【深度学习】11. Transformer解析: Self-Attention、ELMo、Bert、GPT
Transformer 神经网络
Self-Attention 的提出动机
传统的循环神经网络(RNN)处理序列信息依赖时间步的先后顺序,无法并行,而且在捕捉长距离依赖关系时存在明显困难。为了解决这些问题,Transformer 引入了 Self-Attention(自注意力) 机制,彻底摆脱了循环结构。
核心思想是:
- 输入序列中的每个位置都可以同时关注其他所有位置的信息
- 依赖“注意力权重”来决定每个位置对其他位置的依赖程度
这项机制的提出奠定了后续 GPT、BERT 等大型语言模型的基础,其口号正是:
Attention is all you need.
Self-Attention 的基本形式
输入序列为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,我们首先将其映射为特征表示 a 1 , a 2 , a 3 , a 4 a_1, a_2, a_3, a_4 a1,a2,a3,a4。
然后,为了执行注意力计算,每个位置的表示 a i a_i ai 会被分别映射成三个向量:
- 查询向量(Query): q i = W Q a i q_i = W_Q a_i qi=WQai
- 键向量(Key): k i = W K a i k_i = W_K a_i ki=WKai
- 值向量(Value): v i = W V a i v_i = W_V a_i vi=WVai
这些向量的作用分别是:
- q q q:表示当前要“提问”的内容(to match others)
- k k k:表示其他位置的信息索引(to be matched)
- v v v:表示其他位置的具体内容信息(information to be extracted)
这些投影矩阵 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 都是可训练参数。
Scaled Dot-Product Attention 计算过程
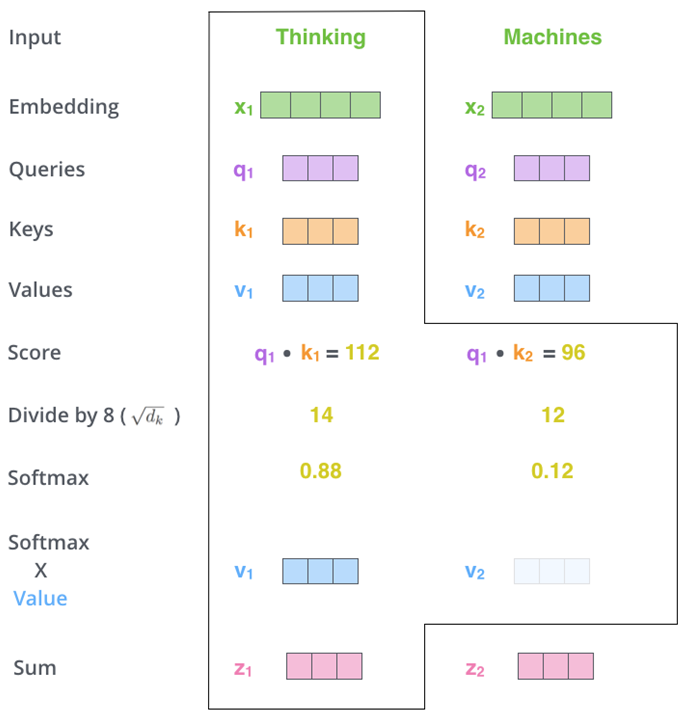
对于每一个查询 q i q_i qi,我们计算它与序列中每一个键 k j k_j kj 的相似度:
α i , j = q i ⊤ k j d \alpha_{i,j} = \frac{q_i^\top k_j}{\sqrt{d}} αi,j=dqi⊤kj
其中 d d d 是向量的维度,用 d \sqrt{d} d 来进行缩放,防止 dot product 值过大。
然后对所有 α i , j \alpha_{i,j} αi,j 做 softmax,得到归一化注意力分布:
softmax ( α i , 1 , α i , 2 , . . . , α i , n ) \text{softmax}(\alpha_{i,1}, \alpha_{i,2}, ..., \alpha_{i,n}) softmax(αi,1,αi,2,...,αi,n)
最后,用这些权重对值向量 v j v_j vj 加权求和,得到当前输出表示 b i b_i bi:
b i = ∑ j softmax ( α i , j ) ⋅ v j b_i = \sum_j \text{softmax}(\alpha_{i,j}) \cdot v_j bi=j∑softmax(αi,j)⋅vj
这种机制允许模型根据输入内容自适应地提取相关信息。
Self-Attention 的并行优势
由于 self-attention 的所有位置间的权重可以同时计算,因此整个计算过程高度并行化,不再像 RNN 那样必须按序列顺序逐步执行。
这一优势为 Transformer 模型带来了巨大的训练速度提升和更强的长距离建模能力。
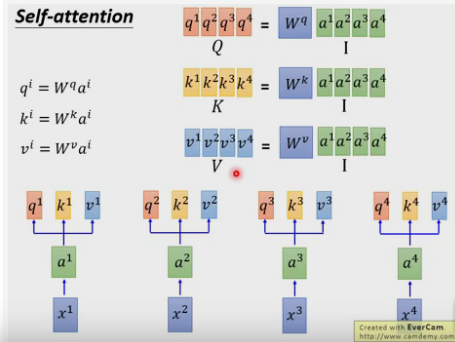
Self-Attention 结构矩阵形式
将所有 a i a_i ai 构成矩阵 A A A 后,统一投影为 Q = A W Q Q = AW_Q Q=AWQ, K = A W K K = AW_K K=AWK, V = A W V V = AW_V V=AWV。
注意力输出矩阵表示为:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(dQK⊤)V
这种矩阵形式便于实现多头注意力机制(Multi-head Attention)。
多头注意力机制(Multi-head Self-Attention)
在基础的 Self-Attention 结构中,所有位置的注意力都是通过一组 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 矩阵计算的。为了增强模型的表达能力,Transformer 引入了**多头注意力(Multi-head Attention)**机制。
基本思想是:
- 不止使用一组查询/键/值矩阵,而是使用多个不同的投影子空间
- 每个头(head)有独立的 W Q ( h ) , W K ( h ) , W V ( h ) W_Q^{(h)}, W_K^{(h)}, W_V^{(h)} WQ(h),WK(h),WV(h)
- 每个头计算一个独立的 Attention 输出,然后将所有头的输出拼接后,再通过线性变换整合
多头计算公式:
设有 h h h 个头,每个头输出 b ( i ) b^{(i)} b(i),则:
MultiHead ( Q , K , V ) = Concat ( b ( 1 ) , b ( 2 ) , . . . , b ( h ) ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(b^{(1)}, b^{(2)}, ..., b^{(h)}) W^O MultiHead(Q,K,V)=Concat(b(1),b(2),...,b(h))WO
其中 W O W^O WO 是最终输出线性层的权重。
这种结构的优势在于:
- 每个头可以捕捉不同维度、不同位置之间的依赖关系
- 实现信息多角度理解,提升模型表示能力
位置编码(Positional Encoding)
由于 Transformer 完全抛弃了 RNN 的序列性结构,模型本身不具备位置感知能力,因此需要通过显式地添加**位置编码(Positional Encoding)**来注入顺序信息。
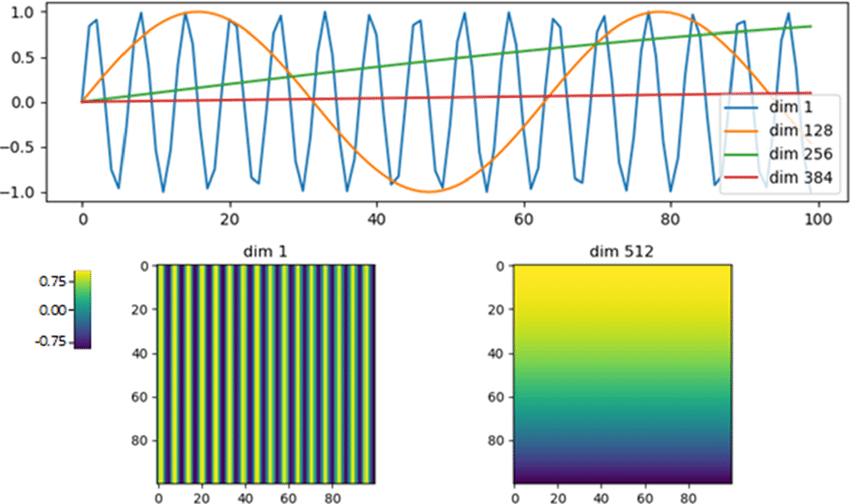
