深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此找到这个维度数据之间的联系。
SENet 注意力模块
场景出发:CNN 的缺点
传统 CNN 在处理一张图片(或特征图)时,默认每个通道都一样重要,全部都送到下一层。但事实是:
-
某些通道可能表示重要信息(比如边缘、血管、肿瘤区域)
-
某些通道是冗余的,或者是噪声
CNN 不会主动区分这些通道的“重要性”,这就是性能的瓶颈。
SENet模块的目标:让网络自己学会哪些通道重要,放大它们;不重要的通道就抑制。
模块结构总览
SENet 主要由三步组成(你可以记成 3 个“S”):
| 步骤 | 名称 | 直观解释 |
|---|---|---|
| ① Squeeze(压缩) | 把整张图“压成一个通道向量” | 得到每个通道的重要性“初始印象” |
| ② Excitation(激励) | 用两层小全连接网络分析通道之间的关系 | 学出权重向量 |
| ③ Scale(重标定) | 把每个通道乘上权重 | 强化重要通道,抑制次要通道 |
✅ 第一步:Squeeze(压缩)
输入:一张特征图,大小是 [B, C, H, W]
意思是:batch大小为B,有C个通道,每张图的高为H,宽为W
操作:对每个通道做平均池化,把每张通道图变成1个值:
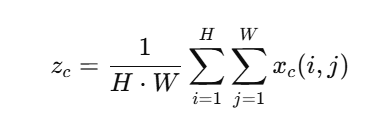
也就是说:
每个通道 → 取平均 → 得到该通道的“整体响应程度”
目的:
-
把一个
[C, H, W]的特征图压成[C, 1, 1] -
每个通道只用一个数字表示,用于描述“它在整个图中有多强”
举个例子
比如你有一个特征图 [3, 4, 4](3个通道,4×4大小),假设:
-
第1通道值都很大(比如检测到边缘)
-
第2通道值都一般
-
第3通道值都很小(基本没信息)
做完池化后得到 [0.9, 0.5, 0.1],这就是对通道重要性的“初印象”。
第二步:Excitation(激励)
上一步你得到了一个大小为 [C] 的通道向量,表示每个通道的“存在感”。
现在要做的事:用两层全连接网络 去学习通道间的依赖关系,并产生新的权重向量 s,表示“真正重要的通道”。
为什么要用两层 FC(全连接)?
-
第一层:降低维度,学出非线性组合(像压缩感知)
-
第二层:恢复维度,输出最终的通道权重
-
使用 ReLU + Sigmoid:
-
ReLU:引入非线性,模拟复杂关系
-
Sigmoid:将权重限制在 [0,1][0, 1][0,1] 区间,便于加权
-
数学形式:
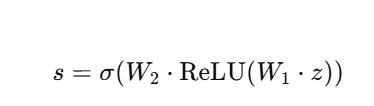
-
W1:将通道数降为 C(比如16分之一)
-
W2:再升回原始通道数 C
-
σ 激活,输出范围在 [0,1]
第三步:Scale(加权重标定)
你现在得到了每个通道的重要性权重 s∈RC,比如:s=[0.95,0.21,0.76,… ]
就把原特征图中每个通道乘上对应的权重:
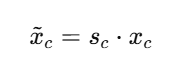
通俗地说:
-
sc 越接近 1 → 通道保持不变或增强
-
sc 越接近 0 → 通道抑制或屏蔽
这样,模型就能自动忽略冗余特征,专注有用特征。
这样做到底有什么用?
-
动态调节特征通道
-
不再“一刀切”地对待每个通道,而是自适应处理
-
-
增强网络的判别能力
-
在分类、检测、分割任务中,能让模型更关注重要区域和通道
-
-
几乎不增加计算量
-
两个小FC层,几乎不影响速度
-
举个真实应用的例子:
以医学图像分割为例(比如CT脑出血):
-
UNet 的解码部分可能生成多个通道
-
有的通道强调脑出血的边缘,有的通道是背景,有的通道是噪声
-
使用 SE 模块后,模型学会:
-
放大表示“出血边缘”的通道
-
减弱“背景”或“无效特征”的通道
-
-
最终输出的掩膜更精准、更聚焦于病灶
第二部分:CBAM 模块(通道注意力 + 空间注意力)
CBAM = 通道注意力(Channel Attention) + 空间注意力(Spatial Attention)
相当于在“看什么通道”的基础上,加了“看图中哪里”的能力。
✅ 一句话总结:
SENet 只关注“哪个通道重要”,CBAM 则进一步判断:
-
哪些通道重要(Channel Attention)
-
哪些空间位置重要(Spatial Attention)
类比人类视觉:不仅知道“哪些颜色”重要(通道),还要知道“看哪里”最重要(空间)
CBAM的结构图:
一个标准的 CBAM 模块如下:
输入特征图 [B, C, H, W]↓
[1] 通道注意力模块(Channel Attention)↓
输出 [B, C, H, W],但每个通道已加权调整↓
[2] 空间注意力模块(Spatial Attention)↓
最终输出 [B, C, H, W],空间区域也被加权强化
模块一:通道注意力(Channel Attention)
这一步其实类似 SENet,但做了些优化。
原理:
通道注意力模块的目标是:学习每个通道的重要程度
CBAM的设计里,它使用了**两个不同的池化方式(MaxPool + AvgPool)**来获取通道描述。
步骤:
-
输入特征图
[B, C, H, W] -
分别做平均池化和最大池化 → 得到两个通道描述向量
[B, C, 1, 1] -
把这两个通道向量送入共享的MLP(两层全连接) → 得到两个权重
-
加和后做 sigmoid 激活 → 得到通道注意力权重向量
[B, C, 1, 1] -
与原始特征图相乘,输出加权通道图
数学表达:
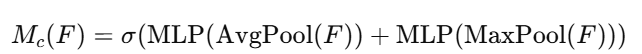
-
输出是大小为
[B, C, 1, 1]的通道注意力图 -
与输入特征图逐通道相乘
模块二:空间注意力(Spatial Attention)
这一步是 CBAM 的关键创新。
原理:
通道注意力告诉我们“要看哪个通道”,但我们还需要知道“在图像的哪个位置重要”。
空间注意力模块学习的是一个二维图,表示每个像素点的重要性。
步骤:
-
输入来自上一步的特征图
[B, C, H, W] -
在通道维上做 max-pooling 和 avg-pooling → 得到两个
[B, 1, H, W]的图 -
将两个图拼接 concat →
[B, 2, H, W] -
用一个 7×7卷积核 处理 → 得到一个
[B, 1, H, W]的空间注意力图 -
与输入图做逐像素点相乘(广播) → 输出最终注意力加权图
数学表达:
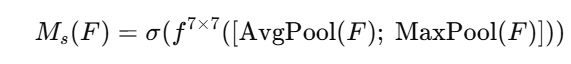
-
输出是大小为
[B, 1, H, W]的空间注意力图 -
与输入图逐元素相乘,实现“看哪里”的目的
第三部分:BAM 模块(瓶颈注意力模块)
全称:Bottleneck Attention Module,发表于 ECCV 2018
BAM 也是“通道注意力 + 空间注意力”的组合,但与 CBAM 串联结构不同,BAM 使用并联结构,即同时计算通道和空间注意力,最后相乘后用于加权特征图。
BAM 的整体结构:
输入特征图 X↓
分支1:通道注意力模块(MLP)↓
分支2:空间注意力模块(空洞卷积)↓
通道注意力 × 空间注意力 → 融合注意力权重↓
加权输入特征:F_out = X × (1 + Attention)
注意:
-
与 CBAM 不同,BAM 是“并行计算注意力”,结果合并
-
输出特征图是
X × (1 + Attention),即保留了原始特征 + 注意力增强项
模块一:通道注意力(Channel Attention)
原理:
与 SENet 类似,使用全局平均池化 + MLP 学习每个通道的重要性。
数学表达:
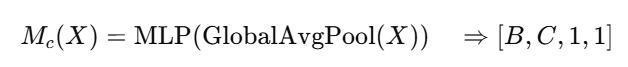
-
通道注意力输出为
[B, C, 1, 1] -
广播乘回输入图
模块二:空间注意力(Spatial Attention)
原理:
使用多个**空洞卷积(dilated conv)**进行多尺度空间建模,增强对空间结构的理解能力。
操作:
-
用多个空洞卷积提取不同尺度的空间结构信息
-
用 ReLU 和 BatchNorm 激活
-
最后输出一个
[B, 1, H, W]的空间注意力图
数学表达:

