【深度学习】7. 深度卷积神经网络架构:从 ILSVRC、LeNet 到 AlexNet、ZFNet、VGGNet,含pytorch代码结构
深度卷积神经网络架构:从 ILSVRC 到 AlexNet
在2012年Alex出现之前,主要还是依赖于SVM,同时数据工程成为分类任务中很大的一个部分,对数据处理的专家依赖性高。
一、ILSVRC 与图像分类任务背景
ILSVRC 简介
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是计算机视觉领域最具影响力的图像分类挑战之一(2010 - 2017),核心目标是推动图像分类、物体检测等算法的发展。
-
任务类型:
- 图像分类
- 物体检测
- 图像分割(后期)
-
数据规模:
- 类别数:1000
- 训练图像:120 万张
- 验证图像:5 万张
- 测试图像:15 万张
ILSVRC 的成功推动了深度卷积神经网络在视觉领域的应用。
二、分类模型的演进历程(Top-5 错误率)
| 年份 | 模型 | 错误率 | 层数 | 是否使用数据增强 | 是否使用 Dropout | 是否使用 BN |
|---|---|---|---|---|---|---|
| 2012 | AlexNet | 15.4% | 8 | ✅ | ✅ | ❌ |
| 2013 | ZFNet | 11.2% | 8 | ✅ | ✅ | ❌ |
| 2014 | GoogLeNet | 6.7% | 22 | ✅ | ❌ | ❌ |
| 2015 | ResNet | 3.57% | 152 | ✅ | ❌ | ✅ |
- 人类错误率参考值:5.1%
- 三个关键要素推动性能提升:
- 大数据(ImageNet)
- GPU 计算能力
- 算法改进(更深层结构、优化技巧)
三、CNN 早期架构回顾:LeNet
LeNet-5 架构(LeCun et al., 1998)
结构:[CONV - POOL - CONV - POOL - FC - FC]
- 卷积层(CONV):5×5 卷积核,步幅 stride = 1
- 池化层(POOL):2×2 池化核,stride = 2
- 输出层:全连接层 FC
这是最早期用于手写数字识别的神经网络之一。
四、AlexNet(Krizhevsky et al., 2012)
成绩突破
- ILSVRC2010:28.2%
- ILSVRC2011:25.8%
- ILSVRC2012:16.4%(第二名为 26.2%)
结构设计
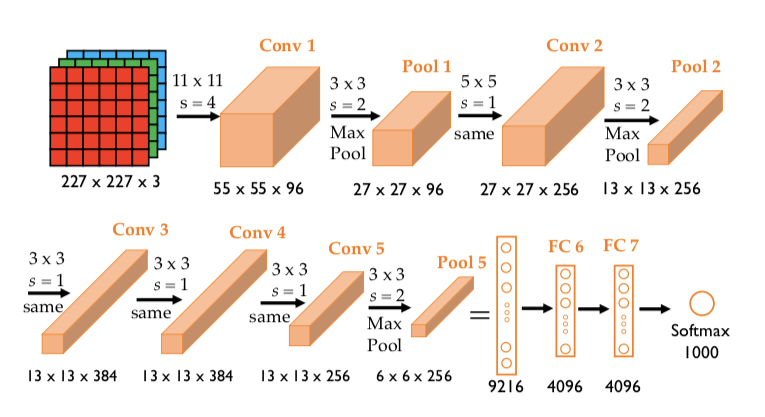
- 5 个卷积层 + 3 个全连接层
- 激活函数:ReLU(首次大规模使用)
- 核大小:
- 第一层使用 11×11 卷积核,stride = 4
- 后续使用 5×5, 3×3 卷积核
- 使用 GPU 并行:前半层在 GPU1,后半层在 GPU2
技术创新点
-
ReLU 激活函数
- 优点:
- 支持高效前向传播
- 梯度流动良好,便于反向传播
- ReLU 显著提高训练速度和非线性能力
- 缺点:
- ReLU 存在死亡问题(Dead ReLU)
- 优点:
-
数据增强:
- 随机旋转
- 图像翻转
- 平移
- 对比度增强
- 自适应直方图均衡化等
-
Dropout:
- 随机丢弃神经元以防止过拟合,训练出 2^N 个子网络的组合效果
- 通常用于全连接层,drop rate = 0.5
-
局部响应归一化(Local Response Normalization, LRN)
局部响应归一化(Local Response Normalization,LRN)是 AlexNet 中提出的一种归一化方法,其灵感来源于生物神经科学中的侧抑制机制:一个神经元的活跃会抑制邻近神经元的响应,以增强对比度、提升特征表达的稀疏性。
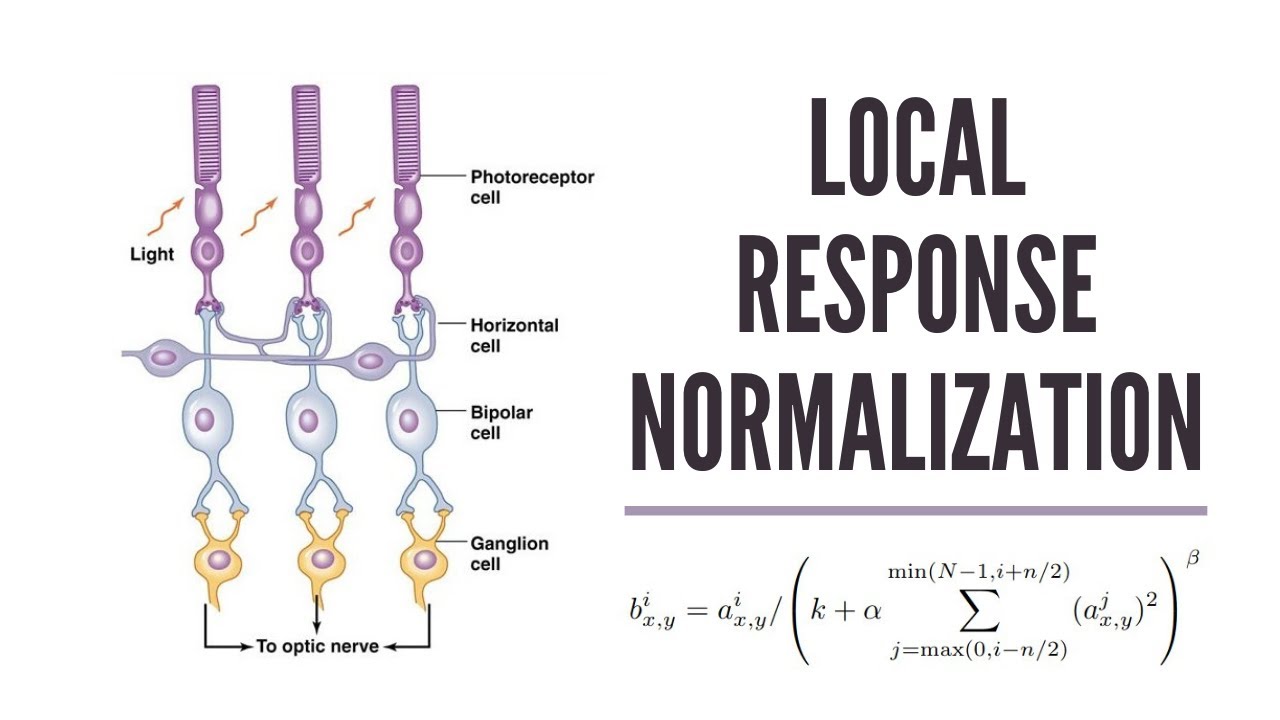
- 模拟神经抑制机制,有助于泛化能力
def manual_lrn(x, size=5, alpha=1e-4, beta=0.75, k=2.0):N, C, H, W = x.shapeout = torch.zeros_like(x)half_size = size // 2for i in range(C):# 定义通道范围start = max(0, i - half_size)end = min(C, i + half_size + 1)# 计算平方和square_sum = torch.sum(x[:, start:end, :, :] ** 2, dim=1, keepdim=True)# 归一化公式denom = (k + alpha * square_sum) ** betaout[:, i:i+1, :, :] = x[:, i:i+1, :, :] / denomreturn out -
重叠池化(Overlapping Pooling)
-
池化核大小 > stride,例如:
- 池化核:3×3,stride:2
- 避免信息过早丢失
-
优于传统非重叠池化(如 2×2,stride=2)
Strandard pooling: Pooling stride = Pooling kernel size
-
AlexNet 的成功标志着深度 CNN 的兴起,但也暴露出如卷积核大小过大、参数量庞大、计算资源消耗高等问题。
Pytorch结构实现
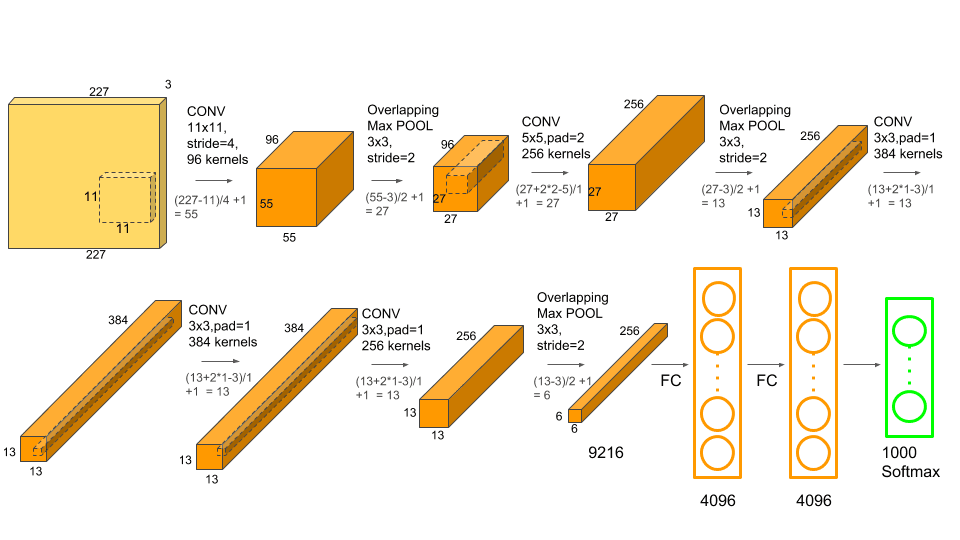
卷积输出尺寸计算公式:
输出尺寸 = ⌊ W − K + 2 P S ⌋ + 1 {输出尺寸} = \left\lfloor \frac{W - K + 2P}{S} \right\rfloor + 1 输出尺寸=⌊SW−K+2P⌋+1
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4)
用 96 个卷积核来扫描输入图像。 AlexNet 的 Conv1 层输出通道数是 96,因为它使用了 96 个 11×11×3 的卷积核,每个核对应输出一个 55×55 的特征图,组合起来就是 96×55×55
