【机器学习基础】机器学习入门核心算法:支持向量机(SVM)

机器学习入门核心算法:支持向量机(SVM)
- 一、算法逻辑
- 1.1 基本概念
- 1.2 核心思想
- 线性可分情况
- 二、算法原理与数学推导
- 2.1 原始优化问题
- 2.2 拉格朗日对偶
- 2.3 对偶问题
- 2.4 核函数技巧
- 2.5 软间隔与松弛变量
- 三、模型评估
- 3.1 评估指标
- 3.2 交叉验证调参
- 四、应用案例
- 4.1 手写数字识别
- 4.2 金融欺诈检测
- 五、经典面试题
- 问题1:SVM为什么采用间隔最大化?
- 问题2:核函数的作用是什么?
- 问题3:SVM如何处理多分类问题?
- 六、高级优化技术
- 6.1 增量学习
- 6.2 多核学习
- 七、最佳实践指南
- 7.1 参数调优建议
- 7.2 特征预处理要点
- 总结与展望
一、算法逻辑
1.1 基本概念
支持向量机(Support Vector Machine, SVM)是一种监督学习算法,核心目标是寻找一个最优超平面,最大化不同类别数据间的分类间隔(Margin)。其核心特性包括:
- 间隔最大化:通过几何间隔最大化提高泛化能力
- 核技巧:隐式映射到高维空间处理非线性问题
- 稀疏性:仅依赖支持向量决定模型
适用场景:
- 小样本、高维数据
- 非线性可分问题
- 对模型解释性要求不高的场景
1.2 核心思想
线性可分情况
设训练集 D = { ( x i , y i ) } i = 1 m , y i ∈ { − 1 , + 1 } D = \{(\boldsymbol{x}_i, y_i)\}_{i=1}^m, \quad y_i \in \{-1, +1\} D={(xi,yi)}i=1m,yi∈{−1,+1}
目标超平面方程:
w T x + b = 0 \boldsymbol{w}^T\boldsymbol{x} + b = 0 wTx+b=0
分类决策函数:
f ( x ) = sign ( w T x + b ) f(\boldsymbol{x}) = \text{sign}(\boldsymbol{w}^T\boldsymbol{x} + b) f(x)=sign(wTx+b)
几何间隔定义:
γ = y i ( w T x i + b ) ∥ w ∥ \gamma = \frac{y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b)}{\|\boldsymbol{w}\|} γ=∥w∥yi(wTxi+b)
二、算法原理与数学推导
2.1 原始优化问题
最大化间隔等价于最小化权值范数:
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \begin{aligned} \min_{\boldsymbol{w},b} & \quad \frac{1}{2}\|\boldsymbol{w}\|^2 \\ \text{s.t.} & \quad y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1, \quad i=1,2,...,m \end{aligned} w,bmins.t.21∥w∥2yi(wTxi+b)≥1,i=1,2,...,m
2.2 拉格朗日对偶
引入拉格朗日乘子 α i ≥ 0 \alpha_i \geq 0 αi≥0
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 m α i [ y i ( w T x i + b ) − 1 ] L(\boldsymbol{w},b,\boldsymbol{\alpha}) = \frac{1}{2}\|\boldsymbol{w}\|^2 - \sum_{i=1}^m \alpha_i[y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) - 1] L(w,b,α)=21∥w∥2−i=1∑mαi[yi(wTxi+b)−1]
KKT条件:
{ α i ≥ 0 y i ( w T x i + b ) − 1 ≥ 0 α i [ y i ( w T x i + b ) − 1 ] = 0 \begin{cases} \alpha_i \geq 0 \\ y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) - 1 \geq 0 \\ \alpha_i[y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) - 1] = 0 \end{cases} ⎩ ⎨ ⎧αi≥0yi(wTxi+b)−1≥0αi[yi(wTxi+b)−1]=0
