【ConvLSTM第二期】模拟视频帧的时序建模(Python代码实现)
目录
- 1 准备工作:python库包安装
- 1.1 安装必要库
- 案例说明:模拟视频帧的时序建模
- ConvLSTM概述
- 损失函数说明
- (python全代码)
- 参考
ConvLSTM的原理说明可参见另一博客-【ConvLSTM第一期】ConvLSTM原理。
1 准备工作:python库包安装
1.1 安装必要库
pip install torch torchvision matplotlib numpy
案例说明:模拟视频帧的时序建模
🎯 目标:给定一个人工生成的动态图像序列(例如移动的方块),使用 ConvLSTM 对其进行建模,输出预测结果,并查看输出的维度和特征变化。
ConvLSTM概述
ConvLSTM 的基本结构,包括:
- ConvLSTMCell:实现了一个时间步的 ConvLSTM 单元,类似于一个“时刻”的神经元。
- ConvLSTM:实现了多层ConvLSTM结构,能够处理一整个时间序列的视频帧数据。
损失函数说明
MSE(均方误差) 衡量预测值和真实值之间的平均平方差。

关于训练终止条件:
可以根据 MSE是否达到某个阈值(如 < 0.001)提前终止训练,这是所谓的 “Early Stopping(提前停止)策略”。
(python全代码)
MSE损失函数曲线如下:可知MSE一直在下降,虽然存在振荡

前9帧图像及预测的第十帧图像得到的动图如下:

python完整代码如下:
import os
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image# 设置字体
plt.rcParams['font.family'] = 'Times New Roman'# 创建保存图像目录
os.makedirs("./Figures", exist_ok=True)# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ====================================
# 一、ConvLSTM 模型结构
# ====================================class ConvLSTMCell(nn.Module):def __init__(self, input_channels, hidden_channels, kernel_size, bias=True):super(ConvLSTMCell, self).__init__()padding = kernel_size // 2self.input_channels = input_channelsself.hidden_channels = hidden_channelsself.conv = nn.Conv2d(input_channels + hidden_channels, 4 * hidden_channels, kernel_size, padding=padding, bias=bias)def forward(self, x, h_prev, c_prev):combined = torch.cat([x, h_prev], dim=1)conv_output = self.conv(combined)cc_i, cc_f, cc_o, cc_g = torch.chunk(conv_output, 4, dim=1)i = torch.sigmoid(cc_i)f = torch.sigmoid(cc_f)o = torch.sigmoid(cc_o)g = torch.tanh(cc_g)c = f * c_prev + i * gh = o * torch.tanh(c)return h, cclass ConvLSTM(nn.Module):def __init__(self, input_channels, hidden_channels, kernel_size, num_layers):super(ConvLSTM, self).__init__()self.num_layers = num_layerslayers = []for i in range(num_layers):in_channels = input_channels if i == 0 else hidden_channelslayers.append(ConvLSTMCell(in_channels, hidden_channels, kernel_size))self.layers = nn.ModuleList(layers)def forward(self, input_seq):b, t, c, h, w = input_seq.size()h_t = [torch.zeros(b, layer.hidden_channels, h, w).to(input_seq.device) for layer in self.layers]c_t = [torch.zeros(b, layer.hidden_channels, h, w).to(input_seq.device) for layer in self.layers]for time in range(t):x = input_seq[:, time]for i, layer in enumerate(self.layers):h_t[i], c_t[i] = layer(x, h_t[i], c_t[i])x = h_t[i]return h_t[-1] # 返回最后一层最后一帧的隐藏状态# ====================================
# 二、生成移动方块序列数据
# ====================================def generate_moving_square_sequence(batch_size, time_steps, height, width):data = torch.zeros((batch_size, time_steps, 1, height, width))for b in range(batch_size):dx = np.random.randint(1, 3)dy = np.random.randint(1, 3)x = np.random.randint(0, width - 6)y = np.random.randint(0, height - 6)for t in range(time_steps):data[b, t, 0, y:y+5, x:x+5] = 1.0x = (x + dx) % (width - 5)y = (y + dy) % (height - 5)return data# ====================================
# 三、模型、损失、优化器
# ====================================class ConvLSTM_Predictor(nn.Module):def __init__(self):super().__init__()self.convlstm = ConvLSTM(input_channels=1, hidden_channels=16, kernel_size=3, num_layers=1)self.decoder = nn.Conv2d(in_channels=16, out_channels=1, kernel_size=1)def forward(self, input_seq):hidden = self.convlstm(input_seq)pred = self.decoder(hidden)return predmodel = ConvLSTM_Predictor().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)# ====================================
# 四、训练过程
# ====================================mse_list = []
max_epochs = 100
mse_threshold = 0.001
height, width = 64, 64for epoch in range(max_epochs):model.train()seq = generate_moving_square_sequence(8, 10, height, width).to(device)input_seq = seq[:, :9]target_frame = seq[:, 9, 0].unsqueeze(1)optimizer.zero_grad()output = model(input_seq)loss = criterion(output, target_frame)loss.backward()optimizer.step()mse = loss.item()mse_list.append(mse)print(f"Epoch {epoch+1}/{max_epochs}, MSE: {mse:.6f}")# 提前停止条件if mse < mse_threshold:print(f"✅ 提前停止:MSE 已达到阈值 {mse_threshold}")break# ====================================
# 五、测试与可视化结果
# ====================================model.eval()
with torch.no_grad():test_seq = generate_moving_square_sequence(1, 10, height, width).to(device)input_seq = test_seq[:, :9]true_frame = test_seq[:, 9, 0]pred_frame = model(input_seq)[0, 0].cpu().numpy()# 保存输入帧
for t in range(9):frame = input_seq[0, t, 0].cpu().numpy()plt.imshow(frame, cmap='gray')plt.title(f"Input Frame t={t}")plt.colorbar()plt.savefig(f"./Figures/input_frame_{t}.png")plt.close()# 保存 Ground Truth
plt.imshow(true_frame[0].cpu().numpy(), cmap='gray')
plt.title("Ground Truth Frame t=9")
plt.colorbar()
plt.savefig("./Figures/ground_truth_t9.png")
plt.close()# 保存预测帧
plt.imshow(pred_frame, cmap='gray')
plt.title("Predicted Frame t=9")
plt.colorbar()
plt.savefig("./Figures/predicted_t9.png")
plt.close()# 保存 MSE 曲线图
plt.plot(mse_list)
plt.title("Training MSE Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE")
plt.grid(True)
plt.savefig("./Figures/mse_curve.png")
plt.close()# ---------------- 生成动图 ----------------frames = []# 添加前9帧输入
for t in range(9):img = Image.open(f"./Figures/input_frame_{t}.png")frames.append(img.copy())# 添加预测帧
img = Image.open("./Figures/predicted_t9.png")
frames.append(img.copy())# 保存动图
frames[0].save("./Figures/sequence.gif", save_all=True, append_images=frames[1:], duration=500, loop=0)
print("✅ 所有图像和动图已保存至 ./Figures 文件夹")
参考
相关文章:
【ConvLSTM第二期】模拟视频帧的时序建模(Python代码实现)
目录 1 准备工作:python库包安装1.1 安装必要库 案例说明:模拟视频帧的时序建模ConvLSTM概述损失函数说明(python全代码) 参考 ConvLSTM的原理说明可参见另一博客-【ConvLSTM第一期】ConvLSTM原理。 1 准备工作:pytho…...

[VMM]分享一个用SystemC编写的页表管理程序
分享一个用SystemC编写的页表管理程序 摘要:分享一个用SystemC编写的页表管理的程序,这个程序将模拟页表(PDE和PTE)的创建、虚拟地址(VA)到物理地址(PA)的转换,以及对内存的读写操作。 为了简化实现,我们做出以下假设: 页表是两级结构:PDE (Page Directory…...

