【机器学习基础】机器学习入门核心算法:K均值(K-Means)

机器学习入门核心算法:K均值(K-Means)
- 1. 算法逻辑
- 2. 算法原理与数学推导
- 2.1 目标函数
- 2.2 数学推导
- 2.3 时间复杂度
- 3. 模型评估
- 内部评估指标
- 外部评估指标(需真实标签)
- 4. 应用案例
- 4.1 客户细分
- 4.2 图像压缩
- 4.3 文档聚类
- 5. 面试题及答案
- 6. 优缺点分析
- **优点**:
- **缺点**:
- 7. 数学证明:为什么均值最小化WCSS?
1. 算法逻辑
K均值是一种无监督聚类算法,核心目标是将n个数据点划分为k个簇(cluster),使得同一簇内数据点相似度高,不同簇间差异大。算法流程如下:
graph TDA[初始化K个质心] --> B[分配数据点到最近质心]B --> C[重新计算质心位置]C --> D{质心是否变化?}D -- 是 --> BD -- 否 --> E[输出聚类结果]
2. 算法原理与数学推导
2.1 目标函数
最小化簇内平方和(Within-Cluster Sum of Squares, WCSS):
J = ∑ i = 1 k ∑ x ∈ C i ∥ x − μ i ∥ 2 J = \sum_{i=1}^k \sum_{x \in C_i} \|x - \mu_i\|^2 J=i=1∑kx∈Ci∑∥x−μi∥2
其中:
- C i C_i Ci 表示第i个簇
- μ i \mu_i μi 表示第i个簇的质心
- ∥ x − μ i ∥ \|x - \mu_i\| ∥x−μi∥ 表示欧氏距离
2.2 数学推导
步骤1:初始化质心
随机选择k个数据点作为初始质心:
μ 1 ( 0 ) , μ 2 ( 0 ) , . . . , μ k ( 0 ) 其中 μ j ( 0 ) ∈ R d \mu_1^{(0)}, \mu_2^{(0)}, ..., \mu_k^{(0)} \quad \text{其中} \mu_j^{(0)} \in \mathbb{R}^d μ1(0),μ2(0),...,μk(0)其中μj(0)∈Rd
步骤2:分配数据点
对每个数据点 x i x_i xi,计算到所有质心的距离,分配到最近质心的簇:
C j ( t ) = { x i : ∥ x i − μ j ( t ) ∥ 2 ≤ ∥ x i − μ l ( t ) ∥ 2 ∀ l } C_j^{(t)} = \{ x_i : \|x_i - \mu_j^{(t)}\|^2 \leq \|x_i - \mu_l^{(t)}\|^2 \ \forall l \} Cj(t)={xi:∥xi−μj(t)∥2≤∥xi−μl(t)∥2 ∀l}
步骤3:更新质心
重新计算每个簇的均值作为新质心:
μ j ( t + 1 ) = 1 ∣ C j ( t ) ∣ ∑ x i ∈ C j ( t ) x i \mu_j^{(t+1)} = \frac{1}{|C_j^{(t)}|} \sum_{x_i \in C_j^{(t)}} x_i μj(t+1)=∣Cj(t)∣1xi∈Cj(t)∑xi
步骤4:收敛条件
当满足以下任一条件时停止迭代:
∥ μ j ( t + 1 ) − μ j ( t ) ∥ < ϵ 或 J ( t ) − J ( t + 1 ) < δ \|\mu_j^{(t+1)} - \mu_j^{(t)}\| < \epsilon \quad \text{或} \quad J^{(t)} - J^{(t+1)} < \delta ∥μj(t+1)−μj(t)∥<ϵ或J(t)−J(t+1)<δ
2.3 时间复杂度
- 每次迭代: O ( k n d ) O(knd) O(knd)
- 总复杂度: O ( t k n d ) O(tknd) O(tknd)
其中k=簇数,n=样本数,d=特征维度,t=迭代次数
3. 模型评估
内部评估指标
-
轮廓系数(Silhouette Coefficient)
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}} s(i)=max{a(i),b(i)}b(i)−a(i)- a ( i ) a(i) a(i):样本i到同簇其他点的平均距离
- b ( i ) b(i) b(i):样本i到最近其他簇的平均距离
- 取值范围:[-1, 1],越大越好
-
戴维森堡丁指数(Davies-Bouldin Index)
D B = 1 k ∑ i = 1 k max j ≠ i ( σ i + σ j d ( μ i , μ j ) ) DB = \frac{1}{k} \sum_{i=1}^k \max_{j \neq i} \left( \frac{\sigma_i + \sigma_j}{d(\mu_i, \mu_j)} \right) DB=k1i=1∑kj=imax(d(μi,μj)σi+σj)- σ i \sigma_i σi:簇i内平均距离
- d ( μ i , μ j ) d(\mu_i, \mu_j) d(μi,μj):簇中心距离
- 取值越小越好
