LangChain02-Agent与Memory模块
Agent与Memory模块深度解析
1. Agent模块原理
1.1 ReAct框架的实现机制
Agent是LangChain中最具智能化的组件,其核心思想基于 ReAct框架(Reasoning + Acting),即通过 思维(Thought) 和 行动(Action) 的协同实现自主决策。ReAct框架的核心流程如下:
- 观察(Observation):接收用户输入或环境反馈。
- 推理(Reasoning):通过LLM生成决策逻辑(如调用哪个工具)。
- 行动(Action):执行工具调用或直接生成回答。
- 结果(Result):将结果反馈给LLM,进入下一轮循环。
示例:天气查询Agent
from langchain.agents import Tool, AgentExecutor, ReActAgent tools = [ Tool( name="Weather API", func=lambda location: get_weather_data(location), description="查询指定地区的实时天气" )
] agent = ReActAgent(tools=tools)
executor = AgentExecutor(agent=agent, tools=tools) result = executor.run("北京今天的天气如何?")
关键点:
- 状态机设计:Agent通过状态转换(如从“提问”到“调用API”)实现复杂流程。
- 上下文感知:每次调用工具时,LLM会结合历史对话生成更精准的指令。
1.2 工具集成与扩展
自定义工具开发指南
LangChain支持通过Tool类封装任意外部功能。例如,开发一个 文件读取工具:
import os class FileReaderTool(Tool): def __init__(self): super().__init__( name="File Reader", func=self.read_file, description="读取指定路径的文本文件内容" ) def read_file(self, file_path): with open(file_path, "r") as f: return f.read()
工具调用的异常处理
- 参数校验:确保输入符合预期(如文件路径是否存在)。
- 错误反馈:捕获异常并返回用户友好的提示:
try: result = tool.run(input)
except Exception as e: return f"调用工具时出错:{str(e)}"
代码示例:天气查询Agent的实现
import requests def get_weather_data(location): url = f"https://api.weatherapi.com/v1/current.json?key=YOUR_API_KEY&q={location}" response = requests.get(url) return response.json()
2. Memory模块实战
2.1 会话历史存储方案
内存存储 vs 持久化存储
| 类型 | 优点 | 缺点 |
|---|---|---|
| 内存存储 | 快速、无需依赖外部服务 | 会话结束后数据丢失 |
| Redis存储 | 持久化、支持高并发 | 需要维护Redis服务 |
| 数据库存储 | 支持复杂查询、安全性高 | 实现复杂、性能较低 |
代码示例:基于Neo4j的会话图谱构建
from langchain.memory import Neo4jGraphMemory
from neo4j import GraphDatabase driver = GraphDatabase.driver("neo4j://localhost:7687", auth=("neo4j", "password"))
memory = Neo4jGraphMemory(driver=driver, session_id="user123") # 存储会话历史
memory.save_context({"input": "你好"}, {"output": "您好!"}) # 查询会话历史
history = memory.load_memory_variables({})
print(history) # 输出:{"history": "Human: 你好\nAI: 您好!"}
2.2 上下文增强技术
历史对话的摘要与精简
-
摘要策略:
- 使用LLM生成对话摘要(如“用户多次询问退货政策”)。
- 通过正则表达式提取关键信息(如订单号、时间戳)。
-
代码示例:动态上下文截取算法
def truncate_context(context, max_tokens=2000): tokens = context.split() if len(tokens) > max_tokens: return " ".join(tokens[:max_tokens]) + "[...]" return context
3. 复杂场景应用
3.1 多Agent协作系统
任务分解与路由机制
多Agent系统通过 任务分解 和 路由决策 实现复杂业务逻辑。例如,一个电商客服系统可能包含以下Agent:
- 意图识别Agent:判断用户问题是退货还是售后。
- 政策查询Agent:调用Qdrant检索相关政策。
- 答案生成Agent:调用LLM生成自然语言回答。
代码示例:客服系统的多Agent路由方案
from langchain.agents import AgentExecutor, ReActAgent
from langchain.tools import Tool # 定义工具
tools = [ Tool(name="Return Policy Lookup", func=query_policy, description="查询退货政策"), Tool(name="After-sales Service", func=contact_support, description="转接人工客服")
] # 定义Agent
intent_recognition_agent = ReActAgent(tools=tools)
policy_lookup_agent = ReActAgent(tools=tools) # 路由逻辑
def route_query(query): if "退货" in query: return policy_lookup_agent else: return intent_recognition_agent
3.2 知识检索增强生成(RAG)
向量数据库与LLM的联合调用
RAG(Retrieval-Augmented Generation)通过以下步骤实现:
- 检索:从向量数据库(如Qdrant)检索相关文档。
- 生成:将检索结果与用户查询输入LLM,生成最终答案。
代码示例:基于Qdrant的RAG系统
from langchain.vectorstores import Qdrant
from langchain.embeddings import TongYiEmbeddings # 构建向量数据库
db = Qdrant.from_documents(docs, embeddings, url="http://localhost:6333") # 检索相关文档
query = "API调用频率限制是多少?"
results = db.similarity_search(query, k=3) # 生成答案
prompt = PromptTemplate(template="根据以下内容回答:{context}\n问题:{query}")
chain = LLMChain(llm=llm, prompt=prompt)
answer = chain.run({"context": results, "query": query})
4. 性能优化与调试
4.1 执行效率提升策略
并行调用与异步处理
- 并行调用:使用
ThreadPoolExecutor并发执行多个工具调用。
from concurrent.futures import ThreadPoolExecutor with ThreadPoolExecutor() as executor: futures = [executor.submit(tool.run, input) for tool in tools] results = [future.result() for future in futures]
- 异步处理:通过
asyncio实现非阻塞调用:
import asyncio async def async_call_tool(tool, input): return await tool.arun(input) async def main(): tasks = [async_call_tool(tool, input) for tool in tools] results = await asyncio.gather(*tasks)
缓存机制的设计
- FIFO缓存:限制缓存大小,优先淘汰最久未使用的数据。
from collections import deque class FIFOCache: def __init__(self, max_size=100): self.cache = {} self.queue = deque() self.max_size = max_size def get(self, key): if key in self.cache: return self.cache[key] return None def set(self, key, value): if len(self.cache) >= self.max_size: oldest = self.queue.popleft() del self.cache[oldest] self.cache[key] = value self.queue.append(key)
4.2 调试工具与监控
日志记录与追踪
- 日志级别:通过
logging模块记录不同级别的日志(DEBUG/INFO/WARNING/ERROR)。
import logging logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__) logger.debug("调试信息")
logger.info("常规信息")
- 追踪工具:使用
OpenTelemetry实现分布式追踪:
from opentelemetry import trace tracer = trace.get_tracer(__name__) with tracer.start_as_current_span("Agent Execution"): result = agent.run(input)
性能指标的可视化监控
- Prometheus + Grafana:监控Agent的响应时间、调用次数等指标。
from prometheus_client import start_http_server, Counter REQUESTS = Counter('agent_requests_total', 'Total number of agent requests') start_http_server(8000) def run_agent(input): REQUESTS.inc() return agent.run(input)
5. 总结与展望
5.1 安全性考量
敏感信息保护策略
- 加密存储:对会话历史、用户偏好等敏感数据加密。
- 权限控制:通过RBAC(基于角色的访问控制)限制工具调用权限。
工具调用的权限控制
- 白名单机制:仅允许特定工具被调用。
- 审计日志:记录所有工具调用行为,便于追溯。
5.2 未来发展方向
多模态Agent的探索
- 视觉-语言融合:结合图像识别与自然语言处理能力。
- 语音交互:支持语音输入输出,提升用户体验。
与区块链技术的结合
- 数据存证:利用区块链的不可篡改性存储关键会话记录。
- 智能合约:通过智能合约自动化执行复杂业务逻辑。
参考资料:
- LangChain官方文档
- Qdrant向量数据库
- TongYiEmbeddings使用指南
版权声明:本文为CSDN博客原创内容,转载请注明出处。
相关文章:

LangChain02-Agent与Memory模块
Agent与Memory模块深度解析 1. Agent模块原理 1.1 ReAct框架的实现机制 Agent是LangChain中最具智能化的组件,其核心思想基于 ReAct框架(Reasoning Acting),即通过 思维(Thought) 和 行动(Ac…...
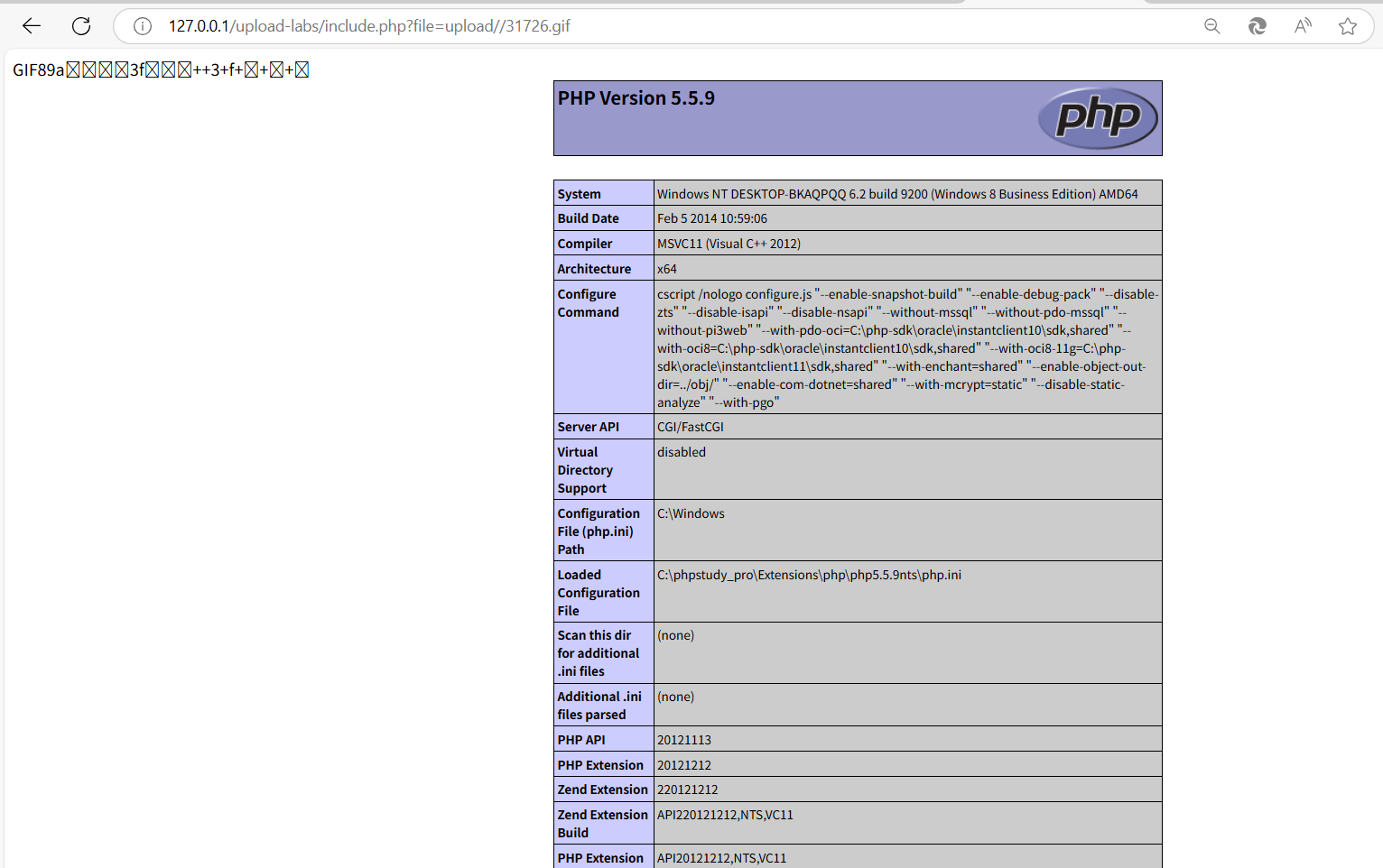
upload-labs通关笔记-第17关文件上传之二次渲染gif格式
系列目录 upload-labs通关笔记-第1关 文件上传之前端绕过(3种渗透方法) upload-labs通关笔记-第2关 文件上传之MIME绕过-CSDN博客 upload-labs通关笔记-第3关 文件上传之黑名单绕过-CSDN博客 upload-labs通关笔记-第4关 文件上传之.htacess绕过-CSDN…...

