DQN和DDQN(进阶版)
来源:
*《第五章 深度强化学习 Q网络》.ppt --周炜星、谢文杰
一、前言
Q表格、Q网络与策略函数

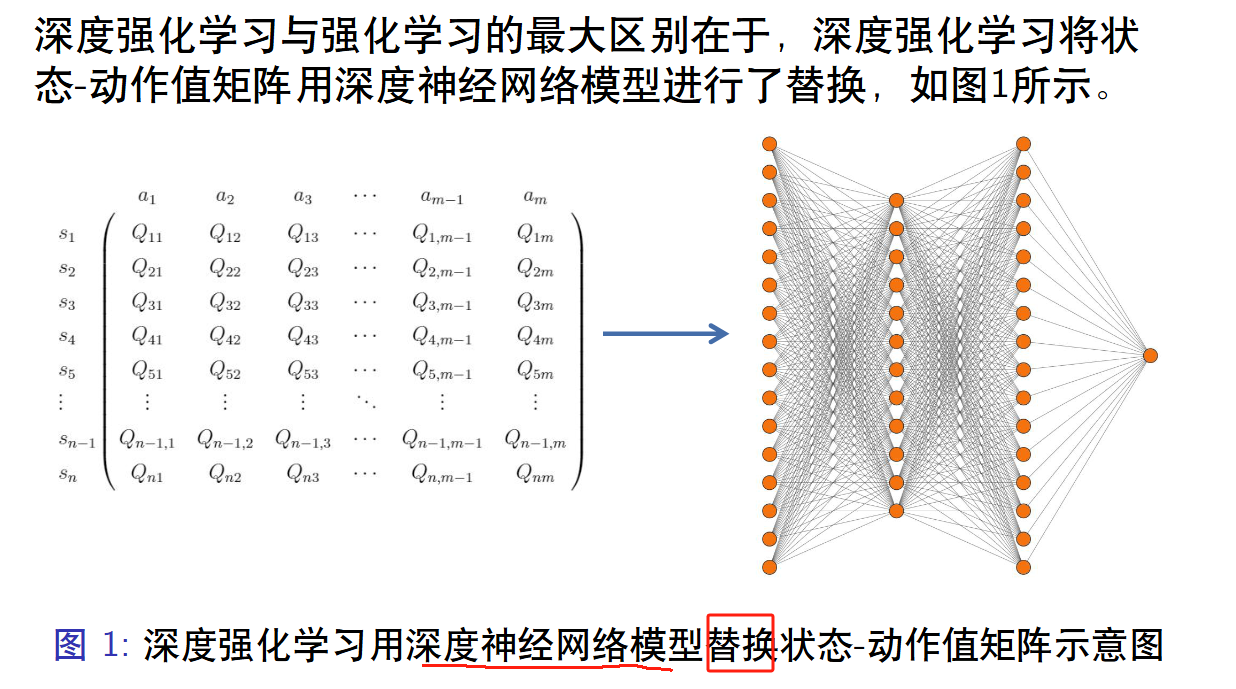
Q表格是有限的离散的,而神经网络可以是无限的。
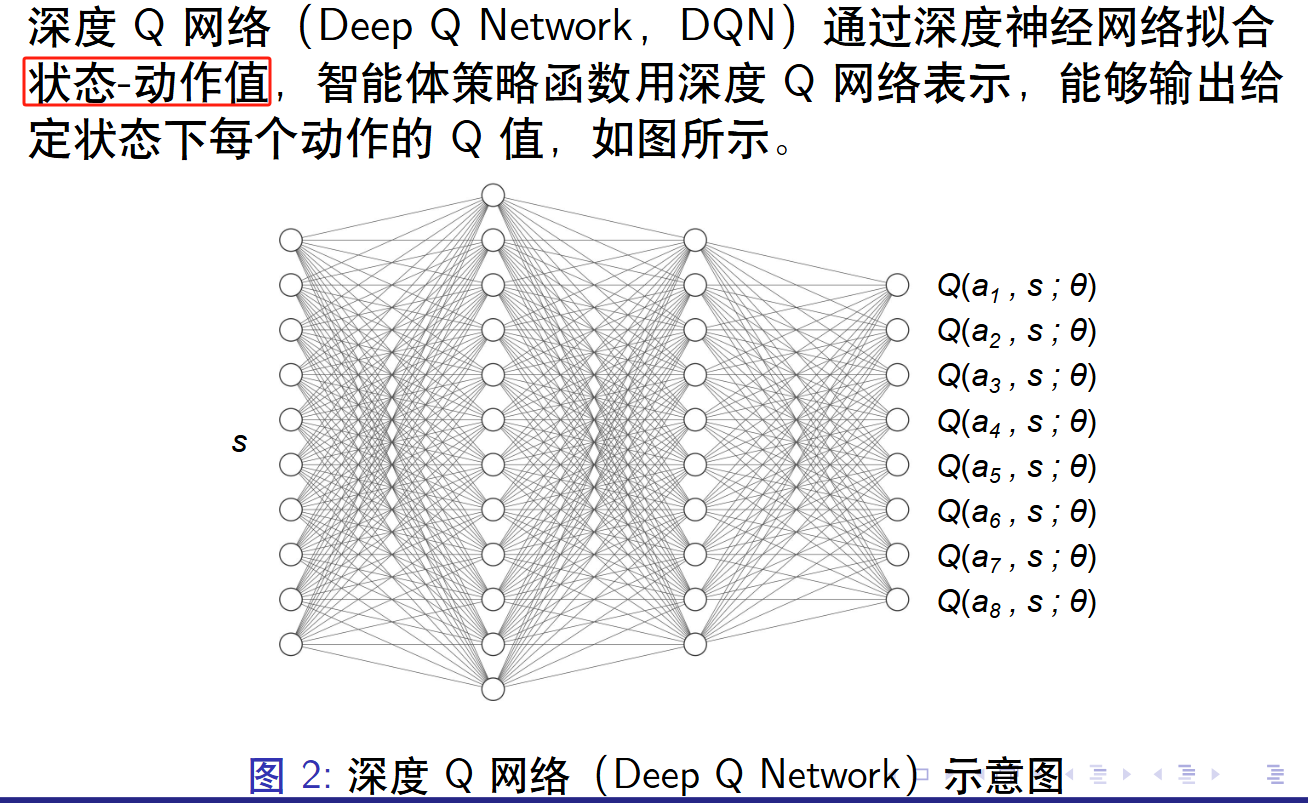
对于动作有限的智能体来说,使用Q网络获得当下状态的对于每个动作的 状态-动作值 。那么 arg max Q ( a , s ; θ ) = a b e s t \argmax Q(a,s; \theta) =a_{best} argmaxQ(a,s;θ)=abest ,那么我们对当前的状态s,会有一个最佳的选择 a b e s t a_{best} abest ,选择的依据是策略 θ \theta θ. 我们的目标是获得最优的策略 θ ∗ \theta^* θ∗.即优化 θ \theta θ,显然神经网络可以通过梯度下降的方法获得最优的策略 θ ∗ \theta^* θ∗.
二、Q-learning
DQN 算法全称是 Deep Q Network,基于经典强化学习算法 Q-learning 演化而来,Q-learning 作为强化学习的重要算法,有
着悠久的历史,在强化学习发展和应用过程中发挥了重要作用.在 Q-learning 算法中,状态-动作值函数 Q(s, a) 的更新公式为:
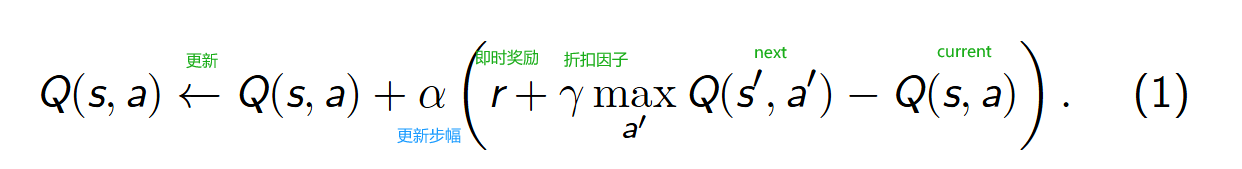
- Q-learning是借助于 Q-Table 的, 不存在 策略隐形表达(即关于 θ \theta θ的参数)
- 其MDP chain为: S → a / r S ′ → a ′ / r ′ S ′ ′ → ⋯ S \stackrel{a/r}→S'\stackrel{a'/r'}→S'' \to \cdots S→a/rS′→a′/r′S′′→⋯ 状态S在动作a下变为状态S’,并获得及时奖励r;……
2.1 代码示例
import numpy as np
import random# 定义网格世界环境
class GridWorld:def __init__(self, rows, cols, start, goal):self.rows = rowsself.cols = colsself.start = startself.goal = goalself.state = startdef reset(self):self.state = self.startreturn self.statedef step(self, action):x, y = self.stateif action == 0: # 上x = max(x - 1, 0)elif action == 1: # 下x = min(x + 1, self.rows - 1)elif action == 2: # 左y = max(y - 1, 0)elif action == 3: # 右y = min(y + 1, self.cols - 1)self.state = (x, y)reward = -1 # 每一步的惩罚done = self.state == self.goalif done:reward = 100 # 到达目标的奖励return self.state, reward, done# Q-learning 算法
