动手学习深度学习V1.1 chapter2 (2.1-2.2)
chapter2:深度学习基础
区分问题:回归问题还是分类问题?
输出结果是不明确的连续值的时候就是回归问题,比如房价预测,销售额预测等。
输出结果是明确几个离散值的时候就是分类问题,比如字符识别,猫狗分类等。
softmax回归是预测明确几个离散值,则适用于分类问题。
---------------------------------------------------------
2.1.1线性回归问题
以房价预测为例子,假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。
模型:就是x和y的表达式
设房屋的面积为 x1,房龄为x2 ,售出价格为 y,则模型是:
![]()
其中 w1和 w2是权重(weight), b是偏差(bias),且均为标量。
定义模型后,就要考虑训练模型
训练集(training set):收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄
样本(sample):一个房屋就是一个样本
标签(label):一个房屋售出的真实价格
特征(feature):用来预测标签的两个因素
预测值表达式:

红线部分是需要训练得出的参数
损失函数(loss function):衡量预测值与真实值误差的函数称为损失函数
书中给出的本例子的损失函数:

分析一波损失函数的特点:
1、通常选择平方函数,通常选取误差为非负数,且预测值与真实值相等时为0,
2、常数1/2使对平方项求导后的常数系数为1
如何衡量模型预测的质量?
所有样本误差的平均值来衡量模型预测的质量
即:
样本平均损失最小,就是我们期望的w1,w2,b的参数值
对于求解w1,w2,b分出两种情况。
解析解:模型和损失函数简单,解可以求出来,就像这次房屋预测的线性模型一样,可以求出一个精确的解。
数值解:复杂的模型没有解析解,只能通过不断去迭代参数降低损失函数的值(深度学习通常为数值解)
数值解不断迭代的求解的做法是可以用在求解解析解,不断逼近解析解从而求解。
ps:通常情况下数值解解决复杂问题更加有意义,很多问题都不是线性这么简单,这也就是激活函数存在的意义,激活函数在后续会介绍。
数值解如何迭代求解?
书中介绍“小批量随机梯度下降(mini-batch stochastic gradient descent)"

这里就是用数值解迭代方式求解解析解的房屋预测问题。
超参数:人为设定,并不是模型训练给出,比如这里的批量大小和学习率。
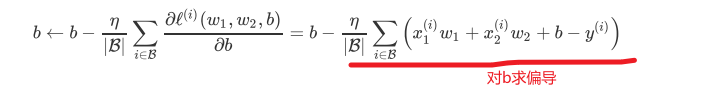 ps:损失函数设定应当是便于求导的,上面设置损失函数方便梯度下降迭代。
ps:损失函数设定应当是便于求导的,上面设置损失函数方便梯度下降迭代。
简单点,梯度下降就是用来求某个函数最小值时,自变量对应取值。
这篇文章细讲了梯度下降,可以了解它的原理,sir, this way:梯度下降![]() https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247626752&idx=4&sn=bfcf5f9c656316175c03d766c7bf3d63&chksm=fa8a4f6576277a914accf065dae89e80626eaa86b49964c677370d7915a52853ed2d33145990&scene=27
https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247626752&idx=4&sn=bfcf5f9c656316175c03d766c7bf3d63&chksm=fa8a4f6576277a914accf065dae89e80626eaa86b49964c677370d7915a52853ed2d33145990&scene=27
学习率:是梯度下降算法中的一个关键参数,它决定了每次更新参数的步长。选择合适的学习率非常重要,学习率过大或过小都会影响模型的收敛效果。过大无法收敛,过小训练时间太长。
-------------------------------------
2.1.2 线性回归的表示方法
神经网络图
之前例子房屋预测神经网络图:
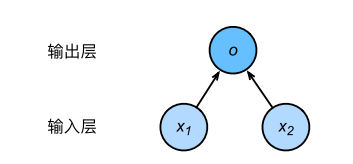
特征向量维度(特征数):输入个数也叫特征数或特征向量维度,这里为2。
层数:层数为1层,线性回归是单层神经网络
神经元:输出层中负责计算o 的单元又叫神经元
全连接层:输出层中的神经元和输入层中各个输入完全连接。
矢量计算:
数字图像是一个数字矩阵,不可避免需要大量运算,书中用两个1000维向量相加验证了矢量运算的优越性。
import torch
from time import time
a = torch.ones(1000)
b = torch.ones(1000)
# 标量运算,逐个相加
start = time()
c = torch.zeros(1000)
for i in range (1000):c[i] = a[i]+b[i]
end= time()
print (end - start)
#向量运算,矢量加法
start = time()
c=a+b
end = time()
print(end - start)
在本人的破电脑上用时如下:
![]()
矢量计算 Win!
一张 500w黑白相机拍出来的图片,如果作为输入,那个维度就是现在的很多倍,时间差异和矢量计算优越性的就会明显体现出来。
在房价预测将标量运算重写为矢量运算,书中这么写:


------------------------------------------------------------
2.2线性回归从零实现
为了更好理解,只利用 Tensor 和 autograd 来实现一个线性回归的训练
2.2.1生成数据集:

实现代码(书中代码有些版本问题,已经处理bug):
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():# 用矢量图显示matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):use_svg_display()# 设置图的尺寸plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
plt.show();数据图像如下:

2.2.2读取数据集
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它 每次返回 batch_size (批量大小)个随机样本的特征和标签。让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输 入个数;标签形状为批量大小。
实现如下(#分线后面的为这部分实现的):
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():# 用矢量图显示matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):use_svg_display()# 设置图的尺寸plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
#plt.show();
####################################################接下来是本部分
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))
# 样本的读取顺序是随机的random.shuffle(indices)for i in range(0, num_examples, batch_size):
# 最后一次可能不足一个batchj = torch.LongTensor(indices[i: min(i+batch_size,num_examples)])
# index_select函数根据索引返回对应元素yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10
for X, y in data_iter(batch_size, features, labels):print(X, y)break
读取效果如下:

2.2.3初始化参数&定义模型&定义损失函数&定义优化算法
初始化参数:初始化w1,w2权重值为均值为0、标准差为0.01的正态随机数,偏差b则初始化成0。
w1,w2,b都是要不断去迭代的,求梯度(偏导数)来迭代参数,因此我们要让它们的 requires_grad=True 。
定义模型:是线性回归的矢量计算表达式的实现,使用 mm() 函数做矩阵乘法。
(ps:torch.mul()执行的是元素级相乘,也称为Hadamard乘积,保持输入矩阵的维度不变。torch.mm()则进行矩阵乘法,要求特定的维度匹配,二维矩阵乘积,返回一个新的矩阵。torch.matmul()更通用,可处理多维矩阵。)
定义损失函数:使用上一节描述的平方损失函数来定义线性回归的损失函数,其中真实值y和预测值为y_hat
定义优化算法:小批量随机梯度下降算法,通过不断迭代模型参数来优化损失函数。这里定义了sgd函数自动求梯度模块计算得来的梯度是一个批量样本的梯度和,将它除以批量大小来得到平均值。
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征 X 和标签 y ),通过调用反向函数 backward 计算小批量随机梯度,并调用优化算法 sgd 迭代模型参 数。由于我们之前设批量大小 batch_size 为10,每个小批量的损失 l 的形状为(10, 1)。回忆一下自动 求梯度一节。由于变量 l 并不是一个标量,所以我们可以调用 .sum() 将其求和得到一个标量,再运行 l.backward() 得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。(如果不清零,PyTorch默认会对梯度进行累加)
在一个迭代周期(epoch)中,我们将完整遍历一遍 data_iter 函数,并对训练数据集中所有样本 都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数 num_epochs 和学习率 lr 都是超参数,分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。
实现如下:
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():# 用矢量图显示matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):use_svg_display()# 设置图的尺寸plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
#####读取数据集#####
def data_iter(batch_size, features, labels):num_examples = len(features)indices = list(range(num_examples))
# 样本的读取顺序是随机的random.shuffle(indices)for i in range(0, num_examples, batch_size):
# 最后一次可能不足一个batchj = torch.LongTensor(indices[i: min(i+batch_size,num_examples)])
# index_select函数根据索引返回对应元素yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10
#for X, y in data_iter(batch_size, features, labels):
# print(X, y)
# break
#####初始化模型参数#####
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)),dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
#####定义模型#####
def linreg(X, w, b):return torch.mm(X, w) + b
##### 定义损失函数#####
def squared_loss(y_hat, y):#return (y_hat - y.view(y_hat.size())) ** 2 / 2
#####定义优化算法#####
def sgd(params, lr, batch_size):for param in params:param.data -= lr * param.grad / batch_size
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
# 训练模型一共需要num_epochs个迭代周期
for epoch in range(num_epochs):# 在每一个迭代周期中,会使用训练集中所有样本一次(假设样本数能够被批量大小整除)。# X和y分别是小批量样本的特征和标签for X, y in data_iter(batch_size, features, labels):# l是有关小批量X和y的损失l = loss(net(X, w, b), y).sum()# 小批量损失对模型参数求梯度l.backward()# 使用小批量随机梯度下降迭代模型参数sgd([w, b], lr, batch_size)# 梯度清零w.grad.data.zero_()b.grad.data.zero_()train_l = loss(net(features, w, b), labels)print('epoch %d, loss %f' % (epoch+1, train_l.mean().item()))
print(true_b,true_w)
print(w,b)运行效果如下:

这里推算出b逼近为4.2,w1和w2逼近为2,-3.4,和生成数据集时设置的结果吻合!
相关文章:
动手学习深度学习V1.1 chapter2 (2.1-2.2)
chapter2:深度学习基础 区分问题:回归问题还是分类问题? 输出结果是不明确的连续值的时候就是回归问题,比如房价预测,销售额预测等。 输出结果是明确几个离散值的时候就是分类问题,比如字符识别…...
数据结构(6)线性表-队列
一、队列的概述 队列也是一种特殊的线性表,只允许在一段插入数据,另一端删除数据。插入操作的一端称为队尾,删除操作的一端称为队头。 如图: 二、队列相关操作 1.队列结构体的声明 类似于栈,他肯定也得借助于数组或…...

NumPy 2.x 完全指南【十七】转置操作
文章目录 1. 什么是转置2. 转置操作2.1 transpose2.2 ndarray.T2.3 moveaxis2.4 rollaxis2.5 permute_dims2.6 swapaxes2.7 matrix_transpose 1. 什么是转置 在线性代数中,矩阵转置是指将矩阵的行和列进行互换,即原矩阵的第 i i i 行、第 j j j 列元素…...

【数据架构04】数据湖架构篇
✅ 10张高质量数据治理架构图 无论你是数据架构师、治理专家,还是数字化转型负责人,这份资料库都能为你提供体系化参考,高效解决“架构设计难、流程不清、平台搭建慢”的痛点! 🌟限时推荐,速速收藏&#…...

使用OpenSSL生成根证书并自签署证书
生成根CA的私钥和证书 # 生成根 CA 的私钥 [rootdeveloper ssl]# openssl genrsa -out rootCA.key 2048 Generating RSA private key, 2048 bit long modulus (2 primes) ... ............................................................ e is 65537 (0x010001)# 使用私钥生…...
uniapp-商城-62-后台 商品列表(分类展示商品的布局)
每一个商品都有类别,比如水果,蔬菜,肉,粮油等等,另外每一个商品都有自己的属性,这些都在前面的章节进行了大量篇幅的介绍。这里我们终于完成了商品类的添加,商品的添加,现在到了该进…...

初识C++:模版
本篇博客主要讲解C模版的相关内容。 目录 1.泛型编程 2.函数模板 2.1 函数模版概念 2.2 函数模版格式 2.3 函数模版的原理 2.4 函数模版的实例化 1.隐式实例化:让编译器根据实参推演模板参数的实际类型 2. 显式实例化:在函数名后的<>中指定模…...

