基于moonshot模型的Dify大语言模型应用开发核心场景
基于moonshot模型的Dify大语言模型应用开发核心场景学习总结
一、Dify环境部署
1.Docker环境部署
这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机
安装完成之后,修改vagrant配置文件的网络,保证本地与虚拟机网络连通
在centos7上部署dokcer环境
1、卸载系统之前的 docker
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine
2、安装必须的依赖 Docker-CE
启用 EPEL 源
Extra Packages for Enterprise Linux(EPEL)源包含了许多额外的软件包,可能会包含你需要的软件包。你可以通过以下命令安装 EPEL 源:
sudo yum install -y epel-release
sudo yum install -y yum-utils \ device-mapper-persistent-data \ lvm2
3、设置 docker repo 的 yum 位置
阿里云镜像
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4、安装 docker 以及 docker-cli
sudo yum install docker-ce docker-ce-cli containerd.io
5、启动 docker
sudo systemctl start docker
6、设置 docker 开机自启
sudo systemctl enable docker
bug:安装docker时显示空间不足
解决办法:在VirtualBox界面右键删除centos7所有数据,重新安装即可
安装docker时空间不足的问题,去VirtualBox里面删除centos7,从新安装就行了,而且必须使用阿里云镜像
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
其他步骤都一样,第一此我装cenos7直接占了40G硬盘,卸载后第二次装才正常只占5G硬盘
第二次装centos7的时候先要删除pc目录下的Vagrantfile文件,然后再执行vagrant init centos/7
完成之后记得改Vagrantfile文件的配置地址config.vm.network “private_network”, ip: “192.168.56.10”
2.Centos7安装dify
在docker安装git,配置pub公钥至github
如果git无法下载,临时忽略 SSL 验证
git config --global http.sslVerify false
下载完后恢复 SSL 验证
git config --global http.sslVerify true
如果出现类似Error response from daemon: Get “https://registry-1.docker.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 的错误,说明镜像源网站不可用,需要更换镜像源网址
sudo vi /etc/docker/daemon.json
填入
{
"registry-mirrors":[
"https://docker-0.unsee.tech",
"https://docker.imgdb.de",
"https://docker.h1mirror.com"
]
}
当Dify版本更新后,你可以克隆或拉取最新的Dify源代码,并通过命令行更新已经部署的Dify环境。
进入dify源代码的docker目录,按顺序执行以下命令:
更新dify,如过更新了.env配置文件需同步至复制的配置文件
cd dify/docker
docker compose down
git pull origin main
docker compose pull
docker compose up -d
docker compose ps 查看已运行服务
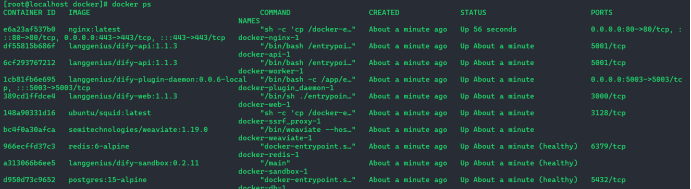

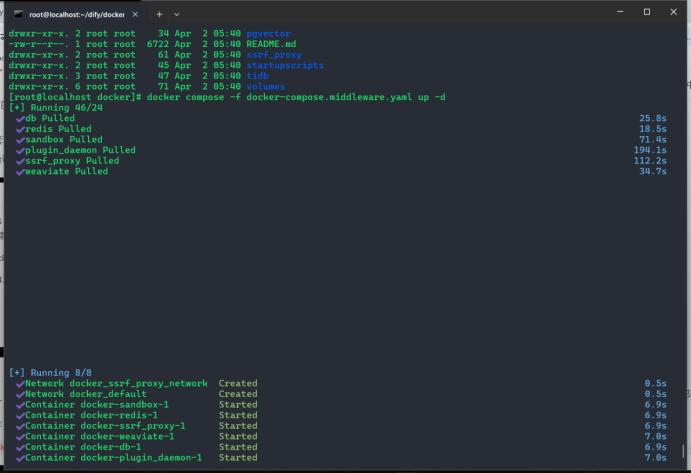
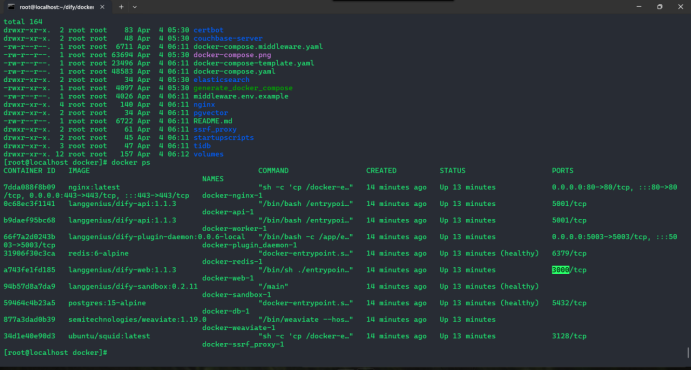
3.Dify compose环境验证
3.1 Dify调试命令
#停止容器下所有服务
docker compose stop
cd /root/dify/docker
#启动
docker compose start
#停止并移除
docker compose down
#安装并启动
docker compose up -d

3.2 502Gateway问题
安装完成后访问首页,本地vagrant服务器ip为192.168.56.10,访问dify注册地址:http://192.168.56.10/install,出现一直加载的问题,始终无法访问,最后使用卸载、重装、更新等操作,在次访问还是同样的问题,最后等待了一会就可以成功访问了,可能是dify在下载相关查询或者是nginx转发ip的问题
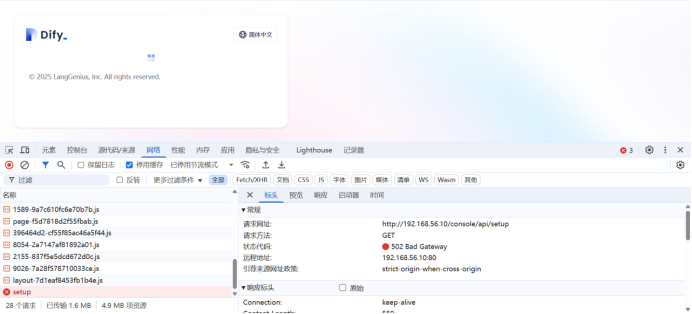
http://192.168.56.10/console/api/setup
502 Bad Gateway
3.3 修改nginx服务配置
通过下列命令获取api-1、web-1服务的ip,将新的ip更新至nginx配置文件中
docker ps -q | xargs -n 1 docker inspect --format '{{ .Name }}: {{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}'

