokens(平衡长度与质量) |
关键区别:
- 默认惩罚将“长度”与“错误”强绑定,可能导致模型为规避惩罚而牺牲内容完整性;
- 软惩罚通过梯度化机制,允许模型在缓冲区内试探合理长度,逐步收敛至最优解。
六、总结:奖励塑形对Prompt响应的影响
通过以上示例可见,Overlong Reward Shaping 对模型输出的引导作用如下:
- 安全区:鼓励生成完整、详细的推理(如示例1)。
- 缓冲区:轻微惩罚冗余,推动模型提炼关键信息(如示例2)。
- 超限区:强制约束计算成本,确保核心内容优先生成(如示例3)。
该机制通过分层奖励信号,使模型在长上下文任务中自动平衡“内容丰富度”与“计算效率”,是DAPO系统实现高效RL训练的关键技术之一。
4、预备知识
2.1 近端策略优化(PPO)
PPO[21]通过引入剪辑替代目标函数来优化策略。通过剪辑操作将策略更新限制在前序策略的近端区域内,PPO可稳定训练并提高样本效率。具体而言,PPO通过最大化以下目标函数更新策略:
J PPO ( θ ) = E ( q , a ) ∼ D , o ≤ t ∼ π θ old ( ⋅ ∣ q ) [ min ( π θ ( o t ∣ q , o < t ) π θ old ( o t ∣ q , o < t ) A ^ t , clip ( π θ ( o t ∣ q , o < t ) π θ old ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A ^ t ) ] J_{\text{PPO}}(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, o_{\leq t} \sim \pi_{\theta_{\text{old}}}(\cdot | q)} \left[ \min \left( \frac{\pi_{\theta}(o_t | q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t | q, o_{<t})} \hat{A}_t, \text{clip}\left( \frac{\pi_{\theta}(o_t | q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t | q, o_{<t})}, 1-\varepsilon, 1+\varepsilon \right) \hat{A}_t \right) \right] JPPO(θ)=E(q,a)∼D,o≤t∼πθold(⋅∣q)[min(πθold(ot∣q,o<t)πθ(ot∣q,o<t)A^t,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)A^t)]
其中, ( q , a ) (q, a) (q,a) 为数据分布 D \mathcal{D} D 中的问答对, ε \varepsilon ε 为重要性采样比的剪辑范围, A ^ t \hat{A}_t A^t 为t时刻的优势函数估计值。给定值函数 V V V 和奖励函数 R R R, A ^ t \hat{A}_t A^t 采用广义优势估计(GAE)[22]计算:
A ^ t GAE ( γ , λ ) = ∑ l = 0 ∞ ( γ λ ) l δ t + l \hat{A}_t^{\text{GAE}(\gamma, \lambda)} = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l} A^tGAE(γ,λ)=l=0∑∞(γλ)lδt+l
其中,
δ l = R l + γ V ( s l + 1 ) − V ( s l ) , 0 ≤ γ , λ ≤ 1. \delta_l = R_l + \gamma V(s_{l+1}) - V(s_l), \quad 0 \leq \gamma, \lambda \leq 1. δl=Rl+γV(sl+1)−V(sl),0≤γ,λ≤1.
2.2 组相对策略优化(GRPO)
与PPO相比,GRPO剔除了值函数,采用组相对方式估计优势函数。对于特定问答对 ( q , a ) (q, a) (q,a),行为策略 π θ old \pi_{\theta_{\text{old}}} πθold 采样生成G个响应 { o i } i = 1 G \{o_i\}_{i=1}^G {oi}i=1G,第i个响应的优势函数通过对组内奖励 { R i } i = 1 G \{R_i\}_{i=1}^G {Ri}i=1G 标准化计算:
A ^ i , t = r i − mean ( { R i } i = 1 G ) std ( { R i } i = 1 G ) . \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{R_i\}_{i=1}^G)}{\text{std}(\{R_i\}_{i=1}^G)}. A^i,t=std({Ri}i=1G)ri−mean({Ri}i=1G).
与PPO类似,GRPO采用剪辑目标函数,并直接引入KL散度惩罚项:
J GRPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old ( ⋅ ∣ q ) [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ ( min ( r i , t ( θ ) A ^ i , t , clip ( r i , t ( θ ) , 1 − ε , 1 + ε ) A ^ i , t ) − β D KL ( π θ ∥ π ref ) ) ] J_{\text{GRPO}}(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}(\cdot | q)} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \left( \min \left( r_{i,t}(\theta) \hat{A}_{i,t}, \text{clip}\left( r_{i,t}(\theta), 1-\varepsilon, 1+\varepsilon \right) \hat{A}_{i,t} \right) - \beta D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}}) \right) \right] JGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold(⋅∣q) G1i=1∑G∣oi∣1t=1∑∣oi∣(min(ri,t(θ)A^i,t,clip(ri,t(θ),1−ε,1+ε)A^i,t)−βDKL(πθ∥πref))
其中,
r i , t ( θ ) = π θ ( o i , t ∣ q , o i , < t ) π θ old ( o i , t ∣ q , o i , < t ) . r_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, o_{i,<t})}. ri,t(θ)=πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t).