import torch
import torch.nn as nn
import torch.nn.functional as Fclass AlexNet(nn.Module):def __init__(self, num_classes=1000):super(AlexNet, self).__init__()# Feature extraction 部分(对应 Conv1 ~ Pool5)self.features = nn.Sequential(# Conv1: 11x11, stride=4, padding=0 -> 输出: 96 x 55 x 55nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),nn.ReLU(inplace=True),# Pool1: 3x3, stride=2 -> 输出: 96 x 27 x 27nn.MaxPool2d(kernel_size=3, stride=2),# Conv2: 5x5, stride=1, padding=2 -> 输出: 256 x 27 x 27nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),nn.ReLU(inplace=True),# Pool2: 3x3, stride=2 -> 输出: 256 x 13 x 13nn.MaxPool2d(kernel_size=3, stride=2),# Conv3: 3x3, stride=1, padding=1 -> 输出: 384 x 13 x 13nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Conv4: 3x3, stride=1, padding=1 -> 输出: 384 x 13 x 13nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Conv5: 3x3, stride=1, padding=1 -> 输出: 256 x 13 x 13nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(inplace=True),# Pool5: 3x3, stride=2 -> 输出: 256 x 6 x 6nn.MaxPool2d(kernel_size=3, stride=2),)# 分类器部分(对应 FC6 ~ FC8)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(256 * 6 * 6, 4096), # Flatten: 256×6×6 = 9216nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes) # 输出为1000类)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1) # 展平为 batch × 9216x = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = AlexNet(num_classes=1000)input_tensor = torch.randn(1, 3, 227, 227) # 输入大小与图一致output = model(input_tensor)print("输出 shape:", output.shape) # 应为 [1, 1000]五、ZFNet 改进
ZFNet(Zeiler and Fergus, 2013)是在 AlexNet 基础上的改进型卷积神经网络,主要优化了第一层卷积的核大小和步幅,并引入了卷积神经网络的可视化方法(Deconvolutional Network),使网络结构更加合理且更具可解释性。
核心结构变化
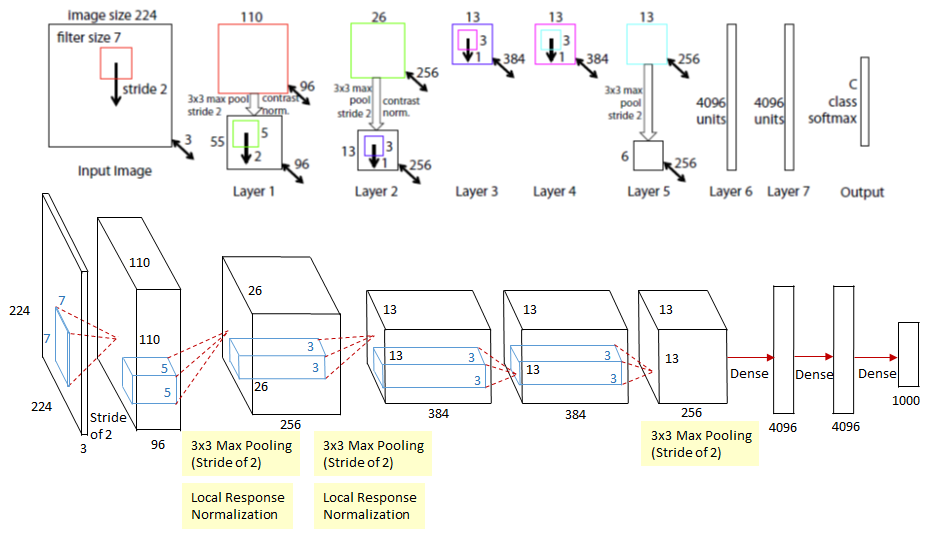
ZFNet 将第一层的卷积核从 11×11 改为更小的 7×7,同时将步幅从 4 减小为 2,从而保留了更多的空间细节,减缓了特征图分辨率下降的速度。
| 模型 | 第一层卷积核 | 步幅 | Conv1 输出尺寸 | Top-5 错误率 |
|---|---|---|---|---|
| AlexNet | 11×11 | 4 | 55×55 | 16.4% |
| ZFNet | 7×7 | 2 | 110×110 | 11.7% |
更小的卷积核与更慢的步幅配合使用,使网络能够感知更细粒度的图像信息,提升了分类精度。
网络结构概览
ZFNet 与 AlexNet 在整体结构上保持一致,包含 5 个卷积层和 3 个全连接层,但第一层卷积参数不同。
可视化贡献:反卷积网络(DeconvNet)
ZFNet 的重要贡献之一是提出了 Deconvolutional Network(反卷积网络)方法,用于分析和可视化 CNN 的内部工作机制。通过将某一神经元的激活反投影回输入图像空间,研究者能够观察到网络到底在“看哪里”。
该方法过程包括:
- 选择某层的强激活区域,抑制其他位置
- 通过反卷积和反池化操作逐层还原
- 显示出该神经元最关注的原始图像区域
这种可视化揭示了 AlexNet 中由于卷积核过大、步幅过快导致的信息丢失,从而指导了 ZFNet 的结构改进。
Pytorch 实现
import torch
