旅游信息检索
旅游信息检索
旅游信息检索是系统中实现数据获取和处理的关键环节,负责根据用户输入的目的地城市和出游天数,动态获取并生成高质量的旅游数据。
模块的工作流程分为以下几个阶段:首先,对用户输入的信息进行标准化处理,将城市名称和时间信息改写为适合搜索引擎的查询模板(query)。随后,系统调用 Google Search API 进行景点和美食信息的文本检索,包括景点描述、距离、推荐美食等详细内容;同时,为了补充图片资源,模块还调用 DuckDuckGo 搜索引擎,专注于获取高质量的景点和美食图片链接。
在数据检索完成后,模块进一步利用大语言模型(LLM)对初步搜索结果进行智能解析与重排序(rerank),从相关性和用户需求角度优化数据质量,确保信息全面、准确、优先级清晰。经过优化后的数据会以结构化的形式存储到数据库中,包含每个景点和美食的名称、详细描述、推荐理由以及图片 URL。
from camel.toolkits import SearchToolkit
from camel.agents import ChatAgent
from camel.models import ModelFactory
from camel.types import ModelPlatformType
from camel.loaders import Firecrawl
from typing import List, Dict, Anyfrom flask import Flask, request, jsonify
import json
import os
from dotenv import load_dotenvload_dotenv()os.environ["GOOGLE_API_KEY"] = os.getenv("GOOGLE_API_KEY")
os.environ["SEARCH_ENGINE_ID"] = os.getenv("SEARCH_ENGINE_ID")
os.environ["FIRECRAWL_API_KEY"] = os.getenv("FIRECRAWL_API_KEY")
os.environ["QWEN_API_KEY"] = os.getenv("QWEN_API_KEY")app = Flask(__name__)class TravelPlanner:def __init__(self, city: str, days: int):#定义地点和时间,设置默认值self.city = cityself.days = daysself.res = None # 初始化模型和智能体self.model = ModelFactory.create(model_platform=ModelPlatformType.OPENAI_COMPATIBLE_MODEL,model_type="Qwen/Qwen2.5-72B-Instruct",url='https://api-inference.modelscope.cn/v1/',api_key=os.getenv('QWEN_API_KEY'))# 初始化各种工具#重排序模型self.reranker_agent = ChatAgent(system_message="你是一搜索质量打分专家,要从{搜索结果}里找出和{query}里最相关的2条结果,保存他们的结果,保留result_id、title、description、url,严格以json格式输出",model=self.model,output_language='中文')#景点抓取agentself.attraction_agent = ChatAgent(system_message="你是一个旅游信息提取专家,要根据内容提取出景点信息并返回json格式,严格以json格式输出",model=self.model,output_language='中文')#美食抓取agentself.food_agent = ChatAgent(system_message="你是一个旅游信息提取专家,要根据内容提取出美食信息并返回json格式,严格以json格式输出",model=self.model,output_language='中文')#base攻略生成agentself.base_guide_agent = ChatAgent(system_message="你是一个旅游攻略生成专家,要根据内容生成一个旅游攻略,严格以json格式输出",model=self.model,output_language='中文')# self.firecrawl = Firecrawl()#后续功能self.search_toolkit = SearchToolkit()def extract_json_from_response(self,response_content: str) -> List[Dict[str, Any]]:"""从LLM响应中提取JSON内容"""try:# 找到JSON内容的开始和结束位置start = response_content.find('```json\n') + 8end = response_content.find('\n```', start)if start == -1 or end == -1:print("未找到JSON内容的标记")return []json_str = response_content[start:end].strip()print(f"提取的JSON字符串: {json_str}") # 调试信息# 解析 JSON 字符串parsed = json.loads(json_str)# 处理不同的JSON结构if isinstance(parsed, dict) and "related_results" in parsed:return parsed["related_results"]elif isinstance(parsed, list):return parsedelse:print("未找到预期的JSON结构")return []except json.JSONDecodeError as e:print(f"解析JSON失败: {str(e)}")print(f"原始内容: {response_content}")return []except Exception as e:print(f"发生错误: {str(e)}")return []def search_and_rerank(self) -> Dict[str, Any]:"""多次搜索并重排序,整合信息"""city = self.citydays = self.daysall_results = {}# 第一次搜索:旅游攻略try:query = f"{city}{days}天旅游攻略 最佳路线"search_results = self.search_toolkit.search_google(query=query, num_result_pages=5)prompt = f"请从以下搜索结果中筛选出最相关的{self.days}条{city}{days}天旅游攻略信息,并按照相关性排序:\n{json.dumps(search_results, ensure_ascii=False, indent=2)}"response = self.reranker_agent.step(prompt)all_results["guides"] = self.extract_json_from_response(response.msgs[0].content)except Exception as e:print(f"旅游攻略搜索失败: {str(e)}")all_results["guides"] = []# 第二次搜索:必去景点try:query = f"{city} 必去景点 top10 著名景点"search_results = self.search_toolkit.search_google(query=query, num_result_pages=5)prompt = f"请从以下搜索结果中筛选出最多{self.days}条{city}最值得去的景点信息,并按照热门程度排序:\n{json.dumps(search_results, ensure_ascii=False, indent=2)}"response = self.reranker_agent.step(prompt)all_results["attractions"] = self.extract_json_from_response(response.msgs[0].content)except Exception as e:print(f"景点搜索失败: {str(e)}")all_results["attractions"] = []# 第三次搜索:必吃美食try:query = f"{city} 必吃美食 特色小吃 推荐"search_results = self.search_toolkit.search_google(query=query, num_result_pages=5)prompt = f"请从以下搜索结果中筛选出最多{self.days}条{city}最具特色的美食信息,并按照推荐度排序:\n{json.dumps(search_results, ensure_ascii=False, indent=2)}"response = self.reranker_agent.step(prompt)all_results["must_eat"] = self.extract_json_from_response(response.msgs[0].content)except Exception as e:print(f"必吃美食搜索失败: {str(e)}")all_results["must_eat"] = []# 第四次搜索:特色美食try:query = f"{city} 特色美食 地方小吃 传统美食"search_results = self.search_toolkit.search_google(query=query, num_result_pages=5)prompt = f"请从以下搜索结果中筛选出最多{self.days}条{city}独特的地方特色美食信息,并按照特色程度排序:\n{json.dumps(search_results, ensure_ascii=False, indent=2)}"response = self.reranker_agent.step(prompt)all_results["local_food"] = self.extract_json_from_response(response.msgs[0].content)except Exception as e:print(f"特色美食搜索失败: {str(e)}")all_results["local_food"] = []# 整合所有信息final_result = {"city": city,"days": days,"travel_info": {"guides": [{"result_id": item.get("result_id"),"title": item.get("title"),"description": item.get("description"),"long_description": item.get("long_description"),}for item in all_results["guides"]],"attractions": [{"result_id": item.get("result_id"),"title": item.get("title"),"description": item.get("description"),"long_description": item.get("long_description"),}for item in all_results["attractions"]],"must_eat": [{"result_id": item.get("result_id"),"title": item.get("title"),"description": item.get("description"),"long_description": item.get("long_description"),}for item in all_results["must_eat"]],"local_food": [{"result_id": item.get("result_id"),"title": item.get("title"),"description": item.get("description"),"long_description": item.get("long_description"),}for item in all_results["local_food"]]}}return final_resultdef extract_attractions_and_food(self) -> Dict:travel_info = self.search_and_rerank()# 提供一个base攻略路线,直接根据整个travel_info生成prompt = f"""参考以下信息,生成一个{self.city}{self.days}天攻略路线,直接根据整个travel_info生成{travel_info}【输出格式】{{"base_guide": "攻略内容"}}"""base_guide = self.base_guide_agent.step(prompt)print(f"这是base攻略: {base_guide.msgs[0].content}")"""提取景点和美食信息"""# 从描述中提取具体的景点和美食attractions_text = " ".join([item["description"] for item in travel_info["travel_info"]["attractions"] + travel_info["travel_info"]["guides"]])print(f"这是景点信息: {attractions_text}")food_text = " ".join([item["description"] for item in travel_info["travel_info"]["must_eat"] + travel_info["travel_info"]["local_food"]])print(f"这是美食信息: {food_text}")# 使用LLM提取并整理信息attractions_prompt = f"""请从以下文本中提取出具体的景点名称,注意不能遗漏景点信息,要尽量多提取景点信息,并为每个景点提供简短描述:{attractions_text}请以JSON格式返回,格式如下:{{"attractions": [{{"name": "景点名称", "description": "简短描述"}}]}}"""food_prompt = f"""请从以下文本中提取出具体的美食名称或者美食店铺,注意不能遗漏美食信息,要尽量多提取美食信息,并为每个美食和店铺提供简短描述:{food_text}请以JSON格式返回,格式如下:{{"foods": [{{"name": "美食名称", "description": "简短描述"}}],"food_shop": [{{"name": "美食店铺", "description": "简短描述"}}]}}"""# 使用attraction_agent处理提取attractions_response = self.attraction_agent.step(attractions_prompt)foods_response = self.food_agent.step(food_prompt)print(f"这是景点信息: {attractions_response.msgs[0].content}")print(f"这是美食信息: {foods_response.msgs[0].content}")return {"base_guide": base_guide.msgs[0].content,"attractions": attractions_response.msgs[0].content,"foods": foods_response.msgs[0].content}def process_attractions_and_food(self) -> Dict:def clean_json_string(json_str: str) -> str:"""清理JSON字符串,移除markdown代码块标记"""# 移除 ```json 开头if '```json' in json_str:json_str = json_str.split('```json')[-1]# 移除 ```结尾if '```' in json_str:json_str = json_str.split('```')[0]return json_str.strip()city = self.city"""处理景点和美食信息,添加图片URL"""# 获取原始数据results = self.extract_attractions_and_food()# 解析JSON字符串base_guide = json.loads(clean_json_string(results['base_guide']))attractions_data = json.loads(clean_json_string(results['attractions']))foods_data= json.loads(clean_json_string(results['foods']))foods_list = foods_data['foods']food_shops_list = foods_data['food_shop']# 创建结果字典result = {"city": city,"days": self.days,"base路线": base_guide,"景点": [],"美食": [],"美食店铺": []}# 处理景点信息for attraction in attractions_data['attractions']:try:# 使用DuckDuckGo搜索图片images = self.search_toolkit.search_duckduckgo(query=f"{city} {attraction['name']} 实景图",source="images",max_results=1)# 添加图片URLattraction_with_image = {"name": attraction['name'],"describe": attraction['description'],"图片url": images[0]["image"] if images else "",}result['景点'].append(attraction_with_image)except Exception as e:print(f"搜索{attraction['name']}的图片时出错: {str(e)}")# 如果出错,仍然添加景点信息,但不包含图片URLresult['景点'].append({"name": attraction["name"],"describe": attraction["description"],"图片url": "",})# 处理美食信息for food in foods_list:try:# 使用DuckDuckGo搜索图片images = self.search_toolkit.search_duckduckgo(query=f"{city} {food['name']} 美食",source="images",max_results=1)# 添加图片URLfood_with_image = {"name": food["name"],"describe": food["description"],"图片url": images[0]["image"] if images else "",}result['美食'].append(food_with_image)except Exception as e:print(f"搜索{food['name']}的图片时出错: {str(e)}")# 如果出错,仍然添加美食信息,但不包含图片URLresult['美食'].append({"name": food["name"],"describe": food["description"],"图片url": ""})# 处理美食店铺信息for food_shop in food_shops_list:try:# 使用DuckDuckGo搜索图片images = self.search_toolkit.search_duckduckgo(query=f"{city} {food_shop['name']} 美食店铺",source="images",max_results=1)# 添加图片URLfood_shop_with_image = {"name": food_shop["name"],"describe": food_shop["description"],"图片url": images[0]["image"] if images else "",}result['美食店铺'].append(food_shop_with_image)except Exception as e:print(f"搜索{food_shop['name']}的图片时出错: {str(e)}")# 如果出错,仍然添加美食店铺信息,但不包含图片URLresult['美食店铺'].append({"name": food_shop["name"],"describe": food_shop["description"],"图片url": ""})try:# 获取当前脚本所在目录current_dir = os.path.dirname(os.path.abspath(__file__))# 创建storage目录路径storage_dir = os.path.join(current_dir, "storage")# 确保storage目录存在os.makedirs(storage_dir, exist_ok=True)# 生成文件名(使用城市名和日期)filename = os.path.join(storage_dir, f"{self.city}{self.days}天旅游信息.json")# 将结果写入JSON文件with open(filename, 'w', encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)print(f"旅游攻略已保存到文件:{filename}")except Exception as e:print(f"保存JSON文件时出错: {str(e)}")return result@app.route('/get_travel_plan', methods=['POST'])
def get_travel_plan():try:# 获取请求数据data = request.get_json()# 验证输入数据if not data or 'city' not in data or 'days' not in data:return jsonify({'status': 'error','message': '请求必须包含city和days参数'}), 400city = data['city']days = data['days']# 验证days是否为整数try:days = int(days)except ValueError:return jsonify({'status': 'error','message': 'days参数必须为整数'}), 400# 创建TravelPlanner实例并获取结果travel_planner = TravelPlanner(city=city, days=days)results = travel_planner.process_attractions_and_food()return jsonify({'status': 'success','data': results})except Exception as e:return jsonify({'status': 'error','message': f'处理请求时发生错误: {str(e)}'}), 500
if __name__ == '__main__':app.run(host='0.0.0.0', port=5002, debug=True)
同样的,我们在本地的5002端口启动了一个服务,我们使用requests库来调用测试一下效果:
import requests
import json# API端点
url = "http://localhost:5000/get_travel_plan"# 请求数据
data = {"city": "上海","days": 3
}# 发送POST请求
try:response = requests.post(url, json=data)# 检查响应状态if response.status_code == 200:result = response.json()print("获取到的旅游计划:")print(json.dumps(result, ensure_ascii=False, indent=2))else:print(f"请求失败: {response.status_code}")print(f"错误信息: {response.text}")except requests.exceptions.RequestException as e:print(f"发送请求时发生错误: {e}")
这个模块用于搜集和整理旅游信息。信息主要包括旅游的一些景点、美食信息及对应图片的url,以便于我们后面将他们转成图文攻略。
在大语言模型的应用开发中,我们常常使用JSON作为中间数据的逻辑保存格式,因为交互方便,很好地表示结构化的信息且方便人类阅读和理解。
以下是生成的三份参考结果
filename = os.path.join(storage_dir, f"{self.city}{self.days}天旅游信息.json")
命名逻辑是 {地点}+{时间}+旅游信息.json
新疆7天旅游信息.json
成都3天旅游信息.json
上海3天旅游信息.json
相关文章:

