deepseek开源资料汇总

参考:DeepSeek“开源周”收官,连续五天到底都发布了什么?
目录
一、首日开源-FlashMLA
二、Day2 DeepEP
三、Day3 DeepGEMM
四、Day4 DualPipe & EPLB
五、Day5 3FS & Smallpond
总结
一、首日开源-FlashMLA
多头部潜在注意力机制(Multi-head Latent Attention)
https://github.com/deepseek-ai/FlashMLA (CUDA)
这是专为英伟达Hopper GPU(H100)优化的高效MLA解码内核,专为处理可变长度序列设计。
在自然语言处理等任务里,数据序列长度不一,传统处理方式会造成算力浪费。而FlashMLA如同智能交通调度员,能依据序列长度动态调配计算资源。例如在同时处理长文本和短文本时,它可以精准地为不同长度的文本分配恰当的算力,避免 “大马拉小车” 或资源不足的情况。发布6小时内,GitHub上收藏量突破5000次,被认为对国产GPU性能提升意义重大。
具体讲解:【DeepSeek开源周】Day 1:FlashMLA 学习笔记_自然语言处理_蓝海星梦-DeepSeek技术社区
-
传统的MHA机制
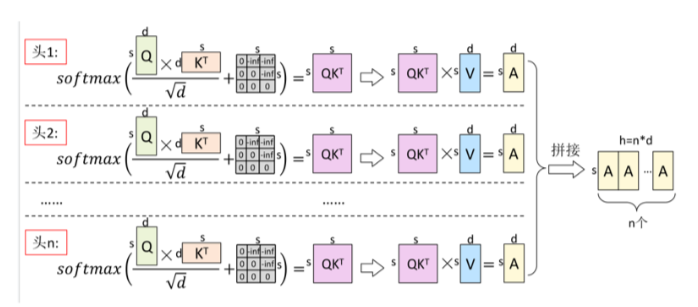
-
DeepSeek-V3的MLA机制
MLA 是多头部潜在注意力机制(Multi-head Latent Attention),其本质是对KV的有损压缩,提高存储信息密度的同时尽可能保留关键细节。 它的核心原理是对注意力键(Key)和值(Value)进行低秩压缩,使用两个线性层和来代替一个大的 Key/Value 投影矩阵,将输入投影到一个低维空间,然后将其投影回原始维度,从而减少存储和计算量。此外,MLA 还可对查询(Query)进行低秩压缩,以进一步减少激活内存。
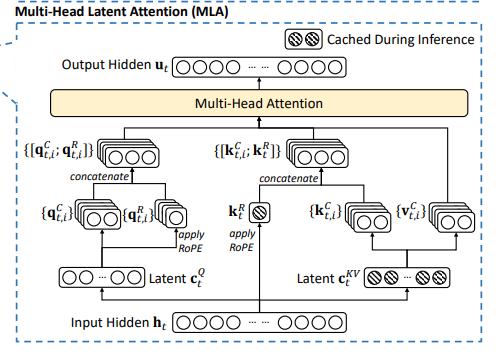
针对MLA与MHA的通俗解释
MLA(Multi-head Latent Attention)和 MHA(Multi-Head Attention)都可以用来实现注意力机制,但它们并不是完全并行的“思考方式”选择,而是针对不同目标优化的设计。
我们可以用图书馆查阅的比喻来理解两者的核心差异:
-
MHA 的思考方式:想象你在一个传统的巨型图书馆查阅资料,每本书(每个注意力头)都完整保留所有原始内容(完整 K/V 缓存),书架按主题(头数 h)严格分区。查阅时每次需要回答问题(计算注意力),必须跑到每个主题区(每个头)翻遍对应书架的所有书籍(加载全部 K/V)
-
MLA 的思考方式:更像是现代化数字图书馆,书籍压缩归档。将相似主题的书籍(h 个头)打包成精华合辑(若干组潜在状态),只保留核心摘要(潜在 K/V),同时为每个合辑建立关键词标签(潜在变量),实时更新内容概要。查阅时先通过关键词标签(潜在状态)定位相关合辑(组),快速浏览摘要(全局注意力),必要时调取合辑内的原始书籍(局部注意力),但频次大幅降低。
相比之下,MHA方式中每个主题区存在重复内容,且随着藏书量增加(序列变长),找书耗时将会快速增长(O(n²)复杂度),这样造成了空间浪费和效率的低下。而MLA找书时间从翻遍全馆变为先看目录再精准查阅(复杂度从降为 O(n) 主导),显著提升了查找效率。
二、Day2 DeepEP
开源EP通信库
https://github.com/deepseek-ai/DeepEP(CUDA)
博客讲解:【DeepSeek开源周】Day 2:DeepEP 学习笔记_开源_蓝海星梦-DeepSeek技术社区
