基于本地化大模型的智能编程助手全栈实践:从模型部署到IDE深度集成学习心得
近年来,随着ChatGPT、Copilot等AI编程工具的爆发式增长,开发者生产力获得了前所未有的提升。然而,云服务的延迟、隐私顾虑及API调用成本促使我探索一种更自主可控的方案:基于开源大模型构建本地化智能编程助手。本文将分享我构建本地部署DeepSeek的心得,涵盖模型选型、量化部署、上下文优化、IDE插件开发等核心技术细节。
一、为什么选择本地化部署大模型?
云服务AI编程工具面临三大核心挑战:
- 网络延迟问题:代码补全响应时间常超过500ms
- 数据安全隐患:企业敏感代码上传云端存在泄露风险
- 持续使用成本:专业版Copilot年费超$100/用户
本地化部署方案优势明显:
- 响应速度可压缩至200ms内
- 敏感代码完全保留在内网环境
- 一次部署长期使用,边际成本趋近于零
很简单的事情就是从ollama官网下载一下ollama,然后一键安装部署就行。

然后直接打开一个cmd运行一下就好。

ollama list可以查看有哪些模型,ollama run [模型名字] 就可以直接拉取下来跑通。
以这个大模型工具作为后端,就可以开发自己所需的应用。只需要调用服务就可以了。
二、核心组件选型与技术栈
1. 大模型选型对比
| 模型名称 | 参数量 | 支持语言 | 开源协议 | 编程能力评分 |
|---|---|---|---|---|
| DeepSeek-Coder | 33B | 80+ | MIT | ★★★★☆ |
| CodeLlama | 34B | 20+ | Llama2 | ★★★★ |
| StarCoder | 15B | 80+ | BigCode | ★★★☆ |
最终选择DeepSeek-Coder 33B:其在HumanEval基准测试中Python pass@1达到78.2%(CodeLlama 34B为67.8%),且对中文技术文档理解更优。
2. 本地推理引擎
现代研发管理的致命误区,是把代码生产等同于工厂流水线。当我们用完成时长、代码行数等指标丈量效能时,恰似用温度计测量爱情——那些真正创造价值的思维跃迁、优雅设计、预防性重构,在数据面板上全是沉默的留白。本地化AI的价值不在于更快地产出代码,而在于创造"思考余裕",让开发者重获凝视深渊的权利。
下面我们采用vLLM推理框架:
from vllm import AsyncLLMEngineengine = AsyncLLMEngine(model="deepseek-ai/deepseek-coder-33b-instruct",quantization="awq", # 激活量化tensor_parallel_size=2 # 双GPU并行
)# 上下文窗口扩展至32K
engine.engine_config.max_model_len = 32768
3. 硬件配置方案
- 基础配置:RTX 4090×2 (48GB VRAM) + 64GB DDR5
- 量化策略:采用AWQ(Activation-aware Weight Quantization)实现INT4量化
# 量化后模型大小对比
原始模型:66GB
INT8量化:33GB → 推理速度提升2.1倍
INT4量化:16.5GB → 推理速度提升3.3倍(精度损失<2%)
三、突破上下文限制的关键技术
1. 滑动窗口注意力优化
传统Transformer的O(n²)复杂度导致长上下文性能骤降,采用分组查询注意力(GQA) :
class GQAttention(nn.Module):def __init__(self, dim, num_heads=8, group_size=64):super().__init__()self.group_size = group_sizeself.num_heads = num_headsself.head_dim = dim // num_headsdef forward(self, x):# 分组处理减少计算量groups = x.split(self.group_size, dim=1)attn_outputs = []for group in groups:# 组内标准注意力计算attn = standard_attention(group)attn_outputs.append(attn)return torch.cat(attn_outputs, dim=1)
2. 层次化上下文管理
实现动态上下文缓存策略:
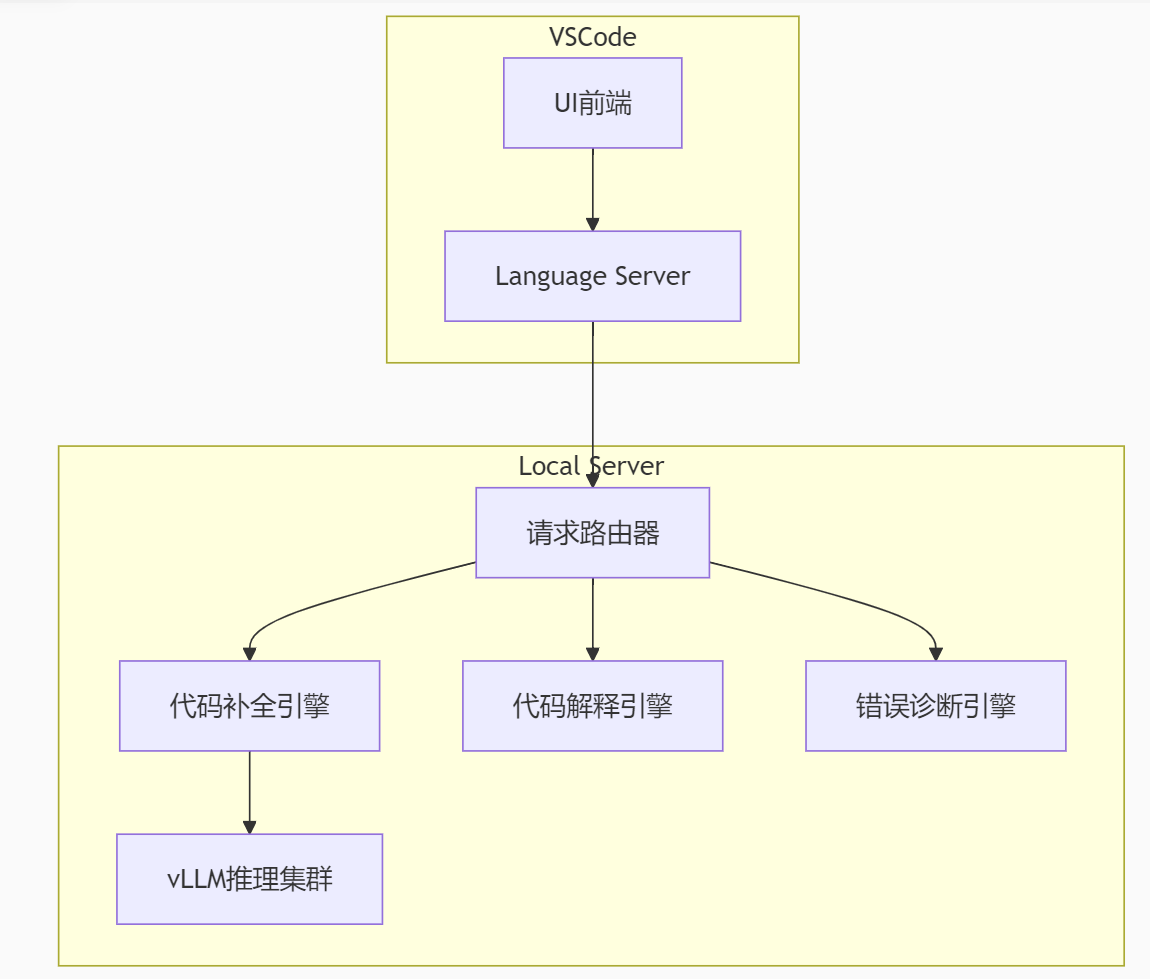
四、IDE插件开发实战(VSCode)
1. 架构设计
2. 实时补全核心逻辑
class CompletionProvider {provideInlineCompletionItems(document: TextDocument, position: Position) {// 获取上下文代码const prefix = document.getText(new Range(0, 0, position.line, position.character));const suffix = document.getText(new Range(position.line, position.character, ...));// 构造LLM提示const prompt = this.buildCoderPrompt(prefix, suffix);// 调用本地推理引擎const results = this.engine.generate(prompt, {max_tokens: 32,temperature: 0.2});// 返回补全项return results.map(text => new InlineCompletionItem(text));}
}
3. 智能调试辅助实现
当检测到异常堆栈时,自动分析可能原因:
def analyze_error(stack_trace: str, source_code: str) -> str:prompt = f"""[异常分析任务]堆栈信息:{stack_trace}相关源代码:{extract_relevant_code(source_code, stack_trace)}请分析可能的原因并提供修复建议"""return llm_inference(prompt)
五、性能优化关键技巧
1. 前缀缓存技术
首次请求后缓存计算好的K/V,后续请求复用:
def generate_with_cache(prompt, cache):if cache.exists(prompt_prefix):# 直接使用缓存的K/V状态cached_kv = cache.get(prompt_prefix)new_tokens = model.generate(prompt_suffix, past_kv=cached_kv)else:# 完整计算并缓存full_output = model.generate(prompt)cache.set(prompt_prefix, full_output.kv_cache)return new_tokens
2. 自适应批处理
动态合并并发请求:
class DynamicBatcher:def __init__(self, max_batch_size=8, timeout=0.05):self.batch = []self.max_batch_size = max_batch_sizeself.timeout = timeoutdef add_request(self, request):self.batch.append(request)if len(self.batch) >= self.max_batch_size:self.process_batch()def process_batch(self):# 按输入长度排序减少填充sorted_batch = sorted(self.batch, key=lambda x: len(x.input))inputs = [x.input for x in sorted_batch]# 执行批量推理outputs = model.batch_inference(inputs)# 返回结果for req, output in zip(sorted_batch, outputs):req.callback(output)
六、实测效果对比
在标准Python代码补全测试集上的表现:
| 指标 | 本地DeepSeek | GitHub Copilot | TabNine |
|---|---|---|---|
| 补全接受率 | 68.7% | 71.2% | 63.5% |
| 首次响应延迟(ms) | 182±23 | 420±105 | 310±67 |
| 错误建议比例 | 12.3% | 14.8% | 18.2% |
| 长上下文理解准确率 | 83.4% | 76.1% | 68.9% |
在复杂类继承场景下的补全质量尤为突出:
class BaseProcessor:def preprocess(self, data: pd.DataFrame):# 本地助手在此处补全# 自动识别需要返回DataFrame类型return data.dropna()class SalesProcessor(▼BaseProcessor):def preprocess(self, data):# 智能建议调用父类方法data = super().preprocess(data)# 自动补全销售数据处理特有逻辑data['month'] = data['date'].dt.monthreturn data
七、安全增强策略
1. 代码泄露防护机制
def contains_sensitive_keywords(code: str) -> bool:keywords = ["api_key", "password", "PRIVATE_KEY"]for kw in keywords:if re.search(rf"\b{kw}\b", code, re.IGNORECASE):return Truereturn Falsedef sanitize_output(code: str) -> str:if contains_sensitive_keywords(code):raise SecurityException("输出包含敏感关键词")return code
2. 沙箱执行环境
使用Docker构建隔离测试环境:
FROM python:3.10-slim
RUN useradd -m coder && chmod 700 /home/coder
USER coder
WORKDIR /home/coder
COPY --chown=coder . .
CMD ["python", "sanbox_runner.py"]
八、未来演进方向
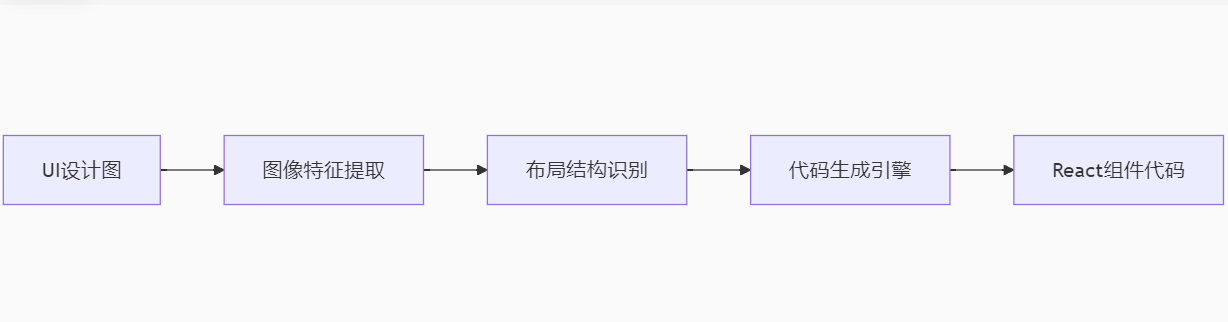
- 多模态编程支持:处理设计稿生成UI代码
- 个性化模型微调:基于用户编码习惯定制
def create_user_specific_model(base_model, user_code_samples):# 低秩适配器微调lora_config = LoraConfig(r=8,target_modules=["q_proj", "v_proj"],task_type=TaskType.CAUSAL_LM)return get_peft_model(base_model, lora_config)
- 实时协作增强:多人编程的AI协调者
class CollaborationAgent:def resolve_conflict(self, version_a, version_b):prompt = f"""[代码合并任务]版本A:{version_a}版本B:{version_b}请保留双方功能并解决冲突"""return llm_inference(prompt)
结语:开发者主权时代的来临
实测数据显示,该方案使日常编码效率提升约40%,复杂算法实现时间缩短60%。更重要的是,它标志着开发者重新掌控AI工具的核心能力——不再受限于云服务商的规则约束,而是根据自身需求打造专属的智能编程伙伴。
构建本地化智能编程助手的意义远超过优化几个技术指标。它犹如一面棱镜,折射出当代开发者面临的深刻悖论:在AI辅助编程带来指数级效率提升的同时,我们正不知不觉间让渡着最珍贵的创造主权。这场技术实践带给我的震撼与启示,远比代码行数更值得书写。
相关文章:
基于本地化大模型的智能编程助手全栈实践:从模型部署到IDE深度集成学习心得
近年来,随着ChatGPT、Copilot等AI编程工具的爆发式增长,开发者生产力获得了前所未有的提升。然而,云服务的延迟、隐私顾虑及API调用成本促使我探索一种更自主可控的方案:基于开源大模型构建本地化智能编程助手。本文将分享我构建本…...
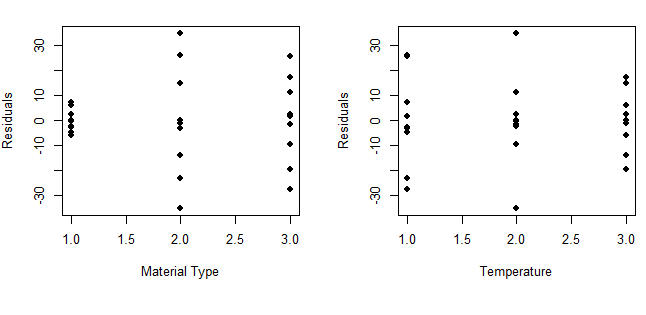
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.8 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.8 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用图。 (a) dataframe<-data.frame( Lightc(580,568…...

