SQL查询——大厂面试真题
前言
本文总结了SQLite数据库的核心操作要点:1. 基础语法:SQL语句不区分大小写,多语句需用分号分隔,支持多种注释方式2. 表操作:包括创建表(定义主键、非空约束等)、插入/更新/删除数据、添加/修改/删除列3. 查询进阶:JOIN连接的四种方式(内/左/右/全连接)、UNION组合查询、子查询嵌套4. 性能优化:索引的创建与管理,视图的创建与应用5. 高级功能:分组排序(GROUP BY)、条件筛选(HAVING)、开窗函数等6. 实战示例:包含第N高数据查询、连续出现N次记录查询等典型场景解决方案
一、SQL 语法要点
SQL 语句不区分大小写 ,但是数据库表名、列名和值是否区分,依赖于具体的 DBMS 以及配置。例如:SELECT 与 select 、Select 是相同的。
多条 SQL 语句必须以分号(;)分隔 。
处理 SQL 语句时, 所有空格都被忽略 。SQL 语句可以写成一行,也可以分写为多行。
二、计算机处理顺序
select
from
where (列名=条件)
group by
order by 条件(按条件分组),聚合语句(函数)
- SQL 支持三种注释
## 注释1
-- 注释2
/* 注释3 */三、操作
1.创建表
create table 表名(
主键名 类型 primary key
第二列名 类型 (text) not null(不为空),
第三列名 类型 (text) not null(不为空),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 默认值为当前时间;
);
id是主键,代表每个用户的唯一标识。username和email是用户的基本信息,不能为空且邮箱唯一。created_at会自动记录每条记录创建的时间。
des ‘表1’
可以先看下表的情况。
2. 向 user 表插入数据
insert into 表1(字段1,字段2)
values
(1,2,3);
(1,3,4);
(2,4,5);
3.查询数据
4.更新数据
update 表1 set 修改的字段名 =要修改值 where 条件=‘ ’;
更新 Bob 的年龄:
UPDATE user SET age = 32 WHERE username = 'Bob'
5.删除数据
delect from 表名 where 字段=‘ ’
DELETE FROM user WHERE username = 'Charlie';6.删除所有数据(清空表):
DELETE FROM user;7.连接表
join的四种写法:
- inner join,取交集
- left join,右表中没有的数据用null填充
- right jion,左表中没有的数据用null填充
- full join,取并集

笛卡尔积:2个矩阵相乘,数据最多的表作为行数。
- 如果一个 JOIN 至少有一个公共字段并且它们之间存在关系,则该 JOIN 可以在两个或多个表上工作。
- 连接用于连接多个表,使用 JOIN 关键字,并且条件语句使用 ON 而不是 WHERE。
SELECT column_name(s)
FROM table1 INNER JOIN table2
ON table1.column_name = table2.column_name;
将玩家表和装备表合并,以下两种方法都可以。
select * from player(形成左表)
right join 右表
on 表1.字段名=表2.字段
select * from 左表,右表
where 表1.字段min = 表2.字段
SELECT customers.cust_id, orders.order_num
FROM customers RIGHT JOIN orders
ON customers.cust_id = orders.cust_id;select 表1.字段1,表1.字段2
from 表1 inner join 表2
条件:on 表1.字段1 = 表2.字段2
8.索引——提高查询效率
更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引。
创建:
create index 索引名称 on 表名(字段)
查询索引:
show index from 表名
删除索引
drop index 索引名称 on 表名
增加索引
alter table 表名 add index 索引名称 (需要添加索引的字段)
9.修改列
添加列
- ALTER TABLE userADD age int(3);
删除列
- ALTER TABLE userDROP COLUMN age;
修改列
- ALTER TABLE `user`MODIFY COLUMN age tinyint;
10.修改主键
添加主键
- ALTER TABLE userADD PRIMARY KEY (id);
删除主键
- ALTER TABLE userDROP PRIMARY KEY;
(二)视图(VIEW)
1.定义
视图是基于 SQL 语句的结果集的可视化的表。
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
2.作用
简化复杂的 SQL 操作,比如复杂的联结;
只使用实际表的一部分数据;
通过只给用户访问视图的权限,保证数据的安全性;
更改数据格式和表示。
3.创建视图
CREATE VIEW 视图名称(例如,top_10_user_view) AS
SELECT id, username
FROM user
WHERE id < 10;
4.删除视图
DROP VIEW top_10_user_view;
(三)组合(UNION)
1.定义
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 用于组合两个或多个 SELECT 查询的结果。其基本语法如下:
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;2.关键点:
-
列的数量和数据类型必须匹配:
-
每个
SELECT查询必须返回相同数量的列,并且对应列的数据类型必须兼容。 -
例如,如果第一个查询返回两个列(
INT和VARCHAR),第二个查询也必须返回两个列,且数据类型分别为INT和VARCHAR。
-
-
自动去除重复行:
-
默认情况下,
UNION会自动去除重复的行。如果你希望保留重复的行,可以使用UNION ALL。
-
-
列名和排序:
-
结果集中的列名将由第一个
SELECT查询中的列名决定。 -
如果需要对最终结果进行排序,可以在最后一个查询后使用
ORDER BY。
-
3.UNION 的示例
假设我们有两个表:Customers 和 Suppliers,它们的结构如下:
Customers 表
| cust_id | cust_name | cust_address |
|---|---|---|
| 1 | Alice | 123 Main St |
| 2 | Bob | 456 Elm St |
| 3 | Charlie | 789 Oak St |
Suppliers 表
| supp_id | supp_name | supp_address |
|---|---|---|
| 1 | Supplier A | 101 Pine St |
| 2 | Supplier B | 202 Maple St |
| 3 | Supplier C | 303 Birch St |
示例 1:
使用 UNION 合并两个表
假设我们想列出所有客户和供应商的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;查询结果:
| name | address |
|---|---|
| Alice | 123 Main St |
| Bob | 456 Elm St |
| Charlie | 789 Oak St |
| Supplier A | 101 Pine St |
| Supplier B | 202 Maple St |
| Supplier C | 303 Birch St |
UNION ALL
如果你希望保留重复的行,可以使用 UNION ALL。UNION ALL 不会自动去除重复行,而是将两个查询的结果直接合并。
示例 2:使用 UNION ALL
假设 Customers 表和 Suppliers 表中有重复的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION ALL
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;如果 Customers 和 Suppliers 表中有重复的行,UNION ALL 会将它们全部保留。
四、ORDER BY 和 UNION
1.定义
ORDER BY 可以在 UNION 查询的最后使用,对整个结果集进行排序。
示例 3:使用 ORDER BY
sql复制
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers
ORDER BY name;查询结果:
| name | address |
|---|---|
| Alice | 123 Main St |
| Bob | 456 Elm St |
| Charlie | 789 Oak St |
| Supplier A | 101 Pine St |
| Supplier B | 202 Maple St |
| Supplier C | 303 Birch St |
2.注意事项
-
列的数量和数据类型:
-
每个
SELECT查询必须返回相同数量的列,并且对应列的数据类型必须兼容。 -
如果列的数量或数据类型不匹配,SQL 会报错。
-
-
去除重复行:
-
默认情况下,
UNION会去除重复行。 -
如果需要保留重复行,使用
UNION ALL。
-
-
性能:
-
UNION默认会去除重复行,这可能会导致额外的性能开销,尤其是在处理大量数据时。 -
如果你确定数据中没有重复行,或者你希望保留重复行,建议使用
UNION ALL。
-
-
排序:
-
ORDER BY只能出现在最后一个查询中,用于对整个结果集进行排序。
-
示例 4:从同一个表中提取不同条件的数据
假设你想列出所有年龄大于20岁的客户和所有年龄小于20岁的客户:
SELECT cust_name, cust_age
FROM Customers
WHERE cust_age > 20
UNION
SELECT cust_name, cust_age
FROM Customers
WHERE cust_age < 20;示例 5:从不同表中提取数据
假设你想列出所有客户的名称和地址,以及所有供应商的名称和地址:
SELECT cust_name AS name, cust_address AS address
FROM Customers
UNION
SELECT supp_name AS name, supp_address AS address
FROM Suppliers;3.分组排序
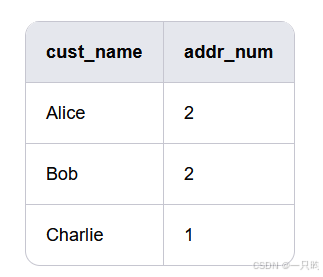
统计每个用户的地址数量

