VectorStore 组件深入学习与检索方法
考虑到目前市面上的向量数据库众多,每个数据库的操作方式也无统一标准,但是仍然存在着一些公共特征,LangChain 基于这些通用的特征封装了 VectorStore 基类,在这个基类下,可以将方法划分成 6 种:
- 相似性搜索
- 最大边际相关性搜索
- 通用搜索
- 添加删除精确查找数据
- 检索器
- 创建数据库
类图如下: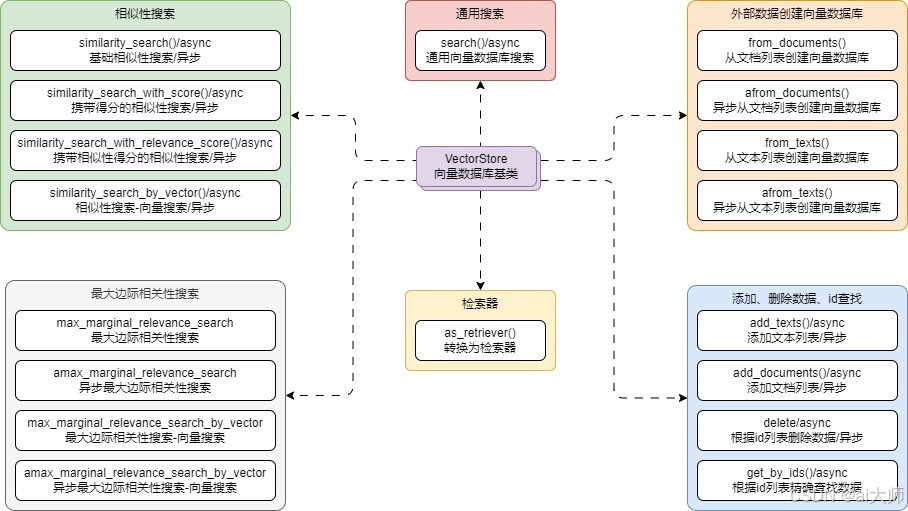
1. 带得分阈值的相似性搜索
在 LangChain 的相似性搜索中,无论结果多不匹配,只要向量数据库中存在数据,一定会查找出相应的结果,在 RAG 应用开发中,一般是将高相似文档插入到 Prompt 中,所以可以考虑添加一个 相似性得分阈值,超过该数值的部分才等同于有相似性。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
在 similarity_search_with_relevance_scores() 函数中,可以传递 score_threshold 阈值参数,过滤低于该得分的文档。
例如没有添加阈值检索 我养了一只猫,叫笨笨,示例与输出如下:
import dotenv
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()embedding = OpenAIEmbeddings(model="text-embedding-3-small")documents = [Document(page_content="笨笨是一只很喜欢睡觉的猫咪", metadata={"page": 1}),Document(page_content="我喜欢在夜晚听音乐,这让我感到放松。", metadata={"page": 2}),Document(page_content="猫咪在窗台上打盹,看起来非常可爱。", metadata={"page": 3}),Document(page_content="学习新技能是每个人都应该追求的目标。", metadata={"page": 4}),Document(page_content="我最喜欢的食物是意大利面,尤其是番茄酱的那种。", metadata={"page": 5}),Document(page_content="昨晚我做了一个奇怪的梦,梦见自己在太空飞行。", metadata={"page": 6}),Document(page_content="我的手机突然关机了,让我有些焦虑。", metadata={"page": 7}),Document(page_content="阅读是我每天都会做的事情,我觉得很充实。", metadata={"page": 8}),Document(page_content="他们一起计划了一次周末的野餐,希望天气能好。", metadata={"page": 9}),Document(page_content="我的狗喜欢追逐球,看起来非常开心。", metadata={"page": 10}),
]
db = FAISS.from_documents(documents, embedding)print(db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨"))# 输出内容
[(Document(metadata={'page': 1}, page_content='笨笨是一只很喜欢睡觉的猫咪'), 0.4592331743070337), (Document(metadata={'page': 3}, page_content='猫咪在窗台上打盹,看起来非常可爱。'), 0.22960424668403867), (Document(metadata={'page': 10}, page_content='我的狗喜欢追逐球,看起来非常开心。'), 0.02157827632118159), (Document(metadata={'page': 7}, page_content='我的手机突然关机了,让我有些焦虑。'), -0.09838758604956)]
添加阈值 0.4,搜索输出示例如下:
print(db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨", score_threshold=0.4))# 输出[(Document(metadata={'page': 1}, page_content='笨笨是一只很喜欢睡觉的猫咪'), 0.45919389344422157)]
对于 score_threshold 的具体数值,要看相似性搜索方法使用的逻辑、计算相似性得分的逻辑进行设置,并没有统一的标准,并且与向量数据库的数据大小也存在间接关系,数据集越大,检索出来的准确度相比少量数据会更准确。
2. as_retriever() 检索器
在 LangChain 中,VectorStore 可以通过 as_retriever() 方法转换成检索器,在 as_retriever() 中可以传递一下参数:
search_type:搜索类型,支持 similarity(基础相似性搜索)、similarity_score_threshold(携带相似性得分+阈值判断的相似性搜索)、mmr(最大边际相关性搜索)。
