如何用Python抓取Google Scholar
文章目录
- @[TOC](文章目录)
- 前言
- 一、为什么要抓取Google Scholar?
- 二、Google Scholar 抓取需要什么
- 三、为什么代理对于稳定的抓取是必要的
- 四、一步一步谷歌学者抓取教程
- 4.1. 分页和循环
- 4.2. 运行脚本
- 五、完整的Google Scholar抓取代码
- 六、抓取Google Scholar的高级提示和替代方案
- 6.1. 处理JavaScript渲染的内容
- 6.2. 添加强大的错误处理和重试逻辑
- 6.3. 保存并继续您的抓取会话
- 6.4. 使用像Decodo的网络抓取 API这样的一体式抓取解决方案
- 总结
文章目录
- @[TOC](文章目录)
- 前言
- 一、为什么要抓取Google Scholar?
- 二、Google Scholar 抓取需要什么
- 三、为什么代理对于稳定的抓取是必要的
- 四、一步一步谷歌学者抓取教程
- 4.1. 分页和循环
- 4.2. 运行脚本
- 五、完整的Google Scholar抓取代码
- 六、抓取Google Scholar的高级提示和替代方案
- 6.1. 处理JavaScript渲染的内容
- 6.2. 添加强大的错误处理和重试逻辑
- 6.3. 保存并继续您的抓取会话
- 6.4. 使用像Decodo的网络抓取 API这样的一体式抓取解决方案
- 总结
前言
Google Scholar是一个免费的学术文章、书籍和研究论文搜索引擎。如果你正在为研究、分析或应用程序开发收集学术数据,这篇博客文章将为你提供可靠的基础。在本指南中,您将学习如何使用Python抓取Google Scholar,设置代理以避免IP禁令,构建一个可用的抓取器,并探索扩展数据收集的高级技巧。

一、为什么要抓取Google Scholar?
网络抓取Google Scholar可以解锁难以手动收集的数据点。从书目数据库到研究趋势分析,用户可能希望自动化这一过程的原因数不胜数。
通过抓取Google Scholar,您可以提取有价值的元数据,如文章标题、摘要、作者和引用计数。这对于创建数据集、构建学术工具或跟踪特定领域内的影响和趋势特别有用。
您还可以提取合著者数据和“引用者”信息,以分析协作网络或学术影响。您可以使用Google Scholar引用数据进行引文分析,提取完整的作者资料进行研究分析,或捕获Google Scholar的有机结果进行比较研究。
二、Google Scholar 抓取需要什么
在开始抓取Google Scholar之前,确保你有正确的设置是很重要的。以下是您需要的内容:
- 已安装Python 3.7或更高版本。Python的灵活性和庞大的库生态系统使其成为网络抓取的首选语言。请确保您的计算机上安装了Python 3.7或更高版本。你可以从官方网站下载。
- 请求和BeautifulSoup4库。您需要两个Python库来发送web请求和解析HTML内容。Requests允许您以编程方式发出HTTP请求,而BeautifulSoup4则使您可以轻松地从HTML文档中导航和提取数据。您可以在终端中使用以下命令安装它们:
pip install requests beautifulsoup4
- 基本熟悉浏览器检查工具。您应该知道如何使用检查元素功能(在Chrome、Firefox、Edge和其他浏览器中可用)。检查页面元素可以帮助您识别抓取器需要查找和提取正确数据的HTML结构、类和标签。
- 可靠的代理服务。Google Scholar积极限制自动访问。如果你抓取的不仅仅是几个页面,那么代理服务至关重要。使用住宅或轮换代理可以帮助您避免IP禁令,并保持稳定的抓取会话。对于小规模的手动测试,代理可能不是必需的,但对于任何严重的刮擦,它们都是必备的。
三、为什么代理对于稳定的抓取是必要的
在抓取Google Scholar时,代理非常有用。Google Scholar具有强大的反机器人机制,如果检测到异常行为,例如在短时间内发送太多请求,可以快速阻止您的IP地址。通过将流量路由到不同的IP地址,代理可以帮助您分发请求,避免达到速率限制或触发验证码。
为了获得最佳效果,建议使用动态住宅代理。住宅IP与真实的互联网服务提供商相关联,使您的流量看起来更像是在家浏览的典型用户。理想情况下,使用轮换代理服务,为每个请求自动分配一个新的IP地址,提供最大的覆盖范围并最大限度地减少被禁止的机会。
在Decodo,我们提供住宅代理,成功率高(99.86%),响应时间快(<0.6秒),地理定位选项广泛(全球195多个地点)。以下是获取计划和代理凭据的简单方法:
- 前往Decodo仪表板并创建一个帐户。
- 在左侧面板上,单击住宅和住宅。
- 选择订阅、Pay As You Go 计划,或选择3天免费测试。
- 在代理设置选项卡中,根据需要选择位置、会话类型和协议。
- 复制您的代理地址、端口、用户名和密码以供以后使用。或者,您可以单击表右下角的下载图标下载代理端点(默认为10)。
四、一步一步谷歌学者抓取教程
让我们一步一步地浏览一下抓取Google Scholar的完整Python脚本。我们将分解代码的每个部分,解释为什么需要它,并向您展示如何将它们组合在一起以创建一个可靠的scraper。
- 导入所需的库
我们首先导入必要的库:用于发出HTTP请求的请求和来自bs4模块的用于解析HTML的BeautifulSoup。使用这些库,您可以像浏览器一样发送HTTP请求,然后解析生成的HTML以准确提取所需内容:
import requests
from bs4 import BeautifulSoup
- 设置代理
在脚本的顶部,我们定义代理凭据并构建代理字符串。此字符串稍后用于配置我们的HTTP请求,使其通过代理传输。在这个例子中,我们将使用一个代理端点来随机化位置,并在每次请求时轮换IP。请确保在适当的位置插入您的用户名和密码凭据:
# Proxy credentials and proxy string
username = 'YOUR_USERNAME'
password = 'YOUR_PASSWORD'
proxy = f"http://{username}:{password}@gate.decodo.com:7000"
- 定义自定义标头和代理
通过使用详细的用户代理字符串,我们确保服务器将请求视为任何常规浏览器请求。这有助于避免自动脚本可能导致的阻塞。当没有提供代理URL时,我们没有将代理设置为None,而是使用空字典,简化了请求逻辑,使代理参数始终收到字典。
def scrape_google_scholar(query_url, proxy_url=None):# Set a user agent to mimic a real browser.headers = {"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/98.0.4758.102 Safari/537.36")}# Always create a proxies dictionary; if no proxy is provided, use an empty dict.proxies = {'http': proxy_url, 'https': proxy_url} if proxy_url else {}
- 检索并验证页面
以下代码块将我们的HTTP GET请求发送到Google Scholar。通过传递头文件dict,我们将自己呈现为一个真正的浏览器,并在配置代理时透明地路由代理。之后,我们立即检查响应的状态代码。如果不是“200 OK”,我们会打印一个错误并返回一个空列表,以防止进一步解析不完整或有错误的页面。
# Retrieve the page using the proxy (or direct connection if proxies is empty).
response = requests.get(query_url, headers=headers, proxies=proxies)
if response.status_code != 200:print("Failed to retrieve page. Status code:", response.status_code)return []
- 解析HTML内容
成功下载页面后,我们使用BeautifulSoup解析其内容。然后,解析器使用类gs_r搜索所有*< div >*元素,该类通常封装每个Google Scholar结果。