分组
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name;
分组后排序
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name
ORDER BY cust_name DESC;
HAVING
HAVING 用于对汇总的 GROUP BY 结果进行过滤。
HAVING 要求存在一个 GROUP BY 子句。
WHERE 和 HAVING 可以在相同的查询中。
开窗函数+over

三、子查询
1.定义
嵌套在较大查询中的 SQL 查询。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
2.用法
子查询可以嵌套在 SELECT,INSERT,UPDATE 或 DELETE 语句内或另一个子查询中。
子查询通常会在另一个 SELECT 语句的 WHERE 子句中添加。
您可以使用比较运算符,如 >,<,或 =。比较运算符也可以是多行运算符,如 IN,ANY 或 ALL。
子查询必须被圆括号 () 括起来。
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。
————————————————
原文链接:https://blog.csdn.net/heshihu2019/article/details/132864791
3.limit取数据
取第2条数据
- limit 1 ,1 跳过1条取1条
- limit 1 offset 1 从第1条(不包括)开始取出第2条。
5.判断null-ifnull函数
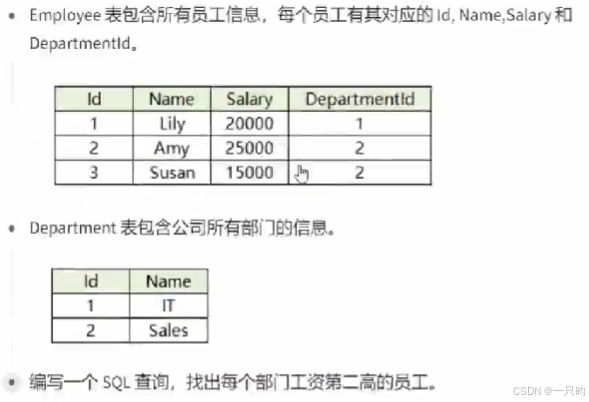
SELECTe.Name AS EmployeeName,e.Salary,d.Name AS DepartmentName
FROMEmployee e
JOINDepartment d ON e.DepartmentId = d.Id
WHEREe.Salary = (SELECTDISTINCT SalaryFROMEmployeeWHEREDepartmentId = e.DepartmentIdORDER BYSalary DESCLIMIT 1 OFFSET 1);三、子查询
子查询是 嵌套在较大查询中的 SQL 查询。子查询也称为内部查询或内部选择,而包含子查询的语句也称为外部查询或外部选择。
子查询可以嵌套在 SELECT,INSERT,UPDATE 或 DELETE 语句内或另一个子查询中。
子查询通常会在另一个 SELECT 语句的 WHERE 子句中添加。
- 使用比较运算符,如 >,<,或 =。
- 比较运算符也可以是多行运算符,如 IN,ANY 或 ALL。
- 子查询必须被圆括号 () 括起来。
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。
SELECT 语句中的 WHERE 子句
SELECT * FROM Customers
WHERE cust_name = 'Kids Place';
UPDATE 语句中的 WHERE 子句
UPDATE Customers
SET cust_name = 'Jack Jones'
WHERE cust_name = 'Kids Place';
DELETE 语句中的 WHERE 子句
DELETE FROM Customers
WHERE cust_name = 'Kids Place';
IN 和 BETWEEN
IN 操作符在 WHERE 子句中使用,作用是在指定的几个特定值中任选一个值。
BETWEEN 操作符在 WHERE 子句中使用,作用是选取介于某个范围内的值。
IN 示例
SELECT *
FROM products
WHERE vend_id IN ('DLL01', 'BRS01');
BETWEEN 示例
SELECT *
FROM products
WHERE prod_price BETWEEN 3 AND 5;(3-5)
SELECT *
FROM (SELECT column_name FROM table_name WHERE condition) AS subquery
JOIN table_name ON subquery.column_name = table_name.column_name;
这个查询将子查询的结果作为一个临时表,然后与 table_name 进行连接。
(一)真题
1.查询不在表里的数据
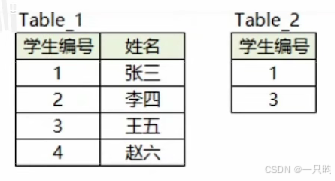
select table_1.姓名 from table_1 a left.jion table_2on table_1.学生编号=table_2.学生编号where table_2.学生编号 is null;2.查找第n高的数据
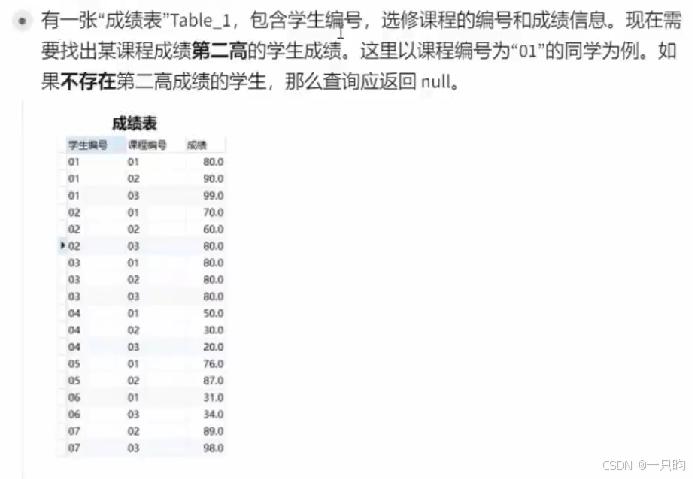
- 考虑:去重distanct;
- 如果不存在,返回null. ifnull(null,返回值)
select 学生编号 from table_1ifnull(select distant 成绩from table_1where 课程编号 ="01"order by 成绩,desclimit 1,1/limit 1 offset 1),null)as "01课程第2高";3.分组排序
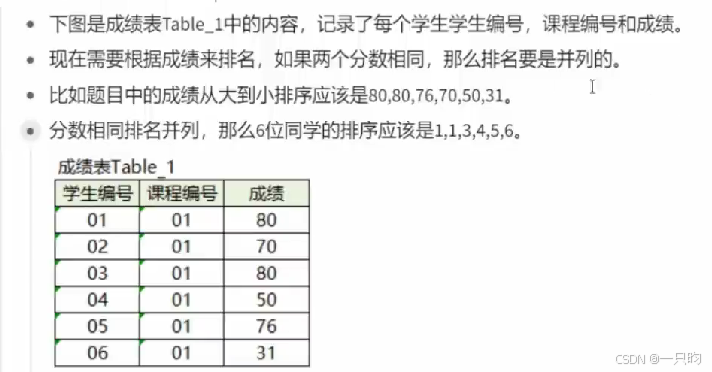
rank开窗函数
PARTITION BY:指定按照哪个字段进行分组。ORDER BY:指定按照哪个字段进行排序。
select *,rank() over ( order by 成绩,desc) as “排名”from table_1;4.连续出现N类

