【MySQL】2-MySQL索引P2-执行计划
欢迎来到啾啾的博客🐱。
记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。
有很多很多不足的地方,欢迎评论交流,感谢您的阅读和评论😄。
目录
- EXPLAIN
- explain output 执行计划输出解释
- 重点
- type列(连接类型,判断索引使用情况)
- extra (额外信息,看SQL执行情况)
- rows * filtered
[MySQL]2-MySQL索引这一篇关于执行计划的部分,因为有检索需求所以单独列出来。
EXPLAIN
explain output 执行计划输出解释
- 官方文档
https://dev.mysql.com/doc/refman/5.7/en/
https://dev.mysql.com/doc/refman/5.7/en/explain.html
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
官方解释是:EXPLAIN语句提供MySQL如何执行语句的信息。
可以查看应在哪些表添加索引以通过索引查找行来加快语句执行速度;
检查是否以最佳顺序连接表(如对SQL有理解,用户可以使用 SELECT STRAIGHT_JOIN指定连接顺序)。
| explain output columns 列名 | json name 使用format=json时输出中显示的效属性名称 | meaning含义 | 详细解释 |
|---|---|---|---|
| id | select_id | The SELECT identifier select标识符 | 这是查询中 SELECT 的顺序号。 id 号每个号码,表示一趟独立的查询 , 一个 sql 的查询趟数越少越好 如果该行引用其他行的并集结果,则值可以是 NULL 。在这种情况下, table 列显示一个类似于 的值,以指示该行引用具有 id 的 M 和 N 值的行并集。 可以查看执行顺序。 多表联查,id值越大,表查询越先执行。 id值相同,看输出顺序 |
| select_type | None 无 | The SELECT type SELECT 类型 | 查询类型,说明单表查询、关联查询、子查询等信息 编辑 编辑 |
| table | table_name | The table for the output row 输出行所引用的表 | 表名。 explain输出的每条记录都对应着都某个单表的访问方法。 M,N>该行指的是具有 M 和 N 的 id 值的行的并集 N>指的是具有 id 值为 N 的行的派生表结果。例如,派生表可能由 FROM 子句中的子查询生成 N>指的是具有 id 值为 N 的行的物化子查询的结果 |
| partitions | partitions | The matching partitions 匹配分区 | 显示分区,对于非分区表值为null |
| type | access_type | The join type 连接类型 | https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types 描述了如何连接表。以下连接类型按照最好到最差排列: system 该表只有一行(=系统表)。const连接类型的特殊情况 const 该表最多一行匹配,该行在查询开始时读取。因为只有一行,所以该行中列的值可以被优化器其余部分视为常数。const 表非常快,因为它们只读取一次。 eq_ref当索引的所有部分都被连接使用且索引是 PRIMARY KEY 或 UNIQUE NOT NULL 索引时,使用此类型。 通常发生在连表查询中,关联的条件是某一张表的主键或者UNIQUE唯一非空索引。 ref ref 可用于使用 = 或 操作符比较的索引列。如果连接不能根据键值选择单行,则使用 ref 。 满足索引最左匹配原则,且不走主键或者唯一非空索引则为ref,非聚簇索引查询一般都为ref。 fulltext 使用fulltext索引进行连接操作 ref_or_null 类似于 ref ,但增加了 MySQL 对包含 NULL 值的行的额外搜索。这种连接类型优化最常用于解决子查询。 在ref基础上增加null值查询则为这个。 index_merge 此连接类型表示使用了索引合并优化。 一般是单表多个索引条件的查询,将多个搜索结果合并为一个,统一回表降低查询代价。 unique_subquery这种类型替换了以下形式的某些 IN 子查询中的 eq_ref。unique_subquery 是一个索引查找函数,它完全替换子查询以提高效率。 index_subquery 此连接类型类似于 unique_subquery 。它替换 IN 子查询,但适用于以下形式的子查询中的非唯一索引: range 仅检索给定范围内的行,使用索引选择行. key_len 包含使用的最长键部分。 ref 列是针对此类型的 NULL 当键列使用任何 = 、 <> 、 > 、 >= 、 < 、 、 BETWEEN 、 LIKE 或 IN() 运算符与常量进行比较时,可以使用 range index index 连接类型与 ALL类似,扫描索引树 ALL 全表扫描,尽量避免 |
| possible_keys | possible_keys | The possible indexes to choose 可能的索引选择 | 表示 MySQL 可以从其中选择以查找此表中行的索引 |
| key | key | The index actually chosen 实际选择的索引 | 表示 MySQL 实际决定使用的键(索引)。如果 MySQL 决定使用 possible_keys 索引之一来查找行,则该索引被列为键值。 |
