【MySQL】09.索引
索引是用来提高数据库的性能的,但查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值在于提高一个海量数据的检索速度。
1. 认识磁盘
MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,在加上IO本身的特征,可以知道提高效率是 MySQL 的一个重要话题。
具体的介绍请看这篇【Linux系统与系统编程】11.磁盘文件系统_硬盘文件系统-CSDN博客
磁盘随机访问(Random Access)与连续访问(Sequential Access)
随机访问
本次IO所给出的扇区地址和上次IO给出扇区地址不连续,这样的话磁头在两次IO操作之间需 要作比较大的移动动作才能重新开始读/写数据。
连续访问
本次IO给出的扇区地址与上次IO结束的扇区地址是连续的,那磁头就能很快的开始这次 IO操作,这样的多个IO操作称为连续访问。
因此尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
磁盘是通过机械运动进行寻址的,随机访问不需要过多的定位,故效率比较高。
2. MySQL 与磁盘交互基本单位
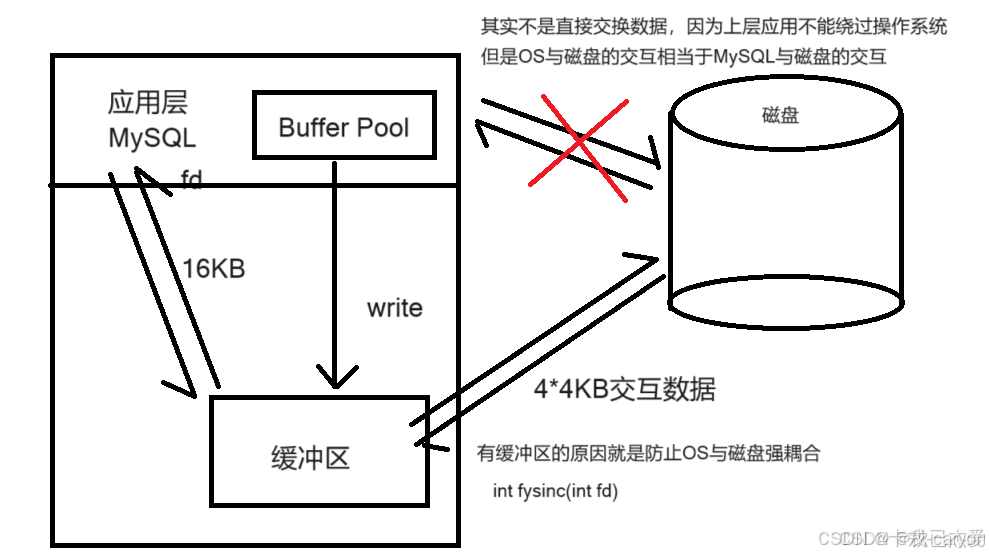
MySQL 作为一款应用软件,可以想象成一种特殊的文件系统。它有着更高的IO场景,为了提高基本的IO效率,MySQL进行IO的基本单位是16KB。这个基本数据单元,在MySQL这里叫做page。
MySQL 中的数据文件是以page为单位保存在磁盘当中的,而 MySQL 的 CURD 操作需要通过计算找到对应的插入位置,或者找到对应要修改或者查询的数据。而只要涉及计算,就需要CPU参与,而为了便于CPU参与,一定要能够先将数据移动到内存当中。 所以在特定时间内,数据一定是磁盘中有,内存中也有。后续操作完内存数据之后,以特定的刷新 策略,刷新到磁盘。而这时,就涉及到磁盘和内存的数据交互,也就是IO了。而此时IO的基本单位就是Page。 为了更好的进行上面的操作, MySQL 服务器在内存中运行的时候,在服务器内部,就申请了被称为 Buffer Pool 的的大内存空间,来进行各种缓存。其实就是很大的内存空间,来和磁盘数据进行IO交互。 为何更高的效率,一定要尽可能的减少系统和磁盘IO的次数。
mysql> show global status like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 | -- 16 * 1024 = 16384
+------------------+-------+
1 row in set (0.00 sec)
3. 索引的理解
3.1 初识索引
首先我们建立一张测试的数据表:
-- 创建测试表
mysql> create table user(-> id int primary key, -- 要添加主键才能产生索引-> age int not null,-> name varchar(20) not null-> );
Query OK, 0 rows affected (0.03 sec)mysql> show create table user \G;
*************************** 1. row ***************************Table: user
Create Table: CREATE TABLE `user` (`id` int NOT NULL,`age` int NOT NULL,`name` varchar(20) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)-- 插入数据(不按顺序插入)
