【论文阅读 | AAAI 2025 | FD2-Net:用于红外 - 可见光目标检测的频率驱动特征分解网络】
论文阅读 | AAAI 2025 | FD2-Net:用于红外 - 可见光目标检测的频率驱动特征分解网络
- 1.摘要&&引言
- 2. 方法
- 2.1总体架构
- 2.2特征分解编码器
- 2.3多模态重建机制
- 2.4训练损失
- 3.实验
- 3.1实验设置
- 3.2主要结果
- 3.3消融研究
- 4.结论

题目:FD2-Net: Frequency-Driven Feature Decomposition Network for Infrared-Visible Object Detection
会议: the Association for the Advance of Artificial Intelligence(AAAI)
论文:https://arxiv.org/abs/2412.09258
代码:未公开
年份:2025
1.摘要&&引言
红外 - 可见光目标检测(IVOD)旨在利用红外和可见光图像中的互补信息,从而提升复杂环境下检测器的性能。
然而,现有方法往往忽略互补信息的频率特性,例如可见光图像中丰富的高频细节和红外图像中有价值的低频热信息,这制约了检测性能。
为解决这一问题,提出了一种新的用于 IVOD 的频率驱动特征分解网络 FD2-Net,该网络能有效捕捉跨多模态视觉空间的互补信息所具有的独特频率表示。
具体而言,我们设计了一个特征分解编码器,其中高频单元(HFU)利用离散余弦变换来捕捉具有代表性的高频特征,而低频单元(LFU)则采用动态感受野对不同物体的多尺度上下文进行建模。接下来,我们采用无参数互补强度策略,通过无缝的跨频率重新耦合来增强多模态特征。
此外,我们创新性地设计了一种多模态重建机制,用于恢复特征提取过程中丢失的图像细节,进一步利用红外和可见光图像的互补信息来提升整体表示能力。
当前的 IVOD 方法仍存在三个缺点:
- 缺点 1:它们往往忽略红外和可见光图像中物体特征的频率特性。红外成像主要捕捉低频热辐射,而可见光成像则强调高频细节。主流架构往往忽视这种固有属性,并将跨模态信息嵌入到统一的特征空间中,这导致无法提取特定于模态的特征。
- 缺点 2:由于感受野固定,这些方法只能提取局部信息,难以适应红外和可见光图像中固有的位置偏差。此外,具有小内核的模型不足以有效捕捉远距离信息,而周围环境提供了关于物体大小、形状和其他特征的重要线索,因此远距离信息至关重要。
- 缺点 3:最近的 IVOD 方法通常采用下采样操作来降低视觉噪声和计算开销,但这可能导致物体信息的丢失。特征表示的这种退化会严重影响检测头的定位和分类能力,最终降低检测性能。
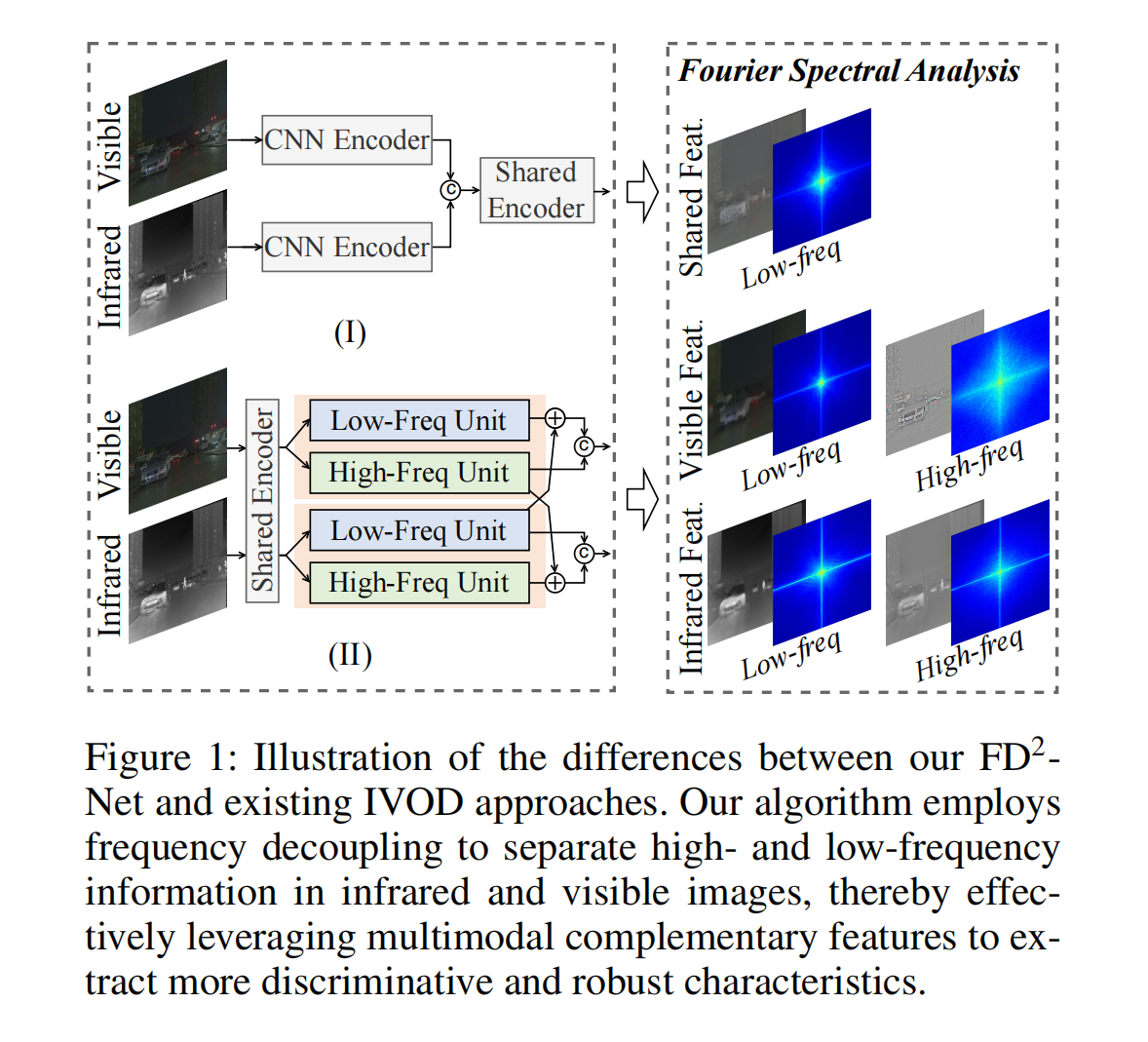
图1:我们的FD2Net与现有IVOD方法的差异示意图。我们的算法采用频率解耦来分离红外和可见光图像中的高频和低频信息,从而有效利用多模态互补特征来提取更具判别性和鲁棒性的特征。
我们的研究探索了一种更合理的范式来解决 IVOD 任务中跨模态特征提取的这些挑战。基于上述分析,我们确定了三个关键对策(CM):
- CM 1:我们从频率的角度重新审视特征提取过程。可见光图像提供了丰富的高频信息,如边缘和纹理,而红外图像则提供了有价值的低频热辐射信息。如图 1(I)所示,传统方法仅依赖冗余的跨模态相似线索,导致关键互补特征的丢失。相比之下,我们可以通过限制特征提取的频率空间,以更可控和可解释的方式从红外和可见光图像中捕捉具有判别性的互补信息。如图 1(II)所示,自适应频率解耦有助于在红外和可见光图像中保留更多具有代表性的低频和高频信息。
- CM 2:从模型设计的角度来看,更大的内核有助于捕捉更广泛的场景上下文,从而减轻红外和可见光图像之间的几何偏差。然而,采用大内核卷积可能会引入大量背景噪声,并忽略感受野内的细粒度细节,这可能不利于小物体的精确检测。因此,我们并行排列多个不同大小的深度膨胀卷积,以在不同的感受野中提取多粒度纹理特征,从而完成 IVOD 任务。
- CM 3:为了应对重复下采样导致的信息丢失,许多现有方法通常采用图像超分辨率等生成方法来缓解这一问题。然而,这些方法不仅需要构建高分辨率和低分辨率样本对,而且其生成过程往往会引入虚假伪影。相反,我们将一种简单而有效的多模态重建机制集成到 IVOD 框架中,利用红外和可见光两种模态的互补信息来恢复特征提取过程中丢失的结构和纹理细节。
本文的贡献可以总结如下:
-
为 IVOD 提出了一种新的范式,称为 FD²-Net,旨在通过从红外和可见光图像中有效提取有价值的互补特征来提高检测性能。
-
设计了高频单元(HFU)和低频单元(LFU),以有效捕捉红外和可见光图像中有判别性的频率信息。此外,还开发了一种互补强度策略,通过无缝的跨频率重新耦合来增强多模态特征。
-
引入了跨重建单元(CRU)来促进跨模态互补信息的融合,从而进一步增强特征表示。
-
大量的定性和定量实验验证了我们的 FD2-Net 的有效性,在 LLVIP(Jia 等人,2021)上达到 96.2% 的准确率,在 FLIR(F.A. Group,2018)上达到 82.9% 的准确率,在 M³FD(Liu 等人,2022a)上达到 83.5% 的准确率。
2. 方法
2.1总体架构
如图 2 所示,我们的 FD2-Net 由三个模块组成:
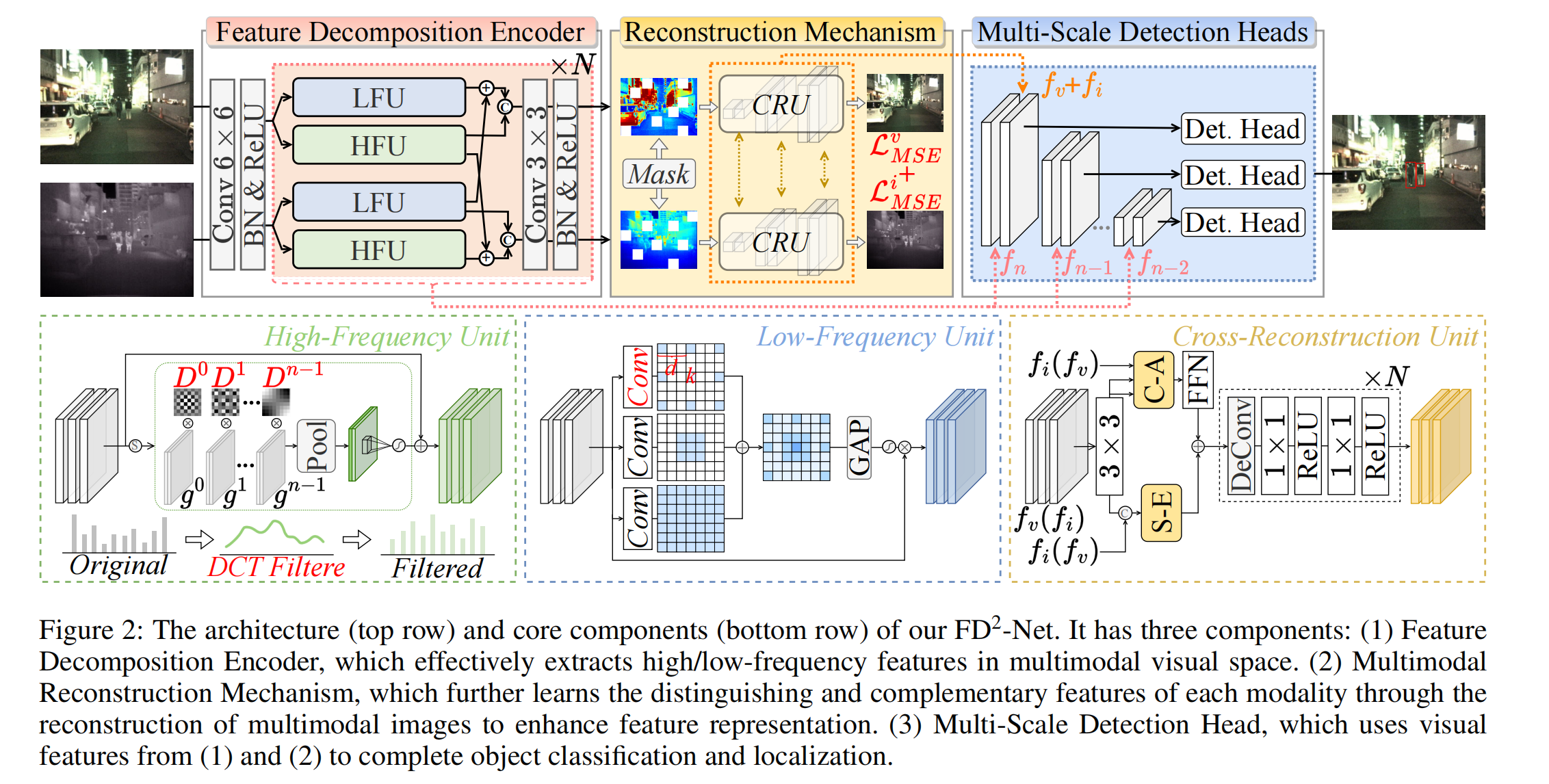
图2:我们的FD2-Net架构(上行)和核心组件(下行)示意图。该网络包含三个组件:
(1)特征分解编码器:在多模态视觉空间中有效提取高频/低频特征;
(2)多模态重建机制:通过多模态图像重建进一步学习各模态的判别性和互补性特征,以增强特征表示;
(3)多尺度检测头:利用来自(1)和(2)的视觉特征完成目标分类和定位。
-
特征分解编码器。受频谱的启发,该模块引入了一个双分支架构,通过特征分解和融合来有效提取有价值的高频和低频特征。随后,通过互补优势策略,对具有代表性的频率特征进行重组,以提高整体表示能力。
-
多模态重建机制。为了增强特征学习,对编码器最后一层的特征应用非对称交叉掩码策略,迫使每种模态从互补模态中获取有用信息。然后使用两个跨重建单元(CRU),利用红外和可见光图像的互补特征来恢复多模态图像。重建过程在像素级受均方误差约束。
-
多尺度检测头。该模块构建了一个特征金字塔网络(FPN),利用编码器各个阶段提取的多尺度特征。在 FPN 的最高分辨率层,集成重建的多模态特征以进一步增强检测。最后,遵循 YOLOv5(Jocher,2020),配置三个不同尺度的检测头来精确检测物体。
2.2特征分解编码器