DeepEP是首个用于MoE(混合专家模型)训练和推理的开源EP通信库。MoE模型训练和推理中,不同专家模型需高效协作,这对通信效率要求极高。DeepEP支持优化的全对全通信模式,就像构建了一条顺畅的高速公路,让数据在各个节点间高效传输。
它还原生支持FP8低精度运算调度,降低计算资源消耗,并且在节点内和节点间都支持NVLink和RDMA,拥有用于训练和推理预填充的高吞吐量内核以及用于推理解码的低延迟内核。简单来说,它让MoE模型各部分间沟通更快、消耗更少,提升了整体运行效率 。
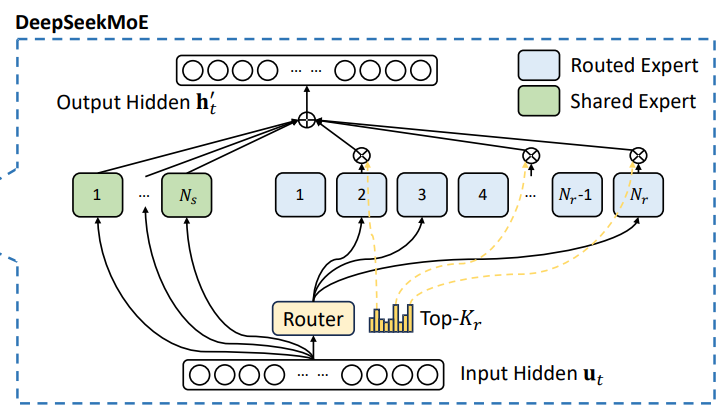
在 DeepSeek‐V3 的 MoE 模块中,主要包含两类专家:
-
路由专家(Routed Experts):每个 MoE 层包含 256 个路由专家,这些专家主要负责处理输入中某些特定、专业化的特征。
-
共享专家(Shared Expert):每个 MoE 层中还有 1 个共享专家,用于捕捉通用的、全局性的知识,为所有输入提供基本的特征提取支持。
token传入MoE时的处理流程:
-
计算得分:首先,经过一个专门的 Gate 网络,该网络负责计算 token 与各个路由专家之间的匹配得分。
-
选择专家:基于得分,Gate 网络为每个 token 选择 Top-K 个最合适的路由专家(DeepSeek‐V3 中通常选择 8 个)
-
各自处理:被选中的专家各自对 token 进行独立处理,产生各自的输出。
-
合并输出:最终,根据 Gate 网络给出的权重加权聚合这些专家的输出,再与共享专家的输出进行融合,形成当前 MoE 层的最终输出表示。
三、Day3 DeepGEMM
矩阵乘法加速库
https://github.com/deepseek-ai/DeepGEMM(python)
博客:【DeepSeek开源周】Day 3:DeepGEMM 学习笔记_学习_蓝海星梦-DeepSeek技术社区
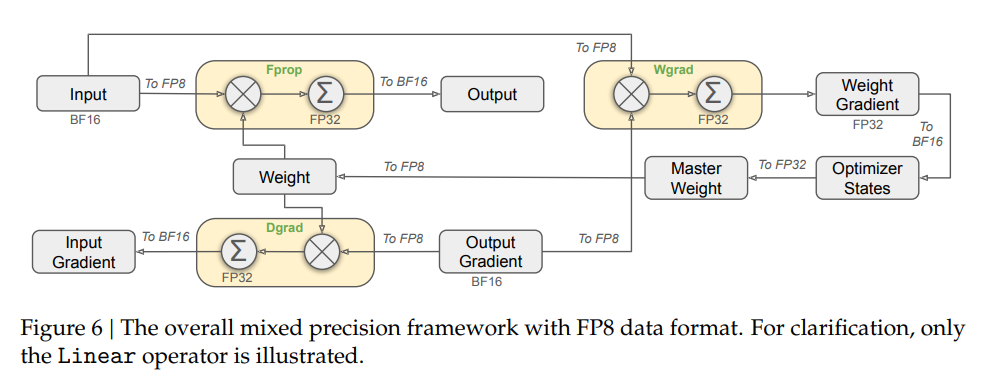
矩阵乘法加速库,为V3/R1的训练和推理提供支持。通用矩阵乘法是众多高性能计算任务的核心,其性能优化是大模型降本增效的关键。DeepGEMM采用了DeepSeek-V3中提出的细粒度scaling技术,仅用300行代码就实现了简洁高效的FP8通用矩阵乘法。
它支持普通GEMM以及专家混合(MoE)分组GEMM,在Hopper GPU上最高可达到1350+ FP8 TFLOPS(每秒万亿次浮点运算)的计算性能,在各种矩阵形状上的性能与专家调优的库相当,甚至在某些情况下更优,且安装时无需编译,通过轻量级JIT模块在运行时编译所有内核。
-
核心亮点
-
FP8 低精度支持:DeepGEMM 最大的特色在于从架构上优先设计为 FP8 服务。传统GEMM库主要优化FP16和FP32,而DeepGEMM针对FP8的特殊性进行了优化设计。
-
极致性能与极简核心实现:DeepGEMM在NVIDIA Hopper GPU上实现了高达1350+ FP8 TFLOPS的计算性能,同时其核心代码仅有约300行
-
JIT 即时编译:DeepGEMM 不是预先编译好所有可能配置的内核,而是利用 JIT 在运行时生成最佳内核。例如,根据矩阵大小、FP8尺度等参数,JIT 会即时优化指令顺序和寄存器分配。
-
传统矩阵乘法 vs. DeepGEMM算法
| 特性 | 传统矩阵乘法 | DeepGEMM算法 |
| 计算方式 | 逐元素顺序计算,无并行加速 | 利用GPU并行计算,分块处理,使用张量核心等优化 |
| 计算速度 | 慢,尤其在大规模矩阵时效率低下 | 极快,能在短时间内完成大规模矩阵乘法 |
