数据的类型——认识你的数据
第02篇:数据的类型——认识你的数据
写在前面:嗨,大家好!我是蓝皮怪。在上一篇文章中,我们聊了统计学的基本概念,今天我们来深入了解一个非常重要的话题——数据的类型。你可能会想:"数据就是数据,还有什么类型之分吗?"哈哈,这个想法我在初学的时候也有过!但是当我深入学习后发现,不同类型的数据就像不同种类的食材,需要用不同的"烹饪方法"来处理和分析。用错了方法,就像用炒菜的方式来做汤一样,结果肯定不理想。
🎯 这篇文章你能学到什么
- 数据类型的完整分类体系(定性vs定量,名义vs有序,离散vs连续)
- 如何快速识别不同类型的数据
- 不同数据类型适用的分析方法
- 避免数据类型识别的常见误区
1. 为什么要区分数据类型?
假设你是一名数据分析师,需要分析一份客户满意度调查结果。调查中,满意度用1-5分表示(1=非常不满意,5=非常满意)。
看到数据后,你的第一反应可能是:直接计算所有客户满意度的平均值,得出3.2分,然后得出结论:“客户满意度一般般。”
但是,这样做对吗?
让我们仔细想想:满意度从1到2的差距,和从4到5的差距,真的是一样的吗?2分的"一般不满意"和3分的"中性"之间的心理距离,真的等同于3分和4分之间的距离吗?
这就是数据类型的重要性!不同类型的数据,需要用不同的分析方法。如果我们错误地把有序型数据(满意度等级)当作连续型数据来处理,就可能得出误导性的结论。
2. 数据类型特征与分析方法对比
| 数据类型 | 可进行数学运算 | 可排序 | 常用统计量 | 常用图表 | 典型分析方法 |
|---|---|---|---|---|---|
| 名义型 | ✗ | ✗ | 频数、众数、比例 | 条形图、饼图 | 频数分布表、卡方检验、列联表分析 |
| 有序型 | ✗ | ✓ | 频数、中位数、四分位数 | 条形图 | 频数分布表、秩和检验、Spearman相关、列联表分析 |
| 离散型 | ✓ | ✓ | 均值、方差、标准差 | 条形图 | 描述性统计、t检验、方差分析 |
| 连续型 | ✓ | ✓ | 均值、方差、标准差 | 直方图、箱线图 | t检验、方差分析、相关分析、回归分析 |
数据类型识别流程与判断技巧
判断数据类型时,可以按照以下思路:
- 这个数据是"类别/属性"还是"数量"?
- 如果是类别/属性:属于定性数据(名义型或有序型)
- 如果是数量:属于定量数据(离散型或连续型)
- 如果是定性数据,类别之间有没有顺序?
- 有顺序:有序型
- 没有顺序:名义型
- 如果是定量数据,理论上能不能无限细分?
- 能细分:连续型
- 不能细分(只能整数):离散型
典型示例:
- “性别” → 类别 → 无顺序 → 名义型
- “学历” → 类别 → 有顺序 → 有序型
- “子女数量” → 数量 → 不能细分(没有0.5个孩子)→ 离散型
- “年龄” → 数量 → 可以细分(25.3岁、25.31岁…)→ 连续型
3. 实际案例分析
让我用一个完整的数据集来展示不同数据类型的分析方法:
3.1 创建示例数据
我写了一个程序,模拟了200个用户的各种信息,包含不同类型的数据。下面是实际运行的结果:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 创建示例数据集
