安全帽目标检测
安全帽数据集
这里我们使用的安全帽数据集是HelmentDetection,这是一个公开数据集,里面包含5000张voc标注格式的图像,分为三个类别,分别是 0: head 1: helmet 2: person
安全帽数据集下载地址、
我们将数据集下载后,首先需要将其转换为YOLO标注格式:
import os
import xml.etree.ElementTree as ET
import random
import shutildef collect_classes(voc_annotations_dir):"""收集 VOC 数据集中所有出现的类别。:param voc_annotations_dir: 包含 VOC 格式 XML 文件的目录:return: 类别名称的集合"""classes = set()# 遍历所有 XML 文件for xml_file in os.listdir(voc_annotations_dir):if not xml_file.endswith('.xml'):continue# 构造输入文件路径voc_annotation_path = os.path.join(voc_annotations_dir, xml_file)# 解析 XML 文件tree = ET.parse(voc_annotation_path)root = tree.getroot()# 遍历每个目标并收集类别for obj in root.findall('object'):class_name = obj.find('name').textclasses.add(class_name)return sorted(classes)def create_class_mapping(classes):"""创建类别名称到索引的映射字典。:param classes: 类别名称列表:return: 类别名称到索引的映射字典"""return {class_name: idx for idx, class_name in enumerate(classes)}def convert_voc_to_yolo(voc_annotation_path, yolo_annotation_path, class_mapping):"""将单个 VOC 格式的标注文件转换为 YOLO 格式。:param voc_annotation_path: VOC 格式 XML 文件路径:param yolo_annotation_path: 输出的 YOLO 格式 TXT 文件路径:param class_mapping: 类别名称到索引的映射字典"""# 解析 XML 文件tree = ET.parse(voc_annotation_path)root = tree.getroot()# 获取图像尺寸size = root.find('size')image_width = int(size.find('width').text)image_height = int(size.find('height').text)# 存储 YOLO 格式的目标信息yolo_lines = []# 遍历每个目标for obj in root.findall('object'):# 获取类别名称class_name = obj.find('name').textif class_name not in class_mapping:print(f"类别 '{class_name}' 不在映射中,跳过该目标。")continue# 获取类别索引class_index = class_mapping[class_name]# 获取边界框坐标bbox = obj.find('bndbox')xmin = float(bbox.find('xmin').text)ymin = float(bbox.find('ymin').text)xmax = float(bbox.find('xmax').text)ymax = float(bbox.find('ymax').text)# 转换为 YOLO 格式的归一化坐标 (x_center, y_center, width, height)x_center = (xmin + xmax) / 2.0 / image_widthy_center = (ymin + ymax) / 2.0 / image_heightwidth = (xmax - xmin) / image_widthheight = (ymax - ymin) / image_height# 添加到 YOLO 格式的行yolo_lines.append(f"{class_index} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")# 写入 YOLO 格式的文件with open(yolo_annotation_path, 'w') as f:f.write("\n".join(yolo_lines))def split_dataset(xml_files, train_ratio=0.8, val_ratio=0.2, test_ratio=0.1):"""将数据集按照指定比例划分为训练集、验证集和测试集。