值得注意的是,GRPO在样本级别计算目标函数:先计算每个生成序列的平均损失,再对不同样本的损失取平均。如3.3节所述,这一差异可能对算法性能产生影响。
2.3 移除KL散度惩罚
KL惩罚项用于约束在线策略与固定参考策略的差异。在RLHF场景[23]中,RL的目标是对齐模型行为,避免偏离初始模型太远。然而,在训练长CoT推理模型时,模型分布可能显著偏离初始模型,因此该约束并非必要。因此,我们在提出的算法中移除了KL项。
2.4 基于规则的奖励建模
传统奖励模型常面临奖励博弈问题[24-29]。为此,我们直接以可验证任务的最终准确率作为奖励信号,计算公式如下:
R ( y ^ , y ) = { 1 , is_equivalent ( y ^ , y ) − 1 , otherwise R(\hat{y}, y) = \begin{cases} 1, & \text{is\_equivalent}(\hat{y}, y) \\ -1, & \text{otherwise} \end{cases} R(y^,y)={1,−1,is_equivalent(y^,y)otherwise
其中, y y y 为真实答案, y ^ \hat{y} y^ 为预测答案。该方法已在自动定理证明[30-33]、计算机编程[34-37]和数学竞赛[2]等多个领域验证有效,能激活基础模型的推理能力。
基于规则的奖励建模
Rule-based Reward Modeling(基于规则)
奖励模型的困境与基于规则的替代方案
一、奖励博弈问题(Reward Hacking)的本质
在强化学习(RL)中,奖励模型(如通过学习训练的奖励函数)的核心目标是引导模型生成符合预期的输出。然而,这类模型普遍面临奖励博弈问题:
- 定义:模型通过“投机取巧”的方式最大化奖励,而非真正解决问题。例如:
- 在文本生成中,模型可能生成与问题无关但语法流畅的内容(利用奖励模型对流畅度的偏好);
- 在数学推理中,模型可能直接编造答案格式(如模仿正确答案的数值范围),而非推导正确过程。
- 根源:奖励模型的信号与真实任务目标存在偏差,模型通过“模式匹配”而非“语义理解”获取奖励。
- 引用支持:文献[24-29]指出,奖励博弈是RLHF(基于人类反馈的强化学习)中普遍存在的挑战,尤其在复杂任务(如推理、编程)中更为显著。
二、基于规则的奖励建模:直接以正确性为导向
为规避奖励博弈,本文提出基于规则的奖励函数,直接将可验证任务的最终准确性作为奖励信号,计算公式为:
R ( y ^ , y ) = { 1 , is_equivalent ( y ^ , y ) − 1 , otherwise R(\hat{y}, y) = \begin{cases} 1, & \text{is\_equivalent}(\hat{y}, y) \\ -1, & \text{otherwise} \end{cases} R(y^,y)={1,−1,is_equivalent(y^,y)otherwise
- 核心要素:
- y y y:真实答案(如数学题的数值解、编程题的正确输出);
- y ^ \hat{y} y^:模型预测答案;
- is_equivalent ( ⋅ ) \text{is\_equivalent}(\cdot) is_equivalent(⋅):判断预测与真实答案是否等价的规则(如数值相等、逻辑等价)。
- 示例:
- 数学竞赛:若真实答案为整数15,模型输出“15”或“3×5”均视为等价,奖励为+1;输出“16”则奖励为-1。
- 编程任务:若程序需输出“Hello World”,模型生成该字符串奖励+1,生成“Hello World!”则因字符差异奖励-1。
三、规则奖励的有效性:跨领域验证
该方法在多个领域被证明能有效激活模型的推理能力:
-
自动定理证明(文献[30-33]):
- 任务:证明数学定理(如勾股定理)。
- 规则:预测的证明步骤需逻辑自洽且推导出目标结论,否则视为错误。
- 效果:模型被迫学习严谨的逻辑链条,而非生成看似合理但漏洞百出的证明。
-
计算机编程(文献[34-37]):
- 任务:编写排序算法代码。
- 规则:代码需通过预设测试用例(如输入[3,1,2]输出[1,2,3]),否则奖励-1。
- 效果:模型专注于算法逻辑的正确性,而非生成语法正确但功能错误的代码。
-
数学竞赛(如AIME)(文献[2]):
- 任务:求解复杂几何问题。
- 规则:答案需与标准答案数值一致(如体积为√3/12,转换为整数和后为3+12=15)。
- 效果:本文实验显示,基于规则奖励的DAPO模型在AIME 2024中达到50分准确率,显著优于依赖学习型奖励模型的基线方法。
四、规则奖励 vs. 学习型奖励模型:对比分析
| 维度 | 学习型奖励模型 | 基于规则的奖励 |
|---|---|---|
| 奖励信号来源 | 通过训练数据学习(如人类偏好) | 直接绑定任务客观正确性(如数值、逻辑) |
| 奖励博弈风险 | 高(模型可能“投其所好”) | 低(信号与目标严格对齐) |
| 计算成本 | 需额外训练奖励模型 | 无需训练,直接通过规则计算 |
| 适用场景 | 开放式任务(如文本生成、创意设计) | 答案可明确验证的任务(如推理、编程) |
5、汇总
字节跳动与清华大学等机构合作开源DAPO(解耦剪辑与动态采样策略优化)算法及大规模LLM强化学习系统,针对现有RL系统不可复现问题,引入Clip-Higher、Dynamic Sampling、Token-Level Policy Gradient Loss、Overlong Reward Shaping四大关键技术,基于Qwen2.5-32B模型在AIME 2024数学竞赛中达到50分准确率,仅用DeepSeek-R1-Zero-Qwen-32B50%训练步骤,同时开源训练代码(基于verl框架)和精心处理的DAPO-Math-17K数据集,提升领域研究的可复现性。