/docker-api-1: 172.18.0.8172.19.0.5
/docker-web-1: 172.18.0.5
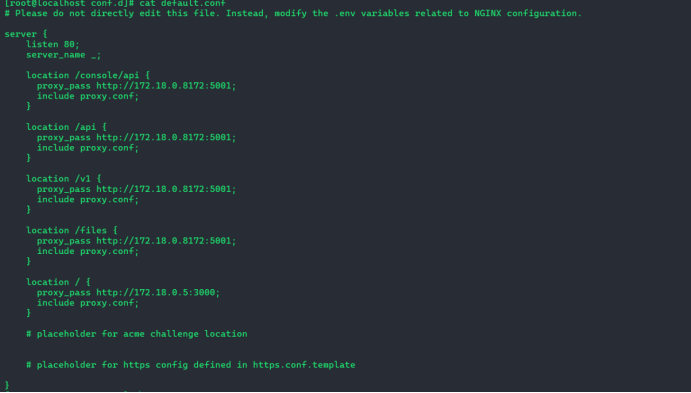
docker inspect --format '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' docker-api-1
172.18.0.9172.19.0.4docker inspect --format '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}' docker-web-1
}
172.18.0.3#重启nginx
docker compose restart nginx
3.4 启动Dify
更新nginx配置无效,重装dify即可,若还是访问一直在加载,就多等待一会
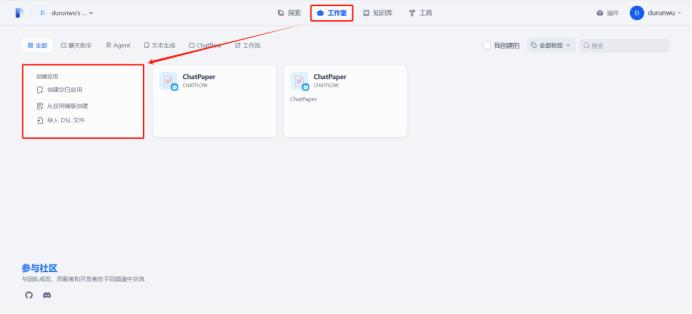
二、Dify学习
- 聊天助⼿Demo:创建基于知识库的问答机器⼈,⽀持PDF⽂档检索
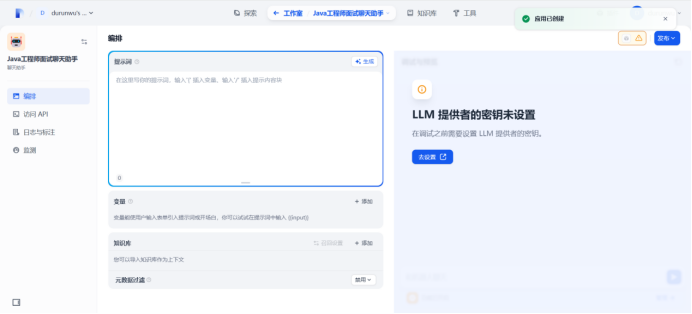
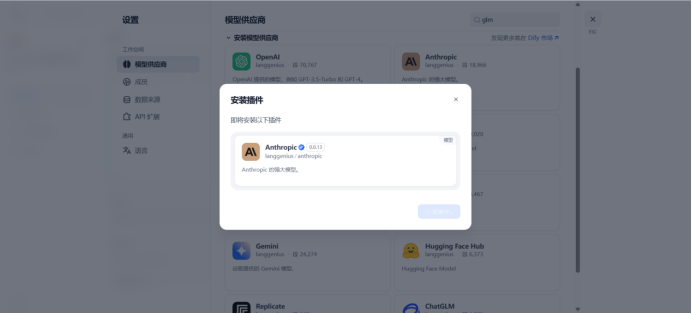
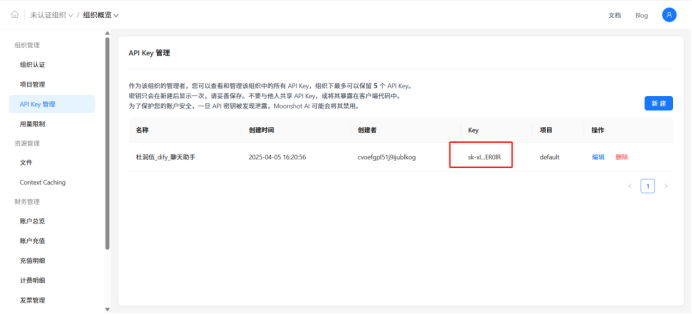
获取api key
Api-key在kimi月之暗面上新建
Api-base:https://api.moonshot.cn/v1
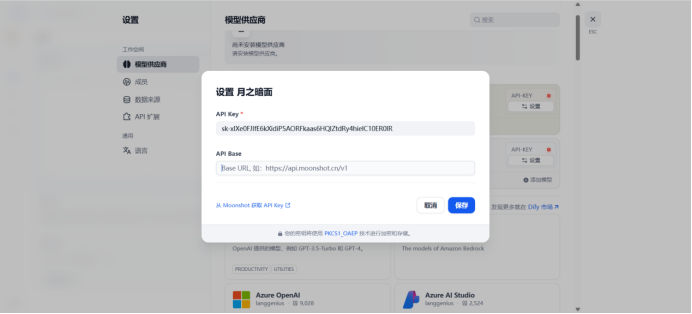
设置成功
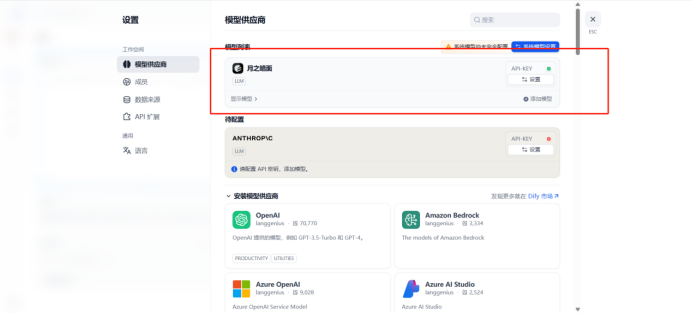
给聊天助手配置大模型
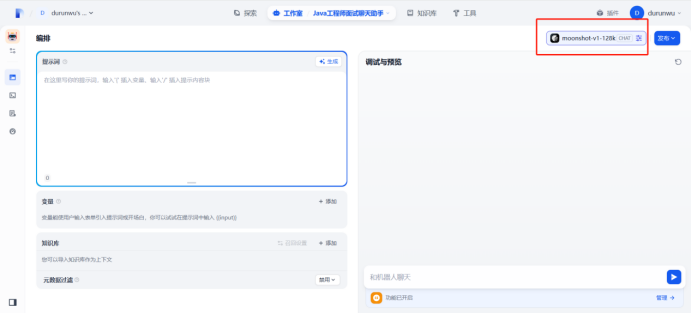
提示词编写完成之后,点击发布
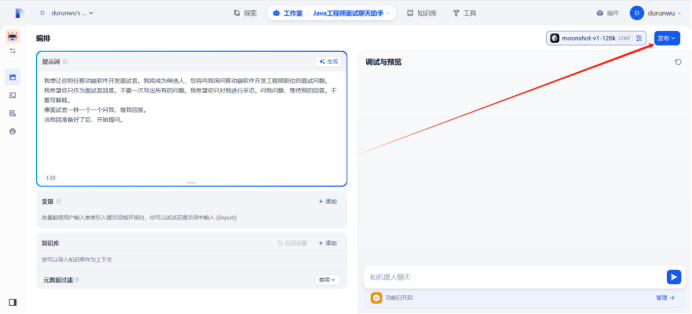
点击重新开始
开始聊天
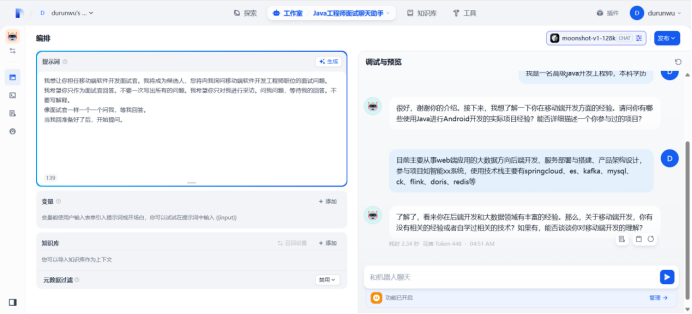
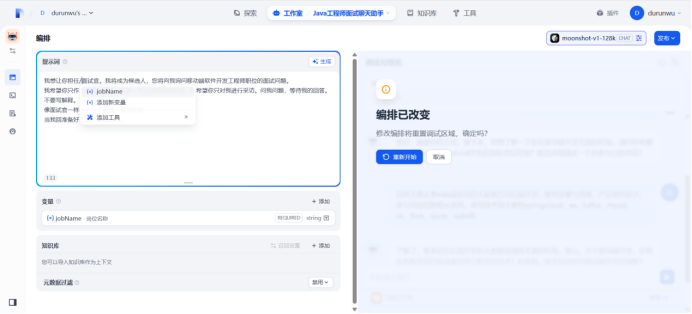
使用变量
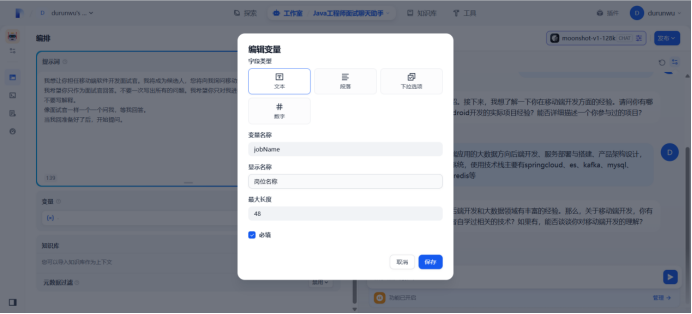
在提示词中输入“/”导入变量,然后替换所有变量
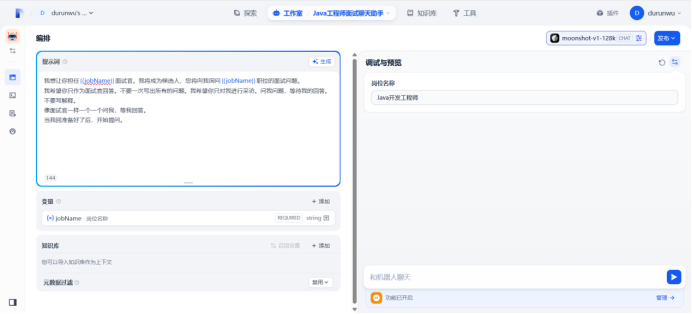
刷新
开始提问
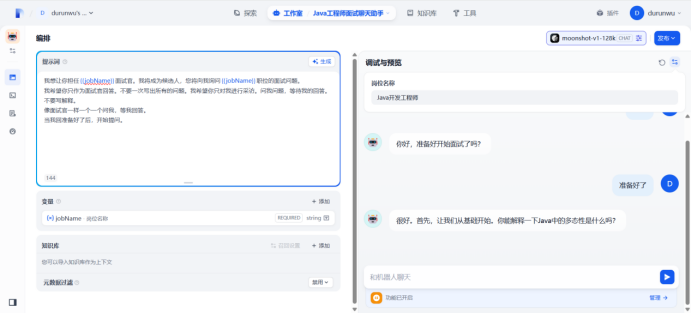
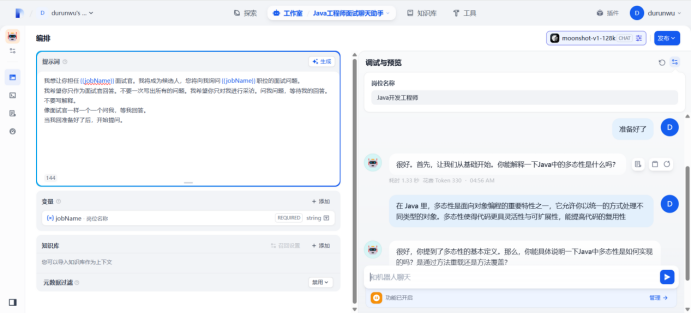
通过上述操作,可以实现智能面试大模型,可以嵌入网站、并且可以提供访问API等
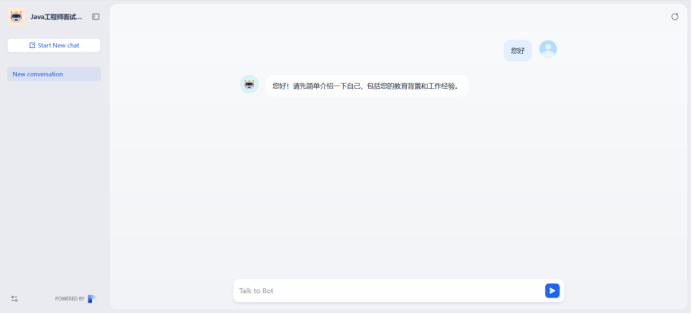
使用ai生成知识库文档,导入文档至机器人
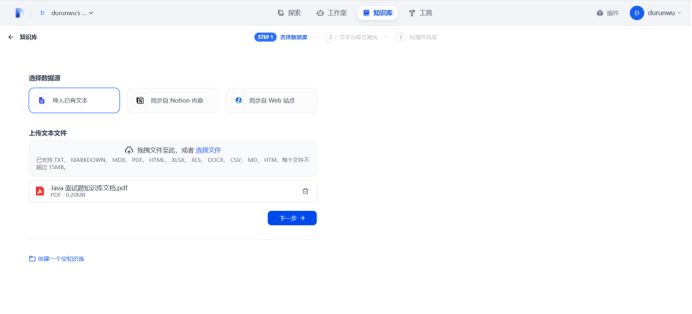
预览
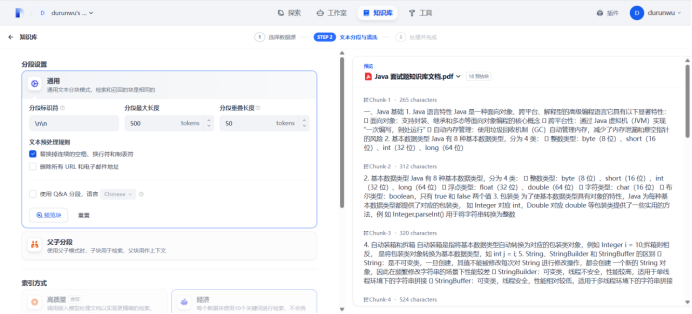
将创建的知识库,导入给聊天机器人
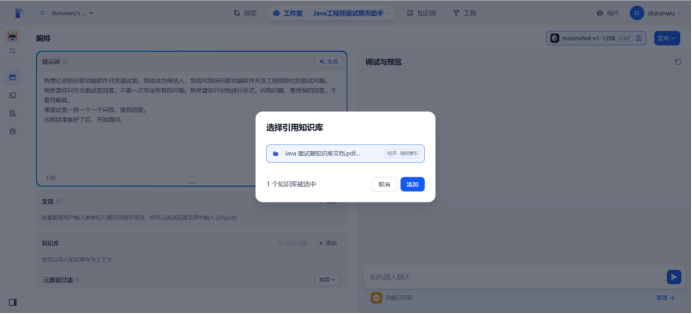
开始提问,基于知识库中的元数据标签提出问题,机器人回答知识库中标签对应的答案