外部评估指标(需真实标签)
- 调整兰德指数(Adjusted Rand Index)
- Fowlkes-Mallows 指数
- 互信息(Mutual Information)
4. 应用案例
4.1 客户细分
- 场景:电商用户行为分析
- 特征:购买频率、客单价、浏览时长
- 结果:识别高价值客户群(K=5),营销转化率提升23%
4.2 图像压缩
- 原理:将像素颜色聚类为K种代表色
- 步骤:
- 将图像视为RGB点集(n=像素数,d=3)
- 设置K=256(256色图像)
- 用簇中心颜色代替原始像素
- 效果:文件大小减少85%且视觉质量可接受
4.3 文档聚类
- 场景:新闻主题分类
- 特征:TF-IDF向量(d≈10,000)
- 挑战:高维稀疏数据需先降维(PCA/t-SNE)
5. 面试题及答案
Q1:K均值对初始质心敏感,如何改进?
A:采用K-means++初始化:
- 随机选第一个质心
- 后续质心以概率 D ( x ) 2 / ∑ D ( x ) 2 D(x)^2 / \sum D(x)^2 D(x)2/∑D(x)2选择
( D ( x ) D(x) D(x)为点到最近质心的距离)
Q2:如何确定最佳K值?
A:常用方法:
- 肘部法则(Elbow Method):绘制K与WCSS曲线,选拐点
from sklearn.cluster import KMeans distortions = [] for k in range(1,10):kmeans = KMeans(n_clusters=k)kmeans.fit(X)distortions.append(kmeans.inertia_) - 轮廓系数法:选择使平均轮廓系数最大的K
Q3:K均值能否处理非凸数据?
A:不能。K均值假设簇是凸形且各向同性。解决方案:
- 使用谱聚类(Spectral Clustering)
- 或DBSCAN等基于密度的算法
6. 优缺点分析
优点:
- 简单高效:时间复杂度线性增长,适合大规模数据
- 可解释性强:簇中心代表原型特征
- 易于实现:核心代码仅需10行
def k_means(X, k):centroids = X[np.random.choice(len(X), k)]while True:labels = np.argmin(np.linalg.norm(X[:,None]-centroids, axis=2), axis=1)new_centroids = np.array([X[labels==j].mean(0) for j in range(k)])if np.allclose(centroids, new_centroids): breakcentroids = new_centroidsreturn labels, centroids
缺点:
- 需预先指定K值:实际应用中K常未知
- 对异常值敏感:均值易受极端值影响
- 仅适用于数值数据:需对类别变量编码
- 局部最优问题:不同初始化可能产生不同结果
- 假设各向同性:在细长簇或流形数据上效果差
7. 数学证明:为什么均值最小化WCSS?
给定簇 C j C_j Cj,优化目标:
min μ j ∑ x i ∈ C j ∥ x i − μ j ∥ 2 \min_{\mu_j} \sum_{x_i \in C_j} \|x_i - \mu_j\|^2 μjminxi∈Cj∑∥xi−μj∥2
求导并令导数为零:
∂ ∂ μ j ∑ ∥ x i − μ j ∥ 2 = − 2 ∑ ( x i − μ j ) = 0 \frac{\partial}{\partial \mu_j} \sum \|x_i - \mu_j\|^2 = -2 \sum (x_i - \mu_j) = 0 ∂μj∂∑∥xi−μj∥2=−2∑(xi−μj)=0
解得:
μ j = 1 ∣ C j ∣ ∑ x i \mu_j = \frac{1}{|C_j|} \sum x_i μj=∣Cj∣1∑xi
证毕:均值是簇内平方和的最优解。
💡 关键洞察:K均值本质是期望最大化(EM)算法的特例:
- E步:固定质心,分配数据点(期望)
- M步:固定分配,更新质心(最大化)
实际应用时建议:
- 数据标准化:消除量纲影响
- 多次运行:取最佳结果(
n_init=10)- 结合PCA降维:处理高维数据
- 对分类型数据用K-mode变种
相关文章:
【机器学习基础】机器学习入门核心算法:K均值(K-Means)
机器学习入门核心算法:K均值(K-Means) 1. 算法逻辑2. 算法原理与数学推导2.1 目标函数2.2 数学推导2.3 时间复杂度 3. 模型评估内部评估指标外部评估指标(需真实标签) 4. 应用案例4.1 客户细分4.2 图像压缩4.3 文档聚类…...
Python Day37
Task: 1.过拟合的判断:测试集和训练集同步打印指标 2.模型的保存和加载 a.仅保存权重 b.保存权重和模型 c.保存全部信息checkpoint,还包含训练状态 3.早停策略 1. 过拟合的判断:测试集和训练集同步打印指标 过拟合是指模型在训…...

