算法学习——从零实现循环神经网络
从零实现循环神经网络
- 一、任务背景
- 二、数据读取与准备
- 1. 词元化
- 2. 构建词表
- 三、参数初始化与训练
- 1. 参数初始化
- 2. 模型训练
- 四、预测
- 总结
一、任务背景
对于序列文本来说,如何通过输入的几个词来得到后面的词一直是大家关注的任务之一,即:通过上文来推测下文的内容。如果通过简单的MLP来进行预测的话,似乎不会得到什么好的结果,所以科学家针对序列数据设计了循环神经网络架构(Recurrent Neural Network, RNN)。
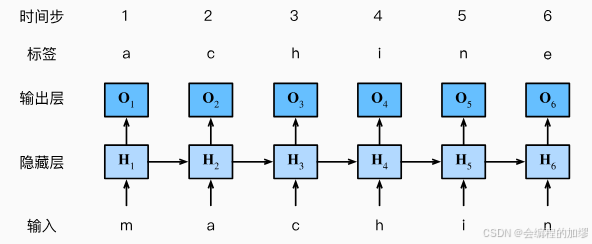
——图片来源:书籍《动手学习深度学习》李沐等
RNN在之前的基础上将上一时刻的隐状态作为这一时刻的隐状态的输入,即: H t = X W + H t − 1 H_{t}=XW+H_{t-1} Ht=XW+Ht−1,从而预测这一时刻的输出,由于不同的时间步长可能有不同的结果,所以在进行此类任务时需要将时间步长也作为预先设定的超参数,例如:预测特定步长的后续的句子

