让MySQL更快:EXPLAIN语句详尽解析
前言
在数据库性能调优中,SQL 查询的执行效率是影响系统整体性能的关键因素之一。MySQL 提供了强大的工具——EXPLAIN 语句,帮助开发者和数据库管理员深入分析查询的执行计划,从而发现潜在的性能瓶颈并进行针对性优化。
EXPLAIN 语句能够模拟 MySQL 优化器的执行过程,返回查询的详细执行计划,包括表的访问顺序、索引的使用情况、连接类型、扫描行数等关键信息。通过理解 EXPLAIN 的输出,开发者可以快速定位低效查询的问题所在,例如全表扫描、缺少索引、临时表或文件排序等,并采取相应的优化措施。
本文将详细介绍 EXPLAIN 的基本用法、输出字段的含义,并通过实际案例演示如何利用 EXPLAIN 分析和优化 SQL 查询。

一、关于EXPLAIN语句
1.1 简介
EXPLAIN 是 MySQL 提供的用于分析 SQL 查询执行计划的工具。它通过在 SELECT 语句前添加 EXPLAIN 关键字,使 MySQL 返回查询的执行计划,而不是实际执行查询。执行计划描述了 MySQL 如何访问表、如何使用索引以及如何连接表等信息。
EXPLAIN 的主要作用包括:
- 分析查询性能:识别慢查询的根源,例如全表扫描或索引未命中。
- 验证索引有效性:确认是否正确使用了索引,或者是否需要添加新的索引。
- 优化查询结构:调整查询语句或表结构以提高执行效率。
1.2 语法
EXPLAIN 的基本语法如下:
EXPLAIN [EXTENDED] [FORMAT = {TRADITIONAL | JSON}] SELECT ...;
- EXTENDED:扩展输出,显示更多信息(如优化后的查询语句)。
- FORMAT = JSON:以 JSON 格式返回结果,便于解析和调试。
示例:
在select前加explain关键字,MySQL会返回该查询的执行计划而不是执行这条SQL
mysql> explain select * from student where id=1;
+----+-------------+---------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | student | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+---------+-------+---------------+---------+---------+-------+------+-------+
1 row in set