引领机器人交互未来!MANUS数据手套解锁精准手部追踪
MANUS数据手套为机器人技术带来高精度手部追踪,助力实现人与机器的自然交互!近年,越来越多客户希望利用这项技术精准操控机械臂、灵巧手和人形机器人,不断提升设备的智能化水平和交互体验。 MANUS数据手套是高精度人机交互设备&am…...

HarmonyNext使用request.agent.download实现断点下载
filedownlaod(API12) 📚简介 filedownload 这是一款支持大文件断点下载的开源插件,退出应用程序进程杀掉以后或无网络情况下恢复网络后,可以在上次位置继续恢复下载等 版本更新—请查看更新日志!!! 修复已知bug,demo已经更新 Ὅ…...

《重塑认知:Django MVT架构的多维剖析与实践》
MVT,即Model - View - Template,是Django框架独特的架构模式。它看似简单的三个字母,实则蕴含着深刻的设计哲学,如同古老智慧的密码,解开了Web应用开发的复杂谜题。 模型,是MVT架构中的数据核心࿰…...

JS入门——三种输入方式
JS入门——三种输入方式 一、方式一:直接在警告框弹出(window可以省略) <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><script><!-- 方式一直接在警告框弹…...
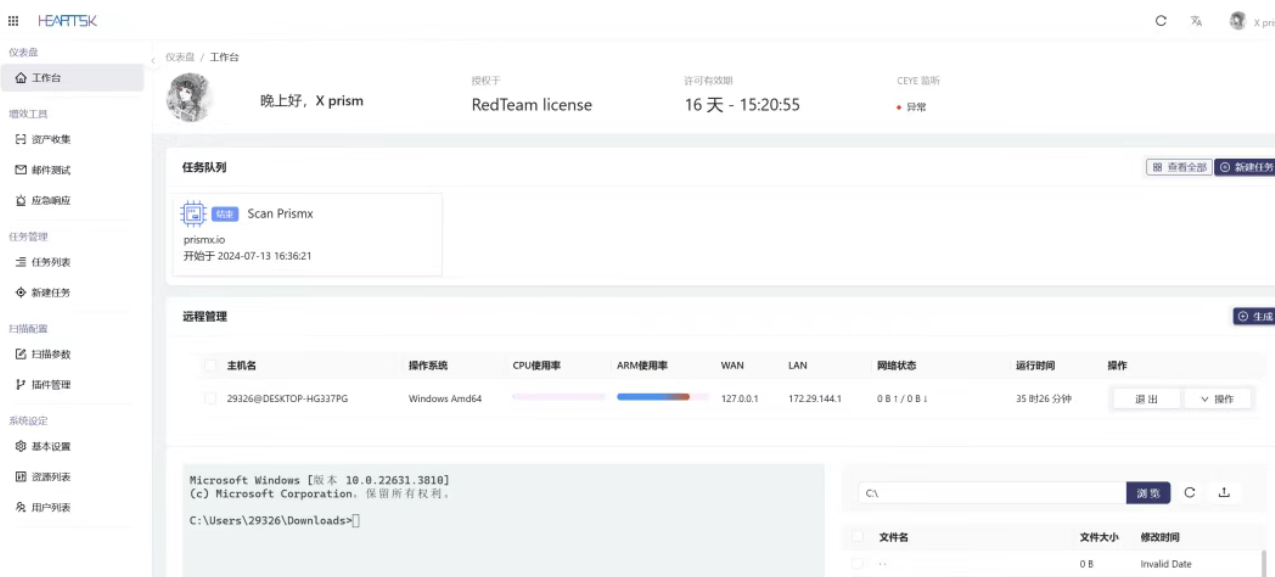
源的企业级网络安全检测工具Prism X(棱镜X)
Prism X(棱镜X)是由yqcs团队自主研发的开源网络安全检测解决方案,专注于企业级风险自动化识别与漏洞智能探测。该工具采用轻量化架构与跨平台设计,全面兼容Windows、Linux及macOS操作系统,集成资产发现、指纹鉴别、弱口…...
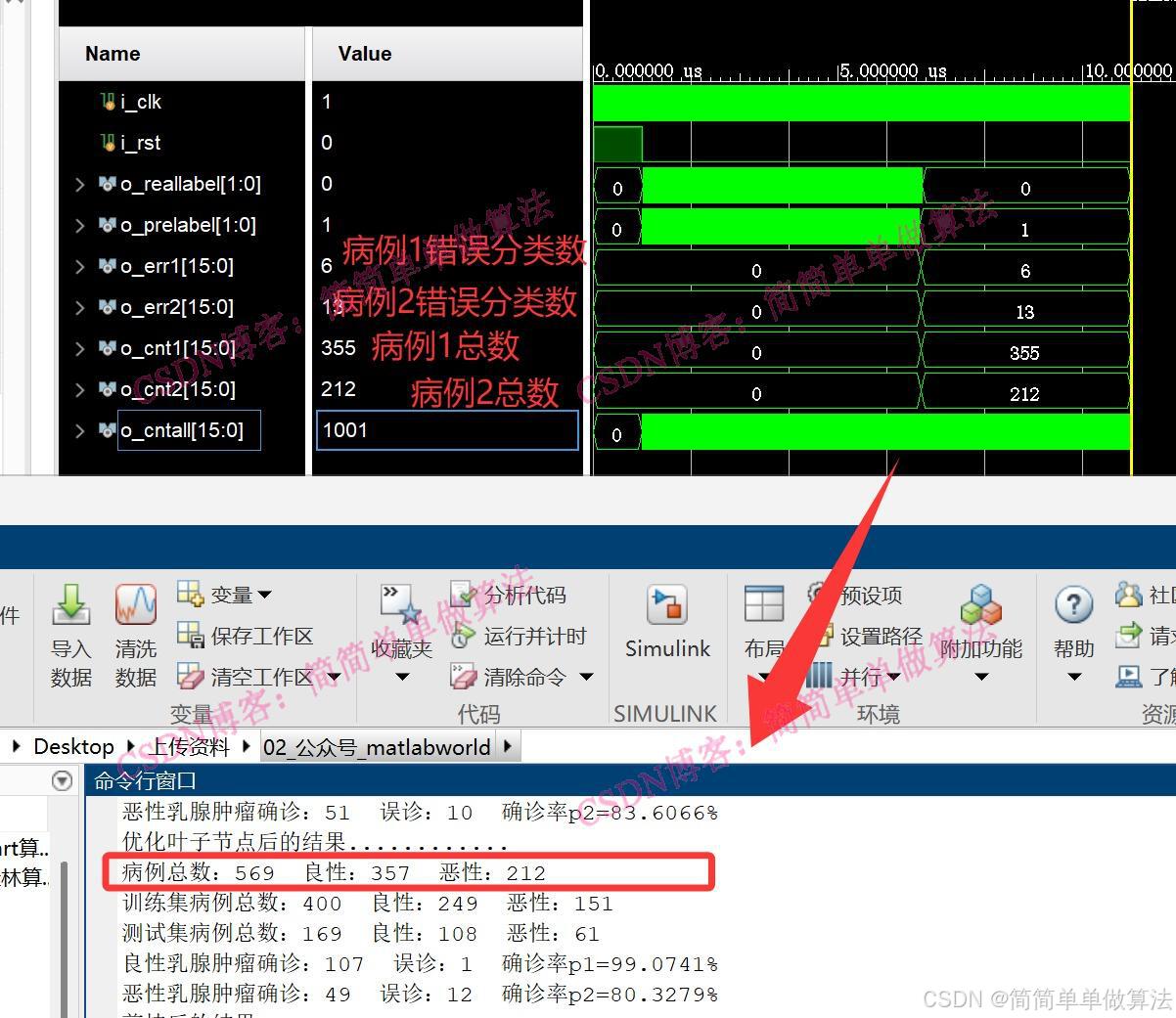
基于FPGA的二叉决策树cart算法verilog实现,训练环节采用MATLAB仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) MATLAB训练结果 上述决策树判决条件: 分类的决策树1 if x21<17191.5 then node 2 elseif x21>17191…...

