RapidOCR集成PP-OCRv5_det mobile模型记录
该文章主要摘取记录RapidOCR集成PP-OCRv5_mobile_det记录,涉及模型转换,模型精度测试等步骤。原文请前往官方博客:
https://rapidai.github.io/RapidOCRDocs/main/blog/2025/05/26/rapidocr%E9%9B%86%E6%88%90pp-ocrv5_det%E6%A8%A1%E5%9E%8Bmobileserver%E8%AE%B0%E5%BD%95/
引言
来自PaddleOCR官方文档:
PP-OCRv5 是PP-OCR新一代文字识别解决方案,该方案聚焦于多场景、多文字类型的文字识别。在文字类型方面,PP-OCRv5支持简体中文、中文拼音、繁体中文、英文、日文5大主流文字类型,在场景方面,PP-OCRv5升级了中英复杂手写体、竖排文本、生僻字等多种挑战性场景的识别能力。在内部多场景复杂评估集上,PP-OCRv5较PP-OCRv4端到端提升13个百分点。
以下代码运行环境
- OS: macOS Sequoia 15.5
- Python: 3.10.14
- PaddlePaddle: 3.0.0
- paddle2onnx: 2.0.2.rc1
- paddlex: 3.0.0
- rapidocr: 2.1.0
1. 模型跑通
该步骤主要先基于PaddleX可以正确使用PP-OCRv5_mobile_det模型得到正确结果。
该部分主要参考文档:docs
安装paddlex:
pip install "paddlex[ocr]==3.0.0"
测试PP-OCRv5_mobile_det模型能否正常识别:
运行以下代码时,模型会自动下载到 /Users/用户名/.paddlex/official_models 下。
测试图:link
from paddlex import create_model# mobile
model = create_model(model_name="PP-OCRv5_mobile_det")# server
model = create_model(model_name="PP-OCRv5_server_det")output = model.predict(input="images/general_ocr_001.png", batch_size=1)
for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/res.json")
预期结果如下,表明成功运行:

2. 模型转换
该部分主要参考文档: docs
转换PP-OCRv5_mobile_det
PaddleX官方集成了paddle2onnx的转换代码:
paddlex --install paddle2onnx
pip install onnx==1.16.0paddlex --paddle2onnx --paddle_model_dir models/official_models/PP-OCRv5_mobile_det --onnx_model_dir models/PP-OCRv5_mobile_det
输出日志如下,表明转换成功:
Input dir: models/official_models/PP-OCRv5_mobile_det
Output dir: models/PP-OCRv5_mobile_det
Paddle2ONNX conversion starting...
[Paddle2ONNX] Start parsing the Paddle model file...
[Paddle2ONNX] Use opset_version = 14 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2025-05-26 21:53:00 [INFO] Try to perform constant folding on the ONNX model with Polygraphy.
[W] 'colored' module is not installed, will not use colors when logging. To enable colors, please install the 'colored' module: python3 -m pip install colored
[I] Folding Constants | Pass 1
[I] Total Nodes | Original: 925, After Folding: 502 | 423 Nodes Folded
[I] Folding Constants | Pass 2
[I] Total Nodes | Original: 502, After Folding: 502 | 0 Nodes Folded
2025-05-26 21:53:08 [INFO] ONNX model saved in models/PP-OCRv5_mobile_det/inference.onnx.
Paddle2ONNX conversion succeeded
Copied models/official_models/PP-OCRv5_mobile_det/inference.yml to models/PP-OCRv5_mobile_det/inference.yml
Done
3. 模型推理验证
验证PP-OCRv5_mobile_det模型
该部分主要是在RapidOCR项目中测试能否直接使用onnx模型。要点主要是确定模型前后处理是否兼容。从PaddleOCR config文件中比较PP-OCRv4和PP-OCRv5 mobile det文件差异:

从上图中可以看出,配置基本一模一样,因此现有rapidocr前后推理代码可以直接使用。
from rapidocr import RapidOCRmodel_path = "models/PP-OCRv5_mobile_det/inference.onnx"
engine = RapidOCR(params={"Det.model_path": model_path})img_url = "https://img1.baidu.com/it/u=3619974146,1266987475&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=516"
result = engine(img_url)
print(result)result.vis("vis_result.jpg")

