基于深度学习的电力负荷预测研究
一、深度学习模型框架
在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,即准确预估未来特定时间段内的电力需求,这关系到电力资源的合理分配与调度。数据收集是模型构建的基石,涵盖历史负荷数据、气象数据、节假日信息、经济指标等诸多变量。历史负荷数据能反映电力需求的周期性、趋势性变化规律;气象数据如温度、湿度、风速等,与人类生活用电行为紧密相关,温度的细微变化可能引发空调等大功率电器使用频率的波动,进而影响负荷;节假日信息可区分工作日与休息日不同的用电模式;经济指标则关联工商业活动强度与居民生活水平,影响整体电力消耗。
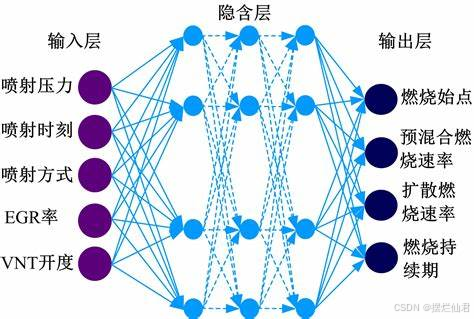
在数据预处理阶段,需对收集到的原始数据进行清洗,去除噪声、异常值与缺失值,确保数据质量。例如,对于缺失的负荷数据,可采用插值法或基于时间序列的预测算法进行填补;异常值可通过统计分析方法或聚类分析识别并修正,以避免其对模型训练过程的干扰,使模型能基于准确、可靠的数据进行学习。
深度学习模型的选择至关重要,常见的有循环神经网络(RNN)及其变体长短期记忆网络(LSTM)、门控循环单元(GRU)。RNN 能处理序列数据,但存在梯度消失问题,难以捕捉长周期的依赖关系。LSTM 通过引入遗忘门、输入门与输出门结构,有效缓解了梯度消失,能记忆长时间序列中的关键信息,对电力负荷这类具有明显时间先后关联的数据有良好适应性;GRU 在 LSTM 基础上进行简化,将遗忘门与输入门整合为更新门,减少参数数量,提高训练效率,在处理部分电力负荷数据时可取得与 LSTM 相当甚至更优的效果。
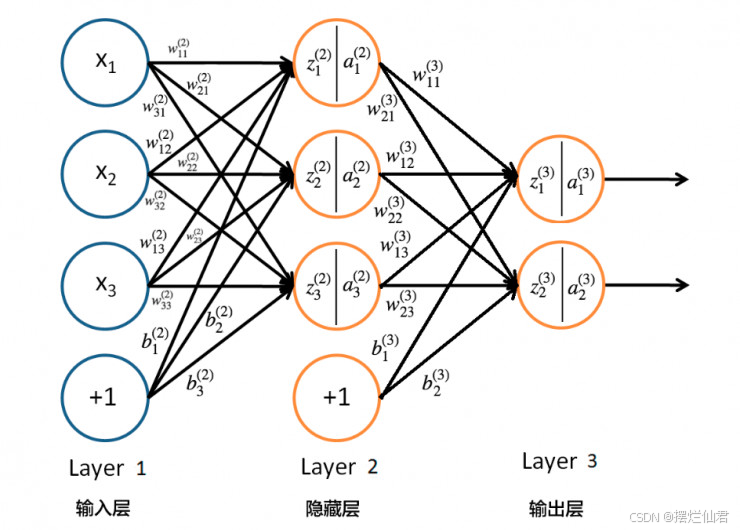
以 LSTM 为例,其模型构建细节如下。输入层接收预处理后的多维数据,包括历史负荷值、对应时刻的气象参数等,数据维度需根据实际数据特征与模型输入要求合理设置。隐藏层由多个 LSTM 单元构成,这些单元相互连接,形成时间序列处理链路。每个 LSTM 单元内部,遗忘门决定了先前时刻记忆信息中有多少被保留或舍弃;输入门控制当前输入数据进入单元状态的程度;输出门则依据单元状态输出有价值的信息用于后续预测。隐藏层的层数与每层神经元数量需通过反复试验确定,过多可能导致过拟合,过少则预测精度不足。输出层通常采用线性激活函数,输出未来特定时间点或时间段的电力负荷预测值。
在模型训练过程中,定义合适的损失函数是关键。对于电力负荷预测这类回归问题,均方误差(MSE)、平均绝对误差(MAE)是常用损失函数,它们衡量预测值与真实值之间的偏差大小,模型训练旨在最小化该误差。采用优化算法如随机梯度下降(SGD)、Adam 等调整模型参数,根据损失函数梯度更新 LSTM 单元的权重与偏置,不断优化模型预测能力。训练过程中需划分训练集、验证集与测试集,利用训练集对模型进行初步训练,通过验证集监控模型在未见数据上的表现,防止过拟合,当验证集误差不再显著下降时停止训练,最后在测试集上评估模型最终性能,确保其在实际应用中具备良好的泛化能力。
二、网络模型优化
在深度学习模型构建过程中,以下三种优化技术被广泛用于提高模型的性能和泛化能力:(1)超参数调优:超参数的选择对模型性能影响巨大,包括学习率、隐藏层数量、神经元数量等。利用网格搜索或随机搜索等方法,通过在验证集上评估不同超参数组合的表现,选择最优的超参数组合。(2)正则化:防止模型过拟合,主要通过L1和L2正则化实现。L2正则化在损失函数中加入权重的平方和,而L1正则化加入权重的绝对值之和,限制模型复杂度,提高泛化能力。(3)数据增强:通过生成新的训练样本来扩充数据集,如对历史负荷数据进行平移、添加噪声扰动,增强模型对数据变化的适应能力,提高泛化性能。
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras import regularizers
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from tensorflow.keras.callbacks import EarlyStopping# 读取数据
data = pd.read_csv('electric_load_data.csv')
features = data[['temperature', 'humidity', 'historical_load', 'holiday_flag']]
labels = data['target_load']# 数据预处理
scaler_features = MinMaxScaler()
scaler_labels = MinMaxScaler()
features_scaled = scaler_features.fit_transform(features)
labels_scaled = scaler_labels.fit_transform(labels.values.reshape(-1, 1))# 数据增强