形式上,设 I ∈ R H × W I \in \mathbb{R}^{H \times W} I∈RH×W 和 V ∈ R 3 × H × W V \in \mathbb{R}^{3 \times H \times W} V∈R3×H×W 分别为输入的红外和可见光图像,其中 H × W H \times W H×W 表示空间分辨率。首先,使用一个 6 × 6 6 \times 6 6×6 的 CBR 模块来降低分辨率并提取浅层多模态视觉特征 { X S I , X S V } ∈ R c × h × w \{ X_S^I, X_S^V \} \in \mathbb{R}^{c \times h \times w} {XSI,XSV}∈Rc×h×w。随后,我们首先将 { X S I , X S V } \{ X_S^I, X_S^V \} {XSI,XSV} 分别按比例 α \alpha α 拆分为两个分量:
• 一个分量用于表示高频成分,记为 Φ H = { X H I , X H V } ∈ R α c × h × w \Phi_H = \{ X_H^I, X_H^V \} \in \mathbb{R}^{\alpha c \times h \times w} ΦH={XHI,XHV}∈Rαc×h×w,用于捕捉边缘、纹理等空间细节;
• 另一个分量 Φ L = { X L I , X L V } ∈ R ( 1 − α ) c × h × w \Phi_L = \{ X_L^I, X_L^V \} \in \mathbb{R}^{(1-\alpha)c \times h \times w} ΦL={XLI,XLV}∈R(1−α)c×h×w 则用于学习上下文、结构信息等低频内容。
高频特征注意力
我们的目标是分别从红外和可见光图像中有效提取高频分量。因此,我们引入了一个高频单元(HFU),它可以过滤出高频信息,并引导模型将注意力集中在更有价值的信息上。离散余弦变换(DCT)在图像压缩中表现出优越性,特别是在增强图像细节和纹理的同时消除噪声。基于此,我们将 DCT 融入 IVOD 中。这种变换引导卷积提取各种高频空间特征,并有效抑制红外 - 可见光图像中的高斯噪声和热噪声等噪声。
离散余弦变换(DCT)
对于图像 x ∈ R H × W x \in \mathbb{R}^{H \times W} x∈RH×W,其中 H H H 和 W W W 是 x x x 的高度和宽度,公式(1)给出了标准二维(2D)DCT 的定义,其数学定义为:
f h , w = ∑ i = 0 H − 1 ∑ j = 0 W − 1 x i , j B i , j h , w (1) f_{h,w} = \sum_{i=0}^{H-1} \sum_{j=0}^{W-1} x_{i,j} B_{i,j}^{h,w} \tag{1} fh,w=i=0∑H−1j=0∑W−1xi,jBi,jh,w(1)
其中基函数定义为:
B i , j h , w = cos ( π h H ( i + 1 / 2 ) ) cos ( π w W ( j + 1 / 2 ) ) (2) B_{i,j}^{h,w} = \cos\left(\frac{\pi h}{H}(i + 1/2)\right) \cos\left(\frac{\pi w}{W}(j + 1/2)\right) \tag{2} Bi,jh,w=cos(Hπh(i+1/2))cos(Wπw(j+1/2))(2)
这里 f ∈ R H × W f \in \mathbb{R}^{H \times W} f∈RH×W 是二维 DCT 频谱, B B B 是二维 DCT 的基函数, h ∈ { 0 , H − 1 } h \in \{0, H-1\} h∈{0,H−1} 且 w ∈ { 0 , W − 1 } w \in \{0, W-1\} w∈{0,W−1}, cos ( ⋅ ) \cos(\cdot) cos(⋅) 表示余弦函数。公式(1)中的常数归一化因子被省略以简化符号。
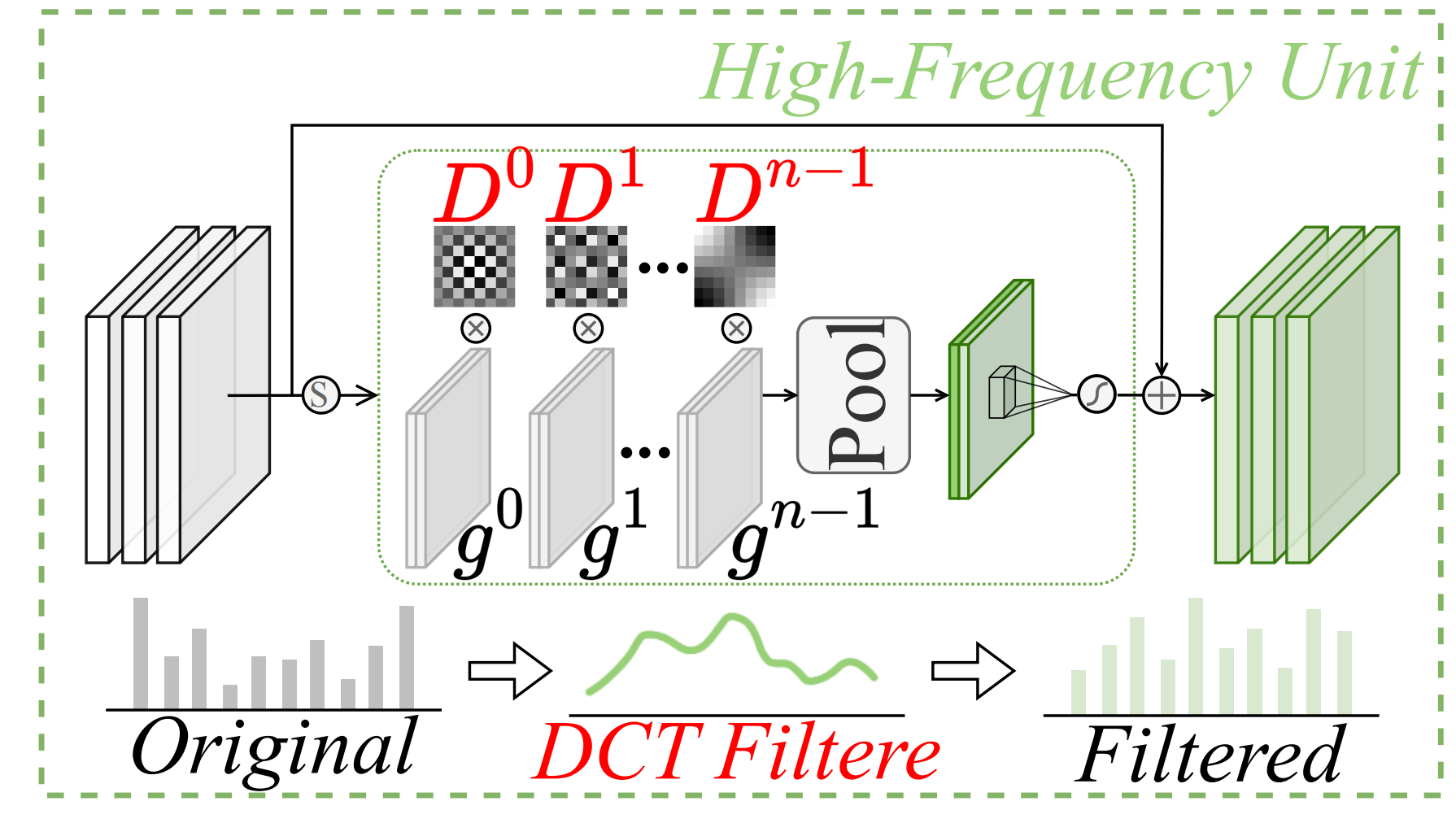
高频单元(HFU)
为了自适应地调节对不同频率分量的强调,以增强空间信息的判别性,我们利用二维 DCT 作为选择性过滤机制。具体来说,高频特征图 Φ H \Phi_H ΦH 沿着通道维度被分成 n n n 个段。每个组 Φ H g \Phi_H^g ΦHg(其中 g ∈ { 0 , n − 1 } g \in \{0, n-1\} g∈{0,n−1})保持 Φ H \Phi_H ΦH 的空间维度,但通道长度仅为 1 / n 1/n 1/n。然后,将一个特定的二维 DCT 频率分量 B u g , v g B_{u_g,v_g} Bug,vg 分配给每个段,连接后得到模态相关的高频特征:
Φ H = [ Φ 0 H ∗ B u 0 , v 0 , … , Φ n − 1 H ∗ B u n − 1 , v n − 1 ] (3) \Phi^H = [\Phi_0^H * B_{u_0,v_0}, \dots, \Phi_{n-1}^H * B_{u_{n-1},v_{n-1}}] \tag{3} ΦH=[Φ0H∗Bu0,v0,…,Φn−1H∗Bun−1,vn−1](3)
其中 [ u g , v g ] [u_g, v_g] [ug,vg] 表示对应于 Φ g H \Phi_g^H ΦgH 的二维频率索引, [ ⋅ , ⋅ ] [\cdot, \cdot] [⋅,⋅] 是连接操作。较大的 g g g 值使同一卷积层内的通道捕捉多频率特征,从而增强特征表示能力。
随后,应用空间注意力机制动态调节频率分量,其数学形式为:
S A H = σ ( F 7 × 7 2 → 1 [ AvgPool ( Φ H ) , MaxPool ( Φ H ) ] ) (4) SA^H = \sigma\left(\mathcal{F}_{7\times7}^{2\to1}\left[\text{AvgPool}(\Phi^H), \text{MaxPool}(\Phi^H)\right]\right) \tag{4} SAH=σ(F7×72→1[AvgPool(ΦH),MaxPool(ΦH)])(4)
其中 σ \sigma σ 为 Sigmoid 函数, F 7 × 7 2 → 1 \mathcal{F}_{7\times7}^{2\to1} F7×72→1 是 7 × 7 7\times7 7×7 卷积层(输入 2 通道,输出 1 通道), AvgPool ( ⋅ ) \text{AvgPool}(\cdot) AvgPool(⋅) 和 MaxPool ( ⋅ ) \text{MaxPool}(\cdot) MaxPool(⋅) 分别为平均池化和最大池化操作。
最终输出为输入特征与注意力图的逐元素乘积:
Φ H ′ = S A h f ⊗ Φ H (5) \Phi^{H'} = SA^{hf} \otimes \Phi^H \tag{5} ΦH′=SAhf⊗ΦH(5)
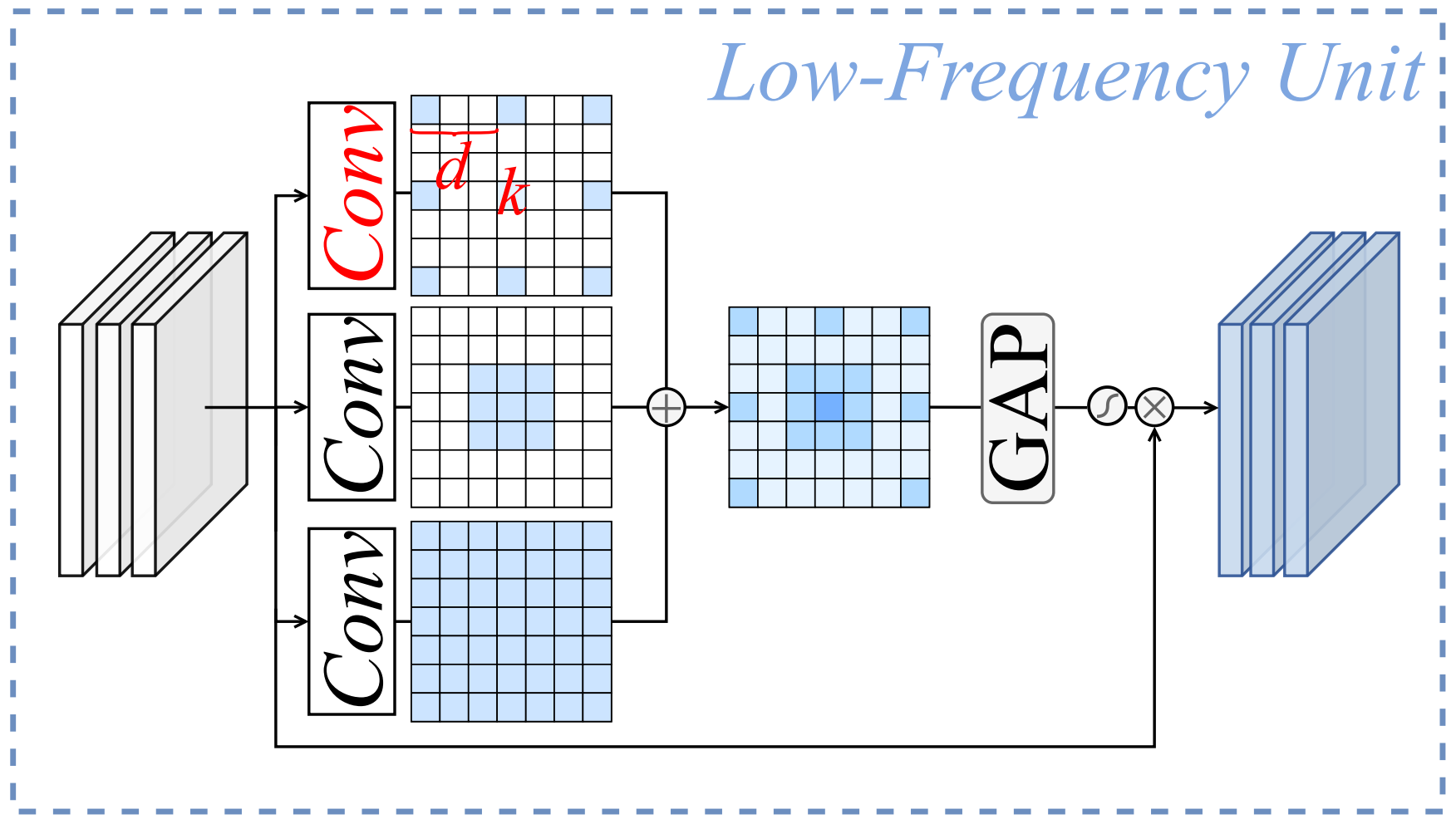
低频上下文细化