RabbitMQ集群与负载均衡实战指南
文章目录 集群架构概述仲裁队列的使用1. 使用Spring框架代码创建2. 使用amqp-client创建3. 使用管理平台创建 负载均衡引入HAProxy 负载均衡:使用方法1. 修改配置文件2. 声明队列 test_cluster3. 发送消息 集群架构 概述 RabbitMQ支持部署多个结点,每个…...

怎么开机自动启动vscode项目
每次开机都得用 vscode 打开多个工程,然后用 vscode 里的终端启动,怎么设置成开机自动启动,省事点。 创建 bat 文件,用 cmd 启动,然后将 bat 文件放到 windows 启动文件夹中 yqp1.bat echo on cls d: cd D:\yqp\add…...

Unity 中 Update、FixedUpdate 和 LateUpdate 的区别及使用场景
在Unity开发中,Update、FixedUpdate 和 LateUpdate 是生命周期函数中最常见也最容易混淆的一组。 一、调用时机 方法名调用频率调用时机说明Update()每帧调用一次跟随帧率(帧率高则调用频率高)FixedUpdate()固定时间间隔调用默认每 0.02 秒执行一次LateUpdate()每帧调用一次…...
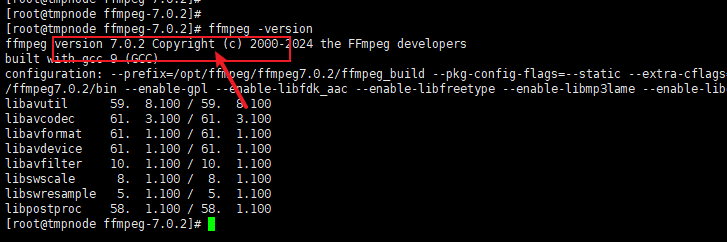
linux安装ffmpeg7.0.2全过程
编辑 白眉大叔 发布于 2025年4月16日 评论关闭 阅读(341) centos 编译安装 ffmpeg 7.0.2 :连接https://www.baimeidashu.com/19668.html 下载 FFmpeg 源代码 在文章最后 一、在CentOS上编译安装FFmpeg 以常见的CentOS为例,FFmpeg的编译说明页面为h…...

Java中的设计模式实战:单例、工厂、策略模式的最佳实践
Java中的设计模式实战:单例、工厂、策略模式的最佳实践 在Java开发中,设计模式是构建高效、可维护、可扩展应用程序的关键。本文将深入探讨三种常见且实用的设计模式:单例模式、工厂模式和策略模式,并通过详细代码实例࿰…...

DexGarmentLab 论文翻译
单个 专家 演示 装扮 15 任务 场景 2500+ 服装 手套 棒球帽 裤子 围巾 碗 帽子 上衣 外套 服装-手部交互 捕捉 摇篮 夹紧 平滑 任务 ...... 投掷 悬挂 折叠 ... 多样化位置 ... 多样化 变形 ... 多样化服装形状 类别级 一般化 类别级(有或没有变形) 服装具有相同结构 变形 生…...