| key_len | key_length | The length of the chosen key 所选索引的长度 | 表示 MySQL 决定使用的键的长度(即:字节数)。 帮你检查是否充分的利用上了索引,值越大越好,主要针对于联合索引,有一定的参考意义。 |
| ref | ref | The columns compared to the index 列与索引的比较 | 当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
| rows | rows | Estimate of rows to be examined 估计要检查的行数 | 表示 MySQL 认为必须检查的行数以执行查询。对于 InnoDB 表,这个数字是一个估计值,可能并不总是准确。 值越小越好 |
| filtered | filtered | Percentage of rows filtered by table condition 行过滤比例 | 表示由表条件过滤的表行估计百分比 |
| Extra | None 无 | Additional information 附加信息 | https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information 查询type为const时为null distinct MySQL 正在寻找不同的值,因此它在找到第一个匹配的行之后,就会停止为当前行组合搜索更多行。 Full scan on NULL key这发生在子查询优化中,作为当优化器无法使用索引查找访问方法时的后备策略。 Impossible HAVING HAVING 子句始终为假,无法选择任何行。 Impossible WHERE WHERE 子句始终为假,无法选择任何行。 Using filesortMySQL 必须进行额外遍历来确定如何以排序顺序检索行。排序是通过遍历所有行(根据连接类型)并存储所有匹配 WHERE 子句的行的排序键和行指针来完成的。然后对这些键进行排序,并按排序顺序检索行。请参阅第 8.2.1.14 节,“ORDER BY 优化”。 using index 该列信息仅通过索引树中的信息从表中检索,无需额外查找实际行。当查询仅使用单个索引中的列时,可以使用此策略。 using index condition 表通过访问索引元组并首先测试它们来确定是否读取完整的表行。这样,索引信息被用来延迟(“推下”)读取完整的表行,除非这是必要的。 Using index for group-by 与 Using index 表访问方法类似, Using index for group-by 表示 MySQL 找到一个可以用来检索 GROUP BY 或 DISTINCT 查询的所有列的索引,而无需对实际表进行任何额外的磁盘访问 Using MRR使用多范围读取优化策略读取 Using temporary为了解决查询,MySQL 需要创建一个临时表来存储结果。这通常发生在查询包含 GROUP BY 和 ORDER BY 子句,这些子句以不同的方式列出列时。 Using where 一个 WHERE 子句用于限制与下一个表匹配的行或发送给客户端的行。除非你明确打算检索或检查表中的所有行,否则如果 Extra 值不是 Using where ,并且表连接类型是 ALL 或 index ,你的查询可能有问题。 |
重点
type列(连接类型,判断索引使用情况)
结果值从最好到最坏依次是: system > const > eq_ref> ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 consts级别。
range效率不高
index和all都是全表扫描
extra (额外信息,看SQL执行情况)
using index 覆盖索引 查询的数据都有索引
using index condition 索引下推
using where 所有过滤动作都由server层处理,没有索引(需要优化)
using MRR
using join buffer (BAK|BNL)
using union(indexs) 使用联合索引,多个查询条件都是索引列会发生索引合并
usring temporaray 使用了临时表,尽量使用索引,而非临时表,例如group by、union、distnct语句会使用到临时表
using filesort 通常出现在order by语句,查询之后需要额外进行排序。可以将条件与排序字段组成联合索引,由于有联合索引,排序字段本身就是有序的,不需要额外排序。
总结:避免临时表,尽量覆盖索引,像排序和函数什么的尽量避免
rows * filtered
rows列与filtered列通常与type列一起来看。
通常希望 rows * filtered的值越小越好,rows尽量小,filtered尽量高。
只要rows小就是好
rows:越小说明需要检查的行越少,即扫描的越少,语句越精准
filtered:越大说明扫描的行都被保留了,说明效率很高。
两者的值越小,说明性能越高。
异常情况:rows大,filtered低,说明有过滤,但是初始扫描行数多了,需要优化索引,联合索引最左侧选择性不高就可能出现这个问题。
相关文章:
【MySQL】2-MySQL索引P2-执行计划
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 有很多很多不足的地方,欢迎评论交流,感谢您的阅读和评论😄。 目录 EXPLAINexplain output 执行计划输出解释重点typ…...
云电脑显卡性能终极对决:ToDesk云电脑/顺网云/海马云,谁才是4K游戏之王?
一、引言 1.1 云电脑的算力革命 云电脑与传统PC的算力供给差异 传统PC的算力构建依赖用户一次性配置本地硬件,特别是CPU与显卡(GPU)。而在高性能计算和游戏图形渲染等任务中,GPU的能力往往成为决定体验上限的核心因素。随着游戏分…...

