万亿参数背后的算力密码:大模型训练的分布式架构与自动化运维全解析
目录
一、技术融合的时代背景
二、深度学习在 AI 大模型中的核心作用
2.1 预训练与微调机制
2.2 多模态深度学习的突破
三、分布式计算:大模型训练的基础设施
3.1 分布式训练核心原理
3.2 数据并行实战(PyTorch DDP)
3.3 模型并行与混合并行
四、自动化技术:提升大模型全生命周期效率
4.1 自动化代码生成
4.2 自动化模型开发流程
4.3 自动化部署与监控
五、行业应用案例
5.1 医疗领域:疾病诊断与药物研发
5.2 金融领域:风险防控与智能投顾
5.3 工业领域:智能制造与质量检测
六、技术融合面临的挑战
七、未来发展趋势
八、收尾
一、技术融合的时代背景
在人工智能技术高速发展的当下,AI 大模型凭借其强大的学习能力和泛化能力,已成为推动各领域变革的核心力量。深度学习作为 AI 大模型的技术基石,通过构建多层神经网络实现复杂模式识别;分布式计算解决了大模型训练所需的海量算力问题;自动化技术则大幅提升了模型开发、部署及应用的效率。三者深度融合,正在重塑整个 AI 生态。
| 技术维度 | 关键作用 | 融合价值 |
|---|---|---|
| 深度学习 | 实现特征提取与模式识别 | 提供模型核心能力 |
| 分布式计算 | 突破单机算力瓶颈,支持大规模训练 | 保障模型训练的资源需求 |
| 自动化技术 | 贯穿模型全生命周期,提升开发与部署效率 | 降低人力成本,加速技术落地 |
二、深度学习在 AI 大模型中的核心作用
2.1 预训练与微调机制
AI 大模型普遍采用 “预训练 + 微调” 的范式。以 GPT-3、ChatGPT 为代表的大语言模型,在预训练阶段通过 Transformer 架构,在海量文本数据上学习通用语言知识。
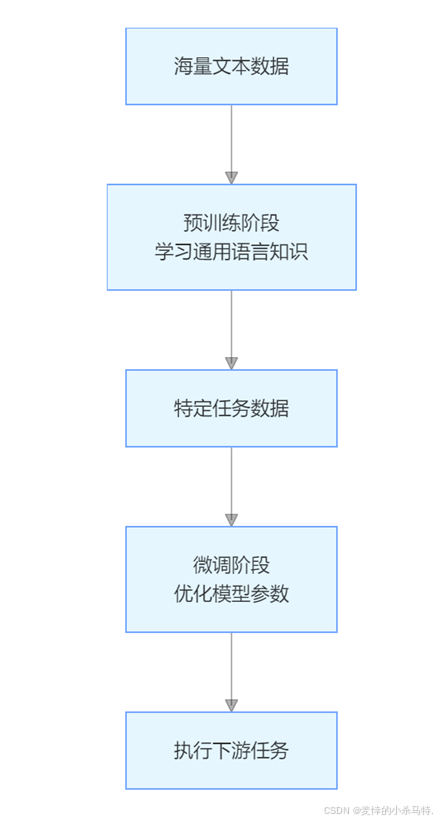
微调阶段针对具体任务,在少量标注数据上优化模型参数。以下是基于 Hugging Face Transformers 库实现文本分类微调的代码示例:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch# 加载预训练模型和分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)# 准备微调数据
texts = ["This is a positive review", "This is a negative review"]
labels = [1, 0]
encoding = tokenizer(texts, truncation=True, padding=True, return_tensors="pt")
input_ids = encoding["input_ids"]
attention_mask = encoding["attention_mask"]
labels = torch.tensor(labels)# 微调过程
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
2.2 多模态深度学习的突破
传统深度学习局限于单一模态数据处理,而 AI 大模型推动了多模态融合的发展。
| 多模态模型 | 核心能力 | 典型应用场景 |
|---|---|---|
| CLIP | 图像与文本跨模态对齐 | 图文检索、图像生成标题 |
| DALL・E 系列 | 文本生成图像 | 创意设计、广告制作 |
| 多模态对话模型 | 处理文本、图像、语音等多种输入 | 智能客服、虚拟助手 |
多模态模型框架代码:
import torch
import torchvision.models as models
import torch.nn as nnclass ImageTextModel(nn.Module):def __init__(self):super(ImageTextModel, self).__init__()self.image_encoder = models.resnet50(pretrained=True)self.text_encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=512, nhead=8),num_layers=6)self.fusion_layer = nn.Linear(512 + 512, 128)self.classifier = nn.Linear(128, 10)def forward(self, images, texts):image_features = self.image_encoder(images).flatten(1)text_embeddings = nn.Embedding(len(vocab), 512)(texts)text_features = self.text_encoder(text_embeddings)text_features = text_features.mean(dim=1)fused_features = self.fusion_layer(torch.cat([image_features, text_features], dim=1))return self.classifier(fused_features)
