K 值选对,准确率翻倍:KNN 算法调参的黄金法则
目录
一、背景介绍
二、KNN 算法原理
2.1 核心思想
2.2 距离度量方法
2.3 算法流程
2.4算法结构:
三、KNN 算法代码实现
3.1 基于 Scikit-learn 的简单实现
3.2 手动实现 KNN(自定义代码)
四、K 值选择与可视化分析
4.1 K 值对分类结果的影响
4.2 交叉验证选择最优 K 值
五、KNN 算法的优缺点与优化
5.1 优点
5.2 缺点
5.3 优化方法
六、KNN 算法的应用场景
七、KNN 与其他算法的对比
八、小结
一、背景介绍
K 近邻算法(K-Nearest Neighbors, KNN)是机器学习中最简单、最直观的算法之一,其核心思想源于人类对相似事物的判断逻辑 ——“近朱者赤,近墨者黑”。该算法无需复杂的训练过程,直接通过计算样本间的距离来进行分类或回归,广泛应用于图像识别、文本分类、推荐系统等领域。
二、KNN 算法原理
2.1 核心思想
KNN 的核心思想是:对于一个待预测样本,找到训练数据中与其最相似的 K 个样本(近邻),根据这 K 个样本的类别(分类问题)或数值(回归问题)进行投票或平均,从而确定待预测样本的类别或数值。
关键点:
相似性度量:通过距离函数衡量样本间的相似性。
K 值选择:近邻数量 K 对结果影响显著。
投票机制:分类问题通常采用多数投票,回归问题采用均值或加权平均。
2.2 距离度量方法
常见的距离度量方法包括:
欧氏距离:适用于连续变量,计算两点间的直线距离。
曼哈顿距离:适用于城市网格路径等场景,计算两点间的折线距离。
余弦相似度:适用于文本、图像等高维数据,衡量向量间的方向相似性。
2.3 算法流程
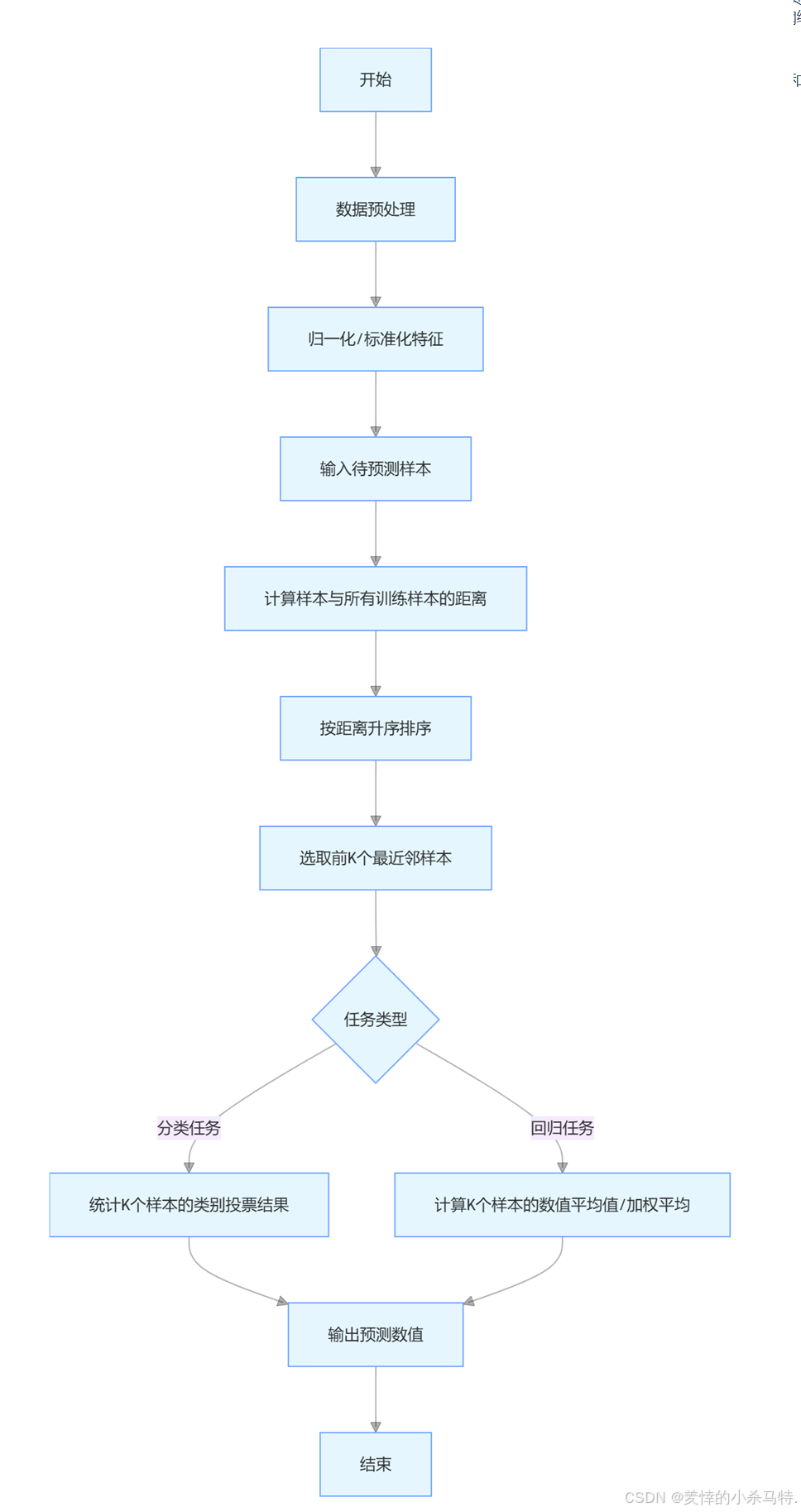
KNN 算法的典型流程如下:
1·数据预处理:对数据进行清洗、归一化,避免特征量纲影响距离计算。
2·计算距离:计算待预测样本与所有训练样本的距离。
3·选择近邻:按距离升序排列,选取前 K 个最近邻样本。
4·分类 / 回归决策:
分类:统计 K 个近邻的类别,选择出现次数最多的类别。
回归:计算 K 个近邻数值的平均值或加权平均值。
2.4算法结构:
三、KNN 算法代码实现
3.1 基于 Scikit-learn 的简单实现
以鸢尾花数据集(Iris Dataset)为例,演示 KNN 分类的完整流程。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 仅取前两个特征,便于可视化
y = iris.target
feature_names = iris.feature_names[:2]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建KNN分类器(K=5)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# 预测测试集
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy with K=5: {accuracy:.2f}") # 输出:Accuracy with K=5: 0.98
3.2 手动实现 KNN(自定义代码)
为深入理解算法原理,我们手动实现 KNN 分类器:
class CustomKNN:def __init__(self, n_neighbors=3):self.n_neighbors = n_neighborsdef fit(self, X_train, y_train):self.X_train = X_trainself.y_train = y_traindef predict(self, X_test):predictions = []for x in X_test:# 计算距离distances = [np.sqrt(np.sum((x - x_train)**2)) for x_train in self.X_train]# 获取最近的K个样本索引k_indices = np.argsort(distances)[:self.n_neighbors]# 获取对应的类别k_nearest_labels = self.y_train[k_indices]# 多数投票most_common = np.bincount(k_nearest_labels).argmax()predictions.append(most_common)return np.array(predictions)# 使用自定义KNN
custom_knn = CustomKNN(n_neighbors=3)
custom_knn.fit(X_train, y_train)
y_pred_custom = custom_knn.predict(X_test)
print(f"Custom KNN Accuracy: {accuracy_score(y_test, y_pred_custom):.2f}") # 输出:0.96
四、K 值选择与可视化分析
4.1 K 值对分类结果的影响
K 值是 KNN 算法的核心超参数,其大小直接影响分类结果:
- K 值过小:模型复杂度高,易受噪声影响,导致过拟合。
- K 值过大:模型趋于平滑,可能忽略局部特征,导致欠拟合。
示例:在鸢尾花数据集上,不同 K 值的分类边界差异如下:
def plot_decision_boundary(clf, X, y, title, k=None):plt.figure(figsize=(8, 6))x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),np.arange(y_min, y_max, 0.02))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)# 绘制散点图for i, color in zip([0, 1, 2], ['r', 'g', 'b']):idx = np.where(y == i)plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i], edgecolor='k')plt.xlabel(feature_names[0])plt.ylabel(feature_names[1])plt.title(f"KNN Decision Boundary (K={k})")plt.legend()plt.show()# K=1(过拟合)
knn1 = KNeighborsClassifier(n_neighbors=1)
knn1.fit(X_train, y_train)
plot_decision_boundary(knn1, X_test, y_test, "K=1", k=1)# K=15(欠拟合)
knn15 = KNeighborsClassifier(n_neighbors=15)
knn15.fit(X_train, y_train)
