YOLOV11改进策略【最新注意力机制】CVPR2025局部区域注意力机制LRSA-增强局部区域特征之间的交互
1.1网络结构
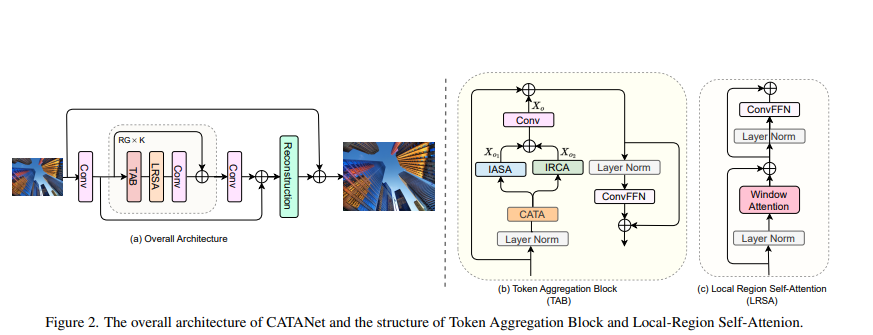
1.2 添加过程
1.2.1 核心代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrangedef patch_divide(x, step, ps):"""Crop image into patches.Args:x (Tensor): Input feature map of shape(b, c, h, w).step (int): Divide step.ps (int): Patch size.Returns:crop_x (Tensor): Cropped patches.nh (int): Number of patches along the horizontal direction.nw (int): Number of patches along the vertical direction."""b, c, h, w = x.size()if h == ps and w == ps:step = pscrop_x = []nh = 0for i in range(0, h + step - ps, step):top = idown = i + psif down > h:top = h - psdown = hnh += 1for j in range(0, w + step - ps, step):left = jright = j + psif right > w:left = w - psright = wcrop_x.append(x[:, :, top:down, left:right])nw = len(crop_x) // nhcrop_x = torch.stack(crop_x, dim=0) # (n, b, c, ps, ps)crop_x = crop_x.permute(1, 0, 2, 3, 4).contiguous() # (b, n, c, ps, ps)return crop_x, nh, nwdef patch_reverse(crop_x, x, step, ps):"""Reverse patches into image.Args:crop_x (Tensor): Cropped patches.x (Tensor): Feature map of shape(b, c, h, w).step (int): Divide step.ps (int): Patch size.Returns:ouput (Tensor): Reversed image."""b, c, h, w = x.size()output = torch.zeros_like(x)index = 0for i in range(0, h + step - ps, step):top = idown = i + psif down > h:top = h - psdown = hfor j in range(0, w + step - ps, step):left = jright = j + psif right > w:left = w - psright = woutput[:, :, top:down, left:right] += crop_x[:, index]index += 1for i in range(step, h + step - ps, step):top = idown = i + ps - stepif top + ps > h:top = h - psoutput[:, :, top:down, :] /= 2for j in range(step, w + step - ps, step):left = jright = j + ps - stepif left + ps > w:left = w - psoutput[:, :, :, left:right] /= 2return outputclass PreNorm(nn.Module):"""Normalization layer.Args:dim (int): Base channels.fn (Module): Module after normalization."""def __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class Attention(nn.Module):"""Attention module.Args:dim (int): Base channels.heads (int): Head numbers.qk_dim (int): Channels of query and key."""def __init__(self, dim, heads, qk_dim):super().__init__()self.heads = headsself.dim = dimself.qk_dim = qk_dimself.scale = qk_dim ** -0.5self.to_q = nn.Linear(dim, qk_dim, bias=False)self.to_k = nn.Linear(dim, qk_dim, bias=False)self.to_v = nn.Linear(dim, dim, bias=False)self.proj = nn.Linear(dim, dim, bias=False)def forward(self, x):q, k, v = self.to_q(x), self.to_k(x), self.to_v(x)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), (q, k, v))out = F.scaled_dot_product_attention(q, k, v) # scaled_dot_product_attention 需要PyTorch2.0之后版本out = rearrange(out, 'b h n d -> b n (h d)')return self.proj(out)class dwconv(nn.Module):def __init__(self, hidden_features, kernel_size=5):super(dwconv, self).__init__()self.depthwise_conv = nn.Sequential(nn.Conv2d(hidden_features, hidden_features, kernel_size=kernel_size, stride=1,padding=(kernel_size - 1) // 2, dilation=1,groups=hidden_features), nn.GELU())self.hidden_features = hidden_featuresdef forward(self, x, x_size):x = x.transpose(1, 2).view(x.shape[0], self.hidden_features, x_size[0], x_size[1]).contiguous() # b Ph*Pw cx = self.depthwise_conv(x)x = x.flatten(2).transpose(1, 2).contiguous()return xclass ConvFFN(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, kernel_size=5, act_layer=nn.GELU):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.dwconv = dwconv(hidden_features=hidden_features, kernel_size=kernel_size)self.fc2 = nn.Linear(hidden_features, out_features)def forward(self, x, x_size):x = self.fc1(x)x = self.act(x)x = x + self.dwconv(x, x_size)x = self.fc2(x)return xclass LRSA(nn.Module):"""Attention module.Args:dim (int): Base channels.num (int): Number of blocks.qk_dim (int): Channels of query and key in Attention.mlp_dim (int): Channels of hidden mlp in Mlp.heads (int): Head numbers of Attention."""def __init__(self, dim, qk_dim=36, mlp_dim=96, heads=4):super().__init__()self.layer = nn.ModuleList([PreNorm(dim, Attention(dim, heads, qk_dim)),PreNorm(dim, ConvFFN(dim, mlp_dim))])def forward(self, x, ps=16):step = ps - 2crop_x, nh, nw = patch_divide(x, step, ps) # (b, n, c, ps, ps)b, n, c, ph, pw = crop_x.shapecrop_x = rearrange(crop_x, 'b n c h w -> (b n) (h w) c')attn, ff = self.layercrop_x = attn(crop_x) + crop_xcrop_x = rearrange(crop_x, '(b n) (h w) c -> b n c h w', n=n, w=pw)x = patch_reverse(crop_x, x, step, ps)_, _, h, w = x.shapex = rearrange(x, 'b c h w-> b (h w) c')x = ff(x, x_size=(h, w)) + xx = rearrange(x, 'b (h w) c->b c h w', h=h)return x1.2.2 添加过程
第一步:在nn文件夹下面创建一个新的文件夹,名字叫做Addmodules, 然后再这个文件夹下面创建LRSA.py文件,然后将LRSA的核心代码放入其中。
第二步:继续在Addmodules文件夹下面创建__init__.py文件,输入以下代码:
from .LRSA import LRSA
__all__ = ("LRSA",)第三步:在task.py文件中导入LRSA
from .Addmodules import LRSA elif m is LRSA:c1 = ch[f]args = [c1, *args]第四步:修改yaml文件
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11n.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10- [-1, 3, LRSA, [1024]]
# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
请多多关注!!!
相关文章:
YOLOV11改进策略【最新注意力机制】CVPR2025局部区域注意力机制LRSA-增强局部区域特征之间的交互
1.1网络结构 1.2 添加过程 1.2.1 核心代码 import torch import torch.nn as nn import torch.nn.functional as F from einops import rearrangedef patch_divide(x, step, ps):"""Crop image into patches.Args:x (Tensor): Input feature map of shape(b, …...