原理
对于输入序列 x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn,我们给每个位置添加一个位置向量 p i p_i pi,得到输入表示:
a i = x i + p i a_i = x_i + p_i ai=xi+pi
原论文中的位置编码设计为:
P E ( i , 2 j ) = sin ( i 10000 2 j / d ) PE(i, 2j) = \sin\left(\frac{i}{10000^{2j/d}}\right) PE(i,2j)=sin(100002j/di)
P E ( i , 2 j + 1 ) = cos ( i 10000 2 j / d ) PE(i, 2j+1) = \cos\left(\frac{i}{10000^{2j/d}}\right) PE(i,2j+1)=cos(100002j/di)
其中 i i i 是位置索引, j j j 是维度索引, d d d 是维度总数。
该方法具有以下优点:
- 每个位置对应的编码唯一
- 可以推广到任意序列长度
- 可以通过位置间的函数关系捕捉相对距离
编码器 - 解码器结构
Transformer 模型整体结构为 Encoder-Decoder 框架:
- Encoder:由若干层 Self-Attention 和前馈网络(Feed-Forward)组成
- Decoder:在 Encoder 基础上引入 Masked Self-Attention,以防止看到未来的词
每一层都包含:
- 多头注意力层
- 残差连接 + 层归一化(Layer Normalization)
- 前馈全连接层(Feed-Forward Network)
Encoder 和 Decoder 都堆叠多层(如 6 层)构成深度网络。
解码器中的 Masked Self-Attention
在解码器中,为了保证生成过程的自回归特性,我们使用 Masking 机制屏蔽掉当前词右侧的词:
- 即 y 3 y_3 y3 只能看到 y 1 , y 2 y_1, y_2 y1,y2
- 实现方法:将未来位置的 attention score 设置为 − ∞ -\infty −∞
这样可以确保每个位置只能访问“过去的词”。
Layer Normalization 和残差连接
在每个子层(如 Attention 或 Feed-Forward)之后,Transformer 都加入了:
-
残差连接(Residual Connection):
Output = LayerNorm ( x + Sublayer ( x ) ) \text{Output} = \text{LayerNorm}(x + \text{Sublayer}(x)) Output=LayerNorm(x+Sublayer(x)) -
层归一化(LayerNorm):标准化子层输出,稳定训练
这种结构让深层网络训练更加稳定,并避免信息在深层网络中衰减。
总结
Transformer 通过以下关键组件实现了对序列的建模:
- 自注意力机制:实现信息全局交互
- 多头注意力:提高表达维度
- 位置编码:引入序列顺序
- 残差连接 + LayerNorm:提升训练效率
- 并行结构:大幅提高计算效率
这些设计使得 Transformer 成为大规模语言建模的核心骨架。
ELMo:上下文词表示的革命性模型
本教程将详细介绍 ELMo(Embeddings from Language Models)模型的提出背景、结构原理、数学表达、实际应用及其对自然语言处理(NLP)领域的深远影响。ELMo 是第一个广泛应用于工业界的上下文词表示方法,在 NLP 中具有划时代的意义。
词向量的背景与局限
在 ELMo 出现之前,词向量的主流方法是 Word2Vec、GloVe 等,这些模型为每个词生成一个固定向量表示,不考虑上下文语义。
例如,词语 “bank” 在下面两个句子中的意思完全不同:
- He sat on the bank of the river.(河岸)
- He deposited money in the bank.(银行)
然而,Word2Vec 或 GloVe 中的 “bank” 向量是唯一的,无法根据上下文调整。
这导致传统词向量在表示歧义词、多义词时存在局限。
ELMo 的基本思想
ELMo(Peters et al., 2018)提出了一种上下文相关的动态词向量表示方法。
其核心思想为:
- 每个词的表示是函数 f ( word , context ) f(\text{word}, \text{context}) f(word,context),由所在上下文动态决定;
- 使用**双向语言模型(BiLM)**获得上下文信息;
- 将不同层的表示融合(非简单拼接)。
因此,同一个词在不同句子中的向量将不同,有效捕捉多义词的含义。
模型结构概览
ELMo 基于一个双向 LSTM(bi-LSTM)语言模型,其整体结构如下:
- 字符级嵌入:使用 CNN 处理每个单词的字符,生成词表示;
- 双向 LSTM:分别从左到右、从右到左处理句子;
- 上下文融合:将每层 LSTM 输出进行加权求和,得到最终的 ELMo 向量。
结构流程如下:
- 输入句子 → 字符嵌入(CharCNN)
- → 前向 LSTM + 后向 LSTM
- → 每层输出加权融合
- → 上下文词向量(ELMo 表示)
数学表达与权重组合
ELMo 的词向量是多个 LSTM 层输出的加权和。对第 k k k 个词,其向量为:
E L M o k t a s k = γ t a s k ∑ j = 0 L s j t a s k ⋅ h k , j ELMo_k^{task} = \gamma^{task} \sum_{j=0}^{L} s_j^{task} \cdot h_{k,j} ELMoktask=γtask∑j=0Lsjtask⋅hk,j
其中:
- h k , j h_{k,j} hk,j 表示第 j j j 层输出(第 0 层为词嵌入,后续为 LSTM 层);
- s j t a s k s_j^{task} sjtask 是 softmax 权重,控制每层贡献度;
- γ t a s k \gamma^{task} γtask 是缩放因子,调节整体表示;
- 所有权重是任务相关的,可通过微调学习。
该机制使模型能自动选择更有信息的层级表示,提升下游任务效果。
与 Word2Vec、BERT 的对比
| 模型 | 是否上下文相关 | 表示方式 | 参数共享 | 应用时代 |