——图片来源:书籍《动手学习深度学习》李沐等
当然,我上面描述的内容似乎不太诱人,时至今日,基于Transformer架构的ChatGPT已经发展的十分迅速了,但是我认为学习RNN可以更好地帮助我们理解Transformer设计的巧妙之处,
⭐ 本文主要是将具体的代码实现,因此不在原理方面进行过多赘述,如果大家对原理感兴趣可以查看其他博客或与我交流讨论!
二、数据读取与准备
在进行一个模型的学习之前,我们首先要知道模型的输入是什么?对于保存了一本书的.txt而言,如果直接把这本书输入到模型中,那么模型如果学习具体东西呢?或者说模型怎么学习字符数据而不是像线性模型那样的数值数据呢?
因此,第一步是需要准备一个词表,将输入的字符转换成与词表对应的数字数据。
1. 词元化
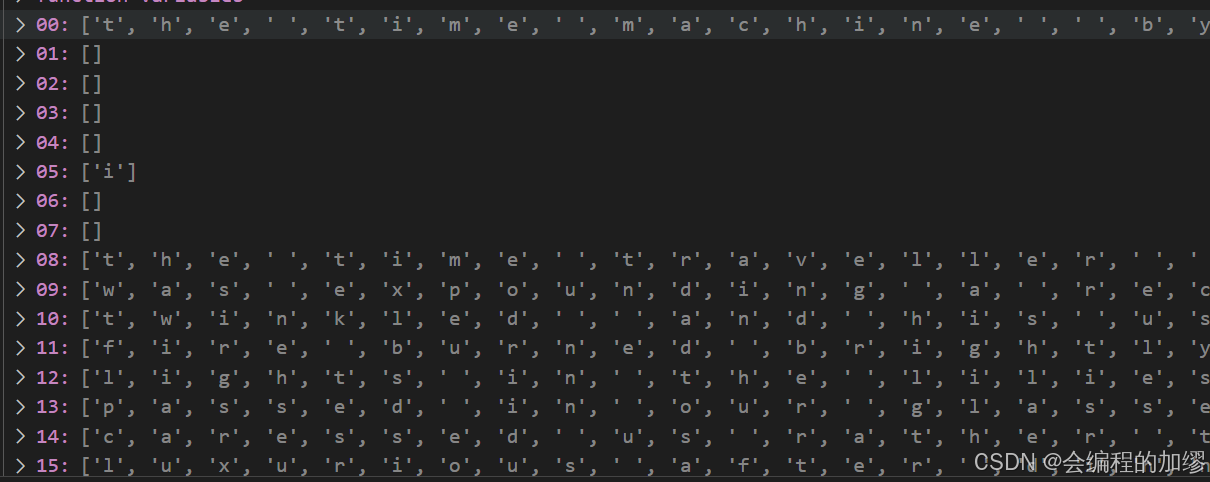
为了更好地对数据进行编码和处理,这里没有选择将每个单词作为一个词表,而是将每个字符作为词表,因此词元化时,是将每个字符分开的:
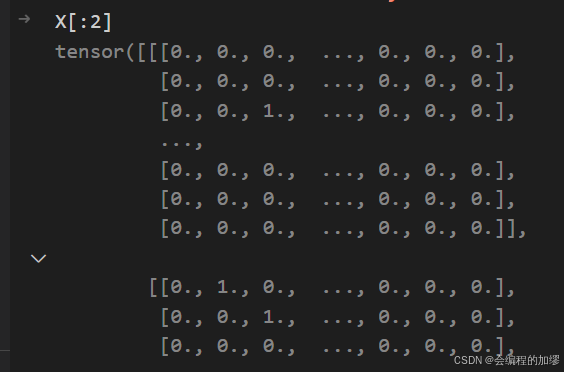
with open(File_path) as f:lines = f.readlines()lines = [re.sub('[^A-Za-z+]', ' ', line).strip().lower() for line in lines] # 文本预处理
tokens = [list(line) for line in lines]
类似于下面这样:
2. 构建词表
根据词元出现的词频,将这些字符按照出现的频率进行排序,同时识别不了的字符就用一些特定的符号进行代替<unk>,从而形成两个主要的数据,这两个数据用于将字符和数字相互转换:
- 列表:
idx_to_token(即可以通过索引来找到对应的词) - 字典:
token_to_idx(通过词来查到具体的索引)
### 获取词表 vocab ###
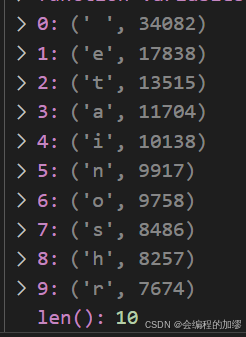
tokens = [token for line in tokens for token in line] # 所有字符展平成一列counter = collections.Counter(tokens)
token_freqs = sorted(counter.items(), key=lambda x: x[1], # 按出现频次排序,形成一个词表(英文字母)reverse=True)
reserved_tokens = []
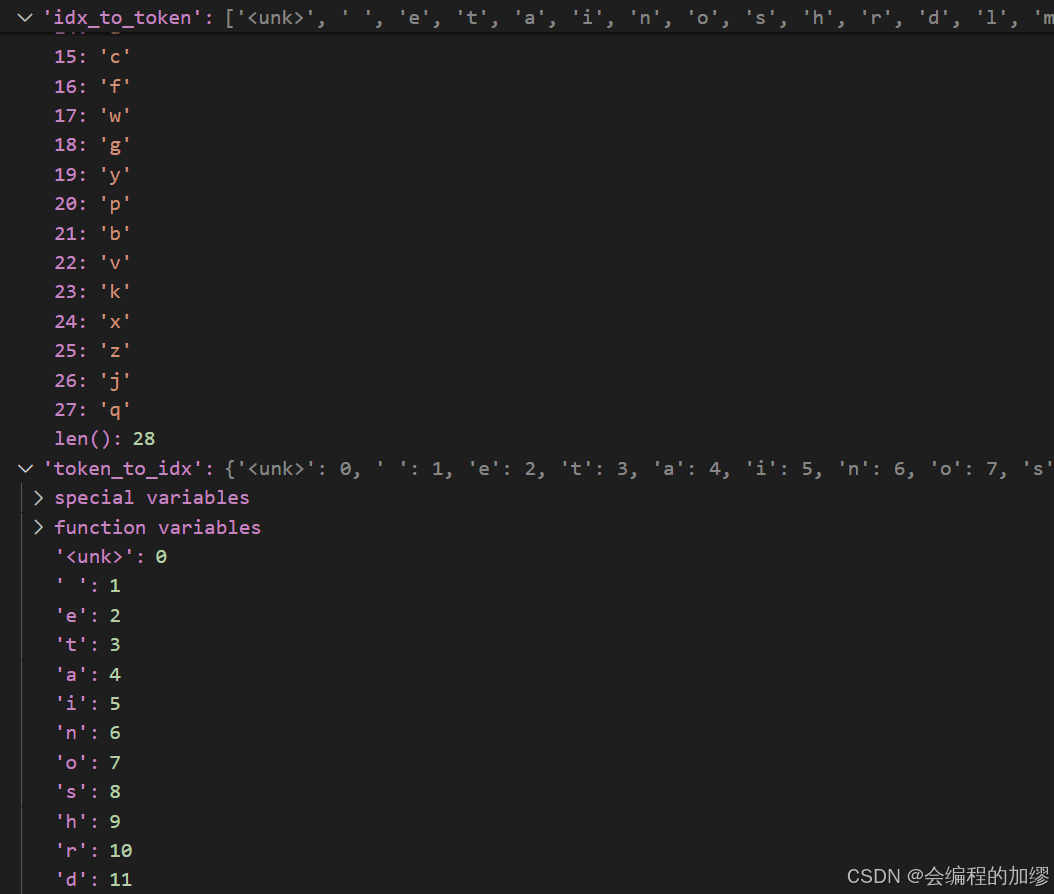
idx_to_token = ['<unk>'] + reserved_tokens
# 字典 ---> 通过token找索引
token_to_idx = {token: idx for idx, token in enumerate(idx_to_token)}min_freq = 0for token, freq in token_freqs: # 迭代频率词表,构建两个索引if freq < min_freq:breakif token not in token_to_idx:idx_to_token.append(token)token_to_idx[token] = len(idx_to_token) - 1vocab = {'idx_to_token':idx_to_token, # 这个词表很重要'token_to_idx':token_to_idx}
字符出现的频率:
词表:
最后,将所有词元化的数据通过这个词表,转换为数字的形式:
### 构建语料库 corpus ###corpus = [vocab['token_to_idx'][token] for line in tokens for token in line]
# print(corpus[:10])# 获取足够多的数据
maxtokens = 10000
if maxtokens > 0:corpus = corpus[:maxtokens]
三、参数初始化与训练
因为我直接将所有代码拆开来看,所以不会单独写一个模型的类或函数,因此直接跳过模型构建的过程。在训练的流程中,能更清除地看到模型具体是哪一个,以及参数是如果更新。
1. 参数初始化
首先,要有效地训练模型我们需要对其参数进行初始化,那么这里可以列出RNN的数学表达式,以便我们知道其有些什么参数:
假设,输入的小批量数据为 X p X_{p} Xp, t t t时刻的输出为 O t O_{t} Ot,则有:
H t = X t W x h + H t − 1 W h h + b h (1) H_{t}=X_{t}W_{xh}+H_{t-1}W_{hh}+b_{h} \tag{1} Ht=XtWxh+Ht−1Whh+bh(1)
O t = H t W h q + b q (2) O_{t}=H_{t}W_{hq}+b_{q} \tag{2} Ot=HtWhq+bq(2)
其中, H H H 表示隐状态, b b b 表示偏置, W W W 表示权重
因此可以看到,可学习的参数包括: W x h 、 W h h 、 W h q 、 b h 、 b q W_{xh}、W_{hh}、W_{hq}、b_{h}、b_{q} Wxh、Whh、Whq、bh、bq
因此,对这些参数进行初始化:
### 参数初始化 ###
num_inputs = num_outputs = vocab_size
# 隐藏层参数
W_xh = torch.randn(size=(num_inputs, num_hiddens), device=device) * 0.01
W_hh = torch.randn(size=(num_hiddens, num_hiddens), device=device) * 0.01
b_h = torch.zeros(num_hiddens, device=device)# 输出层参数
W_hq = torch.randn(size=(num_hiddens, num_outputs), device=device) * 0.01 # 这里没缩放
b_q = torch.zeros(num_outputs, device=device)params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:param.requires_grad_(True) # 初始化时,参数的grad为None
与其他的模型不同,RNN中需要初始化上一时刻的隐状态 H t − 1 H_{t-1} Ht−1,当 t = 1 t=1 t=1时, H t − 1 H_{t-1} Ht−1自然为0:
init_state = (torch.zeros((batch_size, num_hiddens), device=device), )
2. 模型训练
模型训练过程代码如下:
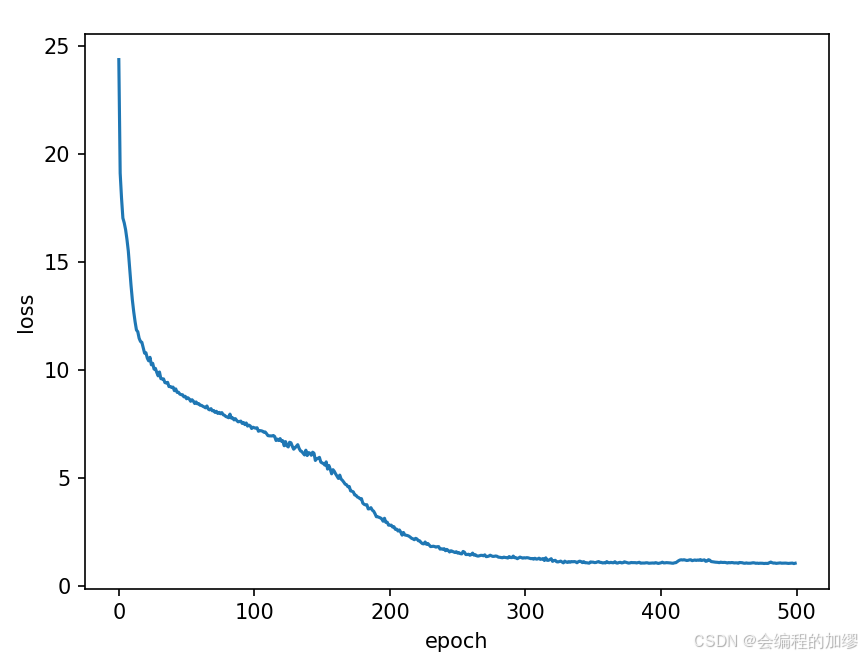
for epoch in range(num_epochs):state, timer = None, Timer()metric = Accumulator(2)### 制作可迭代数据 ###offset = random.randint(0, num_steps) # 随机偏移num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size# print(f'offset:{offset},num_tokens: {num_tokens}')# 选择x数据Xs = torch.tensor(corpus[offset: offset + num_tokens]) # [9952]Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens]) # [9952]Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1) # [32,311]相当于将其分为32份# print(Xs.shape, Ys.shape)num_batches = Xs.shape[1] // num_steps # 8# print(f'num_batches: {num_batches}')for i in range(0, num_steps * num_batches, num_steps):X = Xs[:, i: i + num_steps] # [32, 35]Y = Ys[:, i: i + num_steps] # [32, 35]# 这里就相当于for X, Y in train_iter# print(X, Y)if state is None:state = init_stateelse:for s in state:s.detach_()y = Y.T.reshape(-1) # 1120 = 32 * 35, 把y展平成一维X, y = X.to(device), y.to(device)X = F.one_hot(X.T, vocab_size).type(torch.float32) # [35, 32, 28] 28是one hot 编码的维度W_xh, W_hh, b_h, W_hq, b_q = paramsH, = state outputs = []for input in X:H = torch.tanh(torch.mm(input, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_q # [32, 28]outputs.append(Y)y_hat, state = torch.cat(outputs, dim=0), (H,) # 35# y_hat, state = rnn(X, state, params)l = loss(y_hat, y.long()).mean() # 计算出损失l.backward() # 更新的是params的梯度### 梯度裁剪 ###norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))theta = 1if norm > theta:for param in params:param.grad[:] *= theta / norm### updater 梯度更新 ###with torch.no_grad():for param in params: param -= lr * param.grad # 参数在这里进行更新, 不用除以batch_sizeparam.grad.zero_() # 将梯度置零metric.add(l * y.numel(), y.numel())ppl, speed = math.exp(metric[0] / metric[1]), metric[1] / timer.stop()loss_value.append(ppl)if (epoch+1) % 10 == 0: print(f'=========epoch:{epoch+1}=========Perplexity:{ppl}=======speed:{speed}=======')x = range(0, 500)
plt.plot(x, loss_value)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
需要注意以下几点:
-
每一轮训练都需要将初始状态设置为0,因此在一开始设置了
state=None -
在将X输入模型中时,采用的是独热编码(one-hot),即根据词表,每一列形成28个0/1值(28=26个英文字母+空格+‘unk’)
训练损失(困惑度, perplexity)曲线如下:
四、预测
代码如下,执行预测时需要注意:
- 记得将batch_size设置为1,因为预测的数据没有分成不同的batch_size
- 预热期的作用:一是输入待预测的单词后面,如本例中的’traveller’,二是让隐状态进行更行,方便能预测出更好的结果
batch_size = 1 # 训练时得batch_size
state = (torch.zeros((batch_size, num_hiddens), device=device), )
prefix = "traveller"
num_preds = 50 # 预测步长
outputs_pre = [vocab['token_to_idx'][prefix[0]]]
get_input = lambda: torch.tensor([outputs_pre[-1]], device=device).reshape((1, 1))
for y in prefix[1:]: # 预热期inputs = get_input()X = F.one_hot(inputs.T, vocab_size).type(torch.float32) # [1, 1, 28]W_xh, W_hh, b_h, W_hq, b_q = params_frezonH, = state # [1, 512]outputs = []for x in X: # X [1, 28],相当于把时间步长抽离出来H = torch.tanh(torch.mm(x, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_q # [1, 28], 得到的值是小数咋整?应该要处理一下吧outputs.append(Y)_, state = torch.cat(outputs, dim=0), (H,) # state[1, 512]# _, state = rnn(X, state, params_frezon)outputs_pre.append(vocab['token_to_idx'][y])for _ in range(num_preds):inputs = get_input() X = F.one_hot(inputs.T, vocab_size).type(torch.float32) # [1, 1, 28]W_xh, W_hh, b_h, W_hq, b_q = params_frezonH, = state # 保留预热期的Houtputs = []for x in X: # X [1, 1, 28],相当于把时间步长抽离出来H = torch.tanh(torch.mm(x, W_xh) + torch.mm(H, W_hh) + b_h) # [1, 512]Y = torch.mm(H, W_hq) + b_q # [1, 28], 得到的值是小数咋整?应该要处理一下吧outputs.append(Y)y, state = torch.cat(outputs, dim=0), (H,) # y [1, 28], state [1, 512]# y, state = rnn(X, state, params_frezon)outputs_pre.append(int(y.argmax(dim=1).reshape(1))) # 这里将小数变成整数
# y.argmax用于返回指定维度上最大值的索引位置
# print(outputs_pre)
# print(vocab['idx_to_token'][3])
# predict = [vocab['idx_to_token'][i] for i in outputs_pre]
predict = ''.join([vocab['idx_to_token'][i] for i in outputs_pre])
print(predict)
总结
这个代码实现起来整体比较简单,就是输入数据那里需要多多理解,把输入与输出梳理明白。模型完全可以套着公式来看代码,与MLP最大的区别就是多了一个state的更新和相应的可学习权重 W h h W_{hh} Whh。
完整的代码和数据我放在gitee网站上面了,有需要的朋友直接自取即可: gitee仓库
相关文章:
算法学习——从零实现循环神经网络
从零实现循环神经网络 一、任务背景二、数据读取与准备1. 词元化2. 构建词表 三、参数初始化与训练1. 参数初始化2. 模型训练 四、预测总结 一、任务背景 对于序列文本来说,如何通过输入的几个词来得到后面的词一直是大家关注的任务之一,即:…...
win10使用nginx做简单负载均衡测试
一、首先安装Nginx: 官网链接:https://nginx.org/en/download.html 下载完成后,在本地文件中解压。 解压完成之后,打开conf --> nginx.config 文件 1、在 http 里面加入以下代码 upstream GY{#Nginx是如何实现负载均衡的&a…...
2025电工杯数学建模B题思路数模AI提示词工程
我发布的智能体链接:数模AI扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门槛、快速搭建个性化或具备商业价值的智能体,并发布到豆包、飞书等各个平台。https://www.coze.cn/search/n…...