【Elasticsearch】给所索引创建多个别名
Elasticsearch 是可以给索引创建多个别名的。 为什么可以创建多个别名 1. 灵活性 - 别名可以为索引提供一个更易于理解的名称,方便用户根据不同的业务场景或用途来引用同一个索引。例如,一个索引可能同时服务于多个不同的应用程序或服务,通…...
任务调度)
Linux入门(九)任务调度
设置任务调度文件 /etc/crontab #设置调度任务 crontab -e #将任务设置到调度文件 # * * * * * # 第1个* 分钟 0-59 # 第2个* 小时 0-23 # 第3个* 天 1-31 # 第4个* 月 1-12 # 第5个* 周 0-7 0和7都代表的是星期天 #每分钟执行 */1 * * * * ls -l /etc/ > /tmp/to.txt0 8,…...
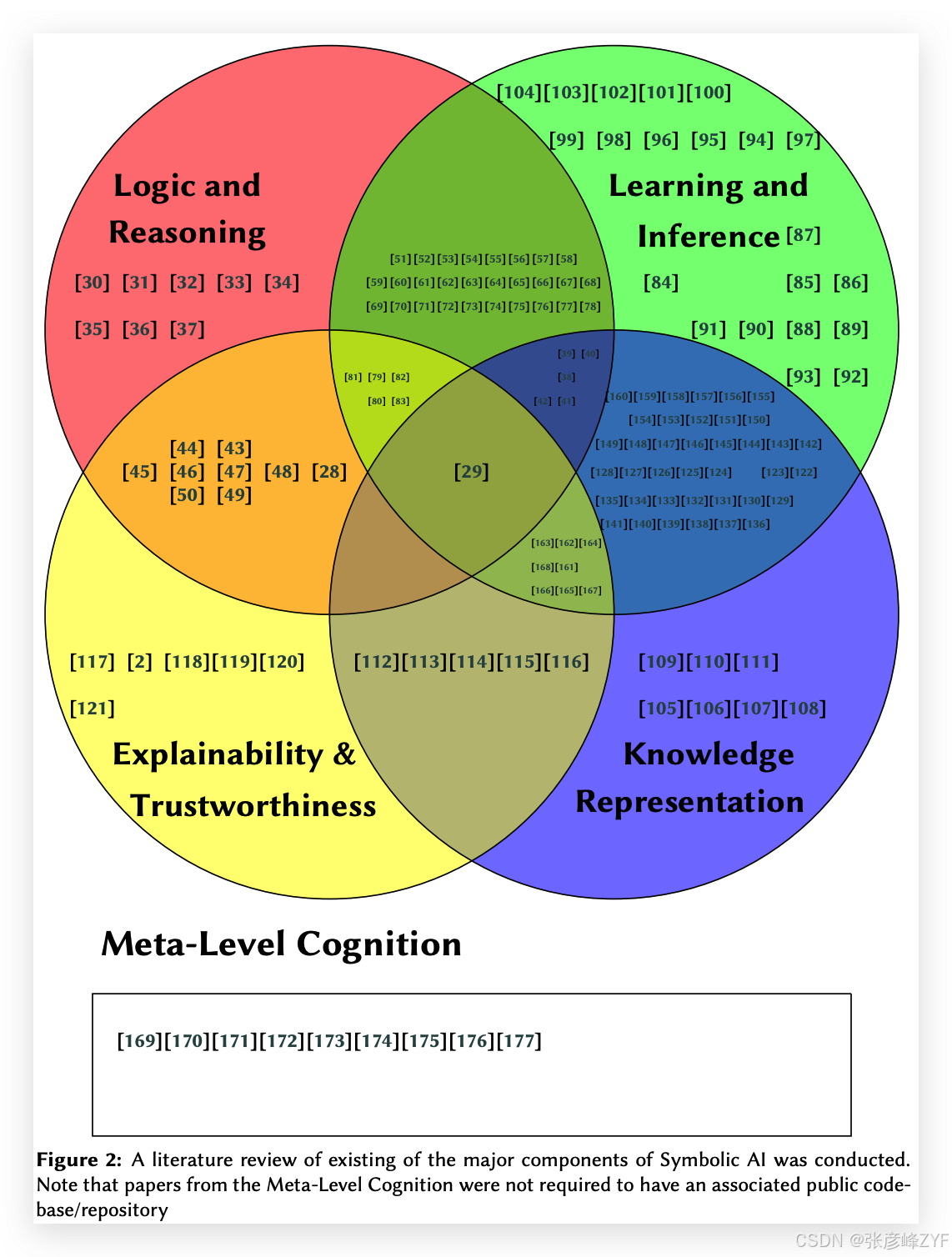
突破认知边界:神经符号AI的未来与元认知挑战
目录 一、神经符号AI的核心领域与研究方法 (一)知识表示:构建智能世界的语言 (二)学习与推理:让机器“思考”与“学习” (三)可解释性与可信度:让AI更透明 …...
Java 处理地理信息数据[DEM TIF文件数据获取高程]
目录 1、导入依赖包 2、读取方法 3、其他相关地理信息相关内容: 1️⃣常用的坐标系 1、GIS 中的坐标系一般分为两大类: 2. ✅常见的地理坐标系 2.0 CGCS2000(EPSG:4490) 2.1 WGS84 (World Geodetic System 1984) (EPSG…...

