.NET ORM开发手册:基于SqlSugar的高效数据访问全攻略
SqlSuger是一个国产,开源ORM框架,具有高性能,使用方便,功能全面的特点,支持.NET Framework和.NET Core,支持各种关系型数据库,分布式数据库,时序数据库。
官网地址:SqlSugar .Net ORM 5.X 官网 、文档、教程 - SqlSugar 5x - .NET果糖网
基础知识
1、在Nuget中搜索 SqlSugarCore安装.NET Core版本,搜索SqlSugar安装.NET Framework版本。
2、它有两种对象SqlSugarClient和SqlSugarScope访问数据库,SqlSugarClient等同于在ADO,EF,Dapper中所使用的数据库访问对象,每次请求new一个新对象,db禁止跨上下文使用,IOC建议用Scope或者瞬发注入。
以下是连接数据库,并检验是否连接成功的Demo
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {var flag = db.Ado.IsValidConnection(); //如果时间长,可以在连接字符串配置 连接超时时间Console.WriteLine(flag == true ? "连接成功" : "连接失败");});DBFirst
DBFirst即数据库优先模式,它指的是先生成数据库,再生成实体类,SqlSuger可以根据表的结构自动生成实体类文件。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {});// 生成student实体类,放在桌面的Models文件夹下,命名空间是XCYN.NET8.Print.ModelsDb.DbFirst.Where("student").CreateClassFile("C:\\Users\\Administrator\\Desktop\\Models", "XCYN.NET8.Print.Models");运行完代码后,会在指定文件夹下生成一个cs文件,将它复制到项目中即可。
接着使用这个类进行查询操作
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 查询student表中id为1的集合var result = Db.Queryable<student>().Where(it => it.id == "1").ToList();result.ForEach(m => {Console.WriteLine(m.Name.ToString());});查询完毕后,还可以在OnLogExecuting委托中打印SQL,方便我们进行SQL优化。
CodeFirst
CodeFirst和DBFirst相比更加灵活,假如需要更换数据库,采用这种方式会自动创建数据表,而且这种方式更符合面向对象的思想。
1、创建一个实体类
public class School{[SugarColumn(IsIdentity = true, IsPrimaryKey = true)]public int Id { get; set; }public string Name { get; set; }//ColumnDataType 一般用于单个库数据库,如果多库不建议用[SugarColumn(ColumnDataType = "Nvarchar(255)")]public string Text { get; set; }[SugarColumn(IsNullable = true)]//可以为NULLpublic DateTime CreateTime { get; set; }}2、创建数据表
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 创建指定的表,字符串类型默认长度200Db.CodeFirst.SetStringDefaultLength(200).InitTables(typeof(School));索引
索引可以加快数据查询的速度,在经常查询的字段上建立索引可以有效地提高查询效率。
按数量划分
1、单列索引
单列索引有可以细分为唯一索引,主键索引,普通索引
唯一索引的值不能重复,只能是唯一的
主键索引是特殊的唯一索引,表的主键拥有主键索引,主键索引不能有空值
普通索引即不是唯一的,也非主键
2、多列索引
多列索引又可被称为:组合索引,联合索引,复合索引,多值索引
将多个字段联合起来建立的索引称之为多列索引。
按功能划分
1、唯一索引
2、主键索引
3、普通索引
4、全文索引
全文索引类似于在Word中按照关键字进行检索
5、空间索引
空间索引常用于空间坐标的场合,比如地图中
按存储方式划分
1、聚集索引
聚集索引指的是在磁盘上按照逻辑顺序存放的索引,一般会将主键索引当做聚集索引
2、非聚集索引
非聚集索引指的是在磁盘上没有按照逻辑顺序存放的索引
通过执行计划分析SQL语句执行的效率
在SQL语句中使用Explain查看执行计划时,type列会显示此次查询走的是哪种索引
ALL:全表扫描,即没有走索引,需要优化
Const:通过主键或唯一索引命中的查询,仅匹配一条
Ref:通过普通索引命中的查询,可匹配多条
Eq-Ref:多表关联查询时,通过主键或唯一索引命中的查询
System:表中仅有一条数据,直接从内存中读取,如查询系统表的时间
Range:通过索引进行范围查询,如Between,>,In
Index:查询了包含索引的字段,但没加筛选条件
效率排行:System > Const > Eq-Ref > Ref > Range > Index > ALL
建议至少达到Range级别,尽量优化到Ref或Eq-Ref
在SqlSuger中,同样可以使用特性来创建索引:
// 普通索引(可以写多个)[SugarIndex("index_School_name", nameof(School.Name), OrderByType.Asc)]// 唯一索引 (true表示唯一索引 或者叫 唯一约束)// [SugarIndex("unique_School_CreateTime", nameof(School.CreateTime), OrderByType.Desc, true)]public class School{[SugarColumn(IsIdentity = true, IsPrimaryKey = true)]public int Id { get; set; }public string Name { get; set; }//ColumnDataType 一般用于单个库数据库,如果多库不建议用[SugarColumn(ColumnDataType = "Nvarchar(255)")]public string Text { get; set; }[SugarColumn(IsNullable = true)]//可以为NULLpublic DateTime CreateTime { get; set; }}给类添加SugarIndex特性,并依次设置:索引名称,字段名称,排序方式,就可以在创建表的同时设置索引,它支持唯一索引,普通索引,以及复合索引
插入数据
添加数据时需要调用Insertable方法,并传入一个实例对象。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 插入单条数据School model = new School(){Name = "张三",Text = "测试数据",CreateTime = DateTime.Now};// Db.Insertable<School>(model).ExecuteCommand();// 返回自增列var id = Db.Insertable(model).ExecuteReturnIdentity();Console.WriteLine(id);
}由于Id是自增的,所以不用指定,还可以返回自增Id。
在分布式的场景下,使用自增Id会面临在多台数据库里出现重复Id的现象,常用的解决方案是使用Guid,即一个绝对不会重复的字符串,但这种方式也有问题,就是在聚集索引里无法排序,这时可以使用雪花ID,它是由时间戳,机器ID,自定义ID组成,既能满足不会重复的要求,也可以排序。
批量插入和单条类似,都是调用Insertable方法,不同的是传入的是一个集合,如果数据量大可以使用Fastest方法,效率更高。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456;AllowLoadLocalInfile=true;",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});List<School> list = new List<School>();for (int i = 0; i < 10000; i++){// 插入单条数据School model = new School(){Name = "张三",Text = "测试数据:" + i.ToString(),CreateTime = DateTime.Now};list.Add(model);}// Db.Insertable(list).ExecuteCommand();Db.Fastest<School>().PageSize(10000).BulkCopy(list); //MySql连接字符串要加AllowLoadLocalInfile=true修改数据
修改数据时调用Updateable方法,不过如果只调用它会将没有传入的值的默认值更新到数据库中,解决方法有两个:给不希望更新的字段设置特性SugerColumn的IsOnlyIgnoreUpdate属性设置为true;或者创建一个跟踪器。
1、给不希望更新的字段设置特性SugerColumn的IsOnlyIgnoreUpdate属性设置为true
[SugarColumn(IsNullable = true, IsOnlyIgnoreUpdate = true)]//可以为NULL,忽略更新public DateTime CreateTime { get; set; } //创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 只更新修改了的字段,不会修改其他字段School model = new School(){Id = 1,};model.Name = "王五";model.Text = "测试数据";Db.Updateable(model).ExecuteCommand();这样就不会更新CreateTime字段了