三、分布式计算:大模型训练的基础设施
3.1 分布式训练核心原理
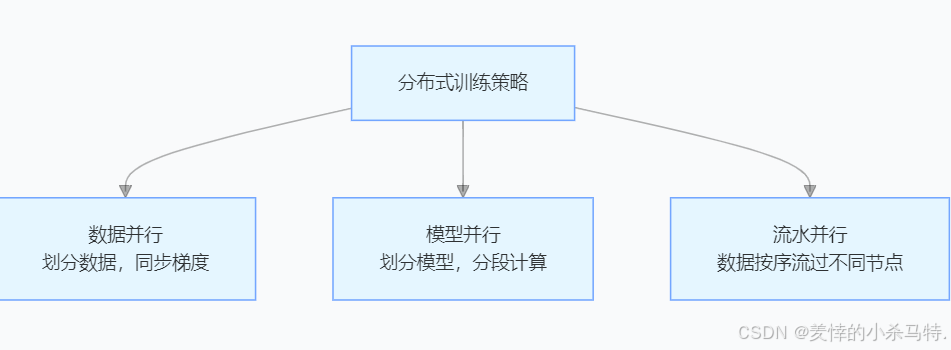
大模型训练需要处理海量数据和庞大的参数,单机计算无法满足需求,分布式训练通过将计算任务分配到多个节点并行处理,显著提升效率。其核心包括数据并行、模型并行和流水并行三种策略:
3.2 数据并行实战(PyTorch DDP)
PyTorch 的 DistributedDataParallel(DDP)是实现数据并行的常用工具。以下是使用 DDP 训练 ResNet-18 模型进行图像分类的完整代码:
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import resnet18
from torch.nn.parallel import DistributedDataParallel as DDP# 初始化分布式环境
dist.init_process_group(backend='nccl')
local_rank = dist.get_rank()
torch.cuda.set_device(local_rank)# 加载数据
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
train_sampler = torch.utils.data.distributed.DistributedSampler(trainset)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32,sampler=train_sampler)# 定义模型、损失函数和优化器
model = resnet18(num_classes=10).to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank])
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001, momentum=0.9)# 训练过程
for epoch in range(10):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0].to(local_rank), data[1].to(local_rank)optimizer.zero_grad()outputs = ddp_model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f'Rank {local_rank}, Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')# 关闭分布式环境
dist.destroy_process_group()
3.3 模型并行与混合并行
对于参数规模超大的模型,模型并行可解决单卡内存不足的问题。混合并行结合数据并行和模型并行,在微软的 DeepSpeed 框架中得到广泛应用。
| 分布式策略 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|
| 数据并行 | 模型规模适中,数据量庞大 | 实现简单,扩展性强 | 通信开销随节点增加 |
| 模型并行 | 模型超大,单卡内存不足 | 降低单卡内存压力 | 协调复杂,效率易受影响 |
| 混合并行 | 超大规模模型 | 综合两者优势 | 部署难度高 |
四、自动化技术:提升大模型全生命周期效率
4.1 自动化代码生成
AI 大模型具备代码生成能力,GitHub Copilot、AWS CodeWhisperer 等工具可根据自然语言描述生成代码。
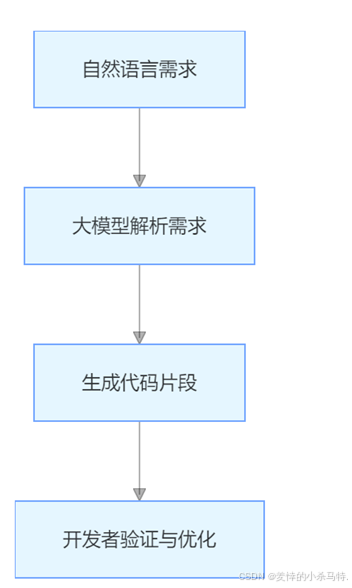
例如,输入 “写一个 Python 函数,计算列表中所有偶数的和”,Copilot 可生成以下代码:
def sum_even_numbers(lst):return sum(x for x in lst if x % 2 == 0)
4.2 自动化模型开发流程
自动化技术贯穿模型开发的全流程,包括数据预处理、超参数调优、模型评估等。例如,使用 Optuna 库进行超参数自动化调优:
import optuna
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 定义模型
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3)self.fc = nn.Linear(16 * 30 * 30, 10)def forward(self, x):x = torch.relu(self.conv1(x))x = x.view(-1, 16 * 30 * 30)x = self.fc(x)return x# 数据加载