def data_augmentation(features, labels):augmented_features = []augmented_labels = []for feature, label in zip(features, labels):# 添加噪声扰动noise = np.random.normal(0, 0.01, feature.shape)augmented_features.append(feature + noise)augmented_labels.append(label)return np.array(augmented_features), np.array(augmented_labels)augmented_features, augmented_labels = data_augmentation(features_scaled, labels_scaled)# 数据集划分
X_train, X_val, y_train, y_val = train_test_split(augmented_features, augmented_labels, test_size=0.2, random_state=42)# 构建LSTM模型
def build_lstm_model(input_shape):model = Sequential()model.add(LSTM(64, input_shape=input_shape, return_sequences=True, kernel_regularizer=regularizers.l2(0.01)))model.add(Dropout(0.2))model.add(LSTM(32, kernel_regularizer=regularizers.l1(0.01)))model.add(Dropout(0.2))model.add(Dense(1, activation='linear'))model.compile(optimizer='adam', loss='mse')return modelmodel = build_lstm_model((X_train.shape[1], X_train.shape[2]))# 学习率调度器
def learning_rate_scheduler(epoch, lr):if epoch < 10:return lrelse:return lr * 0.95callbacks = [EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True),tf.keras.callbacks.LearningRateScheduler(learning_rate_scheduler)
]# 模型训练
history = model.fit(X_train, y_train, epochs=50, batch_size=32,validation_data=(X_val, y_val), callbacks=callbacks)# 模型评估
loss = model.evaluate(X_val, y_val)
print(f"Validation Loss: {loss}")# 预测结果反归一化
predicted = model.predict(X_val)
predicted_load = scaler_labels.inverse_transform(predicted)
true_load = scaler_labels.inverse_transform(y_val)# 计算预测误差
mse = mean_squared_error(true_load, predicted_load)
print(f"Mean Squared Error: {mse}")三、测试结果分析
在电力负荷预测中,准确评估模型的预测性能至关重要。我们主要关注以下几个方面:(1)预测误差分析:计算预测值与真实值之间的误差,包括平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)等指标,以定量评估模型的预测精度。(2)结果可视化:通过绘制预测值与真实值的对比图,直观展示模型的预测效果,并分析预测曲线与实际曲线的吻合程度。(3)模型性能评估:综合考虑模型在不同时间段的表现,评估其在处理不同负荷模式时的适应性和稳定性,其定性分析的结果如下图所示。
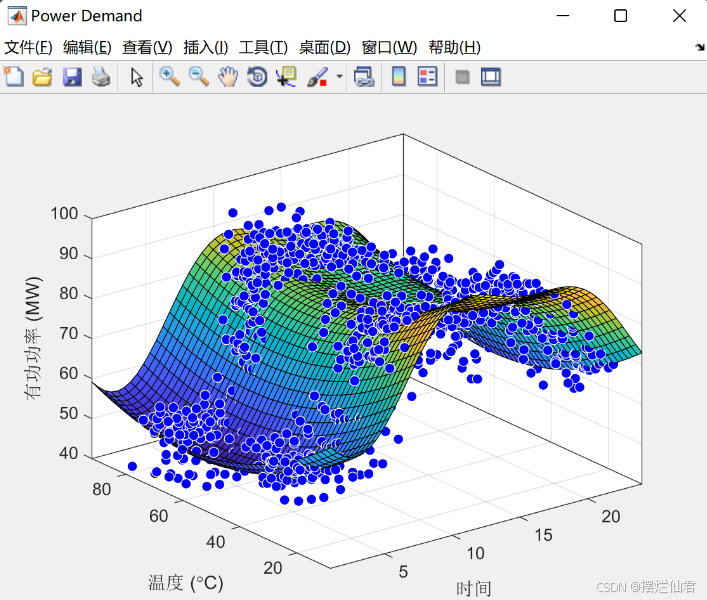
通过对模型预测结果的详细分析,我们可以全面评估模型的性能和可靠性。低预测误差和高R²值表明模型能够较好地捕捉电力负荷的变化趋势,为电力系统调度和资源分配提供有力支持。可视化结果进一步验证了模型的预测效果,使其在实际应用中具有较高的参考价值。
相关文章:
基于深度学习的电力负荷预测研究
一、深度学习模型框架 在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,…...