|---|---|---|---|---|
| Word2Vec / GloVe | 否 | 固定向量 | 是 | 2013-2015 |
| ELMo | 是 | 动态加权层组合 | 是 | 2018 |
| BERT | 是 | 深层 Transformer 表示 | 否 | 2018-至今 |
ELMo 是第一个提出将多个语言模型层表示加权组合的思路,直接启发了后续的 BERT、GPT 等模型的层融合机制。
预训练语言模型:BERT 和 GPT
基于 Transformer 架构,涌现出一系列强大的预训练语言模型,它们以不同方式利用 Transformer 的编码器和解码器模块。
BERT(Bidirectional Encoder Representations from Transformers)
BERT 使用 Transformer 的 Encoder 堆叠结构,强调从上下文中双向建模词语含义,其关键特点如下:
- 输入同时包含左右上下文(不像传统语言模型只看左边)
- 适用于句子级别和段落级别的理解任务(如问答、情感分析)
BERT 的输入结构
BERT 输入由三个部分组成:
- Token Embedding:词语本身的表示
- Segment Embedding:区分句子 A 和句子 B(用于句对任务)
- Position Embedding:位置编码
最终输入为三者之和:
Input i = Token i + Segment i + Position i \text{Input}_i = \text{Token}_i + \text{Segment}_i + \text{Position}_i Inputi=Tokeni+Segmenti+Positioni
BERT 的训练任务
BERT 采用两种预训练目标:
-
Masked Language Modeling (MLM):
- 输入中随机遮蔽一些词(如 15%),模型预测这些被 mask 的词
- 例如输入 “I have a [MASK] car”,目标是预测 “red”
-
Next Sentence Prediction (NSP):
- 判断句子 B 是否是句子 A 的下一个句子(用于建模句子间关系)
这种预训练方式使 BERT 能更好地捕捉句子结构与上下文依赖。
GPT(Generative Pre-trained Transformer)
GPT 使用 Transformer 的 Decoder 堆叠结构,强调自回归生成语言,适用于生成类任务,如对话、写作、摘要。
其主要特点:
- 输入为单向序列,预测下一个词
- 无 NSP 任务,专注语言建模
GPT 的每个解码器层使用 Masked Self-Attention,避免泄露未来信息。
GPT 的训练目标
GPT 的训练任务是标准的语言建模目标:
max ∑ t log P ( w t ∣ w 1 , . . . , w t − 1 ) \max \sum_{t} \log P(w_t | w_1, ..., w_{t-1}) maxt∑logP(wt∣w1,...,wt−1)
即,给定前面所有词,预测下一个词。
GPT vs BERT 的核心差异
| 模型 | 结构 | 训练任务 | 输入方式 | 主要用途 |
|---|---|---|---|---|
| BERT | Encoder | MLM + NSP | 双向 | 分类、抽取、匹配 |
| GPT | Decoder | 自回归语言建模 | 单向 | 生成类任务(文本生成) |
T5:Text-To-Text Transfer Transformer
T5 提出一种统一的 文本到文本 框架,将所有任务(分类、翻译、摘要等)都转换为文本生成问题。
- 输入输出都是文本字符串
- 训练数据包括翻译、问答、情感分类、摘要等任务
T5 的架构
T5 使用标准的 Transformer Encoder-Decoder 结构:
- 编码器读取输入文本
- 解码器逐步生成目标文本
这种设计统一了任务格式,利于大规模预训练与下游迁移。
T5 示例任务:
-
翻译:
- 输入:
translate English to German: That is good. - 输出:
Das ist gut.
- 输入:
-
分类:
- 输入:
sst2 sentence: This movie is great! - 输出:
positive
- 输入:
-
摘要:
- 输入:
summarize: The article discusses... - 输出:
Main idea is...
- 输入:
总结:从 Transformer 到大型语言模型
| 模型 | 核心结构 | 预训练方式 | 使用方向 |
|---|---|---|---|
| Transformer | Encoder-Decoder | 无预训练,原始结构 | 序列建模,翻译等 |
| BERT | Encoder 堆叠 | MLM + NSP | 理解类任务 |
| GPT | Decoder 堆叠 | 自回归语言建模 | 文本生成、对话系统 |
| T5 | Encoder-Decoder | 多任务文本到文本训练 | 通用性强,可迁移学习 |
Transformer 模型的出现彻底改变了 NLP 的范式:从 RNN 到 Attention,从编码器到预训练,从理解到生成,推动了大模型时代的来临。
这一系列模型均依赖 Transformer 架构的强大表达力,通过自注意力机制和深层堆叠结构,成功实现了语言理解与生成的统一建模。
相关文章:
【深度学习】11. Transformer解析: Self-Attention、ELMo、Bert、GPT
Transformer 神经网络 Self-Attention 的提出动机 传统的循环神经网络(RNN)处理序列信息依赖时间步的先后顺序,无法并行,而且在捕捉长距离依赖关系时存在明显困难。为了解决这些问题,Transformer 引入了 Self-Attent…...
)
Ubuntu实现和主机的复制粘贴 VMware-Tools(open-vm-tools)
Ubuntu实现和主机的复制粘贴 VMware-Tools(open-vm-tools) 1.安装open-vm-tools # 更新软件源并安装工具包 sudo apt update sudo apt install open-vm-tools open-vm-tools-desktop -y2.启用剪贴板共享 sudo nano /etc/vmware-tools/tools.conf添加或…...