4. 模型精度测试
测试集text_det_test_dataset包括卡证类、文档类和自然场景三大类。其中卡证类有82张,文档类有75张,自然场景类有55张。缺少手写体、繁体、日文、古籍文本、拼音、艺术字等数据。因此,该基于该测评集的结果仅供参考。
欢迎有兴趣的小伙伴,可以和我们一起共建更加全面的测评集。
该部分主要使用TextDetMetric和测试集text_det_test_dataset来评测。
相关测试步骤请参见TextDetMetric的README,一步一步来就行。我这里简单给出关键代码:
其中,计算 pred.txt 代码如下:(仅列出了Exp1的代码,Exp2和Exp3的代码请前往官方博客阅读)
(Exp1)RapidOCR框架+ONNXRuntime格式模型:
import cv2
import numpy as np
from datasets import load_dataset
from tqdm import tqdmfrom rapidocr import EngineType, ModelType, OCRVersion, RapidOCRengine = RapidOCR(params={"Det.ocr_version": OCRVersion.PPOCRV5,"Det.engine_type": EngineType.ONNXRUNTIME,"Det.model_type": ModelType.MOBILE,}
)dataset = load_dataset("SWHL/text_det_test_dataset")
test_data = dataset["test"]content = []
for i, one_data in enumerate(tqdm(test_data)):img = np.array(one_data.get("image"))img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)ocr_results = engine(img, use_det=True, use_cls=False, use_rec=False)dt_boxes = ocr_results.boxesdt_boxes = [] if dt_boxes is None else dt_boxes.tolist()elapse = ocr_results.elapsegt_boxes = [v["points"] for v in one_data["shapes"]]content.append(f"{dt_boxes}\t{gt_boxes}\t{elapse}")with open("pred.txt", "w", encoding="utf-8") as f:for v in content:f.write(f"{v}\n")
计算指标代码:
from text_det_metric import TextDetMetricmetric = TextDetMetric()
pred_path = "pred.txt"
metric = metric(pred_path)
print(metric)
指标汇总如下(以下指标均为CPU下计算所得):
| Exp | 模型 | 推理框架 | 模型格式 | Precision↑ | Recall↑ | H-mean↑ | Elapse↓ |
|---|---|---|---|---|---|---|---|
| 1 | PP-OCRv5_mobile_det | PaddleX | PaddlePaddle | 0.7864 | 0.8018 | 0.7940 | 0.1956 |
| 2 | PP-OCRv5_mobile_det | RapidOCR | PaddlePaddle | 0.7861 | 0.8266 | 0.8058 | 0.5328 |
| 3 | PP-OCRv5_mobile_det | RapidOCR | ONNXRuntime | 0.7861 | 0.8266 | 0.8058 | 0.1653 |
| 4 | PP-OCRv4_mobile_det | RapidOCR | ONNXRuntime | 0.8301 | 0.8659 | 0.8476 | - |
| 5 | PP-OCRv5_server_det | PaddleX | PaddlePaddle | 0.8347 | 0.8583 | 0.8463 | 2.1450 |
| 6 | PP-OCRv5_server_det | RapidOCR | PaddlePaddle | ||||
| 7 | PP-OCRv5_server_det | RapidOCR | ONNXRuntime | 0.7394 | 0.8442 | 0.7883 | 2.0628 |
| 8 | PP-OCRv4_server_det | RapidOCR | ONNXRuntime | 0.7922 | 0.8128 | 0.7691 | - |
从以上结果来看,可以得到以下结论:
-
Exp1和Exp2相比,H-mean差异不大,说明文本检测 前后处理代码可以共用 。
-
Exp2和Exp3相比,mobile模型转换为ONNX格式后,指标几乎一致,说明 模型转换前后,误差较小,推理速度也有提升 。
-
Exp3和Exp4相比,mobile整体指标弱于PP-OCRv4的。因为测评集集中在中英文的印刷体,手写体少些,因此仅供参考。
-
Exp6直接跑,会报以下错误,暂时没有找到原因。如有知道的小伙伴,欢迎留言告知。
5%|████████▏ | 11/212 [00:42<13:11, 3.94s/it][1] 61275 bus error python t.py/Users/xxxxx/miniconda3/envs/py310/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown warnings.warn('resource_tracker: There appear to be %d ' -
因为Exp6暂时没有找到原因,粗略将Exp5和Exp7相比,可以看到PP-OCRv5 server模型转换为ONNX格式后,H-mean下降了5.8% ,但是转换方式和mobile的相同,具体原因需要进一步排查。如有知道的小伙伴,欢迎留言告知。
-
Exp7和Exp8相比,PP-OCRv5 server模型提升很大(H-mean提升7.72%)。不排除用到了测评集数据。
最终建议:
- 如果是单一中英文场景,建议用PP-OCRv4系列
- 如果是中英日、印刷和手写体混合场景,建议用PP-OCRv5系列
上述表格中基于ONNXRuntime的结果已经更新到开源OCR模型对比中。
5. 集成到rapidocr中
该部分主要包括将托管模型到魔搭、更改rapidocr代码适配等。
托管模型到魔搭
该部分主要是涉及模型上传到对应位置,并合理命名。注意上传完成后,需要打Tag,避免后续rapidocr whl包中找不到模型下载路径。
我这里已经上传到了魔搭上,详细链接参见:link
更改rapidocr代码适配
该部分主要涉及到更改default_models.yaml和paddle.py的代码来适配。
同时,需要添加对应的单元测试,在保证之前单测成功的同时,新的针对性该模型的单测也能通过。
我这里已经做完了,小伙伴们感兴趣可以去看看源码。
写在最后
至此,该部分集成工作就基本完成了。这部分代码会集成到rapidocr==3.0.0中。版本号之所以从v2.1.0到v3.0.0,原因是:语义化版本号。
我在集成过程中,发现v2.1.0中字段不太合理,做了一些改进,动了外部API,因此只能升大版本号。请大家在使用过程中,注意查看最新文档→ docs 。
相关文章:
RapidOCR集成PP-OCRv5_det mobile模型记录
该文章主要摘取记录RapidOCR集成PP-OCRv5_mobile_det记录,涉及模型转换,模型精度测试等步骤。原文请前往官方博客: https://rapidai.github.io/RapidOCRDocs/main/blog/2025/05/26/rapidocr%E9%9B%86%E6%88%90pp-ocrv5_det%E6%A8%A1%E5%9E%8B…...
之间的一致性?)
当 Redis 作为缓存使用时,如何保证缓存数据与数据库(或其他服务的数据源)之间的一致性?
当 Redis 作为缓存使用时,保证缓存数据与数据库(或其他数据源)之间的一致性是一个核心挑战。通常,我们追求的是“最终一致性”,而不是“强一致性”,因为强一致性往往会牺牲性能和可用性,这与使用…...