11 接口自动化-框架封装之统一请求封装和接口关联封装
文章目录 一、框架封装1、统一请求封装和路径处理2、接口关联封装 二、简单封装代码实现config.yml - 放入一些配置数据yaml_util.py - 处理 yaml 数据requests_util.py - 将请求封装在同一个方法中test_tag.py - 测试用例执行conftest.py - 会话之前清除数据 一、框架封装 1、…...

influxdb时序数据库
以下概念及操作均来自influxdb2 官方文档 InfluxDB2 is the platform purpose-built to collect, store, process and visualize time series data. Time series data is a sequence of data points indexed in time order. Data points typically consist of successive meas…...
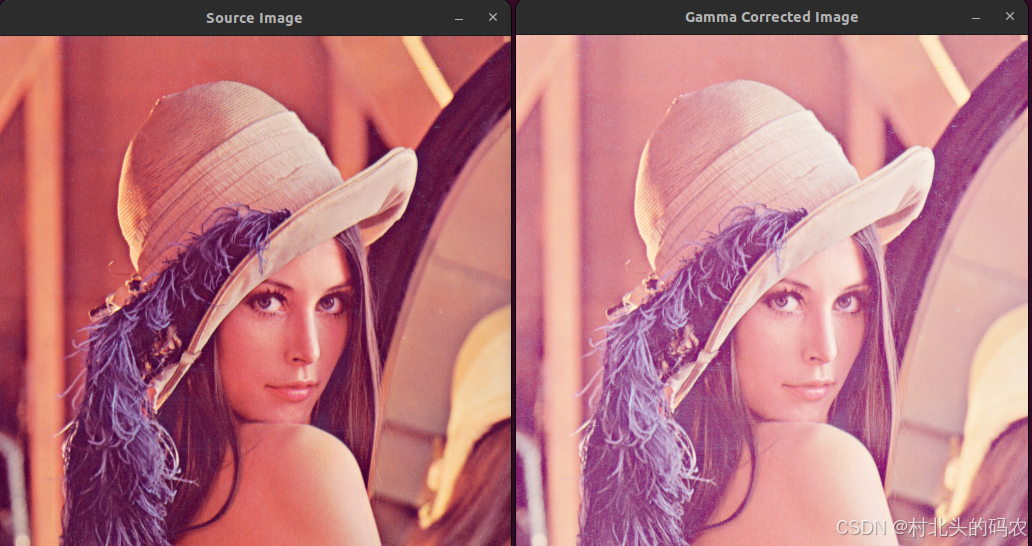
OpenCV CUDA模块图像处理------颜色空间处理之用于执行伽马校正(Gamma Correction)函数gammaCorrection()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::gammaCorrection 是 OpenCV 的 CUDA 模块中用于执行伽马校正(Gamma Correction)的一个函数。伽马校正通常用于…...