整体融合方式
注意力融合方式是:

然后再与输入特征图相乘:
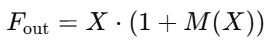
这里的 1 + M(X) 是为了保留部分原始信息,防止模型过度依赖注意力。
第四部分:Non-local Attention(非局部注意力)
全称:Non-local Neural Networks,发表于 CVPR 2018,提出者来自 Facebook AI
Non-local Attention 是一种 全局建模方法,它通过计算任意两个位置之间的关系(非局部),实现信息的长距离传递,弥补了卷积/池化等本地操作的缺陷。
为什么叫“非局部”?
传统 CNN(如卷积、池化)每次只能处理局部邻域,想要获取长距离信息必须多层堆叠。而 Non-local 可以一步捕捉图像中任意两个像素之间的关系,这种跨越距离的机制就叫做“非局部操作”。
数学表达(核心公式)
给定输入特征图 X∈RC×H×WX ,Non-local 输出如下:
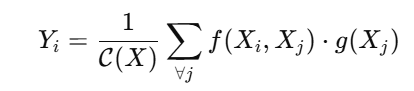
-
Yi:位置 i的输出特征
-
f(Xi,Xj):位置 i 与 j的相似度函数
-
g(Xj):从位置 j 抽取的信息
-
C(X):归一化因子
组成模块详解
Non-local 模块包含以下子模块:
查询-键-值(Q-K-V)机制
与 Transformer 中的 self-attention 思想一致:
-
Query Q=WqXQ
-
Key K=WkXK
-
Value V=WvXV
都是使用 1×1 卷积进行变换,降维。
相似度计算函数 f
常用的是嵌入高斯核(Embedded Gaussian):
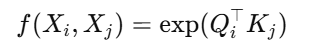
再通过 softmax 归一化:
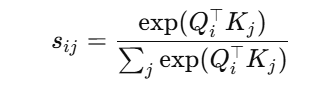
表示位置 i 与所有位置 jj的关系。
输出加权求和:
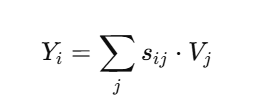
就是所有位置的 Value 乘以其与位置 iii 的相似度,再求和。
残差连接(Residual)
最终输出为:
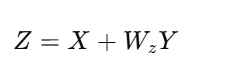
其中 Wz 是一个 1×1 卷积,用于调整通道。
结构图
Input X↓┌─────────────┐│ Query (Wq) │└─────────────┘↓┌─────────────┐│ Key (Wk) │└─────────────┘↓相似度计算(Softmax)↓┌─────────────┐│ Value (Wv) │└─────────────┘↓加权求和输出 → Wz → + Input → 输出 Z
第五部分:Transformer 风格注意力模块在 CNN 中的嵌入
CoT Attention(Contextual Transformer)
来源:论文《Contextual Transformer Networks for Visual Recognition》(ICCV 2021)
CoT Attention 将 局部卷积 和 全局注意力 相结合,兼顾局部细节提取和上下文建模,是将 Transformer 精髓嵌入到 CNN 模块中的一个代表作,既能卷积、又能“看远”。
背景问题
普通自注意力模块存在两个问题:
-
不善于捕捉局部空间关系(不像卷积)
-
计算复杂度高(空间维度平方级)
CoT 的目标是构造一个低成本、高表达力、可嵌入 CNN 的注意力模块,适合视觉场景。
CoT Attention 的核心结构
输入特征图 X∈RB×C×H×WX,CoT Attention 包括三步:
步骤 1:提取上下文上下文信息(K)
使用 3×3 卷积获取每个位置的上下文表示:
K=Conv3x3(X)
这一步像是加强局部语义建模能力,不像传统 attention 那样直接线性变换。
步骤 2:提取 Query,并与 Key 融合形成 Attention Map
先计算 Query:
Q=1x1Conv(X)
然后将 Q 与每个位置对应的上下文 Key 拼接,再经过非线性映射得到每个位置的注意力权重(权重是一个 卷积核 的形式):
A=MLP([Qi,Ki])
-
[Qi,Ki]:表示 Q 和其上下文信息拼接
-
MLP 通常是 1x1 卷积 + BN + ReLU + 1x1 卷积
步骤 3:加权 Value 特征生成输出
用上一步得到的注意力作为动态卷积核,对输入 X 做卷积:
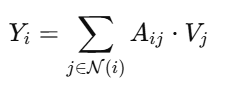
其中:
-
N(i):位置 i 的邻域(比如 3×3 范围)
-
Aij:是对邻域位置的注意力
-
Vj:是邻域内的特征
最终结果是Query 中的每个位置都用一套 attention 卷积核动态聚合周围信息,结合上下文生成新特征。
结构图
Input Feature X↓┌──────────────┐│ 3x3 Conv │ → K (上下文)└──────────────┘↓┌──────────────┐│ 1x1 Conv │ → Q└──────────────┘↓[Q || K] 拼接↓┌──────────────┐│ MLP │ → Attention Weights (动态核)└──────────────┘↓动态卷积 → 输出 Y
