Mac安装配置InfluxDB,InfluxDB快速入门,Java集成InfluxDB
1. 与MySQL的比较
| InfluxDB | MySQL | 解释 |
|---|---|---|
| Bucket | Database | 数据库 |
| Measurement | Table | 表 |
| Tag | Indexed Column | 索引列 |
| Field | Column | 普通列 |
| Point | Row | 每行数据 |
2. 安装FluxDB
brew update
默认安装 2.x的版本
brew install influxdb
查看influxdb版本
influxd version # InfluxDB 2.7.11 (git: fbf5d4ab5e) build_date: 2024-11-26T18:06:07Z
启动influxdb
influxd
访问面板
http://localhost:8086/
配置用户信息
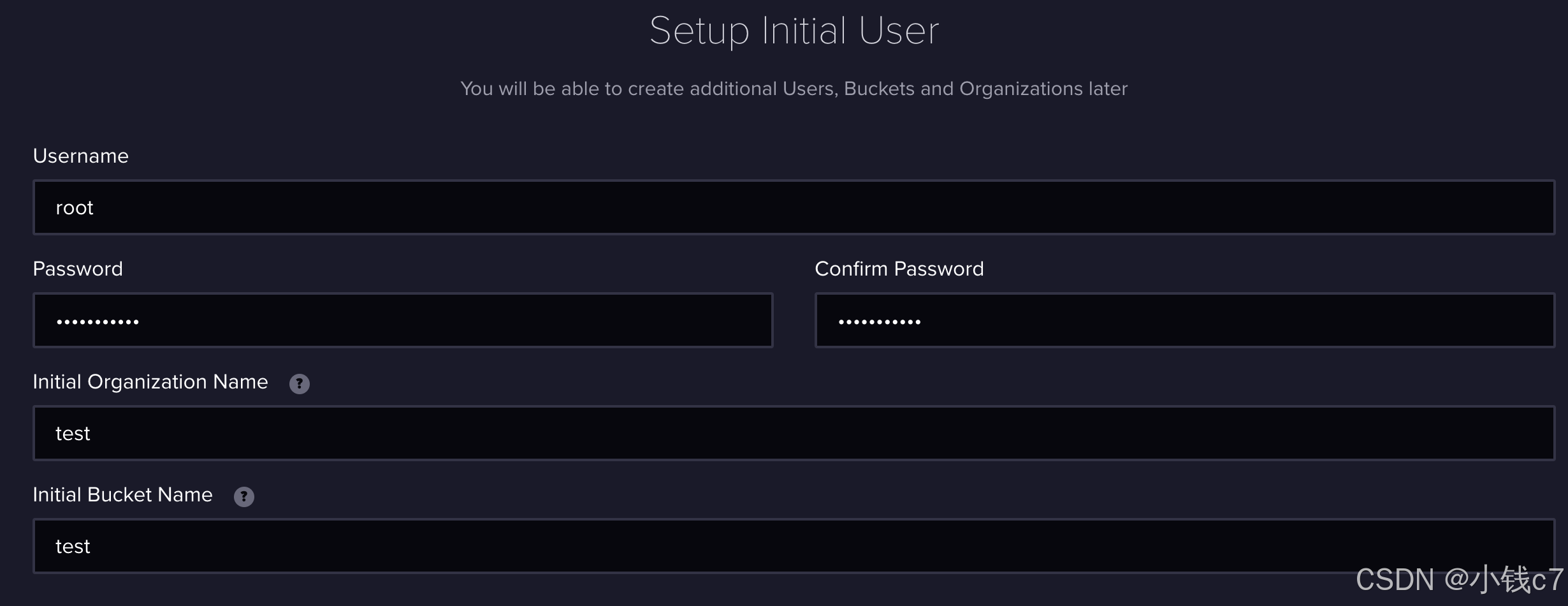
保存token
L5IeK5vutRmkCuyzbz781GVKj4fR6fKGQdl3CaWAPNEKmigrI0Yt8IlEN5_qkO9Lgb80BpcISK0U4WSkWDcqIQ==
3. 使用行协议写入数据
官网规范
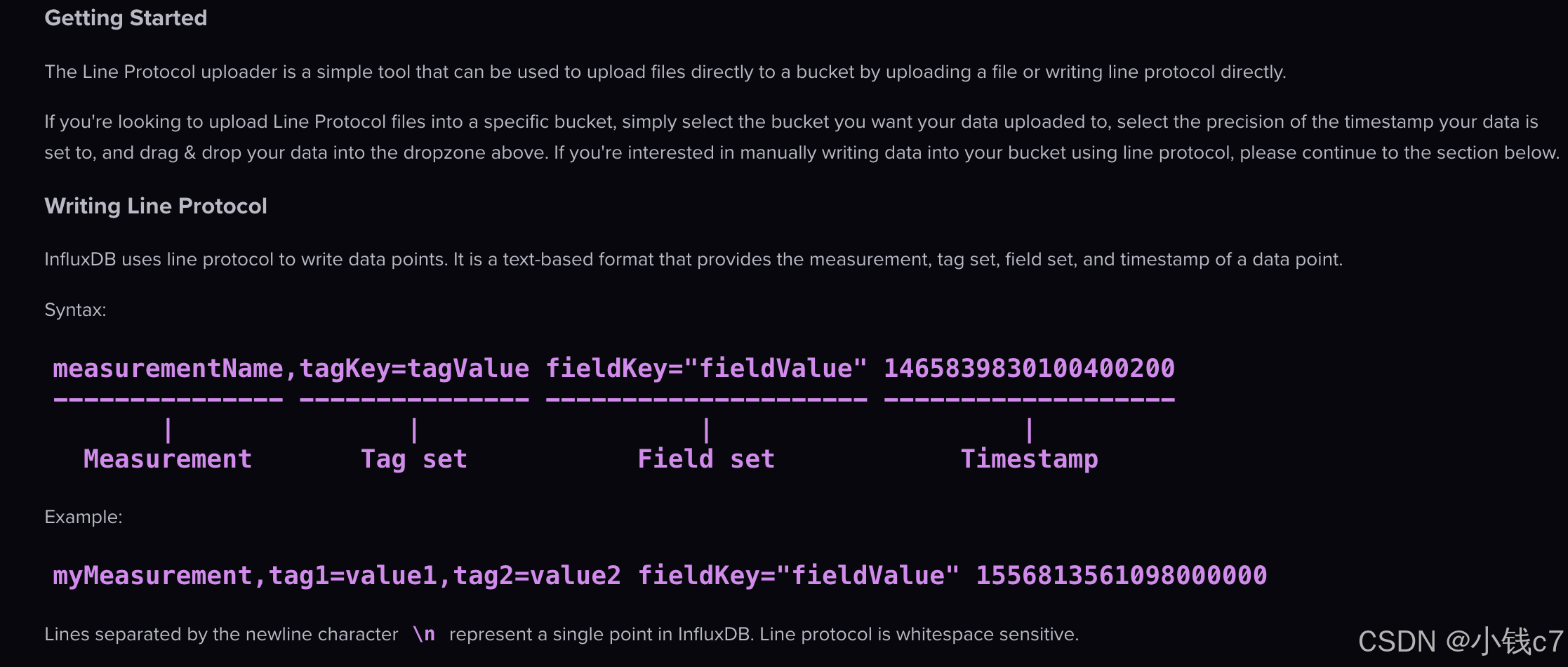
- 首先是一个
measurementName,和指定MySQL的表名一样 - 然后是
Tag,和指定MySQL的索引列一样,多个Tag通过逗号分隔 - 然后是
Field,和指定MySQL的普通列一样多个Field通过逗号分隔,与Tag通过空格分隔 - 最后是时间戳(选填,下面测试时单位为秒)
测试写入:
user,name=jack age=11 1748264631
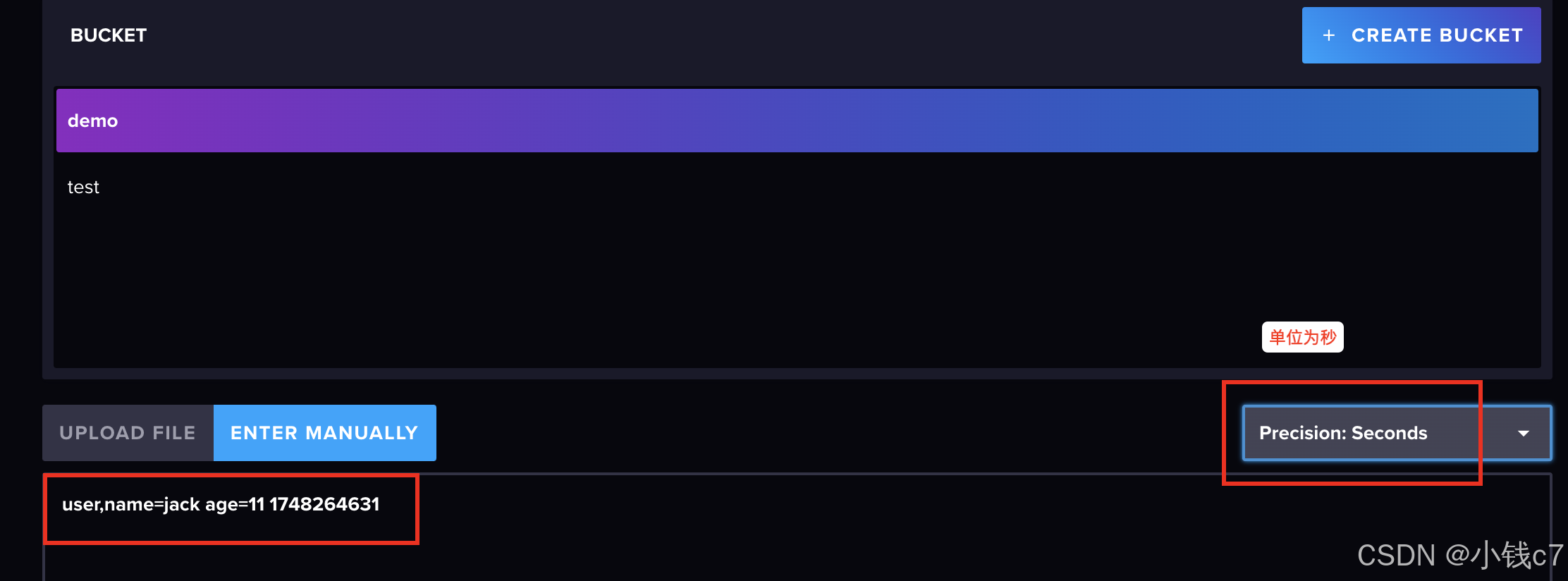
结果:
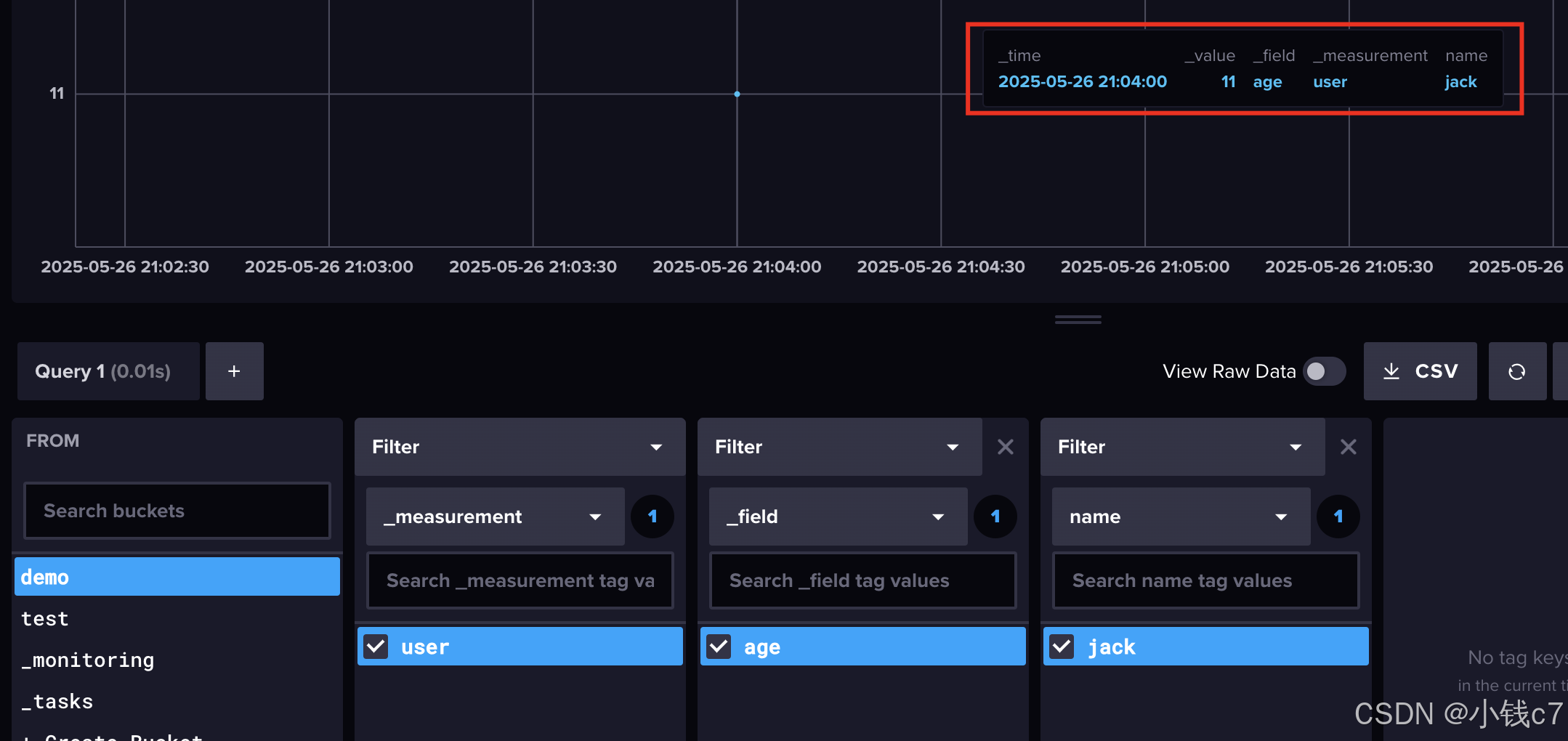
4. 使用Flux查询数据
- from:从哪个Bucket即桶中查询数据
- range:根据时间筛选数据,单位有ms毫秒,s秒,m分钟,h消失,d天,w星期,mo月,y年,比如
range(start: -1d, stop:now())就是过去一天内的数据,其中stop:now()是默认的,可以不写。 - filter:根据列筛选数据
样例并解释:
from(bucket: "demo") # 从demo这个数据库中去数据|> range(start: -1d, stop:now()) # 时间范围筛选|> filter(fn: (r) => r["_measurement"] == "user") # 从这个user这个表查询数据|> filter(fn: (r) => r["name"] == "jack") # 根据索引等值查询,相当于MySQL后面的where条件,influx会根据这个tag上的倒排索引加快查询速度|> filter(fn: (r) => r["_field"] == "age") # 相当于MySQL查询具体的列的数据,只不过有多个Field会被拆分为多行,每行对应一个Field的数据
关于r["_field"] == "age"的问题:为什么需要这么查询?因为Field如果有多个,就会被拆成多行
比如我们插入数据时是这样的:user,name=jack age=18,height=180 1716715200000000000,虽然这是一个数据点Point,但是由于有两个Field,那么查询到的数据其实是两行,如果加了r["_field"] == "age",就只会出现第一条数据,注意Tag不会被拆分为多行
| _measurement | name | _field | _value | _time |
|---|---|---|---|---|
| user | jack | age | 18 | 2024-05-26 00:00:00Z |
| user | jack | height | 180 | 2024-05-26 00:00:00Z |
5. SpringBoot集成
5.1 引入依赖