2.3 对偶问题
转化为对偶形式:
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s.t. ∑ i = 1 m α i y i = 0 , α i ≥ 0 \begin{aligned} \max_{\boldsymbol{\alpha}} & \quad \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i\alpha_j y_i y_j \boldsymbol{x}_i^T\boldsymbol{x}_j \\ \text{s.t.} & \quad \sum_{i=1}^m \alpha_i y_i = 0, \quad \alpha_i \geq 0 \end{aligned} αmaxs.t.i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=0,αi≥0
支持向量:对应 α i > 0 \alpha_i > 0 αi>0的样本点
2.4 核函数技巧
非线性映射:
设 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x)为映射函数,核函数定义为:
κ ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) \kappa(\boldsymbol{x}_i, \boldsymbol{x}_j) = \phi(\boldsymbol{x}_i)^T\phi(\boldsymbol{x}_j) κ(xi,xj)=ϕ(xi)Tϕ(xj)
常用核函数:
| 核函数类型 | 表达式 | 特点 |
|---|---|---|
| 线性核 | x i T x j \boldsymbol{x}_i^T\boldsymbol{x}_j xiTxj | 无映射,处理线性可分 |
| 多项式核 | ( γ x i T x j + r ) d (\gamma\boldsymbol{x}_i^T\boldsymbol{x}_j + r)^d (γxiTxj+r)d | 可调阶数d |
| RBF核(高斯核) | exp ( − γ ∣ x i − x j ∣ 2 ) \exp(-\gamma|\boldsymbol{x}_i - \boldsymbol{x}_j|^2) exp(−γ∣xi−xj∣2) | 应用最广泛 |
2.5 软间隔与松弛变量
引入松弛变量处理噪声数据:
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i s.t. y i ( w T x i + b ) ≥ 1 − ξ i , ξ i ≥ 0 \begin{aligned} \min_{\boldsymbol{w},b,\xi} & \quad \frac{1}{2}\|\boldsymbol{w}\|^2 + C\sum_{i=1}^m \xi_i \\ \text{s.t.} & \quad y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b) \geq 1 - \xi_i, \quad \xi_i \geq 0 \end{aligned} w,b,ξmins.t.21∥w∥2+Ci=1∑mξiyi(wTxi+b)≥1−ξi,ξi≥0
惩罚系数C的作用:
- C→∞:严格硬间隔
- C→0:允许更大分类错误
三、模型评估
3.1 评估指标
| 指标 | 计算公式 | 适用场景 |
|---|---|---|
| 准确率 | T P + T N T P + T N + F P + F N \frac{TP+TN}{TP+TN+FP+FN} TP+TN+FP+FNTP+TN | 类别平衡时 |
| ROC AUC | 曲线下面积 | 综合性能评估 |
| 铰链损失 | max ( 0 , 1 − y i ( w T x i + b ) ) \max(0, 1 - y_i(\boldsymbol{w}^T\boldsymbol{x}_i + b)) max(0,1−yi(wTxi+b)) | 直接反映SVM优化目标 |
3.2 交叉验证调参
网格搜索示例:
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCVparams = {'C': [0.1, 1, 10],'gamma': ['scale', 'auto'],'kernel': ['rbf', 'poly']