import torch.nn as nnclass ZFNet(nn.Module):def __init__(self, num_classes=1000):super(ZFNet, self).__init__()self.features = nn.Sequential(# Conv1: 7x7 kernel, stride=2, padding=1 → Output: 96x110x110nn.Conv2d(3, 96, kernel_size=7, stride=2, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 96x54x54# Conv2: 5x5, padding=2 → Output: 256x54x54nn.Conv2d(96, 256, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 256x26x26# Conv3: 3x3, padding=1nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),# Conv4: 3x3, padding=1nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),# Conv5: 3x3, padding=1nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2), # Output: 256x12x12)self.classifier = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(256 * 12 * 12, 4096),nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1) # Flattenx = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = ZFNet(num_classes=1000)dummy_input = torch.randn(1, 3, 224, 224) # 与 ImageNet 尺寸一致output = model(dummy_input)print("Output shape:", output.shape) # 应为 [1, 1000]
六、VGGNet 结构
VGGNet(Simonyan and Zisserman, 2014)是深度卷积网络发展的重要里程碑,其主要设计思想是用统一的小卷积核(3×3)和最大池化(2×2)层,堆叠出一个非常深但结构规则的网络架构。它不仅在 ImageNet 挑战中取得了优异成绩,还广泛应用于后续各类视觉任务。
统一小卷积核设计
VGGNet 放弃了之前 AlexNet 和 ZFNet 中使用的大卷积核(如 11×11、7×7),转而采用大量 3×3 卷积核的堆叠构建特征提取层。
这种设计的优势包括:
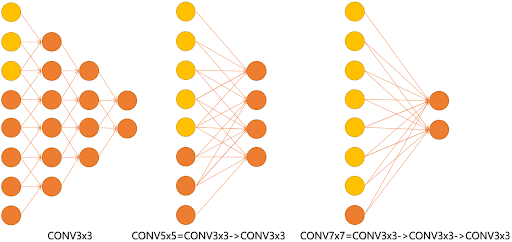
- 两个连续的 3×3 卷积层相当于一个 5×5 卷积(感受野扩大)
- 三个连续的 3×3 卷积层相当于一个 7×7 卷积
- 多层堆叠带来更多非线性、参数更少、表达能力更强
层数对比与模型变体
VGGNet 系列包括多个深度版本,主要有:
- VGG-11、VGG-13、VGG-16、VGG-19
- 常用版本为 VGG-16 和 VGG-19(数字表示层数)
其中:
- AlexNet:8 层(5 conv + 3 fc)
- VGG-16:13 个卷积层 + 3 个全连接层
- VGG-19:16 个卷积层 + 3 个全连接层
卷积层数量显著增加,深度带来了更强的表达能力。
网络结构组成
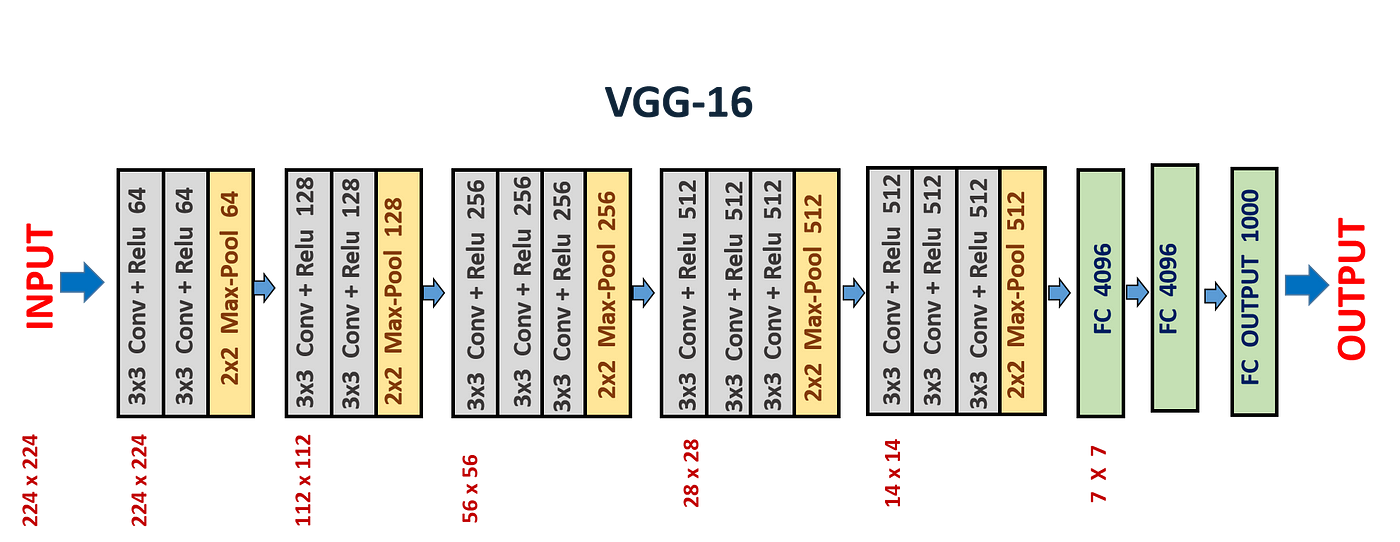
VGGNet 的典型结构如下(以 VGG-16 为例):
- 输入图像大小:224 × 224 × 3
- 卷积核:全部为 3 × 3,stride = 1,padding = 1
- 池化层:2 × 2 最大池化,stride = 2
- 激活函数:ReLU
- 最终全连接层:4096 → 4096 → 1000
整体结构是:
为什么小卷积核更好?
VGGNet 强调多个小卷积核堆叠而不是大卷积核的原因包括:
- 更深层数提供更多非线性变换,提高网络表达力
- 更少参数:3×3 比 5×5、7×7 参数更少,便于训练
- 更易堆叠、结构更统一,适合硬件优化和迁移使用
迁移性与通用性
VGGNet 特别有代表性的一点是:
- 中间层(如 FC7 或 Conv5-3)提取的特征在其他任务上也很有效
- 广泛用于图像检索、物体检测、风格迁移等下游任务
这种“可迁移的中层特征”概念,为后来 ResNet、FPN 等模型的模块化设计打下基础。
Pytorch
import torch
import torch.nn as nnclass VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()self.features = nn.Sequential(# Block 1nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 2nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 3nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 4nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# Block 5nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1) # Flattenx = self.classifier(x)return x# 示例运行
if __name__ == "__main__":model = VGG16(num_classes=1000)x = torch.randn(1, 3, 224, 224) # 输入图像大小为 224×224×3out = model(x)print("Output shape:", out.shape) # 应为 [1, 1000]相关文章:
【深度学习】7. 深度卷积神经网络架构:从 ILSVRC、LeNet 到 AlexNet、ZFNet、VGGNet,含pytorch代码结构
深度卷积神经网络架构:从 ILSVRC 到 AlexNet 在2012年Alex出现之前,主要还是依赖于SVM,同时数据工程成为分类任务中很大的一个部分,对数据处理的专家依赖性高。 一、ILSVRC 与图像分类任务背景 ILSVRC 简介 ILSVRC(…...