| 内存使用 | 内存占用高,可能面临内存不足问题 | 内存管理高效,避免内存瓶颈 |
| 适用场景 | 适用于小型或简单矩阵运算场景 | 专为大规模矩阵运算设计,如深度学习模型训练和推理 |
四、Day4 DualPipe & EPLB
DualPipe:https://github.com/deepseek-ai/DualPipe(python)
EPLB:https://github.com/deepseek-ai/EPLB(python)
博文:https://deepseek.csdn.net/67da0cb5807ce562bfe34746.html
DualPipe是一种用于V3/R1训练中计算与通信重叠的双向管道并行算法。以往的管道并行存在 “气泡” 问题,即计算和通信阶段存在等待时间,造成资源浪费。DualPipe通过实现 “向前” 与 “向后” 计算通信阶段的双向重叠,将硬件资源利用率提升超30%。
EPLB则是一种针对V3/R1的专家并行负载均衡器。基于混合专家(MoE)架构,它通过冗余专家策略复制高负载专家,并结合启发式分配算法优化GPU间的负载分布,减少GPU闲置现象。
五、Day5 3FS & Smallpond
https://github.com/deepseek-ai/3FS(C++)
https://github.com/deepseek-ai/smallpond (python)
博文:https://deepseek.csdn.net/67db6b09b8d50678a24ed021.html
DeepSeep开源了面向全数据访问的推进器3FS,也就是Fire-Flyer文件系统。它是一个专门为了充分利用现代SSD和RDMA网络带宽而设计的并行文件系统,能实现高速数据访问,提升AI模型训练和推理的效率。
此外,DeepSeek还开源了基于3FS的数据处理框架Smallpond,它可以进一步优化3FS的数据管理能力,让数据处理更加方便、快捷。
总结
在 2025 年 2 月 24 日至 28 日的 DeepSeek 开源周期间,DeepSeek 开源了五个核心项目,这些项目涵盖了 AI 开发的计算优化、通信效率和存储加速等关键领域,共同构成了一个面向大规模 AI 的高性能基础设施。
-
FlashMLA:针对 NVIDIA Hopper GPU 优化的多头线性注意力解码内核,显著提升了推理效率,支持实时翻译和长文本处理。
-
DeepEP:专为混合专家模型(MoE)设计的通信库,通过优化节点间数据分发与合并,大幅提升了训练速度。
-
DeepGEMM:基于 FP8 的高效矩阵乘法库,专为 MoE 模型优化,显著提升了大规模矩阵运算效率。
-
DualPipe & EPLB:创新的双向流水线并行算法和动态负载均衡工具,优化了资源利用率,提升了并行训练效率。
-
3FS & Smallpond:高性能分布式文件系统,支持 RDMA 网络和 SSD 存储,解决了海量数据的高速存取与管理问题。
参考:
https://devpress.csdn.net/user/Eternity__Aurora
https://github.com/orgs/deepseek-ai/repositories?type=all
相关文章:
deepseek开源资料汇总
参考:DeepSeek“开源周”收官,连续五天到底都发布了什么? 目录 一、首日开源-FlashMLA 二、Day2 DeepEP 三、Day3 DeepGEMM 四、Day4 DualPipe & EPLB 五、Day5 3FS & Smallpond 总结 一、首日开源-FlashMLA 多头部潜在注意力机制&#x…...

