如何使用DeepSpeed来训练大模型
🔥 DeepSpeed是什么?
-
DeepSpeed 是微软开源的一个 分布式训练加速库。
-
能帮助我们:
-
高效训练大模型(百亿、千亿参数规模)
-
节省显存、加速训练
-
支持 ZeRO 优化器、Offload、混合精度(FP16/BF16)、梯度累积
-
快速启动多机多卡训练
-
总结一句话:
DeepSpeed = 大模型训练神器,尤其适合 SFT、预训练、微调阶段。
🌈 DeepSpeed 安装
1️⃣ 安装基础依赖
通常只需要:
pip install deepspeed对于更大规模训练,可以加上:
pip install deepspeed[all]确保安装了 PyTorch >= 1.12。
🚀 DeepSpeed 快速上手(训练脚本改造)
2️⃣ 修改训练脚本(以 PyTorch / Hugging Face 为例)
🧩 (1)DeepSpeed CLI 启动
假设你已经有一个 train.py(PyTorch训练脚本):
deepspeed train.py --deepspeed ds_config.json-
ds_config.json:DeepSpeed配置文件(稍后详细讲)。
🧩 (2)代码适配(只需两步!)
✅ a. 导入 deepspeed:
import deepspeed✅ b. 替换优化器 & 模型初始化:
model_engine, optimizer, _, _ = deepspeed.initialize(args=your_args,model=model,optimizer=optimizer,model_parameters=model.parameters(),config="ds_config.json"
)
✅ c. 训练 loop 改为:
for batch in dataloader:outputs = model_engine(batch)loss = outputs.lossmodel_engine.backward(loss)model_engine.step()
🎯 小结:只需 initialize 和 model_engine 替换,几行代码搞定!
🔍 DeepSpeed配置文件(ds_config.json)详解
这是 DeepSpeed 的核心,控制训练的优化策略。常见配置如下:
{"train_batch_size": 32,"train_micro_batch_size_per_gpu": 4,"gradient_accumulation_steps": 8,"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu"},"offload_param": {"device": "cpu"}},"fp16": {"enabled": true},"gradient_clipping": 1.0,"steps_per_print": 100,"wall_clock_breakdown": false
}
⚙️ 常见配置解释:
| 参数 | 含义 | 推荐值 / 建议 |
|---|---|---|
train_batch_size | 全局 batch size | 必须设置 |
train_micro_batch_size_per_gpu | 每个GPU的 batch size | 看显存而定 |
gradient_accumulation_steps | 梯度累积步数 | train_batch_size / (num_gpus * micro_batch_size) |
zero_optimization | ZeRO 优化器 | stage 1/2/3 |
offload_optimizer | 优化器 offload | 省显存,慢一点 |
offload_param | 参数 offload | stage 3 时常用 |
fp16 / bf16 | 混合精度 | true |
gradient_clipping | 梯度裁剪 | 1.0 |
📦 Hugging Face 🤗 集成 DeepSpeed
Hugging Face Transformers 已原生支持 DeepSpeed!
只需在 trainer 里加上 --deepspeed 参数即可!
✅ 步骤:
1️⃣ 准备 ds_config.json
2️⃣ 命令行运行:
accelerate config # 配置训练
accelerate launch --multi_gpu --deepspeed ds_config.json train.py
✅ 代码示例:
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=2,per_device_eval_batch_size=2,gradient_accumulation_steps=8,fp16=True,deepspeed="ds_config.json", # 只需加这一行!
)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,
)trainer.train()
💡 高级技巧
✅ ZeRO-3 + Offload
最大化节省显存(即使只有 24GB 显卡也能训练 65B 模型!)
✅ Activation Checkpointing
减少显存占用,开启方式:
"activation_checkpointing": {"partition_activations": true,"contiguous_memory_optimization": true
}
✅ 梯度累积
模拟大 batch size,显存不够时的必杀技。
✅ DeepSpeed Inference Engine
支持推理加速,适合部署阶段。
🌳 项目结构
sft_project/
├── data/
│ ├── train.jsonl
│ └── val.jsonl
├── model/
│ └── (预训练模型文件夹,如LLaMA、Baichuan)
├── deepspeed_config/
│ └── ds_config.json
├── train.py
├── requirements.txt
└── README.md
🎓 总结
| 你想做什么? | 如何用DeepSpeed? |
|---|---|
| 训练大模型 | 用 deepspeed 启动,写好 ds_config.json |
| 不想改代码 | Hugging Face Trainer + --deepspeed 参数 |
| 显存不够 | 开启 ZeRO-3 + Offload + FP16/BF16 |
| 多机多卡训练 | deepspeed --num_gpus=8 或 accelerate launch |
| 部署 | DeepSpeed Inference 加速推理 |
相关文章:

如何使用DeepSpeed来训练大模型
🔥 DeepSpeed是什么? DeepSpeed 是微软开源的一个 分布式训练加速库。 能帮助我们: 高效训练大模型(百亿、千亿参数规模) 节省显存、加速训练 支持 ZeRO 优化器、Offload、混合精度(FP16/BF16࿰…...
》发布)
道可云人工智能每日资讯|《北京市人工智能赋能新型工业化行动方案(2025年)》发布
道可云人工智能&元宇宙每日简报(2025年5月28日)讯,今日人工智能&元宇宙新鲜事有: 河南:打造“AI智慧文旅”沉浸式体验新空间,推动5GAR/VR在文旅消费场景应用 近日,河南省人民政府办公…...
Unity 中实现首尾无限循环的 ListView
之前已经实现过: Unity 中实现可复用的 ListView-CSDN博客文章浏览阅读5.6k次,点赞2次,收藏27次。源码已放入我的 github,地址:Unity-ListView前言实现一个列表组件,表现方面最核心的部分就是重写布局&…...
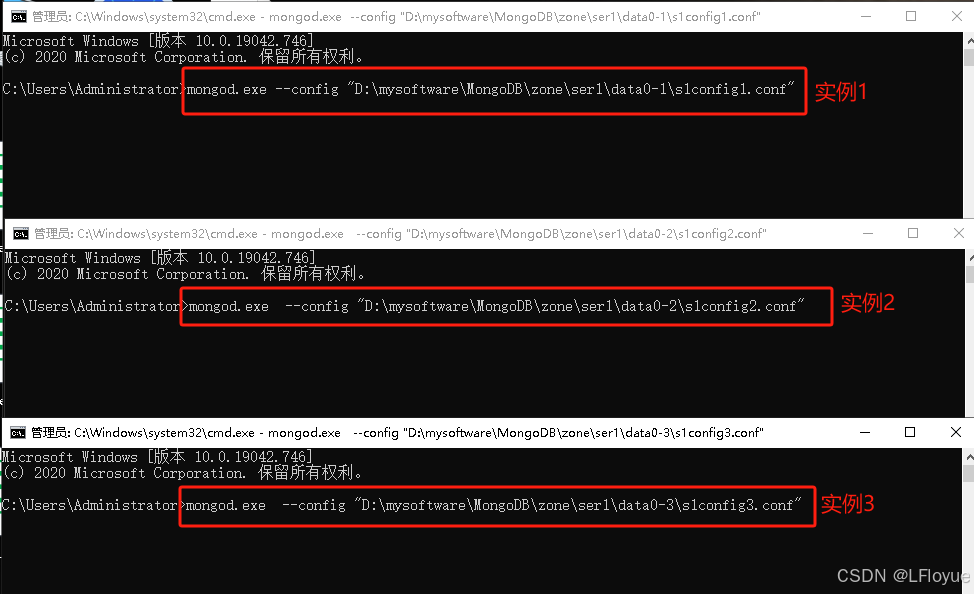
mongodb集群之副本集
目录 1. 适用场景备份高可用性 2. 集群搭建如何搭建资源规划根据资源完成各节点conf文件的配置启动各个mongodb节点初始化集群信息 搭建实例Linux搭建实例(待定)Windows搭建实例 3. 副本集基础操作4.集群平滑升级 1. 适用场景 备份 1)服务器…...

基于微服务架构的社交学习平台WEB系统的设计与实现
设计(论文)题目 基于微服务架构的社交学习平台WEB系统的设计与实现 摘 要 社交学习平台 web 系统要为学习者打造一个开放、互动且社交性强的在线教育环境,打算采用微服务架构来设计并实现一个社交学习平台 web 系统,以此适应学…...

window10下docker方式安装dify步骤
window10下docker方式安装dify步骤(稳定后考虑部署至linux中) 教程:https://blog.csdn.net/qq_49035156/article/details/143264534 教程:https://blog.csdn.net/m0_51171437/article/details/146069890 0、资源要求 ---windows…...

Spark SQL进阶:解锁大数据处理的新姿势
目录 一、Spark SQL,为何进阶? 二、进阶特性深剖析 2.1 窗口函数:数据洞察的新视角 2.2 高级聚合:挖掘数据深度价值 2.3 自定义函数(UDF 和 UDTF):拓展功能边界 三、性能优化实战 3.1 数…...