我们使用浏览器的Inspect工具发现了这个类:通过单击Google Scholar结果框,开发人员工具会突出显示相应的< div >及其类。
# Parse the HTML content.
soup = BeautifulSoup(response.text, "html.parser")# Find all result containers.
results = soup.find_all('div', class_='gs_r')
data = []
- 从每个结果中提取数据
接下来,我们遍历刚刚选择的每个结果块,提取我们关心的字段,如标题、作者、摘录和引用信息,跳过任何非真实出版物(如作者简介摘要)。
for result in results:item = {}# Retrieve the title of the result.title_tag = result.find('h3', class_='gs_rt')if not title_tag:continuetitle_text = title_tag.get_text(strip=True)# Skip user profile blocks.if title_text.startswith("User profiles for"):continueitem['title'] = title_text# Retrieve the authors and publication info.author_tag = result.find('div', class_='gs_a')item['authors'] = author_tag.get_text(strip=True) if author_tag else None# Retrieve the description.description_tag = result.find('div', class_='gs_rs')item['description'] = description_tag.get_text(strip=True) if description_tag else None# Retrieve the "Cited by" number.cited_by_tag = result.find('a', string=lambda x: x and x.startswith("Cited by"))if cited_by_tag:try:# Extract the number from the text.count = int(cited_by_tag.get_text().split("Cited by")[-1].strip())item['cited_by'] = countexcept ValueError:item['cited_by'] = None# Build the absolute URL for the citation link.citation_link = cited_by_tag.get('href', None)if citation_link:item['citation_link'] = "https://scholar.google.com" + citation_linkelse:item['citation_link'] = Noneelse:item['cited_by'] = 0item['citation_link'] = Nonedata.append(item)return data
下面是上面代码的作用:
- 标题提取和过滤。我们在每个结果中寻找一个< h3 class=“gs_rt” >。如果它丢失了,我们完全跳过那个块。我们也会忽略标题以“的用户资料”开头的任何结果,因为这是Google Scholar的作者概述部分,而不是出版物。
- 作者和出版信息。接下来,我们抓取< div class=“gs_a” >中的任何文本。这通常包含作者姓名、期刊标题和出版日期。如果它不存在,我们记录为“无”。
- 说明。该代码段位于< div class=“gs_rs” >中。这是Google Scholar在每个标题下显示的简短摘录。同样,如果它缺失,我们指定None。
- 引用次数和链接。我们搜索文本以“Cited by”开头的< a >标签。如果找到,我们解析下一个整数。我们还将其href属性(相对URL)作为前缀“https://scholar.google.com创建引用论文列表的完整链接。如果没有找到"Cited by”链接,我们将计数和链接设置为合理的默认值。
- 保存记录。最后,每个条目词典(现在包含标题、作者、摘录、引用计数和链接)都附加到我们的数据列表中以供以后使用。
4.1. 分页和循环
要收集第一页以外的结果,我们需要处理Google Scholar的分页。创建一个函数并将其命名为scrap_multiple_pages。它将通过迭代每个页面的开始参数,重复调用我们的单页抓取器,并将所有单个页面结果拼接到一个合并列表中,从而自动分页:
- 初始化一个空列表。我们从all_data=[]开始收集所有页面的每个结果。
- 循环页码。for i in range(num_pages)循环每页运行一次。所以,i=0是第一页,i=1是第二页,以此类推。
- 构造正确的URL。在第一次迭代(i==0)中,我们使用原始的base_URL。在后续迭代中,我们在URL后附加start={i10}。Google Scholar需要一个跳过前N个结果的start参数(每页10个)。我们选择&还是?这取决于base_url*是否已经具有查询参数。
- 刮掉每一页。我们调用*scrape_google_scholar(page_url,proxy_url)*来获取和解析该页面的结果。
- 如果没有结果,就早点停下来。如果一个页面返回一个空列表,我们假设没有什么可以抓取和打破循环的了。
- 汇总所有结果。每个页面的page_data都扩展到all_data上,因此在循环结束时,您有一个包含所有请求页面的每个结果的列表。
def scrape_multiple_pages(base_url, num_pages, proxy_url=None):all_data = []for i in range(num_pages):# For the first page, use the base URL; for subsequent pages, append the "start" parameter.if i == 0:page_url = base_urlelse:if "?" in base_url:page_url = base_url + "&start=" + str(i * 10)else:page_url = base_url + "?start=" + str(i * 10)print("Scraping:", page_url)print("")page_data = scrape_google_scholar(page_url, proxy_url)if not page_data:breakall_data.extend(page_data)return all_data
4.2. 运行脚本
在最后一节中,我们设置了搜索URL和页面计数,调用scraper(具有代理支持),然后循环返回的项目以打印每个项目。运行脚本时,此块:
- 初始化查询。使用您的学者搜索参数定义base_url。设置num_pages以控制要获取的结果页的数量。
- 启动刮刀。调用scrape_multiple_pages(base_url,num_pages,proxy_url=proxy),它在幕后处理分页和代理路由。
- 格式化和输出结果。遍历结果列表中的每个字典。以可读的布局打印标题、作者、描述、“Cited by”计数和完整的引用链接。
最后一个块确保在执行时,脚本通过您的代理无缝连接,在指定数量的页面上获取和解析Google Scholar结果,并以有组织、人性化的格式显示每条记录。
在这个例子中,我们使用“chomsky”作为我们的搜索词。诺姆·乔姆斯基(Noam Chomsky)的大量作品意味着他的名字将产生丰富的出版物、引文数量和相关链接,展示该脚本如何处理不同的结果条目。
if __name__ == '__main__':# Insert your Google Scholar search URL below.base_url = "https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=chomsky&btnG="num_pages = 1 # Adjust this number to scrape more pages.results = scrape_multiple_pages(base_url, num_pages, proxy_url=proxy)# Display the aggregated results.for i, result in enumerate(results, 1):print(f"Result {i}:")print("Title:", result['title'])print("Authors:", result['authors'])print("Description:", result['description'])print("Cited by:", result['cited_by'])print("Citation link:", result.get('citation_link', None))print("-" * 80)
五、完整的Google Scholar抓取代码
下面是我们在本教程中组装的完整Python脚本。您可以复制、运行它,并将其调整到您自己的Google Scholar抓取项目中。
import requests
from bs4 import BeautifulSoup# Proxy credentials and proxy string.
username = 'YOUR_USERNAME'
password = 'YOUR_PASSWORD'
proxy = f"http://{username}:{password}@gate.decodo.com:7000"def scrape_google_scholar(query_url, proxy_url=None):# Set a user agent to mimic a real browser.headers = {"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/98.0.4758.102 Safari/537.36")}# Always create a proxies dictionary; if no proxy is provided, use an empty dict.proxies = {'http': proxy_url, 'https': proxy_url} if proxy_url else {}# Retrieve the page using the proxy (or direct connection if proxies is empty).response = requests.get(query_url, headers=headers, proxies=proxies)if response.status_code != 200:print("Failed to retrieve page. Status code:", response.status_code)return []# Parse the HTML content.soup = BeautifulSoup(response.text, "html.parser")# Find all result containers.results = soup.find_all('div', class_='gs_r')data = []for result in results:item = {}# Retrieve the title of the result.title_tag = result.find('h3', class_='gs_rt')if not title_tag:continuetitle_text = title_tag.get_text(strip=True)# Skip user profile blocks.if title_text.startswith("User profiles for"):continueitem['title'] = title_text# Retrieve the authors and publication info.author_tag = result.find('div', class_='gs_a')item['authors'] = author_tag.get_text(strip=True) if author_tag else None# Retrieve the description.description_tag = result.find('div', class_='gs_rs')item['description'] = description_tag.get_text(strip=True) if description_tag else None# Retrieve the "Cited by" number.cited_by_tag = result.find('a', string=lambda x: x and x.startswith("Cited by"))if cited_by_tag:try:# Extract the number from the text.count = int(cited_by_tag.get_text().split("Cited by")[-1].strip())item['cited_by'] = countexcept ValueError:item['cited_by'] = None# Build the absolute URL for the citation link.citation_link = cited_by_tag.get('href', None)if citation_link:item['citation_link'] = "https://scholar.google.com" + citation_linkelse:item['citation_link'] = Noneelse:item['cited_by'] = 0item['citation_link'] = Nonedata.append(item)return datadef scrape_multiple_pages(base_url, num_pages, proxy_url=None):all_data = []for i in range(num_pages):# For the first page, use the base URL; for subsequent pages, append the "start" parameter.if i == 0:page_url = base_urlelse:if "?" in base_url:page_url = base_url + "&start=" + str(i * 10)else:page_url = base_url + "?start=" + str(i * 10)print("Scraping:", page_url)print("")page_data = scrape_google_scholar(page_url, proxy_url)if not page_data:breakall_data.extend(page_data)return all_dataif __name__ == '__main__':base_url = "https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=chomsky&btnG="num_pages = 1 # Adjust this number to scrape more pages.results = scrape_multiple_pages(base_url, num_pages, proxy_url=proxy)# Display the aggregated results.for i, result in enumerate(results, 1):print(f"Result {i}:")print("Title:", result['title'])print("Authors:", result['authors'])print("Description:", result['description'])print("Cited by:", result['cited_by'])print("Citation link:", result.get('citation_link', None))print("-" * 80)
在编码环境中运行它后,结果如下:

六、抓取Google Scholar的高级提示和替代方案
一旦你运行了一个基本的抓取器,你可能会开始遇到更高级的挑战,比如处理动态内容、缩放抓取量或处理偶尔的访问限制。以下是一些额外的技术和解决方案,可以提高您的谷歌学术抓取能力:
6.1. 处理JavaScript渲染的内容
尽管Google Scholar的大部分主页都是静态HTML,但一些边缘情况或未来的变化可能会引入JavaScript渲染的元素。Selenium、Playwright或Puppeteer等工具可以模拟完整的浏览器环境,使抓取甚至动态加载的内容变得容易。
6.2. 添加强大的错误处理和重试逻辑
大规模抓取时,网络故障、临时服务器问题或偶尔失败的请求是不可避免的。在您的scraper中构建重试机制,以自动重试失败的请求,最好是随机退避间隔。这有助于在长时间的抓取过程中保持稳定性。
6.3. 保存并继续您的抓取会话
如果你打算抓取大量页面,可以考虑实施一个系统,在每几页或结果后保存你的进度。这样,如果您的scraper中断,您可以轻松地从中断的地方继续,而不会重复工作或丢失数据。
wangluo
6.4. 使用像Decodo的网络抓取 API这样的一体式抓取解决方案
为了提高效率和可靠性,可以考虑使用Decodeo的网络抓取 API。它结合了一个强大的网络爬虫,可以访问125M多个住宅、数据中心、移动和ISP代理,无需自己管理IP轮换。其主要特征包括:
- 动态页面的JavaScript渲染;
- 每秒无限制请求,无需担心限制;
- 195+个地理目标位置,用于精确抓取;
- 7天免费试用,无需承诺即可测试服务。
总结
到目前为止,您已经了解到可以使用Python通过Requests和BeautifulSoup库访问Google Scholar,并且使用可靠的代理对于成功设置至关重要。不要忘记遵循最佳实践,并考虑使用简化的工具来提取所需的数据。
相关文章:
如何用Python抓取Google Scholar
文章目录 [TOC](文章目录) 前言一、为什么要抓取Google Scholar?二、Google Scholar 抓取需要什么三、为什么代理对于稳定的抓取是必要的四、一步一步谷歌学者抓取教程4.1. 分页和循环4.2. 运行脚本 五、完整的Google Scholar抓取代码六、抓取Google Scholar的高级提…...