旅游信息检索
旅游信息检索 旅游信息检索是系统中实现数据获取和处理的关键环节,负责根据用户输入的目的地城市和出游天数,动态获取并生成高质量的旅游数据。 模块的工作流程分为以下几个阶段:首先,对用户输入的信息进行标准化处理࿰…...

贝叶斯理论
一、贝叶斯理论的核心思想 贝叶斯理论(Bayesian Theory)是一种基于条件概率的统计推断方法,其核心是通过先验知识和新观测数据的结合,动态更新对事件发生概率的估计。它体现了“用数据修正信念”的思想,广泛应用于机器…...
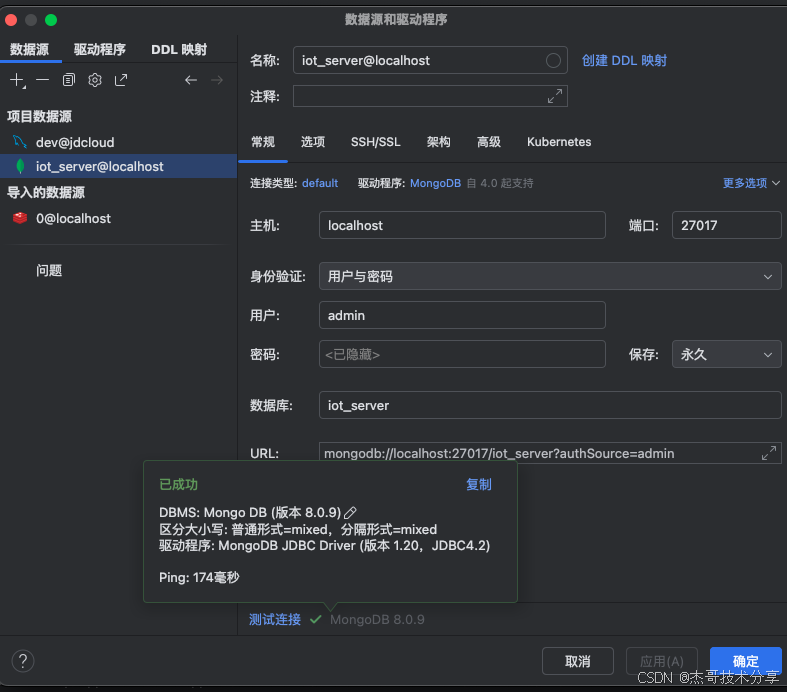
Docker-mongodb
拉取 MongoDB 镜像: docker pull mongo 创建容器并设置用户: 要挂载本地数据目录,请替换此路径: /Users/Allen/Env/AllenDocker/mongodb/data/db docker run -d --name local-mongodb \-e MONGO_INITDB_ROOT_USERNAMEadmin \-e MONGO_INITDB_ROOT_PA…...
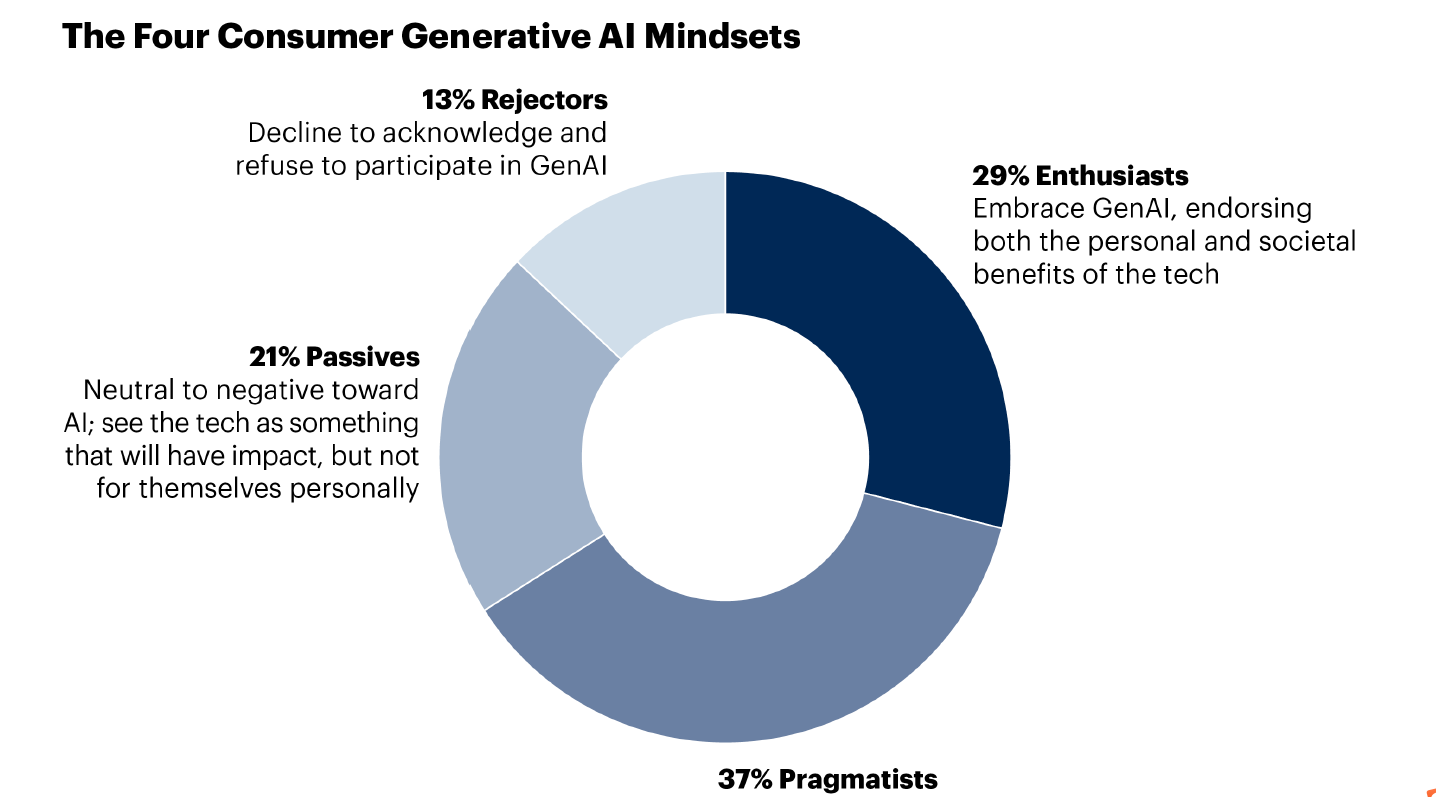
Gartner《Optimize GenAI Strategy for 4 Key ConsumerMindsets》学习心得
一、引言 在当今数字化营销浪潮中,生成式人工智能(GenAI)正以前所未有的速度重塑着市场格局。GenAI 既是一场充满机遇的变革,也是一场潜在风险的挑战。一方面,绝大多数 B2C 营销领导者对 GenAI 赋能营销抱有极高期待,他们看到了 GenAI 在提升时间与成本效率方面的巨大潜…...

