订单越来越到导致接口列表查询数据缓慢解决思路
文章目录
- **一、前期诊断:定位性能瓶颈**
- **1. 数据现状分析**
- **2. 业务场景梳理**
- **二、基础优化:快速提升性能**
- **1. 索引精准优化**
- **2. 表结构优化(垂直分表)**
- **3. 读写分离与缓存策略**
- **三、架构升级:应对千万级数据**
- **1. 水平分表(单库内分表)**
- **2. 分库(分布式架构)**
- **3. 引入搜索引擎(Elasticsearch)**
- **四、长期维护与性能保障**
- **1. 数据归档与冷存储**
- **2. 监控与自动化运维**
- **3. 应急预案**
- **五、总结:优化路线图**
- **回答亮点总结**
- 补充:
当面试官询问数据库层面的订单优化改造时,需结合技术原理与落地步骤,分阶段阐述具体方案。以下是详细的结构化回答,涵盖 诊断分析→基础优化→架构升级→长期维护全流程,突出技术深度与项目落地思维:
一、前期诊断:定位性能瓶颈
1. 数据现状分析
- 核心指标采集:
- 单表数据量(如
orders表是否超过 500 万条)、日增量(判断增长趋势)。 - 字段数量(是否存在大字段如
detail_json导致行存储过大)。 - 主从延迟情况(读写分离场景下,从库复制是否滞后)。
- 单表数据量(如
- 慢查询捕捉:
- 开启数据库慢查询日志(如 MySQL 的
slow_query_log),设置阈值(如long_query_time=1s)。 - 使用工具分析慢查询语句(如
pt-query-digest),统计高频慢查询模式(例如:SELECT * FROM orders WHERE user_id=? AND status=? LIMIT 100000,10)。
- 开启数据库慢查询日志(如 MySQL 的
2. 业务场景梳理
- 区分热数据(近 30 天订单,高频查询 / 更新)与冷数据(历史订单,低频查询)。
- 明确查询特征:
- 列表页查询:主要条件(如
user_id+status+create_time分页)。 - 详情页查询:基于
order_id的单条查询。 - 复杂查询:模糊搜索订单号、多状态统计(如 “待支付 + 已取消” 订单总数)。
- 列表页查询:主要条件(如
二、基础优化:快速提升性能
1. 索引精准优化
- 覆盖索引解决分页慢问题:
- 问题场景:深分页(如
LIMIT 10000, 20)导致数据库扫描大量无用数据。 - 优化方案:
- 创建复合索引
(user_id, status, create_time, id),利用索引排序避免文件排序(EXPLAIN中type=range且Extra=Using index)。 - 改用Keyset 分页:记录最后一条数据的
id,下次查询用WHERE id > last_id AND user_id=? AND status=? LIMIT 20,减少偏移量计算。
- 创建复合索引
- 问题场景:深分页(如
- 复合索引替代单列索引:
- 对高频查询条件组合(如
user_id + status + create_time),创建索引(user_id, status, create_time),遵循最左匹配原则。
- 对高频查询条件组合(如
- 删除无效索引:
- 通过
SHOW INDEX FROM orders查看未使用的索引(可借助sys.schema_unused_indexes视图),删除冗余索引(如仅用于ORDER BY的单列索引,若已被复合索引覆盖则可删除)。
- 通过
2. 表结构优化(垂直分表)
-
大字段拆分:
-
将
detail、attachments等大字段迁移到单独表order_details,主表仅保留order_id和必要字段,减少主表行大小,提升SELECT性能。 -
示例:
-- 原表 CREATE TABLE orders (id BIGINT PRIMARY KEY,user_id BIGINT,status TINYINT,create_time DATETIME,detail TEXT -- 大字段 );-- 拆分后 CREATE TABLE orders (id BIGINT PRIMARY KEY,user_id BIGINT,status TINYINT,create_time DATETIME );CREATE TABLE order_details (order_id BIGINT PRIMARY KEY,detail TEXT,FOREIGN KEY (order_id) REFERENCES orders(id) );
-
-
枚举字段优化:
- 将
status等固定值字段改为ENUM类型(如ENUM('待支付', '已支付', '已取消')),减少存储占用(从INT的 4 字节降至 1 字节)。
- 将
3. 读写分离与缓存策略
-
主从复制实现读负载分流:
- 配置 1 主 N 从架构(如 1 主 2 从),通过中间件(如
MyCat、ShardingSphere-JDBC)将查询请求路由到从库。 - 注意:对实时性要求高的查询(如刚创建的订单立即显示),可走主库或缓存(见下文)。
- 配置 1 主 N 从架构(如 1 主 2 从),通过中间件(如
-
热点数据缓存:
-
对高频查询的订单列表(如用户最近 100 条订单),使用 Redis 缓存:
// 缓存键设计:user:123:orders:recent:page1 String cacheKey = String.format("user:%d:orders:recent:%d", userId, pageNum); List<Order> cachedOrders = redisTemplate.opsForValue().get(cacheKey); if (cachedOrders == null) {cachedOrders = orderRepository.queryRecentOrders(userId, pageNum); // 数据库查询redisTemplate.opsForValue().set(cacheKey, cachedOrders, 5, TimeUnit.MINUTES); // 5分钟过期 } return cachedOrders; -
缓存更新策略:订单状态变更时,删除对应缓存(如
redisTemplate.delete(cacheKey)),保证数据一致性。
-
三、架构升级:应对千万级数据
1. 水平分表(单库内分表)
- 分表策略选择:
- 按时间分表:适用于订单按年月查询的场景(如
