Python打卡训练营-Day13-不平衡数据的处理
@浙大疏锦行
知识点:
- 不平衡数据集的处理策略:过采样、修改权重、修改阈值
- 交叉验证代码
过采样
过采样一般包含2种做法:随机采样和SMOTE
过采样是把少的类别补充和多的类别一样多,欠采样是把多的类别减少和少的类别一样
一般都是缺数据,所以很少用欠采样
随机过采样ROS
随机过采样是从少数类中随机选择样本,并将其复制后添加到训练集。
随机过采样的步骤如下:
确定少数类的样本数。
从少数类中随机选择样本,并将其复制。
将复制的样本添加到训练集。
随机过采样的优点是,它可以增加少数类的样本数,从而提高模型的泛化能力小。
随机过采样的缺点是,它可能会增加训练集的大小,从而增加训练时间。此外,它可能会增加
噪声,并且可能会增加模型的偏差。
smote过采样
smote:过采样是合成样本的方法。
对于少数类中的每个样本,计算它与少数类中其他样本的距离,得到其k近邻(一般k取5或其他合适的值)。
从k近邻中随机选择一个样本。
计算选定的近邻样本与原始样本之间的差值。
生成一个在0到1之间的随机数。
将差值乘以随机数,然后加到原始样本上,得到一个新的合成样本。
重复上述步骤,直到合成出足够数量的少数类样本,使得少数类和多数类样本数量达到某种平衡。
使用过采样后的数据集训练模型并评估模型性能。
SMOTEE的核心思想是通过在少数类样本的特征空间中进行插值来合成新的样本
修改权重
在处理类别不平衡的数据集时,标准机器学习算法(如默认的随机森林)可能会过度偏向多数类,导致对少数类的预测性能很差。为了解决这个问题,常用的策略包括在数据层面(采样)和算法层面进行调整。本文重点讨论两种算法层面的方法:修改类别权重和修改分类阈值。
挑战:标准算法的优化目标(如最小化整体误差)会使其优先拟合多数类,因为这样做能更快地降低总误差。
后果:对少数类样本的识别能力不足(低召回率),即使整体准确率看起来很高。
目标:提高模型对少数类的预测性能,通常关注召回率(Recall)、F1分数(F1-Score))、AUC-PR等指标。
方法一:修改类别权重(Cost-SensitiveLearning)
这种方法在模型训练阶段介入,通过调整不同类别样本对损失函数的贡献来影响模型的学习过程。
核心思想:为不同类别的错误分类分配不同的”代价”或”权重”。通常,将少数类样本错分为多数类的代价设置得远高于反过来的情况。
作用机制:修改模型的损失函数。当模型错误分类一个具有高权重的少数类样本时,会受到更大的惩罚(更高的损失值)。
目的:迫使学习算法在优化参数时更加关注少数类,努力学习到一个能够更好地区分少数类的决策边界。它试图从根本上让模型“学会”识别少数类。
影响:直接改变模型的参数学习过程和最终学到的模型本身。
在RandomForestClassifier中应用(class_weight参数)
Scikit-learn中的RandomForestclassifier提供了class_weight参数来实现代价敏感学
习
1.class_weight=None(默认值):
所有类别被赋予相同的权重(1)。
算法在构建树和计算分裂标准(如基尼不纯度)时,不区分多数类和少数类。
在不平衡数据上,这自然导致模型偏向多数类。
2.class weight='balanced':
算法自动根据训练数据y中各类别的频率来调整权重(1)。
权重计算方式与类别频率成反比:weight=n_samples/(n_classes*np.bincount(y))。
这意味着少数类样本获得更高的权重,多数类样本获得较低的权重。
目的是在训练中“放大"少数类的重要性,促使模型提升对少数类的识别能力。
3.class_weight={dict}(手动设置):
可以提供一个字典,手动为每个类别标签指定权重,例如class_weight={:1,1:10}表示类别1的权重是类别0的10倍。
●优点:
从模型学习的根本上解决问题。
可能得到泛化能力更强的模型。
许多常用算法内置支持,实现方便。
●注意:使用class_weight时,推荐结合交叉验证(特别是StratifiedKFold)来可靠地评估其效果和模型的稳定性。
方法二:修改分类阈值
这种方法在模型训练完成之后介入,通过调整最终分类的决策规则来平衡不同类型的错误。
核心思想:改变将模型输出的概率(或得分)映射到最终类别标签的门槛。
作用机制:模型通常输出一个样本属于正类(通常设为少数类)的概率p。默认情况下,如果p>0.5,则预测为正类。修改阈值意味着改变这个0.5,例如,如果要求更高的召回率,可以将阈值降低(如p>0.3就预测为正类)。
目的:在不改变已训练好的模型的情况下,根据业务需求调整精确率(Precision)和召回率(Recall)之间的权衡。通常用于提高少数类的召回率(但可能会牺牲精确率)。
影响:不改变模型学到的参数或决策边界本身,只改变如何解释模型的输出。
优点:
实现简单,无需重新训练模型。
非常直观,可以直接在PR曲线或ROC曲线上选择操作点。
适用于任何输出概率或分数的模型。
缺点:
治标不治本。如果模型本身就没学好如何区分少数类(概率输出普遍很低),单纯降低阈值可能效果有限或导致大量误报(低精确率)。
实践建议
评估指标先行:明确你的目标,使用适合不平衡数据的指标(Recall,F1-Score,AUC-PRBalanced Accuracy,MCC)来评估模型。
优先尝试根本方法:通常建议首先尝试修改权重(class_weight='balanced')或数据采样方法如SMOT),因为它们试图从源头改善模型学习。
交叉验证评估:在使用class_weight或采样方法时,务必使用分层交叉验证(Stratified K-Fold来获得对模型性能的可靠估计。
阈值调整作为补充:修改阈值可以作为一种补充手段或最后的微调。即使使用了权重调整,有时仍需根据具体的业务需求(如必须达到某个召回率水平)来调整阈值,找到最佳的操作点。
组合策略:有时结合多种方法(如SMOTE+class_weight)可能会产生更好的结果。
总之,修改权重旨在训练一个“更好”的模型,而修改阈值是在一个“已有”模型上调整其表现。
理解它们的差异有助于你选择更合适的策略来应对不平衡数据集的挑战。
import numpy as np # 引入 numpy 用于计算平均值等
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_validate # 引入分层 K 折和交叉验证工具
