CUDA的设备,流处理器(Streams),核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
- CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
- 前言
- 一、介绍CUDA编程的并行原理,了解线程、线程块、网格等概念,了解CUDA的同步机制
- blockSize(线程块尺寸)
- gridSize(网格尺寸)
- 二、CUDA流的应用:CUDASTREAM,CUDA流的使用、同步,用CUDA流完成矩阵运算
- 1 流Streams在GPU上按顺序的操作
- 2 多GPU 编码
- 总结
前言
SIMT和SIMD
CUDA执行的是SIMT架构(单指令多线程架构),SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。
一、介绍CUDA编程的并行原理,了解线程、线程块、网格等概念,了解CUDA的同步机制
基于硬件的支持,通过cuda来实现对底层GPU的调用,关于这部分内容,首先需要熟悉一些关键名词。
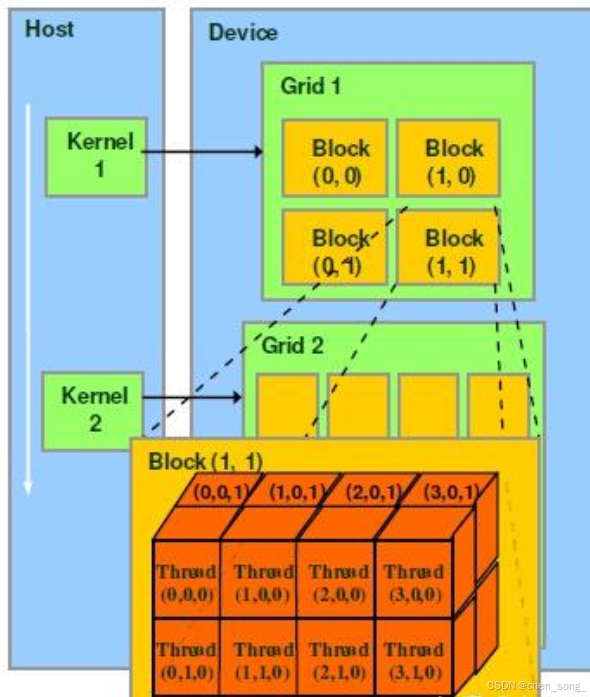
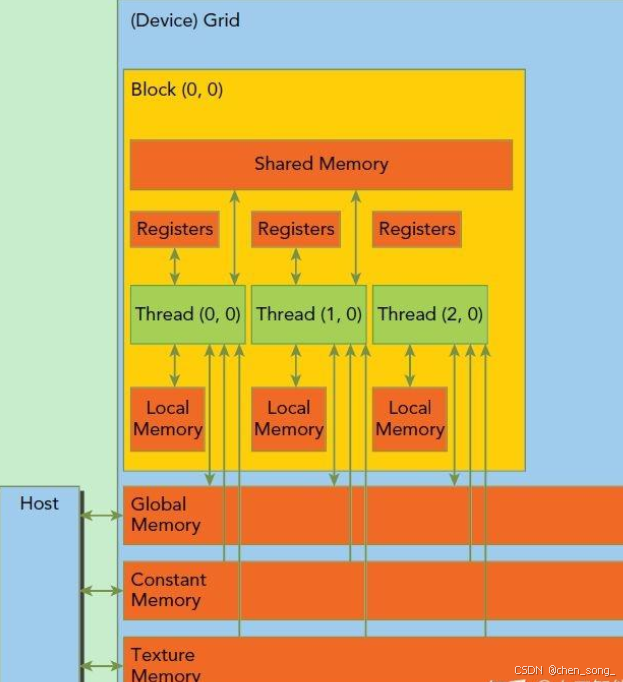
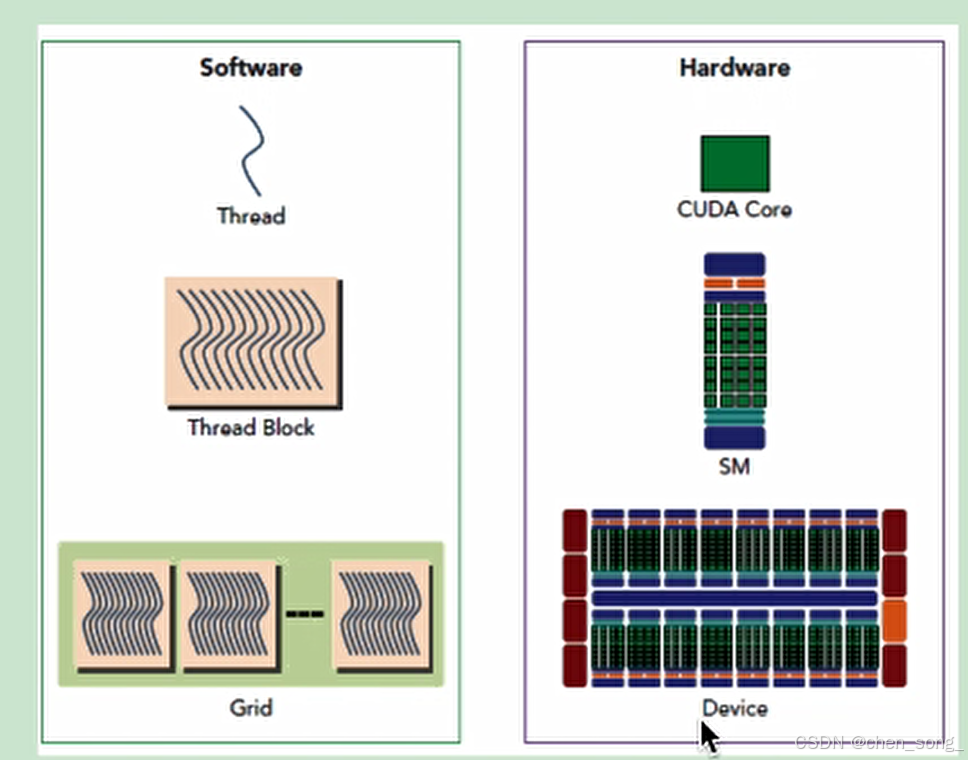