plot_decision_boundary(knn15, X_test, y_test, "K=15", k=15)
4.2 交叉验证选择最优 K 值
通过交叉验证可以有效选择最优 K 值:
from sklearn.model_selection import cross_val_score# 候选K值
k_values = range(1, 31)
cv_scores = []for k in k_values:knn = KNeighborsClassifier(n_neighbors=k)scores = cross_val_score(knn, X_train, y_train, cv=5, scoring='accuracy')cv_scores.append(scores.mean())# 绘制K值与准确率曲线
plt.plot(k_values, cv_scores, marker='o', linestyle='--', color='b')
plt.xlabel('K Value')
plt.ylabel('Cross-Validation Accuracy')
plt.title('K Value Selection via Cross-Validation')
plt.show()
五、KNN 算法的优缺点与优化
5.1 优点
简单易懂:原理直观,无需复杂数学推导。
无需训练:直接使用训练数据进行预测。
泛化能力强:对非线性数据分布有较好的适应性。
5.2 缺点
计算复杂度高:预测时需计算与所有训练样本的距离。
存储成本高:需存储全部训练数据。
对噪声敏感:K 值过小时,异常值可能显著影响结果。
5.3 优化方法
数据预处理:归一化、特征选择。
近似最近邻搜索:KD 树、球树等加速算法。
加权投票:根据距离赋予不同权重。
六、KNN 算法的应用场景
- 图像识别与分类:常用于手写数字识别、人脸识别等任务。
- 推荐系统:基于用户或物品的相似度进行推荐。
- 医疗诊断:根据患者的临床指标预测疾病类别。
- 异常检测:通过判断样本与近邻的距离识别异常点。
七、KNN 与其他算法的对比
| 算法 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| KNN | 基于相似性投票 / 平均 | 简单直观、无需训练 | 计算慢、存储成本高、高维性能差 | 小规模数据、实时预测 |
| 逻辑回归 | 基于概率的线性分类 | 训练快、可解释性强 | 仅适用于线性可分数据、需调参 | 二分类、概率预测 |
| 决策树 | 基于特征划分的树结构分类 | 可解释性强、能处理非线性数据 | 易过拟合、对噪声敏感 | 分类规则提取、快速预测 |
八、小结
KNN 算法以其简单性和直观性成为机器学习入门的经典算法,适用于小规模、低维数据的快速分类 / 回归任务。尽管存在计算效率和高维性能的局限,但其思想为许多复杂算法提供了基础。通过数据预处理、近似搜索和加权机制,KNN 的实用性可进一步提升;未来,随着硬件计算能力的提升和近似搜索算法的发展,KNN 在大规模数据中的应用可能迎来新突破。结合深度学习的特征提取能力,可构建更强大的混合模型。
相关文章:
K 值选对,准确率翻倍:KNN 算法调参的黄金法则
目录 一、背景介绍 二、KNN 算法原理 2.1 核心思想 2.2 距离度量方法 2.3 算法流程 2.4算法结构: 三、KNN 算法代码实现 3.1 基于 Scikit-learn 的简单实现 3.2 手动实现 KNN(自定义代码) 四、K 值选择与可视化分析 4.1 K 值对分类…...