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
import time
import warnings
warnings.filterwarnings("ignore")# 假设 X_train, y_train, X_test, y_test 已经准备好
# X_train, y_train 用于交叉验证和最终模型训练
# X_test, y_test 用于最终评估# --- 1. 默认参数的随机森林 (原始代码,作为对比基准) ---
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
start_time = time.time()
rf_model_default = RandomForestClassifier(random_state=42)
rf_model_default.fit(X_train, y_train)
rf_pred_default = rf_model_default.predict(X_test)
end_time = time.time()
print(f"默认模型训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_default))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_default))
print("-" * 50)# --- 2. 带权重的随机森林 + 交叉验证 (在训练集上进行CV) ---
print("--- 2. 带权重随机森林 + 交叉验证 (在训练集上进行) ---")# 确定少数类标签 (非常重要!)
# 假设是二分类问题,我们需要知道哪个是少数类标签才能正确解读 recall, precision, f1
# 例如,如果标签是 0 和 1,可以这样查看:
counts = np.bincount(y_train)
minority_label = np.argmin(counts) # 找到计数最少的类别的标签
majority_label = np.argmax(counts)
print(f"训练集中各类别数量: {counts}")
print(f"少数类标签: {minority_label}, 多数类标签: {majority_label}")
# !!下面的 scorer 将使用这个 minority_label !!# 定义带权重的模型
rf_model_weighted = RandomForestClassifier(random_state=42,class_weight='balanced' # 关键:自动根据类别频率调整权重# class_weight={minority_label: 10, majority_label: 1} # 或者可以手动设置权重字典
)# 设置交叉验证策略 (使用 StratifiedKFold 保证每折类别比例相似)
cv_strategy = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) # 5折交叉验证# 定义用于交叉验证的评估指标
# 特别关注少数类的指标,使用 make_scorer 指定 pos_label
# 注意:如果你的少数类标签不是 1,需要修改 pos_label
scoring = {'accuracy': 'accuracy','precision_minority': make_scorer(precision_score, pos_label=minority_label, zero_division=0),'recall_minority': make_scorer(recall_score, pos_label=minority_label),'f1_minority': make_scorer(f1_score, pos_label=minority_label)
}print(f"开始进行 {cv_strategy.get_n_splits()} 折交叉验证...")
start_time_cv = time.time()# 执行交叉验证 (在 X_train, y_train 上进行)
# cross_validate 会自动完成训练和评估过程
cv_results = cross_validate(estimator=rf_model_weighted,X=X_train,y=y_train,cv=cv_strategy,scoring=scoring,n_jobs=-1, # 使用所有可用的 CPU 核心return_train_score=False # 通常我们更关心测试折的得分
)end_time_cv = time.time()
print(f"交叉验证耗时: {end_time_cv - start_time_cv:.4f} 秒")# 打印交叉验证结果的平均值
print("\n带权重随机森林 交叉验证平均性能 (基于训练集划分):")
for metric_name, scores in cv_results.items():if metric_name.startswith('test_'): # 我们关心的是在验证折上的表现# 提取指标名称(去掉 'test_' 前缀)clean_metric_name = metric_name.split('test_')[1]print(f" 平均 {clean_metric_name}: {np.mean(scores):.4f} (+/- {np.std(scores):.4f})")print("-" * 50)# --- 3. 使用权重训练最终模型,并在测试集上评估 ---
print("--- 3. 训练最终的带权重模型 (整个训练集) 并在测试集上评估 ---")
start_time_final = time.time()
# 使用与交叉验证中相同的设置来训练最终模型
rf_model_weighted_final = RandomForestClassifier(random_state=42,class_weight='balanced'
)
rf_model_weighted_final.fit(X_train, y_train) # 在整个训练集上训练