orders_202312、orders_202401),缺点是跨月查询需 JOIN 多个表。 - 按用户 ID 分表:通过
user_id % 1024路由到不同表(如orders_0到orders_1023),优点是单用户查询仅命中一张表,缺点是跨用户统计需聚合所有表。
- 按时间分表:适用于订单按年月查询的场景(如
- 分表实现方案:
- 代码层路由:在 DAO 层通过
user_id计算表名(如orders_${user_id % 1024}),适合中小规模系统。 - 中间件路由:使用
ShardingSphere或MyCat,配置分表规则,对应用透明(推荐)。
- 代码层路由:在 DAO 层通过
- 分表后注意事项:
- 分布式 ID 生成:使用雪花算法(Snowflake)或数据库自增序列(如
orders_0自增从 1 开始,orders_1从 1000001 开始)保证全局唯一。 - 跨表查询:避免
SELECT * FROM orders WHERE status=?全表扫描,可通过搜索引擎(见下文)或定期汇总统计结果到汇总表。
- 分布式 ID 生成:使用雪花算法(Snowflake)或数据库自增序列(如
2. 分库(分布式架构)
- 分库场景:单库存储超过硬件瓶颈(如磁盘 IO、连接数),需将数据拆分到多个数据库实例。
- 分库策略:
- 按业务分库:订单库独立于用户库、商品库(垂直分库)。
- 按用户分库:将用户 ID 尾号 0-4 的订单放在库 1,5-9 的放在库 2(水平分库),每个库包含完整的表结构。
- 分库中间件:
- 使用
ShardingSphere-Proxy作为数据库代理层,处理跨库查询(如SELECT COUNT(*) FROM orders WHERE status=?需合并多个库的结果)。 - 引入分布式事务解决方案(如
Seata),保证跨库操作一致性(如订单创建时扣减库存需跨库事务)。
- 使用
3. 引入搜索引擎(Elasticsearch)
-
适用场景:模糊查询(如订单号包含
202401)、多条件组合查询(如 “北京地区 + 金额> 1000 + 待支付”)。 -
实施步骤:
-
数据同步:通过
Canal监听数据库 binlog,实时将订单数据同步到 ES(或使用定时任务批量同步)。 -
ES 索引设计:
{"mappings": {"properties": {"order_id": {"type": "keyword"}, // 精确查询"user_id": {"type": "long"},"status": {"type": "keyword"}, // 枚举值"create_time": {"type": "date", "format": "yyyy-MM-dd HH:mm:ss"},"amount": {"type": "scaled_float", "scaling_factor": 100}, // 金额精确到分"city": {"type": "keyword"} // 地理位置关键词}} } -
查询流程:前端搜索请求→ES 快速检索
order_id列表→通过order_id批量从数据库查询完整订单数据(减少数据库压力)。
-
四、长期维护与性能保障
1. 数据归档与冷存储
-
定期归档历史数据:
-
每月将 3 个月前的订单数据迁移到归档表(如
orders_archive_2023)或冷存储(如 Hive、OSS),主表仅保留近 3 个月数据。 -
归档脚本示例(MySQL):
INSERT INTO orders_archive (SELECT * FROM orders WHERE create_time < '2024-01-01'); DELETE FROM orders WHERE create_time < '2024-01-01';
-
-
冷数据查询方案:
- 对归档数据使用大数据查询引擎(如 Presto)或定期生成统计报表,避免直接查询主库。
2. 监控与自动化运维
- 关键指标监控:
- 数据库层:QPS、TPS、慢查询数量、锁等待时间、主从延迟(如
Seconds_Behind_Master)。 - 应用层:缓存命中率、接口响应时间(如 95% 请求在 500ms 内返回)。
- 数据库层:QPS、TPS、慢查询数量、锁等待时间、主从延迟(如
- 自动化优化工具:
- 使用
AutoOptimize等工具自动分析索引使用情况,建议创建或删除索引。 - 基于数据量阈值自动触发分表扩容(如单表超过 1000 万条时,自动新增分表)。
- 使用
3. 应急预案
- 读写失败重试机制:对因锁竞争导致的写失败(如
Deadlock),在应用层添加重试逻辑(最多 3 次,间隔递增)。 - 流量削峰:在大促期间,通过消息队列(如 Kafka)异步处理订单写入,避免瞬时高并发压垮数据库。
五、总结:优化路线图
| 数据规模 | 阶段 | 核心优化手段 | 实施成本 | 耗时 |
|---|---|---|---|---|
| 10 万~100 万条 | 基础优化 | 索引优化、读写分离、缓存 | 低 | 1~2 周 |
| 100 万~1000 万条 | 分表分库 | 水平分表、垂直分库 | 中 | 2~4 周 |
| 1000 万~1 亿条 | 分布式架构 | 引入 ES、分库 + 分布式事务 | 高 | 4~8 周 |
| 亿级以上 | 云原生架构 | 云数据库(如 AWS Aurora)、Serverless | 极高 | 长期 |
回答亮点总结
- 分层思维:从诊断→优化→架构→维护层层递进,展示系统性解决方案。
- 技术落地细节:给出具体 SQL 示例、分表规则、缓存代码片段,体现工程实践能力。
- 成本意识:区分不同数据规模的优化策略,说明投入产出比(如先做低成本的索引优化,再逐步升级架构)。
- 前瞻性:提到数据归档、监控自动化、云原生架构,展现对长期性能维护的思考。
通过以上回答,既能体现对数据库优化原理的深入理解,又能展示从问题定位到方案落地的全流程把控能力,符合面试官对 “技术深度 + 项目落地” 的考察需求。
补充:
顺带一提:数据没有超过百万级别但是接口响应缓慢,大多情况下可以直接考虑:
- 前端的分页展示条数可以调小
- 解析SQL查看是否用到索引,是否是索引失效行锁升级为表锁,有无锁竞争情况
- 内存配置不足,数据库读写频繁,导致了I/O出现瓶颈
- 是否调用的外部接口,外部接口响应超时
- 高并发情况下,redis热点数据过期,大量请求打入到mysql,增加热点数据的有效期,避免同一时间失效
- 微服务下:a服务接口调用b服务接口,并且都修改了同一张表,导致事务出现死锁情况
大多情况下都是因为开发的代码不规范而导致
相关文章:

订单越来越到导致接口列表查询数据缓慢解决思路
文章目录 **一、前期诊断:定位性能瓶颈****1. 数据现状分析****2. 业务场景梳理** **二、基础优化:快速提升性能****1. 索引精准优化****2. 表结构优化(垂直分表)****3. 读写分离与缓存策略** **三、架构升级:应对千万…...

word格式相关问题
页眉 1 去除页眉横线: 双击打开页眉,然后点击正文样式,横线就没有了。 2 让两部分内容的页眉不一样: 使用“分节符”区分两部分内容,分节符可以在“布局-分隔符”找到。然后双击打开页眉,取消“链接到前一…...
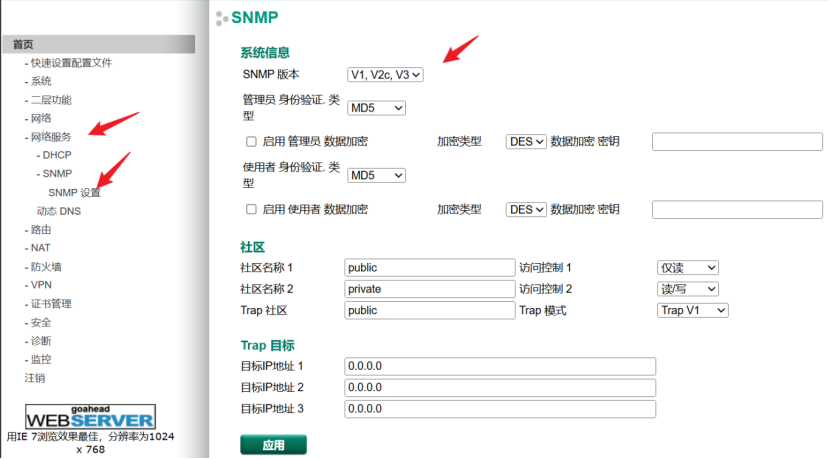
网络-MOXA设备基本操作
修改本机IP和网络设备同网段,输入设备IP地址进入登录界面,交换机没有密码,路由器密码为moxa 修改设备IP地址 交换机 路由器 环网 启用Turbo Ring协议:在设备的网络管理界面中,找到环网配置选项,启用Turb…...
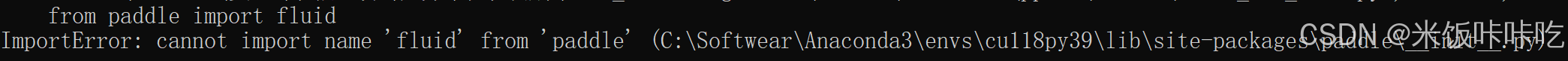
飞桨paddle import fluid报错【已解决】
跟着飞桨的安装指南安装了paddle之后 pip install paddlepaddle有一个验证: import paddle.fluid as fluid fluid.install check.run check()报错情况如下,但是我在pip list中,确实看到了paddle安装上了 我import paddle别的包,…...