篇章十 消息持久化(二)
目录 1.消息持久化-创建MessageFileManger类 1.1 创建一个类 1.2 创建关于路径的方法 1.3 定义内部类 1.4 实现消息统计文件读写 1.5 实现创建消息目录和文件 1.6 实现删除消息目录和文件 1.7 实现消息序列化 1. 消息序列化的一些概念: 2. 方案选择…...

【IDEA】删除/替换文件中所有包含某个字符串的行
目录 前言 正则表达式 示例 使用方法 前言 在日常开发中,频繁地删除无用代码或清理空行是不可避免的操作。许多开发者希望找到一种高效的方式,避免手动选中代码再删除的繁琐过程。 使用正则表达式是处理字符串的一个非常有效的方法。 正则表达式 …...
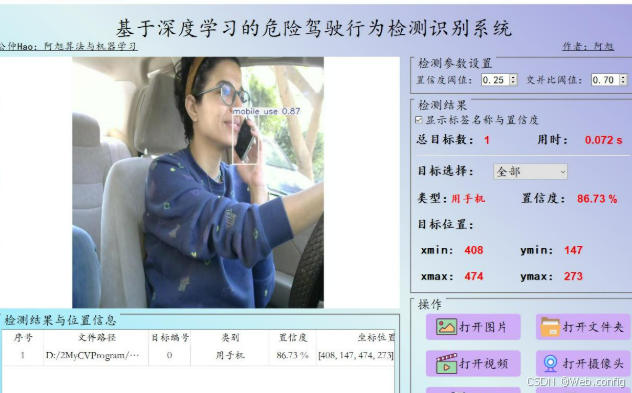
基于深度学习的不良驾驶行为为识别检测
一.研究目的 随着全球汽车保有量持续增长,交通安全问题日益严峻,由不良驾驶行为(如疲劳驾驶、接打电话、急加速/急刹车等)引发的交通事故频发,不仅威胁生命财产安全,还加剧交通拥堵与环境污染。传统识别方…...