rf_pred_weighted = rf_model_weighted_final.predict(X_test) # 在测试集上预测
end_time_final = time.time()print(f"最终带权重模型训练与预测耗时: {end_time_final - start_time_final:.4f} 秒")
print("\n带权重随机森林 在测试集上的分类报告:")
# 确保 classification_report 也关注少数类 (可以通过 target_names 参数指定标签名称)
# 或者直接查看报告中少数类标签对应的行
print(classification_report(y_test, rf_pred_weighted)) # , target_names=[f'Class {majority_label}', f'Class {minority_label}'] 如果需要指定名称
print("带权重随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_weighted))
print("-" * 50)# 对比总结 (简单示例)
print("性能对比 (测试集上的少数类召回率 Recall):")
recall_default = recall_score(y_test, rf_pred_default, pos_label=minority_label)
recall_weighted = recall_score(y_test, rf_pred_weighted, pos_label=minority_label)
print(f" 默认模型: {recall_default:.4f}")
print(f" 带权重模型: {recall_weighted:.4f}")--- 1. 默认参数随机森林 (训练集 -> 测试集) ---
默认模型训练与预测耗时: 1.2171 秒默认随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.77 0.97 0.86 1059
1 0.79 0.30 0.43 441accuracy 0.77 1500
macro avg 0.78 0.63 0.64 1500
weighted avg 0.77 0.77 0.73 1500默认随机森林 在测试集上的混淆矩阵:
[[1023 36]
[ 309 132]]
--------------------------------------------------
--- 2. 带权重随机森林 + 交叉验证 (在训练集上进行) ---
训练集中各类别数量: [4328 1672]
少数类标签: 1, 多数类标签: 0
开始进行 5 折交叉验证...
交叉验证耗时: 3.6423 秒带权重随机森林 交叉验证平均性能 (基于训练集划分):
平均 accuracy: 0.7798 (+/- 0.0085)
平均 precision_minority: 0.8291 (+/- 0.0182)
平均 recall_minority: 0.2650 (+/- 0.0400)
平均 f1_minority: 0.3998 (+/- 0.0455)
--------------------------------------------------
--- 3. 训练最终的带权重模型 (整个训练集) 并在测试集上评估 ---
最终带权重模型训练与预测耗时: 1.1657 秒带权重随机森林 在测试集上的分类报告:
precision recall f1-score support0 0.76 0.97 0.86 1059
1 0.81 0.27 0.41 441accuracy 0.77 1500
macro avg 0.78 0.62 0.63 1500
weighted avg 0.78 0.77 0.72 1500带权重随机森林 在测试集上的混淆矩阵:
[[1030 29]
[ 320 121]]
--------------------------------------------------
性能对比 (测试集上的少数类召回率 Recall):
默认模型: 0.2993
带权重模型: 0.2744
作业:
从示例代码可以看到 效果没有变好,所以很多步骤都是理想是好的,但是现实并不一定可以变好。这个实验仍然有改进空间,如下。
1. 我还没做smote+过采样+修改权重的组合策略,有可能一起做会变好。
2. 我还没有调参,有可能调参后再取上述策略可能会变好
针对上面这2个探索路径,继续尝试下去,看看是否符合猜测。
代码实现
相关文章:
Python打卡训练营-Day13-不平衡数据的处理
浙大疏锦行 知识点: 不平衡数据集的处理策略:过采样、修改权重、修改阈值交叉验证代码 过采样 过采样一般包含2种做法:随机采样和SMOTE 过采样是把少的类别补充和多的类别一样多,欠采样是把多的类别减少和少的类别一样 一般都是缺…...
)
【专题】神经网络期末复习资料(题库)
神经网络期末复习资料(题库) 链接:https://blog.csdn.net/Pqf18064375973/article/details/148332887?sharetypeblogdetail&sharerId148332887&sharereferPC&sharesourcePqf18064375973&sharefrommp_from_link 【测试】 Th…...
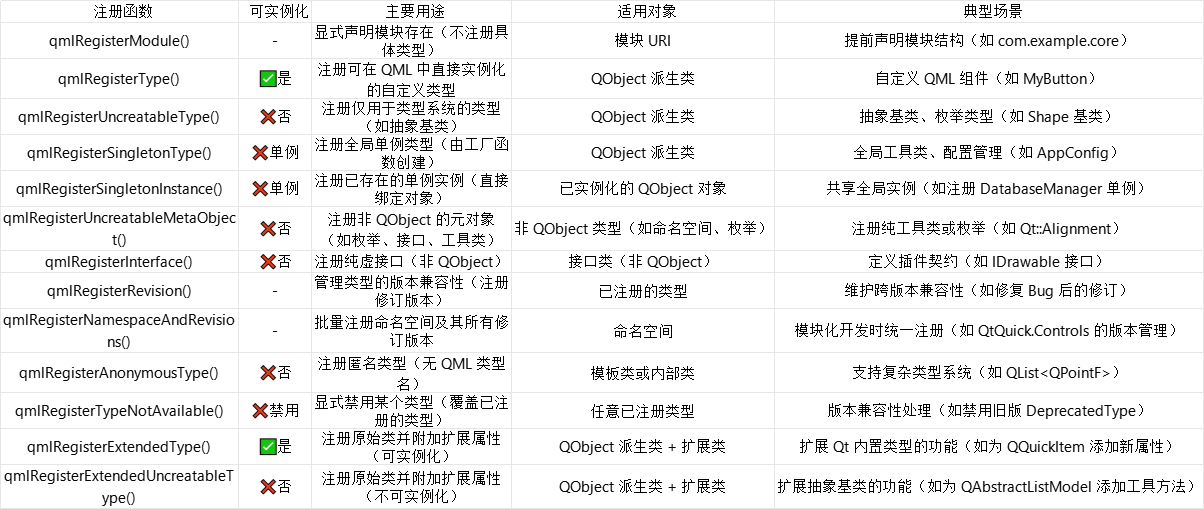
2.qml使用c++
目录 1.概述2.注册方式3. 分类①枚举类②工具类③数据类④资源类②视图类 1.概述 qml是用来干嘛的? 当然是提高UI开发效率的 为什么要混合C? 因为qml无法处理密集型数据逻辑 而加入c则兼顾了性能 达到11>2 总结就是 qml 开发UI, C 实现逻辑 而js的用…...
)
【数据结构】字符串操作整理(C++)
1. 字符串长度与容量 size() / length() 定义:返回字符串的当前长度(字符数)。用法: string s "hello"; cout << s.size(); // 输出:5提示:size() 和 length() 功能完全相同࿰…...

