【图像生成大模型】CogVideoX-5b:开启文本到视频生成的新纪元

CogVideoX-5b:开启文本到视频生成的新纪元
- 项目背景与目标
- 模型架构与技术亮点
- 项目运行方式与执行步骤
- 环境准备
- 模型加载与推理
- 量化推理
- 执行报错与问题解决
- 内存不足
- 模型加载失败
- 生成质量不佳
- 相关论文信息
- 总结
在人工智能领域,文本到视频生成技术一直是研究的热点和难点。它不仅需要模型理解复杂的语言指令,还要将其转化为具有连贯性和视觉吸引力的视频内容。CogVideoX-5b 是由清华大学团队开发的一种先进的开源文本到视频生成模型,它在这一领域取得了显著的突破,为研究人员和开发者提供了一个强大的工具。
项目背景与目标
随着深度学习技术的飞速发展,文本生成图像的技术已经取得了令人瞩目的成就。然而,将文本直接转化为视频内容面临着更多的挑战。视频生成不仅需要生成每一帧的图像,还需要确保这些图像在时间序列上具有连贯性,形成一个自然流畅的视频。CogVideoX-5b 的目标是通过引入专家 Transformer 架构,提升文本到视频生成的质量和效率,使其能够生成高质量、高分辨率的视频内容,同时降低运行成本和硬件要求。
模型架构与技术亮点
CogVideoX-5b 基于扩散模型(diffusion models)框架构建,它通过逐步去除噪声来生成视频内容。其核心架构包括以下几个关键部分:
-
文本编码器(Text Encoder):负责将输入的文本提示转化为语义向量,为视频生成提供语义指导。CogVideoX-5b 使用了 T5 编码器,这是一种基于 Transformer 的强大文本编码器,能够有效地捕捉文本中的语义信息。
-
专家 Transformer(Expert Transformer):这是 CogVideoX-5b 的核心创新之一。它专门用于处理视频生成任务中的时空信息,确保生成的视频在时间和空间上都具有连贯性。通过引入 3D RoPE(3D Rotary Positional Embedding)位置编码,模型能够更好地理解和生成具有深度和动态效果的视频内容。
-
解码器(Decoder):负责将文本编码器和专家 Transformer 的输出转化为具体的视频帧。CogVideoX-5b 使用了高效的解码器架构,能够快速生成高质量的视频内容。
-
优化与量化技术:为了提高模型的运行效率和降低硬件要求,CogVideoX-5b 引入了多种优化技术,如模型 CPU 卸载(model CPU offload)、VAE 分片(VAE tiling)等。此外,通过 PytorchAO 和 Optimum-quanto 进行量化,可以在不显著降低视频质量的情况下,大幅减少模型的内存占用,使其能够在资源受限的设备上运行。
项目运行方式与执行步骤
环境准备
在开始运行 CogVideoX-5b 之前,需要确保已经安装了必要的依赖库。以下是推荐的安装步骤:
pip install --upgrade transformers accelerate diffusers imageio-ffmpeg
这些库分别提供了模型加载、加速计算、视频生成等功能。
模型加载与推理
以下是一个简单的代码示例,展示如何使用 CogVideoX-5b 生成视频:
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video# 定义文本提示
prompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."# 加载模型
pipe = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b",torch_dtype=torch.bfloat16
)# 启用优化
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()# 生成视频
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=49,guidance_scale=6,generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]# 保存视频
export_to_video(video, "output.mp4", fps=8)
量化推理
为了在资源受限的设备上运行模型,可以使用 PytorchAO 进行量化。以下是一个量化推理的示例代码:
import torch
from diffusers import AutoencoderKLCogVideoX, CogVideoXTransformer3DModel, CogVideoXPipeline
from diffusers.utils import export_to_video
from transformers import T5EncoderModel
from torchao.quantization import quantize_, int8_weight_only# 定义量化方式
quantization = int8_weight_only# 加载并量化文本编码器
text_encoder = T5EncoderModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="text_encoder", torch_dtype=torch.bfloat16)