class QLearning:def __init__(self, env, alpha=0.1, gamma=0.99, epsilon=0.1, episodes=1000):self.env = envself.alpha = alpha # 学习率self.gamma = gamma # 折扣因子self.epsilon = epsilon # 探索率self.episodes = episodesself.q_table = np.zeros((env.rows, env.cols, 4)) # Q 表 ,初始为全0def choose_action(self, state):if random.uniform(0, 1) < self.epsilon:return random.choice([0, 1, 2, 3]) # 探索else:return np.argmax(self.q_table[state]) # 利用def train(self):for episode in range(self.episodes):state = self.env.reset()done = Falsewhile not done:action = self.choose_action(state) #根据当前的状态,按照epsion策略选择动作(可能随机,可能最佳)next_state, reward, done = self.env.step(action)best_next_action = np.argmax(self.q_table[next_state]) #获得next_state根据Q表格最好的动作td_target = reward + self.gamma * self.q_table[next_state][best_next_action]#根据 next_state 和 best_next_action 获得未来的收益,再加上即使奖励reward,即当前的状态和动作的价值td_error = td_target - self.q_table[state][action]self.q_table[state][action] += self.alpha * td_errorstate = next_stateif (episode + 1) % 100 == 0:print(f"Episode {episode + 1}/{self.episodes} completed")def test(self):state = self.env.reset()done = Falsepath = [state]while not done:action = np.argmax(self.q_table[state])state, _, done = self.env.step(action)path.append(state)print("Path taken:", path)# 主程序
if __name__ == "__main__":# 定义网格世界rows, cols = 5, 5start = (0, 0)goal = (4, 4)env = GridWorld(rows, cols, start, goal)# 初始化 Q-learningq_learning = QLearning(env, alpha=0.1, gamma=0.99, epsilon=0.1, episodes=1000)# 训练q_learning.train()# 测试q_learning.test()三、DQN
深度强化学习算法中值函数或策略函数一般使用深度神经网络逼近或近似,用 参数化的状态-动作值函数 Q(s, a; θ) 逼近 Q(s, a),可如下表示
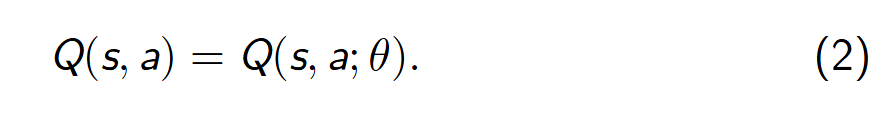
深度强化学习算法在更新过程中不直接对状态-动作值函数Q(s, a; θ) 的数值进行更新,而是更新近似状态-动作值函数Q(s, a; θ) 的深度神经网络模型参数 θ,可表示为