Dify理论+部署+实战
概述 一个功能强大的开源AI应用开发平台,融合后端即服务(Backend as Service)和LLMOps理念,使开发者能够快速搭建生产级的生成式AI应用。 核心优势 直观的用户界面:提供简洁明了的操作界面,使得用户能够…...

内网穿透系列五:自建SSH隧道实现内网穿透与端口转发,Docker快速部署
以下是对这个自建SSH隧道工具的简单介绍: 一款基于OpenSSH构建的内网穿透与端口转发工具,通过SSH隧道技术实现支持所有TCP协议通信,包括SSH、HTTP、HTTPS等各类应用提供灵活部署方式,特别支持Docker容器化快速部署开源工具地址…...

桥梁进行3D建模时的数据采集、存储需求及技术参数
桥梁进行3D建模时的数据采集、存储需求及技术参数 1公里桥梁进行3D建模时的数据采集、存储需求及技术参数的详细分析 1. 照片数量估算 关键影响因素 桥梁类型:梁桥/拱桥/斜拉桥(结构复杂度不同) 建模精度:工程级(1-…...
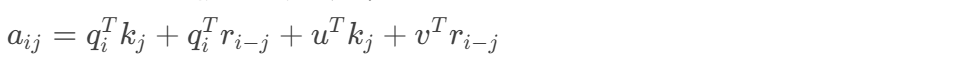
Transformer架构技术学习笔记:从理论到实战的完整解析
引言:重新定义序列建模的里程碑 2017年,Vaswani等人在论文《Attention Is All You Need》中提出的Transformer架构,彻底改变了自然语言处理领域的游戏规则。与传统RNN/LSTM相比,Transformer具有三大革命性特征: 全注意…...
1、python代码实现与大模型的问答交互
一、基础知识 1.1导入库 torch 是一个深度学习框架,用于处理张量和神经网络。modelscope是由阿里巴巴达摩院推出的开源模型库。 AutoTokenizer 是ModelScope 库的类,分词器应用场景包括自然语言处理(NLP)中的文本分类、信息抽取…...

