微服务架构实战:Eureka服务注册发现与Ribbon负载均衡详解
微服务架构实战:Eureka服务注册发现与Ribbon负载均衡详解
- 一 . 服务调用出现的问题
- 二 . EureKa 的作用
- 三 . 服务注册
- 3.1 搭建 EureKaServer
- ① 创建项目 , 引入 spring-cloud-starter-netflix-eureka-server 的依赖
- ② 编写启动类 , 添加 @EnableEurekaServer 注解
- ③ 添加 application.yml 文件 , 编写相关配置
- 3.2 服务注册
- ① 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
- ② 在各自的 application.yml 中 , 编写相关配置
- ③ 给各自的微服务起一个名称
- ④ 启动多个 EureKa 客户端
- 四 . 服务发现
- 五 . Ribbon 负载均衡
- 5.1 负载均衡流程
- 5.2 负载均衡原理
- 5.3 负载均衡策略
- ① 代码方式
- ② 配置文件方式
- 5.4 懒加载
- 5.5 小结
在微服务架构中,服务间的稳定调用是核心挑战之一。传统的RestTemplate直接调用存在单点故障、集群路由选择困难、服务健康状态难以感知等问题。如何实现服务的动态发现?如何优雅地管理多实例负载均衡?本文将深入剖析Spring Cloud中的Eureka服务注册中心与Ribbon负载均衡组件,通过实战演示如何解决服务治理的核心痛点,构建高可用的微服务通信体系。
本专栏的内容均来自于 B 站 UP 主黑马程序员的教学视频,感谢你们提供了优质的学习资料,让编程不再难懂。
专栏地址 : https://blog.csdn.net/m0_53117341/category_12835102.html