3.1 Experience Replay 经验回放
经典的 DQN 算法中有一个关键技术,叫经验回放。智能体在与环境交互过程中获得的经验数据会保存在 经验池(Replay Buffer)之中。经验池中的数据存放形式如下:
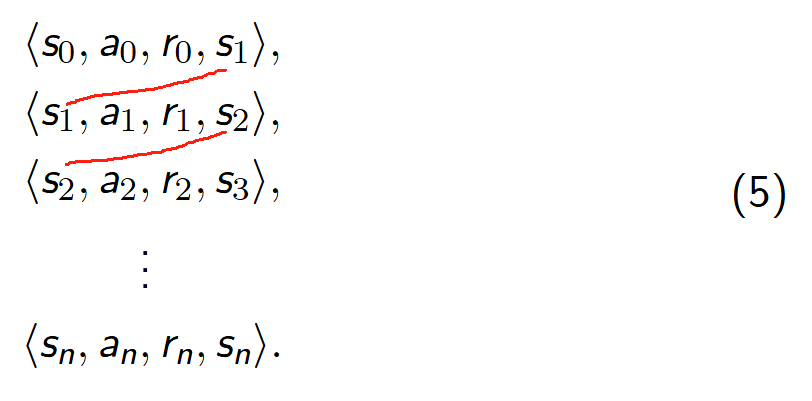
经验池存储满后,我们可以将旧的经验样本数据剔除,保存新的经验样本数据.
from collections import deque
# 创建一个最大长度为 5000 的 deque
dq = deque(maxlen=5000)
# 向 deque 中添加元素
for i in range(5005):dq.append([单一经验条(见Eq.5)])
经验存储
self.replay_buffer = deque(maxlen=buffer_size) ##预先定义的存储池,下为存储命令
def store_experience(self, state, action, reward, next_state, done):self.replay_buffer.append((state, action, reward, next_state, done))
批量采样
batch = random.sample(self.replay_buffer, self.batch_size)
###上面是抽样,下面是数据格式转化
states, actions, rewards, next_states, dones = zip(*batch)states = torch.tensor(states, dtype=torch.float32)
actions = torch.tensor(actions, dtype=torch.int64)
rewards = torch.tensor(rewards, dtype=torch.float32)
next_states = torch.tensor(next_states, dtype=torch.float32)
dones = torch.tensor(dones, dtype=torch.float32)3.2 目标网络
目标:我们要更新 Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ)中的参数 θ \theta θ,那么具体怎么更新呢?
已知:
- Q-learning的更新公式 (Eq.1 ),有当前的状态-动作值Q(s,a)(Q表格中的值与真正的值有误差的) 会随着 迭代关系 逐渐接近 真正的状态-动作值。
r + γ max a ′ Q ( s ′ , a ′ ) r +\gamma \max_{a'} Q(s',a') r+γmaxa′Q(s′,a′) =当下奖励+未来的增益
G a i n t = r + γ G a i n t + 1 Gain_t =r +\gamma Gain_{t+1} Gaint=r+γGaint+1
在Q-learing中其实默认了一种策略,就是选择next_state中best_next_action.即选择使下一个状态收益最大的动作。
由于Q-表格 是有限的,随着迭代次数的增加,所以状态是会大量重复出现,且(状态-动作值)会逐渐有区分,所以会有
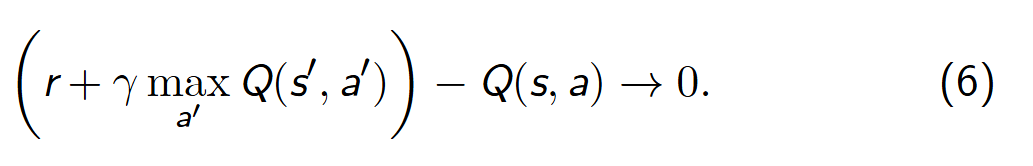
- DQN算法根据Q-learn改编过来的。即有目标如下:
Q ( s , a ; θ ) → ( r + γ max a ′ Q ( s ′ , a ′ ; θ ∗ ) ) Q(s,a;\theta) \to \quad (r+\gamma \max_{a'}Q(s',a';\theta^*)) Q(s,a;θ)→(r+γa′maxQ(s′,a′;θ∗))
且有 θ \theta θ是当下的策略, θ ∗ \theta^* θ∗是最终的最佳策略。那么显然,当我们处于 θ \theta θ的策略的时候(起点),我们无法直接找到 θ ∗ \theta^* θ∗(终点).为什么不能直接找到?(因为可能不收敛)
测试:
假设有一个DQN网络已经定义好了(如3.3)。那么智能体有 Q-网络(即状态-动作值函数网络), 优化器, 损失函数.如下所示:
class DQN_Agent:def __init__(self,)###省略了很多self.q_network = DQN(self.state_dim, self.action_dim) #在线网络,Q网络self.optimizer = optim.Adam(self.q_network.parameters(), lr=self.lr)#优化器self.loss_fn = nn.MSELoss() #损失函数
没有目标网络直接优化:
Q t a r g e t = R t + γ ⋅ max Q ( n e x t s t a t e , a c t i o n ) Q_{target}=R^t+ \gamma \cdot \max Q(nextstate ,action) Qtarget=Rt+γ⋅maxQ(nextstate,action)
Q c a l c u l a t e = Q ( c u r r e n t s t a t e ) Q_{calculate} =Q(currentstate) Qcalculate=Q(currentstate)
###没有目标网络的时候,计算Q_target是用相同的Q网络计算的
q_values = self.q_network(states) #Q(current_state)
next_q_values = self.q_network(next_states) #Q(next_curente)
q_target = q_values.clone()for i in range(self.batch_size):if dones[i] == 1:q_target[i, actions[i]] = rewards[i]else:q_target[i, actions[i]] = rewards[i] + self.gamma * torch.max(next_q_values[i])loss = self.loss_fn(q_values, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
❓问题:Q 网络的更新可能会导致目标值(q_target)和预测值(q_values)之间的相关性过高。这种高相关性会导致训练过程不稳定,甚至发散。
✋解决:我们在中间增加了一个目标网络Target network作为中点(过渡点)。
目标网络的作用
目标网络是一个固定频率更新的网络,它的参数不是每次训练都更新,而是定期从主网络(也称为在线网络)复制过来。这样做的目的是为了降低目标值和预测值之间的相关性,从而提高训练的稳定性
- 目标网络 同原来的神经网络(被称为 行为网络behavior network) 的结构完全相同.因此,Q网络(在线网络,动作-状态值函数网络)初始化。
初始阶段:根据设定的 结构 和随机初始化参数 θ \theta θ. 见方法一中,参数结构分为三层:输入层self.fc1(设定的是全连接网络),隐藏层self.fc2(设定的是全连接),输出层self.fc3(设定的是全链接网络)。而方法二中,我们增加新的结构(即卷积网络),也固定了 θ \theta θ的参数的随机初始化(高斯分布)。 - 初始阶段目标网络同Q网络相同。只是更新频率和更新方式不同!!! Q-网络是通过 优化器(根据梯度下降法)每次迭代更新一次参数,Target-网络 更新速度慢于前者,且是通过直接复制参数的方法更新!
### 目标网络 初始的复制过程
self.q_network = DQN(self.state_dim[0], self.action_dim) # 在线网络
self.target_network = DQN(self.state_dim[0], self.action_dim) # 目标网络,结构复制
self.target_network.load_state_dict(self.q_network.state_dict()) # 初始化目标网络,参数复制self.target_network.eval() # 设置为目标网络模式
self.optimizer = optim.Adam(self.q_network.parameters(), lr=self.lr)
self.loss_fn = nn.MSELoss()
self.target_update_frequency = target_update_frequency # 目标网络更新频率
self.update_count = 0 # 更新计数器####中间省略了
#####更新频率 ,q_values = self.q_network(states) # 使用在线网络计算 Q 值
next_q_values = self.target_network(next_states) # 使用目标网络计算下一个状态的 Q 值
####值得提醒的是,这里用的是taget_network,而不是Q_network,与上一段代码不同
q_target = q_values.clone()for i in range(self.batch_size):if dones[i] == 1:q_target[i, actions[i]] = rewards[i]else:q_target[i, actions[i]] = rewards[i] + self.gamma * torch.max(next_q_values[i])loss = self.loss_fn(q_values, q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step() ###这一小部分是优化器对self.q_network的更新,即每轮训练就会更新一次Q-newrok# 更新目标网络
self.update_count += 1
if self.update_count % self.target_update_frequency == 0:self.target_network.load_state_dict(self.q_network.state_dict())##### 目标网络的更新的步幅是self.target_update_frequency ,且不是通过优化器更新的,而是直接对Q-network参数的复制3.3 DQN的网络定义案例
## 方法一
class DQN(nn.Module):def __init__(self, input_dim, output_dim):super(DQN, self).__init__()self.fc1 = nn.Linear(input_dim, 128)self.fc2 = nn.Linear(128, 128)self.fc3 = nn.Linear(128, output_dim)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x
### 方法二:使用高斯分布对参数进行随机初始化
# 定义DQN网络
class DQN(nn.Module):def __init__(self, input_channels, output_dim):super(DQN, self).__init__()# 第一层:卷积层self.conv1 = nn.Conv2d(input_channels, 16, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(16 * 8 * 8, 128) # 将卷积层的输出展平self.fc2 = nn.Linear(128, 128)self.fc3 = nn.Linear(128, output_dim)self.initialize_weights()def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return xdef initialize_weights(self):# 使用高斯分布初始化权重for layer in self.modules():if isinstance(layer, nn.Linear):nn.init.normal_(layer.weight, mean=0.0, std=0.1) # 高斯分布,均值为0,标准差为0.1if layer.bias is not None:nn.init.constant_(layer.bias, 0.0) # 偏置初始化为0
3.4 环境交互
在与环境交互过程中,智能体采用 ϵ-贪心策略生成轨迹,ϵ-贪心策略表示为

