深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。
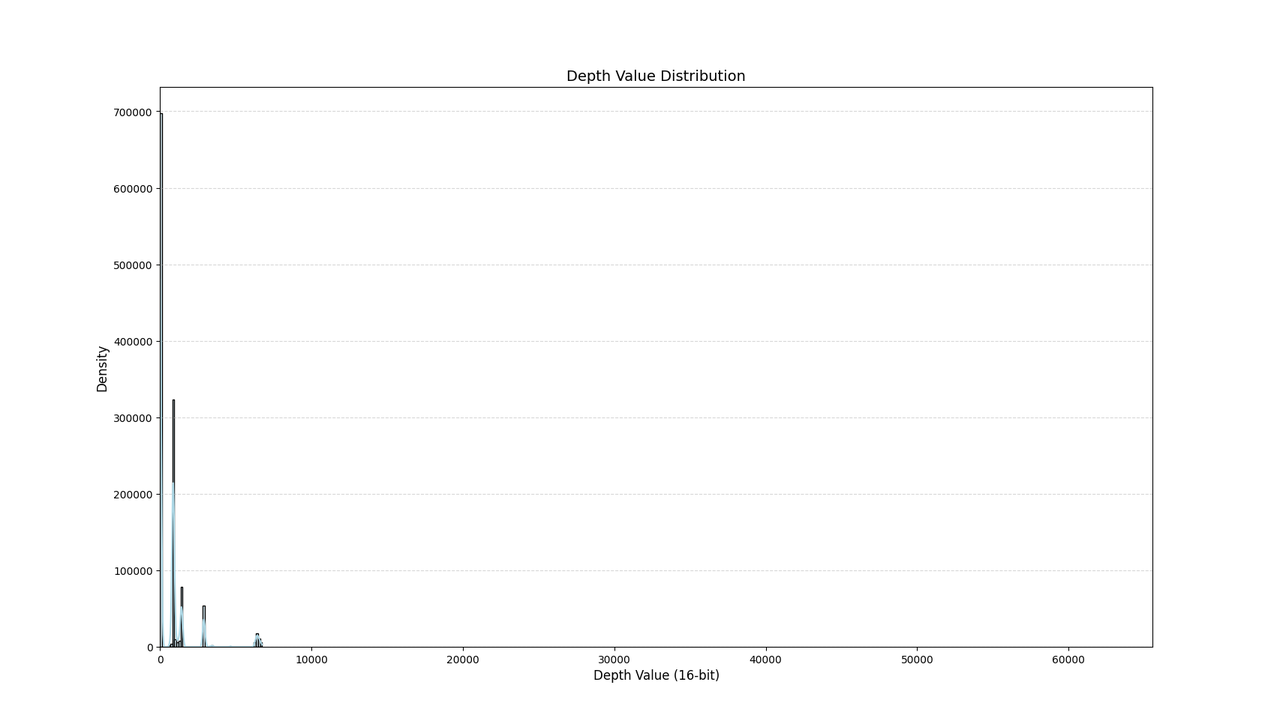
首先打印一张深度图中的深度信息分布:
import cv2
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns def plot_grayscale_histogram(image_path):# 读取图像(保留16位深度)img = cv2.imread(image_path, cv2.IMREAD_UNCHANGED)print(img)if img is None:print("错误:无法读取图像,请检查文件路径")return# 验证图像格式if len(img.shape) != 2 or img.dtype != np.uint16:print("警告:非单通道16位图像,当前形状:", img.shape, "数据类型:", img.dtype)# 创建带KDE的直方图plt.figure(figsize=(10, 6))# 使用展平后的图像数据sns.histplot(x=img.flatten(), # 将二维数组展平为一维bins=50, # 增加bins数量以更好显示16位数据分布color="lightblue",edgecolor="black",kde=True,# stat="density" # 将计数转换为密度概率)# 设置标题和标签plt.title("Depth Value Distribution", fontsize=14)plt.xlabel("Depth Value (16-bit)", fontsize=12)plt.ylabel("Density", fontsize=12)# 添加网格和格式优化plt.grid(axis="y", linestyle="--", alpha=0.5)plt.xlim(0, 65535) # 设置16位数据范围# 显示图形plt.show()# 显示原始深度图的归一化预览normalized = cv2.normalize(img, None, 0, 255, cv2.NORM_MINMAX, dtype=cv2.CV_8U)cv2.imshow('Normalized Preview', normalized)cv2.waitKey(0)cv2.destroyAllWindows()if __name__ == "__main__":image_path = "C:/pyprojects/yolo11/Dataset_depth/images/train/1112_0-rgb.png"plot_grayscale_histogram(image_path)结果如下:

然后我们单独画一下中间的ROI区域:
img = img[342:515, 389:873]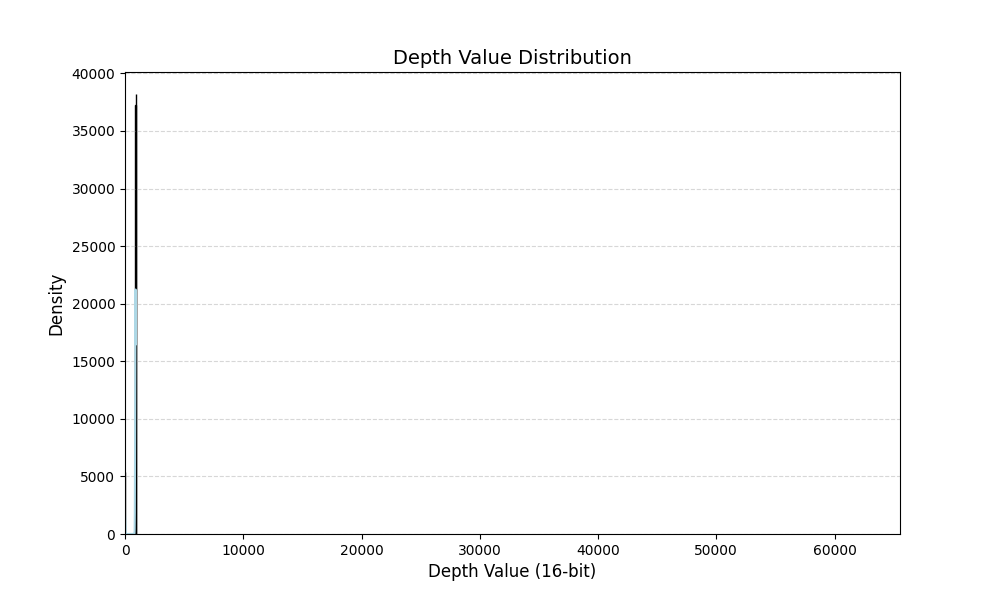
现在随机增加ROI区域的深度,模拟不同纵向的位置:
# 本数据集生成的代码
# 数据增强方法:随机增加ROI区域的深度,模拟箱子在不同纵向位置摆放
# 训练集:76665张,测试集:18975张import cv2
import os
import numpy as np
import shutilimage_file_dir = "C:/pyprojects/yolo11/fheiaunjk/images"
min_val = 0 # 最小偏移量
max_val = 500 # 最大偏移量
output_dir = "C:/pyprojects/yolo11/output"# 正确拼接输出路径
img_output_path = os.path.join(output_dir, "images") # 正确写法
label_output_path = os.path.join(output_dir, "labels") # 正确写法# 直接创建目标目录(无需使用 os.path.dirname)
os.makedirs(img_output_path, exist_ok=True) # 创建 output/images
os.makedirs(label_output_path, exist_ok=True) # 创建 output/labelsfor filename in os.listdir(image_file_dir):# 1. 构建图片完整路径image_file_path = os.path.join(image_file_dir, filename)# 2. 构建标签文件路径labels_dir = image_file_dir.replace("images", "labels")base_name = os.path.splitext(filename)[0] # 去掉文件扩展名label_file_path = os.path.join(labels_dir, f"{base_name}.txt") # 正确路径# 3. 检查标签文件是否存在if not os.path.exists(label_file_path):print(f"警告:标签文件 {label_file_path} 不存在")continue# 4. 读取图片并检查有效性image = cv2.imread(image_file_path, cv2.IMREAD_UNCHANGED)if image is None:print(f"错误:无法读取图片 {image_file_path}")continue# 5. 获取图像尺寸(兼容单通道/多通道)if len(image.shape) == 2: # 单通道(H, W)image_height, image_width = image.shapeprint(f"图像尺寸:{image_width}x{image_height}")else: # 多通道(H, W, C)print(f"错误:图片 {image_file_path} 不是深度图")continuewith open(label_file_path, 'r') as f:lines = f.readlines()i = 0# 绘制每个检测框for k, line in enumerate(lines):parts = line.strip().split()if len(parts) < 5:continue# 解析YOLO格式数据class_id = int(parts[0])x_center = float(parts[1]) * image_widthy_center = float(parts[2]) * image_heightwidth = float(parts[3]) * image_widthheight = float(parts[4]) * image_height# 计算坐标x1 = int(x_center - width/2)y1 = int(y_center - height/2)x2 = int(x_center + width/2)y2 = int(y_center + height/2)# --- 生成单个随机数 ---for m in range(5):i = k * 5 + mrandom_offset = np.random.randint(min_val, max_val + 1) # 生成一个随机整数region = image[y1 : y2, x1 : x2]modified_region = np.clip(region.astype(np.int32) + random_offset, 0, 65535).astype(np.uint16)image[y1 : y2, x1 : x2] = modified_regionimage_output_path = os.path.join(img_output_path, f"{base_name}_{i}.png")cv2.imwrite(image_output_path, image) # 写入图片# 拷贝标签output_label_path = os.path.join(label_output_path, f"{base_name}_{i}.txt")print(output_label_path)shutil.copy2(label_file_path, output_label_path)0523更新:增加ROI区域边缘平滑功能,避免边缘出现明显的锯齿或突变:
# 本数据集生成的代码
# 数据增强方法:随机增加ROI区域的深度,模拟不同纵向位置摆放import cv2
import os
import numpy as np
import shutilimage_file_dir = "Dataset_depth/images/val"
min_val = 0 # 最小偏移量
max_val = 500 # 最大偏移量
output_dir = "/home/hary/ctc/ultralytics-main/output"# 正确拼接输出路径
img_output_path = os.path.join(output_dir, "images") # 正确写法
label_output_path = os.path.join(output_dir, "labels") # 正确写法# 直接创建目标目录(无需使用 os.path.dirname)
os.makedirs(img_output_path, exist_ok=True) # 创建 output/images
os.makedirs(label_output_path, exist_ok=True) # 创建 output/labelsfor filename in os.listdir(image_file_dir):# 1. 构建图片完整路径image_file_path = os.path.join(image_file_dir, filename)# 2. 构建标签文件路径labels_dir = image_file_dir.replace("images", "labels")base_name = os.path.splitext(filename)[0] # 去掉文件扩展名label_file_path = os.path.join(labels_dir, f"{base_name}.txt") # 正确路径# 3. 检查标签文件是否存在if not os.path.exists(label_file_path):print(f"警告:标签文件 {label_file_path} 不存在")continue# 4. 读取图片并检查有效性image = cv2.imread(image_file_path, cv2.IMREAD_UNCHANGED)if image is None:print(f"错误:无法读取图片 {image_file_path}")continue# 5. 获取图像尺寸(兼容单通道/多通道)if len(image.shape) == 2: # 单通道(H, W)image_height, image_width = image.shapeprint(f"图像尺寸:{image_width}x{image_height}")else: # 多通道(H, W, C)print(f"错误:图片 {image_file_path} 不是深度图")continuewith open(label_file_path, 'r') as f:lines = f.readlines()i = 0# 绘制每个检测框for k, line in enumerate(lines):parts = line.strip().split()if len(parts) < 5:continue# 解析YOLO格式数据class_id = int(parts[0])x_center = float(parts[1]) * image_widthy_center = float(parts[2]) * image_heightwidth = float(parts[3]) * image_widthheight = float(parts[4]) * image_height# 计算坐标x1 = int(x_center - width/2)y1 = int(y_center - height/2)x2 = int(x_center + width/2)y2 = int(y_center + height/2)# --- 生成单个随机数 ---for m in range(1):i = k * 1 + mrandom_offset = np.random.randint(min_val, max_val + 1) # 生成一个随机整数# 保存原始ROI区域original_roi = image[y1:y2, x1:x2].copy()# 生成随机偏移后的ROImodified_roi = np.clip(original_roi.astype(np.int32) + random_offset, 0, 65535).astype(np.uint16)# 创建羽化遮罩(核心修改部分)height, width = original_roi.shape[:2]mask = np.zeros((height, width), dtype=np.float32)# 创建椭圆渐变遮罩(比实际区域稍小)cv2.ellipse(mask, (int(width/2), int(height/2)),(int(width/2*0.8), int(height/2*0.8)), # 控制羽化范围0, 0, 360, 1.0, -1)# 添加高斯模糊柔化边缘mask = cv2.GaussianBlur(mask, (0, 0), sigmaX=width/8, sigmaY=height/8)mask = mask / np.max(mask) # 归一化到[0,1]# 混合原始和修改后的区域blended_roi = original_roi.astype(np.float32) * (1 - mask) + \modified_roi.astype(np.float32) * mask# 写回图像并保持数据类型image[y1:y2, x1:x2] = np.clip(blended_roi, 0, 65535).astype(np.uint16)image_output_path = os.path.join(img_output_path, f"{base_name}_{i}.png")cv2.imwrite(image_output_path, image) # 写入图片# 拷贝标签output_label_path = os.path.join(label_output_path, f"{base_name}_{i}.txt")print(f"{output_label_path} has created!")shutil.copy2(label_file_path, output_label_path)相关文章:
深度图数据增强方案-随机增加ROI区域的深度
主要思想:随机增加ROI区域的深度,模拟物体处在不同位置的形态。 首先打印一张深度图中的深度信息分布: import cv2 import matplotlib.pyplot as plt import numpy as np import seaborn as sns def plot_grayscale_histogram(image_path)…...