:param xml_files: 所有 XML 文件的列表:param train_ratio: 训练集比例,默认 0.7:param val_ratio: 验证集比例,默认 0.2:param test_ratio: 测试集比例,默认 0.1:return: 划分后的三个集合(训练集、验证集、测试集)"""random.shuffle(xml_files) # 随机打乱文件顺序total_count = len(xml_files)# 计算各部分的分割点train_end = int(total_count * train_ratio)val_end = train_end + int(total_count * val_ratio)# 划分数据集train_set = xml_files[:train_end]val_set = xml_files[train_end:val_end]test_set = xml_files[val_end:]return train_set, val_set, test_setdef organize_files(voc_images_dir, voc_annotations_dir, output_dir, train_set, val_set, test_set):"""将图片和标注文件按照划分结果组织到对应的文件夹中。:param voc_images_dir: 包含原始图片的目录:param voc_annotations_dir: 包含原始标注文件的目录:param output_dir: 输出目录:param train_set: 训练集文件名列表:param val_set: 验证集文件名列表:param test_set: 测试集文件名列表"""# 创建输出目录结构images_dir = os.path.join(output_dir, "images")labels_dir = os.path.join(output_dir, "labels")os.makedirs(os.path.join(images_dir, "train"), exist_ok=True)os.makedirs(os.path.join(images_dir, "val"), exist_ok=True)os.makedirs(os.path.join(images_dir, "test"), exist_ok=True)os.makedirs(os.path.join(labels_dir, "train"), exist_ok=True)os.makedirs(os.path.join(labels_dir, "val"), exist_ok=True)os.makedirs(os.path.join(labels_dir, "test"), exist_ok=True)def copy_files(file_list, subset):"""复制文件到对应的子集目录中。"""for file_name in file_list:base_name = os.path.splitext(file_name)[0]# 复制图片src_image_path = os.path.join(voc_images_dir, base_name + ".png")dst_image_path = os.path.join(images_dir, subset, base_name + ".png")if os.path.exists(src_image_path):shutil.copy(src_image_path, dst_image_path)else:print(f"警告:未找到图片文件 {src_image_path}")# 复制标注文件src_label_path = os.path.join(voc_annotations_dir, base_name + ".txt")dst_label_path = os.path.join(labels_dir, subset, base_name + ".txt")if os.path.exists(src_label_path):shutil.copy(src_label_path, dst_label_path)else:print(f"警告:未找到标注文件 {src_label_path}")# 复制训练集、验证集和测试集copy_files(train_set, "train")copy_files(val_set, "val")copy_files(test_set, "test")print("图片和标注文件已成功组织到对应的文件夹中!")def batch_convert_voc_to_yolo(voc_images_dir, voc_annotations_dir, output_dir):"""批量将 VOC 格式的标注文件转换为 YOLO 格式,并划分数据集。:param voc_images_dir: 包含原始图片的目录:param voc_annotations_dir: 包含 VOC 格式 XML 文件的目录:param output_dir: 输出目录"""# 收集所有类别classes = collect_classes(voc_annotations_dir)class_mapping = create_class_mapping(classes)print("发现以下类别:", classes)# 获取所有 XML 文件xml_files = [f for f in os.listdir(voc_annotations_dir) if f.endswith('.xml')]# 划分数据集train_set, val_set, test_set = split_dataset(xml_files)print(f"训练集数量:{len(train_set)},验证集数量:{len(val_set)},测试集数量:{len(test_set)}")# 创建临时标注输出目录temp_labels_dir = os.path.join(output_dir, "temp_labels")os.makedirs(temp_labels_dir, exist_ok=True)# 转换所有标注文件为 YOLO 格式for xml_file in xml_files:# 构造输入和输出文件路径voc_annotation_path = os.path.join(voc_annotations_dir, xml_file)yolo_annotation_path = os.path.join(temp_labels_dir, os.path.splitext(xml_file)[0] + ".txt")# 转换单个文件convert_voc_to_yolo(voc_annotation_path, yolo_annotation_path, class_mapping)# 组织文件到对应的文件夹中organize_files(voc_images_dir, temp_labels_dir, output_dir, train_set, val_set, test_set)# 删除临时标注目录shutil.rmtree(temp_labels_dir)print("数据集转换与组织完成!")# 示例用法