<dependency><groupId>com.influxdb</groupId><artifactId>influxdb-client-java</artifactId><version>6.9.0</version>
</dependency>
<dependency><groupId>org.jetbrains.kotlin</groupId><artifactId>kotlin-stdlib</artifactId><version>1.8.20</version>
</dependency>
5.2. 插入数据
5.2.1 基础数据
private final static String token = "L5IeK5vutRmkCuyzbz781GVKj4fR6fKGQdl3CaWAPNEKmigrI0Yt8IlEN5_qkO9Lgb80BpcISK0U4WSkWDcqIQ==";
private final static String org = "test";
private final static String bucket = "demo";
private final static String url = "http://127.0.0.1:8086";
5.2.2 通过行协议插入
private static void writeDataByLine() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();String data = "user,name=tom age=18 1748270504";writeApi.writeRecord(bucket, org, WritePrecision.S, data);
}
5.2.3 通过Point插入
private static void writeDataByPoint() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();Point point = Point.measurement("user").addTag("name", "jerry").addField("age", 20f).time(Instant.now(), WritePrecision.S);writeApi.writePoint(bucket, org, point);
}
5.2.4 通过Pojo类插入
import com.influxdb.annotations.Column;
import com.influxdb.annotations.Measurement;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;import java.time.Instant;@Measurement(name = "user")
@NoArgsConstructor
@AllArgsConstructor
public class InfluxData {@Column(tag = true)String name;@ColumnFloat age;@Column(timestamp = true)Instant time;
}
private static void writeDataByPojo() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();InfluxData influxData = new InfluxData("cat", 30f, Instant.now());writeApi.writeMeasurement(bucket, org, WritePrecision.S, influxData);
}
5.3 查询数据
private static void queryData() {InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());String query = "from(bucket: \"demo\")\n" +" |> range(start: -1d, stop:now())\n" +" |> filter(fn: (r) => r[\"_measurement\"] == \"user\")";List<FluxTable> fluxTables = influxDBClient.getQueryApi().query(query, org);for (FluxTable fluxTable : fluxTables) {// 根据索引列分组for (FluxRecord record : fluxTable.getRecords()) { // 每组的数据System.out.println(record.getValues());}System.out.println();}