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=32)# 目标函数
def objective(trial):model = SimpleNet()optimizer_name = trial.suggest_categorical('optimizer', ['Adam', 'SGD'])lr = trial.suggest_loguniform('lr', 1e-5, 1e-1)optimizer = getattr(optim, optimizer_name)(model.parameters(), lr=lr)criterion = nn.CrossEntropyLoss()for epoch in range(5):running_loss = 0.0for i, data in enumerate(trainloader, 0):inputs, labels = data[0], data[1]optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()return running_loss / len(trainloader)# 调优过程
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=10)print('Best trial:')
best_trial = study.best_trial
print(' Value:', best_trial.value)
print(' Params:')
for key, value in best_trial.params.items():print(' {}: {}'.format(key, value))
4.3 自动化部署与监控
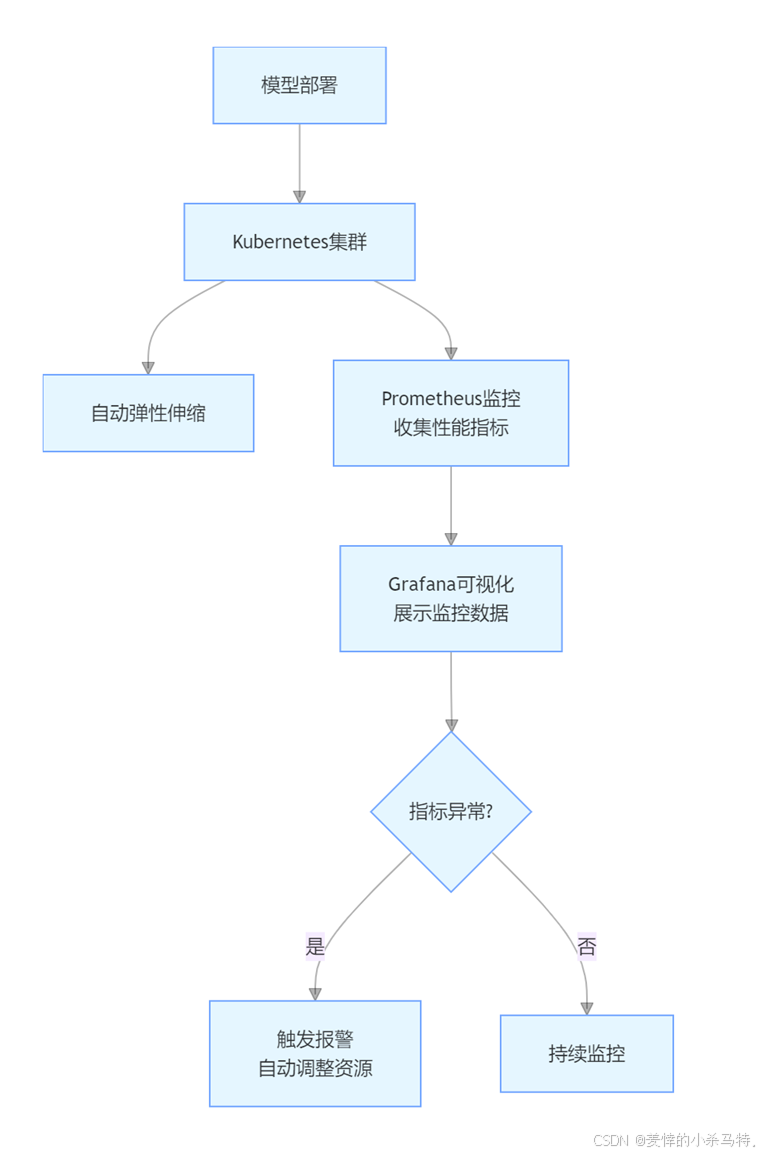
在模型部署阶段,Kubernetes 结合自动化脚本可实现模型的弹性伸缩和高可用部署。Prometheus 和 Grafana 用于自动化监控模型的性能指标。
五、行业应用案例
5.1 医疗领域:疾病诊断与药物研发
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| IBM Watson for Oncology | 分布式整合医疗数据,深度学习模型分析 | 提供个性化癌症治疗方案建议 |
| DeepMind 的 AlphaFold | 分布式训练预测蛋白质结构 | 加速药物研发进程 |
5.2 金融领域:风险防控与智能投顾
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| 蚂蚁集团 OceanBase 数据库 | 分布式计算 + AI 大模型分析交易数据 | 实时风险预警,处理海量交易 |
| 高盛 Marquee 平台 | 自动化 + 深度学习模型提供投资建议 | 智能投资决策,风险管理 |
5.3 工业领域:智能制造与质量检测
| 案例名称 | 技术方案 | 应用效果 |
|---|---|---|
| 西门子 MindSphere 平台 | 部署 AI 大模型实现设备预测性维护 | 减少设备停机时间 |
| 富士康 AI 质检系统 | 多模态深度学习模型检测产品缺陷 | 检测准确率超 99% |
六、技术融合面临的挑战
| 挑战类型 | 具体问题 | 现有解决方案 |
|---|---|---|
| 数据安全 | 分布式数据易泄露,联邦学习存在模型逆向攻击风险 | 同态加密、差分隐私 |
| 模型可解释性 | 大模型参数复杂,决策过程难以解释 | LIME、SHAP 等解释性工具 |
| 资源调度 | 分布式训练资源需求高,调度不当影响效率,能耗问题突出 | 动态资源分配、绿色 AI 技术 |
七、未来发展趋势
通用人工智能(AGI)探索:AI 大模型向更通用化方向发展,尝试解决复杂的多领域任务。
边缘计算与大模型结合:在边缘设备上部署轻量化大模型,实现实时智能决策,降低对云端的依赖。
绿色 AI 技术:研究更高效的算法和硬件架构,降低大模型训练和运行的能耗。
八、收尾
AI 大模型驱动下的深度学习、分布式与自动化融合,正深刻改变着各行业的发展模式。尽管面临诸多挑战,但随着技术的不断创新和突破,三者的深度融合将推动人工智能迈向更高阶段,为人类社会创造更大价值。
相关文章:
万亿参数背后的算力密码:大模型训练的分布式架构与自动化运维全解析
目录 一、技术融合的时代背景 二、深度学习在 AI 大模型中的核心作用 2.1 预训练与微调机制 2.2 多模态深度学习的突破 三、分布式计算:大模型训练的基础设施 3.1 分布式训练核心原理 3.2 数据并行实战(PyTorch DDP) 3.3 模型并行与混…...

