利用 Java 爬虫根据关键词获取某手商品列表
在电商领域,根据关键词获取商品列表是常见的需求。某手作为国内知名的电商平台,提供了丰富的商品资源。通过 Java 爬虫技术,我们可以高效地根据关键词获取某手商品列表,并提取商品的基本信息。本文将详细介绍如何利用 Java 爬虫根据关键词获取某手商品列表,并提供完整的代码示例。
一、准备工作
(一)安装必要的库
确保你的开发环境中已经安装了以下库:
-
Jsoup:用于解析 HTML 文档。
-
Apache HttpClient:用于发送 HTTP 请求。
可以通过 Maven 来管理这些依赖。以下是 Maven 的依赖配置示例:
xml
<dependencies><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.14.3</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version></dependency>
</dependencies>(二)注册平台账号
如果目标平台提供 API 接口,需要注册相应平台的开发者账号,获取 App Key 和 App Secret。这些凭证将用于后续的 API 调用。
二、编写爬虫代码
(一)发送 HTTP 请求
使用 Apache HttpClient 库发送 GET 请求,获取商品列表页面的 HTML 内容。
java
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;public class ProductListCrawler {public static String getHtml(String url) {try (CloseableHttpClient client = HttpClients.createDefault()) {HttpGet request = new HttpGet(url);request.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36");return EntityUtils.toString(client.execute(request).getEntity());} catch (Exception e) {e.printStackTrace();return null;}}
}(二)解析 HTML 内容
使用 Jsoup 解析 HTML 内容,提取商品列表中的商品信息。
java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.HashMap;public class HtmlParser {public static List<Map<String, String>> parseHtml(String html) {List<Map<String, String>> products = new ArrayList<>();Document document = Jsoup.parse(html);Elements productItems = document.select("div.product-item");for (Element item : productItems) {Map<String, String> product = new HashMap<>();product.put("title", item.select("h2.product-title").first().text());product.put("price", item.select("span.product-price").first().text());product.put("description", item.select("div.product-description").first().text());product.put("image_url", item.select("img.product-image").first().attr("src"));products.add(product);}return products;}
}(三)根据关键词获取商品列表
根据关键词构建商品列表页面的 URL,并获取其 HTML 内容。
java
public class ProductListCrawler {public static List<Map<String, String>> getProductListByKeyword(String baseUrl, String keyword, int page) {String url = baseUrl + "?keyword=" + keyword + "&page=" + page;String html = getHtml(url);if (html != null) {return HtmlParser.parseHtml(html);}return new ArrayList<>();}public static void main(String[] args) {String baseUrl = "https://example.com/search"; // 替换为目标平台的商品列表页面 URLString keyword = "耳机"; // 替换为实际关键词int page = 1; // 替换为实际页码List<Map<String, String>> products = getProductListByKeyword(baseUrl, keyword, page);for (Map<String, String> product : products) {System.out.println("商品名称: " + product.get("title"));System.out.println("商品价格: " + product.get("price"));System.out.println("商品描述: " + product.get("description"));System.out.println("商品图片URL: " + product.get("image_url"));System.out.println("----------------------------");}}
}三、保存解析后的商品信息
(一)保存到文件
将商品信息保存到文件中,方便后续处理和分析。
java
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import com.opencsv.CSVWriter;public class SaveToFile {public static void saveAsCsv(List<Map<String, String>> products, String filePath) {try (CSVWriter writer = new CSVWriter(new FileWriter(filePath))) {String[] headers = {"title", "price", "description", "image_url"};writer.writeNext(headers);for (Map<String, String> product : products) {String[] data = {product.get("title"),product.get("price"),product.get("description"),product.get("image_url")};writer.writeNext(data);}System.out.println("数据已保存到 CSV 文件:" + filePath);} catch (IOException e) {e.printStackTrace();}}
}(二)保存到数据库
将商品信息保存到数据库中,方便后续查询和分析。
java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.List;
import java.util.Map;public class SaveToDatabase {public static void saveToMySQL(List<Map<String, String>> products, String url, String user, String password) {String insertSQL = "INSERT INTO products (title, price, description, image_url) VALUES (?, ?, ?, ?)";try (Connection conn = DriverManager.getConnection(url, user, password);PreparedStatement pstmt = conn.prepareStatement(insertSQL)) {for (Map<String, String> product : products) {pstmt.setString(1, product.get("title"));pstmt.setString(2, product.get("price"));pstmt.setString(3, product.get("description"));pstmt.setString(4, product.get("image_url"));pstmt.addBatch();}pstmt.executeBatch();System.out.println("数据已保存到 MySQL 数据库");} catch (SQLException e) {e.printStackTrace();}}
}四、注意事项和建议
(一)遵守平台规则
在编写爬虫时,必须严格遵守目标平台的使用协议,避免触发反爬机制。
(二)合理设置请求频率
避免过高的请求频率,以免对平台服务器造成压力。建议在请求之间添加适当的延时:
java
Thread.sleep(1000); // 每次请求间隔1秒(三)数据安全
妥善保管爬取的数据,避免泄露用户隐私和商业机密。
(四)处理异常情况
在爬虫代码中添加异常处理机制,确保在遇到错误时能够及时记录并处理。
java
try {List<Map<String, String>> products = getProductListByKeyword(baseUrl, keyword, page);if (!products.isEmpty()) {for (Map<String, String> product : products) {System.out.println("商品名称: " + product.get("title"));System.out.println("商品价格: " + product.get("price"));System.out.println("商品描述: " + product.get("description"));System.out.println("商品图片URL: " + product.get("image_url"));System.out.println("----------------------------");}} else {System.out.println("未能获取商品列表。");}
} catch (Exception e) {e.printStackTrace();
}五、总结
通过上述方法,可以高效地利用 Java 爬虫技术根据关键词获取某手商品列表。希望本文能为你提供有价值的参考,帮助你更好地利用爬虫技术获取电商平台数据。在开发过程中,务必注意遵守平台规则,合理设置请求频率,并妥善处理异常情况,以确保爬虫的稳定运行。
相关文章:

利用 Java 爬虫根据关键词获取某手商品列表
在电商领域,根据关键词获取商品列表是常见的需求。某手作为国内知名的电商平台,提供了丰富的商品资源。通过 Java 爬虫技术,我们可以高效地根据关键词获取某手商品列表,并提取商品的基本信息。本文将详细介绍如何利用 Java 爬虫根…...
)
Axure项目实战:智慧运输平台后台管理端-订单管理2(多级交互)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:订单管理2 主要内容:中继器筛选、表单跟随菜单拖动、审批数据互通等 应用场景:订单管理…...
篇章五 项目创建
目录 1.创建一个SpringBoot项目 2.创建核心类 2.1 Exchange类 2.2 MessageQueue类 2.3 Binding类 2.4 Message类 1.Message的组成 2.逻辑删除 3.工厂方法 4.序列化与反序列化 5.offsetBeg和offsetEnd 1.创建一个SpringBoot项目 1.点击 2.填写表单 3.添加依赖 2.创建…...

Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT=0x90的一个例子
Ntfs!ATTRIBUTE_RECORD_HEADER结构$INDEX_ROOT0x90的一个例子 1: kd> dx -id 0,0,899a2278 -r1 ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) ((Ntfs!_FILE_RECORD_SEGMENT_HEADER *)0xc431a400) : 0xc431a400 [Type: _FILE_RECORD_SEGMENT_HEADER …...
:LangChain链的基本使用)
AGI大模型(30):LangChain链的基本使用
为开发更复杂的应用程序,需要使用Chain来链接LangChain中的各个组件和功能,包括模型之间的链接以及模型与其他组件之间的链接。 链在内部把一系列的功能进行封装,而链的外部则又可以组合串联。 链其实可以被视为LangChain中的一种基本功能单元。 API地址:https://python.…...

代码随想录算法训练营第六十六天| 图论11—卡码网97. 小明逛公园,127. 骑士的攻击
继续补,又是两个新算法,继续进行勉强理解,也是训练营最后一天了,六十多天的刷题告一段落了! 97. 小明逛公园 97. 小明逛公园 感觉还是有点难理解原理 Floyd 算法对边的权值正负没有要求,都可以处理。核心…...