一 . 服务调用出现的问题
我们当前使用的是 RestTemplate 来让 order-service 调用 user-service , 那这里其实是存在问题的
我们目前的两个服务都是单节点的 , 如果 user-service 挂掉了 , order-service 就会调用失败 , 也会影响到 order-service .
那如果后续搭建 user-service 集群的话 , 我们到底访问哪一台 user-service 机器呢 ?
也就是服务消费者该如何获取服务提供者的地址信息 ?
那如果有多个服务提供者 , 消费者该如何选择呢 ? 是通过负载均衡策略还是其他策略呢 ?
消费者如何得知服务提供者的健康状态呢 ?
那综合这几点考虑 , 我们应该把节点信息都放到一个统一的位置进行管理 , 那这个统一的位置就是 EureKa .
二 . EureKa 的作用
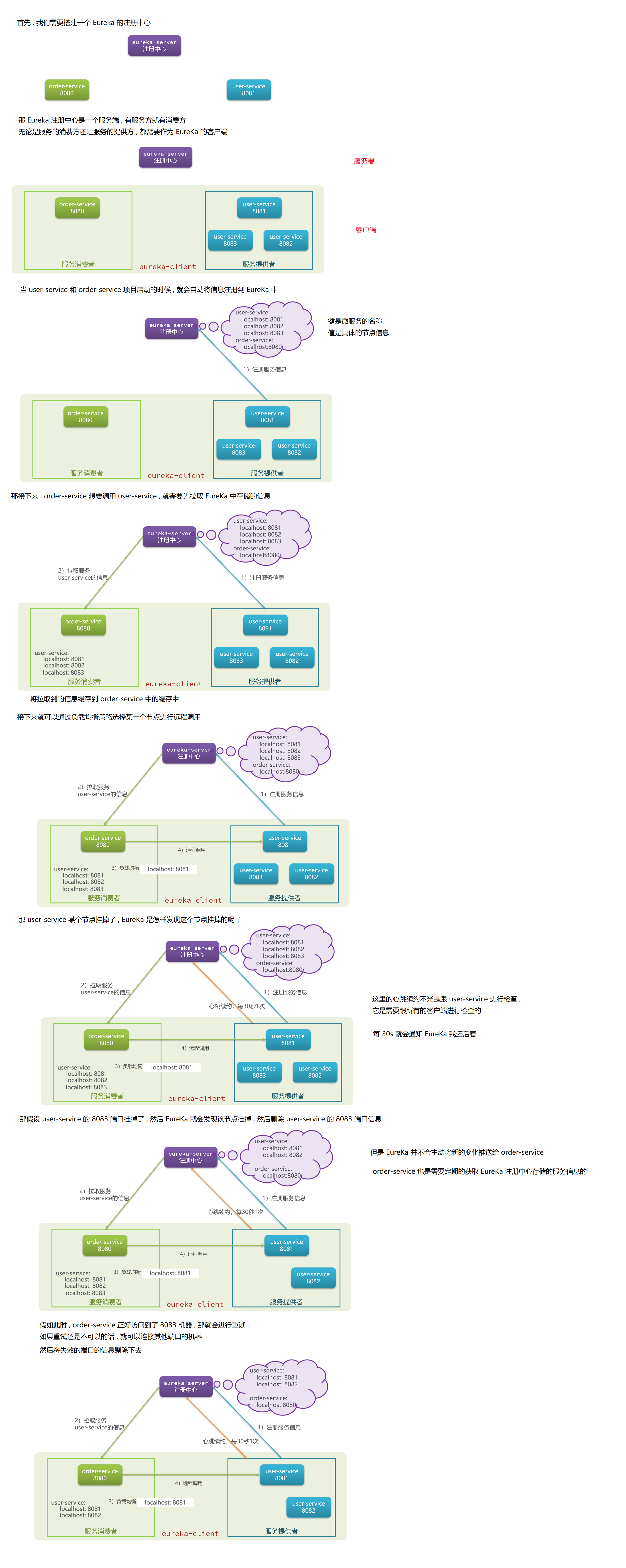
那整体来看 , EureKa 的作用就是服务注册、服务发现、状态监控这三点
那我们重新来看上面的三个问题
服务消费者该如何获取服务提供者的地址信息 ?
- 服务的提供者在启动的时候 , 就需要向 EureKa 注册自己的信息
- EureKa 保存每个服务的信息
- 消费者根据服务名称向 EureKa 拉取提供者的信息
前提 : 必须是已经上传到 EureKa 的服务 , 才能拉取别人的信息
如果有多个服务提供者 , 消费者该如何选择呢 ?
服务消费者利用负载均衡算法 , 从服务列表中挑选一个
消费者如何得知服务提供者的健康状态呢 ?
- 服务提供者会每隔 30s 就向 EureKaServer 发送心跳请求 , 报告健康状态
- EureKa 会更新服务列表信息 , 心跳不正常的就会被剔除掉
- 消费者需要主动拉取最新的消息
小结 :
在 EureKa 架构中 , 微服务角色有两类 :
- EureKaServer : 服务端 , 注册中心
- 记录服务信息
- 进行心跳监控
- EureKaClient : 客户端
- Provider : 服务提供者 (user-service)
- 启动的时候主动注册自己的信息到 EureKaServer
- 每隔 30s 向 EureKaServer 发送心跳
- consumer : 服务消费者 (order-service)
- 启动的时候主动注册自己的信息到 EureKaServer
- 每隔 30s 向 EureKaServer 发送心跳
- 根据服务名称从 EureKaServer 拉取服务列表
- 基于拉取下来的服务列表做负载均衡策略 , 选择一个微服务进行远程调用
- Provider : 服务提供者 (user-service)
三 . 服务注册
基本流程如下 :
- 搭建 EureKaServer
- 将 user-service 和 order-service 都注册到 EureKa 中
- 在 order-service 中完成服务拉取 , 然后通过负载均衡挑选一个服务 , 来去实现远程调用
那我们分别来看
3.1 搭建 EureKaServer
① 创建项目 , 引入 spring-cloud-starter-netflix-eureka-server 的依赖
首先 , 我们创建一个新的模块
那接下来就可以在该模块的 pom.xml 中引入依赖了
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
那这里是不需要指定版本的 , 因为我们在父模块已经指定过了
那这个依赖 , 下载起来还是比较耗时的 , 稍加等待
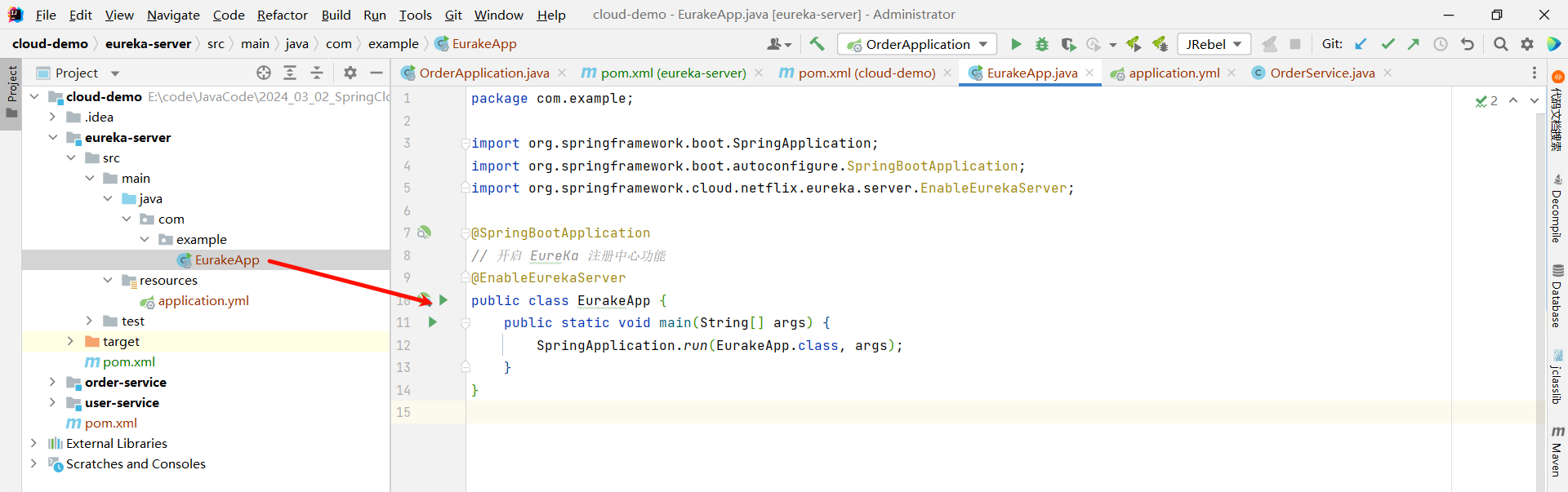
② 编写启动类 , 添加 @EnableEurekaServer 注解
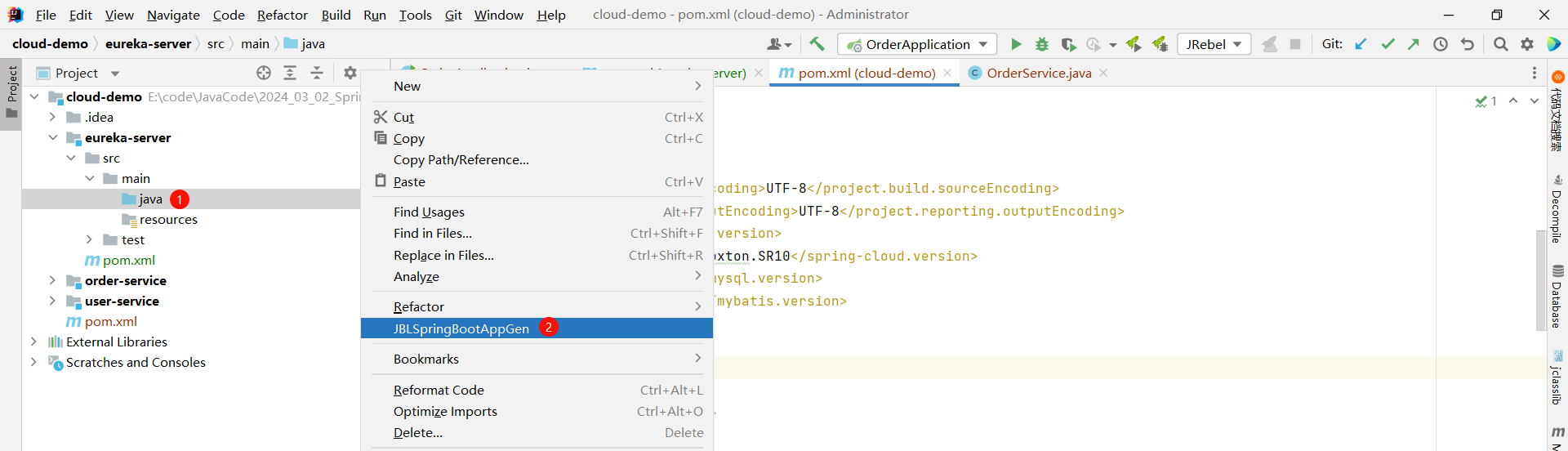
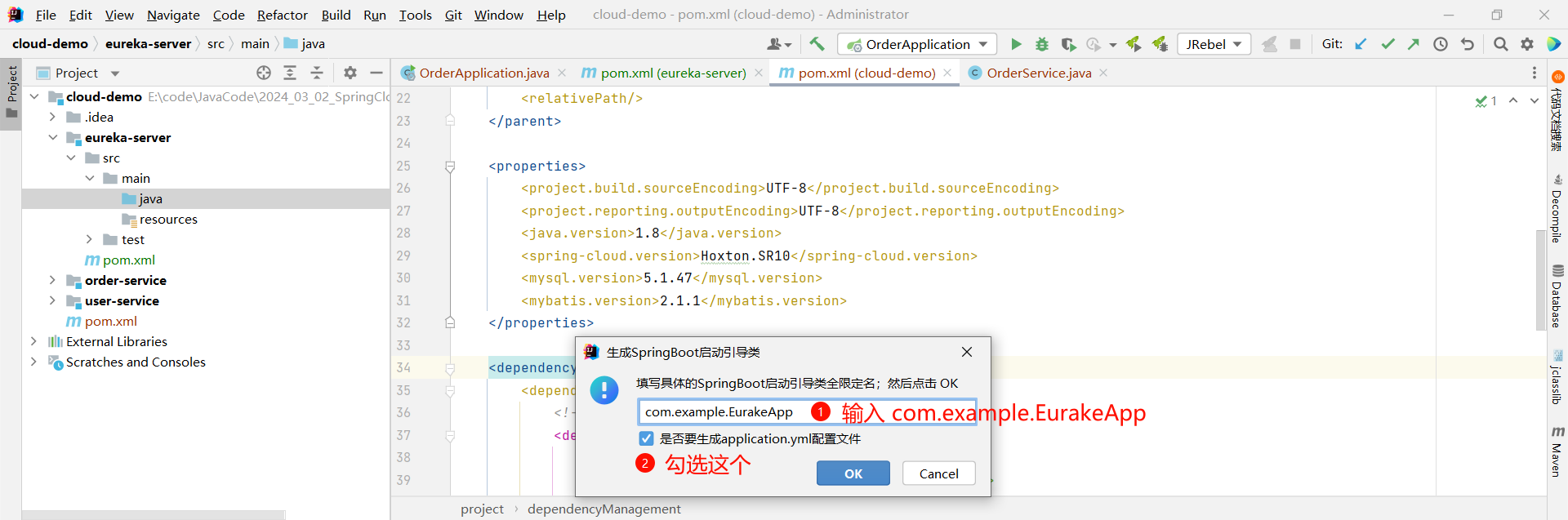
这个功能需要安装插件 :
[番外 1 : JBLSpringBootAppGen 的安装](https://www.yuque.com/jialebihaitao/study/wduur42qulhwgd48?singleDoc# 《番外 1 : JBLSpringBootAppGen 的安装》)
然后在启动类上添加 @EnableEurekaServer 注解
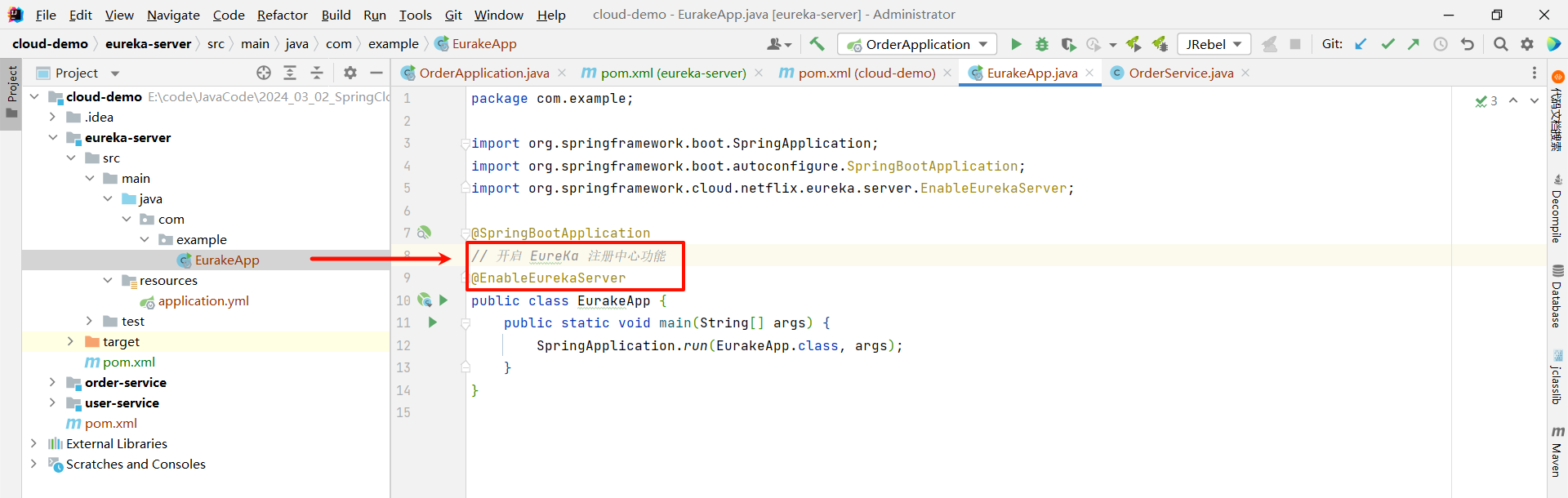
package com.example;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;@SpringBootApplication
// 开启 EureKa 注册中心功能
@EnableEurekaServer
public class EurakeApp {public static void main(String[] args) {SpringApplication.run(EurakeApp.class, args);}
}③ 添加 application.yml 文件 , 编写相关配置
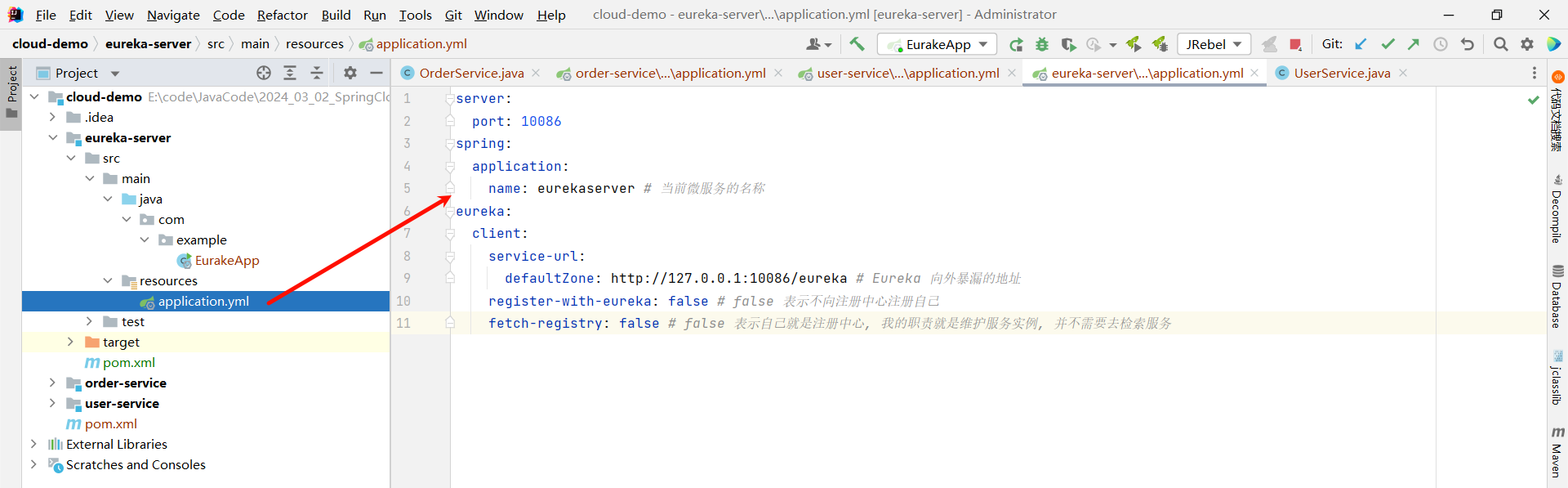
server:port: 10086
spring:application:name: eurekaserver # 当前微服务的名称
eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址register-with-eureka: false # false 表示不向注册中心注册自己fetch-registry: false # false 表示自己就是注册中心, 我的职责就是维护服务实例, 并不需要去检索服务
那接下来 , 我们可以启动一下 , 看一下能否正常运行
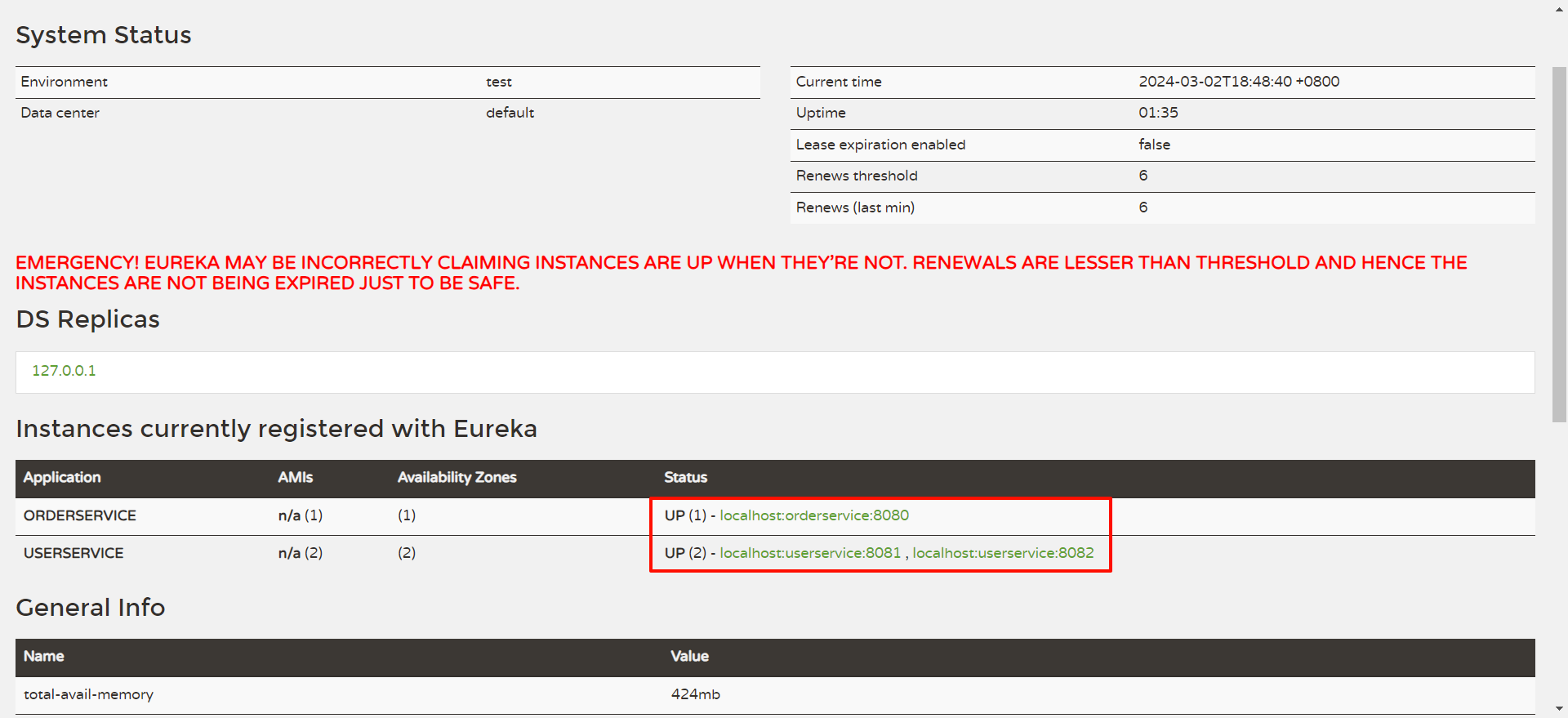
访问 http://127.0.0.1:10086/
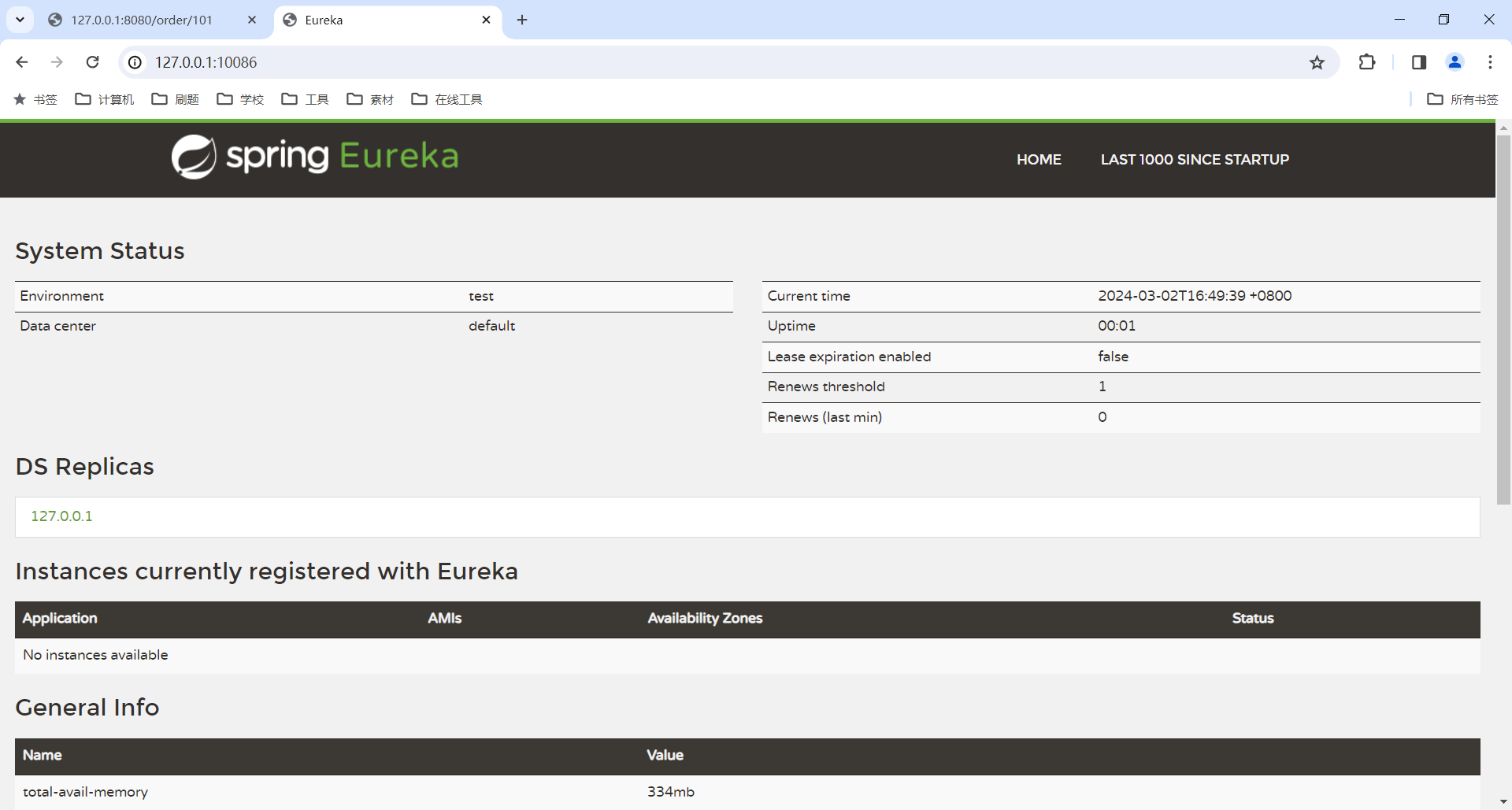
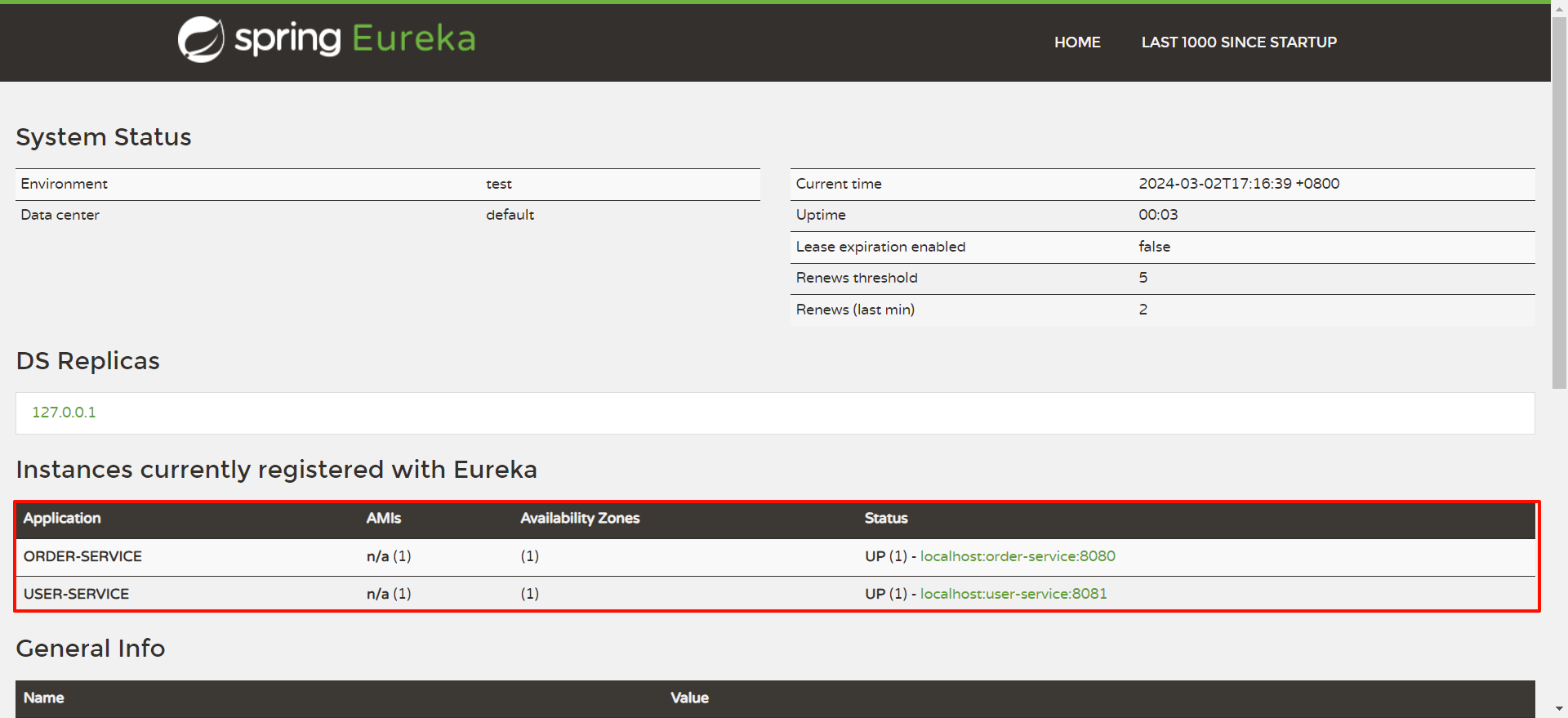
我们重点关注 Instances currently registered with Eureka 这个位置 , 他代表当前已经注册到 Eureka 注册中心的服务 , 那目前还没有任何实例注册到注册中心中
3.2 服务注册
将服务注册到 EureKaServer 的步骤如下 :
- 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
- 在各自的 application.yml 中 , 编写相关配置
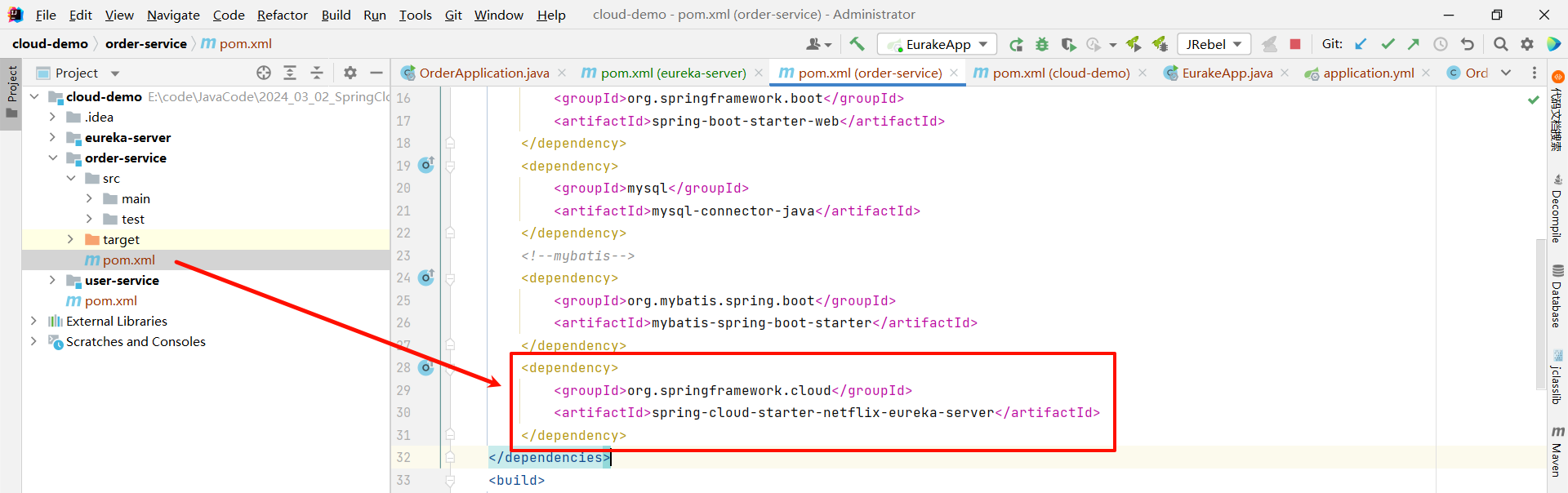
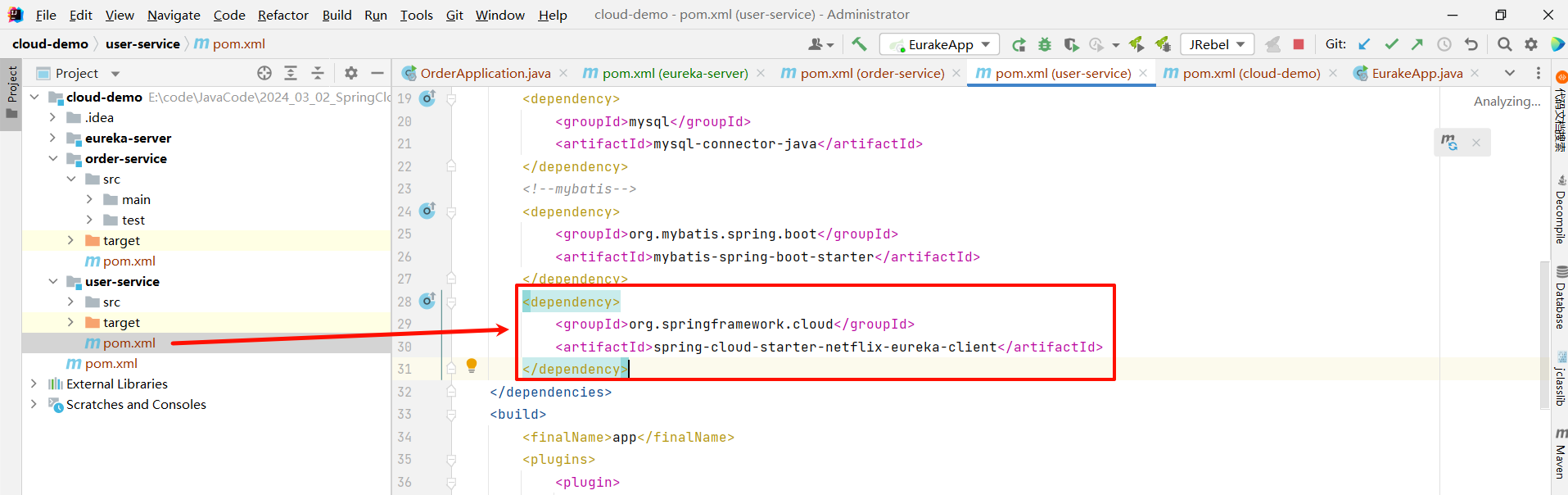
① 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
将下面的依赖粘贴到 user-service 和 order-service 服务中的 pom.xml 中
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
② 在各自的 application.yml 中 , 编写相关配置
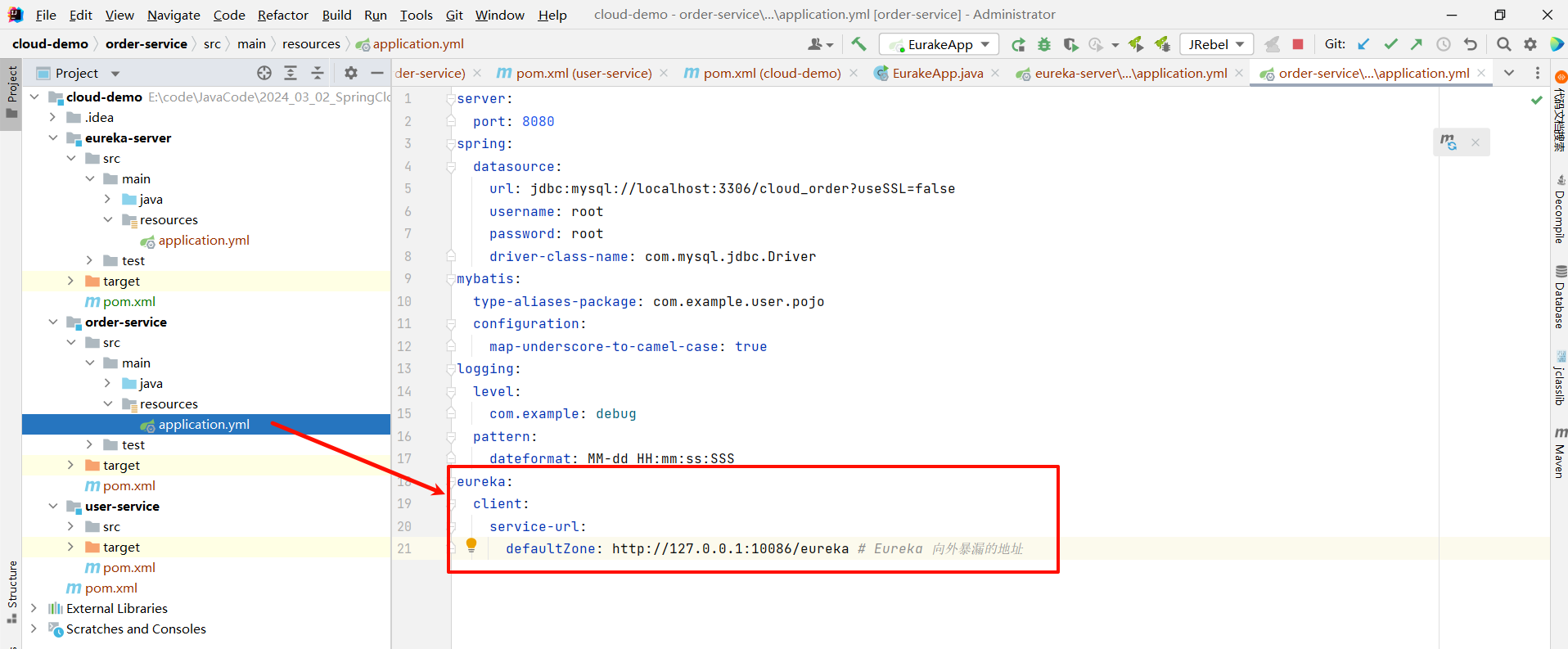
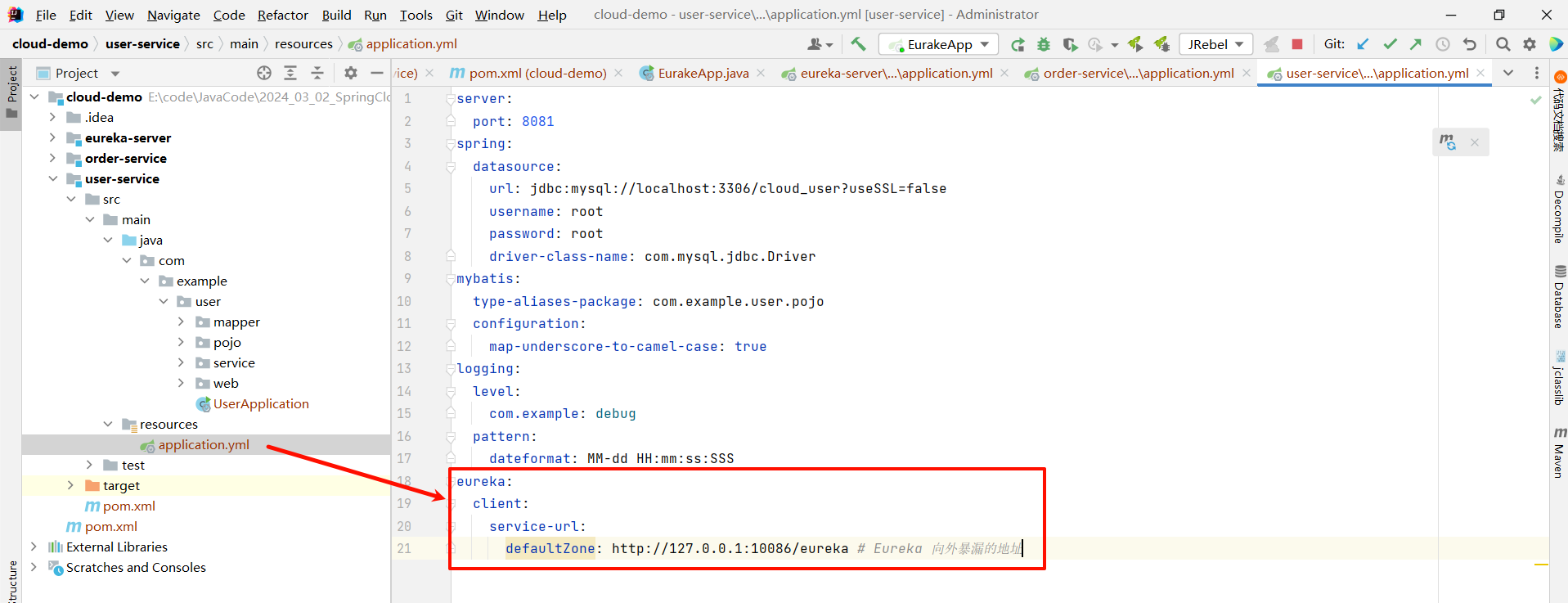
将这段配置粘贴到 user-service 和 order-service 的 application.yml 中
eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址
③ 给各自的微服务起一个名称
那我们需要给 user-service 和 order-service 的微服务起一个名称 , 不然到时候观察 EureKa 注册中心的时候 , 我们并不知道哪个是 user-service , 哪个是 order-service
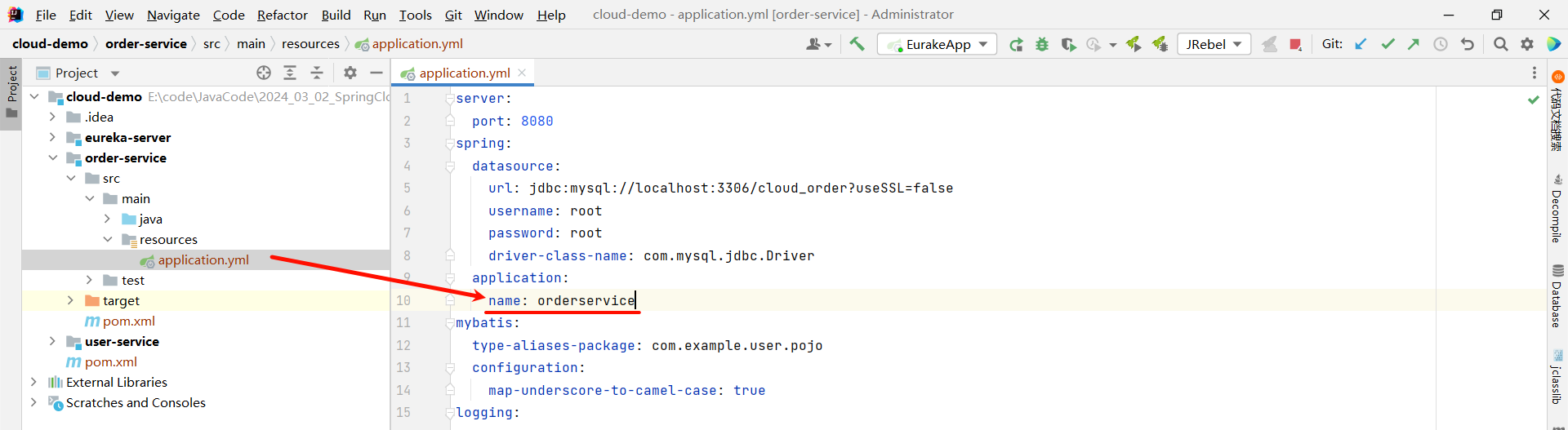
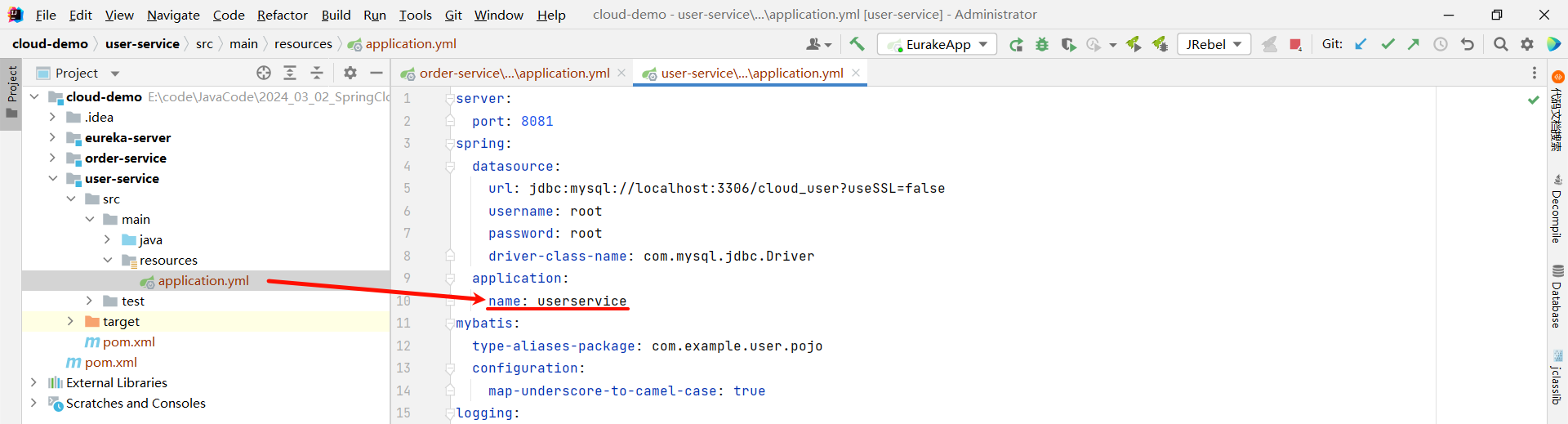
server:port: 8080
spring:datasource:url: jdbc:mysql://localhost:3306/cloud_order?useSSL=falseusername: rootpassword: rootdriver-class-name: com.mysql.jdbc.Driverapplication:name: userservice
mybatis:type-aliases-package: com.example.user.pojoconfiguration:map-underscore-to-camel-case: true
logging:level:com.example: debugpattern:dateformat: MM-dd HH:mm:ss:SSS
eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址
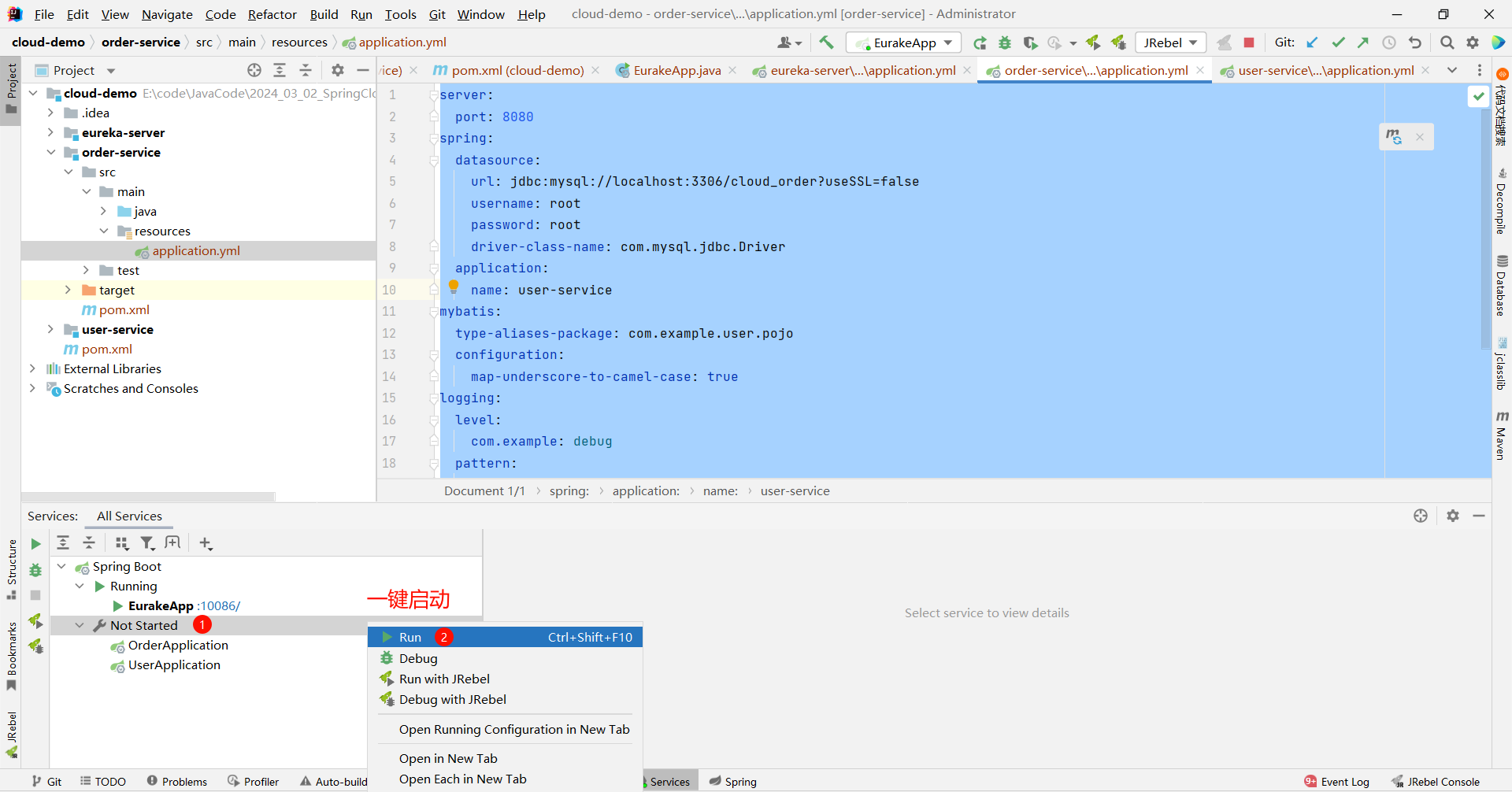
那这时候 , 我们重启 user-service 和 order-service , 就会自动将自身信息注册到 EureKa 中了
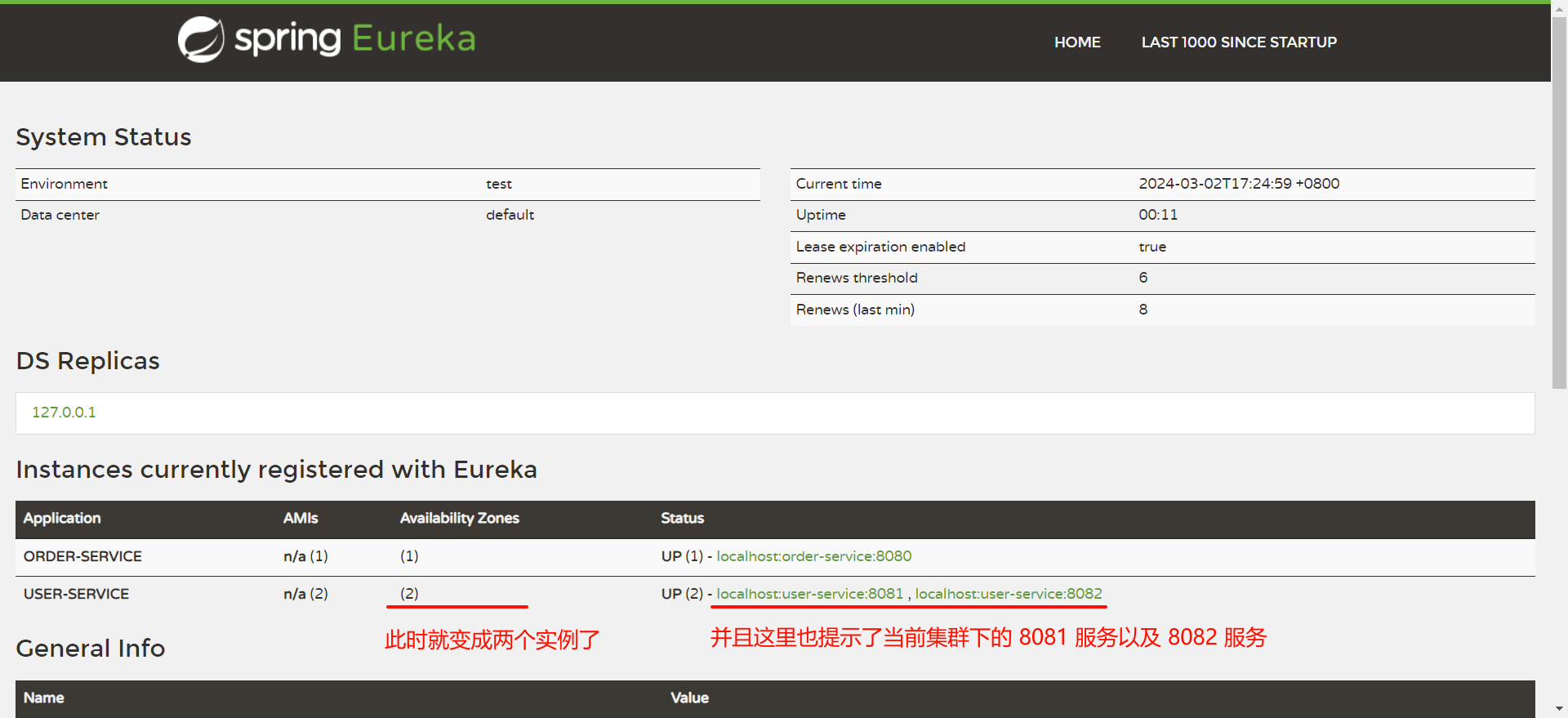
我们回到 EureKa 注册中心看一下 , 此时两个服务已经成功注册
那也有可能在页面 , 会有一个大大的红色警报