计算机网络学习20250525
应用层协议原理 创建一个网络应用,编写应用程序,这些应用程序运行在不同的端系统上,通过网络彼此通信 不需要在网络核心设备(路由器,交换机)上写应用程序网络应用程序工作在网络层以下将应用程序限制在端系统上促进应用程序迅速研发和部署,将复杂问题放到网络边缘网络应…...
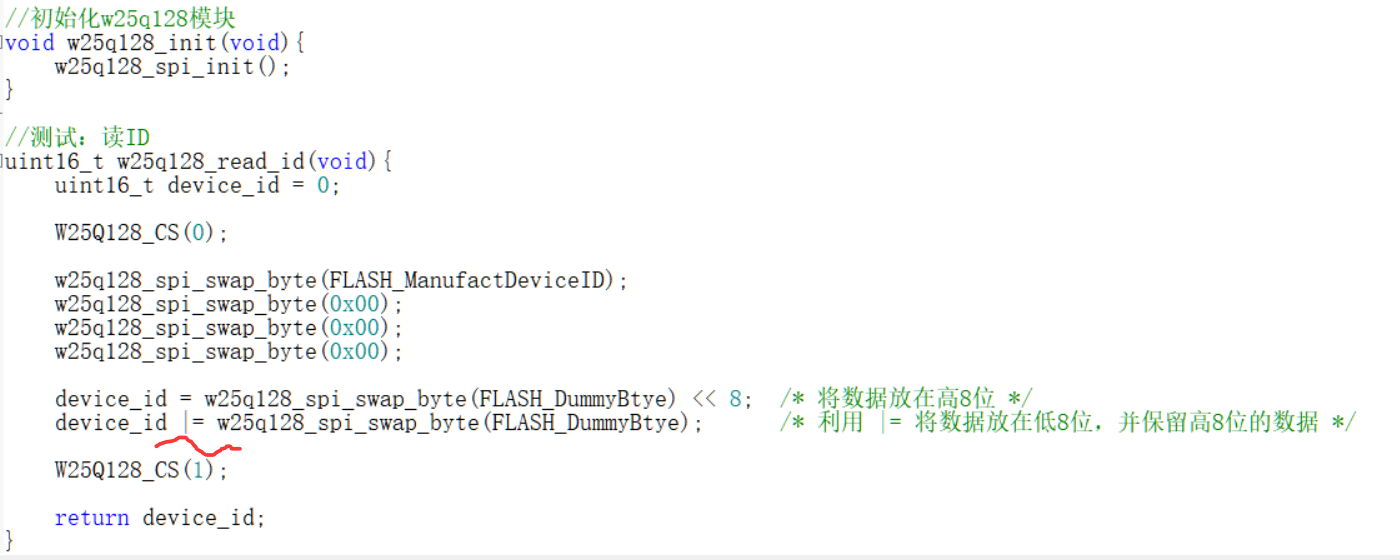
STM32中的SPI通信协议
IIC和SPI的对比 IIC是半双工的通信,无法同时收发信息;SPI是全双工通讯,可以同时收发信息;IIC的通讯协议较复杂,而SPI通讯协议较简单;IIC需要通过地址选择从机,而SPI只主要一个引脚即可选中从机…...

从版本控制到协同开发:深度解析 Git、SVN 及现代工具链
前言:在当今软件开发的浪潮中,版本控制与协同开发无疑扮演着举足轻重的角色。从最初的单兵作战到如今大规模团队的高效协作,一套成熟且得力的版本控制系统以及围绕其构建的现代工具链,已然成为推动软件项目稳步前行的关键引擎。今…...
)
redis Pub/Sub 简介 -16 (PUBLISH、SUBSCRIBE、PSUBSCRIBE)
Redis Pub/Sub 简介:PUBLISH、SUBSCRIBE、PSUBSCRIBE Redis Pub/Sub 是一种强大的消息传递范例,可在应用程序的不同部分之间实现实时通信。它是构建可扩展和响应式系统的基石,允许组件在没有直接依赖的情况下进行交互。本章将全面介绍 Redis…...

《黄帝内经》数学建模与形式化表征方式的重构
黄帝内经的数学概括:《黄帝内经》数学建模与形式化表征方式的重构 摘要:《黄帝内经》通过现代数学理论如动力系统、代数拓扑和随机过程,被重构为一个形式化的人体健康模型。该模型包括阴阳动力学的微分几何、五行代数的李群结构、经络拓扑与同…...
 技术指南)
PyTorch Image Models (timm) 技术指南
timm PyTorch Image Models (timm) 技术指南功能概述 一、引言二、timm 库概述三、安装 timm 库四、模型加载与推理示例4.1 通用推理流程4.2 具体模型示例4.2.1 ResNeXt50-32x4d4.2.2 EfficientNet-V2 Small 模型4.2.3 DeiT-3 large 模型4.2.4 RepViT-M2 模型4.2.5 ResNet-RS-1…...