二、Explain列的含义
EXPLAIN 的输出结果包含多个字段,每个字段提供了不同的信息。以下是关键字段的详细说明:
2.1 概览
以下是 MySQL EXPLAIN 输出列的详细说明,包括每列的定义、示例值、优化目标及判断标准,帮助你深入理解查询执行计划:
| 列名 | 作用描述 | 优化目标(好的输出特征) |
|---|---|---|
| id | 查询的执行顺序标识符 | 子查询或复杂查询时,id 值高的先执行 |
| select_type | 查询类型(简单查询、子查询、UNION 等) | SIMPLE 或 PRIMARY 表示简单或主查询 |
| table | 当前操作的表名(包括临时表或派生表) | 表名清晰,避免过多 <derived> 或 <union> |
| partitions | 匹配的分区(若表有分区) | 分区裁剪合理,避免全分区扫描 |
| type | 数据访问方式(关键性能指标) | const、eq_ref、ref、range 优于 ALL |
| possible_keys | 可能用到的索引 | 包含实际使用的索引 |
| key | 实际使用的索引 | 明确显示有效索引名,非 NULL |
| key_len | 索引使用的字节数 | 与索引字段长度匹配,避免未完全使用索引 |
| ref | 与索引比较的列或常量 | const 或关联字段,避免 NULL |
| rows | 预估扫描的行数(估算值) | 数值越小越好 |
| filtered | 查询条件过滤后剩余行的百分比 | 百分比高(接近 100%) |
| Extra | 额外执行信息(关键优化提示) | 出现 Using index,避免 Using filesort |
2.2 每列详细说明及优化建议
1. id
-
含义:查询的标识符,表示查询中
SELECT 子句的执行顺序。
查询的序列号,标识执行顺序。相同id 按从上到下执行;不同id 时,值大的先执行(如子查询)。 -
示例:
EXPLAIN SELECT * FROM (SELECT * FROM t1) AS t_derived JOIN t2 ON t1.id = t2.id;id=1:派生表t_derived(子查询)。id=1:主查询t2。
-
优化目标:
避免多层嵌套子查询(id 过多),减少复杂查询。 -
单一查询(无子查询或
UNION)时,id 为1。 -
复杂查询中,
id 的层级清晰,避免嵌套过深。
2. select_type
-
含义:查询的类型,描述查询的复杂度。
-
|常见值及优化建议:|||
值 说明 理想情况 SIMPLE 简单查询,不包含子查询或 UNION。最佳,避免复杂嵌套。 PRIMARY 最外层查询。 正常,需关注其依赖的子查询。 SUBQUERY 子查询中的第一个 SELECT。尽量避免,可考虑改写为连接查询。 DEPENDENT SUBQUERY 子查询依赖外部查询结果。 高风险,可能导致性能下降。 UNION UNION 中的第二个或后续查询。正常,需注意 UNION 结果集。UNION RESULT UNION 的结果集。正常,需检查是否需要额外处理。 DERIVED 派生表( FROM 子句中的子查询)。需检查派生表的性能。 MATERIALIZED 物化子查询(MySQL 8.0+)。 正常,但需确认物化效果。
3. table
-
含义:当前查询涉及的表名。
-
理想输出:
- 表名明确,避免派生表(如
<derivedN>)或临时表(如<union1,2>)。 - 若出现派生表,需检查子查询是否可优化为连接查询。
- 表名明确,避免派生表(如
4. partitions
-
含义:查询涉及的分区(如果表是分区表)。
表示查询涉及的分区情况。当表是分区表时,这个列会显示匹配的分区。例如,一个表按照日期字段进行分区,查询中指定了日期范围,那么 partitions 列就会显示涉及到的分区编号或者分区名称。
-
理想输出:
-
分区表中仅扫描相关分区(如
p1),而非全表扫描。 -
若为
NULL,表示表未分区或未使用分区。如果表是分区表,希望 partitions 列显示的分区范围尽量小。这样可以减少查询需要扫描的数据量,提高查询效率。例如,如果一个分区表有 100 个分区,而查询只涉及到其中的 1 - 2 个分区,这就是比较理想的输出。
-
5. type
-
含义:连接类型(访问方法),反映 MySQL 如何查找表中的行。
-
性能排序(从优到劣) :
- system:表仅一行(系统表),是
const 的特例。 - const:通过主键或唯一索引等值查询,最多匹配一行。
- eq_ref:使用主键或唯一索引进行等值连接(如
JOIN)。 - ref:使用非唯一索引进行等值查询。
- range:索引范围查询(如
BETWEEN、>、<)。 - index:全索引扫描(比全表扫描快)。
- ALL:全表扫描(最差)。
- system:表仅一行(系统表),是
-
优化建议:
- 目标是达到
const、eq_ref 或ref。 - 避免
ALL,需添加索引或优化查询条件。
- 目标是达到
6. possible_keys
-
含义:可能使用的索引(候选索引)。
-
理想输出:
-
显示多个候选索引(说明索引设计合理)。
-
若为
NULL,表示无可用索引,需添加索引。列出与查询条件相关的索引。
-
7. key
-
含义:实际使用的索引。如果
key 为NULL,表示没有使用索引,可能是全表扫描。 -
理想输出:
- 明确显示使用的索引(如
idx_name)。 - 若为
NULL,表示未使用索引,需检查possible_keys 并优化索引。 - 显示与
possible_keys 中相同的索引,说明 MySQL 选择了合适的索引。
- 明确显示使用的索引(如
8. key_len
-
含义:使用的索引长度(字节数)。
-
理想输出:
- 值越小越好(表示使用的索引列越少或数据类型更紧凑)。
- 例如,
VARCHAR(100) 使用utf8mb4 编码时,最大占用400 字节。
9. ref
-
含义:显示索引的哪一列被使用,以及与之比较的值(常量或列名)。
- 显示哪些列或常量被用于查找索引列上的值。常见值包括:
const:使用常量值。表的列名:使用其他表的列进行比较。
-
func:使用函数结果。 -
理想输出:
- 显示具体的列名或常量(如
const),表明索引有效。 - 若为
func 或NULL,可能表示索引未正确使用。 - 显示具体的列名或常量,表明索引被有效利用。
- 显示具体的列名或常量(如
10. rows(估计扫描行数)
-
含义:MySQL 估计需要扫描的行数。
-
理想输出:
- 值越小越好(表示过滤条件越精确)。例如,如果一个查询估算只需要检查 10 行就可以得到结果,这比估算检查 10000 行要好得多。这表明查询能够快速定位到所需的数据行。
- 若值过大(如
100000),需优化索引或查询条件。