quantize_(text_encoder, quantization())# 加载并量化 Transformer
transformer = CogVideoXTransformer3DModel.from_pretrained("THUDM/CogVideoX-5b", subfolder="transformer", torch_dtype=torch.bfloat16)
quantize_(transformer, quantization())# 加载并量化 VAE
vae = AutoencoderKLCogVideoX.from_pretrained("THUDM/CogVideoX-5b", subfolder="vae", torch_dtype=torch.bfloat16)
quantize_(vae, quantization())# 创建管道并运行推理
pipe = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b",text_encoder=text_encoder,transformer=transformer,vae=vae,torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()# 生成视频
video = pipe(prompt=prompt,num_videos_per_prompt=1,num_inference_steps=50,num_frames=49,guidance_scale=6,generator=torch.Generator(device="cuda").manual_seed(42),
).frames[0]# 保存视频
export_to_video(video, "output.mp4", fps=8)
执行报错与问题解决
在运行 CogVideoX-5b 时,可能会遇到一些常见的问题和报错。以下是一些常见的问题及其解决方法:
内存不足
如果在运行模型时遇到内存不足的问题,可以尝试以下方法:
- 启用优化:确保启用了模型 CPU 卸载和 VAE 分片等优化功能。这些优化可以显著减少 GPU 内存的使用量。
- 降低推理精度:将推理精度从
bfloat16降低到float16或int8,这可以在一定程度上减少内存占用,但可能会牺牲一些生成质量。 - 减少生成帧数:减少生成的视频帧数,例如将
num_frames从 49 降低到 24 或更低。
模型加载失败
如果在加载模型时遇到问题,可能是由于网络连接问题或模型文件损坏。可以尝试以下方法:
- 检查网络连接:确保网络连接正常,能够访问 Hugging Face 的模型仓库。
- 重新下载模型:如果模型文件损坏,可以尝试重新下载模型。
- 使用本地模型文件:如果网络连接不稳定,可以将模型文件下载到本地,然后从本地加载模型。
生成质量不佳
如果生成的视频质量不符合预期,可以尝试以下方法:
- 调整文本提示:优化文本提示,使其更加具体和详细。例如,明确描述场景中的物体、动作和氛围。
- 调整生成参数:调整生成参数,如
guidance_scale、num_inference_steps等,以找到最佳的生成效果。 - 使用更强大的硬件:如果硬件性能不足,可能会导致生成质量下降。可以尝试在更强大的 GPU 上运行模型。
相关论文信息
CogVideoX-5b 的相关研究发表在论文《CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer》中,论文链接为:arXiv:2408.06072。该论文详细介绍了模型的架构、训练方法和实验结果,为研究人员提供了深入理解 CogVideoX-5b 的理论基础。
总结
CogVideoX-5b 是一个强大的文本到视频生成模型,它通过引入专家 Transformer 架构和多种优化技术,在生成质量和运行效率上取得了显著的突破。通过本文的详细介绍,读者可以快速了解 CogVideoX-5b 的技术原理、运行方式和常见问题的解决方法。希望 CogVideoX-5b 能够为研究人员和开发者提供一个有力的工具,推动文本到视频生成技术的发展。
相关文章:
【图像生成大模型】CogVideoX-5b:开启文本到视频生成的新纪元
CogVideoX-5b:开启文本到视频生成的新纪元 项目背景与目标模型架构与技术亮点项目运行方式与执行步骤环境准备模型加载与推理量化推理 执行报错与问题解决内存不足模型加载失败生成质量不佳 相关论文信息总结 在人工智能领域,文本到视频生成技术一直是研…...
剧本杀小程序:指尖上的沉浸式推理宇宙
在推理热潮席卷社交圈的当下,你是否渴望随时随地开启一场烧脑又刺激的冒险?我们的剧本杀小程序,就是你掌心的“推理魔法盒”,一键解锁无限精彩! 海量剧本库,满足多元口味:小程序汇聚了从古风权…...
2024正式版企业级在线客服系统源码+语音定位+快捷回复+图片视频传输+安装教程
2024正式版企业级在线客服系统源码语音定位快捷回复图片视频传输安装教程; 企业客服系统是一款全功能的客户服务解决方案,提供多渠道支持(如在线聊天、邮件、电话等),帮助企业建立与客户的实时互动。该系统具有智能分…...
深入解析 Oracle session_cached_cursors 参数及性能对比实验
在 Oracle 数据库管理中,session_cached_cursors参数扮演着至关重要的角色,它直接影响着数据库的性能和资源利用效率。本文将深入剖析该参数的原理、作用,并通过性能对比实验,直观展示不同参数设置下数据库的性能表现。 一、sessi…...