LangChain03-图数据库与LangGraph
图数据库与LangGraph集成实践 1. 引言 在构建智能问答系统、推荐引擎或复杂决策流程时,传统的关系型数据库和向量数据库往往难以满足对实体关系建模和多跳推理的需求。图数据库(如 Neo4j、TigerGraph)通过节点-边-属性的结构化表示ÿ…...

rabbitmq单机多实例部署
RabbitMQ 单实例部署 单实例部署是指在一台服务器上运行一个 RabbitMQ 实例。这种部署方式适用于小型应用或开发环境,配置简单,资源占用较少。单实例部署的核心是安装 RabbitMQ 并启动服务,通常需要配置 Erlang 环境,因为 RabbitMQ 是基于 Erlang 编写的。单实例部署的优势…...
Linux10正式版发布,拥抱AI了!
📢📢📢📣📣📣 作者:IT邦德 中国DBA联盟(ACDU)成员,10余年DBA工作经验 Oracle、PostgreSQL ACE CSDN博客专家及B站知名UP主,全网粉丝10万 擅长主流Oracle、MySQL、PG、高斯…...

在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南
当然可以!以下是一篇结构清晰、语言通俗易懂的技术博客草稿,供你参考和使用: 在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南 背景介绍 最近在对一台内网的 OpenEuler-22.03 服务器进行安全扫描时,发现其 SSH 版本存在…...

