热门大型语言模型(LLM)应用开发框架
我们来深入探索这些强大的大型语言模型(LLM)应用开发框架,并且我会尝试用文本形式描述一些核心的流程图,帮助您更好地理解它们的工作机制。由于我无法直接生成图片,我会用文字清晰地描述流程图的各个步骤和连接。
LangChain 🦜🔗:LLM 应用的全能瑞士军刀与编排大师
LangChain 是一个功能极其丰富的开源框架,旨在简化和标准化 LLM 应用的开发。它通过模块化的组件和“链”(Chains)的概念,让开发者能够像搭积木一样构建从简单到复杂的各类 LLM 应用,尤其在 RAG (检索增强生成) 和自主代理 (Agents) 方面表现突出。
-
核心理念:将 LLM 应用的各个环节(如模型调用、数据连接、任务编排、记忆管理)抽象为可复用的组件,并通过“链”将它们串联起来,实现灵活且强大的工作流。
-
关键特性详解:
- LLM 封装 (LLM Wrappers):提供统一接口调用不同的 LLM,如 OpenAI 的
gpt-4、gpt-3.5-turbo,Hugging Face Hub 上的开源模型(如 Llama, Mistral),以及 Azure OpenAI Service 等。这使得底层模型的切换成本大大降低。 - 链 (Chains):这是 LangChain 的灵魂。链定义了一系列操作的执行顺序。
- LLMChain:最基础的链,包含一个提示模板 (PromptTemplate)、一个 LLM 和一个可选的输出解析器 (OutputParser)。
- 顺序链 (Sequential Chains):如
SimpleSequentialChain(单输入单输出)和SequentialChain(多输入多输出),可以将多个链或原子操作按顺序连接。 - 路由链 (Router Chains):能根据输入动态地选择执行哪一个子链,实现更复杂的逻辑分支。
- 文档处理链 (Chains for Document Interaction):如
load_summarize_chain(加载文档并总结),load_qa_chain(加载文档并进行问答)。
- 索引与检索器 (Indexes and Retrievers) - RAG 的核心:
- 文档加载器 (Document Loaders):支持超过80种数据源,从 PDF、TXT、CSV、JSON、HTML 到 Notion、Google Drive、Slack、Databases (SQL, NoSQL) 等。
- 文本分割器 (Text Splitters):将长文档分割成适合 LLM 处理的语义相关的小块 (chunks)。例如
RecursiveCharacterTextSplitter(递归按字符分割,尝试保留段落完整性)、TokenTextSplitter(按 Token 数量分割)。 - 向量化 (Embeddings):将文本块转换为高维向量,捕捉其语义信息。支持 OpenAI, Hugging Face, Cohere 等多种嵌入模型。
- 向量存储 (Vector Stores):将文本块及其向量存储起来,以便进行高效的相似性搜索。集成了 FAISS, Chroma, Pinecone, Weaviate, Milvus, Elasticsearch 等25种以上的向量数据库/搜索引擎。
- 检索器 (Retrievers):根据用户查询(也转换为向量)从向量存储中检索最相关的文本块。除了基本的相似性搜索,还支持 MMR (Maximal Marginal Relevance) 减少结果冗余,以及元数据过滤等。
- 代理 (Agents):赋予 LLM “思考-行动”的能力。Agent 内部有一个 LLM 作为决策核心,可以访问一系列工具 (Tools) 来完成用户指定的任务。
- 工具 (Tools):可以是简单的函数(如计算器、日期获取),也可以是调用外部 API(如 Google 搜索、天气查询、维基百科),甚至可以是其他的链。
- Agent 执行器 (AgentExecutor):负责运行 Agent 的主循环,包括让 LLM 思考、选择工具、执行工具、观察结果,并循环此过程直到任务完成。
- Agent 类型:如
zero-shot-react-description(基于 ReAct 范式,根据工具描述让 LLM 自行决定使用哪个工具),self-ask-with-search(模拟人类先自问问题再通过搜索找答案的过程)。
- 记忆 (Memory):为链和 Agent 提供短期或长期的记忆能力,使对话能够保持上下文连贯。
- 类型:
ConversationBufferMemory(存储完整对话历史),ConversationBufferWindowMemory(仅存储最近 K 轮对话),ConversationSummaryMemory(对历史对话进行摘要),VectorStoreRetrieverMemory(将对话历史存入向量数据库,根据当前输入检索相关历史片段)。
- 类型:
- 回调 (Callbacks):允许开发者在链或 Agent 执行的各个阶段(如开始、结束、出错、接收到 LLM 输出等)注入自定义逻辑,用于日志记录、监控、流式输出、调试等。
- LLM 封装 (LLM Wrappers):提供统一接口调用不同的 LLM,如 OpenAI 的
-
RAG 流程示意图 (文本描述):
-
Agent 执行流程示意图 (文本描述):
-
应用场景:
- 高级 RAG 系统:构建能理解复杂文档、回答专业问题的客服机器人或研究助手。
- 个性化聊天机器人:利用记忆模块记住用户偏好,提供更贴心的对话体验。
- 自主任务执行代理:如自动化预订、信息搜集与整理、代码生成与解释。
- 数据分析与报告生成:连接数据库或 API,自动提取数据、进行分析并生成结构化报告。
Haystack 🌻 (由 deepset AI 开发):生产级语义搜索与问答专家
Haystack 是一个专注于构建端到端、可扩展、生产就绪的语义搜索和问答系统的开源框架。它强调信息检索流程的健壮性和评估能力。
-
核心理念:通过模块化的“管道”(Pipelines)将文档处理、嵌入、检索、阅读/生成等步骤清晰地组织起来,构建高性能的神经搜索系统,并提供评估工具以确保系统质量。
-
关键特性详解:
- 管道 (Pipelines):Haystack 的核心工作流机制。开发者通过 YAML 文件或 Python 代码定义管道,将不同的组件(节点)连接起来。
- 文档存储 (DocumentStores):用于存储文本数据及其元数据和向量表示。支持多种后端,如 Elasticsearch, OpenSearch, FAISS, Milvus, Pinecone, Weaviate 等。Haystack 提供了统一的接口来管理这些存储。
- 文件转换器 (FileConverters):将不同格式的文件(PDF, DOCX, TXT, Markdown 等)转换为 Haystack
Document对象。 - 预处理器 (Preprocessors):对
Document对象进行清洗(如移除多余空格、特殊字符)和分割(按句子、单词或固定长度分割成更小的文档单元)。 - 嵌入器 (Embedders) / 检索器 (Retrievers):
- 稠密检索器 (Dense Retrievers):如
EmbeddingRetriever,使用句子Transformer等模型将文档和查询转换为向量,然后进行相似度搜索。 - 稀疏检索器 (Sparse Retrievers):如
BM25Retriever(基于 Elasticsearch 或 OpenSearch),使用传统的词频统计方法(如 BM25)进行检索。 - 混合检索:可以结合稠密和稀疏检索器的结果。
- 稠密检索器 (Dense Retrievers):如
- 阅读器 (Readers):通常是基于 Transformer 的抽取式问答模型(如 RoBERTa, MiniLM 的微调版本),它们从检索器返回的文档中直接抽取答案片段。