[ARM][汇编] 02.ARM 汇编常用简单指令
目录 1.数据传输指令 MRS - Move from Status Register 指令用途 指令语法 代码示例 读取 CPSR 到通用寄存器 在异常处理程序中读取 SPSR 使用场景 MSR - Move to Status Register 指令语法 使用场景 示例代码 改变处理器模式为管理模式 设置条件标志位 异常处理…...
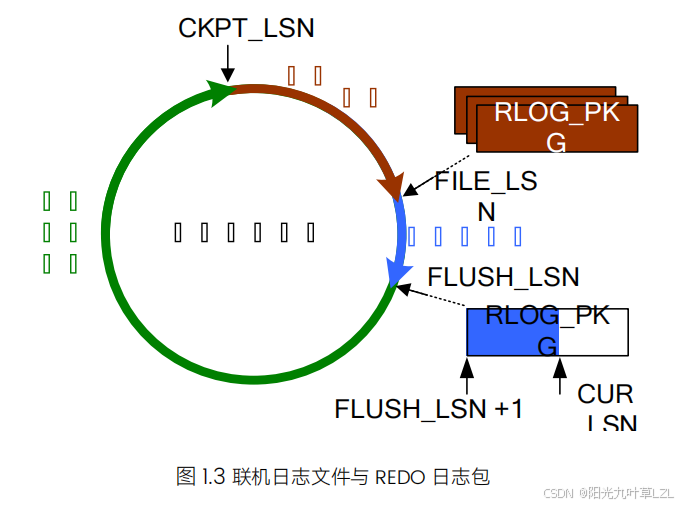
达梦数据库-学习-22-库级物理备份恢复(超详细版)
目录 一、环境信息 二、说点什么 三、概念 1、备份恢复 2、重做日志 3、归档日志 4、LSN 5、检查点 四、语法 1、BACKUP DATABASE 2、DMRMAN RESTORE DATABASE 3、DMRMAN RECOVER DATABASE 4、DMRMAN UPDATE DB_MAGIC 五、实验 1、开归档 (1…...
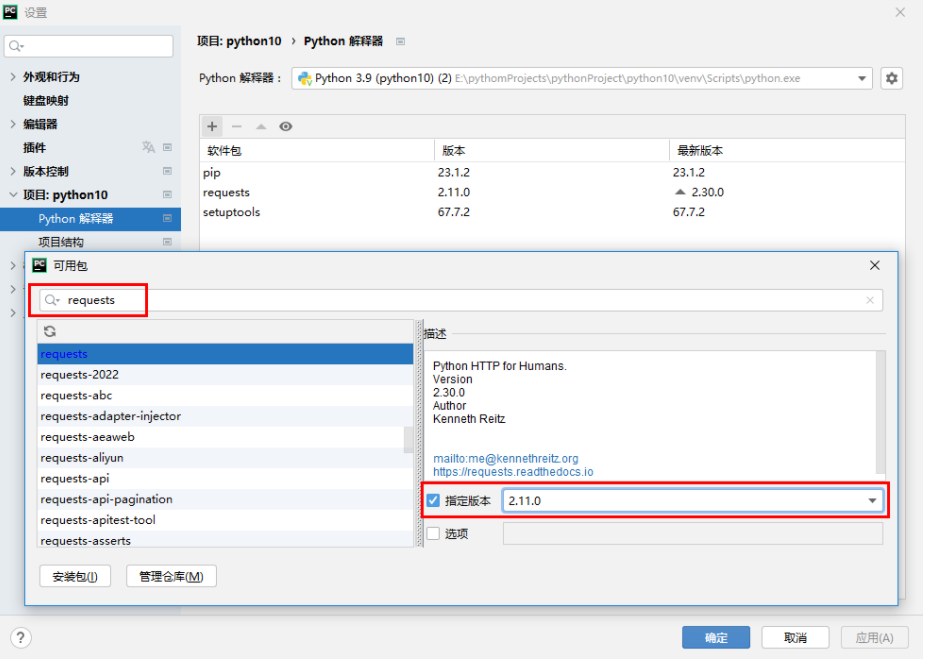
python网络爬虫的基本使用
各位帅哥美女点点关注,有关注才有动力啊 网络爬虫 引言 我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP、JAVA、C#、C、Python。 为什么Python的爬虫技术会…...