mysql> insert into user (id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.01 sec)mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.01 sec)-- 查看插入结果
mysql> select * from user;
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+
5 rows in set (0.01 sec)
我们可以发现我们随机插入的数据,但是插入的数据确是按照id排好序的,这是为什么呢?这就是索引的作用。
3.2 理解索引
MySQL和磁盘进行IO交互的时候为什么要采用Page的方案进行交互呢?为什么不用加载呢?
对应上面的5条记录,如果MySQL要查找id = 2的记录,第一次加载id = 1 ,第二次加载id = 2 ,一次一条记录,那么就需要2次IO。如果要找id = 5 就需要5次IO。 但如果这5条(或者更多)都被保存在一个Page中(16KB,能保存很多记录),那么第一次IO查找id = 2的时候,整个Page会被加载到MySQL的Buffer Pool中,即只是完成了一次IO,这样在查找id = 1,3,4,5 等数据时就完全不需要进行IO了,而是直接在内存中进行了。所以,就在单Page里面,大大减少了IO的次数。
• 单个page
MySQL 中要管理很多数据表文件需要先描述,在组织。
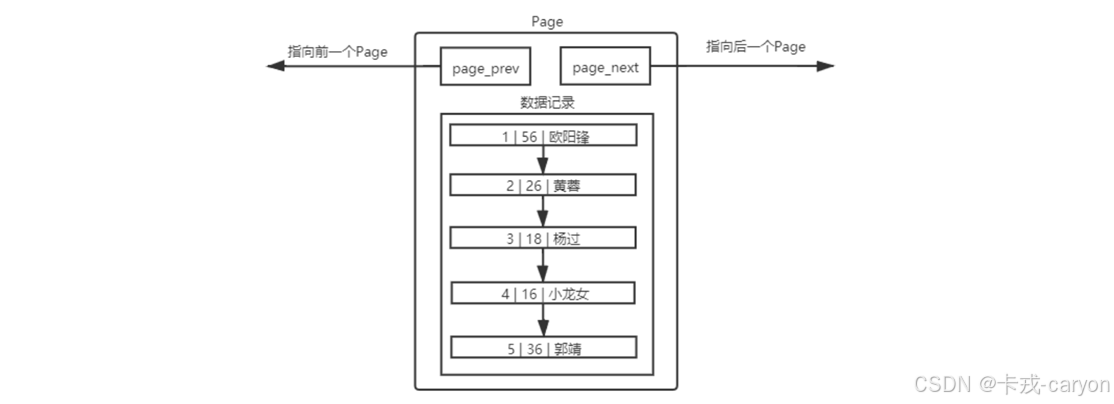
在 MySQL 中所有的page都是16KB ,使用 prev 和 next 构成双向链表。MySQL 会默认按照主键给我们的数据进行排序,从上面的Page内数据记录可以看出,数据是有序且彼此关联的。
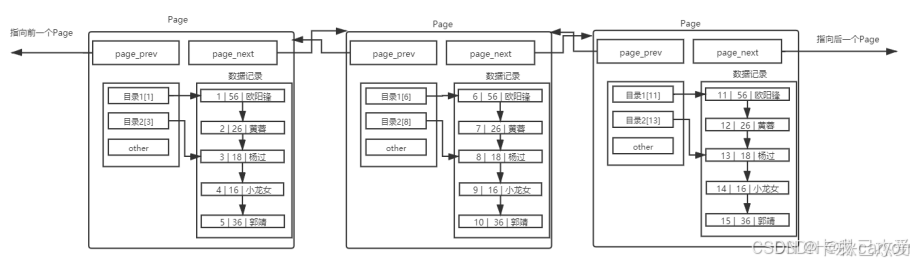
• 多个page
上面页模式在查询某条数据的时候直接将一整页的数据加载到内存中以减少硬盘IO次数,从而提高性能。可以看到现在的页模式内部采用了链表的结构,前一条数据指向后一条数据,本质上还是通过数据的逐条比较来取出特定的数据。
如果有1千万条数据的话,就一定需要多个Page来保存千万条数据,多个Page彼此使用双链表链接起来,而且每个Page内部的数据也是基于链表的。那么查找特定一条记录也一定是线性查找。这效率也太低了吧。
这就引出了多page情况:
• 页目录
对于多page情况,如果我们想要查看某一个page的话就需要遍历查询啊,这效率也有点低吧。
于是引入了页目录:
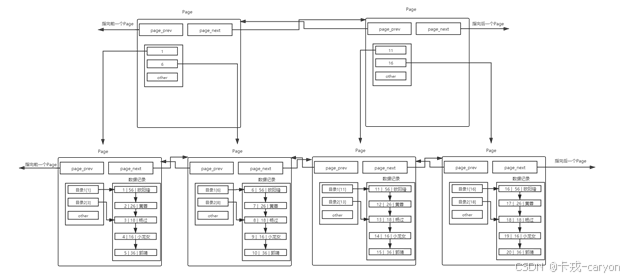
也就是说存在一个目录页来管理页目录,目录页中的数据存放的就是指向的那一页中最小的数据。其实目录页的本质也是页,普通页中存的数据是用户数据,而目录页中存的数据是普通页的地址。
可是我们每次检索数据的时候该从哪里开始呢?虽然顶层的目录页少了,但是还要遍历啊?可以在加目录页。
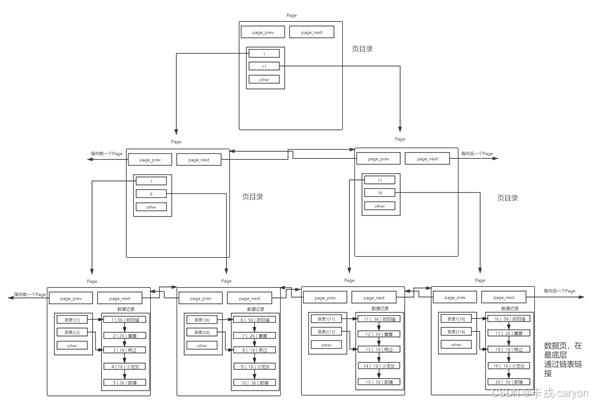
上述结构就是传说中的B+树!至此,我们已经给我们的表user构建完了主键索引。随便找一个id=?我们发现,现在查找的Page数一定减少了,也就意味着IO次数减少了,那么效率也就提高了。
3.3 B树 vs B+树
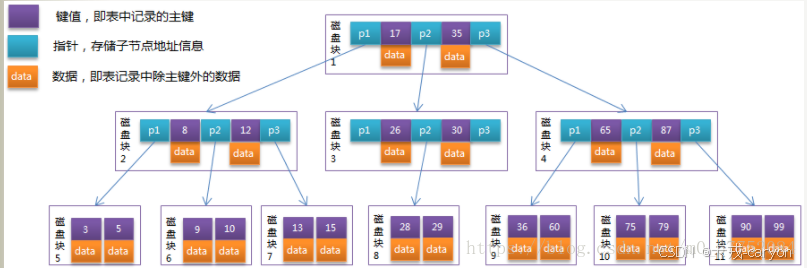
• B树
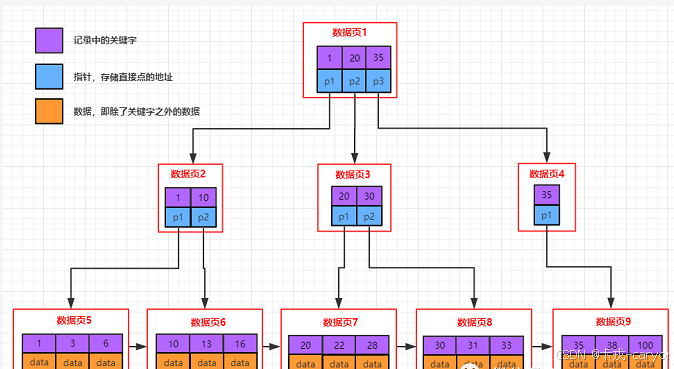
• B+树
我们可以看出:
• B树节点,既有数据,又有Page指针,而B+树只有叶子节点有数据,其他目录页只有键值和 Page指针。
• B+树叶子节点全部相连,而B没有。
• B+树节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。 叶子节点相连,更便于进行范围查找 。
3.4 聚簇索引 VS 非聚簇索引
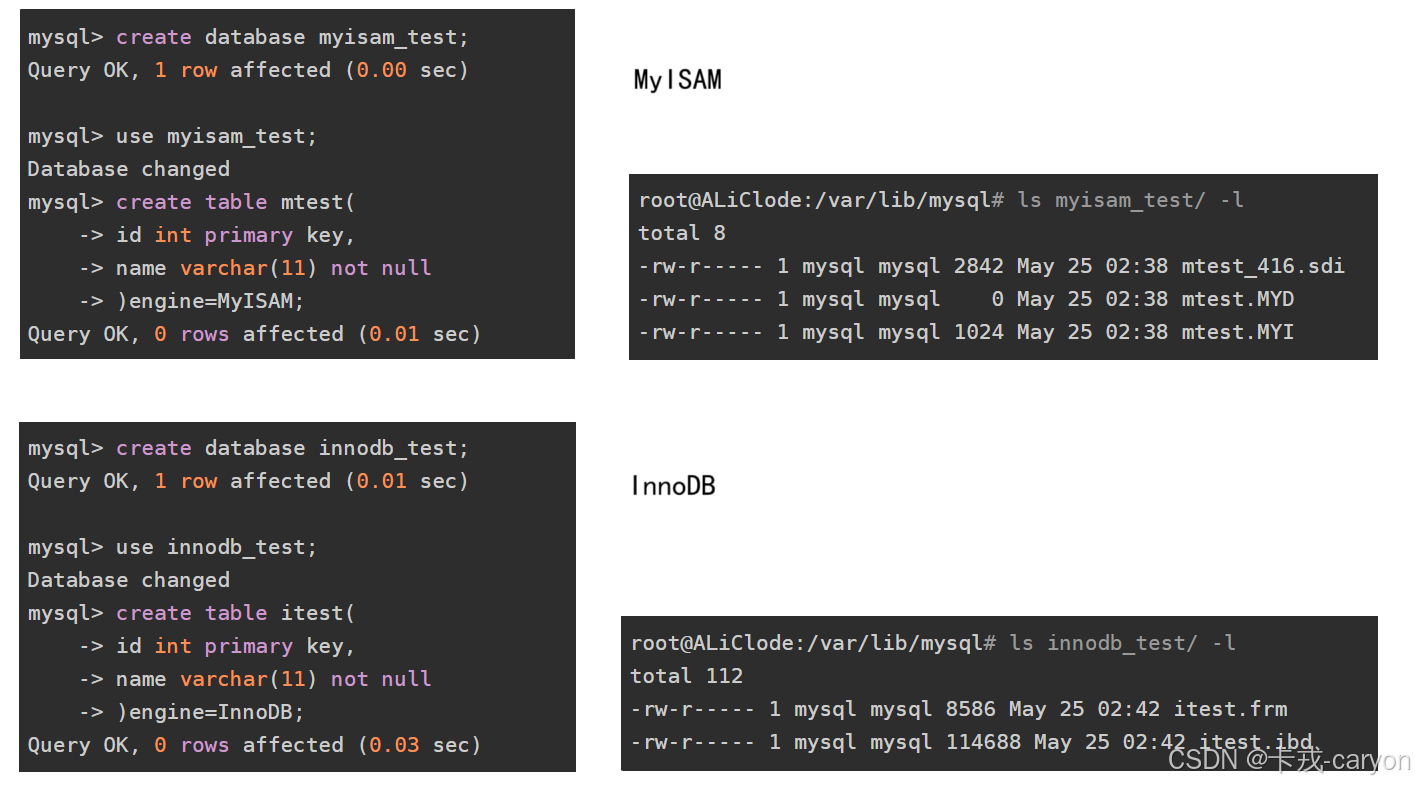
MyISAM 引擎同样使用B+树作为索引结果,叶节点的data域存放的是数据记录的地址。下图为 MyISAM 表的主索引, Col1 为主键。
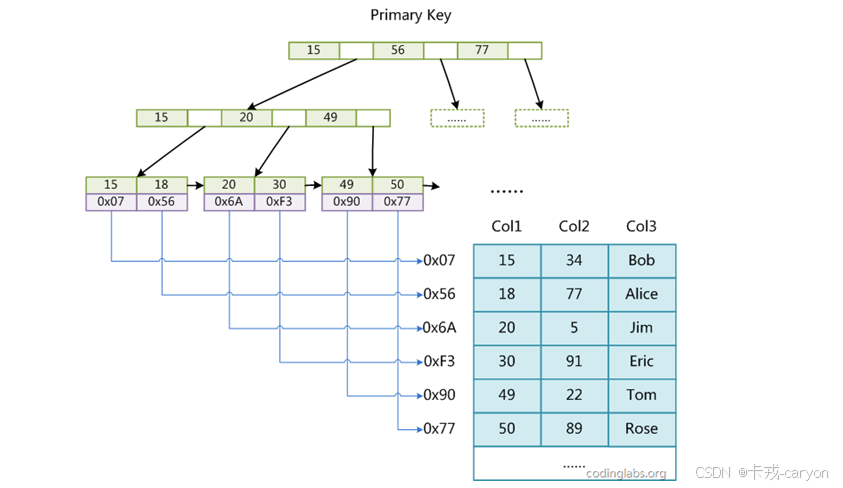
MyISAM 最大的特点是将索引Page和数据Page分离,也就是叶子节点没有数据,只有对应数据的地址。相较于 InnoDB 索引, InnoDB 是将索引和数据放在一起的。
MyISAM 这种用户数据与索引数据分离的索引方案,叫做非聚簇索引。InnoDB 这种用户数据与索引数据在一起索引方案,叫做聚簇索引。
下面是聚簇索引和非聚簇索引的验证:
 4. 索引操作
4. 索引操作
4.1 创建索引
• 创建主键索引
-- 1.在创建表的时候,直接在字段名后指定 primary key
create table user1(
id int primary key,
name varchar(30)
);-- 2.在创建表的最后,指定某列或某几列为主键索引
create table user2(
id int, name varchar(30),
primary key(id)
); -- 3.创建表以后再添加主键
create table user3(
id int,
name varchar(30)
);
alter table user3 add primary key(id);
• 创建唯一索引
-- 1.在表定义时,在某列后直接指定unique唯一属性。
create table user4(
id int primary key,
name varchar(30) unique
);-- 2.创建表时,在表的后面指定某列或某几列为unique
create table user5(
id int primary key,
name varchar(30),
unique(name)
);-- 3.创建表以后再添加唯一键
create table user6(
id int primary key,
name varchar(30)
);
alter table user6 add unique(name);• 创建普通索引
-- 1.在表的定义最后,指定某列为索引
create table user8(
id int primary key,
name varchar(20),
email varchar(30),
index(name)
);-- 2.创建完表以后指定某列为普通索引
create table user9(
id int primary key,
name varchar(20),
email varchar(30)
);
alter table user9 add index(name); -- 3.创建一个索引名为 idx_name 的索引
create table user10(
id int primary key,
name varchar(20),
email varchar(30)
);
create index idx_name on user10(name);
• 创建全局索引
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