thread:一个CUDA的并行程序会被以许多个thread来执行,每个thread都有自己的register 和 local memory 的空间。
block:数个thread会组成一个block,同一个block中的thread可以同步运行,他们通过shared memory来进行通信。
grid:多个block则会再构成grid,每个grid会有自己的global memory、constant memory 和 texture memory。
warp:warp是SM的基本执行单元,一个block里面的线程,通过warp进行调用,使用SIMT模式。如A100机器,每个warp可以执行32个thread。
....
// 2D int thread = 16;int grid = (numRows()*numCols() + thread - 1)/ (thread * thread);const dim3 blockSize(thread, thread);const dim3 gridSize(grid);rgba_to_greyscale<<<gridSize, blockSize>>>(d_rgbaImage, d_greyImage, numRows(), numCols());
.....
blockSize(线程块尺寸)
类型为dim3,表示每个线程块包含的线程数量13
在示例中dim3 blockSize(thread, thread)创建了二维线程块,每块包含thread×thread个线程5
每个线程块最大线程数限制为102457
同一线程块内的线程可通过共享内存通信
gridSize(网格尺寸)
类型为dim3,表示网格中包含的线程块数量
在示例中dim3 gridSize(grid)创建了一维网格,包含grid个线程块3
最大网格维度为65535(x/y/z方向)
执行配置<<<gridSize, blockSize>>>
该语法指定核函数启动时的并行执行结构35
总线程数 = gridSize.x * gridSize.y * gridSize.z * blockSize.x * blockSize.y * blockSize.z13
二、CUDA流的应用:CUDASTREAM,CUDA流的使用、同步,用CUDA流完成矩阵运算
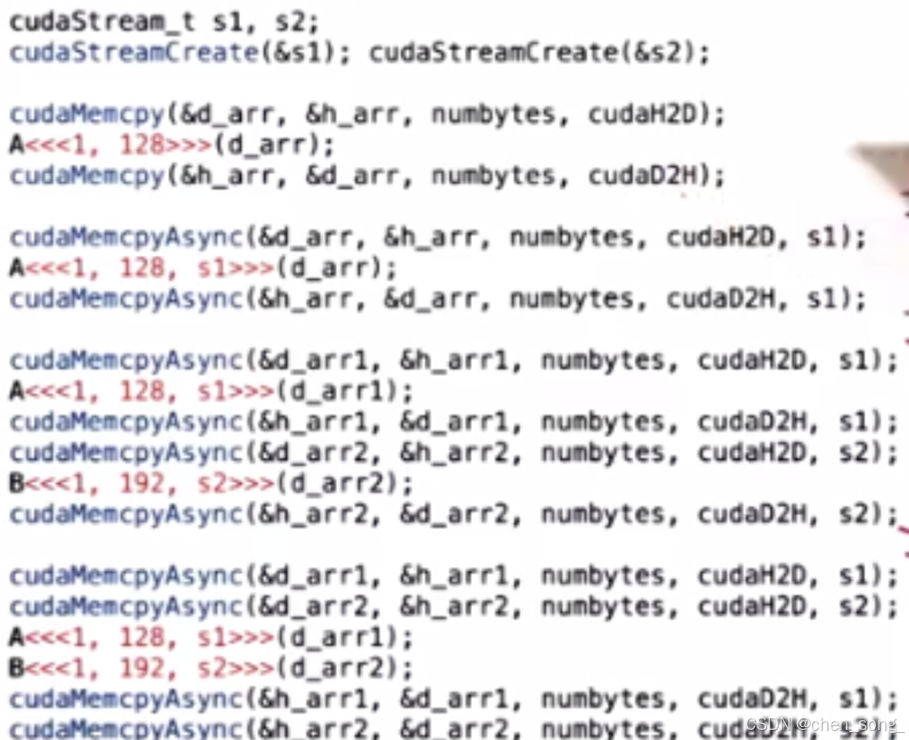
1 流Streams在GPU上按顺序的操作
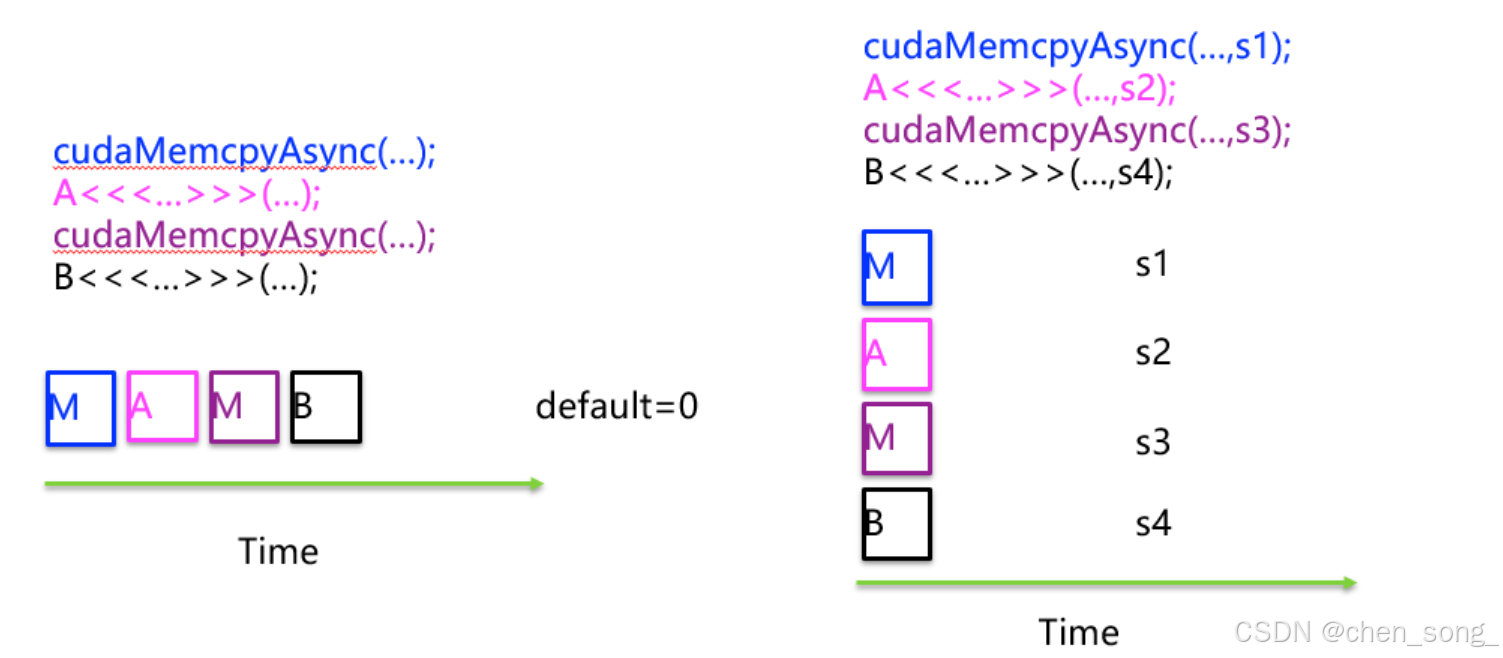
- 定义流
- 创建流
- 使用流
- 销毁流
//1. 定义流 cudaStream_t s1;//2. 创建流cudaStreamCreate(&s1);//3. 使用流cudaMemcpyAsync(...., s1);//4. 销毁流cudaStreamDestroy(s1);
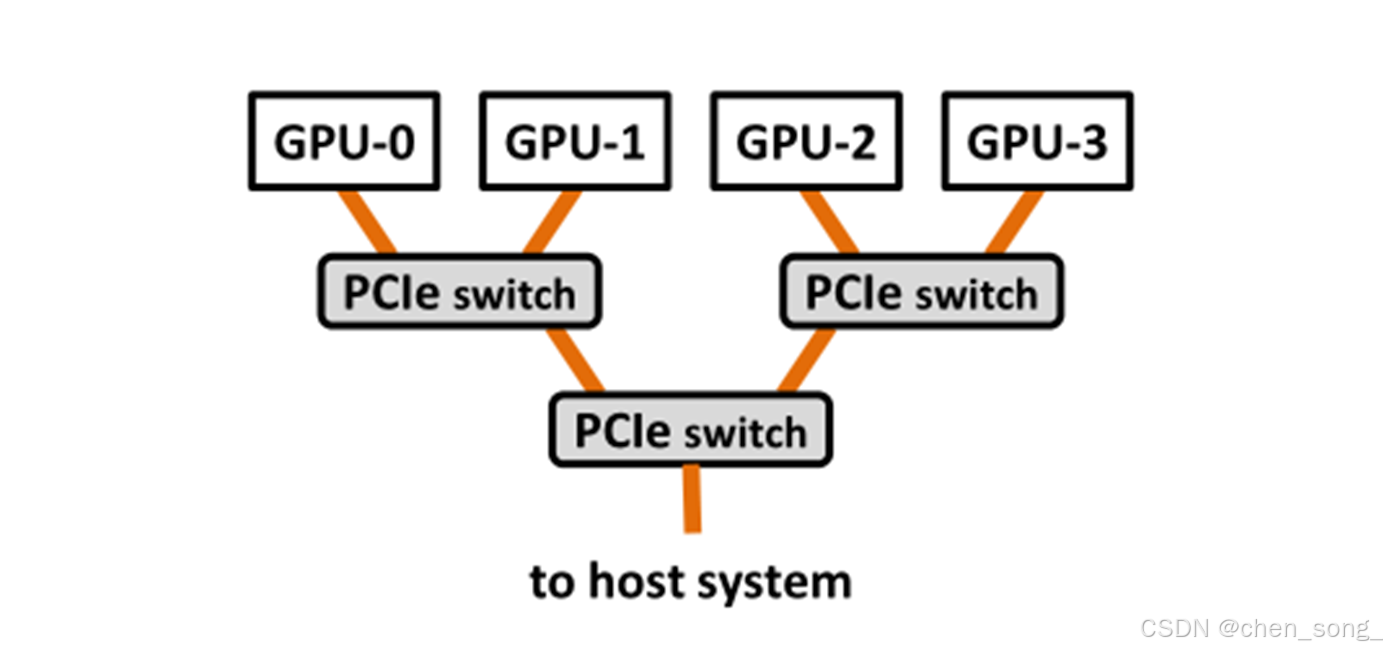
2 多GPU 编码
- 两个GPU之间数据访问是通过PCIe