谈谈对dubbo的广播机制的理解
目录 1、介绍 1.1、广播调用 1、工作原理 1.2、调用方式 1、Reference 注解 2、XML 配置 3、全局配置 1.3、 广播机制的特性 2、重试机制 2.1、默认行为 2.2、自定义逻辑 1、在业务层封装重试逻辑 2、使用 Reference 3、广播调用的实践 3.1、常用参数 1.…...

对接钉钉消息样例:DING消息、机器人
一、钉钉开放平台配置信息 private static String robotCode private static String appkey private static String appsecret private static Long agentId 二、钉钉开放平台token、用户信息 public static Client createClient() throws Exception {Config config n…...

003-类和对象(二)
类和对象(二) 1. 类的6个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数ÿ…...

使用Rancher在CentOS 环境上部署和管理多Kubernetes集群
引言 随着容器技术的迅猛发展,Kubernetes已成为容器编排领域的事实标准。然而,随着企业应用规模的扩大,多集群管理逐渐成为企业IT架构中的重要需求。 Rancher作为一个开源的企业级多集群Kubernetes管理平台,以其友好的用户界面和…...

Java常用数据结构底层实现原理及应用场景
一、线性结构 1. ArrayList 底层实现:动态数组(Object[] elementData)。 核心特性: 默认初始容量为 10,扩容时容量增长为原来的 1.5 倍(int newCapacity oldCapacity (oldCapacity >> 1)…...

利用朴素贝叶斯对UCI 的 mushroom 数据集进行分类
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单而有效的分类算法,特别适合处理文本分类和多类别分类问题。UCI的Mushroom数据集是一个经典的分类数据集,包含蘑菇的特征和类别(可食用或有毒)。 1. 数据…...
Linux火墙管理及优化
网络环境配置 使用3个新的虚拟机【配置好软件仓库和网络的】 F1 192.168.150.133 NAT F2 192.168.150.134 192.168.10.20 NAT HOST-ONLY 网络适配仅主机 F3 192.168.10.30 HOST-ONLY 网络适配仅主机 1 ~]# hostnamectl hostname double1.timinglee.org 【更…...
Visual Studio 制作msi文件环境搭建
一、插件安装 a. 插件寻找 在 Visual Studio 2017 中,如果你希望安装用于创建 MSI 安装包的插件,第一步是:打开 Visual Studio 后,点击顶部菜单栏中的 “工具”(Tools),然后选择下拉菜单中的 “…...
Java中常见的几种设计模式详解)
(Java基础笔记vlog)Java中常见的几种设计模式详解
前言: 在 Java 编程里,设计模式是被反复使用、多数人知晓、经过分类编目的代码设计经验总结。他能帮助开发者更高效地解决常见问题,提升代码的可维护性、可扩展性和复用性。下面介绍Java 中几种常见的设计模式。 单例模式(Singlet…...

C++ vector 深度解析:从原理到实战的全方位指南
一、引言 在 C 编程中,我们经常需要处理一组数据。比如,你想存储一个班级所有学生的成绩,或者保存用户输入的一组数字。最容易想到的方法是使用数组: int scores[100]; // 定义一个能存储100个成绩的数组但数组有两个明显的缺点…...

