DAY 33
知识点回顾:
1. PyTorch和cuda的安装
2. 查看显卡信息的命令行命令(cmd中使用)
3. cuda的检查
4. 简单神经网络的流程
a. 数据预处理(归一化、转换成张量)
b. 模型的定义
i. 继承nn.Module类
ii. 定义每一个层
iii. 定义前向传播流程
c. 定义损失函数和优化器
d. 定义训练流程
e. 可视化loss过程
预处理补充:
注意事项:
1. 分类任务中,若标签是整数(如 0/1/2 类别),需转为long类型(对应 PyTorch 的torch.long),否则交叉熵损失函数会报错。
2. 回归任务中,标签需转为float类型(如torch.float32)。
作业:今日的代码,要做到能够手敲。这已经是最简单最基础的版本了。
import torch
torch.cuda
# 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 打印下尺寸
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# 归一化数据,神经网络对于输入数据的尺寸敏感,归一化是最常见的处理方式
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) #确保训练集和测试集是相同的缩放
# 将数据转换为 PyTorch 张量,因为 PyTorch 使用张量进行训练
# y_train和y_test是整数,所以需要转化为long类型,如果是float32,会输出1.0 0.0
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
import torch
import torch.nn as nn
import torch.optim as optim
class MLP(nn.Module): # 定义一个多层感知机(MLP)模型,继承父类nn.Moduledef __init__(self): # 初始化函数super(MLP, self).__init__() # 调用父类的初始化函数
# 前三行是八股文,后面的是自定义的self.fc1 = nn.Linear(4, 10) # 输入层到隐藏层self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 3) # 隐藏层到输出层
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
model = MLP()
# 分类问题使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()# 使用随机梯度下降优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# # 使用自适应学习率的化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()@浙大疏锦行
相关文章:

DAY 33
知识点回顾: 1. PyTorch和cuda的安装 2. 查看显卡信息的命令行命令(cmd中使用) 3. cuda的检查 4. 简单神经网络的流程 a. 数据预处理(归一化、转换成张量) b. 模型的定义 i. 继承nn.Module类 ii. 定义…...

基于ICEEMDAN-SSA-BP的混合预测模型的完整实现过程
以下将为您详细阐述基于ICEEMDAN-SSA-BP的混合预测模型的完整实现过程,包含原理说明、算法实现、代码解析及优化策略。本教程分为六个核心部分,采用Python 3.9环境开发。 基于ICEEMDAN-SSA-BP的混合时间序列预测模型 一、模型架构设计 1.1 整体流程 #mermaid-svg-o4UD3HaTm…...

常见排序算法详解及其复杂度分析
常见排序算法详解及其复杂度分析 排序算法是数据结构与算法学习中的基础内容,也是面试高频考点。本文将系统介绍几种常见的排序算法,包括它们的原理、时间复杂度、空间复杂度以及 Python 实现方法。 一、冒泡排序(Bubble Sort) …...

DARLR用于具有动态奖励的推荐系统的双智能体离线强化学习(论文大白话)
1. 概述 离线强化学习是现在强化学习研究的一个重点。相比与传统的强化学习它不需要大量的实时交互数据,仅仅依赖历史交互日志就可以进行学习。本文就是将离线强化学习用于推荐系统的一篇文章。 这篇文章主要解决的核心问题有以下几个: 1)…...

第35节:PyTorch与TensorFlow框架对比分析
引言 在深度学习领域,PyTorch和TensorFlow无疑是当前最受欢迎的两大开源框架。 自2015年TensorFlow由Google Brain团队发布,以及2016年Facebook的AI研究团队推出PyTorch以来,这两个框架一直在推动着深度学习研究和工业应用的发展。 本文将从多个维度对这两个框架进行详细对…...