测试工程师要如何开展单元测试
单元测试是软件开发过程中至关重要的环节,它通过验证代码的最小可测试单元(如函数、方法或类)是否按预期工作,帮助开发团队在早期发现和修复缺陷,提升代码质量和可维护性。以下是测试工程师开展单元测试的详细步骤和方法: 一、理…...
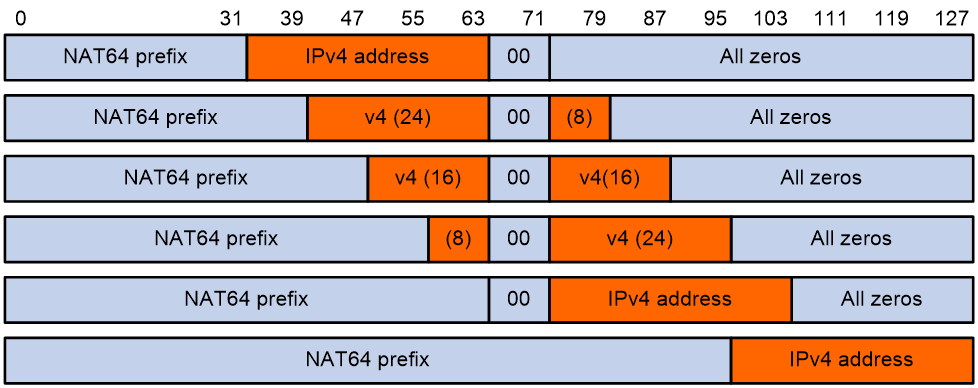
IPv4 地址嵌入 IPv6 的前缀转换方式详解
1. 概述 在 IPv4 和 IPv6 网络共存的过渡期,NAT64(Network Address Translation 64)是一种关键技术,用于实现 IPv6-only 网络与 IPv4-only 网络的互操作。NAT64 前缀转换通过将 IPv4 地址嵌入到 IPv6 地址中,允许 IPv…...
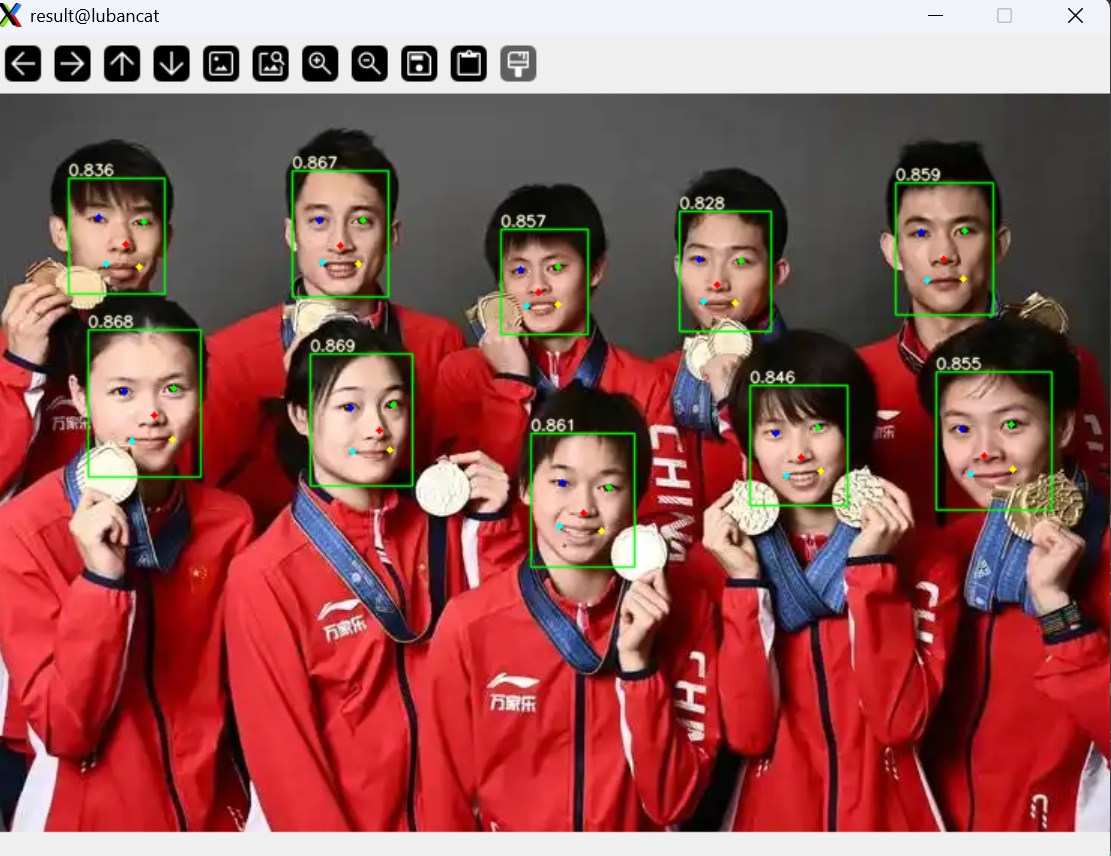
野火鲁班猫(arrch64架构debian)从零实现用MobileFaceNet算法进行实时人脸识别(三)用yolov5-face算法实现人脸检测
环境直接使用第一篇中安装好的环境即可 先clone yolov5-face项目 git clone https://github.com/deepcam-cn/yolov5-face.git 并下载预训练权重文件yolov5n-face.pt 网盘链接: https://pan.baidu.com/s/1xsYns6cyB84aPDgXB7sNDQ 提取码: lw9j (野火官方提供&am…...