基于cornerstone3D的dicom影像浏览器 第二十七章 设置vr相机,复位视图
文章目录 前言一、VR视图设置相机位置1. 相机位置参数2. 修改mprvr.js3. 调用流程1) 修改Toolbar3D.vue2) 修改View3d.vue3) 修改DisplayerArea3D.vue 二、所有视图复位1.复位流程说明2. 调用流程1) Toolbar3D中添加"复位"按钮,发送reset事件2) View3d.vu…...

2025年渗透测试面试题总结-匿名[校招]高级安全工程师(代码审计安全评估)(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。、 目录 匿名[校招]高级安全工程师(代码审计安全评估) 渗透基础 1. 自我介绍 2. SQL注入写Shell(分数…...

Jenkins实践(7):Publish over SSH功能
在 Jenkins 中使用Publish over SSH功能,需要安装对应的插件。以下是详细步骤: 1. 安装 Publish over SSH 插件 进入 Jenkins 管理界面 → Manage Jenkins → Manage Plugins。切换到 Available 选项卡,搜索 "Publish Over SSH"。勾选插件并点击 Install without…...
SQLite 中文写入失败问题总结
SQLite 中文写入失败问题总结与解决方案 在 Windows 下使用 C 操作 SQLite 数据库时,中文字段经常出现 写入成功但内容显示为 BLOB 或 乱码 的问题。根本原因在于 SQLite 要求字符串以 UTF-8 编码 存储,而默认的 std::string 中文通常是 GB2312/ANSI 编…...

