重拾Scrapy框架
基于Scrapy框架实现 舔狗语录+百度翻译 输出结果到txt文档
爬虫脚本
from typing import Iterable, Any, AsyncIteratorimport scrapy
import json
from post.items import PostItemclass BaidufanyiSpider(scrapy.Spider):name = "baidufanyi"allowed_domains = ["fanyi.baidu.com", "api.oick.cn"]start_urls = ["https://api.oick.cn/api/dog"]headers = {"Content-Type": "application/json",}def __init__(self):super().__init__()def parse_post(self, response):word = response.meta["word"]for line in response.body.decode("utf-8").split("\n"):try:new_data = json.loads(line.lstrip("data: "))event = new_data["data"]["event"]if event == "Translating":pi = PostItem()pi["org"] = new_data["data"]["list"][0]["src"]pi["res"] = new_data["data"]["list"][0]["dst"]if word == new_data["data"]["list"][0]["src"]:yield piexcept Exception as e:continuedef parse(self, response):yield scrapy.Request(url=self.start_urls[0], callback=self.parse_detail)def parse_detail(self, response):word = response.text.strip('"')url = "https://fanyi.baidu.com/ait/text/translate"data = {"query": f"{word}","from": "zh","to": "en","needPhonetic": True,}yield scrapy.FormRequest(url=url, method="POST", headers=self.headers, body=json.dumps(data),callback=self.parse_post, meta={"word": word})yield scrapy.Request(url=self.start_urls[0], callback=self.parse_detail,dont_filter=True)items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass PostItem(scrapy.Item):# define the fields for yo在这里插入代码片ur item here like:# name = scrapy.Field()org = scrapy.Field()res = scrapy.Field()piplines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from datetime import datetimeclass PostPipeline:def open_spider(self, spider):self.f = open('result.txt', 'a', encoding='utf-8')def process_item(self, item, spider):new_item = f'{item["org"]}\t{item["res"]}\t{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}\n'self.f.write(new_item)self.f.flush()return itemdef close_spider(self, spider):self.f.close()settings.py
# Scrapy settings for post project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = "post"SPIDER_MODULES = ["post.spiders"]
NEWSPIDER_MODULE = "post.spiders"ADDONS = {}# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = "post (+http://www.yourdomain.com)"# Obey robots.txt rules
# ROBOTSTXT_OBEY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 60 / 120
RANDOMIZE_DOWNLOAD_DELAY = True
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
# COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
# }# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# "post.middlewares.PostSpiderMiddleware": 543,
# }# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# "post.middlewares.PostDownloaderMiddleware": 543,
# }# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
# }# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {"post.pipelines.PostPipeline": 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = "httpcache"
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value
FEED_EXPORT_ENCODING = "utf-8"相关文章:

重拾Scrapy框架
基于Scrapy框架实现 舔狗语录百度翻译 输出结果到txt文档 爬虫脚本 from typing import Iterable, Any, AsyncIteratorimport scrapy import json from post.items import PostItemclass BaidufanyiSpider(scrapy.Spider):name "baidufanyi"allowed_domains [&quo…...

Day 40
单通道图片的规范写法 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader , Dataset from torchvision import datasets, transforms import matplotlib.pyplot as plt import warnings warnings.filterwarnings(&q…...

