微调数据处理
1. 数据爬取
我们将爬取的1G文件都保存到all_m_files目录下
查看原始数据文件数量:
find /root/all_m_files -type f | wc -l
2. 数据预处理
仅保留UTF-8 格式文件,且所有保留的代码文件长度必须大于20行
import os
import pandas as pddef try_read_file(file_path):for encoding in ['utf-8']:try:with open(file_path, "r", encoding=encoding) as f:return f.read().strip()except Exception:continueprint(f"读取文件出错: {file_path},所有常用编码均失败")return Nonedef collect_m_files(dir_path, min_length=20):"""收集所有.m文件及其内容,返回列表"""data_list = []for root, _, files in os.walk(dir_path):for file in files:if file.endswith(".m") and not file.startswith('.'):file_path = os.path.join(root, file)content = try_read_file(file_path)if content and len(content) >= min_length:data_list.append({"filename": os.path.relpath(file_path, dir_path), "content": content})return data_listdef save_to_csv(data_list, output_csv_path):"""保存数据到CSV"""df = pd.DataFrame(data_list)print(f"共收集到 {len(df)} 个文件,正在保存到 {output_csv_path}")df.to_csv(output_csv_path, index=False, encoding="utf-8")print("保存完成!")def main():# 直接指定路径input_dir = "/root/all_m_files"output_csv = "/root/2-数据预处理/data.csv"min_length = 20data_list = collect_m_files(input_dir, min_length)save_to_csv(data_list, output_csv)if __name__ == "__main__":main()
3. 数据质量评测
import random
import argparse
import os
from tqdm import tqdm
import pandas as pddef del_strip_explain(content):new_content = []for c in content:c = c.strip()if c.startswith("%"):continuenew_content.append(c)return new_contentdef read_data(args):# fils = os.listdir(args.dir_path)# contents = []# files = []# # encodings_list = ["utf-8","gbk","gbk2312"]# for fil in fils:# try:# with open(os.path.join(args.dir_path,fil) ,encoding="utf-8") as f:# data = f.read()# except :# try:# with open(os.path.join(args.dir_path,fil), encoding="gbk") as f:# data = f.read()# except:# continue# contents.append(data.split("\n"))# files.append(fil)# return files,contentsdf = pd.read_csv(args.dir_path)return df["filename"].tolist(),df["content"].tolist()# 文件长度
def get_score1(file,content):# 10 30# 10-30 60# 30-100 100# 100-300 80# 300+ 70content = del_strip_explain(content)if isinstance(content, str):content = content.split("\n")elif isinstance(content, list):pass # 已经是列表else:content = []num = len(content)if num<=10:# print(f"{file}文件长度得分:30 ")return 30if 10<num<=30:# print(f"{file}文件长度得分:60 ")return 60if 30<num<=100:# print(f"{file}文件长度得分:100 ")return 100if 100<num<=300:# print(f"{file}文件长度得分:80 ")return 80# print(f"{file}文件长度得分:70 ")return 70# 代码重复率
def get_score2(file,content):content = del_strip_explain(content)if isinstance(content, str):content = content.split("\n")elif isinstance(content, list):pass # 已经是列表else:content = []set_content = set(content)if set_content:return round(len(set_content) / len(content) * 100,2)else:return 0# 关键词得分
def get_score3(file,content):return min(len(set(" ".join(content).split(" ")) & keywords) * 15 ,100)# 有效代码得分
def get_score4(file, content): # 有效代码得分content2 = del_strip_explain(content)content3 = del_print(content2)if not content: # 防止除零return 0return round(len(content3) / len(content) * 100, 2)# 多样性得分
def get_score5(file, content):lens_ = [len(i) for i in content]new_l = []t = []for i in range(len(lens_)):if (i + 1) % 100 == 0:new_l.append(t)t = []else:t.append(lens_[i])else:if t:new_l.append(t)scores = []for l in new_l:if len(l) == 0:continuescores.append(len(set(l)) / len(l))if not scores:return 0 # 防止除零return round(sum(scores) / len(scores) * 100, 2)def del_print(content):new_content = []for c in content:if "$display" in c:continuenew_content.append(c)return new_contentdef get_score(files_list,contents_list):file_info = "\n".join(files_list[:5])print(f"前5个文件名:{file_info}")print("*"*30)all_scores = []scores_desc = ["文件长度得分","代码重复率得分","关键词得分","有效代码得分","多样性得分"]score1_list = []score2_list = []score3_list = []score4_list = []score5_list = []for file,content in tqdm(zip(files_list,contents_list),total=len(files_list )):if isinstance(content, str):content = content.split("\n")else:content = []scores_list = [get_score1,get_score2,get_score3,get_score4,get_score5]scores_weight = [ 1,1,1 ,1 ,1]scores = [ i(file,content) for i in scores_list]score1_list.append(scores[0])score2_list.append(scores[1])score3_list.append(scores[2])score4_list.append(scores[3])score5_list.append(scores[4])info = f"{file} :{sum(scores)/len(scores_list):.2f}\n每项得分:{ scores}"print(info+"\n")scores = sum([ s*w for s,w in zip(scores,scores_weight) ]) / sum(scores_weight)# print("*"*10)all_scores.append( round(scores,3) )print(f"所有文件总分为:{ round(sum(all_scores)/len(files_list),3)}",len(all_scores) )df = pd.DataFrame({"filename":files_list,"总分":all_scores,"文件长度得分":score1_list,"代码重复率得分":score2_list,"关键词得分":score3_list,"有效代码得分":score4_list,"多样性得分":score5_list})df.to_csv("3-数据评分系统/score.csv",index=False,encoding="utf-8")return scoresdef get_keywords(path):with open(path,encoding="utf-8") as f:return f.read().split("\n")if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument('--dir_path', type=str ,required=False,default="/root/2-数据预处理/data.csv", help='文件夹路径')args = parser.parse_args()keywords = set(get_keywords("/root/3-数据评分系统/keywords.txt"))get_score(*read_data(args))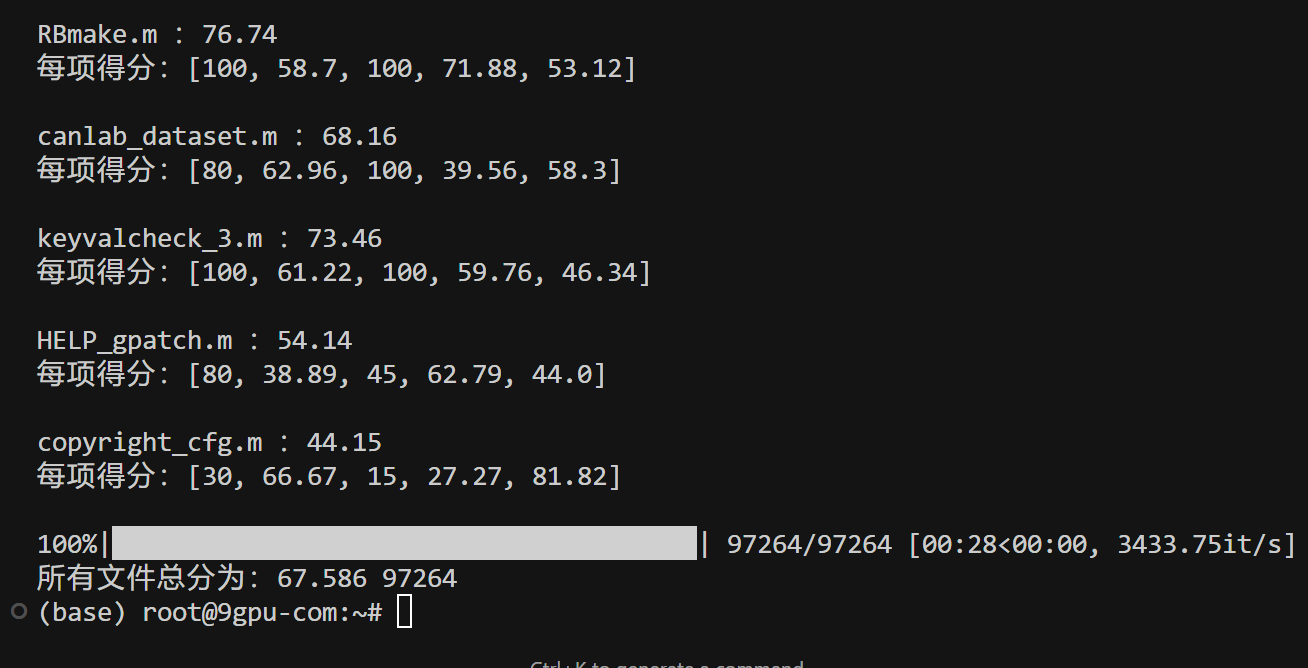