}
最终结果:
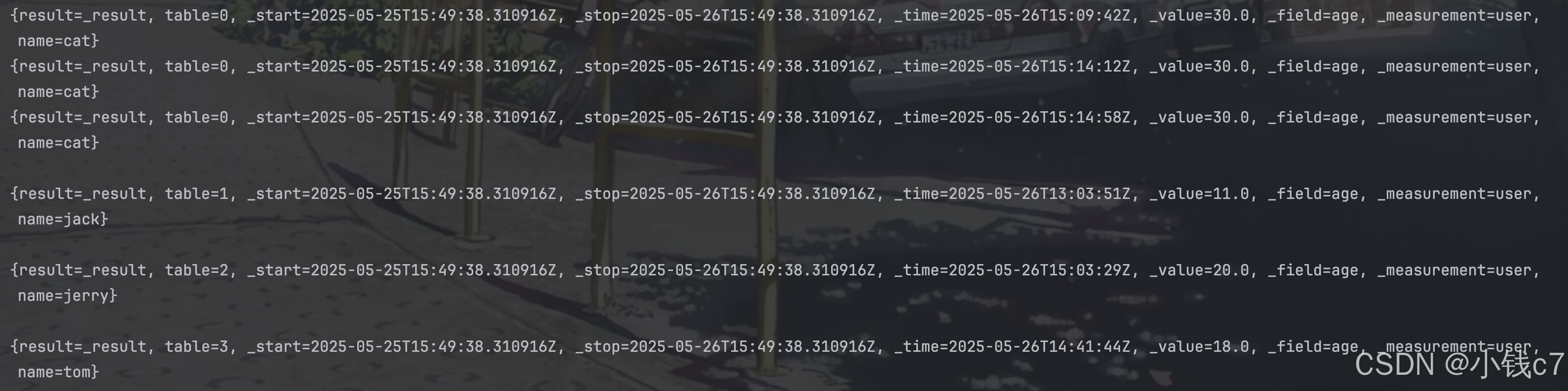
5.4 查询升级
自定义查询参数,时间范围查询
@Data
public class InfluxDataQuery {private String plcName;@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")private LocalDateTime startTime;@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")private LocalDateTime stopTime;private String topic;
}
public List<Map<String, Object>> queryData(InfluxDataQuery queryParams) {String plcName = queryParams.getPlcName();LocalDateTime startTime = queryParams.getStartTime(), stopTime = queryParams.getStopTime();String topic = queryParams.getTopic();if (startTime == null) {throw new RuntimeException("startTime不能为空");}InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token.toCharArray());StringBuilder sb = new StringBuilder();sb.append("\nfrom(bucket: \"").append(bucket).append("\")\n");if (stopTime == null) {stopTime = LocalDateTime.now();}sb.append(" |> range(start:").append(startTime.atOffset(ZoneOffset.UTC).format(DateTimeFormatter.ISO_OFFSET_DATE_TIME)).append(",stop:").append(stopTime.atOffset(ZoneOffset.UTC).format(DateTimeFormatter.ISO_OFFSET_DATE_TIME)).append(")\n");if (StringUtils.hasText(plcName)) {sb.append(" |> filter(fn: (r) => r[\"plcName\"] == \"").append(plcName).append("\")\n");}if (StringUtils.hasText(topic)) {sb.append(" |> filter(fn: (r) => r[\"_measurement\"] == \"").append(topic).append("\")\n");}log.info("query: {}", sb);List<FluxTable> fluxTables = influxDBClient.getQueryApi().query(sb.toString(), org);List<Map<String, Object>> dataList = new ArrayList<>();for (FluxTable fluxTable : fluxTables) {// 根据索引列分组for (FluxRecord record : fluxTable.getRecords()) { // 每组的数据dataList.add(record.getValues());}}return dataList;
}
拼接好的SQL大概长这样子:

相关文章:
Mac安装配置InfluxDB,InfluxDB快速入门,Java集成InfluxDB
1. 与MySQL的比较 InfluxDBMySQL解释BucketDatabase数据库MeasurementTable表TagIndexed Column索引列FieldColumn普通列PointRow每行数据 2. 安装FluxDB brew update默认安装 2.x的版本 brew install influxdb查看influxdb版本 influxd version # InfluxDB 2.7.11 (git: …...
手撕Java+硅基流动实现MCP服务器教程
手撕Java硅基流动实现MCP服务器教程 一、MCP协议核心概念 MCP是什么 MCP 是 Anthropic (Claude) 主导发布的一个开放的、通用的、有共识的协议标准。 ● MCP 是一个标准协议,就像给 AI 大模型装了一个 “万能接口”,让 AI 模型能够与不同的数据源和工…...
EasyRTC嵌入式音视频通信SDK助力1v1实时音视频通话全场景应用
一、方案概述 在数字化通信需求日益增长的今天,EasyRTC作为一款全平台互通的实时视频通话方案,实现了设备与平台间的跨端连接。它支持微信小程序、APP、PC客户端等多端协同,开发者通过该方案可快速搭建1v1实时音视频通信系统,适…...
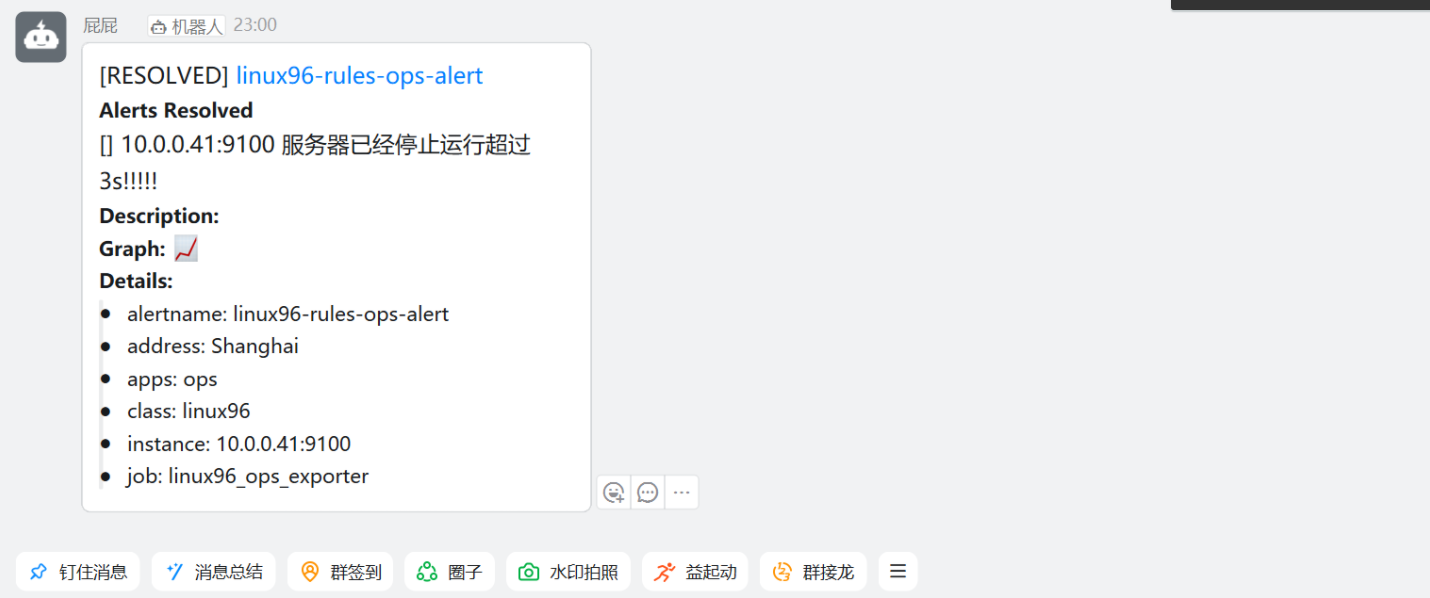
Prometheus学习之pushgateway和altermanager组件
[rootnode-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# pwd /usr/local/alertmanager-0.28.1.linux-amd64[rootnode-exporter41 /usr/local/alertmanager-0.28.1.linux-amd64]# cat alertmanager.yml # 通用配置 global:resolve_timeout: 5msmtp_from: 914XXXXX…...
01 redis 的环境搭建
前言 这一系列文章主要包含的内容主要是 各种常用软件的调试环境的搭建 主要的目的是 搭建一个可打断点的一个调试环境 c 系列 主要是基于 clion 调试, java 系列主要是基于 idea 调试, js 系列主要是基于 webstorm 调试 需要有一定的 c, c, java, js 相关基础 基于的…...
《操作系统真相还原》——加载器
显存 将上一章的中断输出,变为显存输出 加载器 使用mbr引导程序从磁盘中加载loader程序。 MBR %include "boot.inc" SECTION MBR vstart0x7c00 mov ax,cs mov ds,axmov es,axmov ss,axmov fs,axmov sp,0x7c00mov ax,0xb800mov gs,ax;cl…...