机器学习10-随机森林
随机森林学习笔记 一、随机森林简介 随机森林(Random Forest)是一种集成学习算法,基于决策树构建模型。它通过组合多个决策树的结果来提高模型的准确性和稳定性。随机森林的核心思想是利用“集成”的方式,将多个弱学习器组合成一…...
商品条形码查询接口如何用C#进行调用?
一、什么是商品条码查询接口? 1974年6月26日,美国俄亥俄州的一家超市首次使用商品条码完成结算,标志着商品条码正式进入商业应用领域。这项技术通过自动识别和数据采集,极大提升了零售行业的作业效率,减少了人工录入错…...

编译pg_duckdb步骤
1. 要求cmake的版本要高于3.17,可以通过下载最新的cmake的程序,然后设置.bash_profile的PATH环境变量,将最新的cmake的bin目录放到PATH环境变量的最前面 2. g的版本要支持c17标准,否则会报 error ‘invoke_result in namespace ‘…...

多模态大语言模型arxiv论文略读(九十一)
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文标题:FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs ➡️ 论文作者:Haodong C…...

攻防世界 - MISCall
下载得到一个没有后缀的文件,把文件放到kali里面用file命令查看 发现是bzip2文件 解压 变成了.out文件 查看发现了一个压缩包 将其解压 发现存在.git目录和一个flag.txt,flag.txt是假的 恢复git隐藏文件 查看发现是将flag.txt中内容读取出来然后进行s…...
)
数据结构测试模拟题(2)
1、选择排序(输出过程) #include <iostream> using namespace std;int main() {int a[11]; // 用a[1]到a[10]来存储输入// 读取10个整数for(int i 1; i < 10; i) {cin >> a[i];}// 选择排序过程(只需9轮)for(int…...
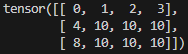
在PyTorch中,对于一个张量,如何快速为多个元素赋值相同的值
我们以“a torch.arange(12).reshape((3, -1))”为例,a里面现在是: 如果我们想让a的右下角的2行3列的元素都为10的话,可以如何快速实现呢? 我们可以用到索引和切片技术,执行如下的指令即可达到目标: a[1…...

苍穹外卖--Redis
1.Redis入门 1.1Redis简介 Redis是一个基于内存的key-value结果数据库 基于内存存储,读写性能高 适合存储热点数据(热点商品、资讯、新闻) 企业应用广泛 Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下:…...

C++ 条件变量虚假唤醒问题的解决
在 C 中,std::condition_variable 的 wait 和 wait_for 方法除了可以传入一个锁(std::unique_lock),还可以传入一个谓词函数(函数或可调用对象)。这个谓词的作用是让条件变量在特定的条件满足时才退出等待。…...
深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此…...

openssl 使用生成key pem
好的,以下是完整的步骤,帮助你在 Windows 系统中使用 OpenSSL 生成私钥(key)和 PEM 文件。假设你的 openssl.cnf 配置文件位于桌面。 步骤 1:打开命令提示符 按 Win R 键,打开“运行”对话框。输入 cmd&…...

python:基础爬虫、搭建简易网站
一、基础爬虫代码: # 导包 import requests # 从指定网址爬取数据 response requests.get("http://192.168.34.57:8080") print(response) # 获取数据 print(response.text)二、使用FastAPI快速搭建网站: # TODO FastAPI 是一个现代化、快速…...
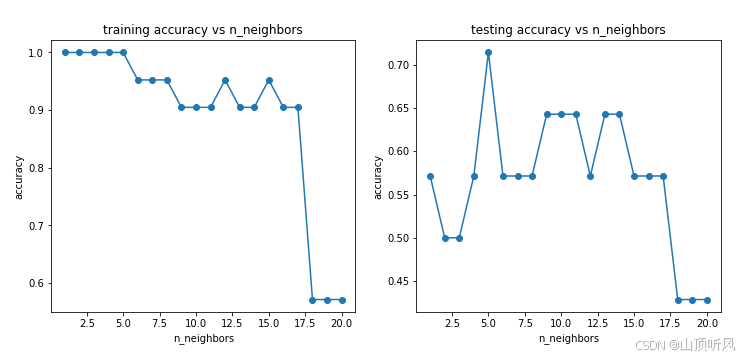
好坏质检分类实战(异常数据检测、降维、KNN模型分类、混淆矩阵进行模型评估)
任务 好坏质检分类实战 task: 1、基于 data_class_raw.csv 数据,根据高斯分布概率密度函数,寻找异常点并剔除 2、基于 data_class_processed.csv 数据,进行 PCA 处理,确定重要数据维度及成分 3、完成数据分离,数据分离…...