电脑革命家测试版:硬件检测,6MB 轻量无广告 清理垃圾 + 禁用系统更新
各位电脑小白和大神们,我跟你们说啊!有个超牛的东西叫电脑革命家测试版,这是吾爱破解论坛的开发者搞出来的免费无广告系统工具集合,主打硬件检测和系统优化,就像是鲁大师这些软件的平替。下面我给你们唠唠它的核心功能…...
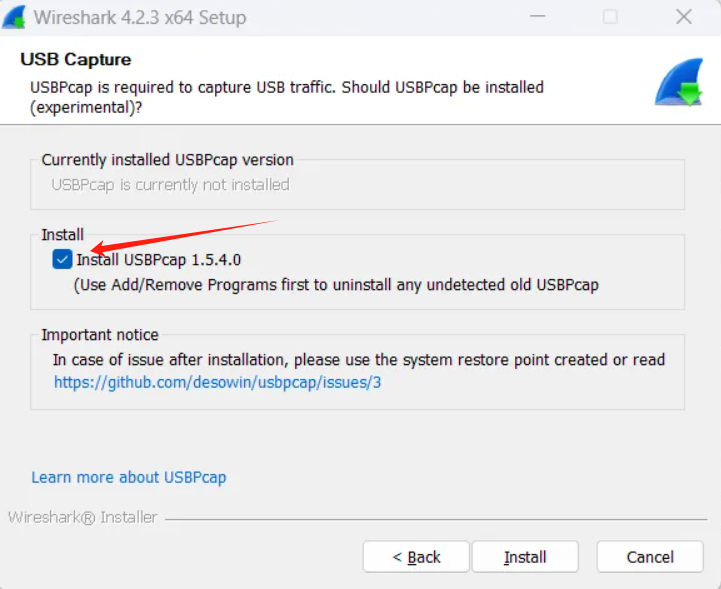
Wireshark对usb设备进行抓包找不到USBPcap接口的解决方案
引言 近日工作需要针对usb设备进行抓包,但按照wireshark安装程序流程一步步走,即使勾选了安装USBPcap安装完成后开启wireshark依然不显示USBPcap接口,随设法进行解决。 最终能够正常显示USBPcap接口并能够正常使用进行抓包 解决方案&#x…...

题目 3298: 蓝桥杯2024年第十五届决赛真题-兔子集结
题目 3298: 蓝桥杯2024年第十五届决赛真题-兔子集结 时间限制: 2s 内存限制: 192MB 提交: 2499 解决: 309 题目描述 在森林幽静的一隅,有一村落居住着 n 只兔子。 某个月光皎洁的夜晚,这些兔子列成一队,准备开始一场集结跳跃活动。村落中…...

Unity开发之Webgl自动更新程序包
之前让客户端更新webgl程序是在程序里写版本号然后和服务器对比,不同就调用 window.location.reload(true);之前做的客户端都是给企业用,用户数少看不出来啥问题。后来自己开发一个小网站,用户数量还是挺多,然后就会遇到各种各样的…...

深入理解设计模式之状态模式
深入理解设计模式之:状态模式(State Pattern) 一、什么是状态模式? 状态模式(State Pattern)是一种行为型设计模式。它允许一个对象在其内部状态发生改变时,改变其行为(即表现出不…...
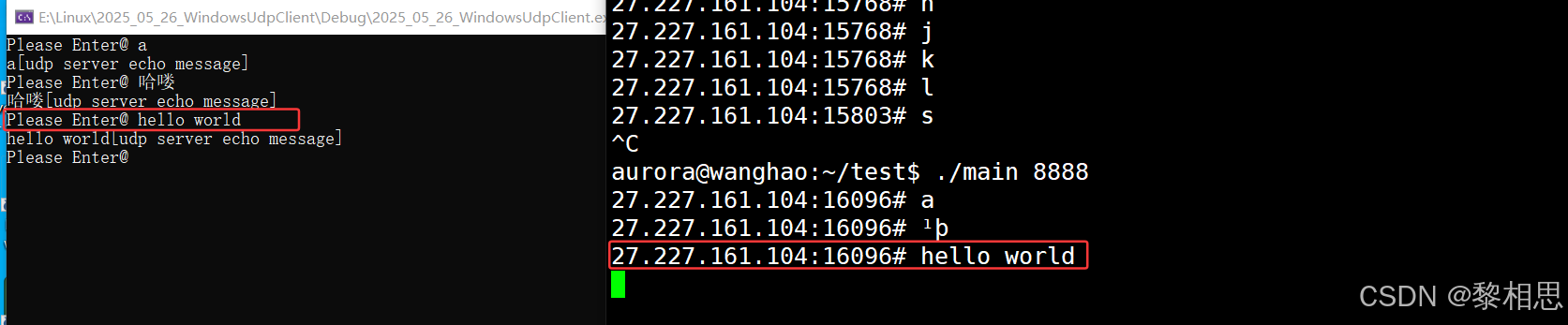
Socket 编程 UDP
目录 1. UDP网络编程 1.1 echo server 1.1.1 接口 1.1.1.1 创建套接字 1.1.1.2 绑定 1.1.1.3 bzero 1.1.1.4 htons(主机序列转网络序列) 1.1.1.5 inet_addr(主机序列IP转网络序列IP) 1.1.1.6 recvfrom(让服务…...
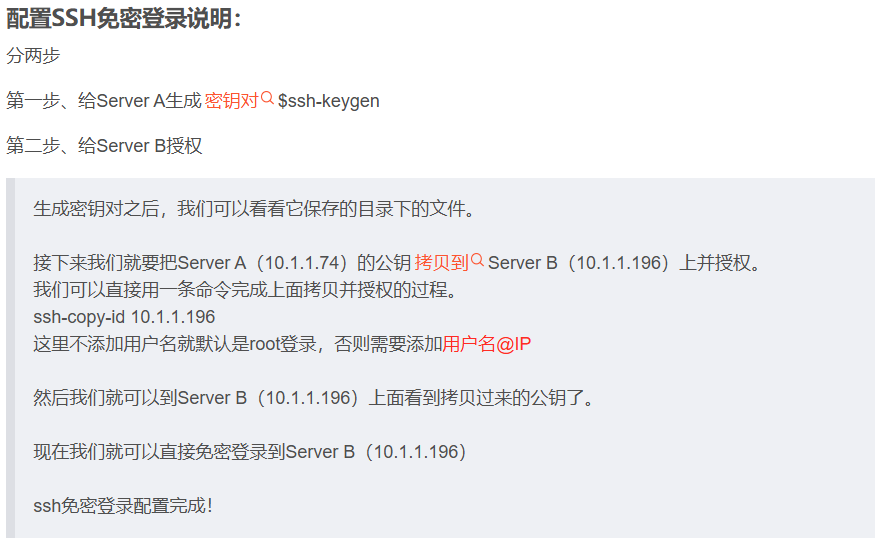
Jenkins实践(8):服务器A通过SSH调用服务器B执行Python自动化脚本
Jenkins实践(8):服务器A通过SSH调用服务器B执行Python自动化脚本 1、需求: 1、Jenkins服务器在74上,Python脚本在196服务器上 2、需要在服务器74的Jenkins上调用196上的脚本执行Python自动化测试 2、操作步骤 第一步:Linux Centos7配置SSH免密登录 Linux Centos7配置S…...