- 生成器 (Generators):使用 LLM(如 GPT, T5)基于检索到的上下文生成更流畅、更全面的答案。
PromptNode是 Haystack 中用于与 LLM 交互的核心组件,可以配置不同的提示模板和模型。 - 排序器 (Rankers):对检索器或阅读器返回的结果进行重新排序,以提升最终答案的相关性。
- 评估 (Evaluation):Haystack 提供了专门的评估流程,可以评估检索阶段的指标(如 Recall@K, MAP)和问答阶段的指标(如 Exact Match, F1-score, SAS - Semantic Answer Similarity)。
- REST API 与 UI:可以方便地将构建的 Haystack 管道通过 REST API 暴露出来,并且提供了一个简单的 Streamlit UI 用于演示和测试。
-
Haystack 索引管道示意图 (文本描述):
-
Haystack 查询管道示意图 (文本描述):
-
应用场景:
- 企业级语义搜索引擎:为公司内部知识库、产品文档、法律合同等提供智能搜索。
- 智能客服问答系统:准确理解用户问题并从 FAQ 或知识库中找到或生成答案。
- 文档分析与洞察提取:从大量报告或文献中快速定位关键信息。
- 金融、法律等行业的合规性检查与信息检索。
AutoGen 🤖💬 (由 Microsoft 开发):赋能多智能体协作与自动化
AutoGen 是一个用于构建和管理多个能够相互对话、协作完成任务的 LLM 代理的框架。它强调通过对话来实现复杂工作流的自动化,并支持人类在环的监督与干预。
-
核心理念:将复杂任务分解给多个具有不同角色和能力的 AI 代理,这些代理通过对话进行协作,共同达成目标。人类可以作为参与者或监督者加入对话。
-
关键特性详解:
- 可对话代理 (Conversable Agents):AutoGen 的核心。每个代理都可以配置其 LLM(或不使用)、系统消息(定义其身份和行为准则)、工具(函数调用)。
UserProxyAgent:代表人类用户,可以发起对话,也可以配置为执行代码(如 Python 脚本,通过code_execution_config设置)或调用函数。AssistantAgent:由 LLM 驱动的助手代理,根据对话历史和指令生成回复或决定调用哪个函数。GroupChatManager:用于协调多个代理在群聊中的发言顺序和流程。
- 多代理对话:代理之间通过发送和接收消息进行通信。开发者可以设计不同的对话模式:
- 两代理对话:例如,一个
UserProxyAgent和一个AssistantAgent相互对话。 - 群聊 (Group Chat):多个代理(包括
UserProxyAgent)在一个群组内讨论,由GroupChatManager控制流程。 - ** سلسله对话 (Sequential Chats)**:任务在一个代理序列中传递。
- 两代理对话:例如,一个
- 函数调用 (Function Calling) / 工具使用:代理可以调用预定义的 Python 函数。这与 OpenAI 的函数调用功能紧密集成,使得 LLM 可以请求执行特定的代码逻辑,从而与外部环境交互或执行复杂计算。
- 代码执行:
UserProxyAgent可以配置为在本地或 Docker 容器中执行 LLM 生成的代码块(如 Python, Shell 脚本),并将结果返回给对话。这对于编程、数据分析等任务非常强大。 - 人在回路 (Human-in-the-loop):人类用户可以随时介入对话,提供反馈、修正方向、批准代码执行或手动执行某些步骤。这对于确保任务的正确性和安全性至关重要。
- 可定制性:可以自定义代理的行为,例如它们如何回复、何时请求人类输入、何时终止对话等。
- 可对话代理 (Conversable Agents):AutoGen 的核心。每个代理都可以配置其 LLM(或不使用)、系统消息(定义其身份和行为准则)、工具(函数调用)。
-
AutoGen 基础双代理对话流程示意图 (文本描述):
-
AutoGen 群聊流程示意图 (简化) (文本描述):
-
应用场景:
- 自动化复杂任务:如“让一个代理写代码,另一个测试,第三个写文档”,或者“一个代理负责搜集最新新闻,另一个总结,第三个写评论”。
- 代码生成、调试与优化:代理可以协作编写、运行和改进代码。
- 研究与内容创作:多个代理分工合作,进行文献回顾、数据分析、报告撰写。
- 模拟与决策支持:模拟不同角色(如CEO, CFO, CTO)在特定场景下的决策过程。
- 交互式学习与辅导:代理扮演老师、学生、提问者等角色。
Semantic Kernel 🧠💡 (由 Microsoft 开发):轻量级 AI 服务编排 SDK
Semantic Kernel (SK) 是一个轻量级的开源 SDK,旨在将 LLM 和其他 AI 服务(如嵌入模型)的能力无缝集成到传统的应用程序中。它提供了一种将自然语言处理能力与现有代码库(C#, Python, Java)结合的优雅方式。
-
核心理念:通过一个“内核”(Kernel)对象来编排“技能”(Skills),其中技能可以包含“语义函数”(由自然语言提示驱动)和“原生函数”(用传统代码编写),从而实现 AI 与业务逻辑的深度融合。
-
关键特性详解:
- 内核 (Kernel):SK 的中心协调器。它加载技能、管理记忆、连接AI服务,并执行用户请求。
- 技能 (Skills):组织功能的单元,可以包含一个或多个函数。技能可以来自文件系统、代码定义或插件。
- 语义函数 (Semantic Functions):核心是带有模板的提示词(Prompt Templates)。这些模板定义了如何与 LLM 交互以完成特定任务(如总结、翻译、情感分析、代码生成等)。SK 的提示模板语言支持变量、内置函数和复杂的逻辑。函数定义通常包含
skprompt.txt(提示模板) 和config.json(配置,如LLM参数)。 - 原生函数 (Native Functions):用 C#, Python 或 Java 编写的普通代码函数,可以通过装饰器(如 Python 中的
@sk_function)暴露给 Kernel。这些函数可以访问本地资源、调用外部 API、执行复杂计算等,弥补了 LLM 在某些方面的不足。
- 语义函数 (Semantic Functions):核心是带有模板的提示词(Prompt Templates)。这些模板定义了如何与 LLM 交互以完成特定任务(如总结、翻译、情感分析、代码生成等)。SK 的提示模板语言支持变量、内置函数和复杂的逻辑。函数定义通常包含
- 记忆 (Memories):为 LLM 提供上下文信息和长期知识。SK 的记忆连接器支持多种向量数据库(如 Azure Cognitive Search, Qdrant, Chroma, Weaviate, Pinecone),用于存储和检索文本嵌入,实现 RAG 功能。
- 连接器 (Connectors):用于 Kernel 与外部服务(主要是 LLM 和记忆存储)的连接。支持 OpenAI, Azure OpenAI, Hugging Face 等 LLM 服务。
- 规划器 (Planners):SK 的一个高级特性,能够根据用户的高层目标和 Kernel 中可用的技能,自动生成一个多步骤的执行计划(Plan)。规划器会分析用户意图,并尝试找到一系列技能调用的组合来达成该意图。
- 例如,用户请求“给我查一下明天北京的天气,然后根据天气写一首关于春天的短诗”,Planner 可能会生成一个计划:1.调用一个
WeatherSkill的GetTomorrowWeather函数获取天气;2.调用一个WritingSkill的WritePoem函数,并将天气信息作为输入。
- 例如,用户请求“给我查一下明天北京的天气,然后根据天气写一首关于春天的短诗”,Planner 可能会生成一个计划:1.调用一个