基于Scikit-learn与Flask的医疗AI糖尿病预测系统开发实战
引言 在精准医疗时代,人工智能技术正在重塑临床决策流程。本文将深入解析如何基于MIMIC-III医疗大数据集,使用Python生态构建符合医疗AI开发规范的糖尿病预测系统。项目涵盖从数据治理到模型部署的全流程,最终交付符合DICOM标准的临床决策支…...

掌握聚合函数:COUNT,MAX,MIN,SUM,AVG,GROUP BY和HAVING子句的用法,Where和HAVING的区别
对于Java后端开发来说,必须要掌握常用的聚合函数:COUNT,MAX,MIN,SUM,AVG,掌握GROUP BY和HAVING子句的用法,掌握Where和HAVING的区别: ✅ 一、常用聚合函数(聚…...

【Node.js】高级主题
个人主页:Guiat 归属专栏:node.js 文章目录 1. Node.js 高级主题概览1.1 高级主题架构图 2. 事件循环与异步编程深度解析2.1 事件循环机制详解事件循环阶段详解 2.2 异步编程模式演进高级异步模式实现 3. 内存管理与性能优化3.1 V8 内存管理机制内存监控…...
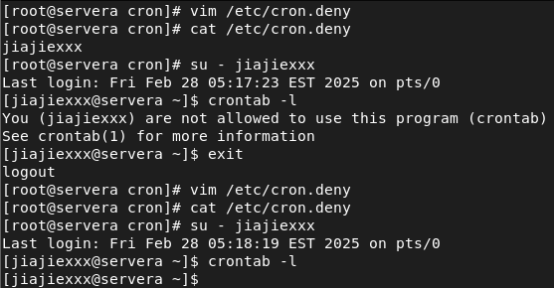
【Linux】定时任务 Crontab 与时间同步服务器
目录 一、用户定时任务的创建与使用 1.1 用户定时任务的使用技巧 1.2 管理员对用户定时任务的管理 1.3 用户黑白名单的管理 一、用户定时任务的创建与使用 1.1 用户定时任务的使用技巧 第一步:查看服务基本信息 systemctl status crond.service //查看周期性…...