他其实并不是报错 , 只是 Eureka 认为 , 当你的实例只有一个节点的时候 , 这个服务就很危险了 .
也就是你对应的服务只启动了一份 .
④ 启动多个 EureKa 客户端
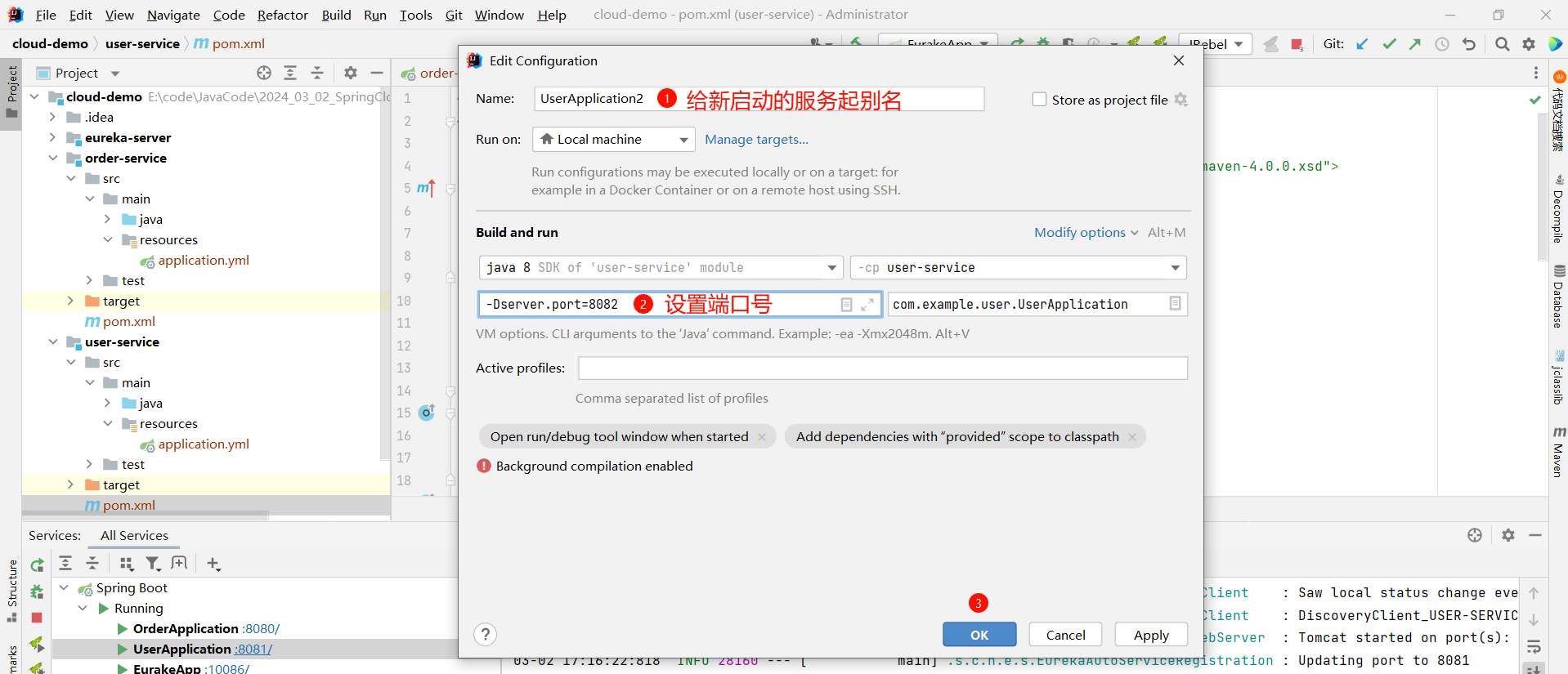
-Dserver.port=8082
那接下来 , 我们启动新的 user-service 服务
然后回到 EureKa 控制中心看一下
四 . 服务发现
虽然我们已经把 user-service 服务和 order-service 服务注册到 EureKa 中了 , 但是我们在访问这两个接口的时候 , 还需要访问固定的 IP

那这是因为我们在代码中已经将端口号写死了
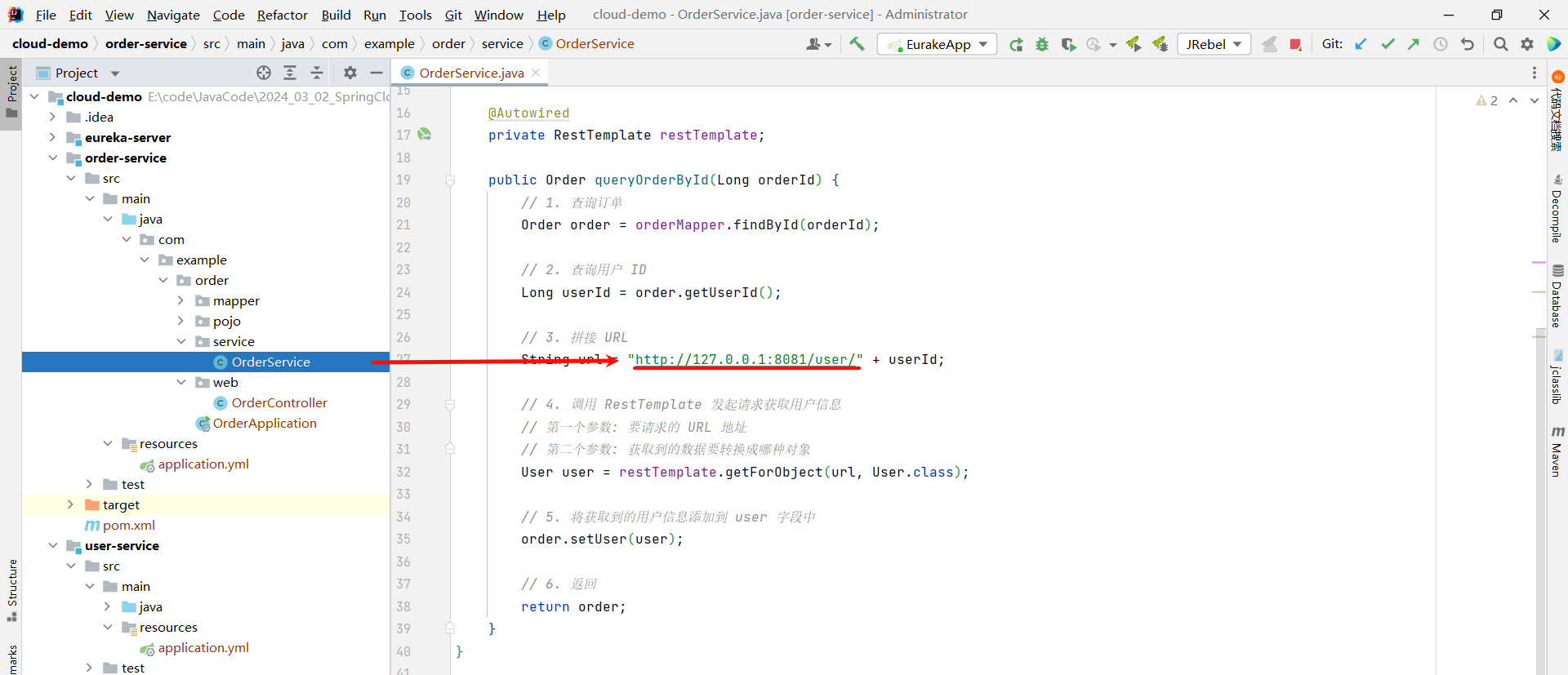
那这样的话 , 即使 user-service 服务搭建了集群 , 我们也只能访问到固定的 8081 端口的服务 , 所以我们需要更换一下写法
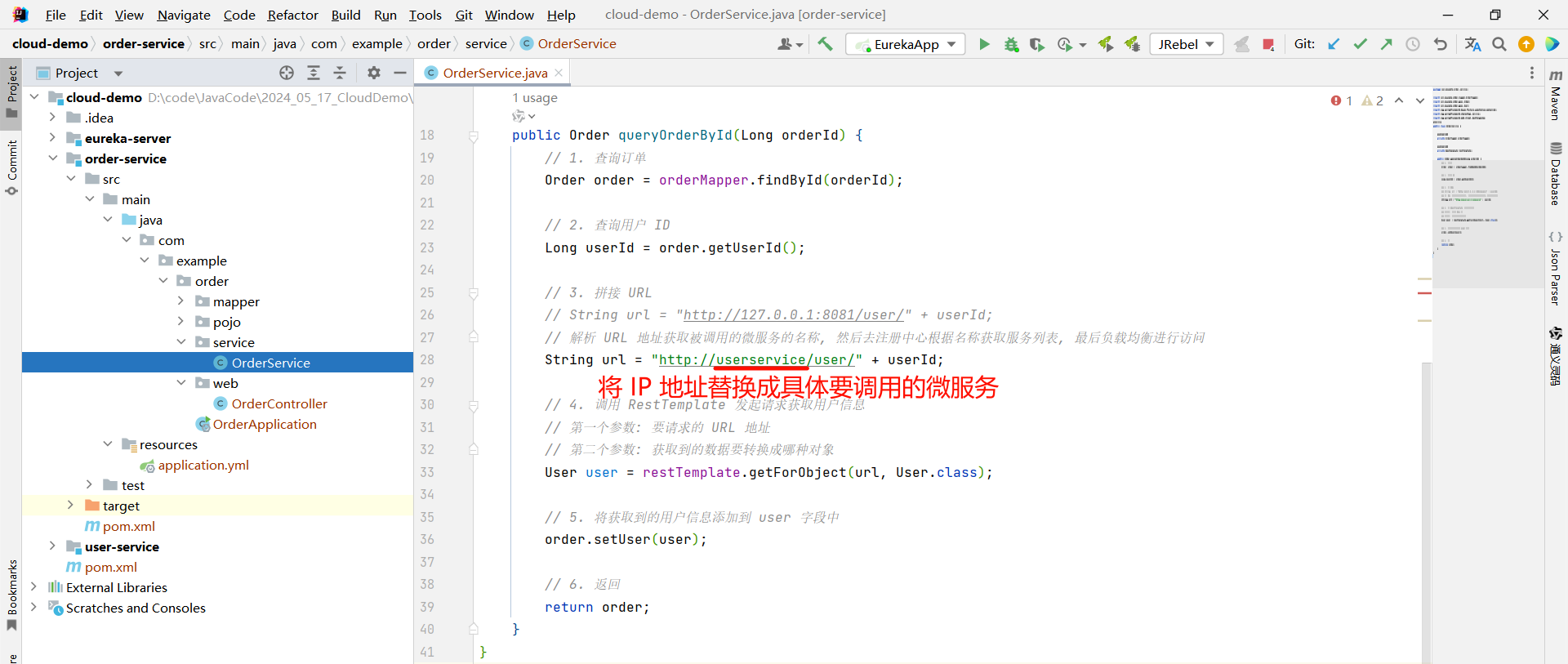
package com.example.order.service;import com.example.order.mapper.OrderMapper;
import com.example.order.pojo.Order;
import com.example.order.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate RestTemplate restTemplate;public Order queryOrderById(Long orderId) {// 1. 查询订单Order order = orderMapper.findById(orderId);// 2. 查询用户 IDLong userId = order.getUserId();// 3. 拼接 URL// String url = "http://127.0.0.1:8081/user/" + userId;// 解析 URL 地址获取被调用的微服务的名称, 然后去注册中心根据名称获取服务列表, 最后负载均衡进行访问String url = "http://userservice/user/" + userId;// 4. 调用 RestTemplate 发起请求获取用户信息// 第一个参数: 要请求的 URL 地址// 第二个参数: 获取到的数据要转换成哪种对象User user = restTemplate.getForObject(url, User.class);// 5. 将获取到的用户信息添加到 user 字段中order.setUser(user);// 6. 返回return order;}
}要注意这个位置需要跟要调用的服务的 application.yml 进行对齐
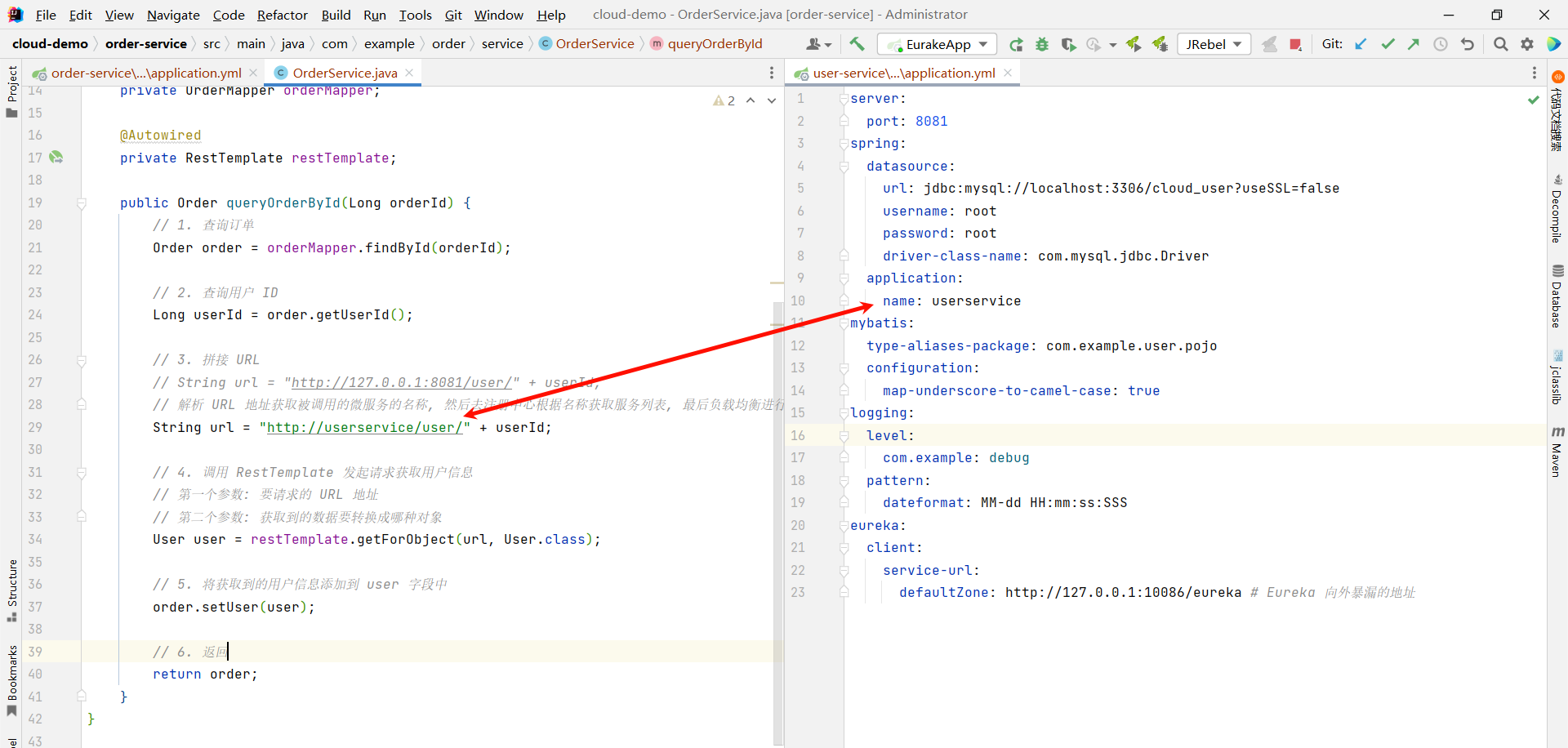
那为了演示负载均衡的效果 , 我们还需要修改一些内容
我们可以将配置文件中的端口号读取出来 , 然后设置到用户名部分 , 这样我们就能通过页面来看到端口号的变化
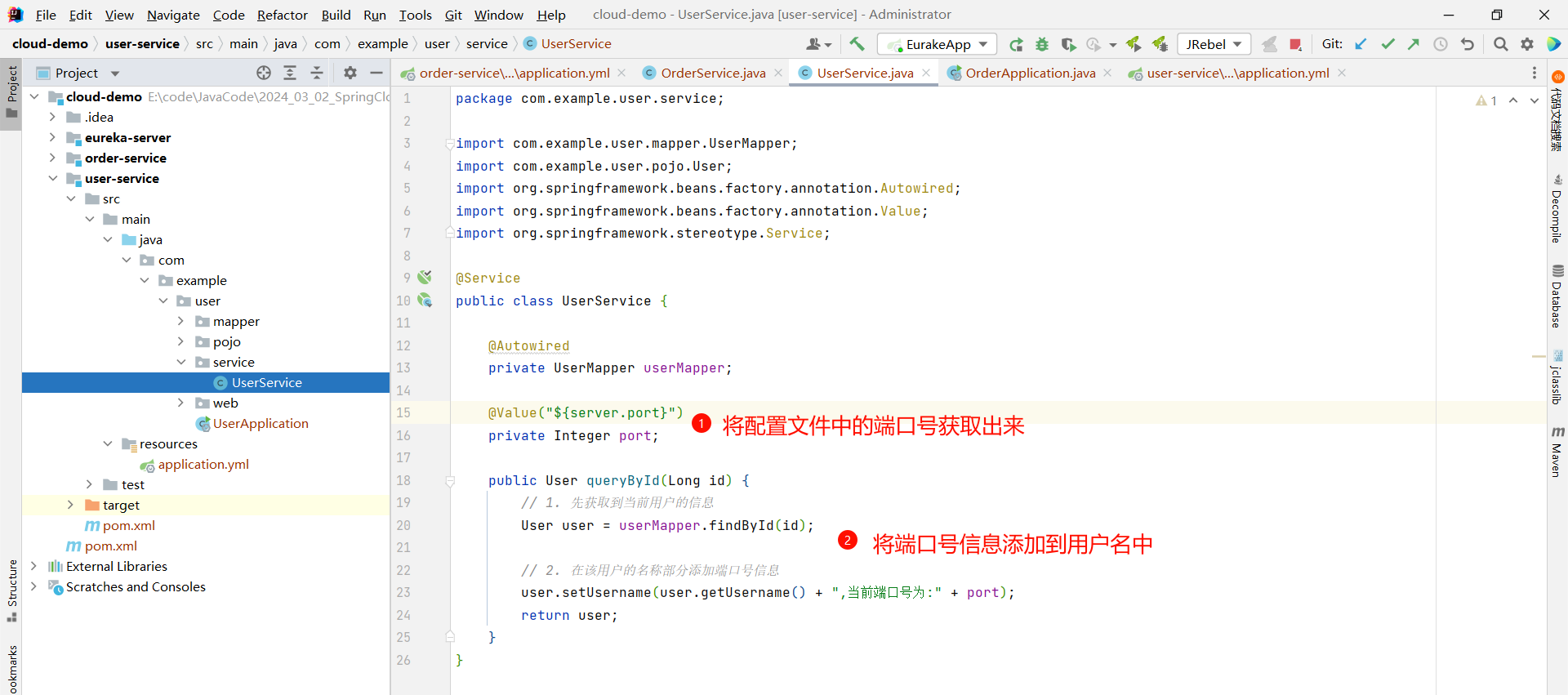
package com.example.user.service;import com.example.user.mapper.UserMapper;
import com.example.user.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;@Service
public class UserService {@Autowiredprivate UserMapper userMapper;@Value("${server.port}")private Integer port;public User queryById(Long id) {// 1. 先获取到当前用户的信息User user = userMapper.findById(id);// 2. 在该用户的名称部分添加端口号信息user.setUsername(user.getUsername() + ",当前端口号为:" + port);return user;}
}
重启 order-service 与 user-service 服务
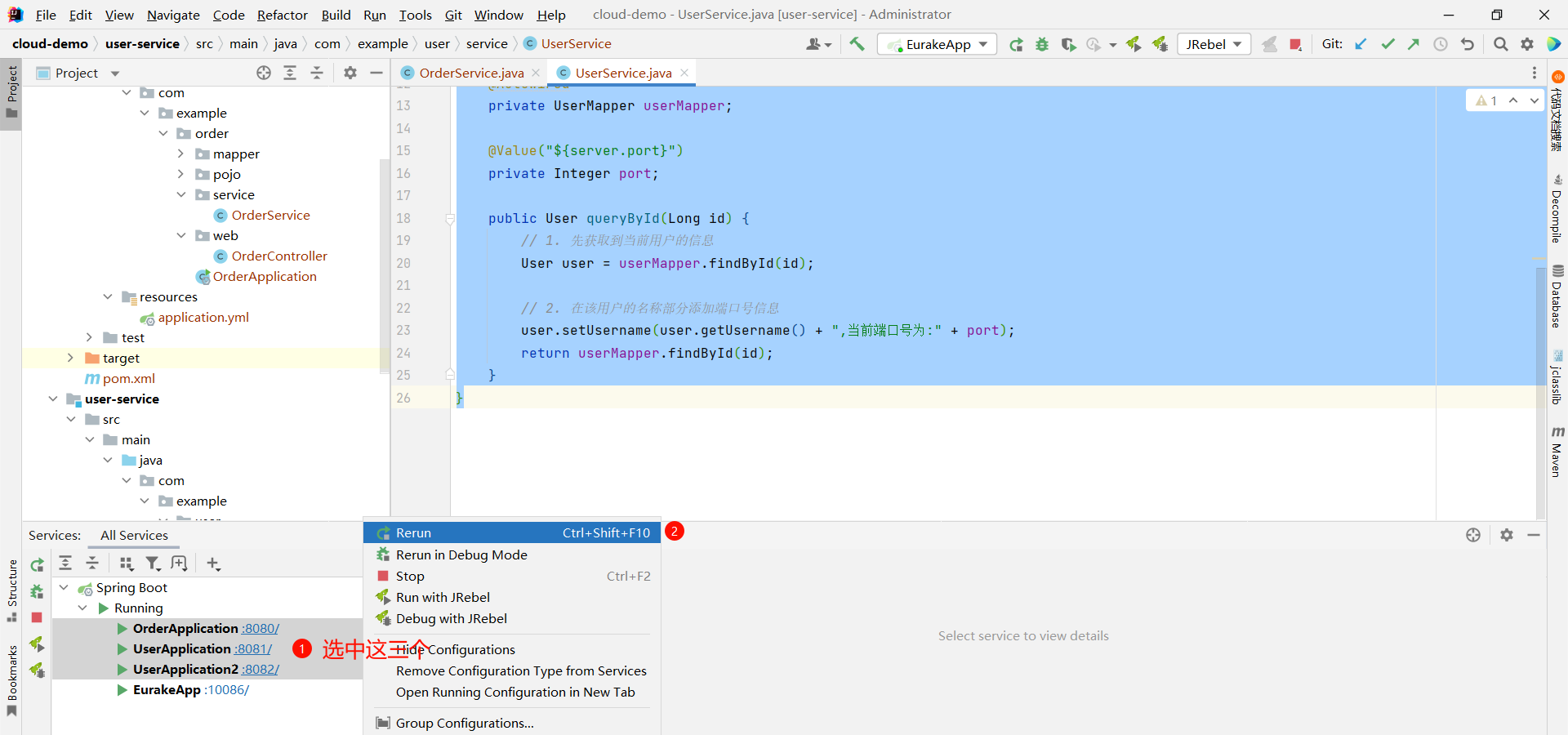
那这次我们再访问 order-service 服务 , 发现报错了
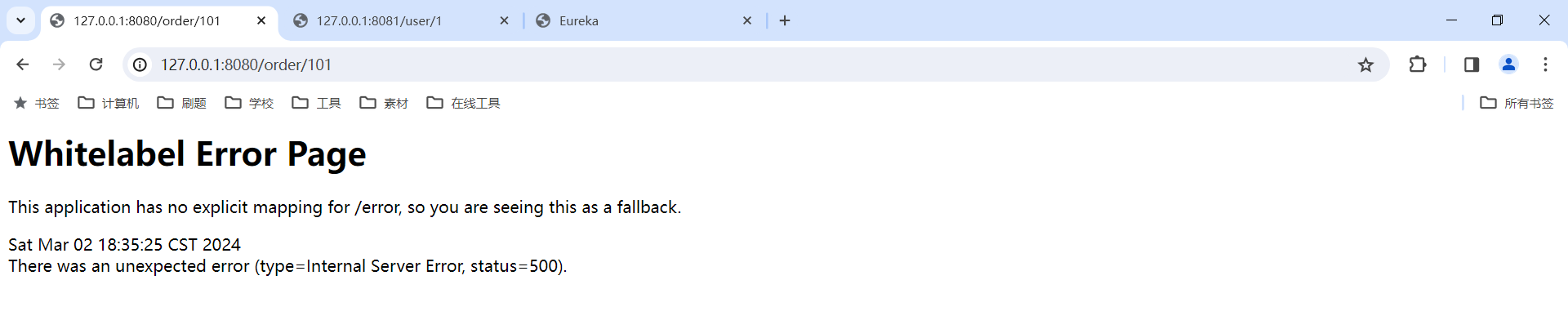
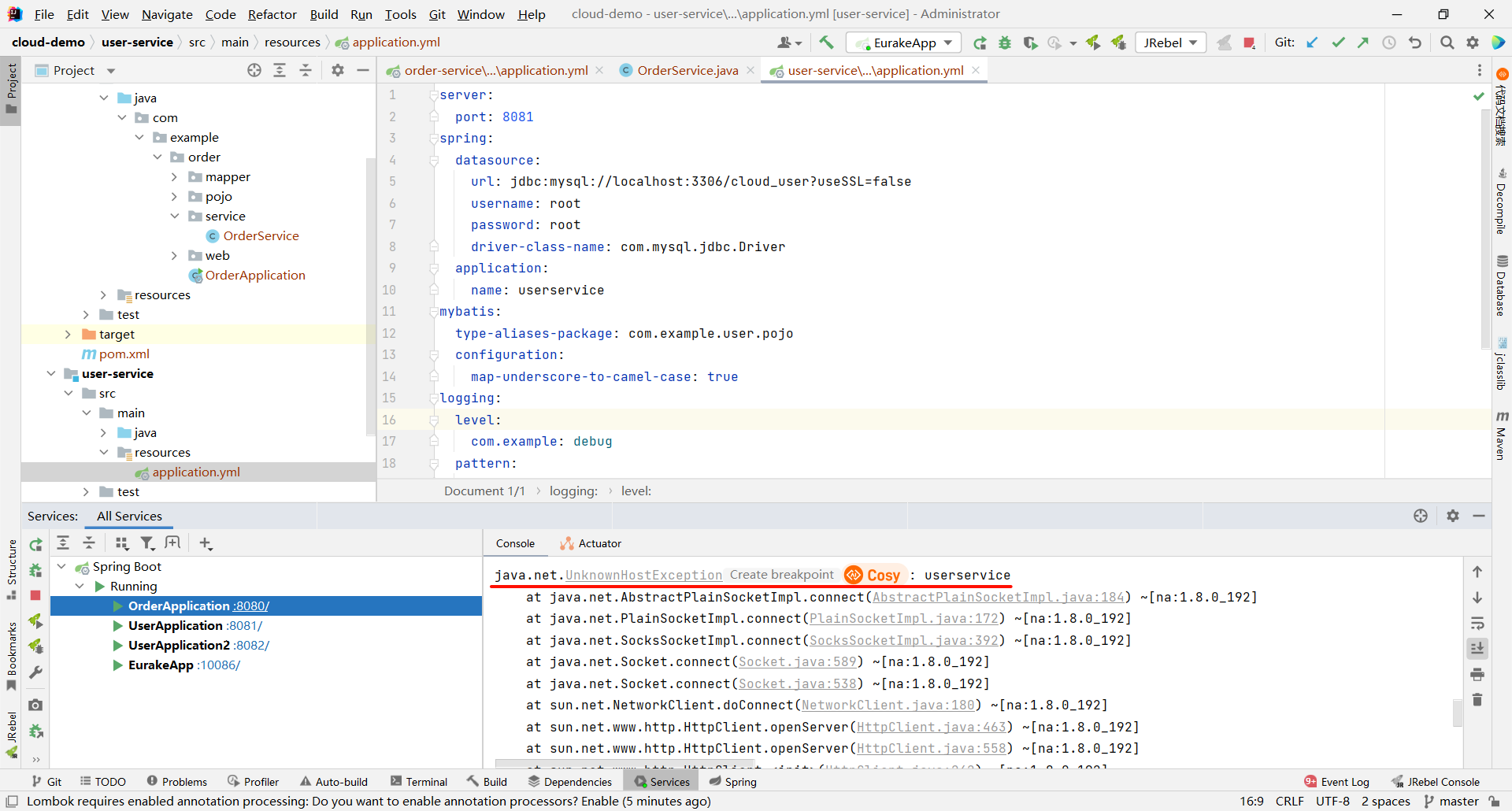
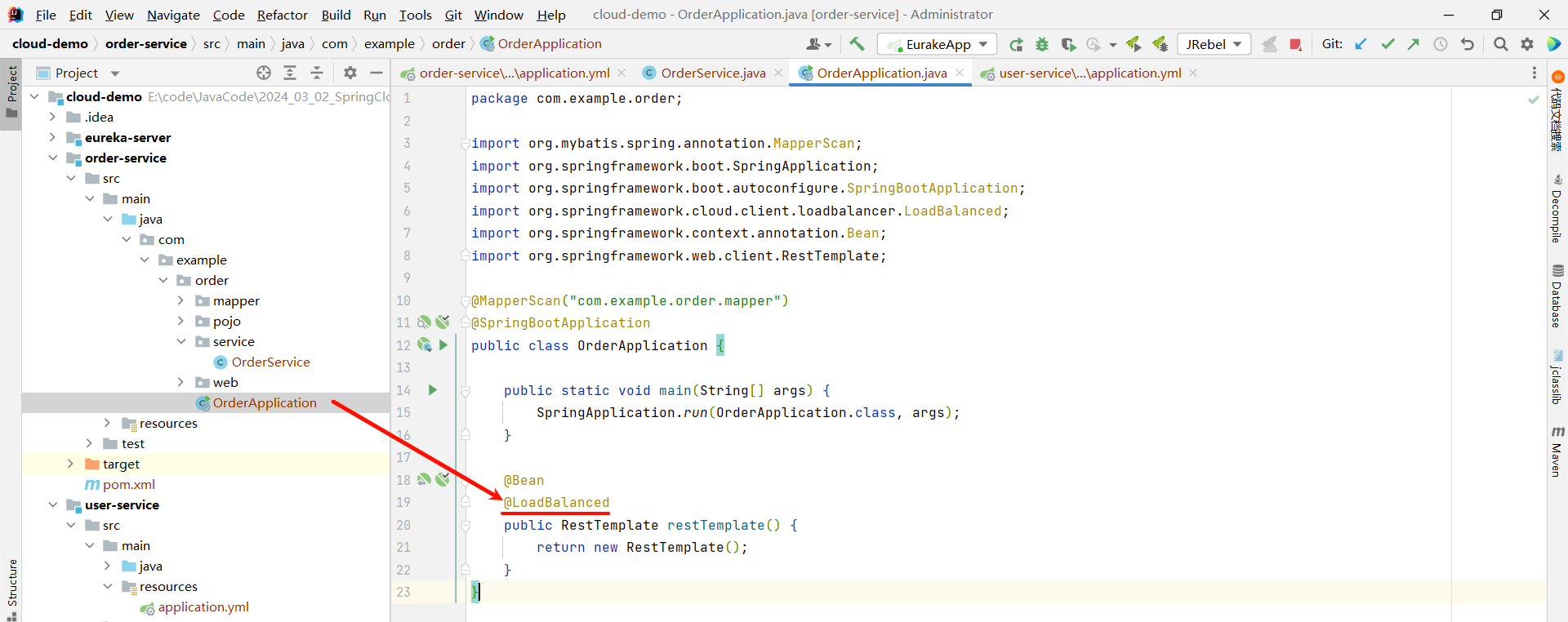
这是因为我们还需要在 order-service 项目的启动类 OrderApplication 中的 RestTemplate 添加负载均衡注解
package com.example.order;import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;@MapperScan("com.example.order.mapper")
@SpringBootApplication
public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}@Bean@LoadBalanced // 开启负载均衡注解public RestTemplate restTemplate() {return new RestTemplate();}
}
这次我们重新运行
我们注意端口号的变化 , 这样就达到了负载均衡的效果 .

