《企业级日志该怎么打?Java日志规范、分层设计与埋点实践》
大家好呀!👋 今天我们要聊一个Java开发中超级重要但又经常被忽视的话题——日志系统!📝 不管你是刚入门的小白,还是工作多年的老司机,日志都是我们每天都要打交道的"好朋友"。那么,如何才能和这位"好朋友"相处得更好呢?🤔 跟着我一起来探索吧!
一、为什么要用日志系统?🤷♂️
想象一下,你正在玩一个超级复杂的乐高积木🏗️,突然有个零件找不到了,或者拼着拼着发现不对劲了…这时候如果有个"回放功能"能让你看看之前每一步是怎么做的,是不是很棒?💡
日志系统就是程序的"回放功能"!它能记录程序运行的每一步,帮我们:
- 调试程序🔧:当程序出问题时,可以查看日志定位问题
- 监控运行状态👀:了解程序在干什么,有没有异常
- 分析性能⏱️:找出程序慢在哪里
- 安全审计🔒:记录重要操作,便于追溯
二、Java日志系统发展史📜
Java日志系统可不是一开始就这么强大的,它经历了一段"进化史":
- 原始时代🦕:
System.out.println()- 简单但功能有限 - Log4j 1.x时代🚀:第一个专业的日志框架
- JUL时代(java.util.logging)🏛️:JDK自带的日志系统
- Logback时代⚡:Log4j的改进版,性能更好
- Log4j 2.x时代🚀🚀:全面升级,功能强大
- SLF4J时代🌈:日志门面,统一各种日志实现
三、主流Java日志框架介绍🛠️
现在Java生态中有几个主流的日志框架,我们一个个来看:
1. Log4j 2.x 🏆
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;public class Log4j2Example {private static final Logger logger = LogManager.getLogger(Log4j2Example.class);public static void main(String[] args) {logger.trace("Trace级别日志");logger.debug("Debug级别日志");logger.info("Info级别日志");logger.warn("Warn级别日志");logger.error("Error级别日志");logger.fatal("Fatal级别日志");}
}
特点:
- 异步日志性能超强⚡
- 插件式架构,扩展性强🔌
- 支持JSON等格式的日志
- 丰富的过滤器和布局
2. Logback 🥈
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class LogbackExample {private static final Logger logger = LoggerFactory.getLogger(LogbackExample.class);public static void main(String[] args) {logger.trace("Trace级别日志");logger.debug("Debug级别日志");logger.info("Info级别日志");logger.warn("Warn级别日志");logger.error("Error级别日志");}
}
特点:
- Log4j的改进版,性能更好🚀
- 原生支持SLF4J
- 配置文件自动热加载🔄
- 更灵活的归档策略
3. java.util.logging (JUL) 🏛️
import java.util.logging.Logger;public class JulExample {private static final Logger logger = Logger.getLogger(JulExample.class.getName());public static void main(String[] args) {logger.finest("Finest级别日志");logger.finer("Finer级别日志");logger.fine("Fine级别日志");logger.config("Config级别日志");logger.info("Info级别日志");logger.warning("Warning级别日志");logger.severe("Severe级别日志");}
}
特点:
- JDK自带,无需额外依赖
- 功能相对简单
- 性能一般
四、日志门面SLF4J介绍🌈
SLF4J (Simple Logging Facade for Java) 不是一个具体的日志实现,而是一个"门面"(Facade),就像是一个"万能遥控器"📱,可以控制各种品牌的电视📺。
为什么需要SLF4J?
- 解耦应用和具体日志实现
- 可以灵活切换日志框架
- 统一的API,学习成本低
使用示例:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;public class Slf4jExample {private static final Logger logger = LoggerFactory.getLogger(Slf4jExample.class);public static void main(String[] args) {// 使用占位符,避免字符串拼接开销logger.debug("用户{}登录成功,IP地址:{}", "张三", "192.168.1.1");try {// 模拟异常int result = 10 / 0;} catch (Exception e) {logger.error("计算发生异常", e);}}
}
五、日志级别详解📶
日志级别就像是手机的静音模式设置:
| 级别 | 说明 | 类比手机模式 |
|---|---|---|
| TRACE | 最详细的跟踪信息 | 开发者模式 |
| DEBUG | 调试信息 | 振动+铃声 |
| INFO | 重要的运行信息 | 仅铃声 |
| WARN | 潜在问题,不影响运行 | 低电量提醒 |
| ERROR | 错误,影响部分功能 | 来电拦截提醒 |
| FATAL | 严重错误,可能导致应用崩溃 | 手机过热关机警告 |
如何选择日志级别?
- 开发环境:DEBUG或TRACE
- 测试环境:INFO
- 生产环境:WARN或ERROR
六、日志架构设计🏗️
一个好的日志系统架构应该像洋葱一样分层🧅:
- 应用层📱:使用SLF4J API记录日志
- 适配层🔌:SLF4J绑定具体实现(如logback-classic)
- 实现层⚙️:具体的日志实现(如Logback)
- 桥接层🌉:处理老旧日志API(如jcl-over-slf4j)
依赖关系图:
你的应用代码↓
SLF4J API (slf4j-api)↓
SLF4J绑定 (如logback-classic/slf4j-log4j12)↓
具体日志实现 (如Logback/Log4j)
七、日志配置最佳实践🎯
1. Logback配置示例 (logback.xml)
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%nlogs/application.loglogs/application.%d{yyyy-MM-dd}.log30%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n51202. Log4j2配置示例 (log4j2.xml)
%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n八、日志记录最佳实践💎
1. 正确的日志姿势👍
// ✅ 好的写法
logger.debug("Processing request with id: {}", requestId);// ❌ 不好的写法