Spring AI系列之Spring AI 集成 ChromaDB 向量数据库
1. 概述 在传统数据库中,我们通常依赖精确的关键词或基本的模式匹配来实现搜索功能。虽然这种方法对于简单的应用程序已经足够,但它无法真正理解自然语言查询背后的含义和上下文。 向量存储解决了这一限制,它通过将数据以数值向量的形式存储…...

lua的注意事项2
总之,下面的返回值不是10,a,b 而且...

主流电商平台的反爬机制解析
随着数据成为商业决策的重要资源,越来越多企业和开发者希望通过技术手段获取电商平台的公开信息,用于竞品分析、价格监控、市场调研等。然而,主流电商平台如京东、淘宝(含天猫)等为了保护数据安全和用户体验࿰…...

前端八股之HTML
前端秘籍-HTML篇 1. src和href的区别 src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系。 (1)src src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置࿱…...

tiktoken学习
1.tiktoken是OpenAI编写的进行高效分词操作的库文件。 2.操作过程: enc tiktoken.get_encoding("gpt2") train_ids enc.encode_ordinary(train_data) val_ids enc.encode_ordinary(val_data) 以这段代码为例,get_encoding是创建了一个En…...
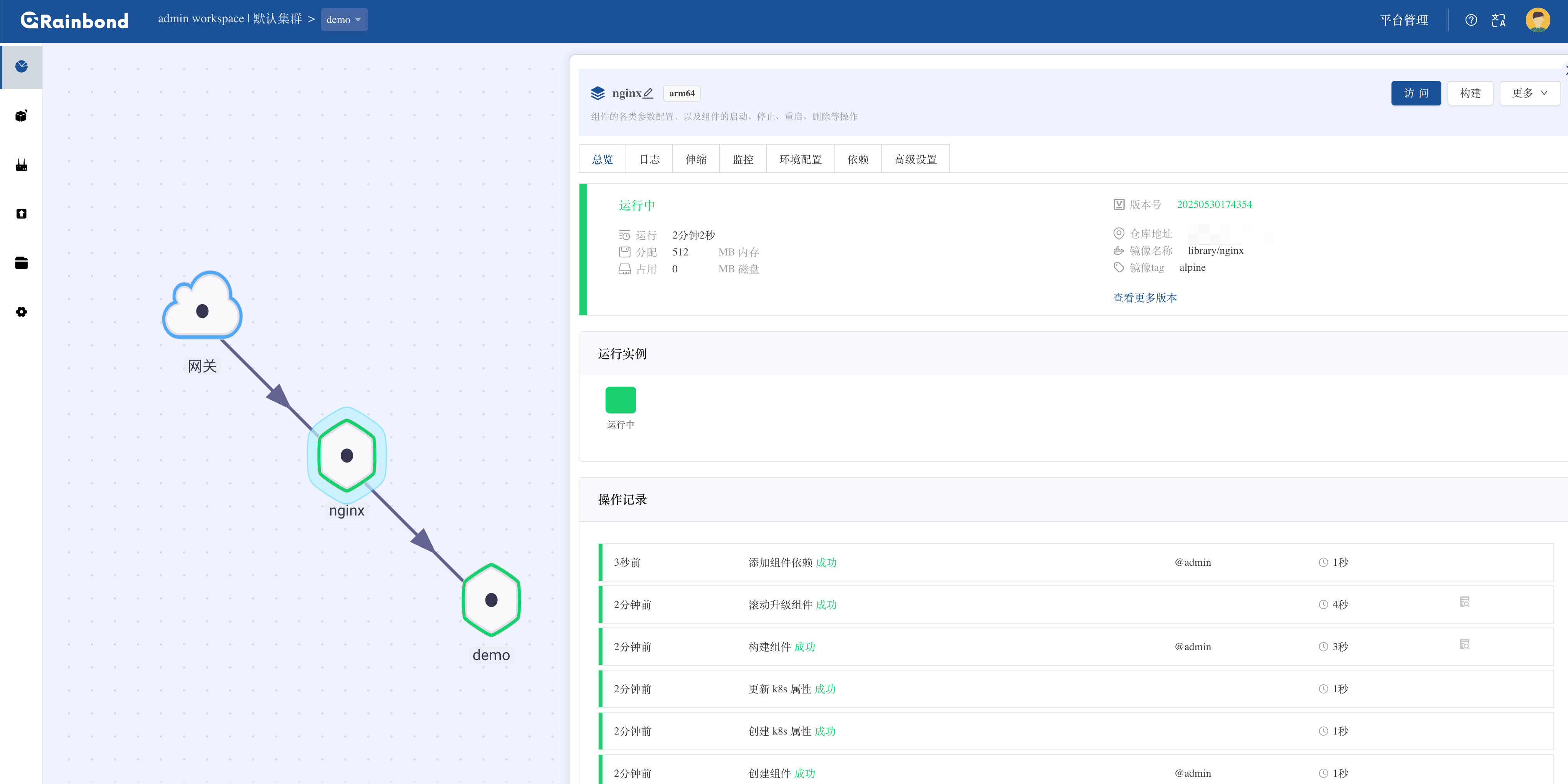
鲲鹏Arm+麒麟V10,国产化信创 K8s 离线部署保姆级教程
Rainbond V6 国产化部署教程,针对鲲鹏 CPU 麒麟 V10 的离线环境,手把手教你从环境准备到应用上线,所有依赖包提前打包好,步骤写成傻瓜式操作指南。别说技术团队了,照着文档一步步来,让你领导来都能独立完成…...