小结 :
- 搭建 EurekaServer
- 引入 eureka-server 依赖
- 在当前服务启动类中添加 @EnableEurekaServer 注解
- 在 application.yml 中配置 eureka 地址
- 服务注册
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 服务发现
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 给 RestTemplate 添加 @LoadBalanced 注解
- 用服务提供者的服务名称来去远程调用
五 . Ribbon 负载均衡
5.1 负载均衡流程
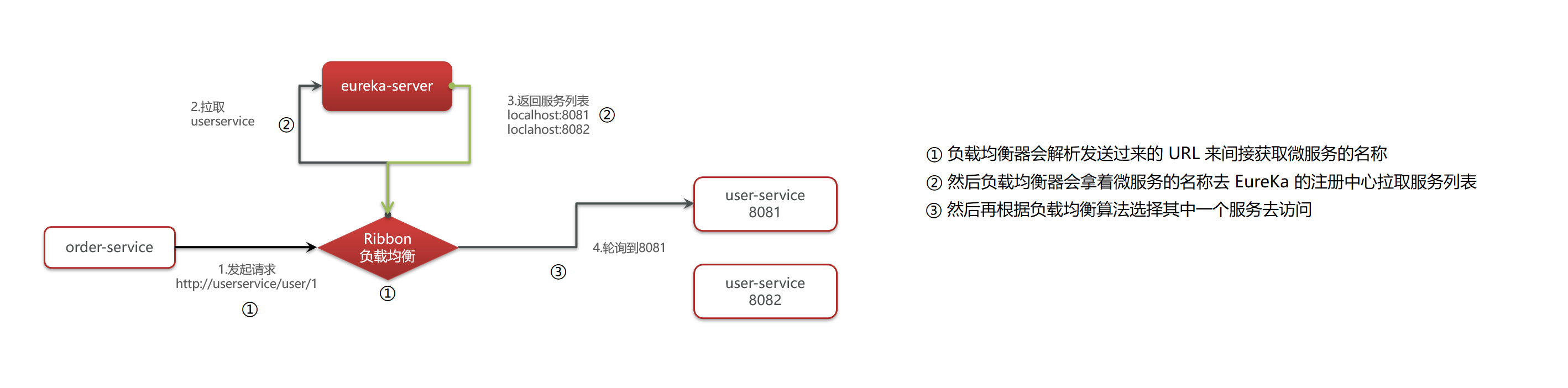
5.2 负载均衡原理
首先 , 我们全局搜索 LoadBalancerInterceptor 类