链表:数据结构的灵动舞者
在数据结构的舞台之上,链表以它灵动的身姿演绎着数据的精彩故事。与顺序表的规整有序不同,链表展现出了别样的灵活性与独特魅力。今天,就让我们一同走进链表的世界,去领略它的定义、结构、操作,对比它与顺序表的优缺点…...
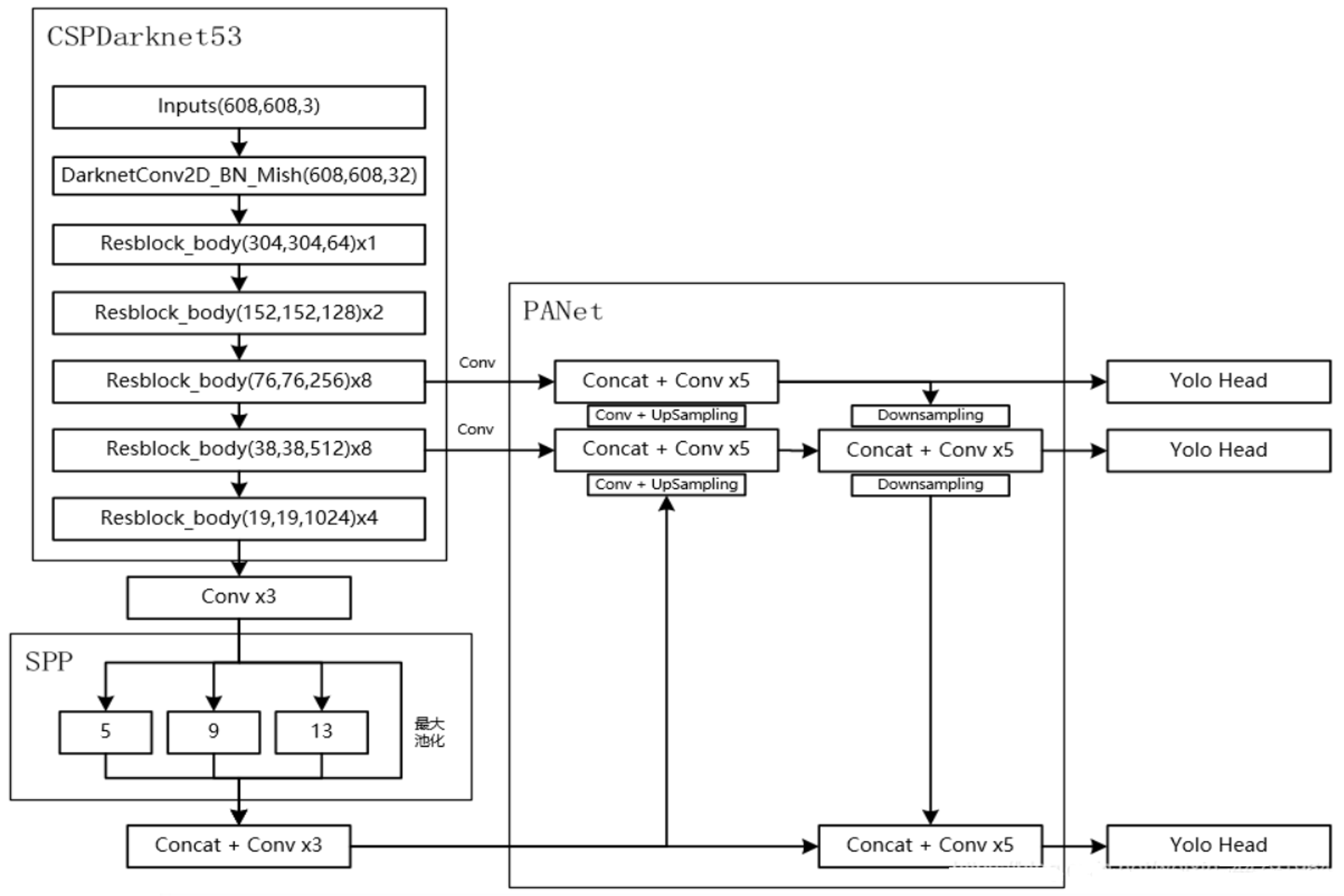
YOLOv4:目标检测的新标杆
引言 YOLO(You Only Look Once)系列作为目标检测领域的经典算法,以其高效的检测速度和良好的准确率闻名。2020年推出的YOLOv4在保持YOLO系列高速检测特点的同时,通过引入多项创新技术,将检测性能提升到了新高度。本文将详细介绍YOLOv4的核心…...
)
PyTorch 2.1新特性:TorchDynamo如何实现30%训练加速(原理+自定义编译器开发)
一、PyTorch 2.1动态编译架构演进 PyTorch 2.1的发布标志着深度学习框架进入动态编译新纪元。其核心创新点TorchDynamo通过字节码即时重写技术,将Python动态性与静态图优化完美结合。相较于传统JIT方案,TorchDynamo实现了零侵入式加速——开发者只需添加…...
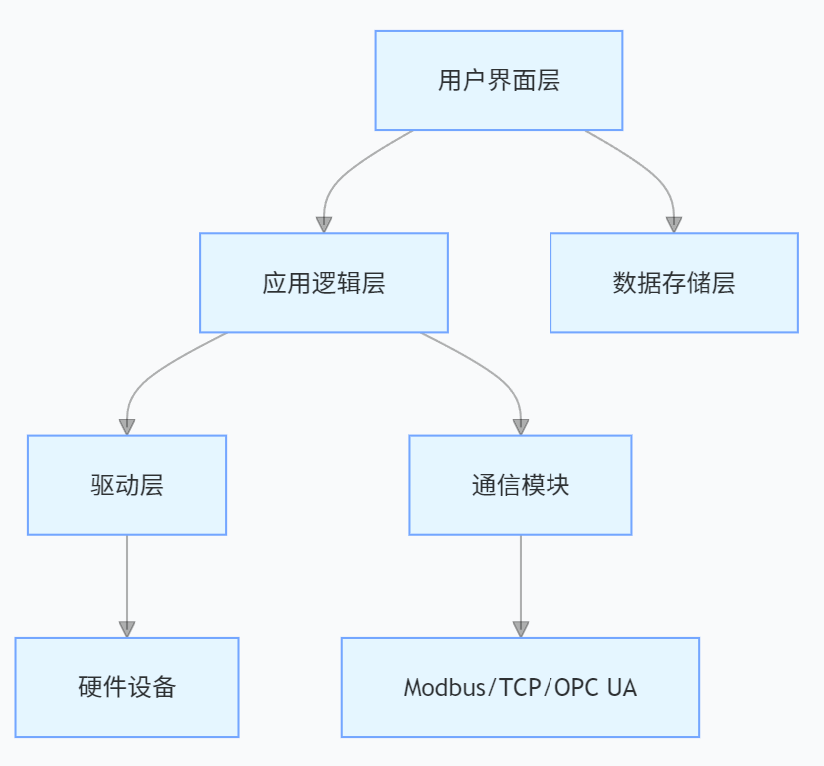
LabVIEW通用测控平台设计
基于 LabVIEW 图形化编程环境,设计了一套适用于工业自动化、科研测试领域的通用测控平台。通过整合研华、NI等品牌硬件,实现多类型数据采集、实时控制及可视化管理。平台采用模块化架构,支持硬件灵活扩展,解决了传统测控系统开发周…...