电网即插即用介绍
一、统一设备信息模型与标准接口 实现即插即用功能的基础在于建立统一的设备信息模型。不同厂家生产的各类电网设备,其内部结构、通信协议、数据格式等往往千差万别。通过制定统一的设备信息模型,能够对设备的各种属性、功能以及接口进行标准化定义&…...

HJ25 数据分类处理【牛客网】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 HJ25 数据分类处理 一、题目描述 二、测试用例 三、解题思路 基本思路: 首先理解题目,题目要求对规则集先进行排序,然后去重,这一步我…...

spring-boot redis lua脚本实现滑动窗口限流
因为项目中没有集成redisson,但是又需要用到限流,所以简单的将redisson中限流的核心lua代码移植过来,并进行改造,因为公司版本的redis支持lua版本为5.1,针对于长字符串的数字,使用tonumber转换的时候会得到…...

USB MSC
主机(如电脑)识别USB MSC(Mass Storage Class)设备中的文件,本质上是通过多层协议协作实现的,涉及USB枚举、SCSI命令传输和文件系统解析三个核心环节。以下是详细机制: 🔍 一、USB…...

css实现文字渐变
在前端开发中,给文字设置渐变色是完全可以实现的,常用的方式是结合 CSS 的 background、-webkit-background-clip 和 -webkit-text-fill-color 属性。下面是一个常见的实现方法: <!DOCTYPE html> <html lang"zh-CN"> …...