- 跨语言支持:目前主要支持 C#, Python 和 Java,并致力于提供一致的开发体验。
-
Semantic Kernel 技能调用流程示意图 (文本描述):
-
Semantic Kernel 规划器流程示意图 (文本描述):
-
应用场景:
- 为现有企业应用赋能:在 CRM、ERP 或 Office 插件中嵌入智能助手 (Copilot) 功能。
- 构建智能业务流程自动化:将需要人类判断和自然语言理解的环节交由 LLM 处理,其他环节由传统代码执行。
- 创建可重用的 AI 插件 (Skills):将特定领域的 AI 能力封装成技能,供不同应用调用。
- 将自然语言作为应用程序的新接口:允许用户通过自然语言与复杂系统交互。
LlamaIndex 🦙📄:LLM 的专业级数据框架与 RAG 利器
LlamaIndex 是一个专注于将 LLM 与外部数据源连接的数据框架,是构建高效、强大的 RAG 应用的核心工具。它提供了从数据摄取、索引构建到查询执行的完整解决方案。
-
核心理念:为 LLM 提供一个简单、灵活且优化的方式来访问和利用私有或领域特定的数据,从而增强 LLM 的知识范围和回答相关性。
-
关键特性详解:
- 数据连接器/读取器 (Data Connectors / Readers):极其强大的数据摄取能力,支持超过150种数据源。
- 文件类:PDF, DOCX, TXT, Markdown, CSV, Excel, PowerPoint, Images (OCR), Audio (transcription)。
- SaaS 应用:Notion, Slack, Salesforce, Google Drive, OneDrive, Asana, Trello, Jira, GitHub, Discord。
- 数据库:PostgreSQL, MySQL, MongoDB, Snowflake, SQL Server, Elasticsearch。
- APIs:可以自定义连接器调用任意 API。
- 节点 (Nodes):文档被加载和解析后,会转换成
Node对象。一个Node代表一个文本块 (chunk),并包含文本内容、元数据 (metadata)、以及与其他节点的关系 (relationships)。 - 索引结构 (Index Structures):LlamaIndex 提供了多种索引类型来组织
Node,以适应不同的查询需求。VectorStoreIndex:最常用的索引,将Node的文本嵌入存储在向量数据库中,通过语义相似度进行检索。与 FAISS, Pinecone, Weaviate, Chroma, Qdrant 等深度集成。ListIndex:按顺序存储Node,适合顺序问答或对所有内容进行总结。TreeIndex:将Node组织成层级树状结构(通常是摘要树),父节点是子节点的摘要。查询时可以自顶向下或自底向上遍历。KeywordTableIndex:从Node中提取关键词,构建关键词到Node的映射,支持基于关键词的检索。KnowledgeGraphIndex:从文本中提取实体和关系,构建知识图谱索引,支持结构化查询和推理。- 组合索引 (Composable Indexes):可以将不同类型的索引组合起来,例如先用关键词索引粗筛,再用向量索引精排。
- 检索器 (Retrievers):从索引中检索与查询相关的
Node。LlamaIndex 提供了多种配置选项,如similarity_top_k(返回最相似的k个节点)、元数据过滤等。 - 节点后处理器 (Node Postprocessors):在检索到
Node之后,但在传递给 LLM 合成答案之前,对Node列表进行进一步处理,如重新排序、过滤低分节点、关键词高亮等。 - 响应合成器 (Response Synthesizers):获取检索到的
Node列表和原始查询,然后使用 LLM 来生成最终的自然语言答案。提供了多种合成策略:refine:逐个处理检索到的文本块,迭代地优化答案。compact:将尽可能多的文本块塞进 LLM 的上下文窗口进行一次性回答。tree_summarize:层级式总结,先总结小块,再总结小块的总结,适合大量文本。
- 查询引擎 (Query Engines):封装了从查询到生成答案的整个流程(检索 -> 后处理 -> 合成)。
- 聊天引擎 (Chat Engines):在查询引擎的基础上增加了对话记忆,支持多轮 RAG 对话。
- 代理 (Agents):LlamaIndex 也提供了 Agent 框架,其 Agent 可以使用 LlamaIndex 的查询引擎作为工具 (QueryEngineTool) 来访问和推理数据。
- 数据连接器/读取器 (Data Connectors / Readers):极其强大的数据摄取能力,支持超过150种数据源。
-
LlamaIndex 数据索引流程示意图 (文本描述):
-
LlamaIndex 查询流程示意图 (文本描述):
-
应用场景:
- 构建任何基于私有数据的问答系统:无论是公司内部文档、个人笔记、研究论文库还是特定领域的知识库。
- 多模态 RAG:结合文本、图像、音频数据进行问答。
- 结构化数据分析与问答:将结构化数据(如 SQL 数据库)与非结构化数据结合起来,通过自然语言进行查询和分析。
- 知识图谱构建与问答:从文本中自动构建知识图谱,并基于图谱进行复杂推理。
- Agentic RAG:创建能够主动查询、分析和综合来自不同数据源信息的智能代理。
总结与选择考量
这些框架各有侧重,但目标都是为了让开发者更高效地利用 LLM 的强大能力。
- 如果您需要一个功能全面、社区庞大、拥有大量预置组件和灵活编排能力的框架,并且希望快速原型化和构建复杂的Agentic应用或RAG流程,LangChain 通常是首选。
- 如果您专注于构建生产级别的、高性能的语义搜索或问答系统,并且非常重视系统的评估、可扩展性和与传统信息检索技术的结合,Haystack 会是一个非常专业的选择。
- 如果您想探索多智能体协作、任务自动化和人类参与的复杂对话系统,特别是需要代理之间进行精细的交互和代码执行,AutoGen 提供了独特的范式。
- 如果您希望以一种**更接近传统软件工程的方式将AI能力(尤其是LLM)轻量级地集成到现有应用程序(特别是C#, Python, Java技术栈)**中,并强调技能的复用和AI与业务逻辑的融合,Semantic Kernel 是一个优秀的选择。
- 如果您项目的核心在于处理和连接多样化的外部数据源以增强LLM(即RAG是关键),并且需要对数据的摄取、索引、查询进行深度优化和精细控制,LlamaIndex 在数据处理方面提供了无与伦比的深度和广度。
在实际项目中,这些框架并非完全互斥,有时甚至可以结合使用它们各自的优势组件。例如,使用 LlamaIndex 构建强大的数据索引和检索器,然后将其作为 LangChain Agent 的一个工具。理解它们的核心设计理念和优势,将帮助您为您的 LLM 应用选择最合适的架构和工具。
相关文章:
应用开发框架)
热门大型语言模型(LLM)应用开发框架
我们来深入探索这些强大的大型语言模型(LLM)应用开发框架,并且我会尝试用文本形式描述一些核心的流程图,帮助您更好地理解它们的工作机制。由于我无法直接生成图片,我会用文字清晰地描述流程图的各个步骤和连接。 Lang…...
Nginx安全防护与HTTPS部署实战
目录 前言一. 核心安全配置1. 隐藏版本号2. 限制危险请求方法3. 请求限制(CC攻击防御)(1)使用nginx的limit_req模块限制请求速率(2)压力测试验证 4. 防盗链 二. 高级防护1. 动态黑名单(1&#x…...
JAVA重症监护系统源码 ICU重症监护系统源码 智慧医院重症监护系统源码
智慧医院重症监护系统源码 ICU重症监护系统源码 开发语言:JavaVUE ICU护理记录:实现病人数据的自动采集,实时记录监护过程数据。支持主流厂家的监护仪、呼吸机等床旁数字化设备的数据采集。对接检验检查系统,实现自动化录入。喜…...