IS-IS 中间系统到中间系统
前言: 中间系统到中间系统IS-IS(Intermediate System to Intermediate System)属于内部网关协议IGP(Interior Gateway Protocol),用于自治系统内部 IS-IS也是一种链路状态协议,使用最短路径优先…...
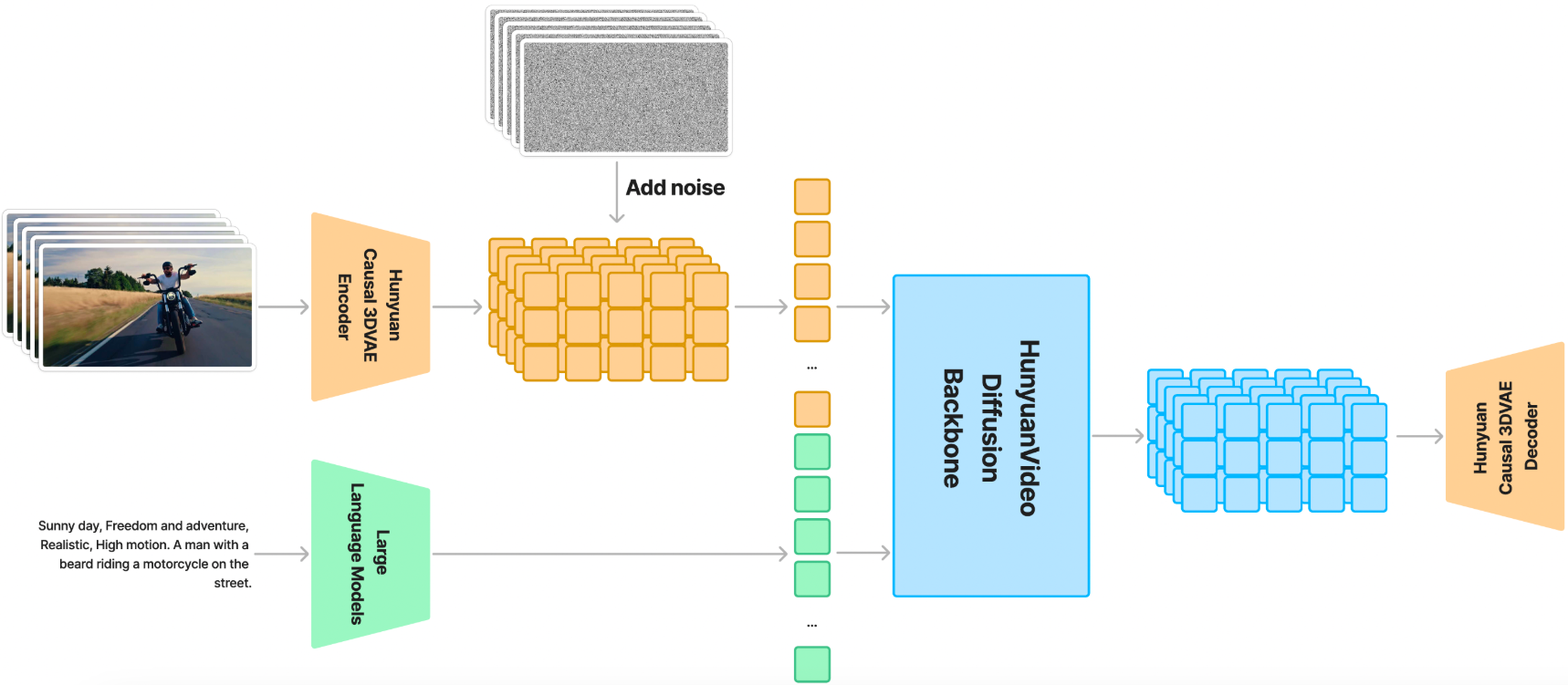
【图像生成大模型】HunyuanVideo:大规模视频生成模型的系统性框架
HunyuanVideo:大规模视频生成模型的系统性框架 引言HunyuanVideo 项目概述核心技术1. 统一的图像和视频生成架构2. 多模态大语言模型(MLLM)文本编码器3. 3D VAE4. 提示重写(Prompt Rewrite) 项目运行方式与执行步骤1. …...
)
GitHub 趋势日报 (2025年05月19日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1public-apis/public-apis免费API的集体清单⭐ 1821⭐ 344364Python2virattt/a…...
如何使用Java生成pdf报告
文章目录 一、环境准备与Maven依赖说明二、核心代码解析1. 基础文档创建2. 中文字体处理3. 复杂表格创建4. 图片插入 三、完整代码示例四、最终效果 这篇主要说一下如何使用Java生成pdf,包括标题,文字,图片,表格的插入和调整等相关…...

