基于ELK的分布式日志实时分析与可视化系统设计
目录
一、ELK平台介绍
1.ELK概述
2.Elasticsearch
3.Logstash
4.Kibana
二、部署ES群集
1.资源清单
2.基本配置
3.安装Elasticsearch(elk1上、elk2上、elk3上)
4.安装logstash(elk1上)
5.Filebeat
6.安装Kibana(elk1上)
一、ELK平台介绍
1.ELK概述
a.日志主要包括系统日志、应用程序日志和安全日志
b.日志被分散的存储在不同的设备上
c.集中管理日志后,日志的统计和检索利用grep、awk、wc实现
d.ELK的组成
Elasticsearch
Logstash
Kibana
2.Elasticsearch
a.概述
是一个基于Lucene的搜索服务器
它提供了一个分分布式多用户能力的全文搜索引擎,基于RESTful web接口
- 能够达到实时搜索、稳定、可靠、快速、安装使用方便
b.核心概念
接近实时(NRT):意味着数据从被索引到可被搜索之间存在极短的延迟(通常1秒内)。这是由于 Lucene 的倒排索引机制和 Elasticsearch 的刷新(refresh)机制决定的,默认每1秒刷新一次,使新数据可见
集群(Cluster):是由一个或多个节点(Node)组成的集合,共同存储数据并提供联合索引和搜索能力。
节点(node):是集群中的一个独立服务器,存储数据并参与索引和搜索
索引(index):是类似数据库中的“表”,用于存储具有相似结构的文档(Documents)
类型(type):用于逻辑划分索引中的不同数据结构(类似数据库的“表”)。
文档(document):是 Elasticsearch 中的基本数据单元,以 JSON 格式存储。
分片和复制(shards & replicas):
分片(Shards):索引可以被拆分为多个分片,提高并行处理能力。分片是独立索引单元,可分布在不同节点上。
副本(Replicas):
每个分片可以有多个副本,提供高可用性(节点故障时数据不丢失)和负载均衡(查询可并行执行)。默认情况下,ES 为每个索引创建1个主分片 + 1个副本(可在索引模板中调整)
3.Logstash
a.介绍
由JRsuby语言编写,运行在Java虚拟机上,是一款强大的数据处理工具
可以实现数据传输、格式处理、格式化输出
设计理念:数据输入、数据加工、数据输出
b.工作的三个阶段
input数据输入端,可以接收来自任何地方的源数据
Filter数据中转层,主要进行格式处理,数据类型转换,数据过滤,字段添加、修改等
Output是logstash工作的最后一个阶段,负责将书籍输出到指定位置,兼容大多数应用
4.Kibana
a.介绍
是一个设计使用和Elasticsearch配置工作的开源分析和可视化平台
可以用它进行搜索、查看、集成Elasticserach中的数据索引
可以利用各种图标、报表、地图组件轻松的对数据进行可视化分析
b.主要功能
Elasticsearch无缝集成:支持直接查询、过滤和聚合 ES 索引中的数据
整合数据:支持从多个 Elasticsearch 索引、Logstash 管道或 Beats 采集的数据进行统一分析。
复杂数据分析:支持 聚合(Aggregations) 操作,如 terms(分组统计)、date_histogram(时间序列分析)、avg(平均值计算)等
让更多的团队成员收益:提供 Dashboard(仪表盘) 功能,可将多个可视化图表组合,并支持共享链接或嵌入到其他系统(如 Confluence、Web 应用
接口灵活:提供 REST API,允许开发者以编程方式管理 Kibana 对象