静态资源js,css免费CDN服务比较
静态资源js,css免费CDN服务比较 分析的 CDN 服务列表: BootCDN (https://cdn.bootcdn.net/ajax/libs)jsDelivr (主域名) (https://cdn.jsdelivr.net/npm)jsDelivr (Gcore 镜像) (https://gcore.jsdelivr.net/npm)UNPKG (https://unpkg.com)ESM (https://esm.sh)By…...

组合型回溯+剪枝
本篇基于b站灵茶山艾府。 77. 组合 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 示例 1: 输入:n 4, k 2 输出: [[2,4],[3,4],[2,3],[1,2],[1,3],[1,4], ]示例 2&#…...

python:机器学习(KNN算法)
本文目录: 一、K-近邻算法思想二、KNN的应用方式( 一)分类流程(二)回归流程 三、API介绍(一)分类预测操作(二)回归预测操作 四、距离度量方法(一)…...
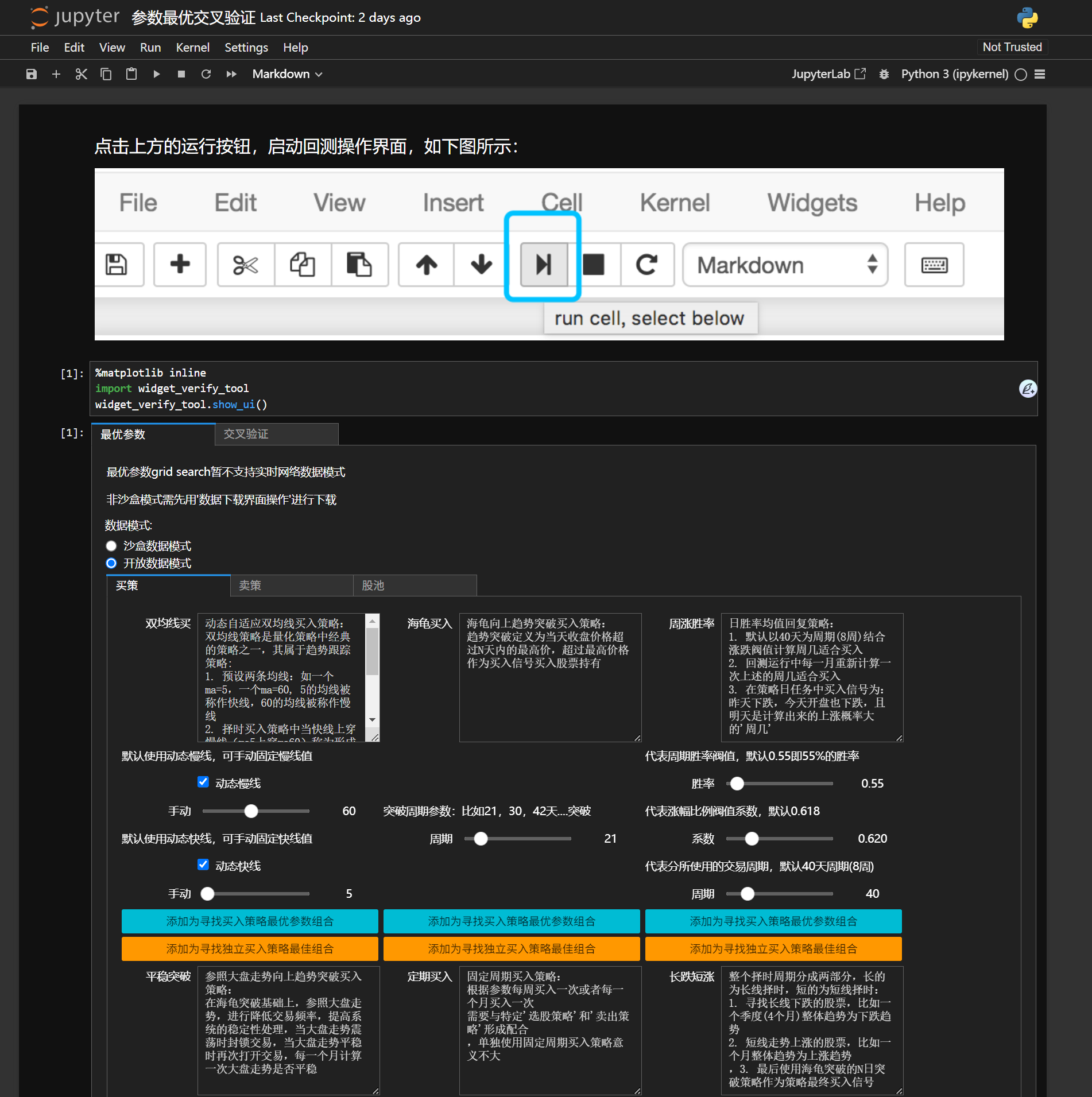
【笔记】2025 年 Windows 系统下 abu 量化交易库部署与适配指南
#工作记录 前言 在量化交易的学习探索中,偶然接触到 2017 年开源的 abu 量化交易库,其代码结构和思路对新手理解量化回测、指标分析等基础逻辑有一定参考价值。然而,当尝试在 2025 年的开发环境中部署这个久未更新的项目时,遇到…...