search_kwargs:其他键值对搜索参数,类型为字典,例如:k、filter、score_threshold、fetch_k、lambda_mult 等,当搜索类型配置为 similarity_score_threshold 后,必须添加 score_threshold 配置选项,否则会报错,参数的具体信息要看 search_type 类型对应的函数配合使用。
并且由于检索器是 Runnable 可运行组件,所以可以使用 Runnable 组件的所有功能(组件替换、参数配置、重试、回退、并行等)。
例如将向量数据库转换成 携带得分+阈值判断的相似性搜索,并设置得分阈值为0.5,数据条数为10条,代码示例如下:
import dotenv
import weaviate
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStore
from weaviate.auth import AuthApiKeydotenv.load_dotenv()# 1.构建加载器与分割器
loader = UnstructuredMarkdownLoader("./项目API文档.md")
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。|!|?", "\.\s|\!\s|\?\s", ";|;\s", ",|,\s", " ", "", ],is_separator_regex=True,chunk_size=500,chunk_overlap=50,add_start_index=True,
)# 2.加载文档并分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)# 3.将数据存储到向量数据库
db = WeaviateVectorStore(client=weaviate.connect_to_wcs(cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud",auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0"),),index_name="DatasetDemo",text_key="text",embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)# 4.转换检索器
retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 10, "score_threshold": 0.5},
)# 5.检索结果
documents = retriever.invoke("关于配置接口的信息有哪些")print(list(document.page_content[:50] for document in documents))
print(len(documents))
输出内容:
['接口说明:用于更新对应应用的调试长记忆内容,如果应用没有开启长记忆功能,则调用接口会发生报错。\n\n接', '如果接口需要授权,需要在 headers 中添加 Authorization ,并附加 access', '接口示例:\n\njson\n{\n "code": "success",\n "data": {', '接口信息:授权+POST:/apps/:app_id/debug\n\n接口参数:\n\n请求参数:\n\nap', '1.2 [todo]更新应用草稿配置信息\n\n接口说明:更新应用的草稿配置信息,涵盖:模型配置、长记忆', '请求参数:\n\napp_id -> uuid:路由参数,必填,需要获取的应用 id。\n\n响应参数:\n\n', 'memory_mode -> string:记忆类型,涵盖长记忆 long_term_memory ', '1.6 [todo]获取应用调试历史对话列表\n\n接口说明:用于获取应用调试历史对话列表信息,该接口支', 'LLMOps 项目 API 文档\n\n应用 API 接口统一以 JSON 格式返回,并且包含 3 个字', '响应参数:\n\nsummary -> str:该应用最新调试会话的长记忆内容。\n\n响应示例:\n\njso']
10
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
- ✨模型优惠查询
相关文章:
VectorStore 组件深入学习与检索方法
考虑到目前市面上的向量数据库众多,每个数据库的操作方式也无统一标准,但是仍然存在着一些公共特征,LangChain 基于这些通用的特征封装了 VectorStore 基类,在这个基类下,可以将方法划分成 6 种: 相似性搜…...
HackMyVM-First
信息搜集 主机发现 ┌──(kali㉿kali)-[~] └─$ nmap -sn 192.168.43.0/24 Starting Nmap 7.95 ( https://nmap.org ) at 2025-05-31 06:13 EDT Nmap scan report for 192.168.43.1 Host is up (0.0080s latency). MAC Address: C6:45:66:05:91:88 (Unknown) …...