11. filtered
-
含义:表示查询条件过滤的行百分比(MySQL 5.7+)。该值表示查询扫描的行中有多少被筛选掉,值的范围是 0 到 100。
- 表示在存储引擎返回的行中,经过 MySQL 服务器层过滤后,实际满足查询条件的行的比例。它是基于表统计信息和索引统计信息的一个估算值。
-
理想输出:
- 值越高越好(如
100% 表示无过滤条件)。 - 若值较低(如
10%),说明查询条件未充分利用索引。 - filtered 的值应该尽可能高。例如,如果 filtered 的值是 90%,意味着存储引擎返回的行中有 90% 的行满足查询条件,这比 filtered 值为 10% 的情况要好,因为减少了不必要的数据处理。
- 值越高越好(如
12. Extra
- 含义:额外信息,提供查询执行的附加说明,帮助诊断查询执行的细节
- |常见值及优化建议:|||
值 说明 优化建议 Using index 使用覆盖索引(查询列全部命中索引)。 无需回表,性能最佳。 Using where 使用 WHERE 条件过滤数据。正常,但需检查过滤条件效率。 Using temporary 需要创建临时表(如 ORDER BY 和GROUP BY 一起使用)。避免,优化查询或添加索引。 Using filesort 需要额外排序操作(如 ORDER BY 未使用索引)。避免,优化排序字段索引。 Distinct 优化了 DISTINCT 查询。正常,无需额外优化。 Range checked for each record 未找到合适索引,需逐行检查。 添加合适索引。
- 良好输出:希望出现像 “Using index” 这样的提示,这表明查询效率较高。尽量避免出现 “Using temporary” 和 “Using filesort”,因为它们表示需要额外的资源开销来处理查询,如临时表和文件排序,这可能会降低查询性能。
三、优化建议及示例
3.1 优化建议
- 关注
type 列:确保查询达到const、eq_ref 或ref 级别,避免ALL。 - 优化
Extra 列:避免Using filesort 和Using temporary。 - 分析
key 和 possible_keys:确认是否使用了预期的索引。 - 减少扫描行数:通过索引或优化查询条件降低
rows 值。 - 检查
filtered:确保过滤条件有效,提高查询效率。
3.2 优化示例
全表扫描
场景:全表扫描(type=ALL)
-
问题 SQL:
EXPLAIN SELECT * FROM users WHERE phone = '123456789'; -
输出:
type=ALL,key=NULL。 -
优化:为
phone 字段添加索引:ALTER TABLE users ADD INDEX idx_phone(phone); -
优化后输出:
type=ref,key=idx_phone,rows=1。
多表连接优化(Using join buffer)
问题描述
多表连接时出现 Using join buffer,性能低下。
原SQL
SELECT u.name, o.order_no
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE u.age > 25 AND o.status = 'completed';
EXPLAIN 分析
EXPLAIN SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id = o.user_id WHERE u.age > 25 AND o.status = 'completed';
输出结果:
id | select_type | table | type | possible_keys | key | rows | Extra
---|-------------|-------|------|---------------|------------|------|-------------------
1 | SIMPLE | u | ALL | idx_age | NULL | 1000 | Using where
1 | SIMPLE | o | ref | idx_user_id | idx_user_id| 500 | Using where; Using join buffer (Block Nested Loop)
问题诊断
- users 表 type=ALL:未使用索引,全表扫描。
- orders 表 Using join buffer:连接时未使用索引,性能差。
优化方案
-
为
users.age 创建索引:ALTER TABLE users ADD INDEX idx_age (age); -
为
orders.user_id 和 orders.status 创建索引:ALTER TABLE orders ADD INDEX idx_user_id_status (user_id, status); -
调整查询:
SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id = o.user_id WHERE u.age > 25 AND o.status = 'completed'; -
验证优化效果:
EXPLAIN SELECT u.name, o.order_no FROM users u JOIN orders o ON u.id = o.user_id WHERE u.age > 25 AND o.status = 'completed';优化后输出:
id | select_type | table | type | possible_keys | key | rows | Extra ---|-------------|-------|------|-----------------------|----------------------|------|--------- 1 | SIMPLE | u | range| idx_age | idx_age | 500 | Using where 1 | SIMPLE | o | ref | idx_user_id_status | idx_user_id_status | 200 | Using where
效果
- users 表 type=range:使用索引范围扫描。
- orders 表 Using join buffer 消失:连接直接通过索引完成。
结束语
EXPLAIN语句是MySQL查询优化的核心工具,如同数据库工程师的"听诊器"。通过本文的详细解析,相信您已经掌握了各输出列的精髓。但需要强调的是,真正的优化功力需要在实践中不断积累。建议每次执行重要查询时养成查看执行计划的习惯,结合业务场景灵活运用索引策略、查询重写等手段。记住:优秀的数据库性能不是偶然,而是源于对每个执行细节的精心雕琢。