4060显卡什么水平 4060显卡参数介绍
NVIDIA的GeForce RTX 40系列显卡基于最新的Ada Lovelace架构,提供了前所未有的图形处理能力和效率。其中,RTX 4060定位中高端市场,针对那些寻求卓越性能同时又注重成本效益的用户群体。那么,4060显卡什么水平呢?本文将…...

Kafka Producer 如何实现Exactly Once消息传递语义
Exactly-Once (精确一次) 是 Kafka 中最高级别的消息传递语义,确保消息既不会丢失也不会重复。以下是 Kafka Producer 实现 Exactly-Once 语义的关键机制: 1. 实现方法 1.1 启用幂等性 (Idempotence) props.put("enable.idempotence", &quo…...

通过ansible playbook创建azure 资源
安装 Ansible 在 macOS 上 Ansible 可以通过多种方式在 macOS 上安装,推荐使用 pip 或 Homebrew。 使用 Homebrew 安装 Ansible 运行以下命令: brew install ansible使用 pip 安装 Ansible 确保 Python 已安装(macOS 通常自带 Python),然后运行: pip install ansible…...
)
C++双线程交替打印奇偶数(活泼版)
C双线程交替打印奇偶数(活泼版) 文章目录 C双线程交替打印奇偶数(活泼版)1.🎮 游戏规则说明书2.🔧 游戏道具准备区2.1🧩 道具清单 3.👯♂️ 创建两个线程小伙伴3.1🧑…...

技术为器,服务为本:AI时代的客服价值重构
在智能化浪潮中,大语言模型的出现为客户服务行业注入了全新动能。然而技术创新的价值不在于技术本身,而在于其赋能服务的深度与广度。AI对于我们来说,如同发动机之于汽车,重要的不是引擎参数,而是整车带给用户的驾驶体…...

hadoop异构存储
Hadoop异构存储是一种基于HDFS的存储优化技术,通过将不同热度的数据分配到不同类型的存储介质上实现性能与成本的平衡。以下是其核心原理和实现方式: 一、核心概念 异构存储基本原理:Hadoop集群允许使用SSD、HDD、ARCHIVE等多种存储介质…...

EasyVoice:开源的文本转语音工具,让文字“开口说话“
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、EasyVoice是什么?1. 核心特性一览2. 技术架构概览 二、安装部署指南…...

扫地机产品异物进入吸尘口堵塞异常检测方案
扫地机产品异物进入吸尘口堵塞异常的检测方案 文章目录 扫地机产品异物进入吸尘口堵塞异常的检测方案一.背景二.石头的音频异常检测的方案2.1 音频检测触发点2.1.1时间周期2.1.2根据清洁机器人清扫模式或清扫区域污渍类型,即当清扫模式为深度清洁模式 或清扫区域污渍类型为重度…...

C++并集查找
前言 C图论 C算法与数据结构 本博文代码打包下载 基本概念 并查集(Union-Find)是一种用于处理动态连通性(直接或间接相连)的数据结构,主要支持两种操作:union 和 find。通过这两个基本操作,可…...
git reset --hard HEAD~1与git reset --hard origin/xxx
git reset --hard HEAD~1与git reset --hard origin/xxx git reset --hard origin/xxx有时候会太长,手工输入略微繁琐,可以考虑: git reset --hard HEAD~1 替代。 或者使用这种方式 git reset撤销当前分支所有修改,恢复到最近一…...
)
window 显示驱动开发-转换 Direct3D 固定函数状态(二)
未使用的User-Mode显示驱动程序函数 启用固定函数顶点着色器转换器时,Direct3D 运行时不会调用以下 用户模式显示驱动程序函数 : MultiplyTransform SetTransform SetMaterial SetLight CreateLight DestroyLight 1. 核心规则 当 固定功能顶点着…...

双路物理CPU机器上安装Ubuntu并部署KVM以实现系统多开
在双路物理CPU机器上安装Ubuntu并部署KVM以实现系统多开,并追求性能最优,需要从硬件、宿主机系统、KVM配置、虚拟机配置等多个层面进行优化。 以下是详细的操作指南和优化建议: 阶段一:BIOS/UEFI 设置优化 (重启进入) 启用虚拟化…...
C++ RB_Tree
一、红黑树是什么?—— 带颜色标记的平衡二叉搜索树 红黑树是一种自平衡二叉搜索树,它在每个节点上增加了一个颜色属性(红色或黑色),通过对颜色的约束来确保树的大致平衡。这种平衡策略被称为 "弱平衡"&…...