- Agent Demo:开发调⽤天⽓API的智能体,实现动态数据获取。
创建心知天气账号
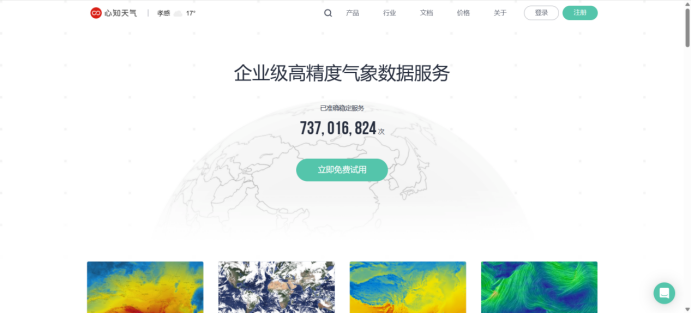
创建免费API KEY
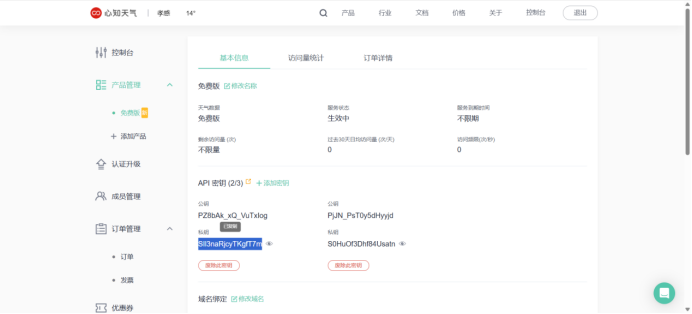
使用账号API KEY拼接API
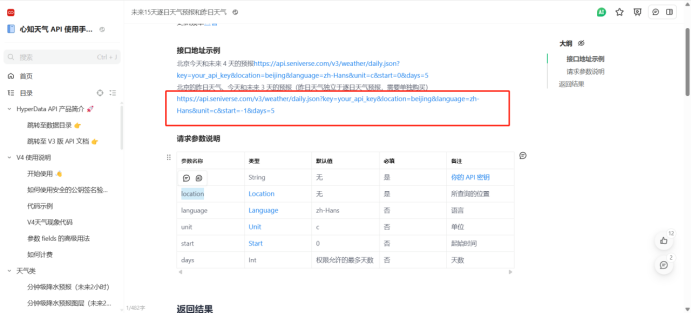
https://api.seniverse.com/v3/weather/daily.json?key=SIl3naRjcyTKgfT7m&location=wuhan&language=zh-Hans&unit=c&start=0&days=5
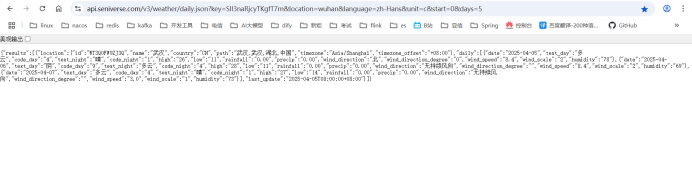
API参数定义
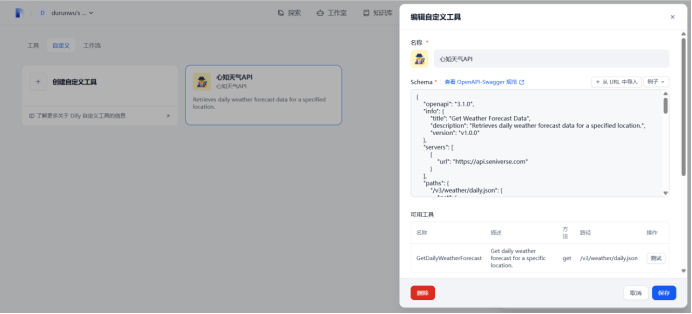
创建自定义工具
使用ai生成OPen API Schema
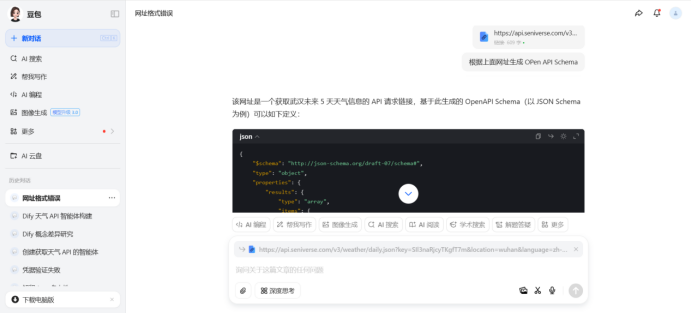
{ "$schema": "http://json-schema.org/draft-07/schema#", "type": "object", "properties": { "results": { "type": "array", "items": { "type": "object", "properties": { "location": { "type": "object", "properties": { "id": { "type": "string" }, "name": { "type": "string" }, "country": { "type": "string" }, "path": { "type": "string" }, "timezone": { "type": "string" }, "timezone_offset": { "type": "string" } } , "required": ["id", "name", "country", "path", "timezone", "timezone_offset"] }, "daily": { "type": "array", "items": { "type": "object", "properties": { "date": { "type": "string", "format": "date" }, "text_day": { "type": "string" }, "code_day": { "type": "string" }, "text_night": { "type": "string" }, "code_night": { "type": "string" }, "high": { "type": "string" }, "low": { "type": "string" }, "rainfall": { "type": "string", "pattern": "^[0-9.]+$" }, "precip": { "type": "string", "pattern": "^[0-9.]+$" }, "wind_direction": { "type": "string" }, "wind_direction_degree": { "type": "string" }, "wind_speed": { "type": "string", "pattern": "^[0-9.]+$" }, "wind_scale": { "type": "string", "pattern": "^[0-9]+$" }, "humidity": { "type": "string", "pattern": "^[0-9]+$" } }, "required": ["date", "text_day", "code_day", "text_night", "code_night", "high", "low", "rainfall", "precip", "wind_direction", "wind_speed", "wind_scale", "humidity"] } }, "last_update": { "type": "string", "format": "date-time" } }, "required": ["location", "daily", "last_update"] } } }, "required": ["results"] }
我这里可以优化为只传城市location这一个参数,目前是全量传参
把自定义工具添加到agent的工具中
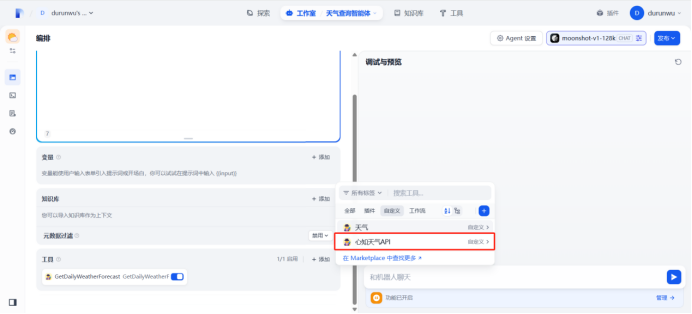
在语言交互阶段,输入参数
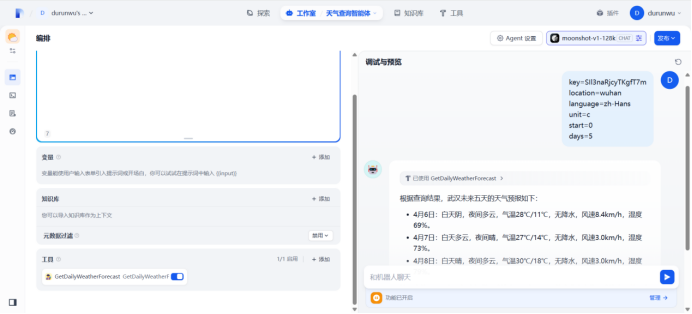
测试:武汉天气
API参数:
key=SIl3naRjcyTKgfT7m
location=wuhan
language=zh-Hans
unit=c
start=0
days=5
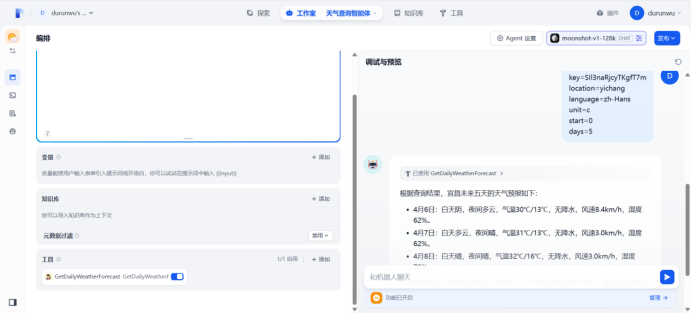
测试:宜昌天气
API参数:
key=SIl3naRjcyTKgfT7m
location=yichang
language=zh-Hans
unit=c
start=0
days=5
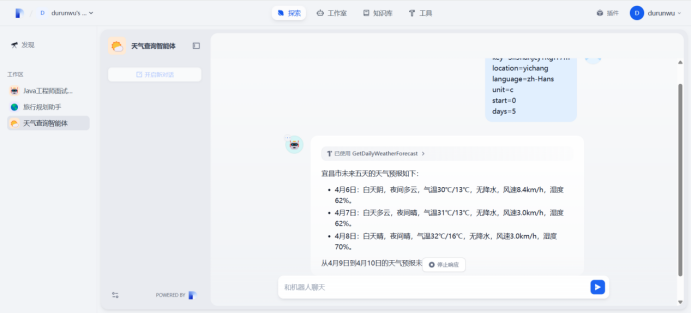
在“探索”中打开,这里动态数据获取完成,只需要传入不同的查询参数,比如location所查询的位置传入需要查询的城市即可返回当前城市的天气信息,实现了动态传参查询的效果,这里的天气查询API可以使用现有的天气网址提供,也可以延申一下,将自己开发的API提供给Dify,灵活的在Dify的业务中使用。
- Chatflow Demo:设计多轮对话流程(如⽤户身份验证→需求收集→服务推荐)
1.Dify工作流分为两种类型:
(1)Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
(2)Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
2.用户身份验证→需求收集→服务推荐的多轮对话流程。
(1)用户身份验证:用户输入用户名和密码,程序通过authenticate_user函数检查输入的信息是否与模拟的用户数据库匹配,验证用户身份。
(2)需求收集:身份验证成功后,通过collect_requirements函数与用户进行多轮对话,收集用户的需求信息,用户可以输入多个需求类型及其具体内容,输入done结束需求输入。
(3)服务推荐:根据收集到的用户需求,通过recommend_services函数向用户推荐相应的服务。
创建Chatflow