JavaScript篇:闭包:JavaScript中的魔法口袋,装下你的编程智慧
大家好,我是江城开朗的豌豆,一名拥有6年以上前端开发经验的工程师。我精通HTML、CSS、JavaScript等基础前端技术,并深入掌握Vue、React、Uniapp、Flutter等主流框架,能够高效解决各类前端开发问题。在我的技术栈中,除了…...
ubuntu系统安装Pyside6报错解决
目录 1,问题: 2,解决方法: 2.1 首先查看pypi是否有你需要包的镜像: 2.2 其它方案: 2.3 如果下载很慢,可以换源: 2.4 查看系统架构 Windows Ubuntu 1,问题…...

DeepSeek 赋能智能零售:从数据洞察到商业革新
目录 一、智能零售的现状与挑战二、DeepSeek 技术特点剖析2.1 基于 Transformer 架构的深度优化2.2 多源数据的深度分析能力2.3 强大的学习与推理能力 三、DeepSeek 在智能零售中的应用场景3.1 精准需求预测3.2 智能补货决策3.3 库存优化布局3.4 个性化推荐与营销3.5 智能客服与…...
榕壹云医疗服务系统:基于ThinkPHP+MySQL+UniApp的多门店医疗预约小程序解决方案
在数字化浪潮下,传统医疗服务行业正面临效率提升与客户体验优化的双重挑战。针对口腔、美容、诊所、中医馆、专科医院及康复护理等需要预约或诊断服务的行业,我们开发了一款基于ThinkPHP+MySQL+UniApp的多门店服务预约小程序——榕壹云医疗服务系统。该系统通过模块化设计与开…...