int gpu1 = 0;int gpu2 = 1;void* d_A = NULL;//1. 设置当前使用gpu索引idcudaSetDevice(gpu1);cudaMalloc(&d_A, 1024);int accessible = 0;cudaDeviceCanAccessPeer(&accessible, gpu1, gpu2);if (accessible){cudaSetDevice(gpu2);//设置gpu2 可以访问gpu1的内存地址cudaDeviceEnablePeerAccess(gpu1, 0);// kernel<<<x, y, z>>>核心函数}- 两个GPU设备之间的数据拷贝函数 字节
cudaMemcpyPeerAsync(void* dst, int dstDevice, const void* src, int srcDevice, size_t count, cudaStream_t stream );
- 如果两个设备允许字节在最短的PCIe路径PCIe路径上传输
- 如果两个设备不允许CUDA驱动通过CPU驱动通过CPU memory传输
CUDA Device Query (Runtime API) version (CUDART static linking)Detected 1 CUDA Capable device(s)Device 0: "NVIDIA GeForce MX150"CUDA Driver Version / Runtime Version 12.9 / 12.9CUDA Capability Major/Minor version number: 6.1Total amount of global memory: 2048 MBytes (2147352576 bytes)
MapSMtoCores for SM 6.1 is undefined. Default to use 192 Cores/SM
MapSMtoCores for SM 6.1 is undefined. Default to use 192 Cores/SM( 3) Multiprocessors x (192) CUDA Cores/MP: 576 CUDA CoresGPU Clock rate: 1532 MHz (1.53 GHz)Memory Clock rate: 3004 MhzMemory Bus Width: 64-bitL2 Cache Size: 524288 bytesMax Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384)Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048Total amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Maximum sizes of each dimension of a block: 1024 x 1024 x 64Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 5 copy engine(s)Run time limit on kernels: YesIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: DisabledDevice supports Unified Addressing (UVA): YesDevice PCI Bus ID / PCI location ID: 2 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.9, CUDA Runtime Version = 12.9, NumDevs = 1, Device0 = NVIDIA GeForce MX150总结
CUDA项目源码地址:https://github.com/chensongpoixs/ccuda
相关文章:
CUDA的设备,流处理器(Streams),核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念 CUDA的设备,流处理器,核&…...