AI Agent开发第74课-解构AI伪需求的魔幻现实主义
开篇 🚀在之前的系列中我们狂炫了AI Agent的各种高端操作(向量数据库联动、多模态感知、动态工作流等…),仿佛每个程序员都能用LLM魔法点石成金✨。 但今天咱们要泼一盆透心凉的冷水——当企业把AI当成万能胶水强行粘合所有需求时,连电风扇都能被玩出量子纠缠的魔幻现实…...
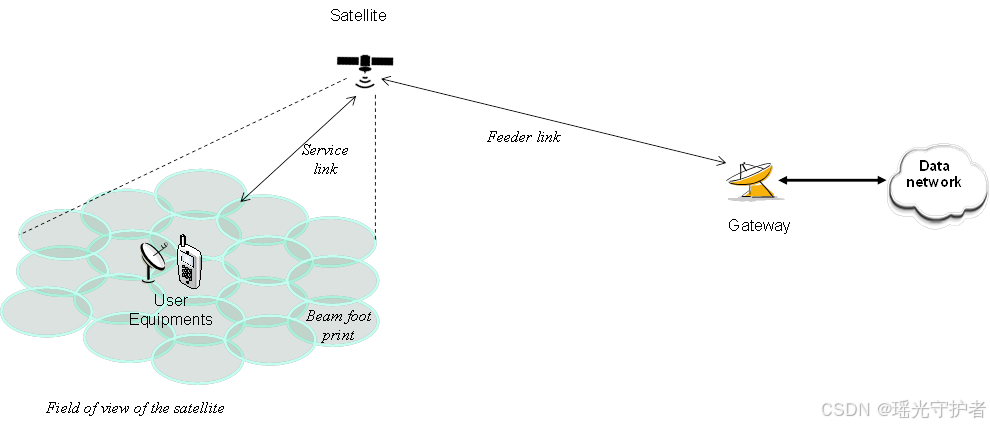
【卫星通信】通信卫星链路预算计算及其在3GPP NTN中的应用
引言 卫星通信是现代信息传播的重要手段,广泛应用于电信、广播、气象监测、导航等领域。卫星链路预算计算是设计和优化卫星通信系统的重要步骤,它帮助工程师评估信号在传输过程中的衰减和增益,从而确保系统在预定条件下可靠地工作。 1. 链路…...

HTTP请求方法:GET与POST的使用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 HTTP协议定义了多种请求方法,其中GET和POST是最常用的两种。它们在Web开发中承担着不同的角色,理解其核心差异和使用场景是构建高效、…...

第十五章:数据治理之数据目录:摸清家底,建立三大数据目录
在上一篇随想篇中,介绍了数据资源资产化的过程,理解了数据资源、数据资产的区别。这些对于本章的介绍会有帮助,如果仍有疑问可以看上一篇【数据资源到数据资产的华丽转身 ——从“沉睡的石油”到“流动的黄金”】。 说到本章要介绍的数据目录…...
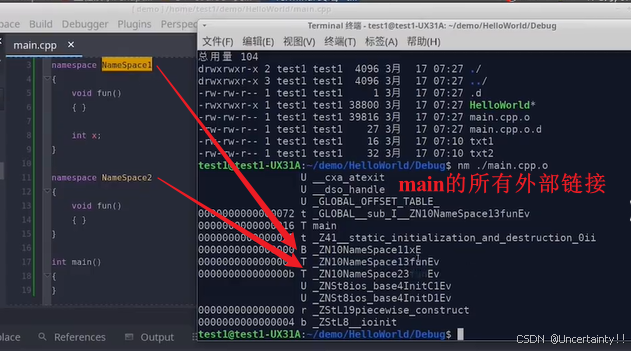
c++命名空间的作用及命名改编
c命名空间的作用及命名改编 命名空间 namespace的作用: std::命名空间,命名空间(namespace)是 C 中用于解决标识符命名冲突问题的机制。在大型程序开发中,不同模块可能会使用相同名称的变量、函数或类等标识符&…...