软考软件评测师——软件工程之开发模型与方法
目录 一、核心概念 二、主流模型详解 (一)经典瀑布模型 (二)螺旋演进模型 (三)增量交付模型 (四)原型验证模型 (五)敏捷开发实践 三、模型选择指南 四…...

前端表单中 `readOnly` 和 `disabled` 属性的区别
前端表单中 readOnly 和 disabled 属性的区别 定义与适用范围 readOnly 是一种属性,仅适用于 <input> 和 <textarea> 元素。当设置了此属性时,用户无法修改这些元素的内容,但仍能聚焦并选中文本。disabled 则是一个更广泛的属性…...
【日志软件】hoo wintail 的替代
hoo wintail 的替代 主要问题是日志大了以后会卡有时候日志覆盖后,改变了,更新了,hoo wintail可能无法识别需要重新打开。 有很多类似的日志监控软件可以替代。以下是一些推荐的选项: 免费软件 BareTail 轻量级的实时日志查看…...
)
OceanBase数据库全面指南(基础入门篇)
文章目录 一、OceanBase 简介与安装配置指南1.1 OceanBase 核心特点1.2 架构解析1.3 安装部署实战1.3.1 硬件要求1.3.2 安装步骤详解1.3.3 配置验证二、OceanBase 基础 SQL 语法入门2.1 数据查询(SELECT)2.1.1 基础查询语法2.1.2 实际案例演示2.2 数据操作(INSERT/UPDATE/DE…...