【RabbitMQ】整合 SpringBoot,实现工作队列、发布/订阅、路由和通配符模式
文章目录 工作队列模式引入依赖配置声明生产者代码消费者代码 发布/订阅模式引入依赖声明生产者代码发送消息 消费者代码运行程序 路由模式声明生产者代码消费者代码运行程序 通配符模式声明生产者代码消费者代码运行程序 工作队列模式 引入依赖 我们在创建 SpringBoot 项目的…...

k8s面试题-ingress
场景:我通过deployment更新pod,ingress是怎么把新的请求流量发送到我新的pod的?是怎么监控到我更新的pod的? 在 Kubernetes 中,Ingress 是一种 API 对象,用于管理外部访问到集群内服务的 HTTP 和 HTTPS 路…...
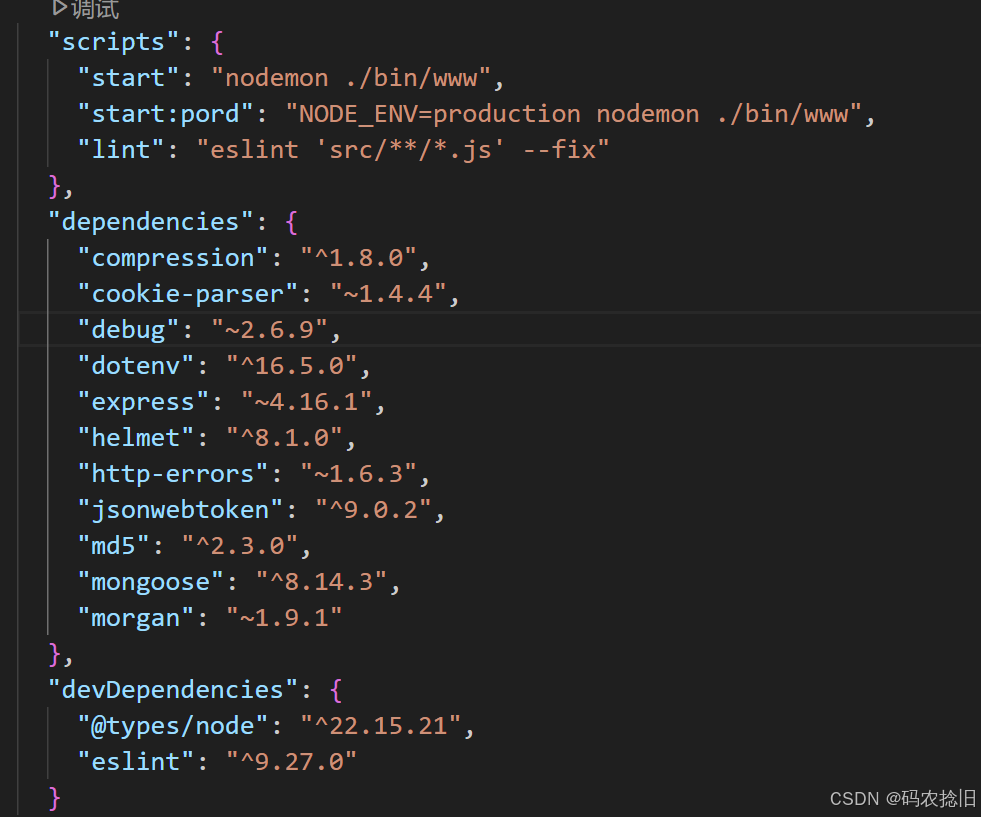
Node.js Express 项目现代化打包部署全指南
Node.js Express 项目现代化打包部署全指南 一、项目准备阶段 1.1 依赖管理优化 # 生产依赖安装(示例) npm install express mongoose dotenv compression helmet# 开发依赖安装 npm install nodemon eslint types/node --save-dev1.2 环境变量配置 /…...

分布式电源的配电网无功优化
分布式电源(Distributed Generation, DG)的大规模接入配电网,改变了传统单向潮流模式,导致电压波动、功率因数降低、网损增加等问题,无功优化成为保障配电网安全、经济、高效运行的关键技术。 1. 核心目标 电压稳定性:抑制DG并网点(PCC)及敏感节点的电压越限(如超过5%…...