HarmonyOS鸿蒙应用规格开发指南
在鸿蒙生态系统中,应用规格是确保应用符合系统要求的基础。本文将深入探讨鸿蒙应用的规格开发实践,帮助开发者打造符合规范的应用。 应用包结构规范 1. 基本配置要求 包结构规范 符合规范的应用包结构正确的HAP配置文件完整的应用信息 示例配置&…...

【Harmony】【鸿蒙】List列表View如何刷新内部的自定义View的某一个控件
创建自定义View Component export struct TestView{State leftIcon?:Resource $r(app.media.leftIcon)State leftText?:Resource | string $r(app.string.leftText)State rightText?:Resource | string $r(app.string.rightText)State rightIcon?:Resource $r(app.med…...

iisARR负均衡
IIS ARR负载均衡详细配置指南 🎯 什么是ARR(Application Request Routing) ARR是IIS的一个扩展模块,它可以: 负载均衡:将请求分发到多个服务器反向代理:隐藏后端服务器架构健康检查…...

uniapp打包报错:重新在manifest.json中生成自己的APPID
在UniApp开发过程中,打包时可能会遇到报错提示需要在manifest.json中重新生成自己的APPID。以下是解决该问题的具体方法: 检查并生成APPID 打开项目根目录下的manifest.json文件,找到appid字段。如果该字段为空或为默认值,需要重…...

人脸识别备案开启安全防护模式!紧跟《办法》!
国家互联网信息办公室与公安部于 2025 年 3 月 13 日联合公布了《人脸识别技术应用安全管理办法》(以下简称《办法》),并自 2025 年 6 月 1 日起正式施行。其中,人脸识别备案成为了规范技术应用、守护信息安全的关键一环。 一、…...

【爬虫】DrissionPage-7
官方文档: https://www.drissionpage.cn/browser_control/get_page_info/ 1. 页面信息 📌 html 描述:返回当前页面的 HTML 文本。注意:不包含 <iframe> 元素的内容。返回类型:str 示例: html_co…...

新浪《经济新闻》丨珈和科技联合蒲江政府打造“数字茶园+智能工厂+文旅综合体“创新模式
5月14日,新浪网《经济新闻》频道专题报道珈和科技在第十四届四川国际茶业博览会上的精彩亮相,并深度聚焦我司以数字技术赋能川茶产业高质量发展创新技术路径,及在成都市“茶业建圈强链”主题推介会上,珈和科技与蒲江县人民政府就智…...

git 撤销最近的几次push
要实现将远程仓库回退到最近5次push之前的状态,同时保留本地改动,可以按照以下步骤操作: 一、本地分支回退(保留改动) # 1. 查看提交历史确认要回退的提交点 git log --oneline# 2. 回退到5次提交前的状态࿰…...

水滴前端面经及参考答案
盒模型是什么,标准盒模型和 IE 盒模型有什么区别? 盒模型是 CSS 中一个基础概念,它描述了元素在页面中所占的空间大小。每个元素都可以看作是一个矩形盒子,从内到外由内容区(content)、内边距(padding)、边框(border)和外边距(margin)组成。 标准盒模型的宽度和高…...
 Hook的使用详解及注意事项)
React 第四十五节 Router 中 useHref() Hook的使用详解及注意事项
前言 React Router 中的 useHref 是一个用于生成完整 URL 路径的钩子, 它可以将相对路径解析为绝对路径,并确保在不同路由层级中正确工作。 它常用于自定义导航组件或需要手动构建链接的场景。 一、useHref核心用途 解析相对路径:自动将相…...

50、js 中var { ipcRenderer } = require(‘electron‘);是什么意思?
在 JavaScript 中,var { ipcRenderer } require(‘electron’); 这行代码的含义是: 1. require(‘electron’) 这是 Node.js 的模块引入语法,用于加载 Electron 的核心模块。electron 是 Electron 框架的主模块,提供了构建桌面…...

LeetCode 438. 找到字符串中所有字母异位词 | 滑动窗口与字符计数数组解法
文章目录 问题描述核心思路:滑动窗口 字符计数数组1. 字符计数数组2. 滑动窗口 算法步骤完整代码实现复杂度分析关键点总结类似问题 问题描述 给定两个字符串 s 和 p,要求找到 s 中所有是 p 的**字母异位词(Anagram)**的子串的起…...