CollUtil详解
CollUtil 是 Hutool 工具库中的一个工具类,专门用于操作集合(Collection)。它提供了许多静态方法,可以简化对集合的常见操作,例如判断集合是否为空、合并集合、过滤集合等。 以下是关于 CollUtil 的详细介绍和常用方法…...

Elasticsearch的运维
Elasticsearch 运维工作详解:从基础保障到性能优化 Elasticsearch(简称 ES)作为分布式搜索和分析引擎,其运维工作需要兼顾集群稳定性、性能效率及数据安全。以下从核心运维模块展开说明,结合实践场景提供可落地的方案…...
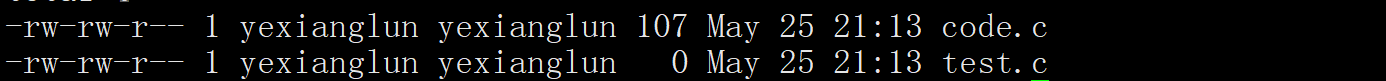
Linux编辑器——vim的使用
vim是一款多模式的编辑器。 基本操作:vim打开默认是命令模式,也就是输入命令然后系统执行指令,想要写代码,只需输入字母i,就进入插入模式,写完代码想要退出,按一下Esc,退回到命令模…...

线性回归原理推导与应用(八):逻辑回归二分类乳腺癌数据分类
乳腺癌数据是sklearn中自带的数据集,需要通过相关特征对是否患有乳腺癌进行分类。 数据清洗与建模 首先加载相关库和相关数据 from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression import numpy as np import…...
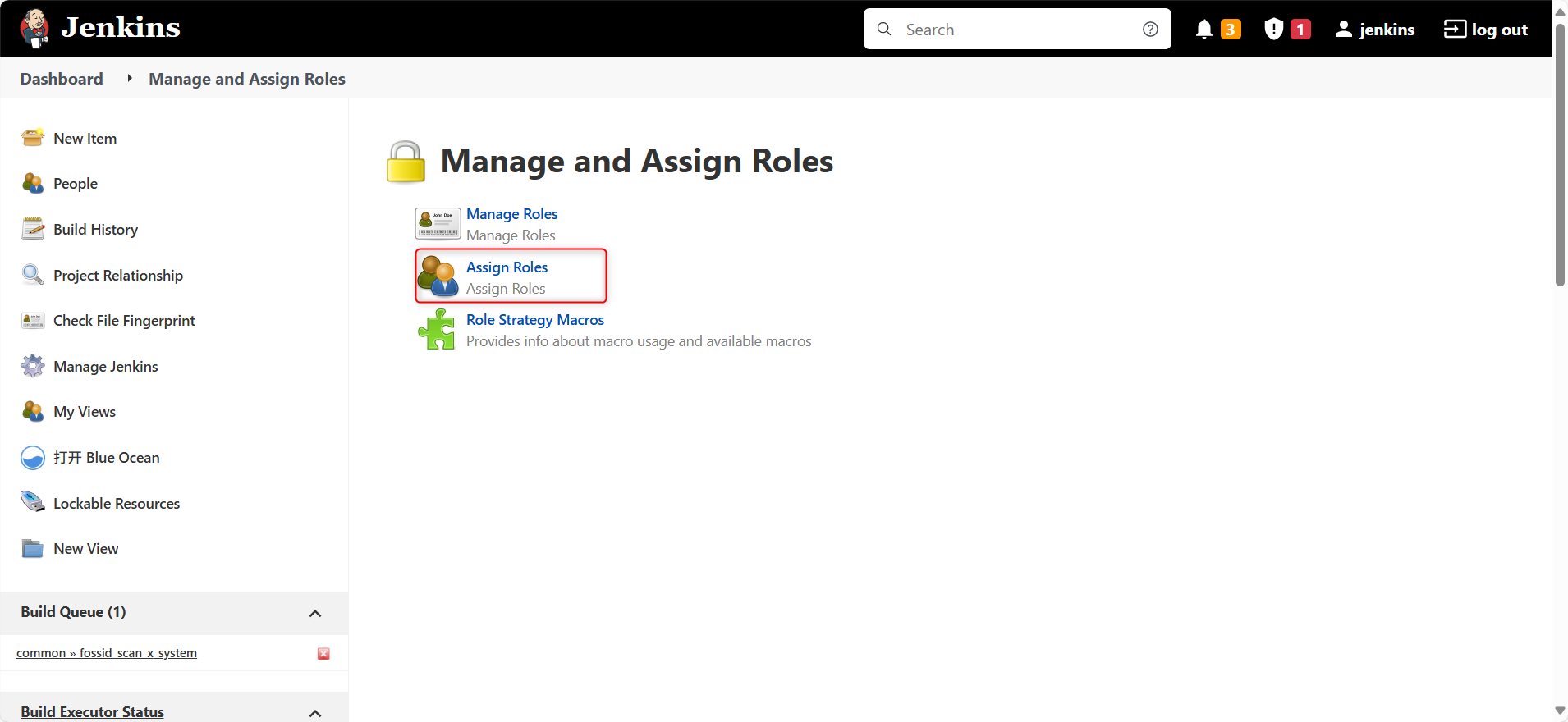
Jenkins分配对应项目权限与用户管理
在日常开发过程中经常会出现用户和权限管理问题,没有配置trigger时,通常需要我们手动构建,但此时前端和后端的朋友没有build权限,导致每次dev环境测试都需要麻烦我们手动去构建,消息传达不及时则会降低开发效率。 现有…...
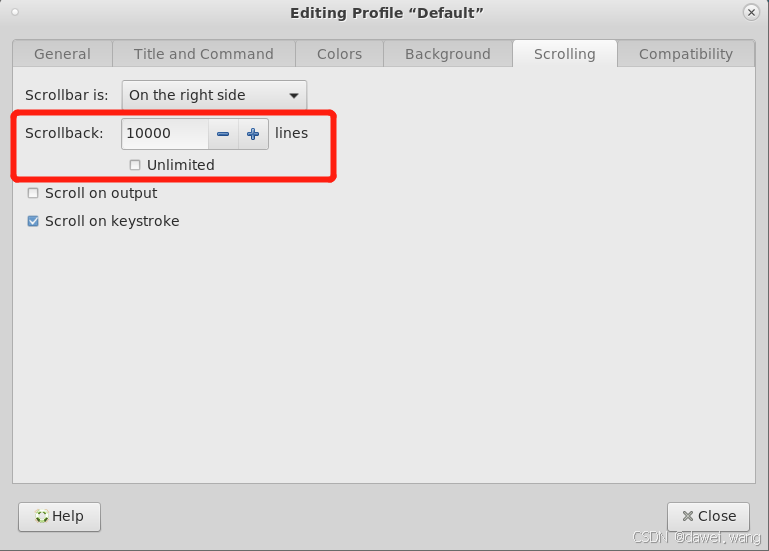
Mate桌面环境系统与终端模拟器参数配置
说明: MATE桌面环境在使用中会优化一些参数配置,例如:电源选项、屏幕配置、字体配置、终端模拟器(Mate Terminal)配置等等。 通常工程师会根据自己喜好调整一些参数,修改后参数的保存位置在/home/u…...
fabric 是一个开源框架,用于使用 AI 增强人类能力。它提供了一个模块化框架,用于使用一组可在任何地方使用的众包人工智能提示来解决特定问题
一、软件介绍 文末提供程序和源码下载 fabric 是一个开源框架,用于使用 AI 增强人类能力。它提供了一个模块化框架,用于使用一组可在任何地方使用的众包人工智能提示来解决特定问题。 二、What and why 什么和为什么 自 2023 年初和 GenAI 以来&…...