np.random.seed(42)
n = 200data = {# 定性数据 - 名义型'性别': np.random.choice(['男', '女'], n, p=[0.52, 0.48]),'血型': np.random.choice(['A', 'B', 'AB', 'O'], n, p=[0.3, 0.25, 0.1, 0.35]),'城市': np.random.choice(['北京', '上海', '广州', '深圳', '杭州'], n, p=[0.25, 0.2, 0.2, 0.2, 0.15]),# 定性数据 - 有序型'学历': np.random.choice(['高中', '本科', '硕士', '博士'], n, p=[0.2, 0.5, 0.25, 0.05]),'满意度': np.random.choice(['不满意', '一般', '满意', '非常满意'], n, p=[0.1, 0.2, 0.5, 0.2]),# 定量数据 - 离散型'家庭人数': np.random.choice([1, 2, 3, 4, 5, 6], n, p=[0.15, 0.25, 0.3, 0.2, 0.08, 0.02]),'子女数量': np.random.choice([0, 1, 2, 3], n, p=[0.3, 0.4, 0.25, 0.05]),# 定量数据 - 连续型'年龄': np.random.normal(32, 8, n).round(1),'身高': np.random.normal(168, 8, n).round(1),'月收入': np.random.lognormal(9.2, 0.5, n).round(0)
}# 确保数据在合理范围内
data['年龄'] = np.clip(data['年龄'], 18, 65)
data['身高'] = np.clip(data['身高'], 150, 190)df = pd.DataFrame(data)
3.2 定性数据分析
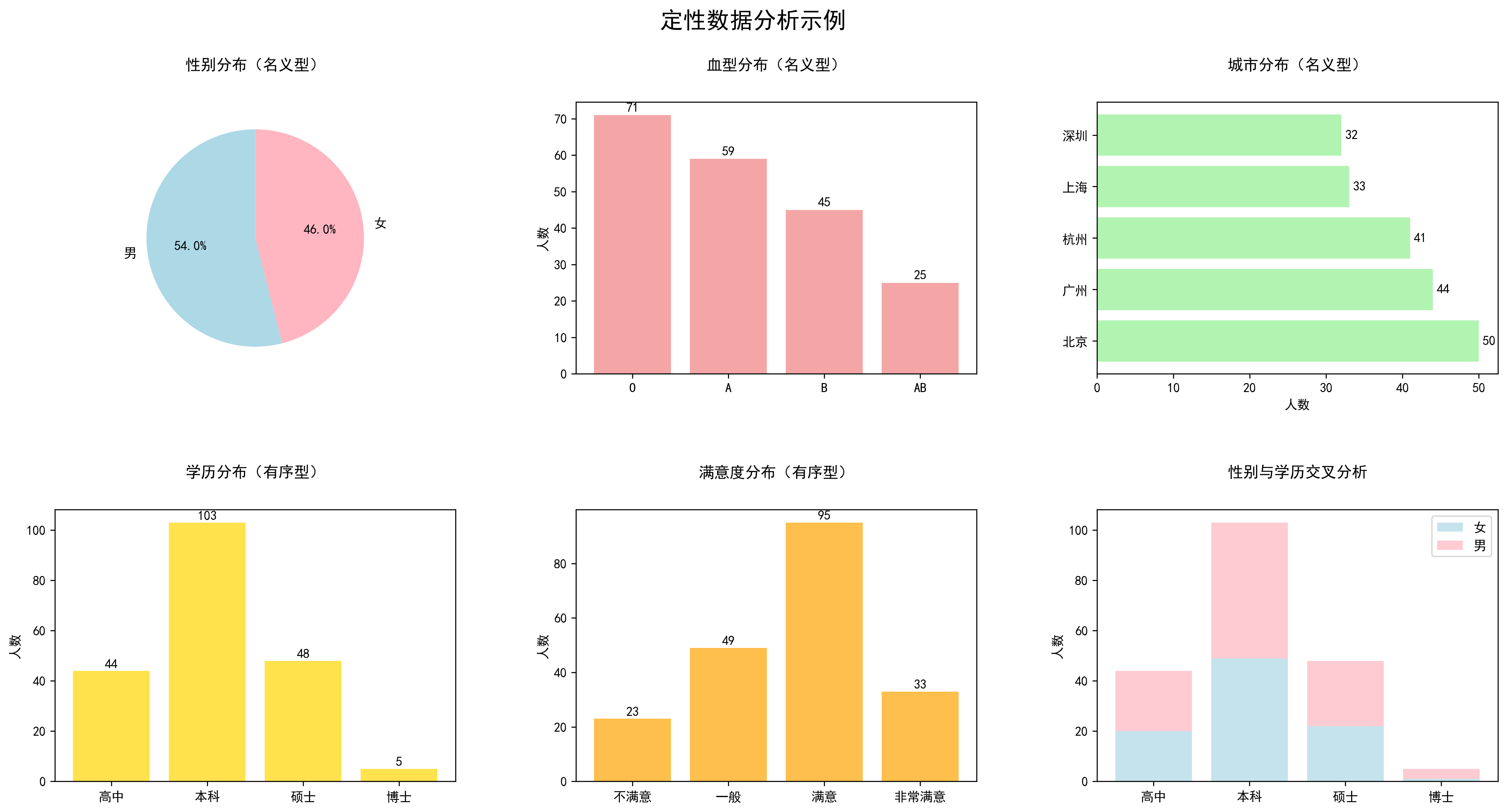
对于定性数据,我们主要关注:
名义型数据分析:
- 性别分布:男性52%,女性48%,比例相对均衡
- 血型分布:O型血最多(35%),AB型最少(10%)
- 城市分布:北京样本最多,各城市分布相对均匀
有序型数据分析:
- 学历分布:本科学历占主体(50%),呈现正常的教育结构
- 满意度分布:大部分人表示满意(50%),整体满意度较高
交叉分析:
- 性别与学历的交叉分析显示,不同性别在各学历层次的分布基本均衡
3.3 定量数据分析
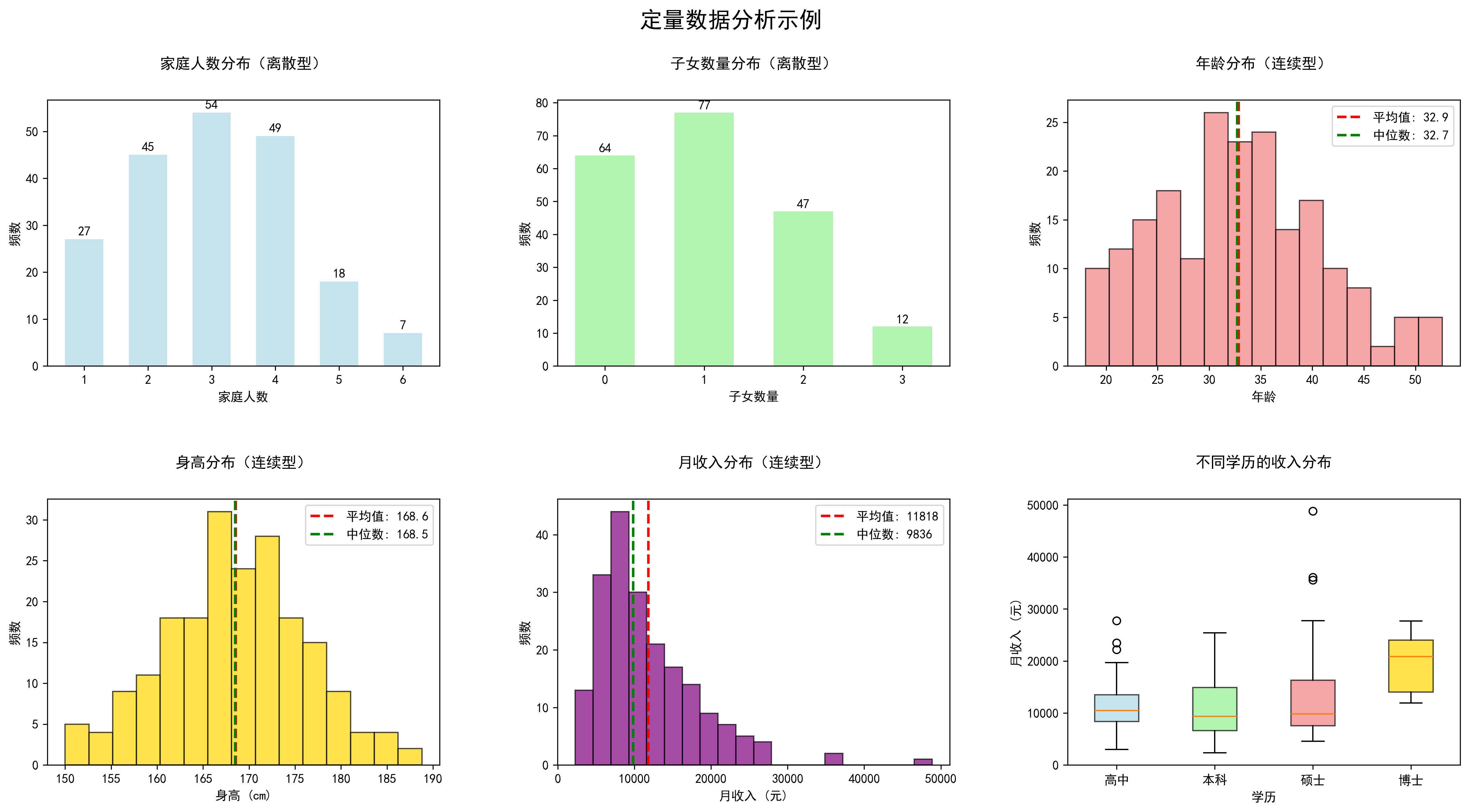
对于定量数据,我们可以计算更丰富的统计量:
离散型数据分析:
- 家庭人数:主要集中在2-4人,符合现代家庭结构
- 子女数量:多数家庭有1个孩子,符合当前生育趋势
连续型数据分析:
- 年龄分布:呈现正态分布,平均年龄32岁
- 身高分布:也呈正态分布,平均身高168cm
- 收入分布:呈现右偏分布,这是收入数据的典型特征
多变量分析:
- 不同学历的收入分布显示,学历越高,收入中位数越高,但也存在个体差异