将docker数据目录迁移到 home目录下
将 Docker 数据目录从默认位置(通常是 /var/lib/docker)迁移到 /home 目录下,可以通过几个步骤来完成。以下是详细的迁移步骤: 步骤 1:停止 Docker 服务 在进行任何操作之前,确保先停止 Docker 服务以避免…...

【论文解读】DETR: 用Transformer实现真正的End2End目标检测
1st authors: About me - Nicolas CarionFrancisco Massa - Google Scholar paper: [2005.12872] End-to-End Object Detection with Transformers ECCV 2020 code: facebookresearch/detr: End-to-End Object Detection with Transformers 1. 背景 目标检测&#…...

Pytest 是什么
Pytest 是 Python 生态中最流行的 测试框架,用于编写、运行和组织单元测试、功能测试甚至复杂的集成测试。它以简洁的语法、强大的插件系统和高度可扩展性著称,广泛应用于 Python 项目的自动化测试中。以下是其核心特性和使用详解: Pytest 的…...

ElasticSearch简介及常用操作指南
一. ElasticSearch简介 ElasticSearch 是一个基于 Lucene 构建的开源、分布式、RESTful 风格的搜索和分析引擎。 1. 核心功能 强大的搜索能力 它能够提供全文检索功能。例如,在海量的文档数据中,可以快速准确地查找到包含特定关键词的文档。这在处理诸如…...

缓存常见问题:缓存穿透、缓存雪崩以及缓存击穿
缓存常见问题 一、缓存穿透 (Cache Penetration) 是什么 缓存穿透是指客户端持续请求一个缓存和数据库中都根本不存在的数据。这导致每次请求都会先查缓存(未命中),然后穿透到数据库查询(也未命中)。如果这类请求量…...
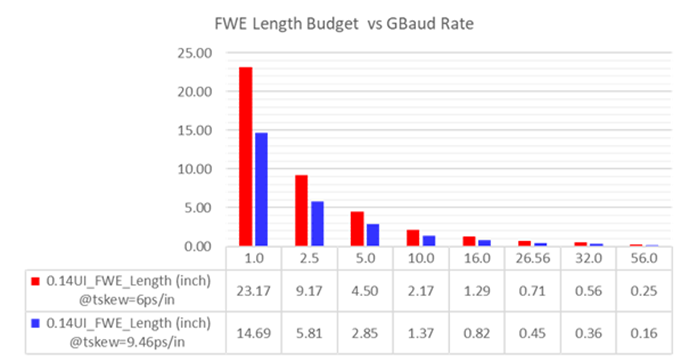
纤维组织效应偏斜如何影响您的高速设计
随着比特率继续飙升,光纤编织效应 (FWE) 偏移,也称为玻璃编织偏移 (GWS),正变得越来越成为一个问题。今天的 56GB/s 是高速路由器中最先进的,而 112 GB/s 指日可待。而用于个人计算机…...

【深度学习】sglang 的部署参数详解
SGLang 的部署参数详解 SGLang(Structured Generation Language)是一个高性能的大语言模型推理框架,专为结构化生成和多模态应用设计。本文将全面介绍SGLang的部署参数,帮助你充分发挥其性能潜力。 🚀 SGLang 项目概览 SGLang是由UC Berkeley开发的新一代LLM推理引擎,…...

SDL2常用函数:SDL_RendererSDL_CreateRendererSDL_RenderCopySDL_RenderPresent
SDL 渲染器系统详解 SDL_Renderer 概述 SDL_Renderer 是 SDL 2.0 引入的核心渲染抽象,它提供了一种高效的、硬件加速的 2D 渲染方式,比传统的表面(Surface)操作更加高效和灵活。 主要函数 1. SDL_CreateRenderer - 创建渲染器 SDL_Renderer* SDL_Cr…...

[git]忽略.gitignore文件
git rm --cached .gitignore 是一个 Git 命令,主要用于 从版本控制中移除已追踪的 .gitignore 文件,但保留该文件在本地工作目录中。以下是详细解析: 一、命令拆解与核心作用 语法解析 git rm:Git 的删除命令,用于从版本库(Repository)中移除文件。--cached:关键参数…...