XPlifeapp:高效打印,便捷生活
在数字化时代,虽然电子设备的使用越来越普遍,但打印的需求依然存在。无论是学生需要打印课表、资料,还是职场人士需要打印名片、报告,一个高效便捷的打印软件都能大大提高工作效率。XPlifeapp就是这样一款超级好用的手机打印软件&…...
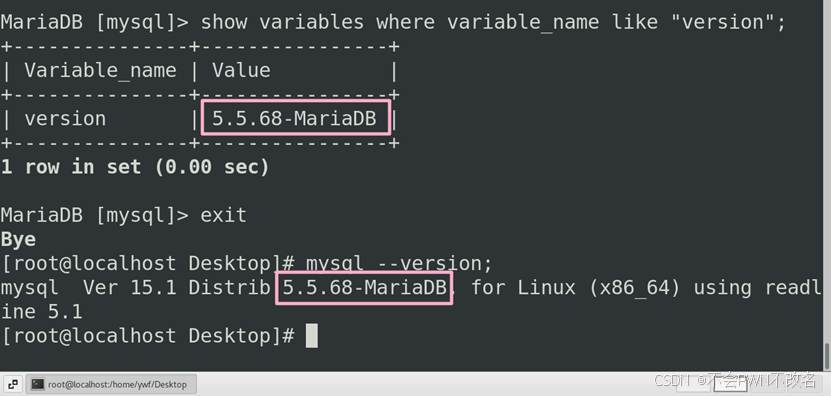
等保测评-Mysql数据库测评篇
Mysql数据库测评 0x01 前言 "没有网络安全、就没有国家安全" 等保测评是什么? 等保测评(网络安全等级保护测评)是根据中国《网络安全法》及相关标准,对信息系统安全防护能力进行检测评估的法定流程。其核心依据《信…...

CSS篇-2
4. position 的值分别是相对于哪个位置定位的? position 属性是 CSS 布局中一个非常核心的概念,它允许我们精确控制元素在文档中的定位方式,从而脱离或部分脱离正常的文档流。理解 position 的不同值以及它们各自的定位基准,是实…...
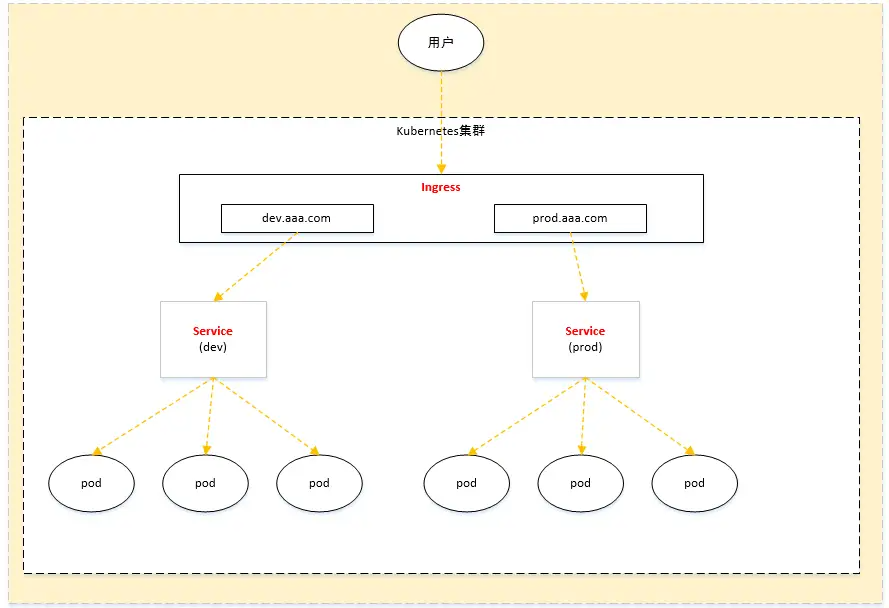
02.K8S核心概念
服务的分类 有状态服务:会对本地环境产生依赖,例如需要把数据存储到本地磁盘,如mysql、redis; 无状态服务:不会对本地环境产生任何依赖,例如不会存储数据到本地磁盘,如nginx、apacheÿ…...

一套qt c++的串口通信
实现了创建线程使用串口的功能 具备功能: 1.线程使用串口 2.定时发送队列内容,防止粘包 3.没处理接收粘包,根据你的需求来,handleReadyRead函数中,可以通过m_receiveBuffer来缓存接收,然后拆分数据来处理 源码 seri…...
)
【高频面试题】数组中的第K个最大元素(堆、快排进阶)
文章目录 数组中的第K个最大元素题目描述示例1示例2提示: 解法1(堆维护前k大元素)解法2 手写堆维护解法3(快速选择算法)例题:P1923 【深基9.例4】求第 k 小的数参考 数组中的第K个最大元素 题目描述 给定…...