命令模式,观察者模式,状态模式,享元模式
什么是命令模式? 核心思想是将原本直接调用的方法封装为对象(如AttackCommand),对象包含执行逻辑和上下文信息(如目标、参数)。比如,玩家的按键操作被封装成一个命令对象&#…...
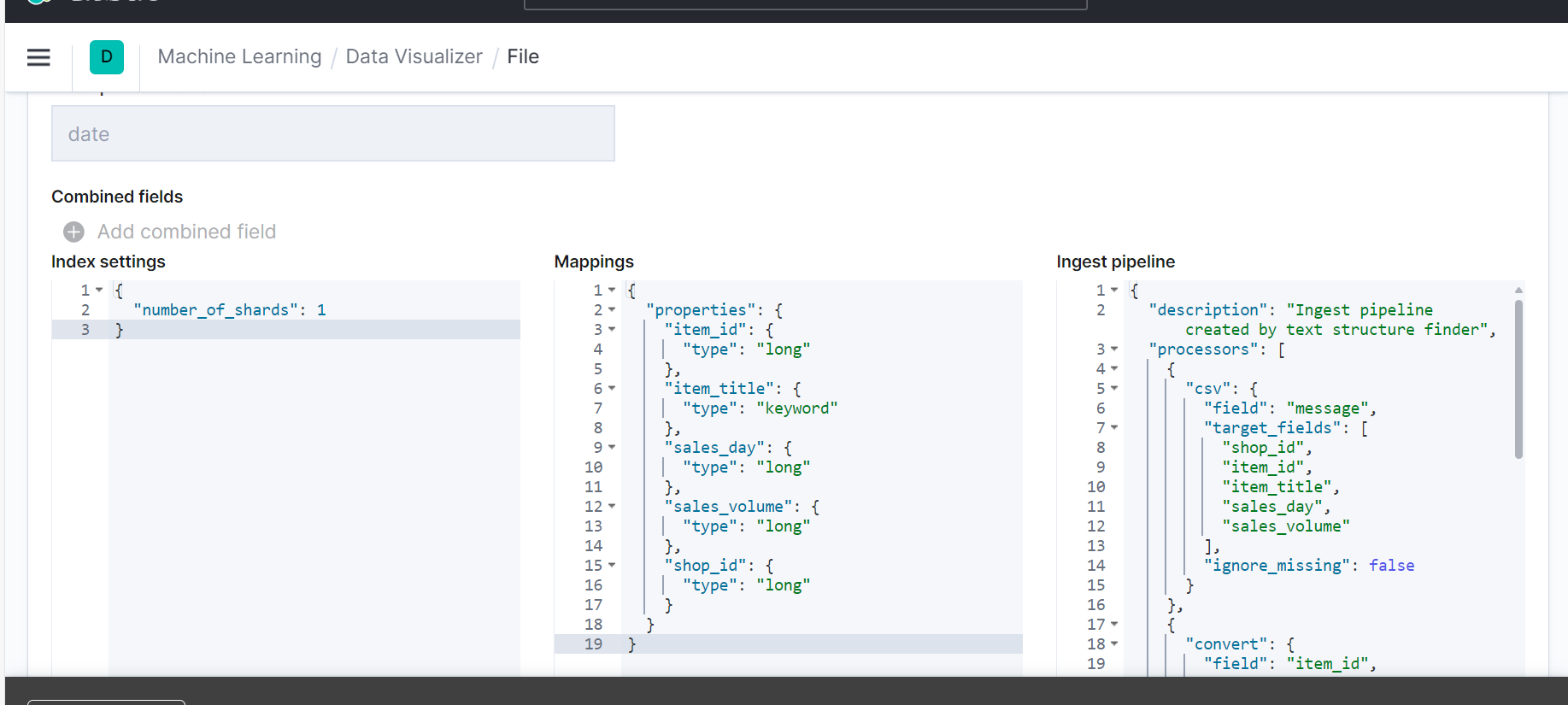
kibana解析Excel文件,生成mapping es导入Excel
一、Excel转为CSV格式 在线免费网站:EXCEL转CSV - 免费在线将EXCEL文件转换成CSV (cdkm.com) 二、登录kibana 点击左边菜单栏找到Machine Learning, 进入后上面菜单选择Data Visualizer,然后上穿转好的csv格式的Excel 点击导入输入建立的m…...
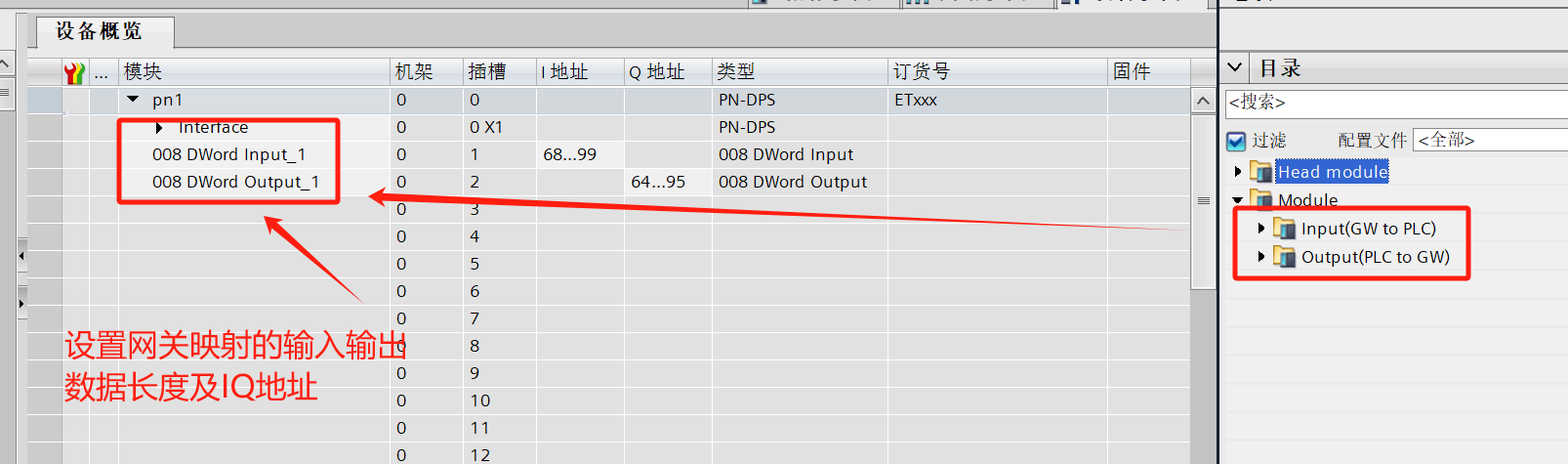
开疆智能Profinet转Profibus网关连接EC-CM-P1 PROFIBUS DP从站通讯模块配置案例
本案例是通过开疆智能Profibus转Profinet网关将正弦研发的Profibus从站模块连接的EM600变频器接入到西门子1200PLC的配置案例。 配置过程 1. 打开网关配置软件“”新建项目并添加模块PN2DPM并设置参数 2. 设置网关的Profibus参数。如站地址,波特率等。(…...