苏州SAP代理公司排名:工业园区企业推荐的服务商
目录 一、SAP实施商选择标准体系 1、行业经验维度 2、实施方法论维度 3、资质认证维度 4、团队实力维度 二、SAP苏州实施商工博科技 1、SAP双重认证,高等院校支持 2、以SAP ERP为核心,助力企业数字化转型 三、苏州使用SAP的企业 苏州是中国工业…...
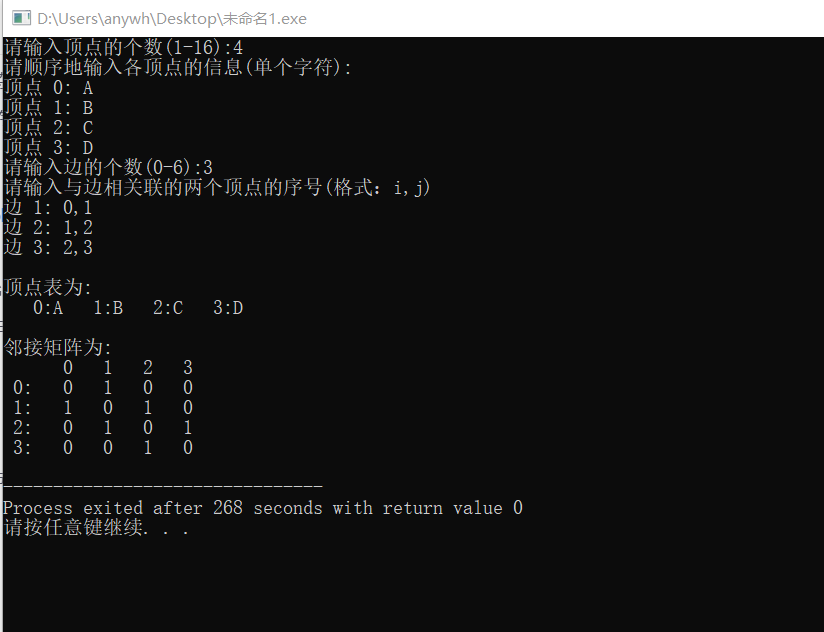
数据结构中无向图的邻接矩阵详解
在计算机科学的浩瀚宇宙中,数据结构无疑是那把开启高效编程大门的关键钥匙。对于计算机专业的大学生们来说,数据结构课程是专业学习路上的一座重要里程碑,而其中的图结构更是充满魅力与挑战,像一幅神秘的画卷等待我们去展开。今天…...

.NET 7 AOT 使用及 .NET 与 Go 语言互操作详解
.NET 7 AOT 使用及 .NET 与 Go 语言互操作详解 目录 .NET 7 AOT 使用及 .NET 与 Go 语言互操作详解 一、背景与技术概述 1.1 AOT 编译技术简介 1.2 Go 语言与 .NET 的互补性 二、.NET 7 AOT 编译实践 2.1 环境准备 2.2 创建 AOT 项目 2.3 AOT 编译流程 2.4 调试信息处…...

OpenCV 第7课 图像处理之平滑(一)
1. 图像噪声 在采集、处理和传输过程中,数字图像可能会受到不同噪声的干扰,从而导致图像质量降低、图像变得模糊、图像特征被淹没,而图像平滑处理就是通过除去噪声来达到图像增强的目的。常见的图像噪声有椒盐噪声、高斯噪声等。 1.1 椒盐噪声 椒盐噪声(Salt-and-pepper N…...

React 编译器
🤖 作者简介:水煮白菜王,一位前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧和知识归纳总结✍。 感谢支持💕💕&#…...

HCIP:MPLS静态LSP的配置及抓包
目录 一、MPLS的简单的一些知识点 1.MPLS的概述: 2.MPLS工作原理: 3.MPLS的核心组件: 4. MPLS标签 5.MPLS标签的处理 6.MPLS转发的概述: 7.MPLS的静态LSP建立方式 二、MPLS的静态LSP的实验配置 1.配置接口的地址和配置OS…...
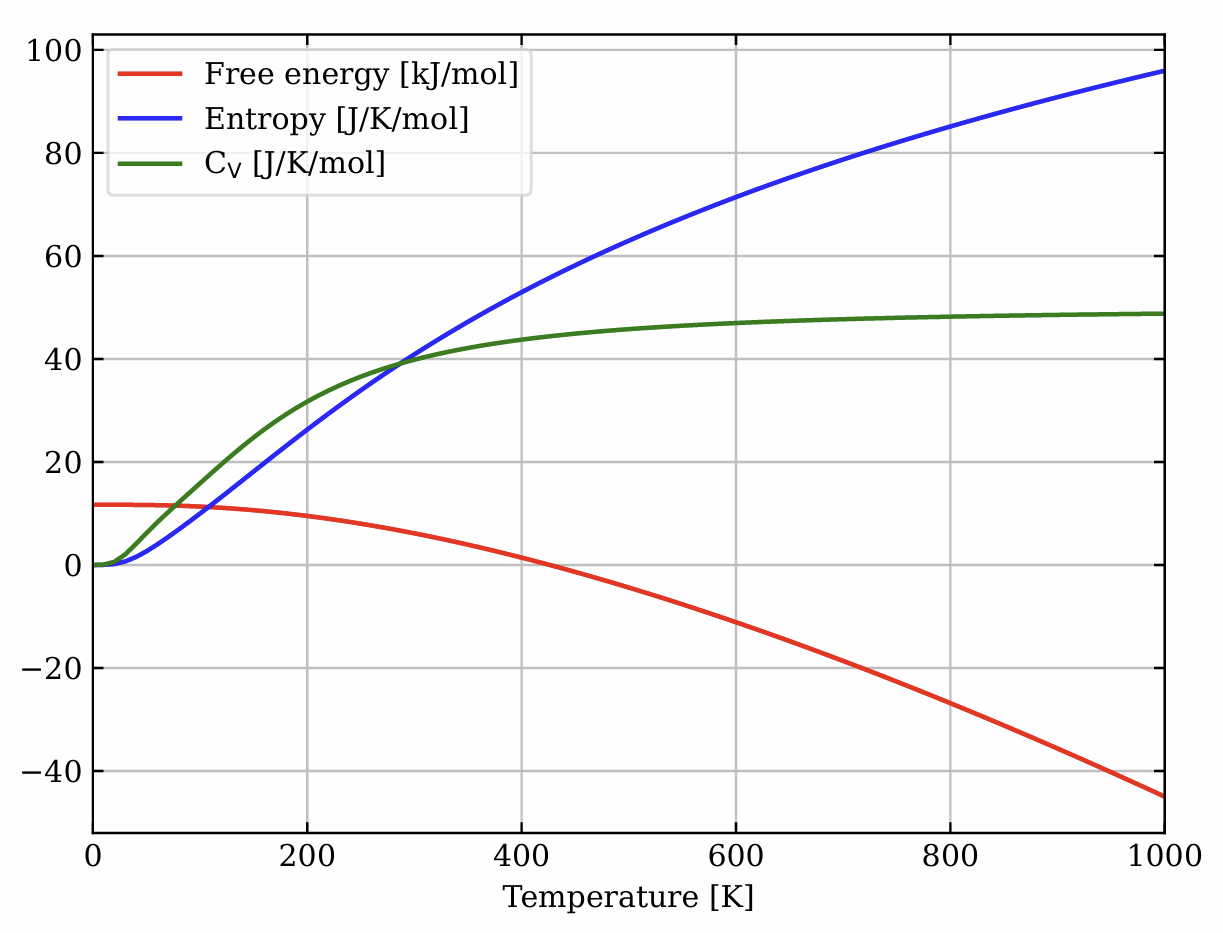
VASP 教程:VASP 结合 Phonopy 计算硅的比热容
VASP 全称为 Vienna Ab initio Simulation Package(The VASP Manual - VASP Wiki)是一个计算机程序,用于从第一性原理进行原子尺度材料建模,例如电子结构计算和量子力学分子动力学。 Phonopy(Welcome to phonopy — Ph…...