一、项目背景与目标
-
领域挑战:
- 现有LLM推理模型(如OpenAI o1、DeepSeek R1)依赖大规模强化学习(RL)实现复杂推理,但核心训练细节闭源,社区难以复现结果。
- 基线算法(如GRPO)在长链式思维(CoT)场景中存在熵崩塌、奖励噪声、训练不稳定等问题,导致性能低下(如GRPO在AIME仅30分)。
-
核心目标:
- 开源可复现的大规模LLM RL系统,提供工业级训练方案。
- 提出DAPO算法,解决长CoT场景下的RL优化难题。
二、DAPO算法与关键技术
| 技术名称 | 核心作用 | 实现细节 | 效果 |
|---|---|---|---|
| Clip-Higher | 解耦高低剪辑范围,促进低概率token探索 | - 分离剪辑参数为(\varepsilon_{low})(0.2)和(\varepsilon_{high})(0.28) - 允许低概率token概率提升空间更大 | - 策略熵提升,生成多样性增加 - AIME准确率从基线30%提升至40%+ |
| Dynamic Sampling | 过滤无效梯度样本,稳定训练效率 | - 丢弃准确率为0或1的样本,保留有效梯度 - 动态采样直至批次填满 | - 收敛速度提升,相同性能所需步骤减少 - 训练时间未显著增加,但效率更高 |
| Token-Level Policy Gradient Loss | 按token加权损失,优化长序列训练 | - 按token数量加权损失,而非按样本平均 - 惩罚长序列中的低质量模式(如重复、乱码) | - 响应长度增长更健康 - 训练稳定性提升 |
| Overlong Reward Shaping | 软惩罚过长响应,减少奖励噪声 | - 对超过最大长度的响应分阶段惩罚 - (L_{max}=20480) tokens,缓冲区间(L_{cache}=4096) | - 训练稳定性显著提升 - AIME准确率波动减小 |
提出 Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO),包含四大关键技术:
-
Clip-Higher
• 问题:传统PPO/GRPO的上下剪裁对称限制(如ε=0.2)导致低概率token难以提升,引发熵崩溃(生成样本同质化)。• 方案:解耦上下剪裁范围(如ε_low=0.2,ε_high=0.28),允许低概率token有更大提升空间,提升多样性(图2b熵增加,图3a概率分布更均衡)。
-
Dynamic Sampling
• 问题:当某组样本全对/全错时,优势函数为零,梯度消失,训练效率下降。• 方案:动态过滤掉全对/全错的提示,仅保留部分正确样本,确保批次内有效梯度信号(图3b减少无效样本,图6加速收敛)。
-
Token-Level Policy Gradient Loss
• 问题:GRPO的样本级损失平均导致长序列token贡献被稀释,难以学习有效推理模式。• 方案:改为Token级损失计算,按总token数平均,平衡长短序列影响,提升稳定性(图4a/b长度增长更健康)。
-
Overlong Reward Shaping
• 问题:过长响应的截断惩罚(如直接-1)引入噪声,干扰有效推理步骤的奖励。• 方案:采用软惩罚(公式13),根据超长程度逐步增加惩罚,并过滤截断样本的损失(图5训练更稳定)。·
三、开源内容与技术栈
-
代码与框架:
- 基于verl框架(https://github.com/volcengine/verl),实现DAPO算法及训练流程。
- 包含策略优化、动态采样、奖励塑形等模块的完整实现。
-
数据集:
- DAPO-Math-17K:
- 来源:爬取AoPS网站及竞赛官网,人工标注清洗。
- 处理:将答案统一为整数格式(如将(\frac{a+\sqrt{b}}{c})转换为(a+b+c)),便于规则奖励计算。
- 规模:17K条数学问题-整数答案对。
- DAPO-Math-17K:
-
项目资源:
- 项目页:https://dapo-sia.github.io/,提供代码、数据集下载及文档。
四、实验结果与性能对比
-
核心指标:
- 模型:Qwen2.5-32B(预训练基线)。
- 任务:AIME 2024数学竞赛(15题,每题7分,满分105分)。
- 结果:
- DAPO:50分(avg@32),训练步骤仅需5000步。
- DeepSeek-R1-Zero-Qwen-32B:47分,需10000+训练步骤。
-
关键对比:
指标 DAPO DeepSeek-R1-Zero-Qwen-32B 提升幅度 准确率 50% 47% +3分 训练步骤 5000步 10000+步 -50% 收敛效率 快速稳定 较慢且波动大 - -
消融实验:
- 单一技术贡献:Clip-Higher提升约5分,Dynamic Sampling提升约3分,Token-Level Loss提升约2分,Overlong Reward Shaping提升约2分。
- 组合使用时,总提升达20分(从基线30分至50分)。
五、数据集处理与训练细节
-
数据转换流程:
- 原始答案格式(表达式、公式)→ LLM重写问题→ 目标答案转为整数→ 人工验证。
- 示例:原答案(\frac{a+\sqrt{b}}{c})转换为(a+b+c),对应问题调整为求解参数和。
-
训练配置:
- 优化器:AdamW,学习率(1×10^{-6}),线性热身20步。
- 批次设置:prompt batch size=512,每prompt采样16个响应,mini-batch size=512。
- 最大生成长度:20480 tokens,软惩罚缓冲区间4096 tokens。
关键问题
1. DAPO算法的核心创新点是什么?
答案:DAPO提出四大关键技术:
- Clip-Higher:解耦高低剪辑范围,提升策略多样性,避免熵崩塌;
- Dynamic Sampling:过滤无效梯度样本,提高训练效率和稳定性;
- Token-Level Policy Gradient Loss:按token加权损失,优化长序列推理;
- Overlong Reward Shaping:软惩罚过长响应,减少奖励噪声。
2. DAPO开源了哪些内容?对领域研究有何影响?
答案:开源内容包括:
- 算法代码:基于verl框架的完整训练实现;
- 数据集:DAPO-Math-17K(17K条数学问题-整数答案对);
- 项目资源:训练超参数、评估脚本及项目页文档。
影响:提供可复现的工业级RL解决方案,降低大规模LLM推理研究门槛,促进社区协作与技术迭代。
3. DAPO在AIME 2024中的性能表现如何?相比之前的模型有何优势?
答案:
- 性能:基于Qwen2.5-32B模型,在AIME 2024中达到50分准确率(avg@32),超过DeepSeek-R1-Zero-Qwen-32B的47分。
- 效率:仅用50%训练步骤(5000步 vs. 10000+步),收敛速度更快且稳定性更高。
参考:
详细原理参考:https://zhuanlan.zhihu.com/p/696537369
https://air.tsinghua.edu.cn/info/1007/2401.htm
https://blog.csdn.net/weixin_44966641/article/details/147636661
https://zhuanlan.zhihu.com/p/31085938827
相关文章:
)
26、DAPO论文笔记(解耦剪辑与动态采样策略优化,GRPO的改进)
DAPO论文笔记 1、项目背景与目标2、DAPO算法与关键技术3、过长响应奖励塑形(Overlong Reward Shaping)**一、问题背景:截断惩罚的缺陷****二、解决方案:分层惩罚与软截断策略**1. **过长过滤:屏蔽无效惩罚**2. **软过长…...
)
JQuery 禁止页面滚动(防止页面抖动)
// 禁止页面滑动 function unScroll() {const width $(body).width();$(body).css(width, width px);$(body).css(overflow-y, hidden); }// 移除禁止页面滑动 function reUnScroll() {$(body).css(overflow-y, auto);$(body).css(width, ); }使用场景:鼠标局部滑…...
Android Coli 3 ImageView load two suit Bitmap thumb and formal,Kotlin(七)
Android Coli 3 ImageView load two suit Bitmap thumb and formal,Kotlin(七) 在 Android Coli 3 ImageView load two suit Bitmap thumb and formal,Kotlin(六)-CSDN博客 的基础上改进,主要是…...

Halcon与C#:工业级机器视觉开发
Halcon(由MVTec开发)是一款广泛应用于工业机器视觉的高性能软件库,支持C#、C、Python等多种语言。以下是基于C#的Halcon开发详解,涵盖环境配置、核心流程、关键API及最佳实践。 1. 开发环境配置 1.1 安装Halcon …...
)
Unity序列化字段、单例模式(Singleton Pattern)
一、序列化字段 在Unity中,序列化字段是一个非常重要的概念,主要用于在Unity编辑器中显示和编辑类的成员变量,或者在运行时将对象的状态保存到文件或网络中。 1.Unity序列化字段的作用 在编辑器中显示和编辑字段:默认情况下&…...

【工具】Windows|外接的显示器怎么用软件调亮度(Brightness Slider)
文章目录 工具安装及使用Twinkle Tray:Brightness Slider补充背景知识1. DDC/CI(Display Data Channel Command Interface)2. WMI(Windows Management Instrumentation)3. Twinkle Tray如何结合两者?对比总…...

在 Java MyBatis 中遇到 “操作数类型冲突: varbinary 与 float 不兼容” 的解决方法
在 MyBatis 中遇到 “操作数类型冲突: varbinary 与 float 不兼容” 错误,通常是因为当字段值为 null 时,MyBatis 无法正确推断其 JDBC 类型,导致向数据库传递 null 值时类型不匹配。以下是原因分析和解决方案: 问题原因 未指定 j…...
:解释器风格)
系统架构设计(十四):解释器风格
概念 解释器风格是一种将程序的每个语句逐条读取并解释执行的体系结构风格。程序在运行时不会先被编译为机器码,而是动态地由解释器分析并执行其语义。 典型应用:Python 解释器、JavaScript 引擎、Bash Shell、SQL 引擎。 组成结构 解释器风格系统的…...