3.4 数据摘要统计
基于我们的示例数据集(200个观测值,10个变量),以下是各变量的详细统计摘要:
📊 数据集摘要统计表
| 变量名 | 大类 | 细分类型 | 统计信息1 | 统计信息2 | 统计信息3 |
|---|---|---|---|---|---|
| 定性变量 | (类别数) | (众数) | (频数/比例) | ||
| 性别 | 定性 | 名义型 | 2 | 男 | 104 (52.0%) |
| 血型 | 定性 | 名义型 | 4 | O | 71 (35.5%) |
| 城市 | 定性 | 名义型 | 5 | 北京 | 50 (25.0%) |
| 学历 | 定性 | 有序型 | 4 | 本科 | 103 (51.5%) |
| 满意度 | 定性 | 有序型 | 4 | 满意 | 95 (47.5%) |
| 定量变量 | (均值) | (标准差) | (范围) | ||
| 家庭人数 | 定量 | 离散型 | 3.0 | 1.3 | 1.0 - 6.0 |
| 子女数量 | 定量 | 离散型 | 1.0 | 0.9 | 0.0 - 3.0 |
| 年龄 | 定量 | 连续型 | 32.9 | 8.0 | 18.0 - 52.6 |
| 身高 | 定量 | 连续型 | 168.6 | 7.7 | 150.0 - 188.8 |
| 月收入 | 定量 | 连续型 | 11818.5 | 6673.6 | 2297.0 - 48852.0 |
📝 数据集说明
- 样本量:200个观测值
- 变量数:10个变量(5个定性,5个定量)
- 定性变量:包含名义型和有序型,主要用于分类和排序分析
- 定量变量:包含离散型和连续型,可进行各种数学运算
🔍 分析要点
- 定性数据重点关注频数分布和众数,了解各类别的分布情况
- 定量数据可以计算均值、标准差等统计量,进行更深入的数值分析
- 不同类型数据适用不同的分析方法,需要根据数据特性选择合适的统计工具
4. 别被这些误区骗了
❌ 误区1:数字就是定量数据
真相:邮政编码100001、学号2021001、球衣号码23,这些虽然是数字,但表示的是类别,属于名义型数据。
❌ 误区2:定性数据无法进行统计分析
真相:实际上可以做频数分析、比例分析、卡方检验等。
❌ 误区3:有序数据可以直接计算均值
真相:满意度1-5分的平均值意义有限,因为相邻等级间距离不等。
❌ 误区4:看起来是整数就是离散型
真相:年龄常记录为整数(如25岁),但仍然是连续型数据。关键看理论上是否可以细分,而不是看实际记录格式。
❌ 误区5:连续数据必须有小数
真相:实际记录可能是整数,但理论上可以细分就是连续型。
❌ 误区6:小数形式的离散型数据混淆
常见错误:看到"某地区人口153.2万人",以为有小数就是连续型。
真相:人口本质上是离散型(不能有0.5个人),153.2万只是为了表述方便的近似值。
判断关键:看数据的本质含义,而不是表现形式。问自己"这个东西能不能被切成一半还有意义?"
🤔 常见困惑:大数值离散数据能否按连续型分析?
实际问题:当离散型数据数值很大时(如人口百万级),能否按连续型来分析?
统计学观点:当离散型数据取值范围很大、可能取值很多时,可以近似按连续型处理。