[Java恶补day6] 15. 三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 示例 1&a…...

Django模板及表单
什么是Django模板 Django模板是一种用于生成动态内容的文件,它使用Django模板语言(Django Template Language,简称DTL)来描述和渲染HTML页面。模板允许开发人员将动态数据与静态HTML结构分离,以实现更灵活和可维护的W…...
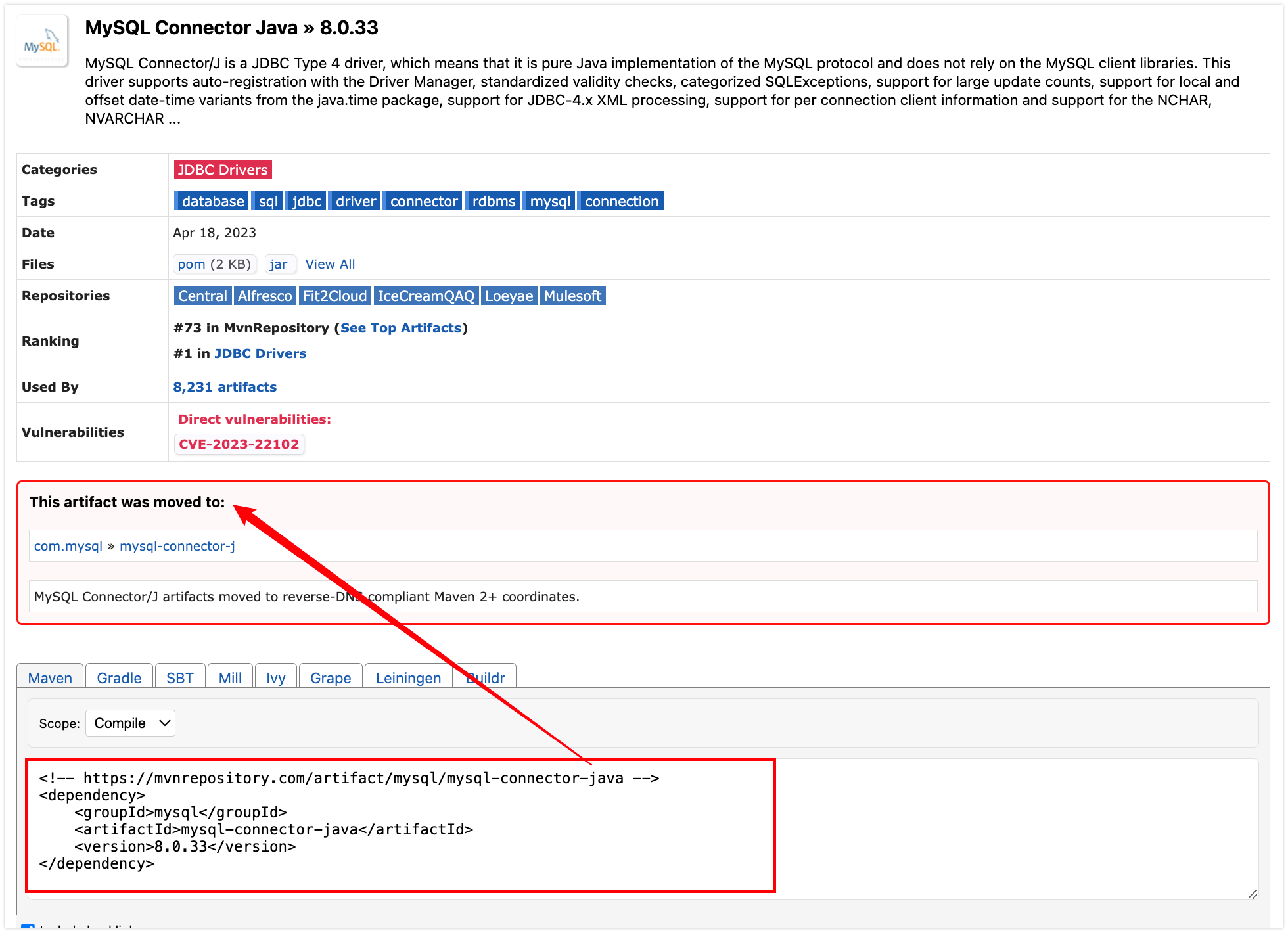
两个mysql的maven依赖要用哪个?
背景 <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId> </dependency>和 <dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId> &l…...