CPU服务器的主要功能有哪些?
服务器作为互联网社会中基础的网络设施,为企业提供了存储和传输文件的功能,而中央处理器作为服务器计算能力的核心部分,能够帮助企业进行十分复杂的科学计算任务,本文就主要来探索一下CPU服务器的主要功能都有哪些吧! …...

如何在 Vue.js 中集成 Three.js —— 创建一个旋转的 3D 立方体
在这篇文章中,我将向大家展示如何将 Three.js 与 Vue.js 结合,创建一个简单的 3D 场景,并展示一个旋转的立方体。通过这个简单的示例,你将学习到如何在 Vue 项目中集成 Three.js,以及如何创建动态的 3D 内容。 1. 安装…...
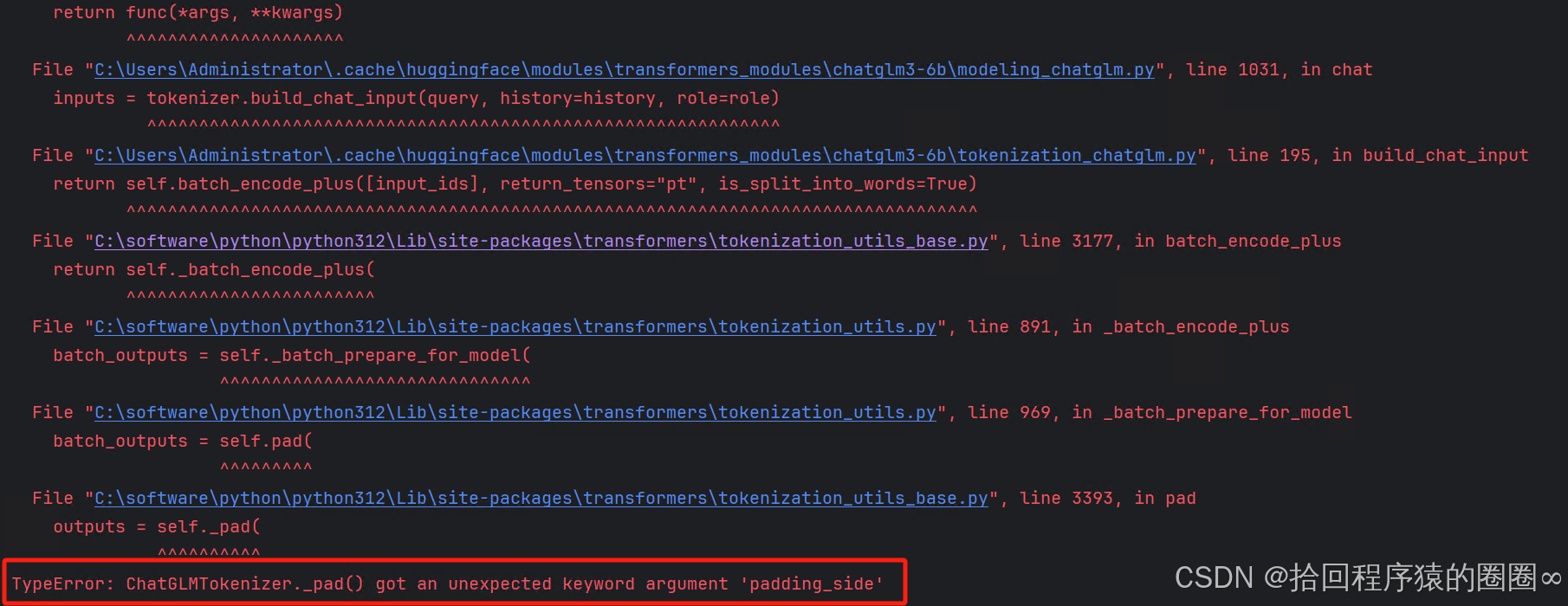
Java开发经验——阿里巴巴编码规范实践解析6
摘要 本文深入解析了阿里巴巴编码规范在数据库设计和Java开发中的实践应用。详细阐述了数据库字段命名、类型选择、索引命名等规范,以及Java POJO类的对应规范。强调了字段命名的重要性,如布尔字段命名规则、表名和字段名的命名禁忌等。同时,…...