企业级智能体 —— 企业 AI 发展的下一个风口?
在AI技术迅猛发展的当下,企业对AI的应用不断深入。企业级智能体逐渐受到关注,它会是企业AI发展的下一个风口吗?先来看企业典型的AI应用场景,再深入了解企业级智能体。 企业典型AI应用场景 1. 内容生成:2025年…...
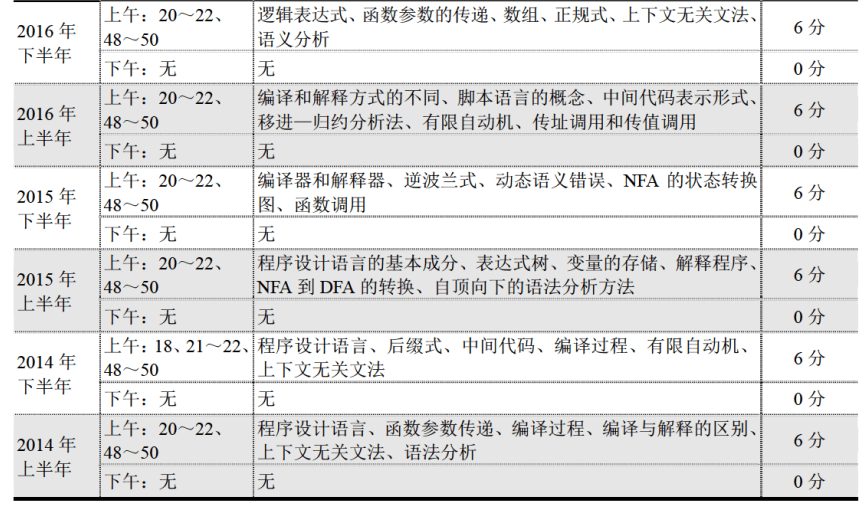
【软考向】Chapter 2 程序设计语言基础知识
程序设计语言概述低级语言 —— 机器指令、汇编语言高级语言 ——翻译:汇编、解释和编译语言处理程序基础 —— 翻译给计算机,汇编、编译、解释三类编译程序基本原理 —— 词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成文法和语言的形式描述确定的有限…...
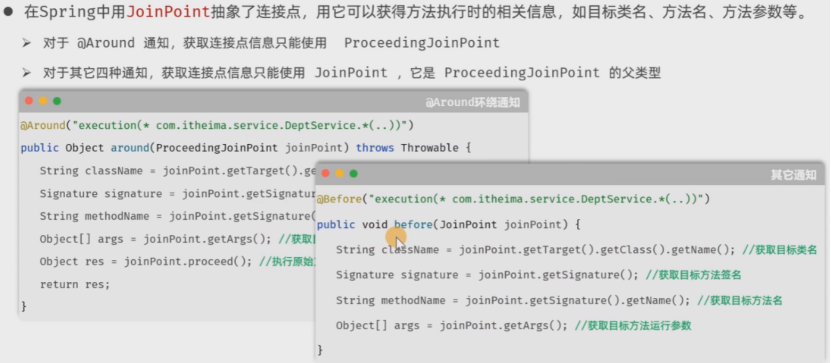
JavaWeb:SpringBootAOP切面实现统计方法耗时和源码解析
介绍 快速入门 1.导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency>2.切面类java Slf4j Aspect Component public class RecordTimeApsect {/*** 统计耗…...
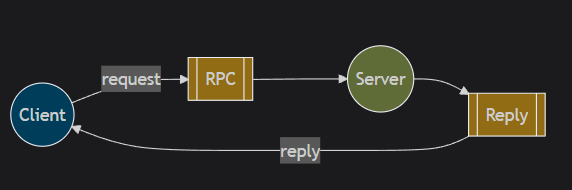
RabbitMQ的其中工作模式介绍以及Java的实现
文章目录 前文一、模式介绍1. 简单模式2. 工作队列模式3. 广播模式4. 路由模式5. 通配符模式6. RPC模式7. 发布确认模式 二、代码实现1、简单模式2、工作队列模式生产者消费者消费者 1消费者 2 3、广播模式 (Fanout Mode)生产者消费者 4、路由模式 (Direct Mode)生产者消费者 5…...
vue2项目搭建
作者碎碎念:开历史倒车了,没想到不兼容,只能从vue3->vue2了。 1 vue3和vue2 这部分参考了官网的《vue3迁移指南》:Vue 3 的支持库进行了重大更新。以下是新的默认建议的摘要: 新版本的 Router, Devtools & test utils 来…...
Spring AI 源码解析:Tool Calling链路调用流程及示例
Tool工具允许模型与一组API或工具进行交互,增强模型功能,主要用于: 信息检索:从外部数据源检索信息,如数据库、Web服务、文件系统或Web搜索引擎等 采取行动:可用于在软件系统中执行特定操作,如…...