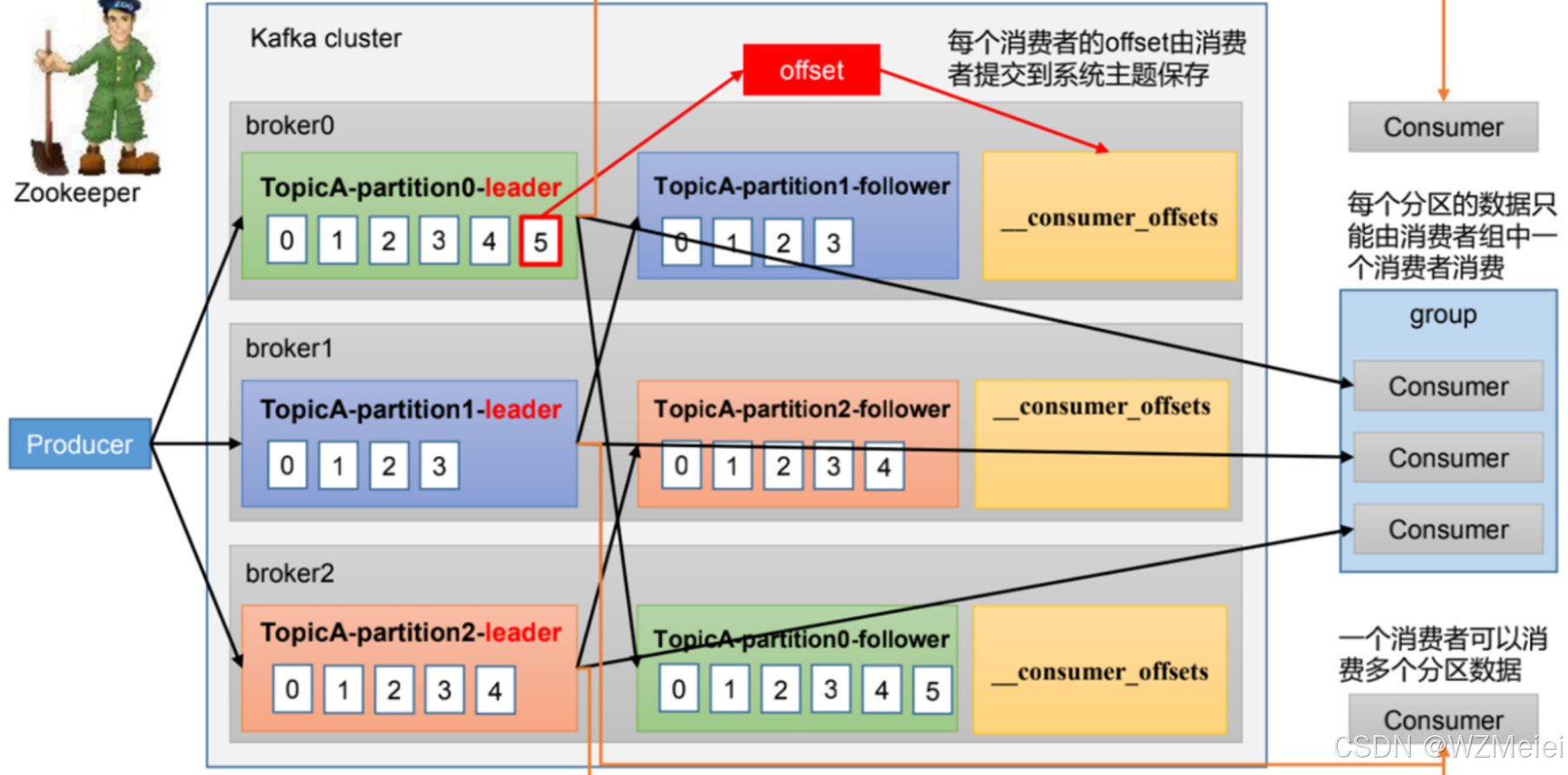
Kafka Consumer工作流程
Kafka Consumer工作流程图 1、启动与加入组 消费者启动后,会向 Kafka 集群中的某个 Broker 发送请求,请求加入特定消费者组。这个 Broker 中的消费者协调器(Consumer Coordinator)负责管理消费者组相关事宜。 2、组内分区分配&am…...
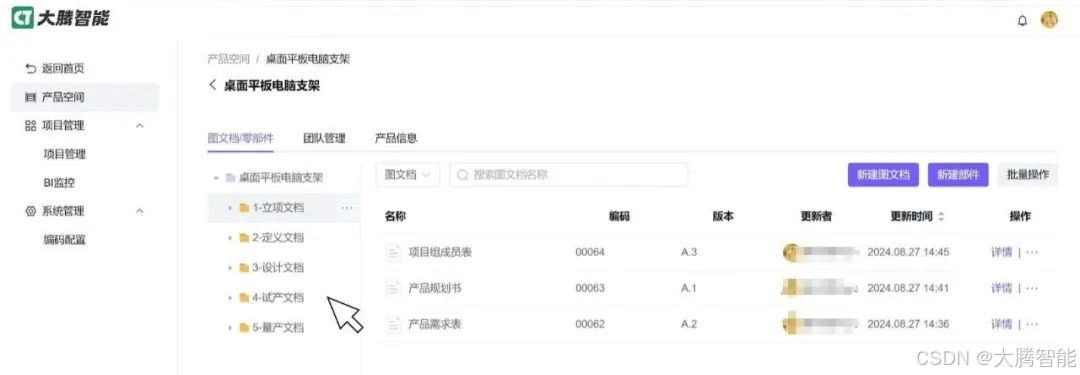
大腾智能 PDM 系统:全生命周期管理重塑制造企业数字化转型路径
在当今激烈的市场竞争中,产品迭代速度与质量已成为企业生存与发展的核心命脉。面对客户需求多元化、供应链协同复杂化、研发成本管控精细化等挑战,企业亟需一套能够贯穿产品全生命周期的数字化解决方案。 大腾智能PDM系统通过构建覆盖设计、研发、生产、…...