[创业之路-364]:企业战略管理案例分析-5-战略制定-宇树科技的使命、愿景、价值观的演变过程
目录 一、宇树科技的使命、愿景、价值观的演变过程 初创阶段(2016 年成立前后):以技术梦想奠基,明确核心使命愿景 发展阶段(2017 - 2023 年):技术突破与市场拓展,价值观逐步成型 …...

React--函数组件和类组件
React 中的函数组件和类组件是两种定义组件的方式,它们有以下主要区别: 1. 语法与定义方式 函数组件: 是 JavaScript 函数,接收 props 作为参数,返回 JSX。 const MyComponent (props) > {return <div>Hell…...

Flask 路由装饰器:从 URL 到视图函数的优雅映射
前置知识,关于Python装饰器的语法,链接:Python 装饰器:从“语法糖”到“代码神器”的深度解析 1、路由装饰器的功能:给 URL 贴 “功能标签” 在 Flask 开发中,你一定见过这样的代码: from fla…...

DDoS防护实战——从基础配置到高防IP部署
一、基础防护:服务器与网络层加固 Linux内核优化: 调整TCP协议栈参数,缓解SYN Flood攻击: # 启用SYN Cookie并减少超时时间 echo 1 > /proc/sys/net/ipv4/tcp_syncookies echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout…...