FART 自动化脱壳框架一些 bug 修复记录
版权归作者所有,如有转发,请注明文章出处:https://cyrus-studio.github.io/blog/ open() 判断不严谨 https://github.com/CYRUS-STUDIO/FART/blob/master/fart10/art/runtime/art_method.cc 比如: int dexfilefp open(dex_pat…...
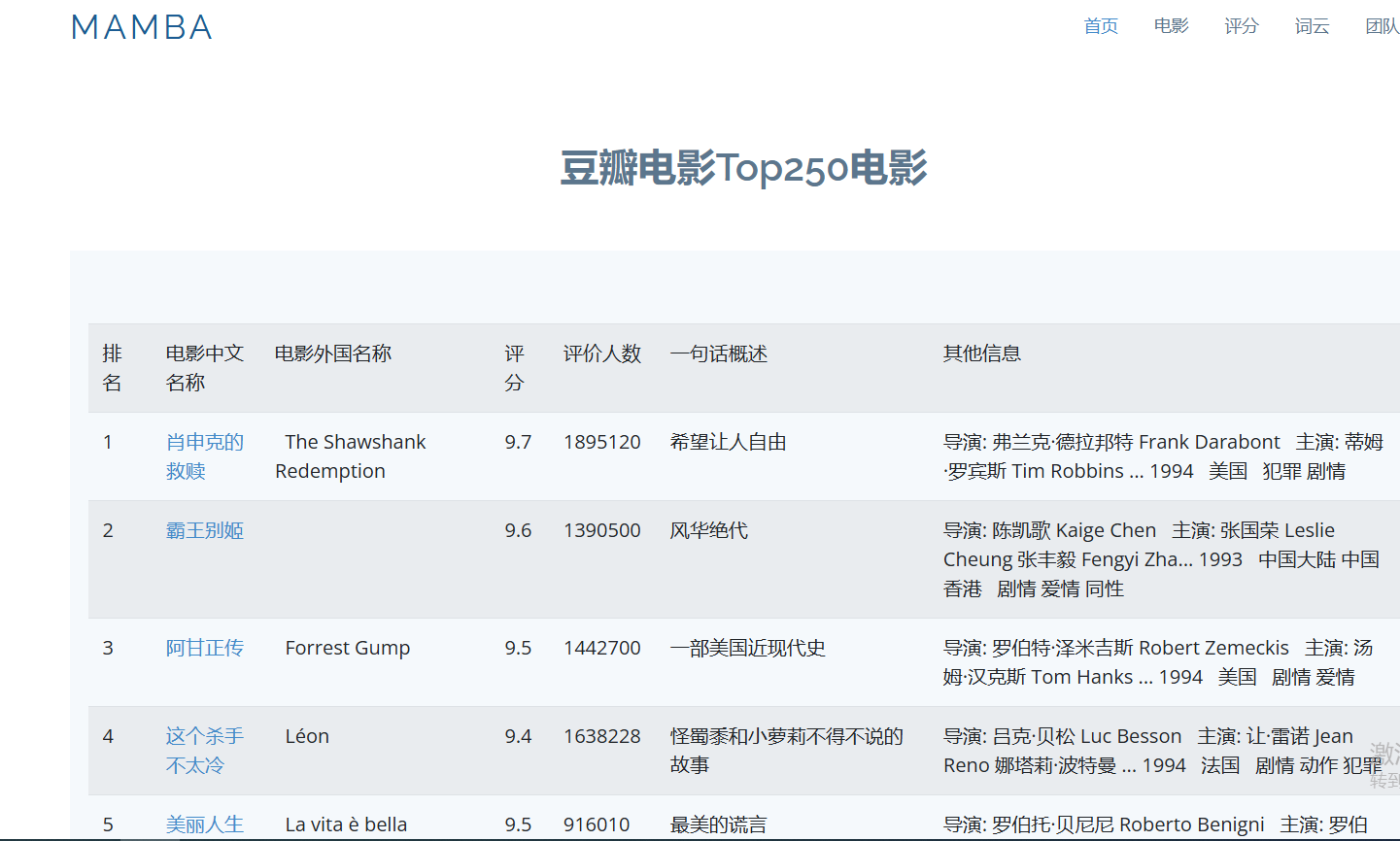
基于Flask实现豆瓣Top250电影可视化
项目截图 概述 该项目旨在对豆瓣Top 250电影进行全面的数据分析,使用了Python爬虫、Flask框架进行开发,并采用了Echarts进行数据可视化以及WordCloud进行词云分析。应用展示了多个功能,如电影列表、评分分布、词频统计和团队信息。 主要功能…...
More SQL(Focus Subqueries、Join)
目录 Subqueries Subqueries That Return One Tuple Subqueries and Self Connection The IN Operator The Exists Operator The Operator ANY The Operator ALL Union, Intersection, and Difference(交并差) Bag Semantics Controlling Dupl…...

项目部署react经历
简单的说: 1. 编译打包并压缩为压缩包 2. 将压缩包上传到服务器(这里以宝塔面板为例:www/wwwroot/目录下) 3. 将文件解压生成比如:www/wwwroot/ttms/build/* 多文件 4. php 项目建站,选择静态ÿ…...

从图像处理到深度学习:直播美颜SDK的人脸美型算法详解
在直播的镜头前,每一位主播都希望自己“光彩照人”。但在高清摄像头无死角的审视下,哪怕是天生丽质,也难免需要一点技术加持。于是,美颜SDK应运而生,成为直播平台提升用户粘性和视觉体验的重要工具。 尤其是在“人脸美…...