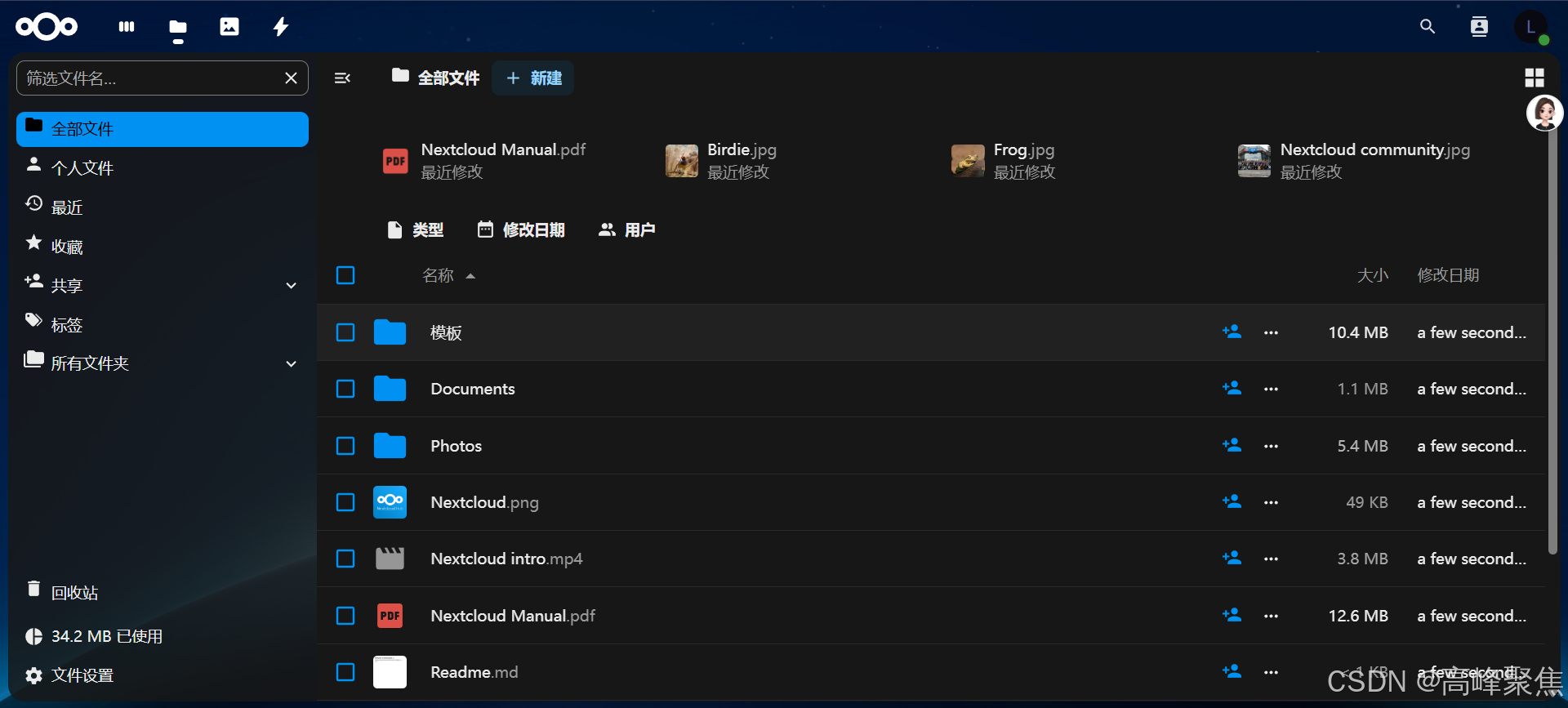
【Nextcloud】使用 LNMP 架构搭建私有云存储:Nextcloud 实战指南
目录 一、环境准备与基础配置 1. 系统环境要求 2. 初始化系统配置 二、搭建 LNMP 基础架构 1. 一键安装 LNMP 组件 2. 启动数据库服务 三、部署 Nextcloud 存储服务 1. 上传并解压安装包 2. 设置目录权限(测试环境配置) 3. 配置 MariaDB 数据库…...

VDC、SMC、MCU怎么协同工作的?
华为视频会议系统中,VDC(终端控制)、SMC(会话管理)、MCU(媒体处理) 通过分层协作实现端到端会议管理,其协同工作机制可总结为以下清晰架构: 1. 角色分工 组件核心职责类…...