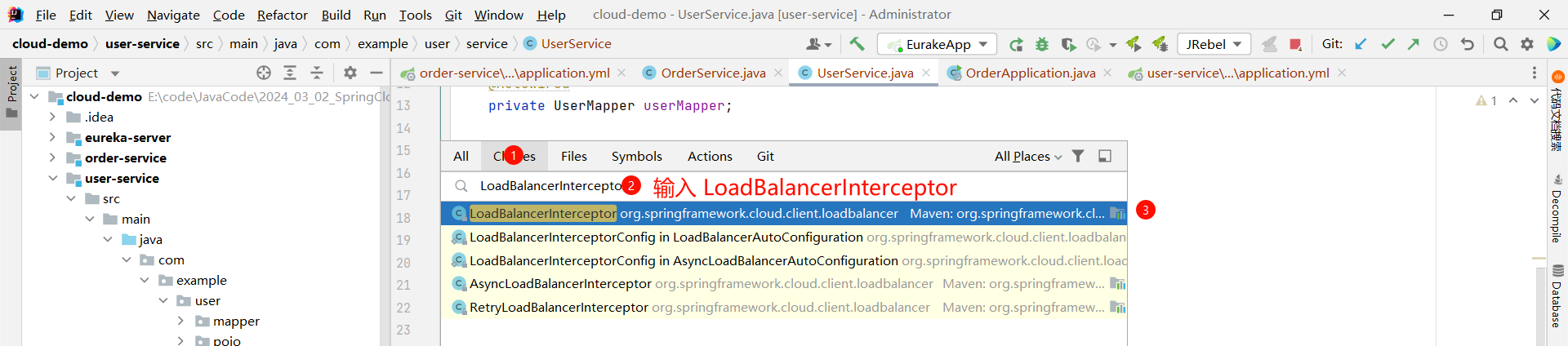
然后在下面的 intercept 方法打个断点
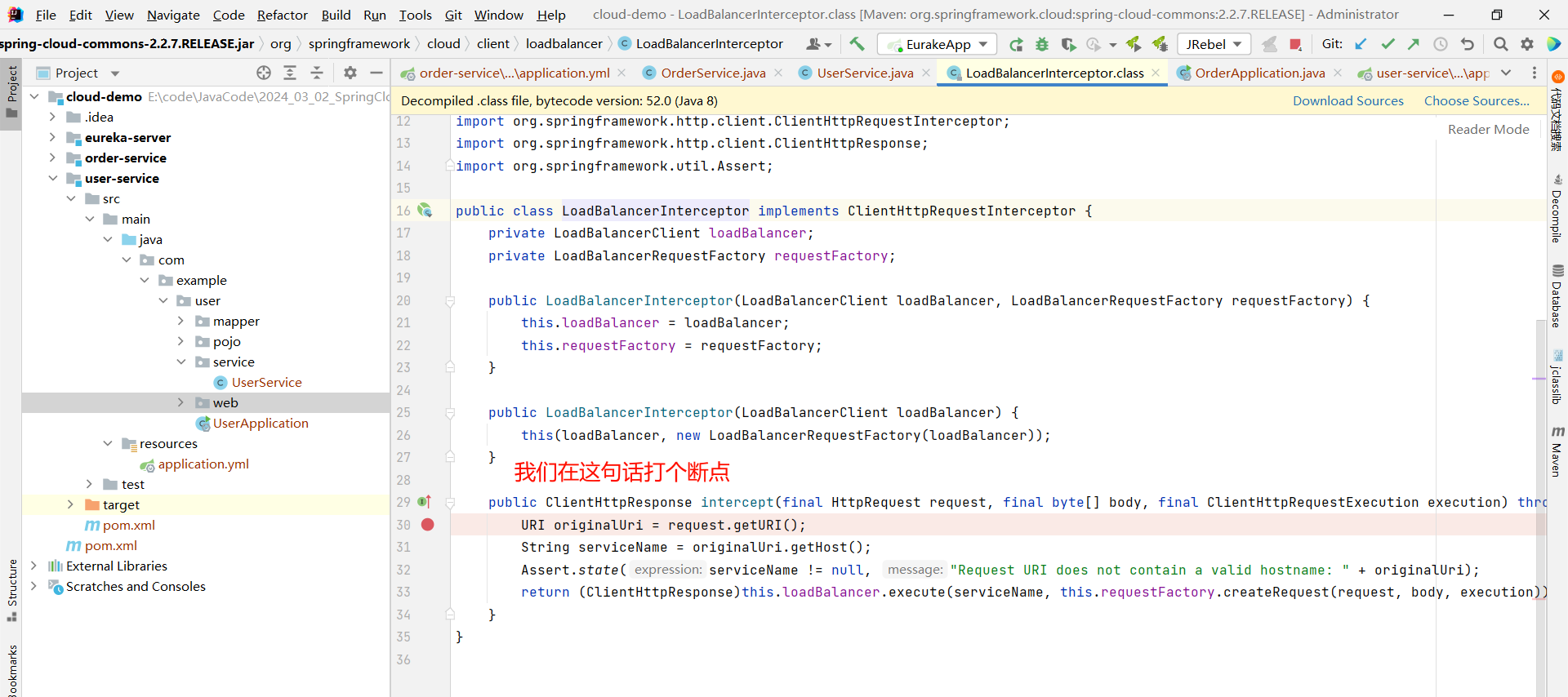
之后让 order-service 以 Debug 的方式运行
此时刷新页面 , 就会被 intercept 方法拦截
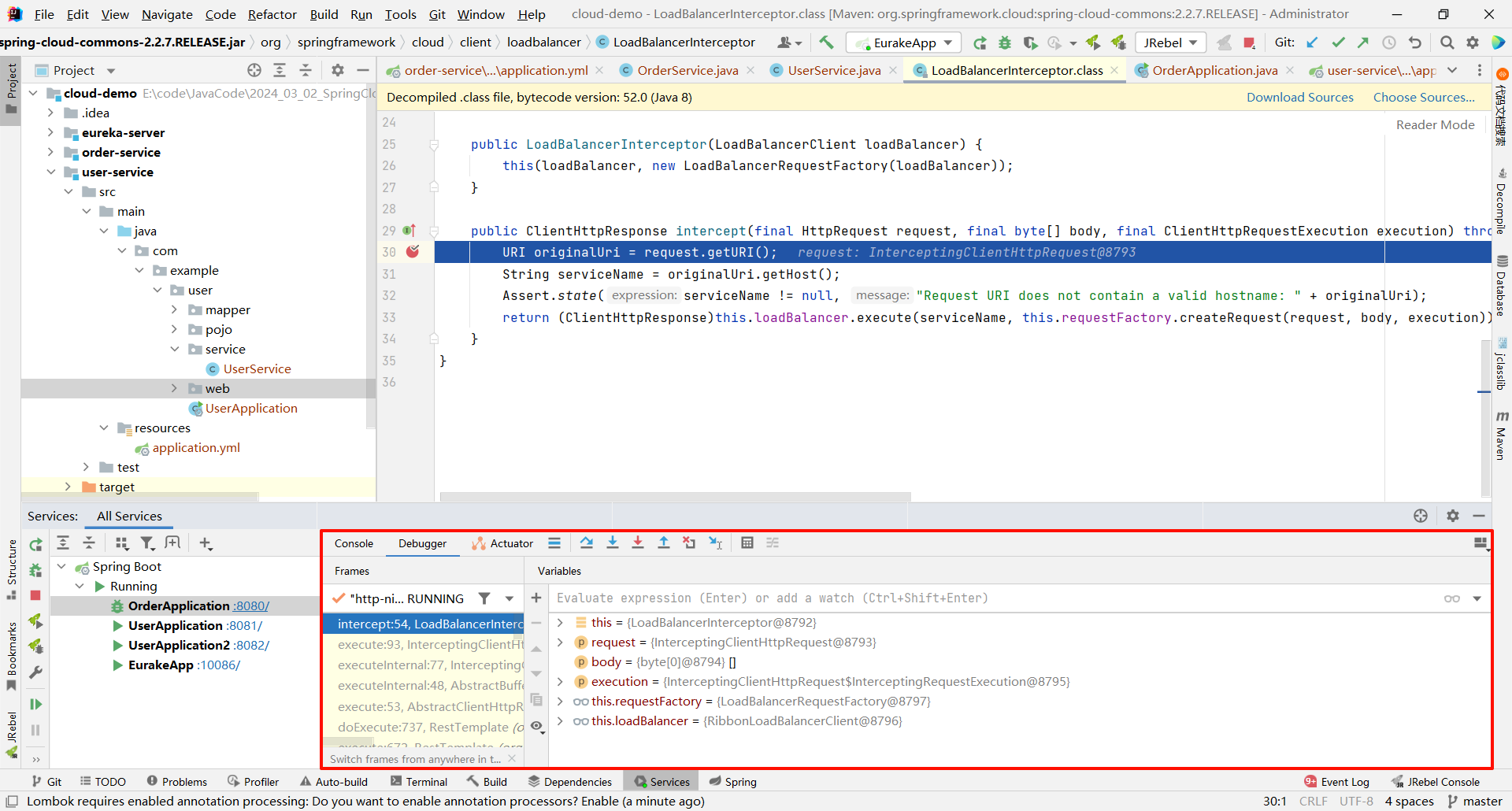
然后我们向下执行 , 发现成功获取到了我们指定的 URL
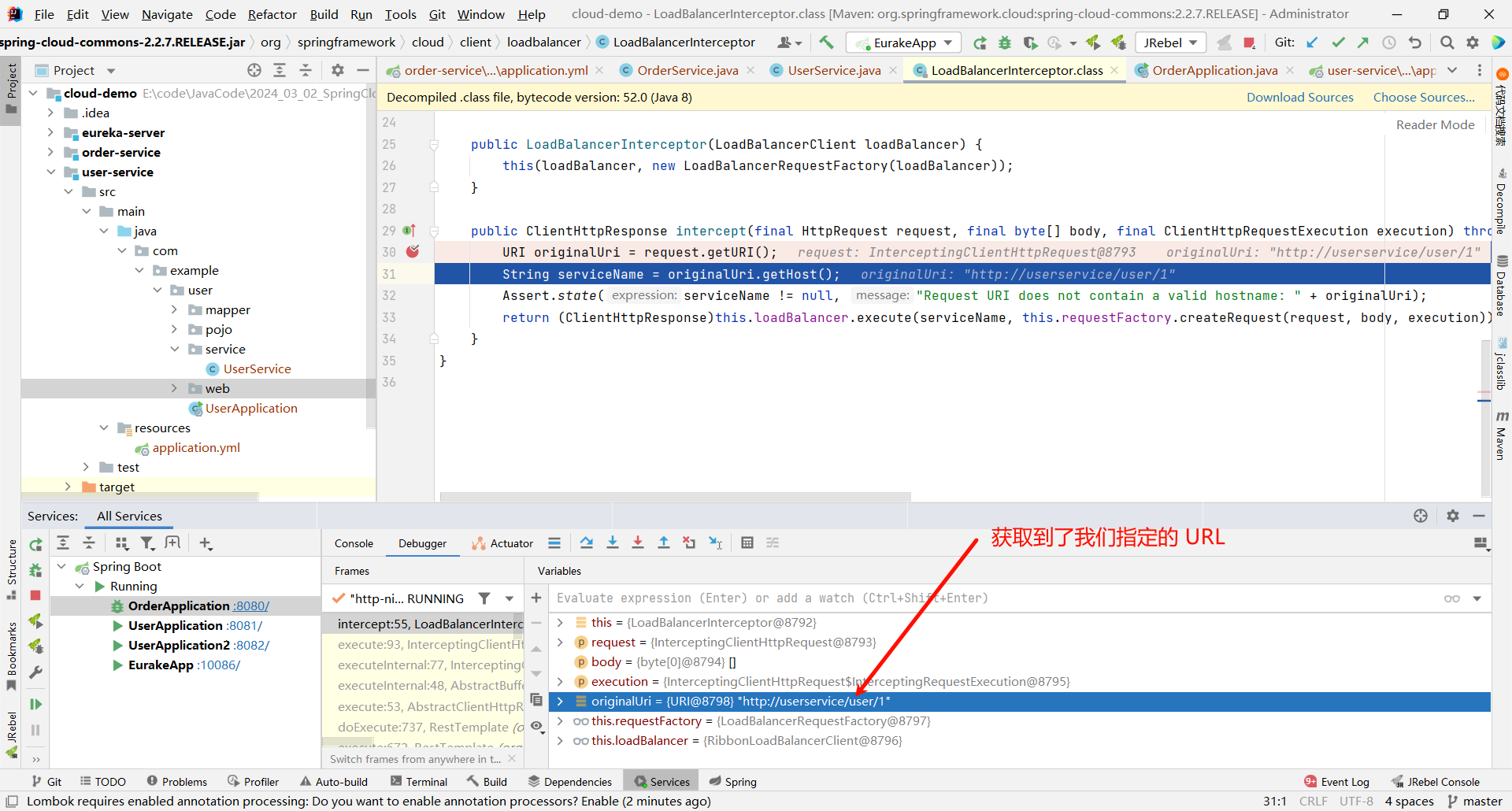
然后再往下执行
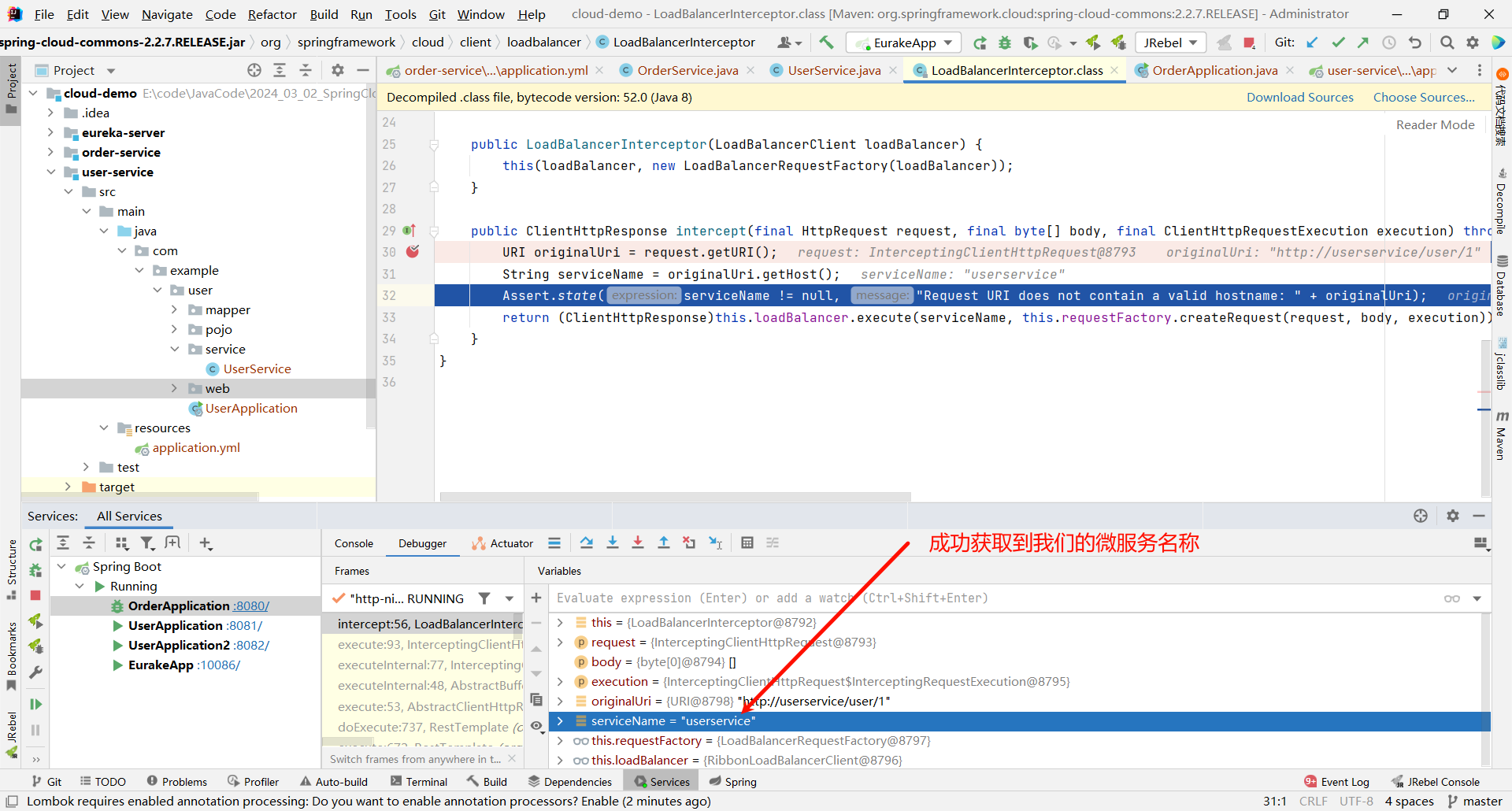
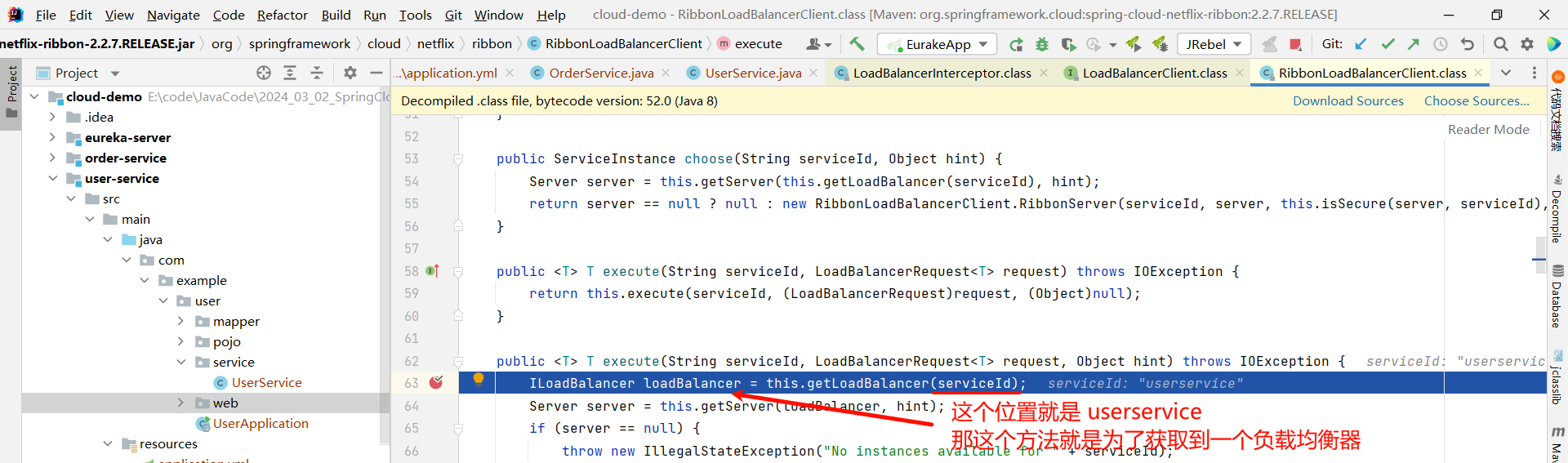
那接下来就是 execute 方法了 , 他的目的肯定是从注册中心获取服务列表 , 我们可以继续深入源码
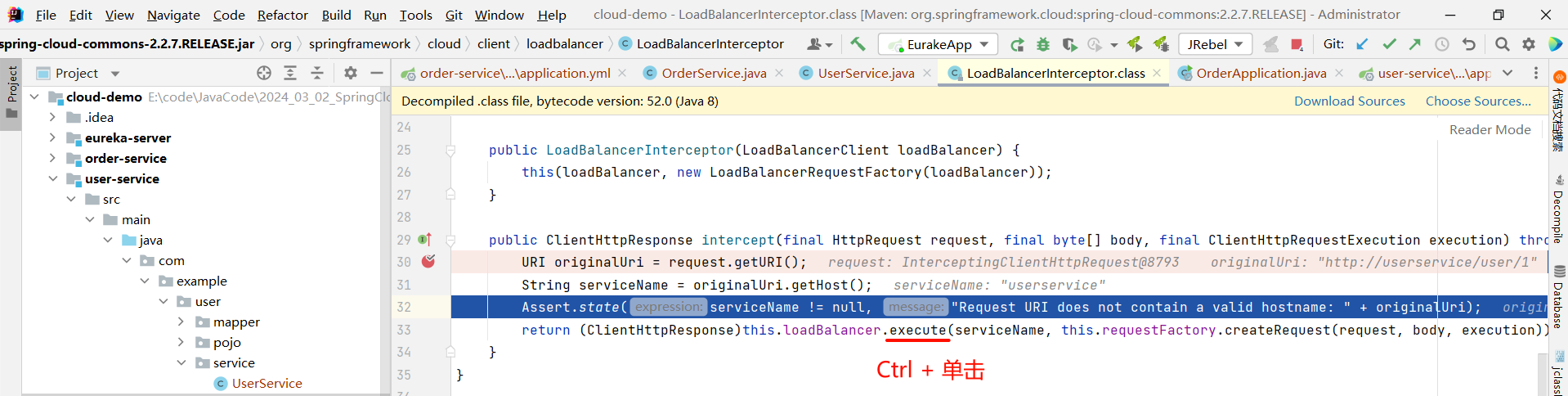
然后我们要看这个接口具体的实现
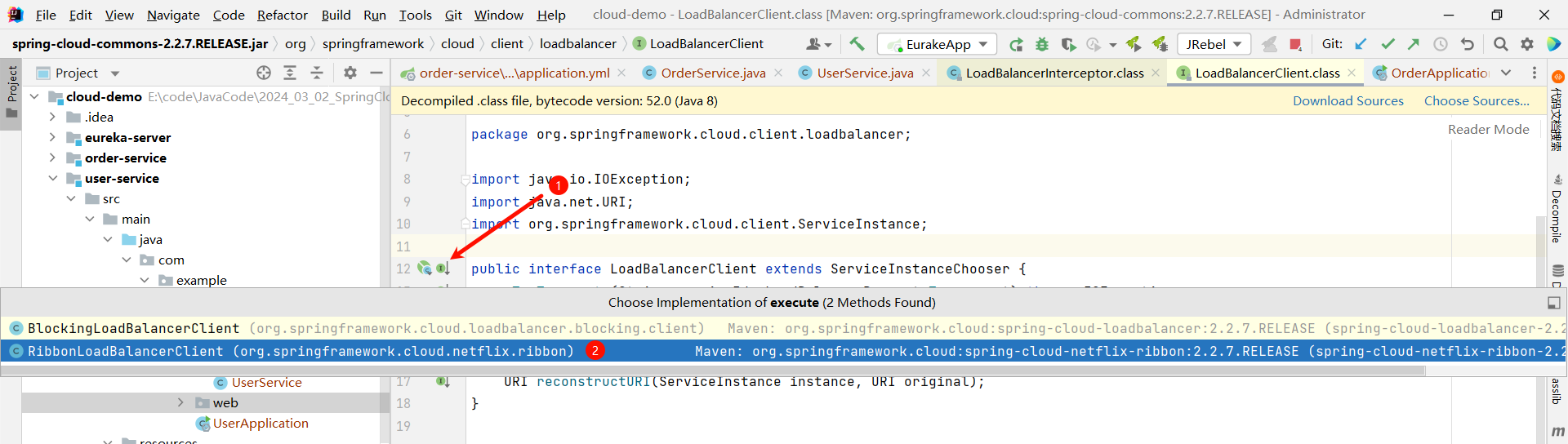
然后在这个方法上添加一个端点 , 看能否执行到这里
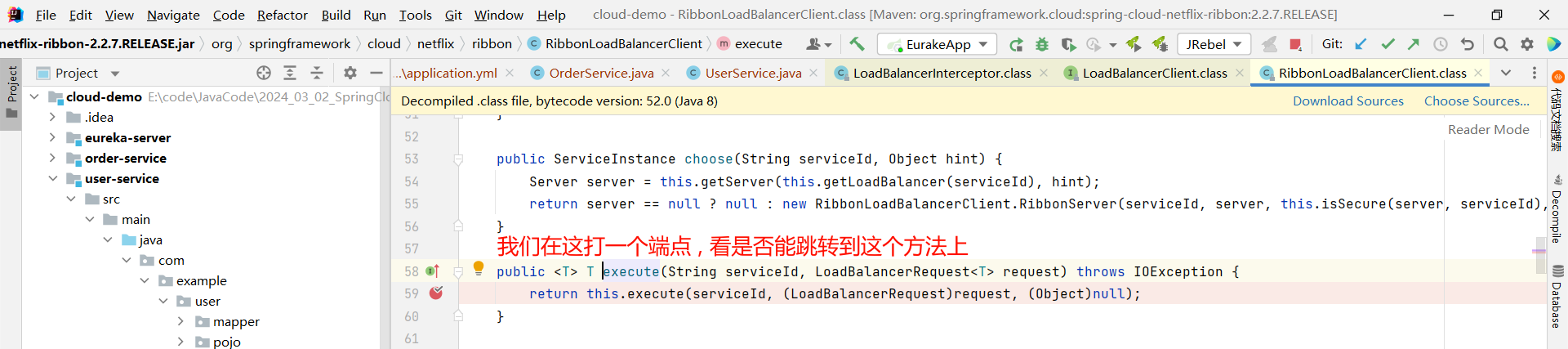
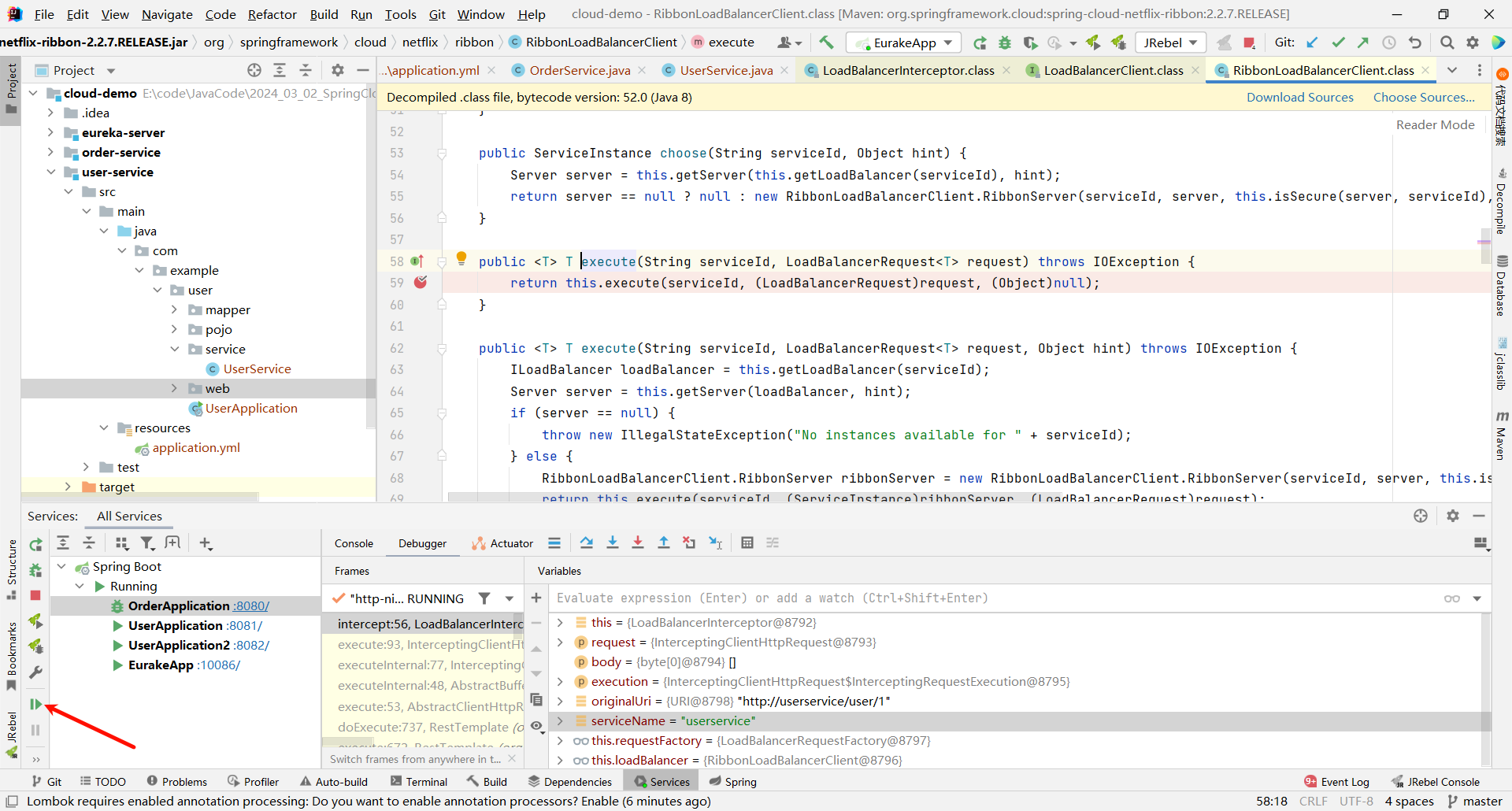
我们发现 , 确实跳转过来了
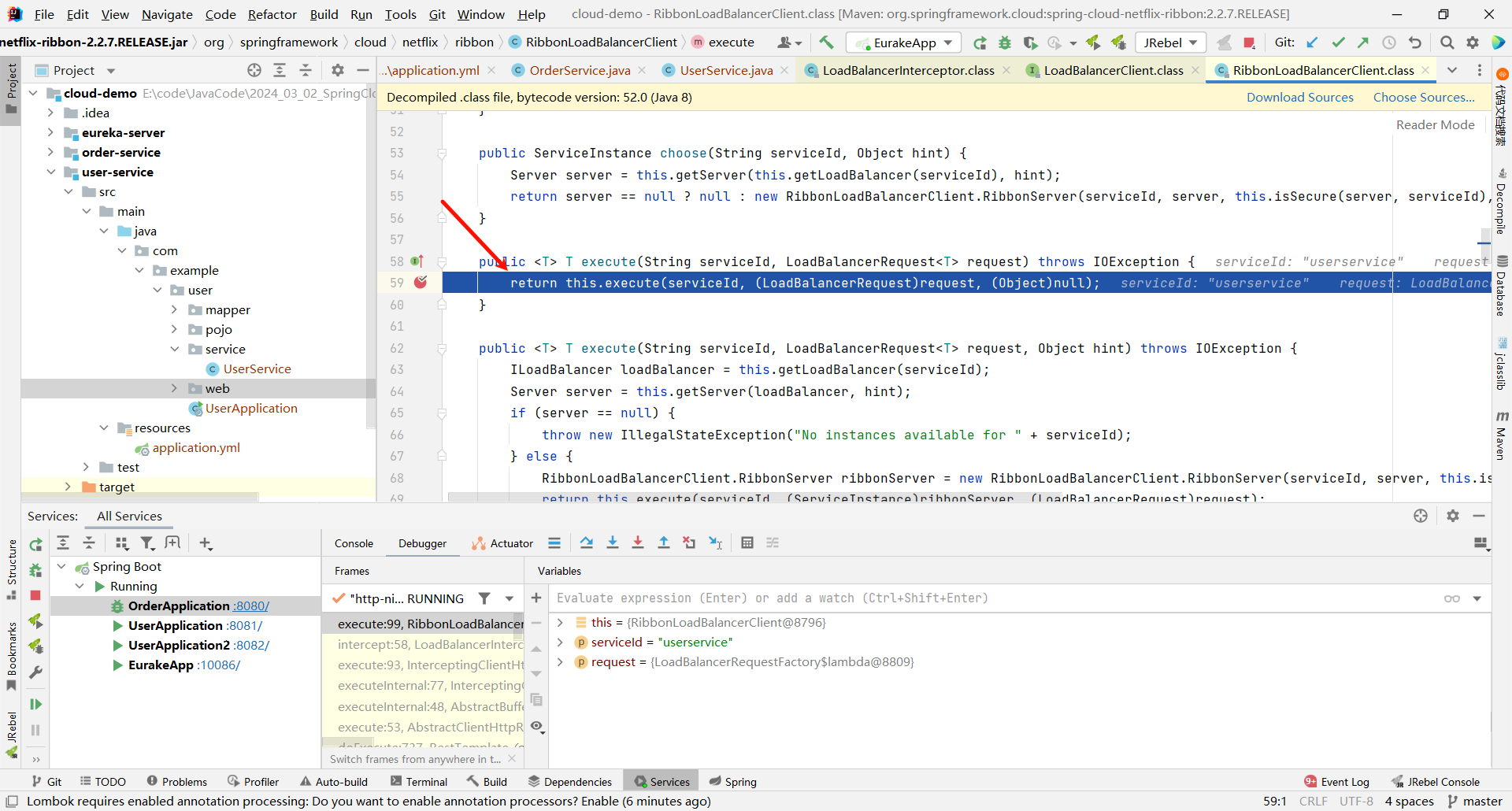
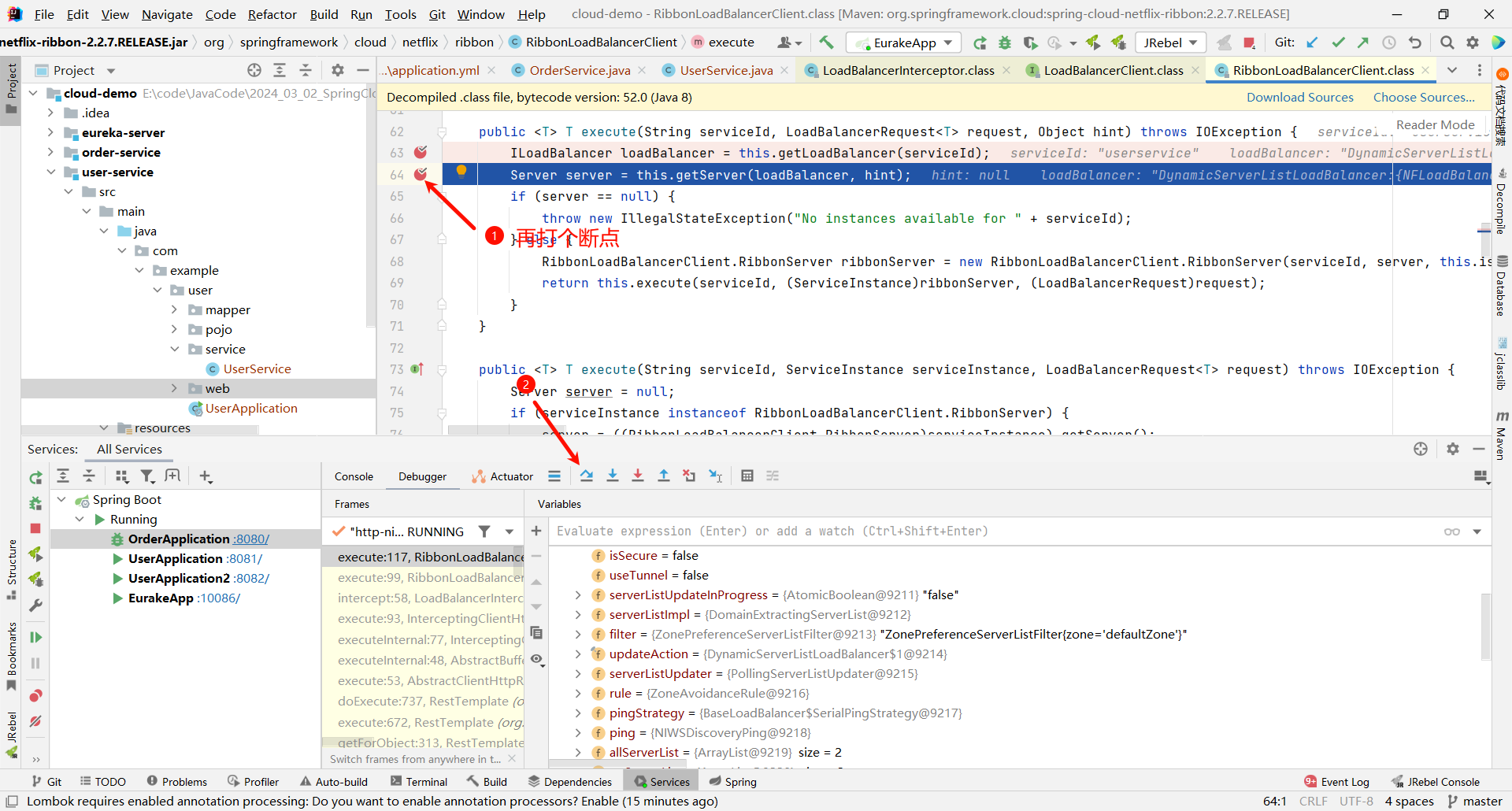
那这个方法是一个重载的方法 , 他还需要继续向下调用 , 那我们就在他的重载方法的位置再打一个断点
将刚刚添加的这个 execute 断点取消
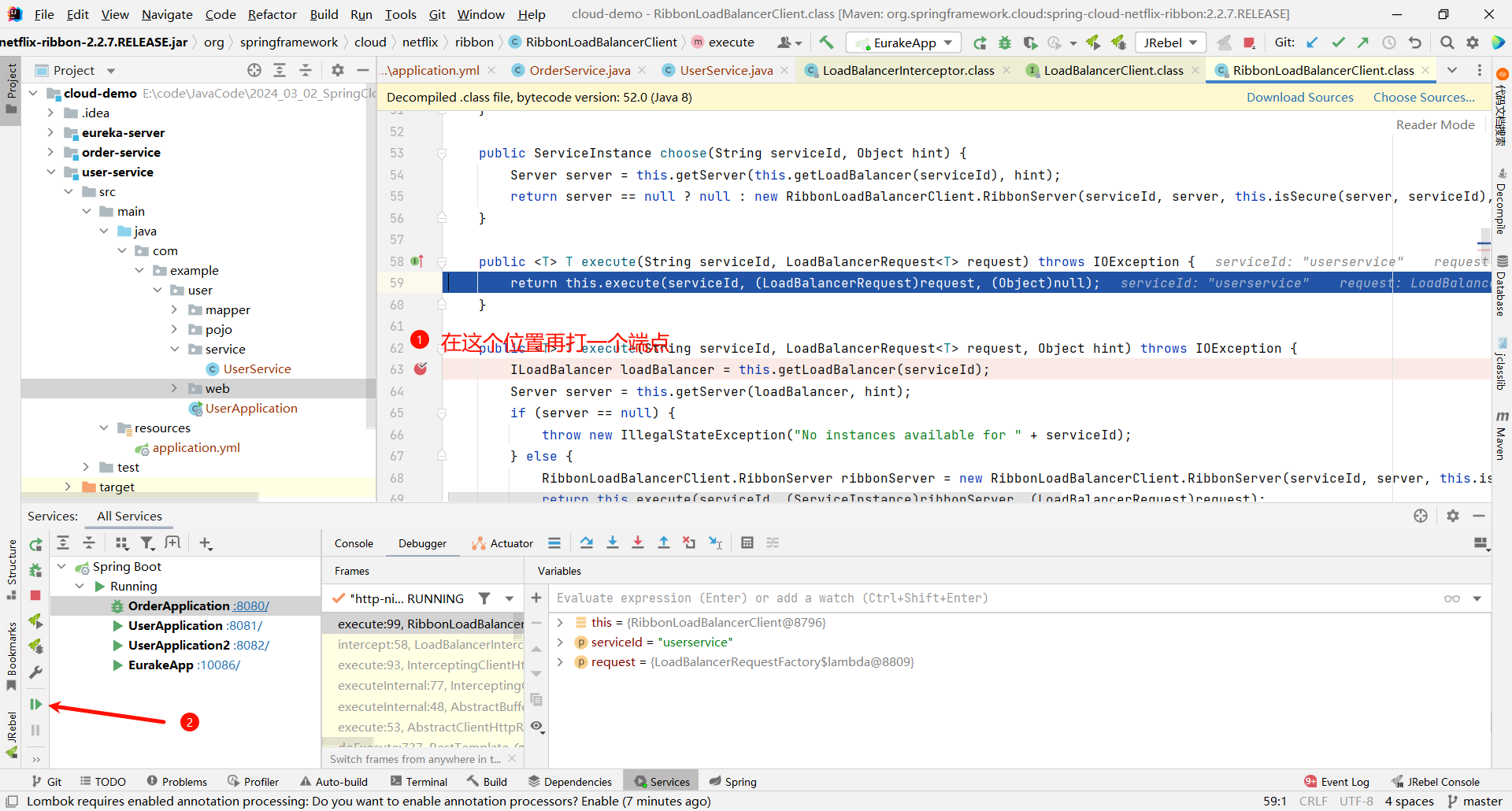
继续向下执行 , 我们看一下 ILoadBalancer 是什么内容
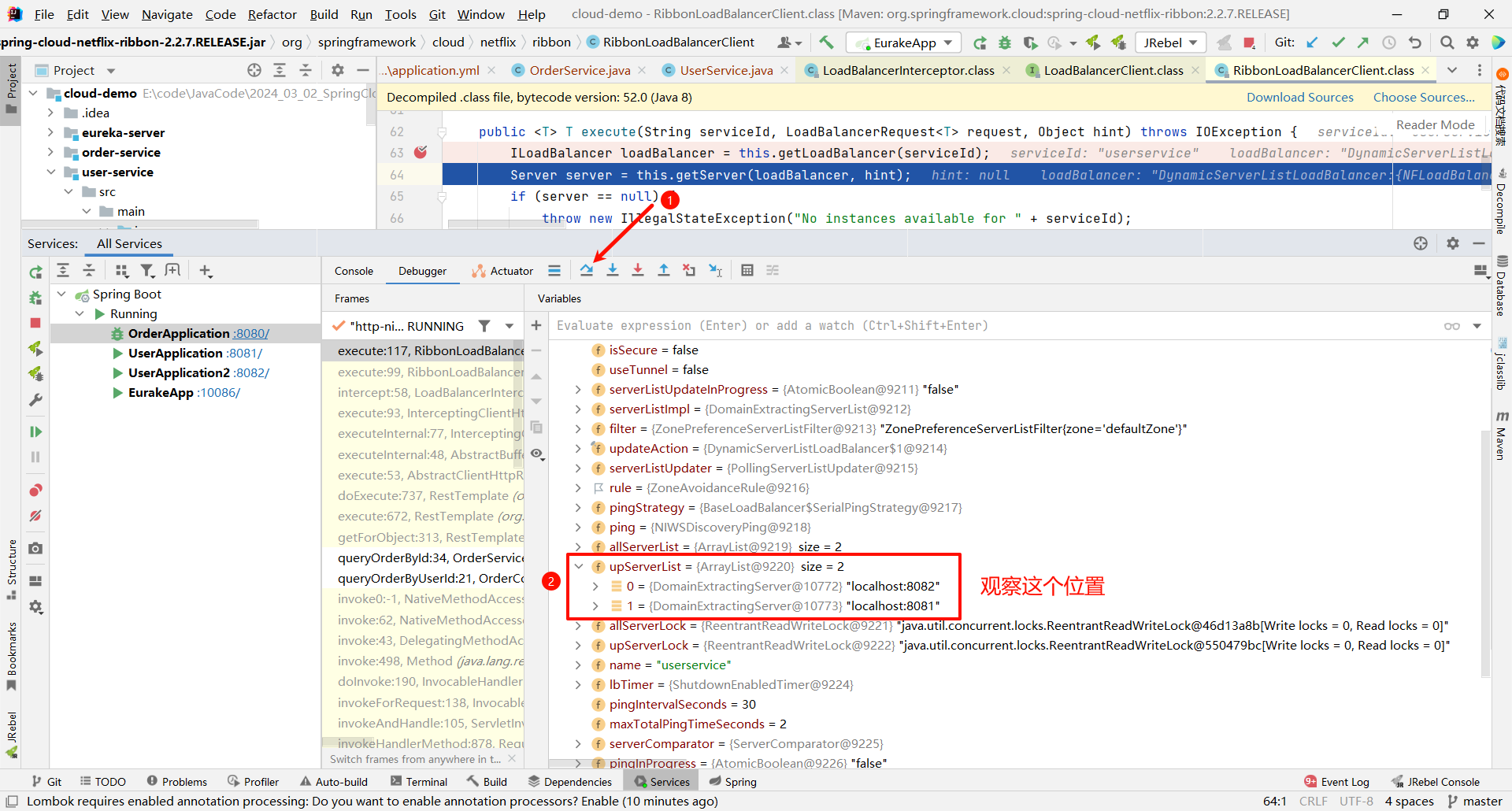
那这个 up 好像有点眼熟 , 这个 up 就代表可用节点的意思
那上面的 allServerList 指的就是所有节点
假如我们总共有三个节点 , 但是有一个节点挂了 . 那 allServerList 就是 3 , upServerList 就是 2
那下面的 getServer 方法就是按照某种策略来去获取某个节点
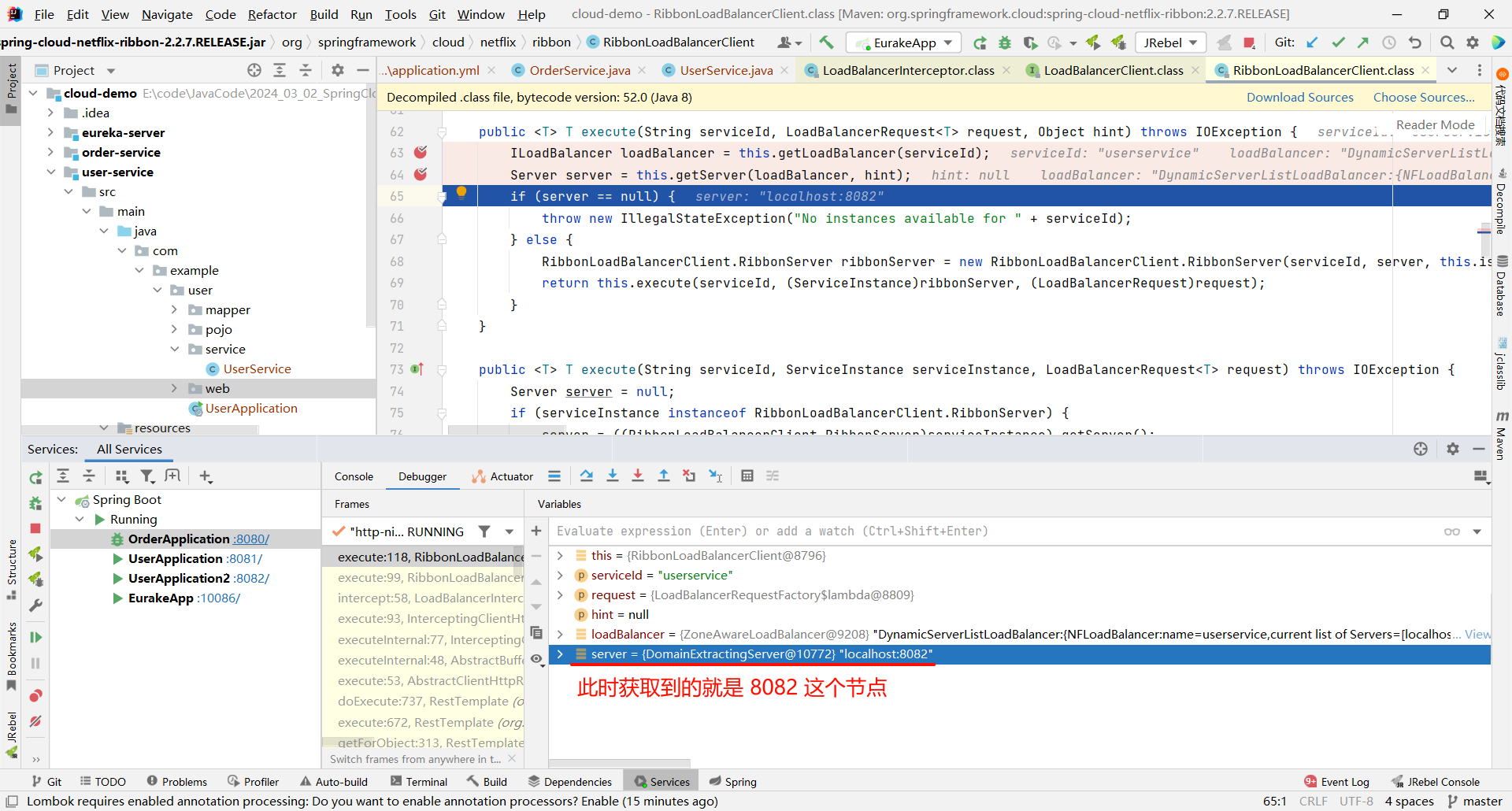
那我们还可以继续深入 getServer 方法
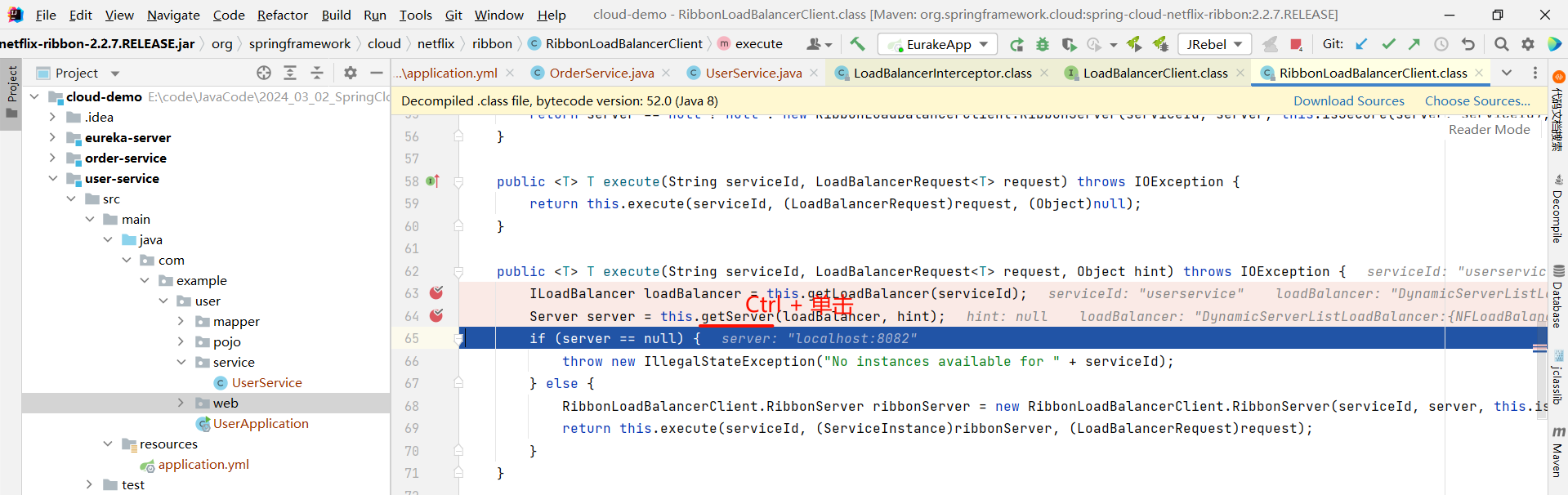
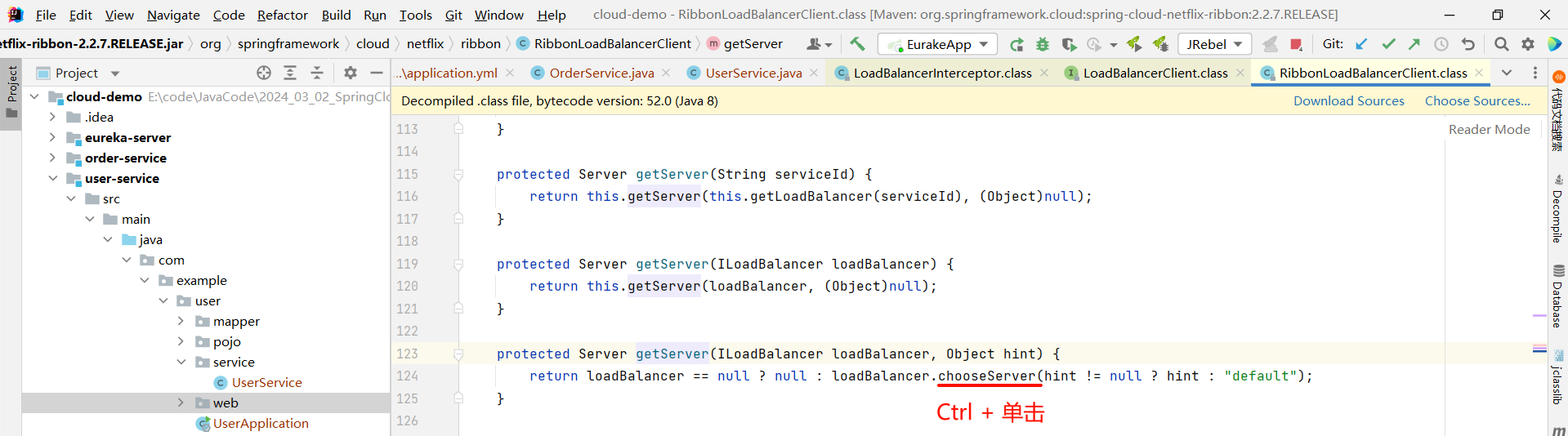
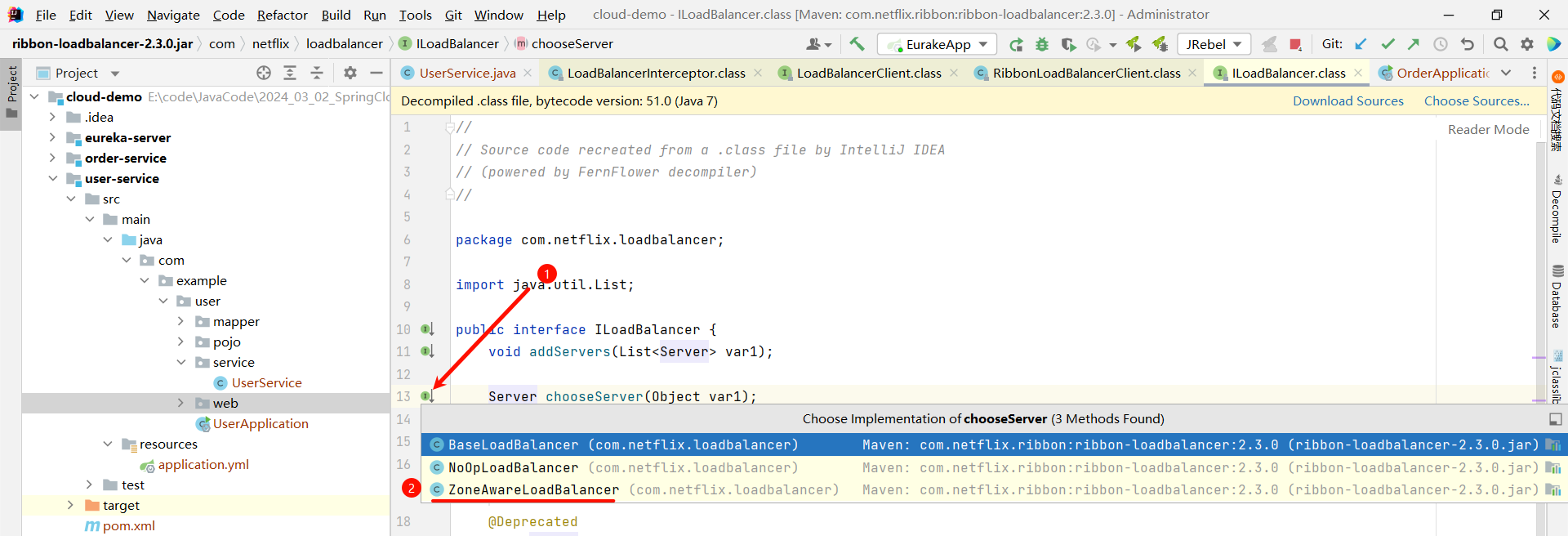
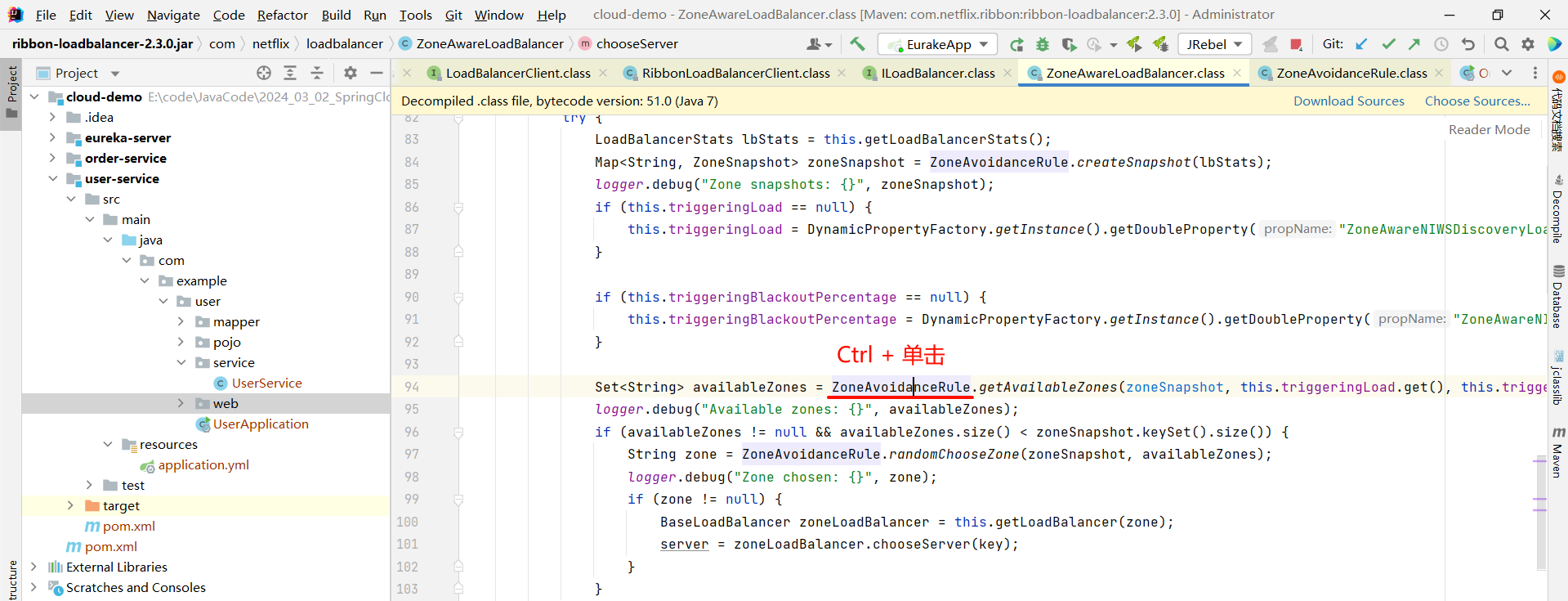
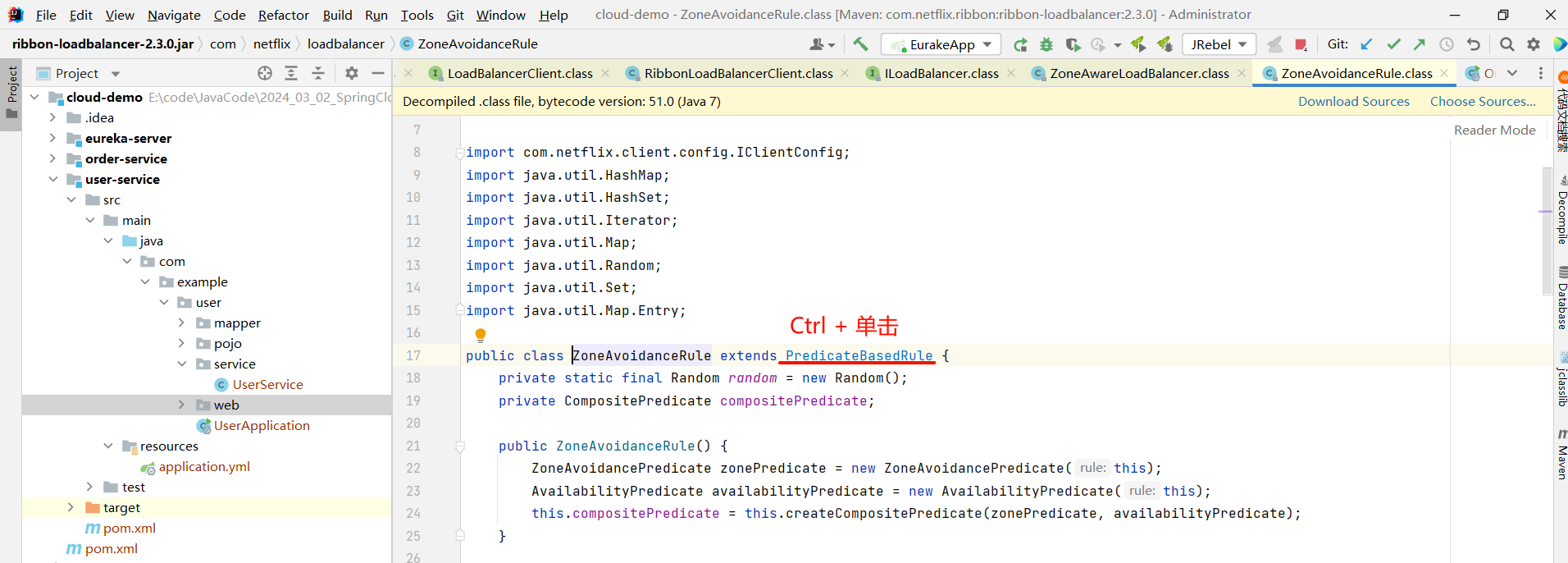
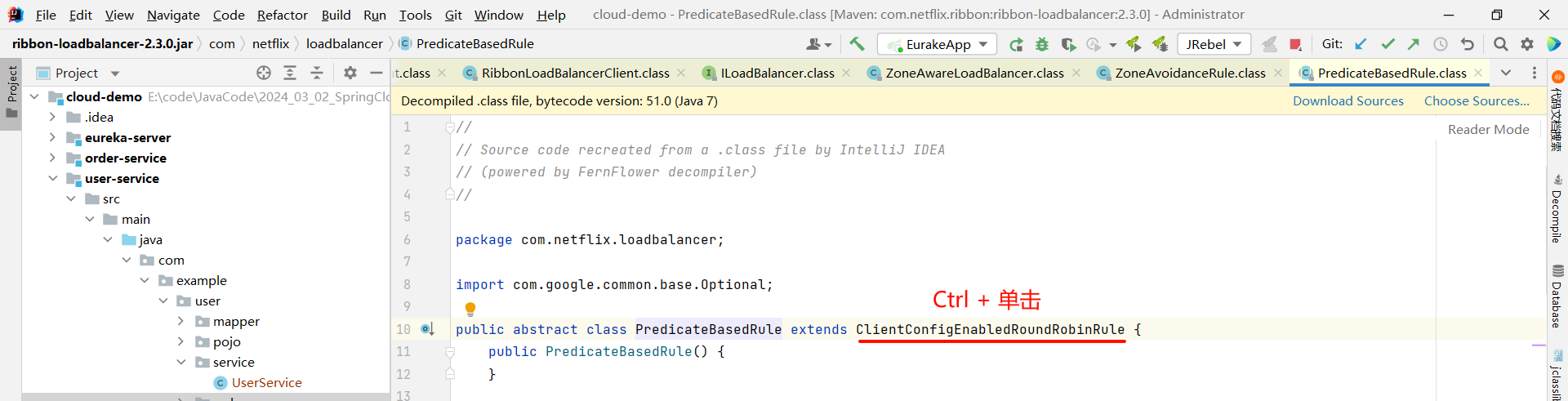
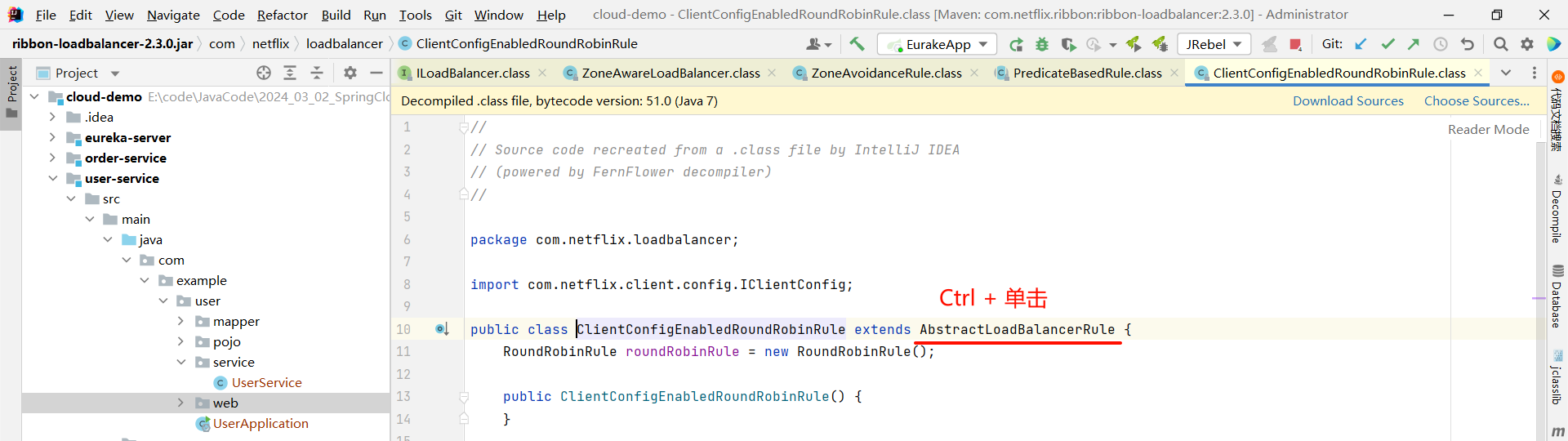
然后我们就找到了负责均衡的最顶层接口
5.3 负载均衡策略
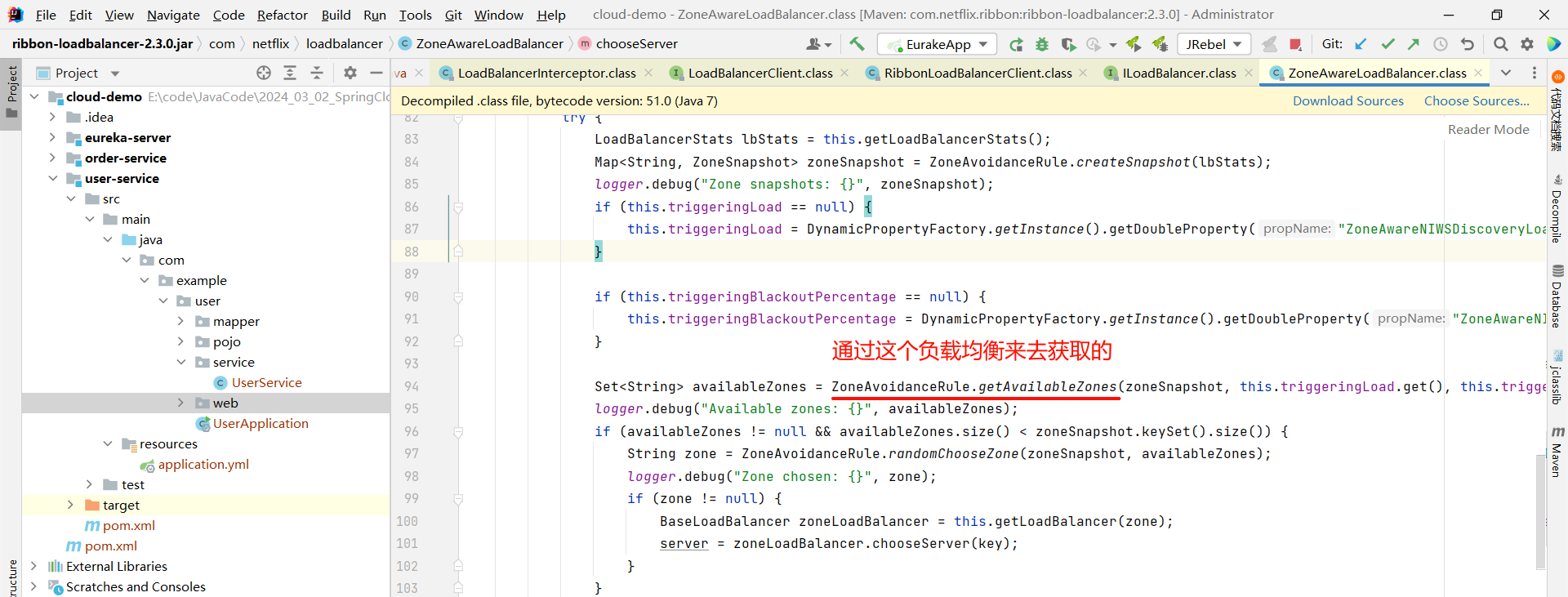
那分析了源码之后 , 我们就可以来看一下整个负载均衡的框图
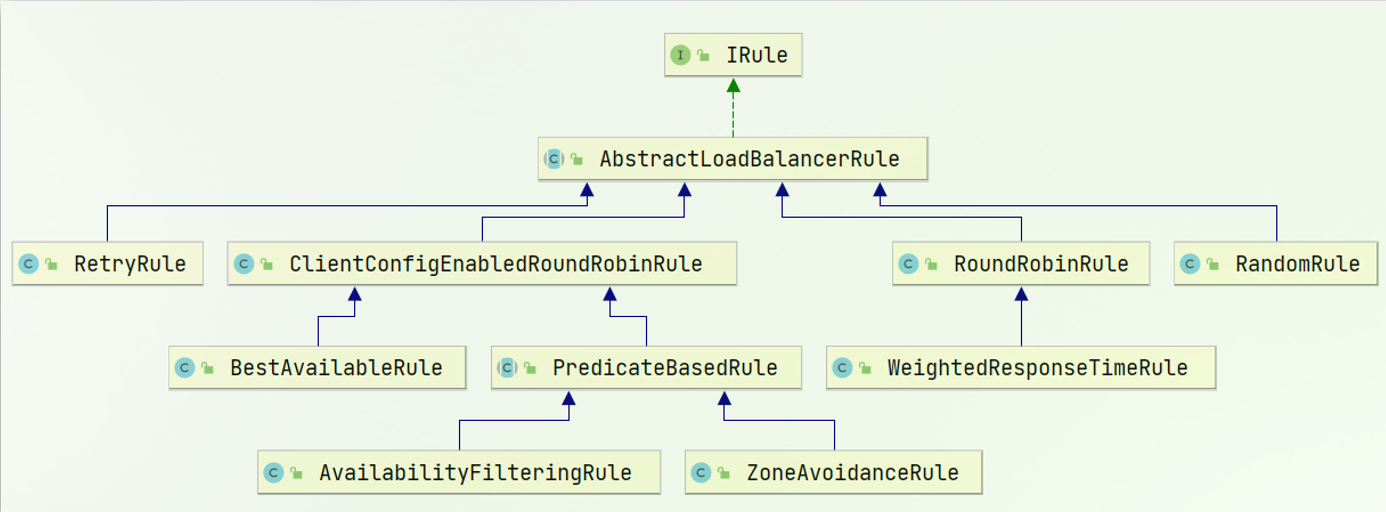
其中 , IRule 是最顶层的接口 , 这里面我们还比较眼熟的是 ZoneAvoidanceRule 这个规则 , 他是负载均衡策略默认的规则 .
那其他我们不认识的 , 其实也是负载均衡的策略 , 我们可以大概看一下
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略 : (1)在默认情况下 , 这台服务器如果 3 次连接失败 , 那这台服务器就会被设置为“短路”状态 . 短路状态将持续 30 秒 , 如果 30s 之后再次连接失败 , 短路的持续时间就会几何级地增加 (30s -> 60s -> 90s …) (2)如果一个服务器的并发连接数过高 , 就会忽略该节点 . |
| WeightedResponseTimeRule | 服务器响应时间越长 , 这个服务器的权重就越小 , 被选中的可能性就越低 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择 , 如果当前节点在北京 , 那也会选择北京的节点进行连接而不是选择上海的节点 . |
| BestAvailableRule | 忽略那些短路的服务器 , 并选择并发数较低的服务器 |
| RandomRule | 随机选择一个可用的服务器 |
| RetryRule | 重试机制 |
那通过定义 IRule 可以实现修改负载均衡的规则 , 有两种方式
① 代码方式
在 order-service 中的启动类下 , 定义一个新的 IRule 覆盖掉本来的配置 (秉持谁用谁配置的原则 , order-service 需要调用 user-service , 就需要 order-service 进行配置)
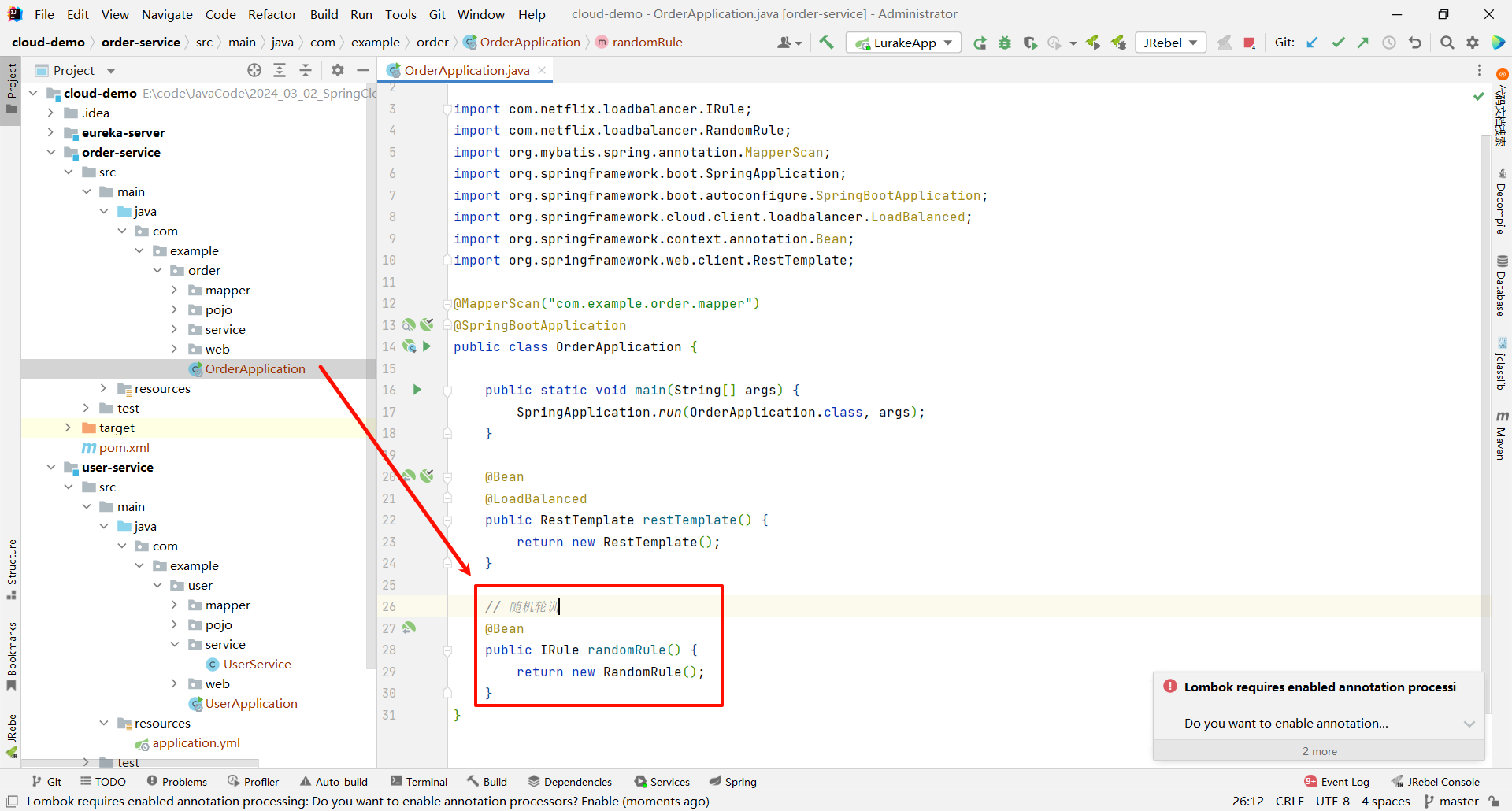
package com.example.order;import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;@MapperScan("com.example.order.mapper")
@SpringBootApplication
public class OrderApplication {public static void main(String[] args) {SpringApplication.run(OrderApplication.class, args);}@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}// 随机轮训@Beanpublic IRule randomRule() {return new RandomRule();}
}
接下来 , 我们重启 order-service , 看一下是否还按照轮训的方式访问
我们注意端口号的变化