2、创建一个跟踪器
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 只更新修改了的字段,不会修改其他字段School model = new School(){Id = 1,};// 创建跟踪Db.Tracking(model);model.Name = "王五";model.Text = "测试数据";Db.Updateable(model).ExecuteCommand();Db.ClearTracking();跟踪器的原理是通过反射获取这个对象哪些字段的值发生了改变,然后将这些字段拼接为SQL。
依据非主键的字段进行更新
这种需求也很常见,毕竟主键只有一个,而更新的依据会由很多种。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 只更新修改了的字段,不会修改其他字段School model = new School(){Name = "李四"};// 创建跟踪Db.Tracking(model);model.Text = "测试数据2";Db.Updateable(model).WhereColumns(m => m.Name).ExecuteCommand();Db.ClearTracking();新增或修改
在表单与列表共存的管理界面中,通常需要同时支持数据新增和修改功能。其业务逻辑可抽象为:当用户提交数据时,系统需自动判断数据记录是否存在——若存在则执行更新操作,不存在则执行新增操作。借助SqlSugar ORM框架,该通用逻辑已被封装为Storageable方法,开发者可直接调用实现"存在即更新,不存在即插入"的智能化存储策略。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 修改或更新数据,首先依据Id查询是否存在,如果不存在则新增,如果存在则修改School model = new School(){Id = 2,Name = "李四",Text = "测试数据",CreateTime = DateTime.Now};Db.Storageable(model).ExecuteCommand();删除数据
删除单条数据,多条数据,依据非主键字段删除数据
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 删除单条数据Db.Deleteable<School>(new School() { Id = 1 }).ExecuteCommand();// 删除多条数据Db.Deleteable<School>(new List<School>() { new School() { Id = 2},new School() {Id = 3},}).ExecuteCommand();// 依据非主键字段删除数据Db.Deleteable<School>().WhereColumns(new List<School>() { new School() { Text = "测试数据:3",},new School() {Text = "测试数据:4",},}, m => new { m.Text }).ExecuteCommand();逻辑删除
有时候我们希望数据能一直存在于数据库中,这样方便回滚数据,追溯数据。这时会用到逻辑删除,只对某个字段的值进行修改,SqlSuger中支持这种方式,默认将IsDelete看做是逻辑删除的字段。
[SugarColumn(IsNullable = true, DefaultValue = "0")]public bool IsDelete { get; set; }使用CodeFirst将字段更新到数据库中后,并将值设置为0,0表示未删除。使用逻辑删除需要用到IsLogic方法。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// Db.CodeFirst.SetStringDefaultLength(200).InitTables(typeof(School));// 逻辑删除数据Db.Deleteable<School>(new School() { Id = 6 }).IsLogic().ExecuteCommand();也支持自定义字段,在ExecuteCommand方法中传入字段的名字即可,还可以指定更新时间,操作人。
自定义逻辑删除字段,更新时间和操作人
首先将更新时间和操作人字段添加到数据库中,这里也将自定义删除标记字段添加进去。
[SugarColumn(IsNullable = true, DefaultValue = "0")]public bool is_delete { get; set; }[SugarColumn(IsNullable = true)]public DateTime? UpdateTime { get; set; }[SugarColumn(IsNullable = true)]public string? ModifierName { get; set; }逻辑删除数据,并指定更新时间和操作人,自定义的删除标记字段。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// Db.CodeFirst.SetStringDefaultLength(200).InitTables(typeof(School));// 逻辑删除数据Db.Deleteable<School>(new School() { Id = 8 }).IsLogic().ExecuteCommand("is_delete", true, "UpdateTime", "ModifierName", "04");查询数据
基础查询
基础查询时要调用Queryable方法,后续再跟一个Linq的扩展方法,比如:Where,Count,Contains,Any,OrderBy,SingleOrDefault,FirstOrDefault等,它们对应不同的SQL语句像是:Where,Count,In,Like,OrderBy,<>,is null等等。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 全表查询var list = Db.Queryable<School>().ToList();list.ForEach(m => {Console.WriteLine(m);});// 查询总数var count = Db.Queryable<School>().Count();Console.WriteLine("Count="+count);// 按条件查询var list2 = Db.Queryable<School>().Where(m => m.Id == 1).ToList();list2.ForEach(m => {Console.WriteLine(m);});// In查询int[] ids = new int[] { 1, 2, 3 };var list3 = Db.Queryable<School>().Where(m => ids.Contains(m.Id)).ToList();list3.ForEach(m => {Console.WriteLine(m);});// In查询(多个字段)List<School> ids2 = new List<School>(){new School(){Id = 1,Name = "张三"},new School(){Id = 2,Name = "李四"},};var list4 = Db.Queryable<School>().Where(m => ids2.Any(n =>m.Id == n.Id && m.Name == n.Name )).ToList();list4.ForEach(m => {Console.WriteLine(m);});// 模糊查询var list5 = Db.Queryable<School>().Where(m => m.Name.Contains("张")).ToList();list5.ForEach(m => {Console.WriteLine(m);});// 排序var list6 = Db.Queryable<School>().OrderBy(m => m.Id).ToList();Console.WriteLine("--------------正序--------------");list6.ForEach(m => {Console.WriteLine(m);});// 倒序list6 = Db.Queryable<School>().OrderBy(m => m.Id, OrderByType.Desc).ToList();Console.WriteLine("--------------倒序--------------");list6.ForEach(m => {Console.WriteLine(m);});扩展:
SingleOrDefault与FirstOrDefault有什么区别?
SingleOrDefault是查询结果只有一条时才正常返回结果,否则抛异常。
FirstOrDefault是在有单条或多条的结果时,返回第一条。
分页查询
分页查询是经常会用到的场景,调用ToPageList方法,并传入当前页码,每页条数即可。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取原生SQL推荐 5.1.4.63 性能OK// Console.WriteLine(UtilMethods.GetNativeSql(sql, pars));//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});var count = 0;var totalPage = 0;for (int i = 1; i < 100; i++){var index = i;var size = 10;var list = Db.Queryable<School>().ToPageList(index, size, ref count, ref totalPage);list.ForEach(m => {Console.WriteLine(m.ToString());});}Console.WriteLine($"合计:{count}条,{totalPage}页");使用Count统计数据时,由于是全表扫描所以耗时很长,当数据大于1个亿的时候需要约1分钟,这时可以在MySQL的Schema中查询表的行数,但这种方法不是很准确