历年厦门大学计算机保研上机真题
2025厦门大学计算机保研上机真题 2024厦门大学计算机保研上机真题 2023厦门大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 数字变换过程的最大值与步数 题目描述 输入一个数字 n n n,如果 n n n 是偶数就将该偶数除以 2 2 2&…...
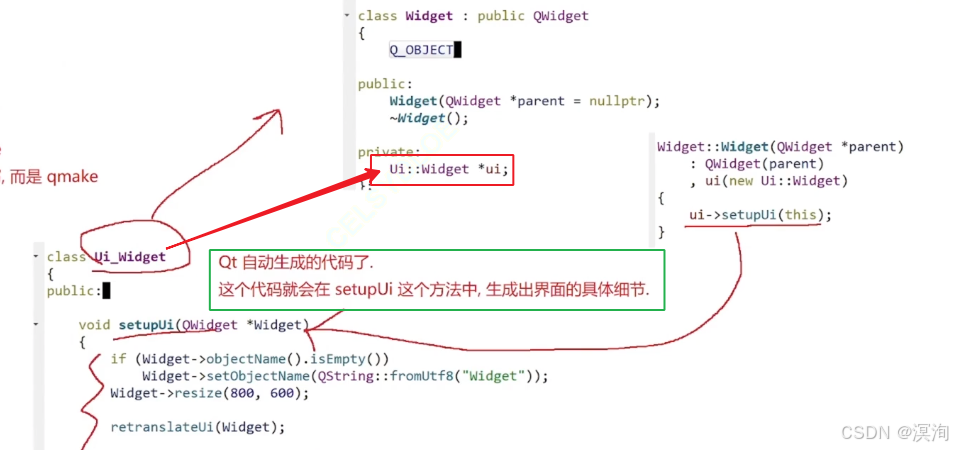
【C++ Qt】认识Qt、Qt 项目搭建流程(图文并茂、通俗易懂)
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本章将开启Qt的学习,Qt是一个较为古老但仍然在GUI图形化界面设计中有着举足轻重的地位,因为它适合嵌入式和多种平台而被广泛使用…...
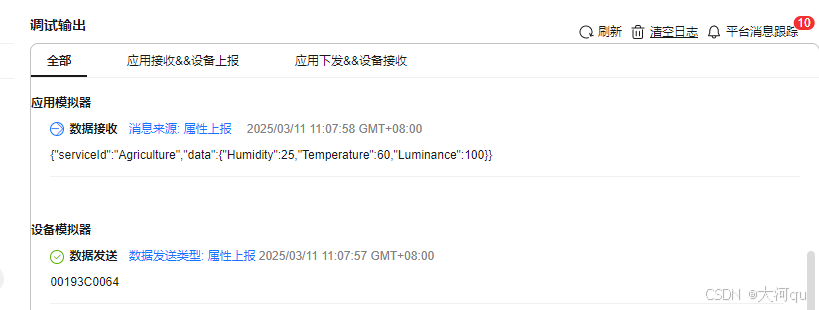
IoT/HCIP实验-1/物联网开发平台实验Part2(HCIP-IoT实验手册版)
文章目录 概述产品和设备实例的产品和设备产品和设备的关联单个产品有多个设备为产品创建多个设备产品模型和物模型设备影子(远程代理) 新建产品模型定义编解码插件开发编解码插件工作原理消息类型与二进制码流添加消息(数据上报消息…...
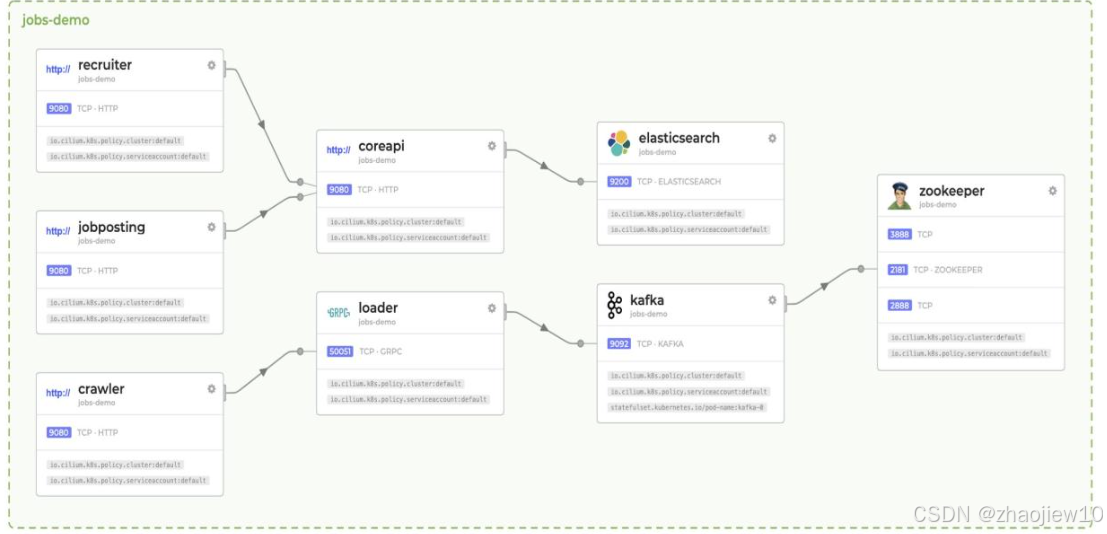
Replacing iptables with eBPF in Kubernetes with Cilium
source: https://archive.fosdem.org/2020/schedule/event/replacing_iptables_with_ebpf/attachments/slides/3622/export/events/attachments/replacing_iptables_with_ebpf/slides/3622/Cilium_FOSDEM_2020.pdf 使用Cilium,结合eBPF、Envoy、Istio和Hubble等技术…...