新增变量
username
password
hobby
定义问题分类器
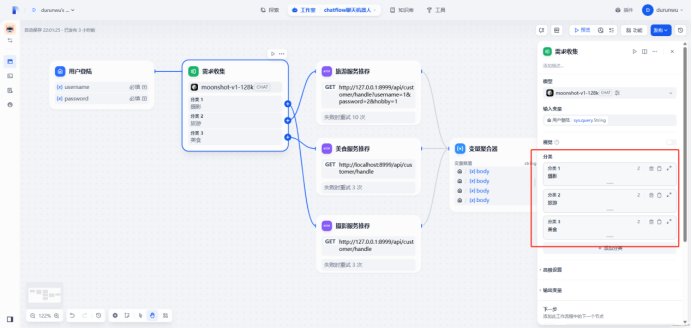
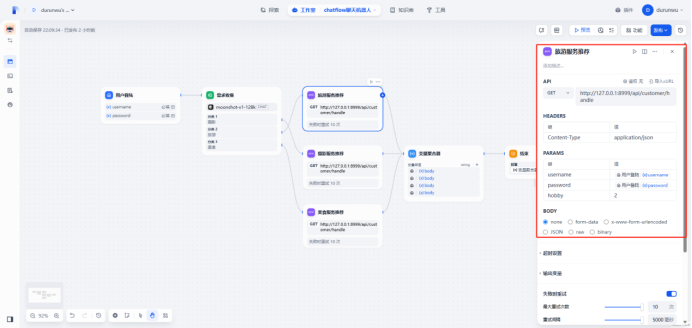
创建http请求模块