【WebRTC】源码更改麦克风权限
WebRTC源码更改麦克风权限 仓库: https://webrtc.googlesource.com/src.git分支: guyl/m125节点: b09c2f83f85ec70614503d16e4c530484eb0ee4f...
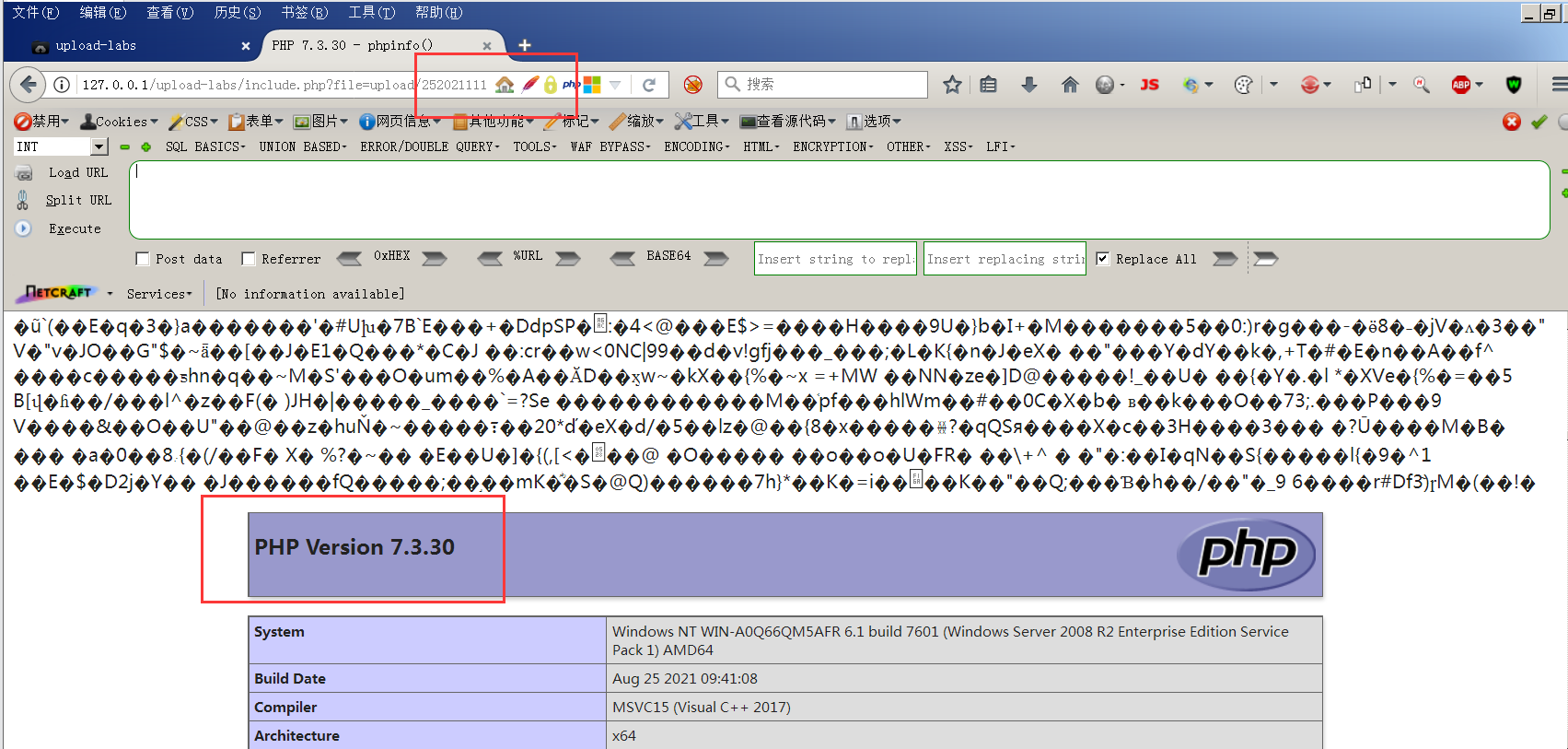
upload-labs通关笔记-第15关 文件上传之getimagesize绕过(图片马)
目录 一、图片马 二、文件包含 三、文件包含与图片马 四、图片马制作方法 五、源码分析 六、制作图片马 1、创建脚本并命名为test.php 2、准备制作图片马的三类图片 3、 使用copy命令制作图片马 七、渗透实战 1、GIF图片马渗透 (1)上传gif图…...
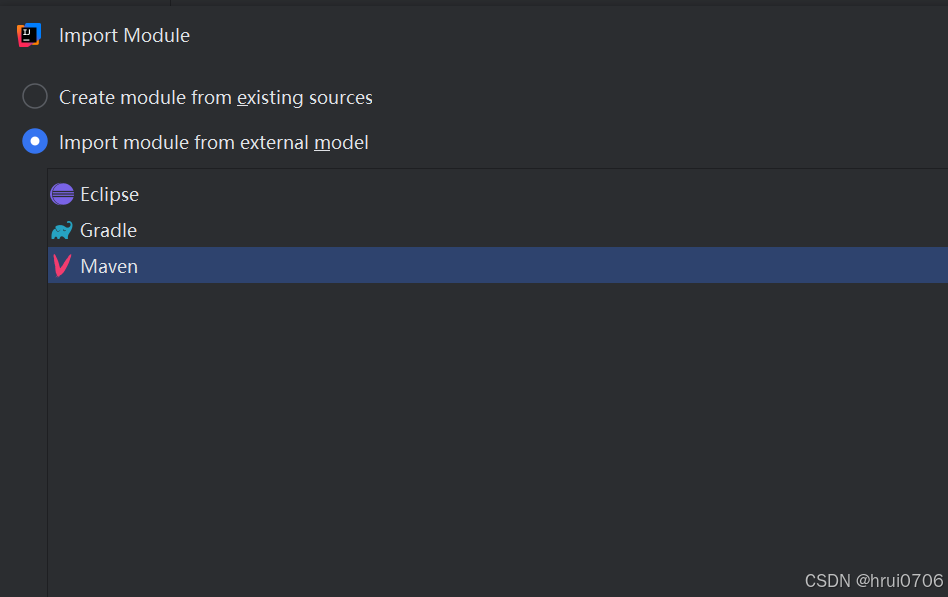
idea无法识别Maven项目
把.mvn相关都删除了 导致Idea无法识别maven项目 或者 添加导入各个模块 最后把父模块也要导入...