基于PDF流式渲染的Word文档在线预览技术
一、背景介绍 在系统开发中,实现在线文档预览与编辑功能是许多项目的核心需求,但在实际的开发过程中,我们经常会面临以下难点: 1)格式兼容性问题:浏览器原生不支持解析Word二进制格式,直接渲染会…...

华为仓颉语言初识:结构体struct和类class的异同
前言 华为仓颉语言是鸿蒙原生应用的一种新的编程语言,采用面向对象的编程思想,为开发者带来新的开发体验。不仅可以和 ArkTs 相互调用,更能提升应用程序的性能,更重要的是仓颉语言的特点结合了 java 和 C 的特点。对开发者来说比…...
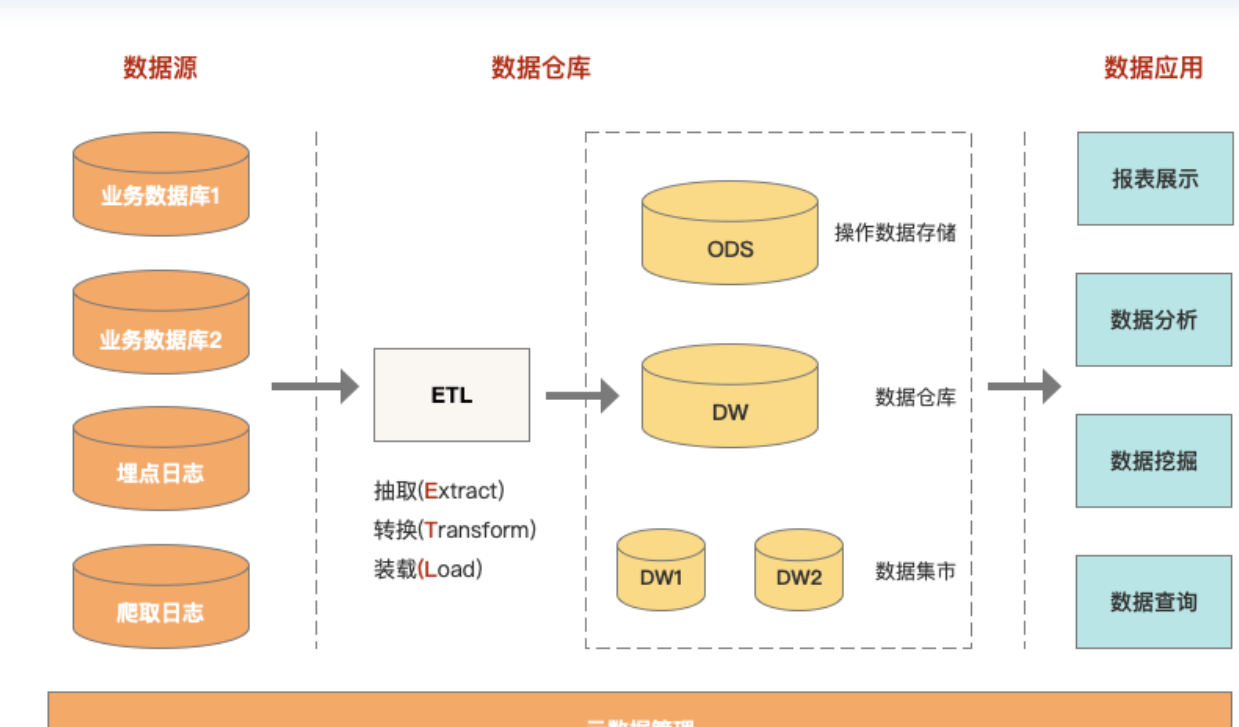
数据仓库基础知识总结
1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 1)数据仓库是用于支持决策、面向分析型数据处理; 2)对多个异构的数据源有效集…...
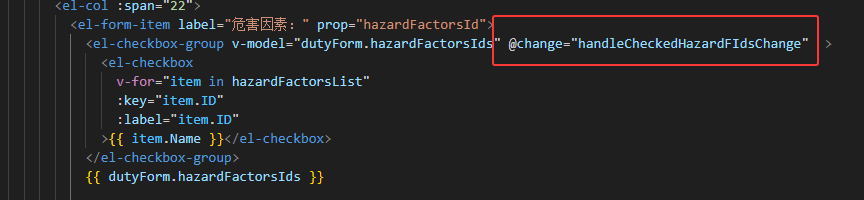
vue2使用element中多选组件el-checkbox-group,数据与UI更新不同步
问题描述 使用element多选checkbox组件,点击勾选取消勾选,视图未变化,再次点击表单其他元素,多选组件勾选状态发生变化,视图和数据未同步 第一次尝试:再el-checkbox-group多选父组件上增加点击事件&…...
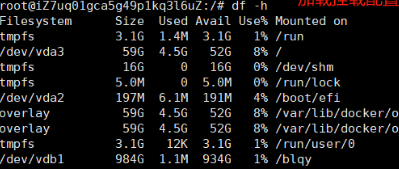
linux磁盘分区及挂载、fdisk命令详解
文章目录 1.Linux磁盘分区概念精要1.1 分区的定义1.2 多分区的必要性1.2.1 数据安全隔离1.2.2 提升存储效率1.2.3 防止系统资源耗尽1.2.4 fdisk用法介绍 2.服务器挂载磁盘实战详细步骤2.1检查磁盘情况及格式化2.2磁盘分区2.3 磁盘目录挂载2.3.1 创建挂载目录2.3.2 …...

anaconda 安装教程以及常用命令
安装教程 安装教程 常用命令 Conda是一个非常强大的包管理和环境管理工具,以下是一些常用命令: 环境管理命令 创建环境 创建指定Python版本的环境:例如,创建名为 myenv,Python版本为3.9的环境。conda create -n m…...