第六部分:Efficient Channel Attention(ECA)
来源:论文《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》(CVPR 2020)
ECA 是对 SENet 的改进,不使用全连接层、参数更少、计算更快、效果不差甚至更好。它用一个小的 1D 卷积代替 FC 层,自适应建模通道间依赖关系。
背景:SENet 的局限
-
对特征做全局平均池化 → 得到每个通道的统计值
-
用 2 层 FC 层建模通道关系 → 得到权重
-
对输入每个通道乘以对应权重
-
两个 FC 层引入了不少参数(尤其是通道数大时)
-
存在“信息瓶颈”问题(中间维度压缩可能丢失信息)
ECA 的创新点
ECA 用一维卷积(1D卷积)替换 FC 层:
-
不使用维度压缩
-
使用局部通道间交互
-
极大减少参数和计算量
简洁结构,性能却优于SENet!
ECA Attention 的结构
输入特征图 X∈RB×C×H×W
步骤 1:全局平均池化(GAP)
得到通道级描述向量 z∈RB×C
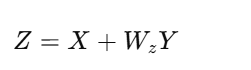
每个通道一个数
步骤 :1D 卷积建模通道关系
将 z∈RB×C 看作一个 1D 向量序列:
s=Conv1D(z)
这一步相当于用滑动窗口对每个通道与其周围通道建模依赖(比如和前后3个通道的关系)
卷积核大小 k 的选择:动态计算,如:
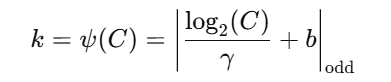
论文中使用 γ=2, b=1(保证输出为奇数)
步骤 :Sigmoid 激活 + 通道加权
得到每个通道的 attention 权重后:
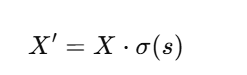
这里 σ\sigmaσ 是 Sigmoid,进行通道维度的加权增强。
ECA 的结构图
Input Feature X↓┌────────────────────┐│ Global Avg Pooling │ → z ∈ ℝ^C└────────────────────┘↓┌────────────────┐│ 1D Conv(k) │ ← 不用FC└────────────────┘↓Sigmoid↓通道加权输出 X'
第七部分:Coordinate Attention(坐标注意力,CA)
来源:论文《Coordinate Attention for Efficient Mobile Network Design》(CVPR 2021)
Coordinate Attention(坐标注意力)是一种结合了通道注意力和位置信息的机制,既保留了通道间的依赖,又引入了精确的空间位置信息编码,适合移动设备和轻量网络,也很适合图像分割等视觉任务。
背景问题
传统的通道注意力(比如SE、ECA)忽略了空间信息,只对通道进行加权,但空间位置信息对于视觉任务尤为关键;而纯空间注意力计算复杂,难以部署。
坐标注意力创新地将空间位置的两条坐标轴信息分开编码,做到:
-
低计算量
-
高效捕捉长距离空间依赖
-
兼顾空间和通道信息
Coordinate Attention 的核心结构
输入特征图 X∈RB×C×H×W
步骤 1:对空间两个坐标轴分别做全局池化
-
沿着 宽度方向做全局平均池化,得到 gh∈RB×C×H×1
-
沿着 高度方向做全局平均池化,得到 gw∈RB×C×1×W
这一步分别捕获了每行和每列的空间特征。
步骤 2:连接两个池化结果并通过共享卷积
将 gh 和 gw 在空间维度上拼接成 RB×C×(H+W)×1,然后通过一个 1×11 \times 11×1 卷积降维(通常降为 C/r,r为缩减率),再经过非线性激活(ReLU)。
步骤 3:分离特征并分别投影
把降维后的特征分为两部分,分别对应 H 和 W 方向,然后各自通过一个 1×1 卷积恢复通道维度,得到两个注意力权重映射:
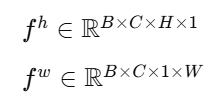
步骤 4:利用广播机制,将两个权重乘到输入特征 X上
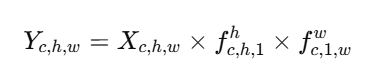
这样既考虑了通道的注意力,也引入了空间的位置信息。
结构图示意
Input X (B, C, H, W)│┌────────────────────┐│ Pool H-axis (Avg) │ → g^h (B, C, H, 1)└────────────────────┘│┌────────────────────┐│ Pool W-axis (Avg) │ → g^w (B, C, 1, W)└────────────────────┘│拼接 (H+W)│┌─────────────────┐│ 1x1 Conv + ReLU │└─────────────────┘│┌────────────────────┐│ Split → 1x1 Conv │└────────────────────┘↓ ↓f^h (B,C,H,1) f^w (B,C,1,W)↓ ↓\ /\ /Element-wise multiplication│Output Feature Y
相关文章:
深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此…...