SELECT column1, column2, ...
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;
GROUP BY 子句在 SQL 中用于将结果集的行分组,以便可以对每个组执行聚合函数(如 COUNT()、SUM()、AVG()、MAX()、MIN() 等)。这通常用于生成汇总或摘要数据。
select 成绩fromselect(成绩,row number()over (selectfromLeft joinon table1.coloum=table2.coloumwhere分组:group by table.id筛选分组后的结果:having count(distinct 字段)>30;(二)基本语法
SELECT column1, column2, ...
FROM table_name
WHERE condition
GROUP BY column1, column2, ...;
column1, column2, ...是你想要分组的列。
table_name是查询的表。
condition是可选的,用于筛选记录。
(三)使用场景
-
生成汇总数据:当你想要对某个列进行汇总统计时,比如计算每个部门的员工数量。
-
与聚合函数一起使用:
GROUP BY通常与聚合函数一起使用,以计算每个组的统计数据。
示例 1:计算每个部门的员工数量
假设有一个 employees 表,包含 department_id 和 employee_name 列。
SELECT department_id, COUNT(employee_name) AS num_employees
FROM employees
GROUP BY department_id;这个查询将返回每个部门的员工数量。
示例 2:计算每个部门的平均工资
假设 employees 表还包含 salary 列。
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id;这个查询将返回每个部门的平均工资。
示例 3:使用多列进行分组
SELECT department_id, job_title, COUNT(employee_name) AS num_employees
FROM employees
GROUP BY department_id, job_title;这个查询将返回每个部门中每个职位的员工数量。
3.注意事项
-
列的选择:在
SELECT列表中,所有非聚合列都必须包含在GROUP BY子句中。如果你在SELECT列表中包含了非聚合列,那么这些列也必须出现在GROUP BY子句中。 -
聚合函数:
GROUP BY通常与聚合函数一起使用,以计算每个组的统计数据。 -
排序:
ORDER BY子句通常用于对GROUP BY的结果进行排序,但排序的列可以是GROUP BY子句中的列,也可以是聚合函数的结果。 -
空值:在分组时,如果分组列中有空值,那么这些空值将被单独分为一个组。
GROUP BY与HAVING的区别
WHERE子句用于在分组之前筛选行。
HAVING子句用于在分组之后筛选组。HAVING通常与聚合函数一起使用,用于筛选满足特定条件的组。
示例 4:使用 HAVING 筛选组
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 50000;这个查询将返回平均工资超过 50000 的部门。
相关文章:
SQL查询——大厂面试真题
前言 本文总结了SQLite数据库的核心操作要点:1. 基础语法:SQL语句不区分大小写,多语句需用分号分隔,支持多种注释方式2. 表操作:包括创建表(定义主键、非空约束等)、插入/更新/删除数据、添加/…...
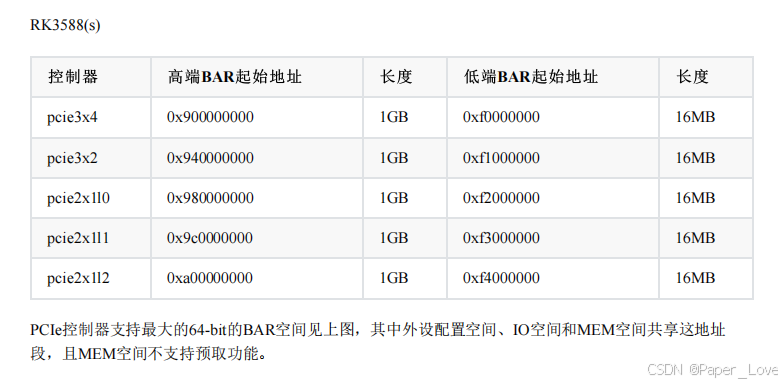
Linux-pcie ranges介绍
参考链接:https://elinux.org/Device_Tree_Usage#PCI_Host_Bridge pcie bar高低端BAR起始地址介绍 pcie设备树节点 / {compatible "rockchip,rk3588";interrupt-parent <&gic>;#address-cells <2>;#size-cells <2>;pcie3x4: p…...
⭐ Unity AVProVideo插件自带播放器 脚本重构 实现视频激活重置功能
一、功能概述 本笔记记录直接修改插件自带的场景播放其中 原始的 MediaPlayerUI 脚本,实现激活时自动重置播放器的功能。 我用的插件版本是 AVPro Video - Ultra Edition 2.7.3 修改后的脚本将具备以下特性: 激活 GameObject 时自动重置播放位置到开头 可配置是否在重置后自…...

互联网大厂Java求职面试:云原生微服务架构设计与AI大模型集成实战
互联网大厂Java求职面试:云原生微服务架构设计与AI大模型集成实战 面试场景设定 人物设定: 李明(技术总监):拥有15年分布式系统架构经验,主导过多个亿级用户系统的重构,对云原生和AI融合有深…...

详解K8s API Server 如何处理请求的?
详解K8s API Server 如何处理请求的? Kubernetes(K8s)是一个强大的容器编排系统,而API Server(kube-apiserver) 是它的核心组件之一。 如果把 K8s 比作一个国家,API Server 就是政府机构,所有资源的创建、修改、删除都要经过它审批! 🎯 API Server 的作用 📌 A…...

微调数据处理
1. 数据爬取 我们将爬取的1G文件都保存到all_m_files目录下 查看原始数据文件数量: find /root/all_m_files -type f | wc -l 2. 数据预处理 仅保留UTF-8 格式文件,且所有保留的代码文件长度必须大于20行 import os import pandas as pddef try_read…...

✨1.1.1 按位与运算替代求余运算优化场景
在计算机编程中,使用按位与运算(&)替代求余运算(%)可以提高效率的特殊场景是:当除数是 2 的整数次幂(即 ( b 2^n ),其中 ( n ) 为自然数)时。例如,( b …...

解决开发者技能差距:AI 在提升效率与技能培养中的作用
企业在开发者人才方面正面临双重挑战。一方面,IDC 预测,到2025年,全球全职开发者将短缺400万人;另一方面,一些行业巨头已暂停开发者招聘,转而倚重人工智能(AI)来满足开发需求。这不禁…...

XCTF-web-easyphp
解析 第一个条件( k e y 1 ): i s s e t ( key1):isset( key1):isset(a) && intval(KaTeX parse error: Expected EOF, got & at position 14: a) > 6000000 &̲& strl…...