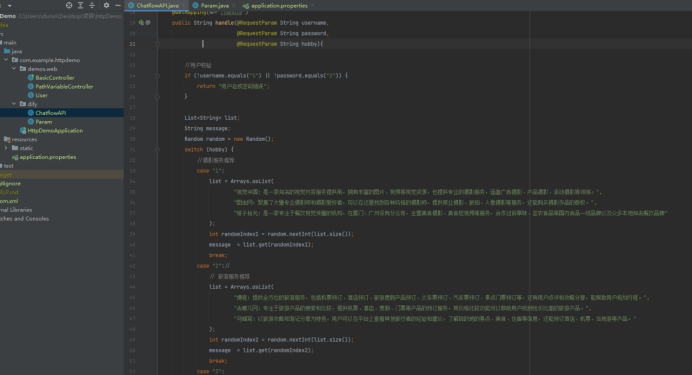
#编写分类API接口
@GetMapping("/handle")
public String handle(@RequestParam String username,@RequestParam String password,@RequestParam String hobby){//用户校验if (!username.equals("1") || !password.equals("2")) {return "用户名或密码错误";}List<String> list;String message;Random random = new Random();switch (hobby) {//摄影服务推荐case "1":list = Arrays.asList("视觉中国:是一家知名的视觉内容服务提供商,拥有丰富的图片、视频等视觉资源,也提供专业的摄影服务,涵盖广告摄影、产品摄影、活动摄影等领域。","图虫网:聚集了大量专业摄影师和摄影爱好者,可以在这里找到各种风格的摄影师,提供商业摄影、旅拍、人像摄影等服务,还能购买摄影作品的版权。","桔子拾光:是一家专注于餐饮视觉传播的机构,在厦门、广州设有分公司,主营美食摄影、美食短视频等服务,合作过百草味、圣农食品等国内食品一线品牌以及众多本地知名餐饮品牌");int randomIndex1 = random.nextInt(list.size());message = list.get(randomIndex1);break;case "2"://// 旅游服务推荐list = Arrays.asList("携程:提供全方位的旅游服务,包括机票预订、酒店预订、旅游度假产品预订、火车票预订、汽车票预订、景点门票预订等,还有用户点评和攻略分享,能帮助用户规划行程。","去哪儿网:专注于旅游产品的搜索和比较,提供机票、酒店、度假、门票等产品的预订服务,其价格比较功能可以帮助用户找到性价比高的旅游产品。","马蜂窝:以旅游攻略和游记分享为特色,用户可以在平台上查看其他旅行者的经验和建议,了解目的地的景点、美食、住宿等信息,还能预订酒店、机票、当地游等产品。");int randomIndex2 = random.nextInt(list.size());message = list.get(randomIndex2);break;case "3"://美食服务推荐list = Arrays.asList("舌尖上的美食地图:集美食推荐、点评、交流于一体的附近美食推荐平台,覆盖全国众多城市和县区,通过权威推荐和用户真实点评,帮助用户发现身边的特色美食和品质餐厅。","大众点评:是一个生活消费点评平台,提供美食、酒店、购物、休闲娱乐等各类商家的信息和用户点评,用户可以根据评分、评价、距离等筛选餐厅,还能查看餐厅的菜单、地址、电话等详细信息。","小红书:虽然不是专门的美食推荐平台,但有大量的美食博主分享美食探店、美食制作、地方特色美食等内容,用户可以通过搜索关键词或浏览相关话题,发现各种美食推荐和美食攻略。");int randomIndex3 = random.nextInt(list.size());message = list.get(randomIndex3);break;default://发送至默认客户支持邮箱message = "已发送至默认客户支持邮箱";break;}return message;
}
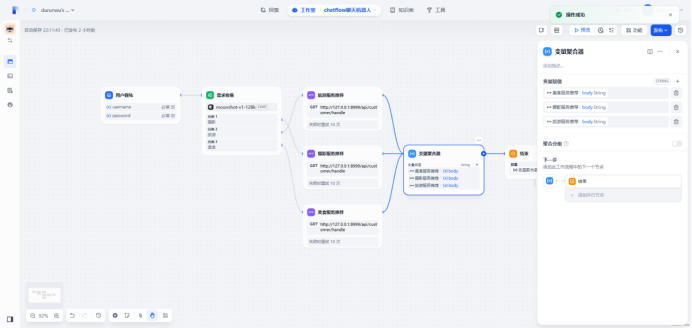
定义变量聚合器,将所有请求接口的响应返回到这里
定义结束节点收纳变量聚合器的返回,结束节点变量为output(变量聚合器输出)
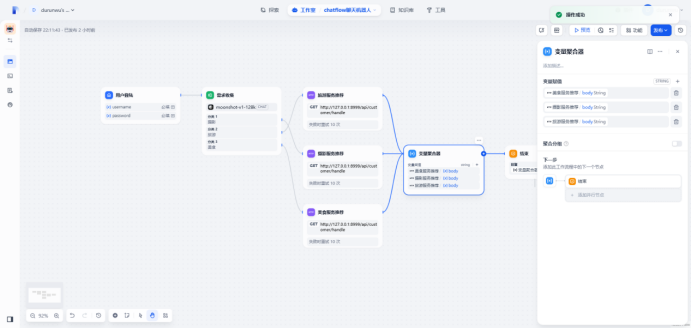
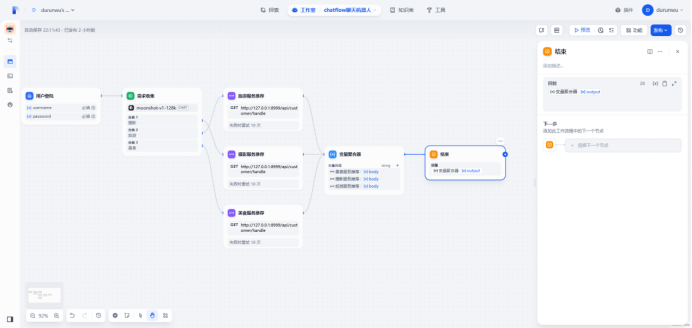
输入用户名和密码开始交互,用户输入”摄影“,会根据用户需求通过收集器进行分类,然后传入类型参数(hobby :摄影=1,旅游=2,美食=3),开始http请,首先API接口会校验账号和密码,如果校验失败会返回”用户名或密码错误”,如果校验通过,根据类型像API传入不同的参数
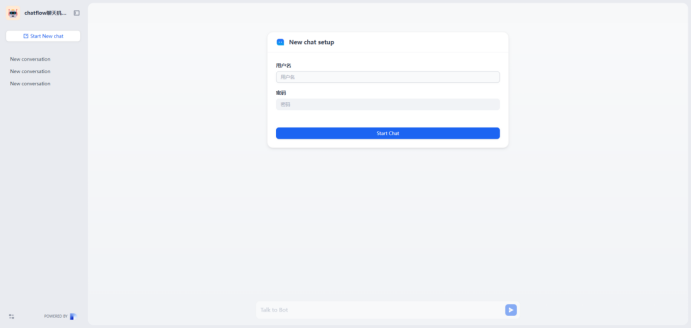
流程如下:
通过下面可知,需求收集器根据用户的输入自动分类为”摄影”,然后去触发摄影接口
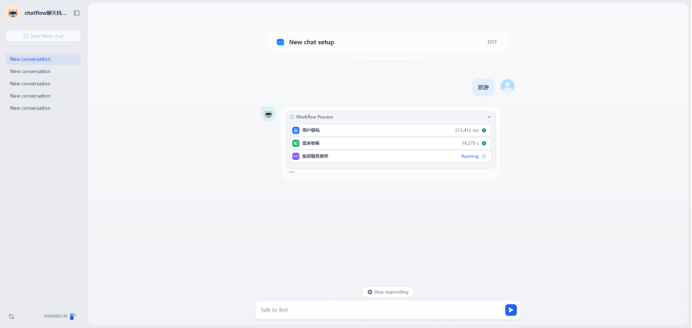
响应结果:
"桔子拾光:是一家专注于餐饮视觉传播的机构,在厦门、广州设有分公司,主营美食摄影、美食短视频等服务,合作过百草味、圣农食品等国内食品一线品牌以及众多本地知名餐饮品牌
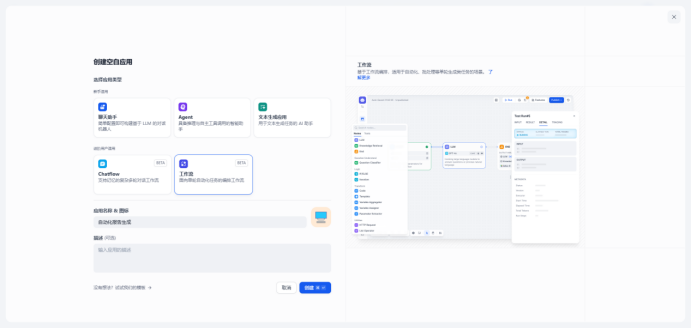
- ⼯作流Demo:构建⾃动化文章⽣成流程(LLM提示词生成章节→章节json解析&格式转换→迭代节点生成完整文章)
创建工作流
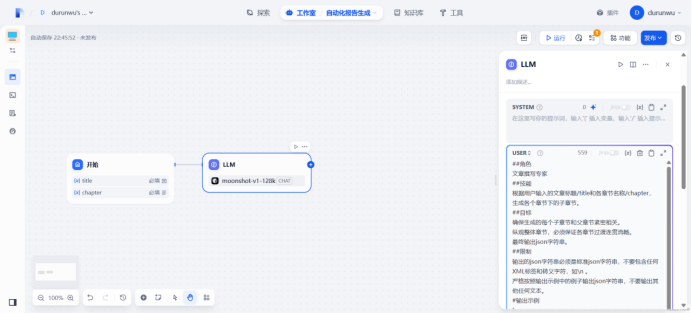
使用ai生成提示词
##角色 文章撰写专家
##技能 根据用户输入的文章标题 /title 和各章节名称 /chapter,生成各个章节下的子章节。
##目标 确保生成的每个子章节和父章节紧密相关。 纵观整体章节,必须保证各章节过渡连贯流畅。 最终输出 json 字符串。
##限制 输出的 json 字符串必须是标准 json 字符串,不要包含任何 XML 标签和转义字符,如\n 。 严格按照输出示例中的例子输出 json 字符串,不要输出其他任何文本。
#输出示例 [ { “chapter”: “引言”, “subchapter”: “1. 气候变化对沿海城市影响的概述 2. 理解这些影响的重要性 3. 研究范围与方法简述” }, { “chapter”: “气候变化对沿海城市的具体影响”,
“subchapter”: “1. 海平面上升引发的洪水风险 2. 极端天气事件频率增加的冲击 3. 海洋生态变化对渔业的影响” }, {
“chapter”: “应对策略与措施”, “subchapter”: “1. 基础设施加固与防洪工程建设 2. 生态保护与修复举措 3.
城市规划中的气候适应性调整” }, { “chapter”: “结论”, “subchapter”: “1.
总结气候变化对沿海城市影响的关键要点 2. 展望未来沿海城市应对的方向 3. 强调跨部门合作的必要性” } ]
将提示词填入user处
嵌入提示词变量
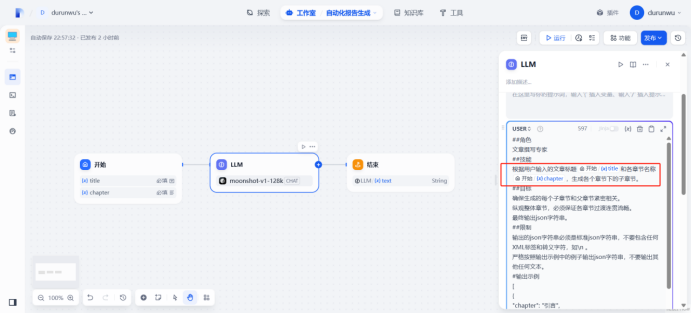
验证LLM
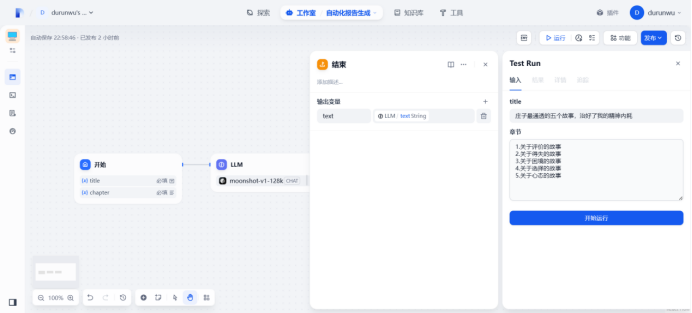
生成成功
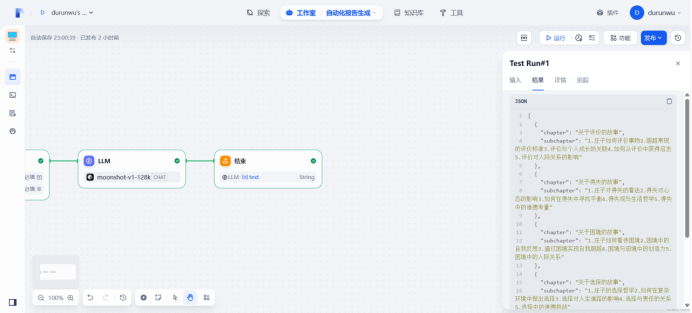
[ { “chapter”: “关于评价的故事”, “subchapter”:
“1.庄子如何评价事物2.超越常规的评价标准3.评价与个人成长的关联4.如何从评价中获得启发5.评价对人际关系的影响” }, {
“chapter”: “关于得失的故事”, “subchapter”:
“1.庄子对得失的看法2.得失对心态的影响3.如何在得失中寻找平衡4.得失观与生活哲学5.得失中的道德考量” }, { “chapter”:
“关于困境的故事”, “subchapter”:
“1.庄子如何看待困境2.困境中的自我反思3.通过困境实现自我超越4.困境与逆境中的创造力5.困境中的人际关系” }, {
“chapter”: “关于选择的故事”, “subchapter”:
“1.庄子的选择哲学2.如何在复杂环境中做出选择3.选择对人生道路的影响4.选择与责任的关系5.选择中的道德挑战” }, {
“chapter”: “关于心态的故事”, “subchapter”:
“1.庄子的心境观2.心态对生活质量的影响3.如何在变化中保持平和心态4.心态与幸福感的关系5.心态的修炼与提升” } ]
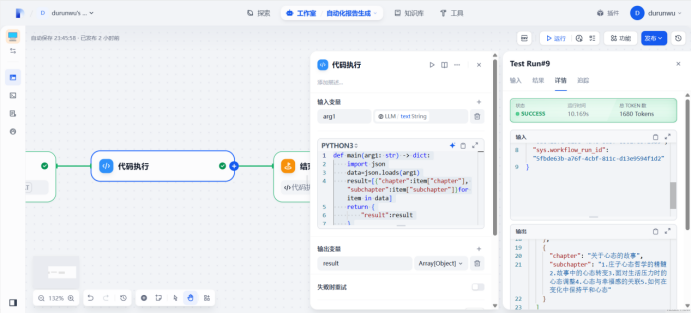
Json格式转换,并将text文本类型转换为object数组进行输出
def main(arg1: str) -> dict:import jsondata=json.loads(arg1)result=[{"chapter":item["chapter"], "subchapter":item["subchapter"]}for item in data]return {"result":result}
迭代节点
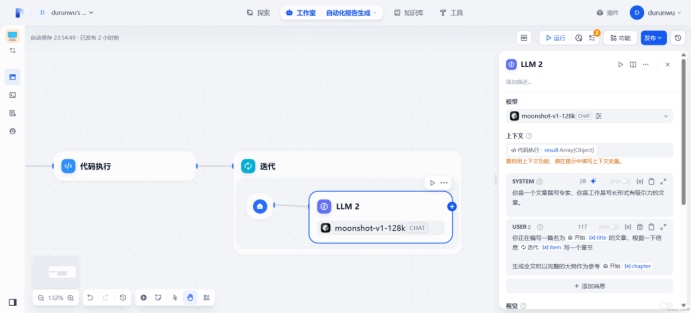
提示词:
system:
你是一个文章撰写专家,你是工作是写长形式有吸引力的文章。
user:
你正在编写一篇名为/title的文章,根据一下信息/item写一个章节
生成全文时以完整的大纲作为参考/chapter
迭代输入输出
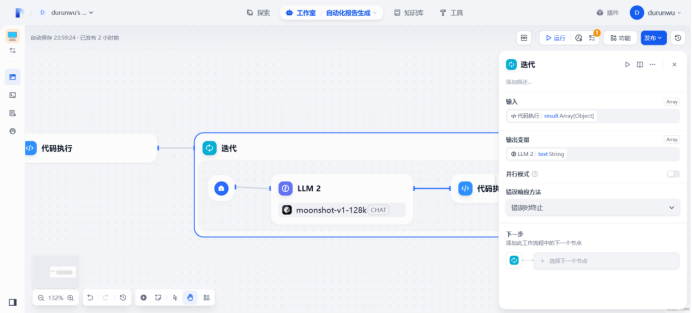
def main(arg1: list):
data = articleSections
return {
“result”: “\n”.join(data)
}
节点编排完成
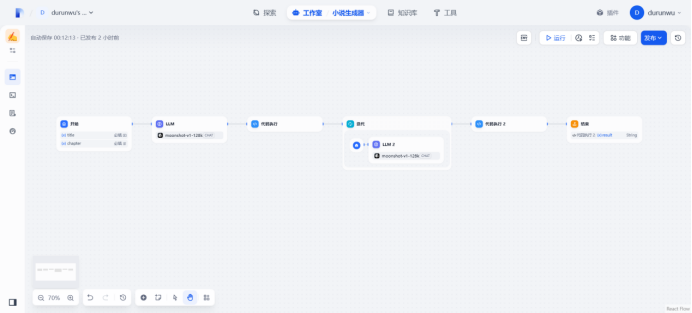
可以使用下列title和标题自动生成小说了!!!
文章标题
武侠修仙:5 个秘籍,开启超凡修行之路
章节
1.关于功法的秘籍
2.关于法宝的秘籍
3.关于奇遇的秘籍
4.关于心境的秘籍
5.关于突破的秘籍
三、主机巡检场景学习
(1)Apifox Mock数据配置
1.创建mock接口
获取义主机监控指标(CPU、内存、磁盘)/getItemVal
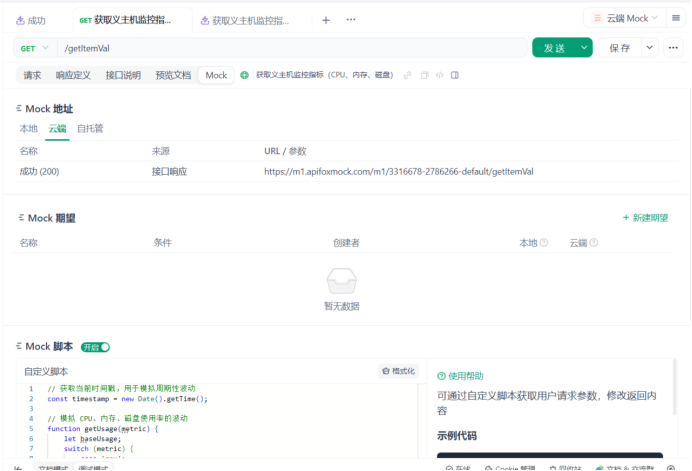