4. 基于分数段筛选数据并抽样
使用jupyter进行评分后的数据质量分析
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果系统中安装了 "SimHei" 字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题df = pd.read_csv('D:/score.csv')plt.figure(figsize=(8, 6))
sns.histplot(df['总分'], bins=20, kde=True)
plt.title('总分分布')
plt.xlabel('总分')
plt.ylabel('频率')
plt.show()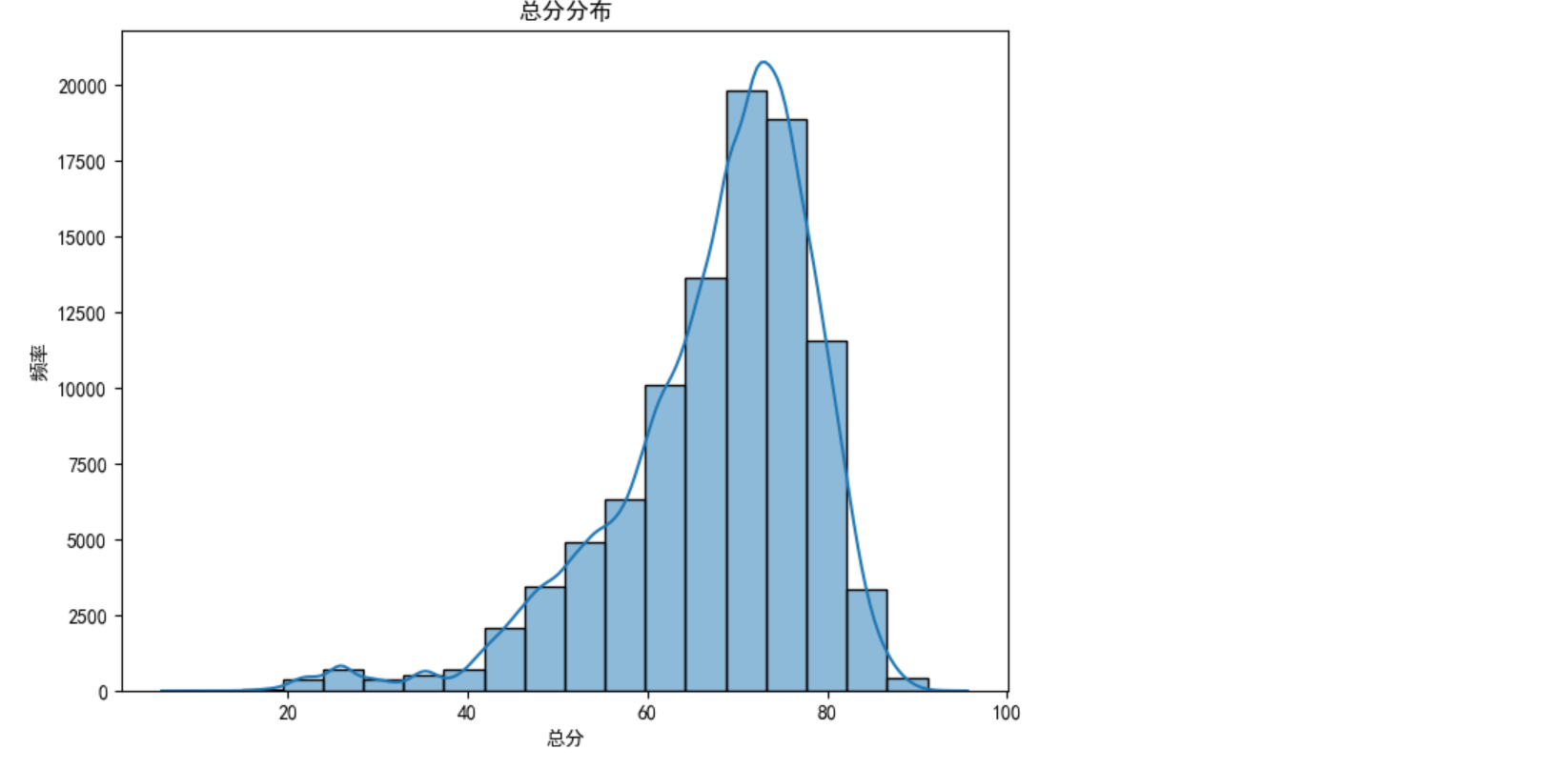
# 找出得分最高和最低的文件
max_score = df.loc[df['总分'].idxmax()]
min_score = df.loc[df['总分'].idxmin()]print('得分最高的文件:')
print(max_score)print('得分最低的文件:')
print(min_score)# 分析特定范围内的文件,比如得分大于70的文件
s = 70
high_score_files = df[df['总分'] > s]
print(f'得分大于{s}的文件数量:', len(high_score_files))
print(high_score_files) 
# 统计各个分数段的比例和数量
bins = [0, 50, 60, 70, 80, 90, 100]
labels = ['0-50', '51-60', '61-70', '70-80', '80-90', '90-100']
df['分数段'] = pd.cut(df['总分'], bins=bins, labels=labels, right=False)count_series = df['分数段'].value_counts(sort=False)
percentage_series = df['分数段'].value_counts(normalize=True, sort=False) * 100# 输出统计信息
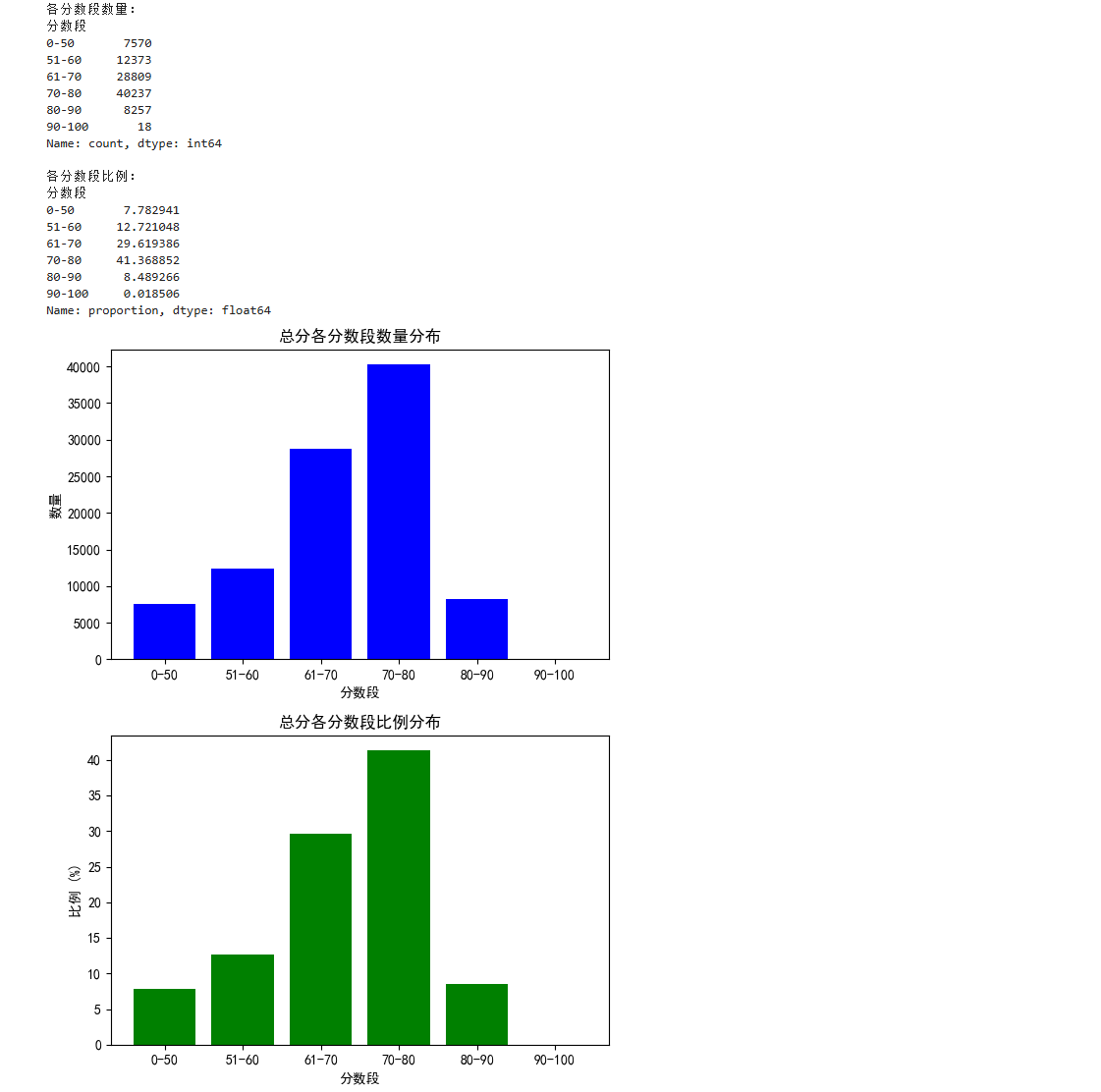
print("各分数段数量:")
print(count_series)
print("\n各分数段比例:")
print(percentage_series)# 绘制柱状图
fig, ax = plt.subplots(2, 1, figsize=(6, 8))# 数量分布图
ax[0].bar(count_series.index.astype(str), count_series.values, color='blue')
ax[0].set_title('总分各分数段数量分布')
ax[0].set_xlabel('分数段')
ax[0].set_ylabel('数量')# 比例分布图
ax[1].bar(percentage_series.index.astype(str), percentage_series.values, color='green')
ax[1].set_title('总分各分数段比例分布')
ax[1].set_xlabel('分数段')
ax[1].set_ylabel('比例 (%)')# 显示图表
plt.tight_layout()
plt.show() 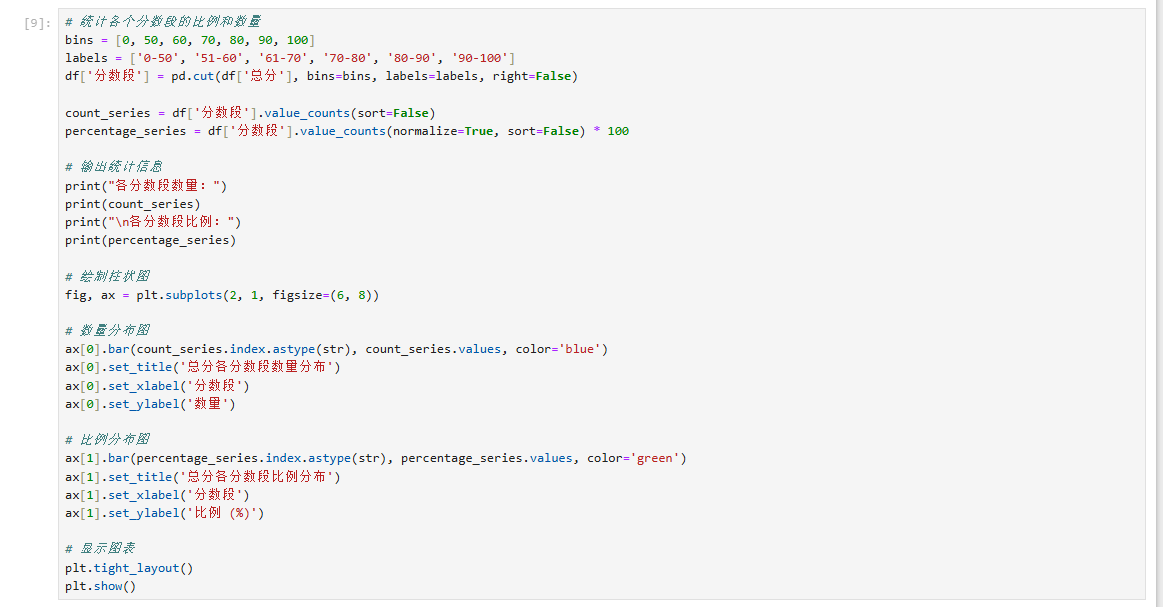
# 筛选出80-90分数段的数据
df_80_90 = df[(df['总分'] >= 80)]# 筛选出71-80分数段的数据
df_70_80 = df[(df['总分'] >= 70)]# 筛选出61-70分数段的数据,并保留50%
rate1 = 0.3
df_61_70 = df[(df['总分'] >= 61) & (df['总分'] < 70)]
df_61_70_sample = df_61_70.sample(frac=rate1, random_state=42)# 筛选出51-60分数段的数据,并保留25%
rate2 = 0.25
df_51_60 = df[(df['总分'] >= 51) & (df['总分'] <= 60)]
df_51_60_sample = df_51_60.sample(frac=rate2, random_state=42)# 筛选出0-50分数段的数据,并保留5%
rate2 = 0.01
df_51_60 = df[(df['总分'] >= 51) & (df['总分'] <= 60)]
df_51_60_sample = df_51_60.sample(frac=rate2, random_state=42)# 合并筛选后的数据
final_df = pd.concat([df_80_90, df_70_80, df_61_70_sample, df_51_60_sample])# 重置索引并丢弃旧的索引
final_df.reset_index(drop=True, inplace=True)
final_df.index.name="file_index"# 将结果保存到新的CSV文件
final_df.to_csv("D:/filtered_file.csv", index=True)print(len(final_df))根据不同分数段保留不同比例的数据样本。结果保存到 D:/filtered_file.csv 文件中
![]()
5. 为筛选后的文件添加内容字段
import pandas as pd
import os# 读取 filtered_file.csv
filtered_path = '/root/4-分析和筛选/filtered_file.csv'
data_dir = '/root/all_m_files'df = pd.read_csv(filtered_path)def read_file_content(filename):file_path = os.path.join(data_dir, filename)if os.path.exists(file_path):try:with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:return f.read()except Exception as e:return f'[ERROR: {e}]'else:return '[FILE NOT FOUND]'# 新增 content 字段
df['content'] = df['filename'].apply(read_file_content)# 保存新文件
df.to_csv('/root/5-通过文件进行筛选/filtered_file_with_content.csv', index=False)
6. 文件内容切分与JSON格式转换
将CSV文件中每个文件的内容切分成多个较小的代码块(chunks),并将结果保存为JSON格式。下
对上一步得到的文件进行切分
import os
import json
import pandas as pd
from tqdm import tqdm
import randomdef split_file(lines):language = "matlab"total_lines = len(lines)start = 0chunks = []while start + min_lines < total_lines:# 随机生成小文件的行数,范围是10到30lines_in_chunk = random.randint(min_lines, max_lines)end = min(start + lines_in_chunk, total_lines)chunk = "\n".join(lines[start:end])chunks.append(chunk)start = end + window # 设定下一个间隔10行后的起点return chunks, languageif __name__ == "__main__":random.seed(415)# 从CSV文件读取数据df = pd.read_csv("/root/5-通过文件进行筛选/filtered_file_with_content.csv")max_lines = 50min_lines = 20window = 40chunk_ids = 0result = []for _, row in tqdm(df.iterrows()):# 假设CSV中有content列,包含文件内容,并按行分割content = row["content"].splitlines() if isinstance(row["content"], str) else []chunks, language = split_file(content) # 切分获取caseif chunks and language:for chunk_content in chunks:json_record = {"file_index": row.get("file_index", chunk_ids),"file_name": row.get("filename", ""),# "chunk_id":chunk_ids,"language": language,"content": chunk_content}result.append(json_record)chunk_ids += 1with open('/root/6-数据切分/split_result.json', 'w', encoding="utf-8") as outfile:json.dump(result, outfile, ensure_ascii=False, indent=4)print(len(df), "个文件切分为:", chunk_ids)
切分后结果保存在新的json文件中
7. 代码块质量评估与重复率计算
import os
import json
from tqdm import tqdm
import random
import re