异步处理与事件驱动中的模型调用链设计
异步处理与事件驱动中的模型调用链设计 在现代AI系统中,尤其是在引入了大模型(如LLM)或多步骤生成流程的业务场景中,传统的同步调用模型已越来越难以应对延迟波动、资源竞争和流程耦合等问题。为了提升系统响应效率、降低调用失败…...

redis配置带验证的主从复制
IP地址主机名192.168.10.161redis161192.168.10.162redis162192.168.10.163redis163 配置主机host161,redis服务连接密码为123456主机host162设置连接host61的redis服务密码 给host161主机的Redis服务设置连接密码,如果从服务器不指定连接密码无法同…...

Ollama-OCR:基于Ollama多模态大模型的端到端文档解析和处理
基本介绍 Ollama-OCR是一个Python的OCR解析库,结合了Ollama的模型能力,可以直接处理 PDF 文件无需额外转换,轻松从扫描版或原生 PDF 文档中提取文本和数据。根据使用的视觉模型和自定义提示词,Ollama-OCR 可支持多种语言…...

OpenCV CUDA 模块中图像过滤------创建一个拉普拉斯(Laplacian)滤波器函数createLaplacianFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createLaplacianFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个 拉普拉斯(Laplacian)滤波器…...
图论学习笔记 3
自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。 多图警告。 众所周知王老师有一句话: ⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不…...

在单片机中如何在断电前将数据保存至DataFlash?
几年前,我做过一款智能插座,需要带电量计量的功能, 比如有个参数是总共用了多少度电 (kWh),这个是需要实时掉存保存的数据。 那问题来了,如果家里突然停电,要怎么在断电前将数据保存至Flash? 问…...
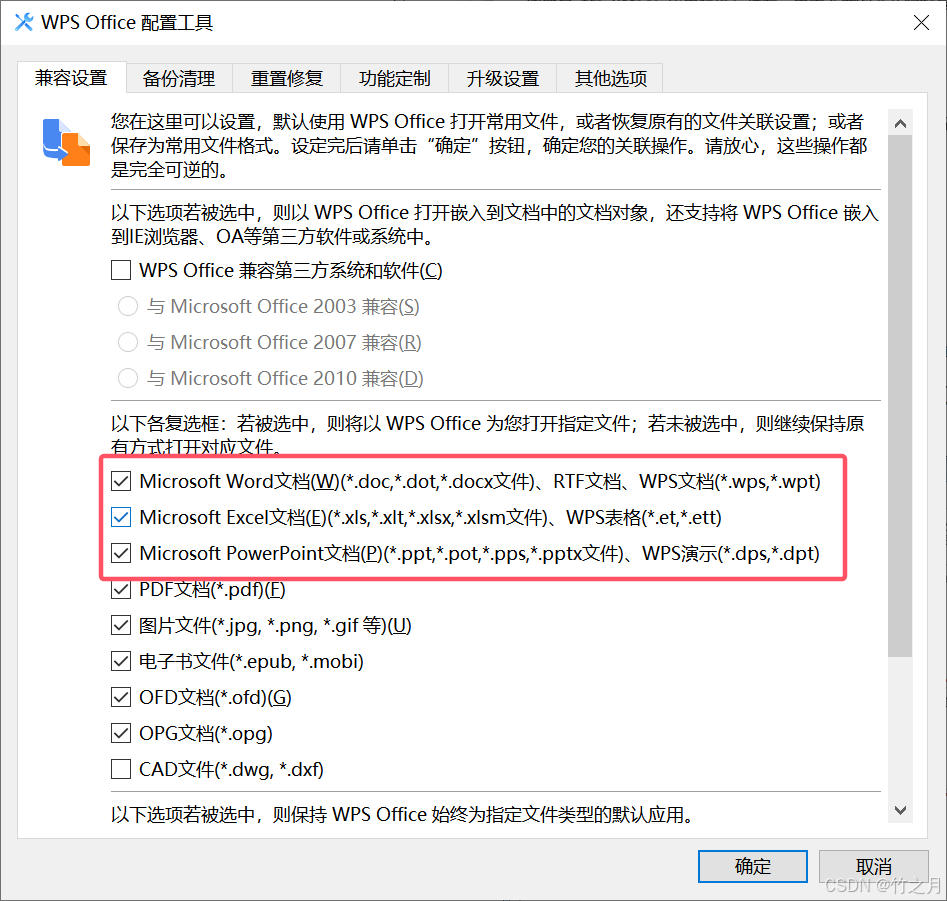
【将WPS设置为默认打开方式】--突然无法用WPS打开文件
1. 点击【开始】——【WPS Office】——【配置工具】; 2. 在出现的弹窗中,点击【高级】; 3. 在“兼容设置”中,将复选框勾上,点击【确定】。...