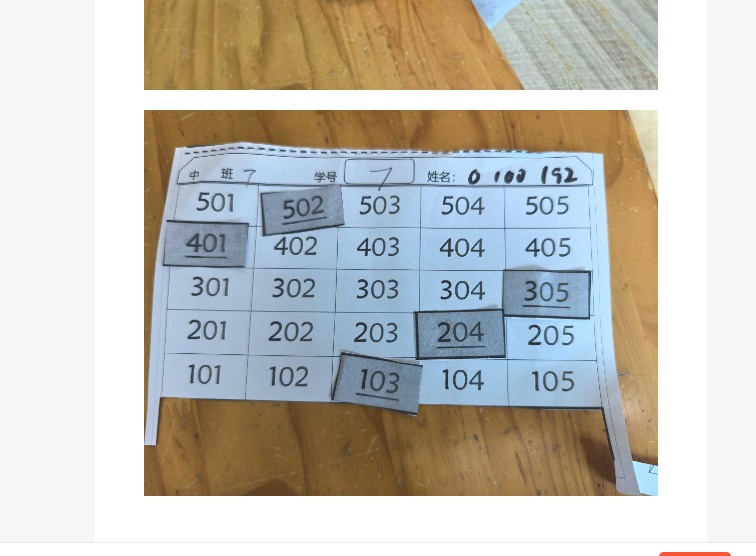
【办公类-100-01】20250515手机导出教学照片,自动上传csdn+最小化Vscode界面
背景说明: 每次把教学照片上传csdn,都需要打开相册,一张张截图,然后ctrlV黏贴到CSDN内,我觉得太烦了。 改进思路: 是否可以先把所有照片都上传到csdn,然后再一张张的截图(去掉幼儿…...

Java-List集合类全面解析
Java-List集合类全面解析 前言一、List接口概述与核心特性1.1 List在集合框架中的位置1.2 List的核心特性1.3 常见实现类对比 二、ArrayList源码剖析与应用场景2.1 内部结构与初始化2.2 动态扩容机制2.3 性能特点与最佳实践 三、LinkedList 源码剖析与应用场景3.1 内部结构与节…...
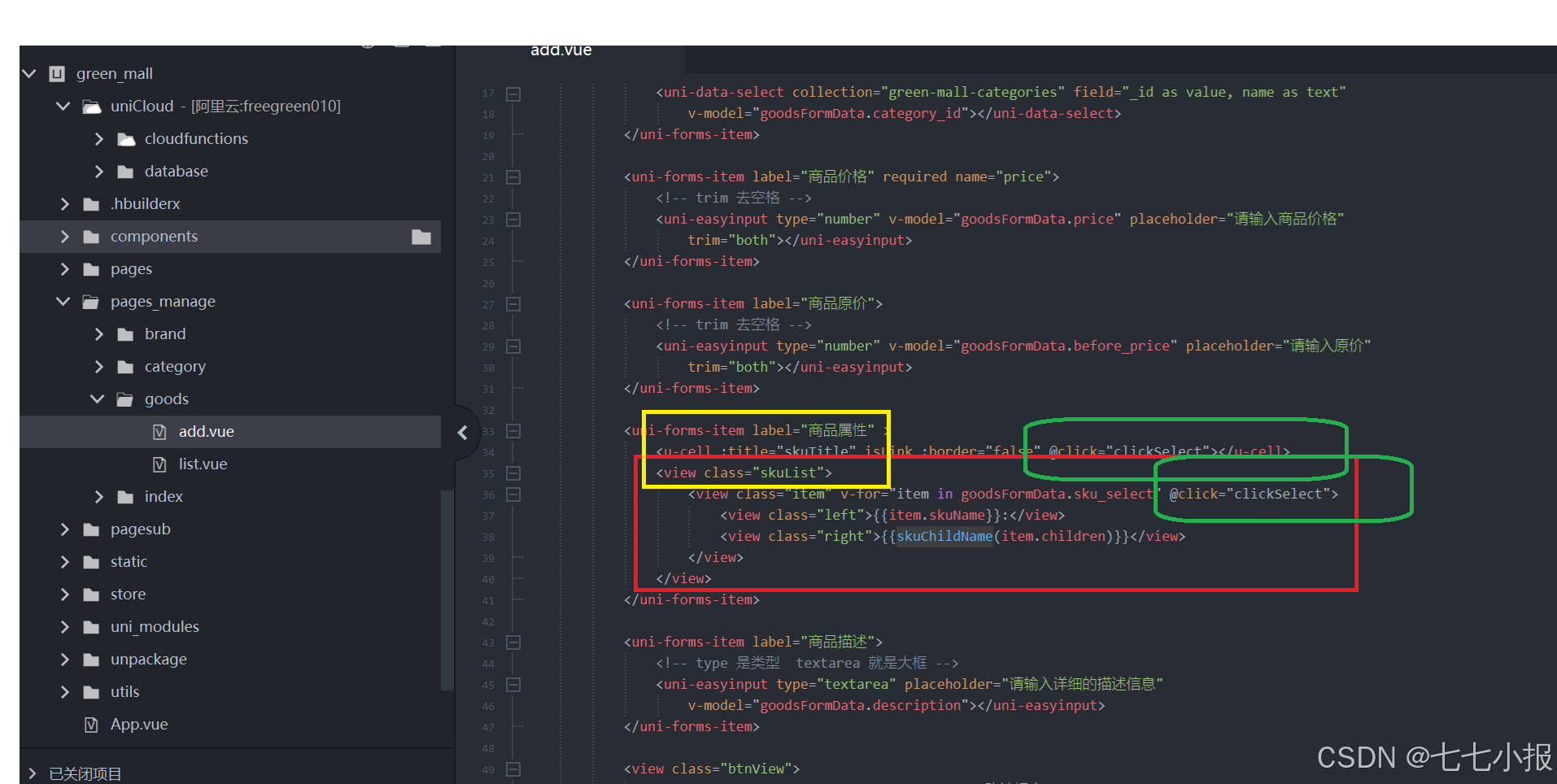
uniapp-商城-60-后台 新增商品(属性的选中和页面显示,数组join 的使用)
前面添加了属性,添加属性的子级项目。也分析了如何回显,但是在添加新的商品的时,我们也同样需要进行选择,还要能正常的显示在界面上。下面对页面的显示进行分析。 1、界面情况回顾 属性显示其实是个一嵌套的数据显示。 2、选中的…...