经验法则:如果离散型变量的可能取值超过20-30个,通常可以用连续型的分析方法。
典型例子:城市人口、公司年收入、网站日访问量等,理论上是离散型,但实际分析中可按连续型处理。
5. 实际应用建议
5.1 数据收集阶段
- 明确测量目标:你想了解什么?
- 选择合适的测量方式:是分类还是数值?
- 考虑后续分析需求:需要什么样的统计分析?
5.2 数据分析阶段
- 先识别数据类型:这是选择分析方法的基础
- 选择合适的统计量:不要盲目计算均值
- 选择合适的可视化方法:让数据"说话"
5.3 结果解释阶段
- 根据数据类型解释结果:名义型数据的"平均值"没有意义
- 注意统计量的适用性:中位数vs均值的选择
- 考虑实际意义:统计显著不等于实际重要
6. 练习一下
基础题
请判断以下变量的数据类型:
- 手机品牌(苹果、华为、小米、OPPO)
- 考试成绩(0-100分)
- 疼痛程度(无痛、轻微、中等、严重、剧烈)
- 银行卡号
- 每日步数
- 体温(℃)
- 星座评级(一星、二星、三星、四星、五星)
- 员工编号
- 某城市人口:285.7万人(容易混淆题)
- 某工厂月产值:127.5万元(容易混淆题)
- 网站日访问量:15.2万次(容易混淆题)
思考题
对于以下情况,你会选择什么统计量和图表?
- 分析公司员工的学历分布
- 比较不同部门的平均工资
- 展示客户满意度调查结果
- 分析网站日访问量的变化趋势
实际案例
某电商平台收集了以下客户数据:
- 年龄、性别、城市、购买金额、购买次数、会员等级、满意度评分
请为每个变量确定数据类型,并设计相应的分析方案。
7. 重点回顾
今天我们学习了数据类型的分类体系:
🎯 核心概念
-
定性数据
- 名义型:纯分类,无顺序
- 有序型:有顺序,但间距不等
-
定量数据
- 离散型:可数的整数值,不可细分
- 连续型:可无限细分的数值,理论上可取任意值
🎯 关键要点
- 数据类型决定了分析方法
- 不要被数据的表面形式迷惑
- 年龄虽然常用整数表示,但本质上是连续型
- 判断连续型vs离散型的关键:理论上是否可以无限细分
🎯 判断技巧
- 看本质不看形式
- 测量通常是连续的,计数通常是离散的
- 问自己:这个值可以有意义地细分吗?
8. 下期预告
下一篇我们聊 “描述性统计:让数据说话”。我们会学到:
- 描述性统计的核心概念和常用统计量(均值、中位数、众数、极差、方差、标准差等)
- 如何用数据总结和刻画样本的主要特征
- 各类统计量的适用场景和解读方法
- 避免常见的描述性统计误区
描述性统计是数据分析的基础,让我们学会用数字把数据的故事讲清楚!
📚 参考资料
本文参考了以下资料,如有引用请注明出处:
- 《统计学原理》,贾俊平等著,中国人民大学出版社
- 《应用统计学》,薛薇著,中国统计出版社
写在最后:感谢阅读!如果这篇文章对你有帮助,欢迎点赞、收藏和分享。有任何问题或建议,欢迎在评论区留言交流,我会认真回复每一条评论!让我们一起学习,一起进步! 📊
相关文章:
数据的类型——认识你的数据
第02篇:数据的类型——认识你的数据 写在前面:嗨,大家好!我是蓝皮怪。在上一篇文章中,我们聊了统计学的基本概念,今天我们来深入了解一个非常重要的话题——数据的类型。你可能会想:"数据就…...