docker常见考点
一、基础概念类 Docker与虚拟机的区别 Docker基于容器化技术,共享宿主机内核,资源消耗更少;虚拟机通过Hypervisor虚拟化硬件,资源占用高。Docker启动速度更快(秒级),虚拟机需要启动完整操作系统…...
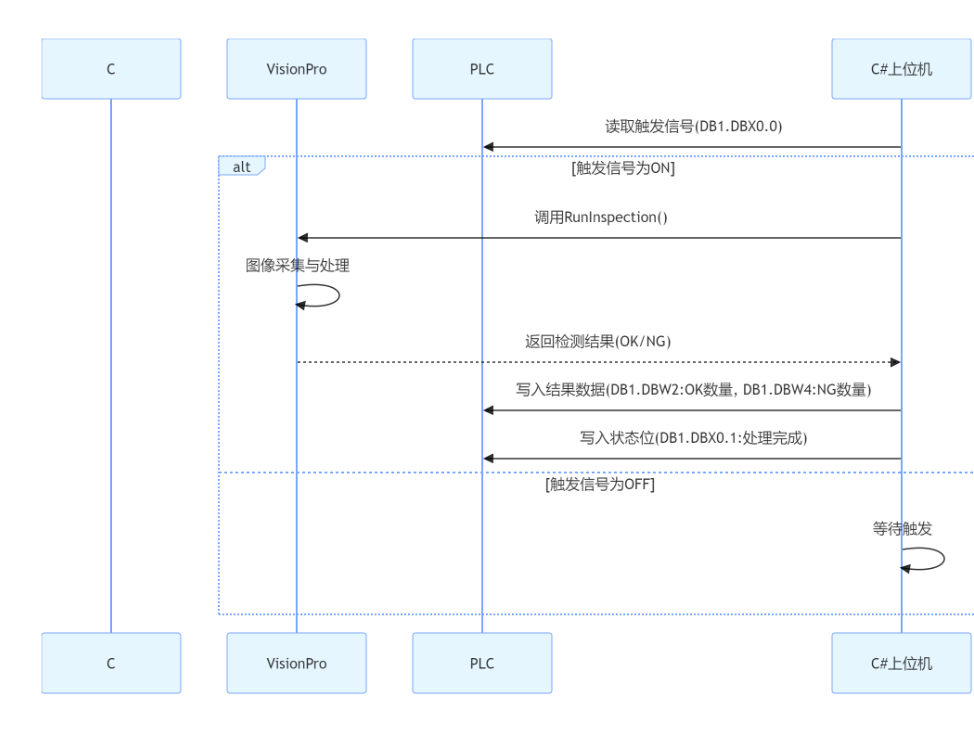
工业自动化实战:基于 VisionPro 与 C# 的机器视觉 PLC 集成方案
一、背景介绍 在智能制造领域,机器视觉检测与 PLC 控制的无缝集成是实现自动化生产线闭环控制的关键。本文将详细介绍如何使用 C# 开发上位机系统,实现 Cognex VisionPro 视觉系统与西门子 S7 PLC 的数据交互,打造高效、稳定的工业检测方案。…...
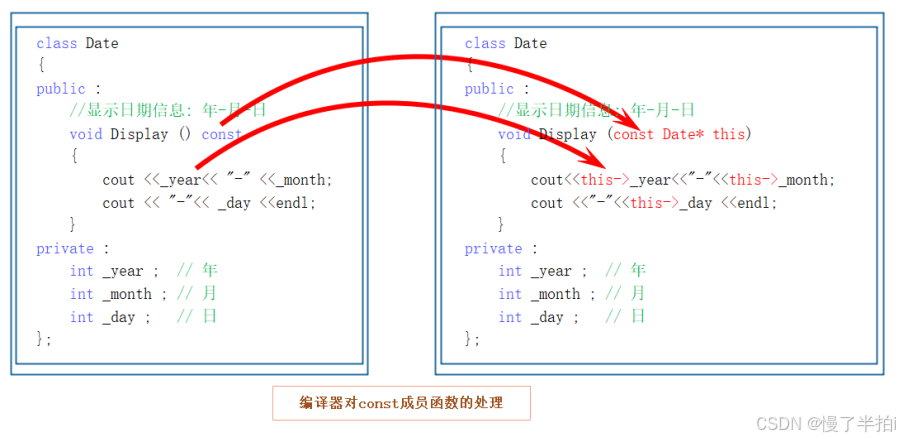
C++ —— B/类与对象(中)
🌈个人主页:慢了半拍 🔥 创作专栏:《史上最强算法分析》 | 《无味生》 |《史上最强C语言讲解》 | 《史上最强C练习解析》|《史上最强C讲解》 🏆我的格言:一切只是时间问题。 目录 一、类的6个默认成员…...