import pandas as pddef split_string(s):# pattern = r'[A-Za-z]+|\d+|[^A-Za-z0-9\s]'tokens = split_pattern.findall( s)return tokensdef get_score2(content): # 代码重复率sp_content = split_string(content)set_content = set(sp_content)try:return round( len(set_content) / len(sp_content) * 100,2)except:return 0if __name__ == "__main__":split_pattern = re.compile(r'[A-Za-z]+|\d|[^A-Za-z0-9\s]')with open("/root/6-数据切分/split_result.json",encoding="utf-8") as f:files_info = json.load(f)for idx,file in tqdm(enumerate(files_info),total=len(files_info)):content = file["content"]score = get_score2(content)del file["content"]file["score"] = scorefile["content"] = contentfiles_info[idx] = filedf = pd.DataFrame(files_info)df.to_csv("/root/7-数据块的质量评测/chunk_scores.csv",index=False)
chunk_scores.csv 文件保存的是经过质量评估后的代码块(chunks)信息,包含每个代码块的元数据和计算得到的质量评分。
文件包含的主要字段
-
file_index
-
原始文件的索引ID,用于追踪代码块来源
-
-
file_name
-
原始文件名,标识代码块来自哪个源文件
-
-
language
-
代码语言类型(当前代码固定为"matlab")
-
-
score
-
核心指标:代码重复率评分(0-100)
-
计算方式:
(唯一token数量 / 总token数量) * 100 -
值越高表示代码重复率越低,独特性越高
-
值越低表示代码重复率越高,可能包含大量重复模式
-
-
-
content
-
代码块的实际内容(20-50行不等的代码片段)
-
数据示例(假设结构)
| file_index | file_name | language | score | content |
|---|---|---|---|---|
| 1 | example1.m | matlab | 78.50 | function y = foo(x)...end |
| 2 | example1.m | matlab | 65.20 | for i=1:10...end |
| 3 | utils.m | matlab | 92.30 | % 独特的功能实现代码... |
8. 代码块筛选
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 如果系统中安装了 "SimHei" 字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示为方块的问题df = pd.read_csv('D:/chunk_scores.csv')# 统计各个分数段的比例和数量
bins = [0, 2,5,8, 10,15, 20,25, 40,100]
labels = ['0-2', '2-5','5-8', '8-10', '10-15','15-20','20-25','25-40', '40-100']
df['分数段'] = pd.cut(df['score'], bins=bins, labels=labels, right=False)count_series = df['分数段'].value_counts(sort=False)
percentage_series = df['分数段'].value_counts(normalize=True, sort=False)# 输出统计信息
print("各分数段数量:")
print(count_series)
print("\n各分数段比例:")
print(percentage_series)# 绘制柱状图
fig, ax = plt.subplots(2, 1, figsize=(6, 8))# 数量分布图
ax[0].bar(count_series.index.astype(str), count_series.values, color='blue')
ax[0].set_title('文件总得分各分数段数量分布')
ax[0].set_xlabel('分数段')
ax[0].set_ylabel('数量')# 比例分布图
ax[1].bar(percentage_series.index.astype(str), percentage_series.values, color='green')
ax[1].set_title('文件总得分各分数段比例分布')
ax[1].set_xlabel('分数段')
ax[1].set_ylabel('比例 (%)')# 显示图表
plt.tight_layout()
plt.show() 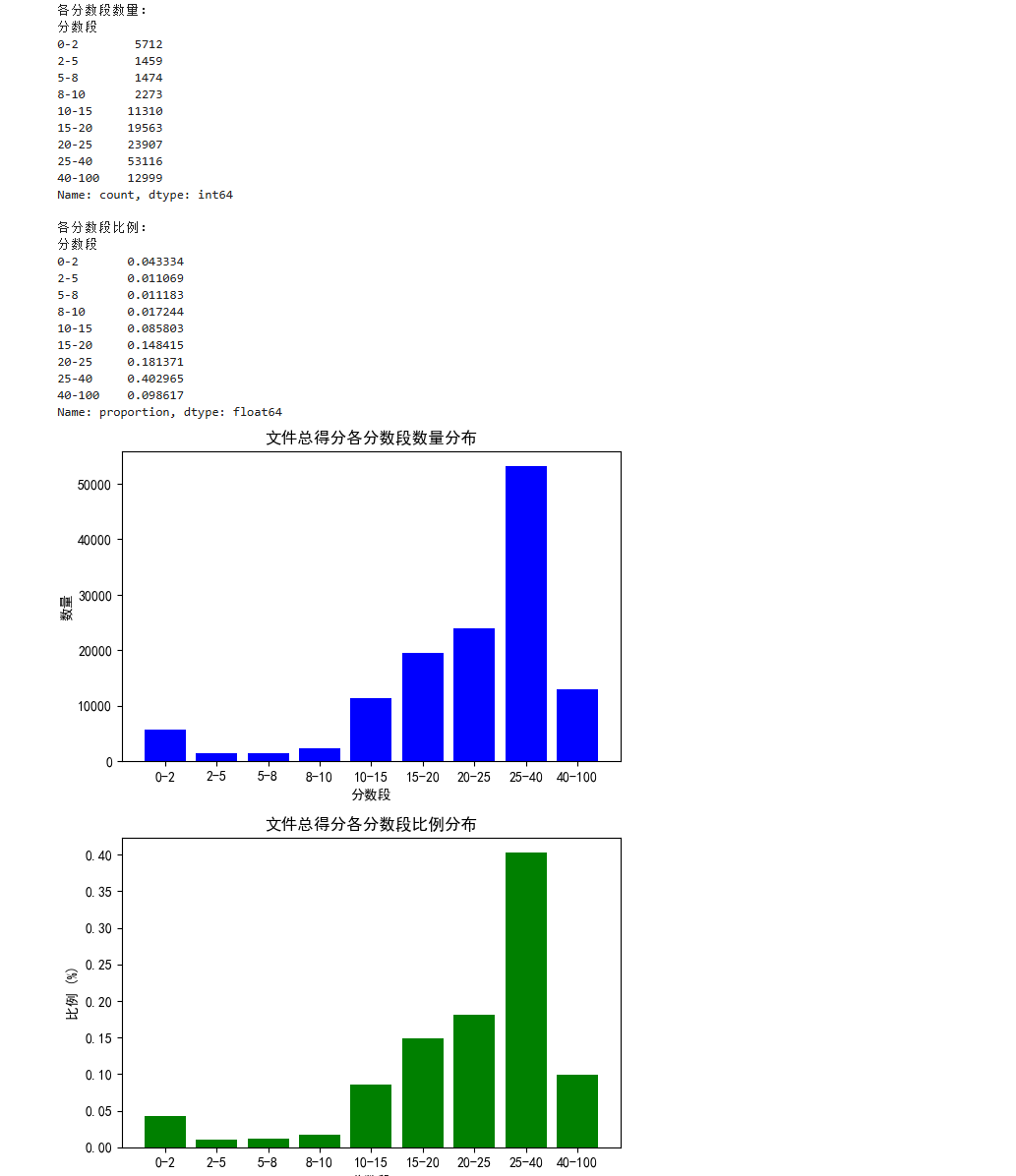
# 筛选出15分数以上的数据
rage0 = 1.0df_4 = df[(df['score'] >= 40)]
df_4 = df_4.sample(frac=rage0, random_state=42)# 筛选出10-15分数段的数据,并保留70%rage1 = 0.9df_3_4 = df[(df['score'] >= 25) & (df['score'] < 40)]
df_3_4 = df_3_4.sample(frac=rage1, random_state=42)# 筛选出8-10分数段的数据,并保留60%
rate2 = 0.8df_2_3 = df[(df['score'] >=20) & (df['score'] < 25)]
df_2_3 = df_2_3.sample(frac=rate2, random_state=42)# 筛选出5-8分数段的数据,并保留30%
rate3 = 0.5
df_1_2 = df[(df['score'] >= 15) & (df['score'] < 20)]
df_1_2 = df_1_2.sample(frac=rate3, random_state=42)# 筛选出1-15分数段的数据,并保留30%
rate4 = 0.1
df_0_1 = df[(df['score'] >= 1) & (df['score'] < 15)]
df_0_1 = df_0_1.sample(frac=rate4, random_state=42)# 合并筛选后的数据
final_df = pd.concat([df_4, df_3_4, df_2_3,df_1_2,df_0_1])del final_df["分数段"]final_df["chunk_id"] = [i for i in range(len(final_df))]columns = ['chunk_id'] + [col for col in final_df.columns if col != 'chunk_id']
final_df = final_df[columns]# final_df.index.name = 'chunk_id'# # # 将结果保存到新的CSV文件
# # final_df.to_csv("chunk_scores_result.csv", index=True)
final_df.to_json("D:/chunk_scores_result.json", orient="records", indent=4, force_ascii=False)print( len(df), "---->" ,len(final_df))![]()
9. 训练集和测试集数据制作
确保在上一文件夹目录下有待处理的json文件
安装 tree_sitter_languages 包
pip install tree_sitter_languagesimport os
import fire
import glob
import gzip
import random
import concurrent.futures
from typing import *
from tqdm.auto import tqdm
from infilling import InFilling
import json
from tqdm import tqdm
from transformers import AutoTokenizerdef stream_jsonl(filename: str):"""Parses each jsonl line and yields it as a dictionary"""if filename.endswith(".gz"):with open(filename, "rb") as gzfp:with gzip.open(gzfp, "rt") as fp:for line in fp:# if any(not x.isspace() for x in line):yield json.loads(line)else:with open(filename, "r",encoding="utf-8") as fp:datas = json.load(fp)print(len(datas))try :for data in datas:yield dataexcept:yield Nonedef choose_mode(modes, weights):return random.choices(modes, weights, k=1)[0]def get_all_file_paths(directory):file_paths = [] # List to store file pathsfor root, directories, files in os.walk(directory):for filename in files:# Join the two strings to form the full filepath.filepath = os.path.join(root, filename)if filepath.endswith(".json"):file_paths.append(filepath) # Add it to the list.return file_pathsdef process(obj):chosen_mode = choose_mode(modes, weights)results = InFilling(obj['content'], obj['language'], chosen_mode,times[chosen_mode])if len(results) == 0:return []contents = []for prefix,middle,suffix in results:# print(chosen_mode)content = {"chunk_id":obj["chunk_id"],"file_index":obj["file_index"],"file_name":obj["file_name"],"score":obj["score"],"language": obj['language'],"prefix": prefix,"middle": middle,"suffix": suffix,"mode":chosen_mode}contents.append(content)return contentsdef process_file(file_path):global