SELECT table_rows FROM Information_Schema.`TABLES`
WHERE table_Schema = 'mes' AND TABLE_NAME = 'school'
还有一种方法是通过缓存技术去实现,比如定时读取表的行数后更新到缓存中,只有当数据增加或删除时才会查询总行数,其他操作都只从缓存中读取。
分组和去重
分组是数据库的常见操作,在统计数据时经常会用到,就好比上学的时候会分班,就是以班级名称为分组依据,比如要统计每个班级里男生和女生的数量时,就是求各个班级的性别的Count值;或者期末时统计考试成绩的平均数时,就是对分数字段求Avg值。
在SqlSuger中使用GroupBy方法并配合Select实现分组查询。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取原生SQL推荐 5.1.4.63 性能OK// Console.WriteLine(UtilMethods.GetNativeSql(sql, pars));//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 以CreateTime分组,显示每组Id的数量var list = Db.Queryable<School>().GroupBy(m => m.CreateTime).Select(m => new{CreateTime = m.CreateTime,Count = SqlFunc.AggregateCount(m.Id),}).OrderBy(m => m.CreateTime).ToList();list.ForEach(m => {Console.WriteLine(m.ToString());});// 去重,去重方法得和Select一起使用,因为主键不可能重复,只能去指定其他可以重复的字段,这里指定的是Textvar count1 = Db.Queryable<School>().Distinct().Select(m => m.Text).Count();var count2 = Db.Queryable<School>().Select(m => m.Text).Count();Console.WriteLine($"去重前:{count1}");Console.WriteLine($"去重后:{count2}");SqlFunc是SqlSuger的开窗函数,比如:SqlFunc.AggregateCount()具有汇总的作用。
去重操作的方法和SQL里的一致都是Distinct方法,也要与Select配合使用。
联表查询
一张表往往不足以包含所有的数据,有时还需要和其他表进行关联来获取更多信息,这时就会用到联表语句Join,它有包括左连接,右连接,内连接,全连接。对应SqlSuger的LeftJoin,RightJoin,InnerJoin,FullJoin。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});var list = Db.Queryable<School>().LeftJoin<Area>((school, area) => school.AreaCode == area.Code ).Select((school, area) => new { SchoolId = school.Id,SchoolName = school.Name,SchoolCreateTime = school.CreateTime,AreaCode = area.Code,AreaName = area.Name}).ToList();list.ForEach(m => {Console.WriteLine($"SchoolId={m.SchoolId}, SchoolName={m.SchoolName},SchoolCreateTime={m.SchoolCreateTime}," +$"AreaCode={m.AreaCode},AreaName={m.AreaName}");});上述的代码中对School和Area表进行了左连接的查询,它们共有AreaCode字段。
导航查询
导航查询和连接查询查询类似,都是对多张表进行关联,只不过它更符合面对象的思维,在一个类中存放另一个类,通过特性来配置两个类的关系,映射的字段名。
1、在School中新增一个Area类的属性
/// <summary>/// 导航查询字段,需配置这个类的字段关联的是外部类的哪个字段/// </summary>[Navigate(NavigateType.OneToOne, nameof(AreaCode), nameof(Area.Code))]public Area AreaObject { get; set; }2、使用Include方法进行导航查询
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取原生SQL推荐 5.1.4.63 性能OK// Console.WriteLine(UtilMethods.GetNativeSql(sql, pars));//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 导航查询var list = Db.Queryable<School>().Includes(m => m.AreaObject).ToList();list.ForEach(m => {Console.WriteLine(m.ToString());});// 对象映射var list2 = Db.Queryable<School>().Includes(m => m.AreaObject).ToList().Adapt<List<SchoolDTO>>();list2.ForEach(m =>{Console.WriteLine(m.ToString());});// 对象映射,将不同名字的字段进行映射var list3 = Db.Queryable<School>().Includes(m => m.AreaObject).Select(m => new SchoolDTO(){SchoolName = m.Name,}, true).ToList();list3.ForEach(m => {Console.WriteLine(m.ToString());});上述代码不仅包含导航查询,还包括对象映射的内容。
对象映射是将一个类的部分属性映射到另一个类中,如果手动操作不仅耗时,而且容易出错,这里使用的是Mapster包,在Nuget上下载后,无需任何配置就可以使用,直接调用Adapt方法即可完成映射。如果两个类的字段名不同,需要使用Select方法,给不同名字的字段进行一一匹配,并给第二个参数赋值为true,让其他字段自动填充。
下面是映射类:
public class SchoolDTO{public int Id { get; set; }public string SchoolName { get; set; }public string Text { get; set; }public DateTime CreateTime { get; set; }/// <summary>/// 所属地区./// </summary>[SugarColumn(IsNullable = true)]public string? AreaCode { get; set; }/// <summary>/// 导航查询字段,需配置这个类的字段关联的是外部类的哪个字段/// </summary>[Navigate(NavigateType.OneToOne, nameof(AreaCode), nameof(Area.Code))]public Area AreaObject { get; set; }public override string ToString(){return $"Id={Id},Name={Name},Text={Text},CreateTime={CreateTime},AreaCode={AreaCode},AreaObject={AreaObject?.ToString()}";}}Json查询
Json查询原理是通过读取Json文件里的查询条件去得到不同的结果,这样就不用再去修改代码后重新编译生成程序了。
1、Json文件内容
[{"FieldName": "id","ConditionalType": "6","FieldValue": "1,2,3"},{"FieldName": "AreaCode","ConditionalType": "0","FieldValue": "110000"}
]FieldName是查询的键名,ConditionalType是查询条件,6对应In,0对应=,FieldValue是值,翻译过来就是id是1,2,3并且AreaCode等于110000。
2、后台代码
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 读取Json,将Json转换为条件对象,再将对象放到Where方法的参数中var json = File.ReadAllText($"{Environment.CurrentDirectory}\\sqlQuery.json");var conModels = Db.Utilities.JsonToConditionalModels(json);var list = Db.Queryable<School>().Where(conModels).ToList();list.ForEach(m => {Console.WriteLine(m.ToString());});无实体查询
无实体查询和Json查询一样都可以动态的查询数据,而不用去修改代码。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 通过字符串和匿名对象来查询SQLvar list = Db.Queryable<School>().Where("Id in(@Id) And AreaCode = @AreaCode",new {Id = new int[3] { 1, 2, 3 },AreaCode = "110000"}).ToList();list.ForEach(m => {Console.WriteLine(m);});将上一节的Json条件拿到这里来,返回的结果是一样的。
事务