openssl 使用生成key pem
好的,以下是完整的步骤,帮助你在 Windows 系统中使用 OpenSSL 生成私钥(key)和 PEM 文件。假设你的 openssl.cnf 配置文件位于桌面。 步骤 1:打开命令提示符 按 Win R 键,打开“运行”对话框。输入 cmd&…...

python:基础爬虫、搭建简易网站
一、基础爬虫代码: # 导包 import requests # 从指定网址爬取数据 response requests.get("http://192.168.34.57:8080") print(response) # 获取数据 print(response.text)二、使用FastAPI快速搭建网站: # TODO FastAPI 是一个现代化、快速…...
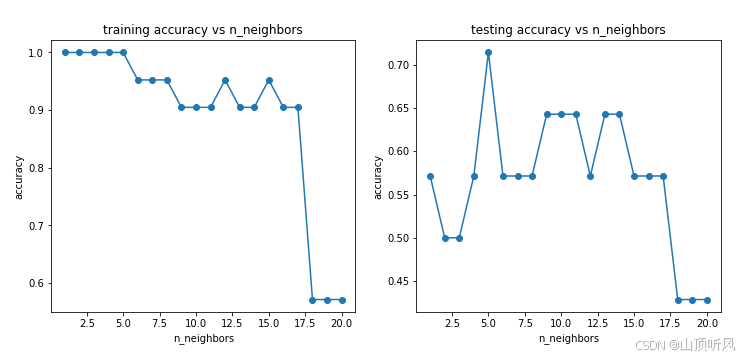
好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务 好坏质检分类实战 task: 1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除 2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分 3、完成数据分离,数据分离…...

链表:数据结构的灵动舞者
在数据结构的舞台之上,链表以它灵动的身姿演绎着数据的精彩故事。与顺序表的规整有序不同,链表展现出了别样的灵活性与独特魅力。今天,就让我们一同走进链表的世界,去领略它的定义、结构、操作,对比它与顺序表的优缺点…...
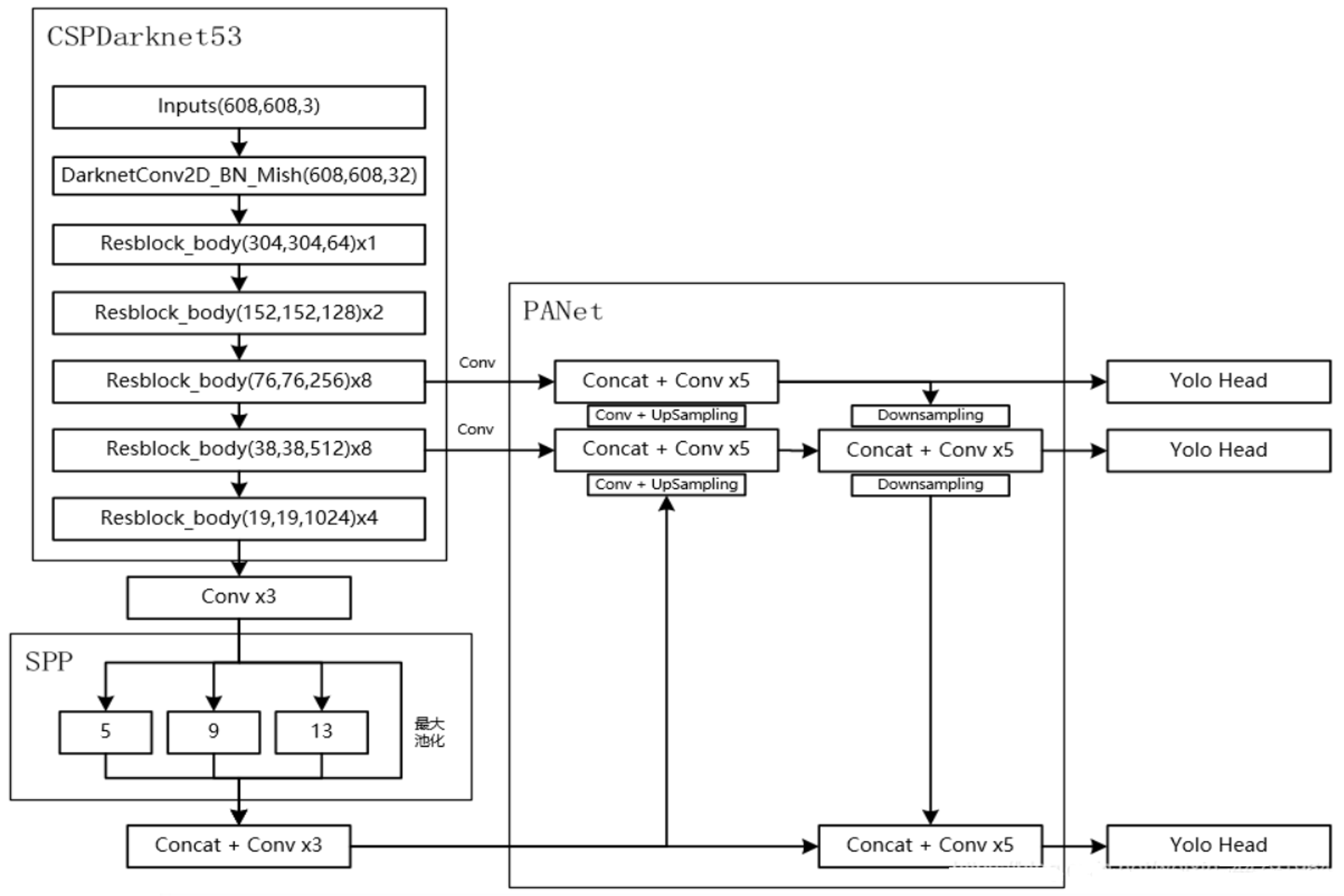
YOLOv4:目标检测的新标杆
引言 YOLO(You Only Look Once)系列作为目标检测领域的经典算法,以其高效的检测速度和良好的准确率闻名。2020年推出的YOLOv4在保持YOLO系列高速检测特点的同时,通过引入多项创新技术,将检测性能提升到了新高度。本文将详细介绍YOLOv4的核心…...
)
PyTorch 2.1新特性:TorchDynamo如何实现30%训练加速(原理+自定义编译器开发)
一、PyTorch 2.1动态编译架构演进 PyTorch 2.1的发布标志着深度学习框架进入动态编译新纪元。其核心创新点TorchDynamo通过字节码即时重写技术,将Python动态性与静态图优化完美结合。相较于传统JIT方案,TorchDynamo实现了零侵入式加速——开发者只需添加…...
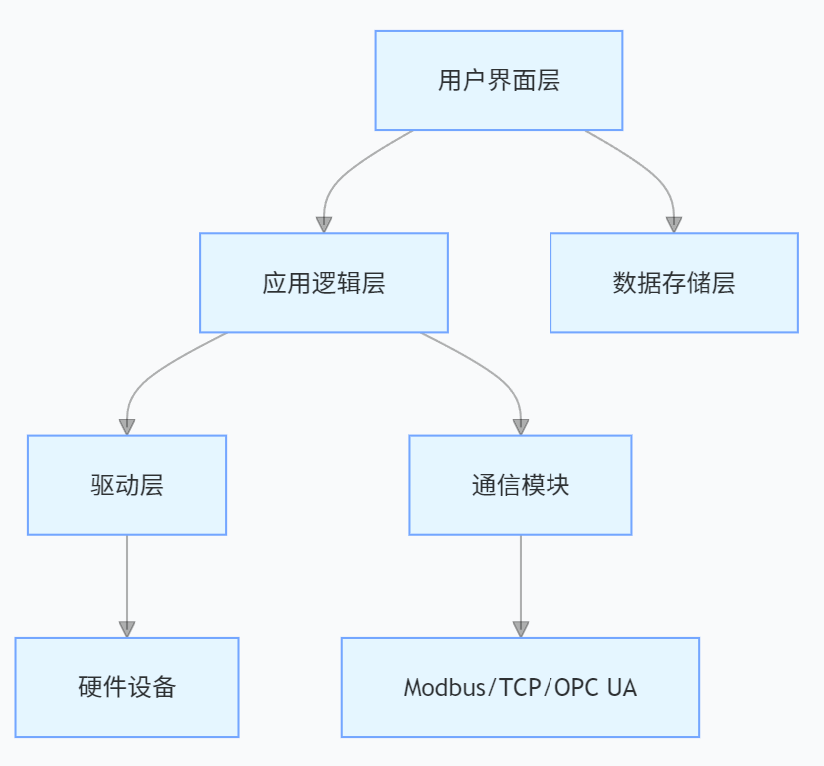
LabVIEW通用测控平台设计
基于 LabVIEW 图形化编程环境,设计了一套适用于工业自动化、科研测试领域的通用测控平台。通过整合研华、NI等品牌硬件,实现多类型数据采集、实时控制及可视化管理。平台采用模块化架构,支持硬件灵活扩展,解决了传统测控系统开发周…...