Elasticsearch性能优化全解析
Elasticsearch作为一款分布式搜索和分析引擎,其性能优化是实际生产环境中必须深入研究的课题。本文基于Elastic官方文档,系统性地总结了从硬件配置、索引设计到查询优化的全链路优化策略,帮助用户构建高性能、高稳定性的集群。 Elasticsearch的优化需结合业务场景综合决策:…...
2025.05.28【Parallel】Parallel绘图:拟时序分析专用图
Improve general appearance Add title, use a theme, change color palette, control variable orders and more Highlight a group Highlight a group of interest to help people understand your story 文章目录 Improve general appearanceHighlight a group探索Paralle…...

tc3975开发板上有ft2232这块的电路,我想知道这个开发板有哪些升级方式,重点关注是怎样通过ft2232实现的烧录升级的
关于TC3975开发板上FT2232芯片支持的升级方式,特别是如何通过FT2232实现烧录升级的问题。首先,我得回忆一下FT2232的基本功能和常见应用场景。 FT2232是FTDI公司的一款双通道USB转UART/FIFO芯片,常用于嵌入式系统的调试和编程。它支持多种协议…...
自动驾驶与智能交通:构建未来出行的智能引擎
随着人工智能、物联网、5G和大数据等前沿技术的发展,自动驾驶汽车和智能交通系统正以前所未有的速度改变人类的出行方式。这一变革不仅是技术的融合创新,更是推动城市可持续发展的关键支撑。 一、自动驾驶与智能交通的定义 1. 自动驾驶(Auto…...

Kotlin Multiplatform与Flutter深度对比:跨平台开发方案的实战选择
简介 在当今多平台应用开发的浪潮中,Kotlin Multiplatform与Flutter代表了两种截然不同的技术路线。KMP以"共享代码、保留原生"为核心理念,允许开发者在业务逻辑层实现高达80%的跨平台代码共享,而Flutter则采用统一渲染引擎,在UI层提供100%的代码共享率。这两种…...
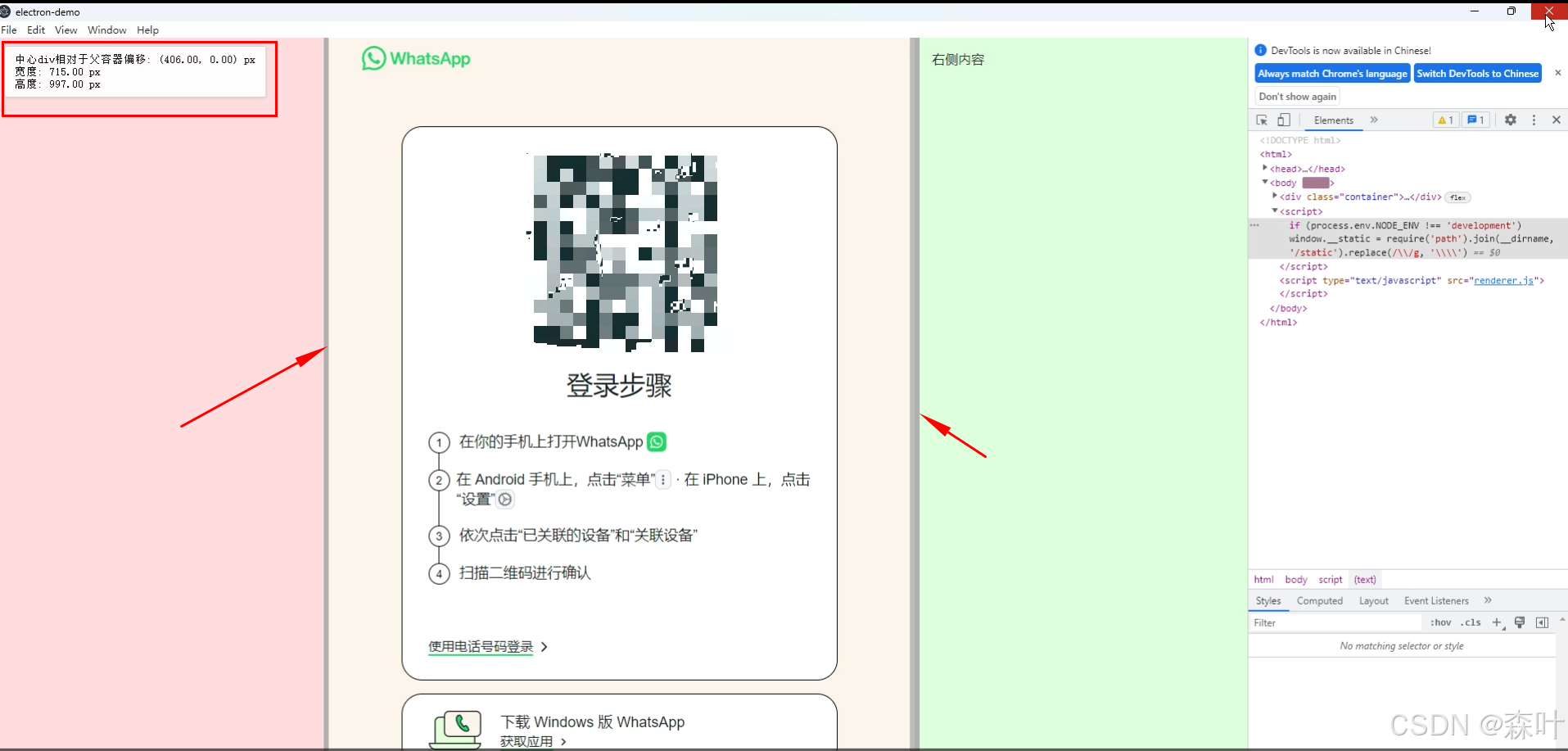
ELectron 中 BrowserView 如何进行实时定位和尺寸调整
背景 BrowserView 是继 Webview 后推出来的高性能多视图管理工具,与 Webview 最大的区别是,Webview 是一个 DOM 节点,依附于主渲染进程的附属进程,Webview 节点的崩溃会导致主渲染进程的连锁反应,会引起软件的崩溃。 …...