GATT 服务的核心函数bt_gatt_discover的介绍
目录 概述 1 GATT 基本概念 1.1 GATT 的介绍 1.2 GATT 的角色 1.3 核心组件 1.4 客户端操作 2 bt_gatt_discover函数的功能和应用 2.1 函数介绍 2.1 发现类型(Discover Type) 3 典型使用流程 3.1 服务发现示例 3.2 级联发现模式 3.3 按UUID过…...
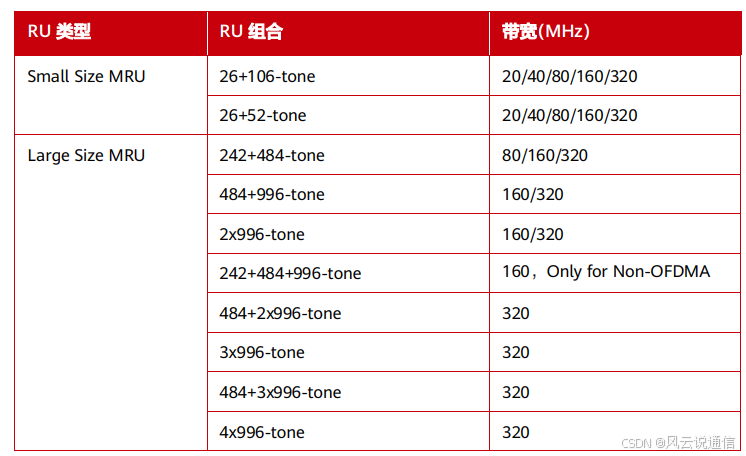
【短距离通信】【WiFi】WiFi7关键技术之4096-QAM、MRU
目录 3. 4096-QAM 3.1 4096-QAM 3.2 QAM 的阶数越高越好吗? 4. MRU 4.1 OFDMA 和 RU 4.2 MRU 资源分配 3. 4096-QAM 摘要 本章主要介绍了Wi-Fi 7引入的4096-QAM对数据传输速率的提升。 3.1 4096-QAM 对速率的提升 Wi-Fi 标准一直致力于提升数据传输速率&a…...