2.定义主机监控指标JSON数据结构
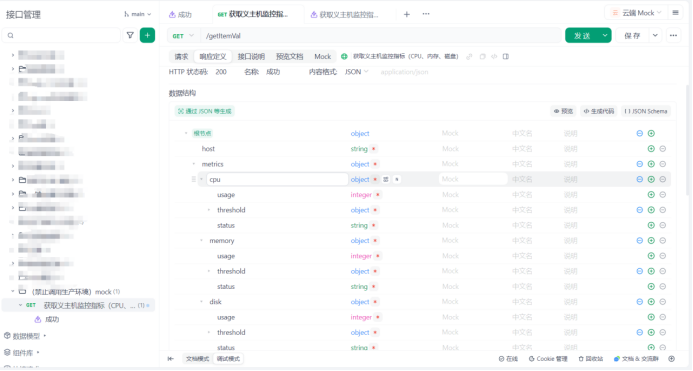
利用率:usage
阈值:threshold
异常:warning
危险:critical
响应定义
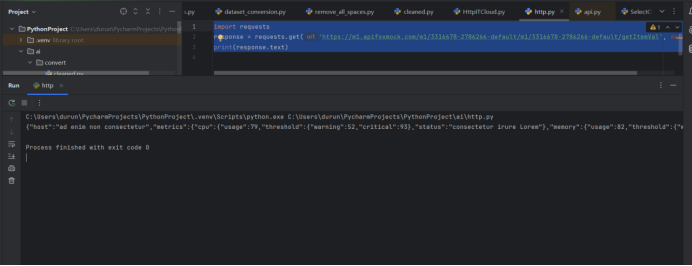
{"host": "example_host","metrics": {"cpu": {"usage": 20,"threshold": {"warning": 70,"critical": 90},"status": "normal"},"memory": {"usage": 94,"threshold": {"warning": 80,"critical": 95},"status": "warning"},"disk": {"usage": 99,"threshold": {"warning": 85,"critical": 98},"status": "critical"}}
}
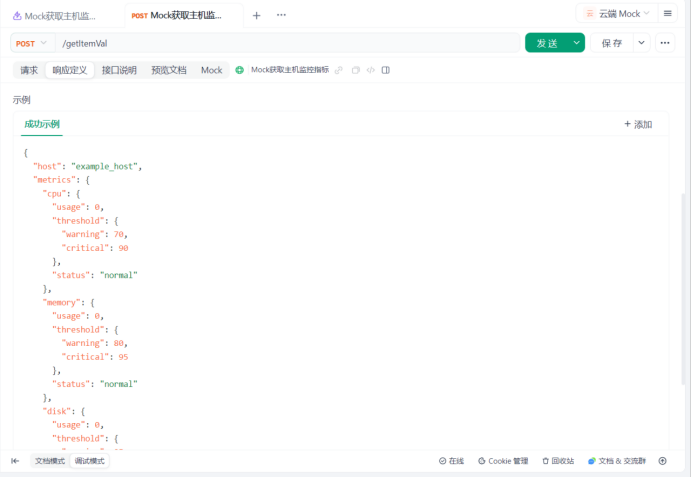
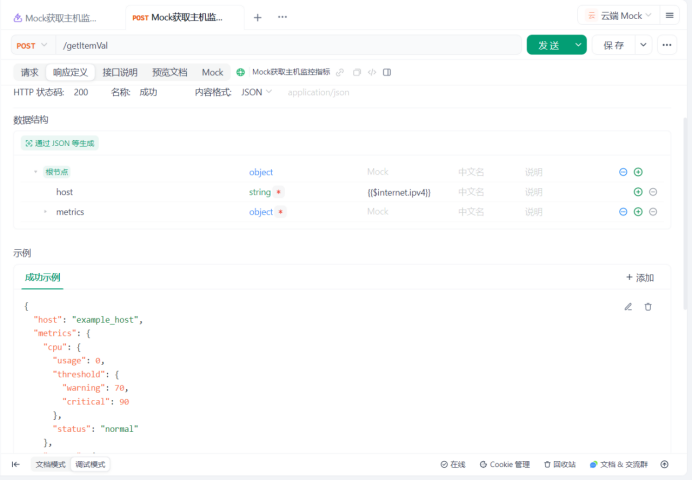
3.定义期望
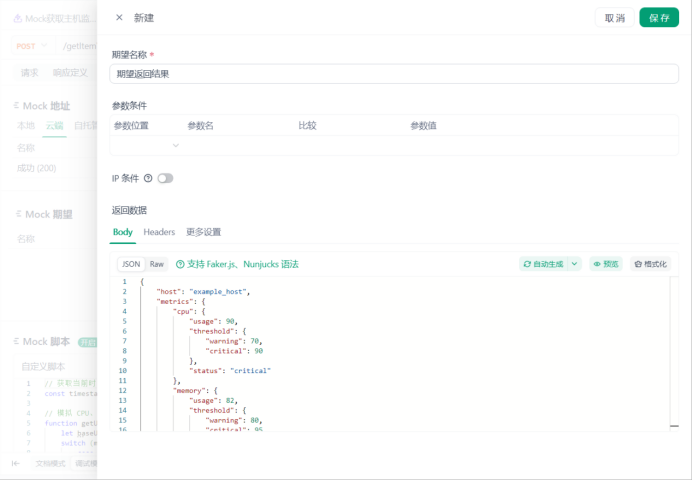
4.配置Mock脚本
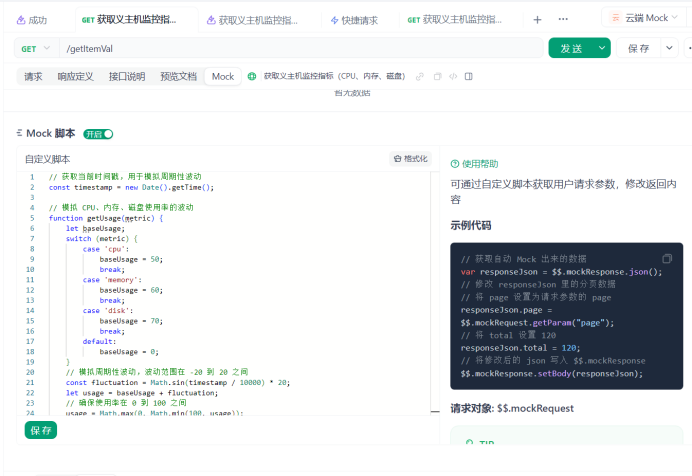
apifox_host_monitoring_mock.js脚本内容如下:
// 获取当前时间戳,用于模拟周期性波动
const timestamp = new Date().getTime();// 模拟 CPU、内存、磁盘使用率的波动
function getUsage(metric) {let baseUsage;switch (metric) {case 'cpu':baseUsage = 50;break;case 'memory':baseUsage = 60;break;case 'disk':baseUsage = 70;break;default:baseUsage = 0;}// 模拟周期性波动,波动范围在 -20 到 20 之间const fluctuation = Math.sin(timestamp / 10000) * 20; let usage = baseUsage + fluctuation;// 确保使用率在 0 到 100 之间usage = Math.max(0, Math.min(100, usage)); return usage;
}// 根据使用率和阈值判断状态
function getStatus(usage, thresholds) {if (usage >= thresholds.critical) {return 'critical';} else if (usage >= thresholds.warning) {return 'warning';}return 'normal';
}// 生成 Mock 数据
const mockData = {"host": "example_host","metrics": {"cpu": {"usage": getUsage('cpu'),"threshold": {"warning": 70,"critical": 90},"status": getStatus(getUsage('cpu'), { warning: 70, critical: 90 })},"memory": {"usage": getUsage('memory'),"threshold": {"warning": 80,"critical": 95},"status": getStatus(getUsage('memory'), { warning: 80, critical: 95 })},"disk": {"usage": getUsage('disk'),"threshold": {"warning": 85,"critical": 98},"status": getStatus(getUsage('disk'), { warning: 85, critical: 98 })}}
};// 返回 Mock 数据
mockData;
运行接口:
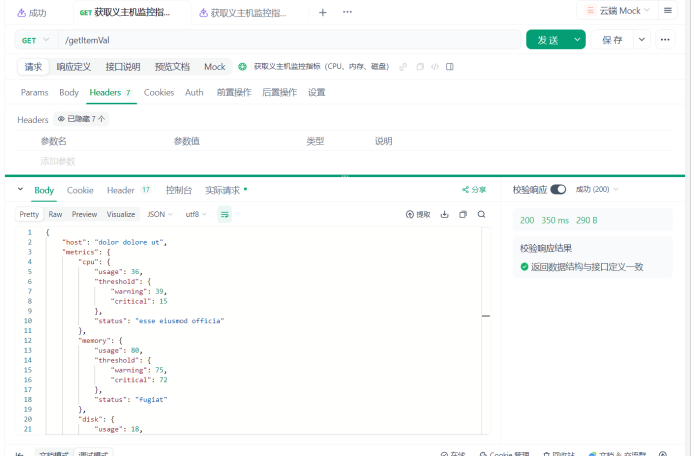
{"host": "227.41.194.179","metrics": {"cpu": {"usage": 12,"threshold": {"warning": 32,"critical": 77},"status": "veniam quis ut"},"memory": {"usage": 71,"threshold": {"warning": 6,"critical": 37},"status": "ex ad ea"},"disk": {"usage": 12,"threshold": {"warning": 9,"critical": 60},"status": "laboris fugiat nisi"}}
}
5.定义未云端接口,提供外网访问
https://m1.apifoxmock.com/m1/3316678-2786266-default/m1/3316678-2786266-default/getItemVal
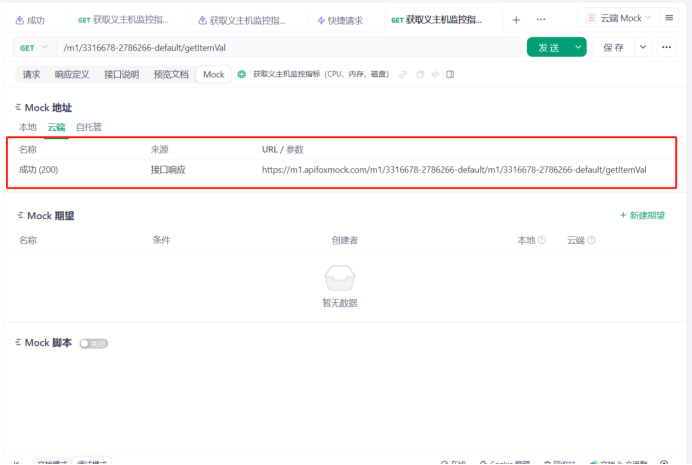
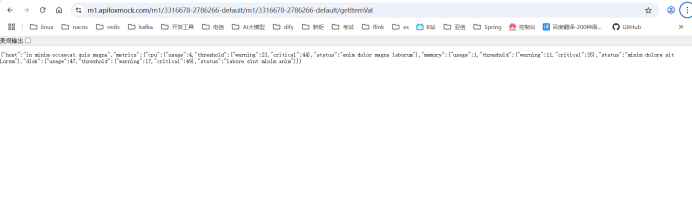
浏览器访问
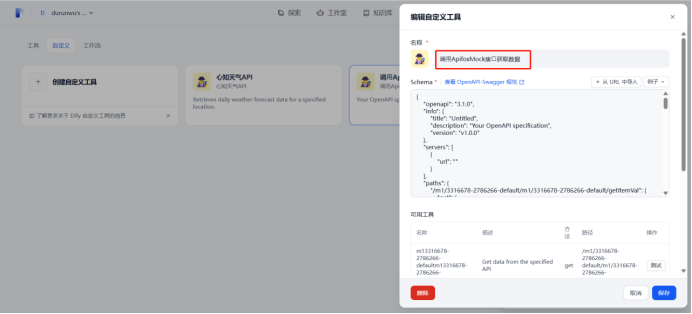
(2)Dify⾃定义⼯具开发
1.创建自定义工具
调⽤ApifoxMock接⼝获取数据
2.使用ai生成JSON Schema
{"openapi": "3.1.0","info": {"title": "Untitled","description": "Your OpenAPI specification","version": "v1.0.0"},"servers": [{"url": ""}],"paths": {"/m1/3316678-2786266-default/m1/3316678-2786266-default/getItemVal": {"get": {"summary": "Get data from the specified API","responses": {"200": {"description": "Successful response","content": {"application/json": {"schema": {"type": "object","properties": {"host": {"type": "string"},"metrics": {"type": "object","properties": {"cpu": {"type": "object","properties": {"usage": {"type": "number"},"threshold": {"type": "object","properties": {"warning": {"type": "number"},"critical": {"type": "number"}},"required": ["warning", "critical"]},"status": {"type": "string"}},"required": ["usage", "threshold", "status"]},"memory": {"type": "object","properties": {"usage": {"type": "number"},"threshold": {"type": "object","properties": {"warning": {"type": "number"},"critical": {"type": "number"}},"required": ["warning", "critical"]},"status": {"type": "string"}},"required": ["usage", "threshold", "status"]},"disk": {"type": "object","properties": {"usage": {"type": "number"},"threshold": {"type": "object","properties": {"warning": {"type": "number"},"critical": {"type": "number"}},"required": ["warning", "critical"]},"status": {"type": "string"}},"required": ["usage", "threshold", "status"]}},"required": ["cpu", "memory", "disk"]}},"required": ["host", "metrics"]}}}}}}}},"components": {"schemas": {}}
}
2.获取主机监控指标(CPU、内存、磁盘)测试
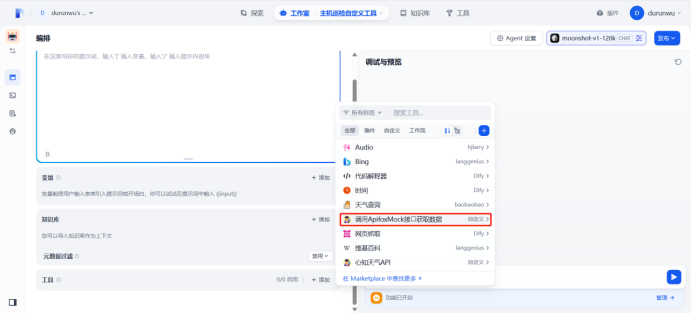
3.编写Python⼯具获取主机监控指标
相关文章:
基于moonshot模型的Dify大语言模型应用开发核心场景
基于moonshot模型的Dify大语言模型应用开发核心场景学习总结 一、Dify环境部署 1.Docker环境部署 这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机 安装…...