FD+Mysql的Insert时的字段赋值乱码问题
方法一 FDQuery4.SQL.Text : INSERT INTO 信息表 (中心, 分组) values(:中心,:分组); FDQuery4.Params[0].DataType : ftWideString; //必须加这个数据类型的定义,否则会有乱码 FDQuery4.Params[1].DataType : ftWideString; //ftstring就不行,必须是…...
第十周作业
一、CSRF 1、DVWA-High等级 2、使用Burp生成CSRF利用POC并实现攻击 二、SSRF:file_get_content实验,要求获取ssrf.php的源码 三、RCE 1、 ThinkPHP 2、 Weblogic 3、Shiro...

Python操作PDF书签详解 - 添加、修改、提取和删除
目录 简介 使用工具 Python 向 PDF 添加书签 添加书签 添加嵌套书签 Python 修改 PDF 书签 Python 展开或折叠 PDF 书签 Python 提取 PDF 书签 Python 删除 PDF 书签 简介 PDF 书签是 PDF 文件中的导航工具,通常包含一个标题和一个跳转位置(如…...

One-shot和Zero-shot的区别以及使用场景
Zero-shot是模型在没有任务相关训练数据的情况下进行预测,依赖预训练知识。 One-shot则是提供一个示例,帮助模型理解任务。两者的核心区别在于是否提供示例,以及模型如何利用这些信息。 在机器学习和自然语言处理中,Zero-Shot 和…...

微软 Build 2025:开启 AI 智能体时代的产业革命
在 2025 年 5 月 19 日的微软 Build 开发者大会上,萨提亚・纳德拉以 "我们已进入 AI 智能体时代" 的宣言,正式拉开了人工智能发展的新纪元。这场汇聚了奥特曼、黄仁勋、马斯克三位科技领袖的盛会,不仅发布了 50 余项创新产品&#…...
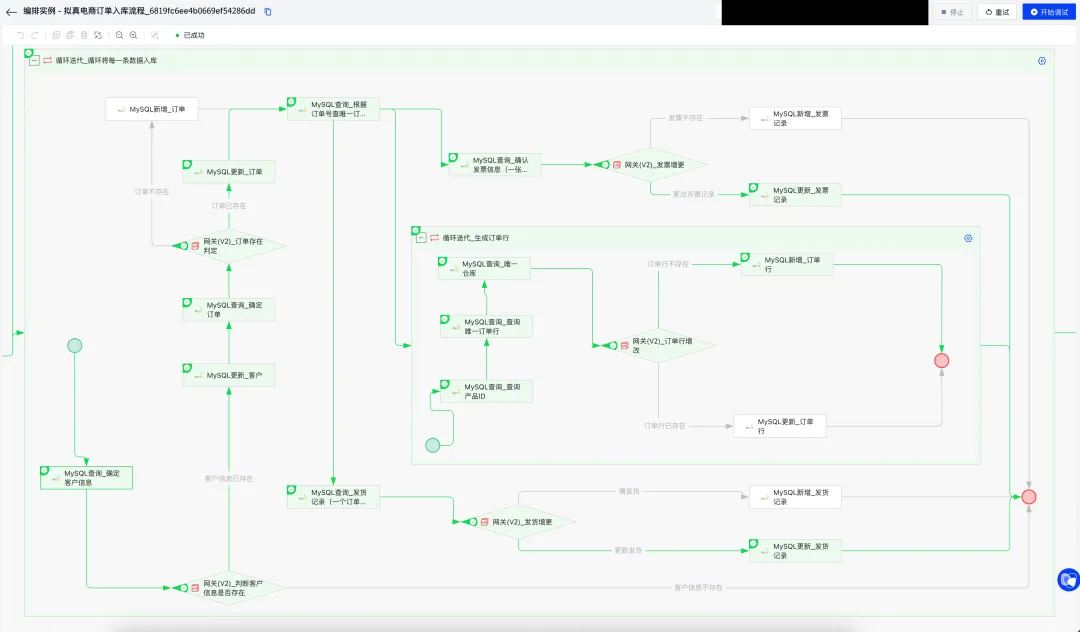
集星獭 | 重塑集成体验:新版编排重构仿真电商订单数据入库
概要介绍 新版服务编排以可视化模式驱动电商订单入库流程升级,实现订单、客户、库存、发票、发货等环节的自动化处理。流程中通过循环节点、判断逻辑与数据查询的编排,完成了低代码构建业务逻辑,极大提升订单处理效率与业务响应速度。 背景…...