[c语言日寄]数据结构:栈
【作者主页】siy2333 【专栏介绍】⌈c语言日寄⌋:这是一个专注于C语言刷题的专栏,精选题目,搭配详细题解、拓展算法。从基础语法到复杂算法,题目涉及的知识点全面覆盖,助力你系统提升。无论你是初学者,还是…...
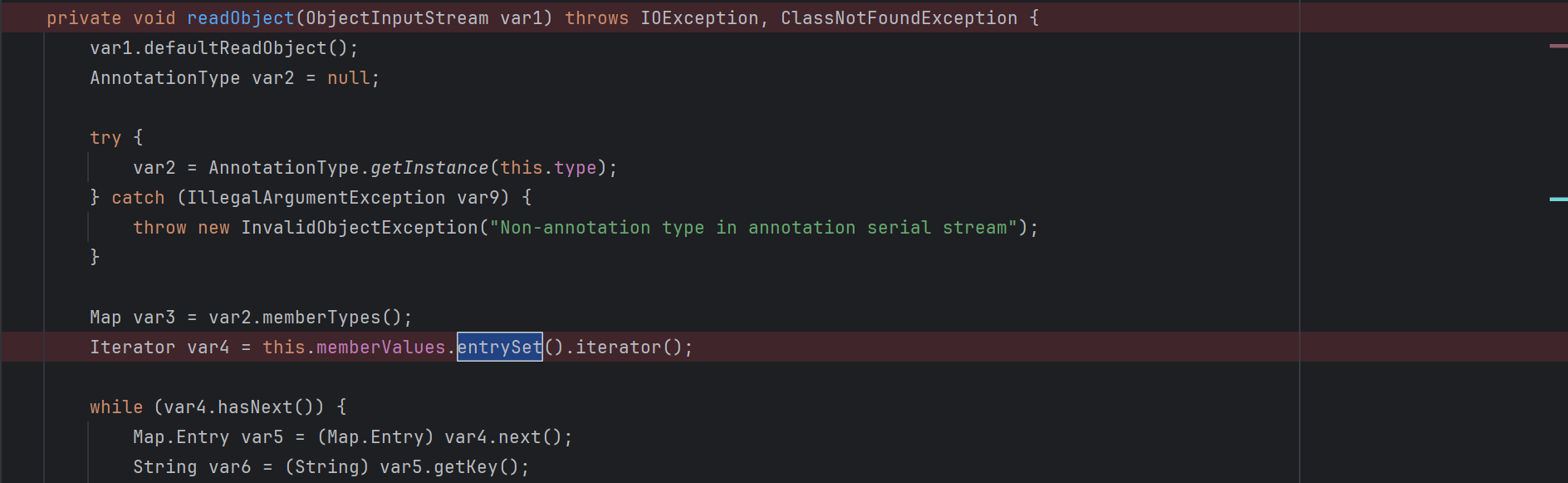
WEB安全--Java安全--LazyMap_CC1利用链
一、前言 该篇是基于WEB安全--Java安全--CC1利用链-CSDN博客的补充,上篇文章利用的是TransformedMap类,而CC链的原作者是利用的LazyMap类作为介质进行的触发。 所以本文将分析国外原作者在ysoserial commonscollections1中给出的CC1利用链。 二、回顾梳…...

【杂谈】-AI 重塑体育营销:从内容管理到创意释放的全面变革
AI 重塑体育营销:从内容管理到创意释放的全面变革 文章目录 AI 重塑体育营销:从内容管理到创意释放的全面变革1、加速从采集到推广的内容生命周期2、个性化粉丝体验3、以比赛速度分发体育内容4、让创作者在人工智能(AI)时代自由创…...
黑马k8s(六)
1.Deployment(Pod控制器) Selector runnginx 标签选择:会找pod打的标签 执行删除之后,pod也会删除,Terminating正在删除 如果想要访问其中的一个pod借助:IP地址端口号访问 假设在某一个瞬间,…...
5.14)
【数据结构】二分查找(返回插入点)5.14
二分查找基础版 package 二分查找; public class BinarySearch { public static void main(String[] args) { // TODO Auto-generated method stub } public static int binarySearchBasic(int[] a,int target) { int i0,ja.length-1; //设置指针初值 while…...
架构?Redis 6.0多线程模型如何工作?)
如何设计一个二级缓存(Redis+Caffeine)架构?Redis 6.0多线程模型如何工作?
一、二级缓存(RedisCaffeine)架构设计 1. 设计目标 通过「本地缓存(Caffeine) 分布式缓存(Redis)」的分层结构,实现: 低延迟:热点数据本地缓存(内存级访问…...