PostgreSQL的扩展 dblink
PostgreSQL的扩展 dblink dblink 是 PostgreSQL 的一个核心扩展,允许在当前数据库中访问其他 PostgreSQL 数据库的数据,实现跨数据库查询功能。 一、dblink 扩展安装与启用 1. 安装扩展 -- 使用超级用户安装 CREATE EXTENSION dblink;2. 验证安装 -…...
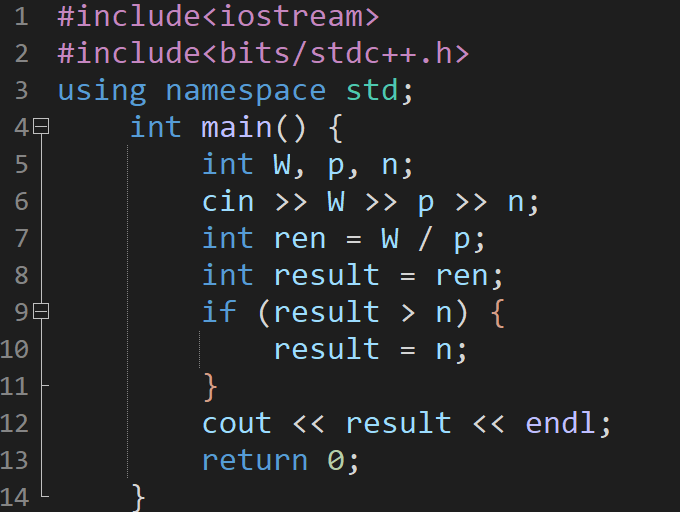
c++5月31日笔记
题目:水龙头 时间限制:C/C 语言 1000MS;其他语言 3000MS 内存限制:C/C 语言 65536KB;其他语言 589824KB 题目描述: 小明在 0 时刻(初始时刻)将一个空桶放置在漏水的水龙头下。已知桶…...
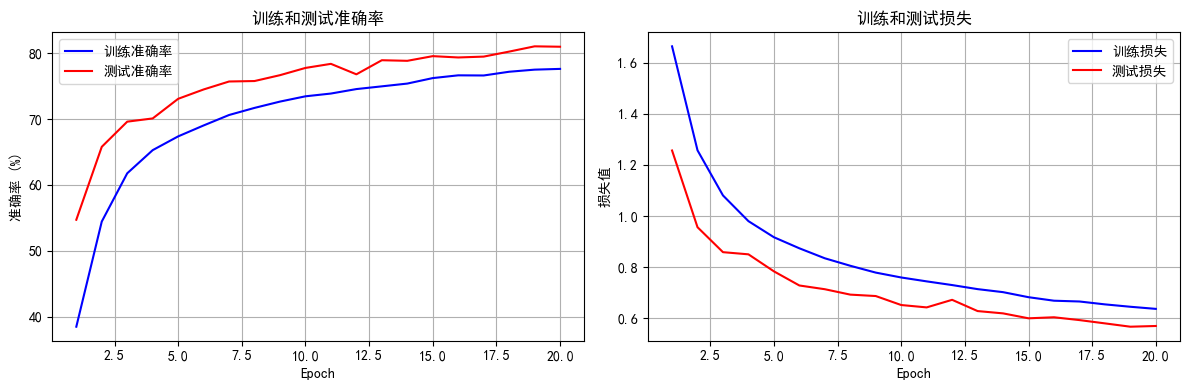
Python打卡训练营Day41
DAY 41 简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 →…...