多模态大语言模型arxiv论文略读(八十八)
MammothModa: Multi-Modal Large Language Model ➡️ 论文标题:MammothModa: Multi-Modal Large Language Model ➡️ 论文作者:Qi She, Junwen Pan, Xin Wan, Rui Zhang, Dawei Lu, Kai Huang ➡️ 研究机构: ByteDance, Beijing, China ➡️ 问题背景…...

创建Workforce
创建你的Workforce 3.3.1 简单实践 1. 创建 Workforce 实例 想要使用 Workforce,首先需要创建一个 Workforce 实例。下面是最简单的示例: from camel.agents import ChatAgent from camel.models import ModelFactory from camel.types import Model…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...

WebSocket 从入门到进阶实战
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受. 聊天系统是WebSocket的最佳实践,以下是使用WebSocket技术实现的一个聊天系统的关键代码,可以通过这些关键代码ÿ…...

CSS:vertical-align用法以及布局小案例(较难)
文章目录 一、vertical-align说明二、布局案例 一、vertical-align说明 上面的文字介绍,估计大家也看不懂 二、布局案例...

Linux 正则表达式 扩展正则表达式 gawk
什么是正则表达式 正则表达式是我们所定义的模式模板(pattern template),Linux工具用它来过滤文本。Linux工具(比如sed编辑器或gawk程序)能够在处理数据时,使用正则表达式对数据进行模式匹配。如果数据匹配…...
Java转Go日记(五十四):gin路由
1. 基本路由 gin 框架中采用的路由库是基于httprouter做的 地址为:https://github.com/julienschmidt/httprouter package mainimport ("net/http""github.com/gin-gonic/gin" )func main() {r : gin.Default()r.GET("/", func(c …...
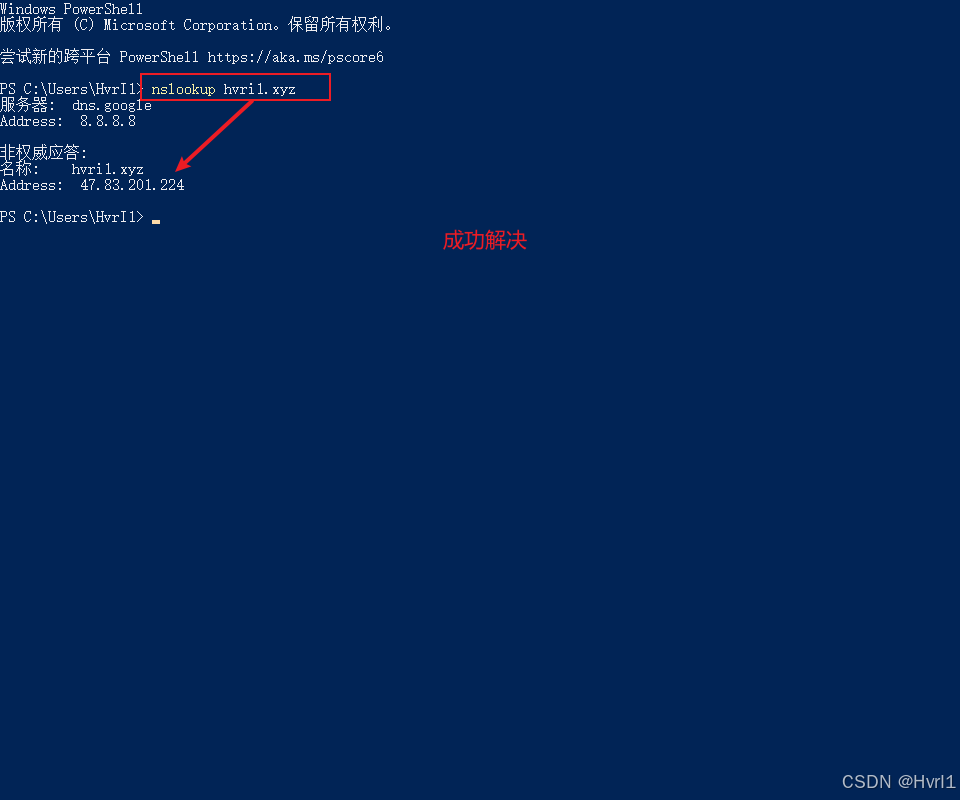
【解决】自己的域名任何端口都访问不到,公网地址正常访问,服务器报错500。
一、问题描述 后端项目部署在服务器上,通过域名访问接口服务器报错500,通过浏览器访问域名的任何端口都是无法访问此网站。 但是通过公网地址访问是可以正常访问到的,感觉是域名出现了问题 二、解决过程 先说结论:问题原因是…...