为了有效捕捉多尺度的低频信息,我们通过一组具有不同内核大小和膨胀率的并行深度卷积(DWC)构建了多粒度卷积。对于第 i i i 个 DWC,内核大小 k i k_i ki 和膨胀率 d i d_i di 的扩展需满足约束:
k i + ( k i − 1 ) × ( d i − 1 ) ≤ R F (6) k_i + (k_i - 1) \times (d_i - 1) \leq RF \tag{6} ki+(ki−1)×(di−1)≤RF(6)
其中 R F RF RF 为感受野上限。通过合并多个小内核分支为单个大内核卷积层(如图 2 所示),可在保持推理速度的同时增强多尺度特征提取能力。设置 R F = 7 RF=7 RF=7,内核大小为 [ 7 , 3 , 3 , 3 ] [7, 3, 3, 3] [7,3,3,3],膨胀率为 [ 1 , 1 , 2 , 3 ] [1, 1, 2, 3] [1,1,2,3]。
为减少信息冗余并提高特征多样性,采用通道混合策略:
- 全局平均池化(GAP):收集通道统计信息;
- 1×1 卷积压缩与恢复:降低特征相似性;
- Sigmoid 加权:生成通道权重以细化多尺度空间特征 Φ L \Phi^L ΦL。
该过程封装为:
Φ L ′ = Φ L ⊗ σ ( F 1 × 1 d → ( 1 − α ) C ( F 1 × 1 ( 1 − α ) C → d ( Φ L ) ) ) (7) \Phi^{L'} = \Phi^L \otimes \sigma\left( \mathcal{F}_{1\times1}^{d \to (1-\alpha)C} \left( \mathcal{F}_{1\times1}^{(1-\alpha)C \to d} (\Phi^L) \right) \right) \tag{7} ΦL′=ΦL⊗σ(F1×1d→(1−α)C(F1×1(1−α)C→d(ΦL)))(7)
其中 d = ( 1 − α ) C / 4 d = (1-\alpha)C/4 d=(1−α)C/4, F 1 × 1 a → b \mathcal{F}_{1\times1}^{a \to b} F1×1a→b 表示输入 b b b 通道、输出 a a a 通道的 1 × 1 1\times1 1×1 卷积层。
互补强度策略
该策略的作用是重新耦合互补特征并实现高效的跨频率信息交互。我们提出一种无参数方法,将跨模态图像中的低频/高频特征以加法形式融入另一模态的特征中,具体如下:
X I H ′ ⇐ X I H ′ + X V H ′ (8) X_{I}^{H'} \Leftarrow X_{I}^{H'} + X_{V}^{H'} \tag{8} XIH′⇐XIH′+XVH′(8)
X V L ′ ⇐ X V L ′ + X I L ′ (9) X_{V}^{L'} \Leftarrow X_{V}^{L'} + X_{I}^{L'} \tag{9} XVL′⇐XVL′+XIL′(9)
对于同一模态内的每个频率特征,我们将两种频率成分拼接后通过一个 3 × 3 3\times3 3×3 卷积层 F ( ⋅ ) \mathcal{F}(\cdot) F(⋅),以获得增强的模态共享特征。最终输出公式如下:
Y I S = F ( [ X I H ′ , X I L ′ ] ) (10) Y_{I}^{S} = \mathcal{F}\left( \left[ X_{I}^{H'}, X_{I}^{L'} \right] \right) \tag{10} YIS=F([XIH′,XIL′])(10)
Y V S = F ( [ X V H ′ , X V L ′ ] ) (11) Y_{V}^{S} = \mathcal{F}\left( \left[ X_{V}^{H'}, X_{V}^{L'} \right] \right) \tag{11} YVS=F([XVH′,XVL′])(11)
图 2 详细展示了 LFU、HFU 及融合策略的工作机制,直观呈现了它们如何通过协同捕捉高频/低频空间信息实现特征增强。
2.3多模态重建机制
如前所述,特征分解编码器专注于显式提取有价值的频率信息。为充分利用互补信息,我们在 FD²-Net 中进一步集成了多模态重建机制。其目标是学习各模态的判别性和互补性特征,同时增强整体特征表示能力。如图 2 所示,该机制包含两个组件:特征级互补掩码和跨重建单元(CRU)。
特征级互补掩码
为更好地利用多模态信息并避免网络始终依赖单一图像学习,我们设计了一种高效的特征增强策略来训练 FD²-Net。如图 2 所示,我们对局部信息进行非对称掩码操作,公式表示为:
M all = M I ⋃ M V , M I ∩ M V = ∅ (12) M_{\text{all}} = M_{I} \bigcup M_{V}, \quad M_{I} \cap M_{V} = \varnothing \tag{12} Mall=MI⋃MV,MI∩MV=∅(12)
其中, M I M_{I} MI 和 M V M_{V} MV 分别表示红外掩码和可见光掩码, M all M_{\text{all}} Mall 表示总不可见区域(占特征图的 30%)。此设计使网络只能从掩码区域对应的互补模态位置获取有效信息。
跨重建单元(CRU)
如引言所述,特征提取导致的信息丢失会使检测器难以定位和识别目标。为解决这一问题,我们引入 CRU,通过细粒度局部交互和粗粒度全局交互学习互补特征。需注意,CRU 是通用图像重建网络,以下仅以可见光图像为例说明其工作流程(为简洁起见,省略 ReLU 激活函数):
x v = Conv 3 × 3 ( x v ) (13) x_v = \text{Conv}_{3\times3}(x_v) \tag{13} xv=Conv3×3(xv)(13)
x v ′ = CA ( x v , x i ) + F E ( Conv 3 × 3 ( F S ( [ x v , x i ] ) ) ) (14) x_v' = \text{CA}(x_v, x_i) + \mathcal{F}_E\left( \text{Conv}_{3\times3}\left( \mathcal{F}_S\left( \left[ x_v, x_i \right] \right) \right) \right) \tag{14} xv′=CA(xv,xi)+FE(Conv3×3(FS([xv,xi])))(14)
f v = Conv 1 × 1 ( Conv 1 × 1 ( TransConv ( x v ′ ) ) ) (15) f_v = \text{Conv}_{1\times1}\left( \text{Conv}_{1\times1}\left( \text{TransConv}(x_v') \right) \right) \tag{15} fv=Conv1×1(Conv1×1(TransConv(xv′)))(15)