mac电脑安装nvm
方案一、常规安装 下载安装脚本:在终端中执行以下命令来下载并运行 NVM 的安装脚本3: bash curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.39.5/install.sh | bash配置环境变量:安装完成后,需要配置环境变量。如…...
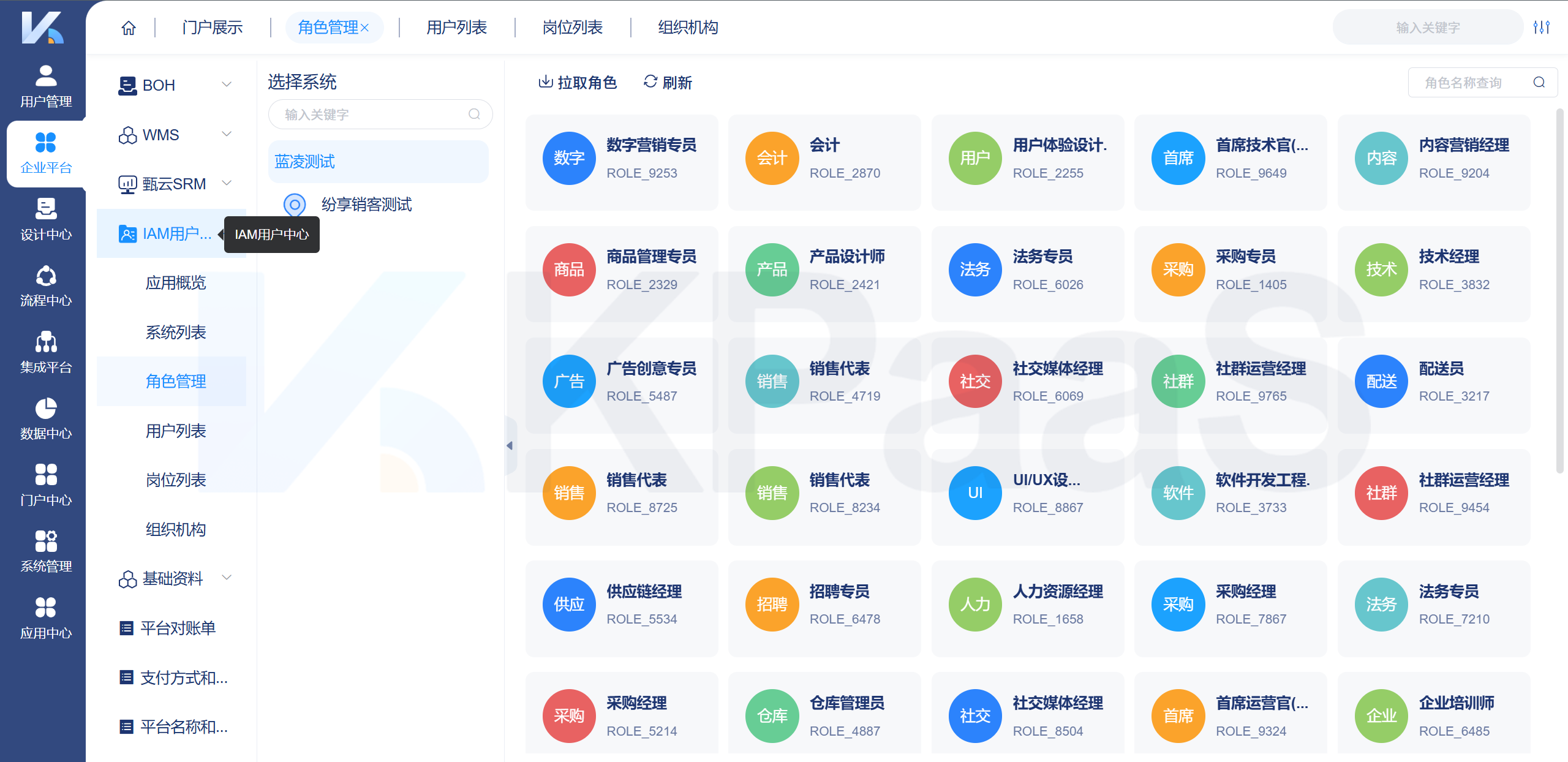
权限分配不合理如何影响企业运营?
“我们明明只给了她CRM的查看权限,怎么客户数据被删了?” “新员工入职三天了,HR系统权限还没开通,流程完全卡住!” “上个月刚给项目经理配了财务权限,怎么又出乱子了?” 这些对话是否在你的…...