CREATE TABLE articles (id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,title VARCHAR(200),body TEXT,FULLTEXT (title,body)
)engine=MyISAM;4.2 查询索引
-- 1.show keys from 表名;
mysql> show keys from user\G;
*************************** 1. row ***************************Table: userNon_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 4Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
1 row in set (0.01 sec)ERROR:
No query specified-- 2.show index from 表名;
mysql> show index from user\G;
*************************** 1. row ***************************Table: userNon_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 4Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment: Visible: YESExpression: NULL
1 row in set (0.00 sec)ERROR:
No query specified-- 3.desc 表名
mysql> desc user;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| age | int | NO | | NULL | |
| name | varchar(20) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)4.3 删除索引
-- 1. 删除主键
alter table 表名 drop primary key;-- 2. 删除普通索引
alter table 表名 drop index 索引名;-- 3. drop删除
drop index name on user8;
相关文章:
【MySQL】09.索引
索引是用来提高数据库的性能的,但查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值在于提高一个海量数据的检索速度。 1. 认识磁盘 MySQL 给用户提供存储服务,而存储的都是数据&…...
【备忘】 windows 11安装 AdGuardHome,实现开机自启,使用 DoH
windows 11安装 AdGuardHome,实现开机自启,使用 DoH 下载 AdGuardHome解压 AdGuardHome启动 AdGuard Home设置 AdGuardHome设置开机自启安装 NSSM设置开机自启重启电脑后我们可以访问 **http://127.0.0.1/** 设置使用 AdGuardHome DNS 效果图 下载 AdGua…...
[Windows] 游戏常用运行库- Game Runtime Libraries Package(6.2.25.0409)
游戏常用运行库 合集 整合了许多游戏会用到的运行库,支持 Windows XP – Windows 11 系统,并且支持自动检测系统勾选推荐的运行库,方便快捷。 本版特点: By:mefcl 整合常见最新游戏所需运行库 根据系统自动勾选推荐…...