}
grid = GridSearchCV(SVC(), params, cv=5)
grid.fit(X_train, y_train)
四、应用案例
4.1 手写数字识别
数据集:MNIST(60,000张28x28灰度图)
特征处理:
- 标准化像素值到[0,1]
- PCA降维保留95%方差
模型配置:
svm = SVC(kernel='rbf', C=10, gamma=0.001)
svm.fit(X_train_pca, y_train)
性能结果:
- 测试集准确率:98.2%
- 推理速度:120样本/秒
4.2 金融欺诈检测
业务场景:信用卡交易异常检测
特征工程:
- 交易金额标准化
- 时间窗口统计特征
- 用户行为序列建模
模型优化:
- 类别不平衡处理:class_weight=‘balanced’
- 使用RBF核捕捉非线性模式
产出效果:
- 欺诈交易召回率:89%
- 误报率:0.3%
五、经典面试题
问题1:SVM为什么采用间隔最大化?
关键点解析:
- 结构风险最小化:最大化间隔等价于最小化VC维,提升泛化能力
- 稀疏解性质:仅依赖支持向量,抗噪声能力强
- 几何解释:最大间隔划分对未见数据最鲁棒
问题2:核函数的作用是什么?
核心理解:
- 隐式映射:无需显式计算 ϕ ( x ) \phi(\boldsymbol{x}) ϕ(x),避免维度灾难
- 非线性扩展:在低维空间计算等价于高维空间的内积
- 灵活性:通过选择不同核函数适应数据结构
问题3:SVM如何处理多分类问题?
常见方案:
- One-vs-One:构建 k ( k − 1 ) 2 \frac{k(k-1)}{2} 2k(k−1)个二分类器
- One-vs-Rest:每个类与剩余类训练一个分类器
- DAGSVM:有向无环图组织分类器
对比分析:
| 方法 | 计算复杂度 | 训练时间 | 存储需求 |
|---|---|---|---|
| One-vs-One | O(k²) | 长 | 大 |
| One-vs-Rest | O(k) | 短 | 小 |
六、高级优化技术
6.1 增量学习
处理大规模数据策略:
- 分块训练:将数据分为多个子集逐块训练
- 保留支持向量:每次迭代仅保留当前支持向量
- 热启动:用已有解初始化新模型
6.2 多核学习
组合多个核函数:
κ ( x i , x j ) = ∑ k = 1 K β k κ k ( x i , x j ) \kappa(\boldsymbol{x}_i, \boldsymbol{x}_j) = \sum_{k=1}^K \beta_k \kappa_k(\boldsymbol{x}_i, \boldsymbol{x}_j) κ(xi,xj)=k=1∑Kβkκk(xi,xj)
其中 β k ≥ 0 \beta_k \geq 0 βk≥0为核权重系数
七、最佳实践指南
7.1 参数调优建议
| 参数 | 典型取值范围 | 作用说明 |
|---|---|---|
| C | 10⁻³ ~ 10³ | 控制间隔与误差的权衡 |
| gamma | 10⁻⁵ ~ 1 | RBF核带宽,影响模型复杂度 |
| epsilon | 0.01 ~ 0.1 | 控制支持向量回归的容忍度 |
7.2 特征预处理要点
- 标准化:对线性核和RBF核必须执行
- 特征选择:使用RFECV进行递归特征消除
- 缺失值处理:SVM不支持缺失值,需提前填充
总结与展望
支持向量机凭借其坚实的数学基础和优秀的泛化性能,在模式识别、数据挖掘等领域持续发挥重要作用。未来发展方向包括:
- 大规模优化算法:提升超大数据集训练效率
- 深度核学习:结合深度神经网络学习核函数
- 异构计算加速:利用GPU/TPU加速核矩阵计算
相关文章:
【机器学习基础】机器学习入门核心算法:支持向量机(SVM)
机器学习入门核心算法:支持向量机(SVM) 一、算法逻辑1.1 基本概念1.2 核心思想线性可分情况 二、算法原理与数学推导2.1 原始优化问题2.2 拉格朗日对偶2.3 对偶问题2.4 核函数技巧2.5 软间隔与松弛变量 三、模型评估3.1 评估指标3.2 交叉验证…...
定时清理流媒体服务器录像自动化bash脚本
定时清理流媒体服务器保存录像文件夹 首先创建一个文件,解除读写权限 touch rm_videos.sh chmod 777 rm_videos.sh将内容复制进去,将对应文件夹等需要修改的内容,根据自己的实际需求进行修改 #!/bin/bash# 设置目标目录(修改为你的实际路…...