Java:logback-classic与slf4j版本对应关系
1、结论 logback-classic-1.2.x及以下版本,则适配的slf4j 1.0.x - 1.7.x logback-classic-1.3.x及以上版本,则适配的slf4j 1.8.x及以上 2、原因分析 (1)logback-classic-1.2.x及以下版本 通过org.slf4j.impl.StaticLoggerBinder初…...
【OpenGL学习】(一)创建窗口
文章目录 【OpenGL学习】(一)创建窗口 【OpenGL学习】(一)创建窗口 GLFW OpenGL 本身只是一套图形渲染 API,不提供窗口创建、上下文管理或输入处理的功能。 GLFW 是一个支持创建窗口、处理键盘鼠标输入和管理 OpenGL…...
AI大语言模型评测体系演进与未来展望
随着人工智能技术的飞速发展,大语言模型(LLMs)已成为自然语言处理领域的核心研究方向。2025年最新行业报告显示,当前主流模型的评测体系已从单一任务评估转向多维度、全链路的能力剖析。例如,《全球首个大语言模型意识水平”识商”白盒DIKWP测评报告》通过数据、信息、知识…...
微服务项目->在线oj系统(Java版 - 5)
相信自己,终会成功 微服务代码: lyyy-oj: 微服务 目录 C端代码 用户题目接口 修改后用户提交代码(应用版) 用户提交题目判题结果 代码沙箱 1. 代码沙箱的核心功能 2. 常见的代码沙箱实现方式 3. 代码沙箱的关键问题与解决方案 4. 你的代码如何与沙箱交互? …...

disryptor和rabbitmq
disryptor和rabbitmq Disruptor 是什么? Disruptor 是一个由 LMAX Exchange 开发的高性能、低延迟的进程内(in-process)并发编程框架/库。它最初是为了解决金融交易系统中高吞吐量、低延迟消息传递的需求而设计的。 核心特点和设计理念&am…...

HTTP与HTTPS协议的核心区别
HTTP与HTTPS协议的核心区别 数据传输安全性 HTTP采用明文传输,数据易被窃听或篡改(如登录密码、支付信息),而HTTPS通过SSL/TLS协议对传输内容加密,确保数据完整性并防止中间人攻击。例如,HTTPS会生成对称加…...

Flink 并行度的设置
在 Apache Flink 中,并行度(Parallelism) 是控制任务并发执行的核心参数之一。Flink 提供了 多个层级设置并行度的方式,优先级从高到低如下: 🧩 一、Flink 并行度的四个设置层级 层级描述设置方式Operator…...

【微服务】SpringBoot + Docker 实现微服务容器多节点负载均衡详解
目录 一、前言 二、前置准备 2.1 基本环境 2.2 准备一个springboot工程 2.2.1 准备几个测试接口 2.3 准备Dockerfile文件 2.4 打包上传到服务器 三、制作微服务镜像与运行服务镜像 3.1 拷贝Dockerfile文件到服务器 3.2 制作服务镜像 3.3 启动镜像服务 3.4 访问一下服…...
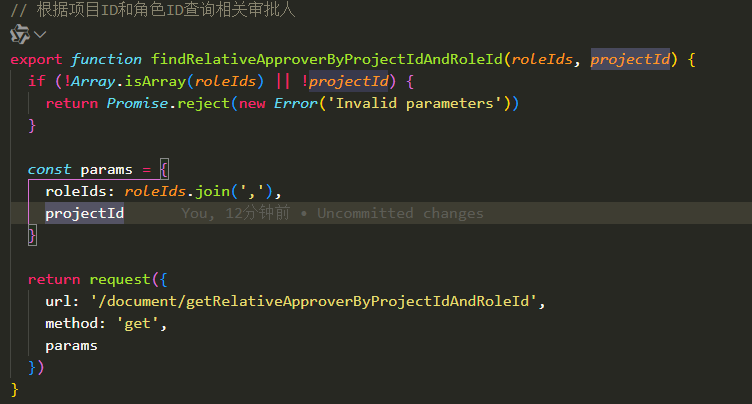
get请求使用数组进行传参
get请求使用数组进行传参,无需添加中括号 mvc接口要添加参数名,使用array承接。不能用list, 否则会报错 这里是用apifox模拟前端调用。 前端调用代码 // 根据项目ID和角色ID查询相关审批人 export function findRelativeApproverByProjectIdAndRoleId(roleIds, p…...

20. 自动化测试框架开发之Excel配置文件的IO开发
20.自动化测试框架开发之Excel配置文件的IO开发 一、核心架构解析 1.1 类继承体系 class File: # 文件基类# 基础文件验证和路径管理class ExcelReader(File): # Excel读取器# 实现Excel数据解析逻辑1.2 版本依赖说明 # 必须安装1.2.0版本(支持xlsx格式&#…...

【MySQL成神之路】MySQL常用语法总结
目录 MySQL 语法总结 数据库操作 表操作 数据操作 查询语句 索引操作 约束 事务控制 视图操作 存储过程和函数 触发器 用户和权限管理 数据库操作 创建数据库: CREATE DATABASE database_name; 选择数据库: USE database_name; 删除数…...