30V/150A MOSFET 150N03在无人机驱动动力系统中的性能边界与热设计挑战
产品技术概述 150N03 是一款基于沟槽式工艺(Trench Technology)的N沟道功率MOSFET,其核心价值在于: 电压/电流规格:VDSS30V, ID150A (Tc25℃) 工艺特征:高密度元胞设计实现超低导通电阻 双面散热架构:顶部裸露铜架底…...

数据共享交换平台之数据资源目录
依据信息资源体系规范,构建多维度、多层级的资源目录体系,完整的展示和管理资源目录。资源目录提供以下功能: 多层级资源目录展示,能够将资源目录按照技术维度和管理维度进行分类管理,并能够将资源目录按照数据湖、基础…...

跨平台浏览器集成库JxBrowser 支持 Chrome 扩展程序,高效赋能 Java 桌面应用
JxBrowser 是 TeamDev 开发的跨平台库,用于在 Java 应用程序中集成 Chromium 浏览器。它支持 HTML5、CSS3、JavaScript 等,具备硬件加速渲染、双向 Java 与 JavaScript 连接、丰富的事件监听等功能,能处理网页保存、打印等操作,助…...
WEBSTORM前端 —— 第3章:移动 Web —— 第3节:移动适配
目录 一、移动Web基础 1.谷歌模拟器 2.屏幕分辨率 3.视口 4.二倍图 二、适配方案 三、rem 适配方案 四、less 1.less – 简介 2.less – 注释 3.less – 运算 4.less – 嵌套 5.less – 变量 6.less – 导入 7.less – 导出 8.less – 禁止导出 五…...

38.springboot使用rabbitmq
pom依赖 <!--amqp依赖,包含RabbitMQ--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId></dependency> 配置文件添加 spring:application:name: message…...

弱光环境下如何手持相机拍摄静物:摄影曝光之等效曝光认知
写在前面 博文内容为一次博物馆静物拍摄笔记的简单总结内容涉及:弱光环境拍摄静物如何选择,以及等效曝光的认知理解不足小伙伴帮忙指正 😃,生活加油 我看远山,远山悲悯 持续分享技术干货,感兴趣小伙伴可以关注下 _ 采…...

Selenium Manager中文文档
1. 什么是 Selenium Manager(测试版) Selenium Manager 是 Selenium 官方提供的命令行工具(用 Rust 实现),用于自动管理浏览器及其驱动(chromedriver、geckodriver、msedgedriver 等)。从 Sele…...

WEB安全--SQL注入--MSSQL注入
一、SQLsever知识点了解 1.1、系统变量 版本号:version 用户名:USER、SYSTEM_USER 库名:DB_NAME() SELECT name FROM master..sysdatabases 表名:SELECT name FROM sysobjects WHERE xtypeU 字段名:SELECT name …...

【HTML】基础学习【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 102 篇 - Date: 2025 - 05 - 31 Author: 郑龙浩/仟墨 文章目录 HTML 基础学习一 了解HTML二 HTML的结构三 HTML标签1 标题2 文本段落3 换行4 加粗、斜体、下划线5 插入图片6 添加链接7 容器8 列表9 表格10 class类 HTML 基础学习 一 了解HTML 一个网页分为为三部分&…...

SAP Business ByDesign:无锡哲讯科技赋能中大型企业云端数字化转型
云端ERP时代,中大型企业的智能化引擎 在数字经济高速发展的今天,中大型企业面临着全球化竞争、供应链复杂化、数据安全等多重挑战。传统的本地化ERP系统已无法满足企业快速响应市场变化的需求,而SAP Business ByDesign(ByD&…...
)
华为OD机考2025B卷 - 无向图染色(Java Python JS C++ C )
最新华为OD机试 真题目录:点击查看目录 华为OD面试真题精选:点击立即查看 题目描述 给一个无向图染色,可以填红黑两种颜色,必须保证相邻两个节点不能同时为红色,输出有多少种不同的染色方案? 输入描述 第一行输入M(图中节点数) N(边数) 后续N行格式为:V1 V2表示…...