其中, CA ( ⋅ ) \text{CA}(\cdot) CA(⋅) 表示跨注意力层, F S \mathcal{F}_S FS 和 F E \mathcal{F}_E FE 为特征压缩与激励操作(原理同 Hu 等人,2018 的 Squeeze-and-Excitation 模块)。对于红外和可见光图像,CRU 的输出分别为 f i f_i fi 和 f v f_v fv。
2.4训练损失
总损失函数由图像重建损失 L rc \mathcal{L}_{\text{rc}} Lrc 和检测损失 L det \mathcal{L}_{\text{det}} Ldet 组成:
-
重建损失:采用原始图像与重建图像的均方误差(MSE)计算:
L rc = 1 2 ∥ f i − I ∥ 2 + 1 2 ∥ f v − V ∥ 2 (16) \mathcal{L}_{\text{rc}} = \frac{1}{2} \left\| f_i - I \right\|_2 + \frac{1}{2} \left\| f_v - V \right\|_2 \tag{16} Lrc=21∥fi−I∥2+21∥fv−V∥2(16)
其中, f i f_i fi 和 f v f_v fv 为重建的红外和可见光特征, I I I 和 V V V 为输入图像。 -
检测损失:与传统算法一致,包含分类损失 L cls \mathcal{L}_{\text{cls}} Lcls、定位损失 L box \mathcal{L}_{\text{box}} Lbox 和置信度损失 L obj \mathcal{L}_{\text{obj}} Lobj:
L det = L cls + L box + L obj (17) \mathcal{L}_{\text{det}} = \mathcal{L}_{\text{cls}} + \mathcal{L}_{\text{box}} + \mathcal{L}_{\text{obj}} \tag{17} Ldet=Lcls+Lbox+Lobj(17) -
总损失:
L total = λ 1 L rc + λ 2 L det (18) \mathcal{L}_{\text{total}} = \lambda_1 \mathcal{L}_{\text{rc}} + \lambda_2 \mathcal{L}_{\text{det}} \tag{18} Ltotal=λ1Lrc+λ2Ldet(18)
其中, λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 为超参数,用于平衡两类损失的权重。
3.实验
3.1实验设置
数据集:
我们使用三个 IVOD 基准数据集将提出的模型与 SOTA 方法进行对比:
-
LLVIP 数据集:这是一个著名的大规模行人数据集,专门采集于低光照条件,主要展示极暗场景。该数据集确保所有红外和可见光图像对在空间和时间上精确对齐,专注于行人检测。
-
FLIR 数据集:提供了一个极具挑战性的多光谱目标检测基准,涵盖白天和夜晚场景。本研究中,我们使用 “对齐” 版本,包含 5,142 对精确对齐的红外 - 可见光图像,其中 4,129 对用于训练,1,013 对用于测试。数据集包含三个主要目标类别:人、汽车和自行车。
-
M³FD 数据集:包含 4,200 对 RGB 和热图像,涵盖六个目标类别:人、汽车、公交车、摩托车、路灯和卡车。遵循先前工作,我们采用随机拆分方法划分训练集和验证集,具体为 80% 图像分配至训练集,剩余图像作为验证集。
实现细节:为确保公平性,我们采用与其他主流方法相同的数据集处理方式(Fu 等人,2023a)。FD²-Net 基于 SOTA 检测器 YOLOv5(Jocher,2020)构建。评估时,我们报告 F1 分数、精确率、召回率和平均精度(mAP),与先前研究一致。参数初始化采用 Xavier 初始化(Glorot 和 Bengio,2010),模型使用随机梯度下降(SGD)训练 150 个 epoch,初始学习率为 0.01,权重衰减为(10^{-4}),动量为 0.9。
3.2主要结果
我们将提出的 FD²-Net 与多个基线和 SOTA 方法进行对比,包括 SDNet(Zhang 和 Ma,2021)、TarDAL(Liu 等人,2022a)、DensFuse(Li 和 Wu,2018)、U2Fusion(Xu 等人,2020)、CDDFuse(Zhao 等人,2023b)、SegMiF(Liu 等人,2023)、DDFM(Zhao 等人,2023c)、MetaF(Zhao 等人,2023a)、LRRNet(Li 等人,2023a)、CSSA(Cao 等人,2023)和 TFDet(Zhang 等人,2024)。这些方法均基于 YOLOv5 检测器构建,以衡量其检测性能。
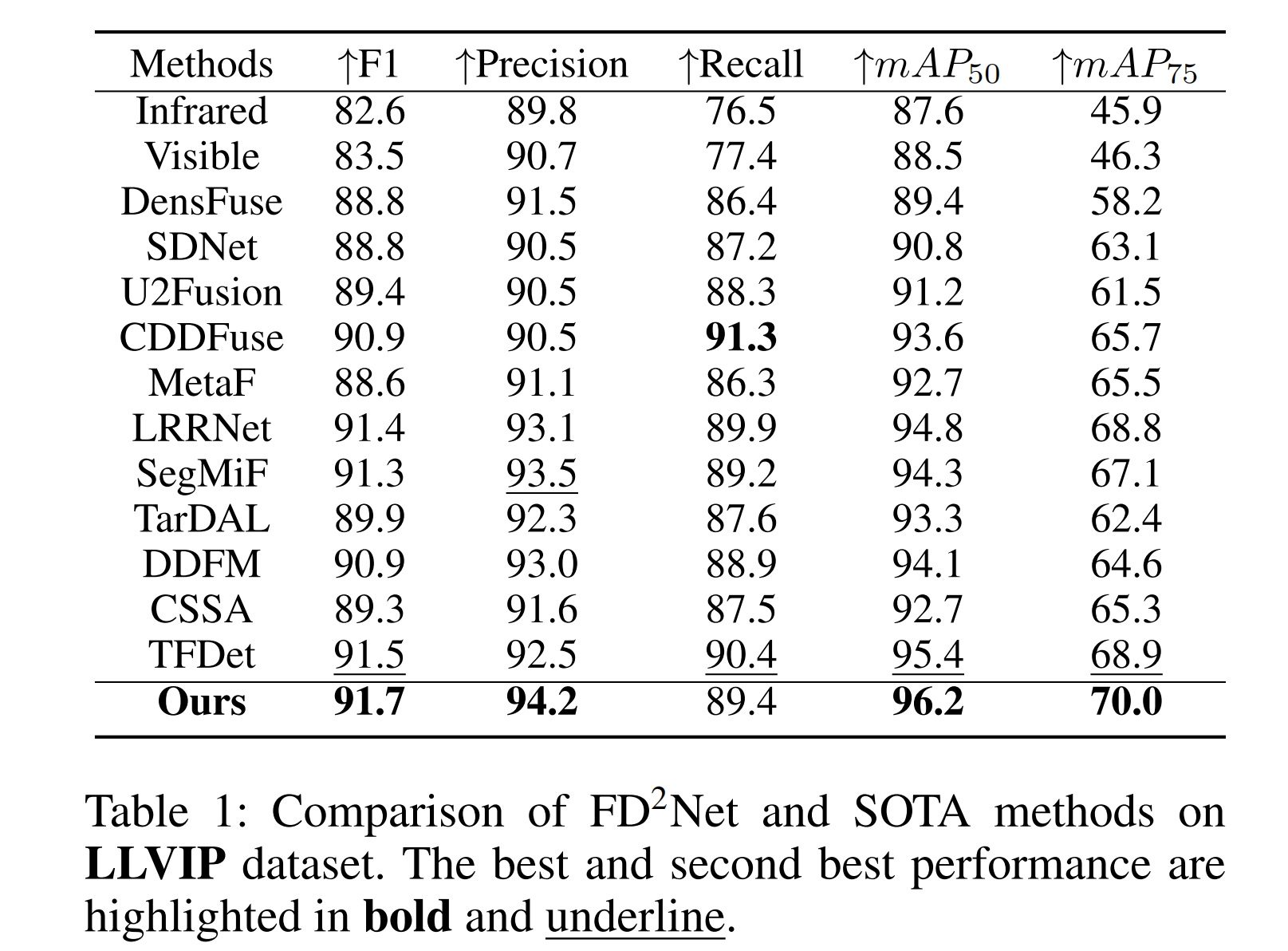
表1:FD²-Net与最先进方法在LLVIP数据集上的对比。最佳和次佳性能分别以粗体和下划线突出显示。
LLVIP 数据集对比结果:表 1 结果表明,我们的方法有效融合了红外和可见光图像中的相似特征和互补特征,显著增强了网络的表示能力。与单模态方法相比,FD²-Net 显著优于红外和可见光单模态检测结果,mAP50 分别提升 8.6% 和 7.7%。此外,与其他 SOTA 网络相比,FD²-Net 始终表现更优,mAP50 提升 1.4%-6.8%。这些结果表明,我们提出的方法显著提升了 IVOD 任务的性能。
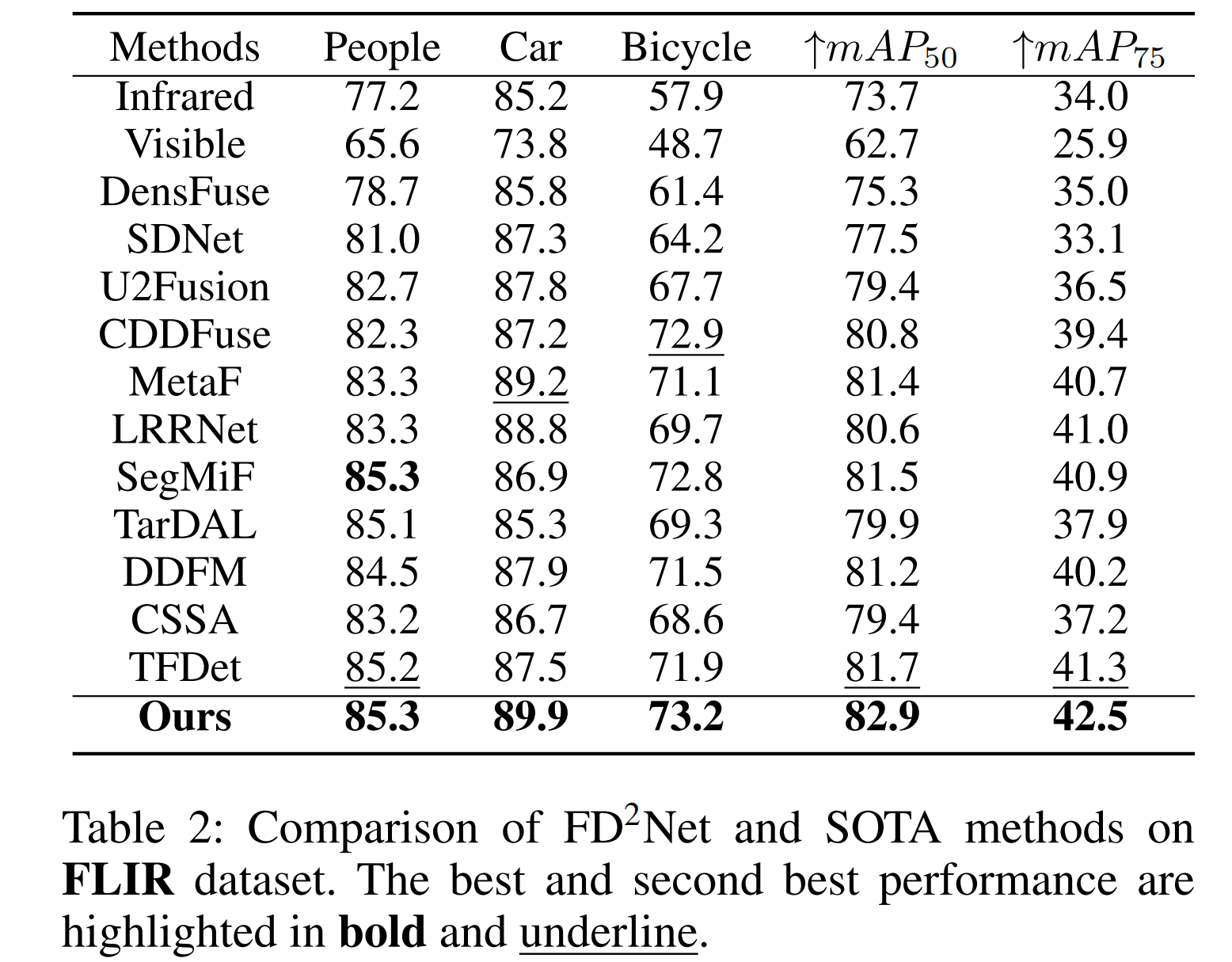
表2:FD²-Net与最先进方法在FLIR数据集上的对比。最佳和次佳性能分别以粗体和下划线突出显示。
FLIR 数据集对比结果:如表 2 所示,FD²-Net 表现卓越,在 mAP50 和 mAP75 指标上分别以 82.9% 和 42.5% 的成绩创下 SOTA 基准。具体而言,我们的方法在 mAP50 上比 CDDFuse 和 SegMiF 分别高出 + 2.1% 和 + 1.4%。当阈值提高至 0.75 时,其他方法的漏检率比 FD²-Net 上升更显著,表明我们的方法具有更高的检测精度。例如,其 mAP75 达到 42.5%,比此前最佳模型 LRRNet 提升 1.5%。
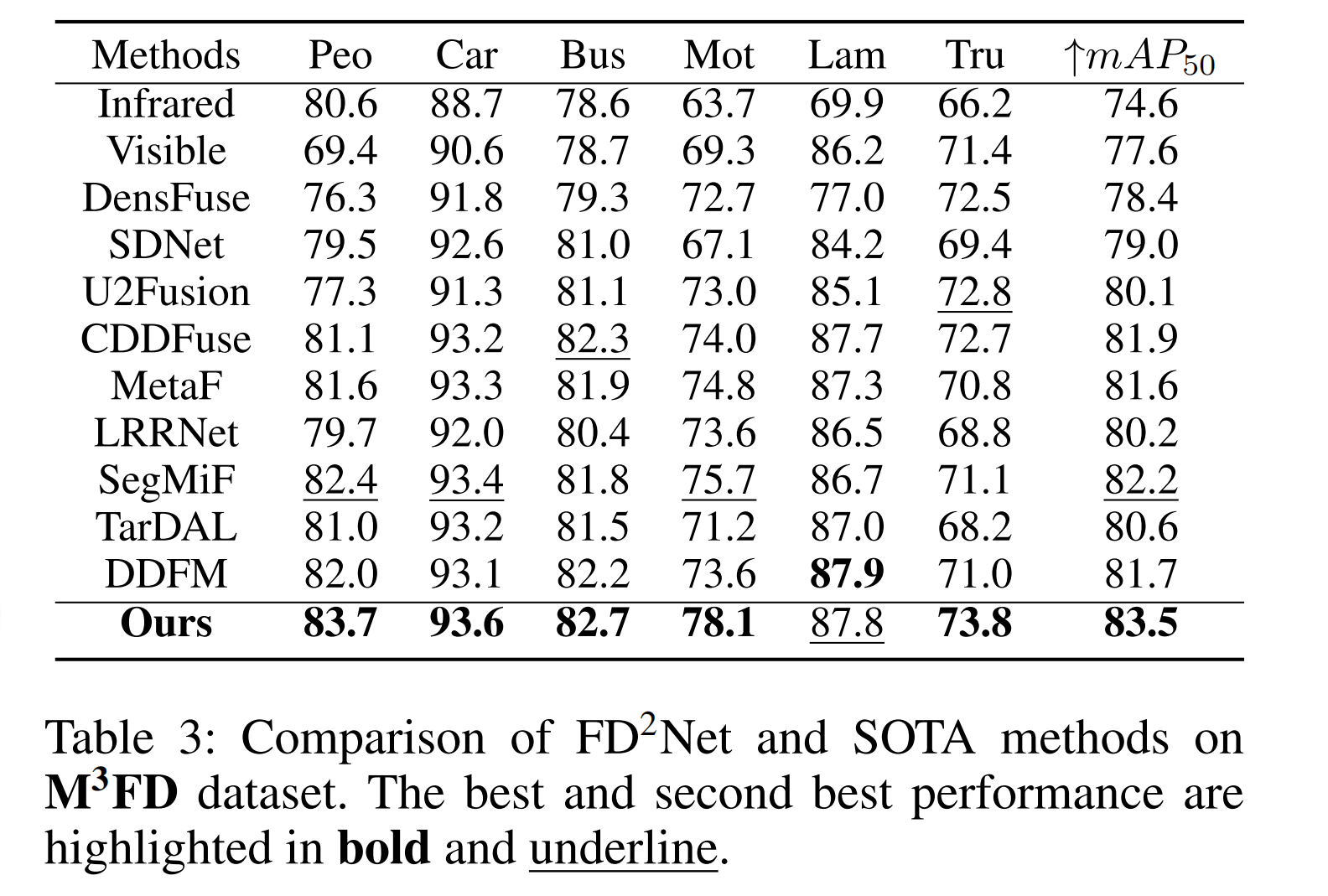
表3:FD2Net与最先进方法在(M^{3} FD)数据集上的对比。最佳和次佳性能分别以粗体和下划线突出显示。
M³FD 数据集对比结果:表 3 总结了在 M³FD 数据集上的对比结果。我们提出的方法以 83.5% 的 mAP50 创下新纪录。此外,我们还展示了各分类的检测精度。值得注意的是,在 “人” 和 “摩托车” 类别中,FD²-Net 比此前最佳方法分别提升 1.3% 和 2.4%。这表明我们的方法在检测弱目标和小目标方面具有更强的能力。