C/C++的OpenCV的锐化
图像锐化技术:使用 C/C的OpenCV 增强图像细节 ✨ 图像锐化是一种常见的图像处理技术,其目的是增强图像的边缘和细节,使图像看起来更清晰、更鲜明。这在很多应用中都非常有用,例如医学成像、卫星图像分析以及提升普通照片的视觉质…...
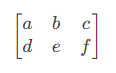
Eigen矩阵存储顺序以及转换
一、Eigen矩阵存储顺序 在矩阵运算和线性代数中,"行优先"(Row-major)和"列优先"(Column-major)是两种不同的存储方式,它们决定了多维数组(如矩阵)在内存中的布局顺序。 1. 行优先(Row-major) 定义:矩阵按行顺序存储在内存中,即第一行的所有元…...

OpenLayers 加载ArcGIS瓦片数据
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 随着GIS应用的不断发展,Web地图也越来越丰富,除了像ESRI、超图、中地数码这样GIS厂商有各自的数据源格式,也有Google…...

2025蓝桥杯WP
引言 在2025年蓝桥杯网络安全赛道中,我们面对涵盖Web安全、逆向工程、PWN、取证分析以及加密解密等多领域的挑战,要求选手具备扎实且全面的安全技术与实战能力。本文将以实战记录的形式,逐题详细还原解题思路与操作步骤,并配以相…...

数字人教师:开启教育智慧革新之旅
在科技浪潮的推动下,教育领域正经历一场由数字人教师引领的深刻变革,这不仅是技术与教育融合的创新实践,更是教育模式重塑的关键路径。 一、数字人教师的崛起:教育变革的必然选择 随着互联网、大数据、人工智能等前沿技术的飞速…...

Linux中Java开发、部署和运维常用命令
在Java开发、部署和运维过程中,Linux操作系统常用的一些命令可以帮助开发人员、运维人员管理系统、查看日志、控制进程等。以下是一些常见的Linux命令: 1. 文件和目录操作 ls:列出当前目录下的文件和文件夹。 ls -l:显示详细信息…...
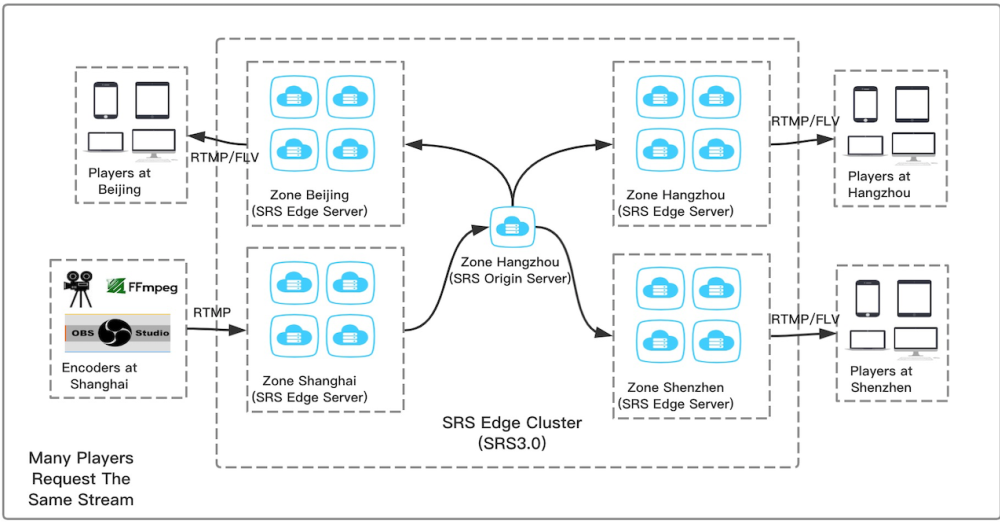
详解srs流媒体服务器的集群
前言: 什么是集群 集群就是多台计算机或服务器等资源,联在一起像一台大机器一样工作。比如一群蚂蚁一起搬东西,这些蚂蚁就类似集群里的各个部分。 为什么要集群 性能更强:能把任务分到多个机器上做,一起处理更快&…...
ubuntu22.04 安装 SecureCRT8.7.3
用到的全部软件,都放在这个网盘里面了,自取。 链接: https://pan.baidu.com/s/1AR6Lj8FS7bokMR5IrLmsIw?pwd3dzv 提取码: 3dzv 如果链接失效了,关注公号:每日早参,回复:资源,即可免费获取&…...