计算机网络学习20250528
地址解析协议ARP 实现IP地址和Mac地址的转换 ARP工作原理: 每台主机或路由器都有一个ARP表,表项:<IP地址,Mac地址,TTL>(TTL一般为20分钟) 主机产生ARP查询分组,包含源目的IP地…...
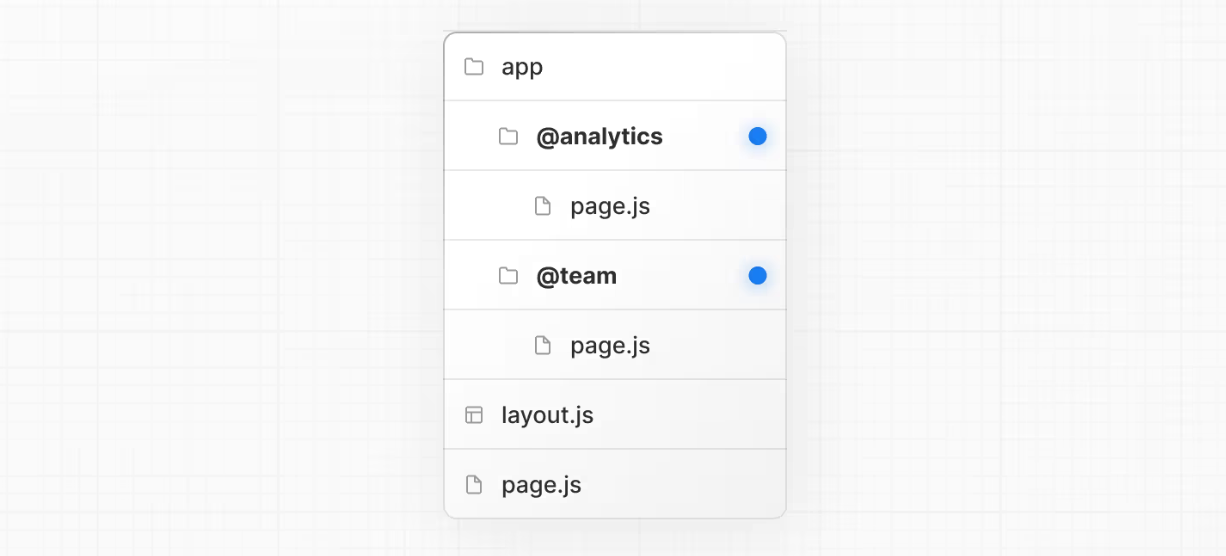
Next.js路由导航完全指南
在前端框架(如 React、Vue 等)或移动端开发中,路由系统是实现页面 / 界面导航的核心机制。Next.js 采用 文件系统路由(File System Routing),即根据项目目录结构自动生成路由。 Next.js 目前有两套路由解决…...
五、web安全--XSS漏洞(1)--XSS漏洞利用全过程
本文章仅供学习交流,如作他用所承受的法律责任一概与作者无关1、XSS漏洞利用全过程 1.1 寻找注入点:攻击者首先需要找到目标网站中可能存在XSS漏洞的注入点。这些注入点通常出现在用户输入能够直接输出到页面,且没有经过适当过滤或编码的地方…...
【C++高级主题】命令空间(六):重载与命名空间
目录 一、候选函数与命名空间:重载的 “搜索范围” 1.1 重载集的构成规则 1.2 命名空间对候选函数的隔离 二、重载与using声明:精准引入单个函数 2.1 using声明与重载的结合 2.2 using声明的冲突处理 三、重载与using指示:批量引入命名…...

利用 Python 爬虫获取淘宝商品详情
在电商领域,淘宝作为中国最大的在线零售平台,拥有海量的商品信息。对于开发者、市场分析师以及电商研究者来说,能够从淘宝获取商品详情信息,对于市场分析、价格比较、商品推荐等应用场景具有重要价值。本文将详细介绍如何使用 Pyt…...