配置简单:通过 Management 模块可轻松管理索引模式、用户权限、警报规则等
可视化多数据源:支持多种图表类型(柱状图、折线图、饼图、热力图等),并可结合 Maps 插件展示地理数据。
简单数据导出:支持将查询结果或图表导出为 CSV、PDF、PNG 格式,方便分享或进一步分析。
二、部署ES群集
1.资源清单
| 操作系统 | IP地址 | 主机名 | 软件包 |
| OpenEuler 24.03 | 192.168.16.142 | elk1 | Elasticsearch、logstash、kibana |
| OpenEuler 24.03 | 192.168.16.143 | elk2 | Elasticsearch、filebeat、httpd |
| OpenEuler 24.03 | 192.168.16.144 | elk3 | Elasticsearch、 |
2.基本配置
a.设置主机名
hostnamectl set-hostname elk1
hostnamectl set-hostname elk2
hostnamectl set-hostname elk3b.在ES主机上设置Host文件(elk1上、elk2上、elk3上)
vi /etc/hosts
192.168.16.142 elk1
192.168.16.143 elk2
192.168.16.144 elk3c.创建es运行用户(elk1上、elk2上、elk3上)
useradd esd.安装java环境(elk1上、elk2上、elk3上)
dnf -y install java-11 tar
java -versione.设置访问限制(elk1上、elk2上、elk3上)
vi /etc/security/limits.confes soft nofile 65535
es hard nofile 65535
es soft nproc 65535
es hard nproc 65535
es soft memlock unlimited
es hard memlock unlimitedvi /etc/sysctl.conf
vm.max_map_count=655360sysctl -p3.安装Elasticsearch(elk1上、elk2上、elk3上)
a.安装Elasticsearch
tar zxf elasticsearch-7.10.0-linux-x86_64.tar.gz
mv elasticsearch-7.10.0 /usr/local/elasticsearch
vi /usr/local/elasticsearch/config/jvm.options-Xmx2g #22
-Xmx2gb.更改Elasticsearch主配置文件
#第一台更改
vi /usr/local/elasticsearch/config/elasticsearch.ymlcluster.name: kgc-elk-cluster #17行,群集名称
node.name: elk1 #23行,本节点主机名
path.data: /elk/data #33行,数据文件路径
path.logs: /elk/logs #37行,日志文件路径
bootstrap.memory_lock: false #43行,锁定物理内存
network.host: 0.0.0.0 #55行,监听地址
http.port: 9200 #59行,监听端口
discovery.seed_hosts: ["elk1", "elk2","elk3"] #68行,群集中的主机列表