前端三剑客之HTML
前端HTML 一、HTML简介 1.什么是html HTML的全称为超文本标记语言(HTML How To Make Love HyperText Markup Language ),是一种标记语言。它包括一系列标签,通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整…...
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

RabbitMQ的核心原理及应用
在分布式系统架构中,消息中间件是实现服务解耦、流量缓冲的关键组件。RabbitMQ 作为基于 AMQP 协议的开源消息代理,凭借高可靠性、灵活路由和跨平台特性,被广泛应用于企业级开发和微服务架构中。本文将系统梳理 RabbitMQ 的核心知识ÿ…...

实时监控服务器CPU、内存和磁盘使用率
实时监控服务器CPU、内存和磁盘使用率 监控内存使用率: free -g | awk NR2{printf "%.2f%%\t\t", $3*100/$2 }awk NR2{...} 取第二行(Mem 行)。 $3 为已用内存,$2 为总内存,$3*100/$2 即计算使用率。监控磁…...

linux国产机安装GCC
目录 1.包管理器安装 2.源码编译安装 linux安装GCC有两种方式,方法一,使用包管理器安装;方法二,源码安装。 1.包管理器安装 Ubuntu 基于 Debian 发行版,使用apt - get进行软件包管理;CentOS 基于 …...

python训练营打卡第30天
模块和库的导入 知识点回顾: 导入官方库的三种手段导入自定义库/模块的方式导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 一、导入官方库 1.标准导入:导入整个库 import mathprint(&quo…...

时间序列预测实战:用 LSTM 预测股票价格
📈 时间序列预测实战:用 LSTM 预测股票价格(PyTorch 实现) 时间序列预测是深度学习在金融领域最常见的应用之一。本文将带你使用 PyTorch 搭建一个基于 LSTM 的模型,对股票收盘价进行预测,完整掌握从数据预处理到预测结果可视化的全流程。 🎯 一、项目目标 任务:基于…...
STM32 | FreeRTOS 消息队列
01 一、概述 队列又称消息队列,是一种常用于任务间通信的数据结构,队列可以在任务与任务间、中断和任务间传递信息,实现了任务接收来自其他任务或中断的不固定长度的消息,任务能够从队列里面读取消息,当队列中的消…...
便捷的Office批量转PDF工具
软件介绍 本文介绍的软件是一款能实现Office批量转换的工具,名为五五Excel word批量转PDF。 软件小巧 这款五五Excel word批量转PDF软件大小不到2M。 操作步骤一 使用该软件时,只需把软件和需要转换的Word或Excel文件放在同一个文件夹里。 操作步骤…...

pom.xml中的runtime
在 Maven 的 pom.xml 文件中,<scope> 元素可以指定依赖项的作用范围,而 runtime 是其中的一个作用范围值。以下是 runtime 作用范围的含义: 定义:runtime 作用范围表示该依赖项在编译时不需要,但在运行时需要。…...