全能邮箱全能邮箱:实现邮件管理的自动化!
全能邮箱全能邮箱:实现邮件管理的自动化! 全能邮箱全能邮箱的配置教程?如何注册烽火域名邮箱? 全能邮箱全能邮箱作为一种创新的邮件管理解决方案,正逐渐改变我们处理邮件的方式。蜂邮EDM将围绕全能邮箱全能邮箱&…...

[特殊字符] Linux 日志查看与分析常用命令全攻略
在日常运维与开发排查中,我们经常需要查看服务日志来定位问题。本文系统整理了几种常用的日志查看命令,包括 tail、cat、grep、split、sed 等,并结合实际应用场景,提供了完整的使用方式和示例。 📌 一、tail 命令 ——…...

mysql-tpcc-mysql压测工具使用
在Linux系统上安装和配置tpcc-mysql进行MySQL的TPC-C基准测试,通常涉及以下几个步骤。请注意,由于tpcc-mysql不是一个官方工具,它可能需要从第三方仓库获取,如Percona提供的版本。 前置条件 确保MySQL或MariaDB已安装࿱…...
Qt找不到windows API报错:error: LNK2019: 无法解析的外部符号 __imp_OpenClipboard
笔者在开发中出现的bug完整报错如下: spcm_ostools_win.obj:-1: error: LNK2019: 无法解析的外部符号 __imp_OpenClipboard,函数 "void __cdecl spcmdrv::vCopyToClipboard(char const *,unsigned __int64)" (?vCopyToClipboardspcmdrvYAXPE…...

机试 | vector/array Minimum Glutton C++
题目地址 : C - Minimum Glutton #include<stdio.h> #include<iostream> #include<vector> #include<algorithm> using namespace std; int main() {//N:菜肴数,X:总甜度阈值,Y:总咸度阈值int…...

OpenCv高阶(十七)——dlib库安装、dlib人脸检测
文章目录 前言一、dlib库简介二、dlib库安装1、本地安装(离线)2、线上安装 三、dlib人脸检测原理1、HOG 特征提取2、 SVM 分类器训练3、 滑动窗口搜索4、非极大值抑制(NMS) 四、dlib人脸检测代码1、导入OpenCV计算机视觉库和dlib机…...

前端内容黑白处理、轮播图、奇妙的头像特效
1、内容黑白处理 (1)filter:滤镜 可以把包裹的区域中每一个像素点,经过固定的算法转换成另一种颜色来呈现 (2)grayscale:灰阶滤镜 取值范围:0~1取0:原图去1ÿ…...

蓝桥杯 10. 安全序列
当然可以,以下是整理后的 Markdown 格式题目描述: 题目描述 小蓝是工厂里的安全工程师,他负责安放工厂里的危险品。 工厂是一条直线,直线上有 n 个空位,小蓝需要将若干个油桶放置在这 n 个空位上。每 2 个油桶中间至…...
-java+ selenium->元素之By class name)
(10)-java+ selenium->元素之By class name
1.简介 继续介绍WebDriver关于元素定位大法,这篇介绍By ClassName。看到ID,NAME这些方法的讲解,应该知道,要做好Web自动化测试,最好是需要了解一些前端的基本知识。有了前端知识,做元素定位会很轻松,同样写网络爬虫也很有帮助 2.常用定位方法(8种) (1)id (2)nam…...
Git - .gitignore 文件
一、.gitignore 文件介绍 在使用 Git 进行版本控制时,.gitignore 文件是一个非常重要的配置文件,用于告诉 Git 哪些文件或目录不需要被追踪和提交到版本库中。合理使用 .gitignore 文件可以避免提交不必要的文件,如临时文件、编译生成的文件…...
混合编程注意事项与性能优化)
MPI与多线程(如OpenMP)混合编程注意事项与性能优化
文章目录 MPI与多线程(如OpenMP)混合编程注意事项与性能优化混合编程注意事项性能优化策略示例代码编译与运行性能调优建议 MPI与多线程(如OpenMP)混合编程注意事项与性能优化 混合编程注意事项 MPI初始化与线程支持级别: 需要在MPI_Init之前调用MPI_Init_thread指…...
——MAC)
计算机网络学习(八)——MAC
一、MAC 在计算机网络中,MAC(Media Access Control,媒体访问控制)地址是数据链路层的重要概念,它用于唯一标识网络中的设备,并且在局域网(如以太网)中发挥关键作用。 MAC 是硬件地址…...