cluster.initial_master_nodes: ["elk1"] #72行,master主机名称#推送配置文件到第二台
scp /usr/local/elasticsearch/config/elasticsearch.yml elk2:/usr/local/elasticsearch/config/elasticsearch.yml#推送配置文件到第三台
scp /usr/local/elasticsearch/config/elasticsearch.yml elk3:/usr/local/elasticsearch/config/elasticsearch.yml#第二台更改
vi /usr/local/elasticsearch/config/elasticsearch.yml
node.name: elk2 #23行,本节点主机名#第三台更改
vi /usr/local/elasticsearch/config/elasticsearch.yml
node.name: elk3 #23行,本节点主机名c.创建数据存放路径并授权
mkdir -p /elk/data
mkdir -p /elk/logs
chown -R es:es /elk/
chown -R es:es /usr/local/elasticsearchd.启动es
su - esnohup /usr/local/elasticsearch/bin/elasticsearch &
exite.查看节点信息
ss -nlpt | grep 9200
LISTEN 0 4096 *:9200 *:* users:(("java",pid=3136,fd=253))4.安装logstash(elk1上)
a.在logstash服务器上安装logstash
#安装
tar zxf logstash-7.10.0-linux-x86_64.tar.gz
mv logstash-7.10.0 /usr/local/logstash
chmod -R 777 /usr/local/logstash/data#添加服务
vi /usr/local/logstash/system.confinput {
file{
path =>"/var/log/messages"
type =>"system"
start_position =>"beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.16.142:9200"]
index =>"system-%{+YYYY.MM.dd}"
}
}#添加读权限
chmod +r /var/log/messagesb.测试安装结果
#采集日志(启动)
/usr/local/logstash/bin/logstash -f /usr/local/logstash/system.conf
#访问验证(elk3上)
curl -XGET "http://localhost:9200/_cat/indices"
#green open system-2025.05.20 xnX0OgCxTmGZ6Msy5A1aXA 1 1 14184 0 5.8mb 2.8mb5.Filebeat
a.在产生日志的客户端上安装Filebeat(elk2上)
dnf install -y httpd
systemctl start httpdb.安装filebeat(elk2上)
tar zxf filebeat-7.10.0-linux-x86_64.tar.gz
mv filebeat-7.10.0-linux-x86_64 /usr/local/filebeatc.配置web01服务器filebeat的输出(elk2上)