Logi鼠标切换桌面失效
Mac上习惯了滑屏切换桌面,所以Logi鼠标也定制了切换桌面的动作,有一天发现这个动作失效了,且只有切换桌面的动作失效。 发现Logi Options出现了这个提示,如图所示(具体原因未知,已配置不自动更新版本&…...

Go语言之匿名字段与组合 -《Go语言实战指南》
Go 没有传统的面向对象继承机制,但它通过“匿名字段(embedding)”实现了类似继承的组合方式,使得一个类型可以“继承”另一个类型的字段和方法。 一、什么是匿名字段 匿名字段就是在结构体中嵌套一个类型而不显式命名字段名。该字…...

Linux 进阶命令篇
一、Linux 系统软件安装命令 (一)Ubuntu 系统(基于 Debian) apt :是 Ubuntu 系统中常用的包管理工具,可以自动处理软件依赖关系。 安装命令格式 :sudo apt install 软件名 示例 :…...
)
OpenCV CUDA模块图像处理------颜色空间处理之拜耳模式去马赛克函数demosaicing()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于在 GPU 上执行拜耳图像(Bayer Pattern)的去马赛克操作(Demosaicing),将单通…...

2025年全国青少年信息素养大赛复赛C++集训(15):因子问题(题目及解析)
2025年全国青少年信息素养大赛复赛C集训(15):因子问题(题目及解析) 题目描述 任给两个正整数N、M,求一个最小的正整数a,使得a和(M-a)都是N的因子。 时间限制:10000 内存限制&…...

如何通过仿真软件优化丝杆升降机设计
通过仿真软件优化丝杆升降机设计可从多维度入手,以下为具体方法和分析: 一、基于有限元分析的结构优化 材料优化:通过ANSYS等软件建立三维模型,施加实际工况载荷(如轴向力、径向力、扭矩),计算…...
Vue3进阶教程:1.初次了解vue
1.初次了解vue vue文件目录和各个文件在这里不做介绍 此课程对针对有点vue基础的同学,或者看过我上部分vue的教程 与之前我的Vue教程不同的是,写法和内容有区别 真正的了解Vue3 1.创建vue组件 1.npm create vuelatest 2.取名 3.TS要选上 4.其他先不选 5…...