@RequestParam 和 @RequestBody、HttpServletrequest 与HttpServletResponse
在Java Web开发中,RequestParam、RequestBody、HttpServletRequest 和 HttpServletResponse 是常用的组件,它们用于处理HTTP请求和响应。下面分别介绍它们的使用场景和使用方法: 1. RequestParam RequestParam 是Spring MVC框架中的注解&am…...
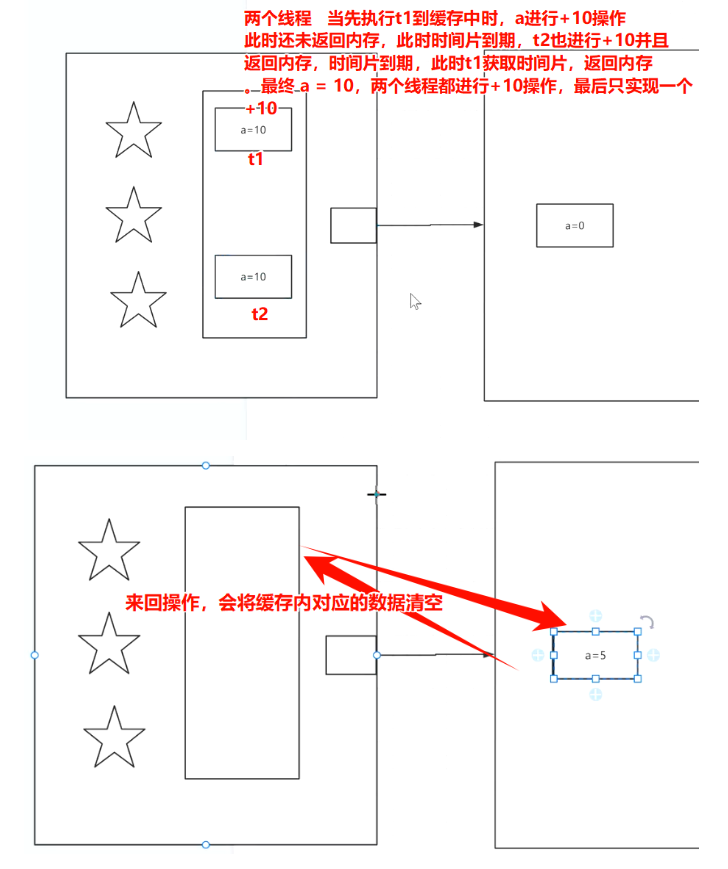
计算机底层的多级缓存以及缓存带来的数据覆盖问题
没有多级缓存的情况 有多级缓存的情况 缓存带来的操作覆盖问题 锁总线带来的消耗太大了。...
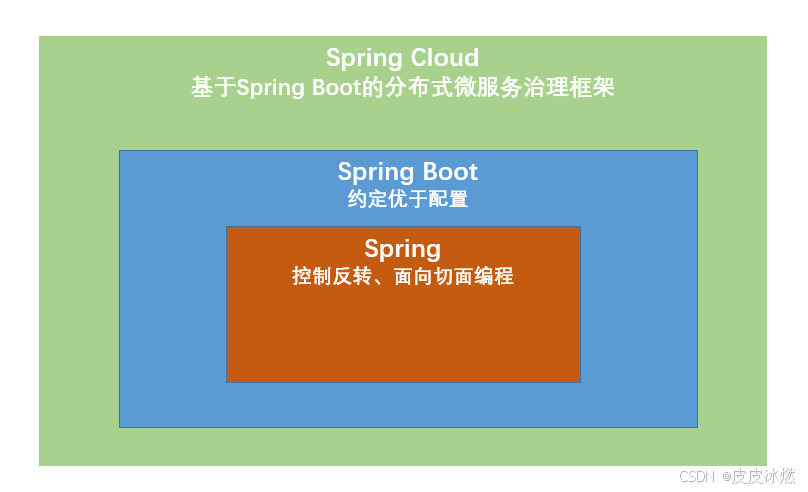
SpringBoot-1-入门概念介绍和第一个Spring Boot项目
文章目录 1 开发JAVA EE应用1.1 EJB1.2 Spring框架1.2.1 IoC(Inversion of Control)控制反转1.2.2 DI(Dependency Injection)依赖注入1.2.3 AOP面向切面编程1.3 Spring Boot1.4 Spring Cloud框架1.5 开发工具2 创建Spring Boot项目2.1 在线项目生成向导2.2 使用IDEA导入项目2.3…...

服务器多用户共享Conda环境操作指南——Ubuntu24.02
1. 使用阿里云镜像下载 Anaconda 最新版本 wget https://mirrors.aliyun.com/anaconda/archive/Anaconda3-2024.02-1-Linux-x86_64.sh bug解决方案 若出现:使用wget在清华镜像站下载Anaconda报错ERROR 403: Forbidden. 解决方案:wget --user-agent“M…...
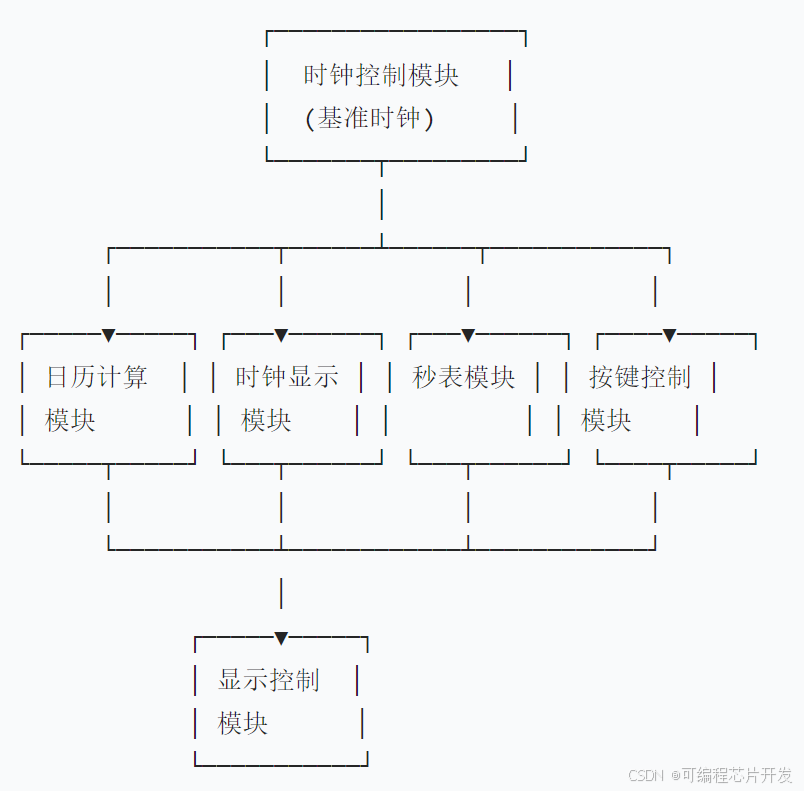
基于FPGA的电子万年历系统开发,包含各模块testbench
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于FPGA的电子万年历系统开发,包含各模块testbench。主要包含以下核心模块: 时钟控制模块:提供系统基准时钟和计时功能。 日历计算模块:…...