智能教育个性化学习路径规划系统实战指南
引言 在数字化教育革命中,如何利用AI技术实现"因材施教"的千年教育理想?本文将通过构建一个完整的智能教育系统,演示如何基于Python生态(Django机器学习)实现从数据采集到个性化推荐的全流程。系统将通过分…...

spark- ResultStage 和 ShuffleMapStage介绍
目录 1. ShuffleMapStage(中间阶段)1.1 作用1.2 核心特性1.3 示例2. ResultStage(最终结果阶段)2.1 作用2.2 核心特性2.3 示例3. 对比总结4. 执行流程示例5. 常见问题Q1:为什么需要区分两种 Stage?**Q2:如何手动观察 Stage 划分?Q3:ShuffleMapStage 的数据一定会落盘吗…...
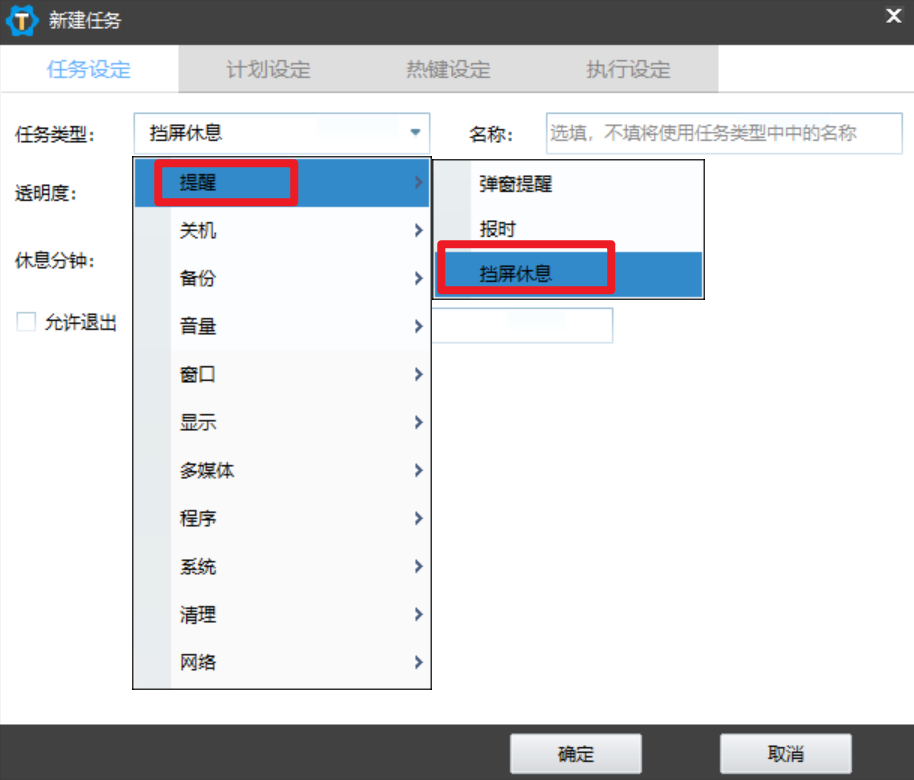
zTasker一款Windows自动化软件,提升效率:大小仅有10MB,免费无广告
一、zTasker是什么? zTasker是一款发布于2023年9月的免费无广告工具,专为Windows用户打造。它以仅8MB的轻量体积、极低资源占用(内存消耗不足10MB)和秒级启动速度脱颖而出,堪称“任务计划程序的终极强化版”。无论是定…...

人工智能100问☞第34问:什么是语音识别与合成?
目录 一、通俗解释 二、专业解析 三、权威参考 在人工智能的世界里,“看、听、说、写”早已不是人类的专属技能。语音识别,让机器有了耳朵;语音合成,让机器长了嘴巴;合在一起,机器就开始“说人话、听人言”了。 一、通俗解释 1、语音识别:让机器听懂人说话 你有没…...

最大流-Ford-Fulkerson增广路径算法py/cpp/Java三语言实现
最大流-Ford-Fulkerson增广路径算法py/cpp/Java三语言实现 一、网络流问题与相关概念1.1 网络流问题定义1.2 关键概念 二、Ford-Fulkerson算法原理2.1 核心思想2.2 算法步骤 三、Ford-Fulkerson算法的代码实现3.1 Python实现3.2 C实现3.3 Java实现 四、Ford-Fulkerson算法的时间…...