YOLO使用SAHI进行小目标检测
目录 一、环境配置二、使用ultralytics的YOLO模型进行训练和推理三、推理可视化的两种方法四、使用SAHI和ultralytics 训练的YOLO模型进行推理一、环境配置 下面是环境的配置过程,根据代码复杂度可以额外安装其他包。 #创建虚拟环境 conda create -n 环境名 python=3.9 #开启…...

[论文阅读]Prompt Injection attack against LLM-integrated Applications
Prompt Injection attack against LLM-integrated Applications [2306.05499] Prompt Injection attack against LLM-integrated Applications 传统提示注入攻击效果差,主要原因在于: 不同的应用对待用户的输入内容不同,有的将其视为问题&a…...

【SpringCache 提供的一套基于注解的缓存抽象机制】
Spring 缓存(Spring Cache)是 Spring 提供的一套基于注解的缓存抽象机制,常用于提升系统性能、减少重复查询数据库或接口调用。 ✅ 一、基本原理 Spring Cache 通过对方法的返回结果进行缓存,后续相同参数的调用将直接从缓存中读…...

DALI DT6与DALI DT8介绍
“DT”全称Device Type,是DALI-2 标准协议中的IEC 62386-102(即为Part 102)部分对不同类型的控制设备进行一个区分。不同的Device Type代表不同特性的控制设备,也代表了这种控制设备拥有的扩展的特性。 在DALI(数字可寻址照明接口)…...

day13 leetcode-hot100-24(链表3)
234. 回文链表 - 力扣(LeetCode) 1.转化法 思路 将链表转化为列表进行比较 复习到的知识 arraylist的长度函数:list.size() 具体代码 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode ne…...