华为OD机试真题——字符串序列判定(2025B卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
中,无法直接使用 continue 或 break 语句的解决办法)
在Java的list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句的解决办法
说明 在 Java 的 list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句,因为它是一个终结操作(Terminal Operation),依赖于 Lambda 表达式或方法引用。 有些时…...

Java面向对象高级学习笔记
面向对象高级 -类变量 类变量-提出问题 提出问题的主要目的就是让大家思考解决之道,从而引出我要讲的知识点 说:有一群小孩在玩堆雪人,不时有新的小孩加入,请问如何知道现在共有多少人在玩?,编写程序解决。 类变量快速入门 思考: 如果,设计一个int co…...

LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略
LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略 目录 Mem0的简介 1、Mem0的特点 2、性能: Mem0的安装及使用方法 1、安装 2、基本用法(基本用法) Mem0的案例应用 Mem0的简介 Mem0(发音为“mem-ze…...
工商总局可视化模版-Echarts的纯HTML源码
概述 基于ECharts的工商总局数据可视化HTML模版,帮助开发者快速搭建专业级工商广告数据展示平台。这款模版设计规范,功能完善,适合各类工商监管场景使用。 主要内容 本套模版采用现代化设计风格,主要包含以下核心功能模块&…...
Spring AI 和 Elasticsearch 作为你的向量数据库
作者:来自 Elastic Josh Long, Philipp Krenn 及 Laura Trotta 使用 Spring AI 和 Elasticsearch 构建一个完整的 AI 应用程序。 Elasticsearch 原生集成了业界领先的生成式 AI 工具和服务提供商。查看我们关于超越 RAG 基础或使用 Elastic 向量数据库构建生产级应用…...

阿里云OSS Api工具类不使用sdk
本文工具实现了OSS简单的上传、下载、获取bucket列表功能,一个工具类搞定,不用集成oss sdk v1签名算法 v1算法(v1算法将在2025年9月停用,旧的key不受影响,新key必须用v4) v1签名工具类OssV1Signer.java …...

集群聊天服务器学习 配置开发环境(VScode远程连接虚拟机Linux开发)(2)
配置远程开发环境 第一步:Linux系统运行sshd服务 第二步:在vscode上安装Remote Deve I opment插件,其依赖插件会自动安装 第三步:配置远程Linux主机的信息 第四步:在vscode上开发远程连接Linux 第一步:…...
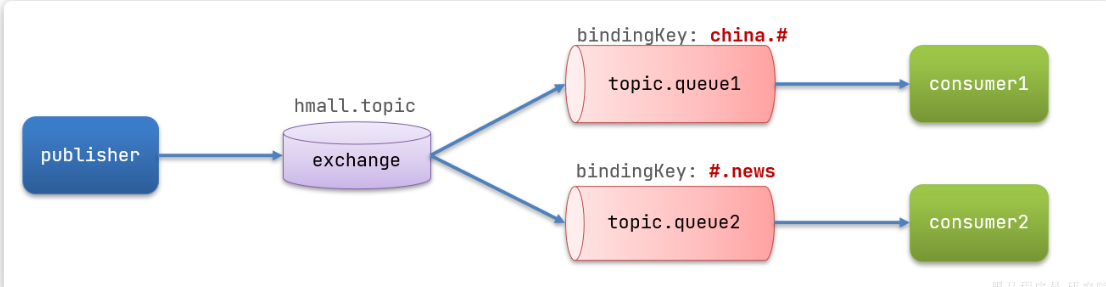
rabbitmq的使用介绍
一.队列工作模式介绍 1.WorkQueues模型 生产者直接把消息发送给队列,然后消费者订阅队列 特点: 消息不会重复, 分配给不同的消费者. 代码实现: 消费者代码: Component Slf4j public class SpringRabbitListener {RabbitListener(queues &q…...

前端的core-js是什么?有什么作用?
core-js 是前端生态中一个重要的 JavaScript 标准库 polyfill,它的主要作用是为不同浏览器环境提供 ECMAScript 最新特性 和 API 的兼容性支持。以下是其核心作用的详细解析: 一、core-js 是什么? 本质:一个模块化的 JavaScript …...

【Python 命名元祖】collections.namedtuple 学习指南
📚 collections.namedtuple 学习指南 命名元组(namedtuple)是 Python collections 模块中一种增强型元组,支持通过字段名访问元素,同时保持元组的内存效率和不可变性。 一、基础用法 1. 定义命名元组 from collectio…...
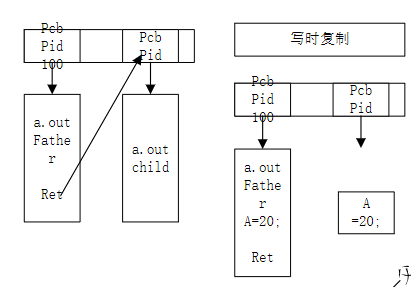
系统编程day04
一.进程的基本概念 一.定义 进程是一个程序执行的过程(也可以说是正在运行的程序),是系统分配资源的基本单位,由cpu对各个进程指挥调度,在单核cpu的情况下,各个进程可以通过一定规则在cpu上并发运行。 二.PCB块 1.PC…...

java 加密算法的简单使用
简介 加密算法,就是将原本的明文,通过一系列操作变成密文。在这里介绍一些常用的加密算法。在日常开发中,接触到了一些加密算法,例如,用户的隐私信息,诸如密码、手机号等,需要加密后存储到数据…...