电子人的分水岭-FPGA模电和数电
为什么模电这么难学?一文带你透彻理解模电 ——FPGA是“前期数电,后期模电”的典型代表 在电子工程的世界里,有两门基础课程让无数学生“闻之色变”:数字电路(数电) 和 模拟电路(模电࿰…...

(6)python爬虫--selenium
文章目录 前言一、初识selenium二、安装selenium2.1 查看chrome版本并禁止chrome自动更新2.1.1 查看chrome版本2.1.2 禁止chrome更新自动更新 2.2 安装对应版本的驱动程序2.3安装selenium包 三、selenium关于浏览器的使用3.1 创建浏览器、设置、打开3.2 打开/关闭网页及浏览器3…...

Python之两个爬虫案例实战(澎湃新闻+网易每日简报):附源码+解释
目录 一、案例一:澎湃新闻时政爬取 (1)数据采集网站 (2)数据介绍 (3)数据采集方法 (4)数据采集过程 二、案例二:网易每日新闻简报爬取 (1&#x…...

HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南
HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南 1. 概述 1.1 鸿蒙系统简介 鸿蒙系统(HarmonyOS)是华为开发的分布式操作系统,具备以下核心特性: 分布式架构:支持跨设备无缝协同微内核设计:提高安全性和性能一次开…...

系统安全及应用学习笔记
系统安全及应用学习笔记 一、账号安全控制 (一)账户管理策略 冗余账户处理 非登录账户:Linux 系统中默认存在如 bin、daemon 等非登录账户,其登录 Shell 应为 /sbin/nologin,需定期检查确保未被篡改。冗余账户清理&…...

STC89C52RC/LE52RC
STC89C52RC 芯片手册原理图扩展版原理图 功能示例LED灯LED灯的常亮效果LED灯的闪烁LED灯的跑马灯效果:从左到右,从右到左 数码管静态数码管数码管计数App.cApp.hCom.cCom.hDir.cDir.hInt.cInt.hMid.cMid.h 模板mian.cApp.cApp.hCom.cCom.hDir.cDir.hInt.…...
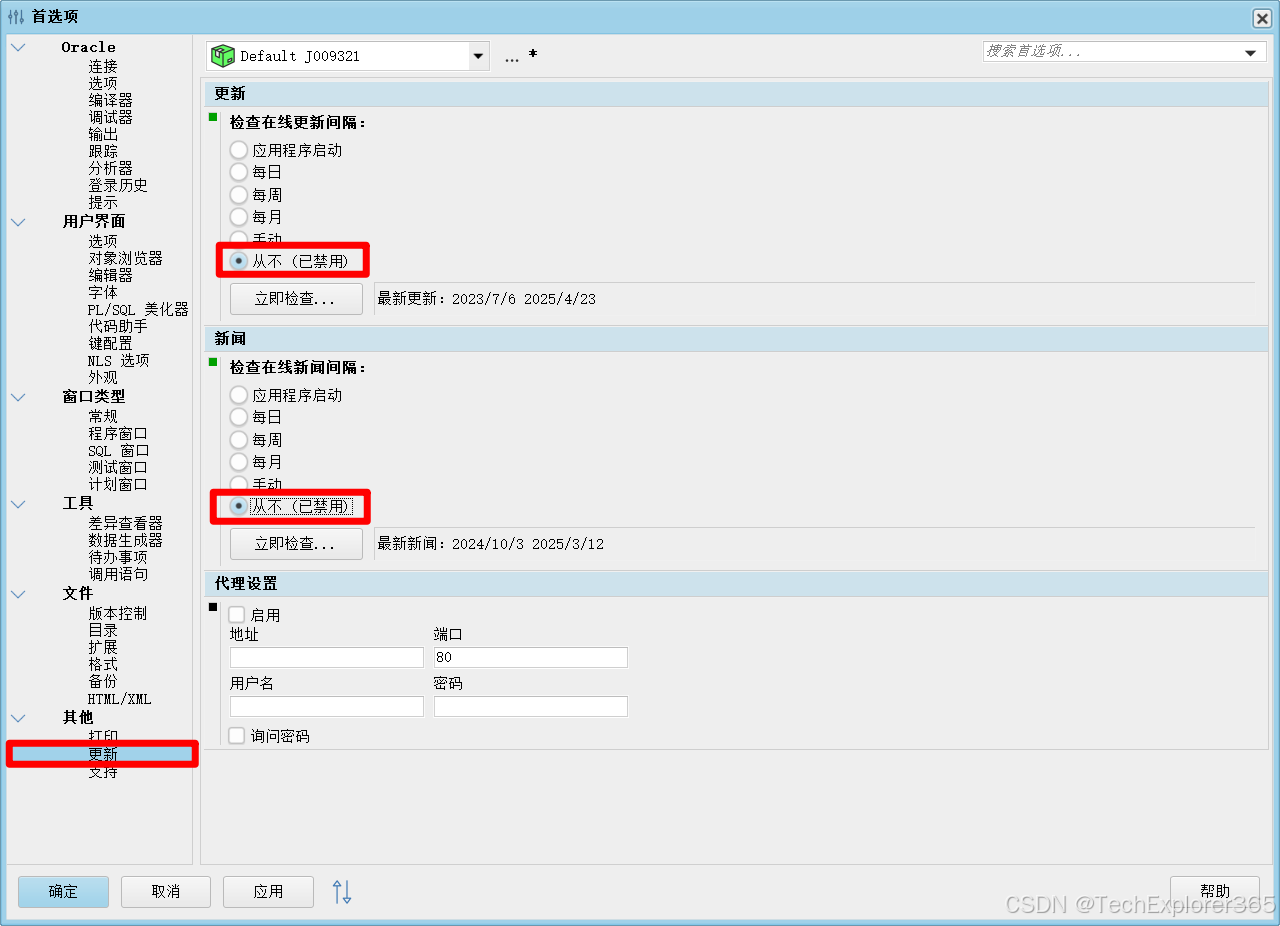
✨ PLSQL卡顿优化
✨ PLSQL卡顿优化 1.📂 打开首选项2.🔧 Oracle连接配置3.⛔ 关闭更新和新闻 1.📂 打开首选项 2.🔧 Oracle连接配置 3.⛔ 关闭更新和新闻...