小程序 - 视图与逻辑
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言: “心有多大,舞台就有多大。” 📚推荐学习: 🍉Vue2 🍋Vue3 🍓Vue2/3项目实战 🥝Node.js实战 🍒T…...
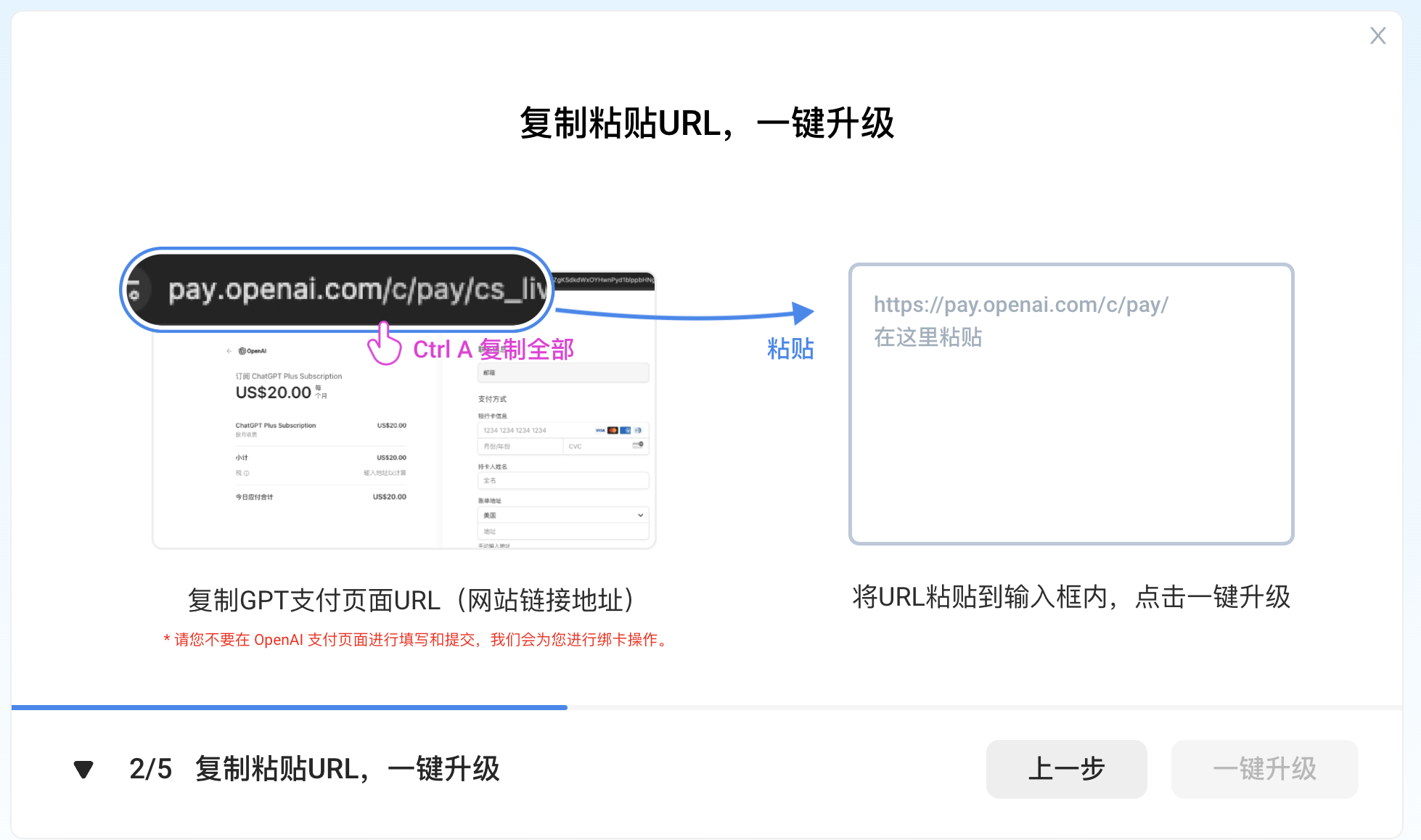
ChatGPT Plus/Pro 订阅教程(支持支付宝)
订阅 ChatGPT Plus GPT-4 最简单,成功率最高的方案 1. 登录 chat.openai.com 依次点击 Login ,输入邮箱和密码 2. 点击升级 Upgrade 登录自己的 OpenAI 帐户后,点击左下角的 Upgrade to Plus,在弹窗中选择 Upgrade plan。 如果…...