以代码为例
###选择动作的策略
def choose_action(self, state):if random.random() < self.epsilon:return random.randint(0, self.action_dim - 1) #随机选择else:state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) # 添加批次维度q_values = self.q_network(state)return torch.argmax(q_values).item() ##目标网络值最大的动作
3.5 损失函数
损失函数 值得是 预测值和实际值之间的误差。
实际值(或者说 TD目标值),根据公式定义来计算。
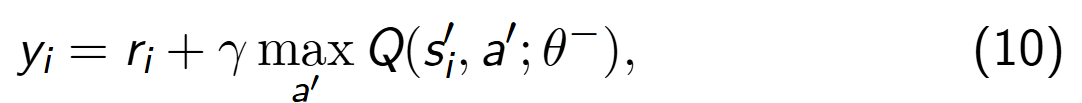


其损失函数代码和网络的更新 见3.3 。
3.6 伪代码

四、DDQN
附录一:DQN案例代码
A.1 智能体
目标网络的引入:self.target_network 是目标网络,它的参数定期从在线网络(self.q_network)复制过来。在 __init__ 方法中,目标网络的参数初始化为在线网络的参数。
目标网络的更新:在 replay 方法中,使用目标网络计算下一个状态的 Q 值(next_q_values)。每次调用 replay 方法时,更新计数器 self.update_count 增加 1。当 self.update_count 达到目标网络更新频率(self.target_update_frequency)时,将在线网络的参数复制到目标网络。
目标网络的作用:目标网络的参数更新频率较低,这使得目标值(q_target)相对稳定,从而减少了目标值和预测值之间的相关性,提高了训练的稳定性。
class DQN_Agent:def __init__(self, env, lr=0.001, gamma=0.99, epsilon=1.0, epsilon_decay=0.995, min_epsilon=0.01, buffer_size=10000, batch_size=32, target_update_frequency=1000):self.env = envself.lr = lrself.gamma = gammaself.epsilon = epsilonself.epsilon_decay = epsilon_decayself.min_epsilon = min_epsilonself.buffer_size = buffer_sizeself.batch_size = batch_sizeself.replay_buffer = deque(maxlen=buffer_size)self.state_dim = (1, 8, 8) # 输入维度:1 个通道,8x8 的图像self.action_dim = 4 # 动作维度 (上, 下, 左, 右)self.q_network = DQN(self.state_dim[0], self.action_dim) # 在线网络self.target_network = DQN(self.state_dim[0], self.action_dim) # 目标网络self.target_network.load_state_dict(self.q_network.state_dict()) # 初始化目标网络self.target_network.eval() # 设置为目标网络模式self.optimizer = optim.Adam(self.q_network.parameters(), lr=self.lr)self.loss_fn = nn.MSELoss()self.target_update_frequency = target_update_frequency # 目标网络更新频率self.update_count = 0 # 更新计数器def choose_action(self, state):if random.random() < self.epsilon:return random.randint(0, self.action_dim - 1)else:state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) # 添加批次维度q_values = self.q_network(state)return torch.argmax(q_values).item()def store_experience(self, state, action, reward, next_state, done):self.replay_buffer.append((state, action, reward, next_state, done))def train(self, episodes):for episode in range(episodes):state = self.env.reset()done = Falsewhile not done:action = self.choose_action(state)next_state, reward, done = self.env.step(action)self.store_experience(state, action, reward, next_state, done)state = next_stateif len(self.replay_buffer) > self.batch_size:self.replay()self.epsilon = max(self.min_epsilon, self.epsilon * self.epsilon_decay)if (episode + 1) % 100 == 0:print(f"Episode {episode + 1}/{episodes} completed, epsilon: {self.epsilon:.4f}")def replay(self):batch = random.sample(self.replay_buffer, self.batch_size)states, actions, rewards, next_states, dones = zip(*batch)states = torch.tensor(states, dtype=torch.float32)actions = torch.tensor(actions, dtype=torch.int64)rewards = torch.tensor(rewards, dtype=torch.float32)next_states = torch.tensor(next_states, dtype=torch.float32)dones = torch.tensor(dones, dtype=torch.float32)q_values = self.q_network(states) # 使用在线网络计算 Q 值next_q_values = self.target_network(next_states) # 使用目标网络计算下一个状态的 Q 值q_target = q_values.clone()for i in range(self.batch_size):if dones[i] == 1:q_target[i, actions[i]] = rewards[i]else:q_target[i, actions[i]] = rewards[i] + self.gamma * torch.max(next_q_values[i])loss = self.loss_fn(q_values, q_target)self.optimizer.zero_grad()loss.backward()self.optimizer.step()# 更新目标网络self.update_count += 1if self.update_count % self.target_update_frequency == 0:self.target_network.load_state_dict(self.q_network.state_dict())def test(self):state = self.env.reset()done = Falsepath = [state]while not done:state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) # 添加批次维度q_values = self.q_network(state)action = torch.argmax(q_values).item()state, _, done = self.env.step(action)path.append(state)print("Path taken:", path)A.2 网络结构
输入层:输入是一个 8x8 的灰度图像,通道数为 1。输入维度为 (batch_size, 1, 8, 8)。
第一层:卷积层:使用 nn.Conv2d,输入通道为 1,输出通道为 16,卷积核大小为 3x3,步长为 1,填充为 1。输出维度为 (batch_size, 16, 8, 8)。应用 ReLU 激活函数。
第二层:全连接层:将卷积层的输出展平为一维张量,维度为 (batch_size, 16 * 8 * 8)。使用 nn.Linear,输入维度为 16 * 8 * 8,输出维度为 128。应用 ReLU 激活函数。
第三层:全连接层:使用 nn.Linear,输入维度为 128,输出维度为 128。应用 ReLU 激活函数。
输出层:使用 nn.Linear,输入维度为 128,输出维度为 output_dim(动作数量,这里是 4)。输出层不使用激活函数,直接输出 Q 值。
class DQN(nn.Module):def __init__(self, input_channels, output_dim):super(DQN, self).__init__()# 第一层:卷积层self.conv1 = nn.Conv2d(input_channels, 16, kernel_size=3, stride=1, padding=1)# 第二层:全连接层self.fc1 = nn.Linear(16 * 8 * 8, 128) # 将卷积层的输出展平# 第三层:全连接层self.fc2 = nn.Linear(128, 128)# 第四层:输出层self.fc3 = nn.Linear(128, output_dim)self.initialize_weights()def forward(self, x):x = torch.relu(self.conv1(x)) # 第一层卷积后应用 ReLUx = x.view(x.size(0), -1) # 展平x = torch.relu(self.fc1(x)) # 第一层全连接后应用 ReLUx = torch.relu(self.fc2(x)) # 第二层全连接后应用 ReLUx = self.fc3(x) # 输出层return xdef initialize_weights(self):# 使用高斯分布初始化权重for layer in self.modules():if isinstance(layer, nn.Conv2d) or isinstance(layer, nn.Linear):nn.init.normal_(layer.weight, mean=0.0, std=0.1) # 高斯分布,均值为0,标准差为0.1if layer.bias is not None:nn.init.constant_(layer.bias, 0.0) # 偏置初始化为0A.3 环境
环境结构说明:
网格世界:网格世界是一个 8x8 的网格,智能体可以在其中向上、下、左、右移动。智能体的目标是从起点 start 到达终点 goal。
状态表示:智能体的状态是一个二维坐标 (x, y)。状态被转换为一个 8x8 的灰度图像,智能体的位置用 1 表示,其余位置用 0 表示。
奖励机制:每一步的奖励为 -1。到达目标位置的奖励为 100。
输入维度:环境的输入是一个 8x8 的灰度图像,通道数为 1。输入维度为 (1, 8, 8)。
class GridWorld:def __init__(self, rows, cols, start, goal):self.rows = rowsself.cols = colsself.start = startself.goal = goalself.state = startdef reset(self):self.state = self.startreturn self.state_to_image(self.state)def step(self, action):x, y = self.stateif action == 0: # 上x = max(x - 1, 0)elif action == 1: # 下x = min(x + 1, self.rows - 1)elif action == 2: # 左y = max(y - 1, 0)elif action == 3: # 右y = min(y + 1, self.cols - 1)self.state = (x, y)reward = -1 # 每一步的惩罚done = self.state == self.goalif done:reward = 100 # 到达目标的奖励return self.state_to_image(self.state), reward, donedef state_to_image(self, state):# 将状态转换为 8x8 的灰度图像img = np.zeros((8, 8), dtype=np.float32)img[state[0], state[1]] = 1.0 # 将智能体的位置设置为 1return img相关文章:
DQN和DDQN(进阶版)
来源: *《第五章 深度强化学习 Q网络》.ppt --周炜星、谢文杰 一、前言 Q表格、Q网络与策略函数 Q表格是有限的离散的,而神经网络可以是无限的。 对于动作有限的智能体来说,使用Q网络获得当下状态的对于每个动作的 状态-动作值 。那么 a…...