logger.debug("Processing request with id: " + requestId); // 字符串拼接影响性能
2. 异常日志记录
try {// 业务代码
} catch (Exception e) {// ✅ 好的写法logger.error("Failed to process request: {}", requestId, e);// ❌ 不好的写法logger.error("Failed to process request: " + e); // 丢失堆栈信息logger.error("Failed to process request: " + e.getMessage()); // 同样不好
}
3. 日志内容规范
- 包含足够的上下文信息
- 避免记录敏感信息(密码、信用卡号等)🔒
- 使用英文或统一语言,避免混合
- 保持格式一致
九、高级日志技巧🔮
1. MDC (Mapped Diagnostic Context)
MDC就像是在日志上贴标签🏷️,可以跟踪整个请求链路:
// 设置MDC
MDC.put("requestId", UUID.randomUUID().toString());
MDC.put("userId", "12345");try {logger.info("用户操作开始");// 业务逻辑logger.info("用户操作成功");
} finally {// 清除MDCMDC.clear();
}
配置文件中使用:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] [%X{requestId}] %-5level %logger{36} - %msg%n
2. 结构化日志
传统日志:
2023-01-01 12:00:00 [main] INFO com.example.Service - 用户123登录成功
结构化日志(JSON格式):
{"timestamp": "2023-01-01T12:00:00Z","level": "INFO","thread": "main","logger": "com.example.Service","message": "用户登录成功","context": {"userId": "123","ip": "192.168.1.1"}
}
配置Logback输出JSON:
3. 动态日志级别调整
不用重启应用就能改日志级别:
// Logback
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
Logger logger = loggerContext.getLogger("com.example");
logger.setLevel(Level.DEBUG);// Log4j2
org.apache.logging.log4j.core.config.Configurator.setLevel("com.example", Level.DEBUG);
十、性能优化⚡
日志虽然重要,但写不好会影响性能:
-
使用异步日志:避免I/O阻塞业务线程
1024true -
合理使用日志级别:生产环境避免DEBUG
-
使用占位符{}:避免不必要的字符串拼接
-
日志采样:高频日志可以采样记录
十一、常见问题排查🔍
1. 日志冲突问题
症状:SLF4J警告"Class path contains multiple SLF4J bindings"
解决方案:
- 运行
mvn dependency:tree查看依赖树 - 排除多余的SLF4J绑定
org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-logging
2. 日志不输出
检查步骤:
- 确认配置文件位置正确(src/main/resources)
- 检查日志级别设置
- 确认没有日志框架冲突
- 检查文件权限(文件日志)
3. 日志文件过大
解决方案:
- 配置合理的滚动策略
- 设置最大历史文件数
- 定期归档旧日志
十二、日志监控与分析🔬
日志收集只是第一步,更重要的是分析:
-
ELK Stack:
- Elasticsearch: 存储和搜索日志
- Logstash: 收集和处理日志
- Kibana: 可视化展示
-
Prometheus + Grafana:监控日志指标
-
商业方案:
- Splunk
- Datadog
- AWS CloudWatch
十三、总结📚
Java日志系统看似简单,实则学问多多!记住这些要点:
- 选择合适的框架:新项目推荐Log4j2或Logback
- 使用日志门面:SLF4J是首选
- 合理配置:异步、滚动、级别一个都不能少
- 规范记录:内容要有用,格式要统一
- 监控分析:日志的价值在于使用
希望这篇长文能帮你成为日志高手!如果有问题,欢迎留言讨论~ 💬
记得点赞收藏哦!👍✨
#Java #日志系统 #Log4j #Logback #SLF4J #最佳实践 #架构设计
推荐阅读文章
-
由 Spring 静态注入引发的一个线上T0级别事故(真的以后得避坑)
-
如何理解 HTTP 是无状态的,以及它与 Cookie 和 Session 之间的联系
-
HTTP、HTTPS、Cookie 和 Session 之间的关系
-
什么是 Cookie?简单介绍与使用方法
-
什么是 Session?如何应用?
-
使用 Spring 框架构建 MVC 应用程序:初学者教程
-
有缺陷的 Java 代码:Java 开发人员最常犯的 10 大错误
-
如何理解应用 Java 多线程与并发编程?
-
把握Java泛型的艺术:协变、逆变与不可变性一网打尽
-
Java Spring 中常用的 @PostConstruct 注解使用总结
-
如何理解线程安全这个概念?
-
理解 Java 桥接方法
-
Spring 整合嵌入式 Tomcat 容器
-
Tomcat 如何加载 SpringMVC 组件
-
“在什么情况下类需要实现 Serializable,什么情况下又不需要(一)?”
-
“避免序列化灾难:掌握实现 Serializable 的真相!(二)”
-
如何自定义一个自己的 Spring Boot Starter 组件(从入门到实践)
-
解密 Redis:如何通过 IO 多路复用征服高并发挑战!
-
线程 vs 虚拟线程:深入理解及区别
-
深度解读 JDK 8、JDK 11、JDK 17 和 JDK 21 的区别
-
10大程序员提升代码优雅度的必杀技,瞬间让你成为团队宠儿!
-
“打破重复代码的魔咒:使用 Function 接口在 Java 8 中实现优雅重构!”
-
Java 中消除 If-else 技巧总结
-
线程池的核心参数配置(仅供参考)
-
【人工智能】聊聊Transformer,深度学习的一股清流(13)
-
Java 枚举的几个常用技巧,你可以试着用用
-
由 Spring 静态注入引发的一个线上T0级别事故(真的以后得避坑)
-
如何理解 HTTP 是无状态的,以及它与 Cookie 和 Session 之间的联系
-
HTTP、HTTPS、Cookie 和 Session 之间的关系
-
使用 Spring 框架构建 MVC 应用程序:初学者教程
-
有缺陷的 Java 代码:Java 开发人员最常犯的 10 大错误
-
Java Spring 中常用的 @PostConstruct 注解使用总结
-
线程 vs 虚拟线程:深入理解及区别
-
深度解读 JDK 8、JDK 11、JDK 17 和 JDK 21 的区别
-
10大程序员提升代码优雅度的必杀技,瞬间让你成为团队宠儿!
-
探索 Lombok 的 @Builder 和 @SuperBuilder:避坑指南(一)
-
为什么用了 @Builder 反而报错?深入理解 Lombok 的“暗坑”与解决方案(二)
相关文章:

《企业级日志该怎么打?Java日志规范、分层设计与埋点实践》
大家好呀!👋 今天我们要聊一个Java开发中超级重要但又经常被忽视的话题——日志系统!📝 不管你是刚入门的小白,还是工作多年的老司机,日志都是我们每天都要打交道的"好朋友"。那么,如…...

python模块管理环境变量
概要 在 Python 应用中,为了将配置信息与代码分离、增强安全性并支持多环境(开发、测试、生产)运行,使用专门的模块来管理环境变量是最佳实践。常见工具包括: 标准库 os.environ:直接读取操作系统环境变量…...

【泛微系统】后端开发Action常用方法
后端开发Action常用方法 代码实例经验分享:代码实例 经验分享: 本文分享了后端开发中处理工作流Action的常用方法,主要包含以下内容:1) 获取工作流基础信息,如流程ID、节点ID、表单ID等;2) 操作请求信息,包括请求紧急程度、操作类型、用户信息等;3) 表单数据处理,展示…...

【算法】力扣体系分类
第一章 算法基础题型 1.1 排序算法题 1.1.1 冒泡排序相关题 冒泡排序是一种简单的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,…...

sql:如何查询一个数据表字段:Scrp 数据不为空?
在SQL中,要查询一个数据表中的字段 Scrp 不为空的记录,可以使用 IS NOT NULL 条件。以下是一个基本的SQL查询示例: SELECT * FROM your_table_name WHERE Scrp IS NOT NULL;在这个查询中,your_table_name 应该替换为你的实际数据…...