放假带出门的充电宝买哪种好用耐用?倍思超能充35W了解一下!
端午节的到来和毕业季的临近,让很多人开始计划出游或长途旅行。而在旅途中,一款好用耐用的充电宝可以省不少事。今天,我们就来聊聊放假带出门的充电宝买哪种好用耐用,看看为什么倍思超能充35W更适合带出门~ 一、为什么需要一款好用…...

云原生DMZ架构实战:基于AWS CloudFormation的安全隔离区设计
在云时代,传统的DMZ(隔离区)概念已经演变为更加灵活和动态的架构。本文通过解析一个实际的AWS CloudFormation模板,展示如何在云原生环境中构建现代化的DMZ安全架构。 1. 云原生DMZ的核心理念 传统DMZ是网络中的"缓冲区",位于企业内网和外部网络之间。而在云环境…...

小工具合集
Freetool.tools - Overview Freetool.tools is a 100% free online utility website offering a wide range of handy tools for everyday tasks. It focuses on simplicity, instant access, and zero cost—no signup, ads, or paywalls. ✅ Key Features & Strengths …...
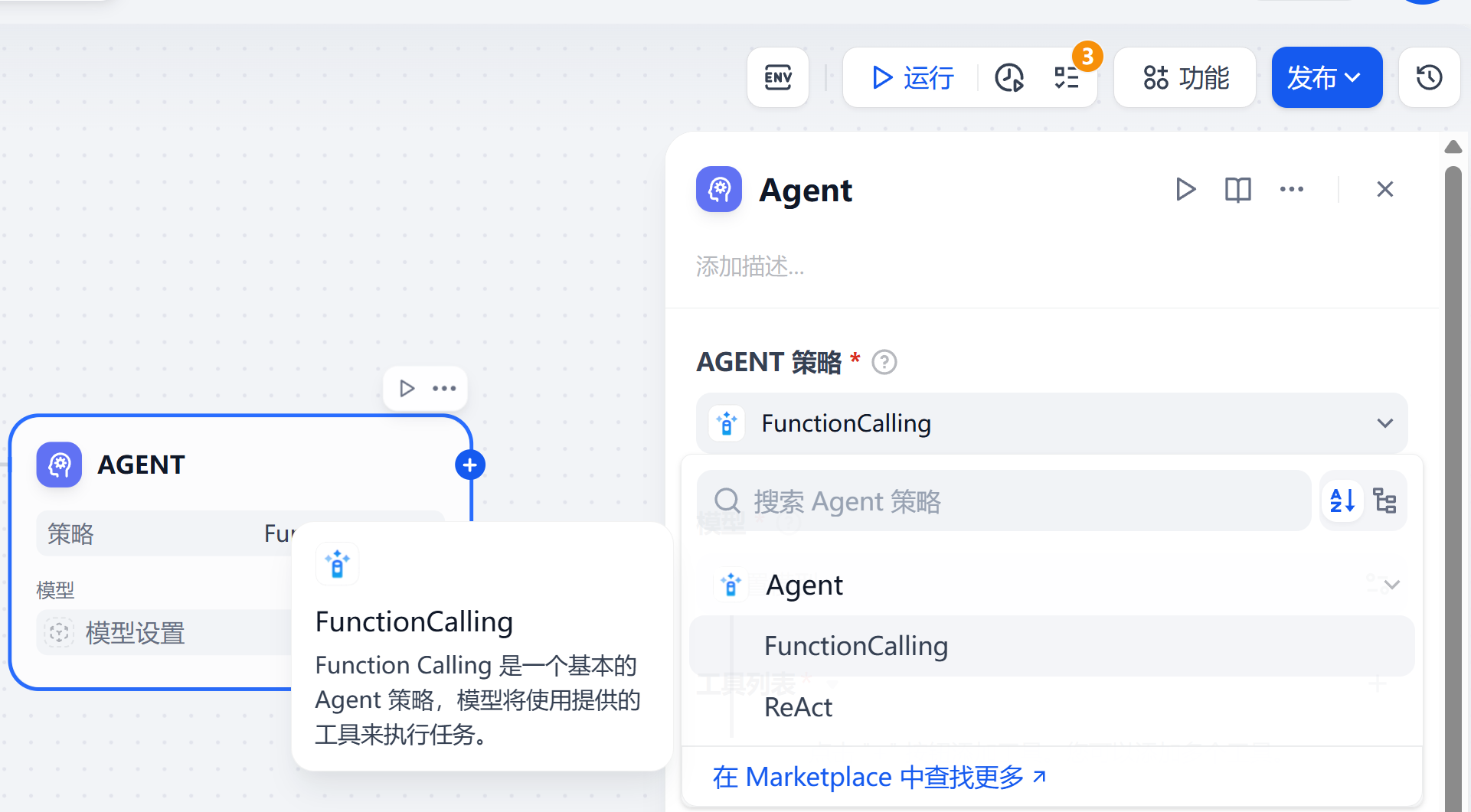
AI智能体策略FunctionCalling和ReAct有什么区别?
Dify 内置了两种 Agent 策略:Function Calling 和 ReAct,但二者有什么区别呢?在使用时又该如何选择呢?接下来我们一起来看。 1.Function Calling Function Call 会通过将用户指令映射到预定义函数或工具,LLM 先识别用…...