aws平台s3存储桶夸域问题处理
当我们收到开发反馈s3存在跨域问题 解决步骤: 配置 S3 存储桶的 CORS 设置: 登录到 AWS 管理控制台。转到 S3 服务。选择你存储文件的 存储桶。点击 权限 标签页。在 跨域资源共享(CORS)配置 部分,点击 编辑。 登陆…...
)
HOT100(二叉树)
二叉树 二叉树的中序遍历 class Solution { public:void traversal(TreeNode* root, vector<int> & vec){if(root nullptr) return;traversal(root->left, vec);vec.push_back(root->val);traversal(root->right, vec);}vector<int> inorderTraver…...
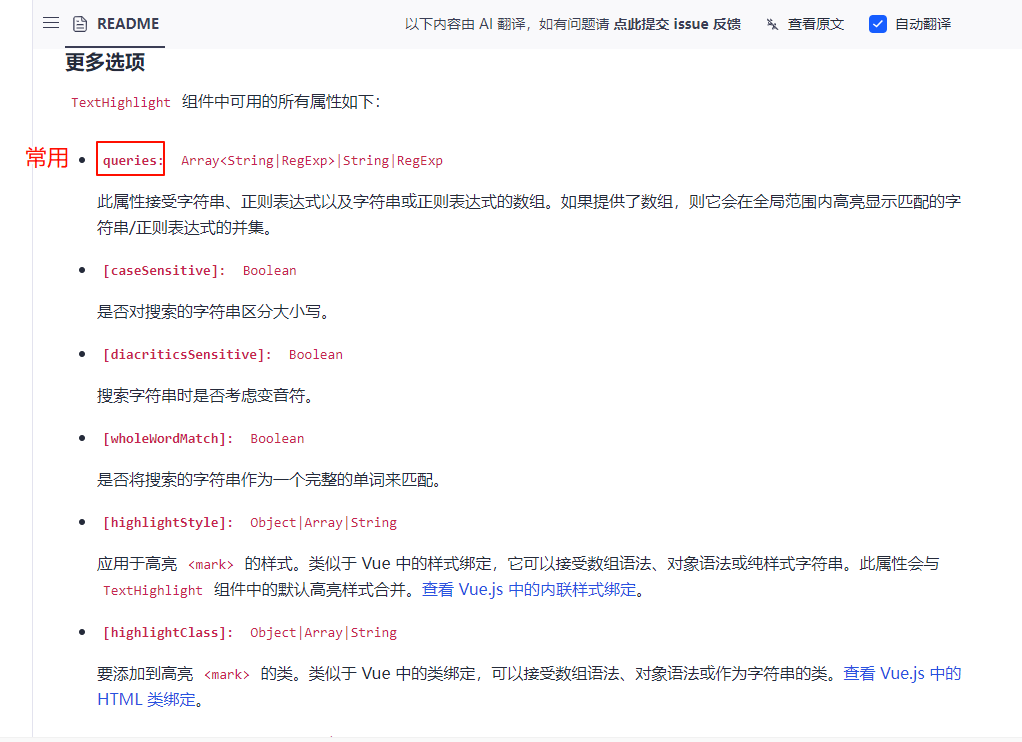
【vue-text-highlight】在vue2的使用教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、下载二、使用步骤1.引入库2.用法 效果速通 前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不断发…...
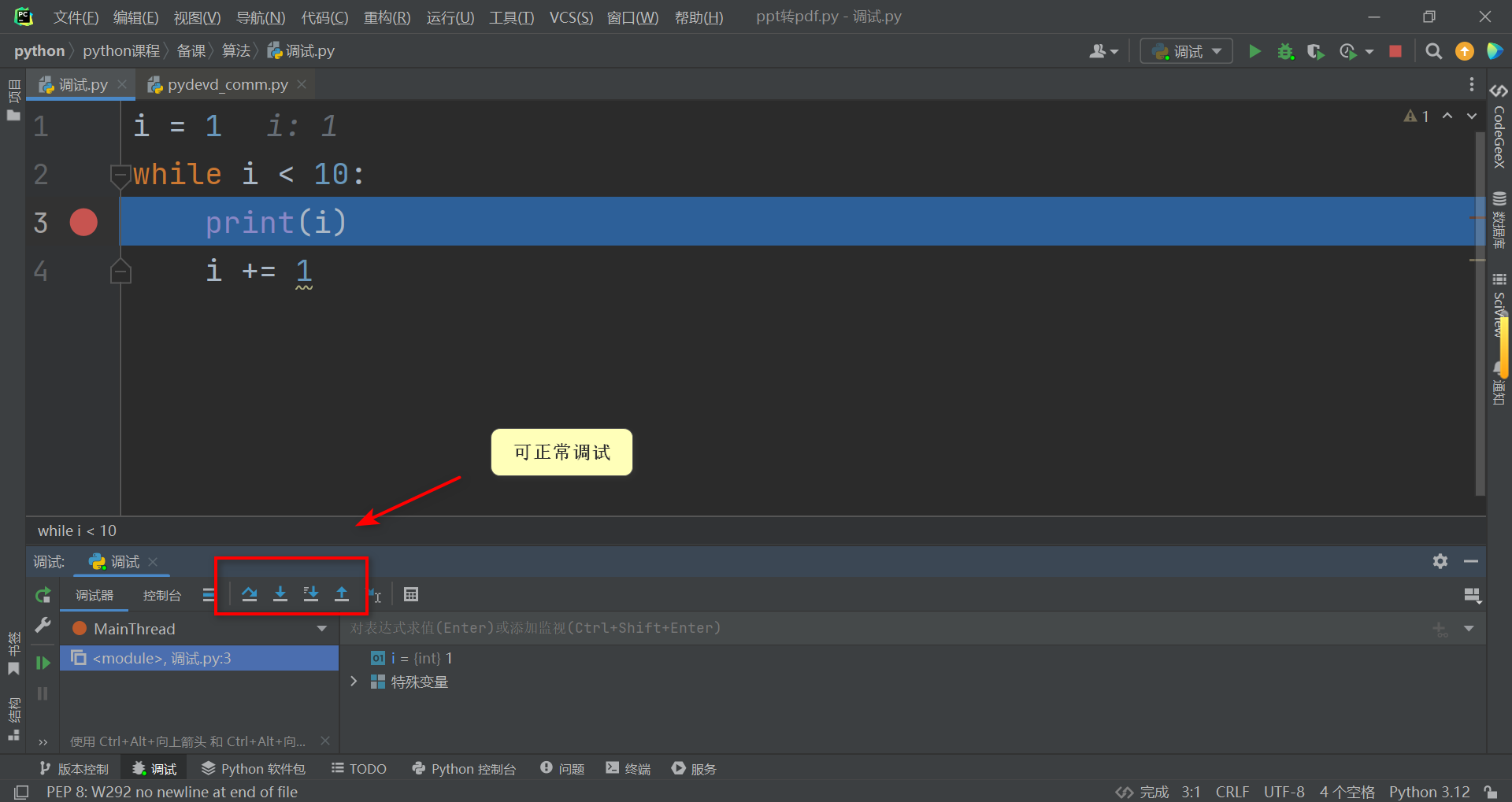
pycharm无法正常调试问题
pycharm无法正常调试问题 1.错误代码 已连接到 pydev 调试器(内部版本号 231.8109.197)Traceback (most recent call last):File "E:\Python\pycharm\PyCharm 2023.1\plugins\python\helpers\pydev\_pydevd_bundle\pydevd_comm.py", line 304, in _on_runr r.deco…...