【机器学习基础】机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN)
机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN) 一、算法逻辑1.1 基本概念1.2 关键要素距离度量K值选择 二、算法原理与数学推导2.1 分类任务2.2 回归任务2.3 时间复杂度分析 三、模型评估3.1 评估指标3.2 交叉验证调参 四、应用…...
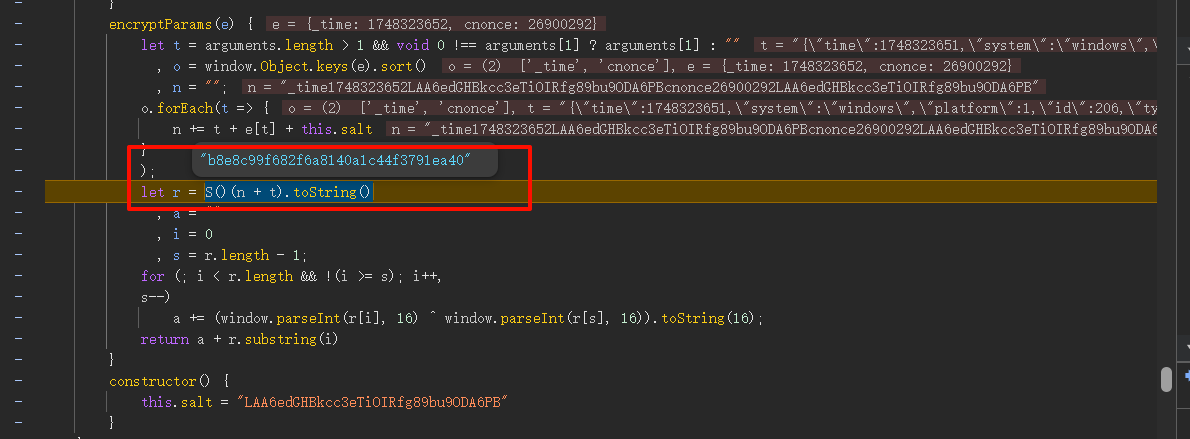
FastMoss 国际电商Tiktok数据分析 JS 逆向 | MD5加密
1.目标 目标网址:https://www.fastmoss.com/zh/e-commerce/saleslist 切换周榜出现目标请求 只有请求头fm-sign签名加密 2.逆向分析 直接搜fm-sign 可以看到 i["fm-sign"] A 进入encryptParams方法 里面有个S()方法加密,是MD5加密 3.代…...