鸿蒙进阶——Framework之Want 隐式匹配机制概述
文章大纲 引言一、Want概述二、Want的类型1、显式Want2、隐式Want3、隐式Want的匹配 三、隐式启动Want 源码概述1、有且仅有一个Ability匹配2、有多个Ability 匹配需要弹出选择对话框3、ImplicitStartProcessor::ImplicitStartAbility3.1、GenerateAbilityRequestByAction3.1.1…...

antv/g6 图谱封装配置(二)
继上次实现图谱后,后续发现如果要继续加入不同样式的图谱实现起来太过麻烦,因此考虑将配置项全部提取封装到js文件中,图谱组件只专注于实现各种不同的组件,其中主要封装的点就是各个节点的横坐标(x),纵坐标…...
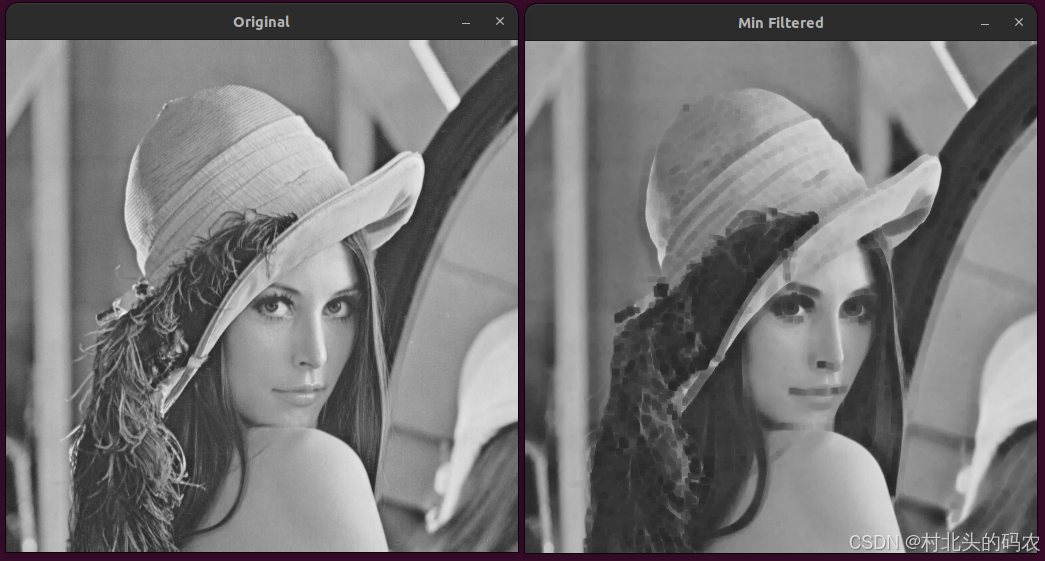
OpenCV CUDA模块图像过滤------用于创建一个最小值盒式滤波器(Minimum Box Filter)函数createBoxMinFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数创建的是一个 最小值滤波器(Minimum Filter),它对图像中每个像素邻域内的像素值取最小值。常用于&…...
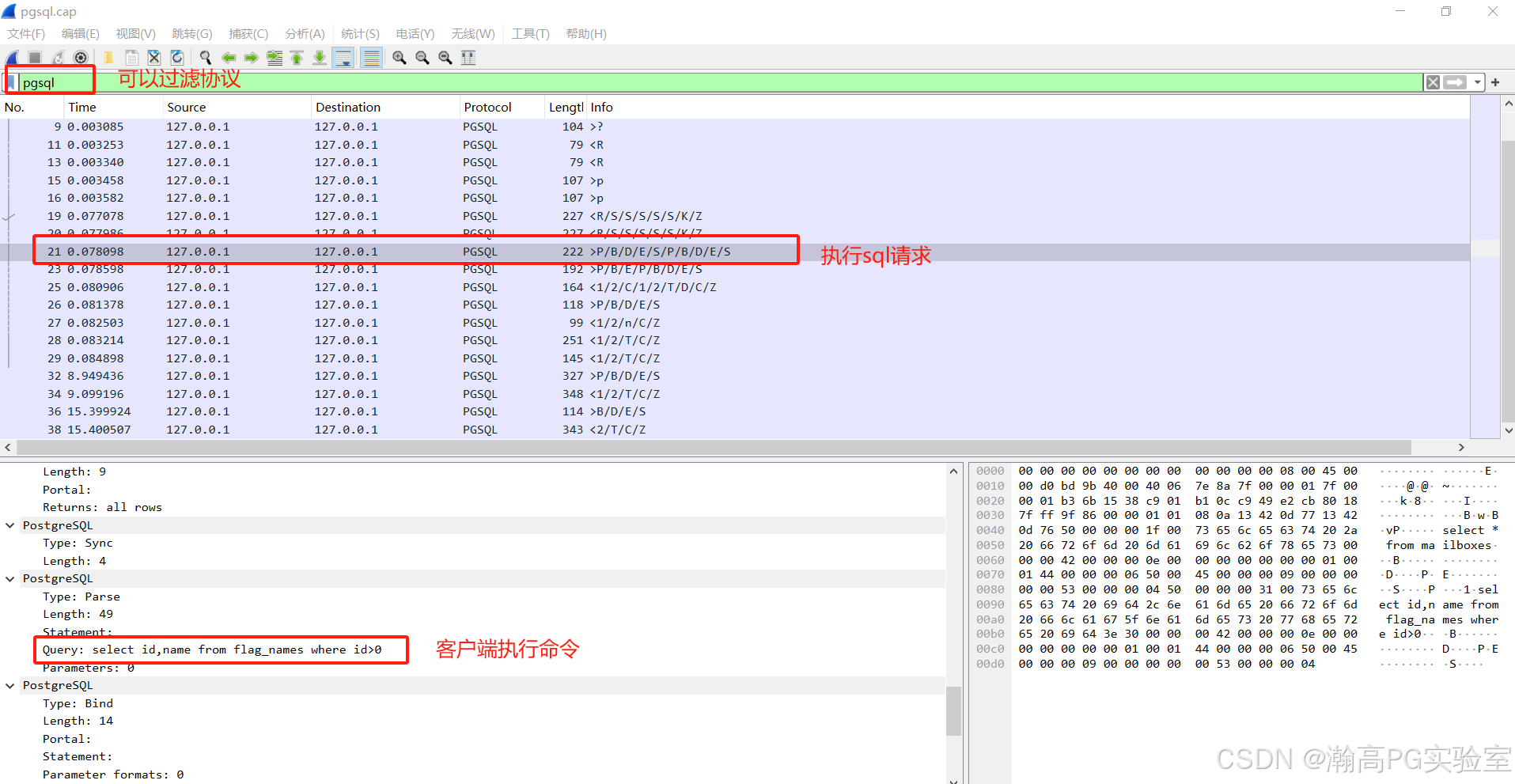
网络抓包命令tcpdump及分析工具wireshark使用
文章目录 环境文档用途详细信息 环境 系统平台:Linux x86-64 Red Hat Enterprise Linux 8,Linux x86-64 Red Hat Enterprise Linux 7,Linux x86-64 SLES 12,银河麒麟 (鲲鹏),银河麒麟 (X86_64),银河麒麟(龙…...