if __name__ == "__main__":# 输入和输出目录voc_images_dir = "D:/project_mine/detection/datasets/HelmetDetection/train/JPEGImages"voc_annotations_dir = "D:/project_mine/detection/datasets/HelmetDetection/train/Annotations"output_dir = "D:/project_mine/detection/datasets/anquanmao"# 批量转换与划分batch_convert_voc_to_yolo(voc_images_dir, voc_annotations_dir, output_dir)
模型训练
模型训练很简单,我们只需要修改一下数据集配置文件即可
path: ../datasets/anquanmao # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:0: head1: helmet2: person
随后,即可开启模型训练
from ultralytics import YOLOmodel=YOLO("yolo11.yaml")#.load("yolo11n.pt")#.load("yolo11s.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="anquanmao.yaml",epochs=60,batch=16, # 根据GPU显存调整(T4建议batch=8)imgsz=640,device="0", # 指定GPU IDoptimizer="AdamW",lr0=1e-4,warmup_epochs=4,label_smoothing=0.1,amp=True)
结果如下:
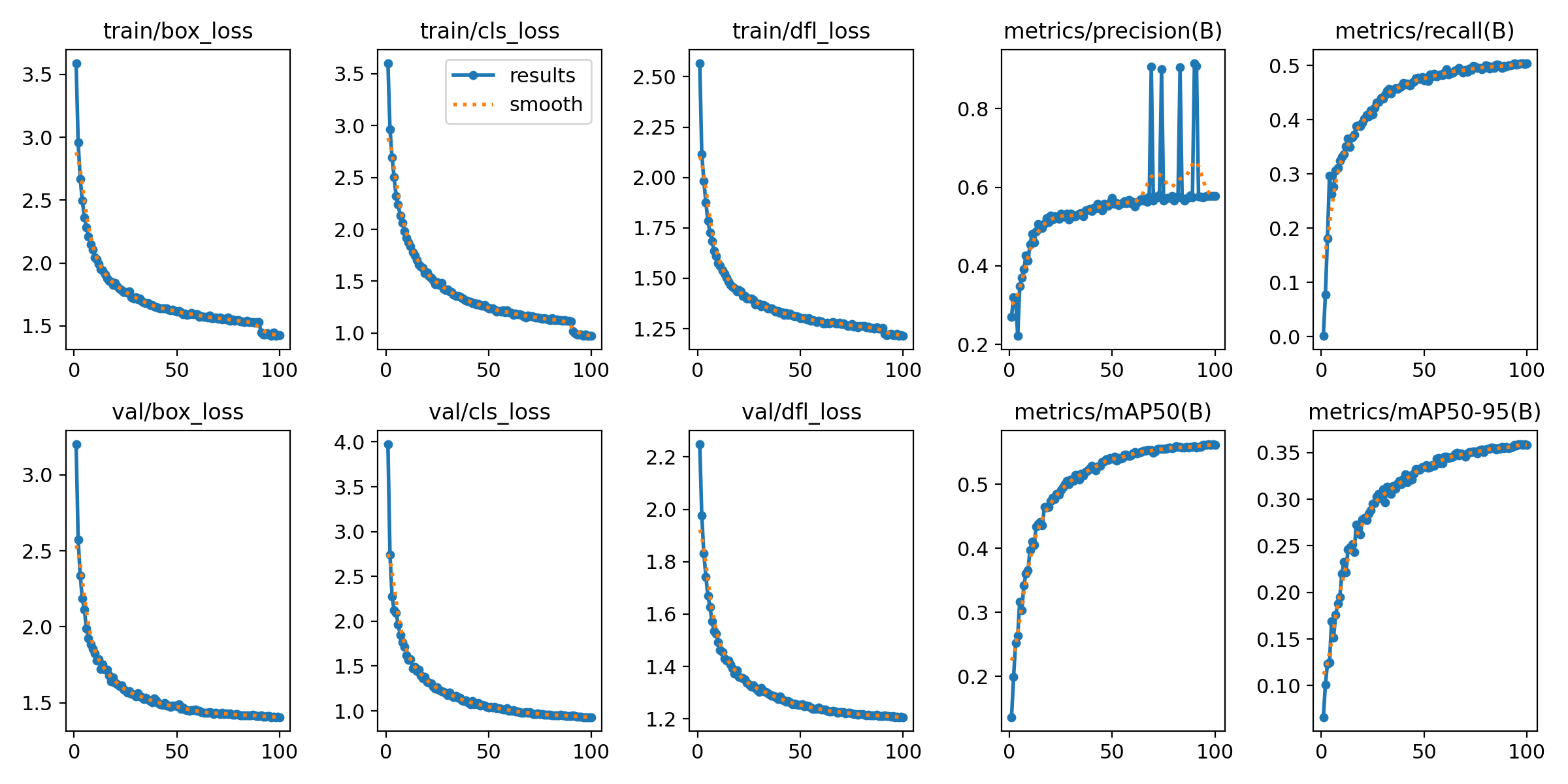
这里的mAP值不高是因为,人这个类别似乎缺失了,导致人这个类别的AP值为0,单独来看,头和安全帽的AP值均在0.5以上。
ONNX模型推理
为使其能够具有更好的扩展性,我们将原本的pt模型文件转换为ONNX格式,随后进行推理,代码如下:
import time
import cv2
import numpy as np
import onnxruntime
#from my_utils.detect.utils import detections_dog
from utils import xywh2xyxy, multiclass_nmsclass SafeHat:#初始化YOLO模型def __init__(self, path, conf_thres=0.7, iou_thres=0.5):self.conf_threshold = conf_thresself.iou_threshold = iou_thres# Initialize modelself.initialize_model(path)#调用推理def __call__(self, image):return self.detect_objects(image)#加载模型并获取模型的输入与输出结构def initialize_model(self, path):self.session = onnxruntime.InferenceSession(path,providers=onnxruntime.get_available_providers())self.get_input_details()self.get_output_details()#执行模型推理过程def detect_objects(self, image):input_tensor = self.prepare_input(image)# Perform inference on the imageoutputs = self.inference(input_tensor)self.boxes, self.scores, self.class_ids = self.process_output(outputs)return self.boxes, self.scores, self.class_ids#前处理操作def prepare_input(self, image):self.img_height, self.img_width = image.shape[:2]input_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# Resize input imageinput_img = cv2.resize(input_img, (self.input_width, self.input_height))# Scale input pixel values to 0 to 1input_img = input_img / 255.0input_img = input_img.transpose(2, 0, 1)input_tensor = input_img[np.newaxis, :, :, :].astype(np.float32)return input_tensor#具体使用onnx推理def inference(self, input_tensor):outputs = self.session.run(self.output_names, {self.input_names[0]: input_tensor})return outputs#后处理操作def process_output(self, output):predictions = np.squeeze(output[0]).T# Filter out object confidence scores below thresholdscores = np.max(predictions[:, 4:], axis=1)predictions = predictions[scores > self.conf_threshold, :]scores = scores[scores > self.conf_threshold]if len(scores) == 0:return [], [], []# Get the class with the highest confidenceclass_ids = np.argmax(predictions[:, 4:], axis=1)# Get bounding boxes for each objectboxes = self.extract_boxes(predictions)indices = multiclass_nms(boxes, scores, class_ids, self.iou_threshold)return boxes[indices], scores[indices], class_ids[indices]#box转换,包含尺度变换与xywh转换def extract_boxes(self, predictions):# Extract boxes from predictionsboxes = predictions[:, :4]boxes = self.rescale_boxes(boxes)boxes = xywh2xyxy(boxes)return boxes#尺度变换def rescale_boxes(self, boxes):# Rescale boxes to original image dimensionsinput_shape = np.array([self.input_width, self.input_height, self.input_width, self.input_height])boxes = np.divide(boxes, input_shape, dtype=np.float32)boxes *= np.array([self.img_width, self.img_height, self.img_width, self.img_height])return boxesdef get_input_details(self):model_inputs = self.session.get_inputs()self.input_names = [model_inputs[i].name for i in range(len(model_inputs))]self.input_shape = model_inputs[0].shapeself.input_height = self.input_shape[2]self.input_width = self.input_shape[3]def get_output_details(self):model_outputs = self.session.get_outputs()self.output_names = [model_outputs[i].name for i in range(len(model_outputs))]# def draw_detections(self, image, draw_scores=True, mask_alpha=0.4):
#
# return detections_dog(image, self.boxes, self.scores,
# self.class_ids, mask_alpha)
#
#
# if __name__ == "__main__":
# model_path = "anquanmao.onnx" # 替换为你的 TFLite 模型路径
# image_path = "down_head.png" # 替换为你的测试图像路径
#
# # 初始化模型
# detector = YOLODet(model_path)
#
# # 加载图像
# image = cv2.imread(image_path)
#
# # 检测对象
# boxes, scores, class_ids = detector(image)
#
# # 绘制检测结果
# result_image = detector.draw_detections(image)
#
# # 显示结果
# cv2.imshow("Detections", result_image)
# cv2.waitKey(0)
# cv2.destroyAllWindows()相关文章:
安全帽目标检测
安全帽数据集 这里我们使用的安全帽数据集是HelmentDetection,这是一个公开数据集,里面包含5000张voc标注格式的图像,分为三个类别,分别是 0: head 1: helmet 2: person 安全帽数据集下载地址、 我们将数据集下载后,…...