WordPress免费网站模板下载
大背景图免费wordpress建站模板 这个wordpress模板设计以简约和专业为主题,旨在为用户提供清晰、直观的浏览体验。以下是对其风格、布局和设计理念的详细介绍: 风格 简约现代:整体设计采用简约风格,使用了大量的白色和灰色调&am…...

【深度学习新浪潮】以图搜地点是如何实现的?(含大模型方案)
1. 以图搜地点的实现方式有哪些? 扫描手机照片中的截图并识别出位置信息,主要有以下几种实现方式: 通过照片元数据获取: 原理:现代智能手机拍摄的照片通常会包含Exif(Exchangeable Image File)元数据。Exif中除了有像素信息之外,还包含了光圈、快门、白平衡、ISO、焦距…...
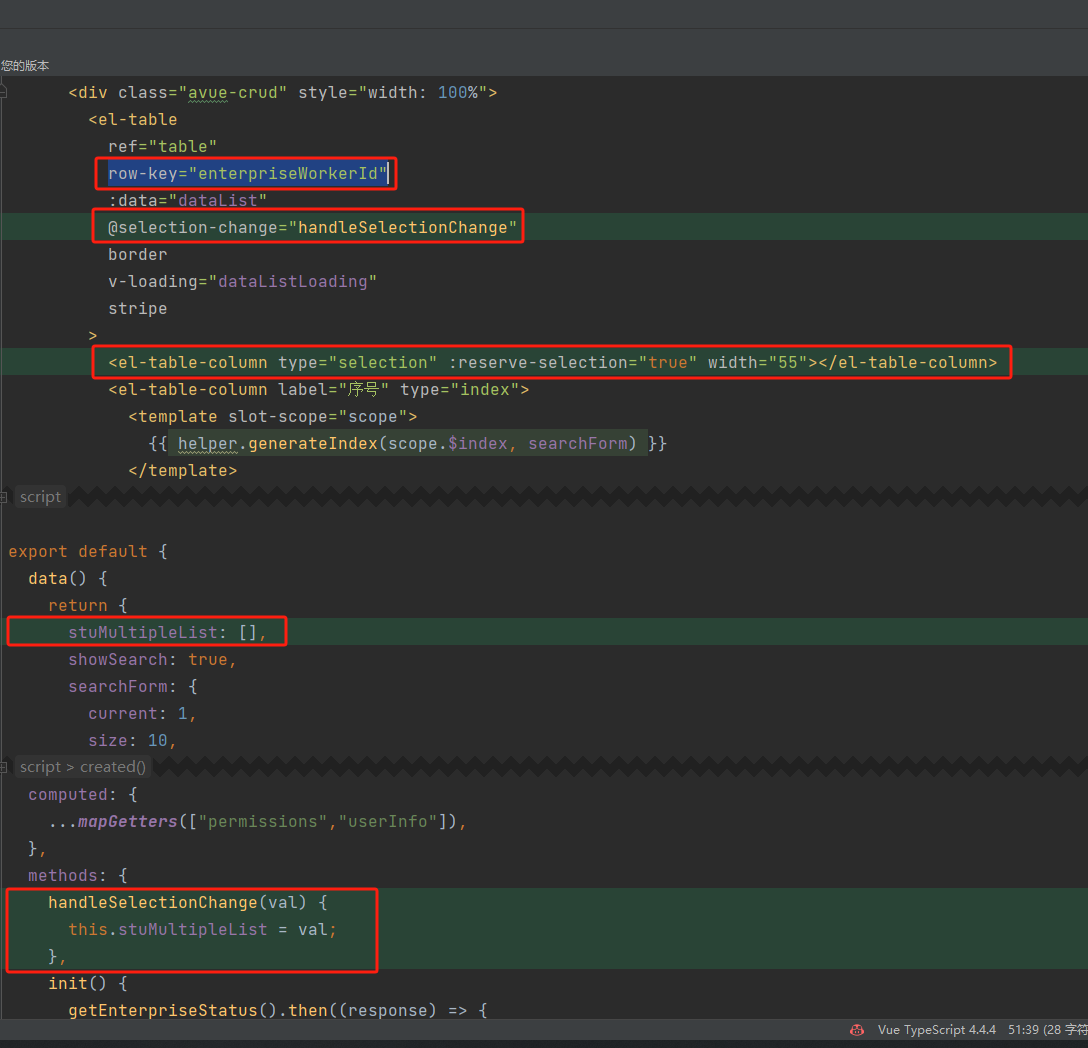
element的el-table翻页选中功能
el-table翻页选中功能 row-key"enterpriseWorkerId" selection-change"handleSelectionChange"<el-table-column type"selection" :reserve-selection"true" width"55"></el-table-column>stuMultipleList: []…...
Python打卡训练营学习记录Day38
知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import torch import torch.nn as nn import torch.opt…...
deepseek开源资料汇总
参考:DeepSeek“开源周”收官,连续五天到底都发布了什么? 目录 一、首日开源-FlashMLA 二、Day2 DeepEP 三、Day3 DeepGEMM 四、Day4 DualPipe & EPLB 五、Day5 3FS & Smallpond 总结 一、首日开源-FlashMLA 多头部潜在注意力机制&#x…...