【组件】翻牌器效果
目录 效果组件代码背景素材 效果 组件代码 <template><divclass"card-flop":style"{height: typeof height number ? ${height}px : height,--box-width: typeof boxWidth number ? ${boxWidth}px : boxWidth,--box-height: typeof boxHeight nu…...
CentOS 7 环境中部署 LNMP(Linux + Nginx + MySQL 5.7 + PHP)
在 CentOS 7 环境中部署 LNMP(Linux Nginx MySQL 5.7 PHP) 环境的详细步骤如下。此方案确保各组件版本兼容,并提供完整的配置验证流程。 1. 更新系统 sudo yum update -y 2. 安装 MySQL 5.7 2.1 添加 MySQL 官方 YUM 仓库 由于MySQL并不…...

NX811NX816美光颗粒固态NX840NX845
NX811NX816美光颗粒固态NX840NX845 美光NX系列固态硬盘颗粒深度解析:技术、性能与市场全景透视 一、技术架构与核心特性解析 1. NX811/NX816:入门级市场的平衡之选 技术定位:基于176层TLC(Triple-Level Cell)3D NAN…...
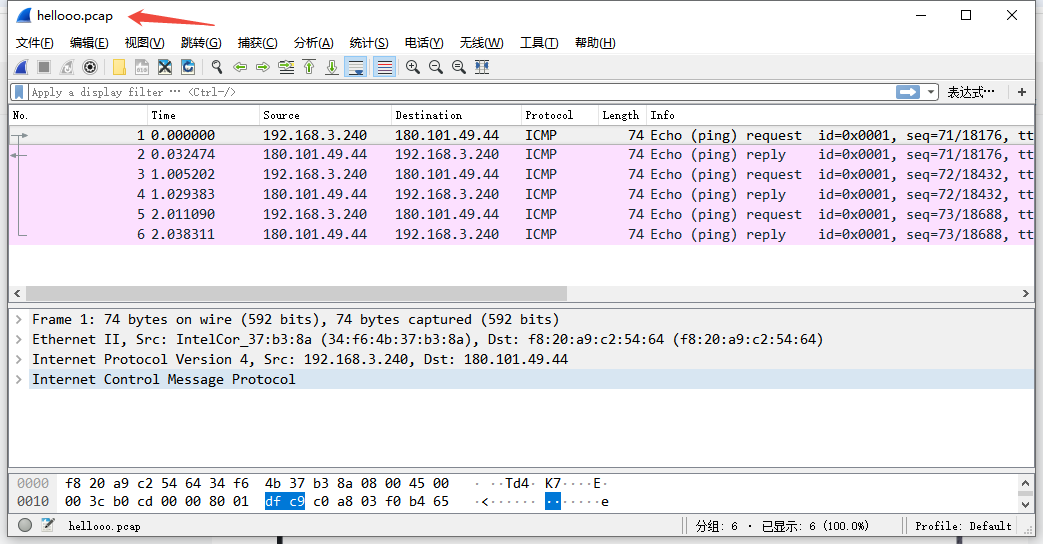
捋捋wireshark
本猿搬砖时会用到wireshark分析pcap包,但频率不高,记过一些笔记,今天捋捋,希望能给初学者节省一点时间。 wireshark是个网络封包分析软件(network packet analyzer),可以用来抓流量包ÿ…...
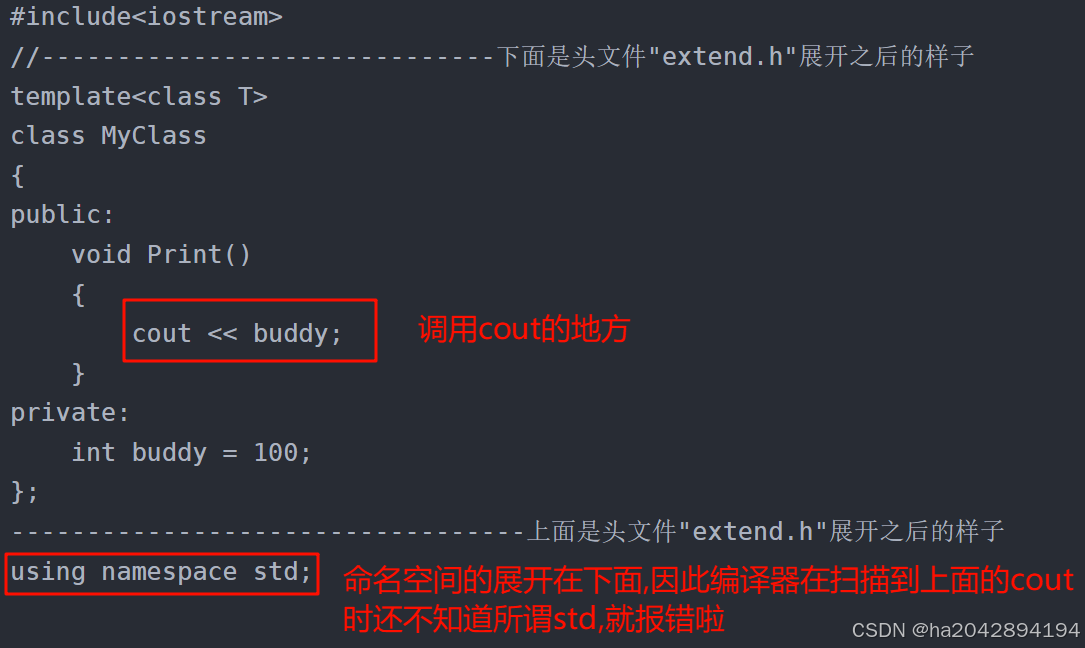
c++学习之---模版
目录 一、函数模板: 1、基本定义格式: 2、模版函数的优先匹配原则: 二、类模板: 1、基本定义格式: 2、类模版的优先匹配原则(有坑哦): 3、缺省值的设置: 4、ty…...