Oracle RMAN自动恢复测试脚本
说明 此恢复测试脚本,基于rman备份脚本文章使用的fullbak.sh做的备份。 数据库将被恢复到RESTORE_LO参数设置的位置。 在恢复完成后,执行一个测试sql,确认数据库恢复完成,数据库备份是好的。恢复测试数据库的参数,比如SGA大小都…...
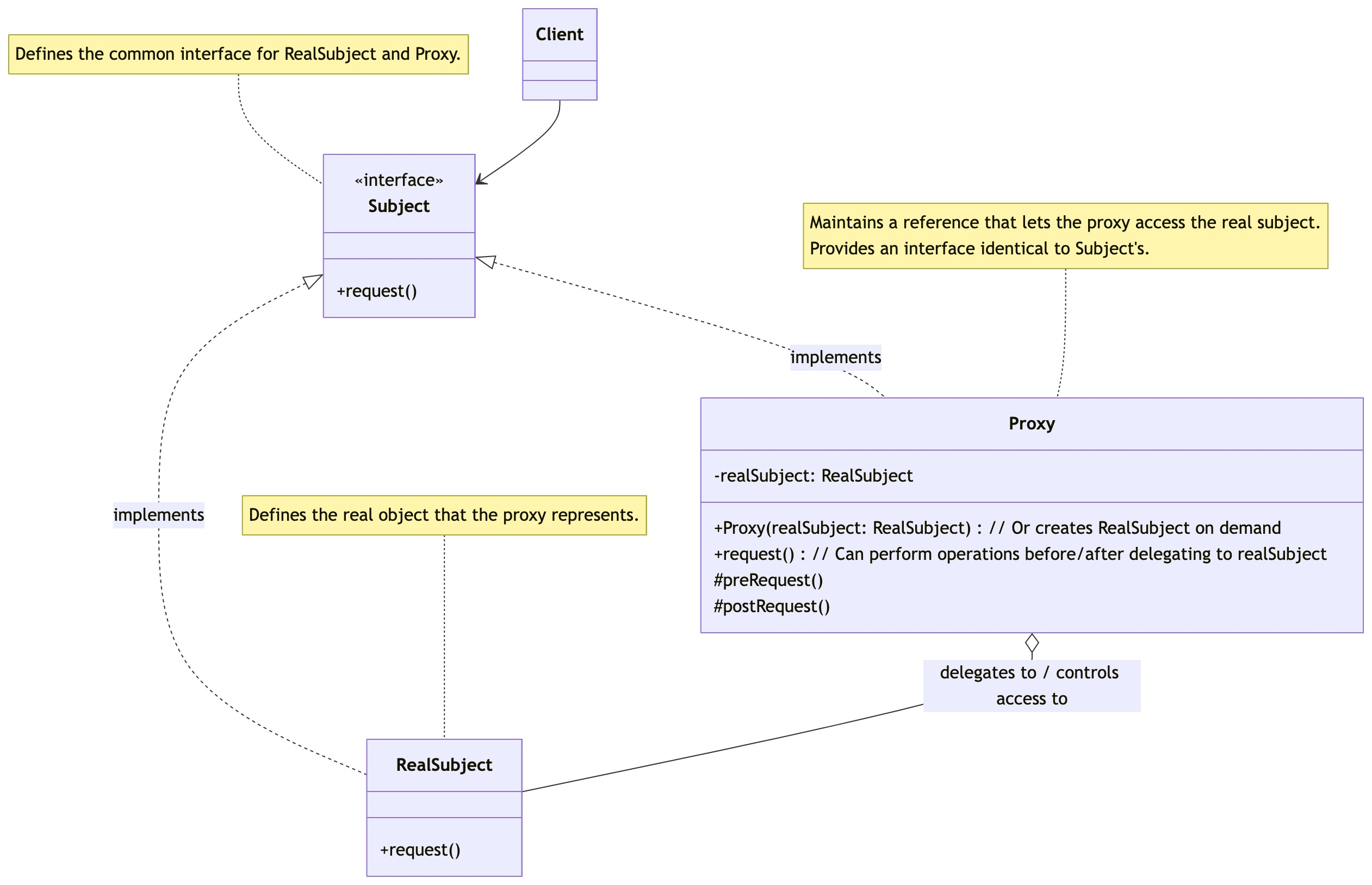
零基础设计模式——结构型模式 - 代理模式
第三部分:结构型模式 - 代理模式 (Proxy Pattern) 在学习了享元模式如何通过共享对象来优化资源使用后,我们来探讨结构型模式的最后一个模式——代理模式。代理模式为另一个对象提供一个替身或占位符以控制对这个对象的访问。 核心思想:为其…...