split_dir, strategyprint(f"Processing {file_path}")name = os.path.basename(file_path)save_name = os.path.join(split_dir, f"{name}")with open(save_name, "w",encoding="utf-8") as f_out:data = stream_jsonl(file_path)for d in data:if d:# result = json.dumps( process(d),ensure_ascii=False)results = process(d)if len(results) != 0:for result in results:result = json.dumps(result,ensure_ascii=False)f_out.write(result + "\n")def main(num_workers: int = 1):global data_dir,split_dir,strategydata_list = get_all_file_paths(data_dir)print(data_list)with concurrent.futures.ThreadPoolExecutor(max_workers=num_workers) as executor:# 使用list comprehension来启动每个线程并获取结果results = [result for result in executor.map(process_file, data_list)] # data_list每个元素做process_filedef split_train_test():train_file = "/root/9-训练集和测试集数据制作/train.json"test_file = "/root/9-训练集和测试集数据制作/test.json"if not os.path.exists(result_dir):os.makedirs(result_dir)files = os.listdir(split_dir)tokenizer = AutoTokenizer.from_pretrained("/root/9-训练集和测试集数据制作/tokenizer_file", trust_remote_code=True)all_data = []for split_file in files:split_file = os.path.join(split_dir, split_file)with open(split_file, encoding="utf-8") as f:all_data += f.readlines()random.shuffle(all_data)new_data = []for data in tqdm(all_data[:]):# if len(data)<200:# continuedata = json.loads(data)prefix = data["prefix"]middle = data["middle"]suffix = data["suffix"]t1, t2, t3 = tokenizer.batch_encode_plus([prefix, middle, suffix], add_special_tokens=False)["input_ids"]l1, l2, l3 = len(t1), len(t2), len(t3)i = 0while len(t1) + len(t2) + len(t3) > 1000: # 2048+512if i >= 10:i = -999breakif len(t3) >= len(t1):t3 = t3[: len(t3) // 2]else:t1 = t1[len(t1) //2 :]i += 1if i == -999:continueif len(t1) != l1:data["prefix"] = tokenizer.decode(t1)if len(t3) != l3:data["suffix"] = tokenizer.decode(t3)data["prefix"] = data["prefix"].strip("\n")data["suffix"] = data["suffix"].strip("\n")data["middle"] = data["middle"].strip("\n")# print(data["middle"])# print("*"*100)new_data.append(data)# if len(new_data)>1000:# breaktest_data = new_data[:int(len(new_data) * test_rate)]train_data = new_data[int(len(new_data) * test_rate):]with open(os.path.join(result_dir,train_file), "w", encoding="utf-8") as f1:json.dump(train_data,f1,ensure_ascii=False,indent=4)with open(os.path.join(result_dir,test_file), "w", encoding="utf-8") as f2:json.dump(test_data,f2,ensure_ascii=False,indent=4)print(f"总长度:{len(all_data)}")print(f"训练集长度:{len(train_data)}")print(f"测试集长度:{len(test_data)}")get_sameples()def get_sameples():f2 = open(os.path.join(result_dir,"samples.txt"), "w", encoding="utf-8")with open(os.path.join(result_dir, "train.json"), "r", encoding="utf-8") as f:all_data = json.loads(f.read())for data in all_data[:200]:f2.write("*" * 200 + "\n")# data = eval(data)f2.write("*" * 30 + "prefix:" + "*" * 30 + "\n")f2.write(data["prefix"] + "\n")f2.write("*" * 30 + "middle:" + str(len(data["middle"])) + f" mode:{data['mode']}" + "*" * 30 + '\n')f2.write(data["middle"] + "\n")f2.write("*" * 30 + "suffix:" + "*" * 30 + "\n")f2.write(data["suffix"] + '\n')f2.close()if __name__ == "__main__":data_dir = "/root/8-代码块的筛选"split_dir = "/root/9-训练集和测试集数据制作/split_temp"strategy = 0result_dir = "/root/9-训练集和测试集数据制作/split_result"if os.path.exists(result_dir) == False:os.mkdir(result_dir)test_rate = 0.05random.seed(824)if not os.path.exists(split_dir):os.makedirs(split_dir)modes = [0,1,2,3,4,5,6]times = [1, 1, 1, 1, 1, 1,0]if strategy == 0:weights = [1, 0, 1, 1, 1, 1,0]fire.Fire(main)else:all_weights = [[1, 0, 0, 0, 0, 0],[0, 1, 0, 0, 0, 0],[0, 0, 1, 0, 0, 0],[0, 0, 0, 1, 0, 0],[0, 0, 0, 0, 1, 0],[0, 0, 0, 0, 0, 1]]for i in range(len(modes)):weights = all_weights[i]fire.Fire(main)split_train_test()# modes 提供切分的模式,无需修改# weights 每种模式的权重# times 选中每种模式,生成的样例数量# mode0 : 简单的按照长度切分,有可能切开某一个单词# mode1 : 按照函数块、循环块切分# mode2 : 按照单行切分# mode3 : 按照括号切分# mode4 : 按照多行切分# mode5 : 没有suffix的切分 # mode6 : 没有prefix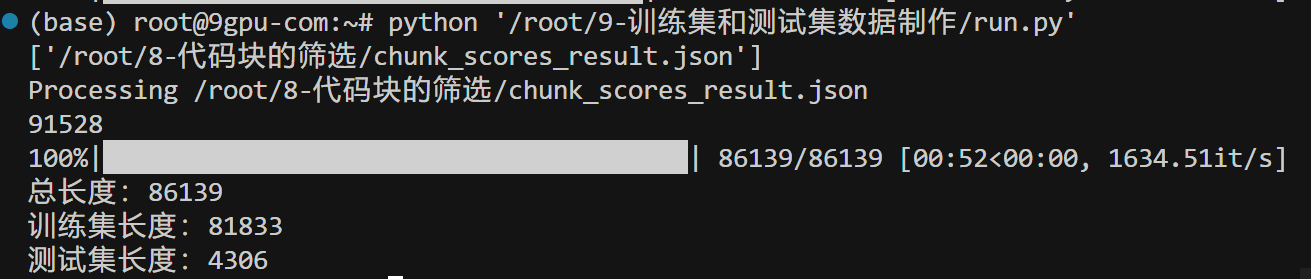
10. 格式微调及转换
# prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'
import json
def trans_data(path,save_path):with open(path,encoding="utf-8") as f:data = json.load(f)result = []for d in data:prefix_code = d["prefix"]suffix_code = d["suffix"]middle_code = d["middle"]prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'result.append({"instruction": prompt,"input": "","output": middle_code,"chunk_id": d["chunk_id"],"file_index": d["file_index"],"file_name": d["file_name"],"score": d["score"],"mode": d["mode"],})with open(save_path,"w",encoding="utf-8")as f:f.write(json.dumps(result,indent=4,ensure_ascii=False))trans_data("/root/9-训练集和测试集数据制作/split_result/train.json","code_train.json")
trans_data("/root/9-训练集和测试集数据制作/split_result/test.json","code_test.json")
# trans_data("label.json","label2.json")
相关文章:
微调数据处理
1. 数据爬取 我们将爬取的1G文件都保存到all_m_files目录下 查看原始数据文件数量: find /root/all_m_files -type f | wc -l 2. 数据预处理 仅保留UTF-8 格式文件,且所有保留的代码文件长度必须大于20行 import os import pandas as pddef try_read…...