相关文章:
让MySQL更快:EXPLAIN语句详尽解析
前言 在数据库性能调优中,SQL 查询的执行效率是影响系统整体性能的关键因素之一。MySQL 提供了强大的工具——EXPLAIN 语句,帮助开发者和数据库管理员深入分析查询的执行计划,从而发现潜在的性能瓶颈并进行针对性优化。 EXPLAIN 语句能够模…...
,并以JSON格式(JWK)打印到浏览器控制台)
基于谷歌浏览器的Web Crypto API生成一对2048位的RSA密钥(公钥+私钥),并以JSON格式(JWK)打印到浏览器控制台
用Google Chrome 浏览器的Web Crypto API生成RSA密钥对:在浏览器环境中生成一对2048位的RSA密钥(公钥私钥),然后以JSON格式(JWK)将它们打印到控制台,方便开发者查看和使用。 // 控制台生成密钥对 (async () > {// 调用Web Crypto API生成…...
[CSS3]rem移动适配
前言 什么是移动端适配? 让页面的元素在屏幕尺寸变化时, 同比放大或缩小 移动适配的方案 rem:目前多数企业在用的解决方案 vw/vh:未来的解决方案 rem 体验rem适配 目标: 能够使用rem单位设置网页元素的尺寸 网页效果: 屏幕宽度不同,网…...