MYSQL order 、group 与row_number详解
一、order by order by A ASC, B DESC,C ASC … 上述语句会先按照A排序,当A相同的时候再按照B排序,当B相同的再按照C排序,并会不按照ABC组合一起排序 二、group by group by A,B,C… select 中的字段必须是group by中的字段,…...

QT之巧用对象充当信号接收者
备注:以下仅为演示不代表合理性,适合简单任务,逻辑简单、临时使用,可保持代码简洁,对于复杂的任务应创建一个专门的类来管理信号和线程池任务. FileScanner类继承QObject和QRunnable,扫描指定目录下的文件获…...

《红警2000》游戏信息
游戏背景:与《红色警戒》系列的其他版本类似,基于红警 95 的背景设定,讲述了第二次世界大战期间,世界各国为了争夺全球霸权而展开战争。游戏画面与音效:在画面上相比早期的红警版本有一定提升,解析度更高&a…...

Vue3 + ThinkPHP8 + PHP8.x 生态与 Swoole 增强方案对比分析
一、基础方案:Vue3 ThinkPHP8 PHP8.x 传统架构 优点 成熟稳定 组合经过长期验证,文档和社区资源丰富ThinkPHP8 对PHP8.x有良好支持,性能比PHP7提升20-30% 开发效率高 TP8的ORM和路由系统大幅减少样板代码Vue3组合式API Vite开发…...
(九)PMSM驱动控制学习---高阶滑膜观测器
在之前的文章中,我们介绍了永磁同步电机无感控制中的滑模观测器,但是同时我们也认识到了他的缺点:因符号函数带来的高频切换分量,使用低通滤波器引发相位延迟;在本篇文章,我们将会介绍高阶滑模观测器的无感…...
25年上半年五月之软考之设计模式
目录 一、单例模式 二、工厂模式 三、 抽象工厂模式 四、适配器模式 五、策略模式 六、装饰器模式 编辑 考点:会挖空super(coffeOpertion); 七、代理模式 为什么必须要使用代理对象? 和装饰器模式的区别 八、备忘录模式 一、单例模式 这个…...