Java工厂方法模式详解
工厂方法模式(Factory Method Pattern)是一种创建型设计模式,它将对象的创建和使用分离,通过定义一个创建对象的接口,让子类决定实例化哪个类。这种模式提高了代码的可扩展性和可维护性,尤其适用于需要根据…...

【pytorch学习】土堆pytorch学习笔记2
说明 主要以https://www.morinha.cc/posts/courses/pytorch-%E5%B0%8F%E5%9C%9F%E5%A0%86的内容为基础,没有的或者自己不是很清楚的再补充上内容,该贴有的内容大部分不再加入进来 新增的更全的参考: https://2048.csdn.net/6801fc28e9858151…...
Eclipse 插件开发 5.3 编辑器 监听输入
Eclipse 插件开发 5.3 编辑器监 听输入 1 插件配置2 添加监听3 查看效果 Manifest-Version: 1.0 Bundle-ManifestVersion: 2 Bundle-Name: Click1 Bundle-SymbolicName: com.xu.click1;singleton:true Bundle-Version: 1.0.0 Bundle-Activator: com.xu.click1.Activator Bundle…...

iOS 集成网易云信IM
云信官方文档在这 看官方文档的时候,版本选择最新的V10。 1、CocoPods集成 pod NIMSDK_LITE 2、AppDelegate.m添加头文件 #import <NIMSDK/NIMSDK.h> 3、初始化 NIMSDKOption *mrnn_option [NIMSDKOption optionWithAppKey:"6f6568e354026d2d658a…...
)
Parasoft C++Test软件单元测试_实例讲解(对多次调用的函数打桩)
系列文章目录 Parasoft C++Test软件静态分析:操作指南(编码规范、质量度量)、常见问题及处理 Parasoft C++Test软件单元测试:操作指南、实例讲解、常见问题及处理 Parasoft C++Test软件集成测试:操作指南、实例讲解、常见问题及处理 进阶扩展:自动生成静态分析文档、自动…...
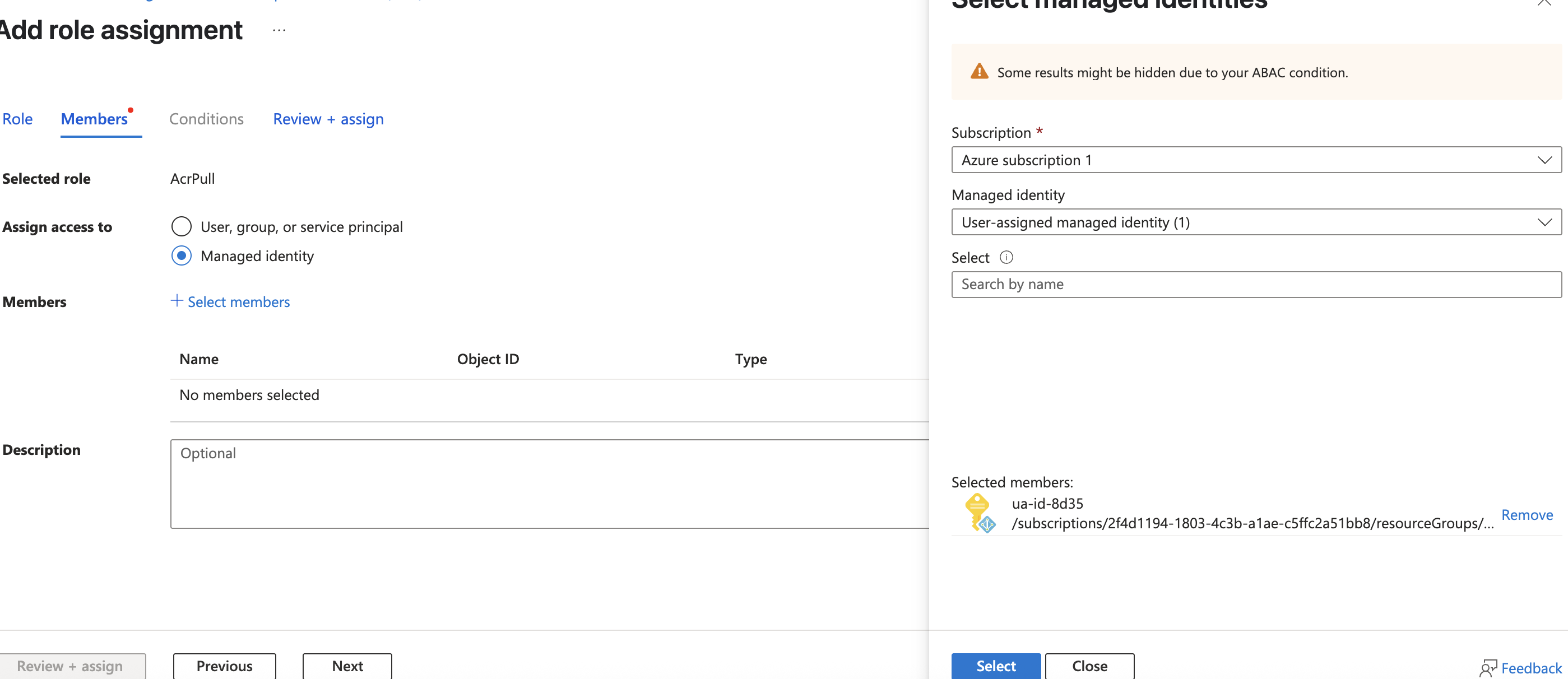
azure web app创建分步指南系列之二
为注册表授权托管标识 你创建的托管标识尚未获得从容器注册表中提取数据的授权。在此步骤中,你将启用授权。 返回容器注册表的管理页面: 在左侧导航菜单中,选择“访问控制 (IAM)”。选择“添加角色分配”。此屏幕截图显示了如何为容器注册表启用添加角色分配。在角色列表中…...