linux strace调式定位系统问题
strace 的基本功能 strace 的主要功能包括: 跟踪系统调用:显示进程执行时调用的系统函数及其参数和返回值。监控信号:记录进程接收到的信号。性能分析:统计系统调用的执行时间和次数。调试支持:帮助定位程序崩溃、性…...

femap许可与云计算集成
随着云计算技术的迅猛发展,越来越多的企业开始将关键应用和服务迁移到云端,以享受其带来的弹性扩展、高效管理和成本优化等优势。Femap作为一款强大的电磁仿真工具,通过与云计算的集成,将为企业带来前所未有的许可管理和仿真分析体…...

车载诊断架构 --- 车载诊断有那些内容(上)
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...
【Hadoop】大数据技术之 HDFS
目录 一、HDFS 概述 1.1 HDFS 产出背景及定义 1.2 HDFS 优缺点 1.3 HDFS 组成架构 1.4 HDFS 文件块大小 二、HDFS 的Shell 操作 三、HDFS 的读写流程(面试重点) 3.1 HDFS 写数据流程 3.2 HDFS 读数据流程 四、DataNode 4.1 DataNode 的工作机制…...

聊一下CSS中的标准流,浮动流,文本流,文档流
在网络上关于CSS的文章中,有时候能听到“标准流”,“浮动流”,“定位流”等等词语,还有像“文档流”,“文本流”等词,这些流是什么意思?它们是CSS中的一些布局方案和特性。今天我们就来聊一下CS…...