Mongo DB | 多种修改数据库名称的方式
目录 方法一:使用 mongodump 和 mongorestore 命令 方法二:使用 db.copyDatabase() 方法 方法三:使用 MongoDB Compass 在 MongoDB 中,更改数据库名称并不是一个直接的操作,因为 MongoDB 不提供直接重命名数据库的命…...
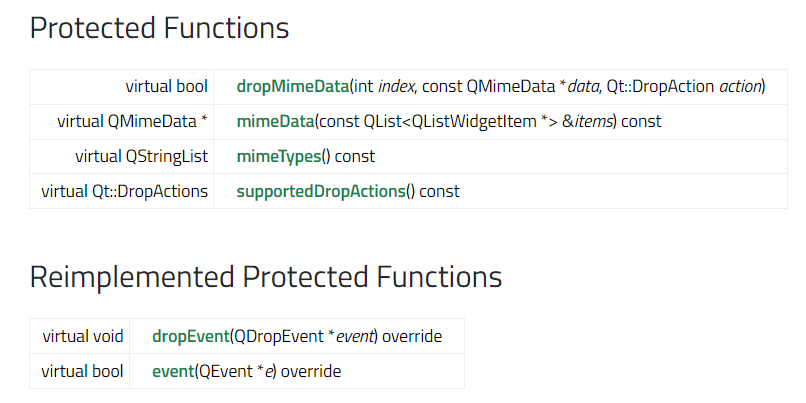
QListWidget的函数,信号介绍
前言 Qt版本:6.8.0 该类用于列表模型/视图 QListWidgetItem函数介绍 作用 QListWidget是Qt框架中用于管理可交互列表项的核心组件,主要作用包括: 列表项管理 支持动态添加/删除项:addItem(), takeItem()批量操作:addItems()…...

Python类属性与实例属性的覆盖机制:从Vector2d案例看灵活设计
类属性与实例属性的交互机制 Python中类属性与实例属性的关系体现了语言的动态特性。当访问一个实例属性时,Python会首先查找实例自身的__dict__,如果找不到,才会去查找类的__dict__。这种机制使得类属性可以优雅地作为实例属性的默认值。 …...

QML与C++交互2
在QML与C的交互中,主要有两种方式:在C中调用QML的方法和在QML中调用C的方法。以下是具体的实现方法。 在C中调用QML的方法 首先,我们需要在QML文件中定义一个函数,然后在C代码中调用它。 示例 //QML main.qml文件 import QtQu…...

EtherNet/IP机柜内解决方案在医疗控制中心智能化的应用潜能和方向分析
引言 在数智化转型浪潮席卷各行各业的今天,医疗领域同样面临着提升运营效率、改善患者体验和加强系统可靠性的多重挑战。Rockwell Automation于2025年5月20日推出的EtherNet/IP机柜内解决方案,为医疗中心的自动化升级提供了一种创新路径。本报告将深入分析这一解决方案的核心…...
)
springboot中各模块间实现bean之间互相调用(service以及自定义的bean)
springboot中各模块间实现bean之间互相调用(service以及自定义的bean) https://blog.csdn.net/qq_29477175/article/details/122827446?ops_request_misc&request_id&biz_id102&utm_termspringboot%E5%A4%9A%E6%A8%A1%E5%9D%97%E4%B9%8B%E…...
)
RabbitMQ 可靠性保障:消息确认与持久化机制(二)
四、持久化机制:数据安全的护盾 (一)交换机持久化 交换机持久化是确保消息路由稳定的重要保障 。在 RabbitMQ 中,交换机负责接收生产者发送的消息,并根据路由规则将消息路由到相应的队列 。如果交换机在 RabbitMQ 重…...

QML学习07Property
Property 1、Property1.1 定义控件1.2 给控件取别名,不向外暴露控件名字 2、总结 1、Property property int myTopMargin: 0 property int myBottomMargin: 0 property real myReal: 0.0 //双精度浮点数 property string myString: "test" property…...