SpringMVC 通过ajax 实现文件的上传
使用form表单在springmvc 项目中上传文件,文件上传成功之后往往会跳转到其他的页面。但是有的时候,文件上传成功的同时,并不需要进行页面的跳转,可以通过ajax来实现文件的上传 下面我们来看看如何来实现: 方式1&…...
opcUA 编译和建模入门教程(zhanzhi学习笔记)
一、使用SIOME免费工具建模 从西门子官网下载软件SIOS,需要注册登录,下载安装版就行。下载后直接安装就可以用了,如图: 安装完成后打开,开始建模,如图左上角有新建模型的按钮。 新建了新工程后,…...

【关联git本地仓库,上传项目到github】
目录 1.下载git2.绑定用户3.git本地与远程仓库交互4.github项目创建5.上传本地项目到github6.完结撒花❀❀❀!!! 1.下载git git下载地址:https://git-scm.com/downloads 下载安装后创建快捷地址:(此处比较…...

初步认识HarmonyOS NEXT端云一体化开发
视频课程学习报名入口:HarmonyOS NEXT端云一体化开发 1、课程设计理念 本课程采用"四维能力成长模型"设计理念,通过“能看懂→能听懂→能上手→能实战”的渐进式学习路径,帮助零基础开发者实现从理论认知到商业级应用开发的跨越。该模型将学习过程划分为四个维度…...
WebRTC技术EasyRTC音视频实时通话驱动智能摄像头迈向多场景应用
一、方案背景 在物联网蓬勃发展的当下,智能摄像头广泛应用于安防、家居、工业等领域。但传统智能摄像头存在视频传输延迟高、设备兼容性差、网络波动时传输不稳定等问题,难以满足用户对实时流畅交互视频的需求。EasyRTC凭借低延迟、高可靠、跨平台特性…...