✨1.1.1 按位与运算替代求余运算优化场景
在计算机编程中,使用按位与运算(&)替代求余运算(%)可以提高效率的特殊场景是:当除数是 2 的整数次幂(即 ( b 2^n ),其中 ( n ) 为自然数)时。例如,( b …...

解决开发者技能差距:AI 在提升效率与技能培养中的作用
企业在开发者人才方面正面临双重挑战。一方面,IDC 预测,到2025年,全球全职开发者将短缺400万人;另一方面,一些行业巨头已暂停开发者招聘,转而倚重人工智能(AI)来满足开发需求。这不禁…...

XCTF-web-easyphp
解析 第一个条件( k e y 1 ): i s s e t ( key1):isset( key1):isset(a) && intval(KaTeX parse error: Expected EOF, got & at position 14: a) > 6000000 &̲& strl…...

Transformer 通关秘籍11:Word2Vec 及工具的使用
将文字文本转换为词向量(word embedding)的过程中,一个非常著名的算法模型应该就是 Word2Vec 了。 相信大家或多或少都听说过,本节就来简单介绍一下 Word2Vec 。 什么是 Word2Vec ? Word2Vec 可以非常有效的创建词嵌入向量&…...
【DAY34】GPU训练及类的call方法
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前…...
Flutte ListView 列表组件
目录 1、垂直列表 1.1 实现用户中心的垂直列表 2、垂直图文列表 2.1 动态配置列表 2.2 for循环生成一个动态列表 2.3 ListView.builder配置列表 列表布局是我们项目开发中最常用的一种布局方式。Flutter中我们可以通过ListView来定义列表项,支持垂直和水平方向展示…...
muduo库的初步认识和基本使用,创建一个简单查询单词服务系统
小编在学习完muduo库之后,觉得对于初学者,muduo库还是有点不好理解,所以在此,小编来告诉大家muduo库的初步认识和基本使用,让初学者也可以更快的上手和使用muduo库。 Muduo由陈硕大佬开发,是⼀个基于 非阻塞…...