ES分词搜索
ES的使用 前言作者使用的版本作者需求 简介ES简略介绍ik分词器简介 使用es的直接简单使用es的查询 es在java中使用备注说明 前言 作者使用的版本 es: 7.17.27spring-boot-starter-data-elasticsearch: 7.14.2 作者需求 作者接到一个业务需求,我们系统有份数据被…...

深入掌握Node.js HTTP模块:从开始到放弃
文章目录 一、HTTP模块入门:从零搭建第一个服务器1.1 基础概念解析1.2 手把手创建服务器 二、核心功能深入解析2.1 处理不同请求类型2.2 实现文件下载功能 三、常见问题解决方案3.1 跨域问题处理3.2 防止服务崩溃3.3 调试技巧 四、安全最佳实践4.1 请求头安全设置4.…...
【数据库】并发控制
并发控制 在数据库系统,经常需要多个用户同时使用。同一时间并发的事务可达数百个,这就是并发引入的必要性。 常见的并发系统有三种: 串行事务执行(X),每个时刻只有一个事务运行,不能充分利用…...
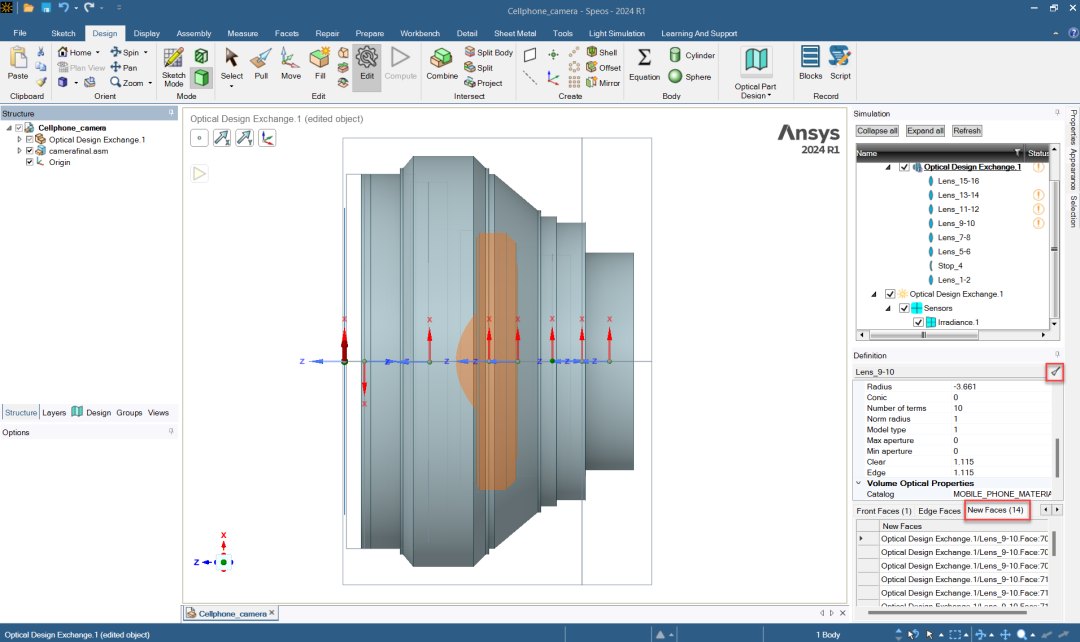
Ansys Zemax | 手机镜头设计 - 第 2 部分:光机械封装
本文该系列文章将讨论智能手机镜头模组设计的挑战,涵盖了从概念、设计到制造和结构变形的分析。本文是四部分系列的第二部分,介绍了在 Ansys Speos 环境中编辑光学元件以及在整合机械组件后分析系统。案例研究对象是一家全球运营制造商的智能手机镜头系统…...

湖北理元理律师事务所债务优化实践:在还款与生活间寻找平衡支点
在个人债务规模持续扩大的社会背景下,如何科学管理债务正成为民生焦点。湖北理元理律师事务所通过其服务案例表明:债务优化的本质不是逃避责任,而是建立可持续的还款体系,让债务人保有基本生活尊严。 一、打破“越还越穷”的恶性…...
mcp-go v0.30.0重磅发布!Server端流式HTTP传输、OAuth支持及多项功能革新全面解读!
随着云原生应用和现代分布式系统需求的不断增长,高效、灵活且稳定的通信协议和客户端交互框架成为开发者关注的焦点。作为开源领域备受期待的项目之一,mcp-go再次迎来重要版本更新——v0.30.0正式发布!本次更新版本不仅实现了众多关键功能&am…...