C 语言学习笔记
文章目录 程序设计入门 --- C 语言第一周 程序设计与 C 语言1 计算机与编程语言:计算机怎么做事情的,编程语言是什么📒 1.1 计算机的普遍应用 —— 离了它,现代人可能不会“活”了**🌐 科学计算:计算机的“最强大脑”时刻****📊 数据处理:现代社会的“数字管家”***…...

【MySQL成神之路】MySQL函数总结
以下是MySQL函数的全面总结,包含概念说明和代码示例: 一、MySQL函数分类 1. 字符串函数 -- CONCAT:连接字符串 SELECT CONCAT(Hello, , World); -- 输出 Hello World -- SUBSTRING:截取子串 SELECT SUBSTRING(MySQL, 2, 3…...
线程池实战——数据库连接池
引言 作者在前面写了很多并发编程知识深度探索系列文章,反馈得知友友们收获颇丰,同时我也了解到友友们也有了对知识如何应用感到很模糊的问题。所以作者就打算写一个实战系列文章,让友友们切身感受一下怎么应用知识。话不多说,开…...

修改 vue-pdf 源码升级 pdfjs-dist 包, 以解决部分 pdf 文件显示花屏问题
文章目录 背景: 客户反馈有部分文件预览花屏 最终解决方案: 自己 fork vue-pdf 仓库, 修改 pdfjs-dist 版本, 升级到 3.3.122 (我是 vue2 项目 node 10 环境)修改源码中引用地址带有 pdfjs-dist/es5/ 的地方, 去掉 es5 , 另外如果还有报错自己搜一下 pdfjs-dist/ , 看看引用…...
基于moonshot模型的Dify大语言模型应用开发核心场景
基于moonshot模型的Dify大语言模型应用开发核心场景学习总结 一、Dify环境部署 1.Docker环境部署 这里使用vagrant部署,下载vagrant之后,vagrant up登陆,vagrant ssh,在vagrant 中使用 vagrant centos/7 init 快速创建虚拟机 安装…...

华为OD机试真题——字符串序列判定(2025B卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 B卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
中,无法直接使用 continue 或 break 语句的解决办法)
在Java的list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句的解决办法
说明 在 Java 的 list.forEach(即 Stream API 的 forEach 方法)中,无法直接使用 continue 或 break 语句,因为它是一个终结操作(Terminal Operation),依赖于 Lambda 表达式或方法引用。 有些时…...

Java面向对象高级学习笔记
面向对象高级 -类变量 类变量-提出问题 提出问题的主要目的就是让大家思考解决之道,从而引出我要讲的知识点 说:有一群小孩在玩堆雪人,不时有新的小孩加入,请问如何知道现在共有多少人在玩?,编写程序解决。 类变量快速入门 思考: 如果,设计一个int co…...

LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略
LLM之Agent:Mem0的简介、安装和使用方法、案例应用之详细攻略 目录 Mem0的简介 1、Mem0的特点 2、性能: Mem0的安装及使用方法 1、安装 2、基本用法(基本用法) Mem0的案例应用 Mem0的简介 Mem0(发音为“mem-ze…...
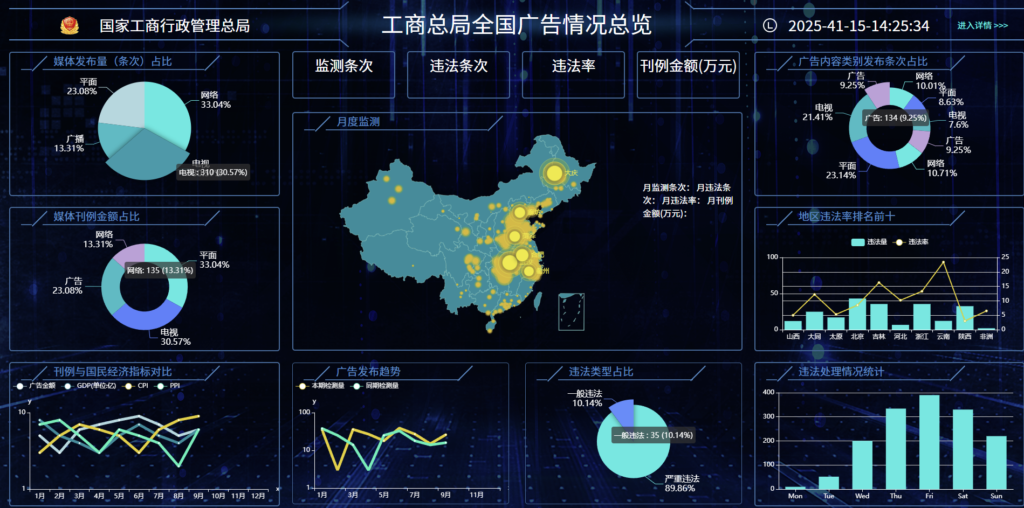
工商总局可视化模版-Echarts的纯HTML源码
概述 基于ECharts的工商总局数据可视化HTML模版,帮助开发者快速搭建专业级工商广告数据展示平台。这款模版设计规范,功能完善,适合各类工商监管场景使用。 主要内容 本套模版采用现代化设计风格,主要包含以下核心功能模块&…...
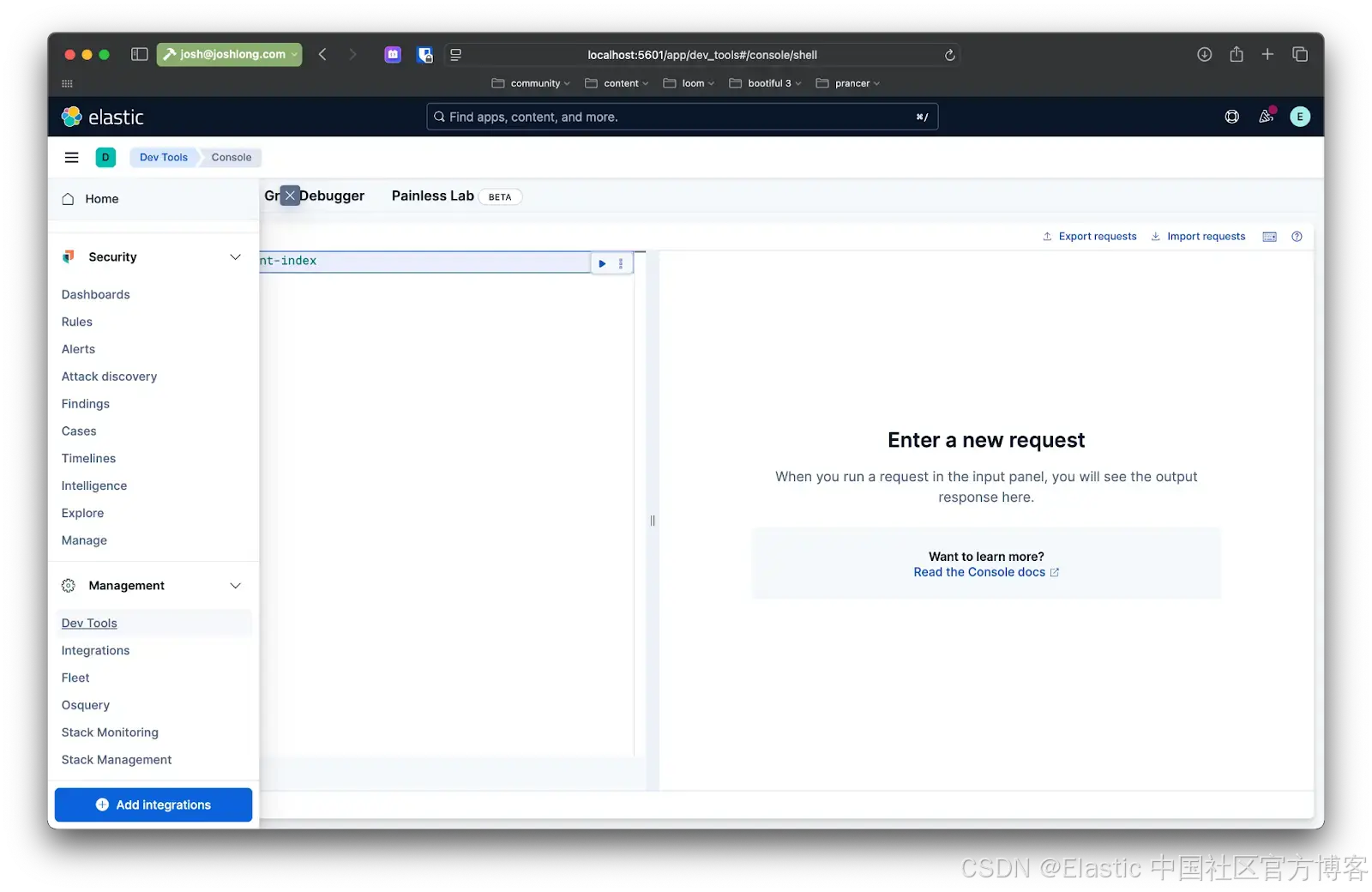
Spring AI 和 Elasticsearch 作为你的向量数据库
作者:来自 Elastic Josh Long, Philipp Krenn 及 Laura Trotta 使用 Spring AI 和 Elasticsearch 构建一个完整的 AI 应用程序。 Elasticsearch 原生集成了业界领先的生成式 AI 工具和服务提供商。查看我们关于超越 RAG 基础或使用 Elastic 向量数据库构建生产级应用…...