分布式ID生成器:原理、对比与WorkerID实战
一、为什么需要分布式ID? 在微服务架构下,单机自增ID无法满足跨服务唯一性需求,且存在: • 单点瓶颈:数据库自增ID依赖单表写入 • 全局唯一性:跨服务生成可能重复 • 扩展性差:分库分表后ID规…...
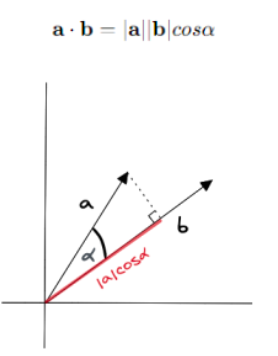
java 代码查重(三)常见的距离算法和相似度(相关系数)计算方法
目录 一、几种距离度量方法 【 海明距离 /汉明距离】 【 欧几里得距离(Euclidean Distance) 】 【 曼哈顿距离 】 【 切比雪夫距离 】 【 马氏距离 】 二、相似度算法 【 余弦相似度 】 【 皮尔森相关系数 】 【 Jaccard相似系数 /杰卡德距离】…...
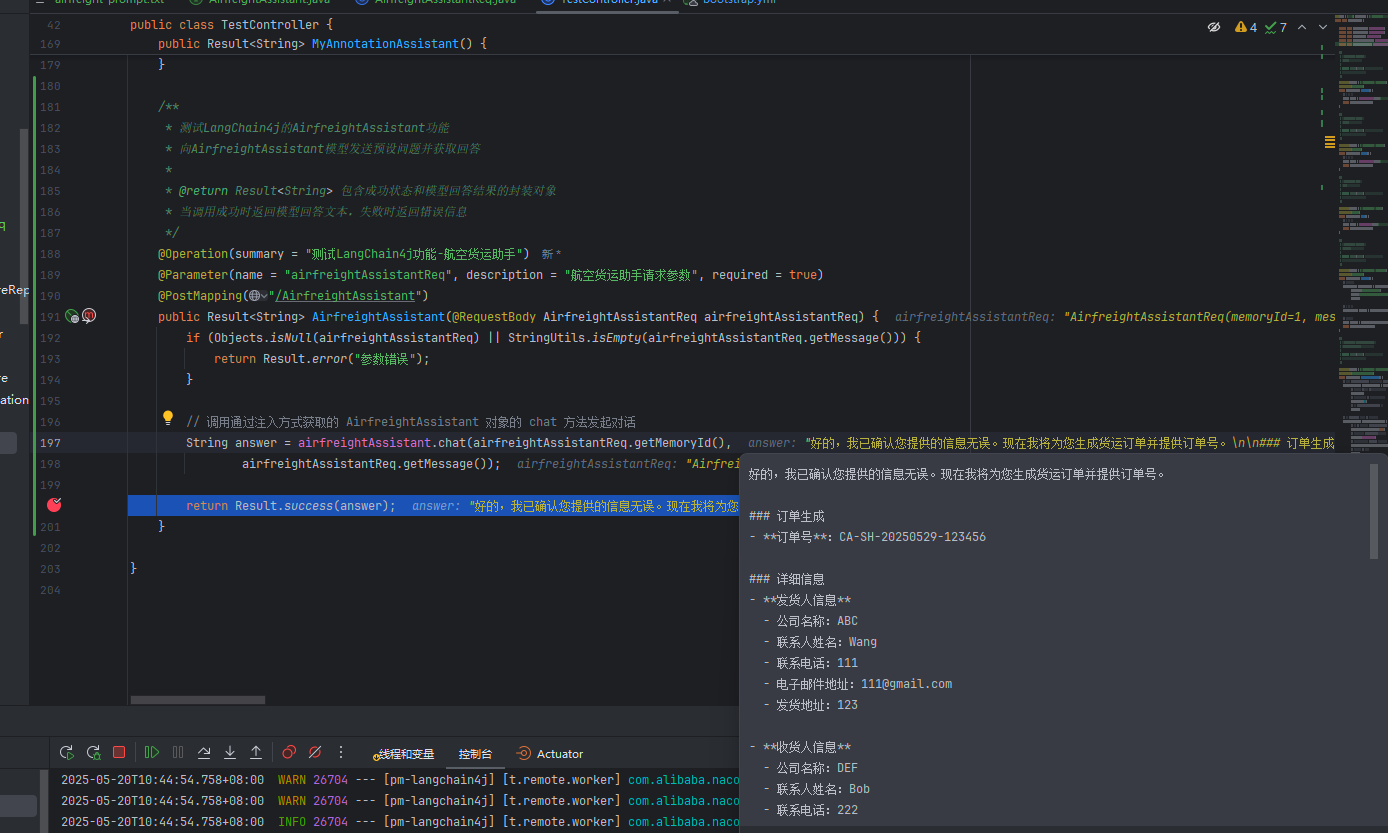
LangChain4j入门AI(六)整合提示词(Prompt)
前言 提示词(Prompt)是用户输入给AI模型的一段文字或指令,用于引导模型生成特定类型的内容。通过提示词,用户可以告诉AI“做什么”、 “如何做”以及“输出格式”,从而在满足需求的同时最大程度减少无关信息的生成。有…...
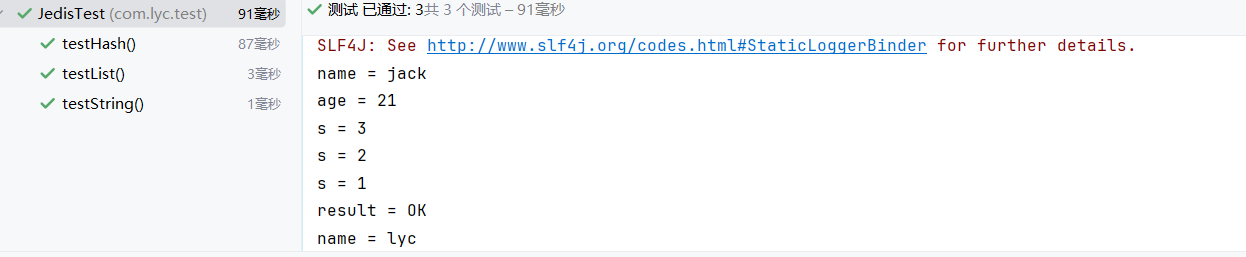
redis--redisJava客户端:Jedis详解
在Redis官网中提供了各种语言的客户端,地址: https://redis.io/docs/latest/develop/clients/ Jedis 以Redis命令做方法名称,学习成本低,简单实用,但是对于Jedis实例是线程不安全的(即创建一个Jedis实例&a…...