向量数据库及ChromaDB的使用
什么是向量数据库? 向量数据库(Vector Database),也叫矢量数据库,主要用来存储和处理向量数据。 在数学中,向量是有大小和方向的量,可以使用带箭头的线段表示,箭头指向即为向量的方…...
CodeBuddy实现pdf批量加密
本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 前言 在信息爆炸的时代,PDF 格式因其跨平台性和格式稳定性,成为办公、学术、商业等领域传递信息的重要载体。从机密合同到个人隐私文档,…...

编程中优秀大模型推荐:特点与应用场景深度分析
编程中优秀大模型推荐:特点与应用场景深度分析 编程中优秀大模型推荐:特点与应用场景深度分析GPT系列模型模型概述技术特点编程应用场景 DeepSeek系列模型模型概述技术特点编程应用场景 Claude系列模型模型概述技术特点编程应用场景 Llama系列模型模型概…...

orm详解--查询执行
深入解析 Django ORM 查询执行阶段 的核心机制,包括查询集的惰性特性、表达式树构建、SQL 编译过程及优化原理。以下是详细分析: 一、查询集(QuerySet)的惰性执行机制 1. 惰性特性的底层实现 核心类:django.db.mode…...
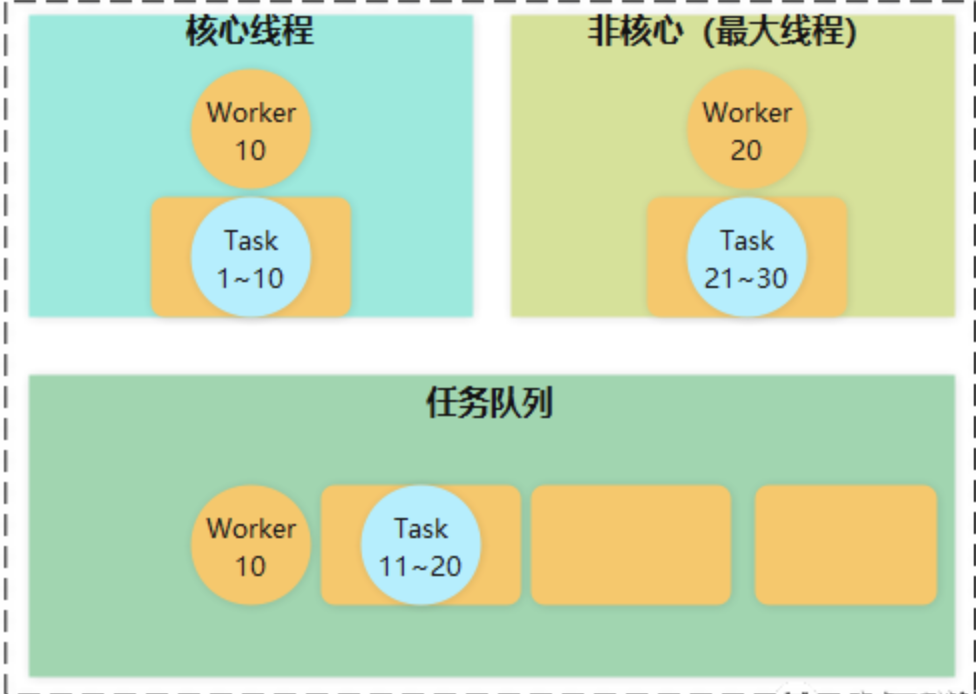
运行打印Hello World启动了多少线程?
序言 看网上说阿里二面问到了一个看似最简单且没有标准答案的一个问题,所有学习编程都是从打印hello World开始的,那运行打印启动了多少个线程? 启动了多少线程? 在运行一个简单的 “Hello World” 程序时,启动的线…...

C++项目中调用C#DLL的的方式
C项目中调用C#DLL的的方式 方法一:使用COM技术方法二:使用C/CLI方法三:使用P/Invoke(适用于C#导出非托管接口) 在C中调用C#编写的DLL,通常需要借助COM(Component Object Model&#…...

咳嗽止咳药笔记250526 , 磷酸苯丙哌林 , 喷托维林 , 右美沙芬
咳嗽止咳药笔记250526 止咳药的种类较多,根据作用机制可分为中枢性止咳药、外周性止咳药、祛痰药、抗组胺药及中成药等。以下是具体分类及效果分析: 一、中枢性止咳药 可待因 效果:直接抑制延髓咳嗽中枢,镇咳作用强且迅速&#x…...

vue pinia 独立维护,仓库统一导出
它允许您跨组件/页面共享状态 持久化 安装依赖pnpm i pinia-plugin-persistedstate 将插件添加到 pinia 实例上 pinia独立维护 统一导出 import { createPinia } from pinia import piniaPluginPersistedstate from pinia-plugin-persistedstateconst pinia creat…...