[蓝帽杯 2022 初赛]网站取证_2
一、找到与数据库有关系的PHP文件 打开内容如下,发现数据库密码是函数my_encrypt()返回的结果。 二、在文件夹encrypt中找到encrypt.php,内容如下,其中mcrypt已不再使用,所以使用php>7版本可能没有执行结果,需要换成较低版本…...

vue3+Pinia+element-plus 后台管理系统项目实战记录
vue3Piniaelement-plus 后台管理系统项目实战记录 参考项目:https://www.bilibili.com/video/BV1L24y1n7tB 全局api provide、inject vue2 import api from/api vue.propotype.$api apithis.$api.xxxvue3 import api from/api app.provide($api, api)import {…...
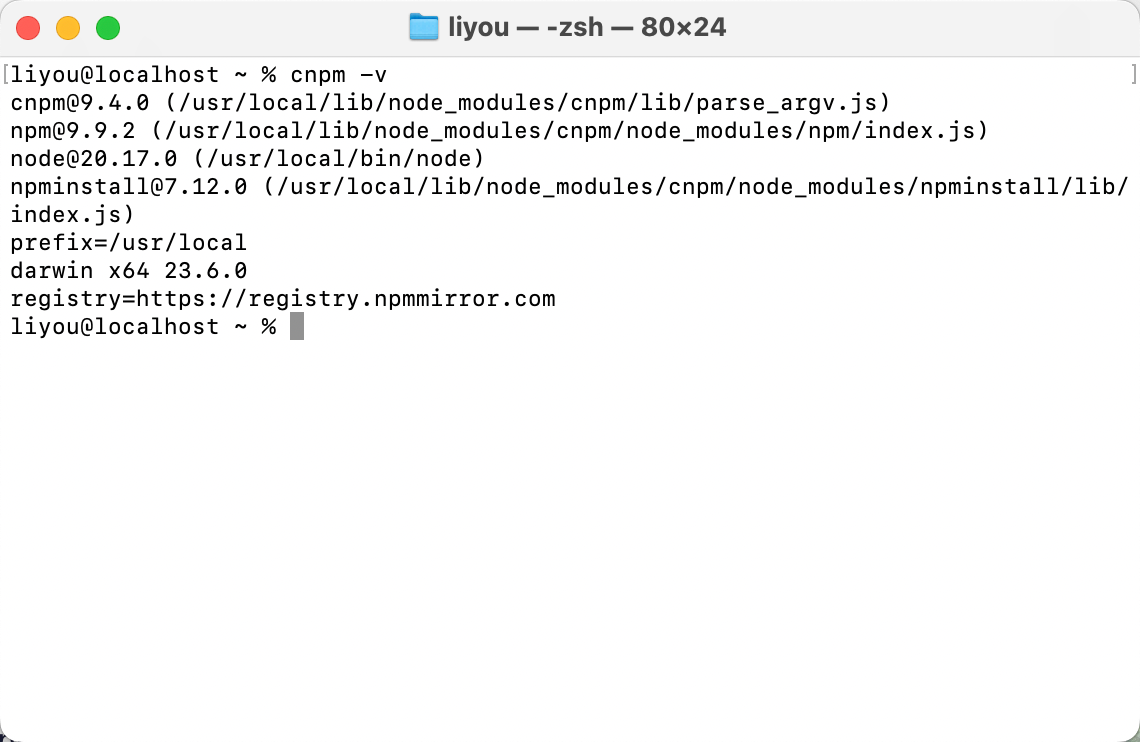
安装 Node.js 和配置 cnpm 镜像源
一、安装 Node.js 方式一:官网下载(适合所有系统) 访问 Node.js 官网 推荐选择 LTS(长期支持)版本,点击下载安装包。 根据系统提示一步步完成安装。 方式二:通过包管理器安装(建…...

MacOS内存管理-删除冗余系统数据System Data
文章目录 一、问题复现二、解决思路三、解决流程四、附录 一、问题复现 以题主的的 Mac 为例,我们可以看到System Data所占数据高达77.08GB,远远超出系统所占内存 二、解决思路 占据大量空间的是分散在系统中各个位置Cache数据; 其中容量最…...