解锁 MCP 中的 JSON-RPC:跨平台通信的奥秘
你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益: 了解大厂经验拥有和大厂相匹配的技术等希望看什么,评论或者私信告诉我! 文章目录 零、 背景一、RPC vs HTTP1.1 什么是RPC1.2 为什么需要 RPC?1.3 RPC 解决了什么…...
与自动故障转移(Failover)实战:用Patroni或Repmgr搭建生产级数据库集群)
流复制(Streaming Replication)与自动故障转移(Failover)实战:用Patroni或Repmgr搭建生产级数据库集群
更多服务器知识,尽在hostol.com 嘿,各位PostgreSQL的“掌舵人”和数据“守护神”们!咱们都知道,PostgreSQL(简称PG)以其强大的功能、稳定性和开源的特性,赢得了越来越多开发者和企业的青睐。但…...
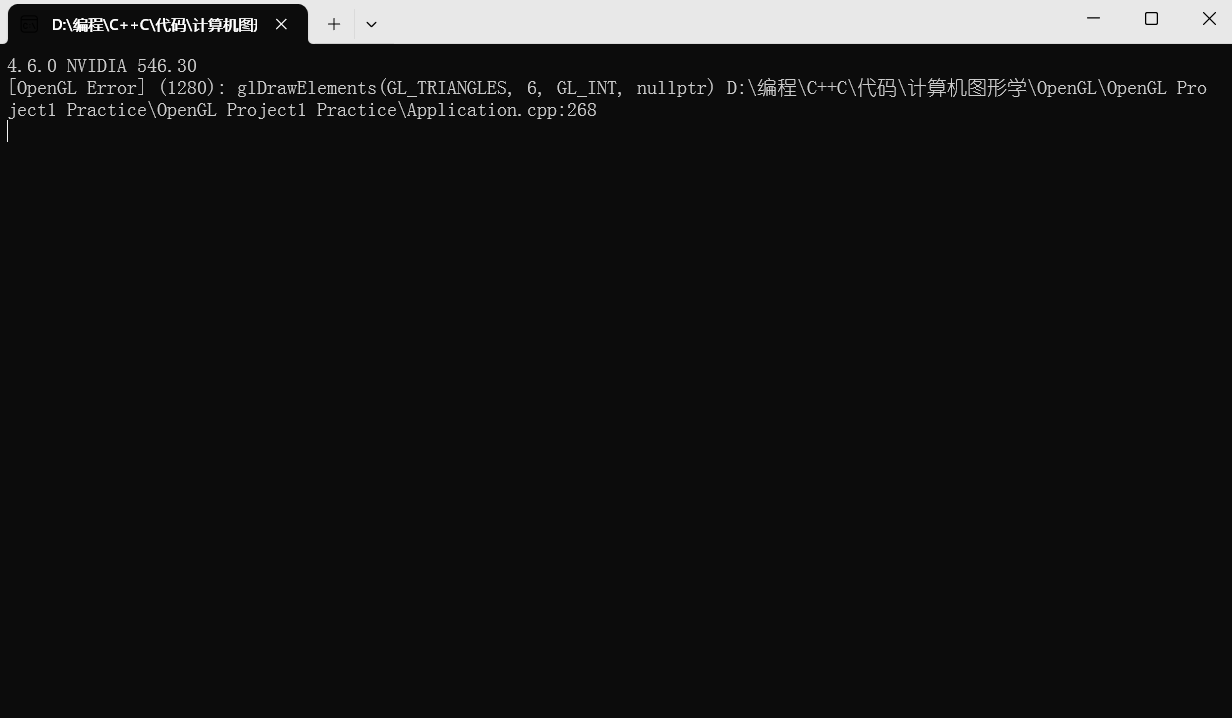
OpenGL Chan视频学习-10 Dealing with Errors in OpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 函数网站: docs.gl 说明: 1.之后就不再单独整理网站具体函数了,网站直接翻译会…...