3D建模的全景图谱:从55个工具到元宇宙的数字革命
3D建模已从专业工程师的工具箱演变为全民创作的数字语言。从代码驱动的精确建模到AI自动生成纹理,从开源协作到程序化生成城市,技术正重塑我们创造虚拟世界的方式。本文将系统解析55个核心3D建模工具/插件,涵盖在线编辑器、开源软件、程序化生…...

Kotlin 活动事件通讯跳转深度讲解
在 Android 开发的浩瀚海洋中,活动(Activity)间的事件通讯与跳转犹如构建复杂应用程序的桥梁与纽带,而 Kotlin 语言的加入,更是为这一过程注入了简洁、优雅与高效的活力。本文将深入剖析 Kotlin 开发中安卓活动事件通讯跳转的方方面面,从基础概念到高级技巧,从代码示例到…...

vue + ant-design + xlsx 实现Excel多Sheet页导出功能
Vue Ant Design 扩展:实现Excel多Sheet页导出功能 引言 在复杂业务场景中,单一Sheet页已无法满足数据展示需求。本文将演示如何基于Vue3 Ant Design Vue xlsx技术栈,实现以下高级导出功能: 动态多Sheet页生成复杂数据集关联…...

关于 Web 安全:6. 常见 CMS 开源系统风险点
一、WordPress 开源内容管理系统(CMS),使用 PHP MySQL 构建; 全球超过 40% 网站使用; 支持插件、主题系统,功能可扩展性极强; 也是风险点最多的系统之一,插件/主题贡献了大部分…...
DAY33 简单神经网络
你需要自行了解下MLP的概念。 你需要知道 梯度下降的思想激活函数的作用损失函数的作用优化器神经网络的概念 神经网络由于内部比较灵活,所以封装的比较浅,可以对模型做非常多的改进,而不像机器学习三行代码固定。 1. 神经网络的概念 (Th…...