在一些情境下数据库的操作会执行多次,而这多次的操作过程中如果发生了点小意外,那么就会抛出异常,导致数据的不一致性,为了避免这种情况的发生,事务就孕育而生了。它可以让这些操作全部执行或者全部不执行,保证了数据的一致性。
在SqlSuger中有3个方法来操作事务:BeginTran开启事务,CommitTran提交事务,RollbackTran回滚事务。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});try{Db.Ado.BeginTran();Area area = new Area();area.Code = "150000";area.Name = "内蒙古自治区";Db.Insertable<Area>(area).ExecuteCommand();School model = new School(){Id = 1,AreaCode = "150000",// Name = "张三",// Text = "测试数据",};Db.Updateable<School>(model).ExecuteCommand();Db.Ado.CommitTran();}catch (Exception ex){Db.Ado.RollbackTran();throw ex;}上述的例子中,首先添加了一个地区,然后修改School的地区代码,如果School的Name和Text为空,则会抛出异常,回滚事务,连第一步添加地区的操作也会失效,这就达到了全部不提交的效果。如果School的Name和Text不为空,则两个操作都能执行,事务便提交上去了。
事务锁
在高并发的场景下,如果对同一条数据进行修改,就有可能会出现问题,比如在抢红包时候,同时有两个用户开启它,那么红包的金额会减少两次,当剩余金额接近0的时候,同时操作就有可能出现负数的情况,这是要避免的,解决方式是给这个操作加锁,避免当A操作进来的时候加一把锁,不让B操作进来,直到A操作结束再放B操作进来。
上面描述的是悲观锁的机制,SqlSuger中使用TranLock方法加锁。
主键查询一般是行锁,如果非主键可以会变成表锁
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});try{Db.Ado.BeginTran();// 查询条件记录后锁表var model = Db.Queryable<School>().TranLock(DbLockType.Wait).Where(m => m.Id == 2).First();model.Text = "企鹅";Db.Updateable<School>(model).ExecuteCommand();Db.Ado.CommitTran();}catch (Exception ex){Db.Ado.RollbackTran();throw ex;}AOP-面向切面编程
在之前的每个例子中都有打印SQL的委托OnLogExecuting,这个就是AOP的一个典型运用,除了打印执行的SQL还可以进行性能检测,将超过一定执行时间的C#文件的名称,代码行数,方法名都打印出来;还可以进行数据处理:在每条插入,修改,删除语句中给指定的列赋值,比如给每个创建日期,修改日期的字段赋值,这样就不用每次手动给这些字段赋值了。
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db =>{db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};db.Aop.OnLogExecuted = (sql, p) =>{// 执行时间超过1秒if (db.Ado.SqlExecutionTime.TotalSeconds > 1){//代码CS文件名var fileName = db.Ado.SqlStackTrace.FirstFileName;//代码行数var fileLine = db.Ado.SqlStackTrace.FirstLine;//方法名var FirstMethodName = db.Ado.SqlStackTrace.FirstMethodName;}};db.Aop.DataExecuting = (oldValue, entityInfo) =>{/*** 列级别事件:插入的每个列都会进事件 ***/if (entityInfo.PropertyName == "CreateTime" && entityInfo.OperationType == DataFilterType.InsertByObject){// 给每条SQL中带有CreateTime的字段赋予现在的时间entityInfo.SetValue(DateTime.Now);}};});// 插入单条数据School model = new School(){Name = "李四",Text = "测试数据",};Db.Insertable<School>(model).ExecuteCommand();分表组件
当数据库的数量量很大的时候,查询会变得非常缓慢,因为索引的数量也是有限制的,这时候就可以进行分表操作,提高查询效率。SqlSuger内置了分表组件,只需调用SplitTables方法就可以进行CRUD操作。
1、建立实体
[SplitTable(SplitType.Year)]//按年分表 (自带分表支持 年、季、月、周、日)[SugarTable("SplitTestTable_{year}{month}{day}")]//3个变量必须要有,这么设计为了兼容开始按年,后面改成按月、按日public class SplitTestTable{[SugarColumn(IsPrimaryKey = true)]public long Id { get; set; }public string Name { get; set; }[SugarColumn(IsNullable = true)]//设置为可空字段 (更多用法看文档 迁移)public DateTime UpdateTime { get; set; }[SplitField] //分表字段 在插入的时候会根据这个字段插入哪个表,在更新删除的时候用这个字段找出相关表public DateTime CreateTime { get; set; }}2、执行SQL,创建数据表
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});// 初始化数据库Db.CodeFirst.SplitTables().InitTables<SplitTestTable>(); // 程序启动时加这一行,如果一张表没有会初始化一张3、CRUD
//创建数据库对象 (用法和EF Dappper一样通过new保证线程安全)SqlSugarClient Db = new SqlSugarClient(new ConnectionConfig(){ConnectionString = "server=localhost;Database=mes;Uid=root;Pwd=123456",DbType = DbType.MySql,IsAutoCloseConnection = true},db => {db.Aop.OnLogExecuting = (sql, pars) =>{//获取无参数化SQL 对性能有影响,特别大的SQL参数多的,调试使用Console.WriteLine(UtilMethods.GetSqlString(DbType.SqlServer, sql, pars));};});#region 插入数据//var data = new SplitTestTable()//{// CreateTime = Convert.ToDateTime("2024-12-1"),//要配置分表字段通过分表字段建表// Name = "Jack"//};雪花ID+表不存在会建表//Db.Insertable(data).SplitTable().ExecuteReturnSnowflakeIdList();//插入并返回雪花ID并且自动赋值ID//data = new SplitTestTable()//{// CreateTime = Convert.ToDateTime("2023-12-1"),//要配置分表字段通过分表字段建表// Name = "Ana"//};雪花ID+表不存在会建表//Db.Insertable(data).SplitTable().ExecuteReturnSnowflakeIdList();//插入并返回雪花ID并且自动赋值ID//data = new SplitTestTable()//{// CreateTime = Convert.ToDateTime("2022-12-1"),//要配置分表字段通过分表字段建表// Name = "Bob"//};雪花ID+表不存在会建表//Db.Insertable(data).SplitTable().ExecuteReturnSnowflakeIdList();//插入并返回雪花ID并且自动赋值ID //data = new SplitTestTable()//{// CreateTime = Convert.ToDateTime("2021-12-1"),//要配置分表字段通过分表字段建表// Name = "Ciri"//};雪花ID+表不存在会建表//Db.Insertable(data).SplitTable().ExecuteReturnSnowflakeIdList();//插入并返回雪花ID并且自动赋值ID #endregion// 查询数据var beginDate = Convert.ToDateTime("2021-1-1");var endDate = Convert.ToDateTime("2025-1-1");var list = Db.Queryable<SplitTestTable>().Where(it => it.Id > 0).SplitTable(beginDate, endDate).OrderBy(m => m.Id, OrderByType.Asc).ToList();// 注意:// 1、 分页有 OrderBy写 SplitTable 后面 ,uinon all后在排序// 2、 Where尽量写到 SplitTable 前面,先过滤在union all // 原理:(sql union sql2) 写SplitTable 后面生成的括号外面,写前生成的在括号里面list.ForEach(m => {Console.WriteLine(m.Id + " " + m.Name + " " + m.CreateTime);});相关文章:

.NET ORM开发手册:基于SqlSugar的高效数据访问全攻略
SqlSuger是一个国产,开源ORM框架,具有高性能,使用方便,功能全面的特点,支持.NET Framework和.NET Core,支持各种关系型数据库,分布式数据库,时序数据库。 官网地址:SqlS…...

【PostgreSQL】数据探查工具1.0研发可行性方案
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 想抢先解锁数据自由的宝子,速速戳我!评论区蹲一波 “蹲蹲”,揪人唠唠你的超实用需求! 【PostgreSQL】数据探查工具1.0研发可行性方案,数据调研之秒解析数据结构,告别熬夜写 SQL【PostgreSQL】数据探查工具…...

C++ 内存管理与单例模式剖析
目录 引言 一、堆上唯一对象:HeapOnly类 (一)设计思路 (二)代码实现 (三)使用示例及注意事项 二、栈上唯一对象:StackOnly类 (一)设计思路 ࿰…...
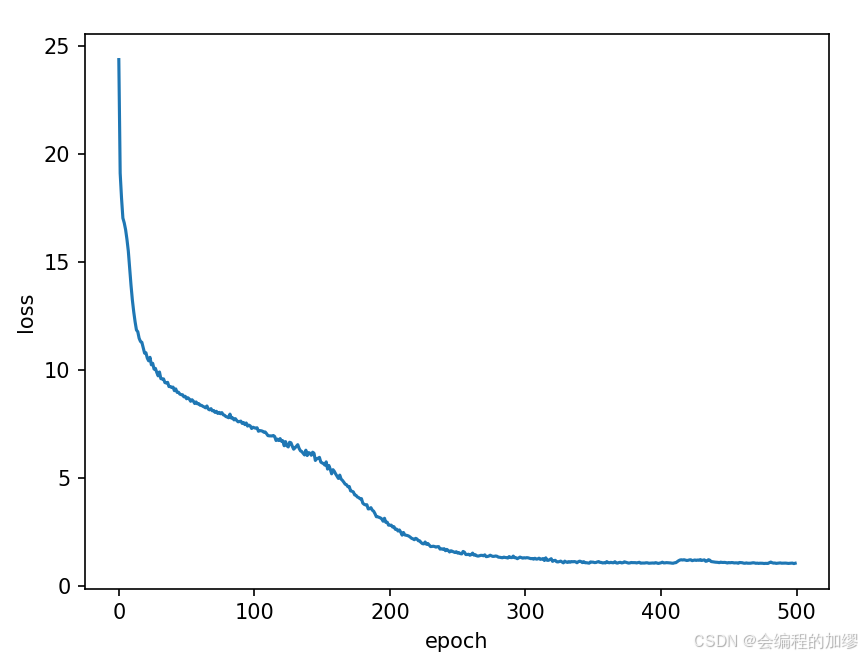
算法学习——从零实现循环神经网络
从零实现循环神经网络 一、任务背景二、数据读取与准备1. 词元化2. 构建词表 三、参数初始化与训练1. 参数初始化2. 模型训练 四、预测总结 一、任务背景 对于序列文本来说,如何通过输入的几个词来得到后面的词一直是大家关注的任务之一,即:…...
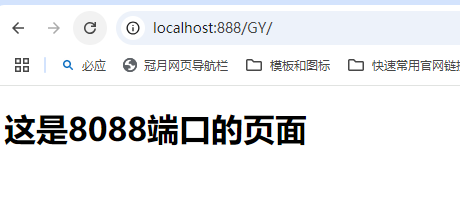
win10使用nginx做简单负载均衡测试
一、首先安装Nginx: 官网链接:https://nginx.org/en/download.html 下载完成后,在本地文件中解压。 解压完成之后,打开conf --> nginx.config 文件 1、在 http 里面加入以下代码 upstream GY{#Nginx是如何实现负载均衡的&a…...
2025电工杯数学建模B题思路数模AI提示词工程
我发布的智能体链接:数模AI扣子是新一代 AI 大模型智能体开发平台。整合了插件、长短期记忆、工作流、卡片等丰富能力,扣子能帮你低门槛、快速搭建个性化或具备商业价值的智能体,并发布到豆包、飞书等各个平台。https://www.coze.cn/search/n…...