2025年- H48-Lc156 --236. 二叉树的最近公共祖先(递归、深搜)--Java版
1.题目描述 递归终止条件: 如果当前节点 root 为 null,表示到达了叶子节点的空子树; 如果当前节点是 p 或 q,就返回它(因为从这里可以回溯寻找公共祖先)。 2.思路 (1) 如果当前节…...

【人工智能】低代码-模版引擎
模板引擎是一种将数据与静态模板结合,生成动态内容的工具。它的核心作用是将业务逻辑与展示层分离,使代码更易维护、复用和管理。 核心功能 变量替换:将模板中的占位符替换为动态数据。 逻辑控制:支持条件判断(if/els…...

Hertz+Kitex快速上手开发
本篇文章以用户注册接口为例,快速上手HertzKitex 以用户注册接口来演示hertz结合kitex实现网关微服务架构的最简易版本 项目结构 api- gateway:网关实现,这里采用hertz框架 idl:接口定义用来生成kitex代码 kitex_genÿ…...

线程池配置经验总结
1. 核心线程数配置(corePoolSize) 1.1 核心线程数的配置影响因素 CPU核心数 CPU密集型任务:核心线程数 ≈ CPU核心数 1IO密集型任务:核心线程数 ≈ CPU核心数 (1 平均等待时间/平均计算时间) 一般经验值:2 CPU核心数 内存大小ÿ…...
机器学习课程设计报告 —— 基于二分类的岩石与金属识别模型
机器学习课程设计报告 题 目: 基于二分类的岩石与金属识别模型 专 业: 机器人工程 学生姓名: XXX 指导教师: XXX 完成日期:…...

分词算法BPE详解和CLIP的应用
一、TL;DR BPE通过替换相邻最频繁的字符和持续迭代来实现压缩CLIP对text进行标准化和预分词后,对每一个单词进行BPE编码和查表,完成token_id的转换 二、BPE算法 2.1 核心思想和原理 paper:Neural Machine Translation of Rare…...

STM32F103_Bootloader程序开发02 - Bootloader程序架构与STM32F103ZET6的Flash内存规划
导言 在工业设备和机器人项目中,固件远程升级能力已成为提升设备维护性与生命周期的关键手段。本文将围绕STM32平台,系统性介绍一个简洁、可靠的Bootloader程序设计思路。 我们将Bootloader核心流程划分为五大功能模块: 启动入口与升级模式判…...
通过Auto平台与VScode搭建远程开发环境(以Stable Diffusion Web UI为例)
文章目录 Stable Diffusion Web UI一、🎯主要功能概述二、🧠支持的主要模型体系三、📦安装方式简述✅ 一、前提准备✅ 二、安装步骤混乱版本(仅用于记录测试过程)第一步:克隆仓库(使用清华大学镜…...