OBOO鸥柏丨2025年鸿蒙生态+国产操作系统触摸屏查询一体机核心股
在信创产业蓬勃发展的当下,OBOO鸥柏积极响应纯国产化号召,推出基于华为鸿蒙HarmonyOS操作系统的触摸屏查询一体机及室内外场景广告液晶显示屏一体机上市,OBOO鸥柏品牌旗下显示产品均采用国产芯片,接入终端控制端需支持安卓Windows…...
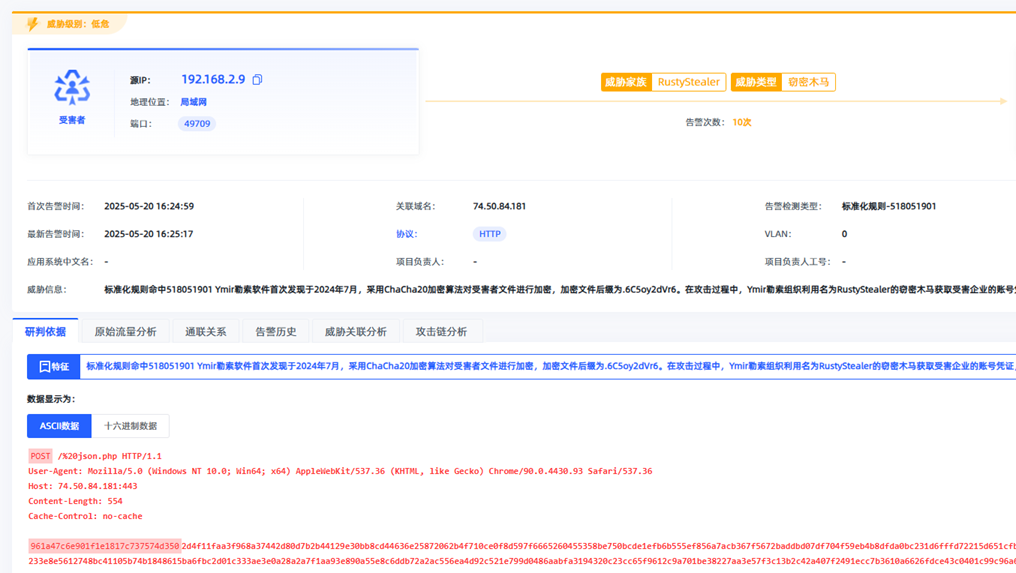
【观成科技】Ymir勒索软件组织窃密木马RustyStealer加密通信分析
1.概述 Ymir勒索软件首次发现于2024年7月,采用ChaCha20加密算法对受害者文件进行加密,加密文件后缀为.6C5oy2dVr6。在攻击过程中,Ymir勒索组织利用名为RustyStealer的窃密木马获取受害企业的账号凭证,为后续横向移动和权限提升奠…...
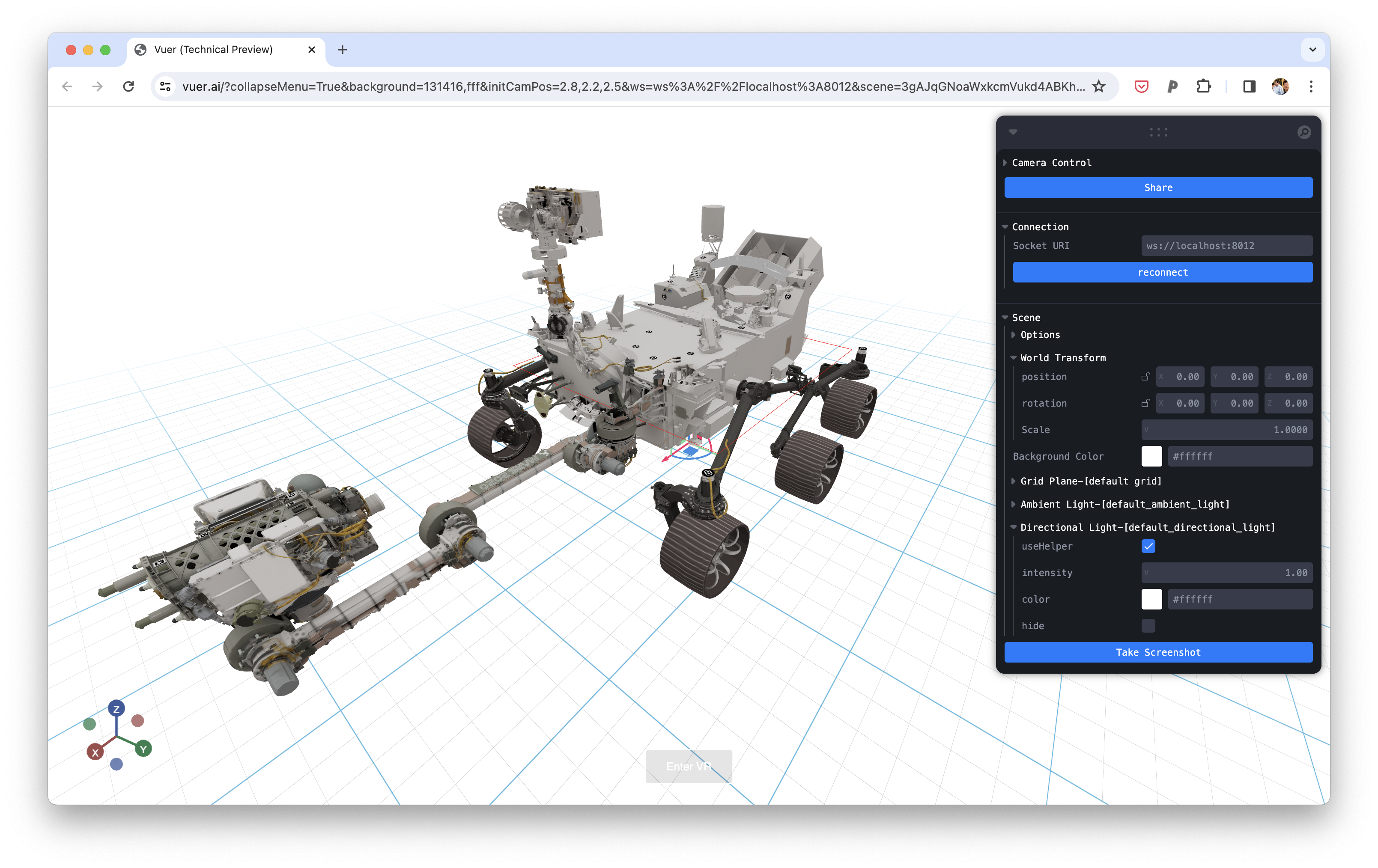
Vuer开源程序 是一个轻量级的可视化工具包,用于与动态 3D 和机器人数据进行交互。它支持 VR 和 AR,可以在移动设备上运行。