美团启动618大促,线上消费节被即时零售传导到线下了?
首先,从市场推广与消费者吸引的角度来看,美团通过联合众多品牌开展大规模促销活动,并发放高额优惠券包,旨在吸引更多消费者参与购物。这种策略有助于提高平台的活跃度和交易量,同时也能够增强用户粘性。对于消费者而言…...
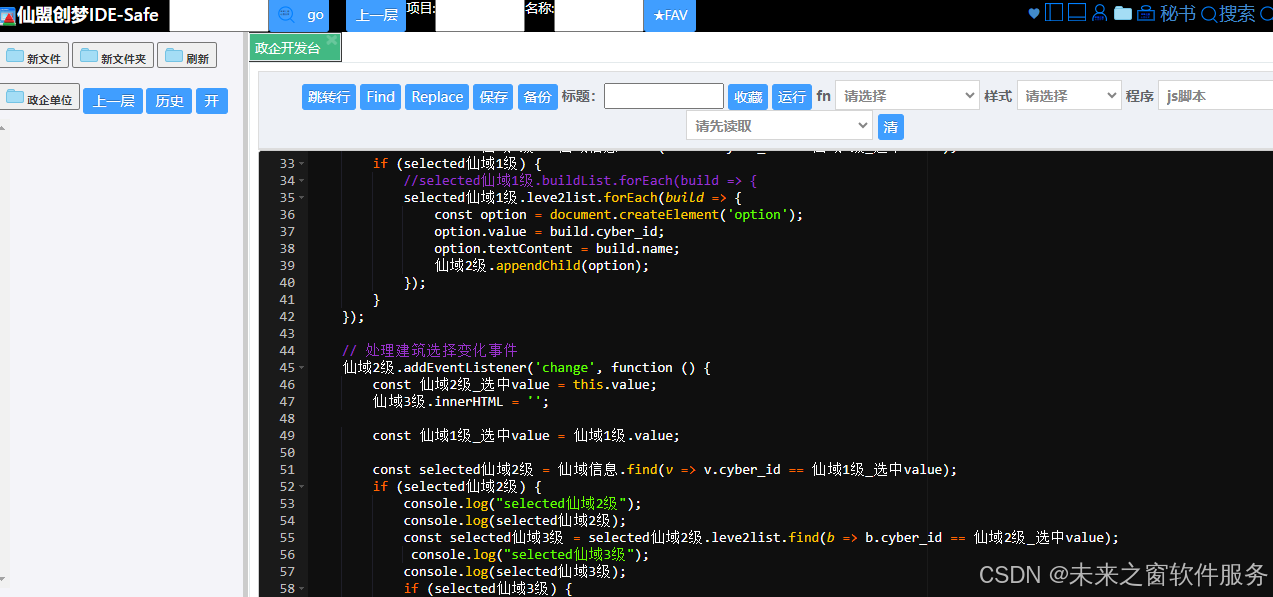
搭建 Select 三级联动架构-东方仙盟插件开发 JavaScript ——仙盟创梦IDE
三级级联开卡必要性 在 “东方仙盟” 相关插件开发中,使用原生 HTML 和 JavaScript 实现三级联动选择(如村庄 - 建筑 - 单元的选择)有以下好处和意义,学校管理: 对游戏体验的提升 增强交互性:玩家能够通…...

服务器如何配置防火墙管理端口访问?
配置服务器防火墙来管理端口访问,是保障云服务器安全的核心步骤。下面我将根据你使用的不同操作系统(Linux: Ubuntu/Debian/CentOS;Windows Server)介绍常用防火墙配置方法。 ✅ 一、Linux 防火墙配置(UFW / firewalld…...

Webhook入门
主要参考资料: 深入解析 Webhook:从原理到实践的全面指南: https://blog.csdn.net/weixin_43114209/article/details/144250750 目录 简介Webhook 与传统 API 调用的区别与轮询 (Polling) 的对比典型工作流程 简介 简单来说,Webhook 是一种“…...

LangChain整合Milvus向量数据库实战:数据新增与删除操作
导读:在AI应用开发中,向量数据库已成为处理大规模语义搜索和相似性匹配的核心组件。本文通过详实的代码示例,深入探讨LangChain框架与Milvus向量数据库的集成实践,为开发者提供生产级别的向量数据管理解决方案。 文章聚焦于向量数…...
LSTM+Transformer混合模型架构文档
LSTMTransformer混合模型架构文档 模型概述 本项目实现了一个LSTMTransformer混合模型,用于超临界机组协调控制系统的数据驱动建模。该模型结合了LSTM的时序建模能力和Transformer的自注意力机制,能够有效捕捉时间序列数据中的长期依赖关系和变量间的复…...

Symbol、Set 与 Map:新数据结构探秘
Symbol、Set 与 Map:新数据结构探秘 引言 ECMAScript 6 (ES6) 引入了三种强大的数据结构:Symbol、Set 与 Map,它们解决了 JavaScript 开发中的特定痛点,为我们提供了更多工具来处理复杂的数据操作。 Symbol:唯一标识…...

Spring Boot+Activiti7入坑指南初阶版
介绍 Activiti 是一个轻量级工作流程和业务流程管理 (BPM) 平台,面向业务人员、开发人员和系统管理员。其核心是一个超快且坚如磐石的 Java BPMN 2 流程引擎。它是开源的,并根据 Apache 许可证分发。Activiti 可以在任何 Java 应用程序、服务器、集群或云中运行。它与 Spri…...

如何在 Odoo 18 中创建 PDF 报告
如何在 Odoo 18 中创建 PDF 报告 Qweb 是 Odoo 强大的模板引擎,旨在轻松将 XML 数据转换为 HTML 文档。其功能特性包括基于属性的自定义、条件逻辑、动态内容插入及多样化的报告模板选项。这种多功能性使 Qweb 成为制作个性化、视觉吸引力强的报告、电子邮件和文档…...

【ROS2实体机械臂驱动】rokae xCoreSDK Python测试使用
【ROS2实体机械臂驱动】rokae xCoreSDK Python测试使用 文章目录 前言正文配置环境下载源码配置环境变量测试运行修改点说明实际运行情况 参考 前言 本文用来记录 xCoreSDK-Python的调用使用1。 正文 配置环境 配置开发环境,这里使用conda做python环境管理&…...

c/c++的opencv椒盐噪声
在 C/C 中实现椒盐噪声 椒盐噪声(Salt-and-Pepper Noise),也称为脉冲噪声(Impulse Noise),是数字图像中常见的一种噪声类型。它的特点是在图像中随机出现纯白色(盐)或纯黑色&#x…...