【Java进阶】图像处理:从基础概念掌握实际操作
一、核心概念:BufferedImage - 图像的画布与数据载体 在Java图像处理的世界里,BufferedImage是当之无愧的核心。你可以将它想象成一块内存中的画布,所有的像素数据、颜色模型以及图像的宽度、高度等信息都存储在其中。 BufferedImage继承自…...

JAVA网络编程——socket套接字的介绍下(详细)
目录 前言 1.TCP 套接字编程 与 UDP 数据报套接字的区别 2.TCP流套接字编程 API 介绍 TCP回显式服务器 Scanner 的多种使用方式 PrintWriter 的多种使用方式 TCP客户端 3. TCP 服务器中引入多线程 结尾 前言 各位读者大家好,今天笔者继续更新socket套接字的下半部分…...

Apache SeaTunnel 引擎深度解析:原理、技术与高效实践
Apache SeaTunnel 作为新一代高性能分布式数据集成平台,其核心引擎设计融合了现代大数据处理架构的精髓。 Apache SeaTunnel引擎通过分布式架构革新、精细化资源控制及企业级可靠性设计,显著提升了数据集成管道的执行效率与运维体验。其模块化设计允许用…...

深入理解 Maven 循环依赖问题及其解决方案
在 Java 开发领域,Maven 作为主流构建工具极大简化了依赖管理和项目构建。然而**循环依赖(circular dependency)**问题仍是常见挑战,轻则导致构建失败,重则引发类加载异常和系统架构混乱。 本文将从根源分析循环依赖的…...

pytest中的元类思想与实战应用
在Python编程世界里,元类是一种强大而高级的特性,它能在类定义阶段深度定制类的创建与行为。而pytest作为热门的测试框架,虽然没有直接使用元类,但在设计机制上,却暗含了许多与元类思想相通的地方。接下来,…...

前端生成UUID
UUID(Universally Unique Identifier)是一种在分布式系统中广泛使用的标识符,具有全球唯一性。在前端开发中,生成可靠的UUID对于数据追踪、会话管理、缓存键生成等场景至关重要。接下来将深入探讨UUID的实现原理、前端生成方案及最佳实践。 一、UUID标准与版本 1. UUID结构…...