深入浅出人工智能:机器学习、深度学习、强化学习原理详解与对比!
各位朋友,大家好!今天咱们聊聊人工智能领域里最火的“三剑客”:机器学习 (Machine Learning)、深度学习 (Deep Learning) 和 强化学习 (Reinforcement Learning)。 听起来是不是有点高大上? 别怕,我保证把它们讲得明明…...
)
索引下探(Index Condition Pushdown,简称ICP)
索引下探(Index Condition Pushdown,简称ICP)是一种数据库查询优化技术,常见于MySQL等关系型数据库中。 1. 核心概念 作用:将原本在服务器层执行的WHERE条件判断尽可能下推到存储引擎层执行。减少回表查询次数支持部…...
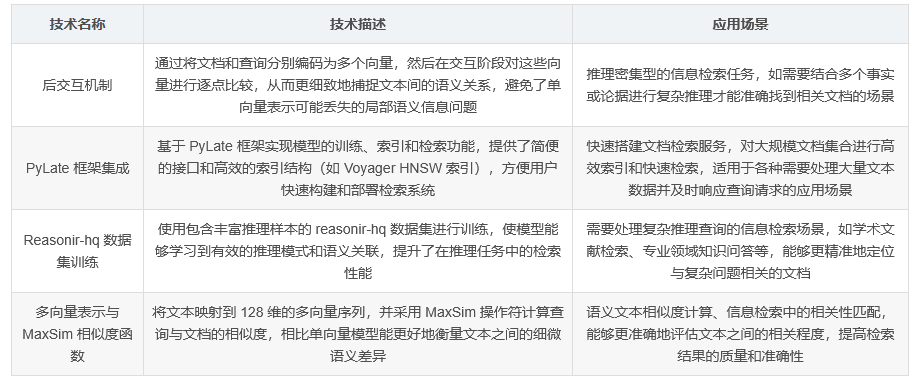
基于 ColBERT 框架的后交互 (late interaction) 模型速递:Reason-ModernColBERT
一、Reason-ModernColBERT 模型概述 Reason-ModernColBERT 是一种基于 ColBERT 框架的后交互 (late interaction) 模型,专为信息检索任务中的推理密集型场景设计。该模型在 reasonir-hq 数据集上进行训练,于 BRIGHT 基准测试中取得了极具竞争力的性能表…...
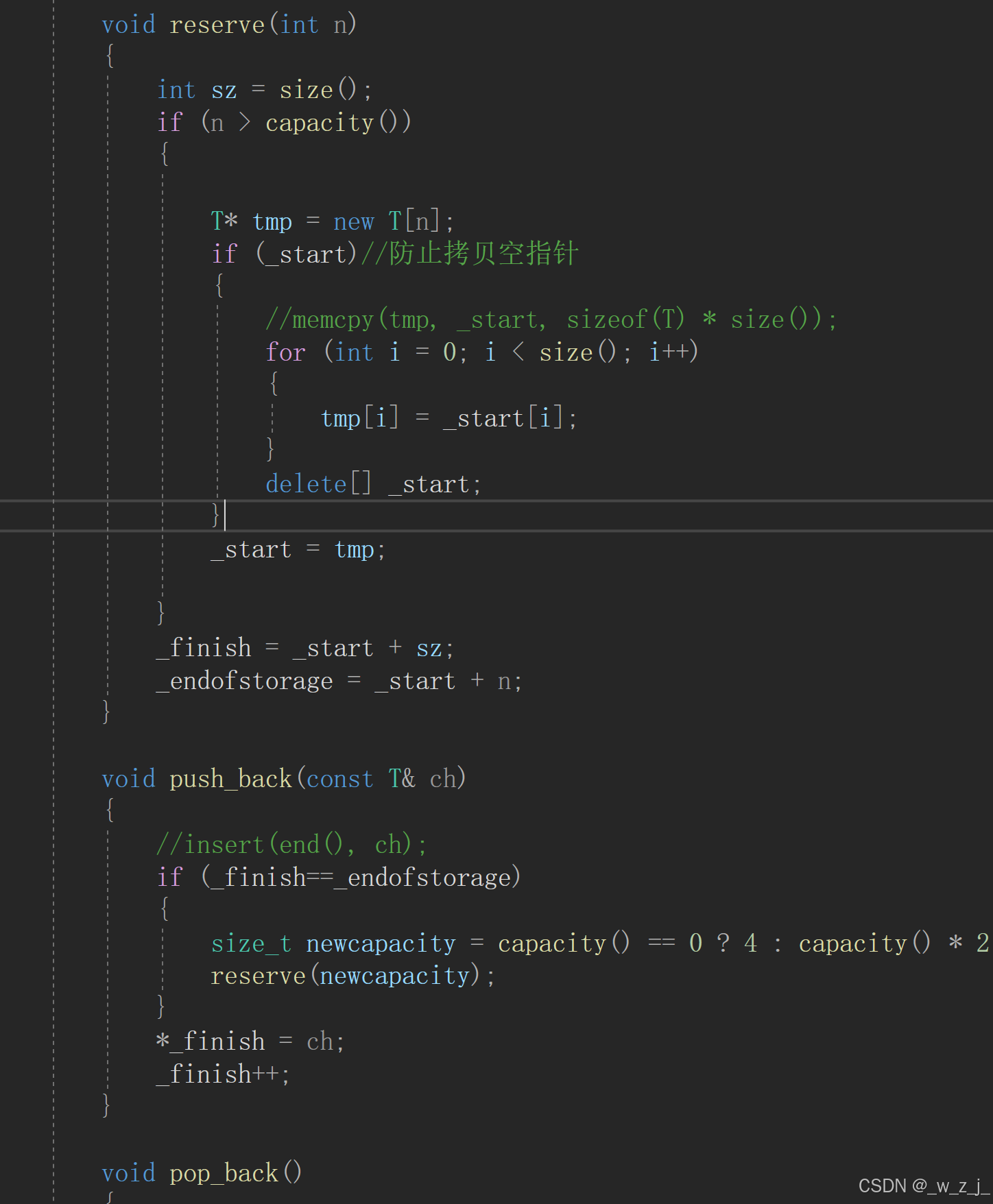
vector中reserve导致的析构函数问题
接上一节vector实现,解决杨辉三角问题时,我在最后调试的时候,发现return vv时,调用析构函数,到第四步时才析构含有14641的vector。我设置了一个全局变量i来记录。 初始为35: 当为39时,也就是第…...
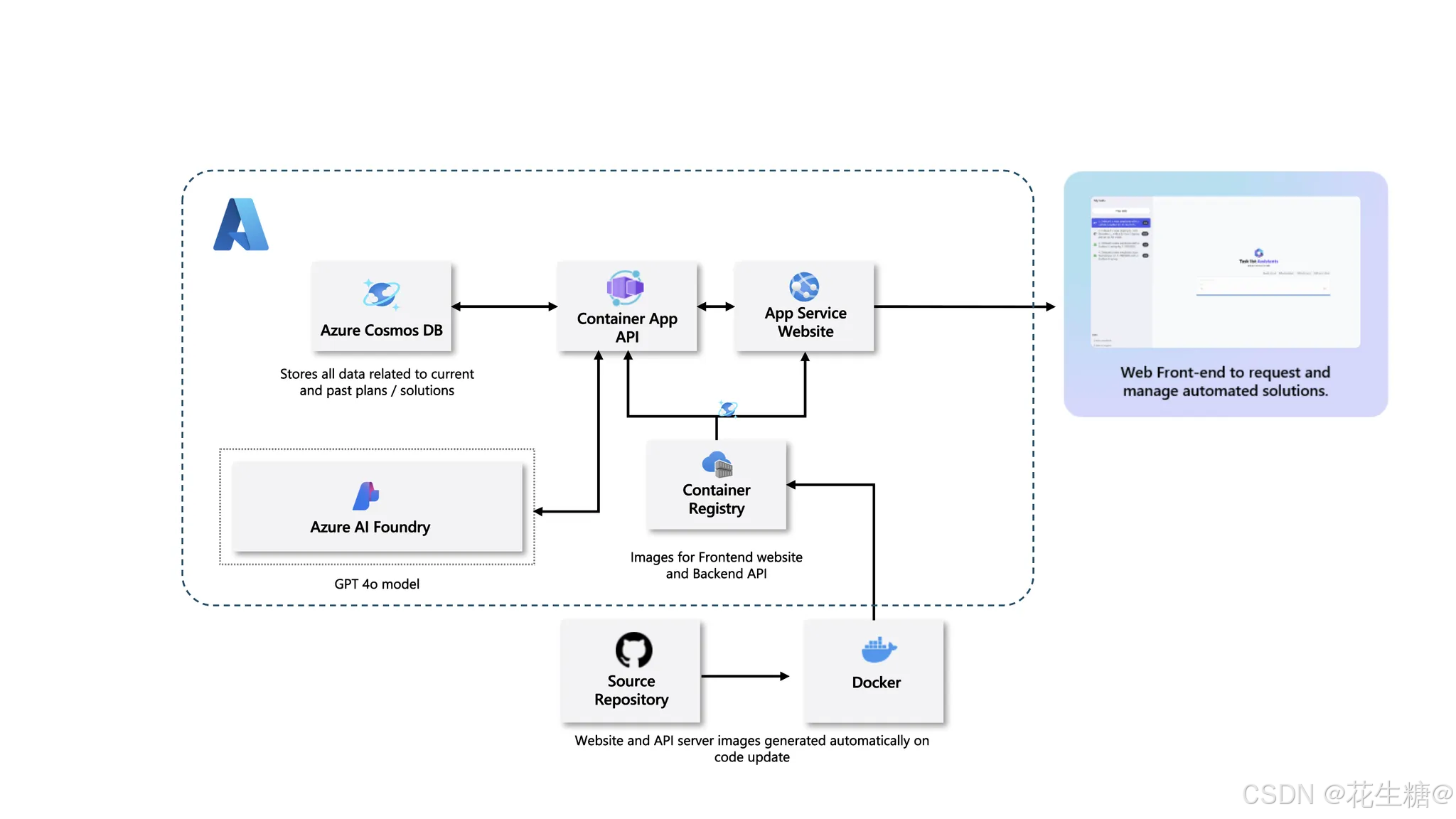
微软开源多智能体自定义自动化工作流系统:构建企业级AI驱动的智能引擎
微软近期推出了一款开源解决方案加速器——Multi-Agent Custom Automation Engine Solution Accelerator,这是一个基于AI多智能体协作的自动化工作流系统。该系统通过指挥多个智能体(Agent)协同完成复杂任务,显著提升企业在数据处理、业务流程管理等场景中的效率与准确性。…...