Java互联网大厂面试:从Spring Boot到Kafka的技术深度探索
Java互联网大厂面试:从Spring Boot到Kafka的技术深度探索 在某家互联网大厂的面试中,面试官A是一位技术老兵,而被面试者谢飞机,号称有丰富的Java开发经验。以下是他们的面试情景: 场景:电商平台的后端开发…...

基于Python的单斜式ADC建模与仿真分析
基于Python的单斜式ADC建模与仿真分析 1 引言 CMOS图像传感器的读出电路中,列级ADC因其面积效率高(每列共享ADC)、功耗低(并行工作降低频率需求)和固定模式噪声小(结构对称性高)等优势成为大像素阵列的首选方案。本文针对50KS/s采样率、10位分辨率的单斜式ADC进行系统…...

笔记本电脑右下角wifi不显示,连不上网怎么办?
解决思路:设备管理器--先禁用wifi6硬件-再启用wifi6硬件(20秒搞定) 笔记本电脑右下角的wifi经常莫名其妙的不显示,连不上网,感觉应该是与什么程序不兼容,导致wifi模块被办掉了,怎么这种情况出现…...

一篇文章玩转CAP原理
CAP 原理是分布式系统设计的核心理论之一,揭示了系统设计中的 根本性权衡。 一、CAP 的定义 CAP 由三个核心属性组成,任何分布式系统最多只能同时满足其中两个: 一致性(Consistency) 所有节点在同一时刻看到的数据完全…...

Vue-收集表单信息
收集表单信息 Input label for 和 input id 关联, 点击账号标签 也能聚焦 input 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><title>表单数据</title><!-- 引入Vue --><scrip…...

私服 nexus 之间迁移 npm 仓库
本文介绍如何将一个 Nexus 特定仓库中的 npm 包内容迁移到另一个 Nexus 特定仓库。此过程适用于需要重构仓库结构或合并仓库的场景。 迁移脚本 以下是完整的迁移脚本,它会自动完成以下操作: 从源仓库获取所有 npm 包列表下载每个包的 .tgz 文件解压并…...