DeepSeek与AI提示语设计的全面指南
文章目录 什么是提示语设计?为什么提示语设计如此重要?DeepSeek提示语设计的基本原则1. 明确性是王道2. 结构化你的需求3. 提供上下文4. 指定输出格式5. 使用示例6. 设定角色 进阶技巧:让你的提示语更上一层楼1. 链式思考2. 反向提问3. 限定条…...

Kafka KRaft + SSL + SASL/PLAIN 部署文档
本文档介绍如何在 Windows 环境下部署 Kafka 4.x,使用 KRaft 模式、SSL 加密和 SASL/PLAIN 认证。stevensu1/kafka_2.13-4.0.0 1. 环境准备 JDK 17 或更高版本Kafka 4.x 版本(本文档基于 kafka_2.13-4.0.0) 2. 目录结构 D:\kafka_2.13-4.…...
)
Codeforces Round 1027 (Div. 3)
A. Square Year 题目大意:拆分完全平方数。 【解题】:如果是完全平方数输出0 平方根就行,不是就输出-1。 code: #include <iostream> #include <string> #include <cmath> using namespace std; typedef long long LL…...

动态内容加载时,爬虫应如何处理?
处理动态内容加载是爬虫开发中的一个常见挑战。许多现代网站使用 JavaScript 动态加载内容,这意味着页面的某些部分可能在初始加载时并不存在,而是通过后续的 AJAX 请求或 JavaScript 执行动态生成的。为了处理这种情况,爬虫需要能够模拟浏览…...