vi /usr/local/filebeat/filebeat.ymlfilebeat.inputs:
- type: logpaths:- /var/log/httpd/access_logoutput.logstash:hosts: ["192.168.16.142:5044"]d.修改logstash的配置文件(elk1上)
vi /usr/local/logstash/config/beats.confinput {beats {port => "5044"codec => "json"}
}
seccomp:enabled: false
output{elasticsearch {hosts => ["192.168.16.142:9200"]index => "weblog-beat-%{+YYYY.MM.dd}"}
}e.运行logstash并验证(elk1上)
/usr/local/logstash/bin/logstash -f /usr/local/logstash/config/beats.conf --path.data=/usr/local/logstash/config.d/web01 &> /tmp/logstash.log &f.启动(elk2上)
/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml6.安装Kibana(elk1上)
a.在elk1上安装Kibana
tar zxf kibana-7.10.0-linux-x86_64.tar.gz
mv kibana-7.10.0-linux-x86_64 /usr/local/kibanab.修改Kibana主配置文件
vi /usr/local/kibana/config/kibana.ymlserver.port: 5601 #2行
server.host: "0.0.0.0" #7行
elasticsearch.hosts: ["http://192.168.16.142:9200"] #28行
kibana.index: ".kibana" #32行chown -R es:es /usr/local/kibanac.启动Kibana服务
su - es
nohup /usr/local/kibana/bin/kibana &nohup /usr/local/kibana/bin/kibana &d.验证Kibana
http://192.168.16.142:5601/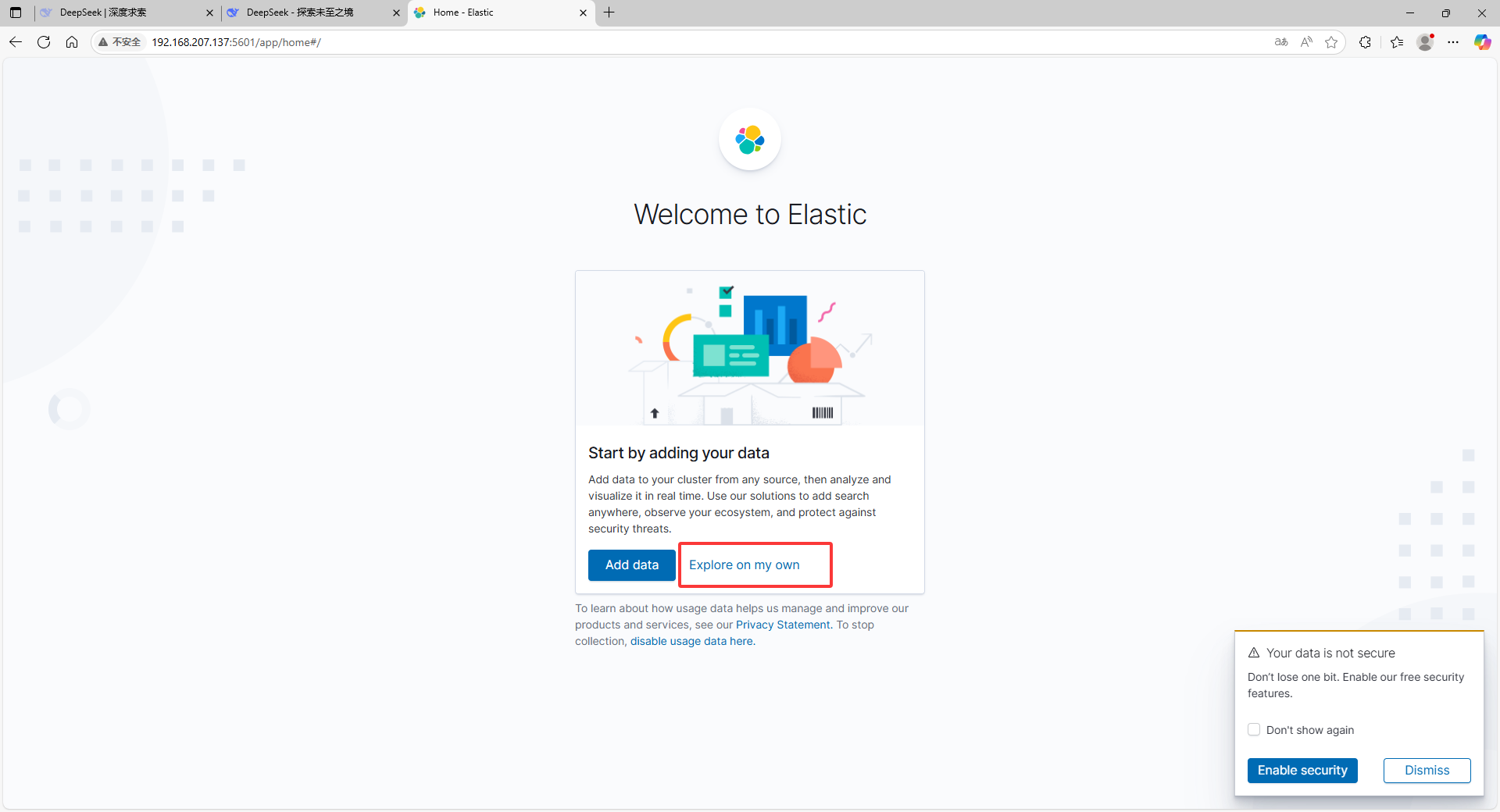
e.将elk1主机的系统日志添加到kinnba
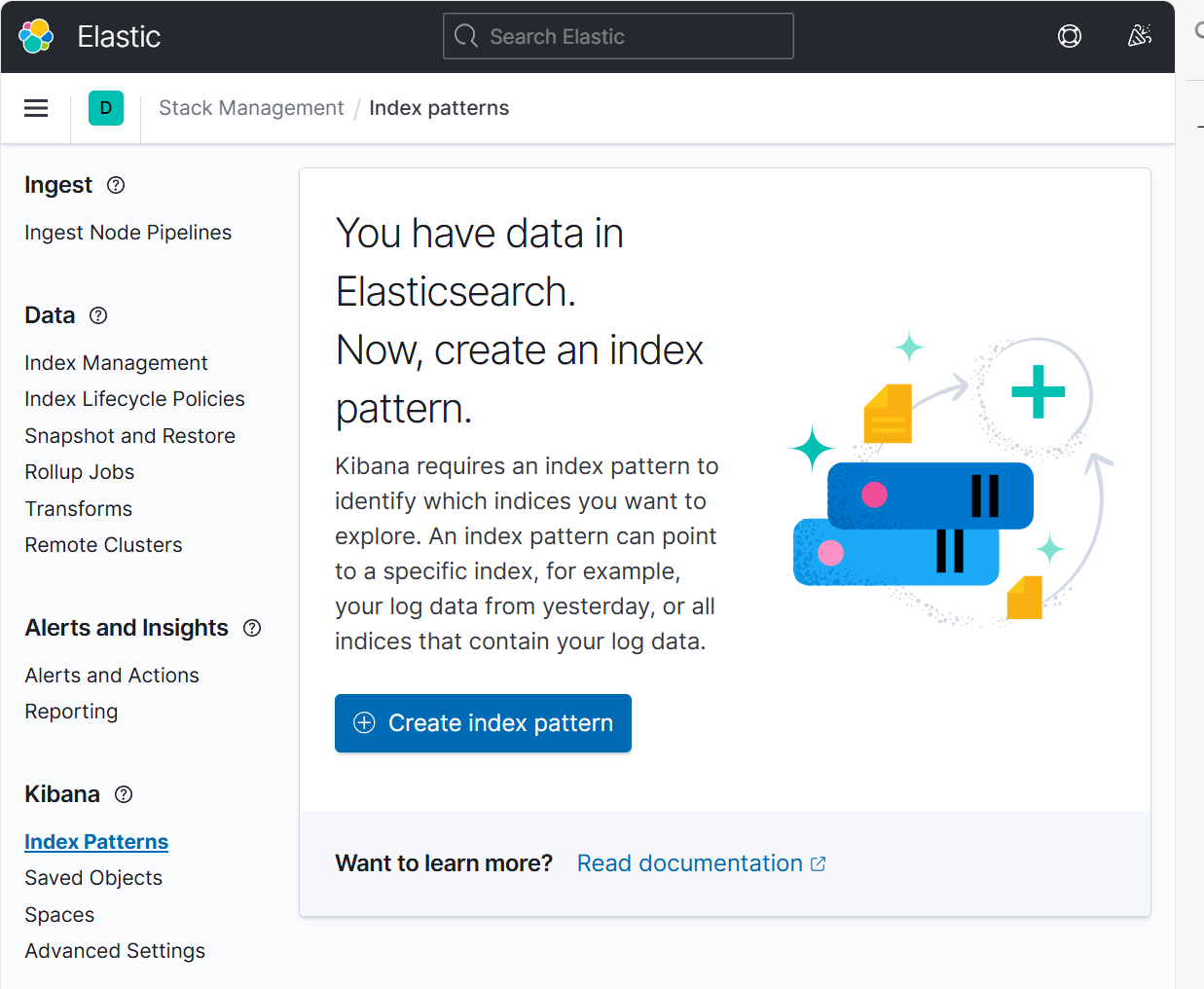
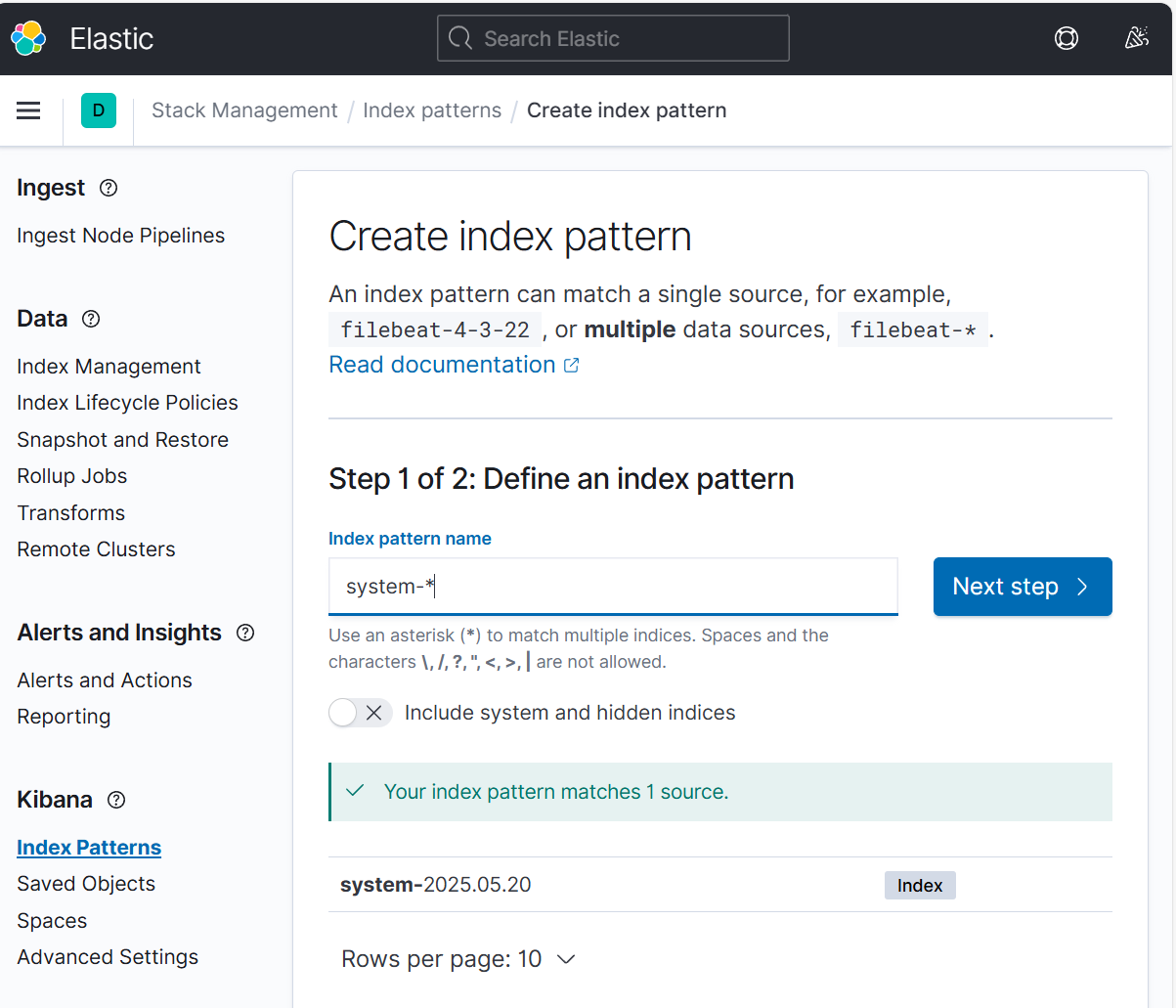
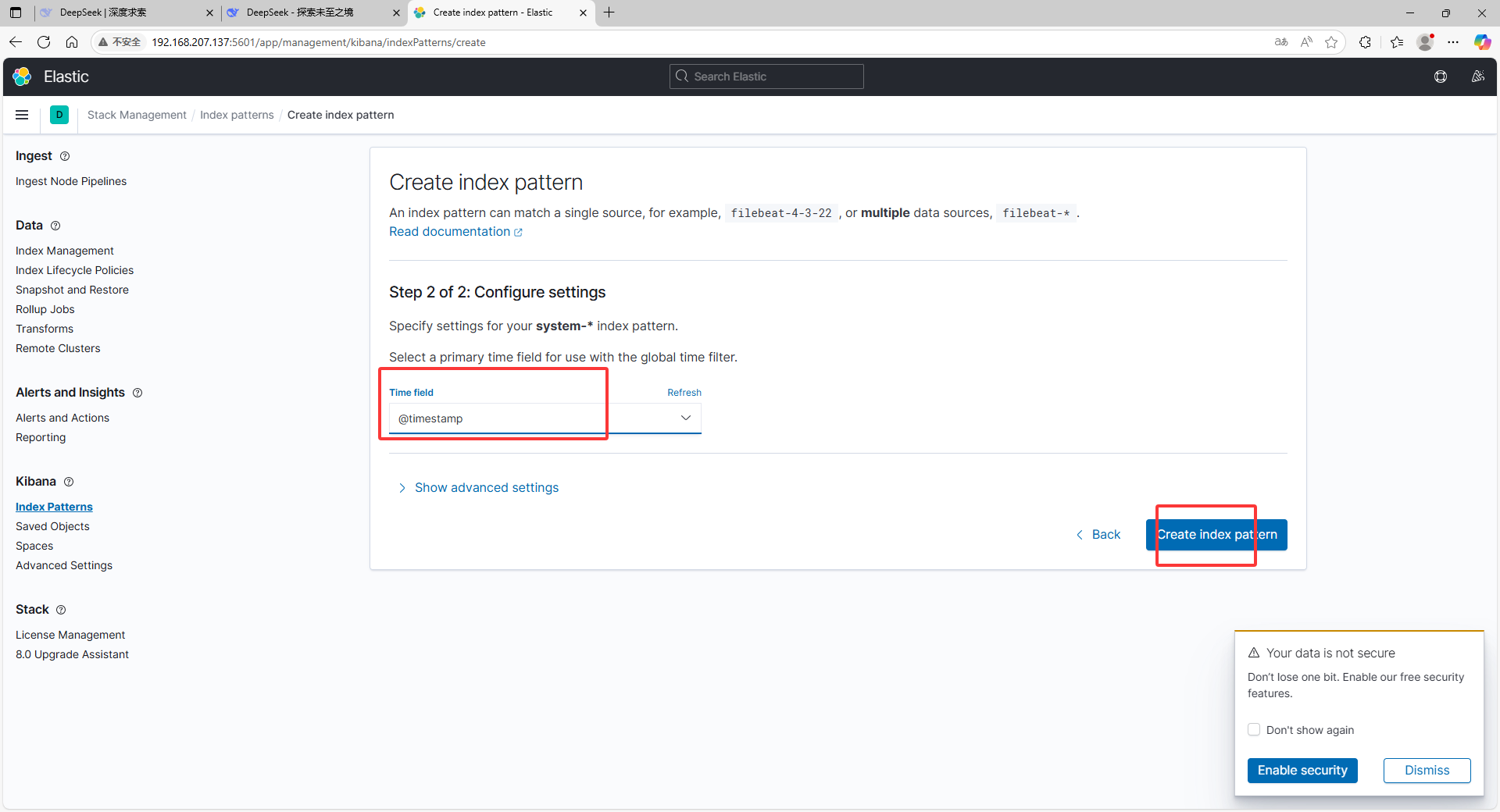
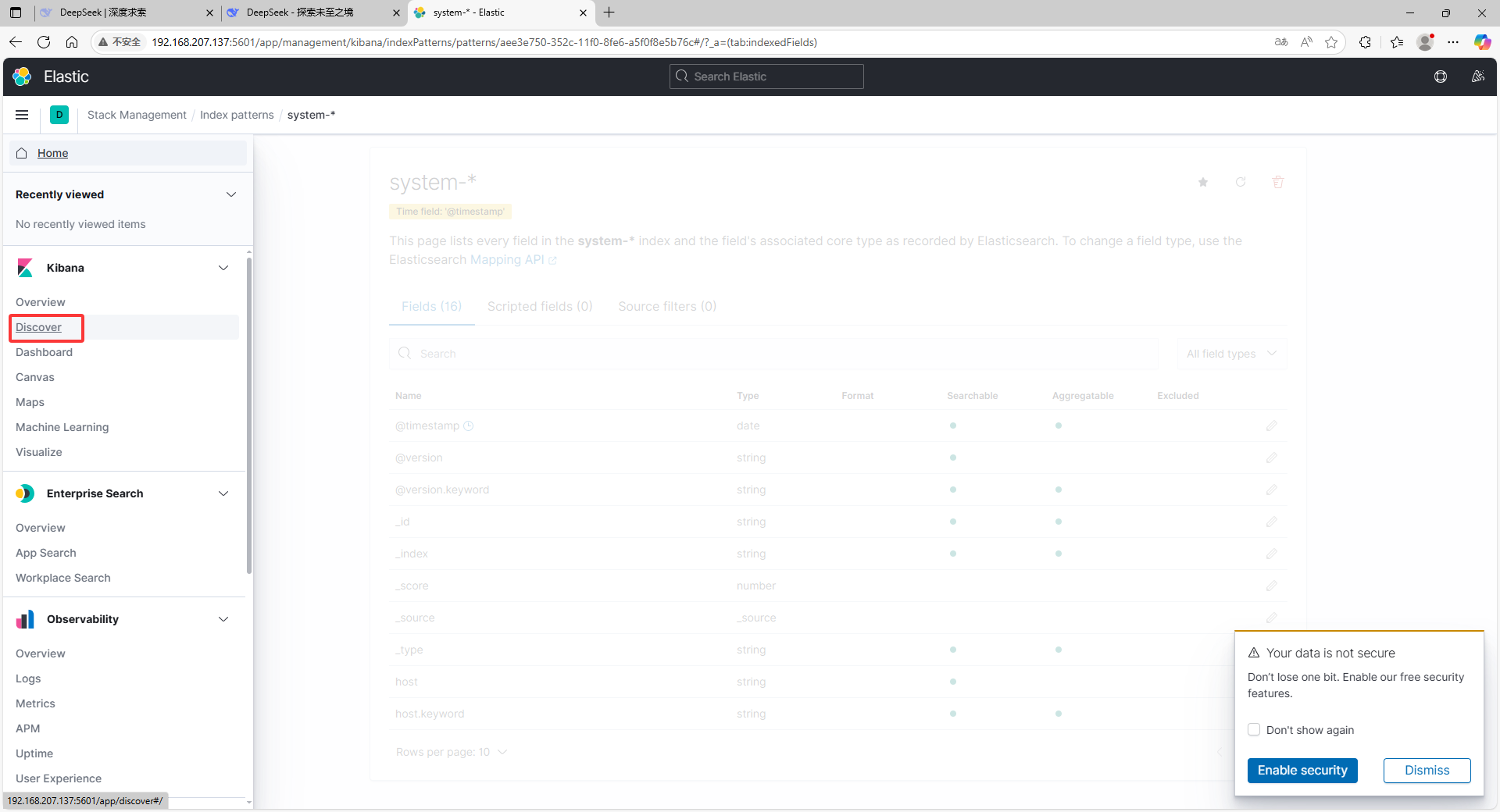
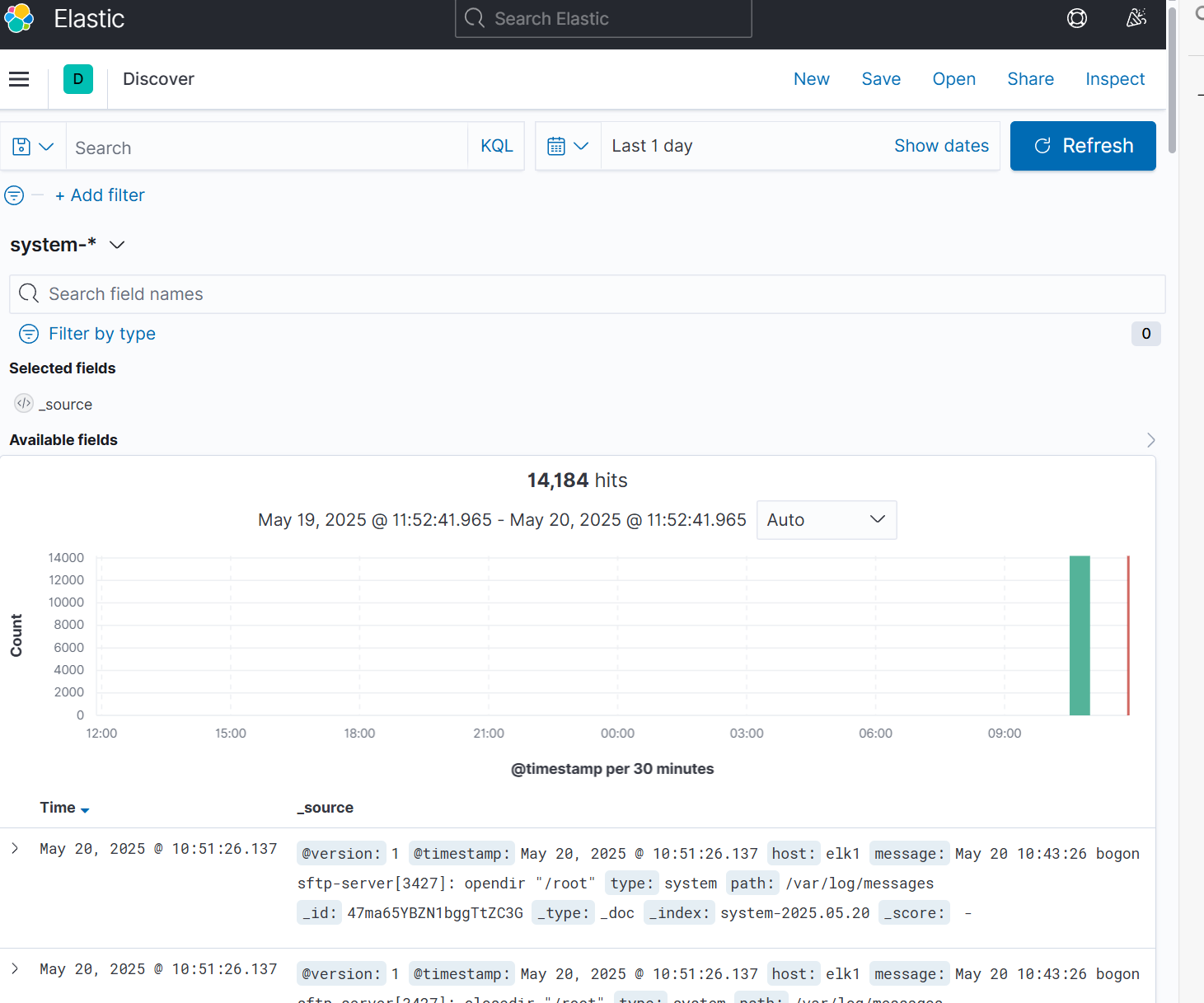
相关文章:
基于ELK的分布式日志实时分析与可视化系统设计
目录 一、ELK平台介绍 1.ELK概述 2.Elasticsearch 3.Logstash 4.Kibana 二、部署ES群集 1.资源清单 2.基本配置 3.安装Elasticsearch(elk1上、elk2上、elk3上) 4.安装logstash(elk1上) 5.Filebeat 6.安装Kibana&#x…...