技术栈ES的介绍和使用
目录 1. 全文搜索引擎(Elastic Search)的由来2. Elastic Search 概述2.1 Elastic Search 介绍2.2 Elastic Search 功能2.3 Elastic Search 特点 3. 安装 Elastic Search3.1 ES 的安装3.2 安装 kibana3.3 ES 客户端的安装 4. Elastic Search 基本概念4.1 …...

跟Gemini学做PPT-模板样式的下载
好的,这里有一些推荐的网站,您可以在上面找到PPT目录样式和模板的灵感: SlideModel (slidemodel.com) 提供各种预先设计的目录幻灯片模板。这些模板100%可编辑,可用于PowerPoint和Google Slides。您可以找到不同项目数量ÿ…...

Windows版本的postgres安装插件http
1、下载安装包 这里使用安装 pgsql-http 的扩展 源码地址:GitHub - pramsey/pgsql-http: HTTP client for PostgreSQL, retrieve a web page from inside the database. 编译的安装地址:http extension for windows updated to include PostgreSQL17 …...

uni-app学习笔记十六-vue3页面生命周期(三)
uni-app官方文档页面生命周期部分位于页面 | uni-app官网。 本篇再介绍2个生命周期 1.onUnload:用于监听页面卸载。 当页面被关闭时,即页面的缓存被清掉时触发加载onUnload函数。 例如:在demo6页面点击跳转到demo4,在demo4页面回退不了到d…...
优化的两极:凸优化与非凸优化的理论、应用与挑战
在机器学习、工程设计、经济决策等众多领域,优化问题无处不在。而在优化理论的世界里,凸优化与非凸优化如同两个截然不同的 “王国”,各自有着独特的规则、挑战和应用场景。今天,就让我们深入探索这两个优化领域的核心差异、算法特…...
(五)MMA(OpenTelemetry/Rabbit MQ/ApiGateway/MongoDB)
文章目录 项目地址一、OpenTelemetry1.1 配置OpenTelemetry1. 服务添加2. 添加服务标识3. 添加请求的标识4. 添加中间价 二、Rabbit MQ2.1 配置Rabbit MQ1. docker-compose2. 添加Rabbit MQ的Connect String 2.2 替换成Rabbit MQ1. 安装所需要的包2. 使用 三、API Gateways3.1 …...

TCP通信与MQTT协议的关系
1. MQTT 处理核心(Mqtt_Pro) void Mqtt_Pro(void) { MQTT_Init(); // 初始化MQTT协议栈(连接参数、缓冲区等) MQTT_SendPro(); // 处理MQTT发送(封装消息,调用TCP发送) MQTT_RecPro();…...

AWS创建github相关的角色
创建github-actions角色 {"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Federated": "arn:aws:iam::11111111:oidc-provider/token.actions.githubusercontent.com…...

数据编辑器所具备的数据整理功能
在企业的数据处理过程中,数据清洗与整理是至关重要的环节,而数据编辑器在这方面发挥着关键作用。在一份包含客户信息的数据表中,常常会出现缺失值的情况。比如客户的年龄、联系方式等字段可能因为各种原因没有被记录,这就形成了缺…...