并不是完全按照 81 -> 82 -> 81 这样轮训的方式获取的了 .
② 配置文件方式
在 order-service 的 application.yml 文件中 , 添加新的配置也可以去修改规则
userservice: # 给某个微服务配置负载均衡规则, 这里是 userservice 服务ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
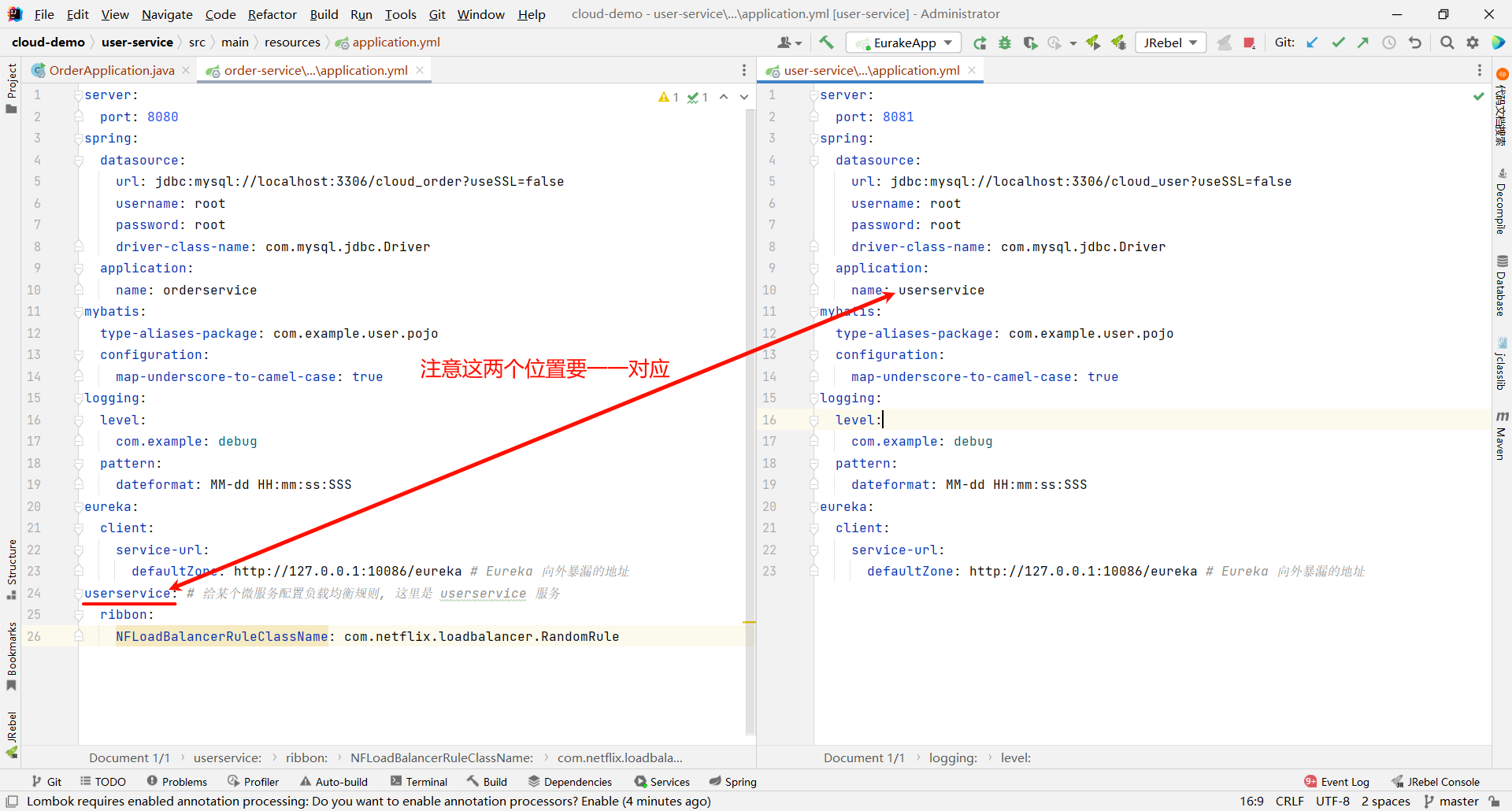
那我们可以重新运行一下
将刚才代码的方式注释掉