【TCP/IP协议族详解】
目录 第1层 链路/网络接口层—帧(Frame) 1. 链路层功能 2. 常见协议 2.1. ARP(地址解析协议) 3. 常见设备 第2层 网络层—数据包(Packet) 1. 网络层功能 2. 常见协议 2.1. ICMP(互联网…...
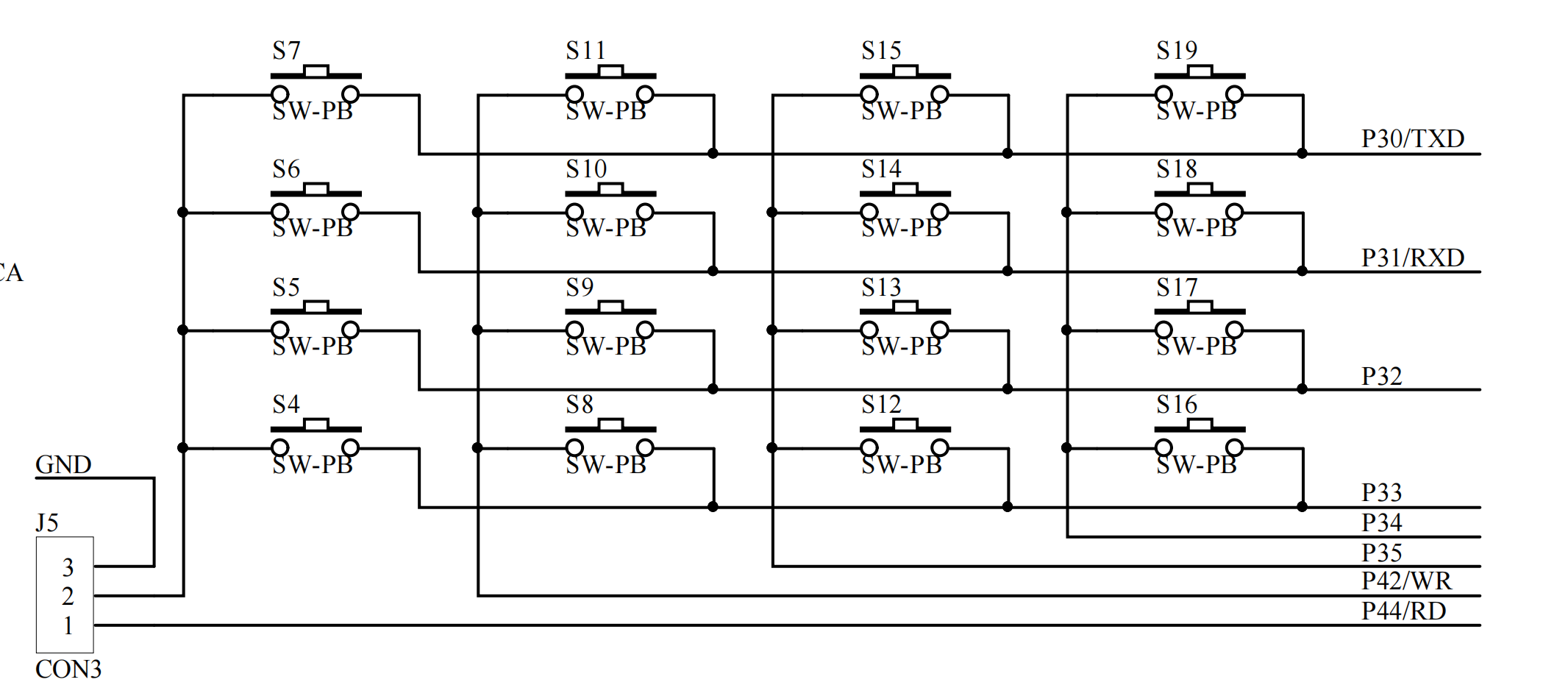
蓝桥杯电子赛_零基础利用按键实现不同数字的显现
目录 一、前提 二、代码配置 bsp_key.c文件 main.c文件 main.c文件的详细讲解 功能实现 注意事项 一、前提 按键这一板块主要是以记忆为主,我直接给大家讲解代码去实现我要配置的功能。本次我要做的项目是板子上的按键有S4~S19,我希望任意一个按键…...
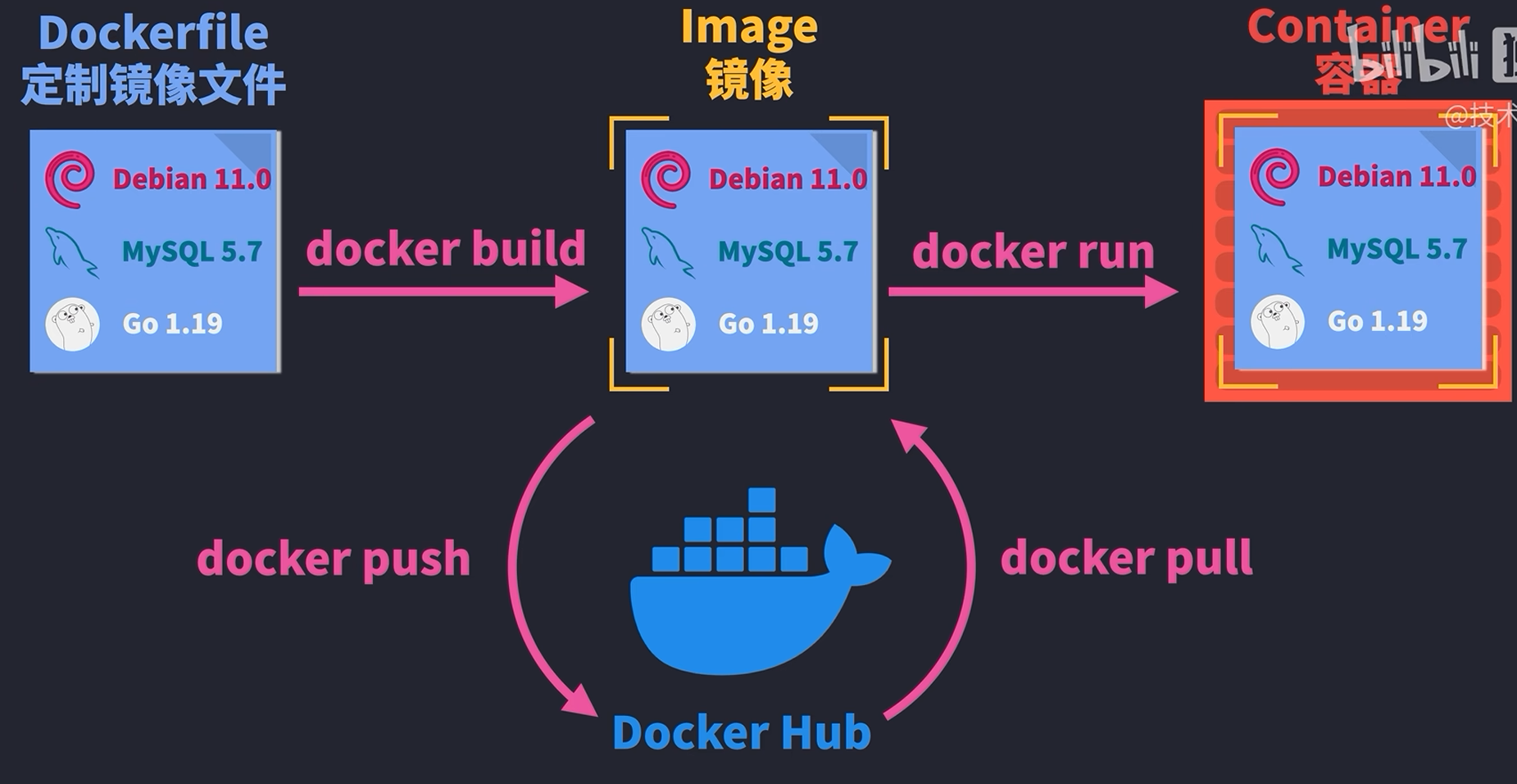
Docker架构详解
一,Docker的四大要素:Dockerfile、镜像(image)、容器(container)、仓库(repository) 1.dockerfile:在dockerfile文件中写构建docker的命令,通过dockerbuild构建image 2.镜像:就是一个只读的模板,镜像可以用来创建docker容器&…...
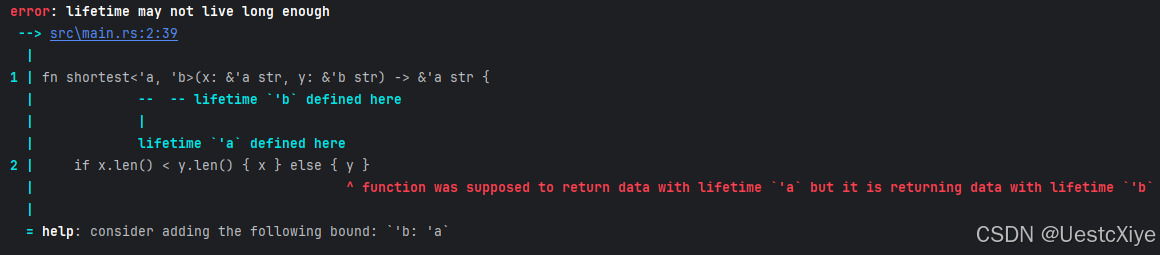
Rust 学习笔记:关于生命周期的练习题
Rust 学习笔记:关于生命周期的练习题 Rust 学习笔记:关于生命周期的练习题生命周期旨在防止哪种编程错误?以下代码能否通过编译?若能,输出是?如果一个引用的生命周期是 static,这意味着什么&…...
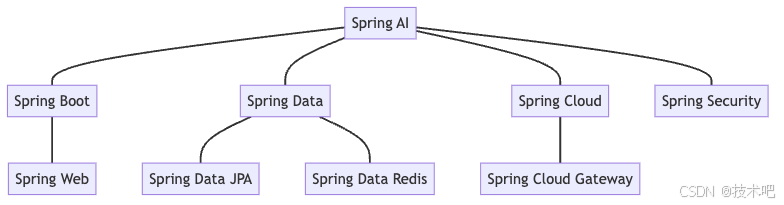
Spring AI 模块架构与功能解析
Spring AI 是 Spring 生态系统中的一个新兴模块,专注于简化人工智能和机器学习技术在 Spring 应用程序中的集成。本文将详细介绍 Spring AI 的核心组件、功能模块及其之间的关系,帮助具有技术基础的读者快速了解和应用 Spring AI。 Spring AI 的核心概念…...