阿里云OSS Api工具类不使用sdk
本文工具实现了OSS简单的上传、下载、获取bucket列表功能,一个工具类搞定,不用集成oss sdk v1签名算法 v1算法(v1算法将在2025年9月停用,旧的key不受影响,新key必须用v4) v1签名工具类OssV1Signer.java …...

集群聊天服务器学习 配置开发环境(VScode远程连接虚拟机Linux开发)(2)
配置远程开发环境 第一步:Linux系统运行sshd服务 第二步:在vscode上安装Remote Deve I opment插件,其依赖插件会自动安装 第三步:配置远程Linux主机的信息 第四步:在vscode上开发远程连接Linux 第一步:…...
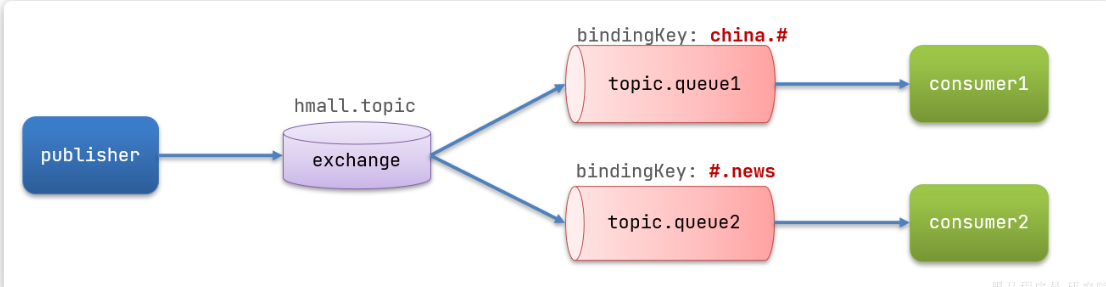
rabbitmq的使用介绍
一.队列工作模式介绍 1.WorkQueues模型 生产者直接把消息发送给队列,然后消费者订阅队列 特点: 消息不会重复, 分配给不同的消费者. 代码实现: 消费者代码: Component Slf4j public class SpringRabbitListener {RabbitListener(queues &q…...

前端的core-js是什么?有什么作用?
core-js 是前端生态中一个重要的 JavaScript 标准库 polyfill,它的主要作用是为不同浏览器环境提供 ECMAScript 最新特性 和 API 的兼容性支持。以下是其核心作用的详细解析: 一、core-js 是什么? 本质:一个模块化的 JavaScript …...

【Python 命名元祖】collections.namedtuple 学习指南
📚 collections.namedtuple 学习指南 命名元组(namedtuple)是 Python collections 模块中一种增强型元组,支持通过字段名访问元素,同时保持元组的内存效率和不可变性。 一、基础用法 1. 定义命名元组 from collectio…...
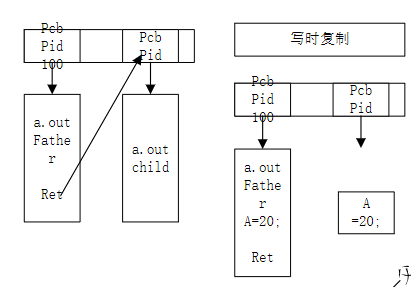
系统编程day04
一.进程的基本概念 一.定义 进程是一个程序执行的过程(也可以说是正在运行的程序),是系统分配资源的基本单位,由cpu对各个进程指挥调度,在单核cpu的情况下,各个进程可以通过一定规则在cpu上并发运行。 二.PCB块 1.PC…...

java 加密算法的简单使用
简介 加密算法,就是将原本的明文,通过一系列操作变成密文。在这里介绍一些常用的加密算法。在日常开发中,接触到了一些加密算法,例如,用户的隐私信息,诸如密码、手机号等,需要加密后存储到数据…...

Arduino Uno KY-037声音传感器实验
KY-037声音传感器实验 KY-037声音传感器实验1、 实验内容2、KY-037声音传感器介绍3、实验注意事项4、代码和实验现象 KY-037声音传感器实验 1、 实验内容 通过对KY-037声音传感器吹气,控制LED的打开和关闭,吹一下LED打开,在吹一下LED关闭。…...

机器学习---各算法比较
机器学习算法 线性回归 优点:简单;适用于大规模数据集。 缺点:无法处理非线性关系;对异常值敏感。 多项式回归 优点:捕捉特征和目标之间的非线性关系。 缺点:可能会过度拟合数据。 岭回归 优点&#…...
基于音频Transformer与动作单元的多模态情绪识别算法设计与实现(在RAVDESS数据集上的应用)
摘要:情感识别技术在医学、自动驾驶等多个领域的广泛应用,正吸引着研究界的持续关注。本研究提出了一种融合语音情感识别(SER)与面部情感识别(FER)的自动情绪识别系统。在SER方面,我们采用两种迁…...

Flink SQL 计算实时指标同比的实现方法
在 Flink SQL 中计算实时指标的同比(Year-on-Year),核心是通过时间窗口划分周期(如日、月、周),并关联当前周期与去年同期的指标值。以下是结合流数据处理特性的具体实现方法,包含数据准备、窗口聚合、历史数据关联等关键步骤。 一、同比的定义与场景 同比指当前周期指…...