Redis分布式缓存核心架构全解析:持久化、高可用与分片实战
一、持久化机制:数据安全双引擎 1.1 RDB与AOF的架构设计 Redis通过RDB(快照持久化)和AOF(日志持久化)两大机制实现数据持久化。 • RDB架构:采用COW(写时复制)技术,主进程…...
【Linux】基础开发工具(下)
文章目录 一、自动化构建工具1. 什么是 make 和 Makefile?2. 如何自动化构建可执行程序?3. Makefile 的核心思想4. 如何清理可执行文件?5. make 的工作原理5.1 make 的执行顺序5.2 为什么 make 要检查文件是否更新?5.2.1 避免重复…...

Python爬虫实战:研究Portia框架相关技术
1. 引言 1.1 研究背景与意义 在大数据时代,网络数据已成为企业决策、学术研究和社会分析的重要资源。据 Statista 统计,2025 年全球数据总量将达到 175ZB,其中 80% 以上来自非结构化网络内容。如何高效获取并结构化这些数据,成为数据科学领域的关键挑战。 传统爬虫开发需…...
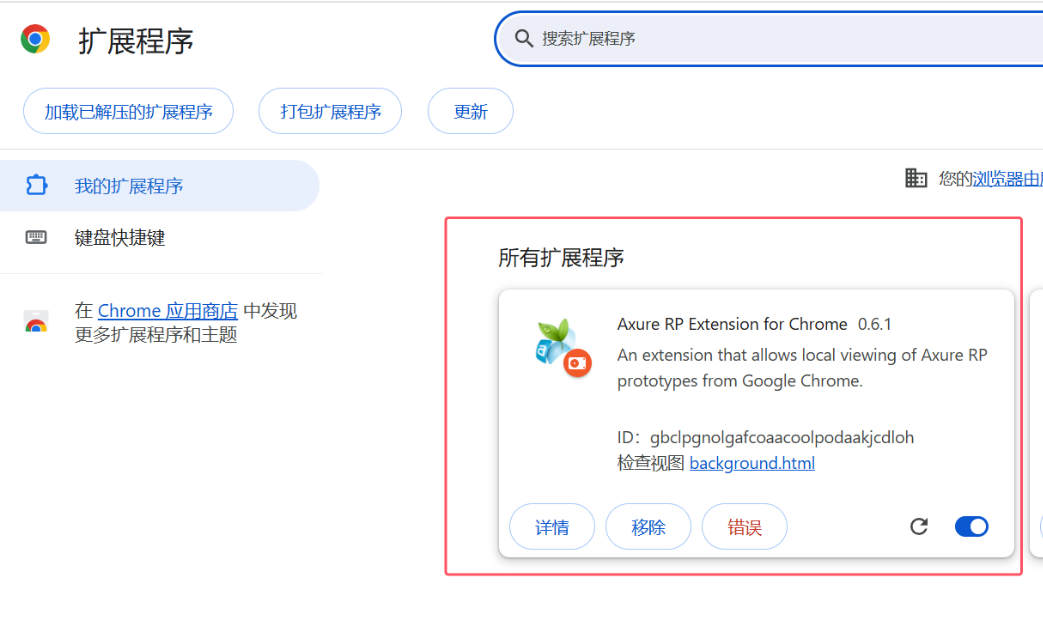
chrome打不开axure设计的软件产品原型问题解决办法
1、打开原型文件夹,进入到其中的如下目录中:resources->chrome->axure-chrome-extension.crx,找到 Axure RP Extension for Chrome插件。 2、axure-chrome-extension.crx文件修改扩展名.rar,并解压到文件夹 axure-chrome-ex…...

达梦数据库-学习-23-获取执行计划的N种方法
目录 一、环境信息 二、说点什么 三、测试数据生成 四、测试语句 五、获取执行计划方法 1、EXPLAIN (1)样例 (2)优势 (3)劣势 2、ET (1)开启参数 (2ÿ…...

【数据结构】树形结构--二叉树
【数据结构】树形结构--二叉树 一.知识补充1.什么是树2.树的常见概念 二.二叉树(Binary Tree)1.二叉树的定义2.二叉树的分类3.二叉树的性质 三.二叉树的实现1.二叉树的存储2.二叉树的遍历①.先序遍历②.中序遍历③.后序遍历④.层序遍历 一.知识补充 1.什…...