第五十二节:增强现实基础-简单 AR 应用实现
引言 增强现实(Augmented Reality, AR)是一种将虚拟信息叠加到真实世界的技术,广泛应用于游戏、教育、工业维护等领域。与传统虚拟现实(VR)不同,AR强调虚实结合,用户无需完全沉浸到虚拟环境中。本文将通过Python和OpenCV库,从零开始实现一个基础的AR应用:在检测到特定…...

前端高频面试题1:HTML/CSS/浏览器/计算机网络
目录 1.为什么会出现margin塌陷? 2.如何解决margin塌陷? 3.HTML5有哪些新特性? 4.常见的语义化标签有哪些?语义化标签的好处? 5.使用css和js做动画有何优劣 6.如何实现文本超出展示省略号 7.deep在css中存在吗&…...
LLaMaFactory 微调QwenCoder模型
步骤一:准备LLamaFactory环境 首先,让我们尝试使用github的方式克隆仓库: git config --global http.sslVerify false && git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git # 创建新环境,指定 Python 版本(以 3.…...

Git全流程操作指南
Git全流程操作指南 一、Git 环境配置 1. 安装 Git Windows:下载 Git for Windows macOS:brew install git Linux: sudo apt-get update && sudo apt-get install git # Debian/Ubuntu sudo yum install git …...
【最新版】Arduino IDE的安装入门Demo
1、背景说明 1、本教程编写日期为2025-5-24 2、Arduino IDE的版本为:Arduino IDE 2.3.6 3、使用的Arduino为Arduino Uno 1、ArduinoIDE的安装 1、下载。网址如下:官网 2、然后一路安装即可。 期间会默认安装相关驱动,默认安装即可。 3、安…...
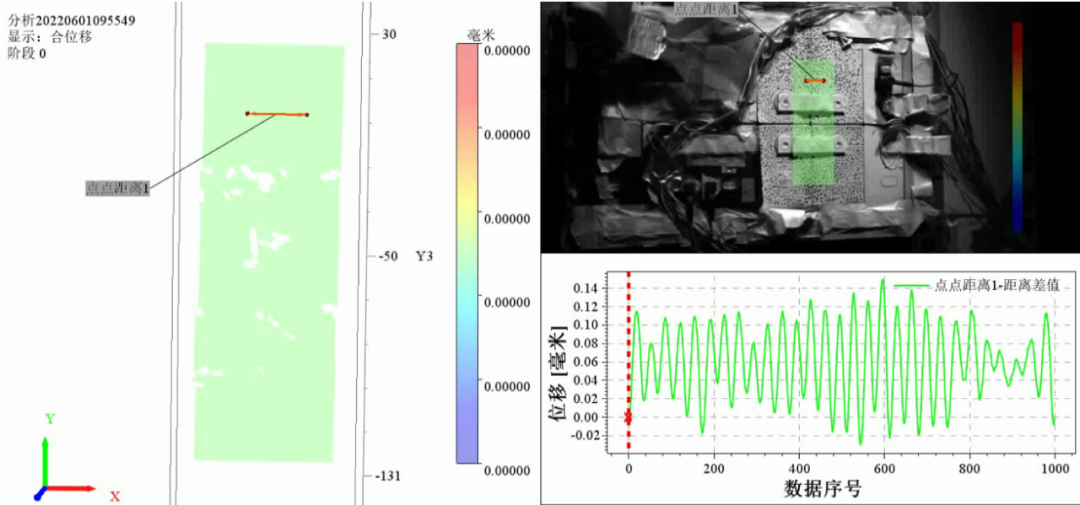
不起火,不爆炸,高速摄像机、数字图像相关DIC技术在动力电池新国标安全性能测试中的应用
2026年7月1日,我国将正式实施GB38031-2025《电动汽车用动力蓄电池安全要求》——这项被称为“史上最严电池安全令”的新国标,首次将“热失控不蔓延、不起火、不爆炸”从企业技术储备上升为强制性要求,标志着电池安全进入“零容忍”时代&#…...
thinkadmin中使用layui日期选择器,数据库存储时间戳
form.html <div class="layui-form-item label-required-prev" id="jiezhi_time-div">...
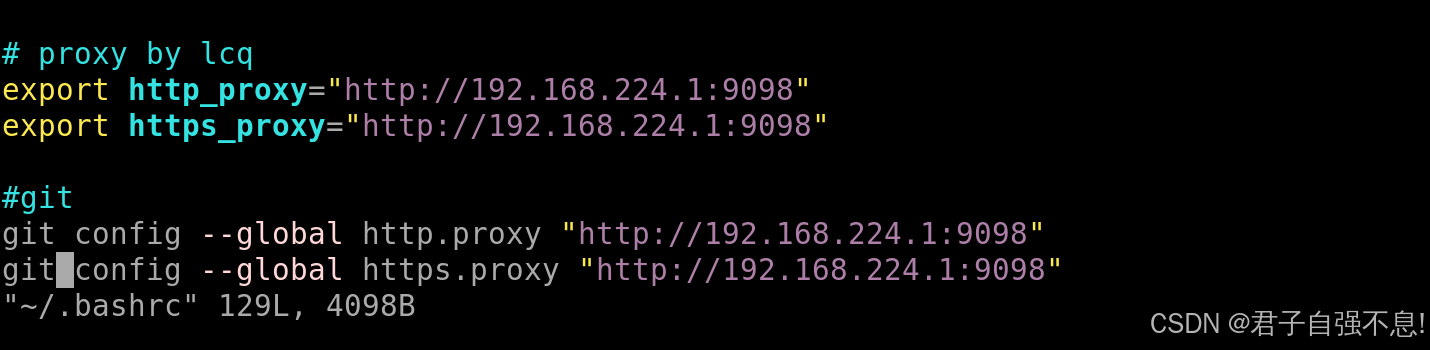
WSL中ubuntu通过Windows带代理访问github
WSL中ubuntu通过Windows带代理访问github 前言: WSL是Windows下的ubuntu访问工具,目前无法访问外网,因此需要配置一下。 步骤一 代理中进行如下设置: 步骤二 ubuntu22.04中修改配置 使用如下命令获取IP地址: ip route | grep default | aw…...
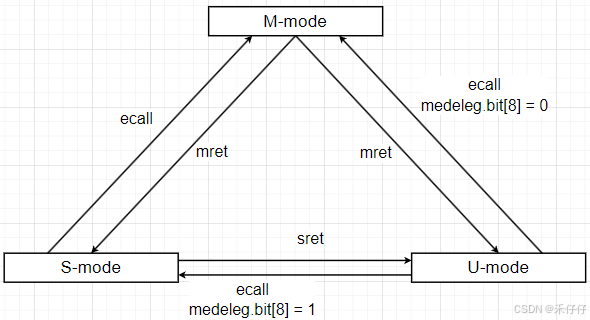
RISC-V特权模式及切换
1 RISC-V特权模式基本概念 1.1 RISC-V特权模式介绍 RISC-V 指令集架构(ISA)采用多特权级别设计作为其核心安全机制,通过层次化的权限管理实现系统资源的隔离与保护。该架构明确定义了四个层次化的特权模式,按照权限等级由高至低…...