Day 37
继续之前的学习 过拟合的判断 import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler import time import matpl…...
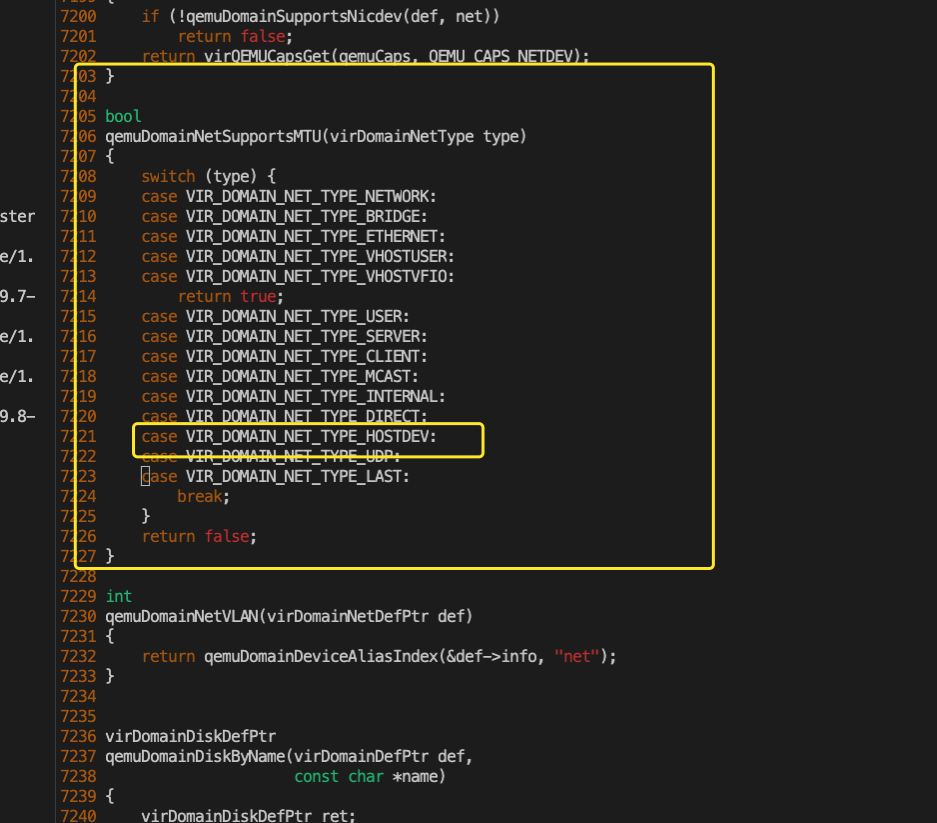
libvirt设置虚拟机mtu实现原理
背景 云计算场景下,可以动态调整虚拟机mtu,提高虚拟机网络性能。设置虚拟机(VM)virtio网卡的MTU(Maximum Transmission Unit)涉及 宿主机(Host)、QEMU/KVM、vhost-net后端 和 虚拟机内部的virtio驱动之间的协作。 原理分析 1.libvirt设置mtu分析 libv…...

AstroNex空间任务智能控制研究与训练数据集
数据集概述 AstroNex空间任务智能控制研究与训练数据集是朗迪锋科技基于Multiverse平台精心打造的首个全面覆盖航天器智能控制全周期的综合数据集产品。该数据集汇集了轨道动力学、姿态控制、机器视觉、环境感知等多维度数据,为航天器智能算法研发提供丰富的训练与…...

汽车副水箱液位传感器介绍
汽车副水箱液位传感器是现代车辆冷却系统中不可或缺的关键部件,其核心功能在于实时监测冷却液存量,确保发动机在最佳温度范围内稳定运行。随着汽车电子化程度不断提升,这一看似简单的传感器已发展成为集机械、电子、材料技术于一体的精密装置,其工作原理与技术演进值得深入…...

Docker+MobaXterm+x11实现容器UI界面转发本地
本文记录了搭建一个可直接ssh访问的container,并可通过x11转发界面的实现过程 0.1 实验环境 PC:windows 11 Server:Ubuntu 18.04 Docker image:Ubuntu 18.04 1. 获取Ubuntu 18.04的镜像 使用Dockerfile获取镜像,对…...