【机器学习基础】机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN)
机器学习入门核心算法:K-近邻算法(K-Nearest Neighbors, KNN) 一、算法逻辑1.1 基本概念1.2 关键要素距离度量K值选择 二、算法原理与数学推导2.1 分类任务2.2 回归任务2.3 时间复杂度分析 三、模型评估3.1 评估指标3.2 交叉验证调参 四、应用…...
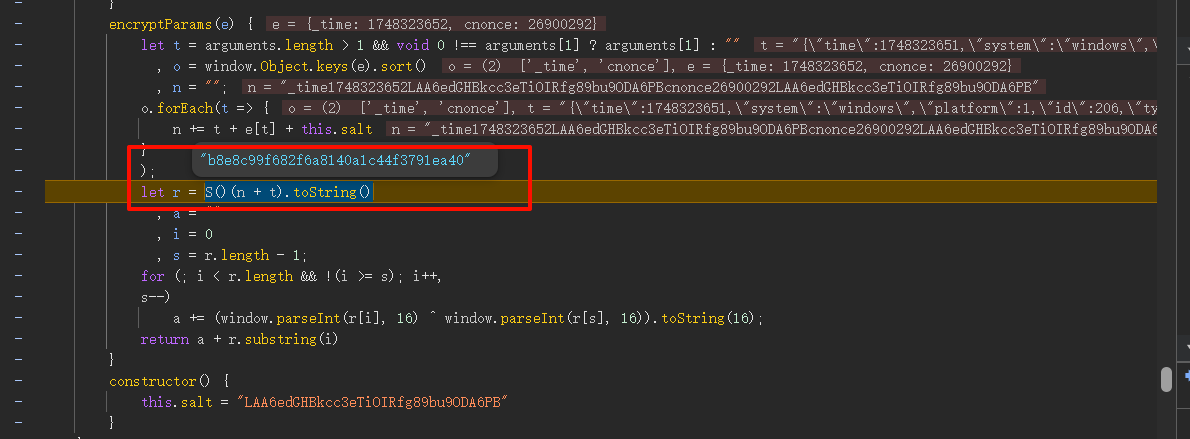
FastMoss 国际电商Tiktok数据分析 JS 逆向 | MD5加密
1.目标 目标网址:https://www.fastmoss.com/zh/e-commerce/saleslist 切换周榜出现目标请求 只有请求头fm-sign签名加密 2.逆向分析 直接搜fm-sign 可以看到 i["fm-sign"] A 进入encryptParams方法 里面有个S()方法加密,是MD5加密 3.代…...