微服务及容器化设计--可扩展的架构设计
引言 在当今快速发展的技术环境中,企业需要构建能够适应变化、支持快速迭代且可靠的软件系统。传统的单体应用架构在面对高并发、大规模部署和复杂业务逻辑时往往力不从心。微服务架构结合容器化技术应运而生,成为现代可扩展系统设计的主流选择。本文将…...
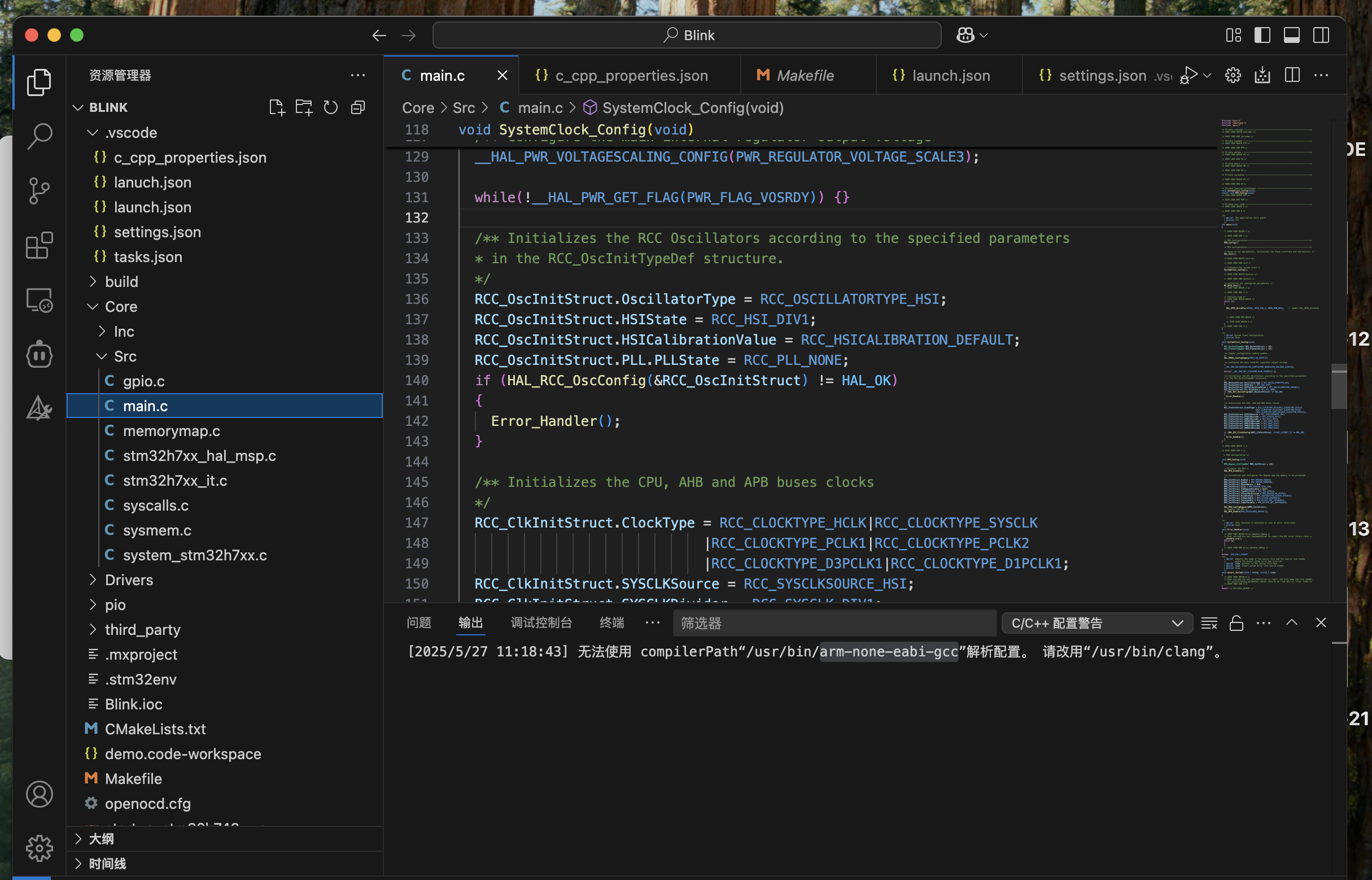
vscode开发stm32,main.c文件中出现很多报错影响开发解决日志
本质上为 .vscode/c_cpp_properties.json文件和Makefile文件中冲突,两者没有同步。 将makefile文件中的内容同步过来即可,下面给出一个json文件的模板,每个人的情况不同,针对性修改即可 {"configurations": [{"na…...
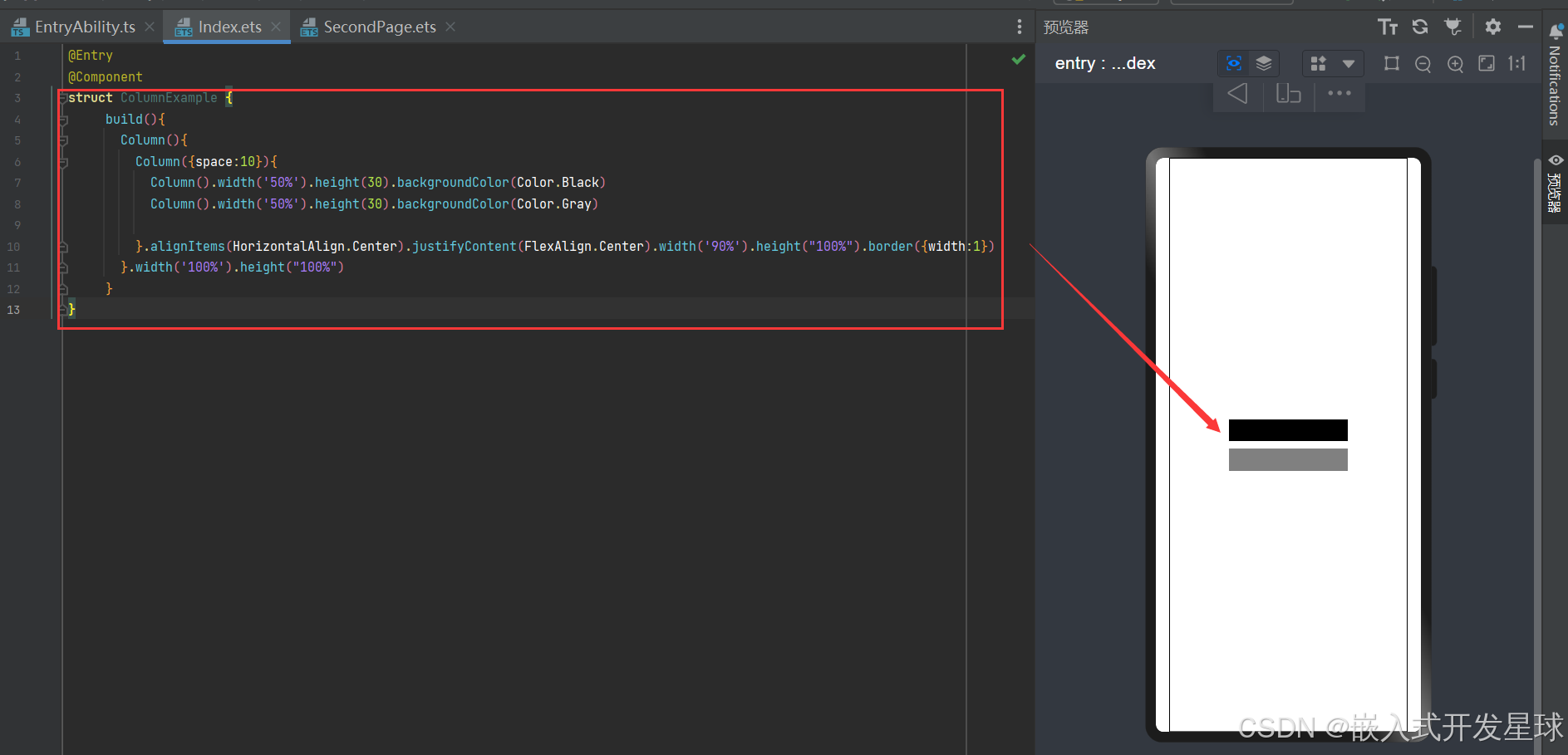