单元测试学习笔记
单元测试是软件测试的基础层级,主要针对代码的最小可测试单元进行验证。单元测试可以帮助快速定位问题边界,提升代码可维护性,支持安全的重构操作。 测试对象: 独立函数/方法纯工具类(如数据处理函数)UI组…...

多模态大语言模型arxiv论文略读(九十)
Hybrid RAG-empowered Multi-modal LLM for Secure Data Management in Internet of Medical Things: A Diffusion-based Contract Approach ➡️ 论文标题:Hybrid RAG-empowered Multi-modal LLM for Secure Data Management in Internet of Medical Things: A Di…...
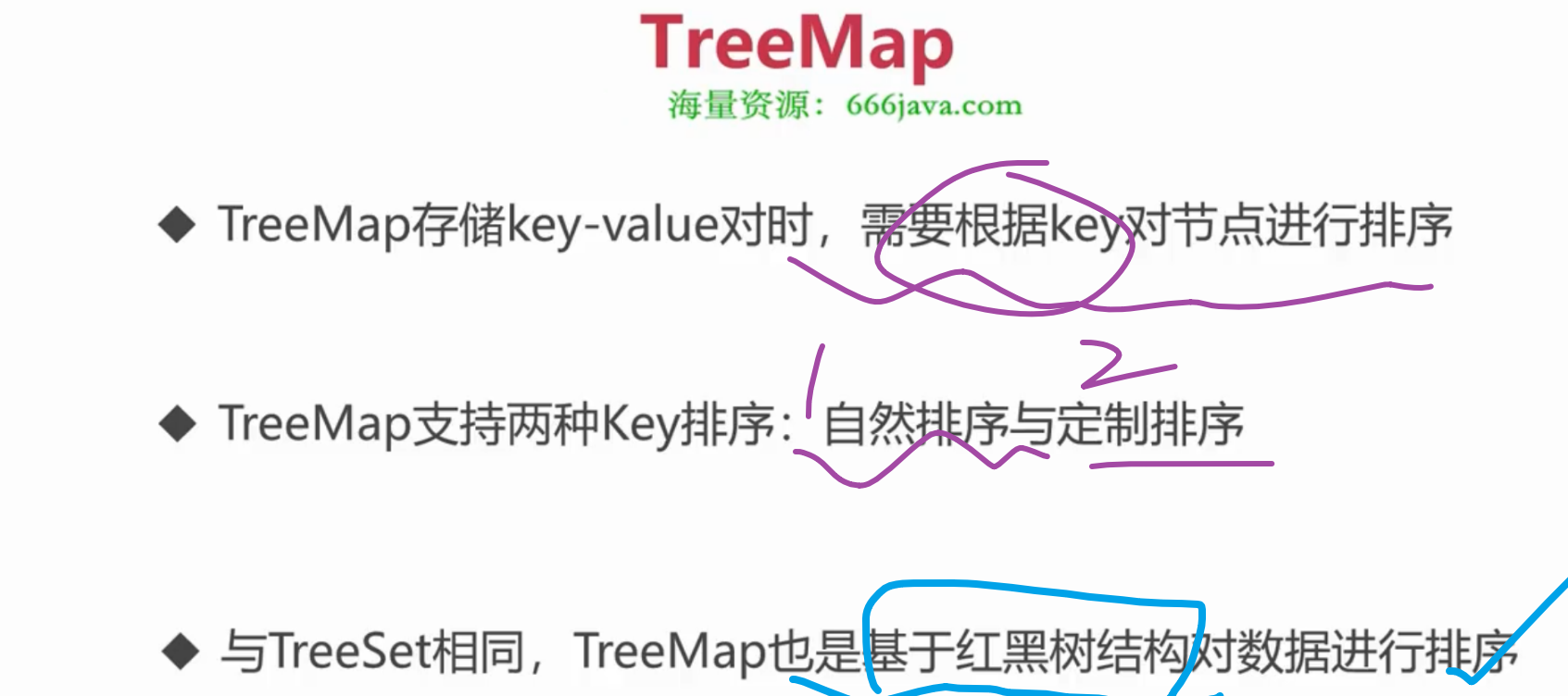
(1-6-1)Java 集合
目录 0.知识概述: 1.集合 1.1 集合继承关系类图 1.2 集合遍历的三种方式 1.3 集合排序 1.3.1 Collections实现 1.3.2 自定义排序类 2 List 集合概述 2.1 ArrayList (1)特点 (2)常用方法 2.2 LinkedList 3…...

spring5-配外部文件-spEL-工厂bean-FactoryBean-注解配bean
spring配外部文件 我们先在Spring里配置一个数据源 1.导c3p0包,这里我们先学一下hibernate持久化框架,以后用mybites. <dependency><groupId>org.hibernate</groupId><artifactId>hibernate-core</artifactId><version>5.2.…...