Go核心特性与并发编程
Go核心特性与并发编程 1. 结构体与方法(扩展) 高级结构体特性 // 嵌套结构体与匿名字段 type Employee struct {Person // 匿名嵌入Department stringsalary float64 // 私有字段 }// 构造函数模式 func NewPerson(name string, age int) *Pe…...
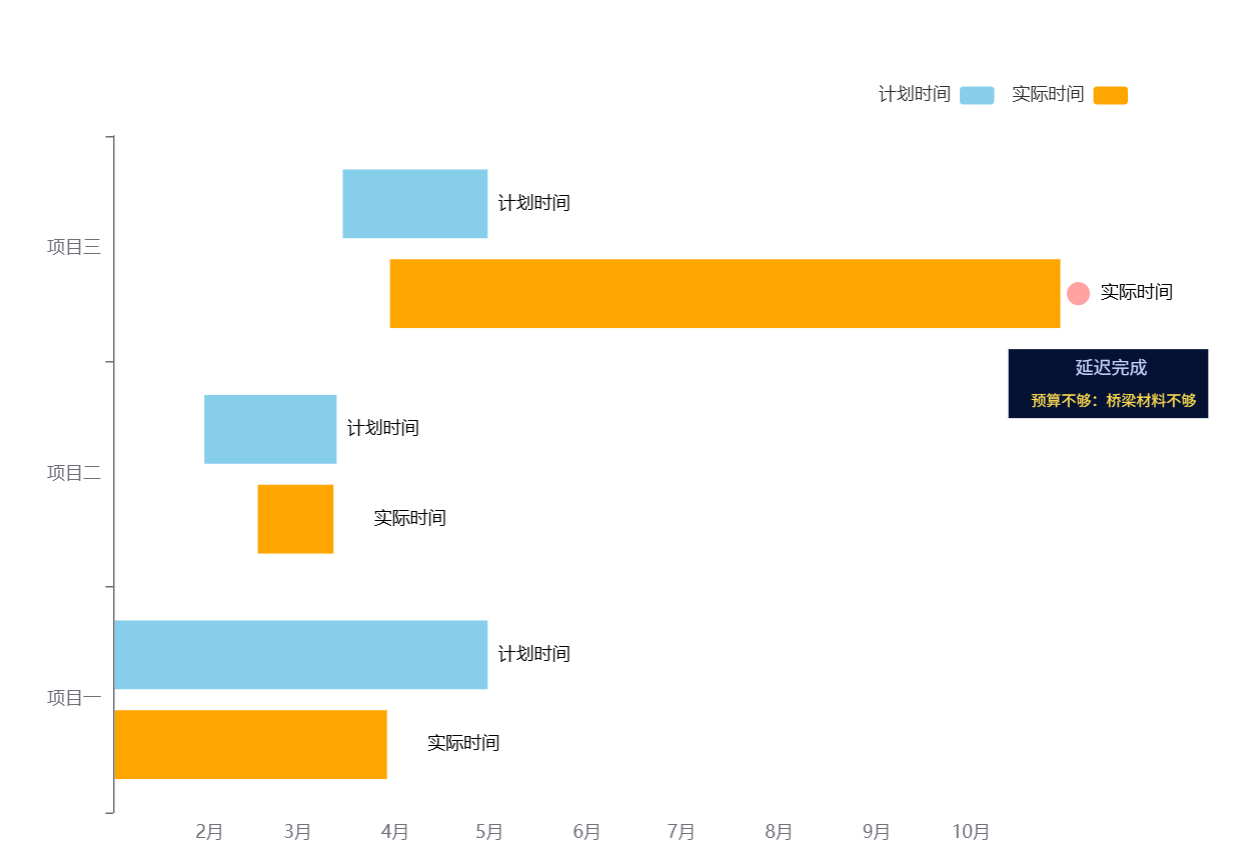
echarts实现项目进度甘特图
描述 echarts并无甘特图配置项,我们可以使用柱状图模拟,具体配置项如下,可以在echarts直接运行 var option {backgroundColor: "#fff",legend: {data: ["计划时间","实际时间"],align: "right",…...

Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中
Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中 在 Flutter 中,build 方法被设计在 StatefulWidget 的 State 类中而非 StatefulWidget 类本身,这种设计基于几个重要的架构原则和实际考量: 1. 核心设计原因 1.1 生命周期管理…...

C#串口打印机:控制类开发与实战
C#串口打印机:控制类开发与实战 一、引言 在嵌入式设备、POS 终端、工业控制等场景中,串口打印机因其稳定的通信性能和广泛的兼容性,仍是重要的数据输出设备。本文基于 C# 语言,深度解析一个完整的串口打印机控制类Printer&…...

2025深圳国际无人机展深度解析:看点、厂商与创新亮点
2025深圳国际无人机展深度解析:看点、厂商与创新亮点 1.背景2.核心看点:技术突破与场景创新2.1 eVTOL(飞行汽车)的规模化展示2.2 智能无人机与无人值守平台2.3 新材料与核心零部件革新2.4 动态演示与赛事活动 3.头部无人机厂商4.核…...
)
Electron 后台常驻服务实现(托盘 + 开机自启)
基于 electron-vite-vue 项目结构 本篇将详细介绍如何为 Electron 应用实现后台常驻运行,包括: ✅ 创建系统托盘图标(Tray)✅ 支持点击托盘菜单控制窗口显示/退出✅ 实现开机自启功能(Auto Launch) &#…...