Java网络编程与Socket安全权限详解
Socket安全权限控制 Java通过java.net.SocketPermission类实现对网络套接字访问的细粒度控制。该权限管理机制通常在Java策略文件中配置,其标准授权语法格式如下: grant {permission java.net.SocketPermission"target", "actions"; };目标主机与端口规…...

AXI协议乱序传输机制解析:提升SoC性能的关键设计
AXI 协议 Out-of-Order 传输机制 概述 AXI (Advanced eXtensible Interface) 协议支持乱序传输 (Out-of-Order) 机制,这是一种重要的性能优化特性,允许数据传输不按照发起顺序完成,从而提高总线带宽利用率和系统整体性能。 基本原理 通道…...
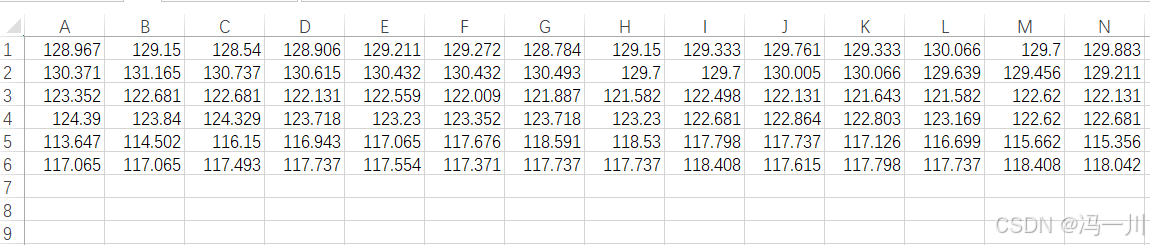
Qt实现csv文件按行读取的方式
Qt实现csv文件按行读取的方式 场景:我有一个保存数据的csv文件,文件内保存的是按照行保存的数据,每行数据是以逗号为分隔符分割的文本数据。如下图所示: 现在,我需要按行把这些数据读取出来。 一、使用QTextStream文本流的方式读取 #include <QFile>void readfil…...

分库分表后的 ID 生成方案
分库分表后的 ID 生成方案 一、问题背景 在分布式系统中,当单表数据量超过千万级时,通常会采用分库分表策略。此时传统的自增ID方案会面临以下问题: 不同分片可能生成相同ID(冲突)单调递增特性被破坏全局唯一性难以保证关键结论:分库分表环境下,ID生成必须满足全局唯一…...