IEEE出版|2025年智能制造、机器人与自动化国际学术会议 (IMRA2025)
【重要信息】 会议官网:www.icimra.com 会议时间: 2025年11月14日-16日 会议地点: 中国湛江 截稿日期:2025年09月16日(一轮截稿) 接收或拒收通知:文章投递后5-7个工作日 会议提交检索:EI Compendex, Scopus IEEE出版|2025年…...
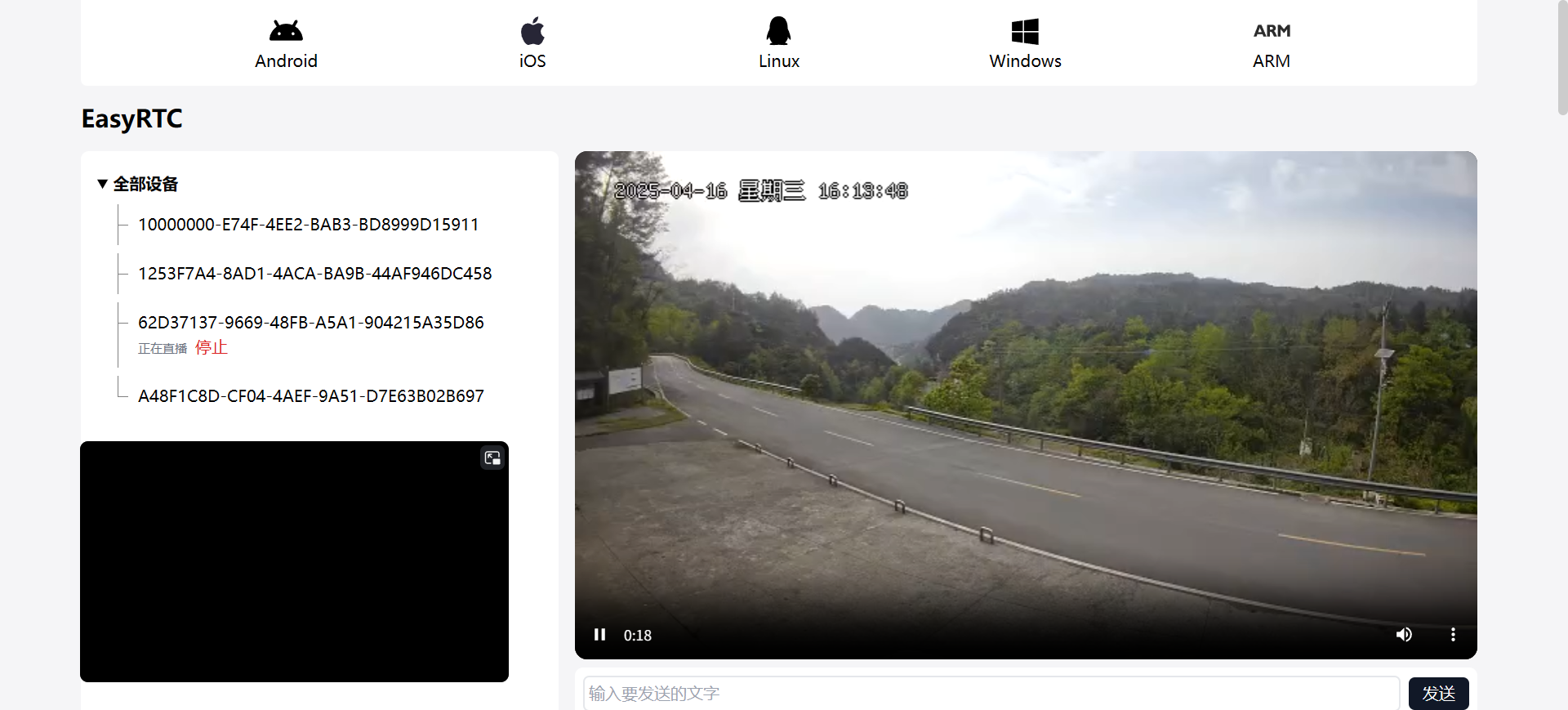
EasyRTC嵌入式SDK音视频实时通话助力WebRTC技术与智能硬件协同发展
一、概述 在万物互联的数字化浪潮下,智能硬件已广泛渗透生活与工业领域,实时音视频通信成为智能硬件实现高效交互的核心需求。WebRTC作为开源实时通信技术,为浏览器与移动应用提供免插件的音视频通信能力,而EasyRTC通过深度优化音…...
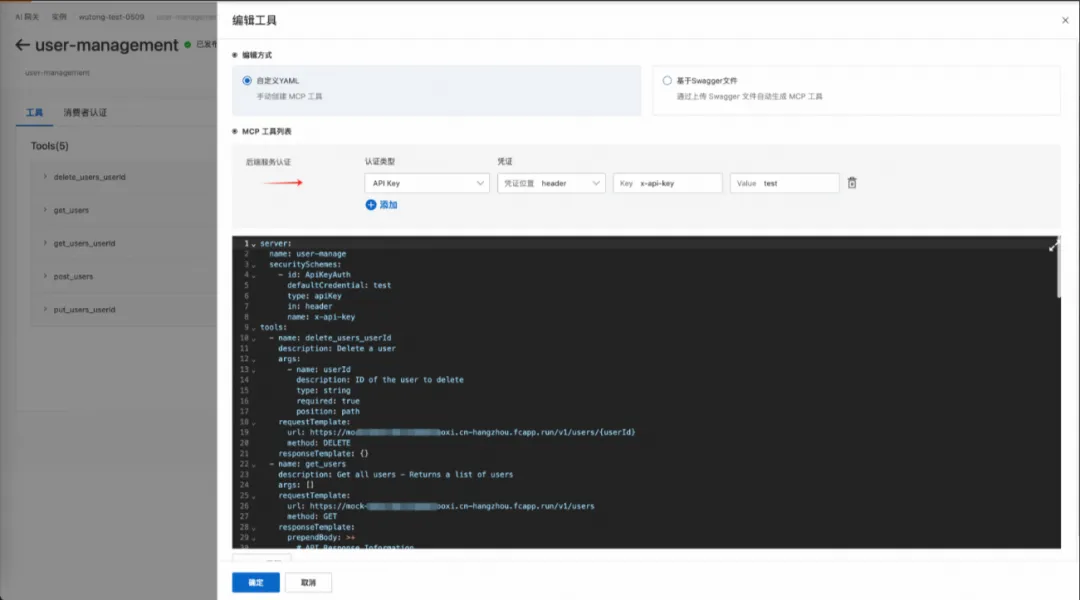
Higress MCP Server 安全再升级:API 认证为 AI 连接保驾护航
Higress MCP Server 安全再升级:API 认证为 AI 连接保驾护航 Higress 作为一款强大的 AI 原生 API 网关,致力于铺设 AI 与现实世界之间最短、最安全、最具成本效益的连接路径。其核心能力之一便是支持将现有的 OpenAPI 规范无缝转换为 MCP Server&#…...