英语六级-阅读篇
目录 2023年12月大学英语真题(二) 十五选十(Section A) 单词表 短语表 译文 Passage Two(Section C) 单词表 短语表 译文 简介:其实我总结这篇文章就是平时记忆该阅读文章单词中出现的…...

右键打开 pycharm 右键 pycharm
文件夹右键打开pycharm aaa.reg notepad 右下角把文件格式改为:ansi Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\Directory\Background\shell\PyCharm] "Open with PyCharm" "Icon""\"D:\\soft\\PyCharm 2024.1.4\\bi…...

机器人坐标系标定
机器人坐标系标定 机器人坐标系标定 1. 知识目标 理解机器人坐标系的定义掌握机器人坐标系的分类 2. 技能目标 能够正确标定机器人坐标系 3. 机器人坐标系的作用 代表不同的物体或边界示例: 相对于桌子、弓箭、坯料、其他机器或边界移动 用途: 使用…...

Flink流处理基础概论
文章目录 引言Flink基本概述传统数据架构的不足Dataflow中的几大基本概念Dataflow流式处理宏观流程数据并行和任务并行的区别Flink中几种数据传播策略Flink中事件的延迟和吞吐事件延迟事件的吞吐如何更好的理解事件的延迟和吞吐flink数据流的几种操作输入输出转换操作滚动聚合窗…...

【RabbitMQ】记录 InvalidDefinitionException: Java 8 date/time type
目录 1. 添加必要依赖 2. 配置全局序列化方案(推荐) 3. 配置RabbitMQ消息转换器 关键点说明 1. 添加必要依赖 首先确保项目中包含JSR-310支持模块: <dependency><groupId>com.fasterxml.jackson.datatype</groupId>&l…...
如何通过API接口实现自动化上货跨平台铺货?商品采集|商品上传实现详细步骤
一、引言:跨平台铺货的技术挑战与 API 价值 在电商多平台运营时代,商家需要将商品同步上架至淘宝、京东、拼多多、亚马逊、Shopee 等多个平台,传统手动铺货模式存在效率低下(单平台单商品上架需 30-60 分钟)、数据一致…...
《三维点如何映射到图像像素?——相机投影模型详解》
引言 以三维投影介绍大多比较分散,不少小伙伴再面对诸多的坐标系转换中容易弄混,特别是再写代码的时候可能搞错,所有这篇文章帮大家完整的梳理3D视觉中的投影变换的全流程,一文弄清楚这个过程,帮助大家搞清坐标系转换…...

Go 语言范围循环变量重用问题与 VSCode 调试解决方法
文章目录 问题描述问题原因1. Go 1.21 及更早版本的范围循环行为2. Go 1.22 的改进3. VSCode 调试中的问题4. 命令行 dlv debug 的正确输出 三种解决方法1. 启用 Go 模块2. 优化 VSCode 调试配置3. 修改代码以确保兼容性4. 清理缓存5. 验证环境 验证结果结论 在 Go 编程中&…...