电脑如何保养才能用得更久
在这个数字化的时代,电脑已经成为了我们生活和工作中不可或缺的伙伴。无论是处理工作文档、追剧娱乐,还是进行创意设计,电脑都发挥着至关重要的作用。那么,如何让我们的电脑“健康长寿”,陪伴我们更久呢?今…...

Oracle的NVL函数
Oracle的NVL函数是一个常用的空值处理函数,主要用于在查询结果中将NULL值替换为指定的默认值。以下是关于NVL函数的详细说明: 基本语法 NVL(expr1, expr2) 如果expr1为NULL,则返回expr2如果expr1不为NULL,则返回expr1本身 …...
【HTML/CSS面经】
HTML/CSS面经 HTML1. script标签中的async和defer的区别2. H5新特性(1 标签语义化(2 表单功能增强(3 音频和视频标签(4 canvas和svg绘画(5 地理位置获取(6 元素拖动API(7 Web Worker(…...
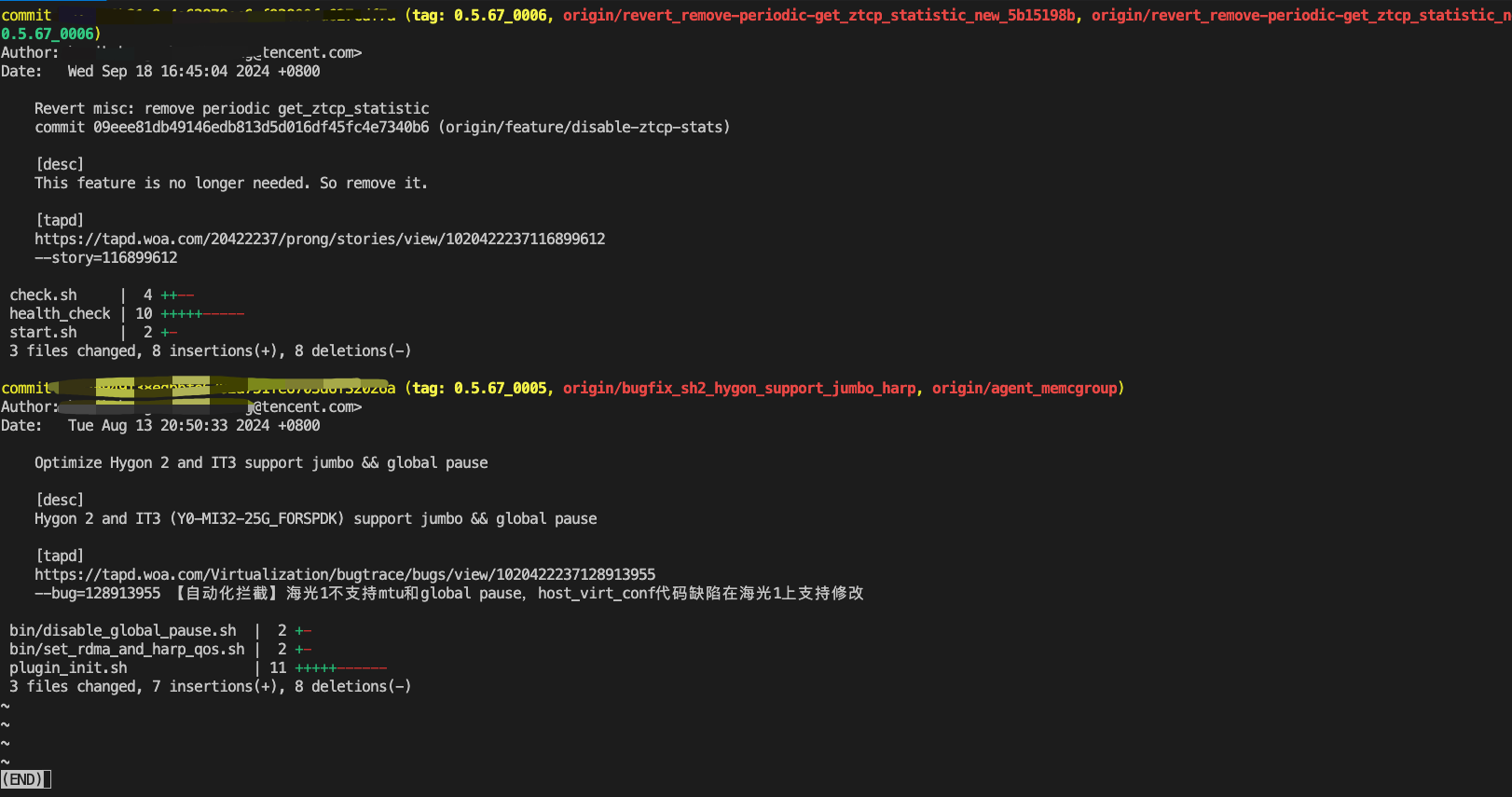
git查看commit属于那个tag
1. 快速确认commit原始分支及合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 查看commit合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 --all 查看commit原始分支 2.查看分支与master关系 # git show --all 0.5.67_0006 --stat 以缩…...