Transformer 通关秘籍11:Word2Vec 及工具的使用
将文字文本转换为词向量(word embedding)的过程中,一个非常著名的算法模型应该就是 Word2Vec 了。 相信大家或多或少都听说过,本节就来简单介绍一下 Word2Vec 。 什么是 Word2Vec ? Word2Vec 可以非常有效的创建词嵌入向量&…...
【DAY34】GPU训练及类的call方法
内容来自浙大疏锦行python打卡训练营 浙大疏锦行 知识点: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前…...
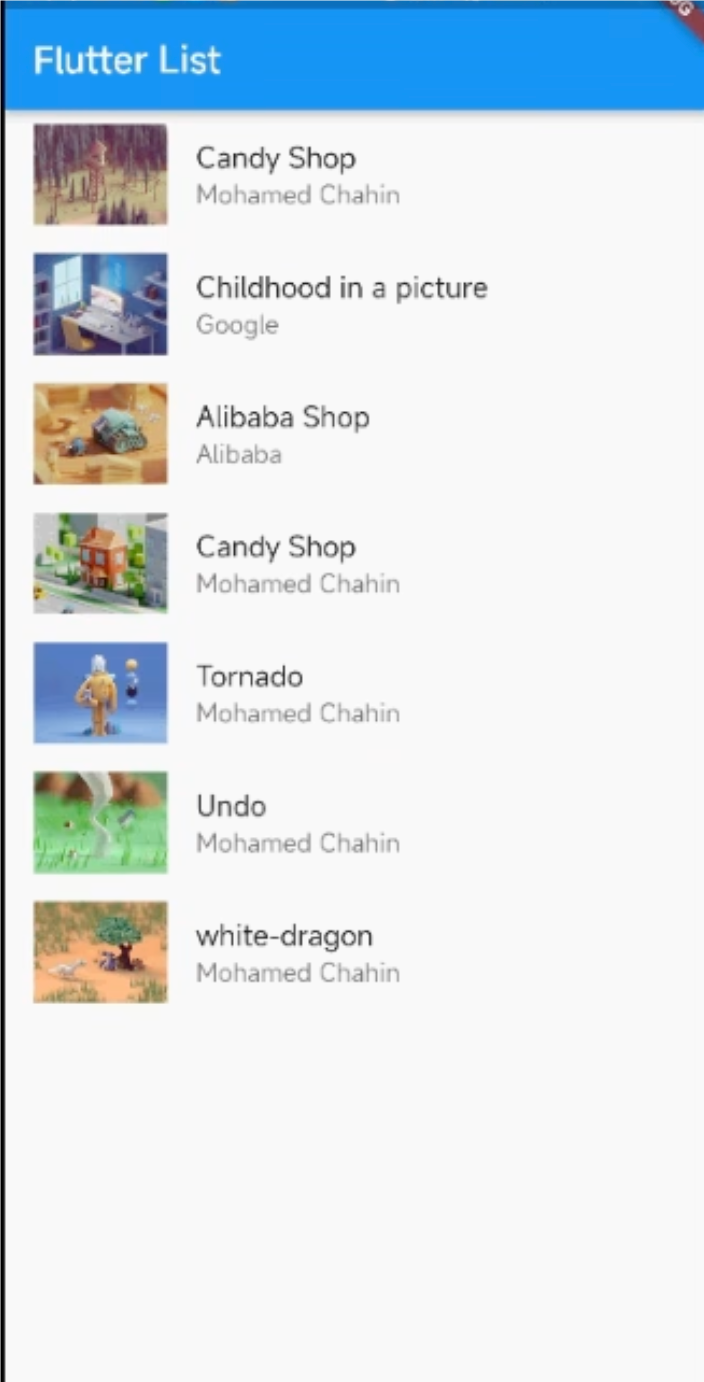
Flutte ListView 列表组件
目录 1、垂直列表 1.1 实现用户中心的垂直列表 2、垂直图文列表 2.1 动态配置列表 2.2 for循环生成一个动态列表 2.3 ListView.builder配置列表 列表布局是我们项目开发中最常用的一种布局方式。Flutter中我们可以通过ListView来定义列表项,支持垂直和水平方向展示…...
muduo库的初步认识和基本使用,创建一个简单查询单词服务系统
小编在学习完muduo库之后,觉得对于初学者,muduo库还是有点不好理解,所以在此,小编来告诉大家muduo库的初步认识和基本使用,让初学者也可以更快的上手和使用muduo库。 Muduo由陈硕大佬开发,是⼀个基于 非阻塞…...

电脑如何保养才能用得更久
在这个数字化的时代,电脑已经成为了我们生活和工作中不可或缺的伙伴。无论是处理工作文档、追剧娱乐,还是进行创意设计,电脑都发挥着至关重要的作用。那么,如何让我们的电脑“健康长寿”,陪伴我们更久呢?今…...