嵌入式鸿蒙系统中水平和垂直以及图片调用方法
利用openharmony操作的具体现象: 第一:Column 作用:沿垂直方向布局的容器。 第二:常用接口 Column(value?: {space?: string | number}) 参数: 参数名参数类型必填参数描述spacestring | number否纵向布局元素垂直方向间距。 从API version 9开始,space为负数或者ju…...
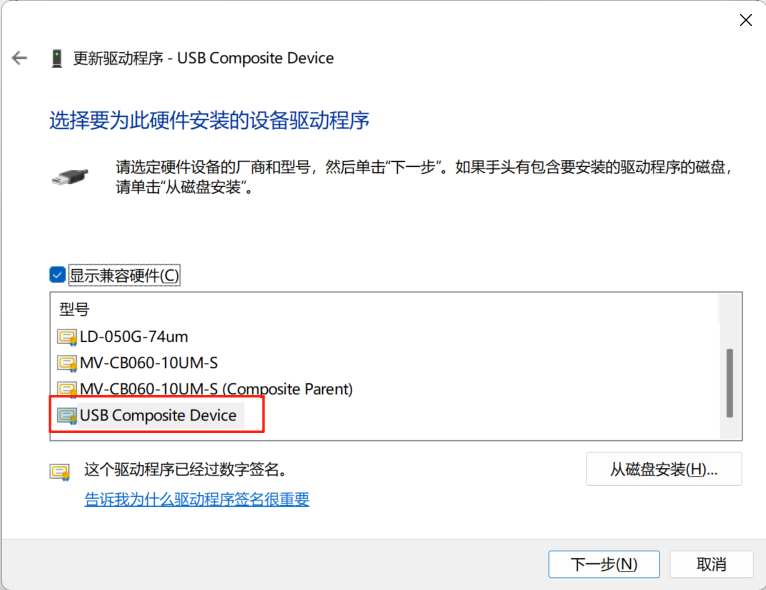
【海康USB相机被HALCON助手连接过后,MVS显示无法连接故障。】
在Halcon里使用助手调用海康USB相机时,如果这个界面点击了【是】 那么恭喜你,相机只能被HALCON调用使用,使用MVS或者海康开发库,将查找不到相机 解决方式: 右键桌面【此电脑】图标 ->选择【管理】 ->选择【设备…...