Leetcode刷题 | Day63_图论08_拓扑排序
一、学习任务 拓扑排序代码随想录 二、具体题目 1.拓扑排序117. 软件构建 【题目描述】 某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依…...
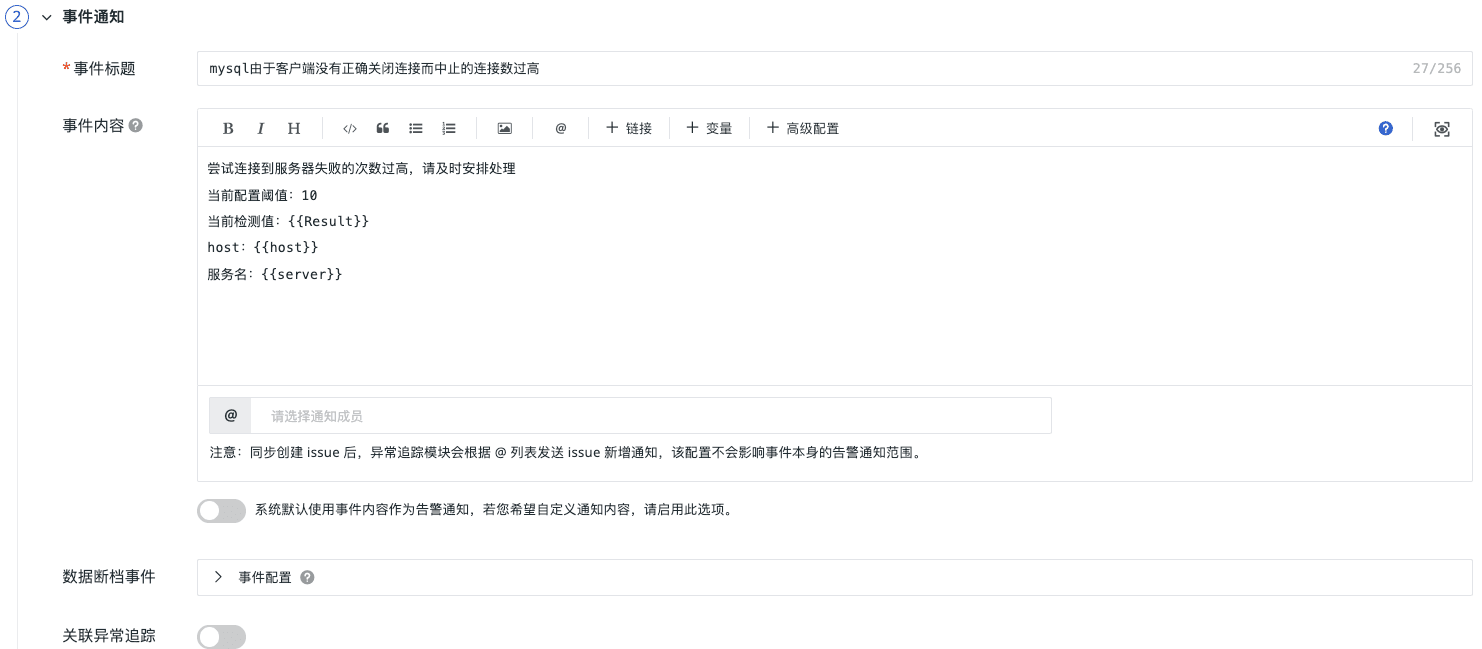
MySQL 可观测性最佳实践
MySQL 简介 MySQL 是一个广泛使用的开源关系型数据库管理系统(RDBMS),以其高性能、可靠性和易用性而闻名,适用于各种规模的应用,从小型网站到大型企业级系统。 监控 MySQL 指标是维护数据库健康、优化性能和确保数据…...