图3:FD2Net与10种最先进方法的可视化对比。绿色框为检测结果,红色虚线框标记漏检目标(假阴性)。
可视化对比:定性结果如图 3 所示,绿色框为检测结果,红色虚线框标记漏检目标(假阴性)。显然,先前方法的预测存在漏检问题,尤其是在图像中的小目标和被遮挡目标检测中。FD²-Net 有效捕捉了与检测目标相关的鲁棒共享特征和判别性特定信息,在各种挑战性场景中表现更优。
3.3消融研究
FD²-Net 组件消融:在 LLVIP 数据集上的消融研究结果表明,与基线(实验 I)相比,引入 HFU(实验 II)和 LFU(实验 III)进行特征提取增强,分别使 mAP50 提升 1.5% 和 2.3%。将多模态图像重建策略 CRU(实验 IV)融入 FD²-Net 后,mAP50 提升 0.9%,且 mAP75 显著提升 3.3%,表明通过图像重建可显著增强目标位置感知能力。采用非对称特征掩码进一步提升特征表示能力,使 AP50 和 AP75 分别提升 2.6% 和 1.8%。这些消融结果证明了所提方法中各主要组件的有效性。
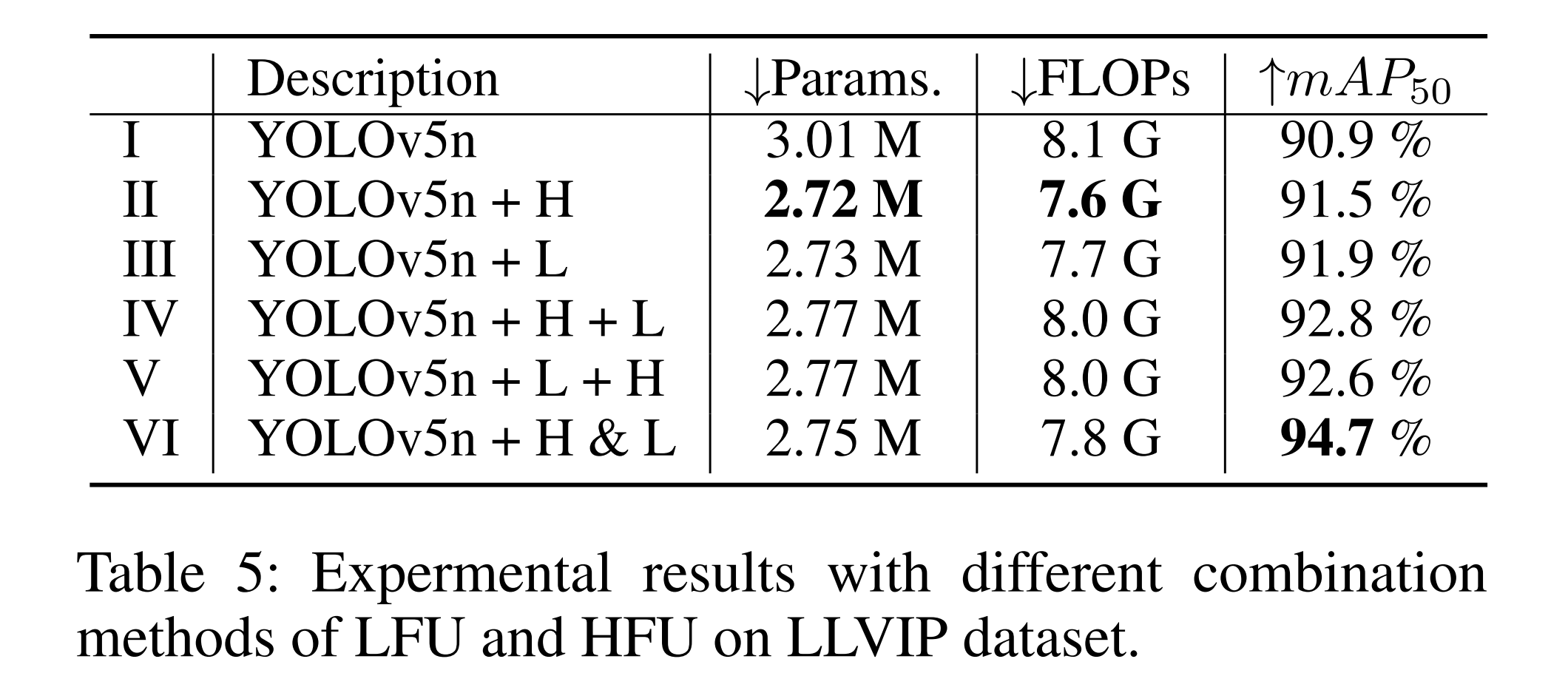
表5:LLVIP数据集上LFU和HFU不同组合方式的实验结果