如何从ISO镜像直接制作Docker容器基础镜像
引言 这段最值得总结的经验知识,就是如何在ISO镜像的基础上,直接做出docker base image,无需联网! 特别地,对于一些老旧OS系统,都能依此做出docker base image! 例如,某些老旧系统,CentOS 6,…...
)
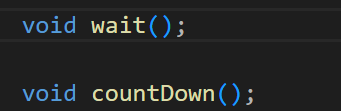
网站缓存入门与实战:浏览器与Nginx/Apache服务器端缓存,让网站速度起飞!(2025)
更多服务器知识,尽在hostol.com 嘿,各位站长和网站管理员朋友们!咱们精心打造的网站,内容再好,设计再炫,如果用户打开它的时候,加载速度慢得像“老牛拉破车”,那体验可就大打折扣了…...
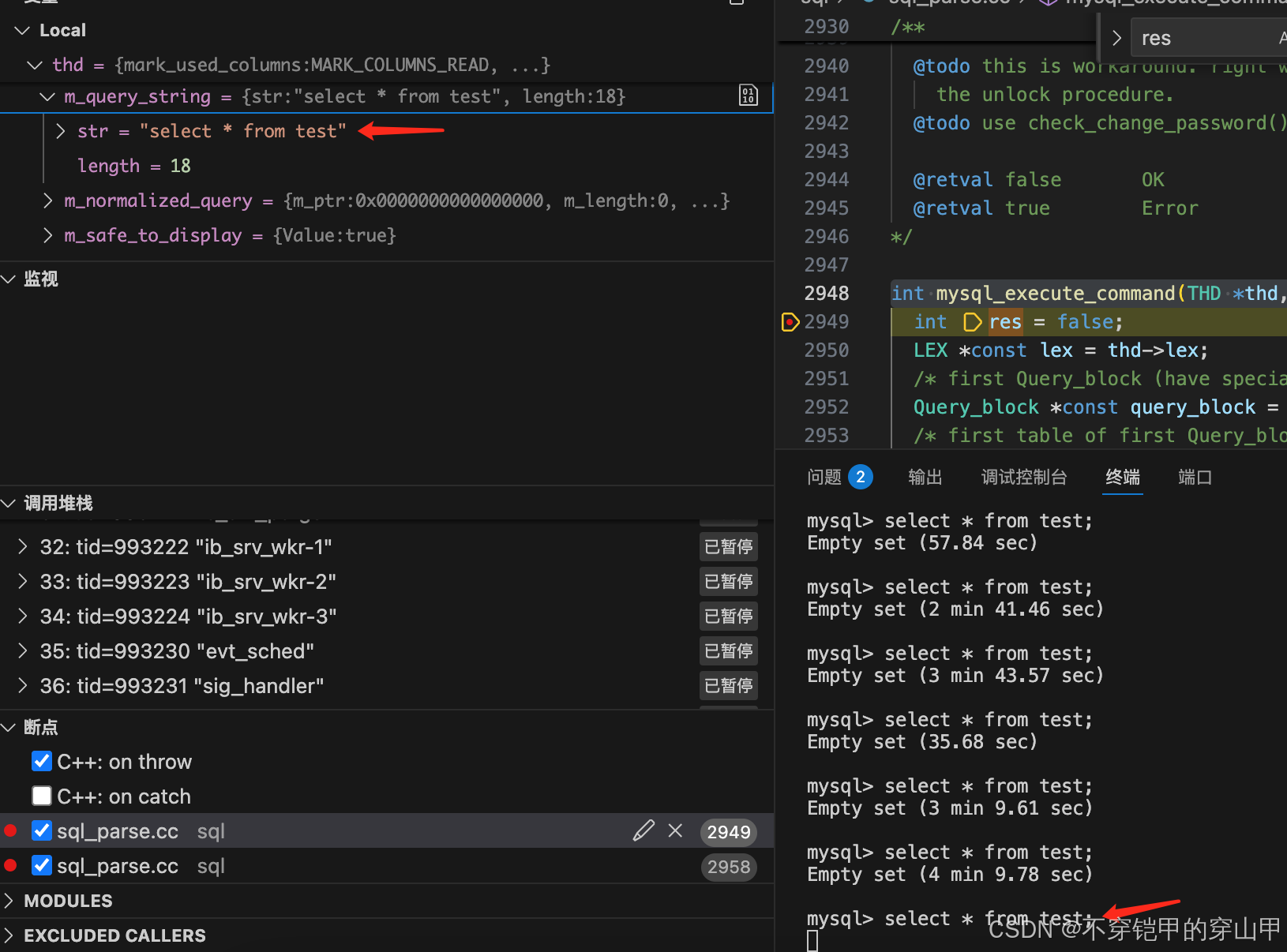
mysql-mysql源码本地调试
前言 先进行mysql源码本地编译:mysql源码本地编译 1.本地调试 这里以macbook为例 1.使用vscode打开mysql源码 2.创建basedir目录、数据目录、配置文件目录、配置文件 cd /Users/test/ mkdir mysqldir //创建数据目录和配置目录 cd mysqldir mkdir conf data …...
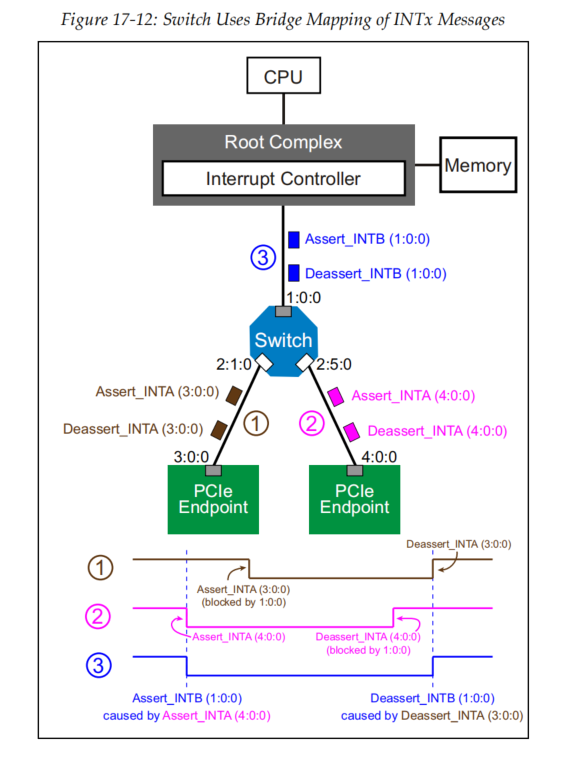
PCIe— Legacy PCI
Legacy Model 该器件通过将其引脚置位到控制器来生成中断。 在较旧的系统中,这个控制 器通常是Intel 8259 PIC,有15个IRQ输入和一个INTR输出。 然后,PIC将断 言INTR以通知CPU一个或多个中断正在挂起。 一旦CPU检测到INTR的断言…...
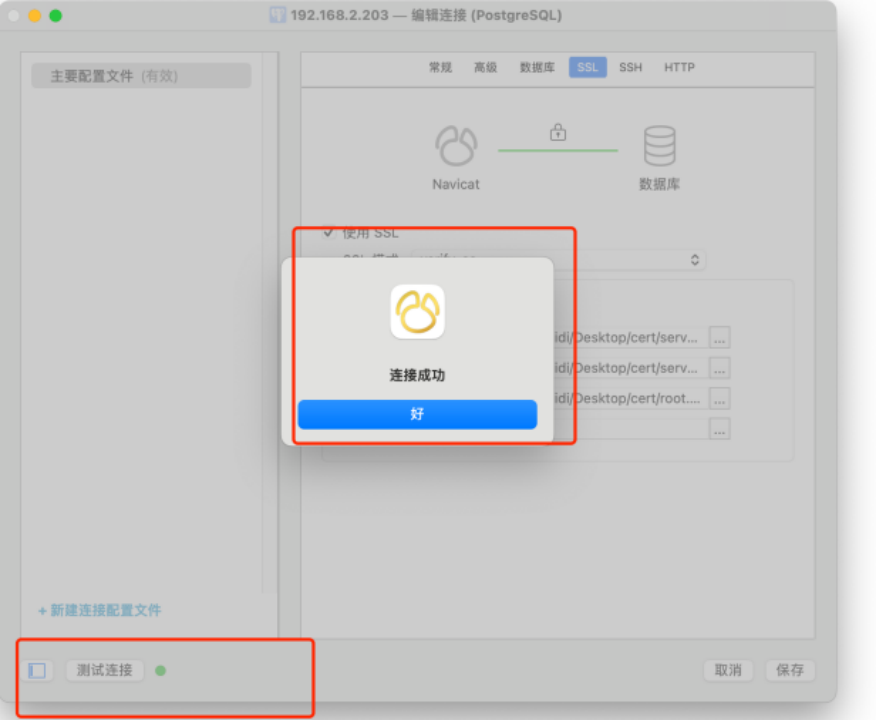
PostgreSQL数据库配置SSL操作说明书
背景: 因为postgresql或者mysql目前通过docker安装,只需要输入主机IP、用户名、密码即可访问成功,这样其实是不安全的,可能会通过一些手段获取到用户名密码导致数据被窃取。而ES、kafka等也是通过用户名/密码方式连接,…...