这次访问的都是 8082 端口了
5.4 懒加载
那我们的 order-service 需要访问 user-service 的节点 , 那 order-service 就需要向 EureKa 的注册中心获取服务列表 , 那这个服务列表是什么时候获取的呢 ?
是调用的时候采取获取 , 还是服务刚启动的时候就获取服务列表呢 ?
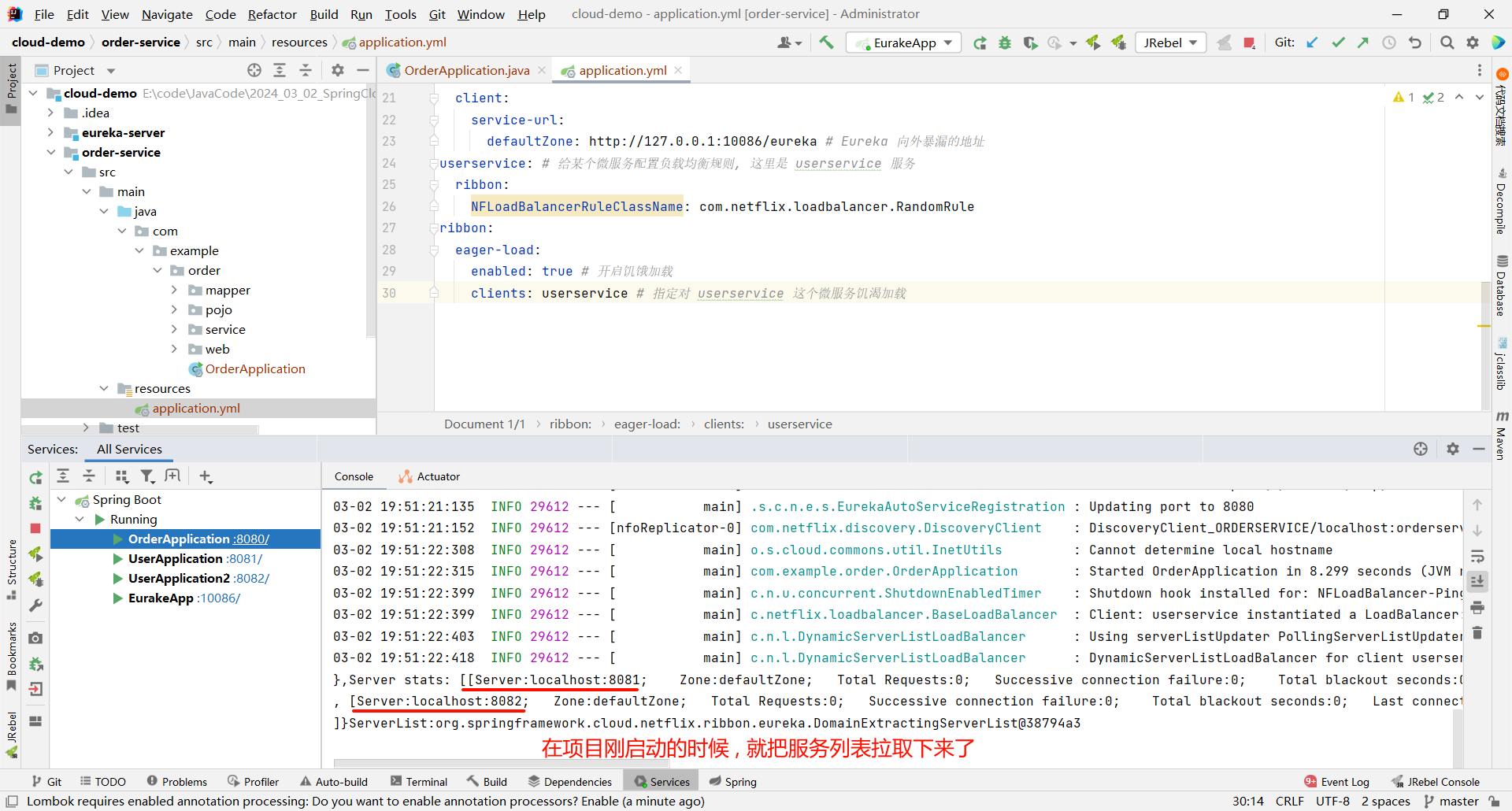
那 Ribbon 默认是懒加载 , 只有第一次访问的时候才会去创建 LoadBalanceClient . 我们可以设置成饥饿加载 , 在项目启动的时候就创建 LoadBalanceClient , 这样就降低了第一次访问的耗时时长 .
我们可以通过配置文件开启饥饿加载 .
ribbon:eager-load:enabled: true # 开启饥饿加载clients: userservice # 指定对 userservice 这个微服务饥渴加载
如果对多个服务开启饥饿加载的话 , 可以使用列表的形式
ribbon:eager-load:enabled: true # 开启饥饿加载clients:- userservice # 指定对 userservice 这个微服务饥渴加载
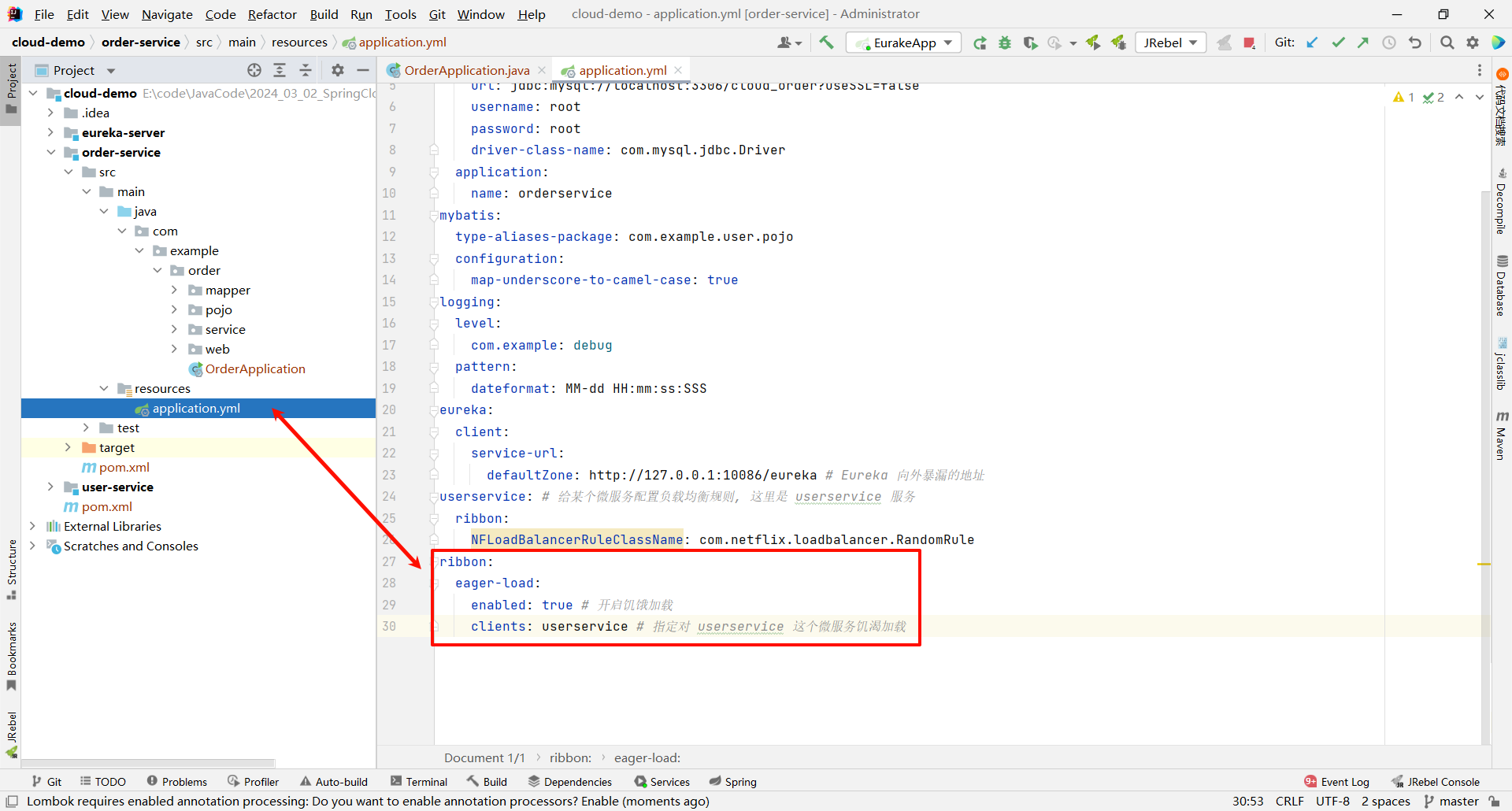
那我们重新启动一下 , 就能够在控制台发现一些蛛丝马迹了
5.5 小结
- Ribbon 负载均衡规则
- 规则接口是 IRule
- 默认实现是 ZoneAvoidanceRule , 根据 zone (地区) 选择服务列表 , 然后轮询
- 负载均衡自定义方式
- 代码方式 : 配置灵活 , 但修改时需要重新打包发布
- 配置方式 : 直观、方便 , 无需重新打包发布 , 在配置中心统一配置即可 , 但是无法做全局配置
- 饥饿加载
- 开启饥饿加载 : 设置 ribbon.eager-load.enabled 为 true
- 指定饥饿加载的微服务名称 : 将需要饥饿加载的微服务添加到 ribbon.eager-load.clients 中
相关文章:
微服务架构实战:Eureka服务注册发现与Ribbon负载均衡详解
微服务架构实战:Eureka服务注册发现与Ribbon负载均衡详解 一 . 服务调用出现的问题二 . EureKa 的作用三 . 服务注册3.1 搭建 EureKaServer① 创建项目 , 引入 spring-cloud-starter-netflix-eureka-server 的依赖② 编写启动类 , 添加 EnableEurekaServer 注解③ 添…...
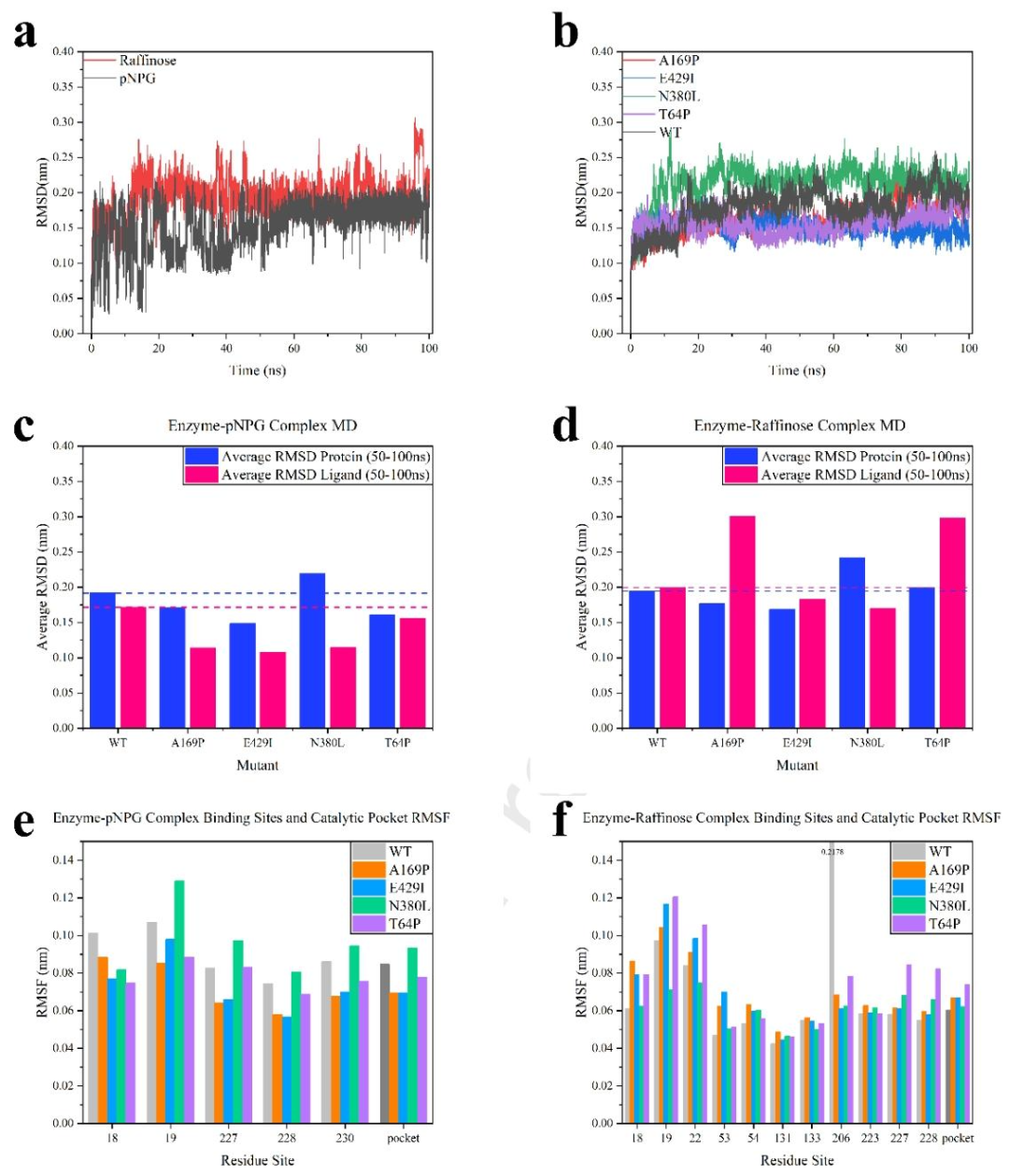
采用多维计算策略(分子动力学模拟+机器学习),显著提升 α-半乳糖苷酶热稳定性
字数 978,阅读大约需 5 分钟 在工业应用领域,α-半乳糖苷酶在食品加工、动物营养及医疗等方面发挥着重要作用。然而,微生物来源的该酶往往存在热稳定性不足的问题,限制了其在工业场景中的高效应用。近日,来自江南大学的…...
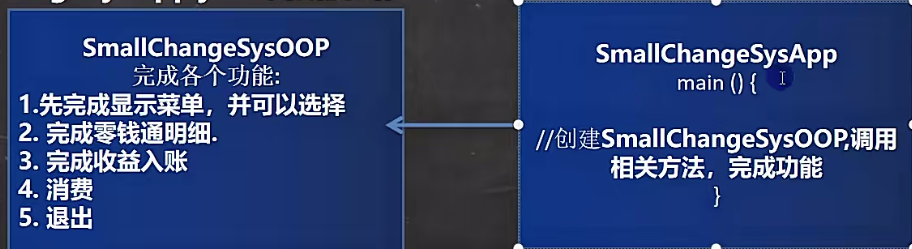
【java】小练习--零钱通
文章目录 前言一、项目开发流程说明二、功能实现2.1 菜单2.2 零钱通明细2.3 零钱通收益2.4 零钱通消费2.5 零钱通退出确认2.6 零钱通金额校验2.7 完整代码 三、零钱通OOP版 前言 本文是我跟着B站韩顺平老师的 Java 教程学习时动手实现“零钱通”项目的学习笔记,主要…...