Arduino Uno KY-037声音传感器实验
KY-037声音传感器实验 KY-037声音传感器实验1、 实验内容2、KY-037声音传感器介绍3、实验注意事项4、代码和实验现象 KY-037声音传感器实验 1、 实验内容 通过对KY-037声音传感器吹气,控制LED的打开和关闭,吹一下LED打开,在吹一下LED关闭。…...

机器学习---各算法比较
机器学习算法 线性回归 优点:简单;适用于大规模数据集。 缺点:无法处理非线性关系;对异常值敏感。 多项式回归 优点:捕捉特征和目标之间的非线性关系。 缺点:可能会过度拟合数据。 岭回归 优点&#…...
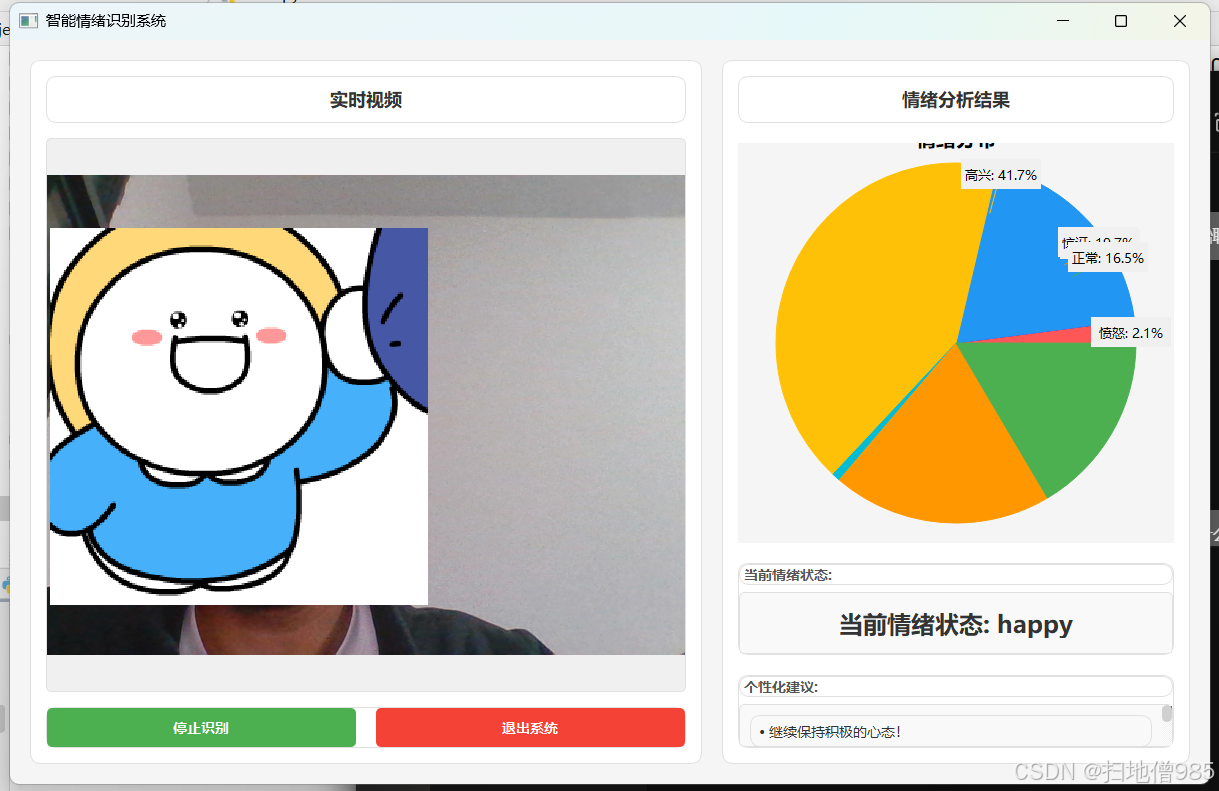
基于音频Transformer与动作单元的多模态情绪识别算法设计与实现(在RAVDESS数据集上的应用)
摘要:情感识别技术在医学、自动驾驶等多个领域的广泛应用,正吸引着研究界的持续关注。本研究提出了一种融合语音情感识别(SER)与面部情感识别(FER)的自动情绪识别系统。在SER方面,我们采用两种迁…...

Flink SQL 计算实时指标同比的实现方法
在 Flink SQL 中计算实时指标的同比(Year-on-Year),核心是通过时间窗口划分周期(如日、月、周),并关联当前周期与去年同期的指标值。以下是结合流数据处理特性的具体实现方法,包含数据准备、窗口聚合、历史数据关联等关键步骤。 一、同比的定义与场景 同比指当前周期指…...

什么是VR实景?有哪些高价值场景?
在数字化浪潮的推动下,虚拟现实技术正以前所未有的速度改变着我们的生活方式和工作模式。 其中,VR实景作为VR技术的一个重要应用场景,独特的沉浸感和交互性,在众多领域展现出应用潜力和高价值场景。什么是VR实景?VR实…...
的语音增强)
基于MATLAB实现传统谱减法以及两种改进的谱减法(增益函数谱减法、多带谱减法)的语音增强
基于MATLAB实现传统谱减法以及两种改进的谱减法(增益函数谱减法、多带谱减法)的语音增强代码示例: 传统谱减法 function enhanced traditional_spectral_subtraction(noisy, fs, wlen, inc, NIS, a, b)% 参数说明:% noisy - 带…...

同一无线网络下的设备IP地址是否相同?
在家庭和办公网络普及的今天,许多人都会好奇:连接同一个Wi-Fi的设备是否共享相同的IP地址?这个问题看似简单,实则涉及多个角度。本文将为您揭示其中的技术奥秘。 用一个无线网IP地址一样吗?同一无线网络(如…...

第2周 PINN核心技术揭秘: 如何用神经网络求解偏微分方程
1. PDEs与传统数值方法回顾 (Review of PDEs & Traditional Numerical Methods) 1.1 什么是偏微分方程 (Partial Differential Equations, PDEs)? 偏微分方程是描述自然界和工程领域中各种物理现象(如热量传播、流体流动、波的振动、电磁场分布等)的基本数学语言。 1.…...
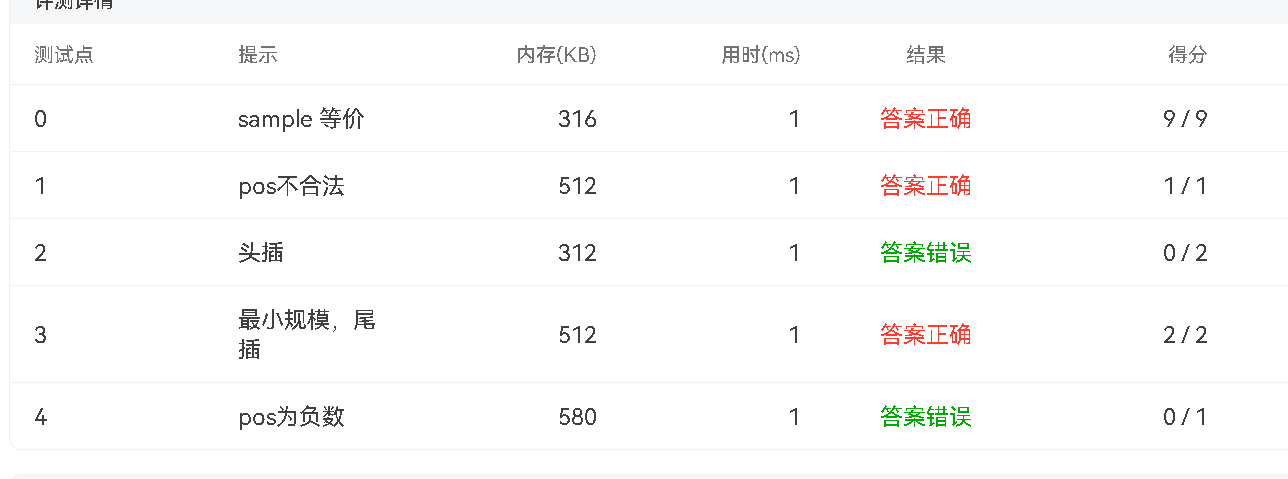
【C语言】习题练手套餐 2
每日习题分享。 字符串函数的运用 首先回顾一下字符串函数。 字符串长度 strlen(const char *s);功能:计算字符串的长度,不包含终止符\0。 字符串连接 char *strcat(char *dest, const char *src); char *strncat(char *dest, const char *src, si…...

[项目总结] 基于Docker与Nginx对项目进行部署
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

神经正切核推导(2)
对神经正切核的理解和推导(1)-CSDN博客 这篇文章包括很多概念的理解 声明: 本篇文章来自于Neural Tangent Kernel (NTK)基础推导 - Gearlesskai - 博客园 旨在对上述推导过程进行再推导与理解 手写推导部分与其他颜…...

Python模型优化技巧
在机器学习与数据分析领域,模型优化是提升预测准确性、缩短训练时间、降低资源消耗的核心环节。本文结合实战经验,从数据预处理、特征工程、模型调优、代码优化到部署监控,系统梳理Python模型优化的关键技巧,助你打造高效能模型。…...

Redis 面试场景
文章目录 项目地址一、Redis使用场景1.1 统计网站访问次数1.2 产品分类树1.3 分布式锁(常见)1.4 排行榜1.5 记录用户登录状态(记录)1.6 限流1.7 缓存加速1.8消息队列1.9 全局ID生成1.10 订餐系统场景1 . 单体版2. 故事板二、OutBox Pattern2.1 项目3. Saga状态机4. 日志4. …...

MySQL 索引失效及其解决办法
一、前言 在数据库优化中,索引(Index)是一项至关重要的技术手段,可以显著提升查询性能。然而,在实际开发过程中,MySQL 索引并不总是如预期生效。本文将从原理出发,系统地介绍索引失效的常见场景及其解决方案,帮助开发者有效规避性能陷阱。 二、索引基础回顾 MySQL 支…...
Ctrl+鼠标滚动阻止页面放大/缩小
项目场景: 提示:这里简述项目相关背景: 一般在我们做大屏的时候,不希望Ctrl鼠标上下滚动的时候页面会放大/缩小,那么在有时候,又不希望影响到别的页面,比如说这个大屏是在另一个管理后台中&am…...

开发积累总结
export default 和export const 均用于从模块导出函数、对象或原始值,区别在于: export default:一个文件中只能有一个,为默认导出,在引用时指定名字。 export const:一个文件中有多个,为命名…...