面试大厂Java:从Spring Boot到微服务架构
面试大厂Java:从Spring Boot到微服务架构 在一个阳光明媚的下午,谢飞机来到了某知名互联网大厂的面试现场,迎接他的是一位严肃的面试官。 第一轮提问: 面试官: 谢飞机,请你简单介绍一下Spring Boot的核心…...

2025年电气工程与轨道交通国际会议:绿色能源与智能交通的创新之路
2025年电气工程与轨道交通国际会议(ICEERT 2025)是一场电气工程与轨道交通领域的国际盛会,将于2025年在武汉隆重召开。此次会议汇聚了全球顶尖的专家学者和行业精英,共同探讨电气工程与轨道交通的最新研究成果和技术趋势。会议将围…...

macOS 安装 Grafana + Prometheus + Node Exporter
macOS 安装指南:Grafana Prometheus Node Exporter 目录简介🚀 快速开始 安装 Homebrew1. 安装 Homebrew2. 更新 Homebrew 安装 Node Exporter使用 Homebrew 安装验证 Node Exporter 安装 Prometheus使用 Homebrew 安装验证安装 安装 Grafana使用 Home…...

WPF log4net用法
WPF log4net用法 一、在工程中管理NuGet程序包,找到log4net,点击安装,如下图已成功安装; 二、在工程中右键添加新建项,选择应用程序配置文件(后缀为.config),然后设置名称,这里设置…...
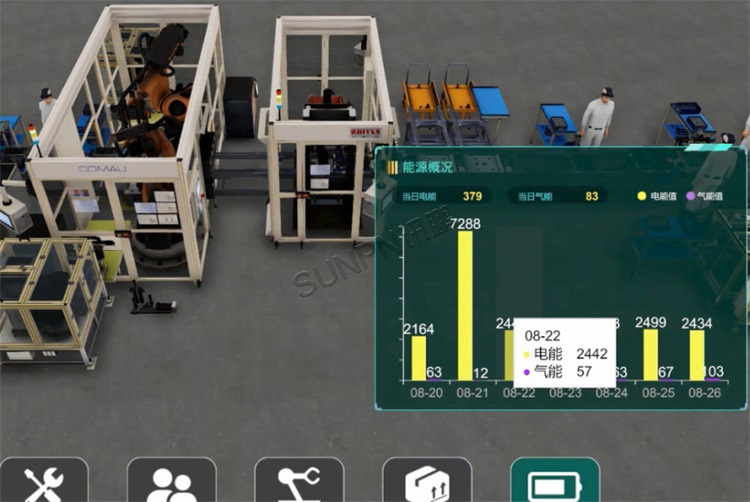
数字孪生数据监控如何提升汽车零部件工厂产品质量
一、汽车零部件工厂的质量挑战 汽车零部件作为汽车制造的基础,其质量直接关系到整车的性能、可靠性和安全性。在传统的汽车零部件生产过程中,质量问题往往难以在早期阶段被发现和解决,导致生产效率低下、生产成本上升,甚至影响到…...