旅游信息检索
旅游信息检索 旅游信息检索是系统中实现数据获取和处理的关键环节,负责根据用户输入的目的地城市和出游天数,动态获取并生成高质量的旅游数据。 模块的工作流程分为以下几个阶段:首先,对用户输入的信息进行标准化处理࿰…...

贝叶斯理论
一、贝叶斯理论的核心思想 贝叶斯理论(Bayesian Theory)是一种基于条件概率的统计推断方法,其核心是通过先验知识和新观测数据的结合,动态更新对事件发生概率的估计。它体现了“用数据修正信念”的思想,广泛应用于机器…...
Docker-mongodb
拉取 MongoDB 镜像: docker pull mongo 创建容器并设置用户: 要挂载本地数据目录,请替换此路径: /Users/Allen/Env/AllenDocker/mongodb/data/db docker run -d --name local-mongodb \-e MONGO_INITDB_ROOT_USERNAMEadmin \-e MONGO_INITDB_ROOT_PA…...
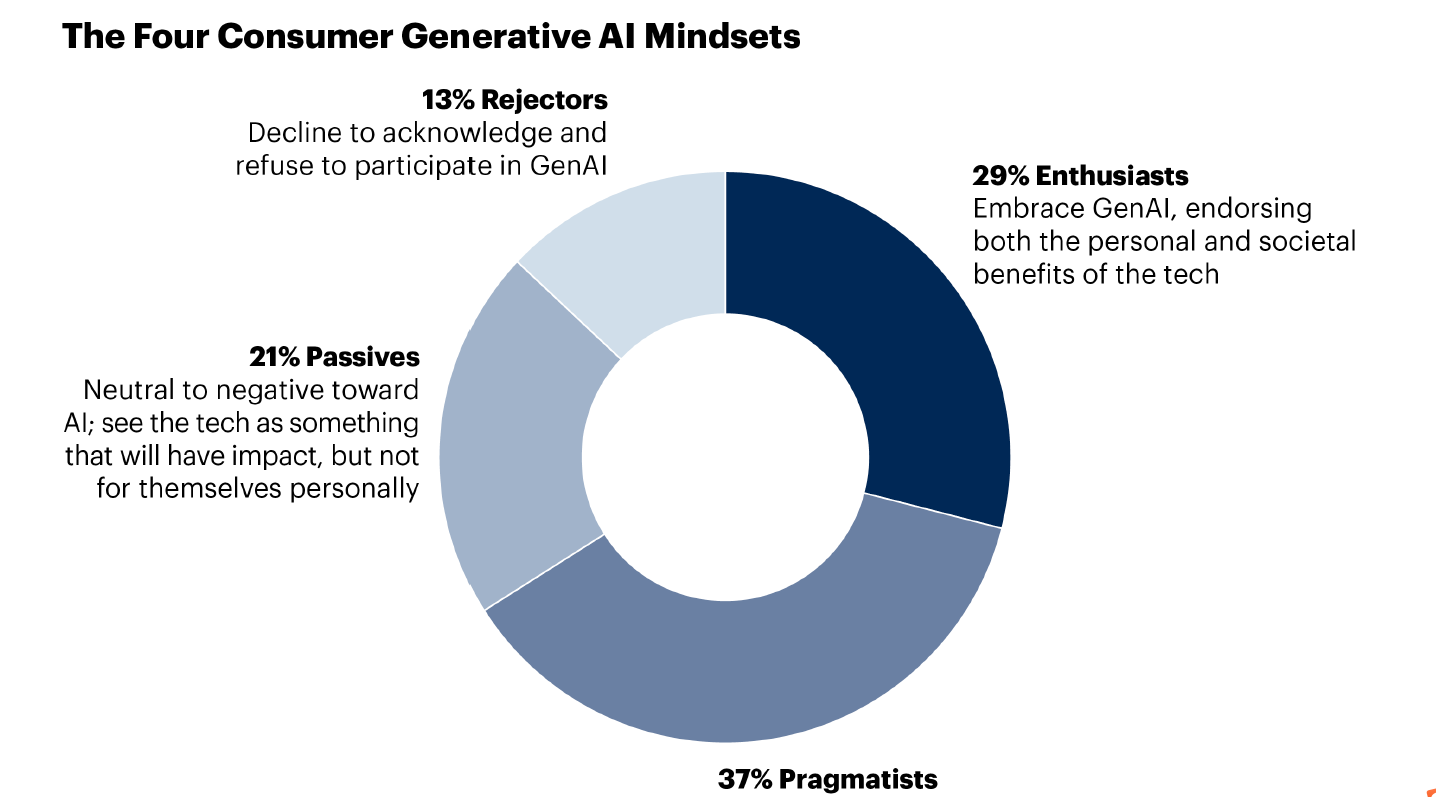
Gartner《Optimize GenAI Strategy for 4 Key ConsumerMindsets》学习心得
一、引言 在当今数字化营销浪潮中,生成式人工智能(GenAI)正以前所未有的速度重塑着市场格局。GenAI 既是一场充满机遇的变革,也是一场潜在风险的挑战。一方面,绝大多数 B2C 营销领导者对 GenAI 赋能营销抱有极高期待,他们看到了 GenAI 在提升时间与成本效率方面的巨大潜…...

[ARM][汇编] 02.ARM 汇编常用简单指令
目录 1.数据传输指令 MRS - Move from Status Register 指令用途 指令语法 代码示例 读取 CPSR 到通用寄存器 在异常处理程序中读取 SPSR 使用场景 MSR - Move to Status Register 指令语法 使用场景 示例代码 改变处理器模式为管理模式 设置条件标志位 异常处理…...
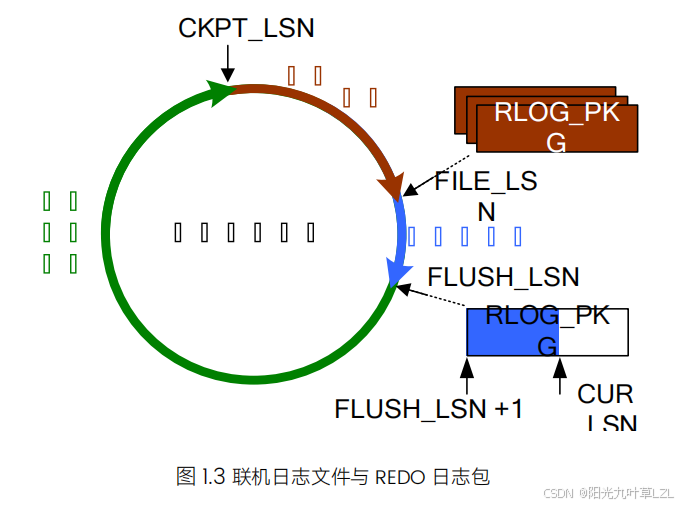
达梦数据库-学习-22-库级物理备份恢复(超详细版)
目录 一、环境信息 二、说点什么 三、概念 1、备份恢复 2、重做日志 3、归档日志 4、LSN 5、检查点 四、语法 1、BACKUP DATABASE 2、DMRMAN RESTORE DATABASE 3、DMRMAN RECOVER DATABASE 4、DMRMAN UPDATE DB_MAGIC 五、实验 1、开归档 (1…...
python网络爬虫的基本使用
各位帅哥美女点点关注,有关注才有动力啊 网络爬虫 引言 我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP、JAVA、C#、C、Python。 为什么Python的爬虫技术会…...

AI Agent开发第74课-解构AI伪需求的魔幻现实主义
开篇 🚀在之前的系列中我们狂炫了AI Agent的各种高端操作(向量数据库联动、多模态感知、动态工作流等…),仿佛每个程序员都能用LLM魔法点石成金✨。 但今天咱们要泼一盆透心凉的冷水——当企业把AI当成万能胶水强行粘合所有需求时,连电风扇都能被玩出量子纠缠的魔幻现实…...
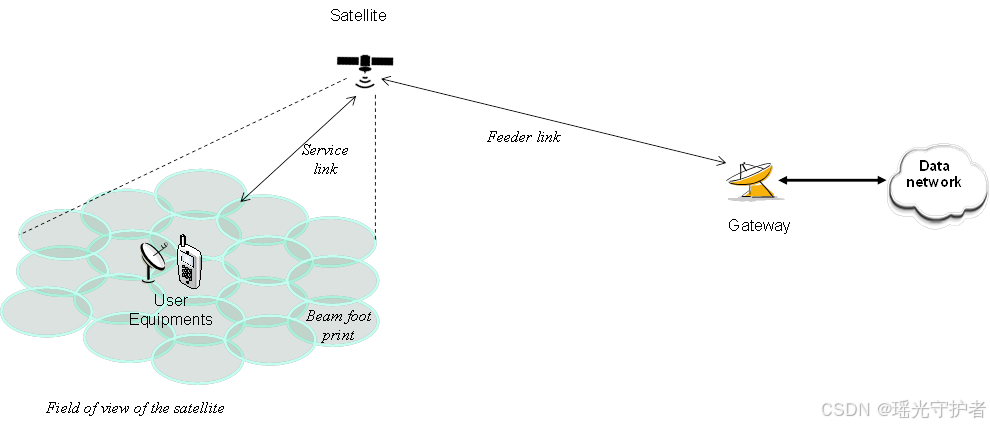
【卫星通信】通信卫星链路预算计算及其在3GPP NTN中的应用
引言 卫星通信是现代信息传播的重要手段,广泛应用于电信、广播、气象监测、导航等领域。卫星链路预算计算是设计和优化卫星通信系统的重要步骤,它帮助工程师评估信号在传输过程中的衰减和增益,从而确保系统在预定条件下可靠地工作。 1. 链路…...

HTTP请求方法:GET与POST的使用场景解析
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 HTTP协议定义了多种请求方法,其中GET和POST是最常用的两种。它们在Web开发中承担着不同的角色,理解其核心差异和使用场景是构建高效、…...

第十五章:数据治理之数据目录:摸清家底,建立三大数据目录
在上一篇随想篇中,介绍了数据资源资产化的过程,理解了数据资源、数据资产的区别。这些对于本章的介绍会有帮助,如果仍有疑问可以看上一篇【数据资源到数据资产的华丽转身 ——从“沉睡的石油”到“流动的黄金”】。 说到本章要介绍的数据目录…...
c++命名空间的作用及命名改编
c命名空间的作用及命名改编 命名空间 namespace的作用: std::命名空间,命名空间(namespace)是 C 中用于解决标识符命名冲突问题的机制。在大型程序开发中,不同模块可能会使用相同名称的变量、函数或类等标识符&…...

Go核心特性与并发编程
Go核心特性与并发编程 1. 结构体与方法(扩展) 高级结构体特性 // 嵌套结构体与匿名字段 type Employee struct {Person // 匿名嵌入Department stringsalary float64 // 私有字段 }// 构造函数模式 func NewPerson(name string, age int) *Pe…...
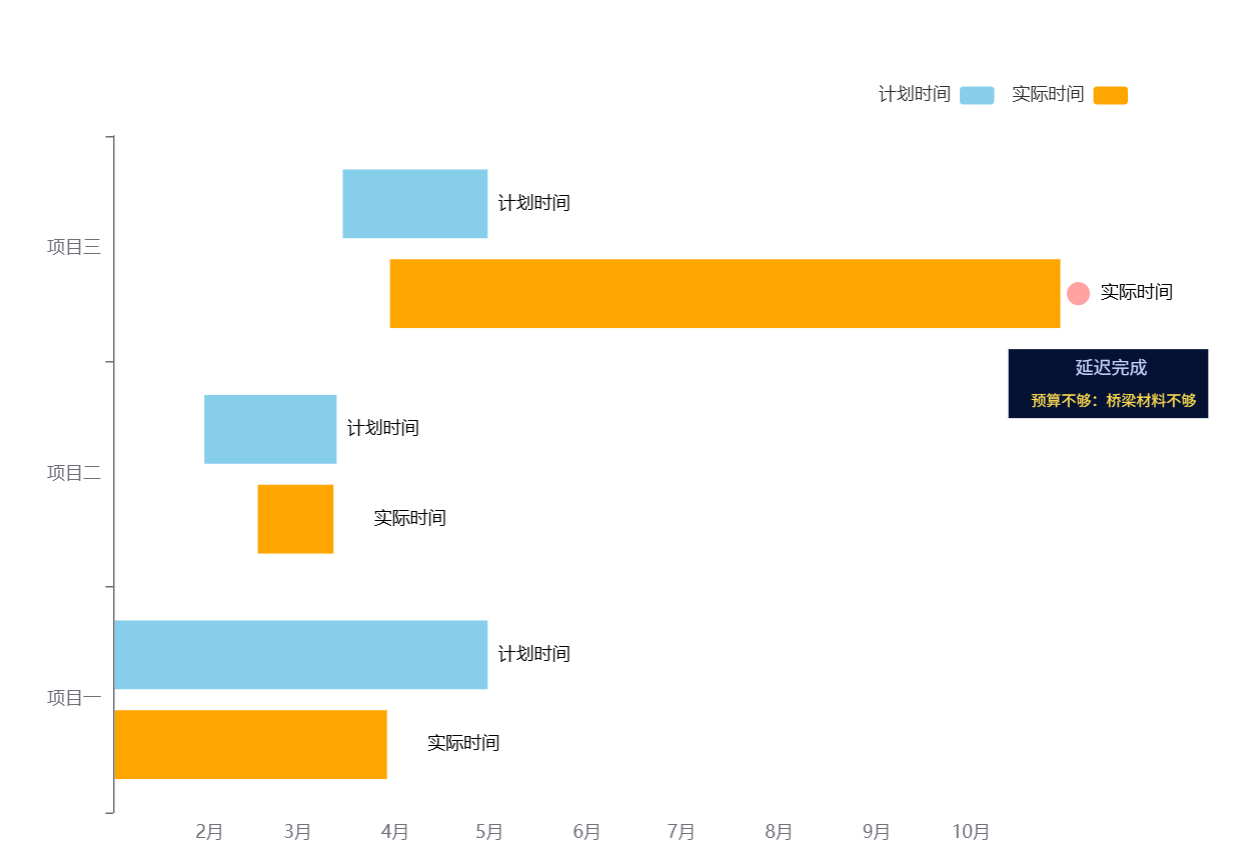
echarts实现项目进度甘特图
描述 echarts并无甘特图配置项,我们可以使用柱状图模拟,具体配置项如下,可以在echarts直接运行 var option {backgroundColor: "#fff",legend: {data: ["计划时间","实际时间"],align: "right",…...

Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中
Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中 在 Flutter 中,build 方法被设计在 StatefulWidget 的 State 类中而非 StatefulWidget 类本身,这种设计基于几个重要的架构原则和实际考量: 1. 核心设计原因 1.1 生命周期管理…...

C#串口打印机:控制类开发与实战
C#串口打印机:控制类开发与实战 一、引言 在嵌入式设备、POS 终端、工业控制等场景中,串口打印机因其稳定的通信性能和广泛的兼容性,仍是重要的数据输出设备。本文基于 C# 语言,深度解析一个完整的串口打印机控制类Printer&…...

2025深圳国际无人机展深度解析:看点、厂商与创新亮点
2025深圳国际无人机展深度解析:看点、厂商与创新亮点 1.背景2.核心看点:技术突破与场景创新2.1 eVTOL(飞行汽车)的规模化展示2.2 智能无人机与无人值守平台2.3 新材料与核心零部件革新2.4 动态演示与赛事活动 3.头部无人机厂商4.核…...
)
Electron 后台常驻服务实现(托盘 + 开机自启)
基于 electron-vite-vue 项目结构 本篇将详细介绍如何为 Electron 应用实现后台常驻运行,包括: ✅ 创建系统托盘图标(Tray)✅ 支持点击托盘菜单控制窗口显示/退出✅ 实现开机自启功能(Auto Launch) &#…...

Spring Boot与Kafka集成实践:从入门到实战
Spring Boot与Kafka集成实践 引言 在现代分布式系统中,消息队列技术扮演着至关重要的角色。Kafka作为一款高性能、高吞吐量的分布式消息队列系统,被广泛应用于日志收集、流处理、事件驱动架构等场景。本文将详细介绍如何在Spring Boot项目中集成Kafka&…...

人形机器人通过观看视频学习人类动作的技术可行性与前景展望
摘要 本文深入探讨人形机器人通过观看视频学习人类动作这一技术路线的正确性与深远潜力。首先阐述该技术路线在模仿人类学习过程方面的优势,包括对人类动作、表情、发音及情感模仿的可行性与实现路径。接着从技术原理、大数据训练基础、与人类学习速度对比等角度论证…...
第三十四天打卡
DAY 34 GPU训练及类的call方法 知识点回归: CPU性能的查看:看架构代际、核心数、线程数 GPU性能的查看:看显存、看级别、看架构代际 GPU训练的方法:数据和模型移动到GPU device上 类的call方法:为什么定义前向传播时可…...

打卡day35
一、模型结构可视化 理解一个深度学习网络最重要的2点: 了解损失如何定义的,知道损失从何而来----把抽象的任务通过损失函数量化出来了解参数总量,即知道每一层的设计才能退出—层设计决定参数总量 为了了解参数总量,我们需要知…...

【【嵌入式开发 Linux 常用命令系列 19 -- linux top 命令的交互使用介绍】
文章目录 Overview常用的交互命令(top 运行时可直接按键)示例使用场景按内存排序,显示某个用户的前 10 个进程:杀死占用资源最多的进程调整刷新频率为 1 秒 提示 Overview 在linux环境下办公经常会遇到杀进程,查看cpu…...
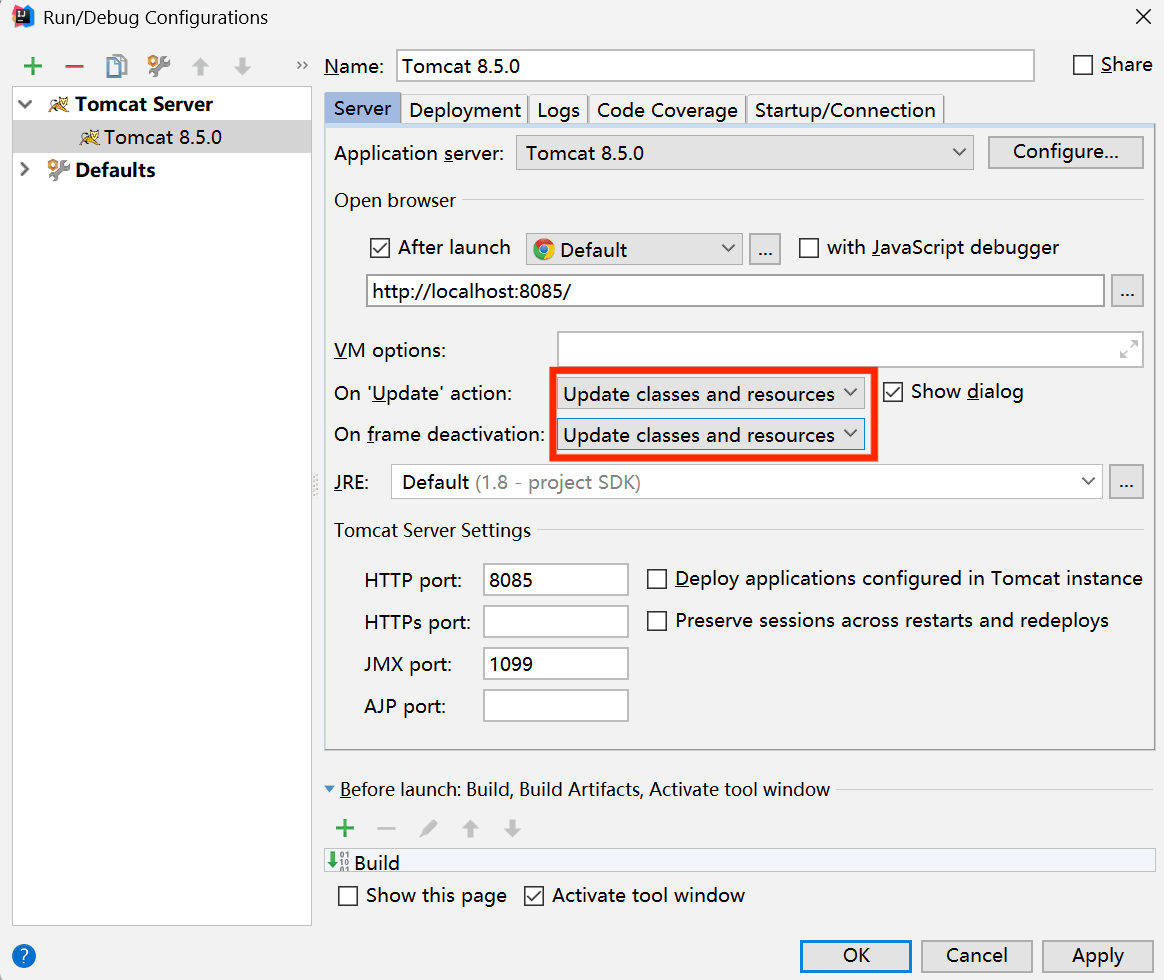
配置tomcat时,无法部署工件该怎么办?
当我们第一次在IDEA中创建Java项目时,配置tomcat可能会出现无法部署工件的情况,如图: 而正常情况应该是: 那么该如何解决呢? 步骤一 点开右上角该图标,会弹出如图页面 步骤二 步骤三 步骤四...

.NET外挂系列:8. harmony 的IL编织 Transpiler
一:背景 1. 讲故事 前面文章所介绍的一些注入技术都是以方法为原子单位,但在一些罕见的场合中,这种方法粒度又太大了,能不能以语句为单位,那这个就是我们这篇介绍的 Transpiler,它可以修改方法的 IL 代码…...
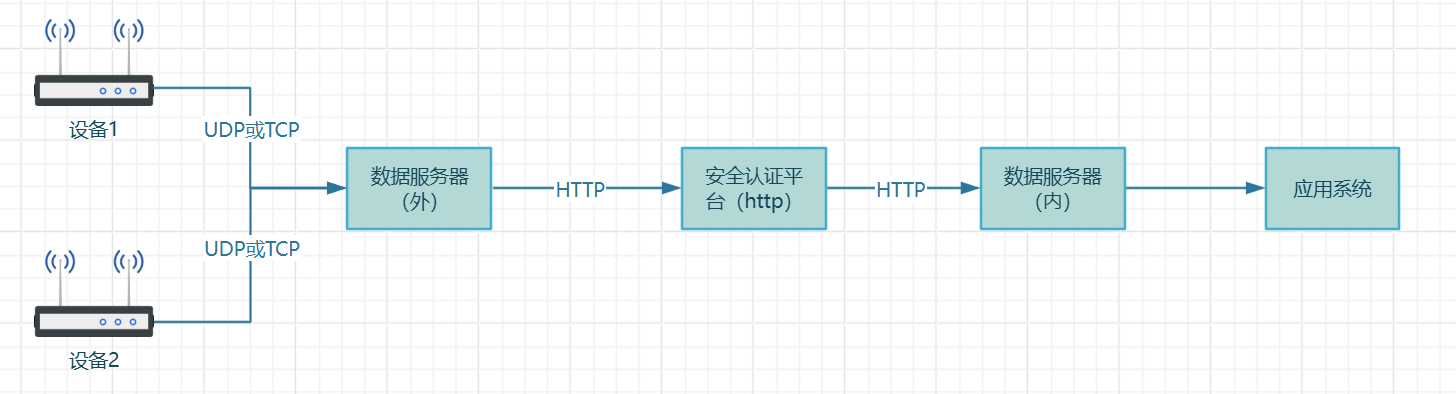
基于netty实现视频流式传输和多线程传输
文章目录 业务描述业务难点流式传输客户端(以tcp为例)服务端测试类测试步骤多线程传输客户端服务端测试类测试步骤多线程流式传输总结业务描述 多台终端设备持续给数据服务器(外)发送视频数据,数据服务器(外)通过HTTP协议将数据经过某安全平台转到数据服务器(内),数据…...

全面指南:使用Node.js和Python连接与操作MongoDB
在现代Web开发中,数据库是存储和管理数据的核心组件。MongoDB作为一款流行的NoSQL数据库,以其灵活的数据模型、高性能和易扩展性广受开发者欢迎。无论是使用Node.js还是Python,MongoDB都提供了强大的官方驱动和第三方库,使得数据库…...