PyTorch的dataloader制作自定义数据集
PyTorch的dataloader是用于读取训练数据的工具,它可以自动将数据分割成小batch,并在训练过程中进行数据预处理。以下是制作PyTorch的dataloader的简单步骤: 导入必要的库 import torch from torch.utils.data import DataLoader, Dataset定…...
LeetCode 1340. 跳跃游戏 V(困难)
题目描述 给你一个整数数组 arr 和一个整数 d 。每一步你可以从下标 i 跳到: i x ,其中 i x < arr.length 且 0 < x < d 。i - x ,其中 i - x > 0 且 0 < x < d 。 除此以外,你从下标 i 跳到下标 j 需要满…...
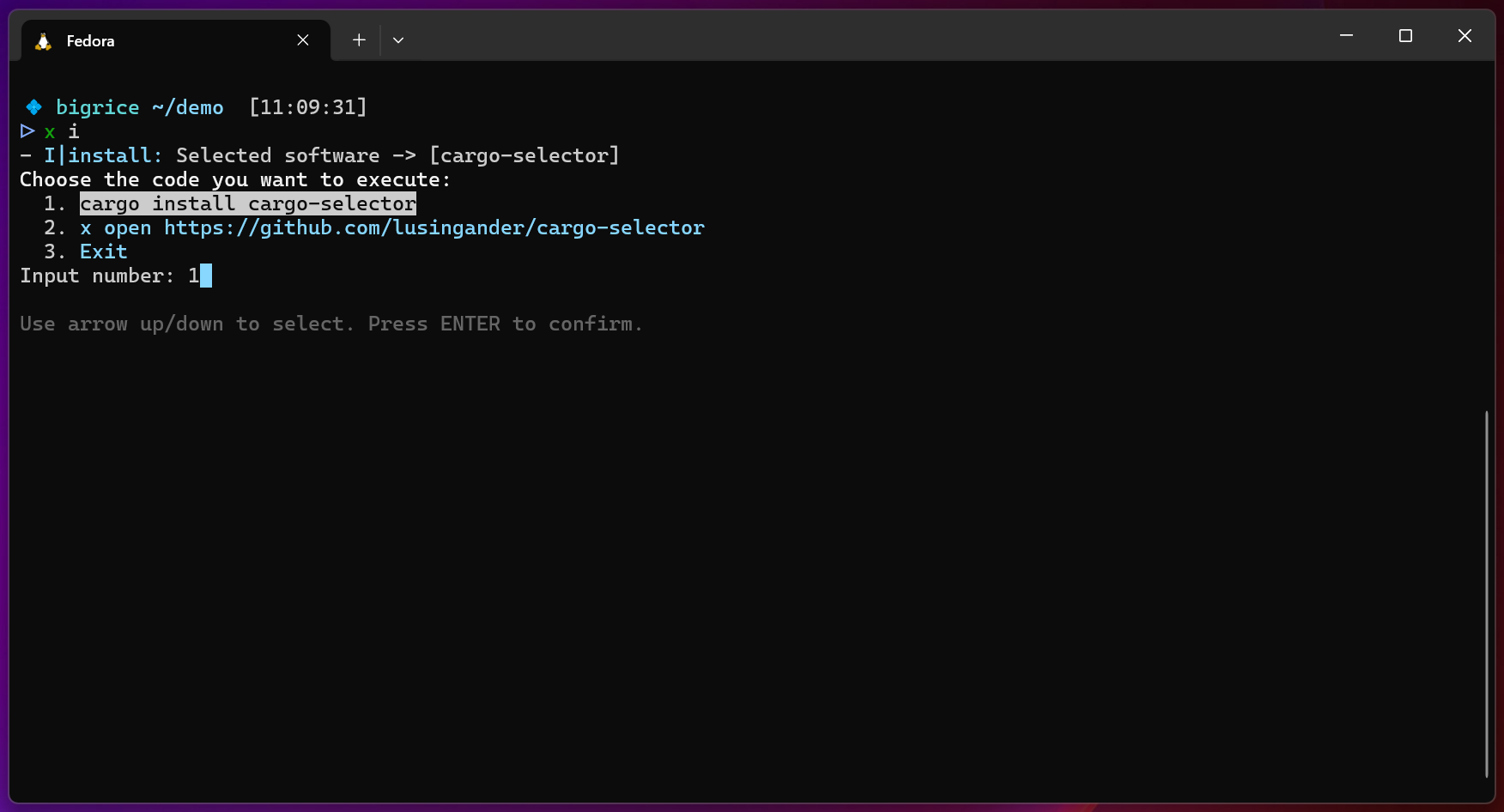
x-cmd install | cargo-selector:优雅管理 Rust 项目二进制与示例,开发体验升级
目录 功能亮点安装优势特点适用场景总结 还在为 Rust 项目中众多的二进制文件和示例而烦恼吗?cargo-selector 让你告别繁琐的命令行,轻松选择并运行目标程序! 功能亮点 交互式选择: 在终端中以交互方式浏览你的二进制文件和示例&…...