一、软件介绍 文末提供程序和源码下载 Vuer开源程序 是一个轻量级的可视化工具包,用于与动态 3D 和机器人数据进行交互。它支持 VR 和 AR,可以在移动设备上运行。 二、Our features include: 我们的功能包括: light-weight and performa…...
)
浅谈学习(费曼学习法)
我们在学习的过程中常常会面临遗忘的问题。 欸,之前明明学过,怎么感觉模模糊糊的,忘记了,当然。。。有可能是因为当时就没有听懂。 但是我经常会有一种情况,我觉得自己当时明明听懂了,理解了呀࿰…...

高光谱成像相机:表型技术在林业育种和精确林业的应用
在林木育种和精确林业管理中,表型数据的精准获取与分析是破解基因型-环境-表型互作关系的关键。传统人工测量方式存在效率低、维度单一、破坏性强等局限,而高光谱成像技术凭借其多波段、高分辨率和非接触式的优势,成为林业表型研究的重要工具…...
)
iOS App启动优化(冷启动、热启动)
App启动优化是提升用户体验的关键环节,主要针对冷启动和热启动进行针对性优化。 冷启动与热启动的定义 冷启动(Cold Launch) 场景:App进程不存在,需系统创建新进程并完成完整初始化(如首次启动或进程被杀死…...