动态拼接内容
服务器端模板引擎(Server-Side Template Engine) 的特性,比如 JSP(Java Server Pages)、ASP.NET、PHP 等技术中常用的 <% %> 语法。 它的核心作用是: 动态拼接内容:在 HTML 中嵌入编程语…...
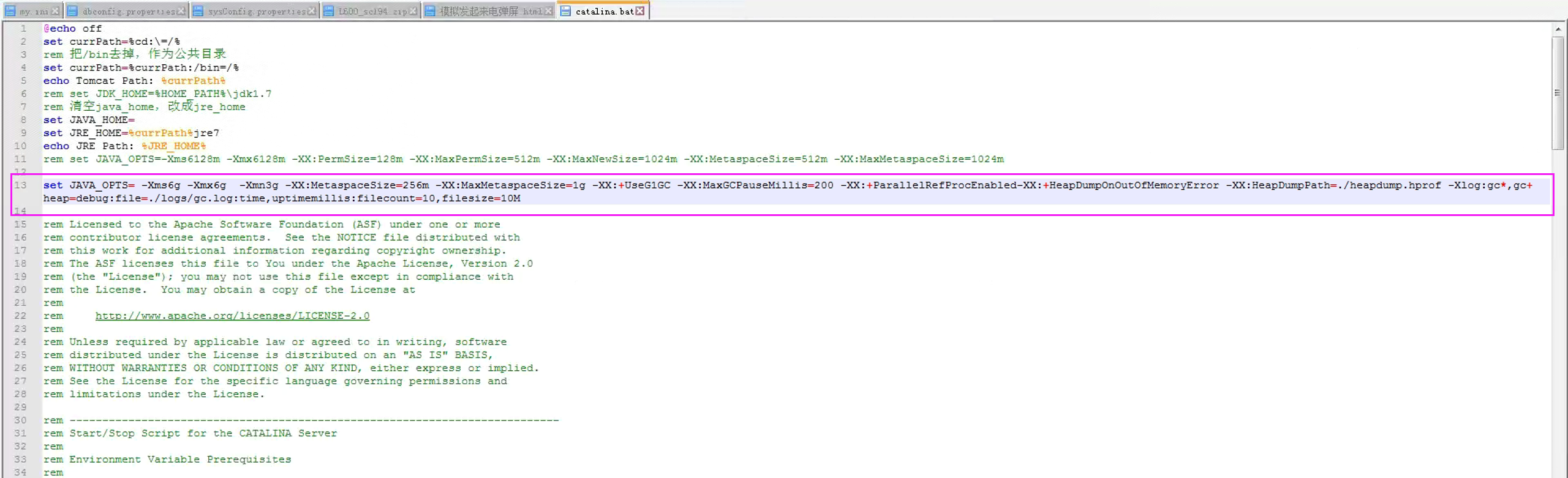
Tomcat运行比较卡顿进行参数调优
在Tomcat conf/catalina.bat或catalina.sh中 的最上面增加参数 1. 初步调整参数(缓解问题) set JAVA_OPTS -Xms6g -Xmx6g -Xmn3g # 增大新生代,减少对象过早晋升到老年代 -XX:MetaspaceSize256m -XX:MaxMetaspaceS…...
)
java直接获取MyBatis将要执行的动态sql命令(不是拦截器方式)
目录 前言 一. 准备数据 1. 传输过来的json条件数据 2. mybatis 配置的动态sql 3. 想要的最终会执行的sql并返回给页面展示 二. 实现方式 三. 最终代码 前言 1.在平常开发过程中,MyBatis使用时非常多的,一般情况下我们只需要在控制台看看MyBatis输出的日志,要不就是实…...
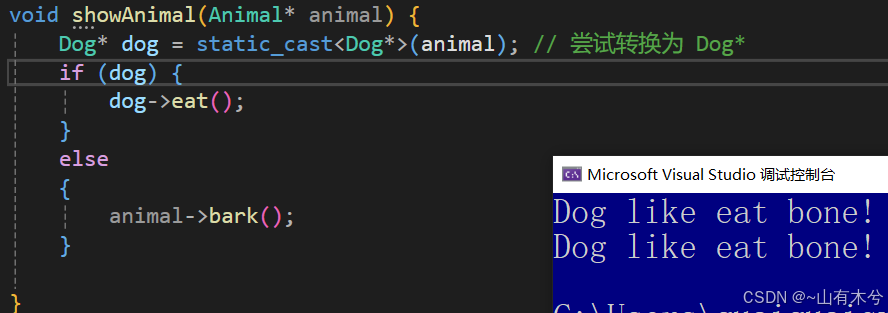
C++四种类型转换方式
const_cast,去掉(指针或引用)常量属性的一个类型转换,但需要保持转换前后类型一致static_cast,提供编译器认为安全的类型转换(最常使用)reinterpret_cast,类似于c语言风格的强制类型转换,不保证安全;dynamic_cast,主要用于继承结构中…...
Canvas: trying to draw too large(256032000bytes) bitmap.
1、错误展示 测试了一下一张图片的显示,发现二个手机上测试的结果不一样,配制好一些的手机,直接就通过,但是屏小一些的测试手机上,直接报下面的错误。 这个意思是图片太大了,直接就崩了。 2、代码编写 lo…...