架构意识与性能智慧的双重修炼
架构意识与性能智慧的双重修炼 ——现代软件架构师的核心能力建设指南 作者:蓝葛亮 🎯引言 在当今快速发展的技术环境中,软件架构师面临着前所未有的挑战。随着业务复杂度的不断增长和用户对性能要求的日益严苛,如何在架构设计中平衡功能实现与性能优化,已成为每个技术…...
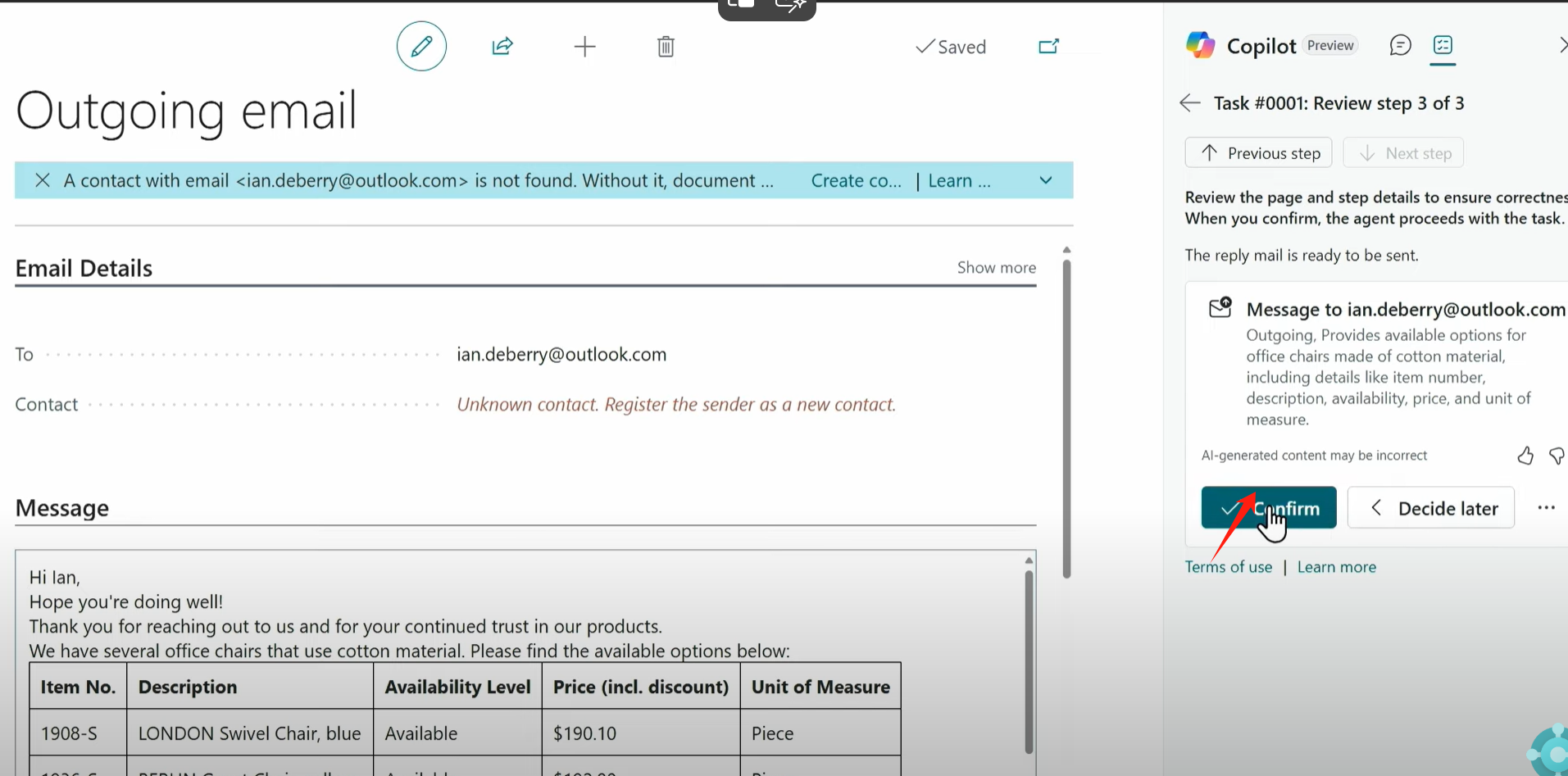
Dynamics 365 Business Central AI Sales Order Agent Copilot
#AI Copilot# #D365 BC 26 Wave# 最近很多客户都陆续升级到 Dynamics 365 Business Central 26 wave, Microsoft 提供一个基于Copilot 的Sales Order Agent,此文将此功能做个介绍. Explorer: 可以看到26版本上面增加了这样一个新图标。 Configuration: 配置过程…...

RabbitMQ 与其他 MQ 的对比分析:Kafka/RocketMQ 选型指南(一)
一、引言 ** 在当今分布式系统大行其道的技术时代,消息队列作为分布式系统的关键组件,起着举足轻重的作用。它就像是一个可靠的信使,在不同的系统模块、服务之间传递信息,让各个部分能够高效、稳定地协同工作。消息队列能够实现系…...

CAS会产生什么问题以及如何解决
什么是 CAS CAS 即 Compare-And-Swap(比较并交换),它是一种无锁算法,用于在多线程环境下实现同步机制。在硬件层面,许多处理器都提供了 CAS 指令,Java 借助这些底层指令来实现并发操作。 基本原理 CAS 操作…...