Unity网络开发实践项目
摘要:该网络通信系统基于Unity实现,包含以下几个核心模块: 协议配置:通过XML定义枚举(如玩家/英雄类型)、数据结构(如PlayerData)及消息协议(如PlayerMsg)&a…...
Jetson Orin Nano - SONY imx415 camera驱动开发
目录 前言: 调试准备工作: 修改内核默认打印等级 一、imx415驱动开发 1、硬件接线 2、设备树修改 2.1 创建 tegra234-p3767-camera-p3768-imx415-C-4lane.dtsi 文件 2.2 tegra234-p3767-camera-p3768-imx415-C-4lane.dtsi 添加到设备树 2.3 编译设备树 3、imx415驱动…...
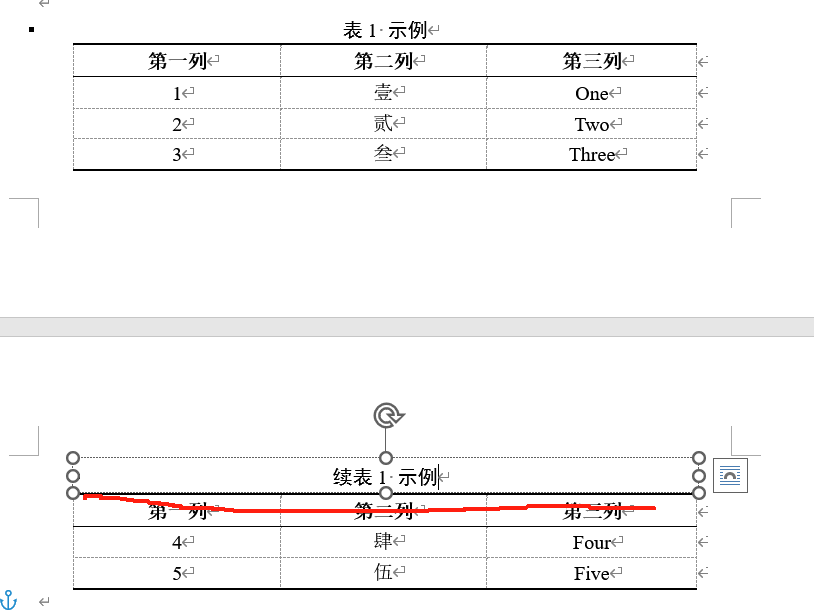
word为跨页表格新加表头和表名
问题: 当表格过长需要跨页时(如下图所示),某些格式要求需要转页接排加续表。 方法一: 1、选中表格,在“表布局”区域点开“自动调整”,选择“固定列宽”(防止后续拆分表格后表格变…...

测试用例篇章
本节概要: 测试⽤例的概念 设计测试⽤例的万能思路 设计测试⽤例的⽅法 一、测试用例 1.1 概念 什么是测试用例? 测试⽤例(Test Case)是为了实施测试⽽向被测试的系统提供的⼀组集合,这组集合包含:测…...

2025年北京市职工职业技能大赛第六届信息通信行业网络安全技能大赛复赛CTF部分WP-哥斯拉流量分析
2025年北京市职工职业技能大赛第六届信息通信行业网络安全技能大赛复赛CTF部分WP-哥斯拉流量分析 一、流量分析 题目没有任何提示,附件gzl.pcap 解题哥斯拉流量300多KB包很多,没啥经验只能挨个看回来之后又狠狠得撸了一把哥斯拉流量分析我这里用的是哥斯拉4.0.1 测试链接…...
Django ToDoWeb 服务
我们的任务是使用 Django 创建一个简单的 ToDo 应用程序,允许用户添加、查看和删除笔记。我们将通过设置 Django 项目、创建 Todo 模型、设计表单和视图来处理用户输入以及创建模板来显示任务来构建它。我们将逐步实现核心功能以有效地管理 todo 项。 Django ToDoWeb 服务 …...

【软件】在 macOS 上安装 Postman
在 macOS 上安装 Postman 是一个简单的过程,以下是详细的步骤: 一、下载 Postman • 访问 Postman 官方网站: 打开浏览器,访问Postman 官方下载页面。 • 下载安装包: 页面会自动识别你的系统,点击“Dow…...
各种数据库,行式、列式、文档型、KV、时序、向量、图究竟怎么选?
慕然回首,发现这些年来涌现出了许多类型的数据库,今天抽空简单回顾一下,以便于后面用到时能快速选择。 1. 关系型数据库(行式) 关系型数据库(RDBMS),我们常说的数据库就是指的关系型数据库。 它的全称是关…...

全志科技携飞凌嵌入式T527核心板亮相OpenHarmony开发者大会
近日,OpenHarmony开发者大会2025(OHDC.2025,以下简称“大会”)在深圳举办,全志科技作为OpenHarmony生态的重要合作伙伴受邀参会,并进行了《全志科技行业智能芯片OpenHarmony方案适配与认证经验分享》的主题…...