@Async 注解 走的是主线程 还是子线程呢
Asyncz注解所在的包 package org.springframework.scheduling.annotation; Async 注解在Spring框架中用于标记一个方法为异步方法。当这个方法被调用时,它不会阻塞调用线程,而是会在一个单独的线程中执行。因此,Async 注解走的是子线程&…...

前端面经 React 组件常见的声明方式
react类组件和函数式组件 函数组件返回值的内容就是要渲染的内容 函数组件使用useState更新状态 ,使用类中变量更新 常见hook 官方 : useEffect 处理副作用,请求APIuseState 更新UIuseLayout 同步更新,会阻塞进程,…...

酒店管理系统设计与实现
本科毕业设计(论文) 设计(论文)题目 酒店管理系统设计与实现 学生姓名 学生学号 所在学院 专业班级 校内指导教师 李建 企业指导教师 毕业设计(论文)真实性承诺及声明 学生对毕业设计(论文)真实性承诺 本人郑重声明:所提交的毕业设计(论文)作品是本人在指导教师的指…...
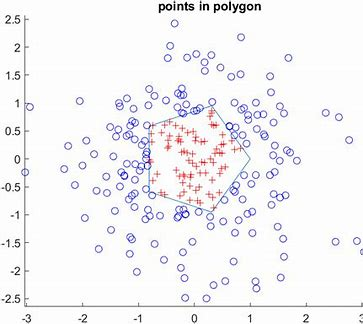
OpenCV---pointPolygonTest
一、基本概念与用途 pointPolygonTest 是 OpenCV 中用于判断点与多边形关系的重要函数,常用于: 目标检测:判断像素点是否属于检测到的轮廓区域碰撞检测:检测物体是否重叠图像分割:确定点是否在分割区域内几何分析&am…...
Qt 的简单示例 -- 地址簿
这个工程里有两个窗口,都是QWidget派生的窗口 主窗口: 1. 运用了布局,按钮控件,单行编辑框,富文本编辑框等窗口部件; 2. 运用了 QMap 类; 3. 实现了点击按钮弹出子窗口的功能,这里子…...