【深度学习-pytorch篇】5. 卷积神经网络与LLaMA分类模型
卷积神经网络与LLaMA分类模型 一、卷积操作基础 卷积是深度学习中用于提取局部特征的核心操作,特别适用于图像识别任务。 自定义二维卷积函数示例 以下函数实现了一个简化版的二维卷积: def convolve2D(image, kernel, padding0, strides1):kernel …...

matlab全息技术中的菲涅尔仿真成像
matlab全息技术中的菲涅尔仿真成像程序。 傅里叶法(重建距离得大)/Fresnel.m , 545 傅里叶法(重建距离得大)/FresnelB.m , 548 傅里叶法(重建距离得大)/Fresnel_solution.m , 1643 傅里叶法(重…...

基于对比学习的推荐系统开发方案,使用Python在PyCharm中实现
以下是一个基于对比学习的推荐系统开发方案,使用Python在PyCharm中实现。本文将详细阐述技术原理、系统设计和完整代码实现。 基于对比学习的推荐系统开发方案 一、技术背景与原理 1.1 对比学习核心思想 对比学习(Contrastive Learning)通过最大化正样本相似度、最小化负…...
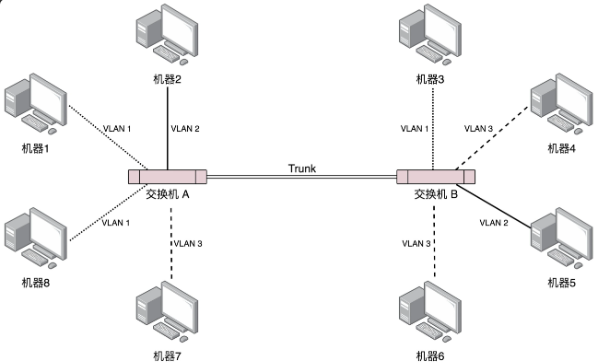
网络协议之办公室网络是怎样的?
写在前面 本文来看下办公室网络怎样的。 1:正文 如果是在一个寝室中组件一个局域网还是比较简单的,只需要一个交换机,然后大家的电脑全部连接到这个交换机上就行了,之后所有的电脑设置CIDR保证在一个局域网就可以了。但是&#…...

鸿蒙OSUniApp PWA开发实践:打造跨平台渐进式应用#三方框架 #Uniapp
UniApp PWA开发实践:打造跨平台渐进式应用 前言 在过去的一年里,我们团队一直在探索如何利用UniApp框架开发高性能的PWA应用。特别是随着鸿蒙系统的普及,我们积累了不少有价值的实践经验。本文将分享我们在开发过程中的技术选型、架构设计和…...

uni-data-picker级联选择器、fastadmin后端api
记录一个部门及部门人员选择的功能,效果如下: 组件用到了uni-ui的级联选择uni-data-picker 开发文档:uni-app官网 组件要求的数据格式如下: 后端使用的是fastadmin,需要用到fastadmin自带的tree类生成部门树 &#x…...

8天Python从入门到精通【itheima】-62~63
目录 第六章开始-62节-数据容器入门 1.学习目标 2.为什么要学习数据容器? 3.什么是Python中的数据容器 4.小节总结 63节-列表的定义语法 1.学习目标 2.为什么需要列表? 3.列表定义的基本语法 4.列表定义的基本语法-案例演示 5.列表定义的基本语…...