改进自己的图片 app
1. 起因, 目的: 前面我写过一个图片 app , 最新做了些改动。 把原来的一列,改为3列, 继续使用瀑布流手机上使用,更流畅,横屏显示为2列。 2. 先看效果 3. 过程: 过程太细碎了,这里只是做一下…...

docker不用dockerfile
好的!既然你不想使用 Dockerfile,我们就完全不写 Dockerfile,改用你 Leader 提到的思路: 用基础镜像启动一个容器 → 手动在容器里安装依赖和复制项目 → 保存为新镜像 这个方式更直观,就像“你进入容器自己配置环境&a…...
Uniapp+UView+Uni-star打包小程序极简方案
一、减少主包体积 主包污染源(全局文件依赖)劲量独立导入 componentsstaticmain.jsApp.vueuni.css 分包配置缺陷,未配置manifest.json中mp-weixin节点 "usingComponents" : true,"lazyCodeLoading" : "requiredC…...

深度学习篇---Pytorch框架下OC-SORT实现
下面将详细介绍如何基于 PyTorch 框架实现 OC-SORT(Observation-Centric SORT)算法。OC-SORT 是一种高性能的多目标跟踪算法,特别适用于复杂场景下的目标跟踪。我们将从算法原理到具体实现逐步展开。 1. 算法概述与核心原理 OC-SORT 在传统…...
)
STM32 HAL库SPI读写W25Q128(软件模拟+硬件spi)
1. 引言 在嵌入式系统开发中,SPI(Serial Peripheral Interface)总线是一种常用的串行通信协议,用于在微控制器和外部设备之间进行高速数据传输。W25Q128 是一款常见的 SPI Flash 芯片,具有 128Mbit(16MB&a…...
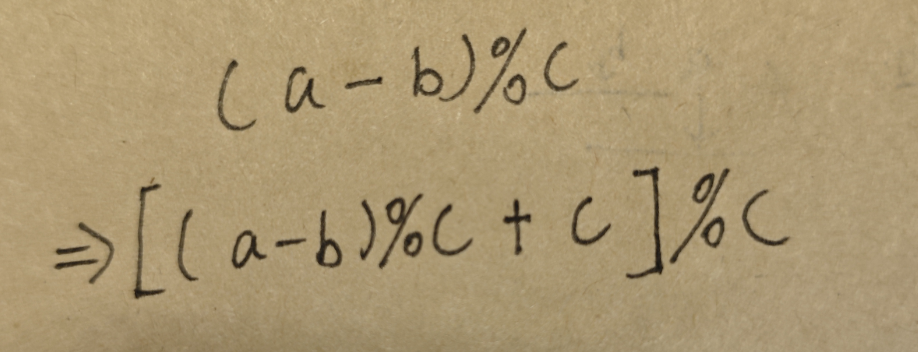
算法题(159):快速幂
审题: 本题需要我们计算出(a^b)%c的值,并按照规定格式输出 思路: 方法一:暴力解法 我们直接循环b次计算出a^b,然后再取余c,从而得出最终结果 时间上:会进行2^31次,他的数量级非常大,…...

【新品发布】嵌入式人工智能实验箱EDU-AIoT ELF 2正式发布
在万物互联的智能化时代,将AI算法深度植入硬件终端的技术,正悄然改变着工业物联网、智慧交通、智慧医疗等领域的创新边界。为了助力嵌入式人工智能在教育领域实现高质量发展,飞凌嵌入式旗下教育品牌ElfBoard,特别推出嵌入式人工智…...
基于javaweb的SpringBoot体检管理系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

Mac Python 安装依赖出错 error: externally-managed-environment
Mac Python 使用 ip3 install -r requirements.txt 出错 This environment is externally managed ╰─> To install Python packages system-wide, try brew installxyz, where xyz is the package you are trying toinstall.If you wish to install a Python library th…...