MyBatis-Flex 全面指南:下一代轻量级持久层框架实战入门
🚀 MyBatis-Flex 全面指南:下一代轻量级持久层框架实战入门 本文将带你全面了解 MyBatis-Flex 的特性、常见用法、最佳实践,帮助你高效构建更简洁、更灵活的 Java 持久层代码。 🧩 什么是 MyBatis-Flex? MyBatis-Flex…...

第十六章 EMQX黑名单与连接抖动检测
系列文章目录 第一章 总体概述 第二章 在实体机上安装ubuntu 第三章 Windows远程连接ubuntu 第四章 使用Docker安装和运行EMQX 第五章 Docker卸载EMQX 第六章 EMQX客户端MQTTX Desktop的安装与使用 第七章 EMQX客户端MQTTX CLI的安装与使用 第八章 Wireshark工具的安装与使用 …...
)
WebSphere(WAS)
WebSphere (WebSphere Application Server)为 SOA 环境提供软件,以实现动态的、互联的业务流程,为所有业务情形提供高度有效的应用程序基础架构。WebSphere 是 IBM 的应用程序和集成软件平台,包含所有必要的中间件基础…...
新编辑器编写指南--给自己的备忘
欢迎使用Markdown编辑器 你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。 新的改变 我们对Markdown编辑器进行了一些功能拓展与语法支持&#x…...

xPSR
在 ARM Cortex-M3 中,xPSR(组合程序状态寄存器) 是核心的状态控制寄存器,由三个子状态寄存器合并而成,用于记录处理器的运算状态、中断状态和执行环境。以下是其深度解析: 🔍 一、xPSR …...
鸿蒙网络数据传输案例实战
一、案例效果截图 二、案例运用到的知识点 核心知识点 网络连接管理:connection模块HTTP数据请求:http模块RPC数据请求:rcp模块文件管理能力:fileIo模块、fileUri模块 其他知识点 ArkTS 语言基础V2版状态管理:Comp…...

【JavaEE】-- 网络原理
文章目录 1. 网络发展史1.1 广域网1.2 局域网 2. 网络通信基础2.1 IP地址2.2 端口号2.3 认识协议2.4 五元组2.5 协议分层2.5.1 分层的作用2.5.2 OSI七层模型(教科书)2.5.3 TCP/IP五层(或四层)模型(工业中常用ÿ…...

1.RV1126-OPENCV 交叉编译
一.下载opencv-3.4.16.zip到自己想装的目录下 二.解压并且打开 opencv 目录 先用 unzip opencv-3.4.16.zip 来解压 opencv 的压缩包,并且进入 opencv 目录(cd opencv-3.4.16) 三. 修改 opencv 的 cmake 脚本的内容 先 cd platforms/linux 然后修改 arm-gnueabi.to…...
PySide6 GUI 学习笔记——常用类及控件使用方法(标签控件QLabel)
文章目录 标签控件QLabel及其应用举例标签控件QLabel的常用方法及信号应用举例Python 代码示例1Python 代码示例2 小结 标签控件QLabel及其应用举例 QLabel 是 PySide6.QtWidgets 模块中的一个控件,用于在界面上显示文本或图像。它常用于作为标签、提示信息或图片展…...

CSS (mask)实现服装动态换色:创意与技术的完美融合
在网页开发中,我们常常会遇到需要对图片元素进行个性化处理的需求,比如改变图片中特定部分的颜色。今天,我们就来探讨一种通过 CSS 和 JavaScript 结合,实现服装动态换色的有趣方法。 一、代码整体结构分析 上述代码构建了一个完…...
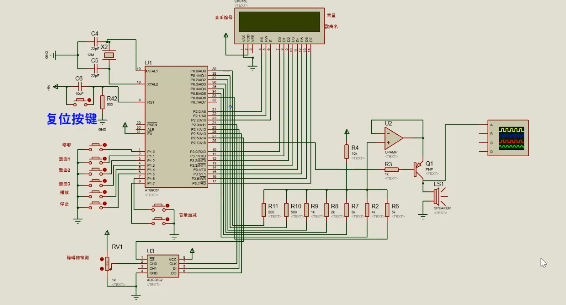
基于51单片机的音乐盒汽车喇叭调音量proteus仿真
地址: https://pan.baidu.com/s/1l3CSSMi4uMV5-XLefnKoSg 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...

彻底理解Spring三级缓存机制
文章目录 前言一、Spring解决循环依赖时,为什么要使用三级缓存? 前言 Spring解决循环依赖的手段,是通过三级缓存: singletonObjects:存放所有生命周期完整的单例对象。(一级缓存)earlySingleto…...