网络的协议和标准
网络的协议和标准 OSI参考模型 应用层 报文 网关 表示层 报文 会话层 报文 传输层 报文 网络层 数据包 路由器 数据链路层 帧 网桥交换机 物理层 位 中继器 集线器 TCP/IP协议簇 逻辑地址:每台设备都有一个ip地址 一个ip地址包包含网络号 子网络号 主机号可…...

十六进制字符转十进制算法
十六进制与十进制对照 十六进制十进制00112233445566778899A10B11C12D13E14F15 十六进制与十进制区别 十六进制是满16进1,十进制是满10进1,这里要注意下区别,16进制的字符里面为什么是0-9没有10,这里面进了一位,表示…...

跟Gemini学做PPT:汇报背景图寻找指南
PPT 汇报背景图寻找指南 既然前端功能已经完善,现在可以专注于汇报了。对于 PPT 背景图,你有几个选择: 1. 内置模板和主题: 优点: 最简单、快速,PowerPoint、Keynote、Google Slides 等演示软件都内置了…...
java交易所,多语言,外汇,黄金,区块链,dapp类型的,支持授权,划转,挖矿(源码下载)
目前这套主要是运营交易所类型的,授权的会贵点,编译后的是可以直接跑的,图片也修复了,后门也扫了 都是在跑的项目支持测,全开源 源码下载:https://download.csdn.net/download/m0_66047725/90887047 更多…...

(已开源-CVPR2024) RadarDistill---NuScenes数据集Radar检测第一名
本文介绍一篇Radar 3D目标检测模型:RadarDistill。雷达数据固有的噪声和稀疏性给3D目标检测带来了巨大挑战。在本文中,作者提出了一种新的知识蒸馏(KD)方法RadarDistill,它可以通过利用激光雷达数据来提高雷达数据的表征。RadarDistill利用三…...
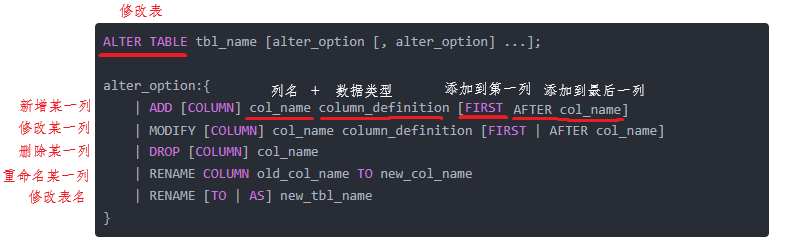
【MySQL】 数据库基础数据类型
一、数据库简介 1.什么是数据库 数据库(Database)是一种用于存储、管理和检索数据的系统化集合。它允许用户以结构化的方式存储大量数据,并通过高效的方式访问和操作这些数据。数据库通常由数据库管理系统(DBMS)管理&…...

中小企业AI算力如何选?【显卡租赁】VS【自建服务器】
对于中小企业而言和科研单位来讲,AI算力的选择需综合考虑成本、灵活性、数据安全和技术迭代风险等因素。以下是显卡租赁与自建服务器的对比分析,帮助中小企业做出最优决策: 1. 成本对比 自建服务器 高昂的前期投入:搭建一个中等规…...