Oracle的NVL函数
Oracle的NVL函数是一个常用的空值处理函数,主要用于在查询结果中将NULL值替换为指定的默认值。以下是关于NVL函数的详细说明: 基本语法 NVL(expr1, expr2) 如果expr1为NULL,则返回expr2如果expr1不为NULL,则返回expr1本身 …...
【HTML/CSS面经】
HTML/CSS面经 HTML1. script标签中的async和defer的区别2. H5新特性(1 标签语义化(2 表单功能增强(3 音频和视频标签(4 canvas和svg绘画(5 地理位置获取(6 元素拖动API(7 Web Worker(…...
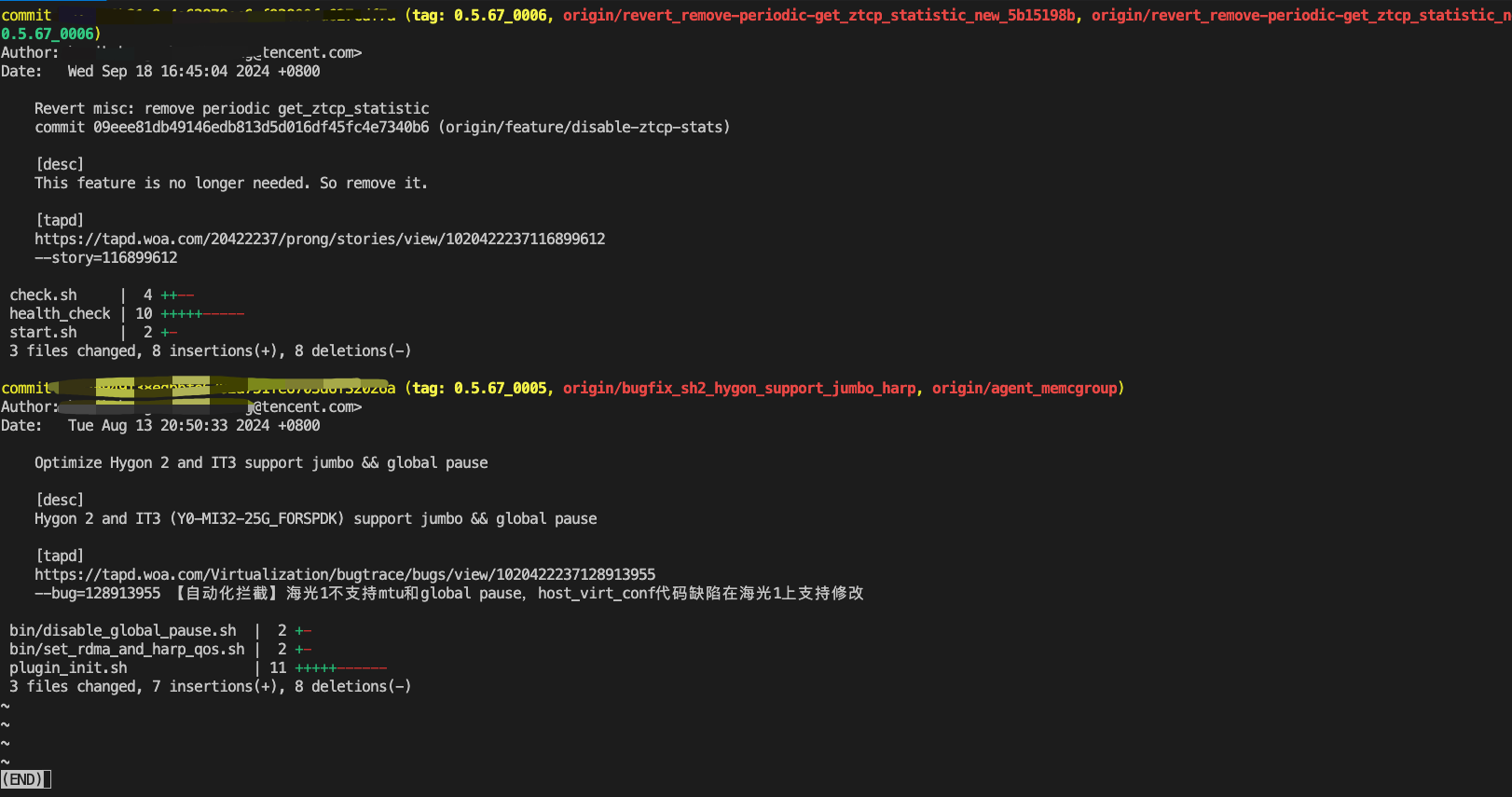
git查看commit属于那个tag
1. 快速确认commit原始分支及合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 查看commit合入tag # git describe 213b4b3bbef2771f7a1b8166f6e6989442ca67c8 --all 查看commit原始分支 2.查看分支与master关系 # git show --all 0.5.67_0006 --stat 以缩…...