FEMFAT许可的有效期限
在工程仿真领域,FEMFAT作为一款领先的疲劳分析软件,为用户提供了强大的功能和卓越的性能。然而,为了确保软件的合法使用和持续合规,了解FEMFAT许可的有效期限至关重要。本文将为您详细解读FEMFAT许可的有效期限,帮助您…...
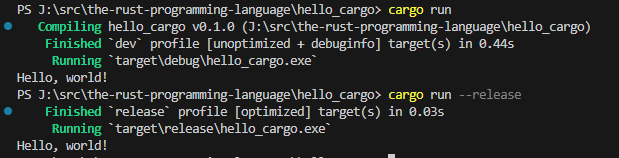
Rust使用Cargo构建项目
文章目录 你好,Cargo!验证Cargo安装使用Cargo创建项目新建项目配置文件解析默认代码结构 Cargo工作流常用命令速查表详细使用说明1. 编译项目2. 运行程序3.快速检查4. 发布版本构建 Cargo的设计哲学约定优于配置工程化优势 开发建议1. 新项目初始化2. …...
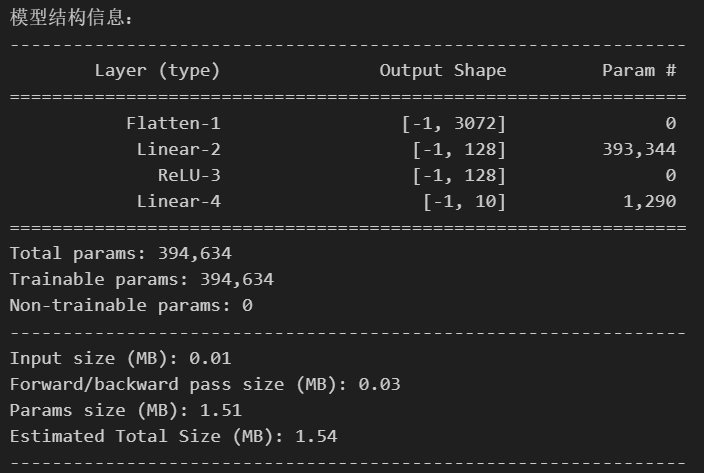
Python训练营打卡Day39
DAY 39 图像数据与显存 知识点回顾 1.图像数据的格式:灰度和彩色数据 2.模型的定义 3.显存占用的4种地方 a.模型参数梯度参数 b.优化器参数 c.数据批量所占显存 d.神经元输出中间状态 4.batchisize和训练的关系 作业:今日代码较少,理解内容…...
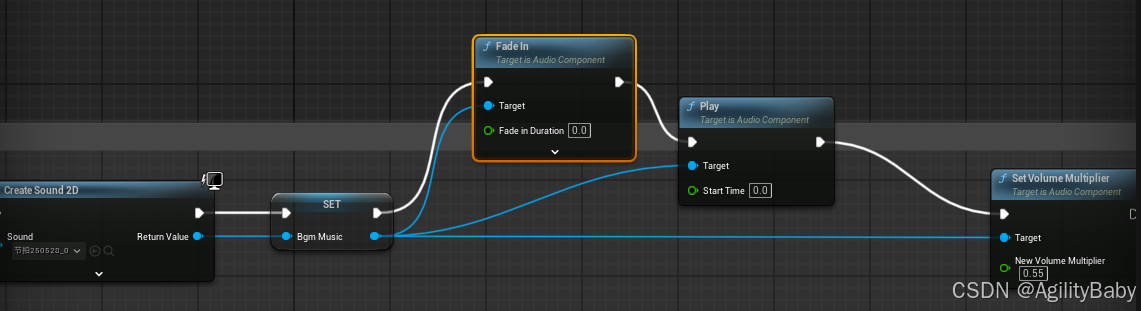
UE5蓝图中播放背景音乐和使用代码播放声音
UE5蓝图中播放背景音乐 1.创建背景音乐Cube 2.勾选looping 循环播放背景音乐 3.在关卡蓝图中 Event BeginPlay-PlaySound2D Sound选择自己创建的Bgm_Cube 蓝图播放声音方法二: 使用代码播放声音方法一 .h文件中 头文件引用 #include "Kismet/GameplayS…...
AI 赋能数据可视化:漏斗图制作的创新攻略
在数据可视化的广阔天地里,漏斗图以其独特的形状和强大的功能,成为展示流程转化、分析数据变化的得力助手。传统绘制漏斗图的方式往往需要耗费大量时间和精力,对使用者的绘图技能和软件操作熟练度要求颇高。但随着技术的蓬勃发展,…...