Spring Boot与Kafka集成实践:从入门到实战
Spring Boot与Kafka集成实践 引言 在现代分布式系统中,消息队列技术扮演着至关重要的角色。Kafka作为一款高性能、高吞吐量的分布式消息队列系统,被广泛应用于日志收集、流处理、事件驱动架构等场景。本文将详细介绍如何在Spring Boot项目中集成Kafka&…...

人形机器人通过观看视频学习人类动作的技术可行性与前景展望
摘要 本文深入探讨人形机器人通过观看视频学习人类动作这一技术路线的正确性与深远潜力。首先阐述该技术路线在模仿人类学习过程方面的优势,包括对人类动作、表情、发音及情感模仿的可行性与实现路径。接着从技术原理、大数据训练基础、与人类学习速度对比等角度论证…...
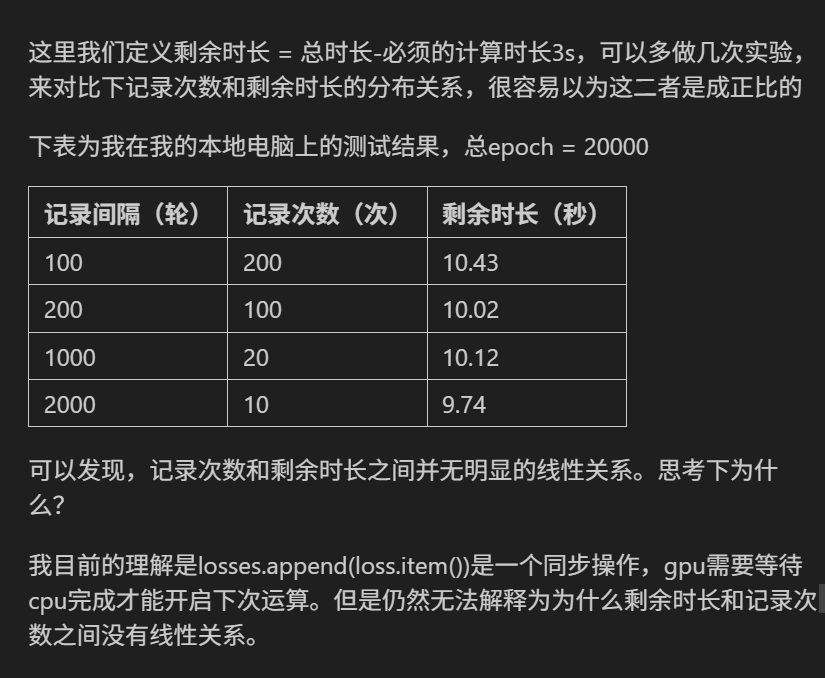
第三十四天打卡
DAY 34 GPU训练及类的call方法 知识点回归: CPU性能的查看:看架构代际、核心数、线程数 GPU性能的查看:看显存、看级别、看架构代际 GPU训练的方法:数据和模型移动到GPU device上 类的call方法:为什么定义前向传播时可…...

打卡day35
一、模型结构可视化 理解一个深度学习网络最重要的2点: 了解损失如何定义的,知道损失从何而来----把抽象的任务通过损失函数量化出来了解参数总量,即知道每一层的设计才能退出—层设计决定参数总量 为了了解参数总量,我们需要知…...

【【嵌入式开发 Linux 常用命令系列 19 -- linux top 命令的交互使用介绍】
文章目录 Overview常用的交互命令(top 运行时可直接按键)示例使用场景按内存排序,显示某个用户的前 10 个进程:杀死占用资源最多的进程调整刷新频率为 1 秒 提示 Overview 在linux环境下办公经常会遇到杀进程,查看cpu…...
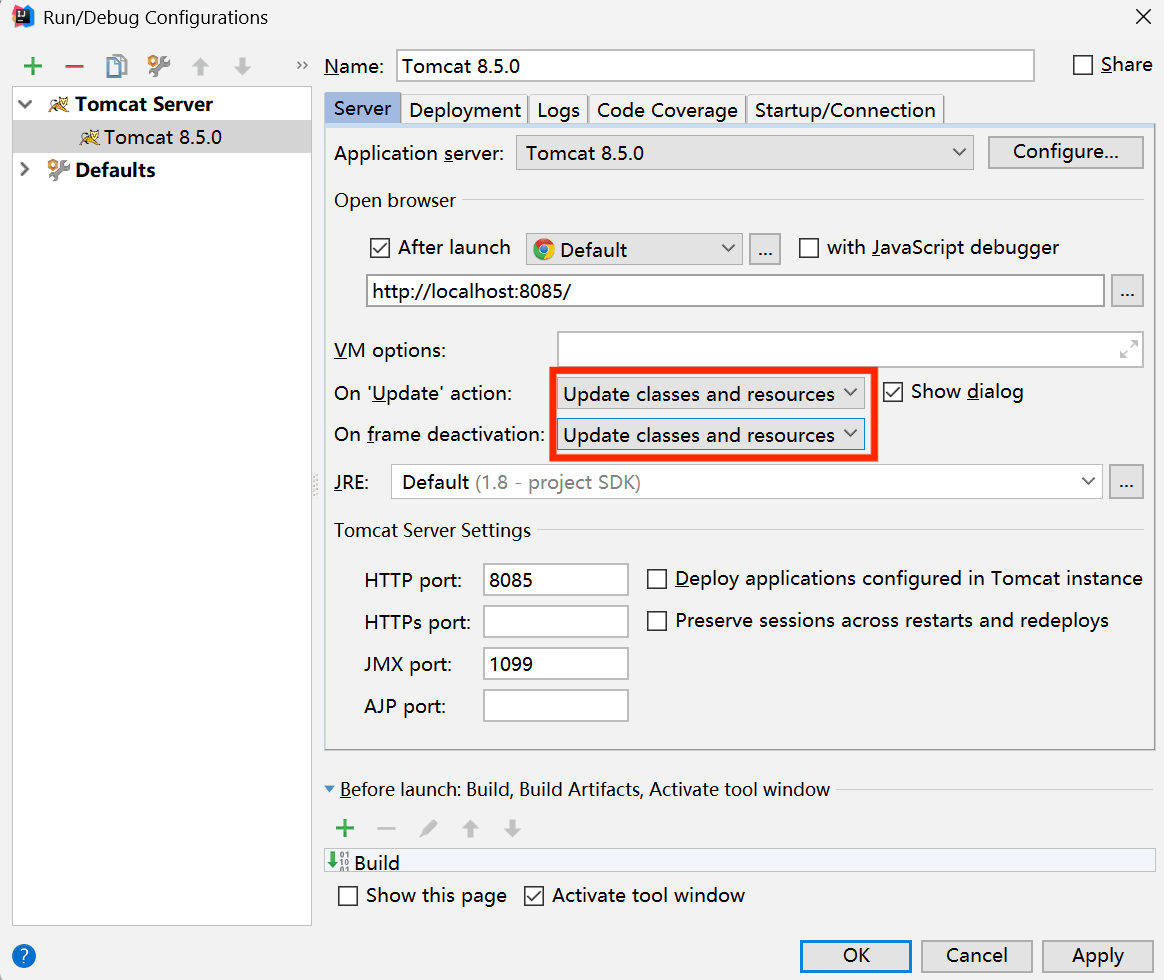
配置tomcat时,无法部署工件该怎么办?
当我们第一次在IDEA中创建Java项目时,配置tomcat可能会出现无法部署工件的情况,如图: 而正常情况应该是: 那么该如何解决呢? 步骤一 点开右上角该图标,会弹出如图页面 步骤二 步骤三 步骤四...