如何从ISO镜像直接制作Docker容器基础镜像
引言 这段最值得总结的经验知识,就是如何在ISO镜像的基础上,直接做出docker base image,无需联网! 特别地,对于一些老旧OS系统,都能依此做出docker base image! 例如,某些老旧系统,CentOS 6,…...
)
网站缓存入门与实战:浏览器与Nginx/Apache服务器端缓存,让网站速度起飞!(2025)
更多服务器知识,尽在hostol.com 嘿,各位站长和网站管理员朋友们!咱们精心打造的网站,内容再好,设计再炫,如果用户打开它的时候,加载速度慢得像“老牛拉破车”,那体验可就大打折扣了…...
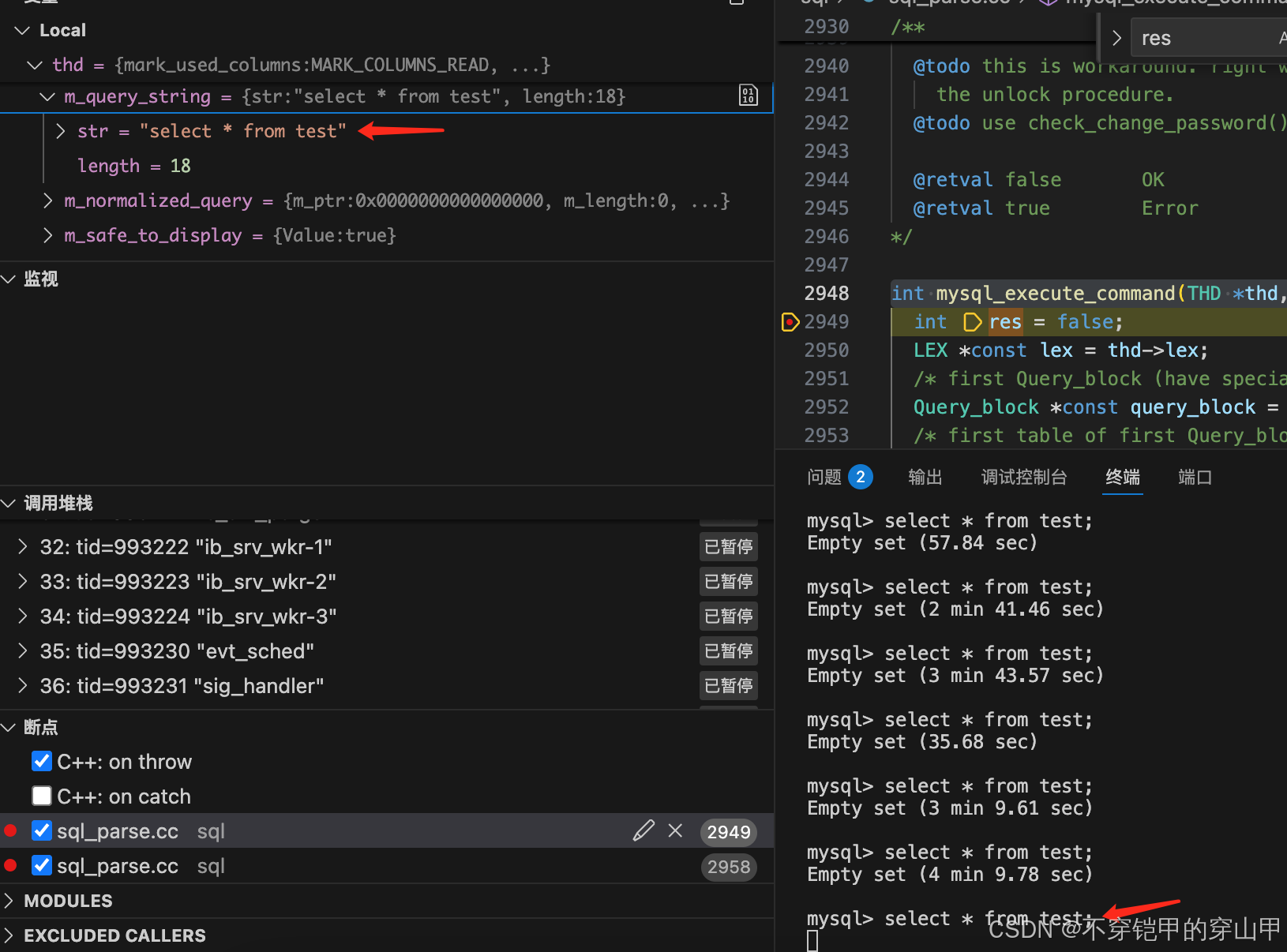
mysql-mysql源码本地调试
前言 先进行mysql源码本地编译:mysql源码本地编译 1.本地调试 这里以macbook为例 1.使用vscode打开mysql源码 2.