软考软件评测师——软件工程之开发模型与方法
目录 一、核心概念 二、主流模型详解 (一)经典瀑布模型 (二)螺旋演进模型 (三)增量交付模型 (四)原型验证模型 (五)敏捷开发实践 三、模型选择指南 四…...

前端表单中 `readOnly` 和 `disabled` 属性的区别
前端表单中 readOnly 和 disabled 属性的区别 定义与适用范围 readOnly 是一种属性,仅适用于 <input> 和 <textarea> 元素。当设置了此属性时,用户无法修改这些元素的内容,但仍能聚焦并选中文本。disabled 则是一个更广泛的属性…...
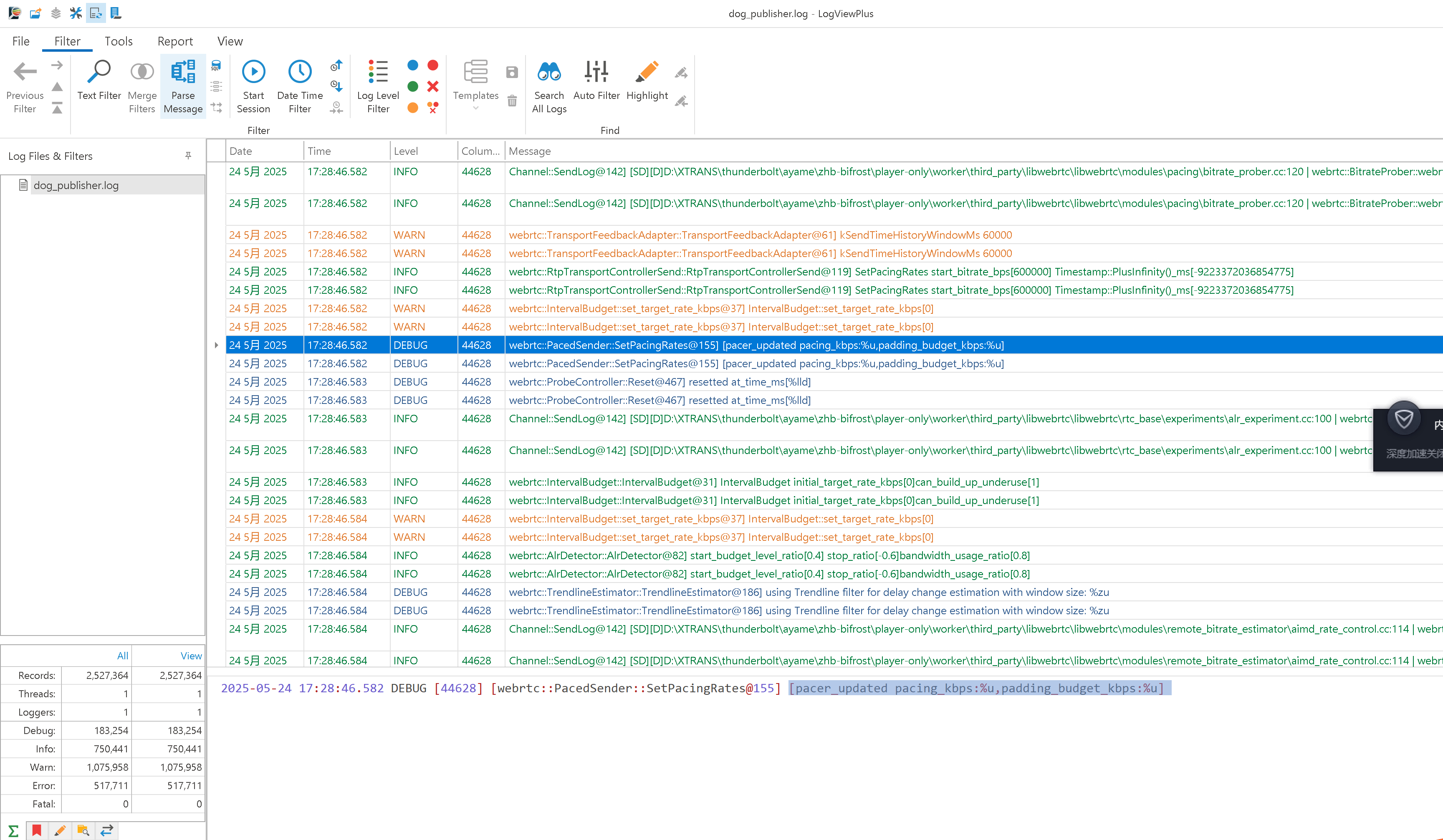
【日志软件】hoo wintail 的替代
hoo wintail 的替代 主要问题是日志大了以后会卡有时候日志覆盖后,改变了,更新了,hoo wintail可能无法识别需要重新打开。 有很多类似的日志监控软件可以替代。以下是一些推荐的选项: 免费软件 BareTail 轻量级的实时日志查看…...
)
OceanBase数据库全面指南(基础入门篇)
文章目录 一、OceanBase 简介与安装配置指南1.1 OceanBase 核心特点1.2 架构解析1.3 安装部署实战1.3.1 硬件要求1.3.2 安装步骤详解1.3.3 配置验证二、OceanBase 基础 SQL 语法入门2.1 数据查询(SELECT)2.1.1 基础查询语法2.1.2 实际案例演示2.2 数据操作(INSERT/UPDATE/DE…...

异步处理与事件驱动中的模型调用链设计
异步处理与事件驱动中的模型调用链设计 在现代AI系统中,尤其是在引入了大模型(如LLM)或多步骤生成流程的业务场景中,传统的同步调用模型已越来越难以应对延迟波动、资源竞争和流程耦合等问题。为了提升系统响应效率、降低调用失败…...

redis配置带验证的主从复制
IP地址主机名192.168.10.161redis161192.168.10.162redis162192.168.10.163redis163 配置主机host161,redis服务连接密码为123456主机host162设置连接host61的redis服务密码 给host161主机的Redis服务设置连接密码,如果从服务器不指定连接密码无法同…...

Ollama-OCR:基于Ollama多模态大模型的端到端文档解析和处理
基本介绍 Ollama-OCR是一个Python的OCR解析库,结合了Ollama的模型能力,可以直接处理 PDF 文件无需额外转换,轻松从扫描版或原生 PDF 文档中提取文本和数据。根据使用的视觉模型和自定义提示词,Ollama-OCR 可支持多种语言…...

OpenCV CUDA 模块中图像过滤------创建一个拉普拉斯(Laplacian)滤波器函数createLaplacianFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::createLaplacianFilter 是 OpenCV CUDA 模块中的一个函数,用于创建一个 拉普拉斯(Laplacian)滤波器…...
图论学习笔记 3
自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。 多图警告。 众所周知王老师有一句话: ⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不…...