深兰科技董事长陈海波率队考察南京,加速AI大模型区域落地应用
近日,深兰科技创始人、董事长陈海波受邀率队赴南京市,先后考察了南京高新技术产业开发区与鼓楼区,就推进深兰AI医诊大模型在南京的落地应用,与当地政府及相关部门进行了深入交流与合作探讨。 此次考察聚焦于深兰科技自主研发的AI医…...

《深度关系-从建立关系到彼此信任》
陈海贤老师推荐的书,花了几个小时,感觉现在的人与人之间特别缺乏这种深度的关系,但是与一个人建立深度的关系并没有那么简单,反正至今为止,自己好像没有与任何一个人建立了这种深度的关系,那种双方高度同频…...

IT选型指南:电信行业需要怎样的服务器?
从第一条电报发出的 那一刻起 电信技术便踏上了飞速发展的征程 百余年间 将世界编织成一个紧密相连的整体 而在今年 我们迎来了第25届世界电信日 同时也是国际电联成立的第160周年 本届世界电信日的主题为:“弥合性别数字鸿沟,为所有人创造机遇”,但在新兴技术浪潮汹涌…...

【ConvLSTM第二期】模拟视频帧的时序建模(Python代码实现)
目录 1 准备工作:python库包安装1.1 安装必要库 案例说明:模拟视频帧的时序建模ConvLSTM概述损失函数说明(python全代码) 参考 ConvLSTM的原理说明可参见另一博客-【ConvLSTM第一期】ConvLSTM原理。 1 准备工作:pytho…...

[VMM]分享一个用SystemC编写的页表管理程序
分享一个用SystemC编写的页表管理程序 摘要:分享一个用SystemC编写的页表管理的程序,这个程序将模拟页表(PDE和PTE)的创建、虚拟地址(VA)到物理地址(PA)的转换,以及对内存的读写操作。 为了简化实现,我们做出以下假设: 页表是两级结构:PDE (Page Directory…...

将docker数据目录迁移到 home目录下
将 Docker 数据目录从默认位置(通常是 /var/lib/docker)迁移到 /home 目录下,可以通过几个步骤来完成。以下是详细的迁移步骤: 步骤 1:停止 Docker 服务 在进行任何操作之前,确保先停止 Docker 服务以避免…...

【论文解读】DETR: 用Transformer实现真正的End2End目标检测
1st authors: About me - Nicolas CarionFrancisco Massa - Google Scholar paper: [2005.12872] End-to-End Object Detection with Transformers ECCV 2020 code: facebookresearch/detr: End-to-End Object Detection with Transformers 1. 背景 目标检测&#…...

Pytest 是什么
Pytest 是 Python 生态中最流行的 测试框架,用于编写、运行和组织单元测试、功能测试甚至复杂的集成测试。它以简洁的语法、强大的插件系统和高度可扩展性著称,广泛应用于 Python 项目的自动化测试中。以下是其核心特性和使用详解: Pytest 的…...