CollUtil详解
CollUtil 是 Hutool 工具库中的一个工具类,专门用于操作集合(Collection)。它提供了许多静态方法,可以简化对集合的常见操作,例如判断集合是否为空、合并集合、过滤集合等。 以下是关于 CollUtil 的详细介绍和常用方法…...

Elasticsearch的运维
Elasticsearch 运维工作详解:从基础保障到性能优化 Elasticsearch(简称 ES)作为分布式搜索和分析引擎,其运维工作需要兼顾集群稳定性、性能效率及数据安全。以下从核心运维模块展开说明,结合实践场景提供可落地的方案…...
Linux编辑器——vim的使用
vim是一款多模式的编辑器。 基本操作:vim打开默认是命令模式,也就是输入命令然后系统执行指令,想要写代码,只需输入字母i,就进入插入模式,写完代码想要退出,按一下Esc,退回到命令模…...

线性回归原理推导与应用(八):逻辑回归二分类乳腺癌数据分类
乳腺癌数据是sklearn中自带的数据集,需要通过相关特征对是否患有乳腺癌进行分类。 数据清洗与建模 首先加载相关库和相关数据 from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression import numpy as np import…...
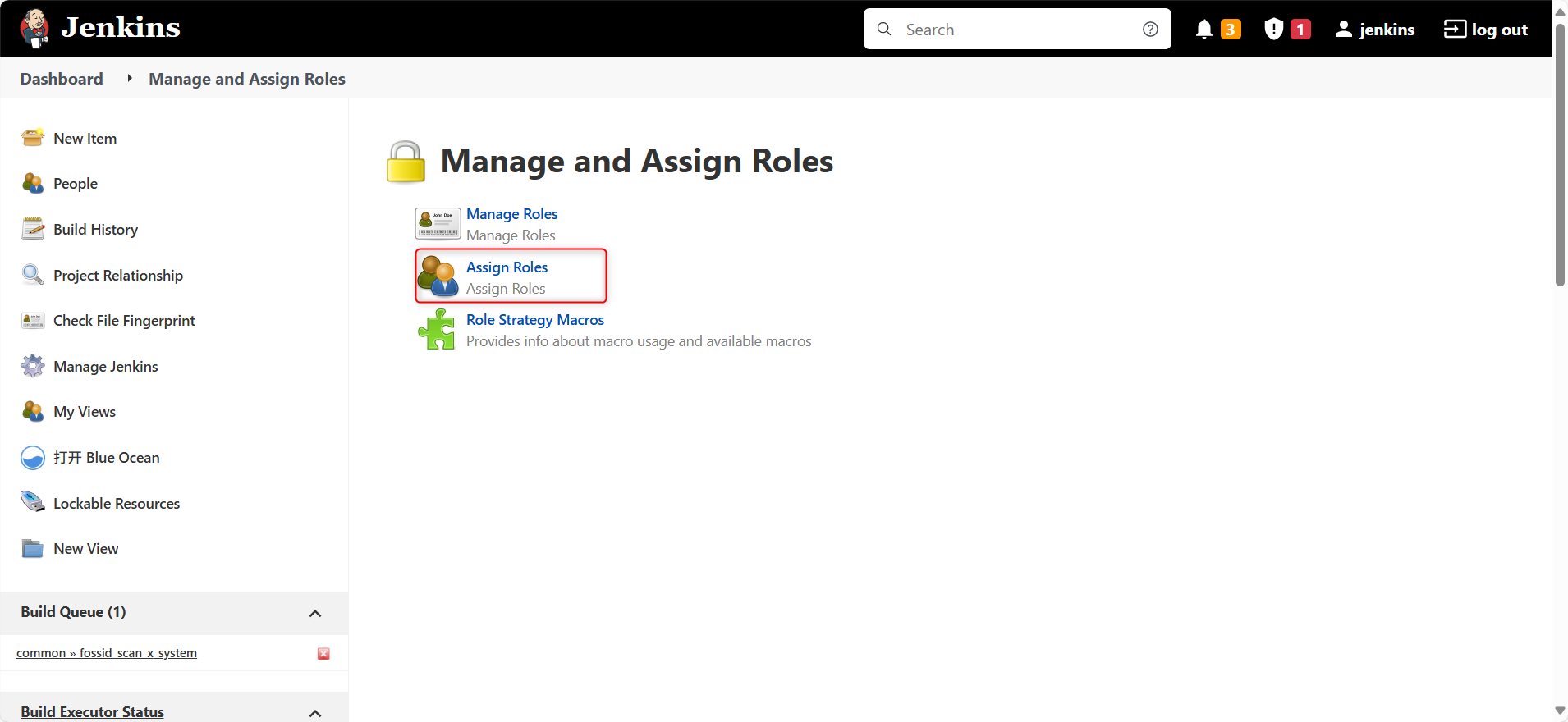
Jenkins分配对应项目权限与用户管理
在日常开发过程中经常会出现用户和权限管理问题,没有配置trigger时,通常需要我们手动构建,但此时前端和后端的朋友没有build权限,导致每次dev环境测试都需要麻烦我们手动去构建,消息传达不及时则会降低开发效率。 现有…...
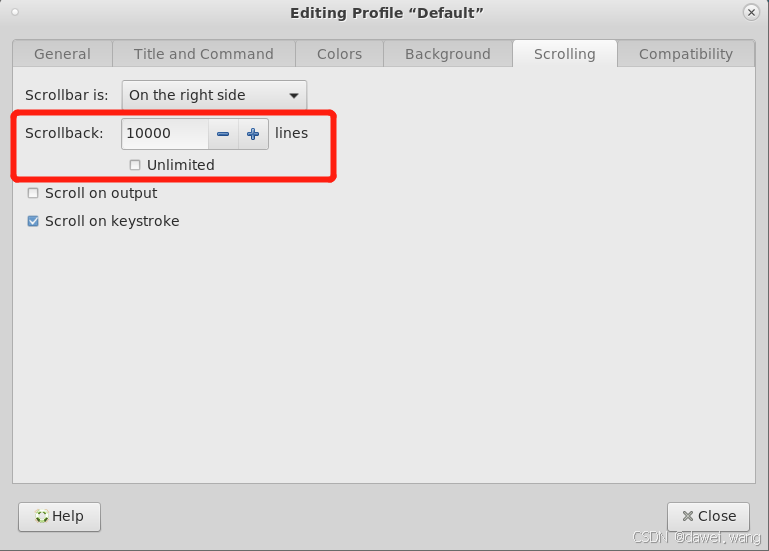
Mate桌面环境系统与终端模拟器参数配置
说明: MATE桌面环境在使用中会优化一些参数配置,例如:电源选项、屏幕配置、字体配置、终端模拟器(Mate Terminal)配置等等。 通常工程师会根据自己喜好调整一些参数,修改后参数的保存位置在/home/u…...
fabric 是一个开源框架,用于使用 AI 增强人类能力。它提供了一个模块化框架,用于使用一组可在任何地方使用的众包人工智能提示来解决特定问题
一、软件介绍 文末提供程序和源码下载 fabric 是一个开源框架,用于使用 AI 增强人类能力。它提供了一个模块化框架,用于使用一组可在任何地方使用的众包人工智能提示来解决特定问题。 二、What and why 什么和为什么 自 2023 年初和 GenAI 以来&…...