关于vector、queue、list哪边是front、哪边是back,增加、删除元素操作
容器的 front、back 及操作方向 1.1vector(动态数组) 结构:连续内存块,支持快速随机访问。 操作方向: front:第一个元素(索引 0)。 back:最后一个元素(索引…...

KubeVela入门到精通-K8S多集群交付
目录 1、介绍 2、部署 3、部署UI界面 4、御载 5、Velaux概念 6、OAM应用模型介绍 7、应用部署计划 8、系统架构 9、基础环境配置 9.1 创建项目 9.2 创建集群 9.3 创建交付目标 9.4 创建环境 9.5、创建服务测试 9.6、服务操作 10、插件、项目、权限管理 10.1 插…...

RocketMq的消息类型及代码案例
RocketMQ 提供了多种消息类型,以满足不同业务场景对 顺序性、事务性、时效性 的要求。其核心设计思想是通过解耦 “消息传递模式” 与 “业务逻辑”,实现高性能、高可靠的分布式通信。 一、主要类型包括 普通消息(基础类型)顺序…...

Eigen 直线拟合/曲线拟合/圆拟合/椭圆拟合
一、直线拟合 使用Eigen库进行直线拟合是数据分析和科学计算中的常见任务,主要通过最小二乘法实现。以下是关键实现方法和示例: 核心原理最小二乘法通过最小化点到直线距离的平方和来求解最优直线参数间接平差法是最小二乘法的具体实现形式,适用于直线拟合场景通过构建误差…...

安卓无障碍脚本开发全教程
文章目录 第一部分:无障碍服务基础1.1 无障碍服务概述核心功能: 1.2 基本原理与架构1.3 开发环境配置所需工具:关键依赖: 第二部分:创建基础无障碍服务2.1 服务声明配置2.2 服务配置文件关键属性说明: 2.3 …...

svn迁移到git保留记录和Python字符串格式化 f-string的进化历程
svn迁移到git保留记录 and Python字符串格式化(二): f-string的进化历程 在将项目从SVN迁移到Git时,保留完整的版本历史记录非常重要。下面是详细的步骤和工具,可以帮助你完成这一过程: 安装Git和SVN工具 首先&#…...
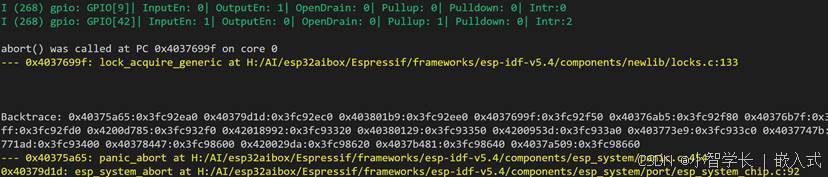
SOC-ESP32S3部分:10-GPIO中断按键中断实现
飞书文档https://x509p6c8to.feishu.cn/wiki/W4Wlw45P2izk5PkfXEaceMAunKg 学习了GPIO输入和输出功能后,参考示例工程,我们再来看看GPIO中断,IO中断的配置分为三步 配置中断触发类型安装中断服务注册中断回调函数 ESP32-S3的所有通用GPIO…...