Linux 下 C 语言实现工厂模式
Linux 下 C 语言实现工厂模式:设计理念与实战 🧠 一、工厂模式简介什么是工厂模式?C 语言实现设计模式的挑战 🏗️ 二、实现简单工厂模式(Simple Factory)1. 定义传感器接口(device.h࿰…...
什么是DevOps的核心目标?它如何解决传统开发与运维之间的冲突?
在当今数字化转型加速的时代,DevOps 已成为软件开发领域备受瞩目的明星理念。今天,本文将聚焦于 DevOps 的核心目标,并深入探讨它如何巧妙化解传统开发与运维之间的冲突,为大家揭开 DevOps 的神秘面纱并分享实用经验。本次介绍的与…...
实战:原理 + 开发 + 运维 + 架构应用指南)
RocketMQ 死信队列(DLQ)实战:原理 + 开发 + 运维 + 架构应用指南
🚀RocketMQ 死信队列(DLQ)实战:原理 开发 运维 架构应用指南 第一章:什么是死信队列(DLQ)? 1.1 死信队列定义 在 RocketMQ 中,死信队列(Dead Letter Que…...
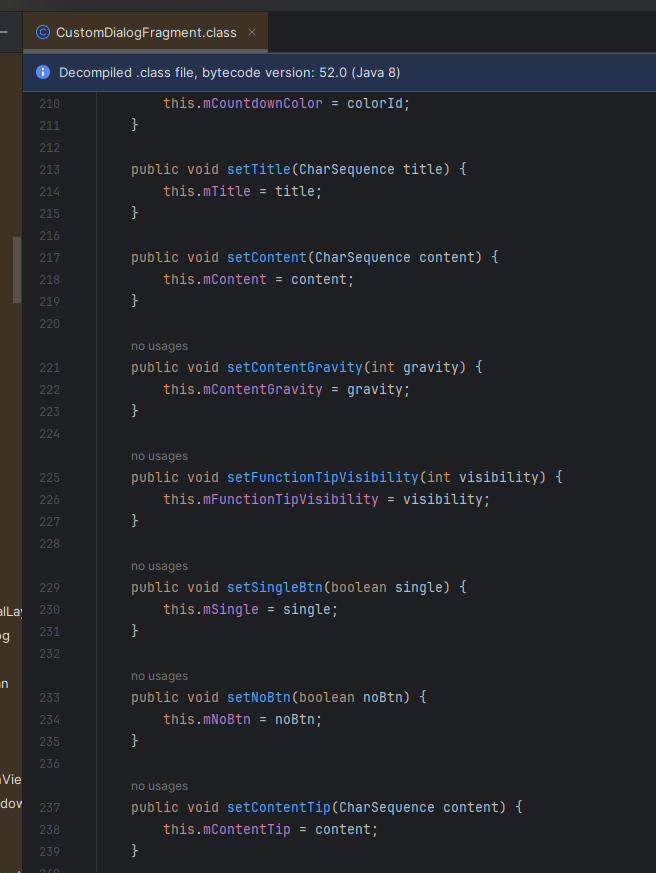
Android studio 查看aar源码出现/* compiled code */
如图查看aar源码时看不到具体实现,在排除是sdk版本导致的问题后,下面说解决方法 打开设置,找到插件 输入decompiler 搜索 这个是自带的反编译工具,启用就好了...
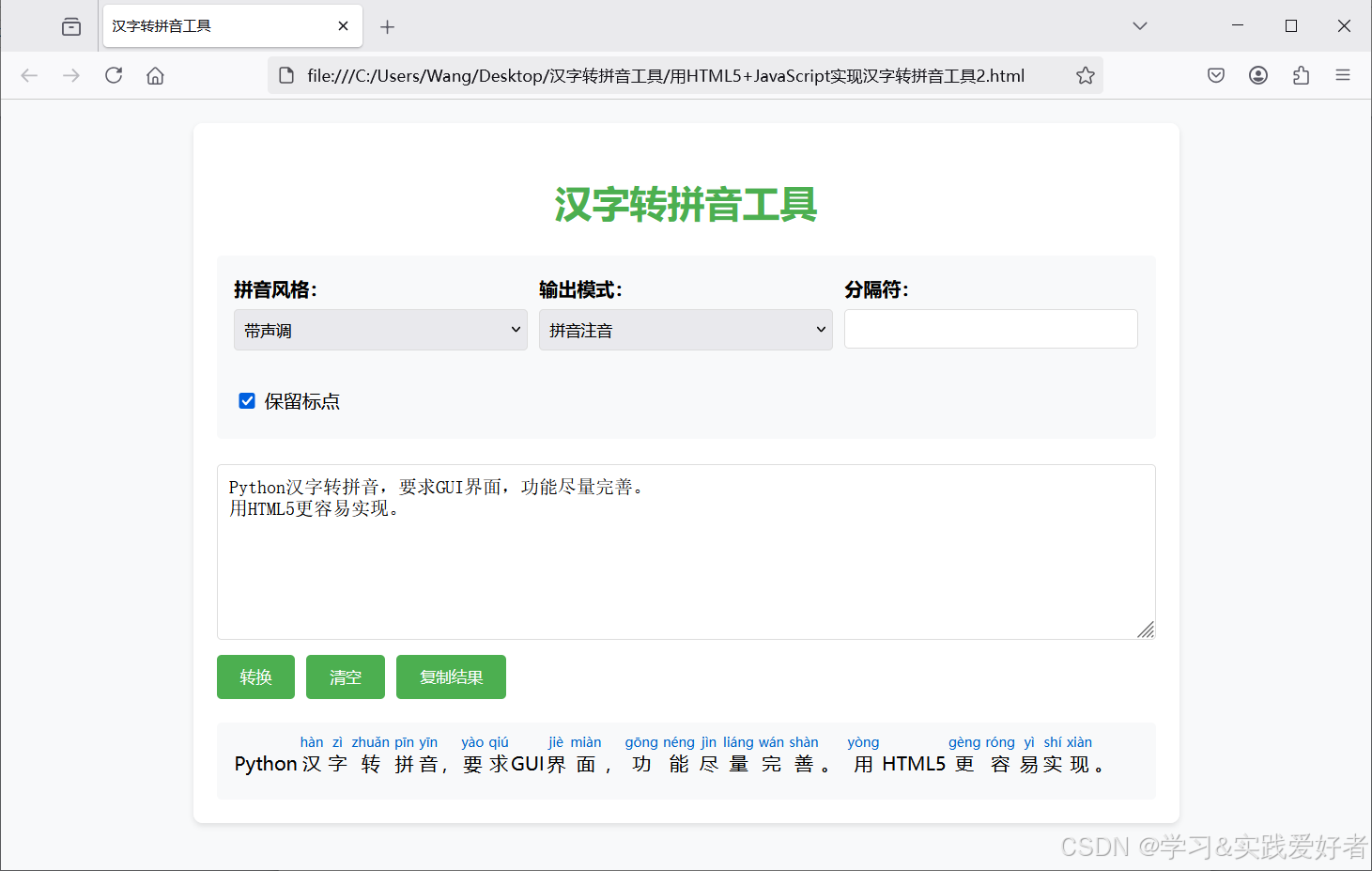
用HTML5+JavaScript实现汉字转拼音工具
用HTML5JavaScript实现汉字转拼音工具 前一篇博文(https://blog.csdn.net/cnds123/article/details/148067680)提到,当需要将拼音添加到汉字上面时,用python实现比HTML5JavaScript实现繁琐。在这篇博文中用HTML5JavaScript实现汉…...
基于Java,SpringBoot,Vue,UniAPP医院预约挂号买药就诊病例微信小程序系统设计
摘要 随着医疗信息化的不断推进以及“互联网医疗”模式的广泛普及,传统医院挂号流程中存在的排队时间长、资源分配不均等问题日益凸显,急需通过数字化手段加以解决。本研究设计并实现了一套基于Java、SpringBoot、Vue与UniAPP技术栈的医院预约挂号微信小…...
ONNX模型的动态和静态量化
引言 通常我们将模型转换为onnx格式之后,模型的体积可能比较大,这样在某些场景下就无法适用。最近想在移动端部署语音识别、合成模型,但是目前的效果较好的模型动辄几个G,于是便想着将模型压缩一下。本文探索了两种压缩方法&…...