web自动化-Selenium、Playwright、Robot Framework等自动化框架使用场景优劣对比
Web 自动化测试框架根据不同的技术栈和应用场景可分为多种类型,以下是常见的框架及其特点、适用场景: 一、主流框架分类 1. Selenium 生态(Python/Java/C#/JavaScript) 核心组件: WebDriver:操作浏览器的…...

使用 Akamai 分布式云与 CDN 保障视频供稿传输安全
作者简介:David Eisenbacher 是 EZDRM 公司的首席执行官兼联合创始人,该公司是首家提供 "DRM 即服务" 的企业。作为 CEO,David 始终秉持为企业确立的使命:为视频服务商提供简洁有效的数字版权管理方案,助力其…...

vue发版html 生成打包到docker镜像进行发版
将Vue项目打包成Docker镜像部署主要分为以下几个步骤: 1. Vue项目打包 执行npm run build生成dist文件夹,包含静态资源文件 注意检查index.html中资源引用路径是否正确(避免绝对路径问题) 2. 编写Dockerfile Copy Code FROM…...

python uv包管理器使用
官方文档:uv官方文档 注:uv安装不依赖python。 使用: python版本管理 # 查看已安装的python列表 uv python list # 安装特定版本 uv python install 3.12 # 指定项目使用的python版本 uv python pin <version># 使用指定版本运行脚本…...
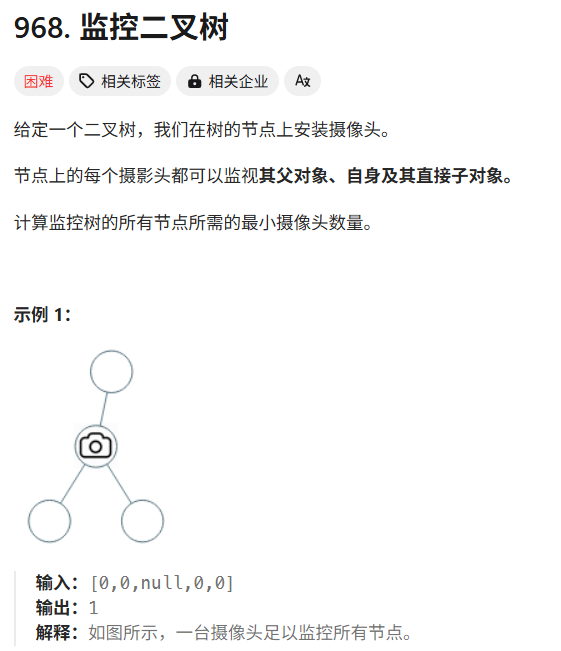
贪心算法实战3
文章目录 前言区间问题跳跃游戏跳跃游戏II用最少数量的箭引爆气球无重叠区间划分字母区间合并区间 最大子序和加油站监控二叉树 前言 今天继续带大家进行贪心算法的实战篇3,本章注意来解答一些运用贪心算法的比较难的问题,大家好好体会,怎么…...