【神经网络与深度学习】扩散模型之原理解释
引言: 在人工智能的生成领域,扩散模型(Diffusion Model)是一项极具突破性的技术。它不仅能够生成高质量的图像,还可以应用于音频、3D建模等领域。扩散模型的核心思想来源于物理扩散现象,其工作方式类似于从…...
跳跃与重复问题的解析:成因、机制及解决方案)
语音合成之十六 语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案
语音合成(TTS)跳跃与重复问题的解析:成因、机制及解决方案 引言TTS中跳跃与重复问题的根本原因注意力机制的失效文本到语音的对齐挑战自回归(AR)TTS模型的固有挑战时长建模的重要性输入数据特征的影响 构建鲁棒性&…...

战略-2.1 -战略分析(PEST/五力模型/成功关键因素)
战略分析路径,先宏观(PEST)、再产业(产品生命周期、五力模型、成功关键因素)、再竞争对手分析、最后企业内部分析。 本文介绍:PEST、产品生命周期、五力模型、成功关键因素、产业内的战略群组 一、宏观环境…...
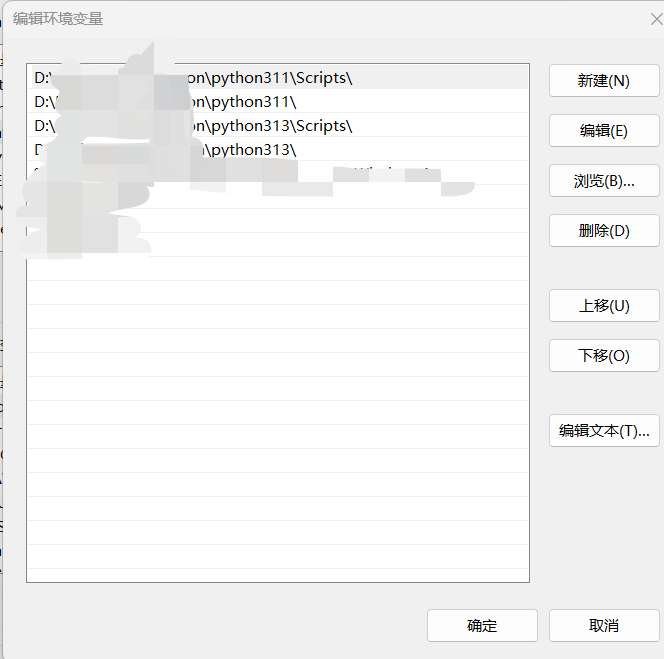
python第三方库安装错位
问题所在 今天在安装我的django库时,我的库安装到了python3.13版本。我本意是想安装到python3.11版本的。我的pycharm右下角也设置了python3.11 但是太可恶了,我在pycharm的项目终端执行安装命令的时候还是给我安装到了python3.13的位置。 解决方法 我…...
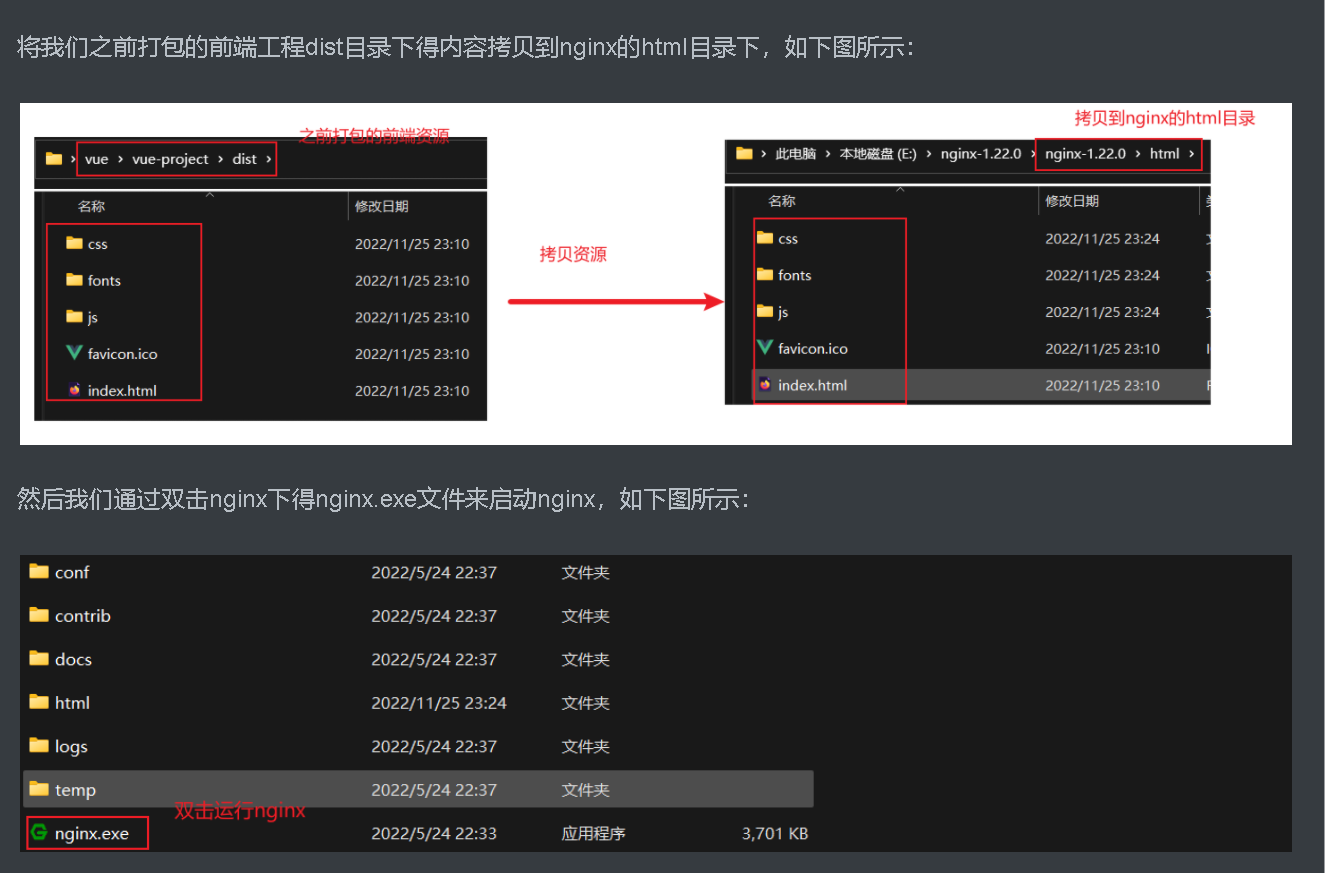
如何把vue项目部署在nginx上
1:在vscode中把vue项目打包会出现dist文件夹 按照图示内容即可把vue项目部署在nginx上...