用 Python 模拟下雨效果
用 Python 模拟下雨效果 雨天别有一番浪漫情怀:淅淅沥沥的雨滴、湿润的空气、朦胧的光影……在屏幕上也能感受下雨的美妙。本文将带你用一份简单的 Python 脚本,手把手实现「下雨效果」动画。文章深入浅出,零基础也能快速上手,完…...
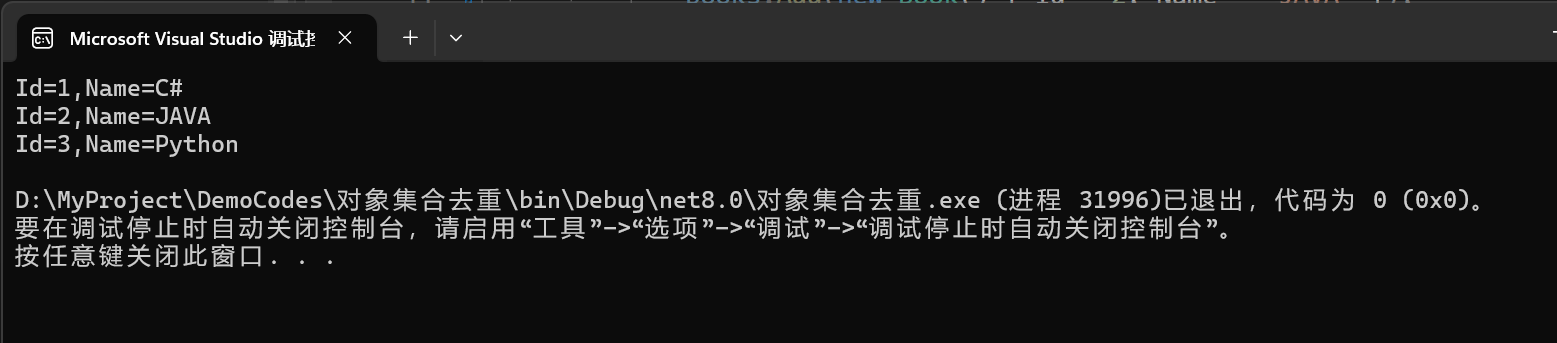
C#对象集合去重的一种方式
前言 现在AI越来越强大了,有很多问题其实不需要在去各个网站上查了,直接问AI就好了,但是呢,AI给的代码可能能用,也可能需要调整,但是自己肯定是要会的,所以还是总结一下吧。 问题 如果有一个…...

【LangChain】
以下是关于 LangChain框架 各核心组件的详细解析,结合其功能定位、技术实现和实际应用场景: 一、LangChain Libraries(核心库) 功能定位 跨语言支持:提供Python/JS双版本API,统一不同语言的LLM开发生态 …...

Java 面试实录:从Spring到微服务的技术探讨
在一个明亮的会议室里,严肃的面试官与搞笑的程序员谢飞机正进行一场关于Java技术栈的面试。场景设定在一家知名互联网大厂,他们的对话充满了技术性与娱乐性。 第一轮:Spring框架与数据库 面试官:“谢飞机,能解释一下…...