Skywalking安装部署使用教程
目录 核心功能 架构设计 安装与配置 使用场景 社区与支持 总结 官网 https:///apache/skywalking 部署Skywalking 添加报警配置 自定义告警规则如果您需要自定义告警规则,则需要编辑 alarm-settings.yml 文件并添加自定义的规则。具体来说,您需要按照 YAML 格式定义…...

网络编程与axios技术
网络编程技术是指通过计算机网络实现不同设备之间数据交互的技术。它基于网络通信协议(如TCP/IP、HTTP)和编程语言的支持,结合库和API实现高效的数据传输与通信。以下是几种主流技术栈(JavaScript、TypeScript、React、Next.js、P…...

【结构设计】以3D打印举例——持续更新
【结构设计】以立创EDA举例——持续更新 文章目录 [TOC](文章目录) 前言立创EDA官网教程一、3D外壳绘制二、3D外壳渲染三、3D外壳打印1.3D打印机——FDM2.3D打印机——光固化 四、3D外壳LOG设计1.激光雕刻机 总结 前言 提示:以下是本篇文章正文内容,下面…...

MySQL中的重要常见知识点(入门到入土!)
基础篇 基础语法 添加数据 -- 完整语法 INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);-- 示例 insert into employee(id,workno,name,gender,age,idcard,entrydate) values(1,1,Itcast,男,10,123456789012345678,2000-01-01) 修改数据 -- 完整语法 UPDA…...
理解全景图像拼接
1 3D到2D透视投影 三维空间上点 p 投影到二维空间 q 有两种方式:1)正交投影,2)透视投影。 正交投影直接舍去 z 轴信息,该模型仅在远心镜头上是合理的,或者对于物体深度远小于其到摄像机距离时的近似模型。…...

云原生安全基石:Linux进程隔离技术详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 进程隔离是操作系统通过内核机制将不同进程的运行环境和资源访问范围隔离开的技术。其核心目标在于: 资源独占:确保…...
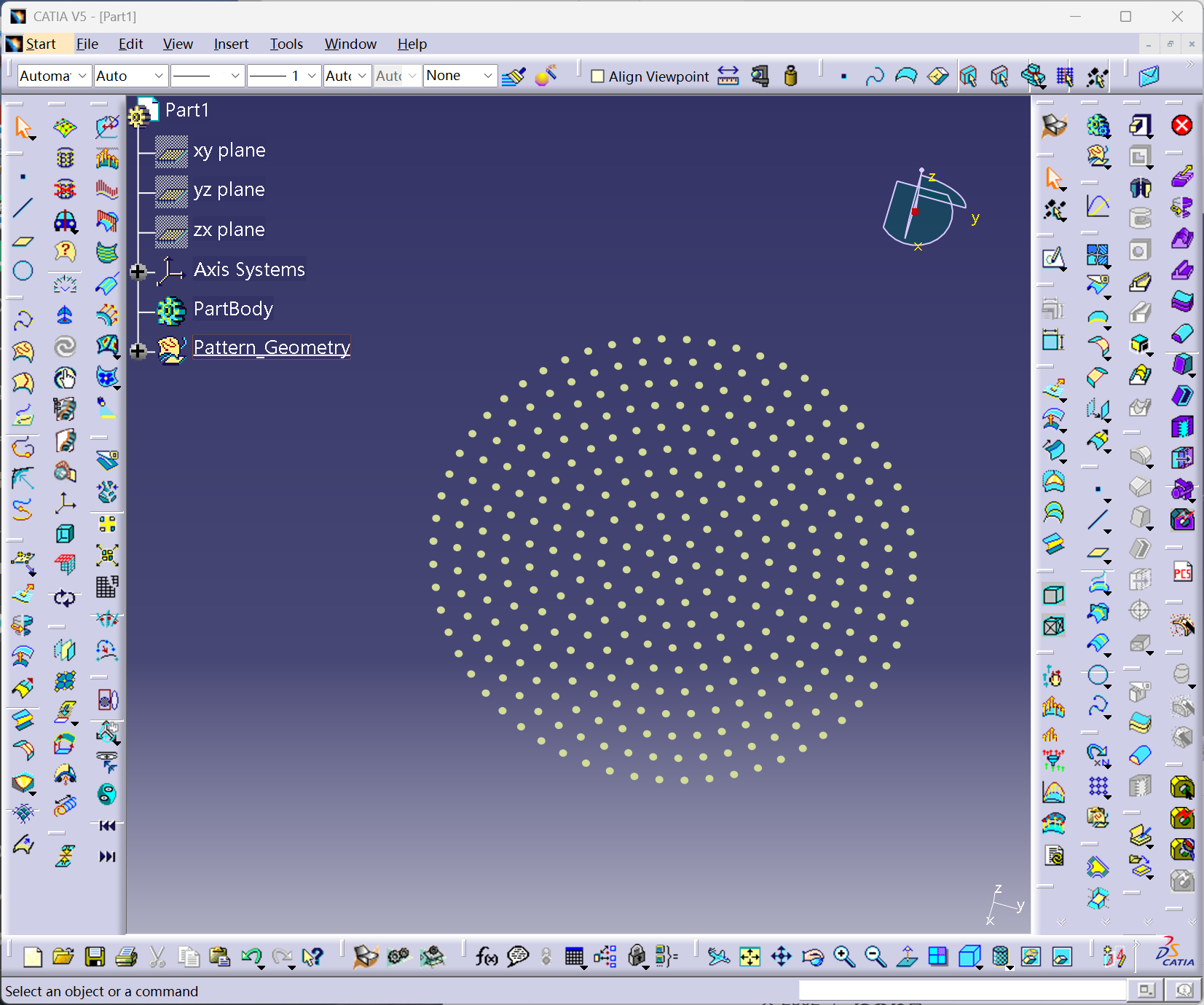
基于PySide6与pycatia的CATIA几何阵列生成器开发实践
引言:参数化设计的工业价值 在航空航天、汽车制造等领域,复杂几何图案的批量生成是模具设计与机械加工的核心需求。传统手动建模方式存在效率低下、参数调整困难等问题。本文基于PySide6+pycatia技术栈,实现了一套支持动态参数配置、智能几何阵列生成的自动…...
Linux学习心得问题总结(三)
day09 文件权限篇 文件权限的属性有哪些?我们应如何理解这些属性? 文件权限的属性包括可读(r)、可写(w)、可执行(x)三种权限,根据文件类型可分为普通文件(.…...