进行性核上性麻痹健康护理全指南:从症状管理到生活照护
进行性核上性麻痹(PSP)是一种罕见的神经退行性疾病,主要影响运动、平衡及眼球运动功能,常表现为步态不稳、吞咽困难、眼球上视受限、情绪改变等。由于目前尚无根治方法,科学的健康护理对延缓病情进展、提升患者生活质量…...
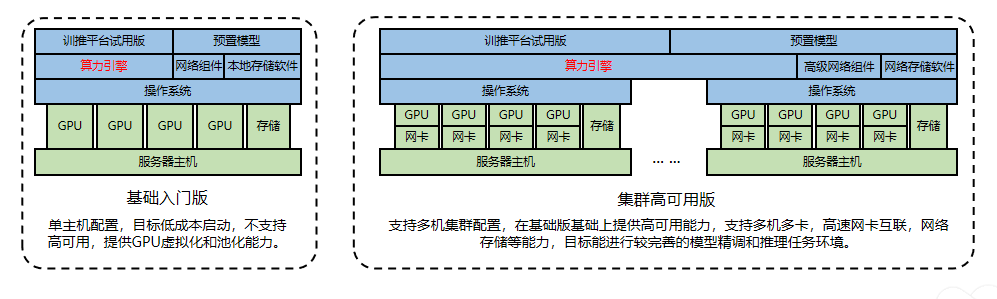
openFuyao开源发布,建设多样化算力集群开源软件生态
openFuyao 开源发布 随着 AI 技术的高速发展,算力需求呈爆发式增长,集群已成为主流生产方式。然而,当前集群软件生态发展滞后于硬件系统,面临多样化算力调度困难、超大规模集群软件支撑不足等挑战。这些问题的根源在于集群生产的…...
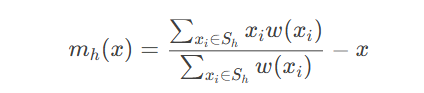
第四十五节:目标检测与跟踪-Meanshift/Camshift 算法
引言 在计算机视觉领域,目标跟踪是实时视频分析、自动驾驶、人机交互等应用的核心技术之一。Meanshift和Camshift算法作为经典的跟踪方法,以其高效性和实用性广受关注。本文将从原理推导、OpenCV实现到实际案例,全面解析这两种算法的核心思想与技术细节。 一、Meanshift算法…...
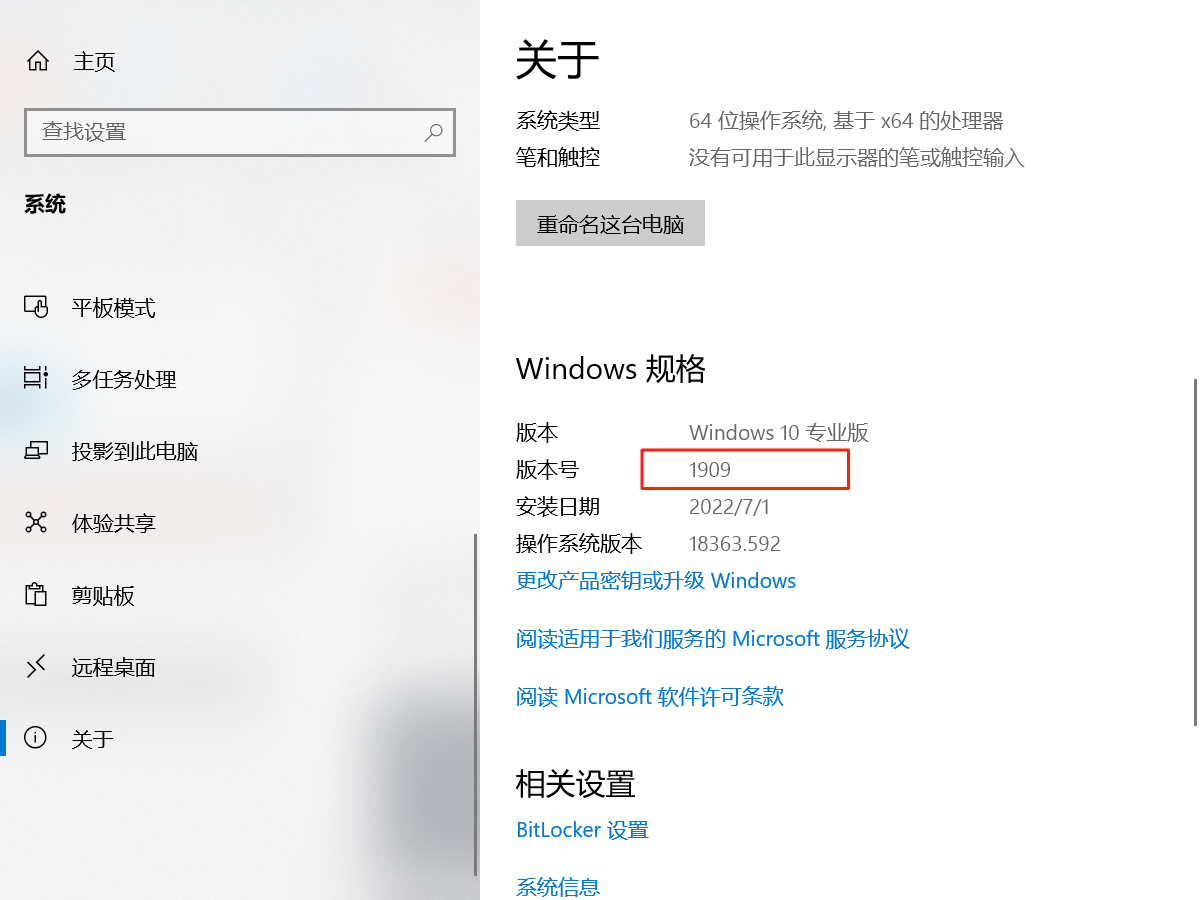
Docker Desktop无法在windows低版本进行安装
问题描述 因工作需要,现在一台低版本的window系统进行Docker Desktop的安装,但是安装过程当中出现了报错信息 系统版本配置 原因分析: 关于本机查看了系统的版本号,版本号如下为1909,但是docker Desktop要求的最低的win10版本…...