[安全清单] Linux 服务器安全基线:一份可以照着做的加固 Checklist
更多服务器知识,尽在hostol.com 嘿,各位服务器的“守护者”们!当你拿到一台崭新的Linux服务器,或者接手一台正在运行的服务器时,脑子里是不是会闪过一丝丝关于安全的担忧?“我的服务器安全吗?”…...

企业级单元测试流程
企业级的单元测试流程不仅是简单编写测试用例,而是一整套系统化、自动化、可维护、可度量的工程实践,贯穿从代码编写到上线部署的全生命周期。下面是一个尽可能完善的 企业级单元测试流程设计方案,适用于 Java 生态(JUnit Mockit…...

安卓开发用到的设计模式(2)结构型模式
安卓开发用到的设计模式(2)结构型模式 文章目录 安卓开发用到的设计模式(2)结构型模式1. 适配器模式(Adapter Pattern)2. 装饰器模式(Decorator Pattern)3. 代理模式(Pro…...
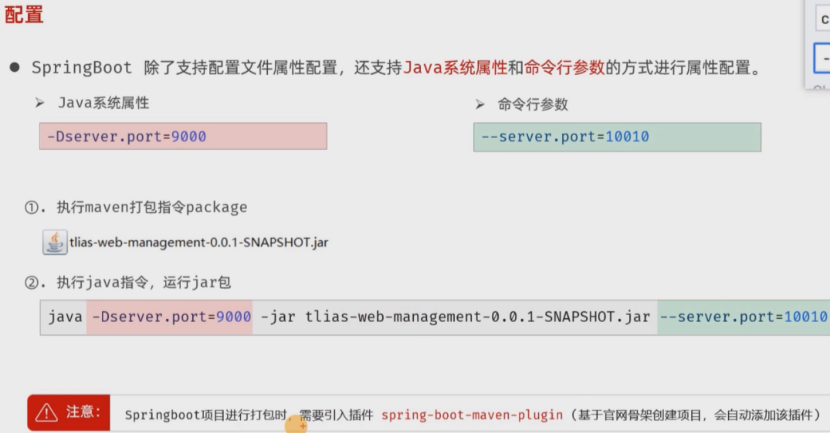
JavaWeb:SpringBoot配置优先级详解
3种配置 打包插件 命令行 优先级 SpringBoot的配置优先级决定了不同配置源之间的覆盖关系,遵循高优先级配置覆盖低优先级的原则。以下是详细的优先级排序及配置方法说明: 一、配置优先级从高到低排序 1.命令行参数 优先级最高,通过keyvalu…...
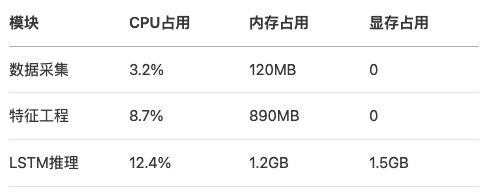
故障率预测:基于LSTM的GPU集群硬件健康监测系统(附Prometheus监控模板)
一、GPU集群健康监测的挑战与价值 在大规模深度学习训练场景下,GPU集群的硬件故障率显著高于传统计算设备。根据2023年MLCommons统计,配备8卡A100的服务器平均故障间隔时间(MTBF)仅为1426小时,其中显存故障占比达38%&…...
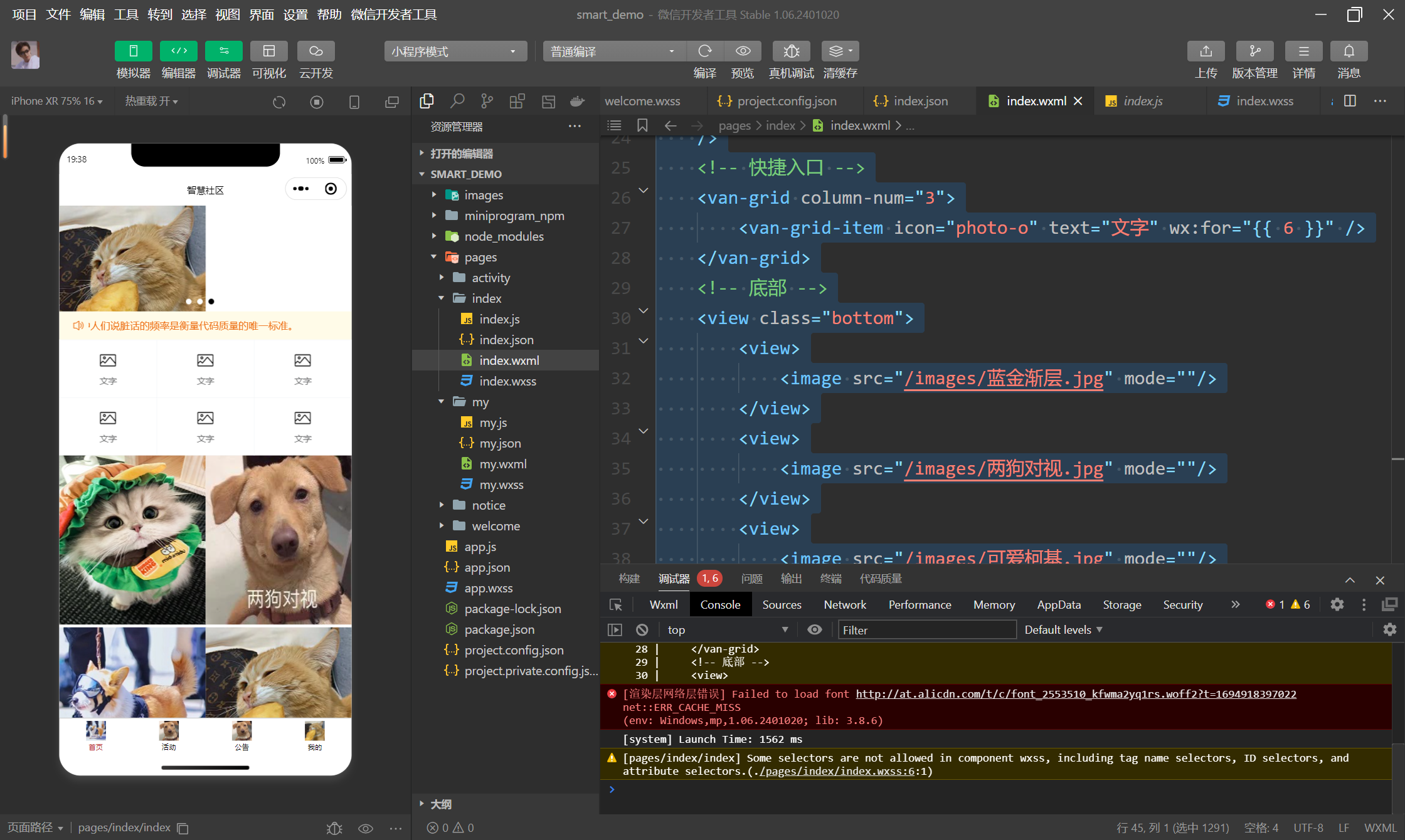
【b站计算机拓荒者】【2025】微信小程序开发教程 - chapter3 项目实践 -1 项目功能描述
1 项目功能描述 # 智慧社区-小程序-1 欢迎页-加载后端:动态变化-2 首页-轮播图:动态-公共栏:动态-信息采集,社区活动,人脸检测,语音识别,心率检测,积分商城-3 信息采集页面-采集人数…...