数据库设计文档撰写攻略
数据库设计文档撰写攻略 一、数据库设计文档的核心价值二、数据库设计文档的核心框架与内容详解2.1 文档基础信息2.2 需求分析与设计原则2.2.1 业务需求概述2.2.2 设计原则 2.3 数据模型设计2.3.1 概念模型(ER 图)2.3.2 逻辑模型(表结构设计&…...
Python数据存储实战:基于pymongo的MongoDB开发深度指南)
Python爬虫(10)Python数据存储实战:基于pymongo的MongoDB开发深度指南
目录 一、为什么需要文档型数据库?1.1 数据存储的范式变革1.2 pymongo的核心优势 二、pymongo核心操作全解析2.1 环境准备2.2 数据库连接与CRUD操作2.3 聚合管道实战2.4 分批次插入百万级数据(进阶)2.5 分批次插入百万级数据(进阶…...

大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战
大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 大模型「瘦身」指南:从LLaMA到MobileBERT的轻量化部署实战摘要引言一、轻量化技术…...

从逻辑视角学习信息论:概念框架与实践指南
文章目录 一、信息论的逻辑基础与哲学内涵1.1 信息的逻辑本质:区分与差异1.2 逆范围原理与信息内容 二、信息论与逻辑学的概念交汇2.1 熵作为逻辑不确定性的度量2.2 互信息与逻辑依赖2.3 信道容量的逻辑极限 三、信息论的核心原理与逻辑基础3.1 最大熵原理的逻辑正当…...

springboot配置mysql druid连接池,以及连接池参数解释
文章目录 前置配置方式参数解释 前置 springboot 项目javamysqldruid 连接池 配置方式 在 springboot 的 application.yml 中配置基本方式 # Druid 配置(Spring Boot YAML 格式) spring:datasource:url: jdbc:mysql://localhost:3306/testdb?useSSL…...

Spring Boot集成Resilience4j实现微服务容错机制
在Spring Boot中集成Resilience4j实现微服务容错 引言 在微服务架构中,服务之间的调用不可避免,但由于网络延迟、服务不可用等问题,调用失败的情况时有发生。为了提高系统的稳定性和可用性,我们需要引入容错机制。Resilience4j是…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

TDengine 运维—容量规划
概述 若计划使用 TDengine 搭建一个时序数据平台,须提前对计算资源、存储资源和网络资源进行详细规划,以确保满足业务场景的需求。通常 TDengine 会运行多个进程,包括 taosd、taosadapter、taoskeeper、taos-explorer 和 taosx。 在这些进程…...

【MySQL成神之路】MySQL索引相关介绍
1 相关理论介绍 一、索引基础概念 二、索引类型 1. 按数据结构分类 2. 按功能分类 三、索引数据结构原理 B树索引特点: 哈希索引特点: 四、索引使用原则 1. 创建索引原则 2. 避免索引失效情况 五、索引优化策略 六、索引维护与管理 七、特殊…...

PPP 拨号失败:ATD*99***1# ... failed
从日志来看,主要有两类问题: 一、led_indicator_stop 报 invalid p_handle E (5750) led_indicator: …/led_indicator.c:461 (led_indicator_stop):invalid p_handle原因分析 led_indicator_stop() 的参数 p_handle (即之前 led_indicator…...