探秘鸿蒙 HarmonyOS NEXT:Navigation 组件的全面解析
鸿蒙 ArkTS 语言中 Navigation 组件的全面解析 一、引言 本文章基于HarmonyOS NEXT操作系统,API12以上的版本。 在鸿蒙应用开发中,ArkTS 作为一种简洁、高效的开发语言,为开发者提供了丰富的组件库。其中,Navigation 组件在构建…...
)
订单导入(常见问题和sql)
1.印章取行,有几行取几行 union select PARAM07 name, case when regexp_count(PO_PARAM_20, chr(10)) > 0 then substr(PO_PARAM_20, 0, instr(PO_PARAM_20, chr(10)) - 1) else PO_PARAM_20 end value,PO_ID …...
PyTorch中diag_embed和transpose函数使用详解
torch.diag_embed 是 PyTorch 中用于将一个向量(或批量向量)**嵌入为对角矩阵(或批量对角矩阵)**的函数。它常用于图神经网络(GNN)或线性代数中生成对角矩阵。 函数原型 torch.diag_embed(input, offset0,…...

算法分析与设计实验:找零钱问题的贪心算法与动态规划解决方案
在计算机科学中,贪心算法和动态规划是两种常用的算法设计策略。本文将通过一个经典的找零钱问题,详细讲解这两种算法的实现和应用。我们将会提供完整的C代码,并对代码进行详细解释,帮助读者更好地理解和掌握这两种算法。 问题描述…...
制作 MacOS系统 の Heic动态壁纸
了解动态桌面壁纸 当macOS 10.14发布后,会发现系统带有动态桌面壁纸,设置后,我们的桌面背景将随着一天从早上、到下午、再到晚上的推移而发生微妙的变化。 虽然有些软件也有类似的动态变化效果,但是在新系统中默认的HEIC格式的动…...
大数据 笔记
kafka kafka作为消息队列为什么发送和消费消息这么快? 消息分区:不受单台服务器的限制,可以不受限的处理更多的数据顺序读写:磁盘顺序读写,提升读写效率页缓存:把磁盘中的数据缓存到内存中,把…...

js中encodeURIComponent函数使用场景
encodeURIComponent 是 JavaScript 中的一个内置函数,它的作用是: 将字符串编码为可以安全放入 URL 的形式。 ✅ 为什么需要它? URL 中有一些字符是有特殊意义的,比如: ? 用来开始查询参数 & 分隔多个参数 连接…...

iOS工厂模式
iOS工厂模式 文章目录 iOS工厂模式简单工厂模式(Simple Factory)工厂方法模式(Factory Method)抽象工厂模式(Abstract Factory)三种模式对比 简单工厂模式(Simple Factory) 定义&am…...
【数据库】-1 mysql 的安装
文章目录 1、mysql数据库1.1 mysql数据库的简要介绍 2、mysql数据库的安装2.1 centos安装2.2 ubuntu安装 1、mysql数据库 1.1 mysql数据库的简要介绍 MySQL是一种开源的关系型数据库管理系统(RDBMS),由瑞典MySQL AB公司开发,目前…...

【缓存】JAVA本地缓存推荐Caffeine和Guava
🌟 引言 在软件开发过程中,缓存是提升系统性能的常用手段。对于基础场景,直接使用 Java集合框架(如Map/Set/List)即可满足需求。然而,当面对更复杂的缓存场景时: 需要支持多种过期策略&#x…...

Prometheus的服务命令和配置文件
一、Prometheus的服务端命令和启动方式 1.服务端命令(具体详情可以--help查看) --config.file“prometheus.yml”指定配置文件,默认是当前目录下的prometheus.yml--web.listen-address"0.0.0.0:9090"web页面的地址与端口…...
物流项目第五期(运费计算实现、责任链设计模式运用)
前四期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...