FFmpeg 安装包全攻略:gpl、lgpl、shared、master 区别详解
这些 FFmpeg 安装包有很多版本和变种,主要区别在于以下几个方面: ✅ 一、从名称中看出的关键参数: 1. 版本号 master:开发版,最新功能,但可能不稳定。n6.1 / n7.1:正式版本,更稳定…...

AI浪潮下,媒体内容运营的五重变奏
算法驱动的个性化推荐 在信息爆炸的时代,用户面临着海量的内容选择,如何让用户快速找到感兴趣的人工智能内容,成为媒体运营的关键。算法驱动的个性化推荐模式应运而生,它通过分析用户的行为数据,如浏览历史、点赞、评论、搜索关键词等,构建用户兴趣画像 ,再依据画像为用…...
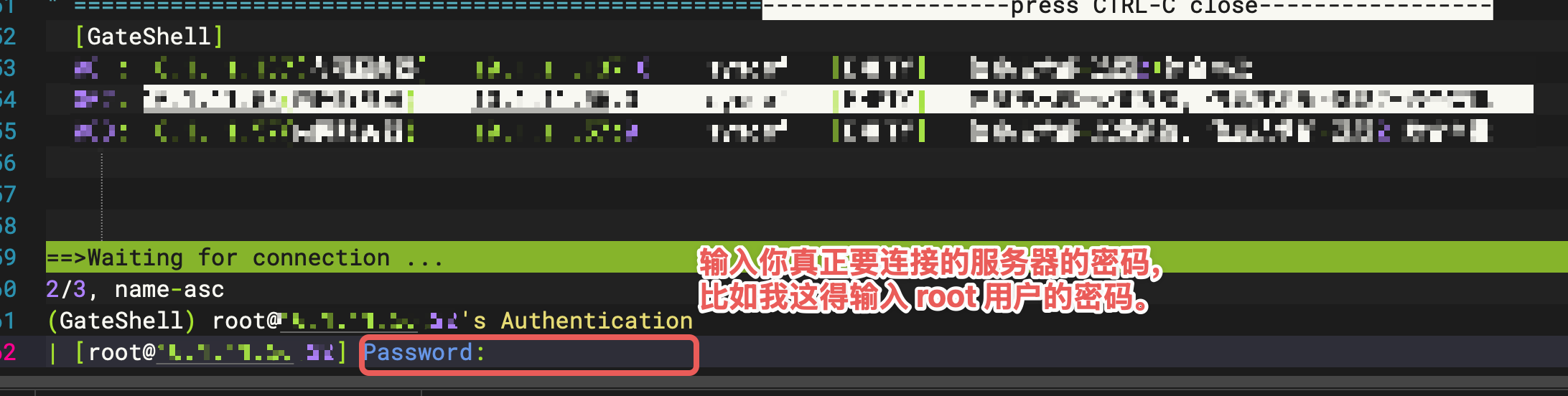
WindTerm 以 SSH 协议的方式通过安恒明御堡垒机间接访问服务器
1. 配置堡垒机秘钥 创建公私钥ssh-keygen -t rsa -b 4096执行完该命令后按照提示一路回车就能够创建出公私钥注意:在创建过程中会让你指定秘钥的存储位置以及对应的密码,最好自行指定一下 id_rsa 是私钥id_rsa.pub 是公钥 在堡垒机中指定创建好的私钥 …...