Baklib构建企业CMS高效协作与安全管控体系
企业CMS高效协作体系构建 基于智能工作流引擎的设计逻辑,现代企业内容管理系统通过预设多节点审核路径与自动化任务分配机制,有效串联市场、技术、法务等跨部门协作链路。系统支持多人同时编辑与版本追溯功能,结合细粒度权限管控模块&#x…...
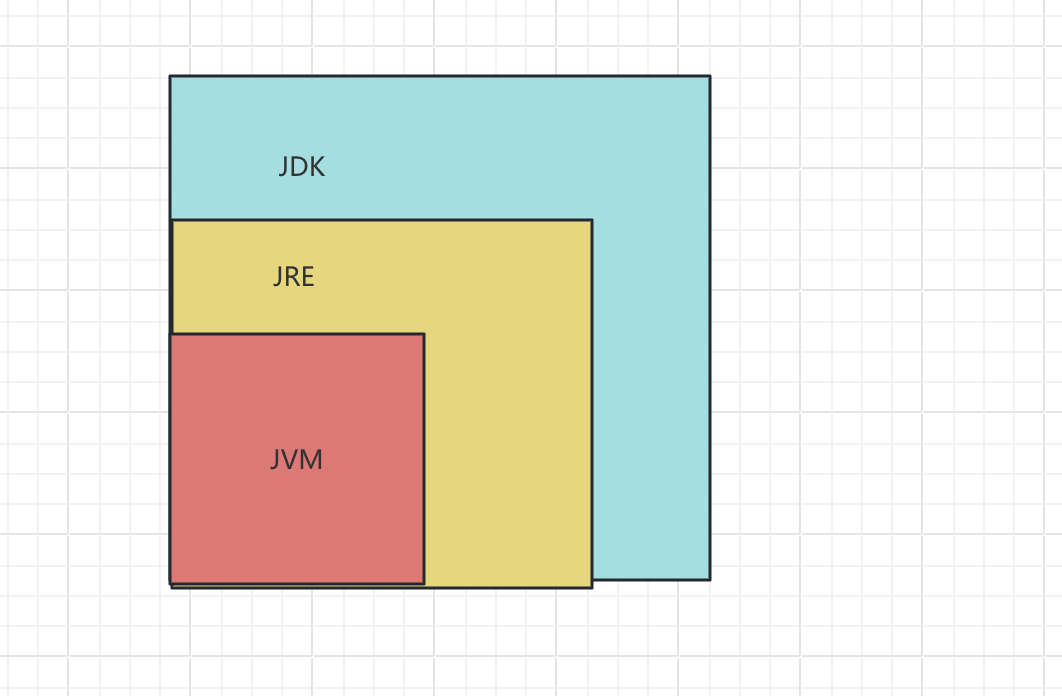
深入理解 JDK、JRE 和 JVM 的区别
在 Java 中,JDK、JRE 和 JVM 是非常重要的概念,它们各自扮演着不同的角色,却又紧密相连。今天,就让我们来详细探讨一下它们之间的区别。 一、JVM JVM 即 Java 虚拟机,它是整个 Java 技术体系的核心。JVM 提供了 Java…...

LSTM 与 TimesNet的时序分析对比解析
前言 Hi,我是GISerLiu🙂, 这篇文章是参加2025年5月Datawhale学习赛的打卡文章!💡 本文将深入探讨在自定义时序数据集上进行下游分类任务的两种主流分析方法。一种是传统的“先插补后分析”策略,另一种是采用先进的端到…...
图论学习笔记 4 - 仙人掌图
先扔张图: 为了提前了解我们采用的方法,请先阅读《图论学习笔记 3》。 仙人掌图的定义:一个连通图,且每条边只出现在至多一个环中。 这个图就是仙人掌图。 这个图也是仙人掌图。 而这个图就不是仙人掌图了。 很容易发现…...

语音识别算法的性能要求一般是多少
语音识别算法的性能要求因应用场景和实际需求而异,但以下几个核心指标是通用的参考标准。以下是具体说明: 1. 准确率(Accuracy) 语音识别的核心性能指标通常是词错误率(WER, Word Error Rate)和字符错误率…...

百度ocr的简单封装
百度ocr地址 以下代码为对百度ocr的简单封装,实际使用时推荐使用baidu-aip 百度通用ocr import base64 from enum import Enum, unique import requests import logging as logunique class OcrType(Enum):# 标准版STANDARD_BASIC "https://aip.baidubce.com/rest/2.0…...
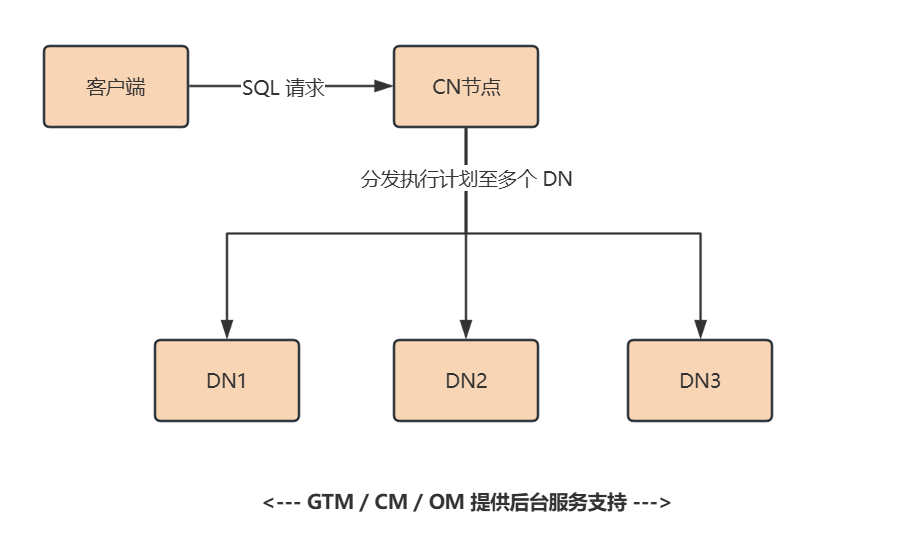
华为高斯数据库(GaussDB)深度解析:国产分布式数据库的旗舰之作
高斯数据库介绍 一、高斯数据库概述 GaussDB是华为自主研发的新一代分布式关系型数据库,专为企业核心系统设计。它支持HTAP(混合事务与分析处理),兼具强大的事务处理与数据分析能力,是国产数据库替代的重要选择。 产…...

LWIP 中,lwip_shutdown 和 lwip_close 区别
实际开发中,建议对 TCP 连接按以下顺序操作以确保可靠性: lwip_shutdown(newfd, SHUT_RDWR); // 关闭双向通信 lwip_close(newfd); // 释放资源...
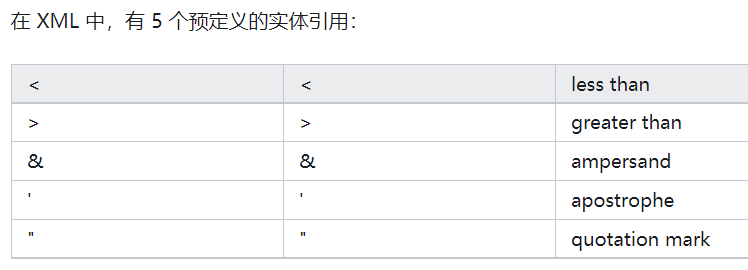
xml双引号可以不转义
最近在开发soap方面的协议,soap这玩意,就避免不了XML,这里我用到了pguixml库。 输入了这个XML后,发现<和>都被转义,但是""没有被转义,很是奇怪啊。毕竟去网上随便一搜转义字符,…...