PostgreSQL跨数据库表字段值复制实战经验分
场景需求 在实际工作中,我们经常需要将一个PostgreSQL数据库中的表字段值复制到另一个数据库中。最近我在处理两个ERP系统数据库(A库和B库)之间的数据同步时,就遇到了这样的需求:需要将B库中sale_order表的合同信息&a…...
【计网】五六章习题测试
目录 1. (单选题, 3 分)某个网络所分配到的地址块为172.16.0.0/29,能接收目的地址为172.16.0.7的IP分组的最大主机数是( )。 2. (单选题, 3 分)若将某个“/19”的CIDR地址块划分为7个子块,则可能的最小子块中的可分配IP地址数量…...
汇川EasyPLC MODBUS-RTU通信配置和编程实现
累积流量计算(MODBUS RTU通信数据处理)数据处理相关内容。 累积流量计算(MODBUS RTU通信数据处理)_流量积算仪modbus rtu通讯-CSDN博客文章浏览阅读219次。1、常用通信数据处理MODBUS通信系列之数据处理_modbus模拟的数据变化后会在原来的基础上累加是为什么-CSDN博客MODBUS通…...

从 CANopen到 PROFINET:网关助力物流中心实现复杂的自动化升级
使用 CANopen PLC 扩展改造物流中心的传送带 倍讯科技profinet转CANopen网关BX-601-EIP将新的 PROFINET PLC 系统与旧的基于 CANopen 的传送带连接起来,简化了物流中心的自动化升级。 新建还是升级?这些问题通常出现在复杂的内部物流设施中,…...
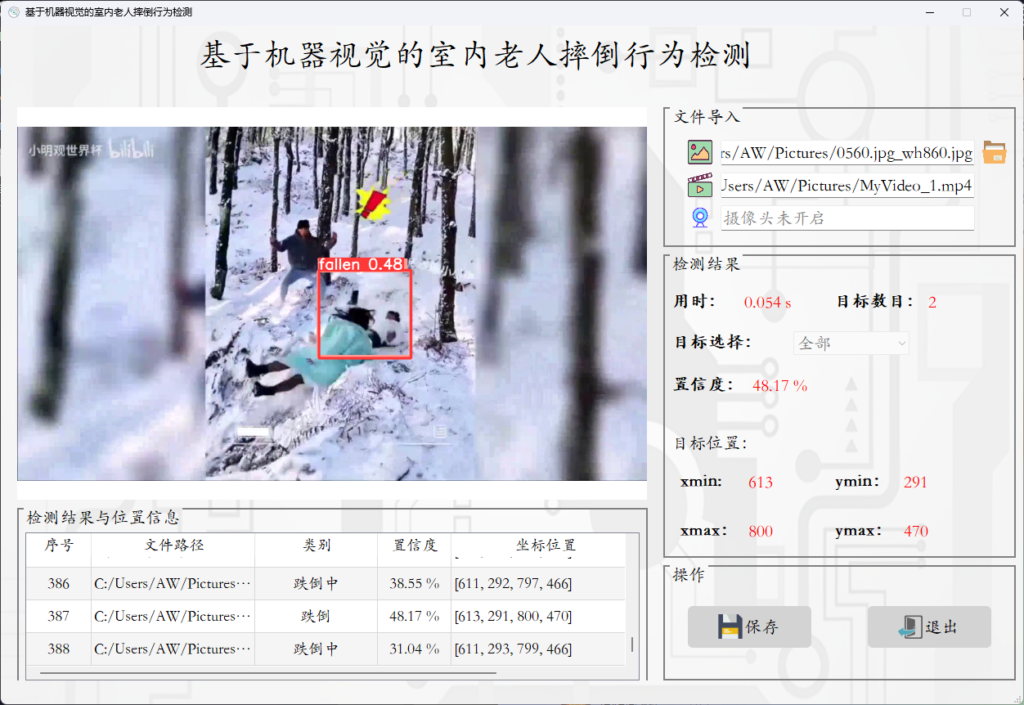
基于Yolov8+PyQT的老人摔倒识别系统源码
概述 基于Yolov8PyQT的老人摔倒识别系统,该系统通过深度学习算法实时检测人体姿态,精准识别站立、摔倒中等3种状态,为家庭或养老机构提供及时预警功能。 主要内容 完整可运行代码 项目采用Yolov8目标检测框架结合PyQT5开发…...
wsl2 不能联网
wsl2 安装后用 wifi 共享是能联网,问题出在公司网络限制 wsl2 IP 访问网络,但是主机可以上网。 解决办法,在主机用 nginx 设置代理,可能需要开端口权限 server {listen 9000;server_name localhost;location /ubuntu/ {#…...