推荐系统排序指标:MRR、MAP和NDCG
文章目录 MRR: Mean Reciprocal RankMAP: Mean Average PrecisionNDCG: Normalized Discounted Cumulative Gain3个度量标准来自于两个度量家族。第一种度量包括基于二进制相关性的度量。这些度量标准关心的是一个物品在二进制意义上是否是好的。第二个系列包含基于应用的度量。…...
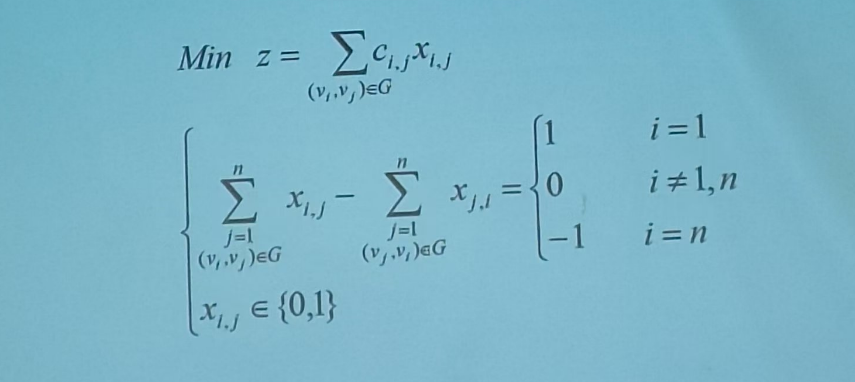
数学建模之最短路径问题
1 问题的提出 这个是我们的所要写的题目,我们要用LINGO编程进行编写这个题目,那么就是需要进行思考这个怎么进行构建这个问题的模型 首先起点,中间点,终点我们要对这个进行设计 2 三个点的设计 起点的设计 起点就是我们进去&am…...
测试概念 和 bug
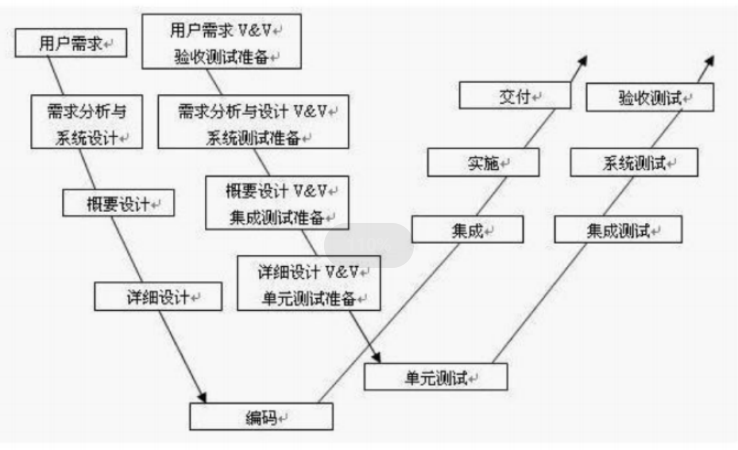
一 敏捷模型 在面对在开发项目时会遇到客户变更需求以及合并新的需求带来的高成本和时间 出现的敏捷模型 敏捷宣言 个人与交互重于过程与工具 强调有效的沟通 可用的软件重于完备的文档 强调轻文档重产出 客户协作重于合同谈判 主动及时了解当下的要求 相应变化…...
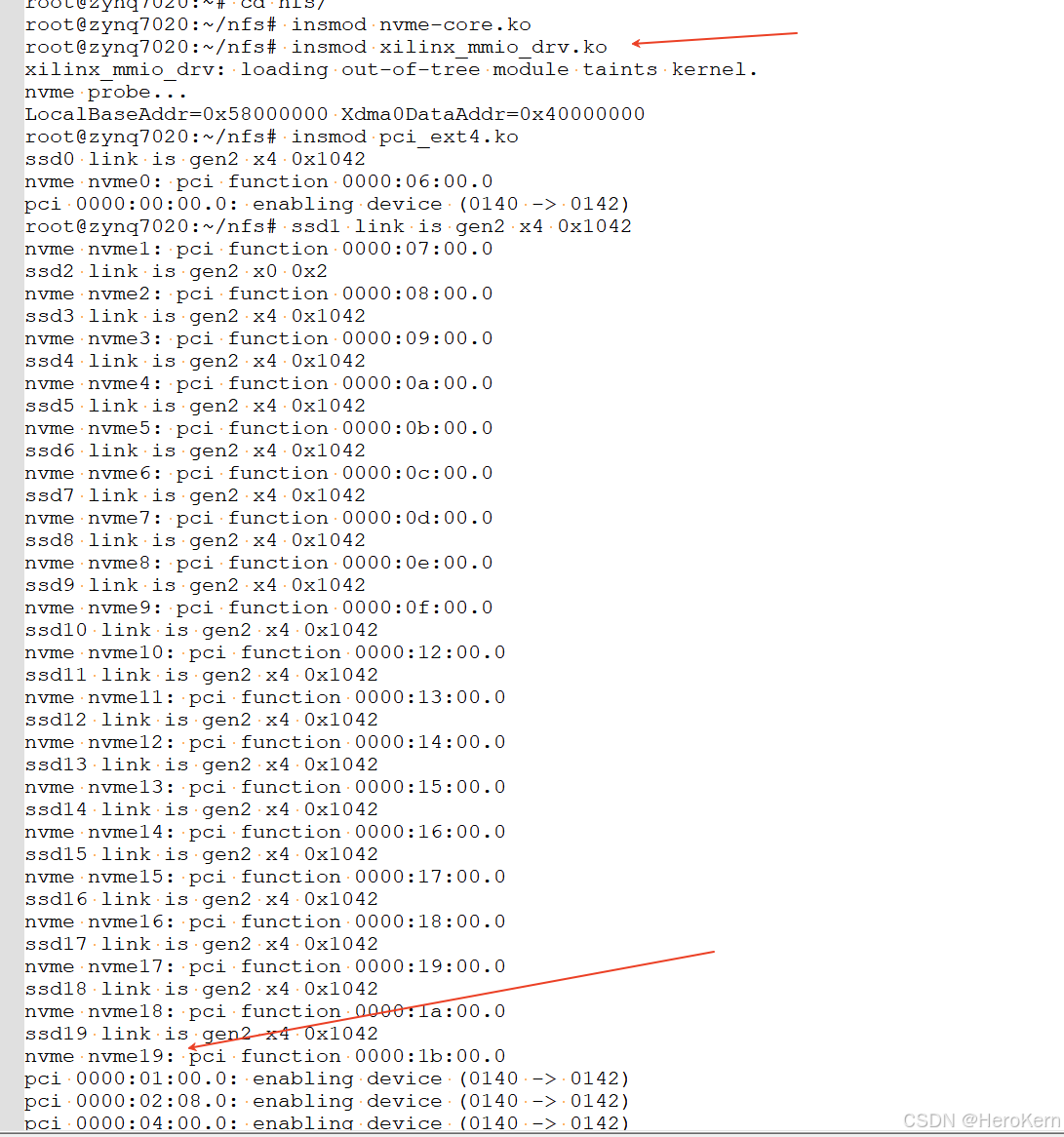
zynq 级联多个ssd方案设计(ECAM BUG修改)
本文讲解采用zynq7045芯片如何实现200T容量高速存储方案设计,对于大容量高速存储卡,首先会想到采用pcie switch级联方式,因为单张ssd的容量是有限制的(目前常见的m.2接口容量为4TB,U.2接口容量为16TB)&…...

brep2seq 论文笔记
Brep2Seq: a dataset and hierarchical deep learning network for reconstruction and generation of computer-aided design models | Journal of Computational Design and Engineering | Oxford Academic 这段文本描述了一个多头自注意力机制(MultiHead Attenti…...