在ROS2(humble)+Gazebo+rqt下,实时显示仿真无人机的相机图像
文章目录 前言一、版本检查检查ROS2版本 二、步骤1.下载对应版本的PX4(1)检查PX4版本(2)修改文件名(3)下载正确的PX4版本 2.下载对应版本的Gazebo(1)检查Gazebo版本(2)卸载不正确的Gazebo版本(3)下载正确的Gazebo版本 3.安装bridge包4.启动 总结 前言 在ROS2的环境下ÿ…...
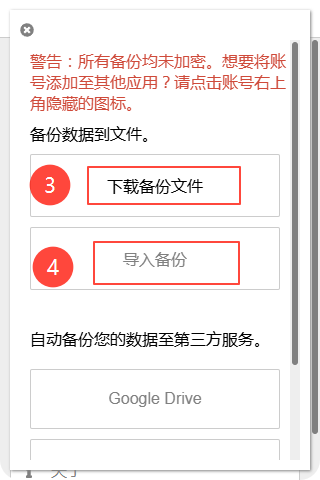
github双重认证怎么做
引言 好久没登陆github了, 今天登陆github后,提醒进行2FA认证。 查看了github通知,自 2023 年 3 月起,GitHub 要求所有在 GitHub.com 上贡献代码的用户启用一种或多种形式的双重身份验证 (2FA)。 假如你也遇到这个问题…...
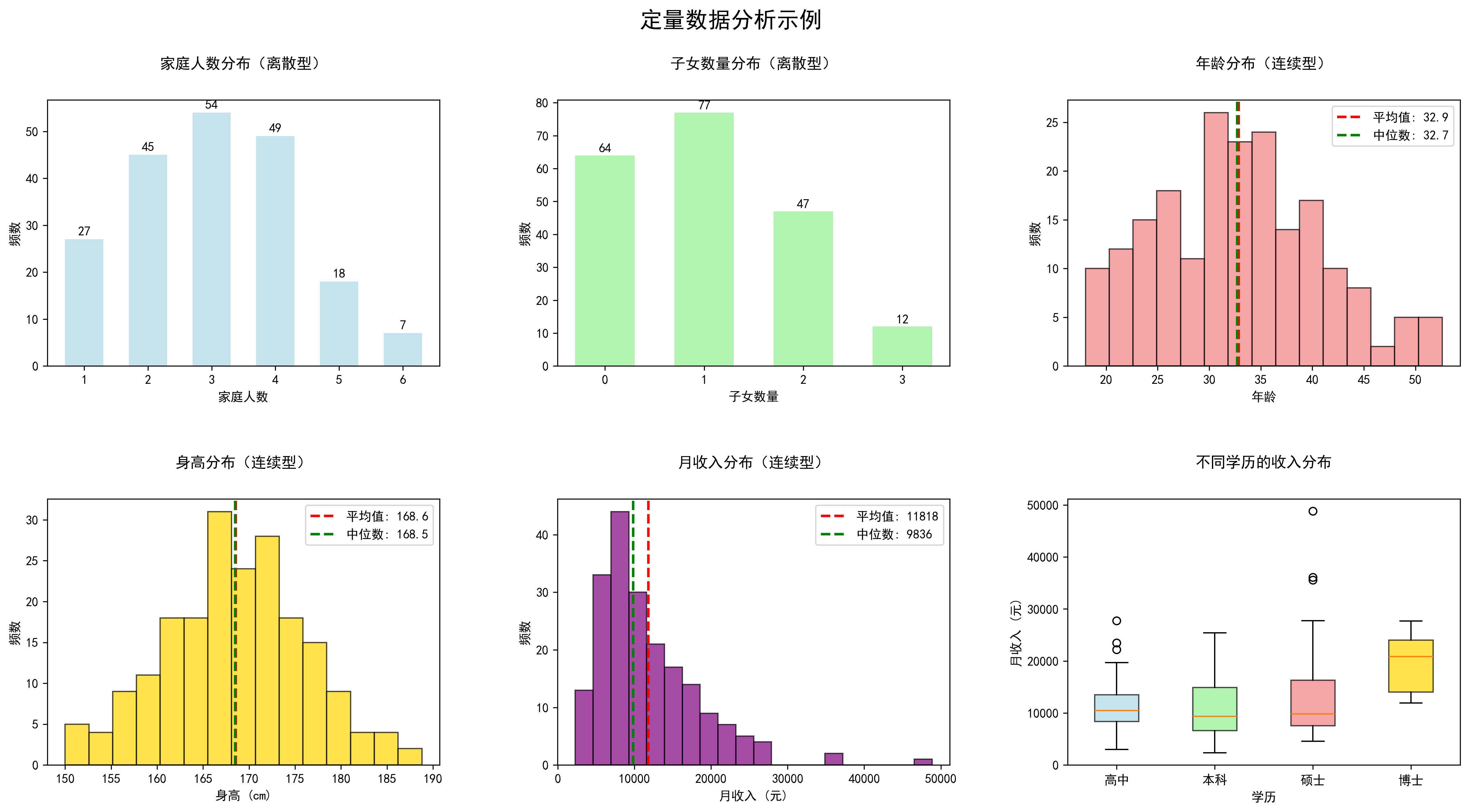
数据的类型——认识你的数据
第02篇:数据的类型——认识你的数据 写在前面:嗨,大家好!我是蓝皮怪。在上一篇文章中,我们聊了统计学的基本概念,今天我们来深入了解一个非常重要的话题——数据的类型。你可能会想:"数据就…...