Python爬虫实战:研究Tornado框架相关技术
1. 引言 1.1 研究背景与意义 网络爬虫作为一种自动获取互联网信息的程序,在信息检索、数据挖掘、舆情分析等领域有着广泛的应用。随着互联网数据量的爆炸式增长,对爬虫的性能和效率提出了更高的要求。传统的同步爬虫在处理大量 URL 时效率低下,而异步爬虫可以显著提高并发…...
【深度学习】11. Transformer解析: Self-Attention、ELMo、Bert、GPT
Transformer 神经网络 Self-Attention 的提出动机 传统的循环神经网络(RNN)处理序列信息依赖时间步的先后顺序,无法并行,而且在捕捉长距离依赖关系时存在明显困难。为了解决这些问题,Transformer 引入了 Self-Attent…...
)
Ubuntu实现和主机的复制粘贴 VMware-Tools(open-vm-tools)
Ubuntu实现和主机的复制粘贴 VMware-Tools(open-vm-tools) 1.安装open-vm-tools # 更新软件源并安装工具包 sudo apt update sudo apt install open-vm-tools open-vm-tools-desktop -y2.启用剪贴板共享 sudo nano /etc/vmware-tools/tools.conf添加或…...

4060显卡什么水平 4060显卡参数介绍
NVIDIA的GeForce RTX 40系列显卡基于最新的Ada Lovelace架构,提供了前所未有的图形处理能力和效率。其中,RTX 4060定位中高端市场,针对那些寻求卓越性能同时又注重成本效益的用户群体。那么,4060显卡什么水平呢?本文将…...

Kafka Producer 如何实现Exactly Once消息传递语义
Exactly-Once (精确一次) 是 Kafka 中最高级别的消息传递语义,确保消息既不会丢失也不会重复。以下是 Kafka Producer 实现 Exactly-Once 语义的关键机制: 1. 实现方法 1.1 启用幂等性 (Idempotence) props.put("enable.idempotence", &quo…...

通过ansible playbook创建azure 资源
安装 Ansible 在 macOS 上 Ansible 可以通过多种方式在 macOS 上安装,推荐使用 pip 或 Homebrew。 使用 Homebrew 安装 Ansible 运行以下命令: brew install ansible使用 pip 安装 Ansible 确保 Python 已安装(macOS 通常自带 Python),然后运行: pip install ansible…...
)
C++双线程交替打印奇偶数(活泼版)
C双线程交替打印奇偶数(活泼版) 文章目录 C双线程交替打印奇偶数(活泼版)1.🎮 游戏规则说明书2.🔧 游戏道具准备区2.1🧩 道具清单 3.👯♂️ 创建两个线程小伙伴3.1🧑…...

技术为器,服务为本:AI时代的客服价值重构
在智能化浪潮中,大语言模型的出现为客户服务行业注入了全新动能。然而技术创新的价值不在于技术本身,而在于其赋能服务的深度与广度。AI对于我们来说,如同发动机之于汽车,重要的不是引擎参数,而是整车带给用户的驾驶体…...

hadoop异构存储
Hadoop异构存储是一种基于HDFS的存储优化技术,通过将不同热度的数据分配到不同类型的存储介质上实现性能与成本的平衡。以下是其核心原理和实现方式: 一、核心概念 异构存储基本原理:Hadoop集群允许使用SSD、HDD、ARCHIVE等多种存储介质…...

EasyVoice:开源的文本转语音工具,让文字“开口说话“
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、EasyVoice是什么?1. 核心特性一览2. 技术架构概览 二、安装部署指南…...

扫地机产品异物进入吸尘口堵塞异常检测方案
扫地机产品异物进入吸尘口堵塞异常的检测方案 文章目录 扫地机产品异物进入吸尘口堵塞异常的检测方案一.背景二.石头的音频异常检测的方案2.1 音频检测触发点2.1.1时间周期2.1.2根据清洁机器人清扫模式或清扫区域污渍类型,即当清扫模式为深度清洁模式 或清扫区域污渍类型为重度…...