springboot3.4.5-springsecurity+session
创建springboot项目,添加以下依赖: LombokSpring WebSpring SecuritySpring Data JDBCMyBatis FrameworkMySQL Driver 添加fastjson2进行序列化和反序列化 <dependency><groupId>com.alibaba.fastjson2</groupId><artifactId>f…...

网络安全利器:蜜罐技术详解
蜜罐是网络安全领域中一种主动防御和情报收集的重要工具。本文将深入探讨蜜罐技术的原理、类型、应用场景以及部署注意事项。 1. 什么是蜜罐? 蜜罐(Honeypot)是一种安全资源,其价值在于被探测、攻击或未经授权使用。简单来说,蜜罐就是一个诱饵系统,用来吸引黑客的注意力…...
Leetcode百题斩-哈希
看来面试前还是要老老实实刷leetcode为好,今天看到一个题库,leetcode百题斩,刚好最近面试的这两题全在里面。瞄了一眼,也有不少题之前居然也刷过。那么,冲冲冲,看多久能把这百题刷完。 第一天,先…...
不存在(APP))
MySQL替换瀚高数据库报错: TO_DAYS()不存在(APP)
文章目录 环境症状问题原因解决方案报错编码 环境 系统平台:中标麒麟(海光)7,中标麒麟(飞腾)7 版本:4.5 症状 MySQL替换为瀚高数据库进行应用系统适配报错:TO_DAYS()不…...