DeepSeek与AI提示语设计的全面指南
文章目录 什么是提示语设计?为什么提示语设计如此重要?DeepSeek提示语设计的基本原则1. 明确性是王道2. 结构化你的需求3. 提供上下文4. 指定输出格式5. 使用示例6. 设定角色 进阶技巧:让你的提示语更上一层楼1. 链式思考2. 反向提问3. 限定条…...

Kafka KRaft + SSL + SASL/PLAIN 部署文档
本文档介绍如何在 Windows 环境下部署 Kafka 4.x,使用 KRaft 模式、SSL 加密和 SASL/PLAIN 认证。stevensu1/kafka_2.13-4.0.0 1. 环境准备 JDK 17 或更高版本Kafka 4.x 版本(本文档基于 kafka_2.13-4.0.0) 2. 目录结构 D:\kafka_2.13-4.…...
)
Codeforces Round 1027 (Div. 3)
A. Square Year 题目大意:拆分完全平方数。 【解题】:如果是完全平方数输出0 平方根就行,不是就输出-1。 code: #include <iostream> #include <string> #include <cmath> using namespace std; typedef long long LL…...

动态内容加载时,爬虫应如何处理?
处理动态内容加载是爬虫开发中的一个常见挑战。许多现代网站使用 JavaScript 动态加载内容,这意味着页面的某些部分可能在初始加载时并不存在,而是通过后续的 AJAX 请求或 JavaScript 执行动态生成的。为了处理这种情况,爬虫需要能够模拟浏览…...

第五十二节:增强现实基础-简单 AR 应用实现
引言 增强现实(Augmented Reality, AR)是一种将虚拟信息叠加到真实世界的技术,广泛应用于游戏、教育、工业维护等领域。与传统虚拟现实(VR)不同,AR强调虚实结合,用户无需完全沉浸到虚拟环境中。本文将通过Python和OpenCV库,从零开始实现一个基础的AR应用:在检测到特定…...

前端高频面试题1:HTML/CSS/浏览器/计算机网络
目录 1.为什么会出现margin塌陷? 2.如何解决margin塌陷? 3.HTML5有哪些新特性? 4.常见的语义化标签有哪些?语义化标签的好处? 5.使用css和js做动画有何优劣 6.如何实现文本超出展示省略号 7.deep在css中存在吗&…...
LLaMaFactory 微调QwenCoder模型
步骤一:准备LLamaFactory环境 首先,让我们尝试使用github的方式克隆仓库: git config --global http.sslVerify false && git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git # 创建新环境,指定 Python 版本(以 3.…...