Redis分布式缓存核心架构全解析:持久化、高可用与分片实战
一、持久化机制:数据安全双引擎 1.1 RDB与AOF的架构设计 Redis通过RDB(快照持久化)和AOF(日志持久化)两大机制实现数据持久化。 • RDB架构:采用COW(写时复制)技术,主进程…...
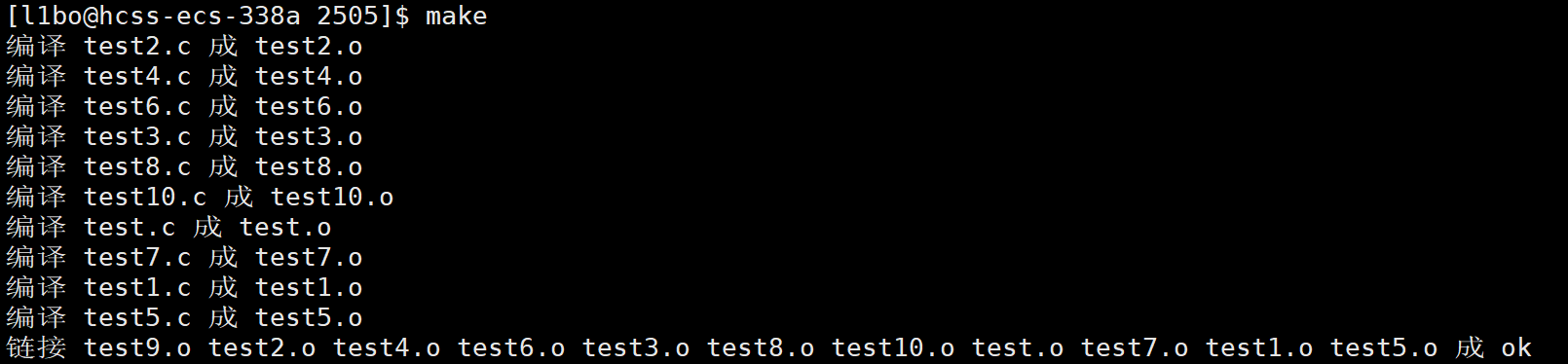
【Linux】基础开发工具(下)
文章目录 一、自动化构建工具1. 什么是 make 和 Makefile?2. 如何自动化构建可执行程序?3. Makefile 的核心思想4. 如何清理可执行文件?5. make 的工作原理5.1 make 的执行顺序5.2 为什么 make 要检查文件是否更新?5.2.1 避免重复…...