EXIST与JOIN连表比较
结论 1:EXIST可以用于链表,且可以利用到索引2:当join无法合理利用到索引,可以尝试EXIST链表3:EXIST在某些情况下可以更好地利用到索引4:大数据量时,要考虑EXIST的使用 EXIST SQL: EXPLAN JOIN…...
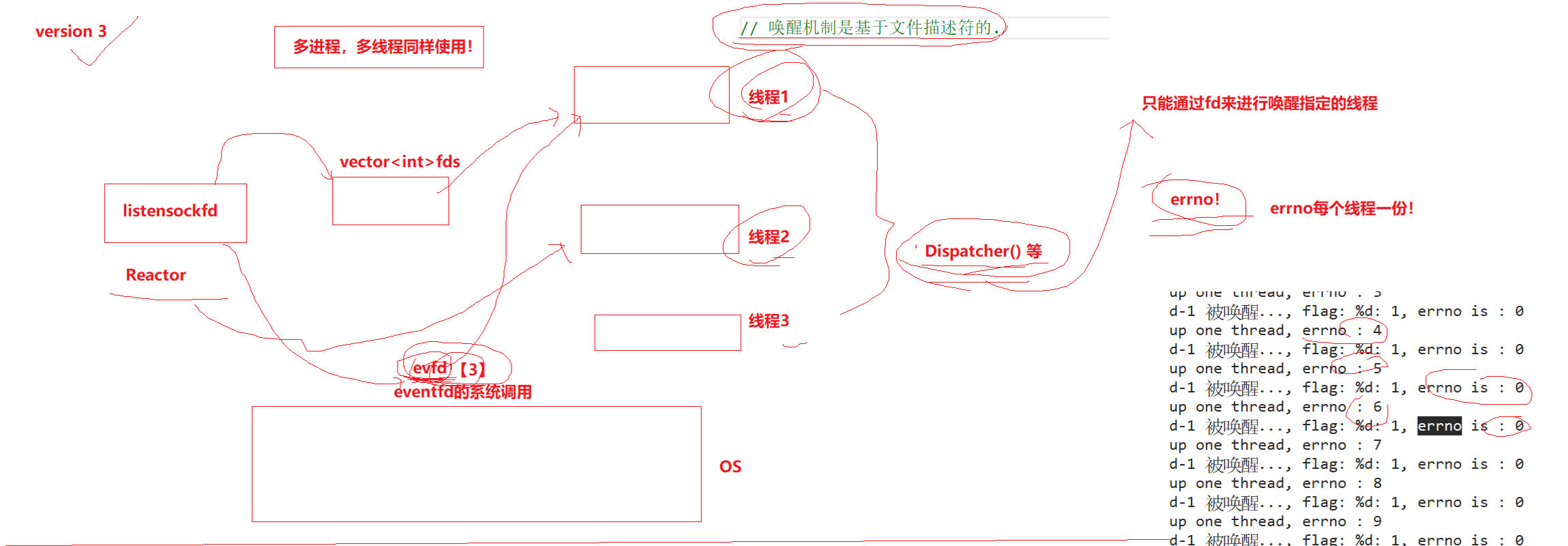
【Linux】利用多路转接epoll机制、ET模式,基于Reactor设计模式实现
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:多路转接epoll,实现echoserver 至此,Linux与…...
)
【jvm第7集】jvm调优工具(命令行工具)
文章目录 JVM 调优工具(命令行工具)jps(Java Virtual Machine Process Status Tool)jstat(JVM Statistics Monitoring Tool)jmap(Memory Map Tool)jstack(Thread Stack T…...
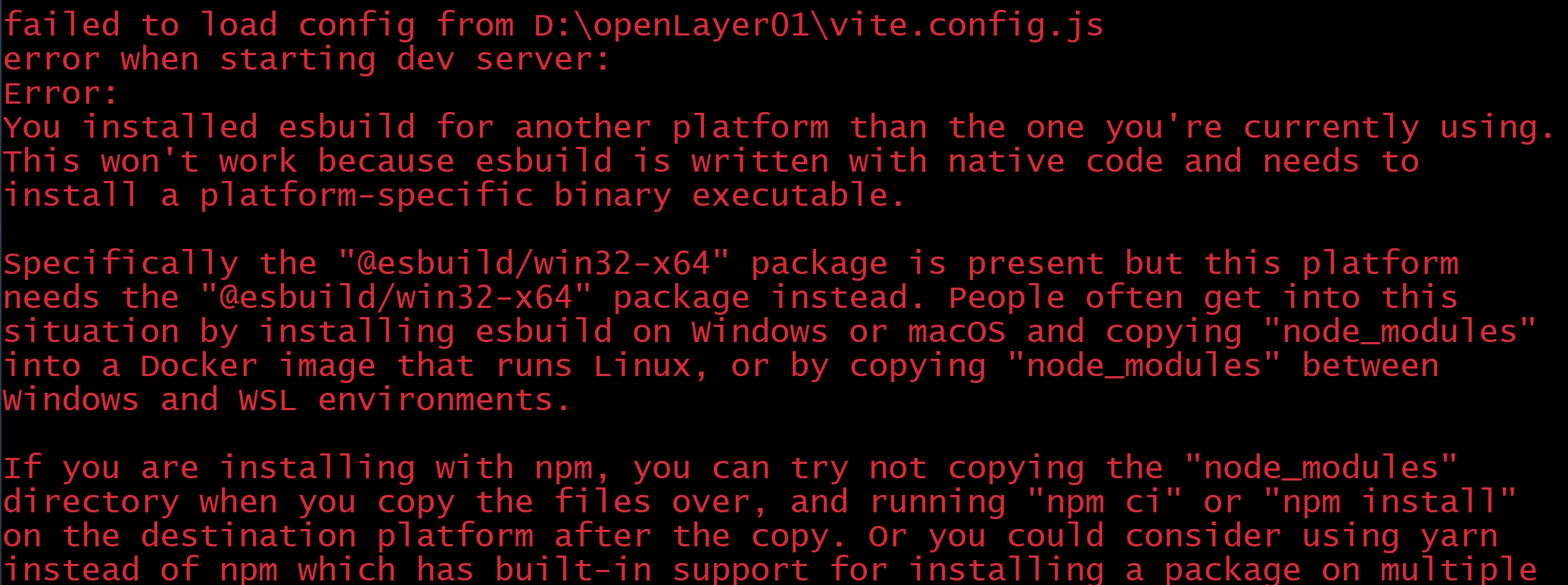
react中运行 npm run dev 报错,提示vite.config.js出现错误 @esbuild/win32-x64
在React项目中运行npm run dev时,如果遇到vite.config.js报错,提示esbuild/win32-x64在另一个平台中被使用,通常是由于依赖冲突或缓存问题导致的。解决方法是删除node_modules文件夹,并重新安装依赖。 如下图: 解决办…...