创建basedir目录、数据目录、配置文件目录、配置文件 cd /Users/test/ mkdir mysqldir //创建数据目录和配置目录 cd mysqldir mkdir conf data …...
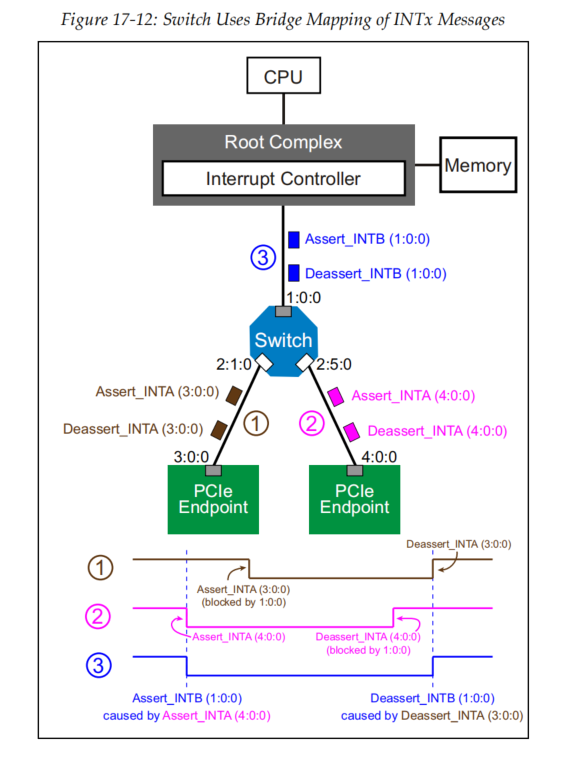
PCIe— Legacy PCI
Legacy Model 该器件通过将其引脚置位到控制器来生成中断。 在较旧的系统中,这个控制 器通常是Intel 8259 PIC,有15个IRQ输入和一个INTR输出。 然后,PIC将断 言INTR以通知CPU一个或多个中断正在挂起。 一旦CPU检测到INTR的断言…...
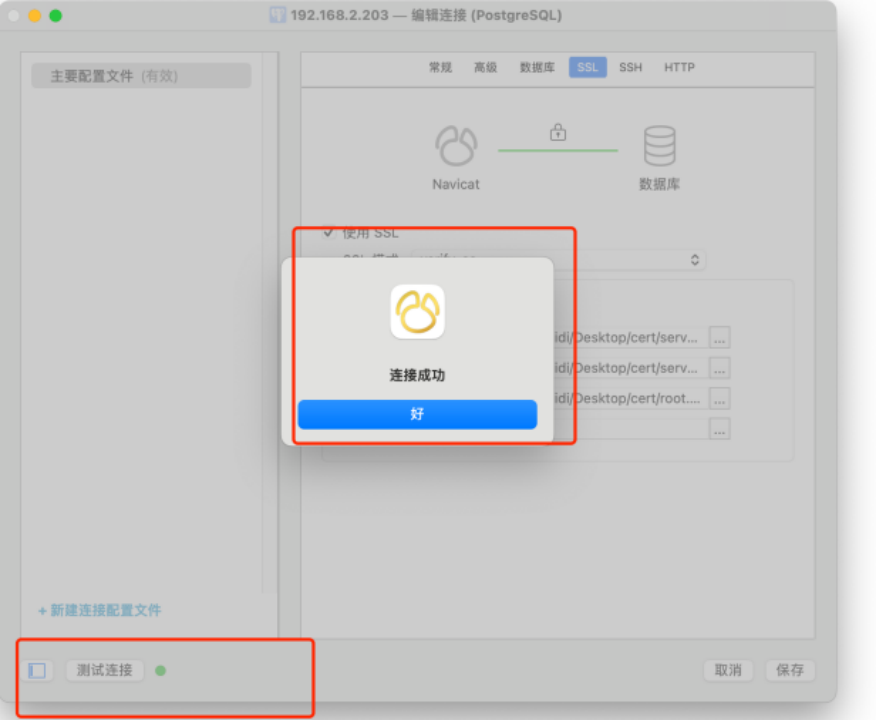
PostgreSQL数据库配置SSL操作说明书
背景: 因为postgresql或者mysql目前通过docker安装,只需要输入主机IP、用户名、密码即可访问成功,这样其实是不安全的,可能会通过一些手段获取到用户名密码导致数据被窃取。而ES、kafka等也是通过用户名/密码方式连接,…...