电脑开机后长时间黑屏,桌面图标和任务栏很久才会出现,但是可通过任务管理器打开应用程序,如何解决
目录 一、造成这种情况的主要原因(详细分析): (1)启动项过多,导致系统资源占用过高(最常见) 检测方法: (2)系统服务启动异常(常见&a…...
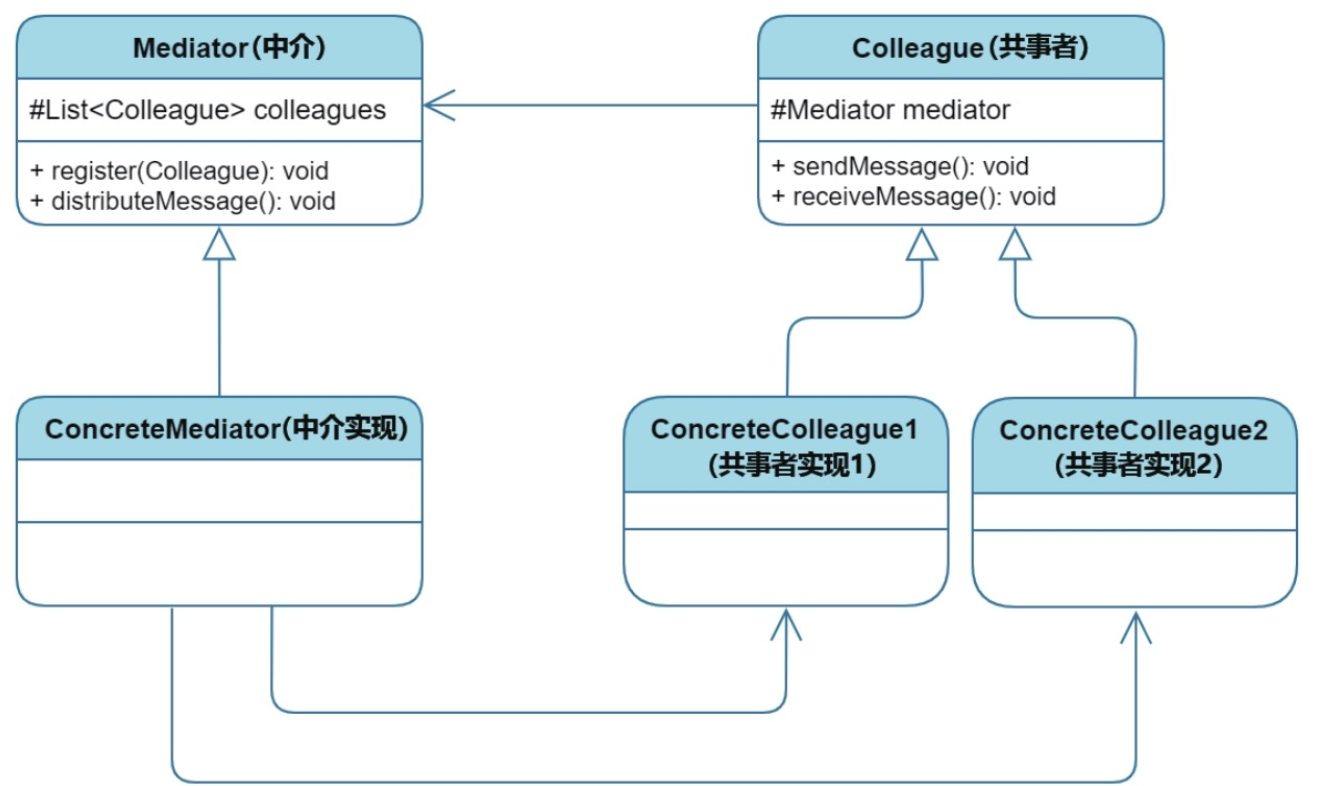
行为型:中介者模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、注意事项 1、核心思想 目的:通过引入一个中介对象来封装一组对象之间的交互,解决对象间过度耦合、频繁交互的问题。不管是对象引用维护还是消息的转发&am…...