鸿蒙UI开发——Builder与LocalBuilder对比
1、概 述 在ArkUI中,有的朋友应该接触过Builder和LocalBuilder。其中有了LocalBuilder的存在,是为了解决组件的父子关系和状态管理的父子关系保持一致的问题。 这里面最直观的表现则是this的指向问题与组件刷新问题,本文对Builder与LocalBu…...
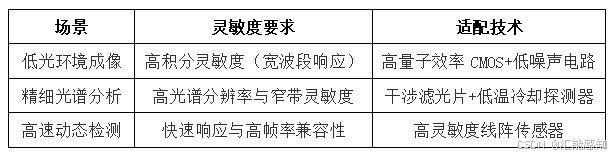
关于光谱相机的灵敏度
一、灵敏度的核心定义 光谱灵敏度(单色灵敏度) 描述光谱相机对单色辐射光的响应能力,即探测器对特定波长入射光的输出信号强度与入射光功率的比值。 例如,若在680nm波长下的光谱灵敏度较高,则表示该相机对此…...
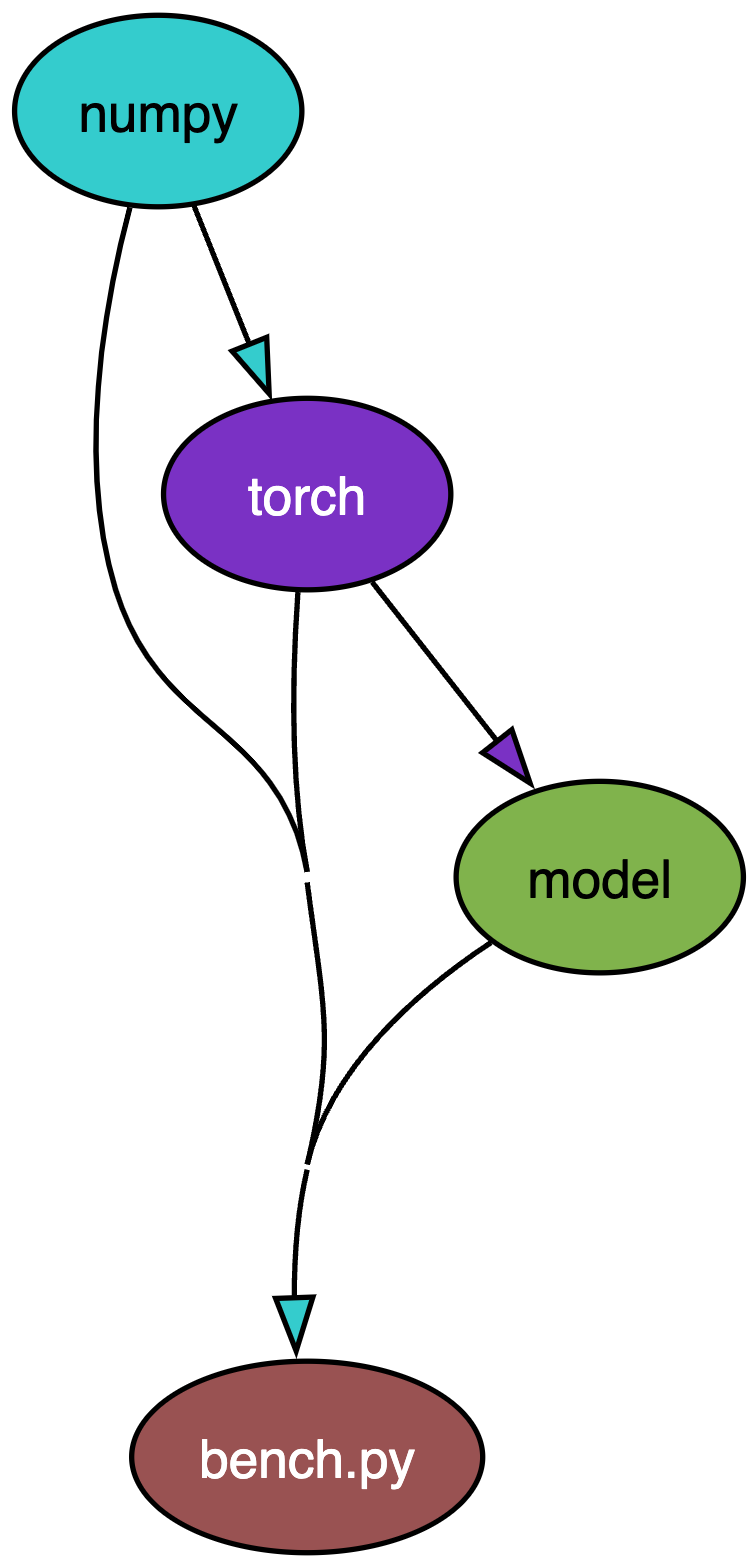
Model 速通系列(一)nanoGPT
这个是新开的一个系列用来手把手复现一些模型工程,之所以开这个系列是因为有人留言说看到一个工程不知道从哪里读起,出于对自身能力的提升与兴趣,故新开了这个系列。由于主要动机是顺一遍代码并提供注释。 该系列第一篇博客是 nanoGPT &…...