MySQL 的 super_read_only 和 read_only 参数
MySQL 的 super_read_only 和 read_only 参数 一、参数基本概念 1. read_only 参数 作用:控制普通用户是否只能读取数据影响范围:所有非SUPER权限的用户默认值:OFF(可读写) 2. super_read_only 参数 作用…...

低碳理念在道路工程中的应用-预制路面
一、引子 在上一篇文章里,给大家介绍了预制基层的应用,有人提出,既然基层能够预制,那么,道路面层能不能预制呢,有没有相关的研究成果和应用实例呢?答案是肯定的,在本篇文章中&#x…...
12-后端Web实战(登录认证)
在前面的课程中,我们已经实现了部门管理、员工管理的基本功能,但是大家会发现,我们并没有登录,就直接访问到了Tlias智能学习辅助系统的后台。 这是不安全的,所以我们今天的主题就是登录认证。最终要实现的效果是&#…...

TIDB创建索引失败 mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory.
TIDB创建索引失败:解决“mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory”问题 在使用 TIDB 数据库时,我们有时会遇到创建索引失败的问题。常见的错误信息为: mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directo…...

Redis 插入中文乱码键
Java 代码: Bean// 静态代理模式: Redis 客户端代理类增强public StringRedisTemplateProxy stringRedisTemplateProxy(RedisKeySerializer redisKeySerializer,StringRedisTemplate stringRedisTemplate,RedissonClient redissonClient) {stringRedisTemplate.setK…...

Mac OS 使用说明
Mac 的启动组合键 了解可通过在启动时按住一个或多个按键来访问的 Mac 功能和工具。 若要使用这些组合键中的任何一个,请在按下电源按钮以开启 Mac 后或在 Mac 开始重新启动后,立即按住相应按键。请一直按住,直至电脑出现对应的行为。 !!!上…...

4.2.2 Spark SQL 默认数据源
在本实战概述中,我们探讨了如何在 Spark SQL 中使用 Parquet 格式作为默认数据源。首先,我们了解了 Parquet 文件的存储特性,包括其二进制存储方式和内嵌的 Schema 信息。接着,通过一系列命令,我们演示了如何在 HDFS 上…...

234. Palindrome Linked List
目录 一、题目描述 方法一、使用栈 方法二、将链表全部结点值复制到数组,再用双指针法 方法三、递归法逆序遍历链表 方法四、快慢指针反转链表 一、题目描述 234. Palindrome Linked List 方法一、使用栈 需要遍历两次。时间复杂度O(n),空间复杂度…...

广州邮科高频开关电源:以创新科技赋能通信能源绿色未来
在数字化浪潮席卷全球的当下,通信网络作为信息社会的基石,其稳定运行对电源系统的可靠性、效率及智能化水平提出了更高要求。作为国内通信电源领域的领军企业,广州邮科凭借其自主研发的高频开关电源技术,以高效节能、智能管控、绿…...

day41 python图像识别任务
目录 一、数据预处理:为模型打下坚实基础 二、模型构建:多层感知机的实现 三、训练过程:迭代优化与性能评估 四、测试结果:模型性能的最终检验 五、总结与展望 在深度学习的旅程中,多层感知机(MLP&…...

无人机报警器探测模块技术解析!
一、运行方式 1. 频谱监测与信号识别 全频段扫描:模块实时扫描900MHz、1.5GHz、2.4GHz、5.8GHz等无人机常用频段,覆盖遥控、图传及GPS导航信号。 多路分集技术:采用多传感器阵列,通过信号加权合并提升信噪比,…...

Docker 替换宿主与容器的映射端口和文件路径
在使用 Docker 容器化应用程序时,经常需要将宿主机的端口和文件路径映射到容器中,以便在本地访问容器中的服务和数据。本文将详细介绍如何替换和配置 Docker 容器的端口和文件路径映射。 1. 端口映射 端口映射用于将宿主机的端口转发到容器中的端口&am…...

我的3种AI写作节奏搭配模型,适合不同类型写作者
—不用内耗地高效写完一篇内容,原来可以这样搭配AI ✍️ 开场:为什么要“搭配节奏”写作? 很多人以为用AI写作,就是丢一句提示词,然后“等它写完”。 但你有没有遇到这些情况: AI写得很快,学境…...