题海拾贝:P8598 [蓝桥杯 2013 省 AB] 错误票据
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》 欢迎点赞,关注! 1、题…...

MySQL 8.0:解析
引言 MySQL 8.0 作为里程碑版本,在功能、性能、安全性等维度进行了全面革新。以下从技术实现、应用场景和实践挑战三个层面,深度解析其核心特性变化: 一、架构级重构:数据字典与原子 DDL 1. 事务性数据字典 技术实现…...

Python量化交易12——Tushare全面获取各种经济金融数据
两年前写过Tushare的简单使用: Python量化交易08——利用Tushare获取日K数据_skshare- 现在更新一下吧,这两年用过不少的金融数据库,akshare,baostock,雅虎的,pd自带的......发现还是Tushare最稳定最好用&…...
封装一个小程序选择器(可多选、单选、搜索)
组件 <template><view class"popup" v-show"show"><view class"bg" tap"cancelMultiple"></view><view class"selectMultiple"><view class"multipleBody"><view class&…...
Dest建筑能耗模拟仿真功能简介
Dest建筑能耗模拟仿真功能简介 全球建筑能耗占终端能源消费的30%以上,掌握建筑能耗模拟是参与绿色建筑认证(如LEED、WELL)、超低能耗设计、既有建筑节能改造的必备能力。DEST作为国内主流建筑能耗模拟工具,广泛应用于设计院、咨询…...

【Hot 100】121. 买卖股票的最佳时机
目录 引言买卖股票的最佳时机我的解题 🙋♂️ 作者:海码007📜 专栏:算法专栏💥 标题:【Hot 100】121. 买卖股票的最佳时机❣️ 寄语:书到用时方恨少,事非经过不知难! 引…...
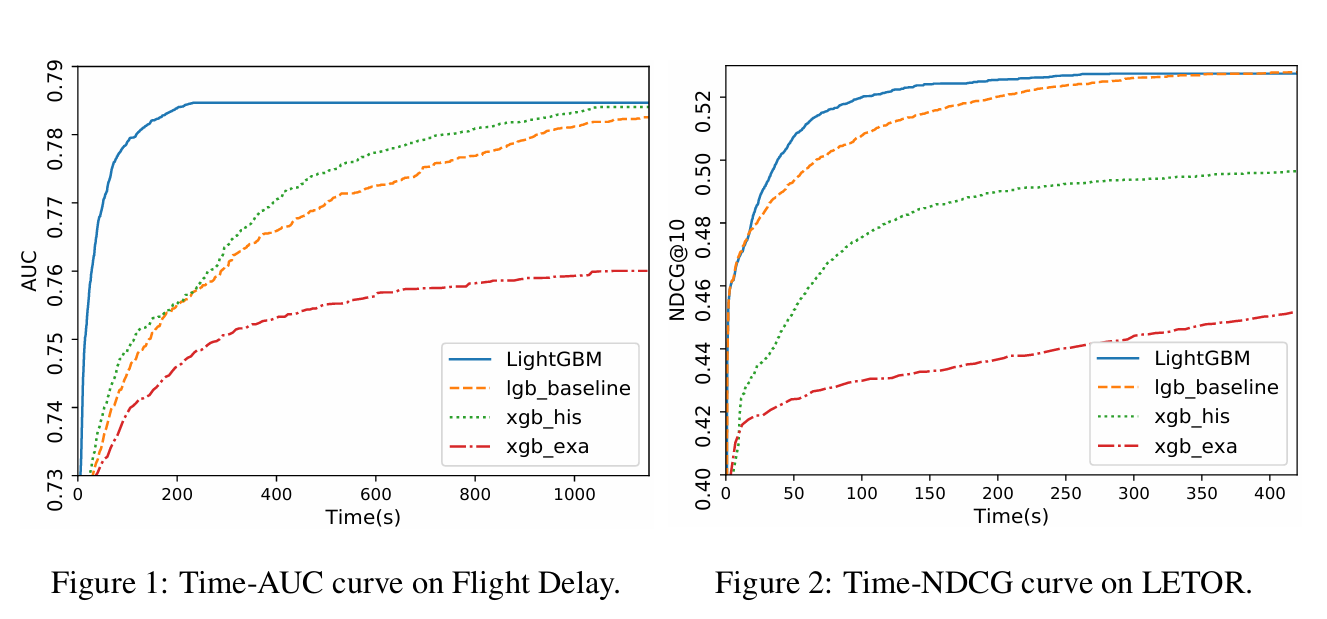
【机器学习基础】机器学习入门核心算法:XGBoost 和 LightGBM
机器学习入门核心算法:XGBoost 和 LightGBM 一、算法逻辑XGBoost (eXtreme Gradient Boosting)LightGBM (Light Gradient Boosting Machine) 二、算法原理与数学推导目标函数(二者通用)二阶泰勒展开:XGBoost 分裂点增益计算&#…...

Linux | Shell脚本的常用命令
一. 常用字符处理命令 1.1 连续打印字符seq seq打印数字;且只能正向打印,不可反向连续打印 设置打印步长 指定打印格式 1.2 反向打印字符tac cat 正向,tac 反向 1.3 打印字符printf printf "打印的内容"指定格式打印内容 换行…...