表4:FD2Net组件消融研究。HFU:高频单元,LFU:低频单元,CRU:跨重建单元,Mask:互补掩码策略。
HFU 和 LFU 的作用:我们的特征分解编码器(FDE)包含高频注意力(HFU)和低频细化(LFU)两个组件。为评估其有效性,我们将 YOLOv5n 中的 C2f 模块分别替换为 HFU 或 LFU。如表 5 所示,单独使用 HFU(YOLOv5n+H)或 LFU(YOLOv5n+L)均导致性能下降 3.2% 和 2.8%,表明单一组件无法有效捕捉红外 - 可见光图像的互补特征。我们进一步探索了三种集成策略:高频 - 低频顺序连接(H+L)、低频 - 高频顺序连接(L+H)和平行连接(H&L)。其中,平行连接实现了最佳性能,mAP50 显著提升至 94.7%,同时参数和 FLOPs 减少。因此,我们采用 FDE 的平行(H&L)设计以最大化模型性能。

图4:左:原始YOLOv5n的特征;右:所提出的FD²-Net的特征
特征图可视化:为研究 FD²-Net 的特征表示能力,我们可视化了原始 YOLOv5 和 FD²-Net 第二阶段的特征图。如图 4 所示,与原始 YOLOv5 相比,FD²-Net 生成的特征模式显著丰富,不仅减少了冗余特征,还增强了代表性特征并使其多样化。
4.结论
本文提出了一种专为红外 - 可见光目标检测任务设计的频率驱动特征分解网络(FD²-Net)。该网络通过高效建模高频和低频特征,促进了有价值互补信息的提取。此外,借助多模态重建机制,更有效地利用了多模态图像中的互补信息。大量定性和定量实验表明,所提网络在具有竞争力的红外 - 可见光目标检测基准中达到了 SOTA 性能。
相关文章:
【论文阅读 | AAAI 2025 | FD2-Net:用于红外 - 可见光目标检测的频率驱动特征分解网络】
论文阅读 | AAAI 2025 | FD2-Net:用于红外 - 可见光目标检测的频率驱动特征分解网络 1.摘要&&引言2. 方法2.1总体架构2.2特征分解编码器2.3多模态重建机制2.4训练损失 3.实验3.1实验设置3.2主要结果3.3消融研究 4.结论 题目:FD2-Net: Frequency-…...