在单片机中如何在断电前将数据保存至DataFlash?
几年前,我做过一款智能插座,需要带电量计量的功能, 比如有个参数是总共用了多少度电 (kWh),这个是需要实时掉存保存的数据。 那问题来了,如果家里突然停电,要怎么在断电前将数据保存至Flash? 问…...
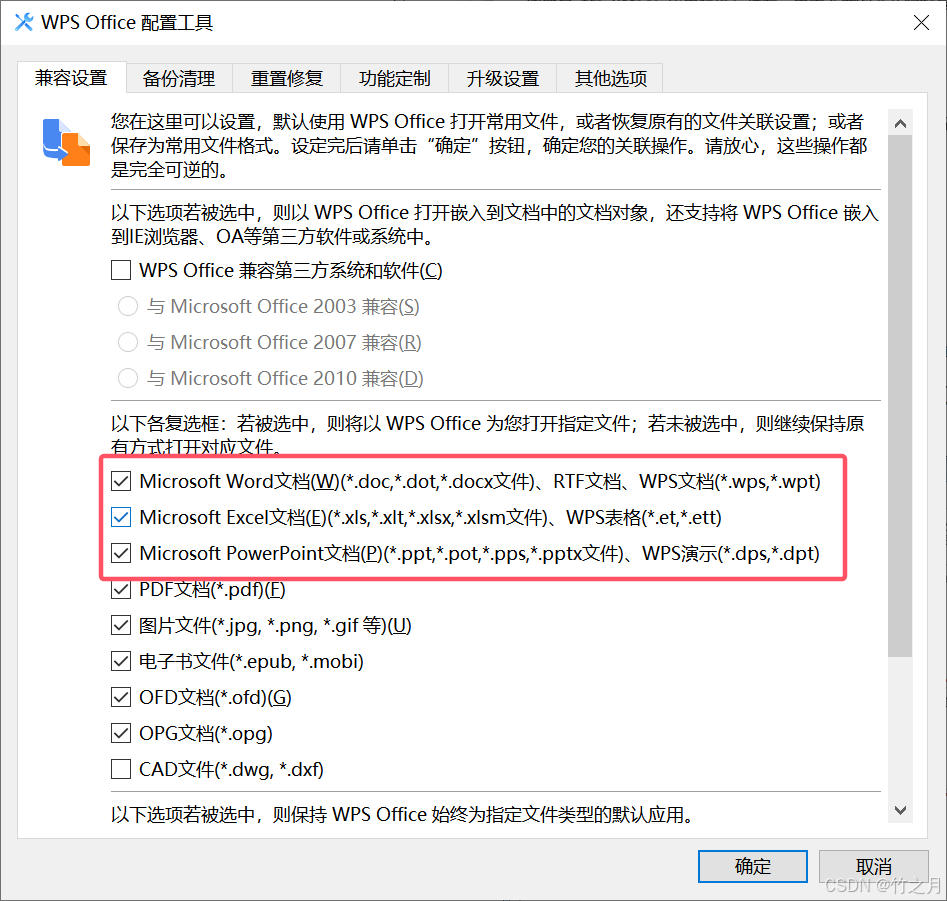
【将WPS设置为默认打开方式】--突然无法用WPS打开文件
1. 点击【开始】——【WPS Office】——【配置工具】; 2. 在出现的弹窗中,点击【高级】; 3. 在“兼容设置”中,将复选框勾上,点击【确定】。...

电子人的分水岭-FPGA模电和数电
为什么模电这么难学?一文带你透彻理解模电 ——FPGA是“前期数电,后期模电”的典型代表 在电子工程的世界里,有两门基础课程让无数学生“闻之色变”:数字电路(数电) 和 模拟电路(模电࿰…...

(6)python爬虫--selenium
文章目录 前言一、初识selenium二、安装selenium2.1 查看chrome版本并禁止chrome自动更新2.1.1 查看chrome版本2.1.2 禁止chrome更新自动更新 2.2 安装对应版本的驱动程序2.3安装selenium包 三、selenium关于浏览器的使用3.1 创建浏览器、设置、打开3.2 打开/关闭网页及浏览器3…...

Python之两个爬虫案例实战(澎湃新闻+网易每日简报):附源码+解释
目录 一、案例一:澎湃新闻时政爬取 (1)数据采集网站 (2)数据介绍 (3)数据采集方法 (4)数据采集过程 二、案例二:网易每日新闻简报爬取 (1&#x…...

HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南
HarmonyOS NEXT~鸿蒙系统与mPaaS三方框架集成指南 1. 概述 1.1 鸿蒙系统简介 鸿蒙系统(HarmonyOS)是华为开发的分布式操作系统,具备以下核心特性: 分布式架构:支持跨设备无缝协同微内核设计:提高安全性和性能一次开…...

系统安全及应用学习笔记
系统安全及应用学习笔记 一、账号安全控制 (一)账户管理策略 冗余账户处理 非登录账户:Linux 系统中默认存在如 bin、daemon 等非登录账户,其登录 Shell 应为 /sbin/nologin,需定期检查确保未被篡改。冗余账户清理&…...

STC89C52RC/LE52RC
STC89C52RC 芯片手册原理图扩展版原理图 功能示例LED灯LED灯的常亮效果LED灯的闪烁LED灯的跑马灯效果:从左到右,从右到左 数码管静态数码管数码管计数App.cApp.hCom.cCom.hDir.cDir.hInt.cInt.hMid.cMid.h 模板mian.cApp.cApp.hCom.cCom.hDir.cDir.hInt.…...
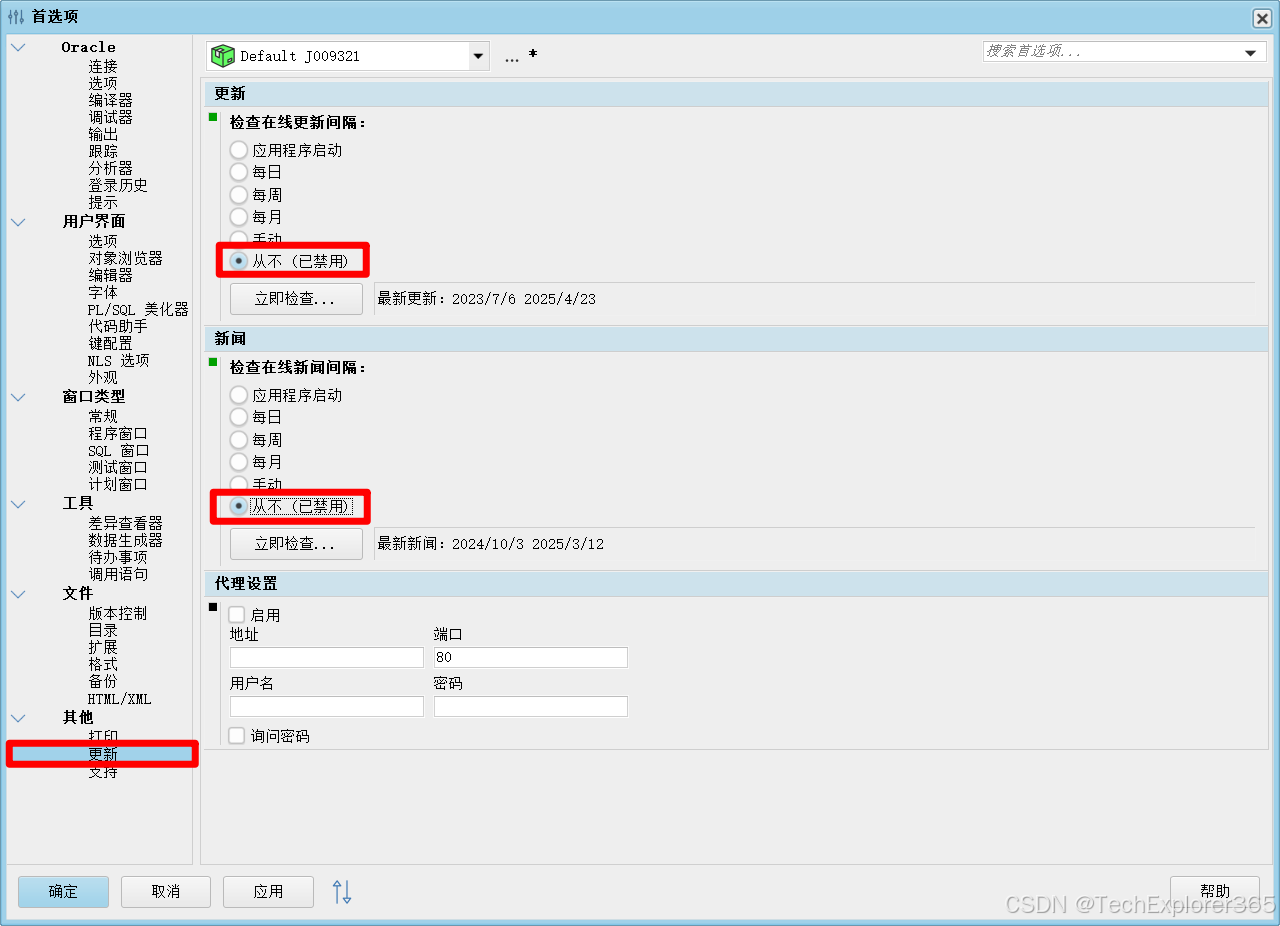
✨ PLSQL卡顿优化
✨ PLSQL卡顿优化 1.📂 打开首选项2.🔧 Oracle连接配置3.⛔ 关闭更新和新闻 1.📂 打开首选项 2.🔧 Oracle连接配置 3.⛔ 关闭更新和新闻...