跑步的强度等级分类
概述 最大心率简化计算公式是【220-年龄】,具体值建议通过实际测试校准。在跑步训练中,以最大心率(Heart Rate Maximum)为指标对强度分类,常见分类对应的心率区间如下: 强度等级心率区间(% HR…...

【JUC】深入解析 JUC 并发编程:单例模式、懒汉模式、饿汉模式、及懒汉模式线程安全问题解析和使用 volatile 解决内存可见性问题与指令重排序问题
单例模式 单例模式确保某个类在程序中只有一个实例,避免多次创建实例(禁止多次使用new)。 要实现这一点,关键在于将类的所有构造方法声明为private。 这样,在类外部无法直接访问构造方法,new操作会在编译…...

2025年全国青少年信息素养大赛复赛C++算法创意实践挑战赛真题模拟强化训练(试卷3:共计6题带解析)
2025年全国青少年信息素养大赛复赛C++算法创意实践挑战赛真题模拟强化训练(试卷3:共计6题带解析) 第1题:四位数密码 【题目描述】 情报员使用4位数字来传递信息,同时为了防止信息泄露,需要将数字进行加密。数据加密的规则是: 每个数字都进行如下处理:该数字加上5之后除…...
Mongodb | 基于Springboot开发综合社交网络应用的项目案例(中英)
目录 Project background Development time Project questions Create Project create springboot project project framework create folder Create Models user post Comment Like Message Serive tier user login and register Dynamic Publishing and Bro…...
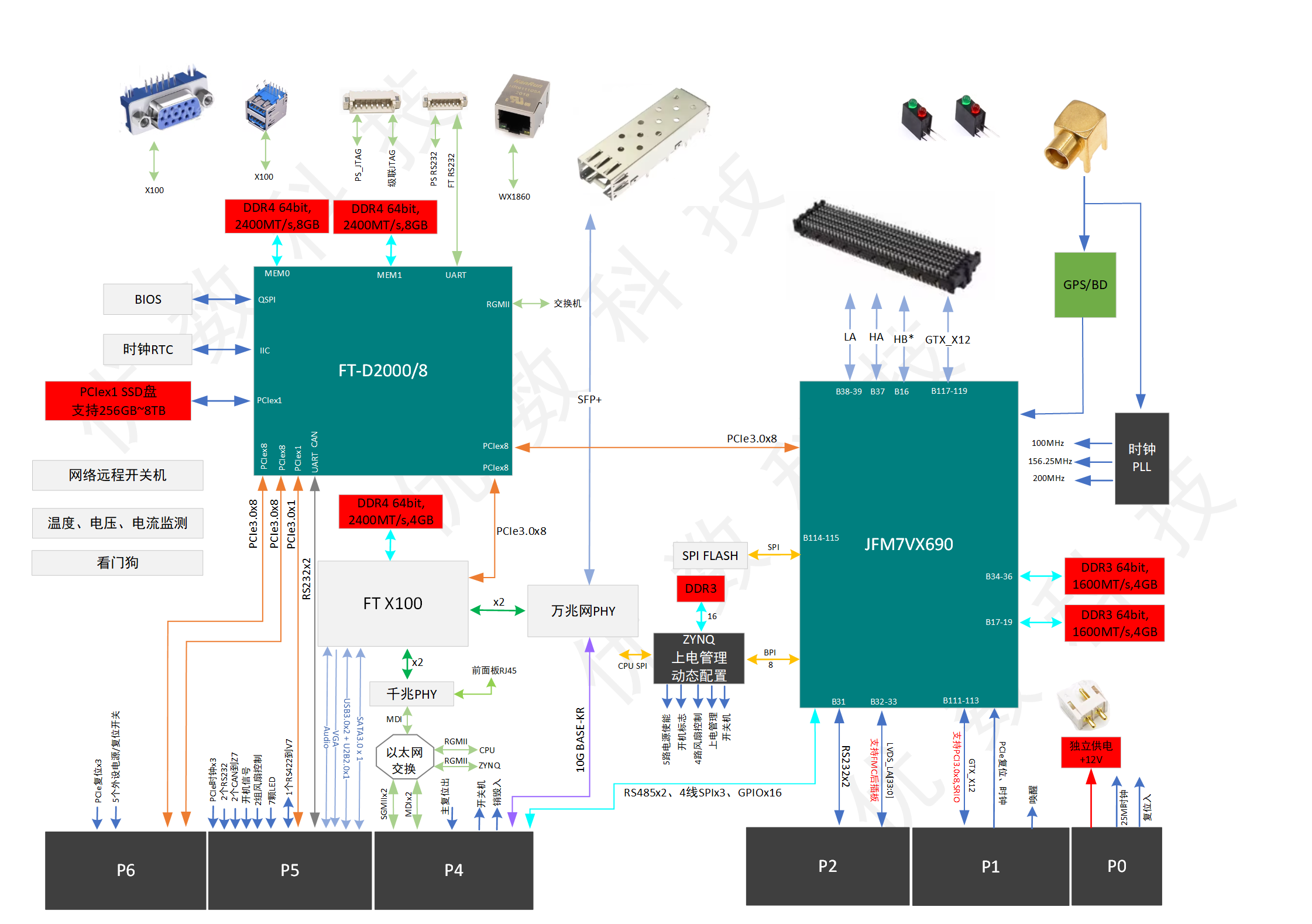
飞腾D2000与FPGA结合的主板
UD VPX-404是基于高速模拟/数字采集回放、FPGA信号实时处理、CPU主控、高速SSD实时存储架构开发的一款高度集成的信号处理组合模块,采用6U VPX架构,模块装上外壳即为独立整机,方便用户二次开发。 UD VPX-404模块的国产率可达到100%࿰…...