互联网大厂Java面试:从Spring到微服务的挑战
文章简介 在这篇文章中,我们将模拟一场互联网大厂的Java面试,场景设置为企业协同与SaaS。面试官提出了一系列技术问题,涵盖了Java核心语言、Spring框架、微服务架构等技术点,并结合实际业务场景进行循序渐进的提问。最后…...

兰亭妙微 | 图标设计公司 | UI设计案例复盘
在「33」「312」新高考模式下,选科决策成为高中生和家长的「头等大事」。兰亭妙微公司受委托优化高考选科决策平台个人诊断报告界面,核心挑战是:如何将复杂的测评数据(如学习能力倾向、学科报考机会、职业兴趣等)转化为…...

OpenCV视觉图片调整:从基础到实战的技术指南
引言:数字图像处理的现代意义与OpenCV深度应用 在人工智能与计算机视觉蓬勃发展的今天,图像处理技术已成为多个高科技领域的核心支撑。根据市场研究机构Grand View Research的数据,全球计算机视觉市场规模预计将从2022年的125亿美元增长到2030年的253亿美元,年复合增长率达…...

C#日期和时间:DateTime转字符串全面指南
C#日期和时间:DateTime转字符串全面指南 在 C# 开发中,DateTime类型的时间格式化是高频操作场景。无论是日志记录、数据持久化,还是接口数据交互,合理的时间字符串格式都能显著提升系统的可读性和兼容性。本文将通过 20 实战示例…...
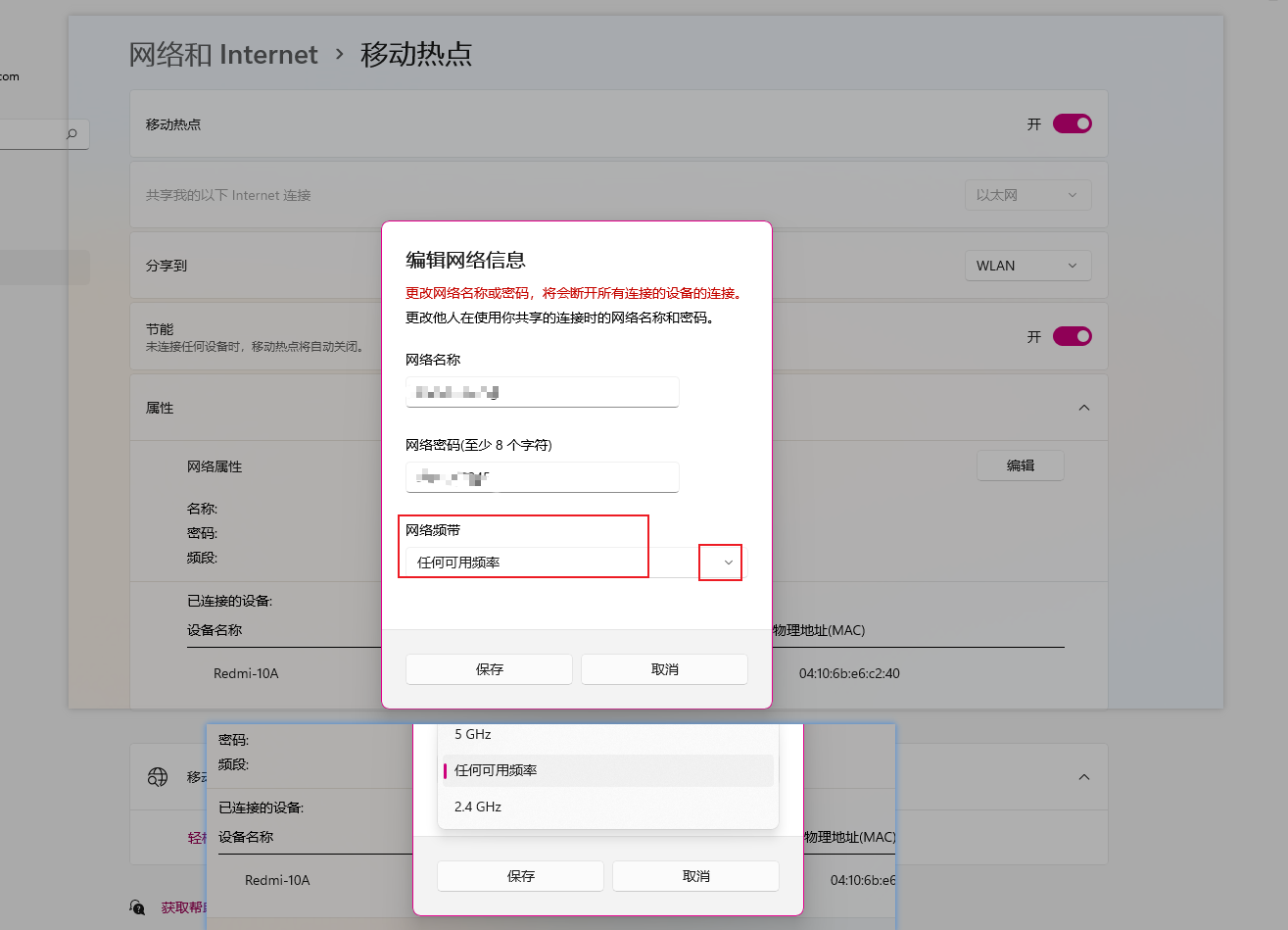
手机收不到WiFi,手动输入WiFi名称进行连接不不行,可能是WiFi频道设置不对
以下是电脑上分享WiFi后,部分手机可以看到并且能连接,部分手机不行,原因是:频道设置为5GHz,修改成,任何可用频率,则可...