MacOs 安装局域网 gitlab 记录
1、安装git brew install git > Downloading https://homebrew.bintray.com/bottles/git-2.7.0.el_capitan.bottle ######################################################################## 100.0% > Pouring git-2.7.0.el_capitan.bottle.tar.gz > Caveats The O…...
)
Flutter 与 Android 原生布局组件对照表(完整版)
本对照表用于帮助 Android 开发者快速理解 Flutter 中的布局组件与原生布局的关系。 📘 Flutter ↔ Android 布局组件对照表 Flutter WidgetAndroid View/Layout说明ContainerFrameLayout / View通用容器,可设置背景、边距、对齐等RowLinearLayout (hor…...
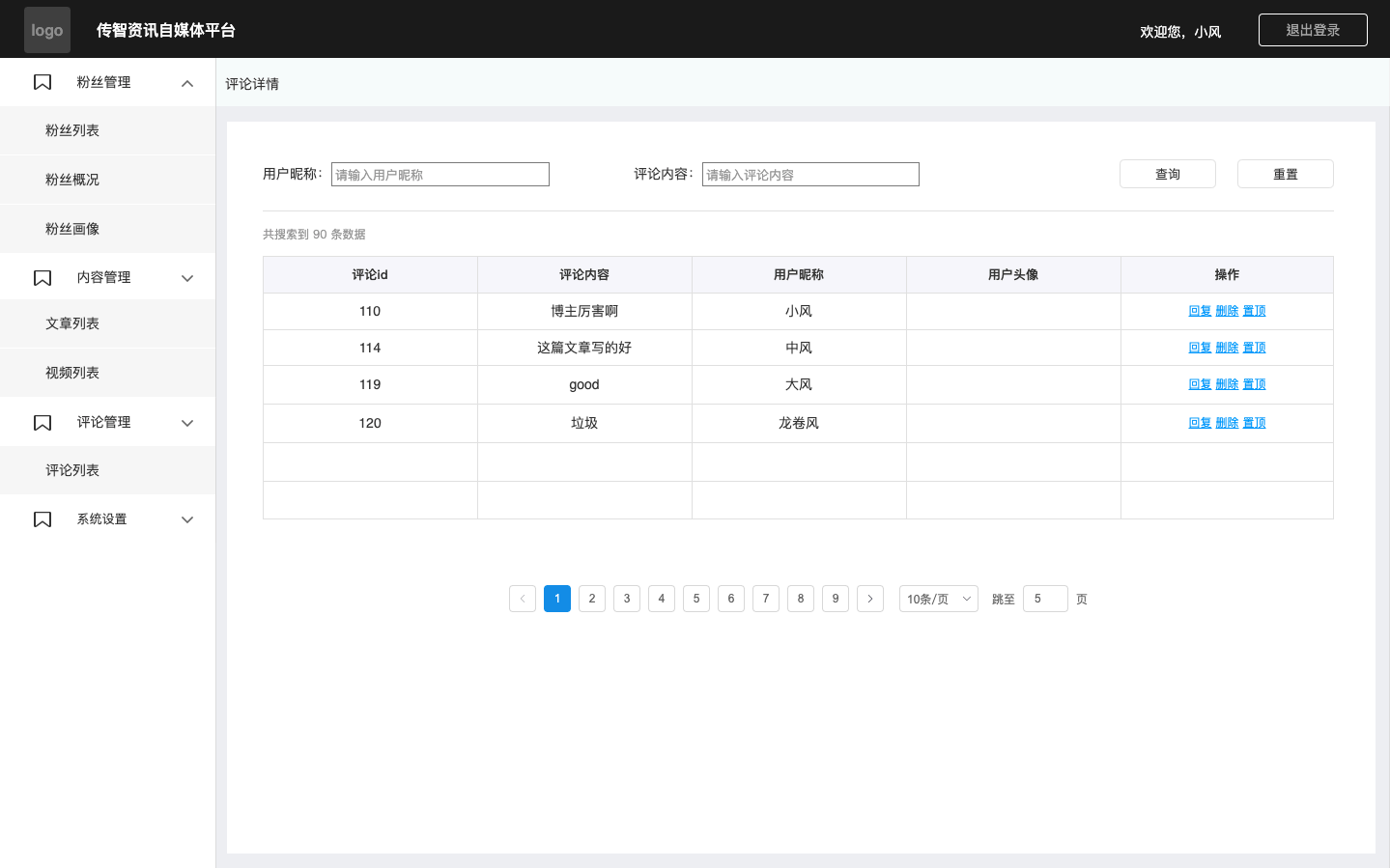
【产品经理从0到1】自媒体端产品设计
后台的定义 “后台” 与“前台”都是相对独立的平台,前台是服务于互联网用户的平台 ,后台主要是支撑前台页面内容、数据及对前台业务情况的统计分析的系统; 后台与前台的区别 第1:使用用户不同 前台用户:互联网用户…...

017搜索之深度优先DFS——算法备赛
深度优先搜索 如果说广度优先搜索是逐层扩散,那深度优先搜索就是一条道走到黑。 深度优先遍历是用递归实现的,预定一条顺序规则(如上下左右顺序) ,一直往第一个方向搜索直到走到尽头或不满足要求后返回上一个叉路口按…...

解决 maven编译项目-Fatal error compiling: 无效的目标发行版: 21 -> [Help 1]
目录 1. 问题描述 2. 排查思路 3. 设置-指定maven使用jdk21 4. 参考资料 1. 问题描述 在idea中使用maven编译时,在系统环境变量中已经设置了jdk为21,但是在执行mvn package时,确提示 Fatal error compiling: 无效的目标发行版: 21 -> [Help 1] [ERROR] Failed to e…...
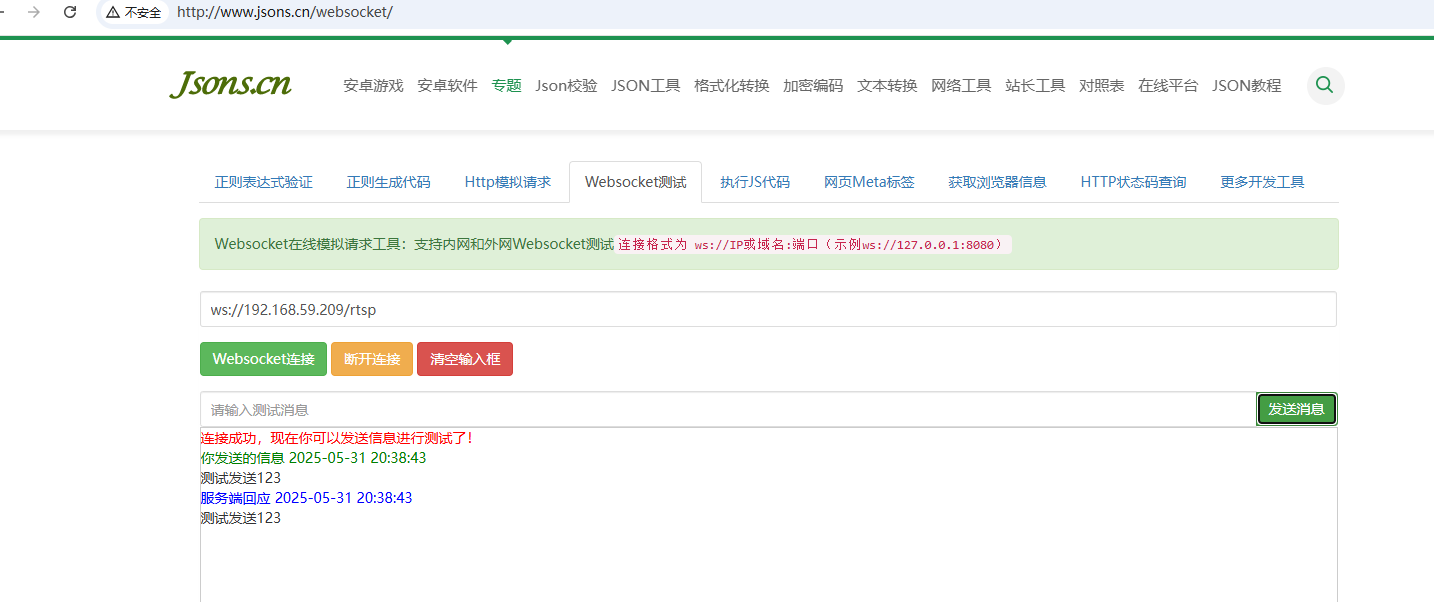
Thinkphp6实现websocket
项目需要连接一台自动售货机,售货机要求两边用websocket连接,监听9997端口。本文实现了一个基于PHP的WebSocket服务器,用于连接自动售货机,支持start/stop/restart命令操作 1.新建文件 新建文件 /command/socket.php <?php namespace a…...