SQL Server 简介和与其它数据库对比
SQL Server 是微软(Microsoft)开发的一种 关系型数据库管理系统(RDBMS),全称是 Microsoft SQL Server。 🔍 SQL Server 是什么? SQL Server 是一个功能强大、企业级的数据库平台,用…...

2025年- H56-Lc164--200.岛屿数量(图论,深搜)--Java版
1.题目描述 2.思路 (1)主函数,存储图结构 (2)主函数,visit数组表示已访问过的元素 (3)辅助函数,用递归(深搜),遍历以已访问过的元素&…...

自证式推理训练:大模型告别第三方打分的新纪元
1. 传统验证体系的困境与技术跃迁的必然性 1.1 传统验证器的局限性 现有强化学习框架依赖显式验证器对答案进行二值化判定,这种模式在数学、代码等可验证领域表现优异。某厂内部数据显示,传统R1-Zero方法在代码生成任务中准确率达92%,但切换…...
vue2使用el-tree实现两棵树间节点的拖拽复制
原文链接:两棵el-tree的节点跨树拖拽实现 参照这篇文章,把它做成组件,新增左侧树(可拖出)被拖节点变灰提示; 拖拽中: 拖拽后: TreeDragComponent.vue <template><!-- …...

前端开发中 <> 符号解析问题全解:React、Vue 与 UniApp 场景分析与解决方案
前端开发中 <> 符号解析问题全解:React、Vue 与 UniApp 场景分析与解决方案 在前端开发中,<> 符号在 JSX/TSX 环境中常被错误解析为标签而非比较运算符或泛型,导致语法错误和逻辑异常。本文全面解析该问题在不同框架中的表现及解…...

封装一个Qt调用动态库的类
封装一个Qt调用动态库的类 由于我的操作系统Ubuntu系统,我就以Linux下的动态库.so为例了,其实windows上的dll库调用方式是一样的,如果你的Qt项目是windows的,这篇文章代码可以直接使用。 一般情况下我们对外输出都是以动态库的形式封装的,这样我们更新版本的时候就很方便…...

[python] 最大公约数 和 最小公倍数
在Python中,计算最大公约数(GCD)和最小公倍数(LCM)的库函数主要来自math模块: 最大公约数(GCD) 使用math.gcd(a, b)函数,支持两个整数参数(Python 3.5&…...

如何在 Django 中集成 MCP Server
目录 背景说明第一步:使用 ASGI第二步:修改 asgi.py 中的应用第三步:Django 数据的异步查询 背景说明 有几个原因导致 Django 集成 MCP Server 比较麻烦 目前支持的 MCP 服务是 SSE 协议的,需要长连接,但一般来讲 Dj…...
从零开始的云计算生活——第十一天,知识延续,程序管理。
一故事背景 今日整体内容是第十天的剩余部分再加上程序管理的开头部分,详细可以回到第十天看新增加内容,现在开始讲解新内容。 二Linux程序与进程 1程序,进程,线程的概念 程序:是一段静态的代码,它是应用软件执行的蓝本。程序…...