Vue3集成Element Plus完整指南:从安装到主题定制下-实现后台管理系统框架搭建
本文将详细介绍如何使用 Vue 3 构建一个综合管理系统,包括路由配置、页面布局以及常用组件集成。 一、路由配置 首先,我们来看系统的路由配置,这是整个应用的基础架构: import {createRouter, createWebHistory} from vue-rout…...
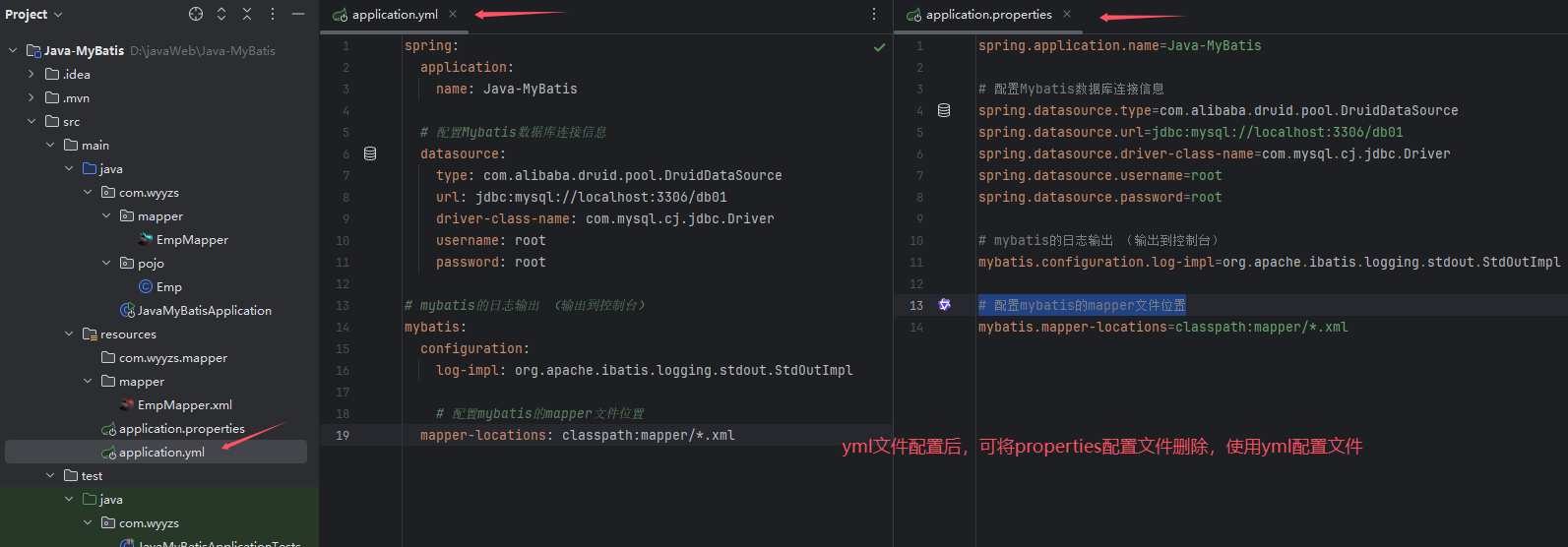
SpringBoot项目配置文件、yml配置文件
一. 配置文件格式 1. SpringBoot项目提供了多种属性配置方式(properties、yaml、yml)。 二. yml配置文件 1. 格式: (1) 数值前边必须有空格,作为分隔符。 (2) 使用缩进表示层级关系,缩进时,不允许使用Tab键,只能使用空…...