【运维实战】Linux 中设置 sudo ,8个有用的 sudoers 配置!
在Linux及其他类Unix操作系统中,只有 root 用户能够执行所有命令并进行关键系统操作,例如安装更新软件包、删除程序、创建用户与用户组、修改重要系统配置文件等。 但担任 root 角色的系统管理员可通过配置sudo命令,允许普通系统用户执行特定…...

Ad Hoc
什么是 Ad Hoc? Ad hoc 一词源于拉丁语,意为“为此目的”或“为此特定原因”。一般来讲,它指的是为解决某一特定问题或任务(而非为了广泛重复应用)而设计的行动、解决方案或组合。在加密货币和区块链领域,…...
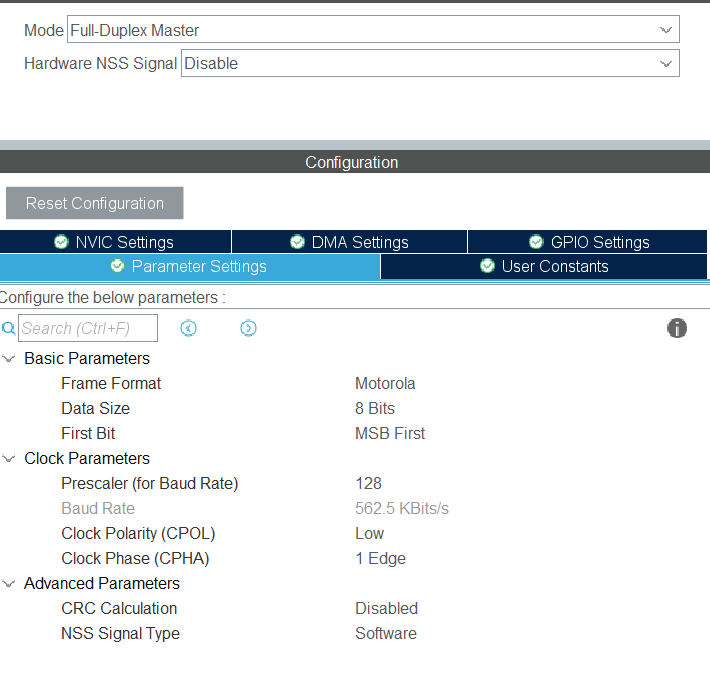
江科大SPI串行外设接口hal库实现
hal库相关函数 初始化结构体 typedef struct {uint32_t Mode; /*SPI模式*/uint32_t Direction; /*SPI方向*/uint32_t DataSize; /*数据大小*/uint32_t CLKPolarity; /*时钟默认极性控制CPOL*/uint32_t CLKPhase; /*…...

[网页五子棋][对战模块]前后端交互接口(建立连接、连接响应、落子请求/响应),客户端开发(实现棋盘/棋子绘制)
文章目录 约定前后端交互接口建立连接建立连接响应针对"落子"的请求和响应 客户端开发实现棋盘/棋子绘制部分逻辑解释 约定前后端交互接口 对战模块和匹配模块使用的是两套逻辑,使用不同的 websocket 的路径进行处理,做到更好的耦合 建立连接 …...

【ArcGIS Pro微课1000例】0071:将无人机照片生成航线、轨迹点、坐标高程、方位角
文章目录 一、照片预览二、生成轨迹点三、照片信息四、查看方位角五、轨迹点连成线一、照片预览 数据位于配套实验数据包中的0071.rar,解压之后如下: 二、生成轨迹点 地理标记照片转点 (数据管理),用于根据存储在地理标记照片文件(.jpg 或 .tif)元数据中的 x、y 和 z 坐…...
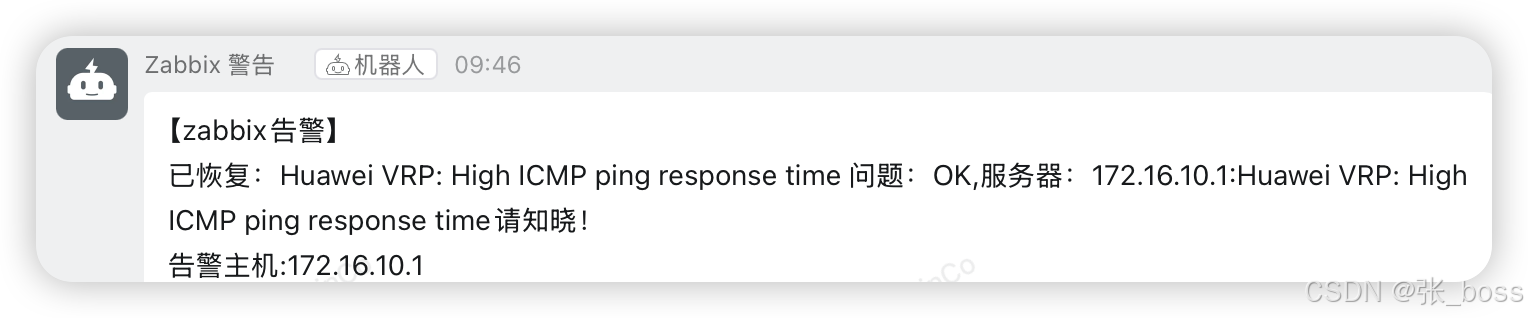
Ubuntu Zabbix 钉钉报警
文章目录 概要Zabbix警监控脚本技术细节配置zabbix告警 概要 提示:本教程用于Ubuntu ,zabbix7.0 Zabbix警监控脚本 提示:需要创建一个脚本 #检查是否有 python3 和版本 rootzabbix:~# python3 --version Python 3.12.3在/usr/lib/zabbix/…...
threejs顶点UV坐标、纹理贴图
1. 创建纹理贴图 通过纹理贴图加载器TextureLoader的load()方法加载一张图片可以返回一个纹理对象Texture,纹理对象Texture可以作为模型材质颜色贴图.map属性的值。 const geometry new THREE.PlaneGeometry(200, 100); //纹理贴图加载器TextureLoader const te…...