Python爬虫实战:研究Portia框架相关技术
1. 引言 1.1 研究背景与意义 在大数据时代,网络数据已成为企业决策、学术研究和社会分析的重要资源。据 Statista 统计,2025 年全球数据总量将达到 175ZB,其中 80% 以上来自非结构化网络内容。如何高效获取并结构化这些数据,成为数据科学领域的关键挑战。 传统爬虫开发需…...
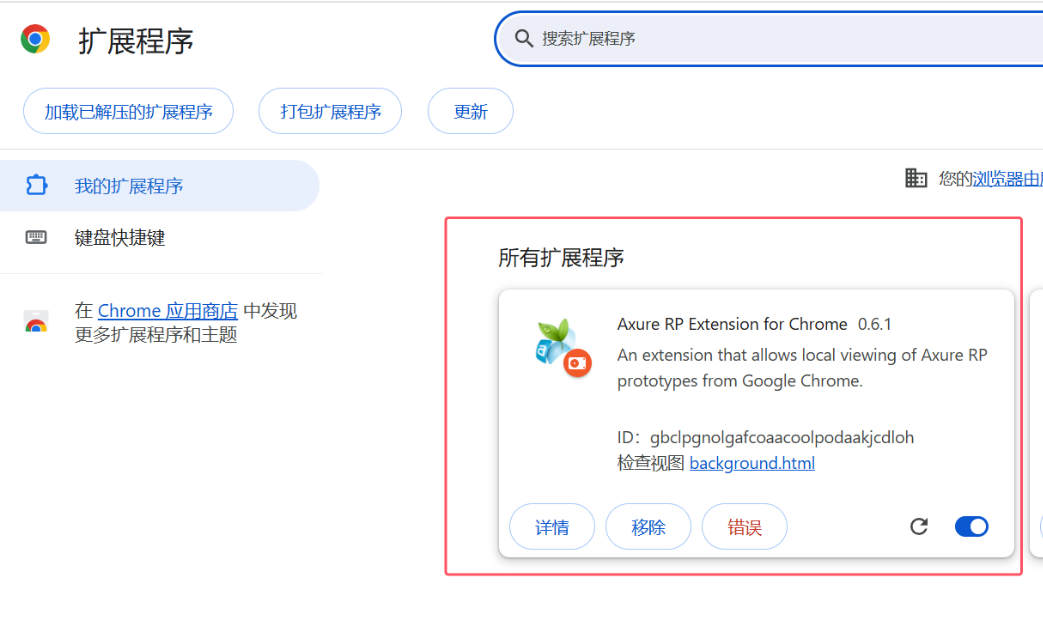
chrome打不开axure设计的软件产品原型问题解决办法
1、打开原型文件夹,进入到其中的如下目录中:resources->chrome->axure-chrome-extension.crx,找到 Axure RP Extension for Chrome插件。 2、axure-chrome-extension.crx文件修改扩展名.rar,并解压到文件夹 axure-chrome-ex…...

达梦数据库-学习-23-获取执行计划的N种方法
目录 一、环境信息 二、说点什么 三、测试数据生成 四、测试语句 五、获取执行计划方法 1、EXPLAIN (1)样例 (2)优势 (3)劣势 2、ET (1)开启参数 (2ÿ…...

【数据结构】树形结构--二叉树
【数据结构】树形结构--二叉树 一.知识补充1.什么是树2.树的常见概念 二.二叉树(Binary Tree)1.二叉树的定义2.二叉树的分类3.二叉树的性质 三.二叉树的实现1.二叉树的存储2.二叉树的遍历①.先序遍历②.中序遍历③.后序遍历④.层序遍历 一.知识补充 1.什…...