玩客云WS1608控制LED灯的颜色
玩客云WS1608控制LED灯的颜色 玩客云设备有个红、绿、蓝三色led灯,在刷入armbian系统以后,这个灯的颜色就会显示异常,往往是一直显示红色。 如果要自动动手调整led灯的颜色,控制命令如下(需要root用户执行࿰…...
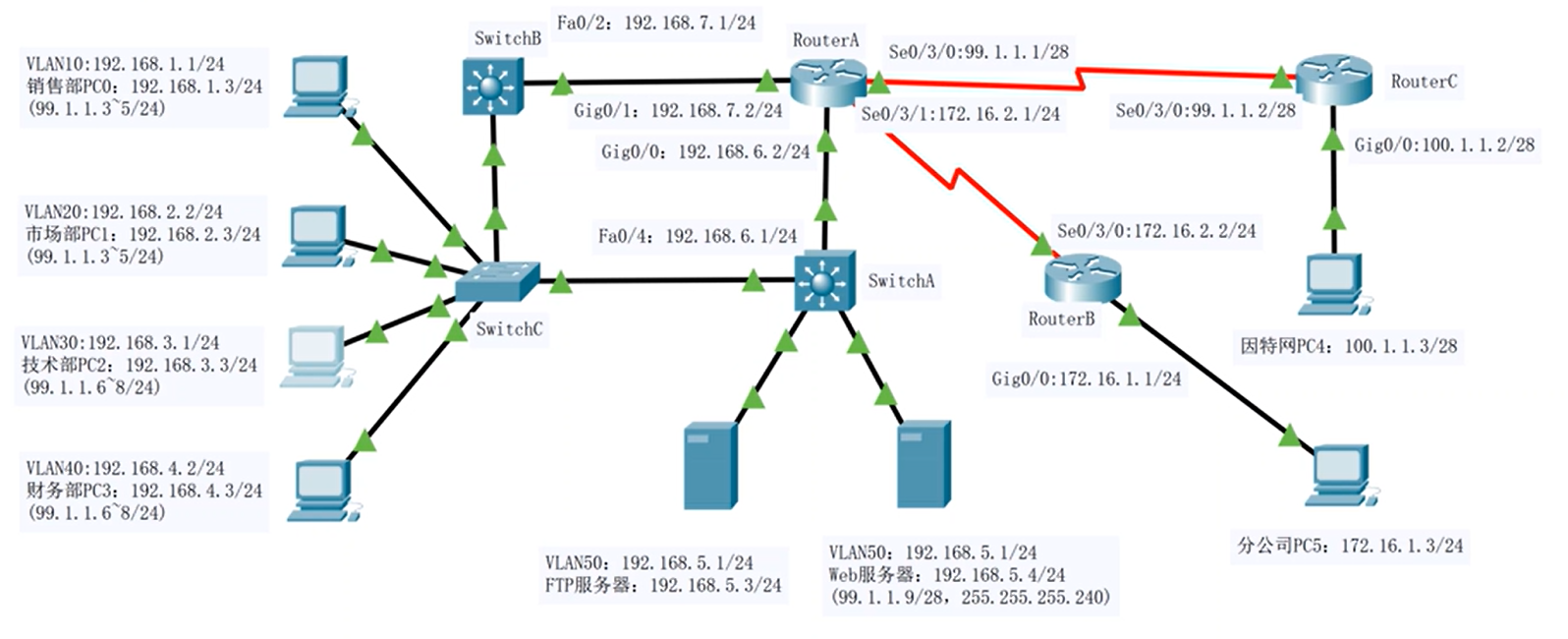
实验三 企业网络搭建及应用
实验三 企业网络搭建及应用 一、实验目的 1.掌握企业网络组建方法。 2.掌握企业网中常用网络技术配置方法。 二、实验描述 某企业设有销售部、市场部、技术部和财务部四个部门。公司内部网络使用二层交换机作为用户的接入设备。为了使网络更加稳定可靠,公司决定…...
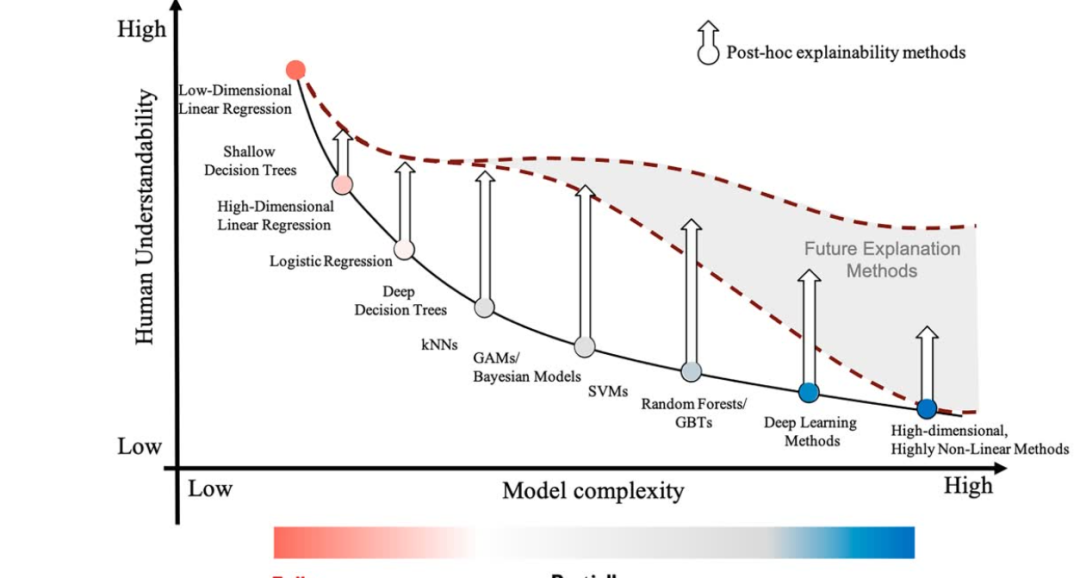
顶会新热门:机器学习可解释性
🧀机器学习模型的可解释性一直是研究的热点和挑战之一,同样也是近两年各大顶会的投稿热门。 🧀这是因为模型的决策过程不仅需要高准确性,还需要能被我们理解,不然我们很难将它迁移到其它的问题中,也很难进…...