yum命令常用选项
刷新仓库列表 sudo yum repolist清理 Yum 缓存并生成新的缓存 sudo yum clean all sudo yum makecache验证 EPEL 源是否已正确启用 sudo yum repolist enabled安装软件包 sudo yum install <package-name> -y更新软件包 sudo yum update -y仅更新指定的软件包。 su…...
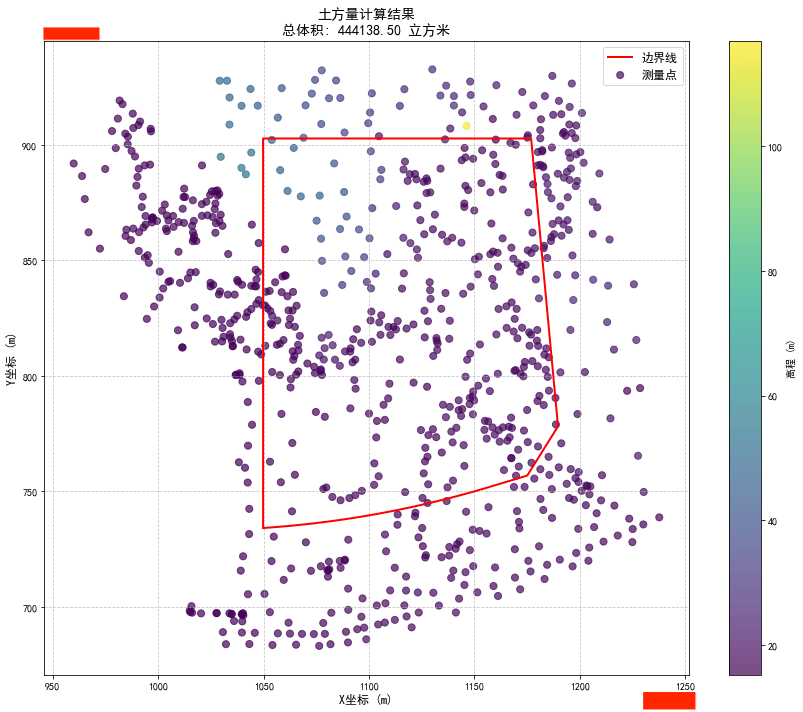
python+vlisp实现对多段线范围内土方体积的计算
#在工程中,经常用到计算土方回填、土方开挖的体积。就是在一个范围内,计算土被挖走,或者填多少,这个需要测量挖填前后这个范围内的高程点。为此,我开发一个app,可以直接在autocad上提取高程点,然…...

鸿蒙Flutter实战:25-混合开发详解-5-跳转Flutter页面
概述 在上一章中,我们介绍了如何初始化 Flutter 引擎,本文重点介绍如何添加并跳转至 Flutter 页面。 跳转原理 跳转原理如下: 本质上是从一个原生页面A 跳转至另一个原生页面 B,不过区别在于,页面 B是一个页面容器…...
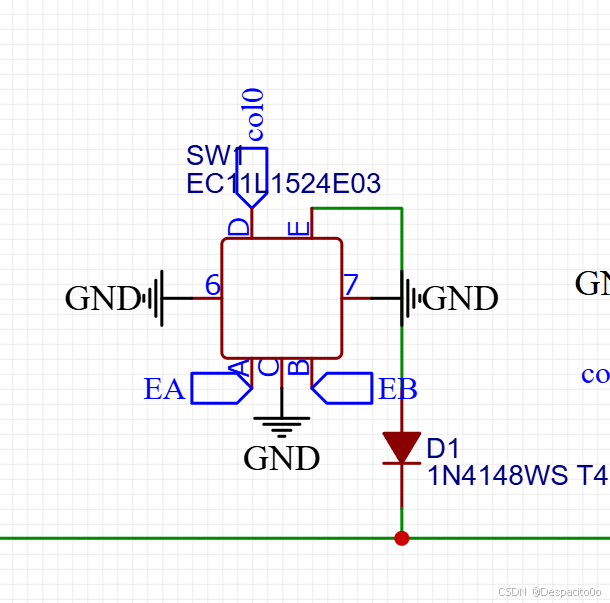
APM32小系统键盘PCB原理图设计详解
APM32小系统键盘PCB原理图设计详解 一、APM32小系统简介 APM32微控制器是国内半导体厂商推出的一款高性能ARM Cortex-M3内核微控制器,与STM32高度兼容,非常适合DIY爱好者用于自制键盘、开发板等电子项目。本文将详细讲解如何基于APM32 CBT6芯片设计一款…...

【C/C++】多线程开发:wait、sleep、yield全解析
文章目录 多线程开发:wait、sleep、yield全解析1 What简要介绍详细介绍wait() — 条件等待(用于线程同步)sleep() — 睡觉,定时挂起yield() — 自愿让出 CPU 2 区别以及建议区别应用场景建议 3 三者协作使用示例 多线程开发&#…...

uint8_t是什么数据类型?
一、引言 在C语言编程中,整数类型是最基本的数据类型之一。然而,你是否真正了解这些看似简单的数据类型?本文将深入探索C语言中的整数类型,在编程中更加得心应手。 二、C语言整数类型的基础 2.1 标准整数类型 C语言提供了多种…...