ElasticSearch简介及常用操作指南
一. ElasticSearch简介 ElasticSearch 是一个基于 Lucene 构建的开源、分布式、RESTful 风格的搜索和分析引擎。 1. 核心功能 强大的搜索能力 它能够提供全文检索功能。例如,在海量的文档数据中,可以快速准确地查找到包含特定关键词的文档。这在处理诸如…...

缓存常见问题:缓存穿透、缓存雪崩以及缓存击穿
缓存常见问题 一、缓存穿透 (Cache Penetration) 是什么 缓存穿透是指客户端持续请求一个缓存和数据库中都根本不存在的数据。这导致每次请求都会先查缓存(未命中),然后穿透到数据库查询(也未命中)。如果这类请求量…...
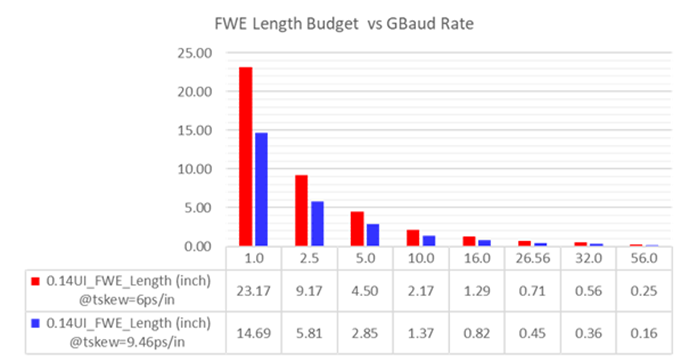
纤维组织效应偏斜如何影响您的高速设计
随着比特率继续飙升,光纤编织效应 (FWE) 偏移,也称为玻璃编织偏移 (GWS),正变得越来越成为一个问题。今天的 56GB/s 是高速路由器中最先进的,而 112 GB/s 指日可待。而用于个人计算机…...

【深度学习】sglang 的部署参数详解
SGLang 的部署参数详解 SGLang(Structured Generation Language)是一个高性能的大语言模型推理框架,专为结构化生成和多模态应用设计。本文将全面介绍SGLang的部署参数,帮助你充分发挥其性能潜力。 🚀 SGLang 项目概览 SGLang是由UC Berkeley开发的新一代LLM推理引擎,…...

SDL2常用函数:SDL_RendererSDL_CreateRendererSDL_RenderCopySDL_RenderPresent
SDL 渲染器系统详解 SDL_Renderer 概述 SDL_Renderer 是 SDL 2.0 引入的核心渲染抽象,它提供了一种高效的、硬件加速的 2D 渲染方式,比传统的表面(Surface)操作更加高效和灵活。 主要函数 1. SDL_CreateRenderer - 创建渲染器 SDL_Renderer* SDL_Cr…...

[git]忽略.gitignore文件
git rm --cached .gitignore 是一个 Git 命令,主要用于 从版本控制中移除已追踪的 .gitignore 文件,但保留该文件在本地工作目录中。以下是详细解析: 一、命令拆解与核心作用 语法解析 git rm:Git 的删除命令,用于从版本库(Repository)中移除文件。--cached:关键参数…...

FEMFAT许可的有效期限
在工程仿真领域,FEMFAT作为一款领先的疲劳分析软件,为用户提供了强大的功能和卓越的性能。然而,为了确保软件的合法使用和持续合规,了解FEMFAT许可的有效期限至关重要。本文将为您详细解读FEMFAT许可的有效期限,帮助您…...
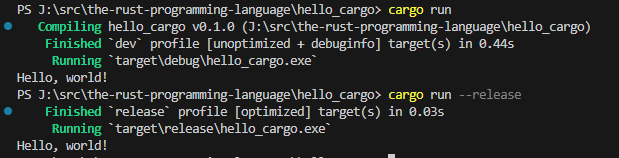
Rust使用Cargo构建项目
文章目录 你好,Cargo!验证Cargo安装使用Cargo创建项目新建项目配置文件解析默认代码结构 Cargo工作流常用命令速查表详细使用说明1. 编译项目2. 运行程序3.快速检查4. 发布版本构建 Cargo的设计哲学约定优于配置工程化优势 开发建议1. 新项目初始化2. …...