PHP 垃圾回收高级特性
PHP 垃圾回收高级特性 1. 循环引用与内存泄漏 单纯的引用计数在遇到循环引用时会导致内存泄漏,主要原因是引用计数无法正确识别那些仅通过循环引用相互关联但实际上已经不可达的对象。 1.1 引用计数的基本原理 引用计数是一种内存管理机制,通过维护每…...

OpenFeign vs MQ:微服务通信如何选型?详解同步与异步的适用场景
OpenFeign vs MQ:微服务通信如何选型?详解同步与异步的适用场景 引言 在微服务架构中,服务之间的通信方式直接影响系统的性能、可靠性和可维护性。常见的通信方式有 OpenFeign(同步HTTP调用) 和 MQ(消息队…...

如何用命令行将 PDF 表格转换为 HTML 表格
本文将介绍如何使用命令行将可填写的 PDF 表单转换为 HTML 表单。只需几行代码即可完成转换。将可填写的 PDF 表单转换为 HTML 表单后,你可以在网页上显示这些表单。本指南使用 FormVu 来演示转换过程。 使用命令行将可填写 PDF 表单转换为 HTML 表单 你可以通过命…...

html5的响应式布局的方法示例详解
以下是HTML5实现响应式布局的5种核心方法及代码示例: 1. 媒体查询(核心方案) /* 默认样式(移动优先) */ .container {padding: 15px; }/* 中等屏幕(平板) */ @media (min-width: 768px) {.container {padding: 30px;max-width: 720px;} }/* 大屏幕(桌面) */ @media …...

如何用Python抓取Google Scholar
文章目录 [TOC](文章目录) 前言一、为什么要抓取Google Scholar?二、Google Scholar 抓取需要什么三、为什么代理对于稳定的抓取是必要的四、一步一步谷歌学者抓取教程4.1. 分页和循环4.2. 运行脚本 五、完整的Google Scholar抓取代码六、抓取Google Scholar的高级提…...

电脑革命家测试版:硬件检测,6MB 轻量无广告 清理垃圾 + 禁用系统更新
各位电脑小白和大神们,我跟你们说啊!有个超牛的东西叫电脑革命家测试版,这是吾爱破解论坛的开发者搞出来的免费无广告系统工具集合,主打硬件检测和系统优化,就像是鲁大师这些软件的平替。下面我给你们唠唠它的核心功能…...
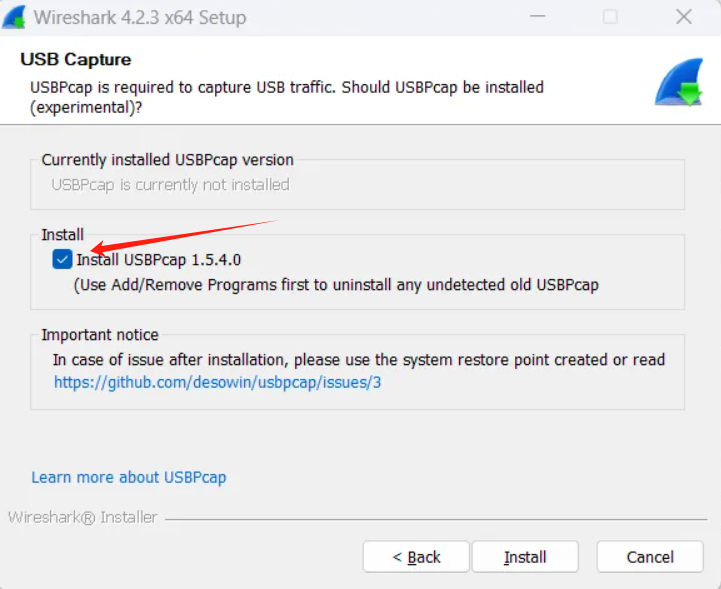
Wireshark对usb设备进行抓包找不到USBPcap接口的解决方案
引言 近日工作需要针对usb设备进行抓包,但按照wireshark安装程序流程一步步走,即使勾选了安装USBPcap安装完成后开启wireshark依然不显示USBPcap接口,随设法进行解决。 最终能够正常显示USBPcap接口并能够正常使用进行抓包 解决方案&#x…...