青少年编程与数学 02-020 C#程序设计基础 04课题、常量和变量
青少年编程与数学 02-020 C#程序设计基础 04课题、常量和变量 一、主函数1. 主函数的基本格式2. 主函数的参数3. 主函数的返回值4. 主函数的作用5. 主函数的示例6. 主函数的注意事项 二、变量1. 变量的声明示例 2. 变量的初始化声明时初始化声明后赋值 3. 变量的类型3.1 值类型…...
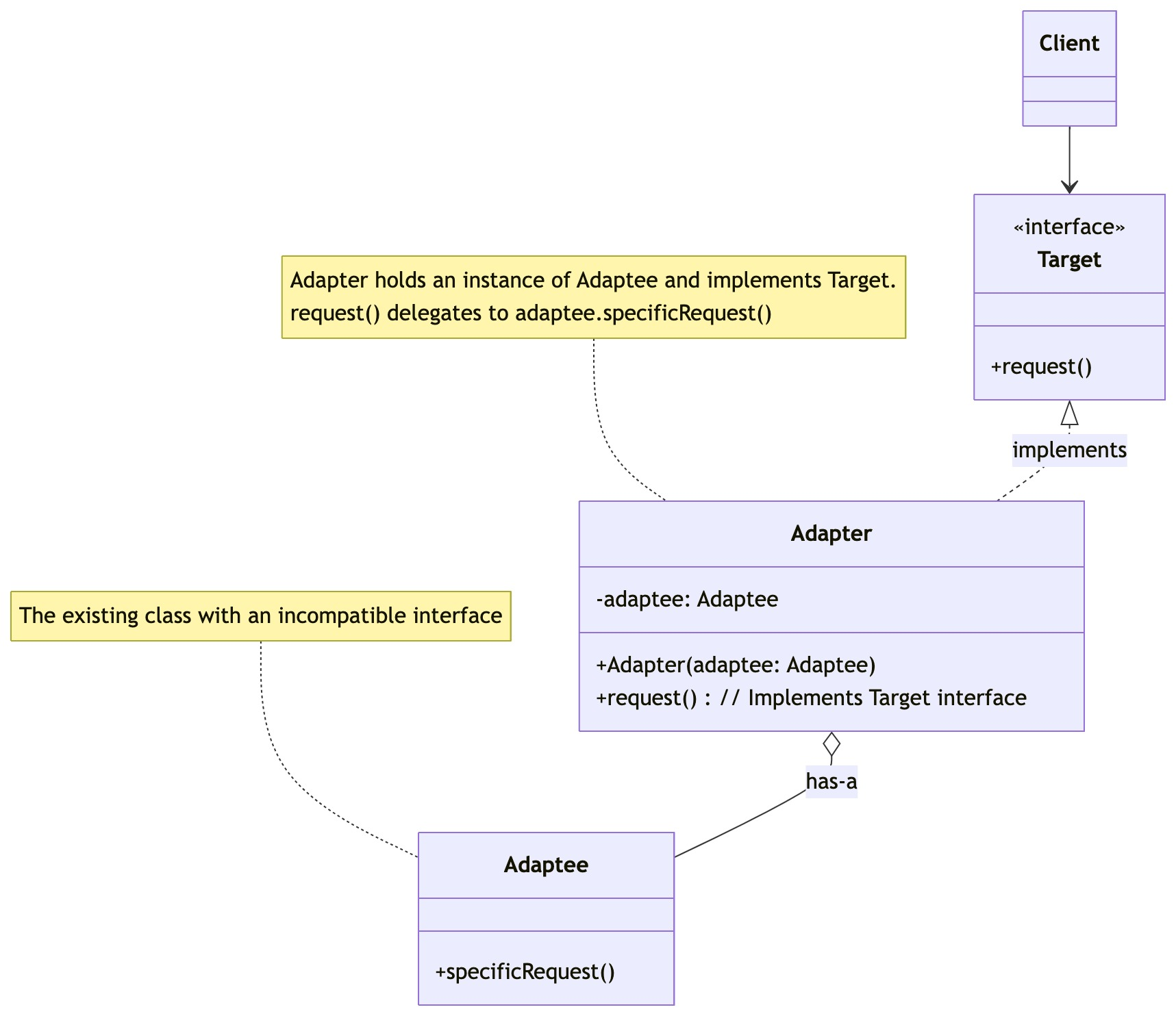
零基础设计模式——结构型模式 - 适配器模式
第三部分:结构型模式 - 适配器模式 (Adapter Pattern) 欢迎来到结构型模式的第一站!结构型模式关注的是如何将类或对象组合成更大的结构,同时保持结构的灵活性和效率。适配器模式是其中非常实用的一个,它能帮助我们解决接口不兼容…...