ReactJS 中的 JSX工作原理
文章目录 前言✅ 1. JSX 是什么?🔧 2. 编译后的样子(核心机制)🧱 3. React.createElement 做了什么?🧠 4. JSX 与组件的关系🔄 5. JSX 到真实 DOM 的过程📘 6. JSX 与 Fr…...
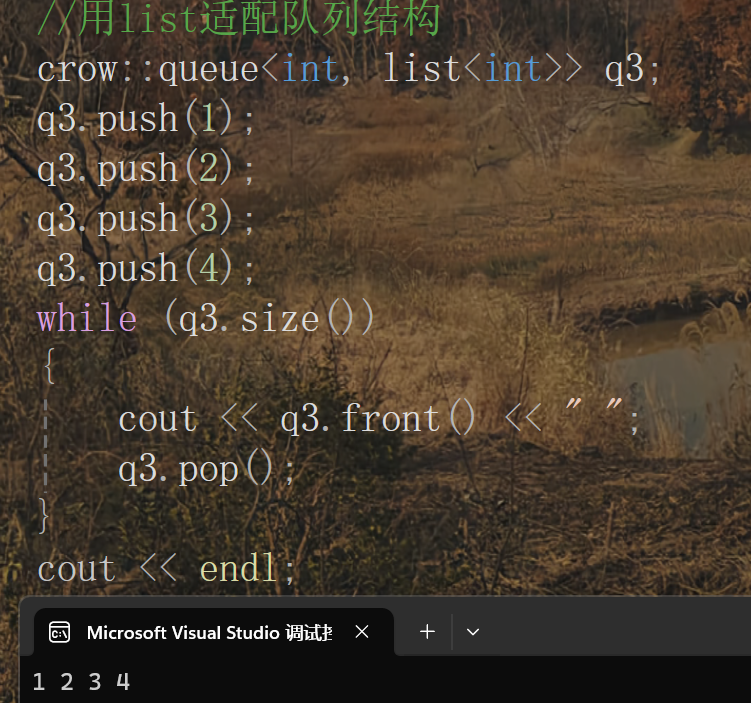
《STL--stack 和 queue 的使用及其底层实现》
引言: 上次我们学习了容器list的使用及其底层实现,相对来说是比较复杂的,今天我们要学习的适配器stack和queue与list相比就简单很多了,下面我们就开始今天的学习: 一:stack(后进先出ÿ…...

ArcGIS Pro 3.4 二次开发 - 地理处理
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 地理处理1 通用1.1 如何执行模型工具1.2 设置地理处理范围环境1.3 在 Geoprocessing 窗格中打开脚本工具对话框1.4 打开特定工具的地理处理工具窗格1.5 获取地理处理项目项1.6 阻止通过GP创建的特征类自动添加到地图中1.7 GPExecut…...

基于springboot的医护人员排班系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

Asp.Net Core FluentValidation校验框架
文章目录 前言一、使用步骤1.安装 NuGet 包2.创建模型3.创建验证器4.配置 Program.cs5.创建控制器6.测试结果 二、常见问题及注意事项三、性能优化建议总结 前言 FluentValidation 是一个流行的 .NET 库,用于构建强类型的验证规则。它通常用于验证领域模型、DTO等对…...
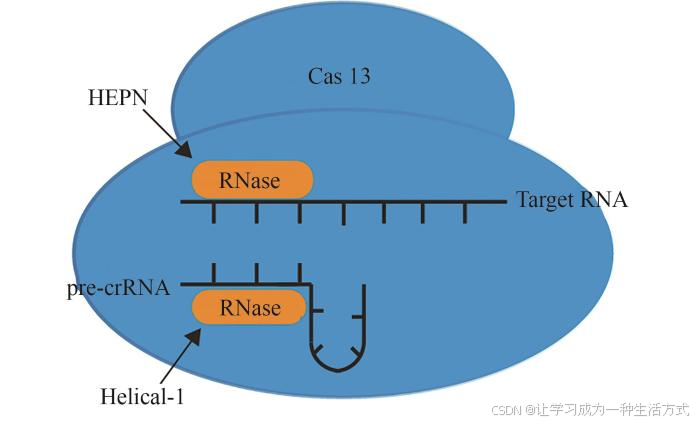
CRISPR-Cas系统的小型化研究进展-文献精读137
Progress in the miniaturization of CRISPR-Cas systems CRISPR-Cas系统的小型化研究进展 摘要 CRISPR-Cas基因编辑技术由于其简便性和高效性,已被广泛应用于生物学、医学、农学等领域的基础与应用研究。目前广泛使用的Cas核酸酶均具有较大的分子量(通…...
利用python工具you-get下载网页的视频文件
有时候我们可能在一个网站看到一个视频(比如B站),想下载,但是页面没有下载视频的按钮。这时候,我们可以借助python工具you-get来实现下载功能。下面简要说下步骤 (一)因为使用的是python工具&a…...

Wi-Fi 切换 5G 的时机
每天都希望 Wi-Fi 在我离开信号覆盖范围时能尽快切到 5G,但每次它都能坚挺到最后半格信号,我却连看个天气预报都看不了…我不得不手工关闭 Wi-Fi,然后等走远了之后再打开,如此反复,不厌其烦。 早上出门上班,…...

【请关注】各类数据库优化,抓大重点整改,快速优化空间mysql,Oracle,Neo4j等
各类数据库优化,抓大重点整改,快速优化,首先分析各数据库查询全部表的空间大小及记录条数的语句: MySQL -- 查看所有表的空间大小 SELECT TABLE_SCHEMA AS 数据库名, TABLE_NAME AS 表名, ENGINE AS 存储引擎, CONCAT(ROUND(DAT…...