MySQL 的 super_read_only 和 read_only 参数
MySQL 的 super_read_only 和 read_only 参数 一、参数基本概念 1. read_only 参数 作用:控制普通用户是否只能读取数据影响范围:所有非SUPER权限的用户默认值:OFF(可读写) 2. super_read_only 参数 作用…...

低碳理念在道路工程中的应用-预制路面
一、引子 在上一篇文章里,给大家介绍了预制基层的应用,有人提出,既然基层能够预制,那么,道路面层能不能预制呢,有没有相关的研究成果和应用实例呢?答案是肯定的,在本篇文章中&#x…...
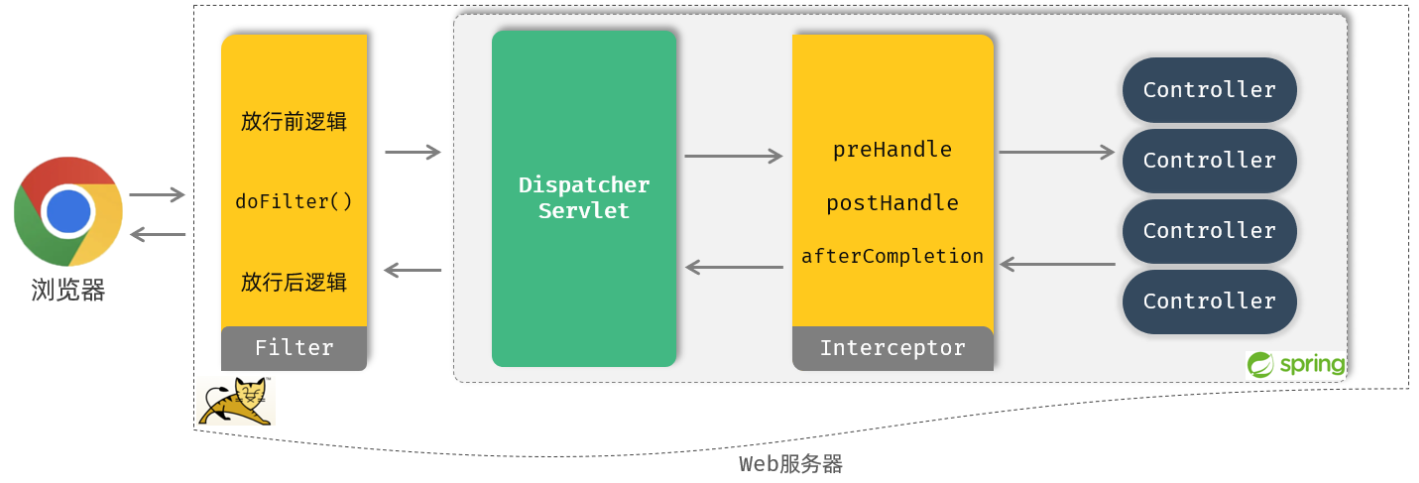
12-后端Web实战(登录认证)
在前面的课程中,我们已经实现了部门管理、员工管理的基本功能,但是大家会发现,我们并没有登录,就直接访问到了Tlias智能学习辅助系统的后台。 这是不安全的,所以我们今天的主题就是登录认证。最终要实现的效果是&#…...

TIDB创建索引失败 mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory.
TIDB创建索引失败:解决“mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directory”问题 在使用 TIDB 数据库时,我们有时会遇到创建索引失败的问题。常见的错误信息为: mkdir /tmp/tidb/tmp_ddl-4000/1370: no such file or directo…...

Redis 插入中文乱码键
Java 代码: Bean// 静态代理模式: Redis 客户端代理类增强public StringRedisTemplateProxy stringRedisTemplateProxy(RedisKeySerializer redisKeySerializer,StringRedisTemplate stringRedisTemplate,RedissonClient redissonClient) {stringRedisTemplate.setK…...

Mac OS 使用说明
Mac 的启动组合键 了解可通过在启动时按住一个或多个按键来访问的 Mac 功能和工具。 若要使用这些组合键中的任何一个,请在按下电源按钮以开启 Mac 后或在 Mac 开始重新启动后,立即按住相应按键。请一直按住,直至电脑出现对应的行为。 !!!上…...

4.2.2 Spark SQL 默认数据源
在本实战概述中,我们探讨了如何在 Spark SQL 中使用 Parquet 格式作为默认数据源。首先,我们了解了 Parquet 文件的存储特性,包括其二进制存储方式和内嵌的 Schema 信息。接着,通过一系列命令,我们演示了如何在 HDFS 上…...

234. Palindrome Linked List
目录 一、题目描述 方法一、使用栈 方法二、将链表全部结点值复制到数组,再用双指针法 方法三、递归法逆序遍历链表 方法四、快慢指针反转链表 一、题目描述 234. Palindrome Linked List 方法一、使用栈 需要遍历两次。时间复杂度O(n),空间复杂度…...