短视频一键搬运 v1.7.1|短视频无水印下载 一键去重
短视频一键搬运是一款全自动智能处理软件,专为短视频创作者设计。它自带去水印、改MD5码、视频去重、视频编辑等功能,能够高效处理大量视频,解放双手并降低成本。该软件支持从多个短视频平台无缝提取视频并去除水印,同时检测敏感词…...

海上石油钻井平台人员安全管控解决方案
一、行业挑战与需求分析 海上钻井平台面临复杂环境风险(如易燃易爆、金属干扰、极端气象)和人员管理难题(如定位模糊、应急响应延迟)。传统RFID或蓝牙定位技术存在精度不足(1-5米)、抗干扰能力差等问题&am…...
ChatGPT Plus充值教程与实用指南:附国内外使用案例与模型排行)
(25年5.28)ChatGPT Plus充值教程与实用指南:附国内外使用案例与模型排行
更多具体来源:查看原文 ChatGPT Plus 充值教程 由于国内卡无法直接充值 chatgpt,通常需要借助虚拟卡。目前咱们常用的方式是通过虚拟卡平台获取。因平台审核要求这里不细说,具体看原文。 ChatGPT Plus主要使用方向 ChatGPT Plus 提供了更…...

“以光惠算”走进校园,湖北大学用F5G-A全光网赋能智慧校园
SUN的联合创始人约翰盖奇,曾在1984年提出过一个大胆的猜想——“网络就是计算机”。 到了大模型时代,40多年前的猜想被赋予了新的内涵。大模型训练和推理所需的资源,远超单台计算机的承载能力,涌现出了新的网络范式:大…...

stm32cube ide如何生成LL库工程
在 STM32Cube IDE 里生成使用 LL(Low Layer)库的工程,可按以下步骤操作: 1. 新建 STM32 工程 启动 STM32Cube IDE,选择File→New→STM32 Project。依据需求挑选目标 MCU 型号,接着点击Next。 2. 配置工程…...
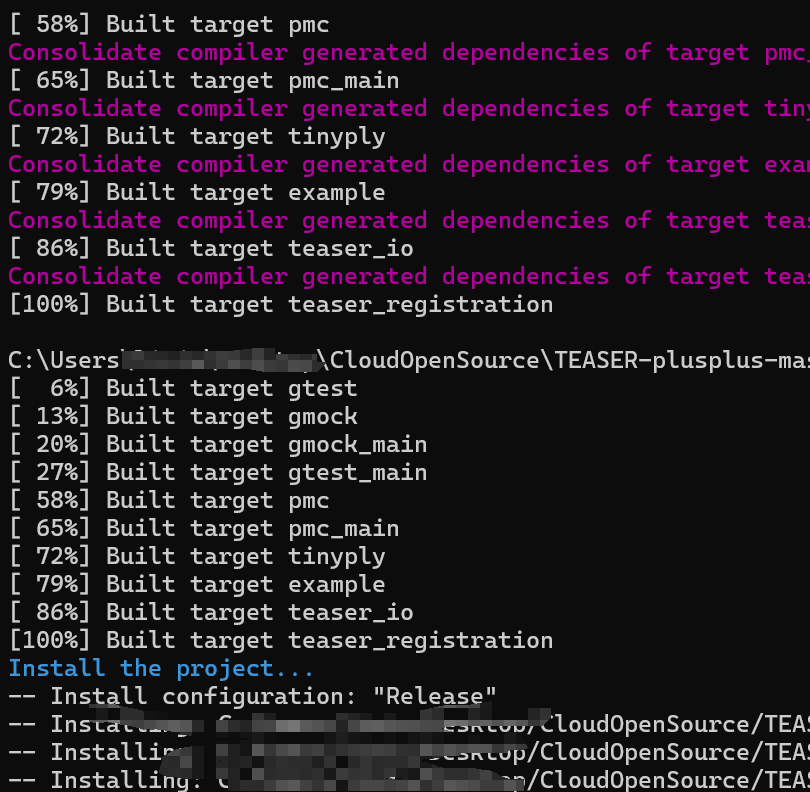
TEASER-plusplu Windows Mingw编译
编译记录: 1.下载该库 v2.0 链接1:https://github.com/MIT-SPARK/TEASER-plusplus 连接2:https://github.com/MIT-SPARK/TEASER-plusplus/releases 2.下载 googletest 链接:https://github.com/google/googletest/releases?page2…...