Python实战:打造高效通讯录管理系统
📋 编程基础第一期《8-30》–通讯录管理系统 📑 项目介绍 在信息化时代,高效管理个人或团队联系人信息变得尤为重要。本文将带您实现一个基于Python的通讯录管理系统,该系统采用字典数据结构和JSON文件存储,实现了联系…...
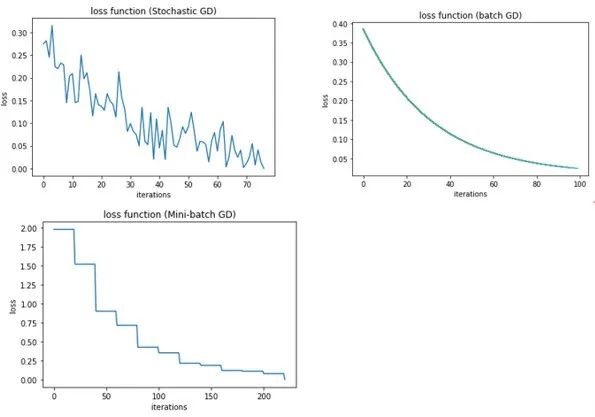
图解深度学习 - 基于梯度的优化(梯度下降)
在模型优化过程中,我们曾尝试通过手动调整单个标量系数来观察其对损失值的影响。具体来说,当初始系数为0.3时,损失值为0.5。随后,我们尝试增加系数至0.35,发现损失值上升至0.6;相反,当系数减小至…...
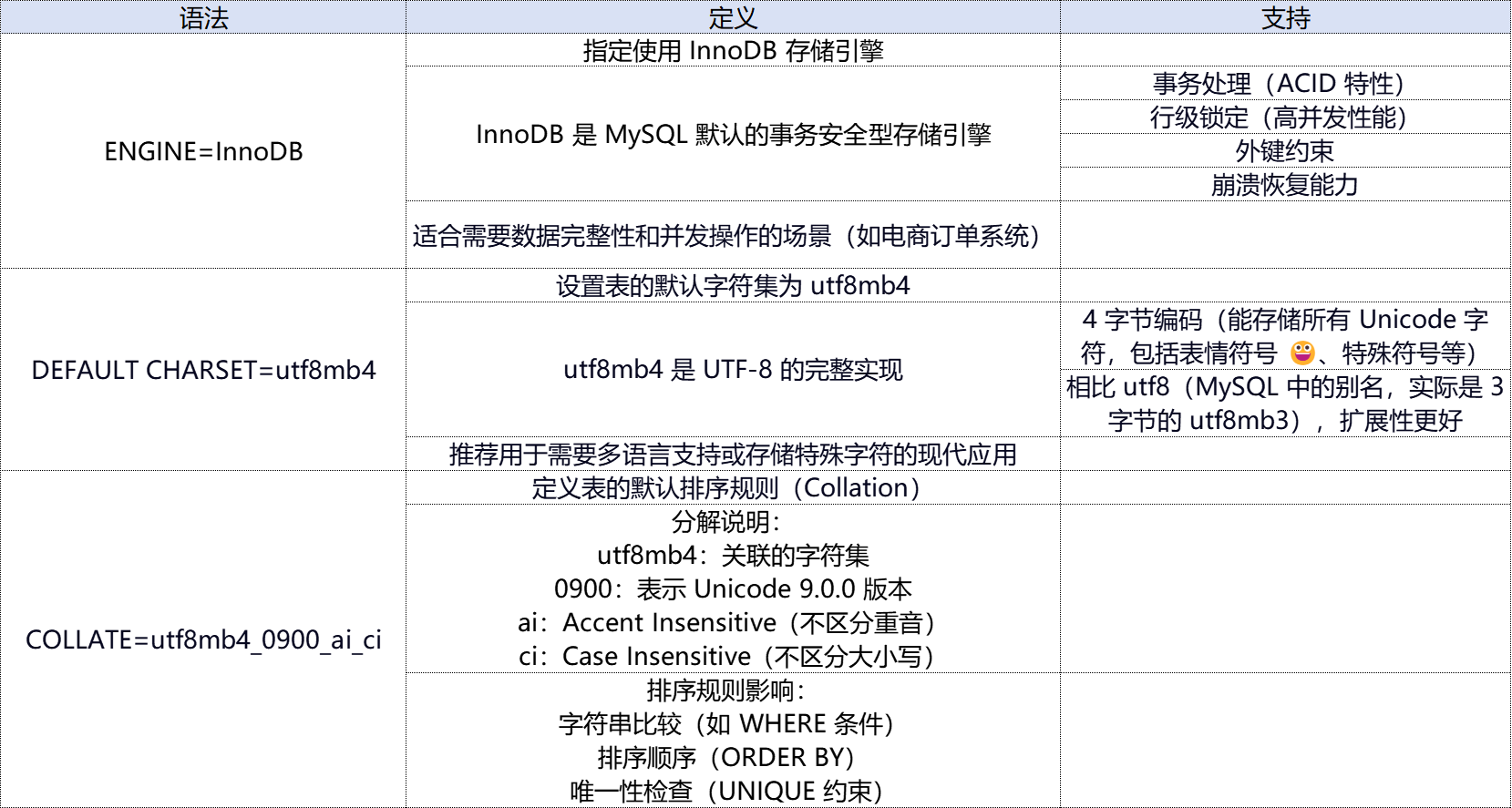
MySql--定义表存储引擎、字符集和排序规则
示例: CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci,email VARCHAR(100) ) ENGINEInnoDB DEFAULT CHARSETutf8mb4 COLLATEutf8mb4_0900_ai_ci;注意事项: 字符集和排序规则可以按列覆盖表…...

【部署】在离线服务器的docker容器下升级dify-import程序
回到目录 在离线服务器的docker容器下升级dify-import程序 dify 0.1.0-release 变化很大,重构整个项目代码并且增加制度类txt文件知识库父子分段支持,详见 读取制度类txt文件导入dify的父子分段知识库(20250526发布). 。下面是kylin Linux环境下&#…...
优化版本,增加3D 视觉 查看前面的记录
上图先 运来的超出发表上限,重新发。。。 #11:06:57Current_POS_is: X:77Y:471Z:0U:-2 C:\Log\V55.txt import time import tkinter as tk from tkinter import messagebox from PIL import Image, ImageTk import socket import threading from date…...

写作-- 复合句练习
文章目录 练习 11. 家庭的支持和老师的指导对学生的学术成功有积极影响。2. 缺乏准备和未能适应通常会导致在挑战性情境中的糟糕表现。3. 吃垃圾食品和忽视锻炼可能导致严重的健康问题,因此人们应注重保持均衡的生活方式。4. 昨天的大雨导致街道洪水泛滥,因此居民们迁往高地以…...
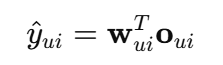
WWW22-可解释推荐|用于推荐的神经符号描述性规则学习
论文来源:WWW 2022 论文链接:https://web.archive.org/web/20220504023001id_/https://dl.acm.org/doi/pdf/10.1145/3485447.3512042 最近读到一篇神经符号集成的论文24年底TOIS的,神经符号集成是人工智能领域中,将符号推理与深…...
Linux:shell脚本常用命令
一、设置主机名称 1、查看主机名称 2、用文件的方式更改主机名称 重启后: 3、 通过命令修改主机名 重启后: 二、网络管理命令 1、查看网卡 2、设置网卡 (1)网卡未被设置过时 (2)当网卡被设定,…...

专业课复习笔记 11
从今天开始每天下午复习专业课。慢慢复习专业课。目标至少考一个一百分吧。毕竟专业课还是比较难的。要是考不到一百分,我感觉自己就废掉了呢。下面稍微复习一下计组。 复习指令格式和数据通路设计。完全看不懂,真是可恶啊。计组感觉就是死记硬背&#…...