yum命令常用选项
刷新仓库列表 sudo yum repolist清理 Yum 缓存并生成新的缓存 sudo yum clean all sudo yum makecache验证 EPEL 源是否已正确启用 sudo yum repolist enabled安装软件包 sudo yum install <package-name> -y更新软件包 sudo yum update -y仅更新指定的软件包。 su…...
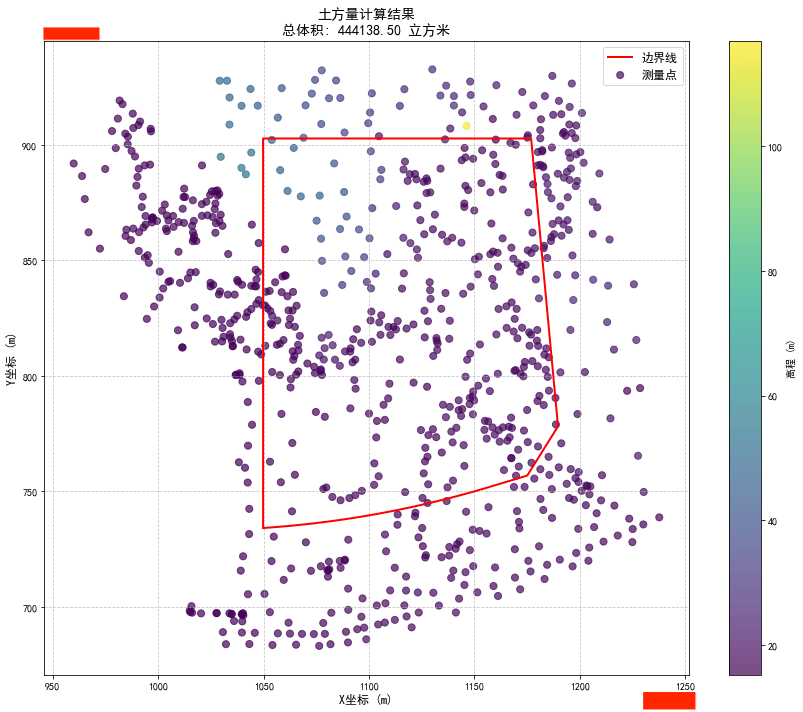
python+vlisp实现对多段线范围内土方体积的计算
#在工程中,经常用到计算土方回填、土方开挖的体积。就是在一个范围内,计算土被挖走,或者填多少,这个需要测量挖填前后这个范围内的高程点。为此,我开发一个app,可以直接在autocad上提取高程点,然…...

鸿蒙Flutter实战:25-混合开发详解-5-跳转Flutter页面
概述 在上一章中,我们介绍了如何初始化 Flutter 引擎,本文重点介绍如何添加并跳转至 Flutter 页面。 跳转原理 跳转原理如下: 本质上是从一个原生页面A 跳转至另一个原生页面 B,不过区别在于,页面 B是一个页面容器…...
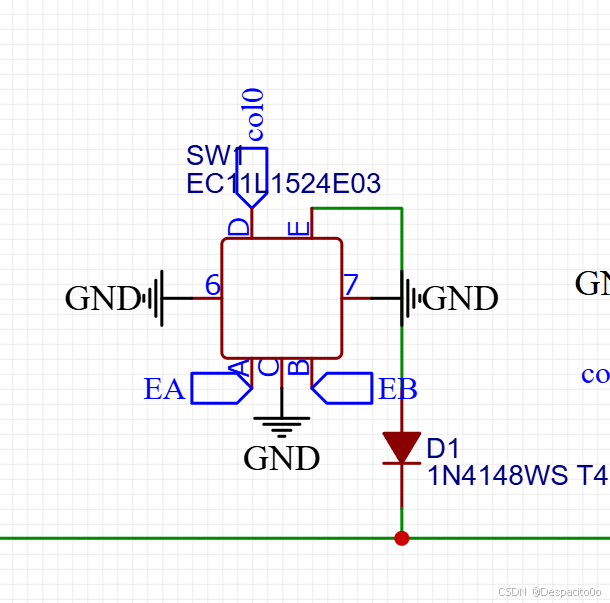
APM32小系统键盘PCB原理图设计详解
APM32小系统键盘PCB原理图设计详解 一、APM32小系统简介 APM32微控制器是国内半导体厂商推出的一款高性能ARM Cortex-M3内核微控制器,与STM32高度兼容,非常适合DIY爱好者用于自制键盘、开发板等电子项目。本文将详细讲解如何基于APM32 CBT6芯片设计一款…...