百度量子蜘蛛3.0横空出世,搜索引擎迎来“量子跃迁“级革命
一、量子蜘蛛3.0的三大颠覆性升级 1. 动态抓取:让内容实时"量子纠缠" - 智能频率调节:根据网站更新频率自动调整抓取节奏,新闻类站点日抓取量达3-5次,静态页面抓取间隔延长至72小时。某财经媒体通过"热点事件15分钟…...

GitHub开源|AI顶会论文中文翻译PDF合集(gpt-translated-pdf-zh)
项目核心特点 该项目专注于提供计算机科学与人工智能领域的高质量中文翻译资源,以下为关键特性: 主题覆盖广泛:包含算法、数据结构、概率统计等基础内容,以及深度学习、强化学习等前沿研究方向。格式统一便捷:所有文…...
是一个通过注解在 Java Bean 上定义和执行验证规则的规范)
JSR 303(即 Bean Validation)是一个通过注解在 Java Bean 上定义和执行验证规则的规范
🛠️ 一、JSR 303是什么? JSR 303(Java Specification Requests 303)是Java EE 6的子规范,全称Bean Validation。它通过注解方式对JavaBean的属性值进行标准化校验,例如检查非空、长度、格式等规则…...

5G 网络中的双向认证机制解析
一、5G 网络中的双向认证机制解析 在 5G 核心网中,双向认证是指UE(用户设备)与网络互相验证对方身份的过程。这一机制通过多层次的安全协议和密钥交换,确保通信双方的合法性,防止中间人攻击和身份伪造。 1. UE 存储的关键信息 UE 作为用户终端,存储以下核心安全信息:…...

DAY07:Vue Router深度解析与多页面博客系统实战
第一部分:Vue Router核心概念深度剖析 1.1 现代前端路由的本质 在单页应用(SPA)时代,前端路由扮演着至关重要的角色。它突破了传统多页面应用的跳转方式,通过以下机制实现无刷新页面切换: Hash模式&#…...
Drawio编辑器二次开发
Drawio (现更名为 Diagrams.net )是一款完全免费的在线图表绘制工具,由 JGraph公司 开发。它支持创建多种类型的图表,包括流程图、组织结构图、UML图、网络拓扑图、思维导图等,适用于商务演示、软件设计等多种场景…...

1.测试过程之需求分析和测试计划
测试基础 流程 1.分析测试需求 2.编写测试计划 3.设计与编写测试用例 4.执行测试 5.评估与总结 测试目标 根据测试阶段不同可分为四个主要目标:预防错误(早期)、发现错误(开发阶段)、建立信心(验收阶段&a…...

第三十七天打卡
过拟合的判断:测试集和训练集同步打印指标模型的保存和加载 仅保存权重保存权重和模型保存全部信息checkpoint,还包含训练状态 早停策略 过拟合判断 import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import load…...
详解:控制窗口样式与行为)
Qt 窗口标志(Window Flags)详解:控制窗口样式与行为
在 Qt 中,windowFlags 用于控制窗口的样式和行为,包括标题栏、边框、最大化/最小化按钮等。合理设置 windowFlags 可以自定义窗口的外观和交互方式。本文将详细介绍常用的窗口标志及其组合效果。 1. 基本概念 windowFlags 是一个 Qt::WindowFlags 类型的…...

ABP VNext + CRDT 打造实时协同编辑
🛠️ ABP VNext CRDT 打造实时协同编辑器 🎉 📚 目录 🛠️ ABP VNext CRDT 打造实时协同编辑器 🎉🧠 背景与挑战🔹 系统架构🛣️ 端到端流程 🚦🔒 安全与鉴…...