web-css
一.CSS选择器: 1.基础选择器 基本选择器: >.标签选择器 格式:标签名称{} >.类选择器(重) 格式:.class属性的值{} >.id选择器 格式:#id属性的值{} >.通配符(表示所有&am…...

关于 smali:2. 从 Java 到 Smali 的映射
一、对照 Java 代码与 Smali 代码差异 1.1 方法调用差异:Java vs Smali Java 方法分类: 方法类型Java 示例Smali 指令特点说明静态方法Utils.print("hi")invoke-static没有 this 指针实例方法obj.show()invoke-virtual有 this,虚…...
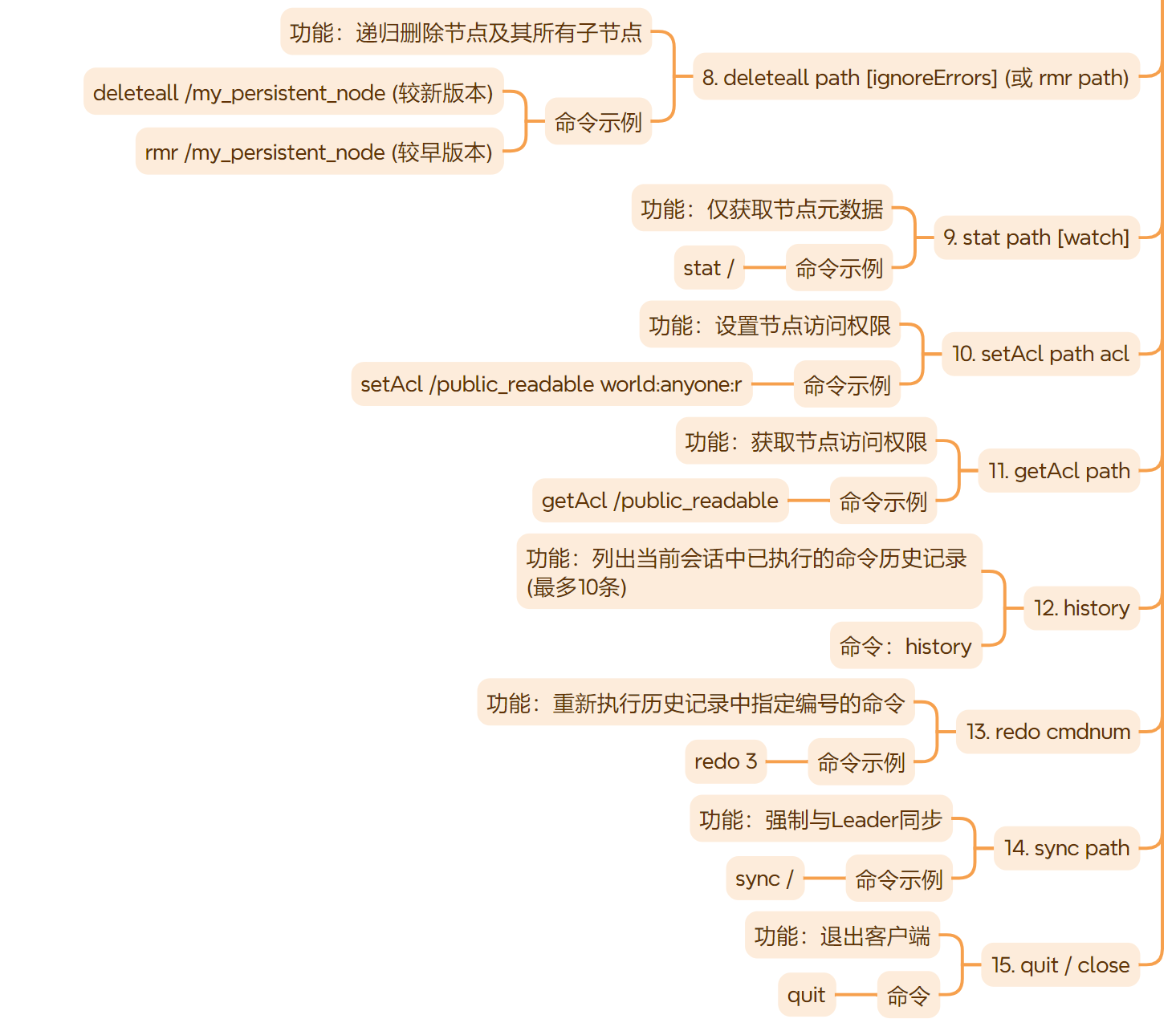
三、zookeeper 常用shell命令
作者:IvanCodes 日期:2025年5月28日 专栏:Zookeeper教程 ZooKeeper Shell (zkCli.sh) 是与ZooKeeper服务器交互的核心工具。本教程将详细介绍常用命令,并重点解析ZooKeeper数据节点 (ZNode) 的特性与分类。 思维导图 一、连接 Zo…...

分布式流处理与消息传递——Paxos Stream 算法详解
Java 实现 Paxos Stream 算法详解 一、Paxos Stream 核心设计 #mermaid-svg-cEJcmpaQwLXpEbx9 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-cEJcmpaQwLXpEbx9 .error-icon{fill:#552222;}#mermaid-svg-cEJcmpaQw…...

智变与重构:AI 赋能基础教育教学的范式转型研究报告
一、研究背景与核心价值 (一)技术驱动下的教育转型浪潮 在全球数字化转型加速的背景下,人工智能作为核心技术力量,正重塑基础教育生态。据《人工智能赋能未来教育研究报告》指出,我国教育数字化战略行动已推动超 70…...

平衡三进制
平衡三进制 - OI Wiki https://oi-wiki.org/math/balanced-ternary/ 上海市计算机学会竞赛平台 | YACS 方法一,先分离后进位 #include <iostream> using namespace std; int n, a[100], cnt; bool flag; int main() {cin >> n;if(n0){cout <<…...