基于PDF流式渲染的Word文档在线预览技术
一、背景介绍 在系统开发中,实现在线文档预览与编辑功能是许多项目的核心需求,但在实际的开发过程中,我们经常会面临以下难点: 1)格式兼容性问题:浏览器原生不支持解析Word二进制格式,直接渲染会…...

华为仓颉语言初识:结构体struct和类class的异同
前言 华为仓颉语言是鸿蒙原生应用的一种新的编程语言,采用面向对象的编程思想,为开发者带来新的开发体验。不仅可以和 ArkTs 相互调用,更能提升应用程序的性能,更重要的是仓颉语言的特点结合了 java 和 C 的特点。对开发者来说比…...
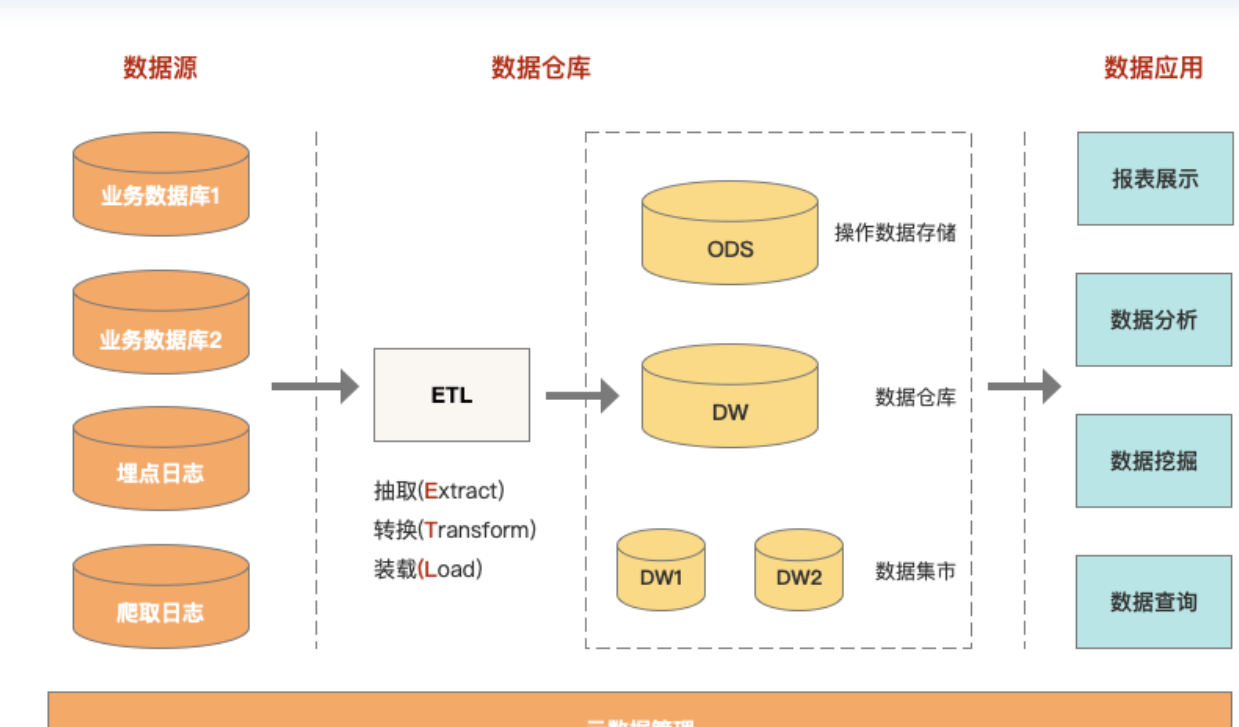
数据仓库基础知识总结
1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 1)数据仓库是用于支持决策、面向分析型数据处理; 2)对多个异构的数据源有效集…...
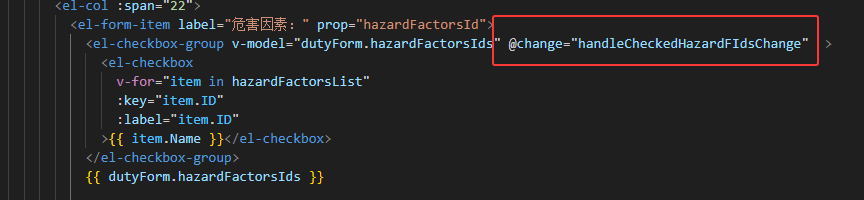
vue2使用element中多选组件el-checkbox-group,数据与UI更新不同步
问题描述 使用element多选checkbox组件,点击勾选取消勾选,视图未变化,再次点击表单其他元素,多选组件勾选状态发生变化,视图和数据未同步 第一次尝试:再el-checkbox-group多选父组件上增加点击事件&…...
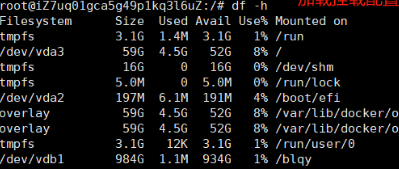
linux磁盘分区及挂载、fdisk命令详解
文章目录 1.Linux磁盘分区概念精要1.1 分区的定义1.2 多分区的必要性1.2.1 数据安全隔离1.2.2 提升存储效率1.2.3 防止系统资源耗尽1.2.4 fdisk用法介绍 2.服务器挂载磁盘实战详细步骤2.1检查磁盘情况及格式化2.2磁盘分区2.3 磁盘目录挂载2.3.1 创建挂载目录2.3.2 …...

anaconda 安装教程以及常用命令
安装教程 安装教程 常用命令 Conda是一个非常强大的包管理和环境管理工具,以下是一些常用命令: 环境管理命令 创建环境 创建指定Python版本的环境:例如,创建名为 myenv,Python版本为3.9的环境。conda create -n m…...

C/C++的OpenCV的锐化
图像锐化技术:使用 C/C的OpenCV 增强图像细节 ✨ 图像锐化是一种常见的图像处理技术,其目的是增强图像的边缘和细节,使图像看起来更清晰、更鲜明。这在很多应用中都非常有用,例如医学成像、卫星图像分析以及提升普通照片的视觉质…...
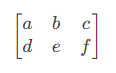
Eigen矩阵存储顺序以及转换
一、Eigen矩阵存储顺序 在矩阵运算和线性代数中,"行优先"(Row-major)和"列优先"(Column-major)是两种不同的存储方式,它们决定了多维数组(如矩阵)在内存中的布局顺序。 1. 行优先(Row-major) 定义:矩阵按行顺序存储在内存中,即第一行的所有元…...

OpenLayers 加载ArcGIS瓦片数据
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 随着GIS应用的不断发展,Web地图也越来越丰富,除了像ESRI、超图、中地数码这样GIS厂商有各自的数据源格式,也有Google…...