双击重复请求的方法
1、限制点击次数 2、vue中 可以自定义一个属性指令 preventReClick.js中定义: import Vue from vue Vue.directive(preventReClick, {inserted: (el, binding) > {el.addEventListener(click, () > {if (!el.disabled) {el.disabled truesetTimeout(() >…...
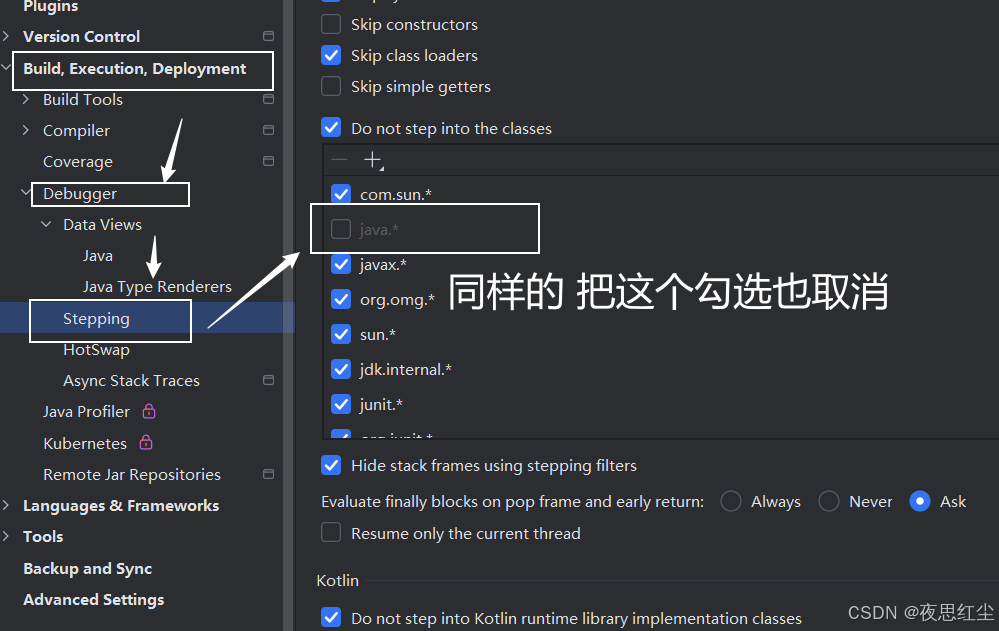
Java[IDEA]里的debug
目录 前言 Debug 使用Debug 总结 前言 这里我说一下就是 java IDEA 工具里的debug工具 里的一个小问题 就是 当我们使用debug去查看内部文档 查看不到 是为什么 Debug 所谓 debug 工具 他就是用来调试程序的 当我们写代码 报错 出错时 我们就可以使用这个工具 因此这个工具…...

一条SQL语句的旅程:解析、优化与执行全过程研究
1、引言 在现代信息系统中,数据库是核心组件之一。SQL(结构化查询语言)作为与数据库交互的主要方式,其执行效率直接影响到整个系统的性能表现。虽然开发者常常只需编写一行简单的 SQL,但数据库内部却经历了一个复杂而精密的过程来完成这条 SQL 的处理。 本文将以一个完整…...

动态规划经典三题_完全平方数
279. 完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而…...
)
LVGL(lv_textarea文本框控件)
文章目录 一、lv_textarea 是什么?二、基本用法1. 创建 lv_textarea 对象2. 设置提示文字(占位符)3. 设置最大长度4. 设置密码模式(显示为\*号)5. 获取和设置内容6. 配合虚拟键盘使用(常用于触摸屏…...

蓝桥杯国14 互质
问题描述 请计算在 [1,2023的2023次幂] 范围内有多少个整数与 2023 互质。由于结果可能很大,你只需要输出对 1097 取模之后的结果。 答案提交 这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个…...

DAO模式
1. 持久化 简单来说,就是把代码的处理结果转换成需要的格式进行储存。 2. JDBC的封装 3. DAO模式 4. Properties类与Properties配置文件 添加 读取 5. 使用实体类传递数据 6. 总结 附录: BaseDao指南 BaseDao指南-CSDN博客...
ECharts图表工厂,完整代码+思路逻辑
Echart工厂支持柱状图(bar)折线图(line)散点图(scatter)饼图(pie)雷达图(radar)极坐标柱状图(polarBar)和极坐标折线图(po…...

Logback 在 Spring Boot 中的详细配置
1. Logback 配置文件 Spring Boot 默认会加载 classpath 下的 logback-spring.xml(推荐)或 logback.xml 作为 Logback 的配置文件。 推荐使用 logback-spring.xml,因为 Spring Boot 提供了扩展支持(例如基于 Profile 的配置&am…...

写起来比较复杂的深搜题目
年轻的拉尔夫开玩笑地从一个小镇上偷走了一辆车,但他没想到的是那辆车属于警察局,并且车上装有用于发射车子移动路线的装置。 那个装置太旧了,以至于只能发射关于那辆车的移动路线的方向信息。 编写程序,通过使用一张小镇的地图…...