前端取经路——量子UI:响应式交互新范式
嘿,老铁们好啊!我是老十三,一枚普通的前端切图仔(不,开玩笑的,我是正经开发)。最近前端技术简直跟坐火箭一样,飞速发展!今天我就跟大家唠唠从状态管理到实时渲染…...
)
计算机视觉与深度学习 | matlab实现EMD-VMD-LSTM时间序列预测(完整源码和数据)
EMD-VMD-LSTM 一、完整代码实现二、代码结构说明三、关键参数说明四、注意事项五、典型输出示例以下是使用MATLAB实现EMD-VMD-LSTM时间序列预测的完整代码,包含数据生成、经验模态分解(EMD)、变分模态分解(VMD)、LSTM模型构建与预测分析。代码通过对比实验验证分解策略的有…...

济南国网数字化培训班学习笔记-第三组-1-电力通信传输网认知
电力通信传输网认知 电力通信基本情况 传输介质 传输介质类型(导引与非导引) 导引传输介质,如电缆、光纤; 非导引传输介质,如无线电波; 传输介质的选择影响信号传输质量 信号传输模式(单工…...

OAT 初始化时出错?问题可能出在 PAM 配置上|OceanBase 故障排查实践
本文作者:爱可生数据库工程师,任仲禹,擅长故障分析和性能优化。 背景 某客户在使用 OAT 初始化OceanBase 服务器的过程中,进行到 precheck 步骤时,遇到了如下报错信息: ERROR - check current session ha…...

1-机器学习的基本概念
文章目录 一、机器学习的步骤Step1 - Function with unknownStep2 - Define Loss from Training DataStep3 - Optimization 二、机器学习的改进Q1 - 线性模型有一些缺点Q2 - 重新诠释机器学习的三步Q3 - 机器学习的扩展Q4 - 过拟合问题(Overfitting) 一、…...
Hass-Panel - 开源智能家居控制面板
文章目录 ▎项目介绍:预览图▎主要特性安装部署Docker方式 正式版Home Assistant Addon方式详细安装方式1. Home Assistant 插件安装(推荐)2. Docker 安装命令功能说明 :3. Docker Compose 安装升级说明Docker Compose 版本升级 功…...

Ubuntu搭建NFS服务器的方法
0 工具 Ubuntu 18.041 Ubuntu搭建NFS服务器的方法 在Ubuntu下搭建NFS(网络文件系统)服务器可以让我们像访问本地文件一样访问Ubuntu上的文件,例如可以把开发板的根文件系统放到NFS服务器目录下方便调试。 1.1 安装nfs-kernel-server&#…...

网感驱动下开源AI大模型AI智能名片S2B2C商城小程序源码的实践路径研究
摘要:在数字化浪潮中,网感已成为内容创作者与商业运营者必备的核心能力。本文以开源AI大模型、AI智能名片及S2B2C商城小程序源码为技术载体,通过解析网感培养与用户需求洞察的内在关联,提出"数据驱动-场景适配-价值重构"…...

COMPUTEX 2025 | 广和通5G AI MiFi解决方案助力移动宽带终端迈向AI新未来
随着5G与AI不断融合,稳定高速、智能的移动网络已成为商务、旅行、户外作业等场景的刚需。广和通5G AI MiFi方案凭借领先技术与创新设计,重新定义5G移动网络体验。 广和通5G AI MiFi 方案搭载高通 4nm制程QCM4490平台,融合手机级超低功耗技术…...

防范Java应用中的恶意文件上传:确保服务器的安全性
防范Java应用中的恶意文件上传:确保服务器的安全性 在当今数字化时代,Java 应用无处不在,而文件上传功能作为许多应用的核心组件,却潜藏着巨大的安全隐患。恶意文件上传可能导致服务器被入侵、数据泄露甚至服务瘫痪,因…...
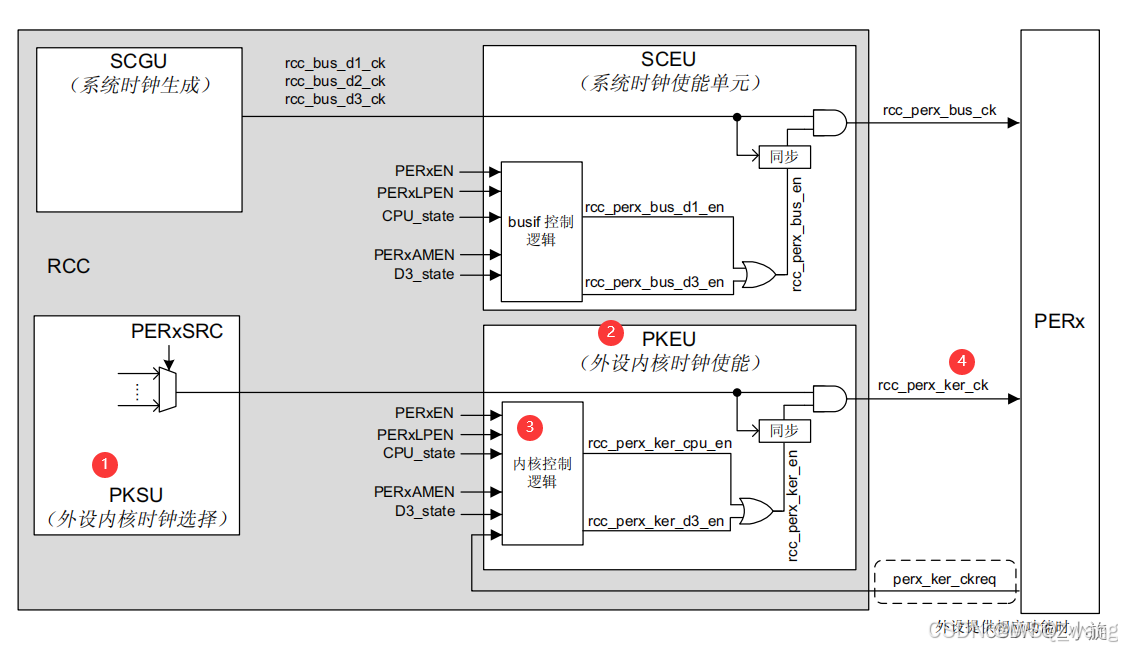
STM32H7时钟树
时钟树分析 STM32H7共有6个外部时钟源,分别是: HSI(高速内部振荡器)时钟:~ 8 MHz、16 MHz、32 MHz 或 64 MHzHSE(高速外部振荡器)时钟:4 MHz 到 48 MHzLSE(低速外部振荡器ÿ…...

git 的 .gitignore 规则文件
# .gitignore 使用注意事项: # 1. 所有的注释只能是独占单行注释,不能在有效代码后注释!否者不生效!比如错误示范: # 实例: MDK/ #忽略MDK目录下所有内容 (跟在有效代码后注释,非法ÿ…...

【通用智能体】Serper API 详解:搜索引擎数据获取的核心工具
Serper API 详解:搜索引擎数据获取的核心工具 一、Serper API 的定义与核心功能二、技术架构与核心优势2.1 技术实现原理2.2 对比传统方案的突破性优势 三、典型应用场景与代码示例3.1 SEO 监控系统3.2 竞品广告分析 四、使用成本与配额策略五、开发者注意事项六、替…...

asp.net web form nlog的安装
一、安装NuGet包 核心包安装 NLog提供日志记录核心功能 NLog.Config自动生成默认配置文件模板 配置NLog文件 配置文件创建 项目根目录自动生成NLog.config文件(通过NuGet安装NLog.Config时创建) <?xml version"1.0" encoding&…...

【图像生成大模型】CogVideoX-5b:开启文本到视频生成的新纪元
CogVideoX-5b:开启文本到视频生成的新纪元 项目背景与目标模型架构与技术亮点项目运行方式与执行步骤环境准备模型加载与推理量化推理 执行报错与问题解决内存不足模型加载失败生成质量不佳 相关论文信息总结 在人工智能领域,文本到视频生成技术一直是研…...
剧本杀小程序:指尖上的沉浸式推理宇宙
在推理热潮席卷社交圈的当下,你是否渴望随时随地开启一场烧脑又刺激的冒险?我们的剧本杀小程序,就是你掌心的“推理魔法盒”,一键解锁无限精彩! 海量剧本库,满足多元口味:小程序汇聚了从古风权…...
2024正式版企业级在线客服系统源码+语音定位+快捷回复+图片视频传输+安装教程
2024正式版企业级在线客服系统源码语音定位快捷回复图片视频传输安装教程; 企业客服系统是一款全功能的客户服务解决方案,提供多渠道支持(如在线聊天、邮件、电话等),帮助企业建立与客户的实时互动。该系统具有智能分…...
深入解析 Oracle session_cached_cursors 参数及性能对比实验
在 Oracle 数据库管理中,session_cached_cursors参数扮演着至关重要的角色,它直接影响着数据库的性能和资源利用效率。本文将深入剖析该参数的原理、作用,并通过性能对比实验,直观展示不同参数设置下数据库的性能表现。 一、sessi…...

【RabbitMQ】整合 SpringBoot,实现工作队列、发布/订阅、路由和通配符模式
文章目录 工作队列模式引入依赖配置声明生产者代码消费者代码 发布/订阅模式引入依赖声明生产者代码发送消息 消费者代码运行程序 路由模式声明生产者代码消费者代码运行程序 通配符模式声明生产者代码消费者代码运行程序 工作队列模式 引入依赖 我们在创建 SpringBoot 项目的…...