Docker Desktop for Windows 系统设置说明文档
1. 文档概述 本文档旨在详细说明 Docker Desktop for Windows 应用程序中“设置 (Settings)”界面下的所有可配置选项及其子选项。对于每个配置项,我们将提供其功能描述、推荐配置(如适用)以及相关注意事项,帮助用户更好地理解和…...

C++高级编程深度指南:内存管理、安全函数、递归、错误处理、命令行参数解析、可变参数应用与未定义行为规避
C高级编程深度指南:内存管理、安全函数、递归、错误处理、命令行参数解析、可变参数应用与未定义行为规避 1. 可变参数1.1 可变参数的定义与原理1.2 使用可变参数的场景1.3 可变参数的实现方式1.3.1 省略号方式1.3.2 模板参数包方式 2.2 动态内存分配函数2.3 内存泄…...

【下拉选项数据管理优化实践:从硬编码到高扩展性架构】
下拉选项数据管理优化实践:从硬编码到高扩展性架构 背景 在大型前端项目中,下拉选项数据管理是一个常见但容易被忽视的痛点。我们的项目中存在多种格式的选项标识符,如代码格式(OPTION_A1)和数字格式(100…...

IPD的基础理论与框架——(四)矩阵型组织:打破部门壁垒,构建高效协同的底层
在传统的组织架构中,企业多采用直线职能制,就像一座等级森严的金字塔,信息沿着垂直的层级传递,员工被划分到各个职能部门。这种架构职责清晰、分工明确,在稳定的市场环境中,能让企业高效运作,发…...

深度学习篇---OC-SORT实际应用效果
OC-SORT 算法在实际应用中的效果可从准确性、鲁棒性、效率三个核心维度评估,其表现与传统多目标跟踪算法(如 SORT、DeepSORT)相比有显著提升,尤其在复杂场景中优势突出。以下是具体分析: 一、准确性:目标关联更可靠 1. 遮挡场景下的 ID 保持能力 优势表现: 传统算法(…...

讲述我的plc自学之路 第十一章
《凡人歌》,道出了我们每个人都是一个凡人,追逐功名利禄是每个人的特性,但也往往被世俗所伤。lora和我听着歌曲的同时,我能感觉到和她内心的那种共鸣和对世俗的妥协。 我以前是不信命的,但是经历过这么多社会的毒打&am…...

OpenLayers 图形绘制
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 图形绘制功能是指在地图容器中绘制点、线、面、圆、矩形等图形。图形绘制功能在WebGIS中具有重要作用,可以辅助查询、编辑、分析功能。本节主…...

小程序为什么要安装SSL安全证书
小程序需要部署SSL安全证书,这是小程序开发及运营的强制性要求,也是保障用户数据安全、提升用户体验和满足平台规范的必要措施。 一、平台强制要求 微信小程序官方规范 微信小程序明确要求所有网络请求必须通过HTTPS协议传输,服务器域名需配…...
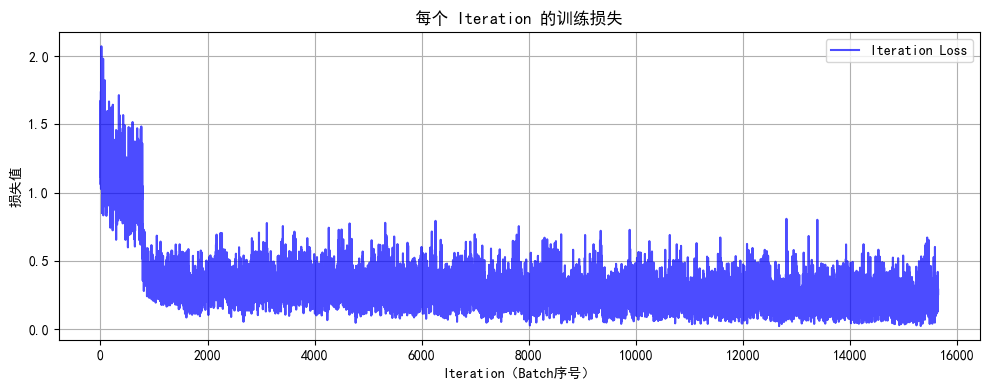
python打卡训练营打卡记录day40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...

互联网大厂Java求职面试:Spring Boot 3.2+自动配置原理、AOT编译及原生镜像
标题:互联网大厂Java求职面试:Spring Boot 3.2自动配置原理、AOT编译及原生镜像 简述 本文详细探讨了在互联网大厂Java求职面试中,技术总监级别面试官与求职者郑薪苦之间的精彩对话,主题聚焦于Spring Boot 3.2自动配置原理、AOT…...