linux、docker、git相关操作
1 linux 1.1解压缩 1.1.1 zip zip xxx.zip file 把file压缩成xxx.zip -r 递归压缩: zip -r example_new.zip 示例集 # 新建压缩包并命名为 example_new.zip zip -r xxx.zip file1 file2 dir1 将多个文件目录压成zip包 unzip file.zip -d target_dir #把file.zip解…...
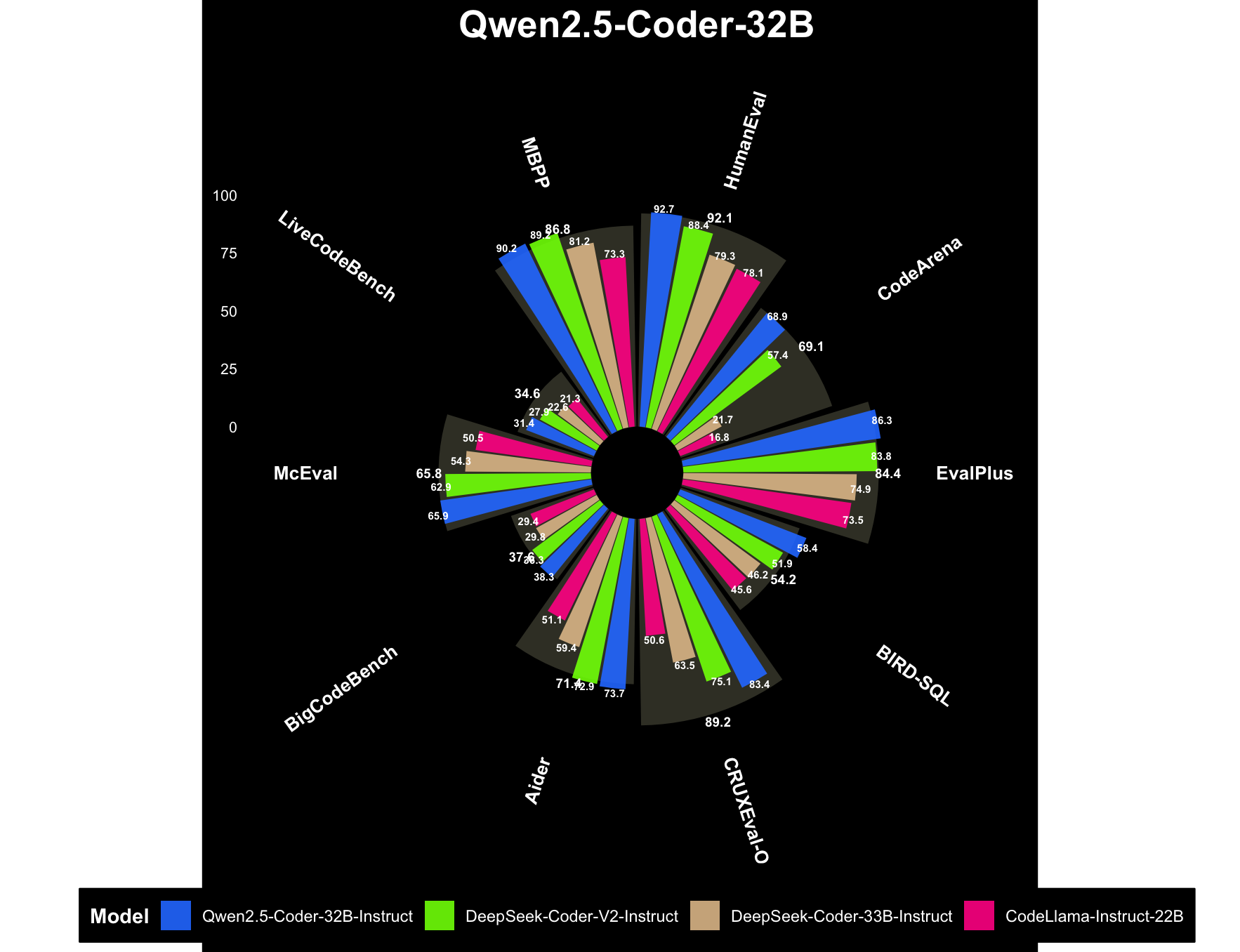
实测,大模型谁更懂数据可视化?
大家好,我是 Ai 学习的老章 看论文时,经常看到漂亮的图表,很多不知道是用什么工具绘制的,或者很想复刻类似图表。 实测,大模型 LaTeX 公式识别,出乎预料 前文,我用 Kimi、Qwen-3-235B-A22B、…...