光谱相机在生态修复监测中的应用
光谱相机通过多维光谱数据采集与智能分析技术,在生态修复监测中构建起“感知-评估-验证”的全周期管理体系,其核心应用方向如下: 一、土壤修复效能量化评估 重金属污染动态监测 通过短波红外(1000-2500nm)波…...
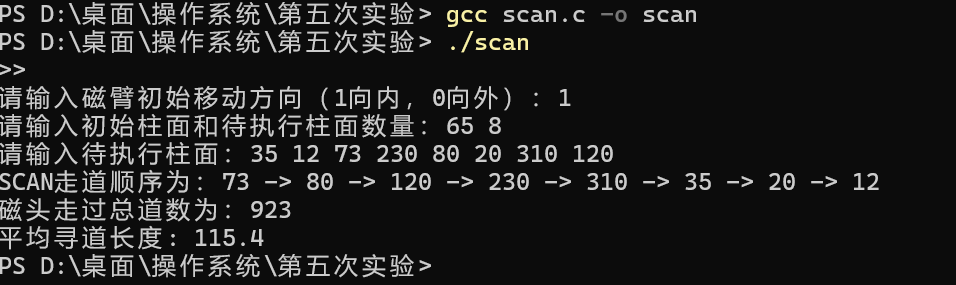
吉林大学操作系统上机实验五(磁盘引臂调度算法(scan算法)实现)
本次实验无参考,从头开始实现。 一.实验内容 模拟实现任意一个磁盘引臂调度算法,对磁盘进行移臂操作列出基于该种算法的磁道访问序列,计算平均寻道长度。 二.实验设计 假设磁盘只有一个盘面,并且磁盘是可移动头磁盘。磁盘是可…...
)
【深度学习-pytorch篇】4. 正则化方法(Regularization Techniques)
正则化方法(Regularization Techniques) 1. 目标 理解什么是过拟合及其影响掌握常见正则化技术:L2 正则化、Dropout、Batch Normalization、Early Stopping能够使用 PyTorch 编程实现这些正则化方法并进行比较分析 2. 数据构造与任务设定 …...
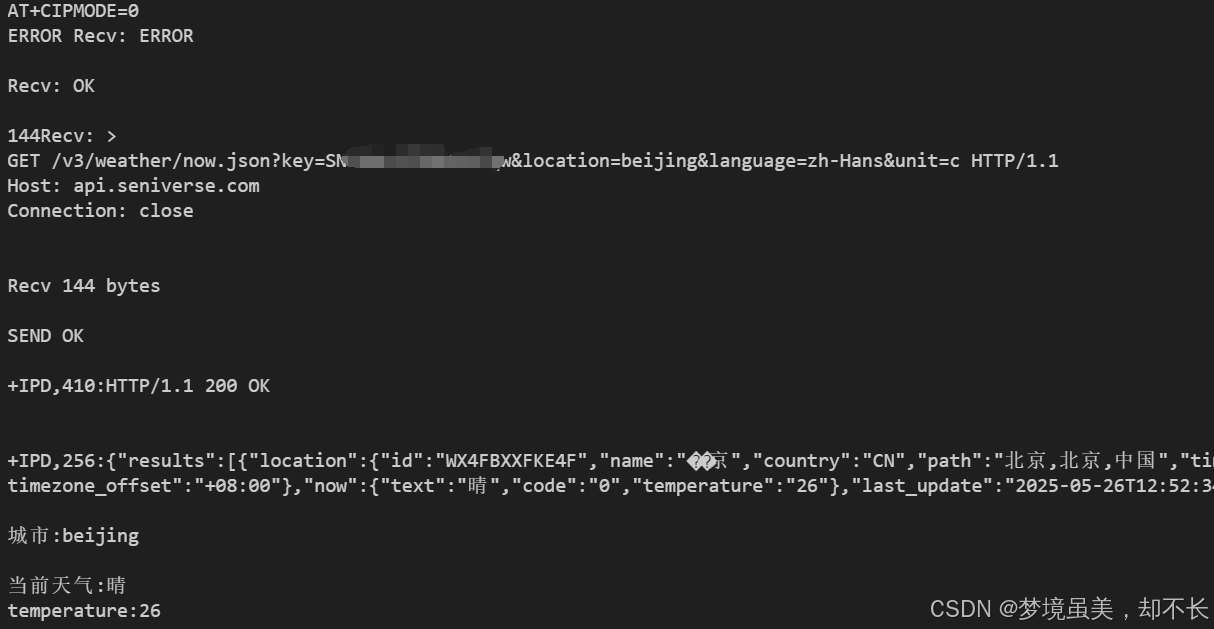
ESP8266+STM32 AT驱动程序,心知天气API 记录时间: 2025年5月26日13:24:11
接线为 串口2 接入ESP8266 esp8266.c #include "stm32f10x.h"//8266预处理文件 #include "esp8266.h"//硬件驱动 #include "delay.h" #include "usart.h"//用得到的库 #include <string.h> #include <stdio.h> #include …...
)
WPF【11_5】WPF实战-重构与美化(MVVM 实战)
11-10 【重构】创建视图模型,显示客户列表 正式进入 MVVM 架构的代码实战。在之前的课程中, Model 和 View 这部分的代码重构实际上已经完成了。 Model 就是在 Models 文件夹中看到的两个文件, Customer 和 Appointment。 而 View 则是所有与…...

⭐️⭐️⭐️ 模拟题及答案 ⭐️⭐️⭐️ 大模型Clouder认证:RAG应用构建及优化
考试注意事项: 一、单选题(21题) 检索增强生成(RAG)的核心技术结合了什么? A. 图像识别与自然语言处理 B. 信息检索与文本生成 C. 语音识别与知识图谱 D. 数据挖掘与机器学习 RAG技术中,“建立索引”步骤不包括以下哪项操作? A. 将文档解析为纯文本 B. 文本片段分割(…...
kali系统的安装及配置
1 kali下载 Kali 下载地址:Get Kali | Kali Linux (https://www.kali.org/get-kali) 下载 kali-linux-2024.4-installer-amd64.iso (http://cdimage.kali.org/kali-2024.4/) 2. 具体安装步骤: 2.1 进入官方地址,点击…...

CSS--background-repeat详解
属性介绍 background-repeat 属性在CSS中用于控制背景图像是否以及如何重复。当背景图像的尺寸小于其容器的尺寸时,该属性决定了图像如何填充额外的空间。默认情况下,背景图像会在横向和纵向上重复,直到覆盖整个元素。 常见取值 repeat …...

Redis的大Key问题如何解决?
大家好,我是锋哥。今天分享关于【Redis的大Key问题如何解决?】面试题。希望对大家有帮助; Redis的大Key问题如何解决? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Redis中的“大Key”问题是指某个键的值占用了过多…...

影楼精修-AI追色算法解析
注意:本文样例图片为了避免侵权,均使用AIGC生成; AI追色是像素蛋糕软件中比较受欢迎的一个功能点,本文将针对AI追色来解析一下大概的技术原理。 功能分析 AI追色实际上可以理解为颜色迁移的一种变体或者叫做升级版,…...
node入门:安装和npm使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、安装npm命令nvm 前言 因为学习vue接触的,一直以为node是和vue绑定的,还以为vue跑起来必须要node,后续发现并不是。 看…...

‘js@https://registry.npmmirror.com/JS/-/JS-0.1.0.tgz‘ is not in this registry
解决方法: 1. npm cache clean --force 2.临时切换到官方源 npm config set registry https://registry.npmjs.org/ npm install js0.1.0 npm config set registry https://registry.npmmirror.com/ # 切换回镜像源...

el-table-column如何获取行数据的值
在Element UI的el-table组件中,你可以通过el-table-column的slot-scope属性(在Vue 2.x中)或者#default插槽的scope属性(在Vue 3.x中)来获取当前行的数据。以下是如何实现这一功能的详细步骤: 在el-table-…...

leetcode450.删除二叉搜索树中的节点:迭代法巧用中间节点应对多场景删除
一、题目深度解析与BST特性剖析 在二叉搜索树(BST)中删除节点,需确保删除操作后树依然保持BST特性。题目要求我们根据给定的节点值key,在BST中删除对应节点。BST的核心特性是左子树所有节点值小于根节点值,右子树所有…...

java虚拟机2
一、垃圾回收机制(GC) 1. 回收区域:GC主要回收堆内存区域。堆用于存放new出来的对象 。程序计数器、元数据区和栈一般不是GC回收的重点区域。 2. 回收单位:GC以对象为单位回收内存,而非字节。按对象维度回收更简便&am…...