Linux性能监控:工具与最佳实践
引言 在Linux系统管理中,性能监控是确保系统健康运行的关键环节。无论是排查系统瓶颈、优化资源分配,还是预防潜在问题,有效的监控工具和技术都能为管理员提供宝贵的数据支持。本文将介绍Linux性能监控的核心工具、方法论和最佳实践。 一、…...
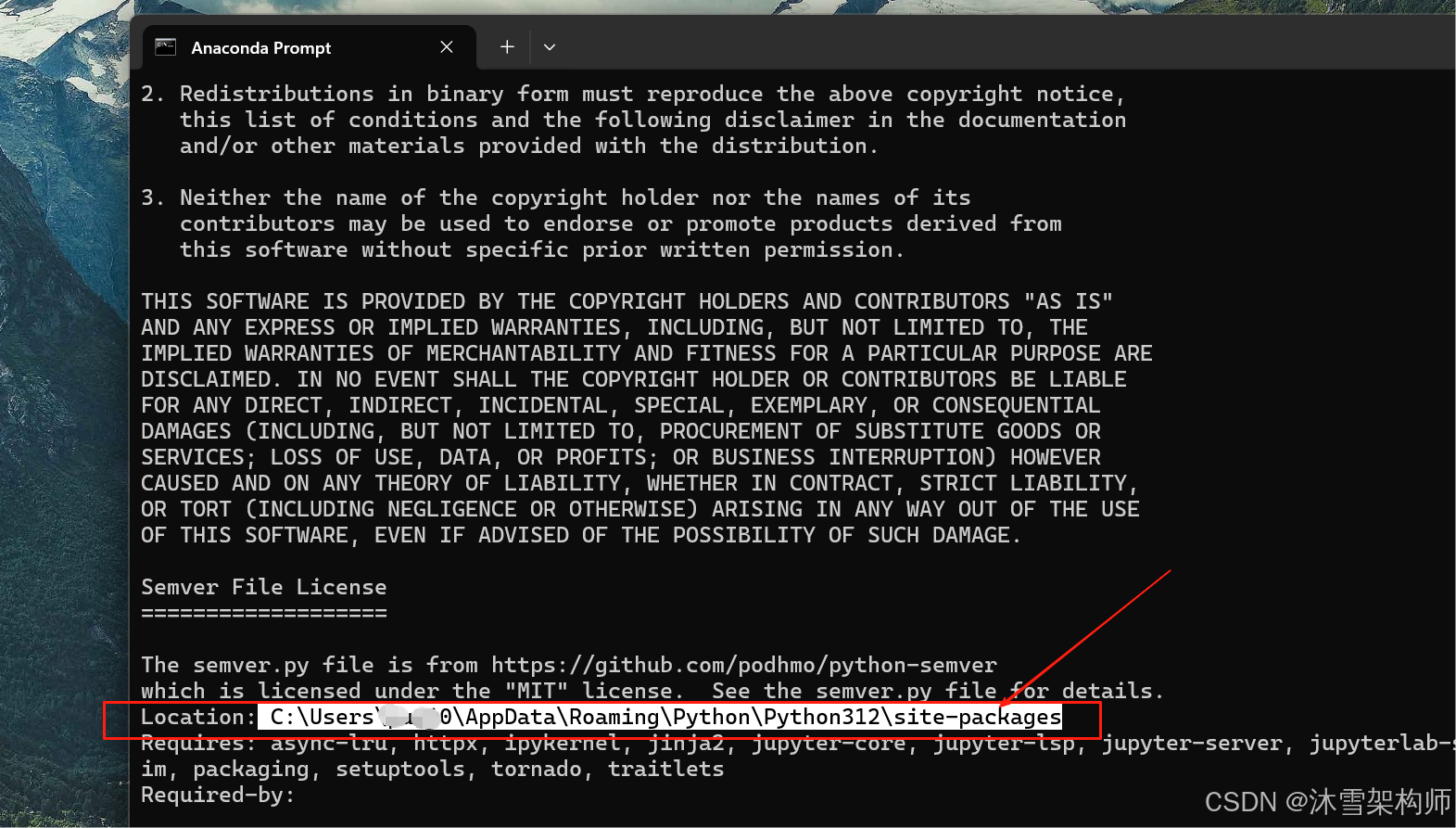
windows11 安装 jupyter lab
1、安装python环境 略 2、安装jupyterlab pip install jupyterlab 3、将jupyterlab的目录配置到path pip show jupyterlab 看到location的值,那么 jupyterlab就安装在与之同级的Scripts下,将Scripts目录设置在Path即可。...

【算法】:动态规划--背包问题
背包问题 引言 什么是背包问题? 背包问题就是一个有限的背包,给出一定的物品,如何合理的装入物品使得背包中的物品的价值最大? 01背包 01背包,顾名思义就是每一种给定的物品要么选择,要么不选ÿ…...
Nginx核心功能
目录 前言一. 正向代理1.配置正向代理(1)添加正向代理(2)验证正向代理 二. 反向代理1.配置nginx七层代理(1)环境安装(2)配置nginx七层代理转发(3)测试 2. 配置…...

AG-UI:重构AI代理与前端交互的下一代协议标准
目录 技术演进背景与核心价值协议架构与技术原理深度解析核心功能与标准化事件体系典型应用场景与实战案例开发者生态与集成指南行业影响与未来展望1. 技术演进背景与核心价值 1.1 AI交互的三大痛点 当前AI应用生态面临三大核心挑战: 交互碎片化:LangGraph、CrewAI等框架各…...
upload-labs通关笔记-第15关 文件上传之图片马getimagesize绕过
系列目录 upload-labs通关笔记-第1关 文件上传之前端绕过(3种渗透方法) upload-labs通关笔记-第2关 文件上传之MIME绕过-CSDN博客 upload-labs通关笔记-第3关 文件上传之黑名单绕过-CSDN博客 upload-labs通关笔记-第4关 文件上传之.htacess绕过-CSDN…...