【C/C++】多线程开发:wait、sleep、yield全解析
文章目录 多线程开发:wait、sleep、yield全解析1 What简要介绍详细介绍wait() — 条件等待(用于线程同步)sleep() — 睡觉,定时挂起yield() — 自愿让出 CPU 2 区别以及建议区别应用场景建议 3 三者协作使用示例 多线程开发&#…...

uint8_t是什么数据类型?
一、引言 在C语言编程中,整数类型是最基本的数据类型之一。然而,你是否真正了解这些看似简单的数据类型?本文将深入探索C语言中的整数类型,在编程中更加得心应手。 二、C语言整数类型的基础 2.1 标准整数类型 C语言提供了多种…...

SystemUtils:你的Java系统“探照灯“——让环境探测不再盲人摸象
各位Java系统侦探们好!今天要介绍的是Apache Commons Lang3中的SystemUtils工具类。这个工具就像编程界的"雷达系统",能帮你一键获取所有系统关键信息,再也不用满世界找System.getProperty()了! 一、为什么需要SystemU…...
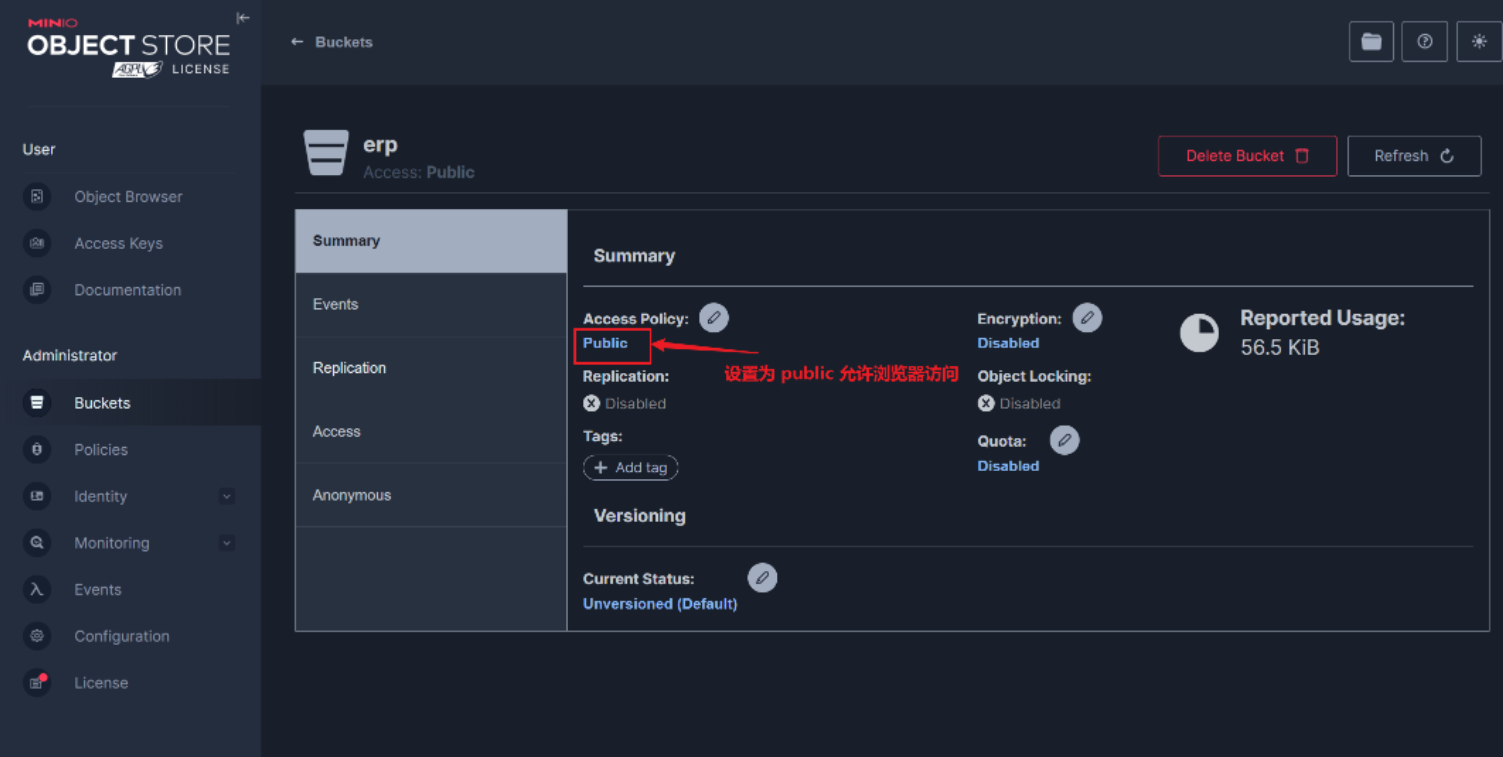
对象存储(Minio)使用
目录 1.安装 MinIO(Windows) 2.启动minio服务: 3.界面访问 4.进入界面 5.前后端代码配置 1)minio前端配置 2)minio后端配置 1.安装 MinIO(Windows) 官方下载地址:[Download High-Perform…...

yolov11使用记录(训练自己的数据集)
官方:Ultralytics YOLO11 -Ultralytics YOLO 文档 1、安装 Anaconda Anaconda安装与使用_anaconda安装好了怎么用python-CSDN博客 2、 创建虚拟环境 安装好 Anaconda 后,打开 Anaconda 控制台 创建环境 conda create -n yolov11 python3.10 创建完后&…...