怎么从一台电脑拷贝已安装的所有python第三方库到另一台
要将Python库从一台电脑拷贝到另一台,可以采用以下方法: 方法一:使用pip命令导出和安装依赖 如果目标电脑在线,且python与pip命令可以正常使用 在源电脑上,打开命令行,执行以下命令导出所有依赖库到requ…...
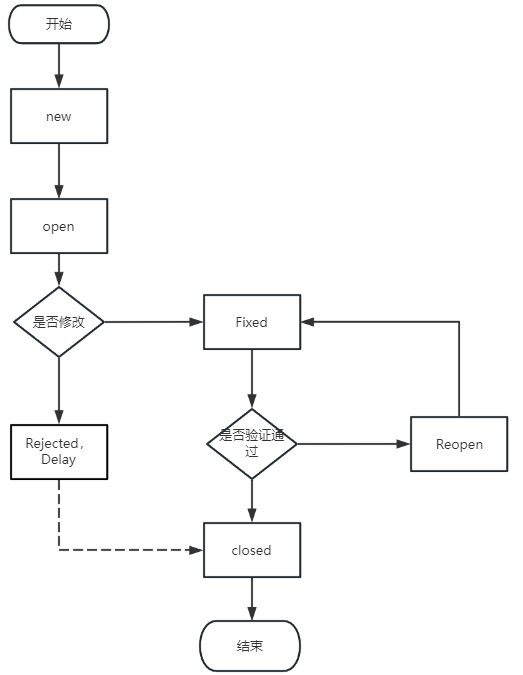
【测试】Bug和用例
软件测试贯穿于软件的整个⽣命周期 软件测试的⽣命周期是指测试流程,这个流程是按照⼀定顺序执⾏的⼀系列特定的步骤,去保证产品质量符合需求。在软件测试⽣命周期流程中,每个活动都按照计划的系统的执⾏。每个阶段有不同的⽬标和交付产物 Bu…...
)
缓存穿透、缓存击穿、缓存雪崩目前记录(纯日记)
今天学了学这三个知识,这命名真是有点东西。 1.先说在命名方面与其余两个内容能明显区分开的缓存雪崩,简单来讲: 缓存雪崩就是缓存宕机了,也甭管咋宕机了,反正就是某一时刻,缓存用不了了。 那咋办&#…...
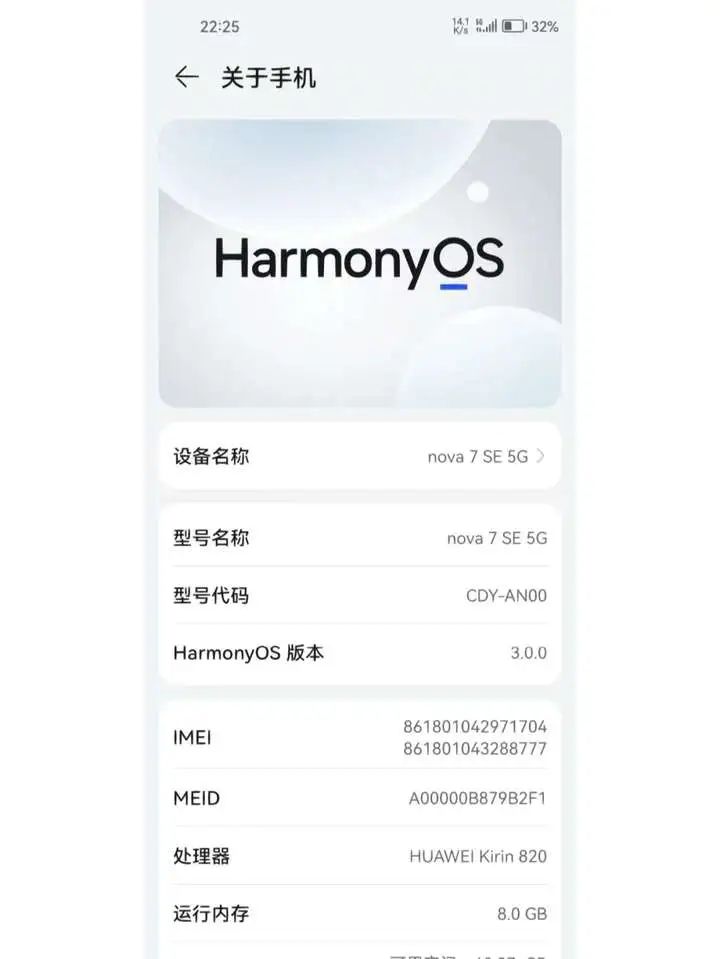
鸿蒙OS的5.0.1.120版本体验怎么样?
点击上方关注 “终端研发部” 设为“星标”,和你一起掌握更多数据库知识 越来越是好用了,之前是凑合能用,现在是大多能用。 我朋友的mate30PRO和PuraX一起用,新系统确实满足我90%以上的需求 一个系统适配一款机型,是要…...
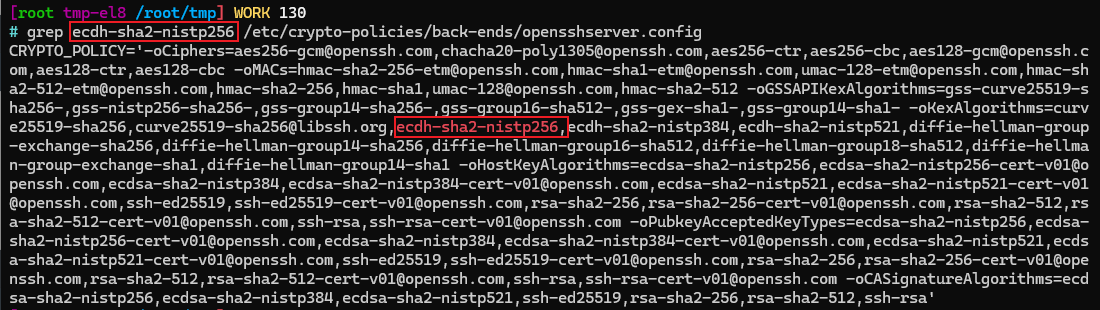
使用ssh-audit扫描ssh过期加密算法配置
使用ssh-audit扫描ssh过期加密算法配置 安装检查ssh的加密算法配置修改ssh的加密算法配置 安装 # pip3安装ssh-audit pip3 instal ssh-audit检查ssh的加密算法配置 # 检查ssh的配置 ssh-audit 192.168.50.149修改ssh的加密算法配置 # 查看ssh加密配置文件是否存在 ls /etc/c…...
详解)
前端工程化 Source Map(源码映射)详解
我们来深入讲解前端 Source Map(源码映射),围绕以下结构展开: 一、为什么要用 Source Map?(Why) 背景问题: 在前端构建中,源代码通常会被压缩(minify&#…...

2025.05.28-华为暑期实习第二题-200分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 02. A先生的旅游路径规划 问题描述 A先生正在为即将到来的假期规划一次城市旅游。这座城市有 n n n...
Java+Playwright自动化-2-环境准备与搭建-基于Maven
1.简介 上一章中已经讲如何通过引入jar包来搭建JavaPlaywright自动化测试环境,这一种是比较老的方法,说白了就是过时的老古董,但是我们必须了解和知道,其实maven搭建无非也就是下载引入相关的jar包,只不过相比之下是简…...
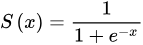
由sigmod权重曲线存在锯齿的探索
深度学习的知识点,一般按照执行流程,有 网络层类型,归一化,激活函数,学习率,损失函数,优化器。如果是研究生上课学的应该系统一点,自学的话知识点一开始有点乱。 一、激活函数Sigmod…...