Windows_Rider C#语言开发环境构建
Windows_Rider C#语言开发环境构建 一、C#语言简介历史背景语言特点应用领域开发工具未来发展方向 二、Rider简介功能特点支持的语言免费版本最新更新 三、开发环境构建(一)安装 JetBrains Rider(二)安装 .NET SDK(三&…...
Unity 打包程序全屏置顶无边框
该模块功能: 1. 打包无边框 2. 置顶 3. 不允许切屏 4.多显示器状态下,程序只在主显示上运行 5.全屏 Unity 打包设置: 如果更改打包设置,最好将Version版本增加一下,否则可能不会覆盖前配置文件 代码: 挂在场景中即可 using UnityEngine; using System; // 确保这行存…...
GAMES104 Piccolo引擎搭建配置
操作系统:windows11 家庭版 inter 17 12 th 显卡:amd 运行内存:>12 1、如何构建? 在github下载:网址如下 https://github.com/BoomingTech/Piccolo 下载后安装 git、vs2022 Git Visual Studio 2022 IDE - …...

第 29 场 蓝桥·算法入门赛
1. 不油腻的星座 "我们只欢迎不油腻的星座!" 在「非哺乳动物星座联盟」的派对上,主持人突然宣布:"请在场的 12 星座中,名字里包含哺乳动物的立刻离场",结果白羊、金牛、狮子、摩羯 44 个星座红着脸…...
用service 和 SCAN实现sqlplus/jdbc连接Oracle 11g RAC时负载均衡
说明 11.2推出的SCAN ,简化了客户端连接(当增加或者减少RAC实例时,不需要修改客户端配置,并且scan listener有各个实例的负载情况,可以实现连接时负载均衡。 不过客户端需要使用专门建立的service,而不能用RAC数据库…...

Jenkins 中获取构建触发用户的完整指南
在持续集成(CI/CD)流程中,追踪构建的触发用户是排查问题、审计操作或通知相关人员的重要需求。然而,Jenkins 默认不直接暴露触发构建的用户信息,尤其是在自动触发场景下。本文将详细介绍 多种获取 Jenkins 构建触发用户的方法,涵盖插件使用、脚本编写和 API 查询,并提供…...
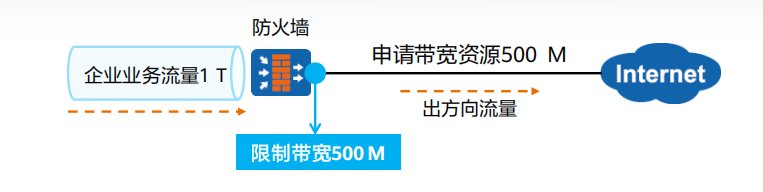
防火墙流量管理
带宽管理介绍 针对企业用户流量,防火墙提供了带宽管理功能,基于出/入接口、源/目的安全区域、源/目的地址、时间段、报文DSCP优先级等信息,对通过自身的流量进行管理和控制。 带宽管理提供带宽限制、带宽保证和连接数限制功能,可…...

uniapp+ts 多环境编译
1. 创建项目 npx degit dcloudio/uni-preset-vue#vite-ts [项目名称] 2.创建env目录 多环境配置文件命名为.env.别名 添加index.d.ts interface ImportMetaEnv{readonly VITE_ENV:string,readonly UNI_PLATFORM:string,readonly VITE_APPID:string,readonly VITE_NAME:stri…...
Linux系统移植①:uboot概念
Linux系统移植①:uboot概念 uboot概念 1、uboot是一个比较复杂的裸机程序。 2、uboot就是一个bootloader,作用就是用原于启动Linux或其他系统。uboot最主要的工作就是初始化DDR。因为Linux是运行再DDR里面的。一般Linux镜像zImage(uImage)设…...
数据结构)
linux 学习之位图(bitmap)数据结构
bitmap 可以高效地表示大量的布尔值,并且在许多情况下可以提供快速的位操作。 1 定义 enum device_state{DOWN,DOEN_DONE,MAILBOX_READY,MAILBOX_PENDING,STATE_BUILD };DECLARE_BITMAP(state,STATE_BUILD);相当于》u32 state[BITS_TO_LONGS(4)] BIT…...
DAY 35
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matplotlib.pyplot as plt# 设置GPU设…...