OpenHarmony 4.1版本应用升级到5.0版本问题记录及解决方案
目录 1. ERROR: ArkTS:ERROR File: E:/Hap/applications_contacts-OpenHarmony-5.0.0-Release/entry/src/main/ets/Application/MyAbilityStage.ts:33:9 No overload matches this call. Overload 1 of 4, (slot: NotificationSlot): Promise, gave the following error. …...

std::initialzer_list 与花括号{}数据列表
author: hjjdebug date: 2025年 05月 22日 星期四 15:50:23 CST descrip: std::initialzer_list 与花括号{}数据列表 文章目录 1.{数值列表}是什么?1.1 数组初始化 时 , 称为数组初始化列表1.2. 当用于容器时, 称为容器初始化列表1.3. 对于结构体或类,{…...
)
萤石云实际视频实时接入(生产环境)
萤石云视频接入 本示例可用于实际接入萤石云开放平台视频,同时支持音频输入和输出。 实际优化内容 1.动态获取token 2.切换各公司和车间时,自动重新初始化播放器 let EZUIKit null; // 第三方库引用 let EZUIKitPlayers []; // 播放器实例数组 le…...

QT中常用的类
Qt 是一个功能强大的跨平台框架,提供了丰富的类库来开发 GUI 和应用程序。以下是 Qt 中常用的核心类,按模块分类整理: 1. GUI 和窗口管理 类名用途示例场景QWidget所有 GUI 控件的基类(按钮、窗口等&…...
:容器操作全栈技术指南 --- 从入门到生产级管控)
Docker系列(四):容器操作全栈技术指南 --- 从入门到生产级管控
引言 本指南以全链路视角拆解Docker技术栈,通过四大核心模块构建从入门到进阶的知识体系,助您系统性掌握容器化落地的关键能力。 容器生命周期管理(一)从创建、启停到资源清理,夯实容器操作的基础语法与核心场景&…...

poppler_path 是用于 Python 库如 pdf2image 进行 PDF 转换时
poppler_path 是用于 Python 库如 pdf2image 进行 PDF 转换时指定 Poppler 可执行文件路径的参数。为了让程序正常工作,需要先安装 Poppler,并配置环境变量或在代码中设置 poppler_path。 以下是 Poppler 的安装与环境变量配置方法,按操作系…...

鸿蒙OSUniApp 开发的多图浏览器组件#三方框架 #Uniapp
使用 UniApp 开发的多图浏览器组件 在移动应用开发中,图片浏览器是非常常见且实用的功能,尤其是在社交、资讯、电商等场景下,用户对多图浏览体验的要求越来越高。随着 HarmonyOS(鸿蒙)生态的不断壮大,开发…...

MongoDB 错误处理与调试完全指南:从入门到精通
在当今数据驱动的世界中,MongoDB 作为最流行的 NoSQL 数据库之一,因其灵活的数据模型和强大的扩展能力而广受开发者喜爱。然而,与任何复杂系统一样,在使用 MongoDB 过程中难免会遇到各种错误和性能问题。本文将全面介绍 MongoDB 的…...

React从基础入门到高级实战:React 核心技术 - 表单处理与验证深度指南
React 表单处理与验证深度指南 在现代 Web 应用中,表单是用户与应用交互的核心方式之一。无论是注册、登录、结账还是数据提交,表单都扮演着至关重要的角色。React 作为一款流行的前端框架,提供了多种处理表单的工具和方法,帮助开…...

【C++】stack,queue和priority_queue(优先级队列)
文章目录 前言一、栈(stack)和队列(queue)的相关接口1.栈的相关接口2.队列的相关接口 二、栈(stack)和队列(queue)的模拟实现1.stack的模拟实现2.queue的模拟实现 三、priority_queu…...
ubuntu中上传项目至GitHub仓库教程
一、到github官网注册用户 1.注册用户 地址:https://github.com/ 2.安装Git 打开终端,输入指令git,检查是否已安装Git 如果没有安装就输入指令 sudo apt-get install git 二、上传项目到github 1.创建项目仓库 进入github主页,点击号…...
)
[Java实战]Spring Boot整合达梦数据库连接池配置(三十四)
[Java实战]Spring Boot整合达梦数据库连接池配置(三十四) 一、HikariCP连接池配置(默认) 1. 基础配置(application.yml) spring:datasource:driver-class-name: dm.jdbc.driver.DmDriverurl: jdbc:dm://…...