.NET外挂系列:8. harmony 的IL编织 Transpiler
一:背景 1. 讲故事 前面文章所介绍的一些注入技术都是以方法为原子单位,但在一些罕见的场合中,这种方法粒度又太大了,能不能以语句为单位,那这个就是我们这篇介绍的 Transpiler,它可以修改方法的 IL 代码…...
基于netty实现视频流式传输和多线程传输
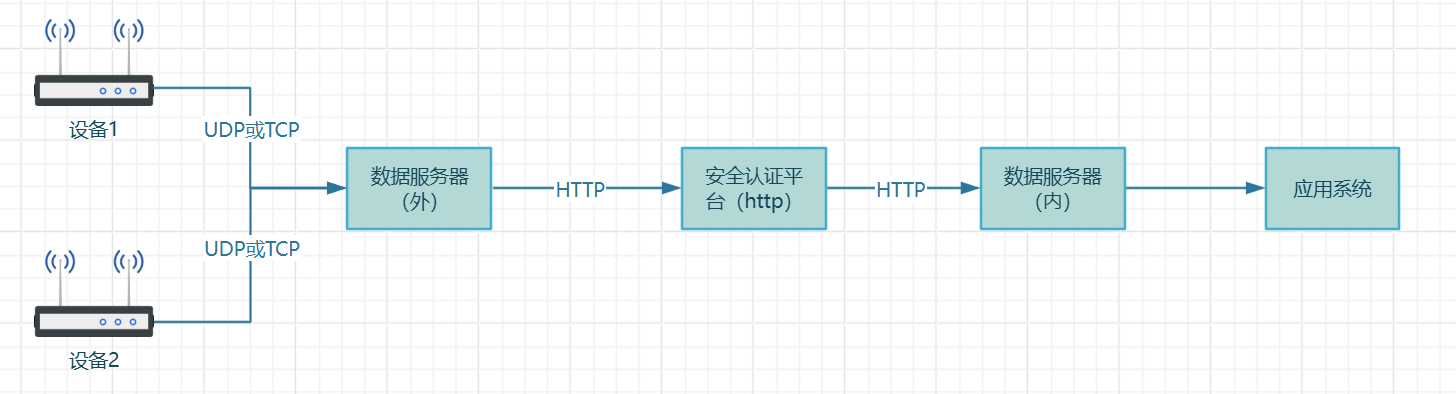
文章目录 业务描述业务难点流式传输客户端(以tcp为例)服务端测试类测试步骤多线程传输客户端服务端测试类测试步骤多线程流式传输总结业务描述 多台终端设备持续给数据服务器(外)发送视频数据,数据服务器(外)通过HTTP协议将数据经过某安全平台转到数据服务器(内),数据…...

全面指南:使用Node.js和Python连接与操作MongoDB
在现代Web开发中,数据库是存储和管理数据的核心组件。MongoDB作为一款流行的NoSQL数据库,以其灵活的数据模型、高性能和易扩展性广受开发者欢迎。无论是使用Node.js还是Python,MongoDB都提供了强大的官方驱动和第三方库,使得数据库…...

游戏引擎学习第308天:调试循环检测
回顾并为今天的内容做准备 我们正在进行游戏开发中的精灵(sprite)排序工作,虽然目前的实现已经有了一些改进,情况也在逐步好转,我们已经实现了一个图结构的排序算法,用来处理精灵渲染顺序的问题。然而&…...

Java 海康录像机通过sdk下载的视频无法在线预览问题
下载的视频格式不对,需将视频转码为H.264/AAC的MP4格式 使用 ffmpeg 对视频进行转码 ffmpeg可以对视频进行转码、加水印等操作,还是挺强大的 代码如下 public static void transcodeToMP4(String inputPath, String outputPath) throws IOException, In…...

WPF性能优化之延迟加载(解决页面卡顿问题)
文章目录 前言一. 基础知识回顾二. 问题分析三. 解决方案1. 新建一个名为DeferredContentHost的控件。2. 在DeferredContentHost控件中定义一个名为Content的object类型的依赖属性,用于承载要加载的子控件。3. 在DeferredContentHost控件中定义一个名为Skeleton的ob…...