Mybatis Plus JSqlParser解析sql语句及JSqlParser安装步骤
MyBatis Plus 整合 JSqlParser 进行 SQL 解析的实现方案,主要包括环境配置和具体应用。通过 Maven 添加mybatis-plus-core 和 jsqlparser 依赖后,可用 CCJSqlParserUtil 解析 SQL 语句,支持对 SELECT、UPDATE 等语句的语法树分析和重构。技术…...

React从基础入门到高级实战:React 高级主题 - 性能优化:深入探索与实践指南
React 性能优化:深入探索与实践指南 引言 在现代Web开发中,尤其是2025年的技术环境下,React应用的性能优化已成为开发者不可忽视的核心课题。随着用户对应用速度和体验的要求日益提高,React应用的规模和复杂性不断增加ÿ…...

负载均衡群集---Haproxy
目录 一、HAproxy 一、概念 二、核心作用 三、主要功能特性 四、应用场景 五、优势与特点 二、 案例分析 1. 案例概述 2. 案例前置知识点 (1)HTTP 请求 (2)负载均衡常用调度算法 (3)常见的 web …...

2025年5月个人工作生活总结
本文为 2025年5月工作生活总结。 研发编码 一个项目的临时记录 月初和另一项目同事向业主汇报方案,两个项目都不满意,后来领导做了调整,将项目合并,拆分了好几大块。原来我做的一些工作,如数据库、中间件等ÿ…...
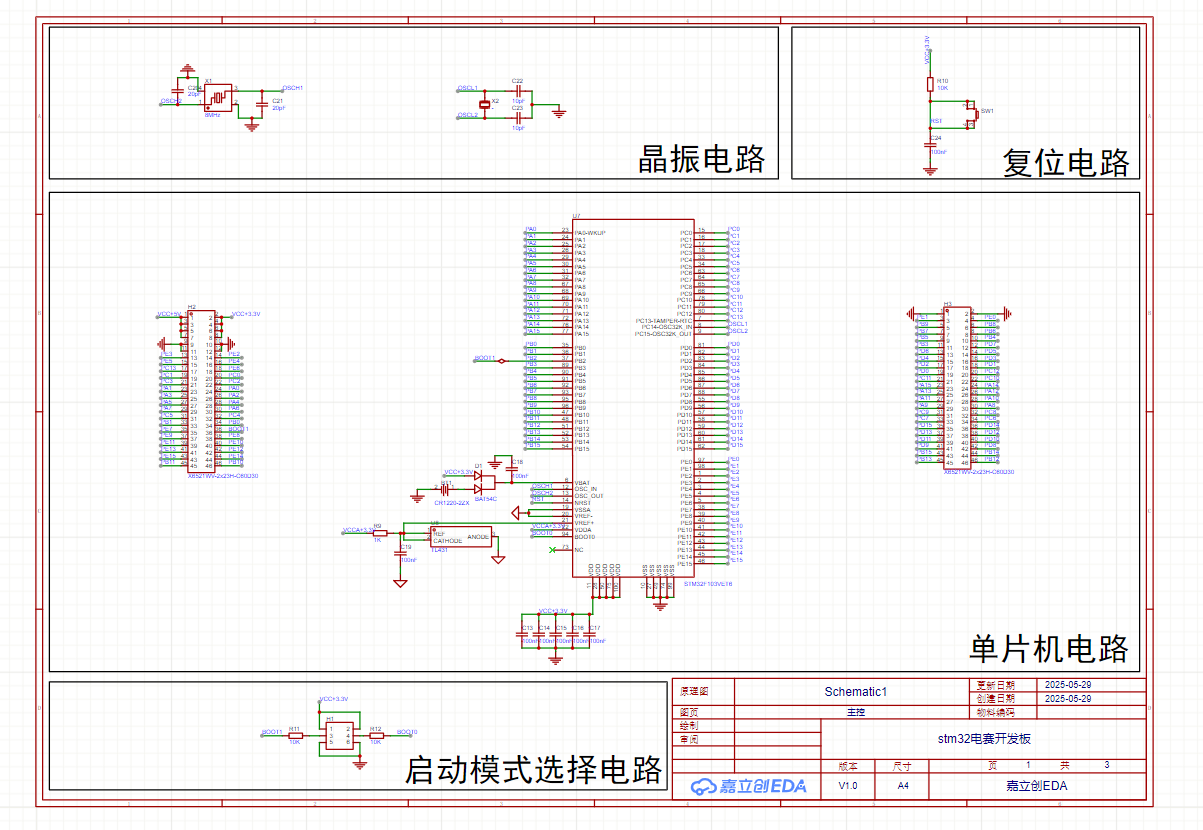
【stm32开发板】单片机最小系统原理图设计
一、批量添加网络标签 可以选择浮动工具中的N,单独为引脚添加网络标签。 当芯片引脚非常多的时候,选中芯片,右键选择扇出网络标签/非连接标识 按住ctrl键即可选中多个引脚 点击将引脚名称填入网络名 就完成了引脚标签的批量添加 二、电源引…...