题目 3298: 蓝桥杯2024年第十五届决赛真题-兔子集结
题目 3298: 蓝桥杯2024年第十五届决赛真题-兔子集结 时间限制: 2s 内存限制: 192MB 提交: 2499 解决: 309 题目描述 在森林幽静的一隅,有一村落居住着 n 只兔子。 某个月光皎洁的夜晚,这些兔子列成一队,准备开始一场集结跳跃活动。村落中…...

Unity开发之Webgl自动更新程序包
之前让客户端更新webgl程序是在程序里写版本号然后和服务器对比,不同就调用 window.location.reload(true);之前做的客户端都是给企业用,用户数少看不出来啥问题。后来自己开发一个小网站,用户数量还是挺多,然后就会遇到各种各样的…...

深入理解设计模式之状态模式
深入理解设计模式之:状态模式(State Pattern) 一、什么是状态模式? 状态模式(State Pattern)是一种行为型设计模式。它允许一个对象在其内部状态发生改变时,改变其行为(即表现出不…...
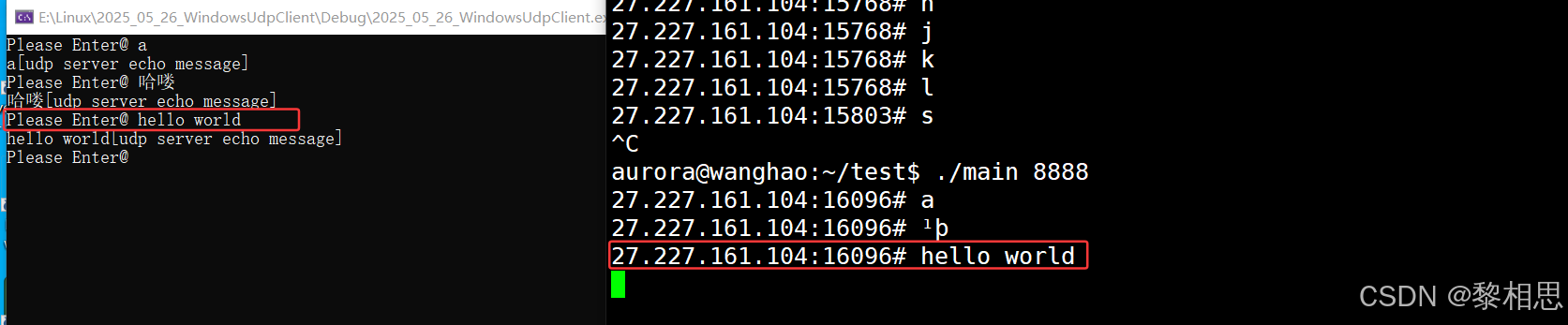
Socket 编程 UDP
目录 1. UDP网络编程 1.1 echo server 1.1.1 接口 1.1.1.1 创建套接字 1.1.1.2 绑定 1.1.1.3 bzero 1.1.1.4 htons(主机序列转网络序列) 1.1.1.5 inet_addr(主机序列IP转网络序列IP) 1.1.1.6 recvfrom(让服务…...
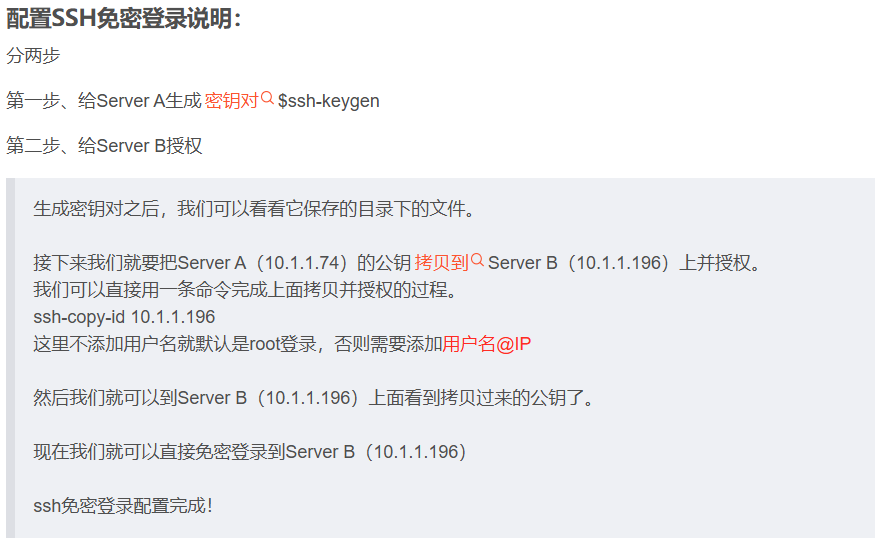
Jenkins实践(8):服务器A通过SSH调用服务器B执行Python自动化脚本
Jenkins实践(8):服务器A通过SSH调用服务器B执行Python自动化脚本 1、需求: 1、Jenkins服务器在74上,Python脚本在196服务器上 2、需要在服务器74的Jenkins上调用196上的脚本执行Python自动化测试 2、操作步骤 第一步:Linux Centos7配置SSH免密登录 Linux Centos7配置S…...

Spring AI系列之Spring AI 集成 ChromaDB 向量数据库
1. 概述 在传统数据库中,我们通常依赖精确的关键词或基本的模式匹配来实现搜索功能。虽然这种方法对于简单的应用程序已经足够,但它无法真正理解自然语言查询背后的含义和上下文。 向量存储解决了这一限制,它通过将数据以数值向量的形式存储…...

lua的注意事项2
总之,下面的返回值不是10,a,b 而且...

主流电商平台的反爬机制解析
随着数据成为商业决策的重要资源,越来越多企业和开发者希望通过技术手段获取电商平台的公开信息,用于竞品分析、价格监控、市场调研等。然而,主流电商平台如京东、淘宝(含天猫)等为了保护数据安全和用户体验࿰…...

前端八股之HTML
前端秘籍-HTML篇 1. src和href的区别 src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系。 (1)src src 是 source 的缩写,指向外部资源的位置,指向的内容将会嵌入到文档中当前标签所在位置࿱…...

tiktoken学习
1.tiktoken是OpenAI编写的进行高效分词操作的库文件。 2.操作过程: enc tiktoken.get_encoding("gpt2") train_ids enc.encode_ordinary(train_data) val_ids enc.encode_ordinary(val_data) 以这段代码为例,get_encoding是创建了一个En…...