C++并集查找
前言 C图论 C算法与数据结构 本博文代码打包下载 基本概念 并查集(Union-Find)是一种用于处理动态连通性(直接或间接相连)的数据结构,主要支持两种操作:union 和 find。通过这两个基本操作,可…...
git reset --hard HEAD~1与git reset --hard origin/xxx
git reset --hard HEAD~1与git reset --hard origin/xxx git reset --hard origin/xxx有时候会太长,手工输入略微繁琐,可以考虑: git reset --hard HEAD~1 替代。 或者使用这种方式 git reset撤销当前分支所有修改,恢复到最近一…...
)
window 显示驱动开发-转换 Direct3D 固定函数状态(二)
未使用的User-Mode显示驱动程序函数 启用固定函数顶点着色器转换器时,Direct3D 运行时不会调用以下 用户模式显示驱动程序函数 : MultiplyTransform SetTransform SetMaterial SetLight CreateLight DestroyLight 1. 核心规则 当 固定功能顶点着…...

双路物理CPU机器上安装Ubuntu并部署KVM以实现系统多开
在双路物理CPU机器上安装Ubuntu并部署KVM以实现系统多开,并追求性能最优,需要从硬件、宿主机系统、KVM配置、虚拟机配置等多个层面进行优化。 以下是详细的操作指南和优化建议: 阶段一:BIOS/UEFI 设置优化 (重启进入) 启用虚拟化…...
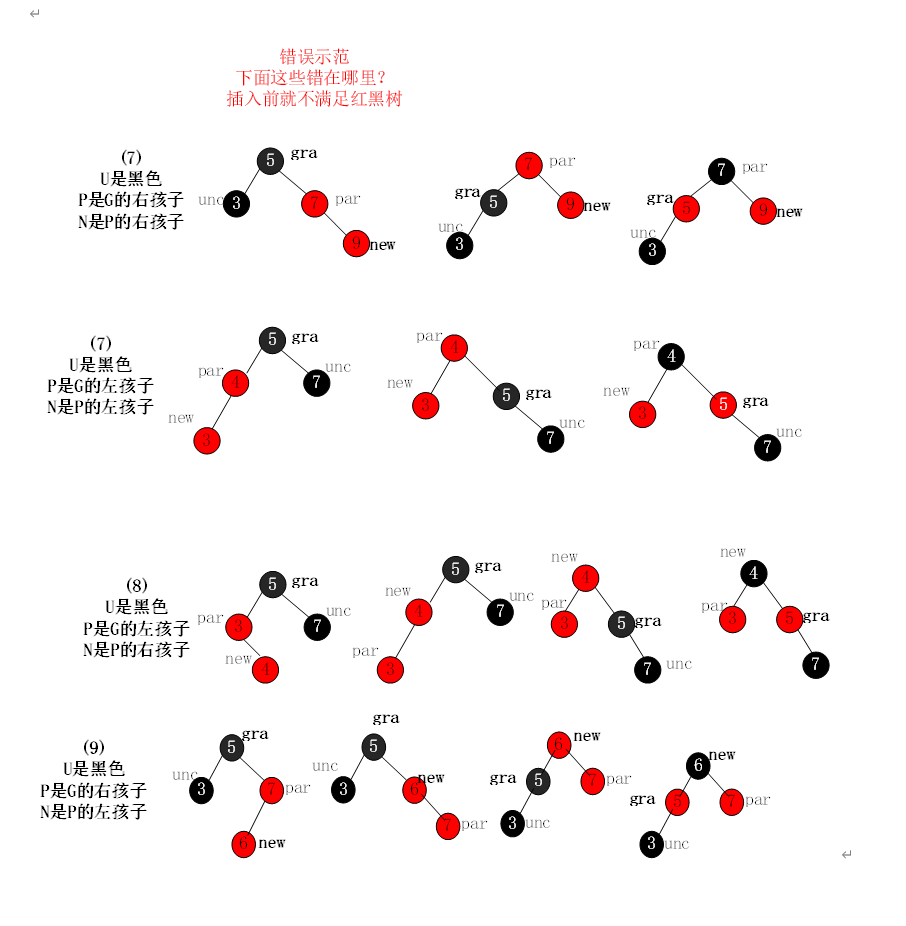
C++ RB_Tree
一、红黑树是什么?—— 带颜色标记的平衡二叉搜索树 红黑树是一种自平衡二叉搜索树,它在每个节点上增加了一个颜色属性(红色或黑色),通过对颜色的约束来确保树的大致平衡。这种平衡策略被称为 "弱平衡"&…...