T5和GPT哪个更强大
一图速览:T5 vs GPT 对比总结 维度T5(Text-to-Text Transfer Transformer)GPT(Generative Pretrained Transformer)📌 模型类型编码器-解码器(Encoder-Decoder)解码器-only…...

tryhackme——Data Exfiltration
文章目录 一、网络拓扑二、数据泄露分类2.1 传统数据泄露2.2 C2通信2.3 隧道 三、隧道3.1 Exfiltration using TCP socket3.2 Exfiltration using SSH3.3 Exfiltrate using HTTP(S)HTTP隧道 3.4 Exfiltration using ICMP3.4.1 ICMP数据包结构3.4.2 MSF实现ICMP数据泄露3.4.3 IC…...

阿里云服务器采用crontab定时任务使acme.sh全自动化申请续签免费SSL证书,并部署在Linux宝塔网站和雷池WAF
阿里云服务器安装Linux宝塔面板用于部署网站,又安装了雷池WAF用于防护网站,网站访问正常。可以参考文章:Linux服务器安装Linux宝塔面板并部署wordpress网站以及雷池WAF 本文介绍使用 acme.sh 通过 DNS API 全自动申请和续签免费Let’s Encry…...

day40 python图像数据与显存
目录 一、图像数据的处理与预处理 (一)图像数据的特点 (二)数据预处理 二、神经网络模型的定义 (一)黑白图像模型的定义 (二)彩色图像模型的定义 (三)…...

Python+VR:如何让虚拟世界更懂你?——用户行为分析的实践
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

【华为鸿蒙电脑】首款鸿蒙电脑发布:MateBook Fold 非凡大师 MateBook Pro,擎云星河计划启动
文章目录 前言一、HUAWEI MateBook Fold 非凡大师(一)非凡设计(二)非凡显示(三)非凡科技(四)非凡系统(五)非凡体验 二、HUAWEI MateBook Pro三、预热…...

性能优化深度实践:突破vue应用性能
一、性能优化深度实践:突破 Vue 应用性能边界 1. 虚拟 DOM 性能边界分析 核心原理: 虚拟 DOM 是 Vue 的核心优化策略,通过 JS 对象描述真实 DOM 结构。当状态变化时: 生成新虚拟 DOM 树Diff 算法对比新旧树差异仅更新变化的真实…...

服务器定时任务查看和编辑
在 Ubuntu 系统中,查看当前系统中已开启的定时任务主要有以下几种方式,分别针对不同类型的定时任务管理方式(如 crontab、systemd timer 等): 查看服务器定时任务 一、查看用户级别的 Crontab 任务 每个用户都可以配…...
SpringBoot Controller接收参数方式, @RequestMapping
一. 通过原始的HttpServletRequest对象获取请求参数 二. 通过Spring提供的RequestParam注解,将请求参数绑定给方法参数 三. 如果请求参数名与形参变量名相同,直接定义方法形参即可接收。(省略RequestParam) 四. JSON格式的请求参数(POST、PUT) 主要在PO…...

double怎么在c/c++中输出保留输出最小精度为一位
在C中,使用std::cout输出double类型时,可以通过<iomanip>头文件中的std::fixed和std::setprecision来控制小数位数的输出。以下是几种常见场景的解决方案: 1. 输出至少1位小数(不足补零) #include <…...

端午节互动网站
端午节互动网站 项目介绍 这是一个基于 Vue 3 Vite 开发的端午节主题互动网站,旨在通过有趣的交互方式展示中国传统端午节文化。网站包含三个主要功能模块:端午节介绍、互动包粽子游戏和龙舟竞赛游戏。 预览网站:https://duanwujiekuaile…...

[特殊字符] NAT映射类型详解:从基础原理到应用场景全解析
网络地址转换(NAT)是解决IPv4地址短缺的核心技术,通过IP地址映射实现内网与公网的通信。本文将系统梳理NAT映射的三大类型及其子类,助你全面掌握其工作机制与应用场景。 目录 🔧 一、基础NAT映射类型:按转…...