AI+微信小程序:智能客服、个性化推荐等场景的落地实践
在移动互联网流量红利逐渐见顶的今天,微信小程序凭借“即用即走”的轻量化特性,已成为企业连接用户的核心阵地。而AI技术的融入,正让小程序从工具型应用进化为“懂用户、会思考”的智能服务终端。本文将结合实际案例,解析AI在微信小程序中的两大核心场景——智能客服与个性…...
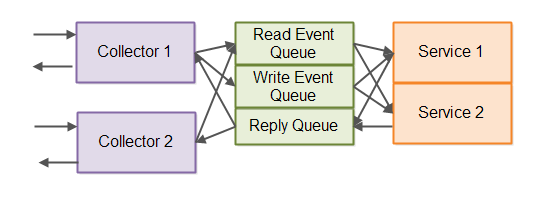
事件驱动架构入门
主要参考资料: 软件架构-事件驱动架构: https://blog.csdn.net/liuxinghao/article/details/113923639 目录 简介事件队列事件日志事件收集器响应队列读事件 vs. 写事件 简介 事件驱动架构是一种系统或组件之间通过发送事件和响应事件彼此交互的架构风格。当某个事…...

基于Web的濒危野生动物保护信息管理系统设计(源码+定制+开发)濒危野生动物监测与保护平台开发 面向公众参与的野生动物保护与预警信息系统
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

索引的选择与Change Buffer
1. 索引选择与Change Buffer 问题引出:普通索引 vs 唯一索引 ——如何选择? 在实际业务中,如果一个字段的值天然具有唯一性(如身份证号),并且业务代码已确保无重复写入,那就存在两种选择&…...
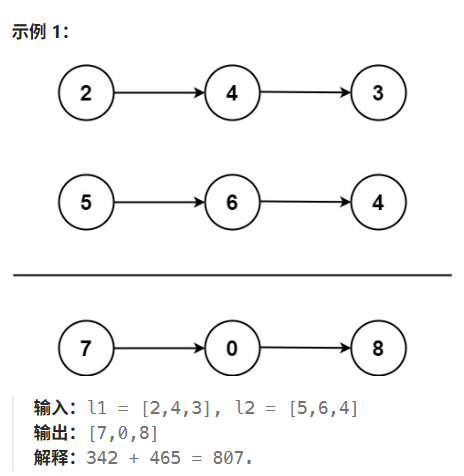
leetcode hot100刷题日记——30.两数之和
解答: 方法一:迭代 迭代大致过程就是: 算两条链表的当前位的和,加上上一位留下来的进位,就是新链表的当前位的数字。计算当前的进位。 这样,我们迭代需要的东西是:链表1,链表2&…...

Fastapi 学习使用
Fastapi 学习使用 Fastapi 可以用来快速搭建 Web 应用来进行接口的搭建。 参考文章:https://blog.csdn.net/liudadaxuexi/article/details/141062582 参考文章:https://blog.csdn.net/jcgeneral/article/details/146505880 参考文章:http…...

Ollama:本地大模型推理与应用的创新平台
引言 随着大语言模型(LLM)和生成式AI的快速发展,越来越多的开发者和企业希望在本地或私有环境中运行AI模型,以满足数据隐私、安全、低延迟和定制化的需求。Ollama 正是在这一背景下诞生的创新平台。它让大模型的本地部署、推理和集成变得前所未有的简单和高效。本文将系统…...

rtpinsertsound:语音注入攻击!全参数详细教程!Kali Linux教程!
简介 2006年8月至9月期间,我们创建了一个用于将音频插入指定音频(即RTP)流的工具。该工具名为rtpinsertsound。 该工具已在Linux Red Hat Fedora Core 4平台(奔腾IV,2.5 GHz)上进行了测试,但预…...

django项目开启debug页面操作有数据操作记录
在项目的主文件中setting中配置 """ Django settings for ProjectPrictice project.Generated by django-admin startproject using Django 3.0.1.For more information on this file, see https://docs.djangoproject.com/en/3.0/topics/settings/For the ful…...

【Vim】高效编辑技巧全解析
本篇将从光标移动技巧、常用快捷操作、组合命令运用等方面逐步讲解 vim 的使用。 📘 高效光标移动技巧 在 Vim 中,光标移动是编辑效率的核心之一。以下是一些必须掌握的移动命令,按使用频率和实用程度分类整理: 🔹 基…...

基于 Node.js 的 Express 服务是什么?
Express 是基于 Node.js 的一个轻量级、灵活的 Web 应用框架,用于快速构建 HTTP 服务(如网站、API 接口等),以下是详细解析: 一、Express 的核心作用 简化 Node.js 原生开发 Node.js 原生 http 模块虽…...