蓝桥杯国14 不完整的算式
!!!!!!!!!!!!!!!理清思路 然后一步步写 问题描述 小蓝在黑板上写了一个形如 AopBC 的算式&#x…...
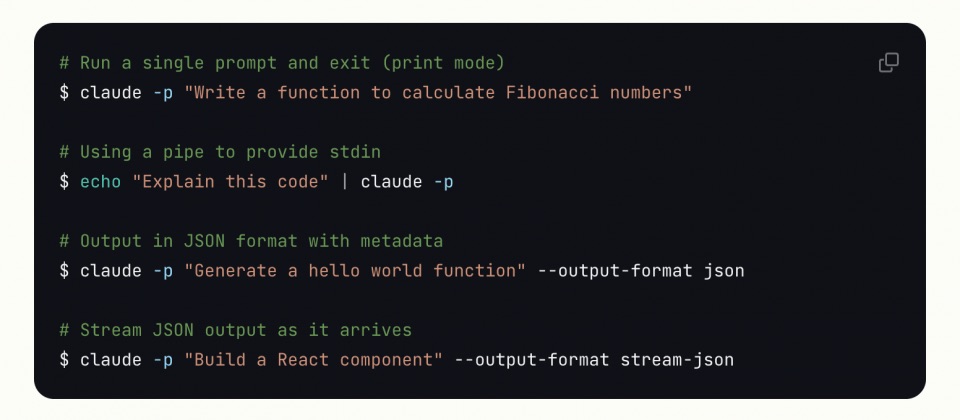
Anthropic推出Claude Code SDK,强化AI助理与自动化开发整合
Anthropic发布Claude Code SDK,协助开发团队将人工智慧助理整合进自动化开发流程,支援多轮对话、MCP协定及多元格式。 Anthropic推出Claude Code SDK,提供开发者与企业一套可程序化整合Claude AI助理至开发流程的工具。此SDK以命令列介面为基…...

6.4.1最小生成树
知识总览 生成树(一定是连通的): 是连通的无向图的一个子图,子图包含这个无向图的所有顶点有n-1条边(少一条边,生成树就不连通了)即为生成树,一个连通图可能有多个生成树 最小生成树(最小代价树): 只有连通的无向图才…...

DAY 33
知识点回顾: 1. PyTorch和cuda的安装 2. 查看显卡信息的命令行命令(cmd中使用) 3. cuda的检查 4. 简单神经网络的流程 a. 数据预处理(归一化、转换成张量) b. 模型的定义 i. 继承nn.Module类 ii. 定义…...

基于ICEEMDAN-SSA-BP的混合预测模型的完整实现过程
以下将为您详细阐述基于ICEEMDAN-SSA-BP的混合预测模型的完整实现过程,包含原理说明、算法实现、代码解析及优化策略。本教程分为六个核心部分,采用Python 3.9环境开发。 基于ICEEMDAN-SSA-BP的混合时间序列预测模型 一、模型架构设计 1.1 整体流程 #mermaid-svg-o4UD3HaTm…...