汽车EPS系统的核心:驱动芯片的精准控制原理
随着科技的飞速发展,电机及其驱动技术在现代工业、汽车电子、家用电器等领域扮演着越来越重要的角色。有刷马达因其结构简单、成本低廉、维护方便等优点,在市场上占据了一定的份额。然而,为了充分发挥有刷马达的性能,一款高效能、…...
【Linux网络编程】传输层协议TCP,UDP
目录 一,UDP协议 1,UDP协议的格式 2,UDP的特点 3,面向数据报 4,UDP的缓冲区 5,UDP使用注意事项 6,基于UDP的应用层协议 二,对于报文的理解 三,TCP协议 1&…...
基于Geotools的Worldpop世界人口tif解析-以中国2020年数据为例
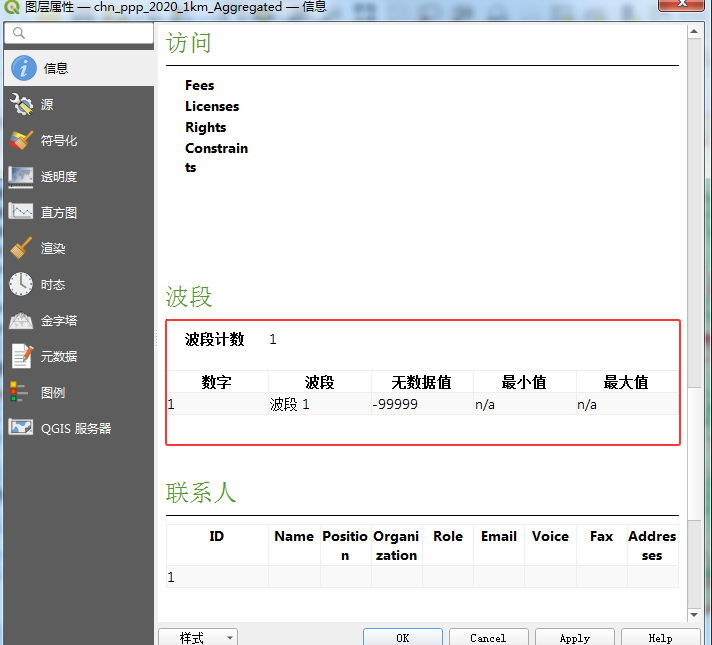
目录 前言 一、Worldpop数据简介 1、数据来源 2、QGIS数据展示 3、元数据展示 二、GeoTools人口解析 1、Maven依赖引入 2、Tif人口计算 三、总结 前言 在当今数字化与信息化飞速发展的时代,地理空间数据的分析与应用已然成为诸多领域研究与决策的关键支撑。…...
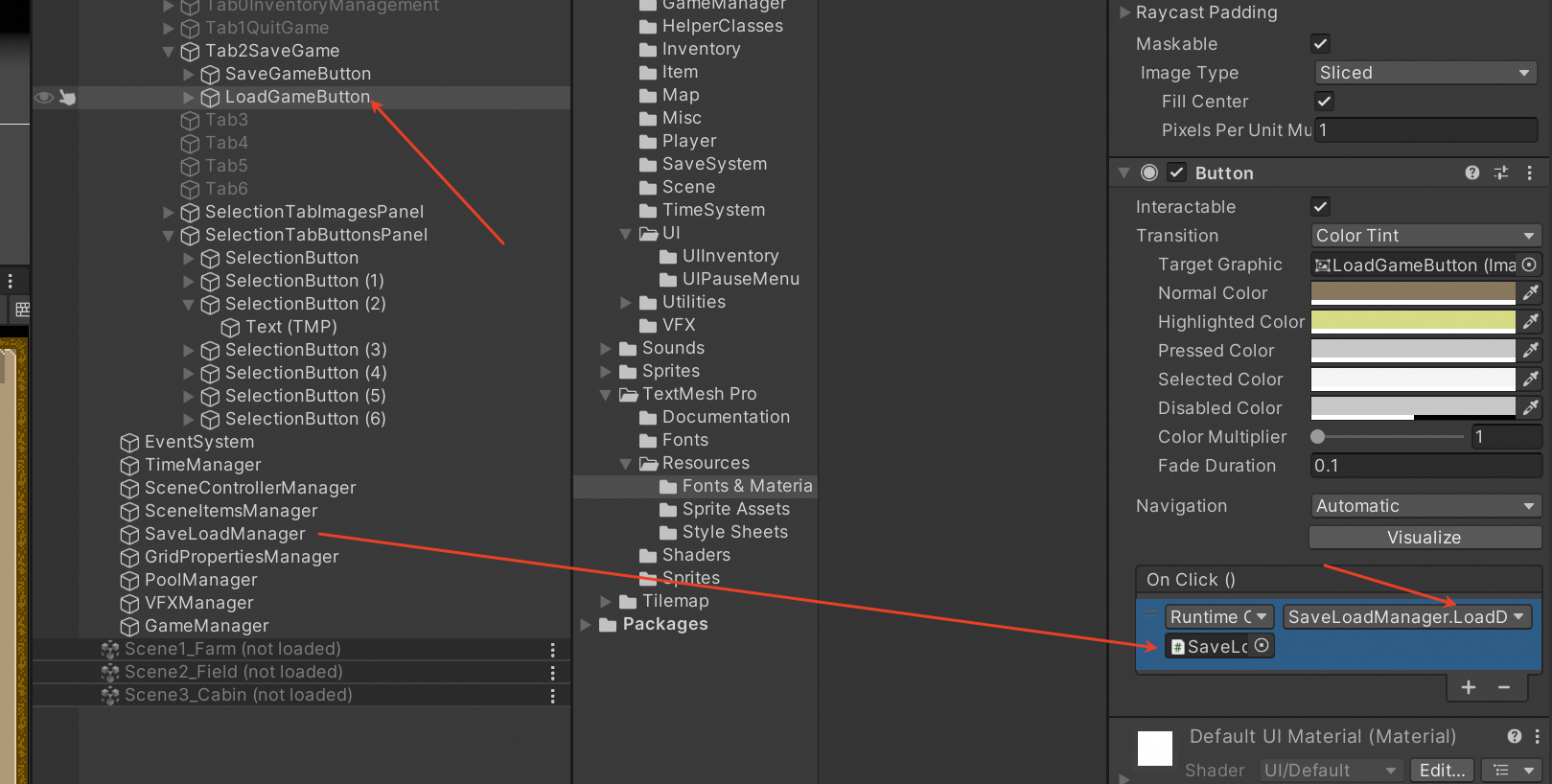
Unity3D仿星露谷物语开发55之保存游戏到文件
1、目标 将游戏保存到文件,并从文件中加载游戏。 Player在游戏中种植的Crop,我们希望保存到文件中,当游戏重新加载时Crop的GridProperty数据仍然存在。这次主要实现保存地面属性(GridProperties)信息。 我们要做的是…...

【无标题】C++23新特性:支持打印volatile指针
文章目录 前言背景与问题C23的解决方案实现原理使用场景硬件开发多线程调试 总结 前言 在C开发中,volatile关键字常用于修饰变量,以确保编译器不会对这些变量进行优化,从而保证程序能够正确地与硬件交互或处理多线程环境下的特殊变量。然而&…...

【第4章 图像与视频】4.2 图像的缩放
文章目录 前言示例-图像的缩放在 Canvas 边界之外绘制图像 前言 在上节中读者已经学会了如何使用 drawImage() 方法将一幅未经缩放的图像绘制到 canvas 之中。现在我们就来看看如何用该方法在绘制图像的时候进行缩放 示例-图像的缩放 未缩放的图像,显示图形原有大…...