微信小程序中,一个页面的数据改变了,怎么通知另一个页面也改变?
在微信小程序中,当一个页面的数据改变后通知另一个页面更新,可以通过以下步骤实现: 方法一:使用全局事件总线(推荐) 步骤说明: 在 app.js 中创建事件系统 在全局 App 实例中实现事件监听和触发…...
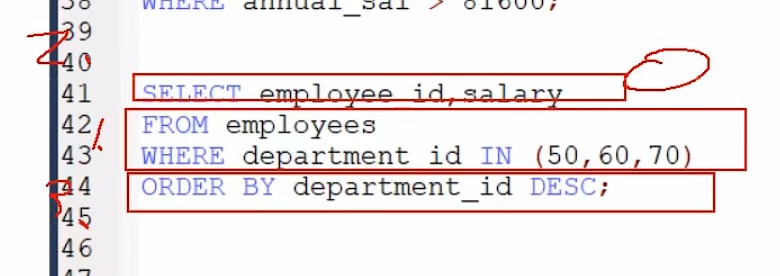
MySQL--day4--排序与分页
(以下内容全部来自上述课程) 1. 排序数据 1.1 排序基本使用 #1.排序 #如果没有使用排序操作,默认情况下查询返回的数据是按照添加数据的顺序显示的 SELECT * FROM employees;# 练习:按照salary从高到低的顺序显示员工信息 # 使用 ORDER …...

自动化测试脚本点击运行后,打开Chrome很久??
亲爱的小伙伴们大家好。 小编最近刚换了电脑,这几天做自动化测试发现打开Chrome浏览器需要等待好长时间,起初还以为代码有问题,或者Chromedriver与Chrome不匹配造成的,但排查后发现并不是!! 在driver.py中…...

iOS热更新技术要点与风险分析
iOS的热更新技术允许开发者在无需重新提交App Store审核的情况下,动态修复Bug或更新功能,但需注意苹果的审核政策限制。以下是iOS热更新的主要技术方案及要点: 一、主流热更新技术方案 JavaScript动态化框架 React Native & Weex 通过Jav…...
:统一过程模型(RUP))
系统架构设计(十二):统一过程模型(RUP)
简介 RUP 是由 IBM Rational 公司提出的一种 面向对象的软件工程过程模型,以 UML 为建模语言,是一种 以用例为驱动、以架构为中心、迭代式、增量开发的过程模型。 三大特征 特征说明以用例为驱动(Use Case Driven)需求分析和测…...