【QT】TXT文件的基础操作
目录 一、QT删除TXT文件内容 方法1:使用QFile打开文件并截断 方法2:使用QSaveFile(更安全的写入方式) 方法3:使用QTextStream 使用示例 注意事项 二、QT操作TXT文件:清空内容并写入新数据 完整实现代…...
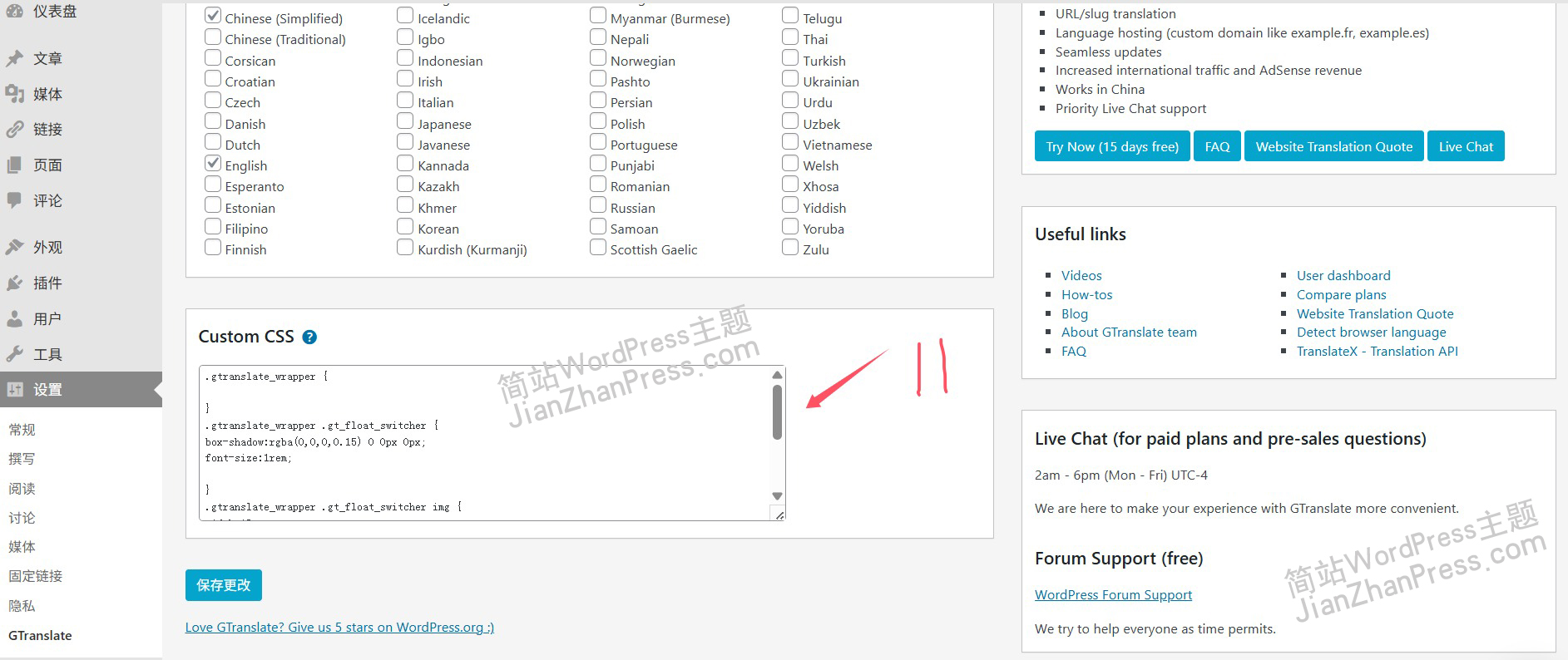
WordPress多语言插件安装与使用教程
WordPress多语言插件GTranslate的使用方法 在wordpress网站后台搜索多语言插件GTranslate并安装,安装完成、用户插件后开始设置,以下为设置方法: 1、先在后台左侧找到Gtranslate,进入到设置界面 2、选择要显示的形式,…...

互联网大厂Java求职面试:短视频平台大规模实时互动系统架构设计
互联网大厂Java求职面试:短视频平台大规模实时互动系统架构设计 面试背景介绍 技术总监(严肃脸): 欢迎来到我们今天的模拟面试,我是技术部的李总监,负责平台后端架构和高可用系统设计。今天我们将围绕一个…...