k8s面试题-ingress
场景:我通过deployment更新pod,ingress是怎么把新的请求流量发送到我新的pod的?是怎么监控到我更新的pod的? 在 Kubernetes 中,Ingress 是一种 API 对象,用于管理外部访问到集群内服务的 HTTP 和 HTTPS 路…...
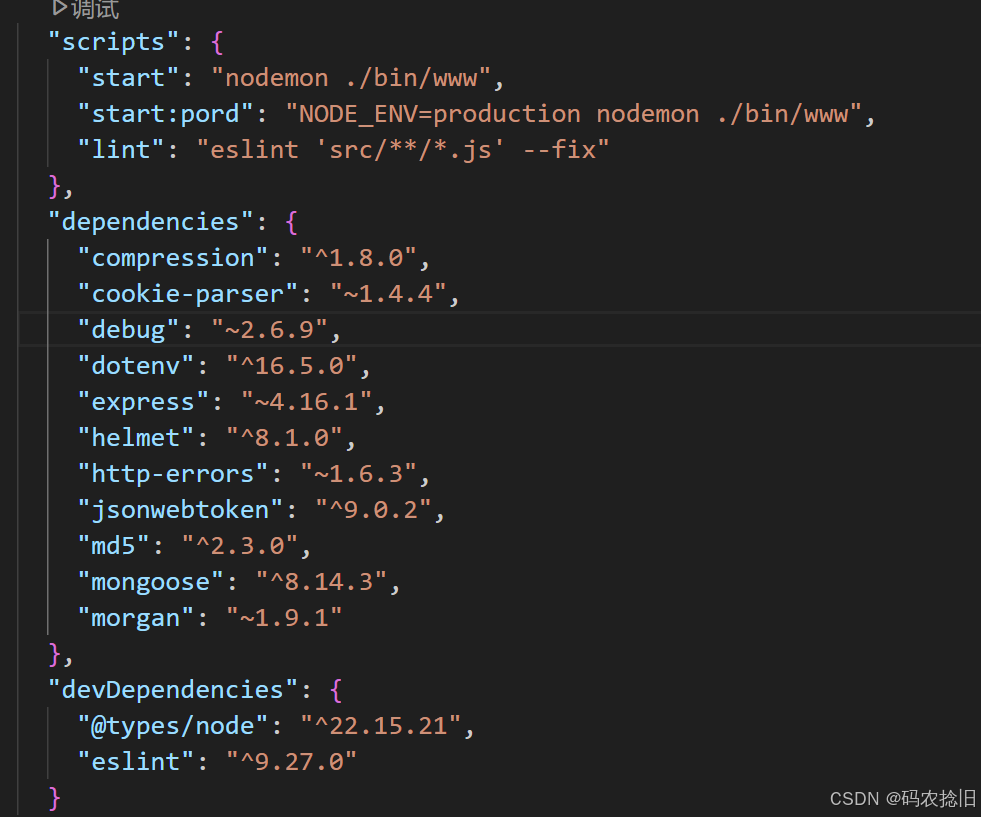
Node.js Express 项目现代化打包部署全指南
Node.js Express 项目现代化打包部署全指南 一、项目准备阶段 1.1 依赖管理优化 # 生产依赖安装(示例) npm install express mongoose dotenv compression helmet# 开发依赖安装 npm install nodemon eslint types/node --save-dev1.2 环境变量配置 /…...

分布式电源的配电网无功优化
分布式电源(Distributed Generation, DG)的大规模接入配电网,改变了传统单向潮流模式,导致电压波动、功率因数降低、网损增加等问题,无功优化成为保障配电网安全、经济、高效运行的关键技术。 1. 核心目标 电压稳定性:抑制DG并网点(PCC)及敏感节点的电压越限(如超过5%…...

【WebRTC】源码更改麦克风权限
WebRTC源码更改麦克风权限 仓库: https://webrtc.googlesource.com/src.git分支: guyl/m125节点: b09c2f83f85ec70614503d16e4c530484eb0ee4f...
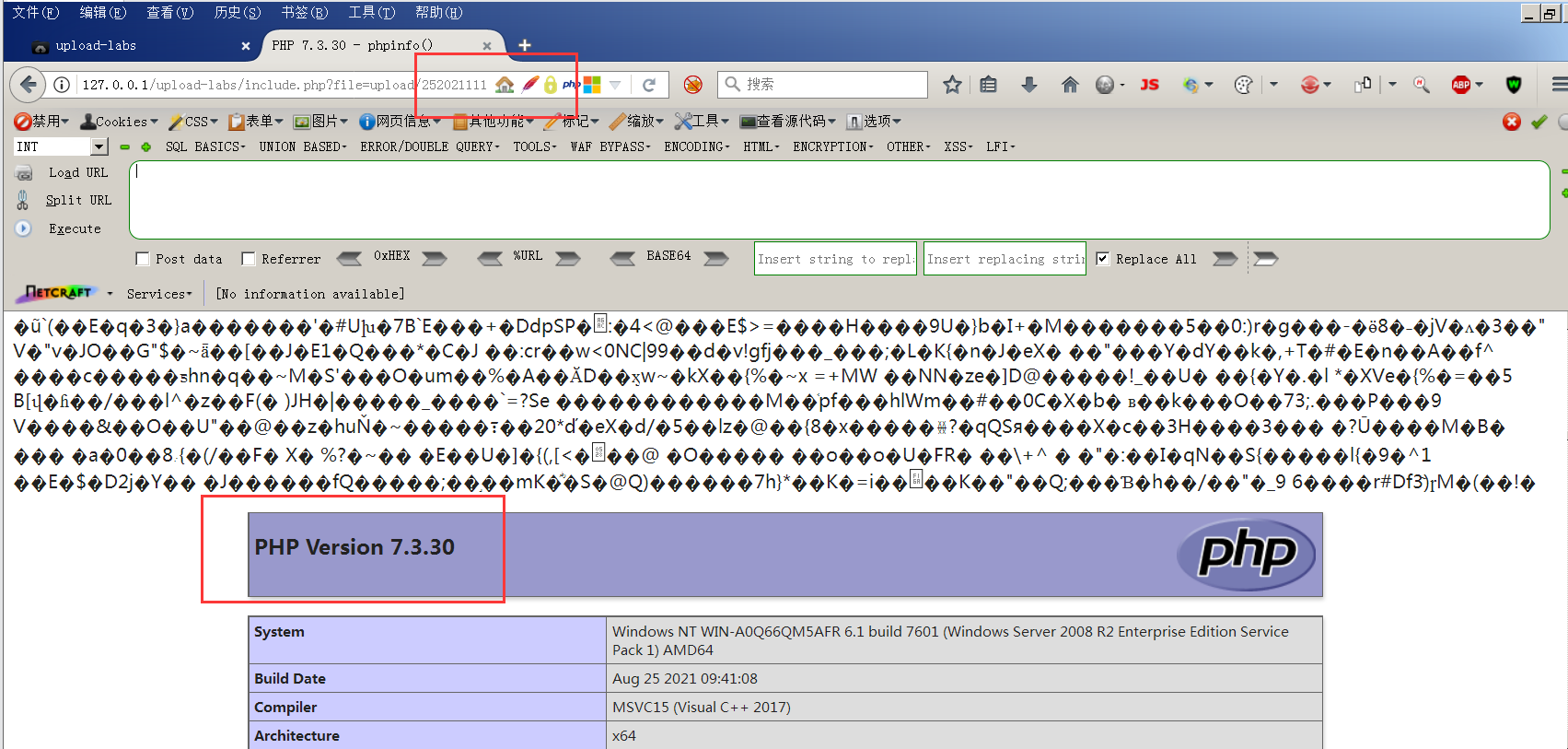
upload-labs通关笔记-第15关 文件上传之getimagesize绕过(图片马)
目录 一、图片马 二、文件包含 三、文件包含与图片马 四、图片马制作方法 五、源码分析 六、制作图片马 1、创建脚本并命名为test.php 2、准备制作图片马的三类图片 3、 使用copy命令制作图片马 七、渗透实战 1、GIF图片马渗透 (1)上传gif图…...
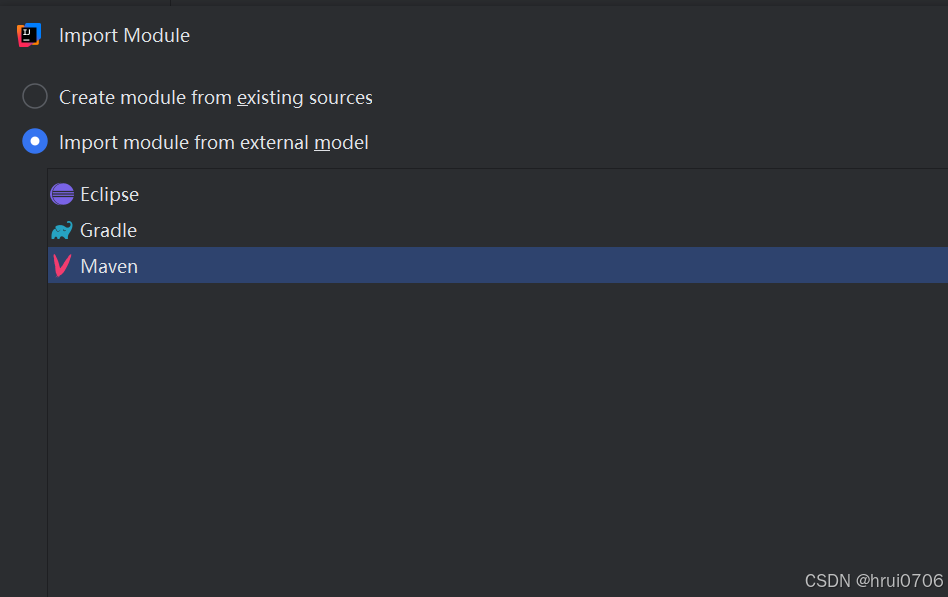
idea无法识别Maven项目
把.mvn相关都删除了 导致Idea无法识别maven项目 或者 添加导入各个模块 最后把父模块也要导入...

前端三剑客之HTML
前端HTML 一、HTML简介 1.什么是html HTML的全称为超文本标记语言(HTML How To Make Love HyperText Markup Language ),是一种标记语言。它包括一系列标签,通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整…...
linux中cpu内存浮动占用,C++文件占用cpu内存、定时任务不运行报错(root) PAM ERROR (Permission denied)
文章目录 说明部署文件准备脚本准备部署g++和编译脚本使用说明和测试脚本批量部署脚本说明执行测试定时任务不运行报错(root) PAM ERROR (Permission denied)报错说明处理方案说明 我前面已经弄了几个版本的cpu和内存占用脚本了,但因为都是固定值,所以现在重新弄个用C++编写的…...

RabbitMQ的核心原理及应用
在分布式系统架构中,消息中间件是实现服务解耦、流量缓冲的关键组件。RabbitMQ 作为基于 AMQP 协议的开源消息代理,凭借高可靠性、灵活路由和跨平台特性,被广泛应用于企业级开发和微服务架构中。本文将系统梳理 RabbitMQ 的核心知识ÿ…...

实时监控服务器CPU、内存和磁盘使用率
实时监控服务器CPU、内存和磁盘使用率 监控内存使用率: free -g | awk NR2{printf "%.2f%%\t\t", $3*100/$2 }awk NR2{...} 取第二行(Mem 行)。 $3 为已用内存,$2 为总内存,$3*100/$2 即计算使用率。监控磁…...